penalties for distributed local search
DESCRIPTION
Penalties for Distributed Local Search. Muhammed B. Basharu. outline. Distributed Constraint Satisfaction Problems Landscape modification in local search. Algorithms DisPeL Stoch-DisPeL Multi-DisPeL Summary. The Distributed Constraint Satisfaction Problem. - PowerPoint PPT PresentationTRANSCRIPT

Penalties for Distributed Local Search
Muhammed B. Basharu

outline
• Distributed Constraint Satisfaction Problems
• Landscape modification in local search.
• Algorithms– DisPeL
– Stoch-DisPeL
– Multi-DisPeL
• Summary

The Distributed Constraint Satisfaction Problem
• Formal description of distributed problems that involve several participants within the CSP framework.
• Key feature is the physical distribution of information about a problem such that a problem can not be solved in a single location.
• Other key assumptions:– Each participant has partial knowledge of the problem.– Privacy – restrictions on how much information participants are willing to
reveal.
• For example in meeting scheduling, each participant has a separate private calendar.

The Distributed Constraint Satisfaction Problem
• Formally, a distributed constraint satisfaction problem is defined as: DisCSP = <A, X, D, C>
• Where:– A is a set of autonomous agents, representing participants in the
problem.– X is a set of decision variables.– D is the set of domains for each variable.– C is the constraints between variables.
• Each variable in a DisCSP is owned/represented by exactly one agent, but each agent may own multiple variables.

Solving DisCSPs
• DisCSPs are solved by collaborative search.
• Agents exchange possible assignments for the variables they represent until they find values that satisfy all constraints.
• Most popular algorithms are distributed backtracking with no-good learning e.g. Asynchronous Backtracking.
• Local search has not received much attention; Distributed Breakout and Distributed Stochastic search.

Landscape modification in local search
• Local search has the advantage of quick convergence, but the weakness of attraction to local minima.
• Schemes that try to deal with local minima by modifying cost landscapes with weights on constraints have attracted a lot of attention.
• Weights on violated constraints are increased whenever the search is stuck; which has the effect of modifying the cost landscape such that the search is naturally driven away from unprofitable regions.
• We argue that weights might not induce the necessary exploration, especially in problems where the landscapes are dominated by plateaus.
(1)
C
i ii cViolWeval1
)(
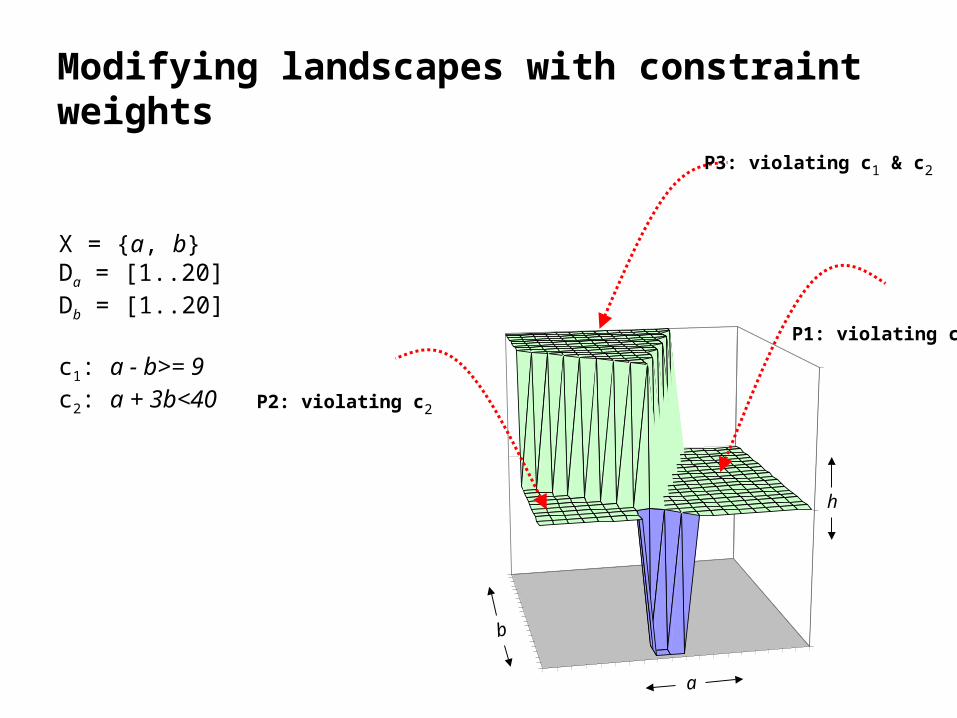
Modifying landscapes with constraint weights
X = {a, b}Da = [1..20]Db = [1..20]
c1: a - b>= 9c2: a + 3b<40 P2: violating c2
P3: violating c1 & c2
P1: violating c1
a
b
h

Modifying landscapes with constraint weights (2)
• Assuming the search starts off at (a=8 and b=4).
a
b
h
a
b
h

Modifying landscapes with penalties
• We propose a finer grained approach focusing on assignments associated with local optima.
• A separate penalty is attached to each value in each variable’s domain.
• When the search is stuck at a local minimum, sizes of the penalties on those values assigned to variables in violated constraints are increased.
n
iii apaVh
1
)()( (2)
where:ai is value assigned to ith variableV(ai) is the number of constraints violated with ai
p(ai) is the penalty attached to ai
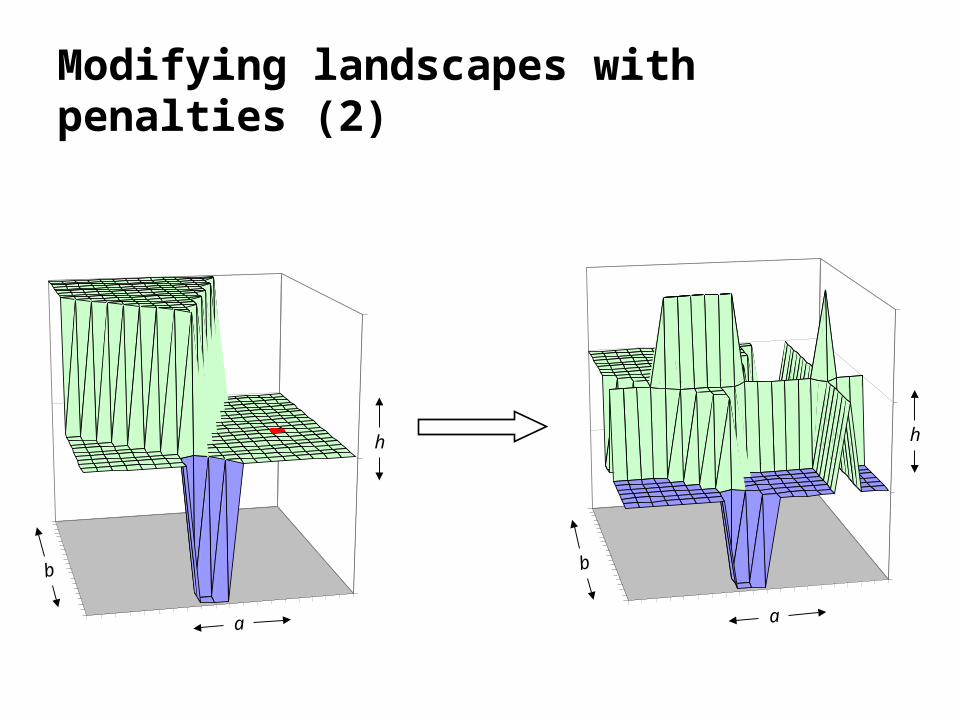
Modifying landscapes with penalties (2)
a
b
h
a
b
h

Penalties in Distributed Local Search
• Distributed Penalty Driven Search (DisPeL)
• DisPeL is a greedy iterative improvement algorithm for solving DisCSPs.
• To minimise communications costs, sequential improvements are accepted rather than just the best improvements in each iteration.
• A total ordering imposed on agents using their lexicographic IDs.
• In each iteration, agents take turns to improve the solution but unconnected agents at the same level can make changes simultaneously.

DisPeL (2)
• Quasi-local-minima (deadlocks) are resolved with a two phased strategy:– Local perturbations to induce exploration.
– “Learn” about and avoid assignments associated with deadlocks if perturbation fails to resolve a deadlock.
• Penalties are used to implement both parts of the strategy.
• Each agent keeps track of a number of recent deadlocks it attempted to resolve.

DisPeL (3)
• Modified evaluation function for each variable/agent.
• In each iteration, agents select the values in their domains with the least sum of constraint violations and penalties.
h(di) = V(di) + p(di) +
t if temporary penalty is imposed
0 otherwise(3)
where:di is the ith value in the domainV(di) is the number of constraints violated by selecting di
p(di) is the fixed penalty on di
t is the temporary penalty (t = 3)

Phase 1: perturbing the search
• Aim: to induce exploration by forcing agents to try values other than their current assignments.
• Earliest deadlocked agent imposes the temporary on its value and asks its “lower” neighbours violating constraints with it to do the same.
• Each agent selects the best value in its domain with eqn (3) and discards the temporary penalty after it is used.

Phase 2: Learning with penalties
• Use penalties to remember “bad” assignments and also to induce exploration in the search.
• Earliest deadlocked agent increases incremental penalty on its current assignment and it asks all its “lower” neighbours to do the same.
• But, learning is short term since penalties are regularly discarded.

receive messages from neighbours
update AgentView
select value minimising equation (3)
send value to neighbours
no
yes
Impose temporary penalty on current value
Ask deadlocked lower priority neighbours to do the same
Add conflict state to no good store
Increase incremental penalties on current value
Ask all lower priority neighbours to do the same
no
yes
deadlocked?
is conflict in no-good
store?
resolve conflict

Penalty resets
• Unlike constraint weights, penalties are “independent” of the underlying landscape and can dominate cost functions.
• As a result, penalties can cause distortions which can divert the search away from promising regions of the search space.
• Therefore, all penalties on a variables entire domain are reset to zero as follows:
– When it has a consistent value.
– When its cost function is distorted by penalties i.e. i. Current assignment has the best evaluation.Ii. There is another value in the domain with lower constraint violations.
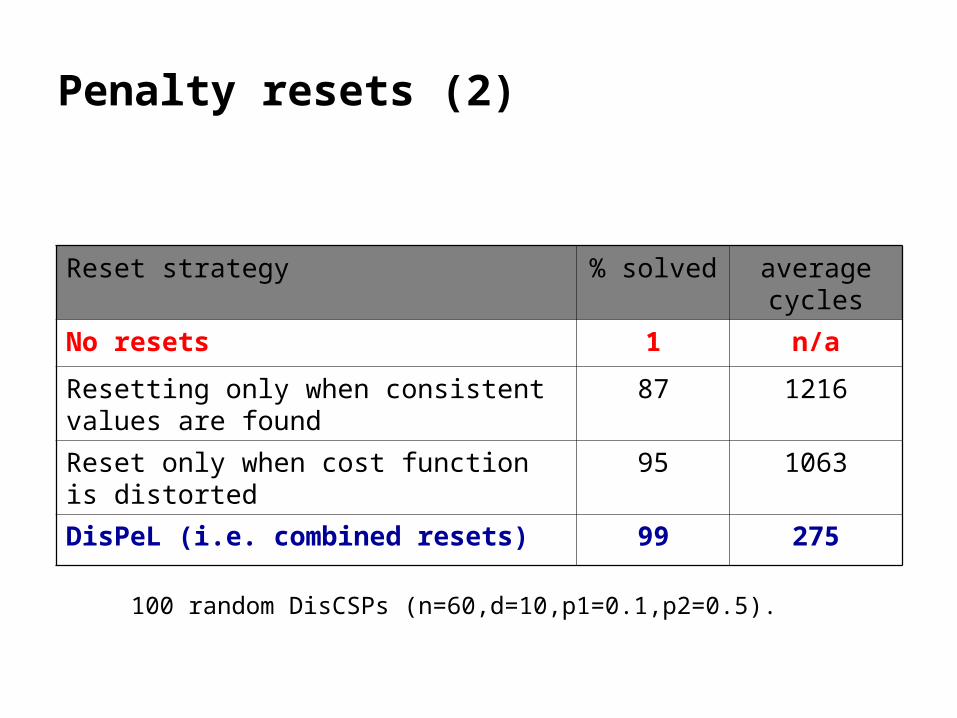
Penalty resets (2)
Reset strategy % solved average cycles
No resets 1 n/a
Resetting only when consistent values are found
87 1216
Reset only when cost function is distorted 95 1063
DisPeL (i.e. combined resets) 99 275
100 random DisCSPs (n=60,d=10,p1=0.1,p2=0.5).

Empirical evaluations
• Compared DisPeL with the Distributed Breakout Algorithm (DBA).
• DBA is earliest distributed local search algorithm, it deals with local minima by modifying cost landscapes with constraint weights.
• Performance of both algorithms were compared on DisCSPs where each agent owns just a single variable.
• Problems used include:– Distributed graph colouring– Random DisCSPs– Car Sequencing Problems
• On each instance, each algorithm had a single attempt with a maximum of 100n iterations before the attempt was deemed unsuccessful.

Results – distributed graph colouring
100 instances for each degree (n=100, k=3).
80
85
90
95
100
4.3 4.4 4.5 4.6 4.7 4.8 4.9 5 5.1 5.2 5.3
degree
% sol
ved
DBA
DisPeL
Percentage of instances solved
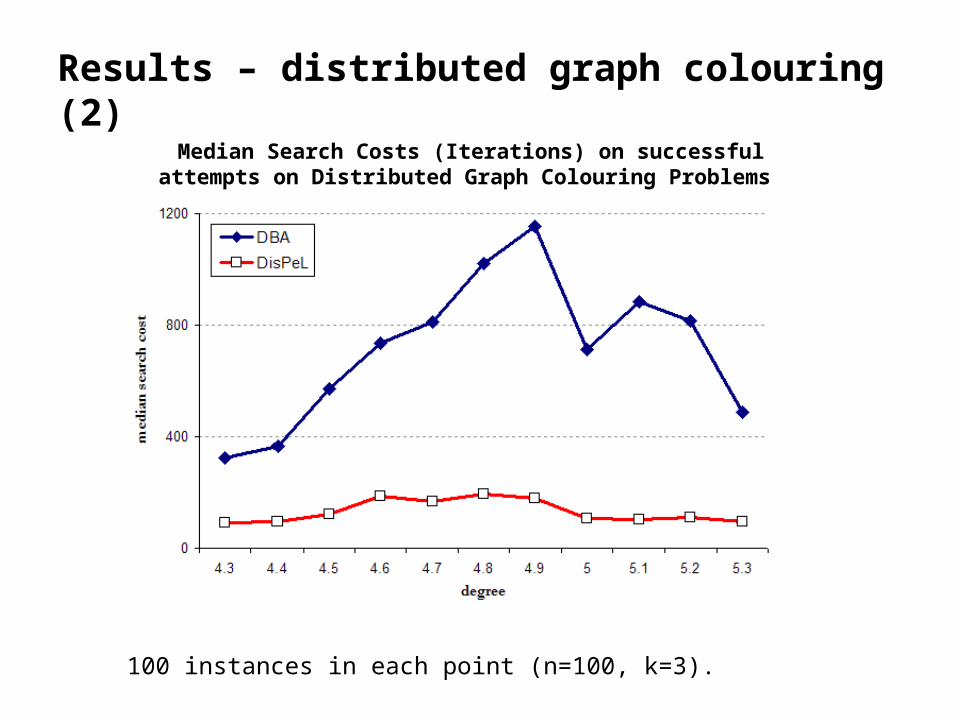
Results – distributed graph colouring (2)
100 instances in each point (n=100, k=3).
Median Search Costs (Iterations) on successful attempts on Distributed Graph Colouring Problems

Other results
• In problems with non-binary constraints, DisPeL solved considerably more problems.
• Similar difference in search costs between the algorithms.
• DisPeL was also tested under conditions of unreliable communications and found that even with a message loss rate of 40% it still solved a high percentage of problems.

Stoch-DisPeL: exploiting randomisation in DisPeL
• Deterministic use of penalties make DisPeL vulnerable to the effects bad random initialisations.
• Stoch-DisPeL: introduces randomisation when agents attempt deadlock resolution.
• Choose with probability p to use the temporary penalty or (1-p) to use incremental penalty.
• Empirical results suggests that performance is optimal at p=0.3
• Additional benefit of speeding up the algorithm, since agents no longer check if a deadlock had previously been encountered.

Dealing with bad initialisations
• Bad initialisation: problem unsolved with DisPeL after 10,000 iterations.
• Good initialisation: solved in 41 iterations with DisPeL.
0%
25%
50%
75%
100%
10 100 1000 10000
iterations
so
lve
d
"bad" initialisation
"good" initialisation

Results
0
25
50
75
100
40 50 60 70 80 90 100 110 120 130 140 150
problem size
% s
olv
ed
Stoch-DisPeL
DisPeL

Results (2)
0
1000
2000
3000
40 50 60 70 80 90 100 110 120 130 140 150
problem size
ite
rati
on
s
Stoch-DisPeL
DisPeL
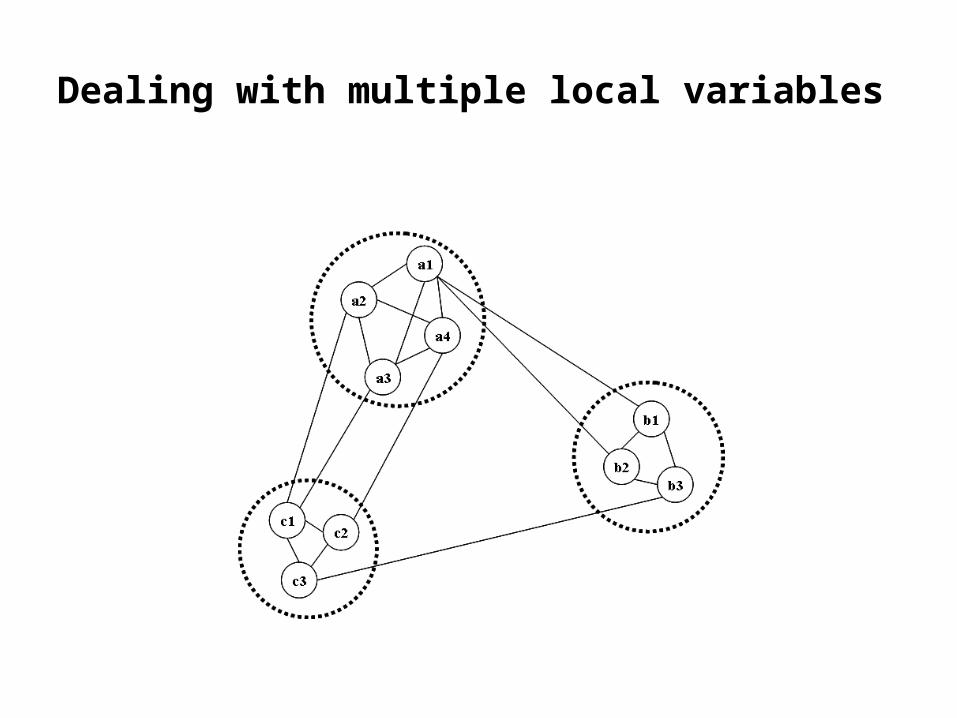
Dealing with multiple local variables

Dealing with multiple local variables (2)
• Extend Stoch-DisPeL for agents with multiple local variables – Multi-DisPeL.
• Agents still take turns to improve the solution.
• Each agent performs a steepest descent search on its local sub-problem.
• Penalties are implemented when internal algorithms are stuck and agents ask neighbours to implement penalties on their variables’ values too.

Multi-DisPeL: evaluations
• Compared its performance against similar versions of DBA and Asynchronous Weak Commitment (AWC).
• Evaluations with:– DisSAT (using solvable 3-SAT instances from SATLib)
– Distributed Graph Colouring
– Random DisCSPs.
• Variables in each problem were distributed evenly amongst agents.
• Evaluation also looked at the effect the number of variables per agent had on performance.

Results – DisSAT
50
60
70
80
90
100
100/2 100/4 100/5 100/10 125/5 125/25 150/3 150/5 150/10
Literals / Agents
% s
olv
ed
Multi-DB
Multi-DisPeL
Percentage of Distributed SAT Problems Solved for Different Number of Literals per Agent
• Multi-DB run for a maximum of 500n iterations with periodic restarts.
• Multi-DisPeL run for a maximum of 100n iterations.

Results – DisSAT (2)
0
2500
5000
7500
10000
100/2 100/4 100/5 100/10 125/5 125/25 150/3 150/5 150/10
Literals / Agents
iter
atio
ns
Multi-DB
Multi-DisPeL
Average Search Costs from Attempts on Distributed SAT Problems

Other results
• Strong performance against the other algorithms on distributed graph colouring and random binary DisCSPs.
• Compared to AWC for agents with multiple local variables, Multi-DisPeL had higher average costs but lower median costs in nearly all tests.

Summary
• Penalties attached to domain values used to modify cost landscapes to deal with local minima.
• Penalties more effective at inducing search exploration than constraint weights.
• But, as penalties are independent of the underlying landscape, they have to be discarded regularly.
• 3 new local search algorithms for solving DisCSPs were introduced based on the ideas above.
• The algorithms showed competitive performance against other distributed local search algorithms.
