protein sequence alignment - kirkwood community college€¦ · protein sequence alignment primary...
TRANSCRIPT

Protein Sequence Alignment
Primary Structure Analysis
Part 1

DNA takes us only so far
• DNA sequencing relatively fast & cheap; but to get meaningful information from sequence, need:
– to be able to distinguish genes from junk (a topic we’ll explore in some depth later on)
– to be able to identify regulatory sequences
– to be able to determine the function of a gene’s protein product – this will be our focus

Primary structure databases: nucleotides vs. proteins
• For nucleotide sequences, GenBank is primary repository for data
– source scientists have full authority over data
– strict historical/archival point of view
– companion database, RefSeq, is reviewed/corrected/annotated version of GenBank
• For protein sequences, there’s SwissProt(UniProt): an entirely different approach to database curation

The SwissProt Way
• SwissProt is not a primary repository like GenBank; instead, it is curated, primarily by a single person (Swiss scientist Amos Bairoch)– entries changed when new information available; flexible,
correctable– considered best-annotated protein database– lot of work for one person, or even team of experts
• URL: http://www.expasy.ch/sprot/

TrEMBL
• TrEMBL is SwissProt’s buffer database, similar in function (if not mechanics) to GenBank: GenBank is to RefSeq as TrEMBL is to SwissProt– consists of entries automatically derived from
translation of DNA ORFs; data goes here before it goes to SwissProt
– most of the protein sequences in both databases have never been isolated in nature; they are all derived from translated data

Searching SwissProt
• Like GenBank, provides variety of access points
• Starting point can be name of protein, or gene, or condition of interest
• Can limit search by specific field (organism, protein name, e.g.)

Example: HER-2 positive breast cancer
• We can start with a very general search:
• This produces almost 3000 hits; we can narrow this to our species:

Example continued
• But this only cuts out about 1000 entries
• Since we know (or think we know) the name of the protein, we can try adding another qualifier:

Example continued
• This results in one relevant entry:

A closer look

Proteomics
• Science of visualization & quantification of set of proteins present in given tissue or organism
• Points of reference:– gel electrophoresis: separation of protein molecules
by mass & charge
– ORF translation: derive AA chain from nucleotide chain
• These often don’t match: more to protein structure (even primary structure) than simple translation tells us

Post-translational modification
• Protein maturation process: modification(s) of primary structure that lead to ultimate tertiary/quaternary structure found in nature
• Includes some combination of:– cuts within AA chain– removal of AA fragments within chain– chemical modifications of single AAs– addition of lipid or sugar molecules
• Storage & retrieval of post-translational modification information is major role of protein databases

Location, location, location
• Protein function related to its location– translation process involves
exposing developing peptide chain to various chemical signals that specify location of mature protein
– translocation: transport of protein across one or more membranes

Final destinations include:
• attachment to cell membrane
• secretion outside cell
• transportation to mitochondria or other organelle
• transportation to nucleus

Folding
• Most important step in making mature protein– compacts peptide chain into stable 3D structure
– final structure usually consists of several relatively independent domains;thousand of known domains• most proteins contain up to 10
• identifiable by scaffolded sequence signatures, or motifs, recognizably preserved over millions of years of evolution
• domain architecture important because hints at 3D structure

Proteins vs. genes
• Protein primary structures relatively simple compared to genes
– AA sequences fairly short (average protein is 350 AAs)
– have clear start & end
– defined on single strand
– although modifications can & do occur between ORF & mature protein, AA order remains stable

Using bioinformatics to determine protein function
• CFTR protein serves as illustrative model:– Specific genetic defects can be identified in
specific CF patients
– Such genetic defects can be shown to lead to functional defects in CFTR
– Next step: develop specific drugs to target specific defects (still in experimental stage)
• Problem: given DNA sequence of gene, how do we find cellular function of protein product?

Model organisms
• Several organisms are known to have easily identifiable & mutable genes:
• These organisms can serve as model organisms for investigation of gene behavior in humans where human genes have recognizable counterparts in the model

Structural clues to protein function
• Proteins with similar primary structure (amino acid sequence) will likely have similar function
• Similarity doesn’t have to extend to entire protein; can be more localized, e.g. regions of unknown protein sequence may resemble functional regions of known protein

Aligning protein sequences
• Can be more effective for discovery than nucleotide sequence alignment
• Sequence similarity often provides clues in function of unknown protein

Alignment scoring & evolution
• Mutation is random process, but biological factors affect which mutations we actually see
• We are most likely to observe the substitution of an amino acid with one that is chemically similar, because drastic change that disrupts protein function is likely to be selected against
• Protein substitution matrix allows alignment algorithms to consider substitution likelihood to give better alignments

Protein similarity
• Proteins much more complex than DNA; this works in our favor in terms of making effective comparisons
• Amino acid similarity examples:– Aspartate and Glutamate have hydrophilic side
chains
– Leucine and Valine have hydrophobic side chains
– A hydrophobic – hydrophilic substitution is more likely to alter protein function than phobic-phobic

Protein similarity
• Can score not only exact matches but also conservative substitutions (mutations that result in functionally similar amino acids)
• Such substitutions are more likely because they wouldn’t be selected against in evolution
• Given all of the above, we can be confident of less ambiguity in protein alignment than in nucleotide alignment

Determining likelihood of substitution
• Method 1: Look at chemical properties of amino acids:– hydrophobic vs. hydrophilic
– charge
– size of side chains
• Method 2: look at frequency of actual substitution occurrence in known sequences based on comparison of similar proteins – this is basis for substitution matrix
• We will examine both methods

Method 1: Biochemical analysis of proteins
• The Swiss Institute of Bioinformatics maintains ExPASy, a set of online tools for protein structure & function analysis
• ExPASy stands for Expert Protein Analysis System
• Two of the tools at ExPASy are ProtParam and ProtScale

ProtParam
• Provides computation of physical & chemical properties of proteins from either user-entered raw sequence or from known entries in SwissProt/Trembl databases
• Analysis includes:– number of amino acids in sequence– molecular weight– amino acid composition (% of total)– extinction coefficient (used for spectrophotometic
analysis)– half-life: amount of time it takes for half of protein to
degrade after synthesis– instability index

Primary structure analysis
• Why analyze primary structure?– Need to take into account amino acid interactions
to get clearer picture of secondary, tertiary structural factors
– Segments with particular compositional types give clues to eventual conformation:• hydrophobic: potential transmembrane or core feature
• coiled-coil: potential protein-protein interaction site
• hydrophilic: potential surface structure

Primary structural analysis
• Sliding window technique– Oldest sequence analysis method– Uses tables of amino acid properties: scale values
• Method– Pick window size based on desired feature:
• for transmembrane feature: 19• for globular feature: 7-11
– With window centered on one amino acid, scale values associated with all amino acids in window are summed & averaged, then result is associated with central AA
– Shift window & continue until end of sequence– When finished, values associated with each AA are plotted
against sequence: property profile

ProtScale
• An example of an online tool for performing sliding-window technique on a protein is ProtScale, also found in the ExPASy suite
• The direct link to this resource is:http://www.expasy.org/cgi-bin/protscale.plNote the extension – this is a perl program

Using ProtScale
• Paste in FASTA sequence or type in accession number
• Choose scale/window size
• Click submit
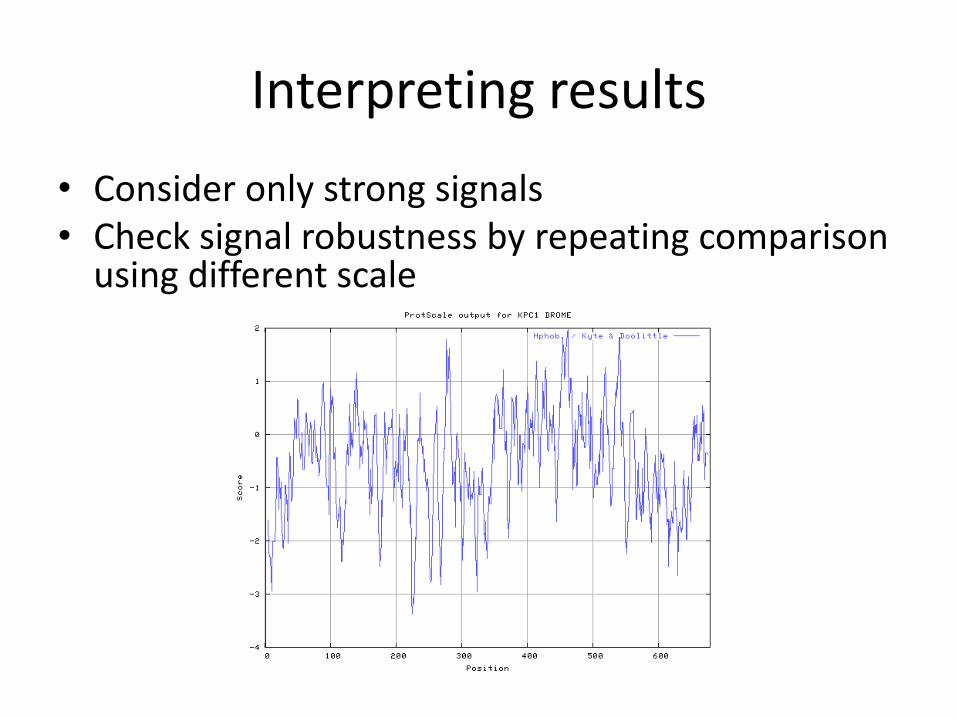
Interpreting results
• Consider only strong signals• Check signal robustness by repeating comparison
using different scale

Sliding-window method: pros & cons
• Advantage: relatively robust (not sensitive to scale changes)
• Disadvantages:
– not precise
– window size is arbitrary
• Could go either way: does not interpret results for you

Testing for transmembrane segments in proteins
• What transmembrane segments indicate:
– One transmembrane segment at N-terminus of sequence suggests protein is secreted
– Several transmembrane segments suggests a channel
• Can perform analysis with ProtParam, but more precise tool is TMHMM, which uses hidden Markov models (a sophisticated computational technique) to predict transmembrane regions

TMHMM
Link: http://www.cbs.dtu.dk/services/TMHMM-2.0/

TMHMM results
• Predictions are precise
• Predicts segments inside/outside cell

Looking for coiled-coil segments
• Coiled-coils are regions formed by intertwining alpha-helices
• May indicate protein-protein interaction site
• May also lead to false results in database searches, so it’s good to know location in case you need to filter out
• Online tool available at:http://www.ch.embnet.org/software/COILS_form.html