office 360 and spark
TRANSCRIPT

Office365+Spark PoweringDelveAnalytics

• Introductions
• DelveAnalytics
• Architecture
• SparkEnvironment
• UsagePatterns
• BestPractices
• Takeaways

PaavanyJayanty
Paavanyis aSenior ProgramManagerin theOffice 365CustomerFabric teamatMicrosoft, whose mission is toattract,retain, andengageuserswith thehelp oftheir bigdataproducts.
YiWang
Yiis aSenior Software Engineer in theOffice 365Customer FabricteamatMicrosoft working onbuilding aplatform toenable bigdataapplications.
Introductions

Office365- FunFacts
Users acrosstheworldserved byO365datacenters
Japan
AsiaPacific
Australia
North America
Europe,Middle East& Africa
SouthAmerica India
>30Million– NumberofiOSandAndroidactivedevicesrunningOutlook
59%- CommercialseatgrowthinFY16Q2
20.6million- NumberofConsumerSubscribersnow
80K– NumberofpartnerssellingO365
1.6billion– Sessionspermonthofphonesandtablets
ContinuedinstallbasegrowthacrossOffice,Exchange,SharePointandSkypeforBusiness

DelveAnalytics
Reinventing productivity through individual empowerment.
DelveAnalytics provides youwith insights into twoofthemostimportant factorsinpersonal productivity:• Howyou spend your time• Who you spend your timewithDelveAnalytics helps you takebackyour time andachieve more.
Offered in theE5SKU, and asanadd-on toE1orE3subscriptions.
DelveAnalytics inherits allOffice 365Security, Privacy andCompliancestandards andcommitments. Your insights areonly available toyou,otherwise service metadataisaggregatedand anonymized andnotpersonally identifiable.
HowmanyhoursdoIspend inMeetings?
Whataremymostactivecollaborations?
HowmanyhoursdoIspendworkingafterwork?
HowmanyhoursdoIspendonemail?
HowmanyhourstoIspendonemailcomparedtotherestoftheorganization?



SparkingDelight!
Keepingmillionsofusershappy isthewaywe,atO365,help
attract,retainandengageourusers.
Wedothiswithacommonanalyticsplatformpoweredby
Sparkandsharedinsightrepositorythatenablesanyoneto
quicklyandeasilyusemulti-signalanalysisofnearreal-time
O365datatogainrichinsights,deeplyunderstand our
customers,andbuildanddelivercustomizedexperiencesthat
trulydelight!
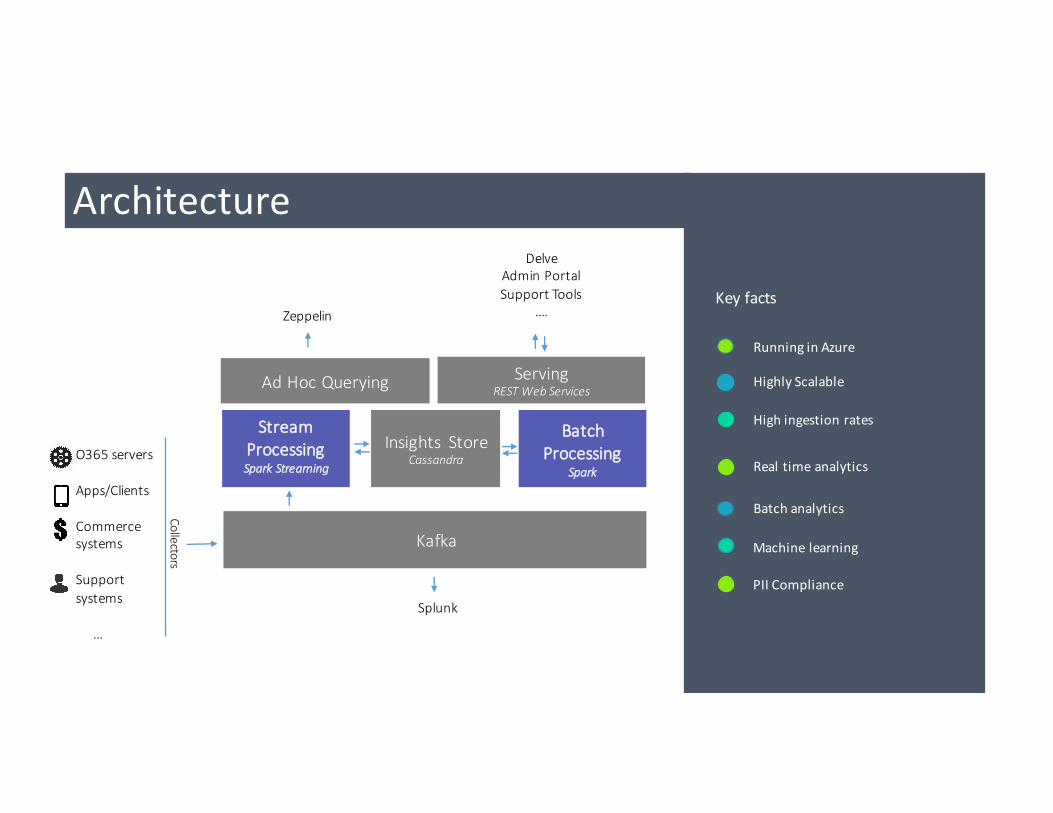
Architecture
StreamProcessingSparkStreaming
BatchProcessing
Spark
Kafka
Insights StoreCassandraO365servers
Apps/Clients
Commercesystems
Supportsystems
…
Collectors
ServingRESTWebServices
DelveAdminPortalSupportTools
….
AdHocQuerying
Zeppelin
RunninginAzure
Batchanalytics
HighlyScalable
Highingestionrates
Realtimeanalytics
Machinelearning
Keyfacts
PIIComplianceSplunk

SupportScenario- Preventcustomerswhoareactivelyusingourservicefromgettingdisabledduetoexpiredsubscriptions(Dunning).
Wedecidedtowinonsatisfactionwiththesecustomersbyproactiveoutreachandhelpingcustomersrenewtheserviceontime.
Usingsparkbatchanalyticsweflaggedcustomerswhowereabouttobedunnedandautomaticallycreatedsupportticketsforoursupportagentstoacton.Wealsogeneratedcustomerprofilessothatouragentsareempoweredwithtargetedinformation.
ServiceScenario– Detect impactofaserviceincidentinrealtimeandnarrowcaststatustocustomers.
Therealityoftheserviceworldisthatit issubjecttoincidentswhichimpacttheuserexperience.Thekeyistohandlethemproactivelyandinatimelymanner:alertbeforetheserviceavailabilitydipsbelowathreshold,investigatetheissueinrealtimeandnarrowcastcommunicationstothespecificsetofimpactedusers.
Usingsparkstreamingwecorrelatetheerrorsignalswithourtopologytodeterminethosewhowereimpactedandproactivelycommunicatewiththem.
Insight Generation Workflows Outreach
Activity
TenantData
ServiceMetadata
Insight
GetProperties
Get InsightsTicketCreation
CustomerProfile
Feedback to refine insights
SparkBatchUseCase SparkStreamingUseCase
Topology
Mobileerrors
OWAerrors
OutlookErrors
Insights
Impactcommunicationtoengineer
Impactcommunicationtotenantadministrator

EnvironmentProduction Environment:• Running onAzure• Version: DSE4.8,Spark 1.4.1• Maintainmultiple clusters powering different scenarios• 3differentDCs inacluster
• Cassandra, Replication Factor=5• Analytics, Replication Factor=5• Exploration, Replication Factor=3
• AllDCs forasingle cluster areinoneVnet.• Noinbound access isallowed fromoutside theVnet.
MachinesUsed:• D14:16cores;112 gbmemory; 3TBattachedlocal SSD• G4:16cores;224 gbmemory; 3TBattachedlocal SSD
Exploration DC- Zeppelin
Analytics DC- Spark analytics jobs
Cassandra DC -Spark Streaming Jobs that ingest data

SparkUsagePatterns
WehavethreeSparkusagepatterns:
• NearReal-Time Processing
• BatchProcessing
• Ad-hocQuerying

UsagePattern#1:NearReal-TimeProcessingSparkStreamingjobspipedatafromonestagetoanother
inrealtime.
Whendoweusethis?
• Scenario needs tobe completed nearreal-time
• Eventdisorders, lateevents orevent drops areaccepted
• Don’t haveabiglook backwindow
Pros: Less datastored inCassandra; NearReal-time;
Cons: Ifsystem is unhealthy, since thebuffering window is
small, thereisno easywaytorecoverthe data.
Real-TimeProcessing
KafkaIngressProcessor
Aggregator
Cassandra Writer

UsagePattern#2:Batch ProcessingSpark Streaming jobs move therawdatafromKafka, dosimple dataconversion andoutput processed rawdatatoCassandra.
Spark BatchJobs do further aggregations and analysis.
When doweuse this?
• Eventaccuracyandorderisveryimportanttothestream
• Needtolookbackafewdays/weeks/monthsofdatafortrends
• Provideacommondatasetsforotherjobstoleverage
• Complicatedjoinswithmultipledatasetstoproducerichinsights
Pros: Highdataaccuracy; Caneasilyrecoverfromissues;
Complicatedanalytics likeTopN becomefeasible;Allowsotherjobsto
reusethecommoncurateddatasets
Real-TimeProcessing
KafkaIngressProcessor
Cassandra Writer

UsagePattern#3:Ad-hocQueryingQuerydatathroughZeppelinwhichsupportssparkinterpreters.
Whendoweusethis?• Explorevaluableexistinginsightsforplanning
• Validatedatatoensureaccuracy
• Ad-hocdataaccess.Dreamupaqueryandrunit!
Pros:Flexible;Democratizesaccesstorichinsights;

StreamingJobs
• Connection timeoutcausesstreamingjobslowness. Solved
byincreasingKeep_alive_ms
• Cacheintermediateresultthatusedfrequentlyto improve
performance.
• DirectapproachismoreefficientthantheReceive-Based
approach.
• Avoidusageofinsertsandupdates instreamingjobs.
BestPractices:StreamingJobs

BatchJobs
• Generatecommondatasetsthatcanbeusedbyother
jobs.
• Tunespark.Cassandra.input.split.size toadjust#of
partitionsizeforbetterjobperformance.
BestPractices:BatchJobs

• Morenodeswithrelativelysmallercapacityismoreperformantthanfewmorepowerfulnodes.• StreamingJobs,BatchJobsandAdhoc QueryshouldlivedinseparateDCs.• Usedirectapproachforsparkstreamingjobs.• Improvejobperformancebyincreasekeep_alive_ms toavoidexpensivereconnectstoCassandra.• Investingindatamodellingearlyonisveryimportant,itwillbeexpensivetochangelater.Yourapiandsparkaccesspatternsshoulddriveschemadesign.
KeyTakeaways

DelveAnalytics-Video
https://www.youtube.com/watch?v=u1Toq7Y0NPo


Appendix

COMPLIANCE
AlldataremainsOffice365compliant.
Allcustomerdataremainssubjecttoestablishedgeographicdataboundaries.
DelveAnalyticsinheritsallOffice365Security,PrivacyandCompliancestandardsandcommitments.
WHAT DOES THIS MEAN?
AllinsightssurfacedviaDelveAnalyticsdashboardarealreadyavailabletoyouinyourinboxandcalendar,suchasresponsetimes,whoyoumeet withandhowoften.
Ifnotalreadyavailabletoyou,thenthisdataisaggregatedandanonymizedandnotpersonallyidentifiable
PRIVACY
TheDelveAnalyticsdashboardsurfacesinformationtoyouaboutyouandalreadydiscoverabletoyou.
CONTROLS
Tenantanduserlevelopt-in/opt-outsettings
SecurityandPrivacy

MonitoringandRecoveryWehavethefollowing inplace:• KafkaMonitors: Monitors thenumber ofKafkabrokers and
Zookeepers thatarealive.• Spark StreamingMonitor: Monitors the#of batches pull from
Kafka, #of records saved toCassandra etc.• Cassandra Monitor: Monitors ifCassandra nodes arehealthy using
ops centerAPI.
• Spark BatchJobMonitor: Monitors ifjobs ransuccessfully ornot.
Recovery:
• Ifthenode isdown automatically bring itup.
Learnings:
• Ifanode isin abad state,bringing itupmight causemore issues.
Monitoring
Recovery
Alerting

• SparkHistoryServer
• DetectFailureandauto-recovery
• Scheduling systems:Cron,AzkabanandOozie
• DebugDiagnostic jobfailure
Challenges