novel and “alternative” parallel programming paradigms laxmikant kale cs433 spring 2000
TRANSCRIPT

Novel and “Alternative” Parallel Programming Paradigms
Laxmikant Kale
CS433
Spring 2000

Parallel Programming models
• We studied:– MPI/Message passing, Shared Memory, Charm++/shared objs– loop-parallel: openMP,
• Other languages/paradigms:– Loop parallelism on distributed memory machines: HPF– Linda, Cid, Chant– Several others:
• Acceptance barrier
• I will assign reading assignments: – papers on the above languages, available on the web.– Pointers on course web page soon.

High Performance Fortran:
• Loop parallelism (mostly explicit) on distributed memory machines– Arrays are the primary data structure (1 or multi-dimensional)
– How do decide which data lives where?
• Provide “distribute” and “align primitives
• distribute A[block, cyclic] (notation difffers)
• Align B with A: same distribution
– Who does which part of the loop iteration?
• “Owner computes”
• A(I,J) = E

Linda
• Shared tuple space:– Specialization of shared memory
• Operations: – read, in, out [eval]
– Pattern matching ( in [2,x] -> reads x in, and removes tuple
• Tuple analysis

Cid
• Derived from Id, a data-flow language• Basic constructs:
– threads
– create new threads
– wait for data from other threads
• User level vs. system level thread– What is a thread?: stack, PC, ..
– Preemptive vs non-preemptive

Cid
• Multiple threads on each processor– Benefits: adaptive overlap
– Need a scheduler: use the OS scheduler?
– All threads on one PE share address space
• Thread mapping– At creation time, one may ask the system to map it to a PE
– No migration after a thread starts running
• Global pointers– Threads on different processors can exchange data via these
– (In addition to fork/join data exchange)

Cid
• Global pointers:– register any C structure as a global object (to get a globalID)
– “get” operation gets a local copy of a given object
• in read or write mode
– asynchronous “get”s are also supported
• get doesn’t wait for data to arrive
• HPF style global arrays• Grainsize control
– Especially for tree structure computations
– Create a thread, if other processors are idle (for example)

Chant
• Threads that send messages to each other– Message passing can be MPI style
– User level threads
• Simple implementation in Charm++ is available

CRL
• Cache coherence techniques with software-only support– release consistency
– get(Read/Write, data), work on data, release(data)
– get makes a local copy
– data-exchange protocols underneath provide the (simplified) consistency

Multi-paradigm interoperabilty
• Which one of these paradigms is “the best”?– Depends on the application, algorithm or module
– Doesn’t matter anyway, as we must use MPI (openMP)
• acceptance barrier
• Idea:– allow multiple modules to be written in different paradigms
• Difficulty:– Each paradigm has its own view of how to schedule
processors
– Comes down to scheduler
• Solution: have a common scheduler

Converse
• Common scheduler• Components for easily implementing new paradigms
– User level threads
• separates 3 functions of a thread package
– message passing support
– “Futures” (origin: Halstead: MultiLisp)
• What is a “future”
• data, ready-or-not, caller blocks on access
– Several other features

Other models


Object based load balancing
• Load balancing is a resource management problem• Two sources of imbalances
– Intrinsic: application-induced
– External: environment induced

Object based load balancing
• Application induced imbalances:– Abrupt, but infrequent, or
– Slow, cumulative
– rarely: frequent, large changes
• Principle of peristence– Extension of principle of locality
– Behavior, including computational load and communication patterns, of objects tend to persist over time
• We have implemented strategies that exploit this automatically!


Crack propagation example:
Decomposition into 16 chunks (left) and 128 chunks, 8 for each PE (right). The middle area contains cohesive elements. Both decompositions obtained using Metis. Pictures: S. Breitenfeld, and P. Geubelle
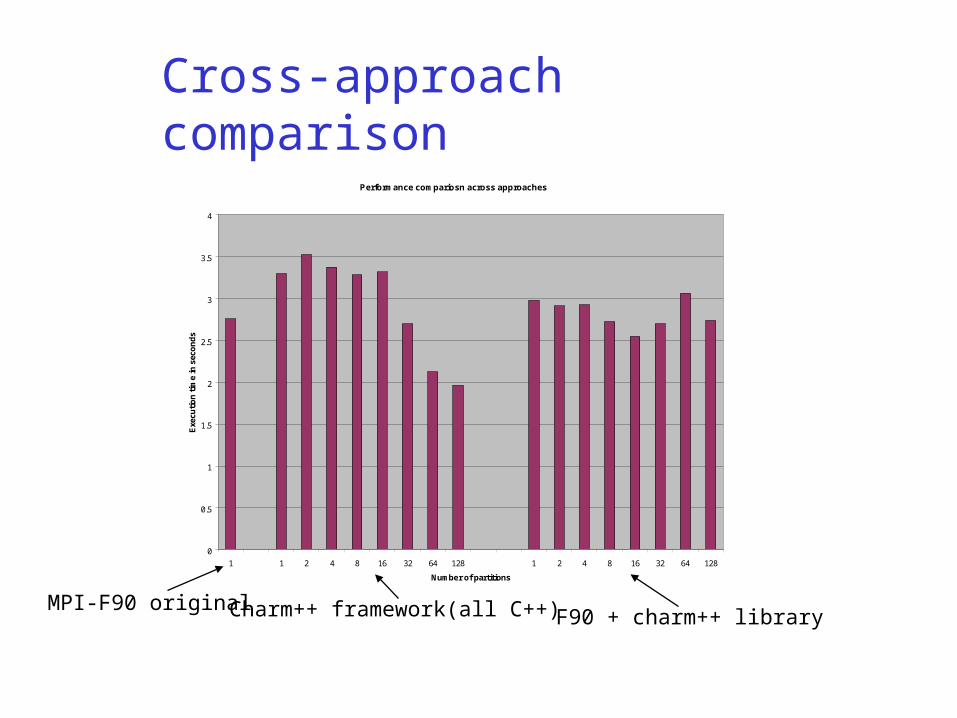
Performance compariosn across approaches
0
0.5
1
1.5
2
2.5
3
3.5
4
1 1 2 4 8 16 32 64 128 1 2 4 8 16 32 64 128
Number of partitions
Exe
cuti
on
tim
e in
sec
on
ds
MPI-F90 original Charm++ framework(all C++) F90 + charm++ library
Cross-approach comparison

Load balancer in action

Cluster: handling intrusion

Applying to other languages
• Need:• MPI on Charm++
– threaded MPI: multiple threads run on each PE
– threads can be migrated!
– Uses the load balancer framework
• Non-threaded irecv/waitall library– More work, but more efficient
• Currently rocket simulation program components– rocflo, rocsolid are being ported via this approach

What next?
• Timeshared parallel clusters• Web submission via appspector, and extension to
“faucets”• New applications:
– CSE simulations
– Operations Research
– Biological problems
– New applications??
• More info: http://charm.cs.uiuc.edu,– http://www.ks.uiuc.edu

Using Global Loads
• Idea:– For even a moderately large number of processors, collecting
a vector of load on each PE is not much more expensive than the collecting the total (per message cost dominates)
– How can we use this vector without creating serial bottleneck?
– Each processor know if it is overloaded compared with avg.
• Also knows which Pes are underloaded
• But need an algorithm that allows each processor to decide whom to send work to without global coordination, beyond getting the vector
– Insight: everyone has the same vector
– Also, assumption: there are sufficient fine-grained work pieces

Global vector scheme: contd
• Global algorithm: if we were able to make the decision centrally:
Receiver = nextUnderLoaded(0);
For (I=0, I<P; I++) {
if (load[I] > average) {
assign excess work to receiver, advancing receiver to the next as needed;
}
To make a distribued algorithm run the same algorithm on each processor! Except ignore any reassignment that doesn’t involve me.

Tree structured computations
• Examples: – Divide-and-conquer
– State-space search:
– Game-tree search
– Bidirectional search
– Branch-and-bound
• Issues:– Grainsize control
– Dynamic Load Balancing
– Prioritization

State Space Search
• Definition:– start state, operators, goal-state (implicit/explicit)
– Either search for goal state or for a path leading to one
• If we are looking for all solutions:– same as divide and conquer, except no backward
communication
• Search for any solution: – Use the same algorithm as above?
– Problems: inconsistent and not monotonically increasing speedups,

State Space Search
• Using priorities:– bitvector priorities
– Let root have 0 prio
– Prio of child:
– parent + my rank
p01 p02p03
p

Effect of Prioritization
• Let us consider shared memory machines for simplicity:– Search directed to left part of the tree
– Memory usage: let B be branching factor of tree, D its depth:
• O(D*B + P) nodes in the queue at a time
• With stack: O(D*P*B)
– Consistent and monotonic speedups

Need prioritized load balancing
• On non shared memory machines?• Centralized solution:
– Memory bottleneck too!
• Fully distributed solutions:• Hierarchical solution:
– Token idea

Bidirectional Search
• Goal state is explicitly known and operators can be inverted– Sequential:
– Parallel?

Game tree search
• Tricky problem:• alpha beta, negamax

Scalability
• The Program should scale up to use a large number of processors. – But what does that mean?
• An individual simulation isn’t truly scalable• Better definition of scalability:
– If I double the number of processors, I should be able to retain parallel efficiency by increasing the problem size

Isoefficiency
• Quantify scalability• How much increase in problem size is needed to retain
the same efficiency on a larger machine?• Efficiency : Seq. Time/ (P · Parallel Time)
– parallel time =
• computation + communication + idle