optimizing for space 1comp 512, rice university copyright 2011, keith d. cooper & linda torczon,...
TRANSCRIPT

Optimizing for Space
1COMP 512, Rice University
Copyright 2011, Keith D. Cooper & Linda Torczon, all rights reserved.
Students enrolled in Comp 512 at Rice University have explicit permission to make copies of these materials for their personal use.
Faculty from other educational institutions may use these materials for nonprofit educational purposes, provided this copyright notice is preserved.
Comp 512Spring 2011

COMP 512, Rice University
2
Does Space Matter?
Embedded Computing
• More embedded systems than workstations + PCs
• In many of them, space is a serious constraint Feasibility–-either technical or economic
Networked Computing
• User interface includes transmitted, compiled code
• Response time = transmission time + running time
Excel Phenomenon
• Big companies won’t upgrade if it requires new disks for all
• Need to add features while keeping code size (roughly) fixed

COMP 512, Rice University
3
Optimizing for Space
What can the compiler do to decrease code size?
• Eliminate useless & unreachable code (DEAD, CLEAN, …)
• Constant folding (SCCP)
• Remove redundant code (DVNT, GCSE,
identities)
• Don’t make the code bigger
• Reduce code duplication
• Use shorter code sequences (code shape)
Beyond the compiler’s control
• Eliminate uncalled procedures, methods, & variables
• Need a better linkage editor & better object code format
Close applications in Java
Big libraries, GUIs, ...
*

COMP 512, Rice University
4
Don’t Make the Code Bigger
Class of optimizations that increase code size
• LCM inserts operations to eliminate partial redundancies
• Regional scheduling (usually) requires compensation code
• Inlining, cloning, forward substitution all have the potential to expand the code (exponentially)
Should avoid these if code size is a concern (generate small code)
B1
B5B3
B6
B2 B4
Scheduling B1,B2,B3
•Op from B1 B2 requires duplicate in B4 (unless it is partially dead in B1)
•Op from B2B1 might require compensation code in B4
We will see a technique that avoids this code bloat …
Restrict them to avoid code growth

COMP 512, Rice University
5
Reduce Code Duplication
Hoisting
• Same operation appears in several blocks
• Blocks have common ancestor
• Operands available in ancestor
Move the operation to end of ancestor
Problems
• Must find appropriate ancestor
• Might lengthen some paths (non-optimal )
This only saves space, not time

COMP 512, Rice University
6
Reduce Code Duplication
Implementing Hoisting
• Compute VERYBUSY expressions
• VERYBUSY(b) = s succ(b) USED(s) (VERYBUSY(s) - KILLED(s))
• If x VERYBUSY(b) and b dominates > 1 copy of x, then insert a copy of x at the end of b and delete the dominated copies of x
(or let DEAD do it)
Optimality
• Equations for VERYBUSY incorporate down-safety
• Can ignore down safety for more shrinkage Slows down non-down-safe paths If x can diverge, down safety is required for correctness
Best reference: Fischer & LeBlanc, Crafting a Compiler or Chapter 10 of Engineering a Compiler
Anticipability from LCM

COMP 512, Rice University
7
Reduce Code Duplication
Cross-jumping
• Procedure prolog & epilog are boilerplate
• Many copies of same sequence(s)
• Use one copy and jump there from other locations
• Replaces multiple copies with one
Generalization
• Operation(s) preceding branch to L1 might match
• Can move them down to L1
Used in BLISS-11 compiler (Wulf), Cedar/Mesa system (Zellweger), and TI’s DSP compilers (Humphreys)
Interprocedural optimization

COMP 512, Rice University
8
Reduce Code Duplication
Implementing Cross-jumping
• At head of each block, look back up entering edges
• If all predecessors have same op before branch, move it down
• Repeat until operations differ
Literally 20 lines of code
Caveats
• With fall-through branch model, makes some paths longer
• Can confuse debugger (source pc map is now onto)
• For best results (prolog & epilog), do it at link time
Best reference: Wulf et al., Book on BLISS-11

COMP 512, Rice University
9
Reduce Code Duplication
Procedure abstraction
• Find repeated multi-operation sequences
• Create mini-procedures for them with cheap call (branch)
• Replace copies of sequence with cheap call
• Use full-strength pattern matching – suffix trees
Caveats
• Lengthens execution paths
• Can confuse debugger
• Need to run at link-time for best results
But may speed up execution in a shared system because of smaller working sets!

COMP 512, Rice University
10
Difficult details
• Some sequences differ in register numbers or labels Abstract names
(RISC ) Rotate register names to match (if
possible)
• Some sequences overlap Choose higher payoff, or split sequence
Implementation experience
• 5% compression on average, with about 2.5% slowdown 1% slowdown for each 2% compression, as a rule of thumb Can limit slowdown with profiling information (2-3% for <1%)
• Quite fast, in practice
Reduce Code Duplication
References: Fraser, Myers, & Wendt, SIGPLAN 84 CCC, and Cooper & McIntosh, SIGPLAN PLDI 98

COMP 512, Rice University
11
Use Shorter Code Sequences
The “Superoptimizer”
• Find the shortest possible assembly code sequence
• For short sequences, can use exhaustive search
• Sequences are “equivalent” if they produce the same result
• Can produce surprising (and short) code sequences
This can be done during instruction selection, or offline (GCC)
Practicality
• Exhaustive nature of search makes it EXPENSIVE
• Limits search to short sequences (< 10 operations)
• Must pick sequences to study (opportunity)

COMP 512, Rice University
12
Use Shorter Code Sequences
The Superoptimizer Algorithm
1. Assume a short assembly sequence of k operations
2. For 1 ≤ i < k do
a. Generate each sequence of length i
b. Test the sequences for equivalence & exit if equivalent
Efficient equivalence testing is critical
Testing sequences
• Execute it on three sets of input (done if it fails)
• Construct boolean expressions to characterize functions & compare their minterm representations
Massalin claims the first test is sufficient, in practiceBest Reference: Massalin, in ASPLOS I, 1987
This technique is actually used in porting GCC.

COMP 512, Rice University
13
Array Linearization (Carry Optimization)
Implemented as far back as Fortran I
Has same access pattern, simpler address polynomial
• Collapses three loops into one fewer operations
• Minimizes address-arithmetic overhead faster & smaller
• Equivalent to C loop that autoincrements a pointer…
(Assume Linear Function Test Replacement)
for i 1 to n for j = 1 to m for k = 1 to p A[i,j,k] = …
for ii 1 to n x m x p A’[ii] = …
Allen & Cocke, “A Catalog of Optimizing Transformations”, 1972 (on 512 web site)

COMP 512, Rice University
14
List Scheduling
Conflict between run-time speed and code space
• For faster code, would like to schedule larger regions
• Scheduling larger regions introduces compensation code
• Can use notion of “down safety” to constrain growth Phil Schielke, LCTES 1998 (on readings
page)
B1
B4B3B2
Moving an op from B1 to B2
• May require copies in B3 and B4
Moving an op from B2 to B1
• Might need to undo it in B3 and B4
COMP 512, Rice University
15
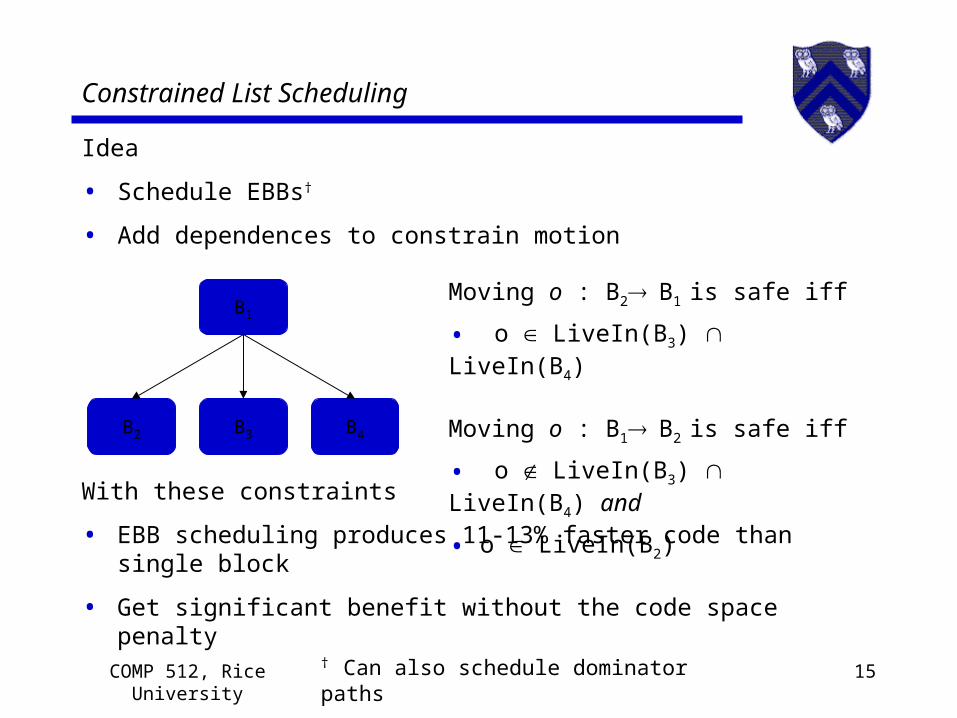
Constrained List Scheduling
Idea
• Schedule EBBs†
• Add dependences to constrain motion
B1
B4B3B2
Moving o : B2 B1 is safe iff
• o LiveIn(B3) LiveIn(B4)
Moving o : B1 B2 is safe iff
• o LiveIn(B3) LiveIn(B4) and
• o LiveIn(B2)With these constraints
• EBB scheduling produces 11-13% faster code than single block
• Get significant benefit without the code space penalty
† Can also schedule dominator paths

COMP 512, Rice University
16
Instruction Selection & Packing Issues
Obvious Points
• Choose short ops and branches
ARM Processor
• Has 32 bit ops and 16 bit ops (“thumb” ISA)
• Shifting into “thumb” ops can halve code size (for those ops)
TI C6000
• Has a complex fetch-packet/execute packet architecture

COMP 512, Rice University
17
Problems with Instruction Fetch
• Partially filled fetch packets result in extra fetching
• Short loops fetch extra packets (worst case example)
4
5
2
2
4
1
2 6
B 1 1 1 1 1 2
8
8
8
8

COMP 512, Rice University
18
Instruction Selection & Packing Issues
Obvious Points
• Choose short ops and branches
ARM Processor
• Has 32 bit ops and 16 bit ops (“thumb” ISA)
• Shifting into “thumb” ops can halve code size (for those ops)
TI C6000
• Has a complex fetch-packet/execute packet architecture
• Scheduling for too much width can make some fetch slots unusable Scheduler should pay attention to operation density
• Cutest feature – multi-cycle NOP

COMP 512, Rice University
19
Miscellany
Block merging
• One of CLEAN’s transformations
• Eliminates branch & improves local optimization
Activation record merging (Murtagh)
• Shrink prolog code by eliminating allocation points
• Optimize non-local references within same record
• Trades data space for code space + little bit of speed
Induction variable merging
• Discover equivalent induction variables
• Shift to one index and save on updates and registers
• Opportunities created by value-numbering & reassociation

COMP 512, Rice University
20
Miscellany
Dynamic decompression of code
• Use serious compression on code
• Decompress on the fly at run-time
Minimize spill code
• Register allocator inserts load & store operations
• Fewer spills produce smaller, faster code
• Choose spill candidate that needs fewest spill operations
• … but spill code minimization is another lecture
Decompress in hardware(Mudge) or in software (Huffman decoder?)
Normally, allocator spills for speed not space

COMP 512, Rice University
21
Generate Smaller Code
An optimizer is the concatenation of a series of passes
• What’s the best order of application for the optimizations? Long-standing open question
• Is the notion of “best” program specific? Might produce better code
• We built a simple genetic algorithm to find the “best” sequence for specific programs
better smaller or faster
FrontEnd
Opt. BackEnd
...
A different approach
In our compiler, we could reorder the passes
This is not typical.

COMP 512, Rice University
22
Generate Smaller Code
• The Problem 10 genes, population of 20 chromosomes (of length 12) Test fitness by measuring code size Number of operations executed as secondary fitness criteria
• The algorithm Test & rank the 20 chromosomes Discard worst + 3 chosen at random from 11—19 Generate 4 new chromosomes from crossover using 1—10 Mutate survivors from 2 — 19 (elitism
excludes 1) Replace any duplicates
• Ran 1000 generations (3 - 4 hours per program on a 1998 SPARC)
• Refine the best sequence (get rid of cruft) Run a “knockout” test on the sequence

COMP 512, Rice University
23
• GA did better than any fixed sequence Beat the compiler’s default string (used for five years)
• Showed us how to construct a better fixed sequence Beats the old default in code size (11% on
average) Produces faster compilations and smaller code
• Program specific mutations beat both fixed sequences Beat “old” default by 0 to 41% (13% on average) Beat “new” default by 0.1 to 7% (13% vs.
11%)
• This GA converged in 200 to 300 generations (others do better)
Converges an order of magnitude faster than random probing
Smaller code is often faster than larger code
Generate Smaller Code

COMP 512, Rice University
24
Experimental Results
Improving the Genetic Algorithm
• Experiments aimed at understanding & improving convergence
GA now dominates both the hill climber and random probing of the search space, in results/work.
*
• Larger population helps Tried pools from 50 to 1000, 100 to 300 is about right
• Use weighted selection in reproductive choice (vs. random) Fitness scaling to exaggerate late, small improvements
• Crossover 2 point, random crossover Apply “mutate until unique” to each new string
• Variable length chromosomes With fixed string, GA discovers NOPs Varying string rarely has useless pass

COMP 512, Rice University
25
Experimental Results
Improving the Genetic Algorithm
• Experiments aimed at understanding & improving convergence
GA now dominates both the hill climber and random probing of the search space, in results/work.
*
• Larger population helps Tried pools from 50 to 1000, 100 to 300 is about right
• Use weighted selection in reproductive choice (vs. random) Fitness scaling to exaggerate late, small improvements
• Crossover 2 point, random crossover Apply “mutate until unique” to each new string
• Variable length chromosomes With fixed string, GA discovers NOPs Varying string rarely has useless pass
Bottom Line:
• Generating compact code works better than generating large code and compressing it
• Adaptive compilation can find program-specific sequences that generate compact code
• Some transformations never show up in those sequences (LCM)