nyai #9: concepts and questions as programs by brenden lake
TRANSCRIPT

Concepts and questions as programs
Brenden LakeNew York University

scene understandinglanguage acquisition
creativity
general purpose problem solving
commonsense reasoning
language understanding
human abilities that elude the best algorithms
concept learning question asking

scene understandinglanguage acquisition
creativity
general purpose problem solving
commonsense reasoning
language understanding
human abilities that elude the best algorithms
concept learning question asking

Outline
case study 1:handwritten characters
case study 2:recursive visual concepts
Concept learning
Question asking
...Are any ships 3 tiles long?
case study 3:question asking in simple games
Are the blue ship and red ship parallel?

Concepts and questions as programs,learning as program induction
...
Are any objects 3 tiles long?
( >
( +
( map
( lambda
x
( =
( size x )
3
)
)
( set Blue Red Purple )
)
)
0
)
G GG
angle = 120start = Fniter = 3
F F �G+G+G� F
Are the blue and red objects parallel?
( =
( orient Blue )
( orient Red )
)
procedure GENERATETYPE P ()for i = 1 ... do
ni P (ni|)for j = 1 ... ni do
sij P (sij|si(j�1))end for
Ri P (Ri|S1, ..., Si�1)end for
{, R, S}return @GENERATETOKEN( )
end procedure
procedure GENERATETOKEN( )for i = 1... do
S(m)i P (S(m)
i |Si)
L(m)i P (L(m)
i |Ri, T(m)1 , ..., T (m)
i�1 )
T (m)i f(L(m)
i , S(m)i )
end for
A(m) P (A(m))I(m) P (I(m)|T (m), A(m))return I(m)
end procedure
1

...
Three cognitive principles
compositionality
causality
learning-to-learn

scene understandinglanguage acquisition
creativity
general purpose problem solving
commonsense reasoning
language understanding
human abilities that elude the best algorithms
concept learning question asking

Outline
case study 1:handwritten characters
case study 2:fractal concepts
Concept learning
Question asking
...
Are any ships 3 tiles long?
active learning with rich questions
Are the blue ship and red ship parallel?

Outline
case study 1:handwritten characters
case study 2:fractal concepts
Concept learning
Question asking
...
Are any ships 3 tiles long?
active learning with rich questions
Are the blue ship and red ship parallel?
Josh Tenenbaum Russ Salakhutdinov
Lake, Salakhutdinov, & Tenenbaum (2015). Science.

where are the others?
generating new examples
generating new concepts
How do people learn such rich concepts from very little data?
parsing
the speed of learning the richness of representation
“one-shot learning”
(e.g., Carey & Bartlett, 1978; Markman, 1989;
Tenenbaum, 1999; Bloom, 2000;
Smith et al., 2002)

Training data (ImageNet)• 1.2 million images• ~1000 images per
category
Architecture:• dozens of layers• millions of parameters
Concept learning in computer vision:deep neural networks and big data
input output:“daisy”
layers of feature maps

We would like to study one-shot learning in a domain with…
1) Natural, high-dimensional concepts.
2) A reasonable chance of building models that can see most of the structure that people see.
3) Insights that generalize across domains.
A testbed domain for one-shot learning

Classic stimulus sets

1600+ concepts20 examples each
Omniglot stimulus set(https://github.com/brendenlake/omniglot)

where are the others?
generating new examples
generating new concepts
human-level concept learning
parsing
the speed of learning the richness of representation
“one-shot learning”

generating new examples
generating new concepts
parsing
the speed of learning the richness of representation
human-level concept learning
classification

generating new examples
generating new concepts
parsing
the speed of learning the richness of representation
human-level concept learning
classification

1 2 12 1
23 1 2 1 2
1 2 1 2 1 2 1 2 12
1 2 1 2 1 2 1 2 1 2
121 2
12 1 2 1 2
probabilistic motor programscharacter
strokes
sub-strokes
12
34
51
2345 123
45123 45
123
45
1 2
345 1
2345 12 345
1
23
45 1234 5
123
45
1 234
5
1
234512
34
5
1
2 3
45
123
4 51 2345
123
45
12345
12345
1 2
345
123 4 5 1234
5
1 23
45
1 2
34
5
primitive elements (sub-strokes)
people drawing a new character
Wednesday, October 17, 2012
Human drawings

1 2 12 1
23 1 2 1 2
1 2 1 2 1 2 1 2 12
1 2 1 2 1 2 1 2 1 2
121 2
12 1 2 1 2
probabilistic motor programscharacter
strokes
sub-strokes
12
34
51
2345 123
45123 45
123
45
1 2
345 1
2345 12 345
1
23
45 1234 5
123
45
1 234
5
1
234512
34
5
1
2 3
45
123
4 51 2345
123
45
12345
12345
1 2
345
123 4 5 1234
5
1 23
45
1 2
34
5
primitive elements (sub-strokes)
people drawing a new character
Wednesday, October 17, 2012
Human drawings

the number of subparts ni, for each part i = 1, ...,k, from their empirical distributions asmeasuredfrom the background set. Second, a template fora part Si is constructed by sampling subparts
from a set of discrete primitive actions learnedfrom the background set (Fig. 3A, i), such thatthe probability of the next action depends onthe previous. Third, parts are then grounded as
parameterized curves (splines) by sampling thecontrol points and scale parameters for eachsubpart. Last, parts are roughly positioned tobegin either independently, at the beginning,
SCIENCE sciencemag.org 00 MONTH 2015 • VOL 000 ISSUE 0000 3
Fig. 3. A generative model of handwritten characters. (A) New types are generated by choosing primitive actions (color coded) from a library (i),combining these subparts (ii) to make parts (iii), and combining parts with relations to define simple programs (iv). New tokens are generated by runningthese programs (v), which are then rendered as raw data (vi). (B) Pseudocode for generating new types y and new token images I (m) for m = 1, ..., M.The function f (·, ·) transforms a subpart sequence and start location into a trajectory.
Human parses Machine parsesHuman drawings
-505 -593 -655 -695 -723
-1794-646 -1276
Training item with model’s five best parses
Test items
1 2 3 4 5stroke order:
Fig. 4. Inferringmotor programs from images. Parts are distinguishedby color, with a colored dot indicating the beginning of a stroke and anarrowhead indicating the end. (A) The top row shows the five best pro-grams discovered for an image along with their log-probability scores(Eq. 1). For classification, each program was refit to three new test images(left in image triplets), and the best-fitting parse (top right) is shownwith its image reconstruction (bottom right) and classification score (logposterior predictive probability). Subpart breaks are shown as black dots.(B) Nine human drawings of three characters (left) are shown with theirground truth parses (middle) and best model parses (right).
RESEARCH | RESEARCH ARTICLE
MS no: RAaab3050/CF/PSYCHOLOGY
Original
Human drawings

the number of subparts ni, for each part i = 1, ...,k, from their empirical distributions asmeasuredfrom the background set. Second, a template fora part Si is constructed by sampling subparts
from a set of discrete primitive actions learnedfrom the background set (Fig. 3A, i), such thatthe probability of the next action depends onthe previous. Third, parts are then grounded as
parameterized curves (splines) by sampling thecontrol points and scale parameters for eachsubpart. Last, parts are roughly positioned tobegin either independently, at the beginning,
SCIENCE sciencemag.org 00 MONTH 2015 • VOL 000 ISSUE 0000 3
Fig. 3. A generative model of handwritten characters. (A) New types are generated by choosing primitive actions (color coded) from a library (i),combining these subparts (ii) to make parts (iii), and combining parts with relations to define simple programs (iv). New tokens are generated by runningthese programs (v), which are then rendered as raw data (vi). (B) Pseudocode for generating new types y and new token images I (m) for m = 1, ..., M.The function f (·, ·) transforms a subpart sequence and start location into a trajectory.
Human parses Machine parsesHuman drawings
-505 -593 -655 -695 -723
-1794-646 -1276
Training item with model’s five best parses
Test items
1 2 3 4 5stroke order:
Fig. 4. Inferringmotor programs from images. Parts are distinguishedby color, with a colored dot indicating the beginning of a stroke and anarrowhead indicating the end. (A) The top row shows the five best pro-grams discovered for an image along with their log-probability scores(Eq. 1). For classification, each program was refit to three new test images(left in image triplets), and the best-fitting parse (top right) is shownwith its image reconstruction (bottom right) and classification score (logposterior predictive probability). Subpart breaks are shown as black dots.(B) Nine human drawings of three characters (left) are shown with theirground truth parses (middle) and best model parses (right).
RESEARCH | RESEARCH ARTICLE
MS no: RAaab3050/CF/PSYCHOLOGY
Original
Human drawings

Original
Human drawings
the number of subparts ni, for each part i = 1, ...,k, from their empirical distributions asmeasuredfrom the background set. Second, a template fora part Si is constructed by sampling subparts
from a set of discrete primitive actions learnedfrom the background set (Fig. 3A, i), such thatthe probability of the next action depends onthe previous. Third, parts are then grounded as
parameterized curves (splines) by sampling thecontrol points and scale parameters for eachsubpart. Last, parts are roughly positioned tobegin either independently, at the beginning,
SCIENCE sciencemag.org 00 MONTH 2015 • VOL 000 ISSUE 0000 3
Fig. 3. A generative model of handwritten characters. (A) New types are generated by choosing primitive actions (color coded) from a library (i),combining these subparts (ii) to make parts (iii), and combining parts with relations to define simple programs (iv). New tokens are generated by runningthese programs (v), which are then rendered as raw data (vi). (B) Pseudocode for generating new types y and new token images I (m) for m = 1, ..., M.The function f (·, ·) transforms a subpart sequence and start location into a trajectory.
Human parses Machine parsesHuman drawings
-505 -593 -655 -695 -723
-1794-646 -1276
Training item with model’s five best parses
Test items
1 2 3 4 5stroke order:
Fig. 4. Inferringmotor programs from images. Parts are distinguishedby color, with a colored dot indicating the beginning of a stroke and anarrowhead indicating the end. (A) The top row shows the five best pro-grams discovered for an image along with their log-probability scores(Eq. 1). For classification, each program was refit to three new test images(left in image triplets), and the best-fitting parse (top right) is shownwith its image reconstruction (bottom right) and classification score (logposterior predictive probability). Subpart breaks are shown as black dots.(B) Nine human drawings of three characters (left) are shown with theirground truth parses (middle) and best model parses (right).
RESEARCH | RESEARCH ARTICLE
MS no: RAaab3050/CF/PSYCHOLOGY

Original
Human drawings
the number of subparts ni, for each part i = 1, ...,k, from their empirical distributions asmeasuredfrom the background set. Second, a template fora part Si is constructed by sampling subparts
from a set of discrete primitive actions learnedfrom the background set (Fig. 3A, i), such thatthe probability of the next action depends onthe previous. Third, parts are then grounded as
parameterized curves (splines) by sampling thecontrol points and scale parameters for eachsubpart. Last, parts are roughly positioned tobegin either independently, at the beginning,
SCIENCE sciencemag.org 00 MONTH 2015 • VOL 000 ISSUE 0000 3
Fig. 3. A generative model of handwritten characters. (A) New types are generated by choosing primitive actions (color coded) from a library (i),combining these subparts (ii) to make parts (iii), and combining parts with relations to define simple programs (iv). New tokens are generated by runningthese programs (v), which are then rendered as raw data (vi). (B) Pseudocode for generating new types y and new token images I (m) for m = 1, ..., M.The function f (·, ·) transforms a subpart sequence and start location into a trajectory.
Human parses Machine parsesHuman drawings
-505 -593 -655 -695 -723
-1794-646 -1276
Training item with model’s five best parses
Test items
1 2 3 4 5stroke order:
Fig. 4. Inferringmotor programs from images. Parts are distinguishedby color, with a colored dot indicating the beginning of a stroke and anarrowhead indicating the end. (A) The top row shows the five best pro-grams discovered for an image along with their log-probability scores(Eq. 1). For classification, each program was refit to three new test images(left in image triplets), and the best-fitting parse (top right) is shownwith its image reconstruction (bottom right) and classification score (logposterior predictive probability). Subpart breaks are shown as black dots.(B) Nine human drawings of three characters (left) are shown with theirground truth parses (middle) and best model parses (right).
RESEARCH | RESEARCH ARTICLE
MS no: RAaab3050/CF/PSYCHOLOGY

Original
Human drawings
the number of subparts ni, for each part i = 1, ...,k, from their empirical distributions asmeasuredfrom the background set. Second, a template fora part Si is constructed by sampling subparts
from a set of discrete primitive actions learnedfrom the background set (Fig. 3A, i), such thatthe probability of the next action depends onthe previous. Third, parts are then grounded as
parameterized curves (splines) by sampling thecontrol points and scale parameters for eachsubpart. Last, parts are roughly positioned tobegin either independently, at the beginning,
SCIENCE sciencemag.org 00 MONTH 2015 • VOL 000 ISSUE 0000 3
Fig. 3. A generative model of handwritten characters. (A) New types are generated by choosing primitive actions (color coded) from a library (i),combining these subparts (ii) to make parts (iii), and combining parts with relations to define simple programs (iv). New tokens are generated by runningthese programs (v), which are then rendered as raw data (vi). (B) Pseudocode for generating new types y and new token images I (m) for m = 1, ..., M.The function f (·, ·) transforms a subpart sequence and start location into a trajectory.
Human parses Machine parsesHuman drawings
-505 -593 -655 -695 -723
-1794-646 -1276
Training item with model’s five best parses
Test items
1 2 3 4 5stroke order:
Fig. 4. Inferringmotor programs from images. Parts are distinguishedby color, with a colored dot indicating the beginning of a stroke and anarrowhead indicating the end. (A) The top row shows the five best pro-grams discovered for an image along with their log-probability scores(Eq. 1). For classification, each program was refit to three new test images(left in image triplets), and the best-fitting parse (top right) is shownwith its image reconstruction (bottom right) and classification score (logposterior predictive probability). Subpart breaks are shown as black dots.(B) Nine human drawings of three characters (left) are shown with theirground truth parses (middle) and best model parses (right).
RESEARCH | RESEARCH ARTICLE
MS no: RAaab3050/CF/PSYCHOLOGY

Original
Human drawings
the number of subparts ni, for each part i = 1, ...,k, from their empirical distributions asmeasuredfrom the background set. Second, a template fora part Si is constructed by sampling subparts
from a set of discrete primitive actions learnedfrom the background set (Fig. 3A, i), such thatthe probability of the next action depends onthe previous. Third, parts are then grounded as
parameterized curves (splines) by sampling thecontrol points and scale parameters for eachsubpart. Last, parts are roughly positioned tobegin either independently, at the beginning,
SCIENCE sciencemag.org 00 MONTH 2015 • VOL 000 ISSUE 0000 3
Fig. 3. A generative model of handwritten characters. (A) New types are generated by choosing primitive actions (color coded) from a library (i),combining these subparts (ii) to make parts (iii), and combining parts with relations to define simple programs (iv). New tokens are generated by runningthese programs (v), which are then rendered as raw data (vi). (B) Pseudocode for generating new types y and new token images I (m) for m = 1, ..., M.The function f (·, ·) transforms a subpart sequence and start location into a trajectory.
Human parses Machine parsesHuman drawings
-505 -593 -655 -695 -723
-1794-646 -1276
Training item with model’s five best parses
Test items
1 2 3 4 5stroke order:
Fig. 4. Inferringmotor programs from images. Parts are distinguishedby color, with a colored dot indicating the beginning of a stroke and anarrowhead indicating the end. (A) The top row shows the five best pro-grams discovered for an image along with their log-probability scores(Eq. 1). For classification, each program was refit to three new test images(left in image triplets), and the best-fitting parse (top right) is shownwith its image reconstruction (bottom right) and classification score (logposterior predictive probability). Subpart breaks are shown as black dots.(B) Nine human drawings of three characters (left) are shown with theirground truth parses (middle) and best model parses (right).
RESEARCH | RESEARCH ARTICLE
MS no: RAaab3050/CF/PSYCHOLOGY

...
relation:!attached along
relation:!attached along
relation:!attached at start
exemplars
raw data
object template
parts
sub-parts
primitives(1D curvelets, 2D patches, 3D geons, actions, sounds, etc.)
type leveltoken level
inference✓I
latent programraw binary image
Bayes’ rulerenderer prior on parts,
relations, etc.
P (✓|I) = P (I|✓)P (✓)
P (I)
Bayesian Program Learning (BPL)

...
relation:!attached along
relation:!attached along
relation:!attached at start
exemplars
raw data
object template
parts
sub-parts
primitives(1D curvelets, 2D patches, 3D geons, actions, sounds, etc.)
type leveltoken level
inference✓I
latent programraw binary image
Bayes’ rulerenderer prior on parts,
relations, etc.
P (✓|I) = P (I|✓)P (✓)
P (I)
Bayesian Program Learning (BPL)
Key ingredients for learning good programs:
compositionalitycausality
learning-to-learn

Principle 1: Compositionality
Parts:
motor powers wheelshandlebars on postwheels below platform
Relations:
supports
(e.g., Winston, 1975; Fodor, 1975; Marr & Nishihara, 1978; Biederman, 1987)Building complex representations from simpler parts/primitives.

Principle 1: Compositionality
wheels
Parts:
motor powers wheelshandlebars on postwheels below platform
Relations:
supports
(e.g., Winston, 1975; Fodor, 1975; Marr & Nishihara, 1978; Biederman, 1987)Building complex representations from simpler parts/primitives.

Principle 1: Compositionality
handlebars
wheels
Parts:
motor powers wheelshandlebars on postwheels below platform
Relations:
supports
(e.g., Winston, 1975; Fodor, 1975; Marr & Nishihara, 1978; Biederman, 1987)Building complex representations from simpler parts/primitives.

Principle 1: Compositionality
handlebars
posts
wheels
Parts:
motor powers wheelshandlebars on postwheels below platform
Relations:
supports
(e.g., Winston, 1975; Fodor, 1975; Marr & Nishihara, 1978; Biederman, 1987)Building complex representations from simpler parts/primitives.

Principle 1: Compositionality
handlebars
posts
seats
wheels
Parts:
motor powers wheelshandlebars on postwheels below platform
Relations:
supports
(e.g., Winston, 1975; Fodor, 1975; Marr & Nishihara, 1978; Biederman, 1987)Building complex representations from simpler parts/primitives.

Principle 1: Compositionality
handlebars
posts
seats
motors
wheels
Parts:
motor powers wheelshandlebars on postwheels below platform
Relations:
supports
(e.g., Winston, 1975; Fodor, 1975; Marr & Nishihara, 1978; Biederman, 1987)Building complex representations from simpler parts/primitives.

Principle 1: Compositionality
Segway
One-shot learning
handlebars
posts
seats
motors
wheels
Parts:
motor powers wheelshandlebars on postwheels below platform
Relations:
supports
(e.g., Winston, 1975; Fodor, 1975; Marr & Nishihara, 1978; Biederman, 1987)Building complex representations from simpler parts/primitives.

Principle 2: CausalityRepresenting hypothetical real-world processes that produce perceptual
observations.(analysis-by-synthesis; intuitive theories; concepts as causal explanations)
same causal process different examples
(e.g., computer science: Revow et al, 1996; Hinton & Nair, 2006; Freyd, 1983; cog. psychology and cog. neuroscience; Freyd, 1983; Loncamp et al., 2003; James & Gauthier, 2006, 2009)

Principle 2: CausalityRepresenting hypothetical real-world processes that produce perceptual
observations.(analysis-by-synthesis; intuitive theories; concepts as causal explanations)
same causal process different examples
(e.g., computer science: Revow et al, 1996; Hinton & Nair, 2006; Freyd, 1983; cog. psychology and cog. neuroscience; Freyd, 1983; Loncamp et al., 2003; James & Gauthier, 2006, 2009)
…
Is it growing too close to my house?
How will it grow if I trim it?

Principle 2: CausalityRepresenting hypothetical real-world processes that produce perceptual
observations.(analysis-by-synthesis; intuitive theories; concepts as causal explanations)
an airplane is parked on the tarmac at an airport
a group of people standing on top of a beach
a woman riding a horse on a dirt road
Figure 6: Perceiving scenes without intuitive physics, intuitive psychology, compositionality, andcausality. Image captions are generated by a deep neural network (Karpathy & Fei-Fei, 2015) usingcode from github.com/karpathy/neuraltalk2. Image credits: Gabriel Villena Fernandez (left),TVBS Taiwan / Agence France-Presse (middle) and AP Photo / Dave Martin (right). Similarexamples using images from Reuters news can be found at twitter.com/interesting jpg.
same properties is important for e�cient representation and quick learning of the game. Further,new levels may contain di↵erent numbers and combinations of objects, where a compositionalrepresentation of objects – using intuitive physics and intuitive psychology as glue – would aid inmaking these crucial generalizations (Figure 2D).
Deep neural networks have at least a limited notion of compositionality. Networks trained forobject recognition encode part-like features in their deeper layers (Zeiler & Fergus, 2014), wherebythe presentation of new types of objects can activate novel combinations of feature detectors.Similarly, a DQN trained to play Frostbite may learn to represent multiple replications of thesame object with the same features, facilitated by the invariance properties of a convolutionalneural network architecture. Recent work has shown how this type of compositionality can bemade more explicit, where neural networks can be used for e�cient inference in more structuredgenerative models (both neural networks and 3D scene models) that explicitly represent the numberof objects in a scene (Eslami et al., 2016). Beyond the compositionality inherent in parts, objects,and scenes, compositionality can also be important at the level of goals and sub-goals. Recentwork on hierarchical-DQNs shows that by providing explicit object representations to a DQN, andthen defining sub-goals based on reaching those objects, DQNs can learn to play games with sparserewards (such as Montezuma’s Revenge) by combining these sub-goals together to achieve largergoals (Kulkarni, Narasimhan, Saeedi, & Tenenbaum, 2016).
We look forward to seeing these new ideas continue to develop, potentially providing even richernotions of compositionality in deep neural networks that lead to faster and more flexible learning.To capture the full extent of the mind’s compositionality, a model must include explicit represen-tations of objects, identity, and relations – all while maintaining a notion of “coherence” whenunderstanding novel configurations. Coherence is related to our next principle, causality, which isdiscussed in the section that follows.
26
same causal process different examples
(e.g., computer science: Revow et al, 1996; Hinton & Nair, 2006; Freyd, 1983; cog. psychology and cog. neuroscience; Freyd, 1983; Loncamp et al., 2003; James & Gauthier, 2006, 2009)
…
Is it growing too close to my house?
How will it grow if I trim it?

Principle 2: CausalityRepresenting hypothetical real-world processes that produce perceptual
observations.(analysis-by-synthesis; intuitive theories; concepts as causal explanations)
an airplane is parked on the tarmac at an airport
a group of people standing on top of a beach
a woman riding a horse on a dirt road
Figure 6: Perceiving scenes without intuitive physics, intuitive psychology, compositionality, andcausality. Image captions are generated by a deep neural network (Karpathy & Fei-Fei, 2015) usingcode from github.com/karpathy/neuraltalk2. Image credits: Gabriel Villena Fernandez (left),TVBS Taiwan / Agence France-Presse (middle) and AP Photo / Dave Martin (right). Similarexamples using images from Reuters news can be found at twitter.com/interesting jpg.
same properties is important for e�cient representation and quick learning of the game. Further,new levels may contain di↵erent numbers and combinations of objects, where a compositionalrepresentation of objects – using intuitive physics and intuitive psychology as glue – would aid inmaking these crucial generalizations (Figure 2D).
Deep neural networks have at least a limited notion of compositionality. Networks trained forobject recognition encode part-like features in their deeper layers (Zeiler & Fergus, 2014), wherebythe presentation of new types of objects can activate novel combinations of feature detectors.Similarly, a DQN trained to play Frostbite may learn to represent multiple replications of thesame object with the same features, facilitated by the invariance properties of a convolutionalneural network architecture. Recent work has shown how this type of compositionality can bemade more explicit, where neural networks can be used for e�cient inference in more structuredgenerative models (both neural networks and 3D scene models) that explicitly represent the numberof objects in a scene (Eslami et al., 2016). Beyond the compositionality inherent in parts, objects,and scenes, compositionality can also be important at the level of goals and sub-goals. Recentwork on hierarchical-DQNs shows that by providing explicit object representations to a DQN, andthen defining sub-goals based on reaching those objects, DQNs can learn to play games with sparserewards (such as Montezuma’s Revenge) by combining these sub-goals together to achieve largergoals (Kulkarni, Narasimhan, Saeedi, & Tenenbaum, 2016).
We look forward to seeing these new ideas continue to develop, potentially providing even richernotions of compositionality in deep neural networks that lead to faster and more flexible learning.To capture the full extent of the mind’s compositionality, a model must include explicit represen-tations of objects, identity, and relations – all while maintaining a notion of “coherence” whenunderstanding novel configurations. Coherence is related to our next principle, causality, which isdiscussed in the section that follows.
26
same causal process different examples
(e.g., computer science: Revow et al, 1996; Hinton & Nair, 2006; Freyd, 1983; cog. psychology and cog. neuroscience; Freyd, 1983; Loncamp et al., 2003; James & Gauthier, 2006, 2009)
…
Is it growing too close to my house?
How will it grow if I trim it?
Machine caption generation:“A group of people standing on top of a beach”

1 2 3 4 5 6 7 8 9 100
1000
2000
3000
4000
5000Number of strokes
frequ
ency
number of strokes 1 2
3
1 2
3
1 2
3
≥ 31 2
Start position for strokes in each positionstroke start positions
Stroke
global transformations
relations between strokes1
2
12 1
2
1
2
independent (34%) attached at start (5%) attached at end (11%) attached along (50%)
Principle 3: Learning-to-learn
stroke primitives
Experience with previous concepts helps for learning new concepts.(e.g., Harlow, 1949; Schyns, Goldstone, & Thibaut, 1998; Smith et al., 2002)

...
relation:!attached along
relation:!attached along
relation:!attached at start
Bayesian Program Learning (BPL)
exemplars
raw data
object template
parts
sub-parts
primitives(1D curvelets, 2D patches, 3D geons, actions, sounds, etc.)
type leveltoken level
...
relation:!attached along
relation:!attached along
relation:!attached at start
v) exemplars
vi) raw data
iv) object!template
iii) parts
ii) sub-parts
i) primitives
A B
type leveltoken level
https://github.com/brendenlake/BPL

...
relation:!attached along
relation:!attached along
relation:!attached at start
exemplars
raw data
object template
parts
sub-parts
primitives(1D curvelets, 2D patches, 3D geons, actions, sounds, etc.)
type leveltoken level
...
relation:!attached along
relation:!attached along
relation:!attached at start
v) exemplars
vi) raw data
iv) object!template
iii) parts
ii) sub-parts
i) primitives
A B
type leveltoken level
Bayesian Program Learning (BPL)

...
relation:!attached along
relation:!attached along
relation:!attached at start
exemplars
raw data
object template
parts
sub-parts
primitives(1D curvelets, 2D patches, 3D geons, actions, sounds, etc.)
type leveltoken level
inference✓I
latent programraw binary image
Bayes’ rulerenderer prior on parts,
relations, etc.
P (✓|I) = P (I|✓)P (✓)
P (I)
Bayesian Program Learning (BPL)

generating new examples
generating new concepts
parsingthe speed of learning the richness of representation
Large-scale behavioral experiments to evaluate the model

“Generate a new example”Which grid is produced by the model?
A B A B
A B A B

A B A B
A B A B
“Generate a new example”Which grid is produced by the model?

lesioned learning-to-learnBPLExample
Lesion analysis of key principles
lesionedcompositionality

Standard evaluation paradigm
Computationalmodel
Behavioralexperiment
compare behavior

Novel, large-scale, reverse engineering paradigm
Behavioral data(Omniglot)
Computationalmodel
Behavioralexperiment
(drawing new examples)
visual Turing test(behavioral experiment)
simulatedbehavior
humanbehavior
Standard evaluation paradigm
Computationalmodel
Behavioralexperiment
compare behavior

Novel, large-scale, reverse engineering paradigm
Behavioral data(Omniglot)
Computationalmodel
Behavioralexperiment
(drawing new examples)
visual Turing test(behavioral experiment)
simulatedbehavior
humanbehavior
Standard evaluation paradigm
Computationalmodel
Behavioralexperiment
compare behavior
repeated for each alternative model

Experimental design
• Participants (judges) on Amazon Mechanical Turk (N = 147)
• Each judge saw behavior from only one algorithm
• Instructions: Computer program that simulates how people draw a new example. Can you tell humans from machines?
• Pre-experiment comprehension tests
• 49 trials with accuracy displayed after each block of 10.

new exemplarsnew exemplars (dynamic)new concepts (from type)new concepts (unconstrained)40
45
50
55
60
65
70
75
80
85Id
entifi
catio
n (ID
) Lev
el(%
judg
es w
ho c
orre
ctly
ID m
achi
ne v
s. h
uman
)
Generating
new exemplars
Indistinguishable
BPL Lesion (no compositionality)
BPLBPL Lesion (no learning-to-learn)
Bayesian Program Learning models
Visual Turing Test — Generating new examples
error bars ± 1 SEM

generating new examples
generating new concepts
parsingthe speed of learning the richness of representation
Large-scale behavioral experiments to evaluate the model

One-shot classification performance
Erro
r rat
e (%
)
0
5
10
15
20
25
30
35
People
BPL Lesion (no compositionality)
BPLBPL Lesion (no learning-to-learn)
Deep Siamese Convnet(Koch et al., 2015)
Hierarchical DeepDeep Convnet
Bayesian Program Learning models Deep neural networks
After all models pre-trained on 30 alphabets of characters.
(no causality)

Generating new concepts
(unconstrained)
Alphabet
Human or Machine?
Generating new concepts(from type)
Alphabet
Human or Machine?
Human or Machine?
Human or Machine?
Generating new examples (dynamic)
Humanor Machine?
More large-scale behavioral experiments to evaluate BPL model

Generating new concepts
(unconstrained)
Alphabet
Human or Machine?
Generating new concepts(from type)
Alphabet
Human or Machine?
Human or Machine?
Human or Machine?
Generating new examples (dynamic)
Humanor Machine?
More large-scale behavioral experiments to evaluate BPL model

new exemplarsnew exemplars (dynamic)new concepts (from type)new concepts (unconstrained)40
45
50
55
60
65
70
75
80
85Id
entifi
catio
n (ID
) Lev
el(%
judg
es w
ho c
orre
ctly
ID m
achi
ne v
s. h
uman
)
Generating
new exemplars
Generating new
exemplars (dynamic)
Generating new
concepts (from typ
e)
Generating new
concepts (unconstra
ined)
Indistinguishable
BPL Lesion (no compositionality)
BPLBPL Lesion (no learning-to-learn)
Bayesian Program Learning models
Visual Turing Testshttp://cims.nyu.edu/~brenden/supplemental/turingtests/turingtests.html
https://github.com/brendenlake/visual-turing-tests

• Simple visual concepts with real-world complexity.
• Computational model that embodies three principles — compositionality, causality, and learning-to-learn — supporting rich concept learning from very few examples
• Through large-scale, multi-layered behavioral evaluations, the model’s creative generalizations are difficult to distinguish from human behavior
• Current and future directions include understanding developmental and neural mechanisms.
Interim conclusions: Case study 1

Outline
case study 1:handwritten characters
Concept learning
Question asking
...
Are any ships 3 tiles long?
active learning with rich questions
Are the blue ship and red ship parallel?
case study 2:recursive visual concepts

Outline
case study 1:handwritten characters
Concept learning
Question asking
...
Are any ships 3 tiles long?
active learning with rich questions
Are the blue ship and red ship parallel?
case study 2:recursive visual concepts
Steve Piantadosi

If the mind can infer compositional, causal programs from their outputs— what are the limits?

What is another exampleof the same species?
causal knowledge influences perception and extrapolation

What is another exampleof the same species?
causal knowledge influences perception and extrapolation

What is another exampleof the same species?
causal knowledge influences perception and extrapolation
Angle: 35 degreesStart symbol: F+FGF ➔ C0FF-[C1-F+F]+[C2+F-F]G G ➔ C0FF+[C1+F]+[C3-F]
more similar according to L-system program more similar according to deep neural network

Before infection After infection
A surface was infected with a new type of alien crystal.The crystal has been growing for some time.
A B CWhat do you think the crystal will look like if you let it grow longer?

Before infection After infection
A surface was infected with a new type of alien crystal.The crystal has been growing for some time.
A B CWhat do you think the crystal will look like if you let it grow longer?

Before infection After infection
A surface was infected with a new type of alien crystal.The crystal has been growing for some time.
A B CWhat do you think the crystal will look like if you let it grow longer?

Before infection After infection
A surface was infected with a new type of alien crystal.The crystal has been growing for some time.
A B CWhat do you think the crystal will look like if you let it grow longer?

L-system (Lindenmayer, 1968)Angle: 120 degreesStart symbol: FF ➔ F-G+F+G-FG ➔ GG
Legend“+” : right turn“-” : left turn“F” : go straight“G” : go straight
Itera
tion
1Ite
ratio
n 2
…
F-G+F+G-F
Image Dynamics Symbolic
F-G+F+G-F…-GG+F-G+FG-F+GG-…
F-G+F+G-F
Compositional language for expressing causal processes

L-system (Lindenmayer, 1968)Angle: 120 degreesStart symbol: FF ➔ F-G+F+G-FG ➔ GG
Legend“+” : right turn“-” : left turn“F” : go straight“G” : go straight
Itera
tion
1Ite
ratio
n 2
…
F-G+F+G-F
Image Dynamics Symbolic
F-G+F+G-F…-GG+F-G+FG-F+GG-…
F-G+F+G-F
Compositional language for expressing causal processes

Experiment 1 - Classification• No feedback• Six choices• Distractors generated by replacing rule (with new rule from grammar)
• Participants recruited on Amazon Mechanical Turk in USA (N = 30)• 24 different fractal concepts
“latent” condition
Before infection After infection
“stepwise” condition
Before infection Step 1 Step 2
Visual Recursion Task (VRT)[Maurício Martins and colleagues]

24 different fractal concepts

Human performance
Results - Experiment 1 - Classification
chance

Bayesian program learning
Meta-grammar
L-System
Image
rend
erer
I
Axiom = FAngle =120F ➔ F-G+F+G-FG ➔ GG
depth = 2L
I
(context free)
d
Start ➔ XYZ
X ➔ FG
Z ➔ FG ‘’
Y ➔ F G YY-Y++Y-
‘’
Angle ➔ 6090
120
Axiom ➔ FM
L

Bayesian program learning
Meta-grammar
L-System
Image
rend
erer
I
Axiom = FAngle =120F ➔ F-G+F+G-FG ➔ GG
depth = 2L
I
(context free)
d
Start ➔ XYZ
X ➔ FG
Z ➔ FG ‘’
Y ➔ F G YY-Y++Y-
‘’
Angle ➔ 6090
120
Axiom ➔ F
Bayesian Inference (MCMC algorithm)
Infe
renc
e
P (L, d|I) / P (I|L, d)P (L)P (d)
M
L

Bayesian program learning
Meta-grammar
L-System
Image
rend
erer
I
Axiom = FAngle =120F ➔ F-G+F+G-FG ➔ GG
depth = 2L
I
(context free)
d
Start ➔ XYZ
X ➔ FG
Z ➔ FG ‘’
Y ➔ F G YY-Y++Y-
‘’
Angle ➔ 6090
120
Axiom ➔ F
Bayesian Inference (MCMC algorithm)
Infe
renc
e
P (L, d|I) / P (I|L, d)P (L)P (d)
M
L
NoteThe model has several key advantage: it has exactly the right programming language.
If people can infer programs like these, it’s because their “language of thought” is general enough to represent these causal descriptions, and many more…

Perceptual similarity:Pre-trained neural network for object recognitioncosine distance (in last hidden layer)
best match
worst match

Human performance
chance
Model performance
Bayesian program learning: 100%
Pre-trained neural network: 8.3%
neural net
program induction
Results - Experiment 1 - Classification

Human performance
chance
Why is the model better than people?A failure of search?
neural net
program induction (with limited MCMC)
Limited search (MCMC) predicts which concepts are easier to learn: r = 0.57
Easy
Hard
Rational process models (Griffiths, Vul, Hamrick, Lieder, Goodman, etc.)

The “look for a smaller copy” heuristic
Iteration 2 Iteration 3 Iteration 2 Iteration 3

Experiment 2 - Generation

Experiment 2 - Generation

Experiment 2 - Generation

Experiment 2 - Generation

Experiment 2 - Generation

Experiment 2 - Generation

Experiment 2 - Generation

Experiment 2 - Generation
• Participants recruited on Amazon Mechanical Turk in USA (n = 30)• 13 different fractal concepts(subset of previous experiment)• No feedback
“latent” condition
Before infection After infection
“stepwise” condition
Before infection Step 1 Step 2 Step 3

individual decisions (clicks)
Results - Experiment 2 - Generation
precisely right exemplar
***
**
** p < 0.001* p < 0.05
Always use “all” button

individual decisions (clicks)
Results - Experiment 2 - Generation
precisely right exemplar
***
**
** p < 0.001* p < 0.05random
deep neural networkAlways use “none” button
baselines:
Always use “all” button

individual decisions (clicks)
Results - Experiment 2 - Generation
precisely right exemplar
***
**
** p < 0.001* p < 0.05random
deep neural networkAlways use “none” button
baselines:
Always use “all” button

What do you think the crystal will look like if you let it grow longer?
number above image
indicates frequency

What do you think the crystal will look like if you let it grow longer?
number above image
indicates frequency

What do you think the crystal will look like if you let it grow longer?
number above image
indicates frequency

What do you think the crystal will look like if you let it grow longer?
number above image
indicates frequency

Interim conclusions: Case study 2
• Explored very difficult concept learning task
• Computational model that infers causal processes from composition of primitives
• People generalized in ways consistent with model (and inconsistent with other models), despite model’s substantial advantages.
• Generation aided by having a sequence of examples, rather than just one — A pattern the model does not fully explain.

scene understandinglanguage acquisition
creativity
general purpose problem solving
commonsense reasoning
language understanding
human abilities that elude the best algorithms
concept learning question asking

Outline
case study 1:handwritten characters
case study 2:fractal concepts
Concept learning
Question asking
...
Are any ships 3 tiles long?
active learning with rich questions
Are the blue ship and red ship parallel?

Outline
case study 1:handwritten characters
case study 2:fractal concepts
Concept learning
Question asking
...
Are any ships 3 tiles long?
active learning with rich questions
Are the blue ship and red ship parallel?
Todd GureckisAnselm Rothe
Rothe, Lake, & Gureckis (2016). Proceedings of the 38th Annual Conference of the Cognitive Science Society. (More content in prep.).

rich, human questions
active learning for people and machines
?

rich, human questions
active learning for people and machines
How does it make
sound?
?

rich, human questions
active learning for people and machines
How does it make
sound?
What is the difference
between the second and the third?
?

rich, human questions
active learning for people and machines
How does it make
sound?
What is the difference
between the second and the third?
Which features are especially important?
?

rich, human questions
active learning for people and machines
How does it make
sound?
What is the difference
between the second and the third?
Which features are especially important?
simple, machine questions
?

rich, human questions
active learning for people and machines
How does it make
sound?
What is the difference
between the second and the third?
Which features are especially important?
simple, machine questions
What is the the category label of this
object??
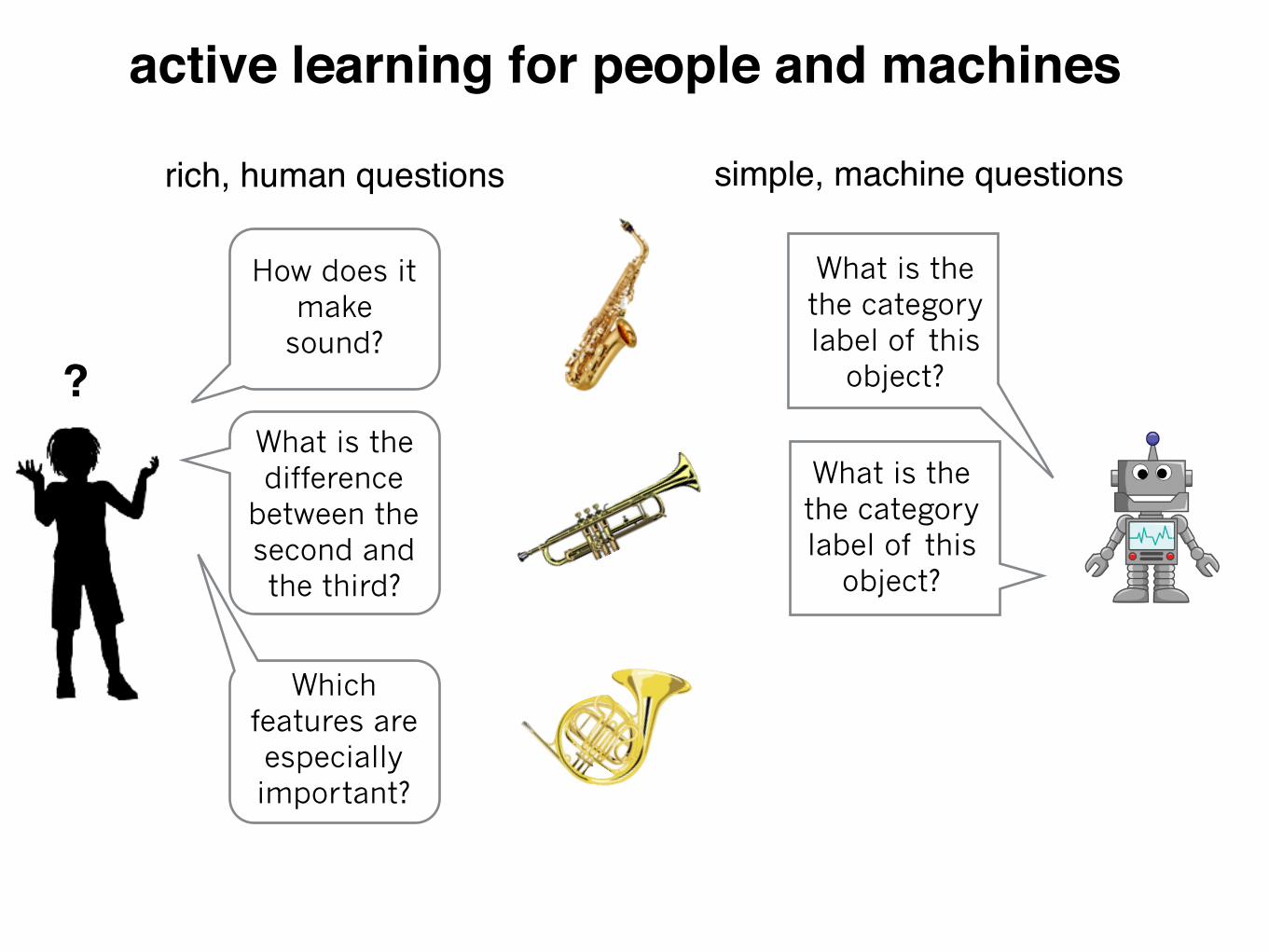
rich, human questions
active learning for people and machines
How does it make
sound?
What is the difference
between the second and the third?
Which features are especially important?
simple, machine questions
What is the the category label of this
object?
What is the the category label of this
object?
?

rich, human questions
active learning for people and machines
How does it make
sound?
What is the difference
between the second and the third?
Which features are especially important?
simple, machine questions
What is the the category label of this
object?
What is the the category label of this
object?
What is the the category label of this
object?
?

We need a task that frees people to ask rich questions, yet is still amendable to formal (ideal observer) modeling.
A testbed domain for question asking

We need a task that frees people to ask rich questions, yet is still amendable to formal (ideal observer) modeling.
A testbed domain for question asking
(Battleship task: Gureckis & Markant, 2009; Markant & Gureckis, 2012, 2014)

Experiment 1: Free-form question asking
11 Markant & Gureckis 2009
A B C D E F123456
Hidden gameboardPossible ships
randomsamples
A B C D E F123456
Revealed gameboard
.enerative model Current data /context
Identify the hidden gameboard!
Goal
�[
�[
�[
Possible sizes
Ground truth
3 ships (blue, purple, red)3 possible sizes (2-4 tiles)
1.6 million possible configurations

Experiment 1: Free-form question asking
...
Phase 1: Sampling
11 Markant & Gureckis 2009
A B C D E F123456
Hidden gameboardPossible ships
randomsamples
A B C D E F123456
Revealed gameboard
.enerative model Current data /context
Identify the hidden gameboard!
Goal
�[
�[
�[
Possible sizes
Ground truth
3 ships (blue, purple, red)3 possible sizes (2-4 tiles)
1.6 million possible configurations

Experiment 1: Free-form question asking
...
Phase 1: Sampling
11 Markant & Gureckis 2009
A B C D E F123456
Hidden gameboardPossible ships
randomsamples
A B C D E F123456
Revealed gameboard
.enerative model Current data /context
Identify the hidden gameboard!
Goal
�[
�[
�[
Possible sizes
Ground truth
3 ships (blue, purple, red)3 possible sizes (2-4 tiles)
1.6 million possible configurations
Phase 2: Question asking
Is the red ship horizontal?
Constraints• one word answers• no combinations

RESULTS
17
A B C D E F123456
Context Example questions
...
RESULTS
17
At what location is the top left part of the purple ship?What is the location of one purple tile?Is the blue ship horizontal?Is the red ship 2 tiles long?Is the purple ship horizontal?Is the red ship horizontal?
Context Example questions
...
Game board Example Questions
Results: generated questions
x18 different game scenarios…

“How many squares long is the blue ship?”“How long is the blue ship?”“How many tiles is the blue ship?”…
} shipsize(blue)
“Is the blue ship horizontal?”“Does the blue one go from left to right?”…
horizontal(blue)
...
}
Extracting semantics from free-form questions

In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference

In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference
In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference

In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference
In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference

81
In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference
In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference

A B C D E F123456
Tria
l 4
At what location is the top left part of the purple ship?What is the location of one purple tile?Is the blue ship horizontal?Is the red ship 2 tiles long?Is the purple ship horizontal?Is the red ship horizontal?
question options
At what location is the top left part of the purple ship?What is the location of one purple tile?
Experiment 2: Evaluating questions for quality
ranked list
best
worst

People are very good at evaluating questionsRESULTS
30
●
●
●
● ●
●
●
● ●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●●● ●
● ●●
●●
●
●●
●
●
●
●
● ●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
● ●
●
●●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
1 2 3 4 5
6 7 8 9 10
11 12 13 14 15
16 17 18
2345
2345
2345
2345
0 0.5 1 0 0.5 1 0 0.5 1EIG (normalized)
Aver
age
rank
sco
re (E
xp 2
)
Bayesian ideal observer score
Aver
age
hum
an ra
nk s
core
(5 =
bes
t)
average r = 0.82across 18 different game scenarios
“Good questions rule out many hypotheses”

In a warm-up phase participants played five rounds of thestandard Battleship game (i.e., turning over tiles to find theships) to ensure understanding of the basic game play. Then,in the main phase, participants were given the opportunity toask free-form questions in 18 trials. We defined 18 different“contexts” which refer to partially revealed game boards (seeFigure 2A).
At the beginning of a trial, we introduced participants toa partly revealed game board by letting them click on a pre-determined sequence of tiles (which are the past queries Xand answers D in Equation 2). We chose this format of tile-uncovering moves, resembling the warm-up phase, to givethe impression that a human was playing a game that waspaused in an unfinished state. Subsequently, as a comprehen-sion check, participants were asked to indicate the possiblecolors of each covered tile (e.g., whether the tile could behiding a piece of the red ship). The task would only continueafter all tiles were indicated correctly (or a maximum of sixguesses were made).
Next, participants were given the following prompt: “Ifyou had a special opportunity to ask any question about thegrid, ships, or tiles - what would you ask?” (represented as xin Equation 2). A text box recorded participants’ responses.The only two restrictions were that combinations of questionswere not allowed (i.e., putting two questions together with“and” or “or”) and questions had to be answerable with a sin-gle piece of information (e.g., a word, a number, true/false, ora single coordinate). Thus, participants could not ask for theentire latent configuration at once, although their creativitywas otherwise uninhibited. Due to practical limitations par-ticipants asked only one question per trial, no feedback wasprovided and there was no painting phase. We emphasizedto participants that they should ask questions as though theywere playing the game they already had experience with inthe earlier part of the experiment.Question asking contexts. To produce a variety of differenttypes of partial knowledge states or “contexts” from whichpeople could ask questions, we varied the number of uncov-ered tiles (6 or 12), the number of partly revealed ships (0 to3), and the number of fully revealed ships (0 to 2). These fac-tors were varied independently while excluding impossiblecombinations leading to a total of 18 contexts/trials.
Results
We recorded 720 questions (18 trials ⇥ 40 participants).Questions that did not conform with the rules or that were am-biguous were discarded (13%) along with (3%) which weredropped due to implementation difficulties. The remaining605 questions (84%) were categorized by type (see Table 1).Question content. As a first stage of our analysis, we man-ually coded commonalities in the meaning of questions in-dependent of the specific wording used. For example, thequestions “How many squares long is the blue ship?” and“How many tiles is the blue ship?” have the same meaning
Table 1: The natural language questions obtained in Exp. 1 wereformalized as functions that could be understood by our model. Thetable shows a comprehensive list. Column N reports the number ofquestions people generated of that type. Questions are organizedinto broad classes (headers) that reference different aspects of thegame.
N Location/standard queries
24 What color is at [row][column]?24 Is there a ship at [row][column]?31 Is there a [color incl water] tile at [row][column]?
Region queries
4 Is there any ship in row [row]?9 Is there any part of the [color] ship in row [row]?5 How many tiles in row [row] are occupied by ships?1 Are there any ships in the bottom half of the grid?
10 Is there any ship in column [column]?10 Is there any part of the [color] ship in column [column]?3 Are all parts of the [color] ship in column [column]?2 How many tiles in column [column] are occupied by ships?1 Is any part of the [color] ship in the left half of the grid?
Ship size queries
185 How many tiles is the [color] ship?71 Is the [color] ship [size] tiles long?8 Is the [color] ship [size] or more tiles long?5 How many ships are [size] tiles long?8 Are any ships [size] tiles long?2 Are all ships [size] tiles long?2 Are all ships the same size?2 Do the [color1] ship and the [color2] ship have the same size?3 Is the [color1] ship longer than the [color2] ship?3 How many tiles are occupied by ships?
Ship orientation queries
94 Is the [color] ship horizontal?7 How many ships are horizontal?3 Are there more horizontal ships than vertical ships?1 Are all ships horizontal?4 Are all ships vertical?7 Are the [color1] ship and the [color2] ship parallel?
Adjacency queries
12 Do the [color1] ship and the [color2] ship touch?6 Are any of the ships touching?9 Does the [color] ship touch any other ship?2 Does the [color] ship touch both other ships?
Demonstration queries
14 What is the location of one [color] tile?28 At what location is the top left part of the [color] ship?5 At what location is the bottom right part of the [color] ship?
for our purposes and were formalized as shipsize(blue), whereshipsize is a function with parameter value blue. Since thefunction shipsize also works with red and purple as parametervalues, it represents a cluster of analogous questions. Withinthese functional clusters we then considered the frequency bywhich such questions were generated across the 18 contextsto get a sense of participant’s question asking approach (firstcolumn in Table 1).
At a broader level, there are natural groups of questiontypes (Table 1). While this partitioning is far from the onlypossible scheme, it helps to reveal qualitative differences be-tween questions. An important distinction contrasts loca-tion/standard queries with rich queries. Location queriesask for the color of a single tile and are the only questiontype afforded by the “standard” Battleship task (Gureckis &Markant, 2009; Markant & Gureckis, 2012, 2014). Richqueries incorporate all other queries in Table 1 and reference
What principles and representations can explain the productivity and creativity of question asking?
How do people think of a question to ask?

“Color at tile A1?”( color A1 )
“Size of the blue ship?”( size Blue )
“Orientation of the blue ship?”( orient Blue )
Game primitives ...
question asking as program synthesis

(+ X X ) (= X X )
Primitive operators
“Color at tile A1?”( color A1 )
“Size of the blue ship?”( size Blue )
“Orientation of the blue ship?”( orient Blue )
Game primitives ...
question asking as program synthesis

(+ X X ) (= X X )
Primitive operators
“Are the blue ship and the red ship parallel?”( = ( orient Blue ) ( orient Red ))
“What is the total sizeof all the ships?”(+
(+ ( size Blue )( size Red )
)( size Purple )
)
Novel questions
compositionality
“Color at tile A1?”( color A1 )
“Size of the blue ship?”( size Blue )
“Orientation of the blue ship?”( orient Blue )
Game primitives ...
question asking as program synthesis

(+ X X ) (= X X )
Primitive operators
“Are the blue ship and the red ship parallel?”( = ( orient Blue ) ( orient Red ))
“What is the total sizeof all the ships?”(+
(+ ( size Blue )( size Red )
)( size Purple )
)
Novel questions
compositionality
“Color at tile A1?”( color A1 )
“Size of the blue ship?”( size Blue )
“Orientation of the blue ship?”( orient Blue )
Game primitives ...
learning-to-learn
question asking as program synthesis

How many ships are three tiles long?( + ( map ( lambda x ( = ( size x ) 3 ) ) ( set Blue Red Purple ) ))
Are any ships 3 tiles long?( > ( + ( map ( lambda x ( = ( size x ) 3 ) ) ( set Blue Red Purple ) ) ) 0)
Are all ships three tiles long?( = ( + ( map ( lambda x ( = ( size x ) 3 ) ) ( set Blue Red Purple ) ) ) 3)
Compositionality in question structure

3 All questions
GROUP QUESTION FUNCTION EXPRESSION
location What color is at A1? location (color A1)Is there a ship at A1? locationA (not (= (color A1) Water))Is there a blue tile at A1? locationD (= (color A1) Blue)
segmentation Is there any ship in row 1? row (> (+ (map (� x (and (= (row x) 1) (not (= (color x) Water)))) (set A1 ... F6))) 0)Is there any part of the blue ship in row 1? rowD (> (+ (map (� x (and (= (row x) 1) (= (color x) Blue))) (set A1 ... F6))) 0)Are all parts of the blue ship in row 1? rowDL (> (+ (map (� x (and (= (row x) 1) (= (color x) Blue))) (set A1 ... F6))) 1)How many tiles in row 1 are occupied by ships? rowNA (+ (map (� x (and (= (row x) 1) (not (= (color x) Water)))) (set A1 ... F6)))Are there any ships in the bottom half of the grid? rowX2 ...Is there any ship in column 1? col (> (+ (map (� x (and (= (col x) 1) (not (= (color x) Water)))) (set A1 ... F6))) 0)Is there any part of the blue ship in column 1? colD (> (+ (map (� x (and (= (col x) 1) (= (color x) Blue))) (set A1 ... F6))) 0)Are all parts of the blue ship in column 1? colDL (> (+ (map (� x (and (= (col x) 1) (= (color x) Blue))) (set A1 ... F6))) 1)How many tiles in column 1 are occupied by ships? colNA (+ (map (� x (and (= (col x) 1) (not (= (color x) Water)))) (set A1 ... F6)))Is any part of the blue ship in the left half of the grid? colX1 ...
ship size How many tiles is the blue ship? shipsize (size Blue)Is the blue ship 3 tiles long? shipsizeD (= (size Blue) 3)Is the blue ship 3 or more tiles long? shipsizeM (or (= (size Blue) 3) (> (size Blue) 3))How many ships are 3 tiles long? shipsizeN (+ (map (� x (= (size x) 3)) (set Blue Red Purple)))Are any ships 3 tiles long? shipsizeDA (> (+ (map (� x (= (size x) 3)) (set Blue Red Purple))) 0)Are all ships 3 tiles long? shipsizeDL (= (+ (map (� x (= (size x) 3)) (set Blue Red Purple))) 3)Are all ships the same size? shipsizeL (= (map (� x (size x)) (set Blue Red Purple)))Do the blue ship and the red ship have the same size? shipsizeX1 (= (size Blue) (size Red))Is the blue ship longer than the red ship? shipsizeX2 (> (size Blue) (size Red))How many tiles are occupied by ships? totalshipsize (+ (map (� x (size x)) (set Blue Red Purple)))
orientation Is the blue ship horizontal? horizontal (= (orient Blue) H)How many ships are horizontal? horizontalN (+ (map (� x (= (orient x) H) (set Blue Red Purple))))Are there more horizontal ships than vertical ships? horizontalM (> (+ (map (� x (= (orient x) H) (set Blue Red Purple)))) 1)Are all ships horizontal? horizontalL (= (+ (map (� x (= (orient x) H) (set Blue Red Purple)))) 3)Are all ships vertical? verticalL (= (+ (map (� x (= (orient x) H) (set Blue Red Purple)))) 0)Are the blue ship and the red ship parallel? parallel (= (orient Blue) (orient Red))
touching Do the blue ship and the red ship touch? touching (touch Blue Red)Are any of the ships touching? touchingA (or (touch Blue Red) (or (touch Blue Purple) (touch Red Purple)))Does the blue ship touch any other ship? touchingXA (or (touch Blue Red) (touch Blue Purple))Does the blue ship touch both other ships? touchingX1 (and (touch Blue Red) (touch Blue Purple))
demonstration What is the location of one blue tile? demonstration (draw (select (set A1 ... F6) Blue))*At what location is the top left part of the blue ship? topleft (topleft Blue)At what location is the bottom right part of the blue ship? bottomright (bottomright Blue)
3
Questions as programs

Defining an infinite set of questions through compositionality

Preliminary results for generating questionsExample for ideal observer maximizing expected information gain (EIG):

Preliminary results for generating questions
(+( +
( * 100 (size Red) )( * 10 (size Blue) )
)(size Purple)
)
Example for ideal observer maximizing expected information gain (EIG):

Preliminary results for generating questions
(+( +
( * 100 (size Red) )( * 10 (size Blue) )
)(size Purple)
)
Example for ideal observer maximizing expected information gain (EIG):
Learning a generative model of questions:
Lake and Gureckis: Proposal for Huawei
as-programs framework developed in the previoussection. We will use a log-linear modeling frame-work to learn a distribution over questions wherethe probability of a question is a function of its fea-tures, f1(·), . . . , f
K
(·). The features will include theexpected information gain (EIG) of a question in thecurrent context, f1(·), as well as features that encodeprogram length, answer type, and various grammat-ical operators. We define the energy of a question x
to be
E(x) = ✓1f1(x) + ✓2f2(x) + · · ·+ ✓
K
f
K
(x), (1)
where ✓i
is a weight assigned to feature fi
. The prob-ability of a question x is determined by its energy
P (x; ✓) =exp�E(x)
Px
02X exp�E(x0), (2)
where high-energy questions have a lower probabil-ity of being asked. The distribution has support onX which is the finite subset of grammar with pro-grams below a particular length limit, ensuring avalid probability distribution.The model can be trained via maximum likelihood
estimation (MLE), with the goal of finding the bestweighting ✓ of the features given the training set.Gradient ascent can be used to find an approximateMLE, although computing the gradient requires es-timating the expected values of the features [21],
E
P
(fi
) =X
x
02XP (x0; ✓)f
i
(x0). (3)
This is an intractable sum that requires enumer-ating all grammatical questions, but it can be ap-proximated using techniques for approximate prob-abilistic inference such as MCMC, importance sam-pling, etc. A data set of questions will be dividedinto a train/test split, and success is determined bythe model’s ability to predict which questions peopleasked in the test set (based on the log-likelihood ofthe semantic forms).
4.1.2 Extensions to new games
The probabilistic model of question asking can beevaluated and extended in other ways. In addi-tion to predicting human questions in new Battle-ship configurations, the creative capability of the
model can be evaluated by asking it to generate gen-uinely novel human-like questions, which are high-probability questions that never appeared in thetraining set. Evaluating the quality of these ques-tions – in terms of their understandability, plausi-bility, and creativity – provides a strong test of theproductivity of the model, which is a hallmark of thehuman ability to ask questions.We will also explore extensions to other classic
games. This will provide an opportunity to under-stand how much of the formal machinery is specificto the Battleship task, and how much is applicable toother games or goal-directed dialogs, more generally.For example, we will explore extensions to gamessuch as “Hangman.” In this game, there is a hiddenword marked by placeholders for each letter. Tra-ditionally, the person playing the game asks aboutthe presence of a letter, one at a time, e.g.,“Arethere any ‘A’s?”, after which the game master re-veals each occurrence of the letter ‘A.’ To studyquestion-asking in this scenario, we proposed to con-duct a behavioral experiment, similar to the experi-ment presented in Section 3.1, to allow for free-formquestion asking during a game of Hangman. Possi-ble questions include queries about types of letters,“How many vowels does the word contain?”, andqueries about particular letter slots, “What is thefirst letter in the word?” As with the data set of Bat-tleship questions, we would then convert these ques-tions into programs, before determining the neces-sary minimal modifications to the Battleship-specificgrammar and feature weights, in order to providea working model of this new domain. We wouldaim to develop a recipe for applying the model toa new game/domain, with the aim of re-using asmany pieces as possible. In this way, we can de-velop general question-asking principles and reducethe amount of training data needed for each new do-main.
4.2 Simple goal-directed dialogs
In the previous sections, we considered the task ofone-o↵ question asking while playing board games.We see these tasks as important case studies forcollecting empirical data, and for developing formalrepresentations of rich questions – here, structuredLISP-like programs that can be evaluated on possi-ble game states. These tasks also provide a window
Lake and Gureckis: Proposal for Huawei
as-programs framework developed in the previoussection. We will use a log-linear modeling frame-work to learn a distribution over questions wherethe probability of a question is a function of its fea-tures, f1(·), . . . , f
K
(·). The features will include theexpected information gain (EIG) of a question in thecurrent context, f1(·), as well as features that encodeprogram length, answer type, and various grammat-ical operators. We define the energy of a question x
to be
E(x) = ✓1f1(x) + ✓2f2(x) + · · ·+ ✓
K
f
K
(x), (1)
where ✓i
is a weight assigned to feature fi
. The prob-ability of a question x is determined by its energy
P (x; ✓) =exp�E(x)
Px
02X exp�E(x0), (2)
where high-energy questions have a lower probabil-ity of being asked. The distribution has support onX which is the finite subset of grammar with pro-grams below a particular length limit, ensuring avalid probability distribution.The model can be trained via maximum likelihood
estimation (MLE), with the goal of finding the bestweighting ✓ of the features given the training set.Gradient ascent can be used to find an approximateMLE, although computing the gradient requires es-timating the expected values of the features [21],
E
P
(fi
) =X
x
02XP (x0; ✓)f
i
(x0). (3)
This is an intractable sum that requires enumer-ating all grammatical questions, but it can be ap-proximated using techniques for approximate prob-abilistic inference such as MCMC, importance sam-pling, etc. A data set of questions will be dividedinto a train/test split, and success is determined bythe model’s ability to predict which questions peopleasked in the test set (based on the log-likelihood ofthe semantic forms).
4.1.2 Extensions to new games
The probabilistic model of question asking can beevaluated and extended in other ways. In addi-tion to predicting human questions in new Battle-ship configurations, the creative capability of the
model can be evaluated by asking it to generate gen-uinely novel human-like questions, which are high-probability questions that never appeared in thetraining set. Evaluating the quality of these ques-tions – in terms of their understandability, plausi-bility, and creativity – provides a strong test of theproductivity of the model, which is a hallmark of thehuman ability to ask questions.We will also explore extensions to other classic
games. This will provide an opportunity to under-stand how much of the formal machinery is specificto the Battleship task, and how much is applicable toother games or goal-directed dialogs, more generally.For example, we will explore extensions to gamessuch as “Hangman.” In this game, there is a hiddenword marked by placeholders for each letter. Tra-ditionally, the person playing the game asks aboutthe presence of a letter, one at a time, e.g.,“Arethere any ‘A’s?”, after which the game master re-veals each occurrence of the letter ‘A.’ To studyquestion-asking in this scenario, we proposed to con-duct a behavioral experiment, similar to the experi-ment presented in Section 3.1, to allow for free-formquestion asking during a game of Hangman. Possi-ble questions include queries about types of letters,“How many vowels does the word contain?”, andqueries about particular letter slots, “What is thefirst letter in the word?” As with the data set of Bat-tleship questions, we would then convert these ques-tions into programs, before determining the neces-sary minimal modifications to the Battleship-specificgrammar and feature weights, in order to providea working model of this new domain. We wouldaim to develop a recipe for applying the model toa new game/domain, with the aim of re-using asmany pieces as possible. In this way, we can de-velop general question-asking principles and reducethe amount of training data needed for each new do-main.
4.2 Simple goal-directed dialogs
In the previous sections, we considered the task ofone-o↵ question asking while playing board games.We see these tasks as important case studies forcollecting empirical data, and for developing formalrepresentations of rich questions – here, structuredLISP-like programs that can be evaluated on possi-ble game states. These tasks also provide a window
Goal: predict human questions in novel scenarios
x
✓f(·)
: question: features (EIG, length, etc.): trainable parameters
energy:
generative model:

Preliminary results for generating questions
(+( +
( * 100 (size Red) )( * 10 (size Blue) )
)(size Purple)
)
Example for ideal observer maximizing expected information gain (EIG):
(topleft( map
(lambda x
(topleft(colortiles x)
))(set Blue Red Purple)
))
Example question:Learning a generative model of questions:
Lake and Gureckis: Proposal for Huawei
as-programs framework developed in the previoussection. We will use a log-linear modeling frame-work to learn a distribution over questions wherethe probability of a question is a function of its fea-tures, f1(·), . . . , f
K
(·). The features will include theexpected information gain (EIG) of a question in thecurrent context, f1(·), as well as features that encodeprogram length, answer type, and various grammat-ical operators. We define the energy of a question x
to be
E(x) = ✓1f1(x) + ✓2f2(x) + · · ·+ ✓
K
f
K
(x), (1)
where ✓i
is a weight assigned to feature fi
. The prob-ability of a question x is determined by its energy
P (x; ✓) =exp�E(x)
Px
02X exp�E(x0), (2)
where high-energy questions have a lower probabil-ity of being asked. The distribution has support onX which is the finite subset of grammar with pro-grams below a particular length limit, ensuring avalid probability distribution.The model can be trained via maximum likelihood
estimation (MLE), with the goal of finding the bestweighting ✓ of the features given the training set.Gradient ascent can be used to find an approximateMLE, although computing the gradient requires es-timating the expected values of the features [21],
E
P
(fi
) =X
x
02XP (x0; ✓)f
i
(x0). (3)
This is an intractable sum that requires enumer-ating all grammatical questions, but it can be ap-proximated using techniques for approximate prob-abilistic inference such as MCMC, importance sam-pling, etc. A data set of questions will be dividedinto a train/test split, and success is determined bythe model’s ability to predict which questions peopleasked in the test set (based on the log-likelihood ofthe semantic forms).
4.1.2 Extensions to new games
The probabilistic model of question asking can beevaluated and extended in other ways. In addi-tion to predicting human questions in new Battle-ship configurations, the creative capability of the
model can be evaluated by asking it to generate gen-uinely novel human-like questions, which are high-probability questions that never appeared in thetraining set. Evaluating the quality of these ques-tions – in terms of their understandability, plausi-bility, and creativity – provides a strong test of theproductivity of the model, which is a hallmark of thehuman ability to ask questions.We will also explore extensions to other classic
games. This will provide an opportunity to under-stand how much of the formal machinery is specificto the Battleship task, and how much is applicable toother games or goal-directed dialogs, more generally.For example, we will explore extensions to gamessuch as “Hangman.” In this game, there is a hiddenword marked by placeholders for each letter. Tra-ditionally, the person playing the game asks aboutthe presence of a letter, one at a time, e.g.,“Arethere any ‘A’s?”, after which the game master re-veals each occurrence of the letter ‘A.’ To studyquestion-asking in this scenario, we proposed to con-duct a behavioral experiment, similar to the experi-ment presented in Section 3.1, to allow for free-formquestion asking during a game of Hangman. Possi-ble questions include queries about types of letters,“How many vowels does the word contain?”, andqueries about particular letter slots, “What is thefirst letter in the word?” As with the data set of Bat-tleship questions, we would then convert these ques-tions into programs, before determining the neces-sary minimal modifications to the Battleship-specificgrammar and feature weights, in order to providea working model of this new domain. We wouldaim to develop a recipe for applying the model toa new game/domain, with the aim of re-using asmany pieces as possible. In this way, we can de-velop general question-asking principles and reducethe amount of training data needed for each new do-main.
4.2 Simple goal-directed dialogs
In the previous sections, we considered the task ofone-o↵ question asking while playing board games.We see these tasks as important case studies forcollecting empirical data, and for developing formalrepresentations of rich questions – here, structuredLISP-like programs that can be evaluated on possi-ble game states. These tasks also provide a window
Lake and Gureckis: Proposal for Huawei
as-programs framework developed in the previoussection. We will use a log-linear modeling frame-work to learn a distribution over questions wherethe probability of a question is a function of its fea-tures, f1(·), . . . , f
K
(·). The features will include theexpected information gain (EIG) of a question in thecurrent context, f1(·), as well as features that encodeprogram length, answer type, and various grammat-ical operators. We define the energy of a question x
to be
E(x) = ✓1f1(x) + ✓2f2(x) + · · ·+ ✓
K
f
K
(x), (1)
where ✓i
is a weight assigned to feature fi
. The prob-ability of a question x is determined by its energy
P (x; ✓) =exp�E(x)
Px
02X exp�E(x0), (2)
where high-energy questions have a lower probabil-ity of being asked. The distribution has support onX which is the finite subset of grammar with pro-grams below a particular length limit, ensuring avalid probability distribution.The model can be trained via maximum likelihood
estimation (MLE), with the goal of finding the bestweighting ✓ of the features given the training set.Gradient ascent can be used to find an approximateMLE, although computing the gradient requires es-timating the expected values of the features [21],
E
P
(fi
) =X
x
02XP (x0; ✓)f
i
(x0). (3)
This is an intractable sum that requires enumer-ating all grammatical questions, but it can be ap-proximated using techniques for approximate prob-abilistic inference such as MCMC, importance sam-pling, etc. A data set of questions will be dividedinto a train/test split, and success is determined bythe model’s ability to predict which questions peopleasked in the test set (based on the log-likelihood ofthe semantic forms).
4.1.2 Extensions to new games
The probabilistic model of question asking can beevaluated and extended in other ways. In addi-tion to predicting human questions in new Battle-ship configurations, the creative capability of the
model can be evaluated by asking it to generate gen-uinely novel human-like questions, which are high-probability questions that never appeared in thetraining set. Evaluating the quality of these ques-tions – in terms of their understandability, plausi-bility, and creativity – provides a strong test of theproductivity of the model, which is a hallmark of thehuman ability to ask questions.We will also explore extensions to other classic
games. This will provide an opportunity to under-stand how much of the formal machinery is specificto the Battleship task, and how much is applicable toother games or goal-directed dialogs, more generally.For example, we will explore extensions to gamessuch as “Hangman.” In this game, there is a hiddenword marked by placeholders for each letter. Tra-ditionally, the person playing the game asks aboutthe presence of a letter, one at a time, e.g.,“Arethere any ‘A’s?”, after which the game master re-veals each occurrence of the letter ‘A.’ To studyquestion-asking in this scenario, we proposed to con-duct a behavioral experiment, similar to the experi-ment presented in Section 3.1, to allow for free-formquestion asking during a game of Hangman. Possi-ble questions include queries about types of letters,“How many vowels does the word contain?”, andqueries about particular letter slots, “What is thefirst letter in the word?” As with the data set of Bat-tleship questions, we would then convert these ques-tions into programs, before determining the neces-sary minimal modifications to the Battleship-specificgrammar and feature weights, in order to providea working model of this new domain. We wouldaim to develop a recipe for applying the model toa new game/domain, with the aim of re-using asmany pieces as possible. In this way, we can de-velop general question-asking principles and reducethe amount of training data needed for each new do-main.
4.2 Simple goal-directed dialogs
In the previous sections, we considered the task ofone-o↵ question asking while playing board games.We see these tasks as important case studies forcollecting empirical data, and for developing formalrepresentations of rich questions – here, structuredLISP-like programs that can be evaluated on possi-ble game states. These tasks also provide a window
Goal: predict human questions in novel scenarios
x
✓f(·)
: question: features (EIG, length, etc.): trainable parameters
energy:
generative model:

compositionality, causality, and learning-to-learn for building more human-like learning algorithms
...
Are any ships 3 tiles long?
( >
( +
( map
( lambda
x
( =
( size x )
3
)
)
( set Blue Red Purple )
)
)
0
)
G GG
angle = 120start = Fniter = 3
F F �G+G+G� F
Are the blue ship and red ship parallel?
( =
( orient Blue )
( orient Red )
)
procedure GENERATETYPE P ()for i = 1 ... do
ni P (ni|)for j = 1 ... ni do
sij P (sij|si(j�1))end for
Ri P (Ri|S1, ..., Si�1)end for
{, R, S}return @GENERATETOKEN( )
end procedure
procedure GENERATETOKEN( )for i = 1... do
S(m)i P (S(m)
i |Si)
L(m)i P (L(m)
i |Ri, T(m)1 , ..., T (m)
i�1 )
T (m)i f(L(m)
i , S(m)i )
end for
A(m) P (A(m))I(m) P (I(m)|T (m), A(m))return I(m)
end procedure
1

Future directions: Causal, compositional, and embodied concepts
learning new gestures
learning new dance moves learning new spoken words
“Ban Ki-moon”“Kofi Annan”
learning new handwritten characters

Developmental origins of one-shot learningWith Eliza Kosoy and Josh Tenenbaum
Which is another example? Draw another example
Child 2
Child 1
One-shot classification One-shot generationlinked?

with Shannon Tubridy, Jason Fuller, & Todd Gureckis
Can we decode letter identity from pre-motor cortex, especially for novel letters?
Neural mechanisms of one-shot learning
Overlapping representations for reading and writing letters in pre-motor cortex.
Fig. 2. Activations found in the group study for the three contrasts, and for each experimental situation. (a) Activations on lateral views of 3D left hemispheres.(b) Inclusive masking analysis of the group activations. The four contrasts where a premotor activation appeared (letter vs control and letter vs pseudolettersin reading; letter vs control and pseudoletter vs control in writing) have been masked to sort out precisely the spatial overlap in the precentral clusters. Theresulting area is shown here on brain slices, in x, y, and z.
(e.g., Longcamp et al., 2003)
N A B KStimuli:

Question asking in simple goal directed dialogswith Anselm Rothe and Todd Gureckis
Concierge : What type of food are you thinking?
Guest : I feel like Italian food.
Concierge: How large is your party?
Guest : Four people.
Concierge : <insert question here>
Are you willing to travel between 20 and 30 minutes for four star place?
Should the average entree price be more or less than $20?
Do you prefer a four star Italian restaurant or three star French?
?

Learning to play new video games
compositionalitycausality
learning-to-learn
but also,intuitive physics
intuitive psychology
How can people learn to play a new game so quickly?What are the underlying cognitive principles?
(Lake et al., in press, Behavioral and Brain Sciences)

Learning to play new video games
compositionalitycausality
learning-to-learn
but also,intuitive physics
intuitive psychology
How can people learn to play a new game so quickly?What are the underlying cognitive principles?
(Lake et al., in press, Behavioral and Brain Sciences)

Conclusions
How can people learn such rich concepts from only one or a few examples?
• Bayesian Program Learning answers this question for a range of simple visual concepts.
• Embodies three principles — compositionality, causality, and learning-to-learn — likely to be important for rapid learning of rich concepts in many domains.
How can people synthesize novel questions when faced with uncertainty?
• Questions can be represented as programs, and synthesized utilizing compositionality and learning-to-learn

Thank you
FundingMoore-Sloan Data Science Environment at NYU, NSF Graduate Research Fellowship, the Center for Minds, Brains and Machines (CBMM) funded by NSF STC award CCF-1231216, and ARO MURI contract W911NF-08-1-0242
Josh Tenenbaum Russ SalakhutdinovCollaborators Steve Piantadosi
Todd Gureckis Anselm Rothe