terry jones laxmikant kale. colony project funding provided by colony motivation, goals &...
Post on 22-Dec-2015
214 views
TRANSCRIPT

Terry JonesLaxmikant Kale

Colony Project funding provided by
Colony Motivation, Goals & Approach Research, A Look Back, A Look Forward
Full-Featured Linux on Blue Gene Parallel Aware System Software Virtualization for fault tolerance &
resource management Acknowledgements
Outline

Colony Project funding provided by
Outline
Colony Motivation, Goals & Approach Research, A Look Back, A Look Forward
Full-Featured Linux on Blue Gene Parallel Aware System Software Virtualization for fault tolerance &
resource management Acknowledgements

Colony Project funding provided by
Lawrence Livermore National Laboratory
Terry Jones
University of Illinois at Urbana-Champaign
Laxmikant KaleCelso MendesSayantan Chakravorty
International Business Machines
Jose MoreiraAndrew TaufernerTodd Inglett
Parallel Resource Instrumentation Framework
Scalable Load Balancing OS mechanisms for Migration Processor Virtualization for Fault
Tolerance Single system management space Parallel Awareness and Coordinated
Scheduling of Services Linux OS for cellular architecture
Services and Interfaces to Support Systems with Very Large Numbers of Processors
Collaborators
Topics
Title
Colony Project Overview

Colony Project funding provided by
PARALLEL RESOURCE MGMT
Strategies for scheduling and load balancing must be improved. Difficulties in achieving a balanced partitioning and dynamically scheduling workloads can limit scaling for complex problems on large machines.
GLOBAL SYSTEM MGMT
System management is inadequate. Parallel jobs require common operating system services, such as process scheduling, event notification, and job management to scale to large machines.
Develop infrastructure and strategies for automated parallel resource management
Today, application programmers must explicitly manage these resources. We address scaling issues and porting issues by delegating resource management tasks to a sophisticated runtime system and parallel OS.
Develop a set of services to enhance the OS to improve its ability to support systems with very large numbers of processors
We improve operating system awareness of the requirements of parallel applications. We enhance operating system support for parallel execution by providing coordinated scheduling and improved management services for very large machines.
Colony Motivation & Goals

Colony Project funding provided by
Virtualization lightweight mechanisms for virtual
resources better balance for large set of small
entities
Parallel Awareness Adaptability
apps go through different phases configurability versus adaptability
Checkpoint / Restart Migration
Strategies Being Investigated

Colony Project funding provided by
Outline
Colony Motivation, Goals & Approach Research, A Look Back, A Look Forward
Full-Featured Linux on Blue Gene Parallel Aware System Software Virtualization for fault tolerance &
resource management Acknowledgements

Colony Project funding provided by
Analysis of OS interference When do “health of the system” daemons have a
place
TLB misses demonstrate need for large page support
Analysis of system administration needs in Blue Gene env SSI / Centralized Database
Where is time spent on multi-rack Blue Gene machines
Logistics of porting full-featured Linux to compute nodes Which kernel?
Keeping IBM’s lawyers happy
Linux on Compute Node

Colony Project funding provided by
330 Calls found in at least two of the following OSs:
281 of these are found in Linux 65 of these are found in BGL 68 of these are found in RedStorm
AIX, FreeBSD, Linux, OpenSolaris, HPUX
Common Calls
I/O, sockets, signals, fork/exec Good coverage by lightweight kernels
Exceptions: fork/exec, mmap, some socket calls Three codes very similar (Ares, Ale3d, Blast) BGL and RedStorm had largely the same coverage
Evaluation of 7 apps/libs 78 system calls, 45 satisfied by lightweight kernels
System Call Usage Trends

Colony Project funding provided by
Linux System Call Count
0
50
100
150
200
250
300
350
2.4.2 2.4.18 2.4.19 2.4.20 2.6.0 2.6.3 2.6.18
Linux Version
Count of System Calls
The pre-TCP UNIX of 1977 (version 6) had 215 “operating system procedures”(includes calls like sched and panic), 43 of which listed as “system call entries”
• New Requirements unmet by traditional operating systems are surfacing• New Hardware platforms are surfacing• Sometimes system calls can meet the new requirement: Linux growth

Colony Project funding provided by
Full Featured Linux on BlueGene
A Look Back…Since Last PI meeting
• Compute node Linux demonstrated running NAS parallel benchmark, Charm++ application, and other programs
• We assessed operating system evolution on the basis of several key factors related to system call functionality. These results were the basis for a paper presenting the system call usage trends for Linux and Linux-like lightweight kernels. Comparisons are made with several other operating systems employed in high performance computing environments including AIX, HP-UX, OpenSolaris, and FreeBSD.
• Compute node Linux delivered to LLNL
A Look Forward• Demonstrate on machines at LLNL
• Demonstrate larger scaling results

Colony Project funding provided by
Outline
Colony Motivation, Goals & Approach Research, A Look Back, A Look Forward
Full-Featured Linux on Blue Gene Parallel Aware System Software Virtualization for fault tolerance &
resource management Acknowledgements

Colony Project funding provided by
Health of system monitoring More granular control
Not enough bandwidth to monitor
everything
What to monitor Orphaned processes
Critical daemons (asynch I/O, inetd,
syslogd, …)
Idle time/system time/user time
Daemons Always Bad?
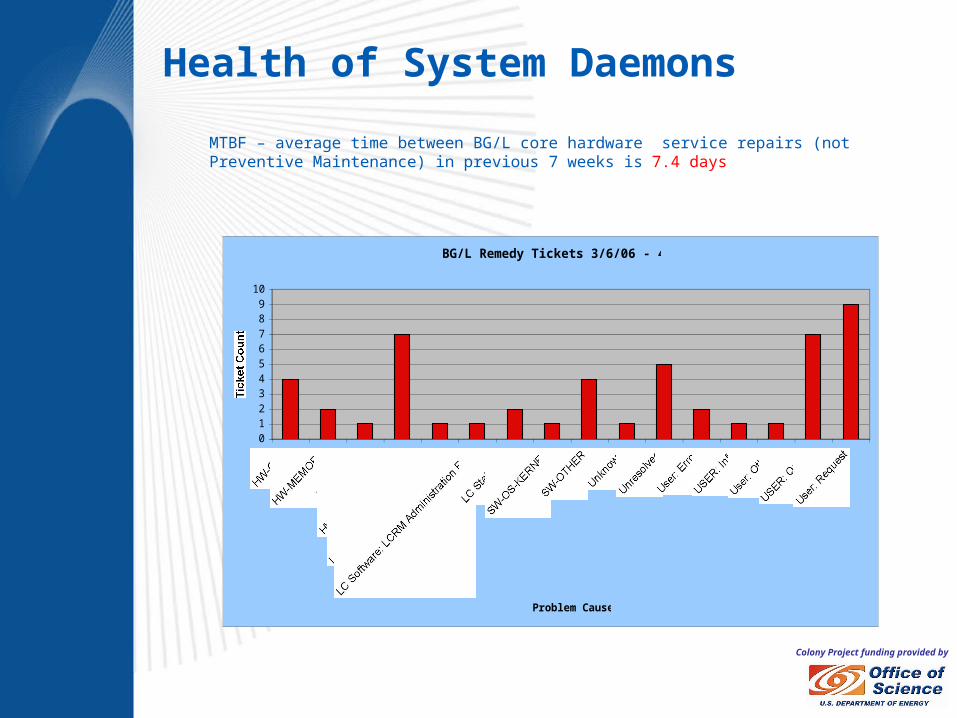
Colony Project funding provided by
BG/L Remedy Tickets 3/6/06 - 4/26/06
0123456789
10
HW-CPU
HW-MEMORYHW-OTHER
HW-POWER_SUPPLY
LC Network: Equipment Failure
LC Software: LCRM Administration Error
LC Staff ErrorSW-OS-KERNEL
SW-OTHERUnknown
UnresolvedUser: ErrorUSER: InfoUser: OtherUSER: QueryUser: Request
Problem Cause
Ticket Count
MTBF – average time between BG/L core hardware service repairs (not Preventive Maintenance) in previous 7 weeks is 7.4 days
Health of System Daemons

Colony Project funding provided by
Turn monitoring on takes several hours
Source of hangs (hw, system sw, app)
Subset attach
Smarter, possibly asynchronous, compute node
daemons
I want to know right now if the system is okay
Debug their application without system
administration
Unified stack trace (All but one in barrier)
SNMP TRAPS
Debugging

Colony Project funding provided by
OS Interference/Noise Examples
Left sample includes noise introducedby thread placement on an SMP

Colony Project funding provided by
OS Interference/Noise Examples 2
Left sample includes noise introducedby thread placement on an SMP

Colony Project funding provided by
Parallel Aware Scheduling
A Look Back…Since Last PI meeting
• Extend several tools for analyzing os interference
• Studies of os interference at 2000+ node counts.
• Ongoing: Can HPC exploit real-time Linux work (Suse/Novell)?
A Look Forward• Demonstrate code scaling on Colony Linux kernel
• Demonstrate Parallel Aware Scheduling with Hyperthreading
• Demonstrate larger scaling results

Colony Project funding provided by
Outline
Colony Motivation, Goals & Approach Research, A Look Back, A Look Forward
Full-Featured Linux on Blue Gene Parallel Aware System Software Virtualization for fault tolerance &
resource management Acknowledgements

Colony Project funding provided by
Divide the computation into a large number of pieces Independent of the number of processors
Let the runtime system map objects to processors Implementations: Charm++, Adaptive-MPI (AMPI)
User View System implementation
P0 P1 P2
Processor Virtualization with Migratable Objects
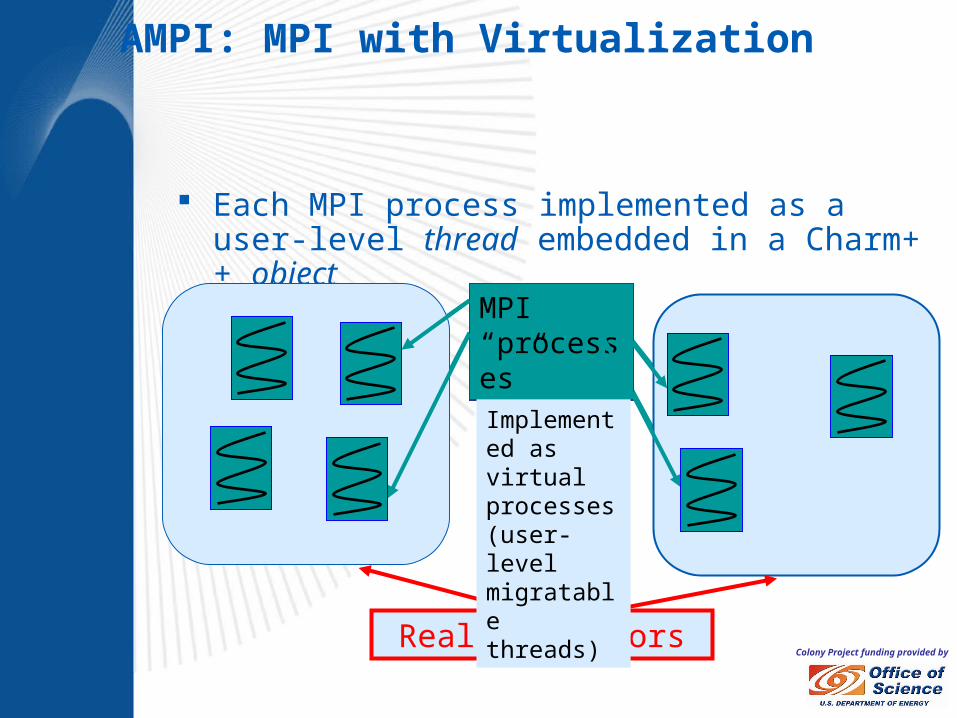
Colony Project funding provided by
Each MPI process implemented as a user-level thread embedded in a Charm++ object
MPI processes
Real Processors
MPI “processes”
Implemented as virtual processes (user-level migratable threads)
AMPI: MPI with Virtualization

Colony Project funding provided by
BlueGene/L Migrating threads on BG/L Performance of Centralized Load Balancers
Resource Management Load Balancing: Scalable, topology aware
Fault Tolerance Various levels of tolerance, multiple schemes
Research Using Processor Virtualization

Colony Project funding provided by
Port , optimize and scale existing Charm++/AMPI applications on BlueGene/L
Molecular Dynamics: NAMD (Univ.Illinois) Collection of (charged) atoms, with bonds Simulations with millions of timesteps desired
Cosmology: ChaNGa (Univ.Washington) N-Body problem, with gravitational forces Simulation and analysis/visualization done in parallel
Quantum Chemistry: CPAIMD (IBM/NYU/others) Car-Parrinello Ab Initio Molecular Dynamics Fine-grain parallelization, long time simulations
Efforts are leveraging on current collaborations/grants
Utilize Blue Gene

Colony Project funding provided by
Migrating threads in AMPI: A user-level thread should be able to migrate to
any other processor as needed Virtual Memory issues on BlueGene/L
Since VM space is limited, we cannot reserve virtual space for each thread on all processors
As we do on other machines A solution:
Memory-aliased threads All threads use the same stack space in virtual
memory But each has a different space in physical memory! Mmap then on each context switch, from physical memory
Has a slightly larger overhead (see ICPP’06 paper) Started working with IBM on other possibilities
BlueGene/L and Thread Migration

Colony Project funding provided by
Measurement Based runtime decisions Communication volumes and Computational loads Object Migration
Preliminary work on Advanced Load Balancers Communication-aware load balancing
considers objects’ communication graph Multi-Phase load balancing
Balance for each program phase separately Asynchronous load balancing
overlap of load balancing and computation Ongoing work:
Centralized load-balancers for NAMD and Cosmology on BG/L
Highly Scalable load balancers Topology-aware load balancing
considers network topology major goal: optimize hop´bytes metric
Resource Management Work

Colony Project funding provided by
Existing load balancing strategies don’t scale on extremely large machines Consider an application with 1M objects on 64K processors
Centralized: Object load and communication data sent to one processor, which makes decisions Becomes a bottleneck
Distributed: Load balancing among neighboring processors Does not achieve good balance quickly
Hybrid (Gengbin Zheng, PhD Thesis, 2005) Dividing processors into independent sets of groups, and groups are organized in hierarchies (decentralized)
Each group has a leader (the central node) which performs centralized load balancing
Load Balancing on Large Machines

Colony Project funding provided by
Research from BGW day, October 2006.
Cosmological Code ChaNGa Results for Basic Load Balancers
Results from 20,480 processors
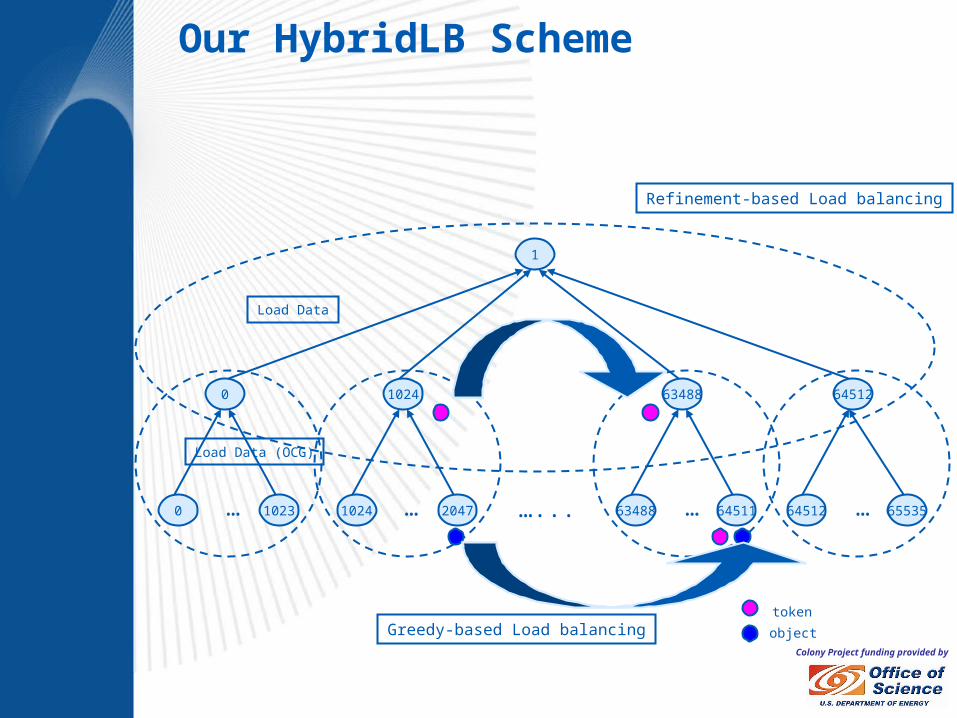
Colony Project funding provided by
Refinement-based Load balancing
0 … 1023 6553564512 …1024 … 2047 6451163488 ……...
0 1024 63488 64512
1
Load Data (OCG)
Greedy-based Load balancing
Load Data
token
object
Our HybridLB Scheme

Colony Project funding provided by
Problem Assign K objects to P processors, such that: Compute load on processors is balanced Communicating objects are placed on nearby processors.
Two Phase Solution Coalesce objects into P computationally-balanced tasks
Map the tasks to the correct processors So as to minimize “hops-per-byte” metric
Topology-aware mapping of tasks

Colony Project funding provided by
Automatic checkpointing / fault-detection / restart Scheme 1: checkpoint to file-system Scheme 2: In-memory checkpointing
Proactive reaction to impending faults Migrate objects when a fault is imminent Keep “good” processors running at full
pace Refine load balance after migrations
Scalable Fault Tolerance Using message-logging to tolerate frequent
faults in a scalable fashion
Fault Tolerance
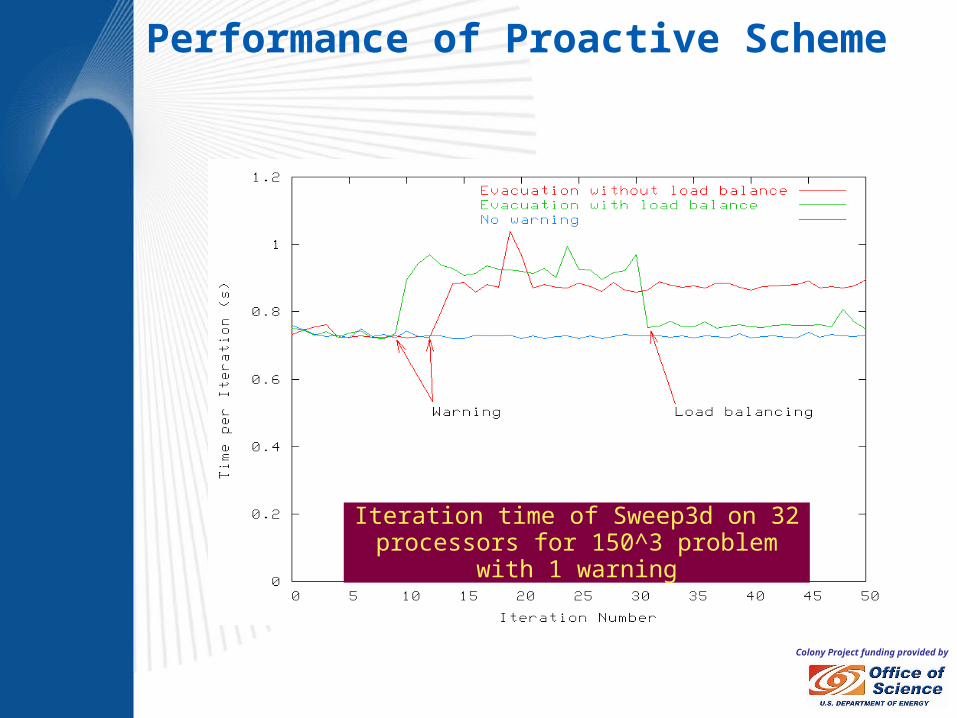
Colony Project funding provided by
Iteration time of Sweep3d on 32 processors for 150^3 problem with 1 warning
Performance of Proactive Scheme

Colony Project funding provided by
Basic idea: if one out of 100,00 processors fails, we shouldn’t have to send the “innocent” 99,999 processors scurrying back to their checkpoints, and duplicate all the work since their last checkpoint.
Basic scheme: everyone logs messages sent to others Asynchronous checkpoints On failure,
the objects from the failed processors are resurrected (from their checkpoints) on other processors,
Their acquaintances re-send messages since last checkpoint
The failed objects catch up with the rest, and continue
Of course, several wrinkles and issues arise
Scalable Fault Tolerance

Colony Project funding provided by Time
Progress
Pow
er
Normal Checkpoint-Resart method
Progress is slowed down with failures
Power consumption is continuous

Colony Project funding provided by
Our Checkpoint-Resart method
(Message logging + Object-based virtualization)
Progress is faster with failures
Power consumption is lower during recovery

Colony Project funding provided by
Message Logging allows fault-free processors to continue with their execution
However, sooner or later some processors start waiting for crashed processor
Virtualization allows us to move work from the restarted processor to waiting processors
Chares are restarted in parallel Restart cost can be reduced
Fast Restart
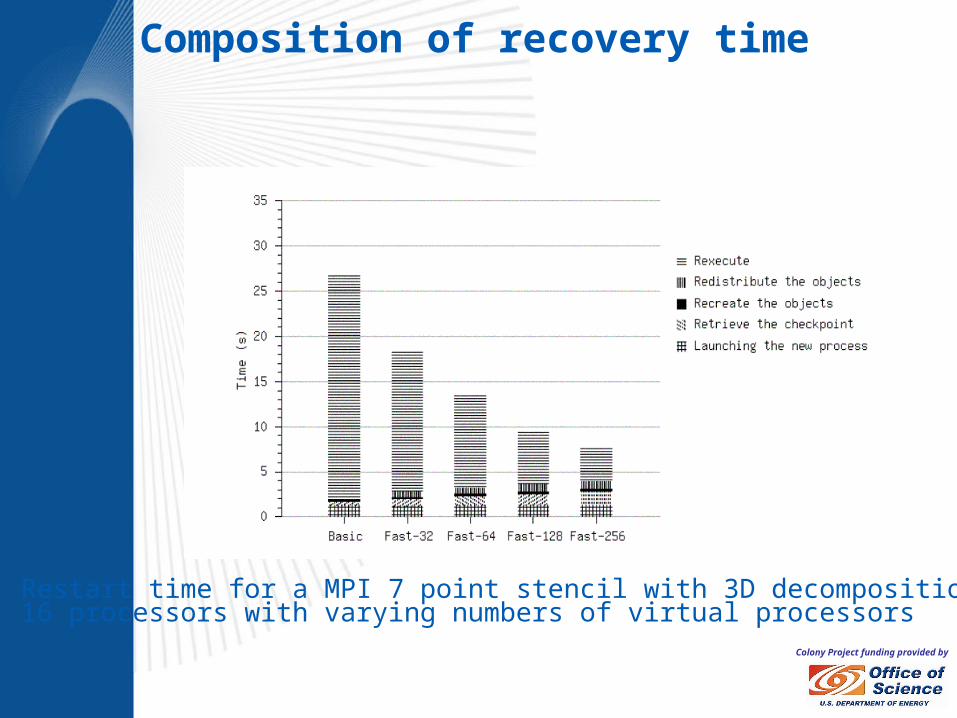
Colony Project funding provided by
Restart time for a MPI 7 point stencil with 3D decomposition on 16 processors with varying numbers of virtual processors
Composition of recovery time

Colony Project funding provided by
Benefit of virtualization in the fault free case:
NAS benchmarks
2 4 8 16 320
500
1000
1500
2000
2500
3000
3500
4000 MG class B
Processors
Mflo
ps
4 9 16 250
500
1000
1500
2000
2500
3000 SP class B
Processors
Mflo
ps
2 4 8 16 320
100
200
300
400
500
600
700
800
900 CG class B
Processors
Mflo
ps
2 4 8 16 320
100020003000400050006000700080009000
10000 LU class B
Processors
Mflo
ps
AMPI
AMPI-FTmultiple vp
AMPI-FT 1vp

Colony Project funding provided by
Virtualization for Fault Tolerance and Resource Mgmt
A Look Back…Since Last PI meeting
A Look Forward• Demonstrate new schemes to remove hot spots• Demonstrate ft up to one million cores• Demonstrate resource management up to one million cores
• We completed and demonstrated a prototype of our fault tolerance scheme based on message-logging [Chakravorty07], showing that the distribution of objects residing on a failing processor can significantly improve the recovery time after the failure.
• We extended the set of load balancers available in Charm++, by integrating the recently developed balancers based on machine topology. These balancers use metrics based on volume of communication and number of hops as factors in their balancing decisions
• We assessed the effectiveness of our in-memory checkpointing by performing tests on a large BlueGene/L machine. In these tests, we used a 7-point stencil with 3-D domain decomposition, written in MPI. Our results are quite promising to 20,480 processors.
• Our proactive fault tolerance scheme is based on the hypothesis that, some faults can be predicted. We leverage the migration capabilities of Charm++, to evacuate objects from a processor where faults are imminent. We assessed the performance penalty due to incurred overheads as well as memory footprint penalties for up to 20,480 processors.

Colony Project funding provided by
Outline
Colony Motivation, Goals & Approach Research, A Look Back, A Look Forward
Full-Featured Linux on Blue Gene Parallel Aware System Software Virtualization for fault tolerance &
resource management Acknowledgements

Colony Project funding provided by
…and in conclusion…
For Further Info http://www.hpc-colony.org http://charm.cs.uiuc.edu http://www.research.ibm.com/bluegene
Partnerships and Acknowledgements DOE Office of Science ASC Program Collaborating Partners
UIUC IBM LLNL
Colony Team Laxmikant Kale, Celso Mendes, Sayantan Chakravorty, Andrew
Tauferner, Todd Inglett, Jose Moreira, Terry Jones Noise Application written by Jeff Fier Thanks to Jose Castanos, George Almasi, Edi Shumeli for their help FTQ due to Matt Sottile & Ron Minnich This work was performed under the auspices of the U.S. Department of Energy by University of
California Lawrence Livermore National Laboratory under contract No. W-7405-Eng-48.

Colony Project funding provided by
Extra Viewgraphs
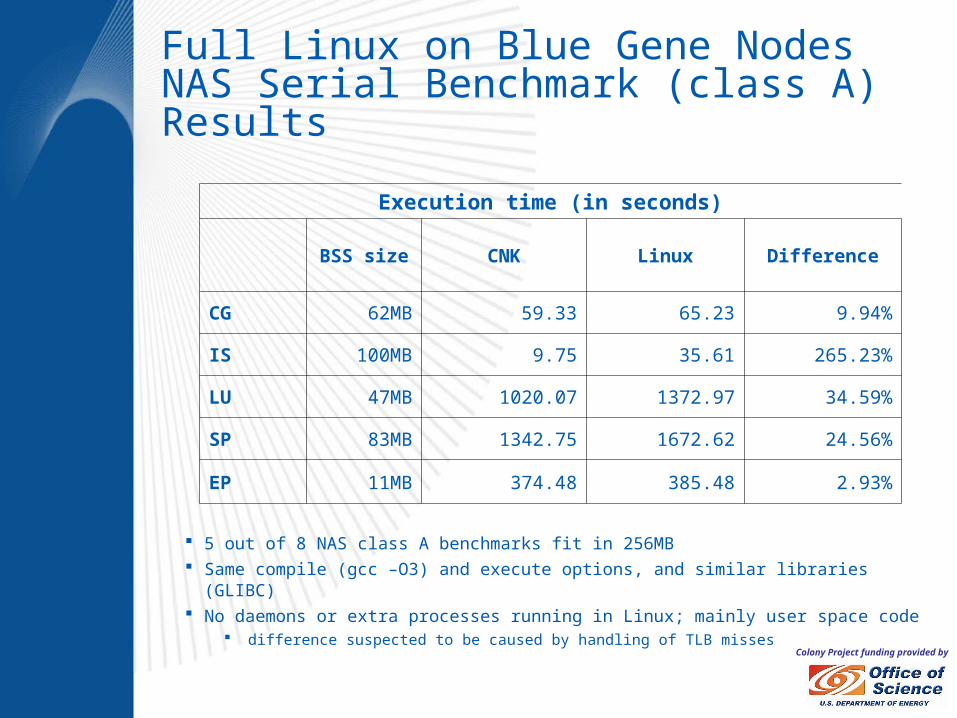
Colony Project funding provided by
Full Linux on Blue Gene NodesNAS Serial Benchmark (class A) Results
5 out of 8 NAS class A benchmarks fit in 256MB Same compile (gcc –O3) and execute options, and similar libraries (GLIBC) No daemons or extra processes running in Linux; mainly user space code
difference suspected to be caused by handling of TLB misses
Execution time (in seconds)
BSS size CNK Linux Difference
CG 62MB 59.33 65.23 9.94%
IS 100MB 9.75 35.61 265.23%
LU 47MB 1020.07 1372.97 34.59%
SP 83MB 1342.75 1672.62 24.56%
EP 11MB 374.48 385.48 2.93%

Colony Project funding provided by
Time
Node1a
Node1b
Node1c
Node1d
Node2a
Node2b
Node2c
Node2d
Node1a
Node1b
Node1c
Node1d
Node2a
Node2b
Node2c
Node2d
Time
OS Scheduling on a 2x4 System

Colony Project funding provided by
Recent Parallel Aware Scheduling ResultsMiranda -- Instability & Turbulence
High order hydrodynamics code for computing fluid instabilities and turbulent mix
Employs FFTs and band-diagonal matrix solvers to compute spectrally-accurate derivatives, combined with high-order integration methods for time advancement
Contains solvers for both compressible and incompressible flows
Has been used primarily for studying Rayleigh-Taylor (R-T) and Richtmyer- Meshkov (R-M) instabilities, which occur in supernovae and Inertial Confinement Fusion (ICF)

Colony Project funding provided by
Top Down (start with Full-Featured OS)
Why?Broaden domain of applications that can run on the most powerful machines through OS support More general approaches to processor virtualization, load balancing and
fault tolerance Increased interest in applications such as parallel discrete event simulation Multi-threaded apps and libraries
Why not?
Difficult to sustain performance with increasing levels of parallelism Many parallel algorithms are extremely sensitive to serializations We will address this difficulty with parallel aware scheduling
Question: How much should system software offer in terms of features?
Answer: Everything required, and as much desired as possible

Colony Project funding provided by
Single Process Space Process query: These services provide information about which
processes are running on the machine, who they belong to, how they are grouped into jobs, and how much resources they are using.
Process creation: These services support the creation of new processes and their grouping into jobs.
Process control: These services support suspension, continuation, and termination of processes.
Process communication: These services implement communications between processes.
Single File Space any completely qualified file descriptor (e.g., “/usr/bin/ls”)
represents exactly the same file to all the processes running on the machine.
Single Communication Space we will provide mechanisms in which any two processes can establish
a channel between them.
The Logical View
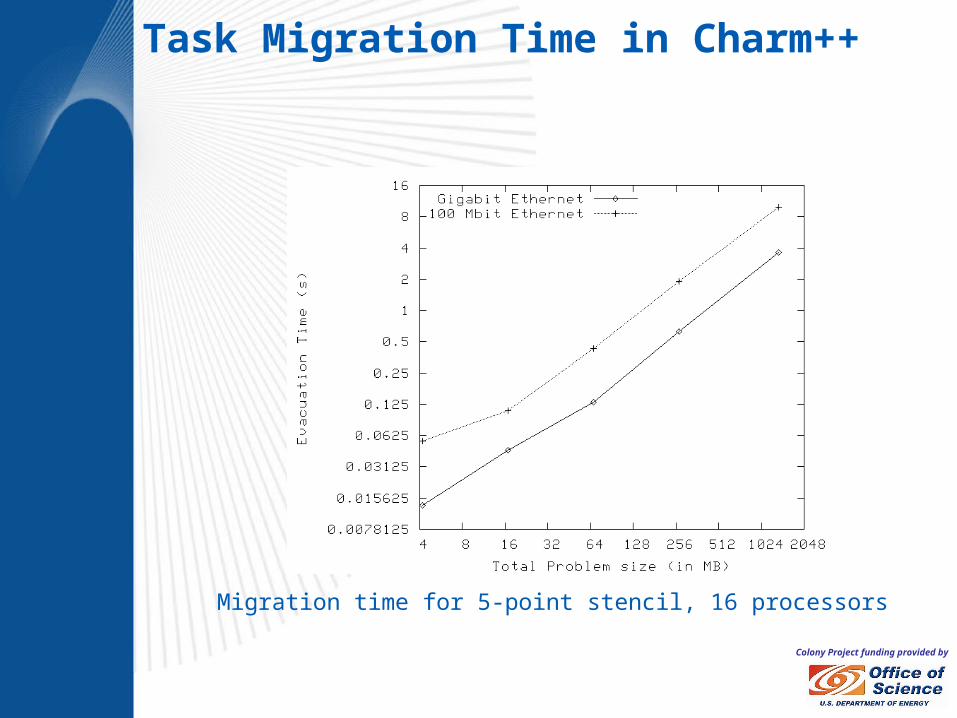
Colony Project funding provided by
Migration time for 5-point stencil, 16 processors
Task Migration Time in Charm++
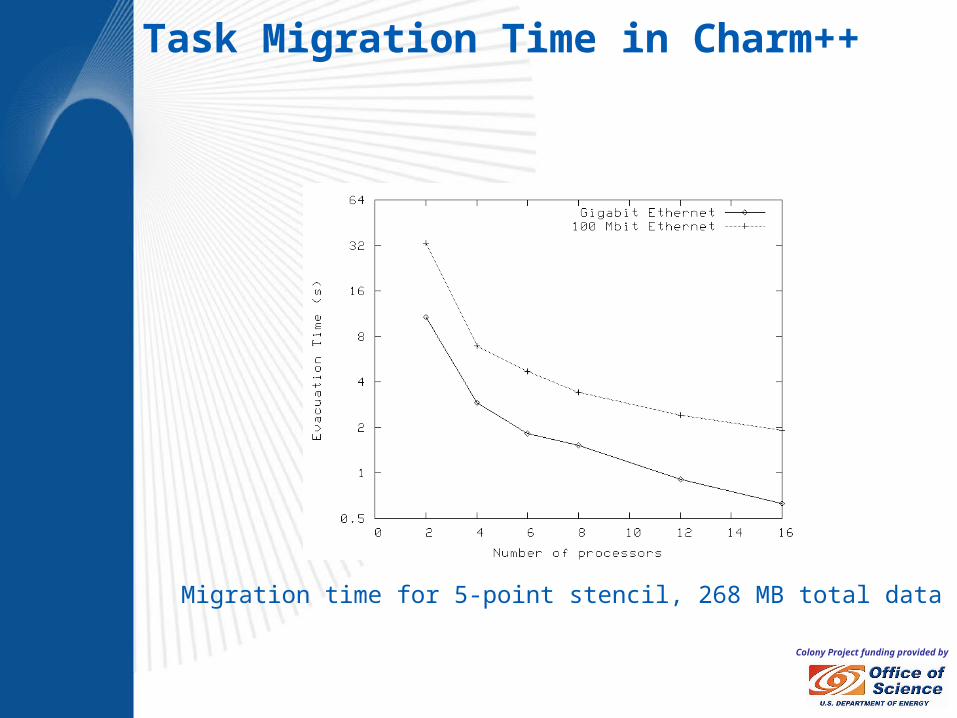
Colony Project funding provided by
Migration time for 5-point stencil, 268 MB total data
Task Migration Time in Charm++