nvidia : flop wars, Épisode iii - lal events directory ... · maxwell volta stacked dram unified...
TRANSCRIPT

1
NVIDIA : FLOP WARS, ÉPISODE III François Courteille| [email protected] | Ecole Polytechnique | 4-June-13

2
OUTLINE
NVIDIA and GPU Computing Roadmap
Inside Kepler Architecture SXM
Hyper-Q
Dynamic Parallelism
Computing and Visualizing : OpenGL support
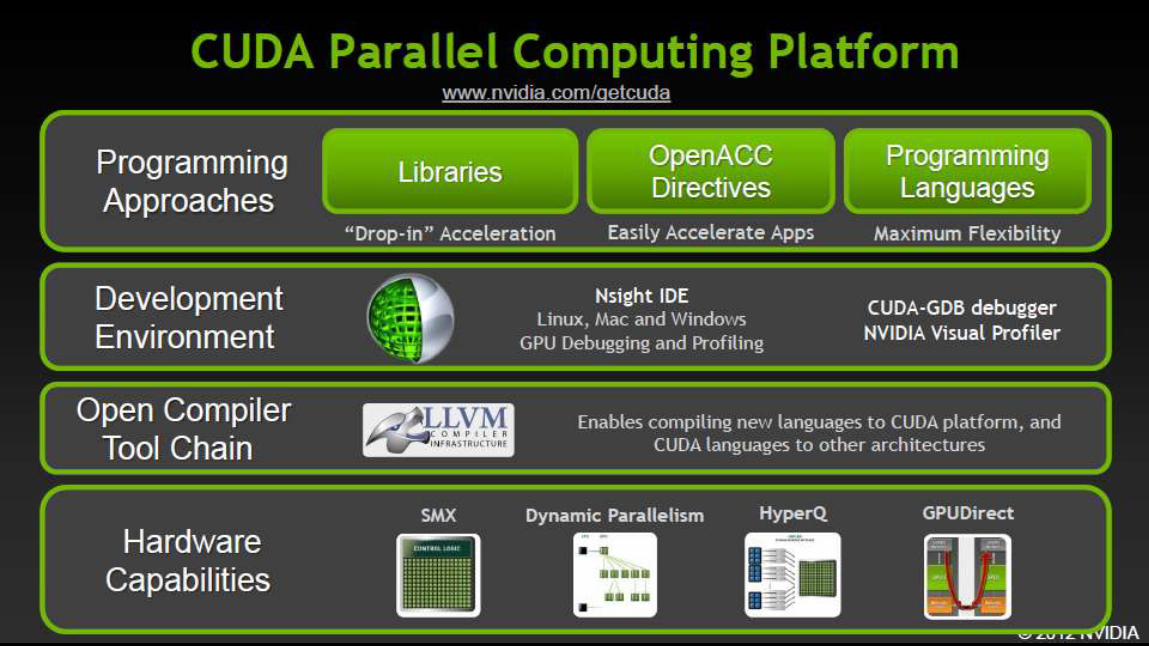
Programming GPUs – The Software Ecosystem OpenACC :
Libraries
Languages and Frameworks
Application porting examples : MiniFE & Enzo

3
Cloud
VGX ™
GeForce® GRID
GPU
GeForce®
Quadro®
, Tesla®
NVIDIA - Core Technologies and Brands
Mobile
Tegra® Founded 1993
Invented GPU 1999 – Computer Graphics

4
5
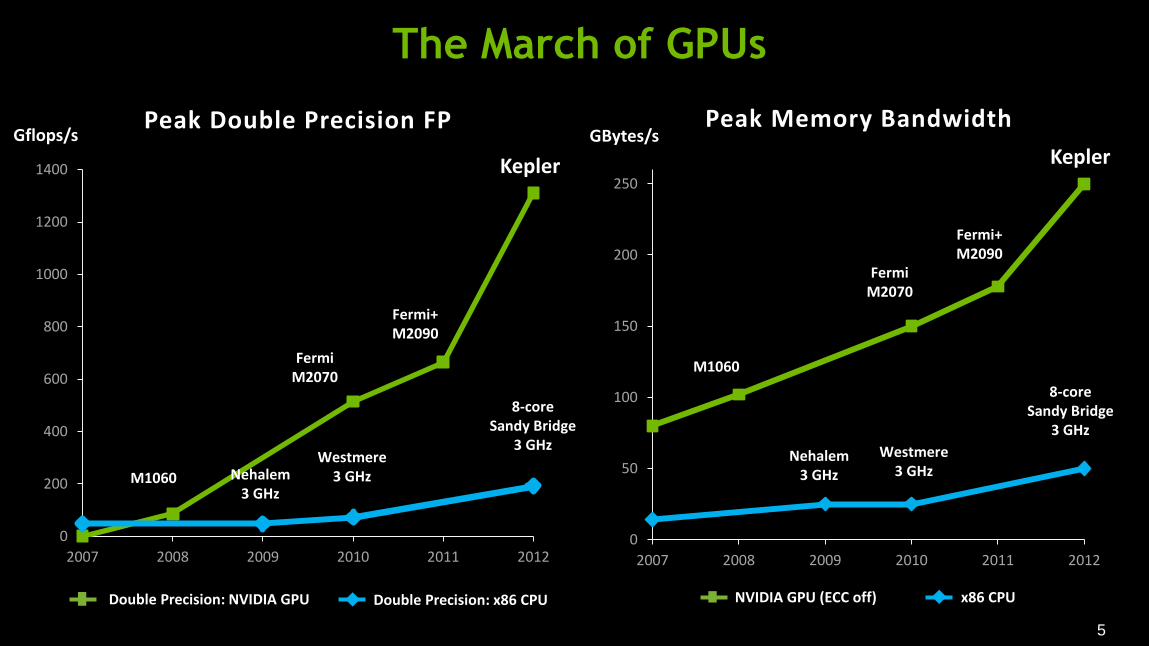
The March of GPUs
0
50
100
150
200
250
2007 2008 2009 2010 2011 2012
GBytes/s Peak Memory Bandwidth
M1060
Nehalem 3 GHz
Westmere 3 GHz
8-core Sandy Bridge
3 GHz
Fermi M2070
Fermi+ M2090
0
200
400
600
800
1000
1200
1400
2007 2008 2009 2010 2011 2012
Gflops/s Peak Double Precision FP
Nehalem 3 GHz
Westmere 3 GHz
Fermi M2070
Fermi+ M2090
M1060
8-core Sandy Bridge
3 GHz
NVIDIA GPU (ECC off) x86 CPU Double Precision: NVIDIA GPU Double Precision: x86 CPU
Kepler Kepler

6
2012 2014 2008 2010
DP G
FLO
PS p
er
Watt
Kepler
Tesla
Fermi
Maxwell
Volta Stacked DRAM
Unified Virtual Memory
Dynamic Parallelism
FP64
CUDA
32
16
8
4
2
1
0.5
Tesla CUDA Architecture Roadmap


8
Data Center Workstation
NVIDIA Tesla Series Products

9
Kepler GPU Fastest, Most Efficient HPC Architecture Ever
3x Performance per Watt
Easy Speed-up for Legacy
MPI Apps
Parallel Programming Made
Easier than Ever
Dynamic
Parallelism
SMX
Hyper-Q
10
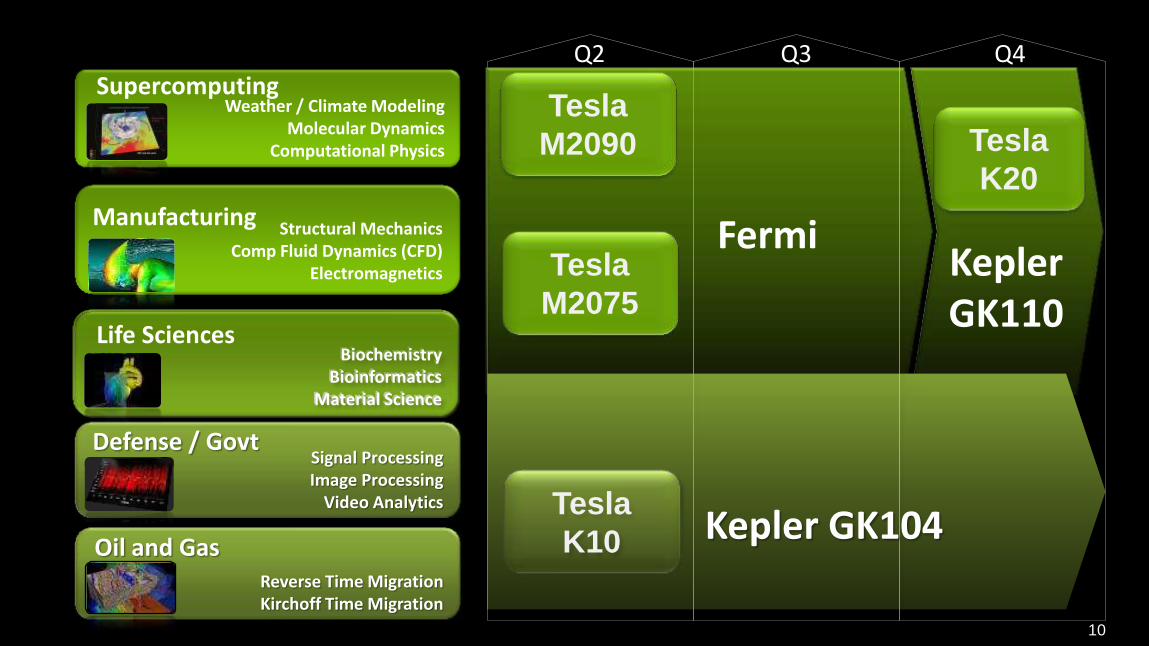
Biochemistry
Bioinformatics Material Science
Biochemistry
Bioinformatics Material Science
Structural Mechanics
Comp Fluid Dynamics (CFD) Electromagnetics
Signal Processing Image Processing
Video Analytics
Defense / Govt
Manufacturing
Reverse Time Migration Kirchoff Time Migration
Weather / Climate Modeling
Molecular Dynamics Computational Physics
Supercomputing
Oil and Gas
Life Sciences
Q2 Q3 Q4
Tesla
M2075
Tesla
M2090
Tesla
K10
Tesla
K20
Kepler GK110
Fermi
Kepler GK104

11
Tesla K10
Same Power, 2x Performance of Fermi Product Name M2090 K10
GPU Architecture Fermi Kepler GK104
# of GPUs 1 2
Board Per GPU
Single Precision Flops 1.3 TF 4.58 TF 2.29 TF
Double Precision Flops 0.66 TF 0.190 TF 0.095 TF
# CUDA Cores 512 3072 1536
Memory size 6 GB 8 GB 4GB
Memory BW (ECC off) 177.6 GB/s 320 GB/s 160GB/s
PCI-Express Gen 2: 8 GB/s Gen 3: 16 GB/s
Board Power 225 watts 225 watts
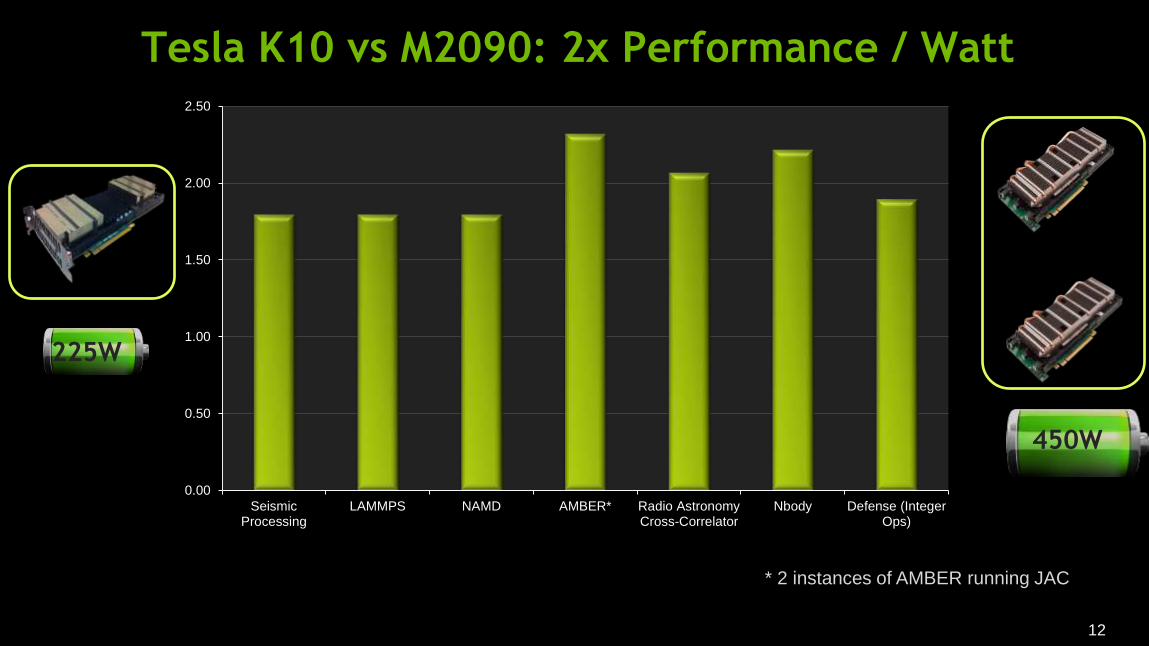
12
Tesla K10 vs M2090: 2x Performance / Watt
* 2 instances of AMBER running JAC
0.00
0.50
1.00
1.50
2.00
2.50
SeismicProcessing
LAMMPS NAMD AMBER* Radio AstronomyCross-Correlator
Nbody Defense (IntegerOps)
225W
450W
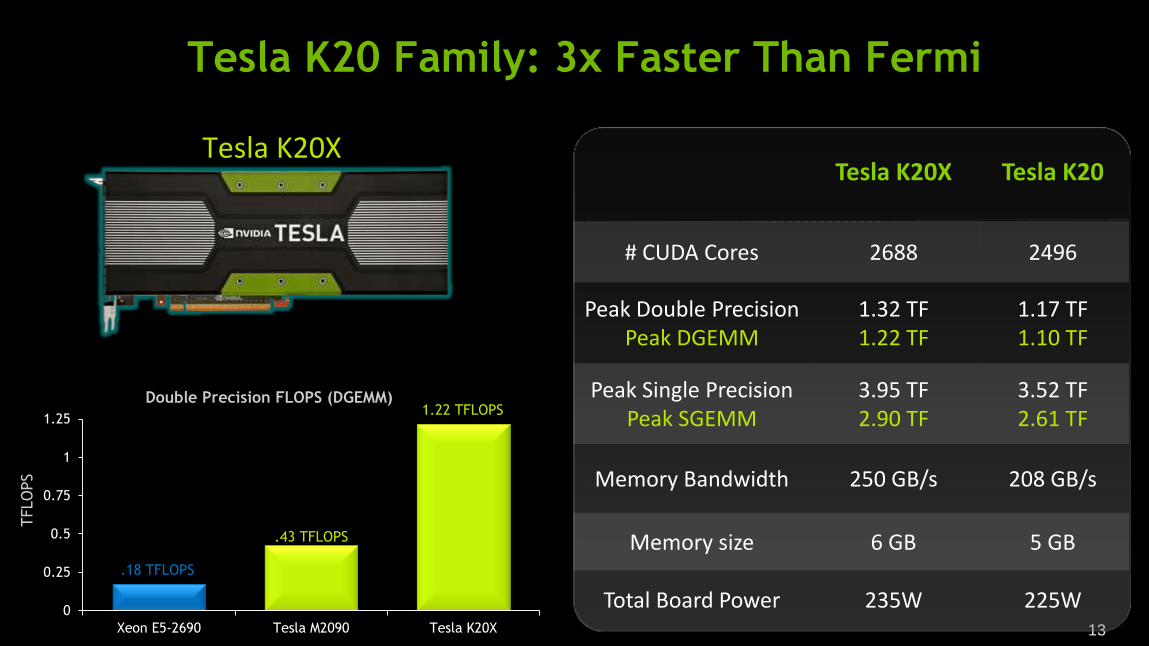
13
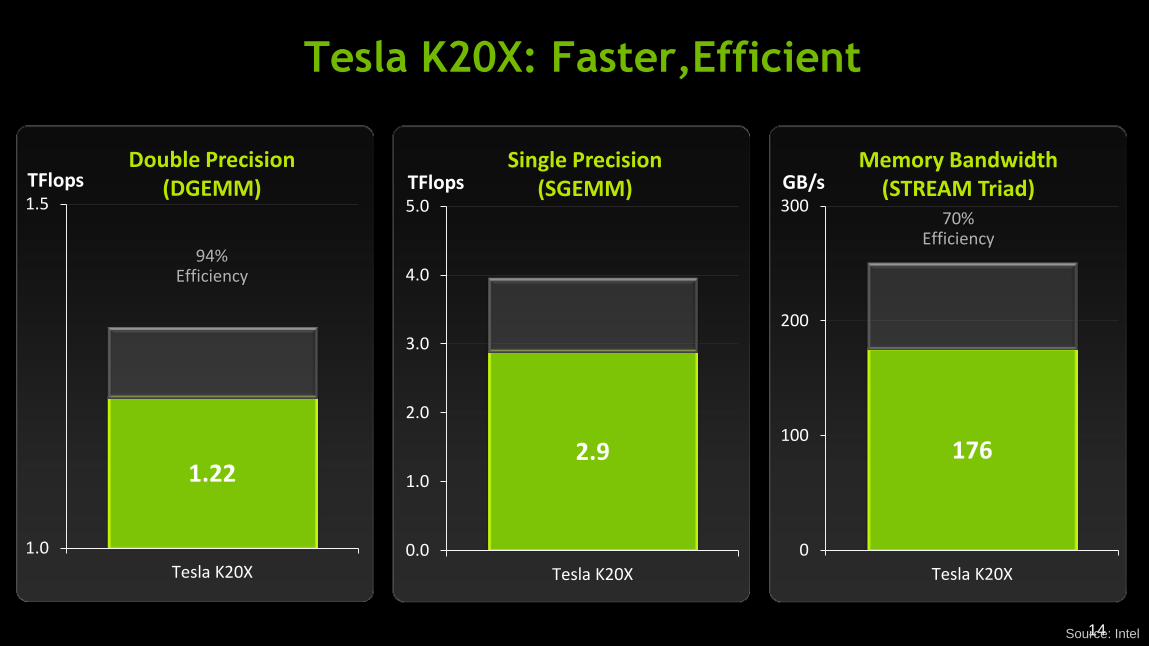
Tesla K20X Tesla K20
# CUDA Cores 2688 2496
Peak Double Precision Peak DGEMM
1.32 TF 1.22 TF
1.17 TF 1.10 TF
Peak Single Precision Peak SGEMM
3.95 TF 2.90 TF
3.52 TF 2.61 TF
Memory Bandwidth 250 GB/s 208 GB/s
Memory size 6 GB 5 GB
Total Board Power 235W 225W
Tesla K20 Family: 3x Faster Than Fermi
0
0.25
0.5
0.75
1
1.25
Xeon E5-2690 Tesla M2090 Tesla K20X
TFLO
PS
.18 TFLOPS
.43 TFLOPS
1.22 TFLOPS Double Precision FLOPS (DGEMM)
Tesla K20X
14
Tesla K20X: Faster,Efficient
1.22
1.0
1.5
Tesla K20X
TFlops
94% Efficiency
Double Precision (DGEMM)
176
0
100
200
300
Tesla K20X
GB/s
70% Efficiency
Memory Bandwidth (STREAM Triad)
2.9
0.0
1.0
2.0
3.0
4.0
5.0
Tesla K20X
TFlops Single Precision
(SGEMM)
Source: Intel
15
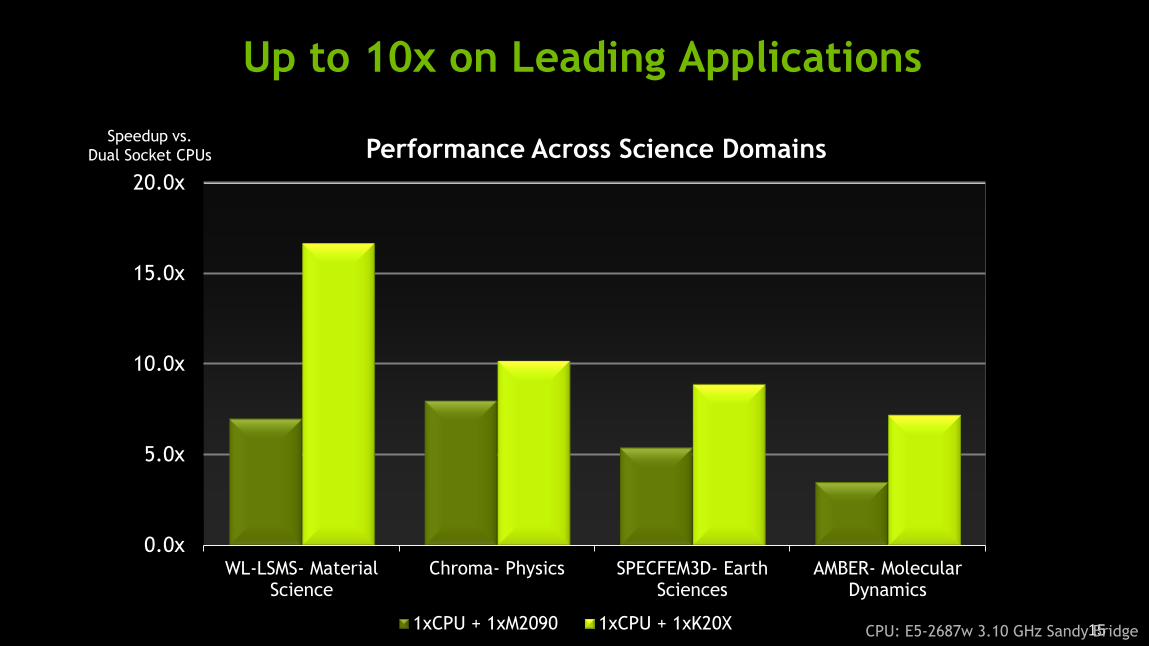
Up to 10x on Leading Applications
0.0x
5.0x
10.0x
15.0x
20.0x
WL-LSMS- MaterialScience
Chroma- Physics SPECFEM3D- EarthSciences
AMBER- MolecularDynamics
1xCPU + 1xM2090 1xCPU + 1xK20X
Performance Across Science Domains Speedup vs.
Dual Socket CPUs
CPU: E5-2687w 3.10 GHz Sandy Bridge

16
Titan: World’s Fastest Supercomputer
18,688 Tesla K20X GPUs
27 Petaflops Peak: 90% of Performance from GPUs
17.59 Petaflops Sustained Performance on Linpack

17
World’s Most Energy Efficient Supercomputer
3150 MFLOPS/Watt
128 Tesla K20 Accelerators
$100k Energy Savings / Yr
300 Tons of CO2 Saved / Yr 0
1000
2000
3000
CINECA Eurora-Tesla K20
NICS Beacon-Greenest Xeon
Phi System
C-DAC- GreenestCPU System
MFLOPS/Watt
CINECA Eurora
“Liquid-Cooled” Eurotech Aurora Tigon
Greener than Xeon Phi, Xeon CPU

www.nvidia.com/GPUTestDrive
GPU Test Drive
Double your Fermi Performance with Kepler GPUs

19
Tesla K20/K20X Details
20
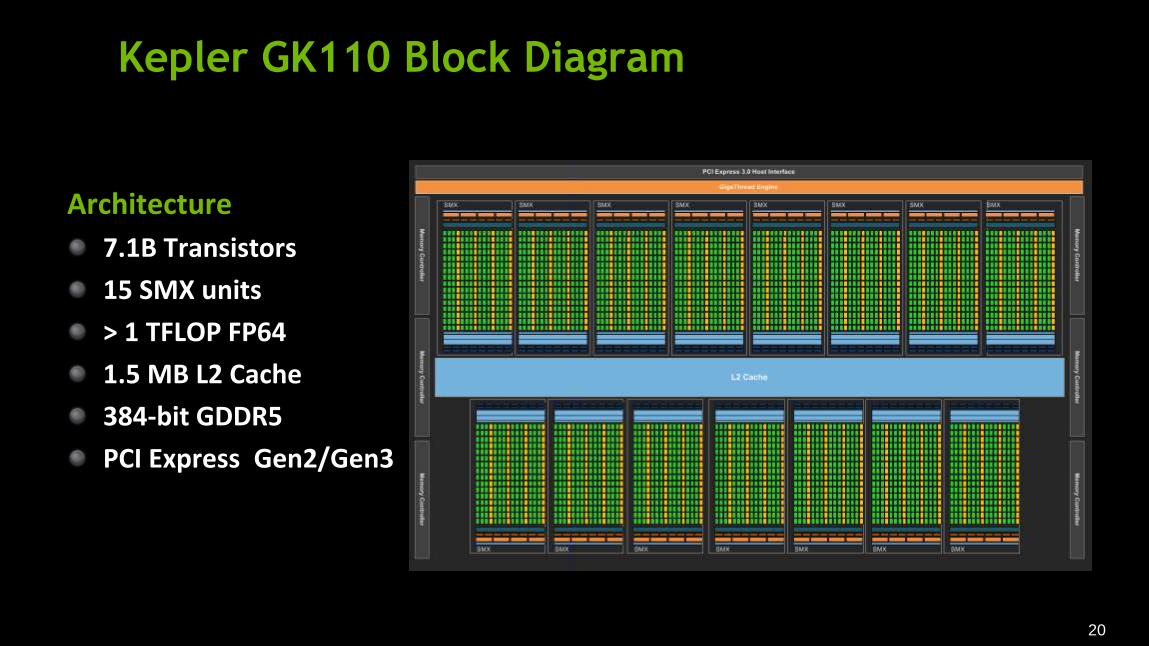
Kepler GK110 Block Diagram
Architecture
7.1B Transistors
15 SMX units
> 1 TFLOP FP64
1.5 MB L2 Cache
384-bit GDDR5
PCI Express Gen2/Gen3

21
Kepler GK110 SMX vs Fermi SM
Ground up redesign for perf/W
6x the SP FP units
4x the DP FP units
Significantly slower FU clocks
3x sustained perf/W
Processors are getting wider, not faster

22
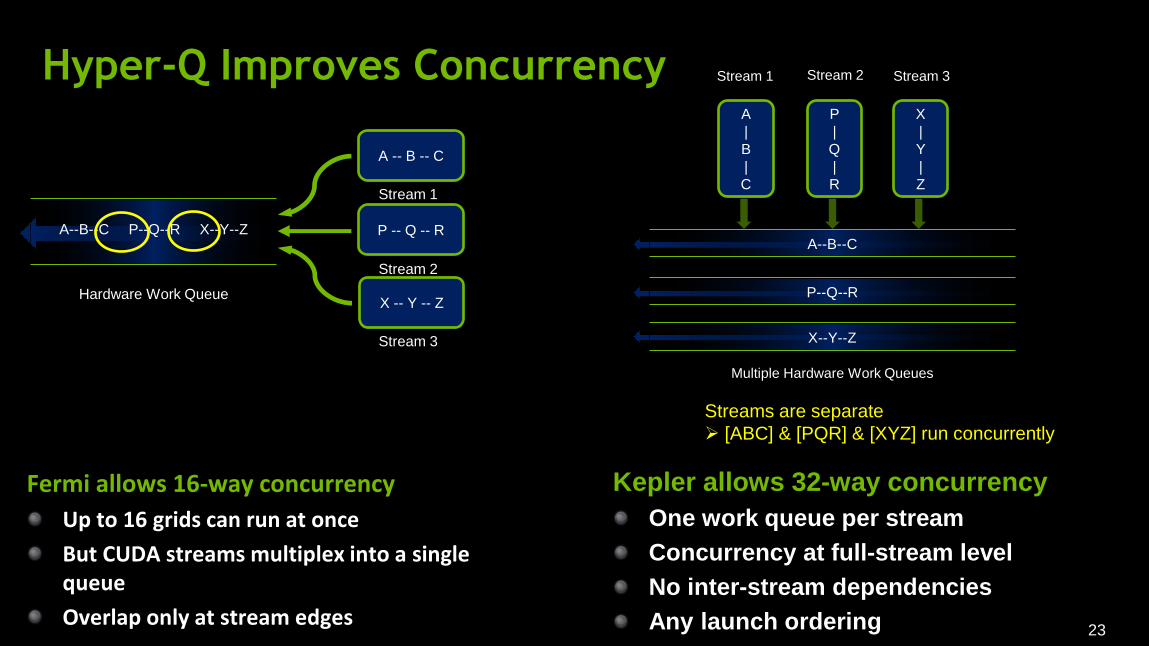
Hyper-Q
23
Hyper-Q Improves Concurrency
Fermi allows 16-way concurrency
Up to 16 grids can run at once
But CUDA streams multiplex into a single queue
Overlap only at stream edges
P -- Q -- R
A -- B -- C
X -- Y -- Z
Stream 1
Stream 2
Stream 3
Hardware Work Queue
A--B--C P--Q--R X--Y--Z
A
|
B
|
C
P
|
Q
|
R
X
|
Y
|
Z
Stream 1 Stream 2 Stream 3
Multiple Hardware Work Queues
A--B--C
P--Q--R
X--Y--Z
Kepler allows 32-way concurrency
One work queue per stream
Concurrency at full-stream level
No inter-stream dependencies
Any launch ordering
Streams are separate
[ABC] & [PQR] & [XYZ] run concurrently
24
Hyper-Q
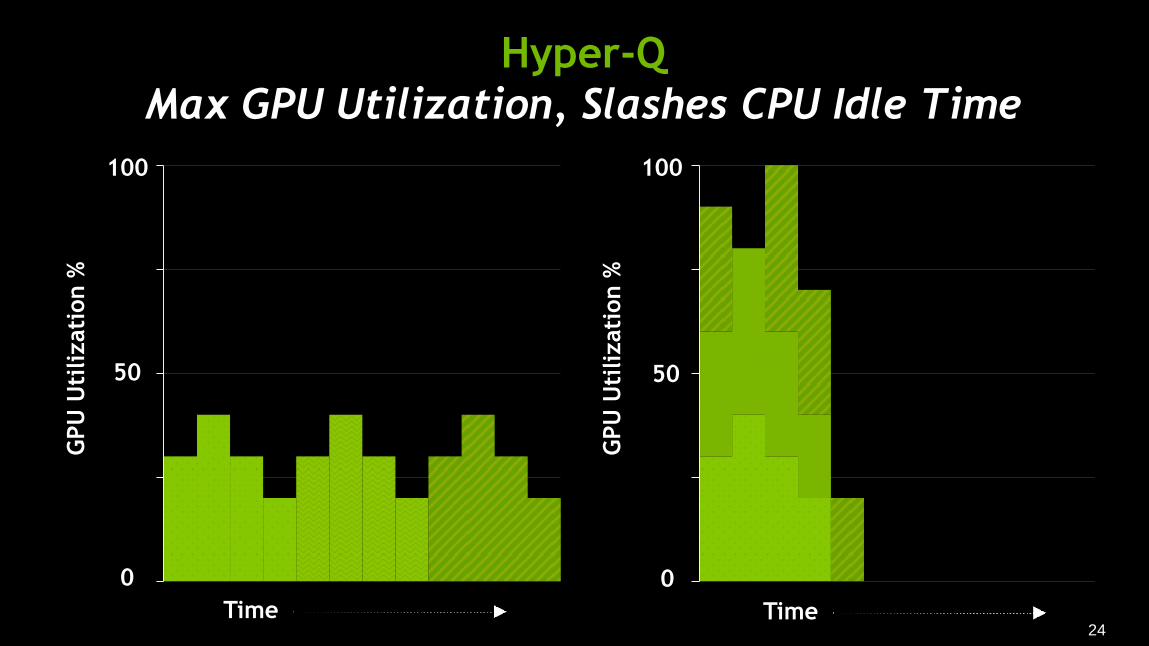
Max GPU Utilization, Slashes CPU Idle Time
Time Time
GPU
Uti
lizati
on %
GPU
Uti
lizati
on %
100
50
0
100
50
0

25
Better Utilization with Hyper-Q
FERMI 1 Work Queue
KEPLER 32 Concurrent Work Queues
Grid Management Unit selects most
appropriate task from up to 32
hardware queues (CUDA streams)
Improves scheduling of concurrently
executed grids
Particularly interesting for MPI
applications when combined with Multi
Process Server, but not limited to MPI
applications
26
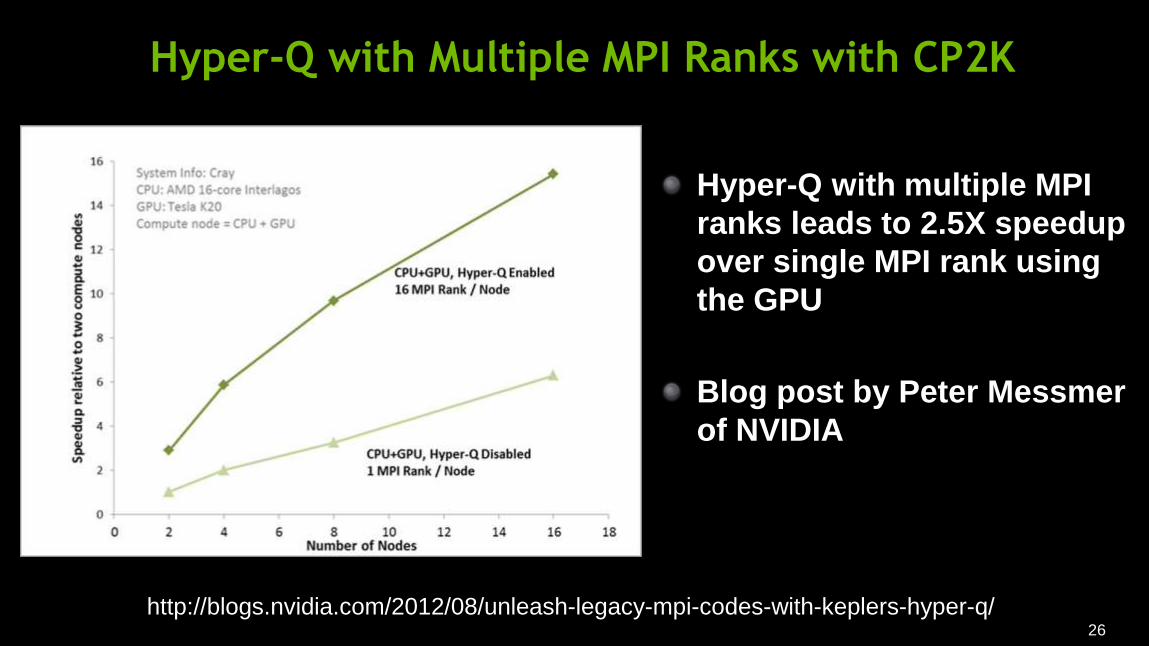
Hyper-Q with Multiple MPI Ranks with CP2K
Hyper-Q with multiple MPI
ranks leads to 2.5X speedup
over single MPI rank using
the GPU
Blog post by Peter Messmer
of NVIDIA
http://blogs.nvidia.com/2012/08/unleash-legacy-mpi-codes-with-keplers-hyper-q/

27
Dynamic Parallelism Simpler Code, More General, Higher Performance
CPU Kepler GPU
Too coarse Just right Too fine
Better load balancing for dynamic workloads
• when work-per-block is data-dependent
( e.g. Adaptive Mesh CFD )
Launch new kernels from the GPU
Dynamically - based on run-time data
Simultaneously - from multiple threads at once
Independently - each thread can launch a
different grid
28
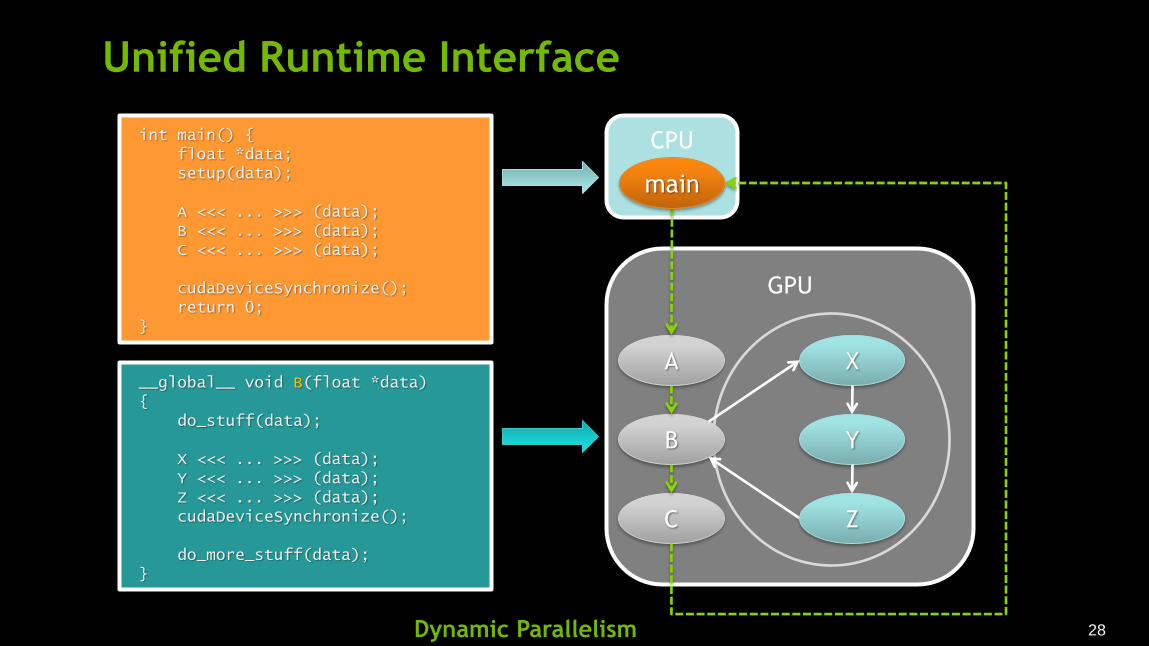
GPU
Unified Runtime Interface
__global__ void B(float *data) { do_stuff(data); X <<< ... >>> (data); Y <<< ... >>> (data); Z <<< ... >>> (data); cudaDeviceSynchronize(); do_more_stuff(data); }
A
B
C
X
Y
Z
CPU int main() { float *data; setup(data); A <<< ... >>> (data); B <<< ... >>> (data); C <<< ... >>> (data); cudaDeviceSynchronize(); return 0; }
main
Dynamic Parallelism
29
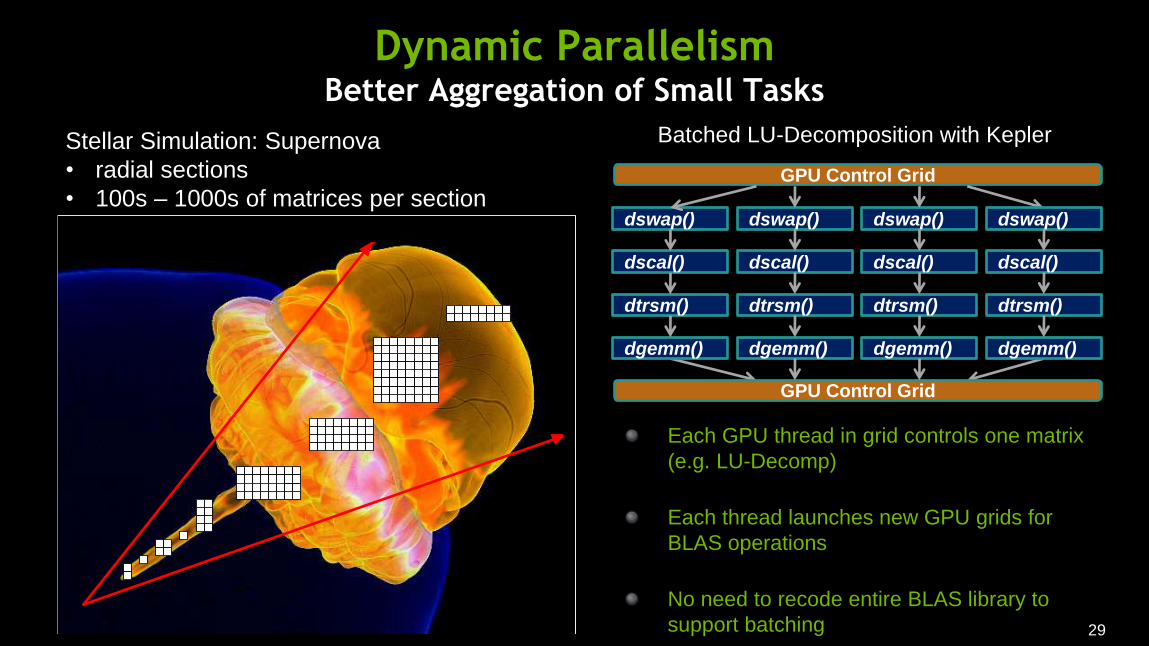
Dynamic Parallelism Better Aggregation of Small Tasks
GPU Control Grid
dswap()
dscal()
dtrsm()
dgemm()
GPU Control Grid
dswap()
dscal()
dtrsm()
dgemm()
dswap()
dscal()
dtrsm()
dgemm()
dswap()
dscal()
dtrsm()
dgemm()
Each GPU thread in grid controls one matrix
(e.g. LU-Decomp)
Each thread launches new GPU grids for
BLAS operations
No need to recode entire BLAS library to
support batching
Batched LU-Decomposition with Kepler Stellar Simulation: Supernova
• radial sections
• 100s – 1000s of matrices per section
30
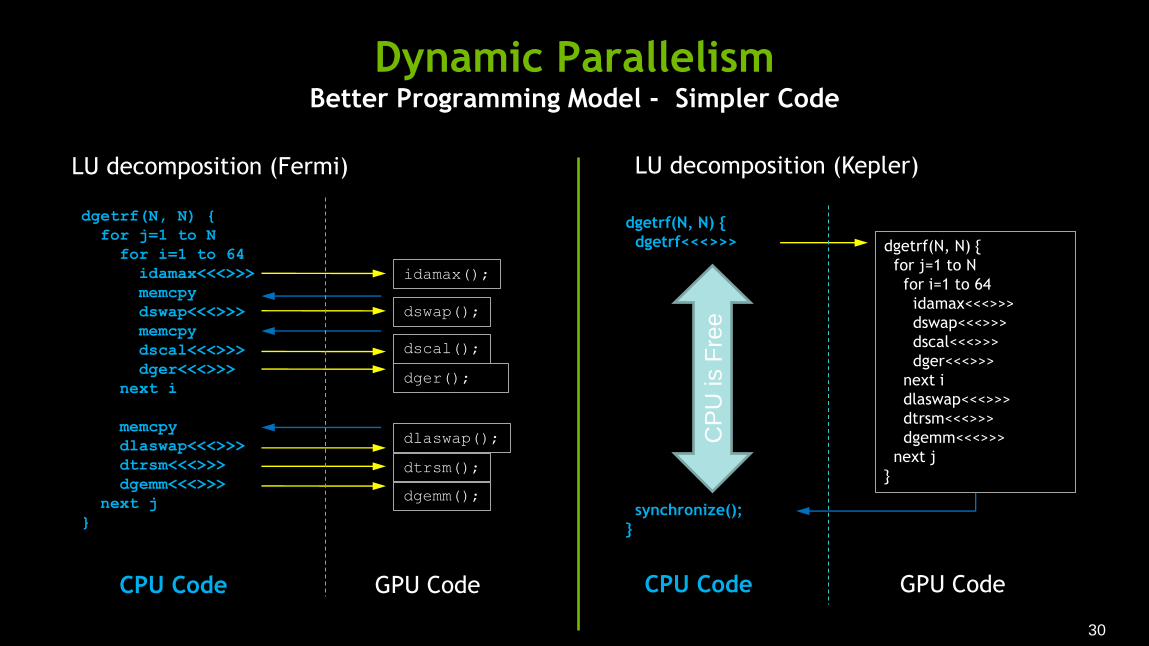
Dynamic Parallelism Better Programming Model - Simpler Code
LU decomposition (Fermi)
dgetrf(N, N) {
for j=1 to N
for i=1 to 64
idamax<<<>>>
memcpy
dswap<<<>>>
memcpy
dscal<<<>>>
dger<<<>>>
next i
memcpy
dlaswap<<<>>>
dtrsm<<<>>>
dgemm<<<>>>
next j
}
idamax();
dswap();
dscal();
dger();
dlaswap();
dtrsm();
dgemm();
GPU Code CPU Code
LU decomposition (Kepler)
dgetrf(N, N) {
dgetrf<<<>>>
synchronize();
}
dgetrf(N, N) {
for j=1 to N
for i=1 to 64
idamax<<<>>>
dswap<<<>>>
dscal<<<>>>
dger<<<>>>
next i
dlaswap<<<>>>
dtrsm<<<>>>
dgemm<<<>>>
next j
}
GPU Code CPU Code
CP
U is F
ree
31
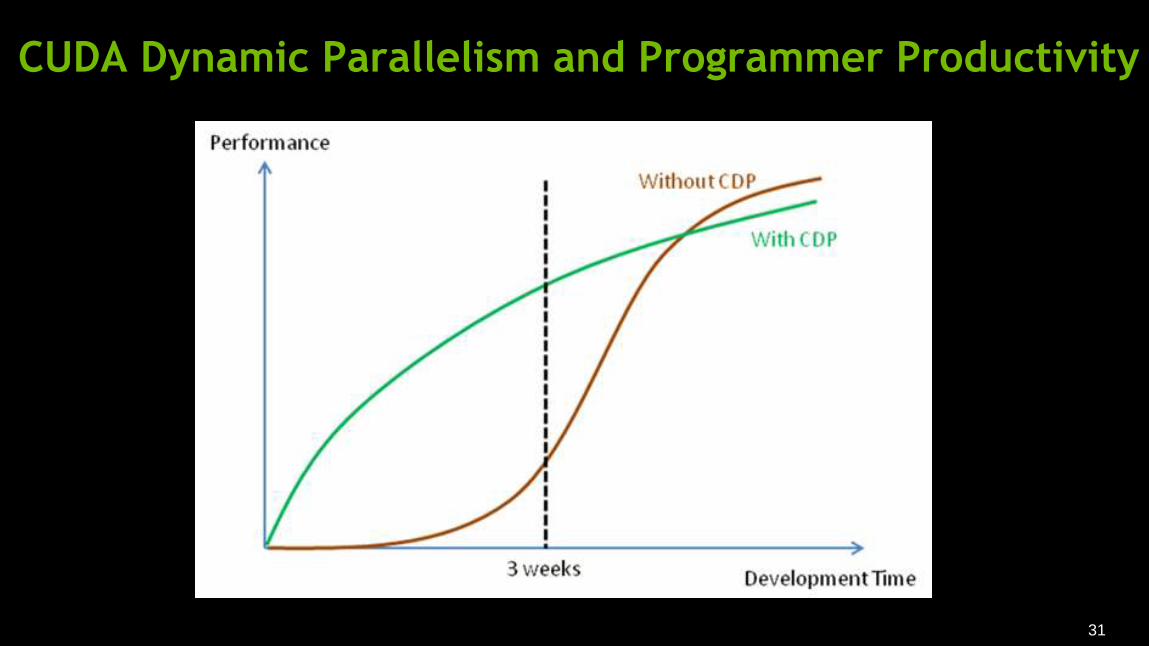
CUDA Dynamic Parallelism and Programmer Productivity

32
GPU Management: nvidia-smi
Multi-GPU systems are widely available
Different systems are set up differently
Want to get quick information on - Approximate GPU utilization
- Approximate memory footprint
- Number of GPUs
- ECC state
- Driver version
Inspect and modify GPU state
Thu Nov 1 09:10:29 2012
+------------------------------------------------------+
| NVIDIA-SMI 4.304.51 Driver Version: 304.51 |
|-------------------------------+----------------------+----------------------+
| GPU Name | Bus-Id Disp. | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K20X | 0000:03:00.0 Off | Off |
| N/A 30C P8 28W / 235W | 0% 12MB / 6143MB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla K20X | 0000:85:00.0 Off | Off |
| N/A 28C P8 26W / 235W | 0% 12MB / 6143MB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Compute processes: GPU Memory |
| GPU PID Process name Usage |
|=============================================================================|
| No running compute processes found |
+-----------------------------------------------------------------------------+

33
OpenGL and Tesla
Tesla K20/K20X for high performance Compute
Tesla K20/K20X for Graphics and Compute
Use interop to mix OpenGL and Compute
Tesla K20 / K20X

34
NVIDIA indeX™
Cluster-based graphics infrastructure • Real-time manipulation of huge datasets
• Combine volume and surface rendering
• Project size scales with cluster size
• Interactive collaboration with global teams
35
HPC
“long running”
Application w/
Data
New Apps
Encoding
Raytracing
(iray , optix)
realityserver
(CUDA)
HPC + Viz
Readback Viz
frames of
HPC results
HP RGS
Dell Teradici
Rack / Blade WS
MAXIMUS-QUADRO(Active Thermals)
Tesla
Desktop Workstation ISV App
< Remoted / Backracked >
CITIRX HDX
VMware
MS RemoteFX
NICE DCV
Server
NVIDIA GRID (Passive Thermal)


37
Introducing GeForce GTX TITAN The Ultimate CUDA Development GPU
Personal Supercomputer on Your Desktop
2688 CUDA Cores
4.5 Teraflops Single Precision
288 GB/s Memory Bandwidth
1.27 Teraflops Double Precision
38
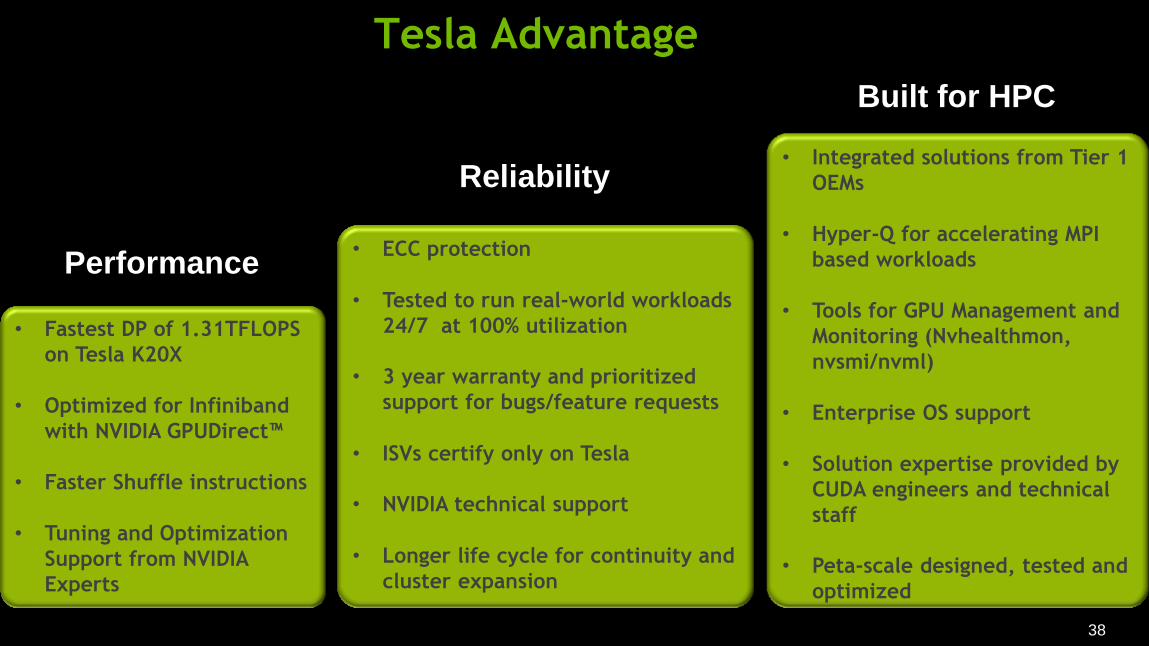
Tesla Advantage
• Fastest DP of 1.31TFLOPS
on Tesla K20X
• Optimized for Infiniband
with NVIDIA GPUDirect™
• Faster Shuffle instructions
• Tuning and Optimization
Support from NVIDIA
Experts
Performance • ECC protection
• Tested to run real-world workloads
24/7 at 100% utilization
• 3 year warranty and prioritized
support for bugs/feature requests
• ISVs certify only on Tesla
• NVIDIA technical support
• Longer life cycle for continuity and
cluster expansion
Reliability • Integrated solutions from Tier 1
OEMs
• Hyper-Q for accelerating MPI
based workloads
• Tools for GPU Management and
Monitoring (Nvhealthmon,
nvsmi/nvml)
• Enterprise OS support
• Solution expertise provided by
CUDA engineers and technical
staff
• Peta-scale designed, tested and
optimized
Built for HPC

39
Accelerated Computing 10x Performance, 5x Energy Efficiency
CPU Optimized for Serial Tasks
GPU Accelerator Optimized for Many
Parallel Tasks
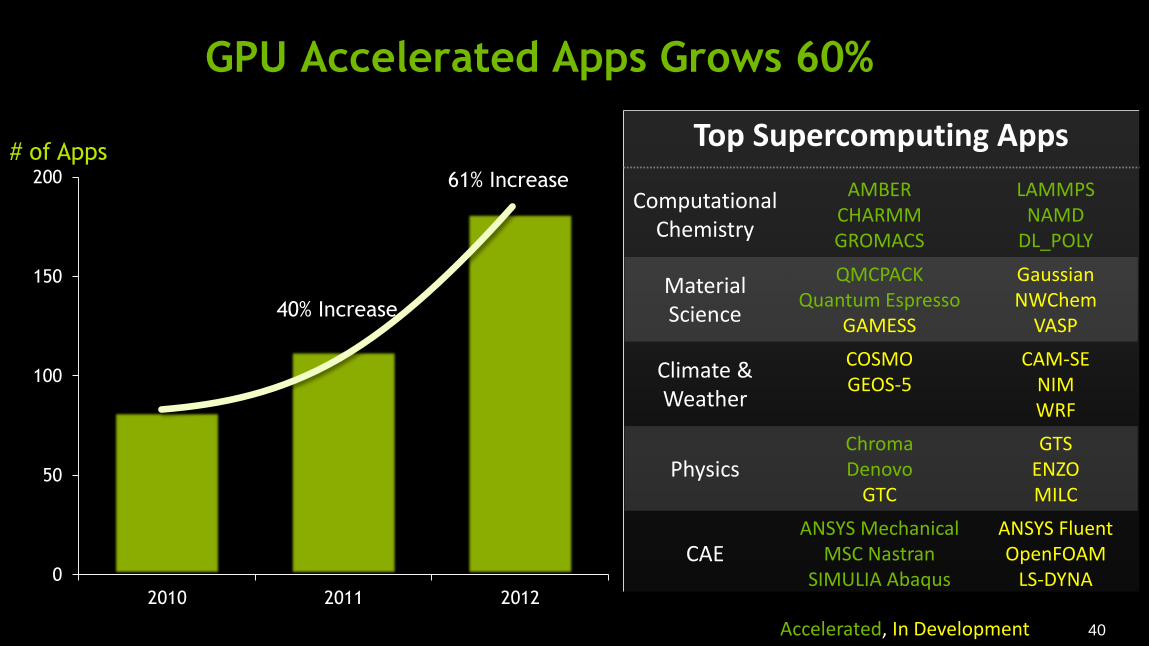
40
Top Supercomputing Apps
Computational Chemistry
AMBER CHARMM GROMACS
LAMMPS NAMD
DL_POLY
Material Science
QMCPACK Quantum Espresso
GAMESS
Gaussian NWChem
VASP
Climate & Weather
COSMO GEOS-5
CAM-SE NIM WRF
Physics Chroma Denovo
GTC
GTS ENZO MILC
CAE ANSYS Mechanical
MSC Nastran SIMULIA Abaqus
ANSYS Fluent OpenFOAM
LS-DYNA 0
50
100
150
200
2010 2011 2012
# of Apps
40% Increase
61% Increase
Accelerated, In Development
GPU Accelerated Apps Grows 60%

41
200+ GPU-Accelerated Applications www.nvidia.com/appscatalog

42

43
Small Changes, Big Speed-up
Application Code
+
GPU CPU Use GPU to Parallelize
Compute-Intensive Functions Rest of Sequential
CPU Code
44
45
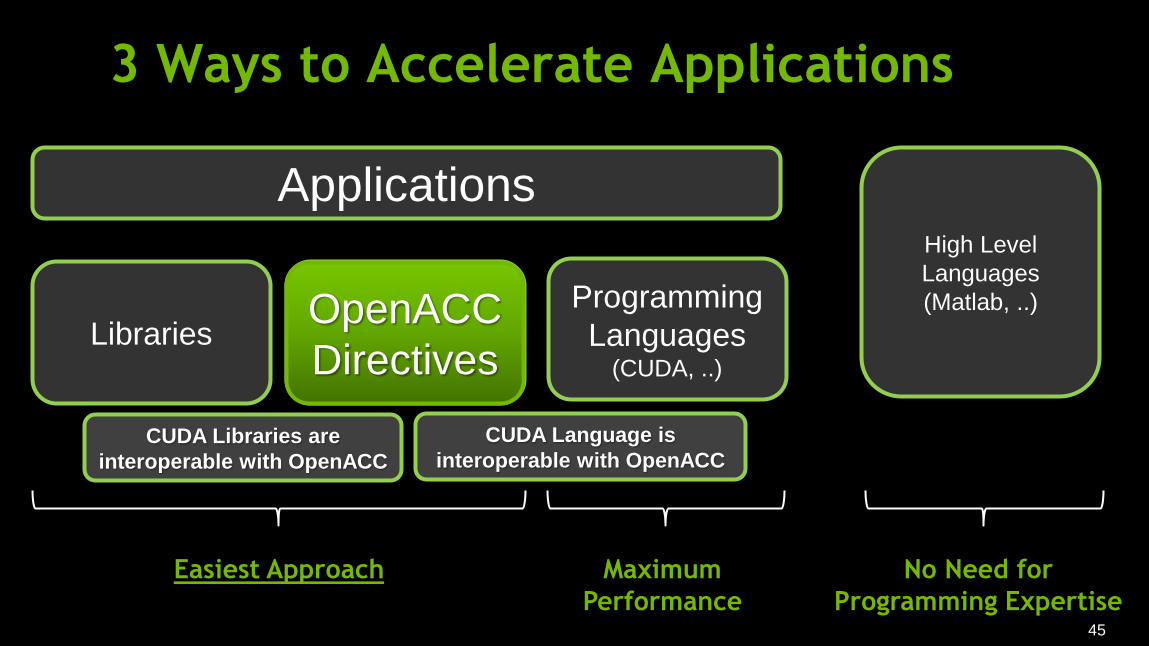
3 Ways to Accelerate Applications
Libraries Directives (OpenACC)
Programming
Languages (CUDA, ..)
Applications
Easiest Approach Maximum
Performance
High Level
Languages
(Matlab, ..)
No Need for
Programming Expertise
CUDA Libraries are
interoperable with OpenACC
CUDA Language is
interoperable with OpenACC
OpenACC
Directives
46
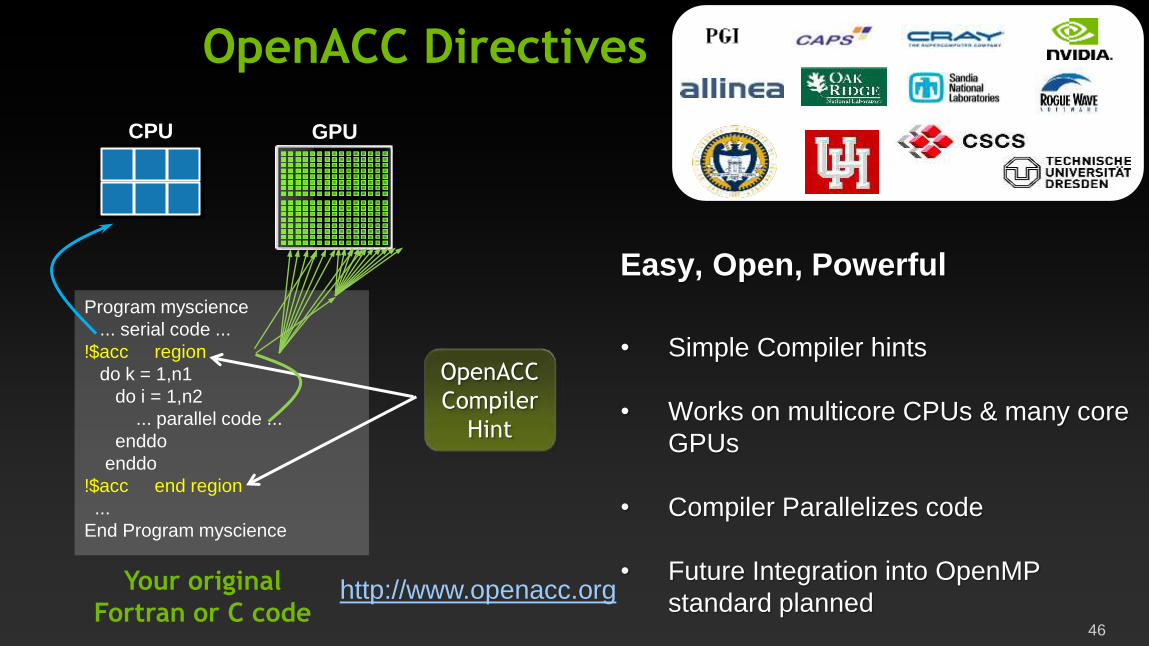
OpenACC Directives
Program myscience
... serial code ...
!$acc region
do k = 1,n1
do i = 1,n2
... parallel code ...
enddo
enddo
!$acc end region
...
End Program myscience
CPU GPU
Your original
Fortran or C code
Easy, Open, Powerful
• Simple Compiler hints
• Works on multicore CPUs & many core
GPUs
• Compiler Parallelizes code
• Future Integration into OpenMP
standard planned
OpenACC
Compiler
Hint
http://www.openacc.org

47
Familiar to OpenMP Programmers
main() {
double pi = 0.0; long i;
#pragma omp parallel for reduction(+:pi)
for (i=0; i<N; i++)
{
double t = (double)((i+0.05)/N);
pi += 4.0/(1.0+t*t);
}
printf(“pi = %f\n”, pi/N);
}
CPU
OpenMP
main() {
double pi = 0.0; long i;
#pragma acc kernels
for (i=0; i<N; i++)
{
double t = (double)((i+0.05)/N);
pi += 4.0/(1.0+t*t);
}
printf(“pi = %f\n”, pi/N);
}
CPU GPU
OpenACC
48
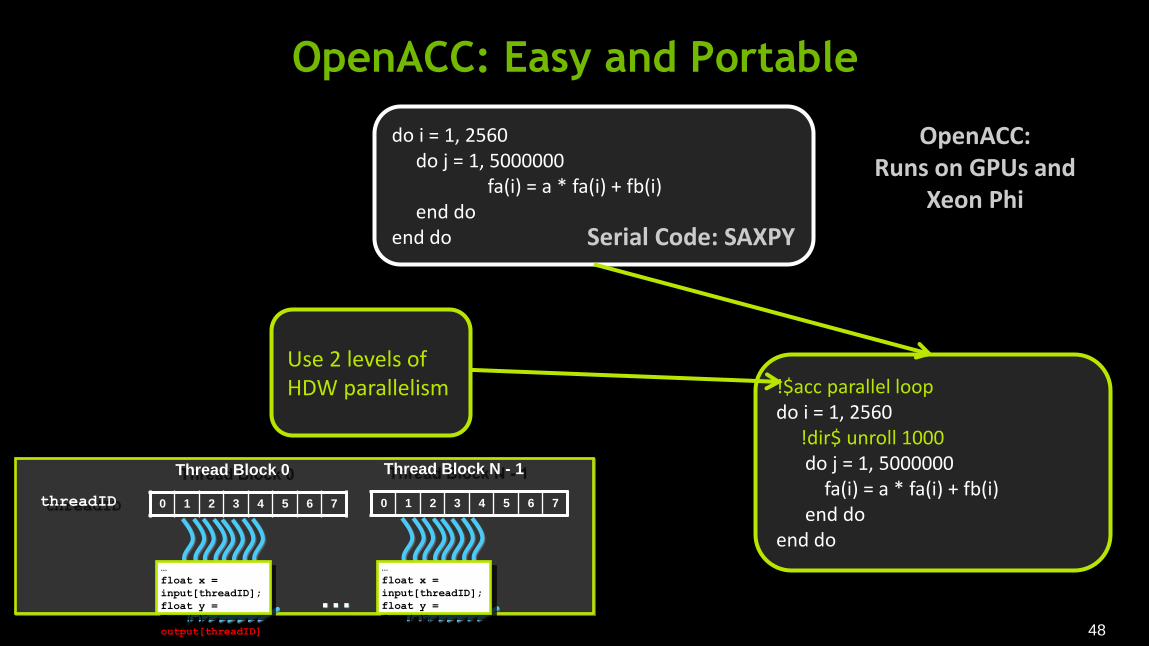
OpenACC: Easy and Portable
do i = 1, 2560 do j = 1, 5000000 fa(i) = a * fa(i) + fb(i) end do end do Serial Code: SAXPY
OpenACC: Runs on GPUs and
Xeon Phi
!$acc parallel loop do i = 1, 2560 !dir$ unroll 1000 do j = 1, 5000000 fa(i) = a * fa(i) + fb(i) end do end do
Use 2 levels of HDW parallelism
threadID
Thread Block 0
…
Thread Block N - 1
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
…
float x =
input[threadID];
float y =
func(x);
output[threadID]
= y;
…
…
float x =
input[threadID];
float y =
func(x);
output[threadID]
= y;
…

49
Additions for OpenACC 2.0
Procedure calls
Separate compilation
Nested parallelism
Device-specific tuning, multiple devices
Data management features and global data
Multiple host thread support
Loop directive additions
Asynchronous behavior additions
New API routines for target platforms
(CUDA, OpenCL, Intel Coprocessor Offload Infrastructure)
See http://www.openacc.org/sites/default/files/OpenACC-2.0-draft.pdf

50
Exploit GPU with LESS effort; maintain ONE legacy source
Applying OpenACC to Legacy Codes
Example: REAL-WORLD application tuning using directives (comparing CPU+GPU vs. multi-core)
ELAN Computational
Electro-Magnetics
COSMO Weather
• Goals: optimize w/ less effort, preserve code base • Kernels 6.5X to 13X faster than 16-core Xeon • Overall speedup 3.2X
• Goal: preserve physics code (22% of runtime), augmenting dynamics kernels already in CUDA
• Physics speedup 4.2X vs. multi-core Xeon
Results from EMGS, MeteoSwiss/CSCS
(from GTC 2013)

51
Small Effort. Real Impact.
Large Oil Company
3x in 7 days
Solving billions of
equations
iteratively for oil
production at
world’s largest
petroleum
reservoirs
Univ. of Houston
Prof. M.A. Kayali
20x in 2 days
Studying
magnetic systems
for innovations in
magnetic storage
media and
memory, field
sensors, and
biomagnetism
Ufa State Aviation
Prof. Arthur
Yuldashev
7x in 4 Weeks
Generating
stochastic
geological models
of oilfield
reservoirs with
borehole data
Uni. Of Melbourne
Prof. Kerry Black
65x in 2 days
Better understand
complex reasons
by lifecycles of
snapper fish in
Port Phillip Bay
GAMESS-UK
Dr. Wilkinson,
Prof. Naidoo
10x
Used for various
fields such as
investigating
biofuel production
and molecular
sensors. * Achieved using the PGI Accelerator Compiler

52
Example: Jacobi Iteration
Iteratively converges to correct value (e.g. Temperature), by computing new values at each point from the average of neighboring points.
Common, useful algorithm
Example: Solve Laplace equation in 2D: 𝛁𝟐𝒇(𝒙, 𝒚) = 𝟎
A(i,j) A(i+1,j) A(i-1,j)
A(i,j-1)
A(i,j+1)
𝐴𝑘+1 𝑖, 𝑗 =𝐴𝑘(𝑖 − 1, 𝑗) + 𝐴𝑘 𝑖 + 1, 𝑗 + 𝐴𝑘 𝑖, 𝑗 − 1 + 𝐴𝑘 𝑖, 𝑗 + 1
4

53
Jacobi Iteration Fortran Code do while ( err > tol .and. iter < iter_max ) err=0._fp_kind do j=1,m do i=1,n Anew(i,j) = .25_fp_kind * (A(i+1, j ) + A(i-1, j ) + & A(i , j-1) + A(i , j+1)) err = max(err, Anew(i,j) - A(i,j)) end do end do do j=1,m-2 do i=1,n-2 A(i,j) = Anew(i,j) end do end do iter = iter +1 end do
Iterate until converged
Iterate across matrix
elements
Calculate new value from
neighbors
Compute max error for
convergence
Swap input/output arrays

54
Jacobi Iteration: OpenACC Fortran Code
!$acc data copy(A), create(Anew) do while ( err > tol .and. iter < iter_max ) err=0._fp_kind !$acc kernels do j=1,m do i=1,n Anew(i,j) = .25_fp_kind * (A(i+1, j ) + A(i-1, j ) + & A(i , j-1) + A(i , j+1)) err = max(err, Anew(i,j) - A(i,j)) end do end do !$acc end kernels ... iter = iter +1 end do !$acc end data
Copy A in at beginning of
loop, out at end. Allocate
Anew on accelerator
55
3 Ways to Accelerate Applications
Applications
Libraries
“Drop-in”
Acceleration
Programming
Languages OpenACC
Directives
Maximum
Flexibility
Easily Accelerate
Applications

56
NVIDIA cuBLAS NVIDIA cuRAND NVIDIA cuSPARSE NVIDIA NPP
Vector Signal Image Processing
GPU Accelerated Linear Algebra
Matrix Algebra on GPU and Multicore NVIDIA cuFFT
C++ STL Features for CUDA
Sparse Linear Algebra IMSL Library
Building-block Algorithms for CUDA
Some GPU-accelerated Libraries
ArrayFire Matrix Computations

57
Explore the CUDA (Libraries) Ecosystem
CUDA Tools and Ecosystem described in detail on NVIDIA Developer Zone:
developer.nvidia.com/cuda-tools-ecosystem
58
3 Ways to Accelerate Applications
Applications
Libraries
“Drop-in”
Acceleration
Programming
Languages OpenACC
Directives
Maximum
Flexibility
Easily Accelerate
Applications

59
GPU Programming Languages
OpenACC, CUDA Fortran Fortran
OpenACC, CUDA C C
Thrust, CUDA C++ C++
PyCUDA, Copperhead, NumbaPro
(Continuum Analytics)
Python
GPU.NET, Hybridizer(AltiMesh) C#
MATLAB, Mathematica, LabVIEW Numerical analytics

60
MATLAB
http://www.mathworks.com/discovery/
matlab-gpu.html
Get Started Today These languages are supported on all CUDA-capable GPUs.
You might already have a CUDA-capable GPU in your laptop or desktop PC!
CUDA C/C++
http://developer.nvidia.com/cuda-toolkit
Thrust C++ Template Library
http://developer.nvidia.com/thrust
CUDA Fortran
http://developer.nvidia.com/cuda-toolkit
GPU.NET
http://tidepowerd.com
PyCUDA (Python)
http://mathema.tician.de/software/pycuda
Mathematica
http://www.wolfram.com/mathematica/new
-in-8/cuda-and-opencl-support/

61
Easiest Way to Learn CUDA
$$
Learn from the Best • Prof. John Owens – UC Davis
• Dr. David Luebke – NVIDIA Research
• Prof. Wen-mei W. Hwu – U of Illinois
Anywhere, Any Time • Online
• Worldwide
• Self Paced
It’s Free! • No Tuition
• No Hardware
• No Books
Engage with an Active Community • Forums and Meetups
• Hands-on Projects
50k Enrolled
127 Countries
Introduction to Parallel Programming www.udacity.com
Heterogeneous Parallel Programming www.coursera.org

62
NVIDIA Tesla Update
Supercomputing’12 Sumit Gupta
General Manager
Tesla Accelerated Computing
Thank You