pure and applied mathematicswatanabe- · 1純粋数学と応用数学の遠い関係....
TRANSCRIPT

純粋数学と応用数学の遠い関係
- 代数幾何と機械学習を例として
渡辺澄夫
東京工業大学
「数学と情報社会」 東北大学 知の館
2018年3月8日

1 純粋数学と応用数学の遠い関係
2 純粋数学の先生がたに
機械学習を紹介します
4 機械学習にも数学が
3 数学と応用数学がつながった例
目次

1 純粋数学と応用数学の遠い関係

数学 と 実世界
数学
実世界 実世界
実世界

幻の架橋
純粋数学 応用数学

2 純粋数学の先生がたに
機械学習を紹介します

7
いま「人工知能」と呼ばれているものは
言葉
声
英語
定理
珈琲
表情
動作
日本語
証明
数学外見は ロボットとは
限りません

8
人間は【関数】を持っている
人間さん
りんご・・・みかん・・・ぶどう・・・
y = f(x)
集合 {x},{y}は明確には定義されないこともあります。
それよりも {x} の次元が極めて大きいことが問題です。

9
しかし人間の関数は
言葉で説明できない
人間さん
これは紅茶ですが、なぜ私が
紅茶だとわかるか説明できません

10
実行できるけど 説明できない ・・・
【実行できるけど説明できないこと】 = 人間 だった。
◎ 歩く 走る 泳ぐ 自転車に乗る
◎ 漫画を読む 友達を見つける 定義を感じとる
◎ 会話をする 夢を見る 証明を思いつく
説明できない → 教えられなかった
人間さん人工知能さん
教えられない!

11
人間と同じく人工知能も学習
?
りんごみかんぶどう
学習
「学習」ができるようになったことが現代の人工知能の発展のための決定的な要因になった。
赤ちゃん
りんごみかんぶどう
小学生
?
学習

12
人間の学習は 何が行っているか
人間は神経回路を持っている。
学習する=神経回路が
変化する

13
生体の神経回路をまねて作ったモデル
画像 x
結合荷重 w
神経回路の答 f(x,w) 神経回路網の答えと正しい答えの誤差は
(y-f(x,w))2
誤差が小さくなるようにw を変えていく
正しい答 y 誤差

14
知らないものも予測できる どのくらい ?
◎ たくさんの例を学習すると神経回路網は少しずつ知らないものについても正しく答えられるようになってくる。
2 りんご!
テスト:
未知のもの りんご!!
差が汎化誤差勝負じゃ
人間には負けないぞ。
◎ 多項式やフーリエ級数でも学習はできますが なぜか神経回路網のほうが高精度です(数学的には未解決)。
1 りんご!
学習データ りんご!!
差が学習誤差一徹くん
根性

3 数学と応用数学がつながった例
たった一例ですが 数学と応用数学がつながった「きっかけ」を紹介します
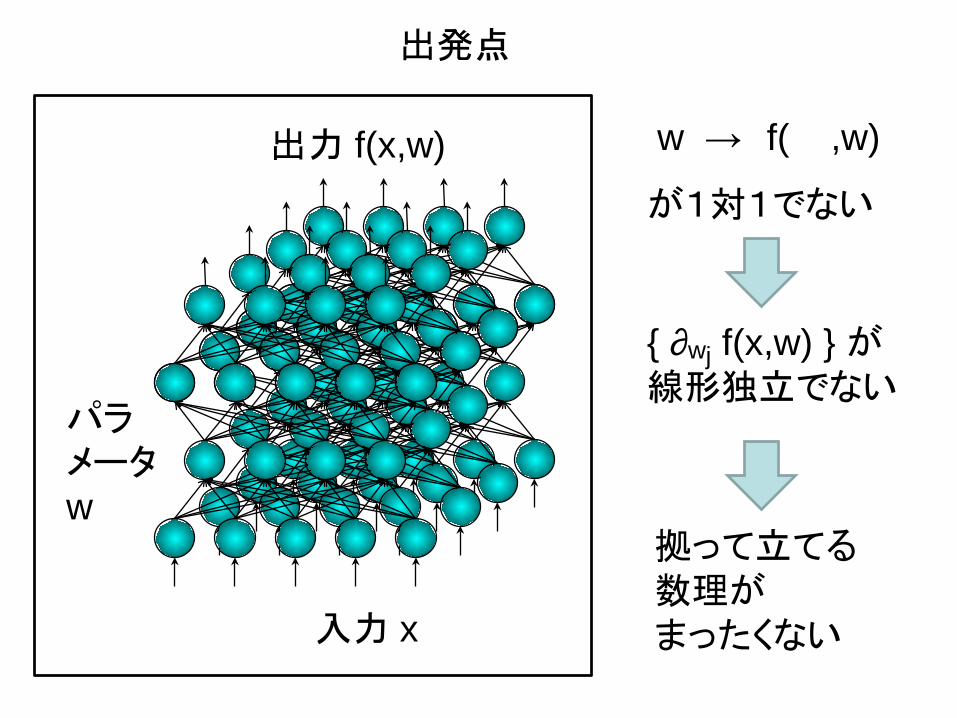
出発点
入力 x
パラメータw
出力 f(x,w) w → f( ,w)
が1対1でない
{ ∂wj f(x,w) } が線形独立でない
拠って立てる数理がまったくない

雪原をさまよう

18
きっかけ1: ベルンシュタイン・佐藤のb関数
任意の解析関数 f(w) に対して、ある微分作用素 Dw と多項式 b(z) が存在して、任意の z∈Cについて
Dw f(w)z+1=b(z) f(w)z
この定理がとても重要なことを述べていることは普通の人でも感じ取れます。
統計学や機械学習の論文を読んでも答えはありませんでした。
まったくの偶然で下記の定理に出会いました。

19
R
代数幾何の本には、このように具体的な記載は書かれていませんがこのように書いてあれば普通の人でも理解できます。
Rd
各局所座標で
∃w=g(u)
K(g(u))= u12k1 u2
2k2 ・・ ud2kd
∃多様体 M
∀K(w) ≧0
パラメータ集合
きっかけ2: 特異点解消定理 (M.F.Atiyah, 柏原)

きっかけ3: つながり
ζ(z) = ∫ K(w) z φ(w) dw
δ(t-K(w))
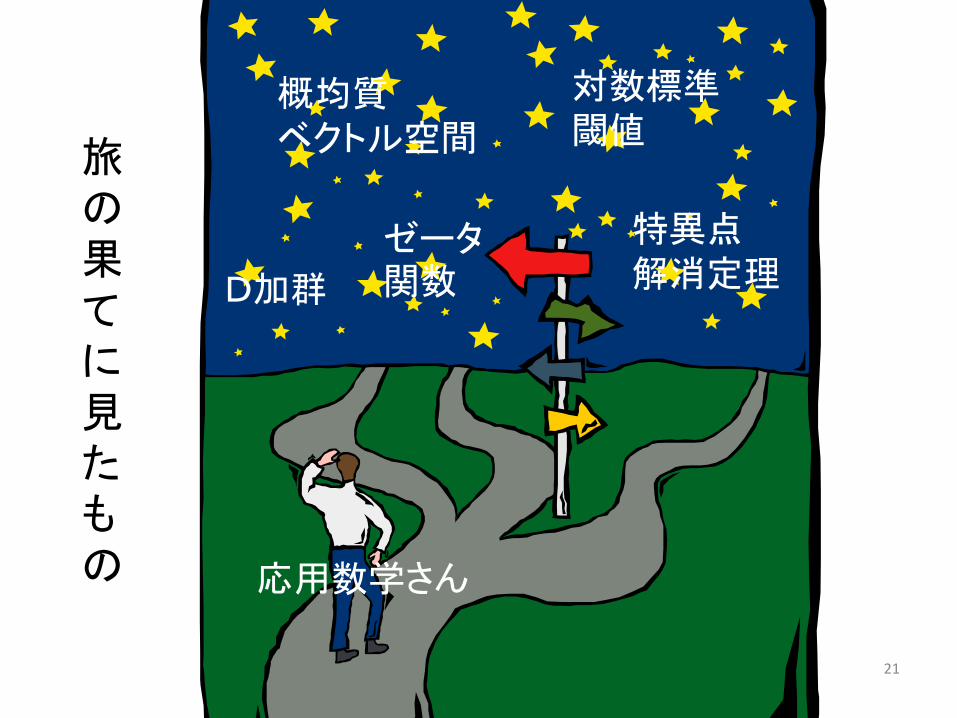
21
D加群
特異点解消定理
ゼータ関数
対数標準閾値
概均質ベクトル空間
応用数学さん
旅の果てに見たもの

4 機械学習にも 数学が
データは とても 複雑 法則はないモデルも とても 複雑 法則はない
しかし「学習結果の正しさ」を表す量には数学的な法則がある。

統計的学習
データ (X,Y) ~ q(x)q(y|x)
パラメータ w
(1) {Xi,Yi ; i=1,2,…n} 独立
(2) 予測モデル p(y|x,w)
(3) 事前分布 ϕ(w)
※ 神経回路では p(y|x,w) ∝exp( -C(y-f(x,w))2 )

統計的学習の例
Ew[ ] =( ) Π p(Yi|Xi,w) ϕ(w) dw
Π p(Yi|Xi,w) ϕ(w) dw
n
i=1
n
i=1
p*(y|x) = Ew[ p(y|x,w) ] 予測
事後分布による平均

25
汎化損失と学習損失
Gn = ー E(X,Y) [ log p*(Y|X) ]汎化損失
新しい(X,Y)に対する予測の誤差
Tn = ー(1/n) Σ log p*(Yi |Xi) 学習損失n
i=1
学習した(Xi,Yi )に対する予測の誤差

26
学習曲線
例数(n)
S
E[Tn]=S+(λ-2ν)/n
E[Gn]=S+λ/n
S:条件つき確率(Y|X)のエントロピー

27
実対数閾値 λ
関数 ζ(z) を
ζ(z) = ∫ K(w) z φ(w) dw
この関数は Re(z)>0 で解析的であるが、複素平面
全体に有理型関数として一意に解析接続できる。その極はすべて負の実数である。最も原点に近い極を (-λ) とするとき λ を実対数閾値という。
K(w) : 真 q(y|x) とモデル p(y|x,w) のKL情報量

28
特異揺らぎ ν
事後分布による分散を Vw[ ] と書く。
V= Σi Vw[ log p(Yi |Xi,w) ]
2ν = lim n→∞ E[ V ]
λ と ν は双有理変換によらない。
○ 確率的な現象に対して「n →∞」の漸近展開の係数を考えると幾何学的な量が現れることが多い。

29
統計学と数学
学習損失から汎化損失を平均的に推測できる。
E[Gn] = E[ Tn + V/n ]
E[Gn] = E[Tn] + d/n
統計学でよく知られていた情報量規準 AIC の一般化である。
※ AIC とは、{ ∂wj f(x,w) } が線形独立であれば
→ 統計学や機械学習のモデル設計に役立ちそうである。

終わりに

応用数学は雪原をさまよう遠くに山が見つかれば・・・

32
数学者のみなさまに
数学の定理がえられたとき
大学2年生のとき わかるような
記述も あわせて書いておくと
100年後の応用数学に
つながるかもしれません。

数学的自然は なくなることはない
いつか誰かが見つける
数学的自然