rio distribution: reconstructing the onion - shyamsundar ranganathan
TRANSCRIPT

RIO Distribution: Reconstructing the onion!Shyamsundar RanganathanDeveloper

What's with the onion anyway!● View the xlators in the volume graph as layers of an onion
○ At the heart is the posix xlator, and the outermost is the access interface○ Each layer has well understood and standard membranes○ But, unlike an onion, each layer functions differently!
● More metaphorically,○ Peeling the layers apart can make you cry○ But, is a cleansing ritual (at times!)
● This presentation is about,
"How the volume graph is reconstructed changing distribution to RIO?"

RIO Distribution in a nutshell● RIO stands for Relation Inherited Object distribution
○ or, a.was.k.a DHT2● Objects:
○ inode objects■ further classified as directory inodes and file inodes
○ data objects■ Exists for file inodes only

The file system objects (example)
User View
. (‘root’)File1Dir1
File2Dir2

Dir Object File Object
Data
Data
root
File2
Dir2Dir1
File1
The file system objects (example)
inodes/dinode File data
1
A
CB
D
A
D
A Data Object
. (‘root’)User View
File1
Dir1
File2
Dir2

RIO Distribution in a nutshell● RIO stands for Relation Inherited Object distribution
○ or, a.was.k.a DHT2
● Objects:○ inode objects
■ further classified as directory inodes and file inodes
○ data objects■ Exists for file inodes only
● Relations:○ inode objects to parent inode objects○ data objects to file inode objects

Dir Object File Object
Data
Data
root
File2
Dir2Dir1
File1
Object relations
inodes/dinode File data
1
A
CB
D
A
D
A Data Object
. (‘root’)User View
File1
Dir1
File2
Dir2

RIO Distribution in a nutshell● RIO stands for Relation Inherited Object distribution
○ or, a.was.k.a DHT2
● Objects:○ inode objects
■ further classified as directory inodes and file inodes
○ data objects■ Exists for file inodes only
● Relations:○ inode objects to parent inode objects○ data objects to file inode objects
● Inheritance○ file inode inherits location based on parent inode,
■ Directory inodes do not inherit this property, hence achieves distribution
○ data object inherits GFID/inode# of the file inode

Dir Object File Object
Object inheritance
Metadata Ring(few bricks)
Data Ring(many bricks)
1
A
CB
D
A
D
Data Object
Bricks/Subvols
Data
root
File2
Dir2Dir1
File1
. (‘root’)User View
File1
Dir1
File2
Dir2

RIO Distribution in a nutshell (contd.)● Salient principles:
○ Each directory belongs to a single RIO subvolume
○ Files inode and data is separated into different subvolumes■ Thus, there are 2 rings for distribution of objects
○ Layout is per ring and is common to all objects in the ring
● Rationale:
○ Improve scalability and consistency
○ Retain, and in some cases, improve metadata performance
○ Improved rebalance

Peeking into the RIO layer● Consistency handling
○ Handle cross client operation consistency from a single point○ Funnel entry operations, to the parent inode location, and metadata
operations to the inode location○ Hence, RIO is split as RIOc(lient) and RIOs(erver)
■ RIOc is a router for operations
■ RIOs manages FOP consistency and transaction needs
● Journals○ Transactions need journals to avoid orphan inodes○ Managing on-disk cache of size and time on inode, based on data
operations, needs journals to track dirty inodes

Rebuilding the Onion(DHT -> RIO)
<prior xlators>
DHT
Client/Server Protocol
POSIX xlator
<prior xlators>
Client/Server Protocol
POSIX xlator
RIO Client
RIO Server
Other intervening xlators
Direct descendant in graph
Changed layer
Legend:

Changed on-disk format● New on disk backend, like the .glusterfs
namespace on the bricks
● Reuse existing posix xlator for inode and
fd OPs○ redefine entry FOPs (and lookup)
● Re-add dentry backpointers○ Needed for hard link and rename
operations
● Extend utime xlator work, for caching,○ time information (a/mtime)○ size information (size, blocks, IO block)
<prior xlators>
Client/Server Protocol
POSIX2 xlator
RIO Client
RIO Server
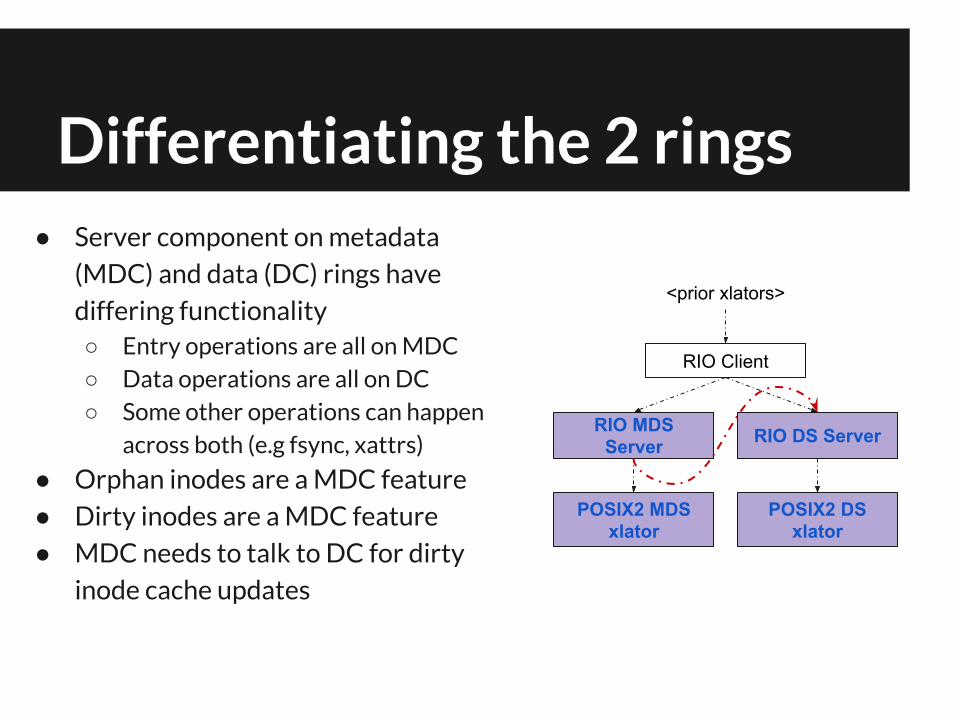
Differentiating the 2 rings● Server component on metadata
(MDC) and data (DC) rings have
differing functionality○ Entry operations are all on MDC○ Data operations are all on DC○ Some other operations can happen
across both (e.g fsync, xattrs)
● Orphan inodes are a MDC feature
● Dirty inodes are a MDC feature
● MDC needs to talk to DC for dirty
inode cache updates
<prior xlators>
POSIX2 MDS xlator
RIO Client
RIO MDS Server
POSIX2 DS xlator
RIO DS Server

Changing the abstractions● iatt assumptions:
○ Operations on data and metadata would return incomplete iatt
information
○ Looking at iatt2 or statx like extensions to disambiguate the
same
● Anonfd:
○ Changes to data need to be reflected in the metadata cache
(dirty inodes)
○ Hence active inodes need to be tracked on the metadata servers
○ Thus, ending the use of anonfd’s!?

● The MDC needs replication, and never disperse!○ There is no data on the MDC○ Only metadata needs to be replicated and made available
Adding the availability layers● Consistency handling by RIOs needs a leader, without which,
○ <n> RIOs instances on the replicas need to resolve who creates the inode and who links the name
○ locking becomes a cross replicate subvolume operation, reducing efficiency
● Brings LEX (Leader Election Xlator) and possibly DRC-like (Duplicate Request Cache, like xlator)

Adding the availability layers
<prior xlators>
Client/Server (Leader)
POSIX2
RIO Client
RIO MDS Server
Client/Server (Follower)
Client/Server Protocol
AFR
AFR/Disperse
RIO DS Server

As we scale out...
NOTE: Legend in slide 12 does not hold good for this image

Thoughts on some other layers● Unsupported
○ Quota, Tier (?)
● Sharding○ Based on name distribution in DHT, RIO is based on GFID based
distribution■ Still gets a new GFID for every shard, but cost is higher with this methodology
○ Thinking of ways to distribute data, based on offsets, and leave the rest of the shard handling to its own xlator
● GFProxy does not need to change much,○ Possibly DC can be have a proxy, and MDC can be without one, when,
#MDS << #DS
● Layers and functionality that need to adapt
○ Tier(?), geo-rep

Status● Work happening on the experimental branch
○ RIOc/s(ds/mds), POSIX2 xlators being worked on○ Current contributors: Kotresh, Susant, Shyam
● Abilities supported as of this writing,○ Directory/File creation and data operations○ xattr, stat for all inodes
● Missing abilities○ Directory listing, unlink, rename
● Target is alpha release with gluster 4.0○ Tracked using this github issue #243

Questions?