polimedia syposium - linking the data sets
TRANSCRIPT

PolimediaSymposiumLinking the data sets
Damir Juric (TU Delft)
Amsterdam, 23.01.2013.

Background: the PoliMedia project
• The PoliMedia project:– driven by research questions from historians – interested in media coverage across several types of
media outlets – Cross-media comparisons
• conducted over a longer period of time, on different topics • focus on the coverage of the debates in the Dutch parliament • insight on the different choices that different media make while
reporting on those debates
– three phases :• modeling phase: creating a semantic model• data production phase: creating links between debates and
associated media sources • application phase: searching and navigating linked datasets

Introduction
• Polimediasemantic model needs to represent:
– people
– topics
– time
– media types
• Model has to be expressive enough:
– describing events from the Dutch parliament

Data Sets
• Primary data set:– The Dutch parliamentary debates
(Handelingender Staten-Generalor Dutch Hansard)
– transcripts of speeches that politicians had in the parliament
– this project uses data from the Political Mashup
– all debates until the year 1995:• published as XML documents (OCR
with satisfactory quality is being used).
• data shows a fine-grained structure.

Data Sets
• Secondary data set:
– different media types:
• newspaper articles and radio bulletins
– National Library of the Netherlands
• newscasts– evening news and current affairs
programs

Semantic model: Goals
• Goal of the project:
– to publish the links on the Web
– to use open Web formats and standards
– Web query language
– unique identifiers (URI’s)
• Model has to be expressive:
– important information regarding parliamentary debates should be easily accessed

Debate Metadata
Topic 1
Topic 2
Speaker 1 / Content
Speaker 2 / Content
Speaker 3 / Content
Speaker 1 / Content
Aan de orde is de behandeling van: - de brief van de minister vanEconomischeZakeninzakeBorssele(16226, nr. 26).De beraadslagingwordtgeopend.
NEs={EconomischeZaken, Borssele}
NEs={Borssele, Partij van de Arbeid, D66}
Metadata
Speaker 1
Debate: The structure
Speaker 2
Speaker 3
Mijnheer de Voorzitter! Met de verdragen tot uitbreiding van de EEG met
Denemarken,Engeland, Ierland en Noorwegenwordteen van de doelstellingenvan onsbuitenlandsbeleidverwezenlijkt.

Semantic model: Description
Part of semantic model representation of the debates dataset

Semantic model: Description
Semantic model representation of the debates dataset

Polimedia linking method
• The challenge: how to create a representation of the speech that contains enough information, so it can be used as a query to retrieve relevant media articles from the archive?
• Debate speeches and newspaper articles are generally different types of documents (so computing document similarity doesn’t work) in the style and scope
• Speeches can contain large number of NEs and digressions:– Problem: hard to distinguish the right context for each speech
• Newspaper articles: – very strict and concise
– words are used sparingly

Polimedia linking method
• Our PoliMedia linking method consists of four steps:
1. topics: enriching the existing debate metadata with topics
2. preselection of articles: when the candidate articles were published and who spoke in the debate (timeframe and speakers)?
3. automatic query creation: candidate articles are ranked based on similarity to the query (automatically created from speech text) by comparing vectors of topics and named entities
4. link creation: links are created between a speech and an article if the similarity score is above a threshold t

Topics
• Topic modeling:– popular tool for the unsupervised analysis of text,
– used to check models, summarize the corpus, and guide exploration of its contents
– topic models lead to semantically meaningful decompositions of text because they tend to place high probability on words that represent concepts
• Extracting topics from speech:– ten words that represent one topic discussed inside the speech are extracted
– all speeches contained inside one debate segment are concatenated into one text
– set of ten words that represent one topic of the debate segment as a whole is extracted from that text
• Input: text /number of iterations/number of topics
• Output: generic names for topics/words that cluster around one topic
• Example:– Test case: debate nr. 1975/number of iterations: 2000/numbner of topics: 1

Kombrink
rente
inkomstenbelasting
bronheffing
vereenvoudiging
tarief
contourennota
Nederland
word
tussen
wetgeving
sociale
moeten
fraude
fraudebestrijding
vraag
misbruik
ten
gebruik
kamer
misbruikfraudebestrijdingismo-rapport
Contourennota
Kombrink
EEG
Netherlandse
OESO-verband
Nederland
Contou
Engwirda
Couprie
Midden-Oosten
Euro-kapitaalmarkt
Tariefnota
Staatssecretaris
Regering
Financiën
Zwitserland
Brussel
Grave
TopicSet Speech
NE Speech
TopicSet Topic
NE Topic
Automatic query creation
Debate Metadata
Topic 1
Topic 2
Speaker 1 / Content
Speaker 2 / Content
Speaker 3 / Content
Speaker 1 / Content
Metadata
Actor
NERsSpeech TopicSet Speech NER Topic
ExpandedQuery =
+
ActorFromSpeech
Speaker X =
TimeFrame
TopicSet Topic
Automatic query creation
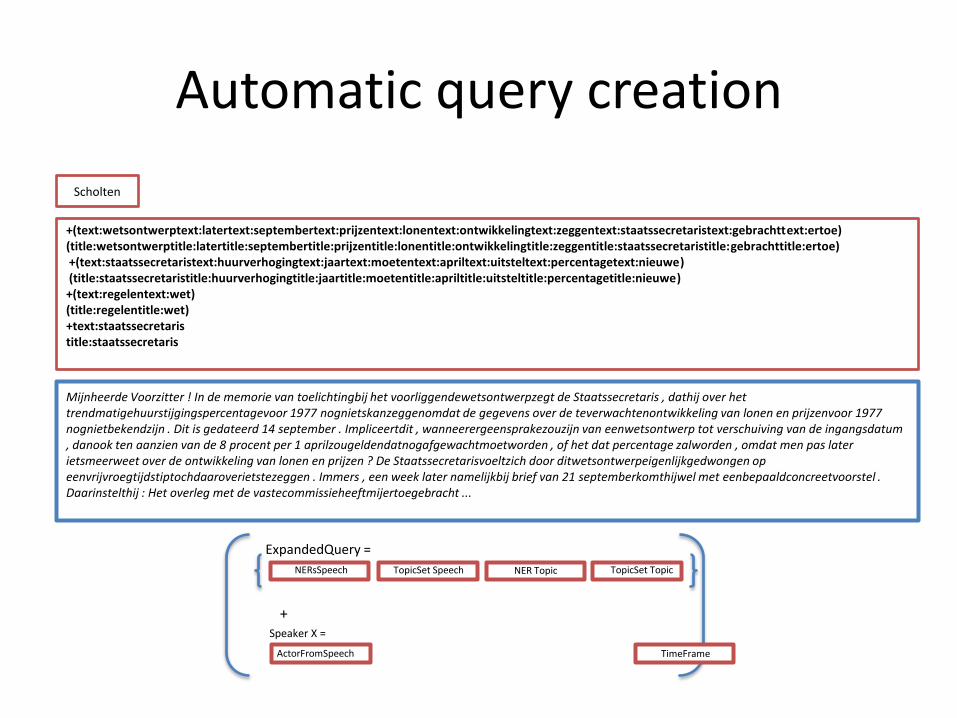
Scholten
+(text:wetsontwerptext:latertext:septembertext:prijzentext:lonentext:ontwikkelingtext:zeggentext:staatssecretaristext:gebrachttext:ertoe) (title:wetsontwerptitle:latertitle:septembertitle:prijzentitle:lonentitle:ontwikkelingtitle:zeggentitle:staatssecretaristitle:gebrachttitle:ertoe)+(text:staatssecretaristext:huurverhogingtext:jaartext:moetentext:apriltext:uitsteltext:percentagetext:nieuwe)(title:staatssecretaristitle:huurverhogingtitle:jaartitle:moetentitle:apriltitle:uitsteltitle:percentagetitle:nieuwe) +(text:regelentext:wet) (title:regelentitle:wet) +text:staatssecretaristitle:staatssecretaris
Mijnheerde Voorzitter ! In de memorie van toelichtingbij het voorliggendewetsontwerpzegt de Staatssecretaris , dathij over het trendmatigehuurstijgingspercentagevoor 1977 nognietskanzeggenomdat de gegevens over de teverwachtenontwikkeling van lonen en prijzenvoor 1977 nognietbekendzijn . Dit is gedateerd 14 september . Impliceertdit , wanneerergeensprakezouzijn van eenwetsontwerp tot verschuiving van de ingangsdatum, danook ten aanzien van de 8 procent per 1 aprilzougeldendatnogafgewachtmoetworden , of het dat percentage zalworden , omdat men pas later ietsmeerweet over de ontwikkeling van lonen en prijzen ? De Staatssecretarisvoeltzich door ditwetsontwerpeigenlijkgedwongen op eenvrijvroegtijdstiptochdaaroverietstezeggen . Immers , een week later namelijkbij brief van 21 septemberkomthijwel met eenbepaaldconcreetvoorstel . Daarinstelthij : Het overleg met de vastecommissieheeftmijertoegebracht ...

Example of the relevant article
vvd: van dam baseertbeleidteveel op rossige prognoses van planbureaukamermeerderheidtegenuitstel van huurverhoging
den haag — eenmeerderheid van de tweedekamervoelternietsvoor de huurverhoging van volgendjaaruitte, stellen van 1 april tot 1 juli. de fractiesvan kvp, arp, chu, vvd, ds'7o en de kleinechristelijkepairtijenwillen de huurverhoging op 1 aprillatendoorgaan. staatssecretaris van dam van volkshuisvestingwiluitstelom op 1 julivolgendjaareennieuwhuurbeleidtekunneninvoeren. daarvoorzalhij op kortetetmijndriewetsontwerpenindienen: de huurprijzenwet, de wet op de huurcommissie en eenwijziging van het burgerlijkwetboek.debewindsmanzeidat met het afwijzen van uitstel in feiteinvoering van het nieuwehuurbeleid op 1 julivolgendjaaronmogelijkwordtgemaakt. het nieuwestelselzaldan pas in 1978 ingevoerdkunnenworden. „met eenuitstel van driemaandenkomen we preciesuit", aldus de heer van dam. de arp'erscholten, die medenamenskvp en chusprak, zegde de regeringallemedewerking toe om de nieuwehuurwetnog in dezekabinetsperiodetebehandelen, maarhijtwijfeldeeraan of op 1 juli1977 het nieuwehuurbeleid al ingevoerdkanworden. de confessionelen en de vvdhouden vast aaneenhuurverhoging van 8 procent op 1 april. staatssecretaris van dam wil pas op 1 julizonverhoging. zou de verhogingtoch op 1 aprilmoeteningaan, danwilhijeenverhoging van 7 procent. de bewindsmankomtvolgens de confessionelentevroeg met eenverlaging van de jaarlijksehuurverhoging.het d'66-kamerlid nypelsdiendeeenmotie in waarinhij de regeringverzoektbijverwerping van het uitsteltekomen met eenwetsontwerpvoor 7 procent op 1 april. ook de pvda'etkombrinksuggereerdedezeoplossing. de heerkombrink deed eendringendberoep op de confessionelenom het uitstelteaanvaarden. de vvder de beer vonddatelrnietvoldoenderedenenzijnvooruitstel van de huurverhoging. de staatssecretarisbaseertzijnbeleidteveel op „de rossige prognoses van het centraal plan bureau", vindt de vvd. ook de christendemocratenvindendat van dam teveel van prognoses uitgaat die vaaktelaagzijn.depvda is het met de regeringeensdat de huren op 1 juli met 8 procentomhoogmoeten. wijst de kamerdataf, danmoeten de huren op 1 april met 7 procentwordenverhoogd. men moetnietalleenkijkennaar de ontwikkeling van lonen en prijzen, men moetookkijkennaar het vrijbesteedbareinkomen. de stijgingdaarvanzal in de komendejarenuiterstgeringzijn", zeikombrink. cpn-woordvoerderdraagstrazeidat de hurenbevrorenmoetenworden op het huidigepeil.

Polimedia pipeline
RDF
semantic modelRDF files
NERs Speech
TopicSet Speech
NERs Topic
TopicSet Topic
contextual vectors
PoliticalMashup
(xml)
Query NE
Stopword removal
Topic modeling
Query content
Expanded query creation
SRU Query (actor, date range)
automatic query creation
KB(preselect data)
similarity calculation
ranking
filtering
articlemetadata

Evaluation
•We tried three different approaches:
• Experiment 1: NEs in speech
• Experiment 2: NEs + topics in speech
• Experiment 3: NEs + topics in speech and debate
• Conclusion:• best approach:
• named entities (speech + debate descriptions) and topics (speech + debate)

• structural elements of transcript:
• used to create complex and rich query from the speech
• treating particular speech as a part of the bigger context (conversation) and creating a query that is amixture of those elements:
• higher number or related articles retrieved
• What we learned?
• definition of link can be vague
• simple document similarity methods doesn't work
• journalist use their own “compression” methods when writing about debates
• long speeches with dozens of NEs and topics are sometimes represented with few concise sentences
Results discussion

End
• Thank you for listening• more information on polimedia.nl

similarity measures
• similarity measures: metric that measures similarity or dissimilarity (distance) between two text strings for approximate string matching or comparison and in fuzzy string searching
• Given two segments, the expanded query Q and the document from media archive D, the term frequency (TF) is associated to a term t from the query Q and the document D, the similarity between Q and D is computed according to the cosine similarity formula, where the generated value varies between 0 and 1:
• CosineSimilarity(Q,D) =
• BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of the inter-relationship between the query terms within a document (e.g., their relative proximity).
Given a query Q, containing keywords t1, ..., tn, the BM25 score of a document D is:
• BM25Score(Q,D) =
• where function represents term frequency of the term qtfrom the document D, is the length of the document D in words, and avgdl is the average document length in the text collection from which documents are drawn. Parameters k1 and bare free parameters. Function is the inverse document frequency weight of the query term qt.

similarity measures
• The overlap coefficient is a similarity measure related to the Jaccard index that computes the overlap between two sets which is defined as follows:
• If set X is a subset of Y or the converse then the overlap coefficient is equal to one.
overlap(Q,D) =