partitioning algorithms for improving efficiency of topic modeling parallelization
TRANSCRIPT

PartitioningAlgorithmsforImprovingEfficiency
ofTopicModelingParallelization
HungNghiepTran
UniversityofInformationTechnology
Vietnam
AtsuhiroTakasu
NationalInstituteofInformatics
Japan
Originalpaper:HungNghiepTran,AtsuhiroTakasu.PartitioningAlgorithmsforImprovingEfficiencyofTopicModelingParallelization.PacRim2015.Resource: Seethelastslide(SlideShareconvention.)

IntroductionTopicmodeling,e.g.,LDA.
Topicmodelingisslow.2
Imagesource:D.M.Blei,ProbabilisticTopicModels,Comm.ACM55,4(2012),77-84.

IntroductionTopicmodeling,e.g.,LDA.
Topicmodelingisslow.3
Imagesource:D.M.Blei,ProbabilisticTopicModels,Comm.ACM55,4(2012),77-84.

Introduction
Parallelization.CollapsedGibbsSamplingissequentialinnature.àDifficulttoparallelize.
4
Word
Document
Topic
Document
Word
Topic
Data
Params

Introduction
Parallelization.CollapsedGibbsSamplingissequentialinnature.àDifficulttoparallelize.
5
Word
Document
Topic
Document
Word
Topic
Data
Params

Introduction• Datapartitioning-basedapproach[1].
§ Howitworks:• Partitiondatabothhorizontallyandvertically.
• Nonconflictingparallelsampleoneachdiagonalline.
§ Howit‘sgood:• SharethesamecopyofDataandParams.
• Theoreticallylinearspeedup.
• Loadbalancing.§ Alltheotherprocessesmustwaitfor
theslowestone.à Difficulttoloadbalance.
6Do
cument
Word
[1]F.Yan,etal.,ParallelInferenceforLatentDirichletAllocationonGraphicsProcessingUnits,NIPS(2009).
Topic
Document
Word
Topic

Introduction• Datapartitioning-basedapproach[1].
§ Howitworks:• Partitiondatabothhorizontallyandvertically.
• Nonconflictingparallelsampleoneachdiagonalline.
§ Howit‘sgood:• SharethesamecopyofDataandParams.
• Theoreticallylinearspeedup.
• Loadbalancing.§ Alltheotherprocessesmustwaitfor
theslowestone.à Difficulttoloadbalance.
7Do
cument
Word
[1]F.Yan,etal.,ParallelInferenceforLatentDirichletAllocationonGraphicsProcessingUnits,NIPS(2009).
Topic
Document
Word
Topic

OurGoal
To develop data partitioning algorithmsthat achieve better load balance toimprove efficiency of topic modelingparallelization.
8
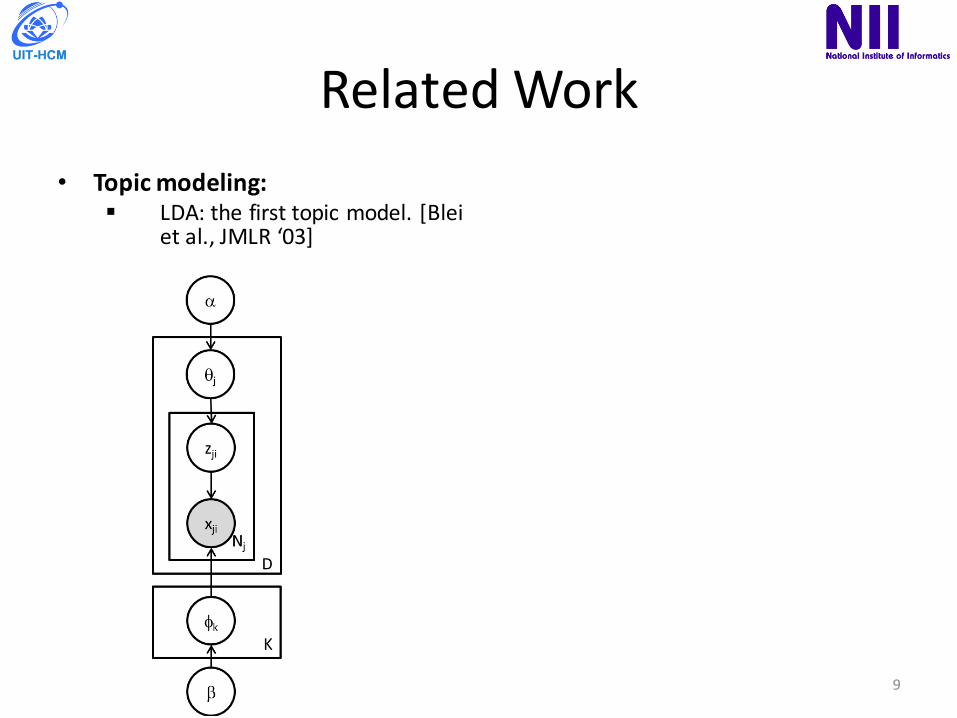
RelatedWork• Topicmodeling:
§ LDA:thefirsttopicmodel.[Bleietal.,JMLR‘03]
• Advancedtopicmodeling:§ BagofTimestamps(BoT):time-
awaremodeling. [Masadaetal.,ADWM‘09]
9

RelatedWork• Topicmodeling:
§ LDA:thefirsttopicmodel.[Bleietal.,JMLR‘03]
• Advancedtopicmodeling:§ BagofTimestamps(BoT):time-
awaremodeling. [Masadaetal.,ADWM‘09]
10

RelatedWorkParallelizationapproach:1. CopyandSync:Samplingonmultiplecopiesofdatathen
synchronizeaftereachsamplingiteration.E.g.,[Newmanetal.,JMLR‘09].
àWeakness:Syncingoverhead.
2. Non-blockingaccess:Accesstoshareddatabyusingatomicoperation.E.g.,[SmolaandNarayanamurthy,VLDB‘10].
àWeakness:Moreconflictwhenincreasingparallelprocesses.
3. Datapartitioning-based:Accesstoshareddatabypartitioningdata.E.g.,[Yanetal.,NIPS‘09].
àWeakness:Loadbalancing.
11

RelatedWorkParallelizationapproach:1. CopyandSync:Samplingonmultiplecopiesofdatathen
synchronizeaftereachsamplingiteration.E.g.,[Newmanetal.,JMLR‘09].
àWeakness:Syncingoverhead.
2. Non-blockingaccess:Accesstoshareddatabyusingatomicoperation.E.g.,[Smola&Narayanamurthy,VLDB‘10].
àWeakness:Moreconflictwhenincreasingparallelprocesses.
3. Datapartitioning-based:Accesstoshareddatabypartitioningdata.E.g.,[Yanetal.,NIPS‘09].
àWeakness:Loadbalancing.
12

RelatedWorkParallelizationapproach:1. CopyandSync:Samplingonmultiplecopiesofdatathen
synchronizeaftereachsamplingiteration.E.g.,[Newmanetal.,JMLR‘09].
àWeakness:Syncingoverhead.
2. Non-blockingaccess:Accesstoshareddatabyusingatomicoperation.E.g.,[Smola&Narayanamurthy,VLDB‘10].
àWeakness:Moreconflictwhenincreasingparallelprocesses.
3. Datapartitioning-based:Accesstoshareddatabypartitioningdata.E.g.,[Yanetal.,NIPS‘09].
àWeakness:Loadbalancing.
13
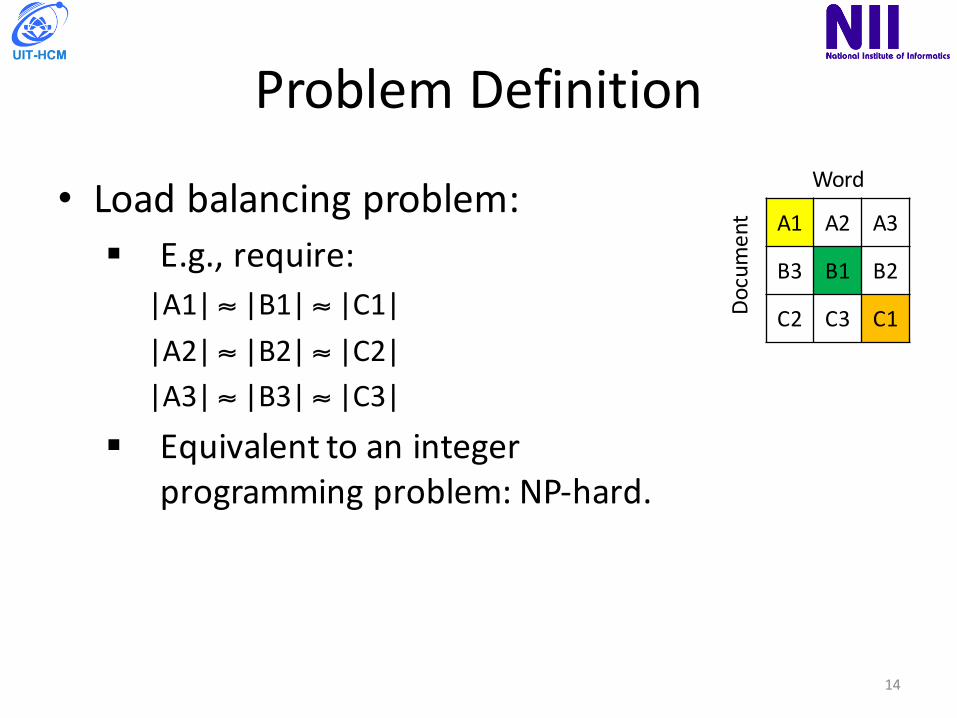
ProblemDefinition
• Loadbalancingproblem:§ E.g.,require:
|A1|≈ |B1| ≈ |C1||A2|≈ |B2| ≈ |C2||A3|≈ |B3| ≈ |C3|
§ Equivalenttoanintegerprogrammingproblem:NP-hard.
14
A1 A2 A3
B3 B1 B2
C2 C3 C1Document
Word

ProblemDefinition
• Loadbalancingratio𝜂:§ Optimalcost:dividingworkequally.
• E.g.,C#$% ='#%()+#,-%#./0
1
§ Actualcost:costoftheslowestpartitiononeachdiagonalline.• E.g.,𝐶 = 𝐴1 + 𝐵2 + |𝐵3|
§ Loadbalancingratio𝜂 = :;<=:
àMinimizeloadbalancingratio𝜂.
15
A1 A2 A3
B3 B1 B2
C2 C3 C1Document
Word
E.g.,A1,B2,B3arethepartitionsthathavethemostwordtokensoneachdiagonalline,respectively.

ProblemDefinition
• Loadbalancingratio𝜂:§ Optimalcost:dividingworkequally.
• E.g.,C#$% ='#%()+#,-%#./0
1
§ Actualcost:costoftheslowestpartitiononeachdiagonalline.• E.g.,𝐶 = 𝐴1 + 𝐵2 + |𝐵3|
§ Loadbalancingratio𝜂 = :;<=:
àMinimizeloadbalancingratio𝜂.
16
A1 A2 A3
B3 B1 B2
C2 C3 C1Document
Word
E.g.,A1,B2,B3arethepartitionsthathavethemostwordtokensoneachdiagonalline,respectively.

ProposedApproach
• Toachievebetterloadbalance:Step1:DistributewordtokensevenlyinDocument-Wordmatrix.
à Bypermutingrowsandcolumns.
Step2:DivideDocument-Wordmatrix into𝑃×𝑃 approx.equalpartitions.
àSimplybycountingwordtokensinrows,thendividingrowsintoPconsecutivegroups,eachcontainsapprox.𝐶#$% wordtokens.
àSimilarlyforcolumns.
• Note:Eachstepisdoneseparatelyforrowsandcolumns.
17

ProposedApproach
• Toachievebetterloadbalance:Step1:DistributewordtokensevenlyinDocument-Wordmatrix.
à Bypermutingrowsandcolumns.
Step2:DivideDocument-Wordmatrix into𝑃×𝑃 approx.equalpartitions.
àSimplybycountingwordtokensinrows,thendividingrowsintoPconsecutivegroups,eachcontainsapprox.𝐶#$% wordtokens.
àSimilarlyforcolumns.
• Note:Eachstepisdoneseparatelyforrowsandcolumns.
18

ProposedApproach
• Toachievebetterloadbalance:Step1:DistributewordtokensevenlyinDocument-Wordmatrix.
à Bypermutingrowsandcolumns.
Step2:DivideDocument-Wordmatrix into𝑃×𝑃 approx.equalpartitions.
àSimplybycountingwordtokensinrows,thendividingrowsintoPconsecutivegroups,eachcontainsapprox.𝐶#$% wordtokens.
àSimilarlyforcolumns.
• Note:Eachstepisdoneseparatelyforrowsandcolumns.
19

ProposedApproach
• Toachievebetterloadbalance:Step1:DistributewordtokensevenlyinDocument-Wordmatrix.
à Bypermutingrowsandcolumns.
Step2:DivideDocument-Wordmatrix into𝑃×𝑃 approx.equalpartitions.
àSimplybycountingwordtokensinrows,thendividingrowsintoPconsecutivegroups,eachcontainsapprox.𝐶#$% wordtokens.
àSimilarlyforcolumns.
• Note:Eachstepisdoneseparatelyforrowsandcolumns.
20

PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmoreword
tokens.§ Assumethereareonly5
documentsand5words.• Output:
§ Heuristic1(alsoAlgorithmA1):Darkestandlightestrowsareinterposed.
§ Heuristic2 (alsoAlgorithmA2):SimilarlytoHeuristic1butdofrombothends.
21

PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmoreword
tokens.§ Assumethereareonly5
documentsand5words.• Output:
§ Heuristic1(alsoAlgorithmA1):Darkestandlightestrowsareinterposed.
§ Heuristic2 (alsoAlgorithmA2):SimilarlytoHeuristic1butdofrombothends.
22
Input

PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmoreword
tokens.§ Assumethereareonly5
documentsand5words.• Output:
§ Heuristic1(alsoAlgorithmA1):Darkestandlightestrowsareinterposed.
§ Heuristic2 (alsoAlgorithmA2):SimilarlytoHeuristic1butdofrombothends.
23
Input
Heuristic1’sOutput

PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmoreword
tokens.§ Assumethereareonly5
documentsand5words.• Output:
§ Heuristic1(alsoAlgorithmA1):Darkestandlightestrowsareinterposed.
§ Heuristic2 (alsoAlgorithmA2):SimilarlytoHeuristic1butdofrombothends.
24
Input
Heuristic1’sOutput
Heuristic2’sOutput

PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmorewordtokens.§ Assumetherearealotofrows.
• Output:§ Heuristic3 (alsoAlgorithmA3):
• First,createPrangesofrows,eachcontainsalldarkandlightrows.
• ThenuniformlyrandomlypermuteeachofthosePrangesofrows.
à Theoutputisarandomlyshuffledmatrixwiththeconditionthatrowcolor(numberofwordtokensineachrow)aredistributedevenly.
25

PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmorewordtokens.§ Assumetherearealotofrows.
• Output:§ Heuristic3 (alsoAlgorithmA3):
• First,createPrangesofrows,eachcontainsalldarkandlightrows.
• ThenuniformlyrandomlypermuteeachofthosePrangesofrows.
à Theoutputisarandomlyshuffledmatrixwiththeconditionthatrowcolor(numberofwordtokensineachrow)aredistributedevenly.
26
Input
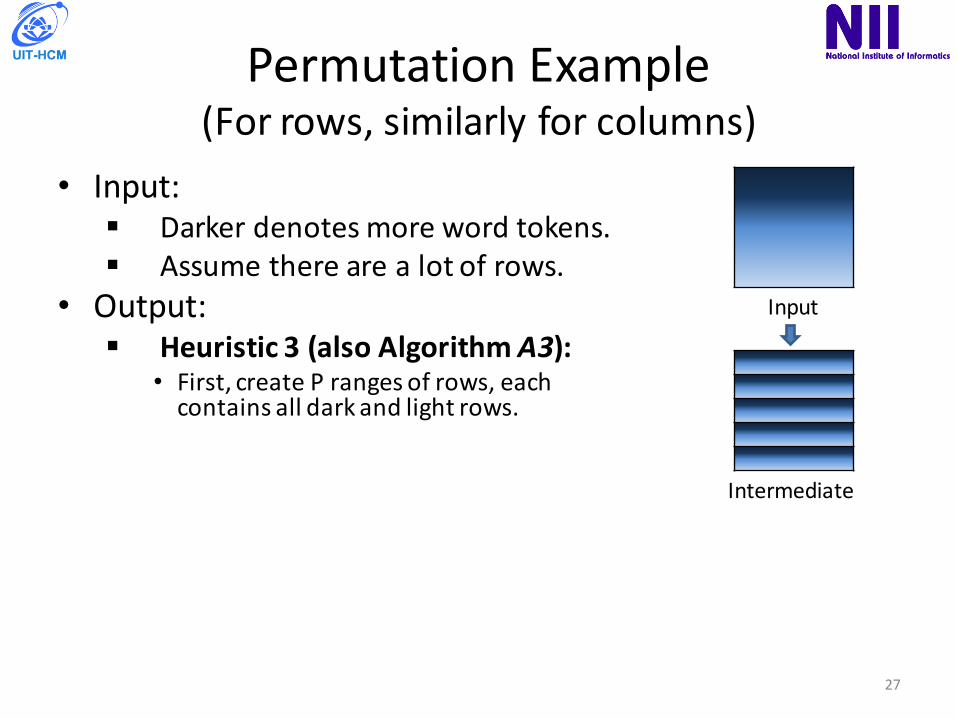
PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmorewordtokens.§ Assumetherearealotofrows.
• Output:§ Heuristic3 (alsoAlgorithmA3):
• First,createPrangesofrows,eachcontainsalldarkandlightrows.
• ThenuniformlyrandomlypermuteeachofthosePrangesofrows.
à Theoutputisarandomlyshuffledmatrixwiththeconditionthatrowcolor(numberofwordtokensineachrow)aredistributedevenly.
27
Input
Intermediate
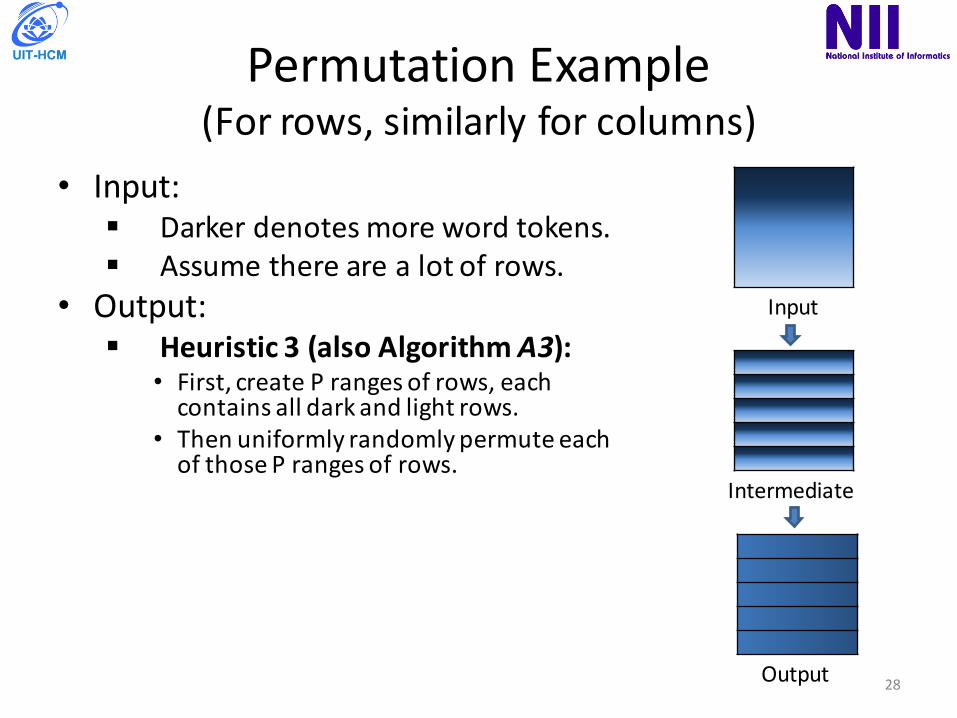
PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmorewordtokens.§ Assumetherearealotofrows.
• Output:§ Heuristic3 (alsoAlgorithmA3):
• First,createPrangesofrows,eachcontainsalldarkandlightrows.
• ThenuniformlyrandomlypermuteeachofthosePrangesofrows.
à Theoutputisarandomlyshuffledmatrixwiththeconditionthatrowcolor(numberofwordtokensineachrow)aredistributedevenly.
28
Input
Intermediate
Output

PermutationExample(Forrows,similarlyforcolumns)
• Input:§ Darkerdenotesmorewordtokens.§ Assumetherearealotofrows.
• Output:§ Heuristic3 (alsoAlgorithmA3):
• First,createPrangesofrows,eachcontainsalldarkandlightrows.
• ThenuniformlyrandomlypermuteeachofthosePrangesofrows.
à Theoutputisarandomlyshuffledmatrixwiththeconditionthatrowcolor(numberofwordtokensineachrow)aredistributedevenly.
29
Input
Intermediate
Output

ExtendingtoParallelBoT
• BagofTimestamps(BoT)[Masadaetal.,ADWM‘09]:§ Time-awaremodeling.§ BettertopicqualitythanLDA,but
trainingisslower.§ Timestampsaretreatedaswords.
30

HowtoExtendtoParallelBoT
• TreatDocument-Timestamp(D-TS)matrixsimilarlyasDocument-Word (D-W) matrix.à Whenpartitioning:PartitionD-Wmatrix
normallyasinLDA,partitionD-TSmatrixthesamewayasD-Wmatrix.
à Whensampling:AlternatelysamplingeachdiagonallineofD-WmatrixandeachdiagonallineofD-TSmatrix.
31

HowtoExtendtoParallelBoT
• TreatDocument-Timestamp(D-TS)matrixsimilarlyasDocument-Word (D-W) matrix.à Whenpartitioning:PartitionD-Wmatrix
normallyasinLDA,partitionD-TSmatrixthesamewayasD-Wmatrix.
à Whensampling:AlternatelysamplingeachdiagonallineofD-WmatrixandeachdiagonallineofD-TSmatrix.
32

HowtoExtendtoParallelBoT
• TreatDocument-Timestamp(D-TS)matrixsimilarlyasDocument-Word (D-W) matrix.à Whenpartitioning:PartitionD-Wmatrix
normallyasinLDA,partitionD-TSmatrixthesamewayasD-Wmatrix.
à Whensampling:AlternatelysamplingeachdiagonallineofD-WmatrixandeachdiagonallineofD-TSmatrix.
33

ExperimentalData
• OrdinarydatasetsNIPSandNYTimes:§ Source:http://archive.ics.uci.edu/ml/datasets/Bag+of+Words
• NewdatasetMAS:§ Dataaboutscientificpapers,withpublishedyearinformation.§ Tobereleasedfromhttps://sites.google.com/site/tranhungnghiep
34

Evaluation• Tomeasuretheefficiencyofpartitioningdata:
§ Loadbalancingratio𝜂.• Thehigherthebetter.𝑆𝑝𝑒𝑒𝑑𝑢𝑝𝑓𝑎𝑐𝑡𝑜𝑟 ≈ 𝜂×|𝑃𝑎𝑟𝑎𝑙𝑙𝑒𝑙𝑝𝑟𝑜𝑐𝑒𝑠𝑠𝑒𝑠|.
• Tomeasurethequalityofextractedtopics:§ Abilitytodescribedata:Perplexity.
• Thelowerthebetter.
𝑃𝑒𝑟𝑝 𝑥 = exp − ST log𝑝 𝑥 ,
withlog𝑝 𝑥 = ∑ 𝑙𝑜𝑔∑ 𝜃.|[𝜙]^_|..[` .
• Baselinealgorithm:[Yanetal.,NIPS‘09]§ Randomlypermutedocumentsandwordsinthedatamatrix.§ Usethepermutationwiththehighest𝜂.
35

ImprovementonLoadBalancing
Loadbalancingratio𝜼 onNIPS.
36
• A3givesthehighestresults.• A1andA2areverycompetitive.
Note:𝑆𝑝𝑒𝑒𝑑𝑢𝑝𝑓𝑎𝑐𝑡𝑜𝑟 ≈ 𝜂×|𝑃𝑎𝑟𝑎𝑙𝑙𝑒𝑙𝑝𝑟𝑜𝑐𝑒𝑠𝑠𝑒𝑠|.
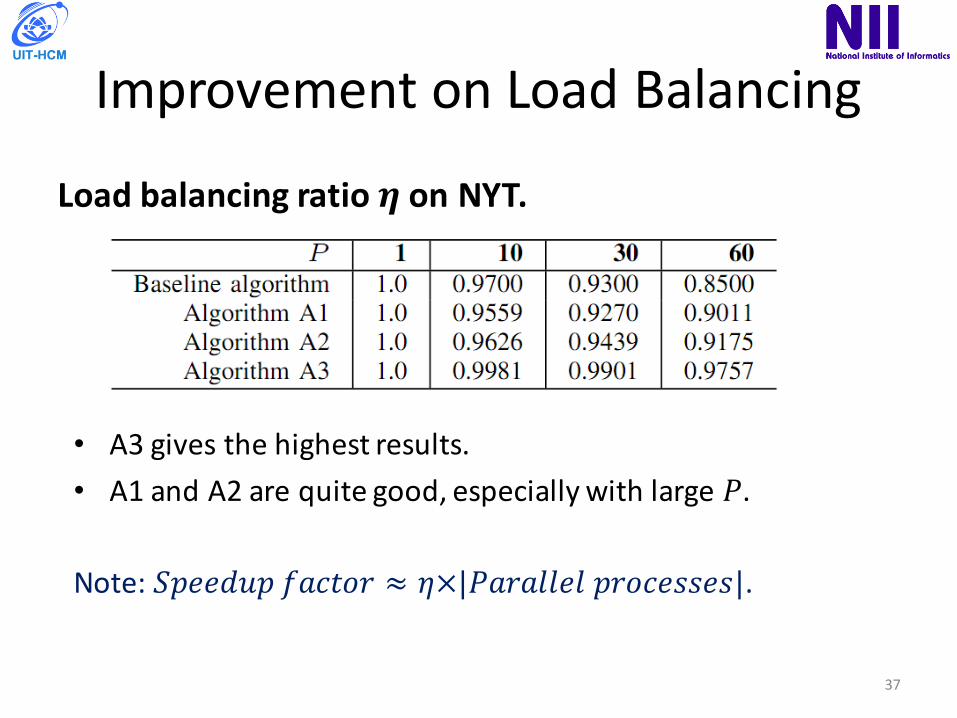
ImprovementonLoadBalancing
Loadbalancingratio𝜼 onNYT.
37
• A3givesthehighestresults.• A1andA2arequitegood,especiallywithlarge𝑃.
Note:𝑆𝑝𝑒𝑒𝑑𝑢𝑝𝑓𝑎𝑐𝑡𝑜𝑟 ≈ 𝜂×|𝑃𝑎𝑟𝑎𝑙𝑙𝑒𝑙𝑝𝑟𝑜𝑐𝑒𝑠𝑠𝑒𝑠|.

TheQualityofTopicModelingusingParallelBoTAlgorithm
PerplexityoftheBoTmodellearnedbytheparallelBoTalgorithmonMASdataset.
38
• Parallelalgorithmdoesnotaffectthequalityoftopics.• WhenPislarge,qualityisslightlybetter.

Conclusion
• Wehavedevelopeddatapartitioningalgorithmsthatachievebetterloadbalancetoimproveefficiencyoftopicmodelingparallelization.
• WehavealsodemonstratedtheextensibilityofthesealgorithmsonBoTmodel.
39

Conclusion
• Wehavedevelopeddatapartitioningalgorithmsthatachievebetterloadbalancetoimproveefficiencyoftopicmodelingparallelization.
• WehavealsodemonstratedtheextensibilityofthesealgorithmsonBoTmodel.
40

Conclusion
• Wehavedevelopeddatapartitioningalgorithmsthatachievebetterloadbalancetoimproveefficiencyoftopicmodelingparallelization.
• WehavealsodemonstratedtheextensibilityofthesealgorithmsonBoTmodel.
41

Futurework
• Weplantodevelopmethodsforimprovingparallelizationefficiencyonadvancedtopicmodels.
42
Thankyouverymuch!

Futurework
• Weplantodevelopmethodsforimprovingparallelizationefficiencyonadvancedtopicmodels.
Thankyouverymuch!
Originalpaper:HungNghiepTran,Atsuhiro Takasu.PartitioningAlgorithmsforImprovingEfficiencyofTopicModelingParallelization.PacRim 2015.Code&Data:https://github.com/tranhungnghiep/Parallel_Topic_Modeling.Otherresource:https://sites.google.com/site/tranhungnghiep/code-data/time-aware-topic-modeling-parallelization.