nguyen ngoc tuan – 50702771 le nguyen duy vu - 50703018 11/24/2010 1
TRANSCRIPT

Nguyen Ngoc Tuan – 50702771
Le Nguyen Duy Vu - 50703018
11/24/2010 1

1. Introduction to Data Warehouses and OLAP systems.
2. Security problem description and its related works.
3. Classify Security Threats & Identify Security Requirements.
4. Solution of Thee-tier Security Architecture.
5. Conclusion
11/24/20102

Introduction to Data Warehouses and OLAP systems
11/24/2010 3

A decision support database that is maintained separately from the organization’s operational database.
“A subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decision-making process.”
W. H. Inmon
11/24/20104

11/24/20105

Subject-orientedDW is organized around major subjects, such as: customer,
supplier, product and sales.Integrated:
DW is usually constructed by integrating multiple heterogeneous sources: relational databases, flat files and on-line transaction records, etc.
Time-variant: data stored to provide information from a historical perspective
(e.g., the past 5-10 years).Nonvolatile:
DW is always a physically separate store of data transformed form.
11/24/20106

Information processing:supports querying, basic statistical analysis, and reporting
using crosstabs, tables, charts, or graphs.
Analytical processing:supports basic OLAP operations, including slice-and-dice,
drill-down, roll-up, and pivoting.
Data mining:
11/24/20107

Data cubes (aka. Hypercubes, or OLAP cubes):multidimensional matrices is Data Warehouse and OLAP data modelsupport analysis to query data in different perspectives
11/24/20108
Example of 3-dimensional data cube model
Three dimensions are: Product Location Year

2 type of tables:Dimensional tableFact table
2 type of schema:Star schemaSnowflake schema: dimensional tables from star schema are
organized into hierarchy by normalizationFact constellation: set of fact tables that share some
dimension tables.
11/24/20109

Star schema
11/24/201010

Snowflake schema:
11/24/2010 11

Fact constellation
11/24/2010 12

OLAP (On-Line Analytical Processing): decision support system that enable analysts to construct a mental image about the underlying data (collected from Data Warehouse) by exploring it:from different perspectives, at different level of generations, and in interactive manner.
11/24/201013

OLAP provides a user-friendly environment for interactive data analysis.
Roll-up (aka. drill up): performs aggregation on a data cube, either by climbing up a
concept hierarchy for a dimension or by dimension reduction.Drill-down (reverse of roll-up):
navigates from less detailed data to more detailed data.Slide and dice:
performs a selection on one dimension of the given cube, resulting a sub cub.
Pivot (rotate): visualization operation that rotates the data axes in order to
provide an alternative presentation of the data.
11/24/201014

Security problem description and its related works
11/24/2010 15

Insiders who have legitimate accesses to data through OLAP queriesAccess control techniques are not directly applicable due to
the difference in data models
Indirect inferences of protected dataInference control is absent in most commercial OLAP
systems
11/24/201016

Restricted-based methods:Cell suppression:
hide cells that contain small COUNT values, detect possible inferences related to these cells and remove them
using linear programmingPartitioning:
defines a partition on sensitive data and restricts queries to aggregate only to complete blocks in the partition
Micro-aggregation: replace clusters of sensitive data with their averages
Perturbed-based techniques: add random noise to data
11/24/201017

Classify Security Threats & Identify Security Requirements
11/24/2010 18

In OLAP Systems, sensitive data can be inferred from answers to legitimate queries.
There are two kind of inferenceOne dimensional inference (1-d inference)Multi-dimensional inference (m-d inference)
A cell is inferred using two or more of its descendantsNeither of those descendants causes 1-d inferences
Examples
11/24/2010 19

11/24/201020

1-d inference: Adversary:
Prohibited from accessing cuboid <quarter, employee>Allowed to access its descendant <quarter, department>Suppose: Knows about empty cells, Bob & Alice taking the same
amount of commission in Q3 Infer that <Q3, Bob> and <Q3, Alice> as 5500, half of <Q3, Book>
11/24/2010 21

M-d inference with SUMAdversary
Prohibited from accessing cuboid <quarter, employee>Allowed to access its descendants <quarter, department>, <year,
employee>Supposed: know empty cellsInfer that: <Q1, Bob> = (<Y1, Bob> + <Y1, Alice>) – (<Q2,
Book> + <Q3, Book>) = 1500
11/24/2010 22

M-d inference with MAXAdversary
Prohibited from accessing cuboid <quarter, employee>Allowed to access its descendants <quarter, department>, <year,
employee>knows MAX(<Y1, Mallory>) = 6400, MAX (<Q4, Book>) =
6000 <Q4, Mallory> ≠ 6400. Similarly, <Q2, Mallory> and <Q3, Mallory> ≠ 6400. Conclusion: <Q1, Mallory> = 6400
11/24/2010 23

M-d inference with SUM, MAX & MINAdversary
Assumption like above examples. Adversary can ask queries using SUM, MAX, MIN
Get <Q1, Mallory> = 6400, MAX(<Y1, Mallory>) = 6400, MIN(<Y1, Mallory>) = 6000, SUM(<Y1, Mallory>) = 12400 {(<Q2, Mallory>, <Q3, Mallory>, <Q4, Mallory>} = {6000, 6000, 0}
Continue to MAX, MIN, SUM on <Q2, Book> <Q#, Book>, <Q4, Book> <Q4, Mallory> = 6000
11/24/2010 24

Security solution for OLAP systems combine access control and inference controlAchieve a balance among following objectives
Security: from both unauthorized access and malicious inferencesApplicability: cover a wide range of scenarios without need for
significant modificationsEfficiencyAvailabilityPracticality
11/24/2010 25

Solution of Thee-tier Security Architecture
11/24/2010 26

In statistical databases: two tier (sensitive data, aggregation queries)
Apply this architecture to OLAP has some drawbacksUnacceptable delay for query processingInference control methods cannot take advantage of the
special characteristics of an OLAP application
11/24/2010 27

Three tier: query tier, aggregation tier and data tier
11/24/2010 28

Aggregation tier must satisfy 3 propertiesAggregation layer is secure with respect to Data layer,
enforced by inference control
Its size must be comparable with the Data layer
Problem of inference control can be partitioned into blocks in Data layer and Aggregation layer. Security need only to ensure each corresponding pair of blocks in the two tiers
11/24/2010 29

Reduce performance overhead of inference controlAggregation tier can pre-computed: computation intensive
part of inference control can be shifted to offline processing
Reduce size of inputs to inference control algorithms reduce complexity
Localizing inference control tasks to each block of data failure in one block won’t affect other block
11/24/2010 30

Cardinality-based methodDetect inferences based on the number of answered queriesWe consider one-level hierarchy, each dimension can only
have two attributes: core cuboid <quarter, employee>, its descendants are <all, employee>, <quarter, all> and <all, all>
11/24/2010 31

Cardinality-based method
11/24/2010 32

Cardinality-based methodExistence of 1-d inferences and the number of empty cells
k=number of dimensions, dmax is greatest domain size of all dimensions
Number of empty cells0 2k-1.dmax
Free of 1-d inference
Always have 1-d inference
11/24/2010 33

Cardinality-based methodExistence of m-d inferences and the number of empty cells
Cuboid with no empty cells is free of m-d inferencesTheorem:
Cc is core cuboid, Call is collection of all aggregation cuboids
ith attribute of Cc has di values, du and dv is the 2 smallest among di’s
w is number of Cc empty cellsWe have: Cc is free from m-d inference if w < 2(du-4) + 2(dv-4) -1, di ≥ 4 for all
1 ≤ I ≤ k.Cc has m-d inference if w ≥ 2(du-4) + 2(dv-4) -1.
11/24/2010 34

Parity-based methodBased on a simple fact that even number is closed under the
operation of addition and subtraction
The nature of m-inference is to keep adding (or subtracting) sets of cells until the result yields one cell
We consider multi-dimensional range (MDR) query is considered. An MDR is an operation of addition (or subtraction)
11/24/2010 35

We use:q*(<Q1, Bob>, <Q4, Alice>) = x1 + x2 + x3 + x4 + x5 + x6q*(<Q1, Bob>, <Q2, Bob>) = x1 + x2…Restricting MDR queries to only include even number of cells
hard to obtain (maybe)
11/24/2010 36

Parity-based methodInference:
q*(<Q1, Bob>, <Q2, Bob>) = x1 + x2 = 1500+ q*(<Q2, Alice>, <Q3, Alice>) = x4 + x5 = 2000+ q*(<Q3, Alice>, <Q4, Alice>) = x5 + x6 = 1500+ q*(<Q3, Bob>, <Q3, Alice>) = x3 + x5 = 2500- q*(<Q1, Bob>, <Q4, Alice>) = x1+ x2 + x3 + x4+ x5 +x6 = 6500= x5 + x5 = 1000 x5 = 500
11/24/2010 37

Parity-based methodDerivability:
a set of queries Q1 is derivable from another set Q2, then the answer to Q1 can be computed using answers to Q2. Q1 is free of inferences if Q2 is.
Find another collection of even MDR queries Qp that are equivalent to Q* and whose inferences are easier to detect.
Then, denote Qp as an undirected simple graph G(Cc, Qp). After that, check G whether or not a bipartite graph (graph no cycle composed of odd number of edges)
11/24/2010 38

Approachdetect inferences caused by queries involving both MAXs
and SUMs is intractablenot directly detect inferences, but instead first prevents m-d
inferences and then remove 1-d inferencesAccess control
Define 2 functions:Below() partitions data cube along the dependency latticeSlide() partitions data cube along dimensions.
Object is the intersection of the two above partitions.
11/24/2010 39

Access controlExample:
Employee’s yearly or more detailed commission is sensitive.This requirement only applied to first year dataSpecifies as Object(L, S), L = <year, employee>, S includes all
cells in the first four quarters of <quarter, employee>
11/24/2010 40

Lattice-based inference controlGiven to set of cells S and T. For any cell c in S, we say
c is redundant with respect to T if S includes both c and c’s ancestors
c is non-comparable to T if T contains no c’ that c is ancestor/ descendant of c’.
Reducible inference: only check if S – {c} causes any inferences to T
Example: we want to protect Object(L, S), where S is complete cuboid(means “no slide”), and L = {<a1, b1, c2, d2>, <a1, b2, c1, d2>}.
11/24/2010 41
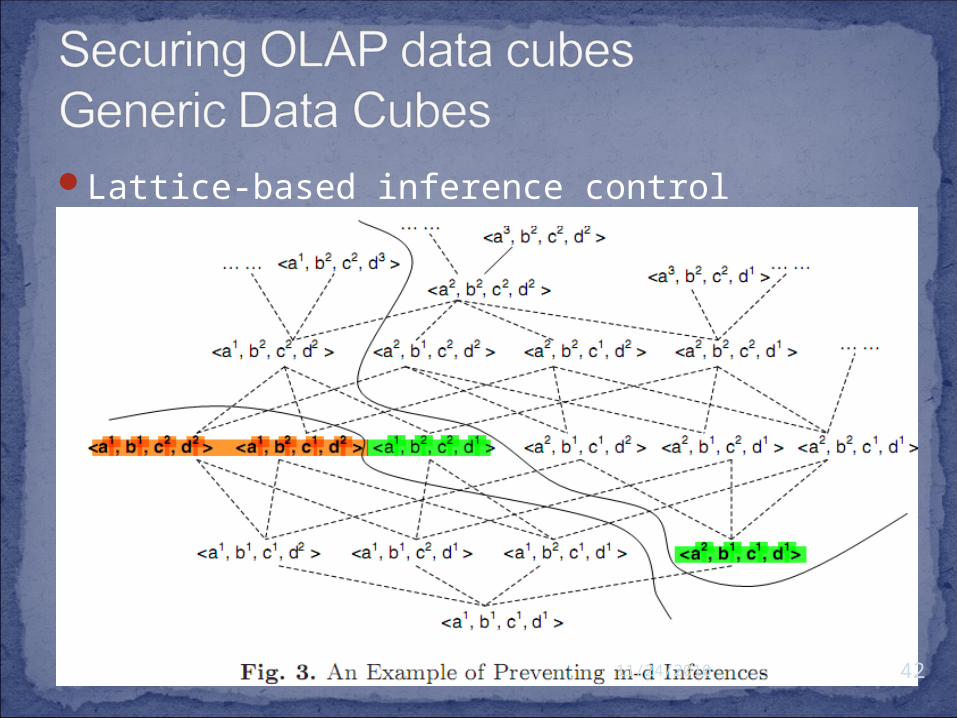
Lattice-based inference control
11/24/2010 42

Lattice-based inference controlMore generally, as long as any cuboid cr satisfies that all
ancestors are included by T (under LOWER curve), the descendant closure of cr is the maximal result for preventing m-d inferences
After m-d inferences are prevented,remove 1-d inferencescontrol m-d inferences to this new objectRepeating the two above steps until removing all 1-d references
The final result is a set of cells that are guaranteed to be free of inferences to the object
11/24/2010 43

Implement lattice-based inference control method in three-tier architecture:The authorization object computed through the above
iterative process comprises the data tierThe complement of the object is the aggregation tier since it
does not cause any inferences to the data tier
11/24/2010 44

Conclusion
11/24/2010 45

The most challenging security threat in Data Warehouse and OLAP systems is:Data stored in data warehouse may be disclosed through
seemingly innocent OLAP queries2 main inference threat that should be considered:
1-d inference m-d inference
We presented 3 methods to prevent / remove inference:Cardinality-based methodParity-based methodLattice-based inference control
All above methods are applicable to the three-tier inference control architecture, that especially suits OLAP systems.
11/24/2010 46

Lingyu and Sushil Jajodia. Security in Data Warehouses and OLAP Systems.
11/24/2010 47

11/24/2010 48