rozkłady zmiennych losowych -...
TRANSCRIPT

Rozkłady zmiennych losowych
Dane zbierane podczas pomiarów zawsze układają się w pewien określony sposób.
To w jaki, zależy przede wszystkim od zjawiska, które jest obserwowane.
Sposób, w jaki układają się dane- rozkład zmiennej losowej.
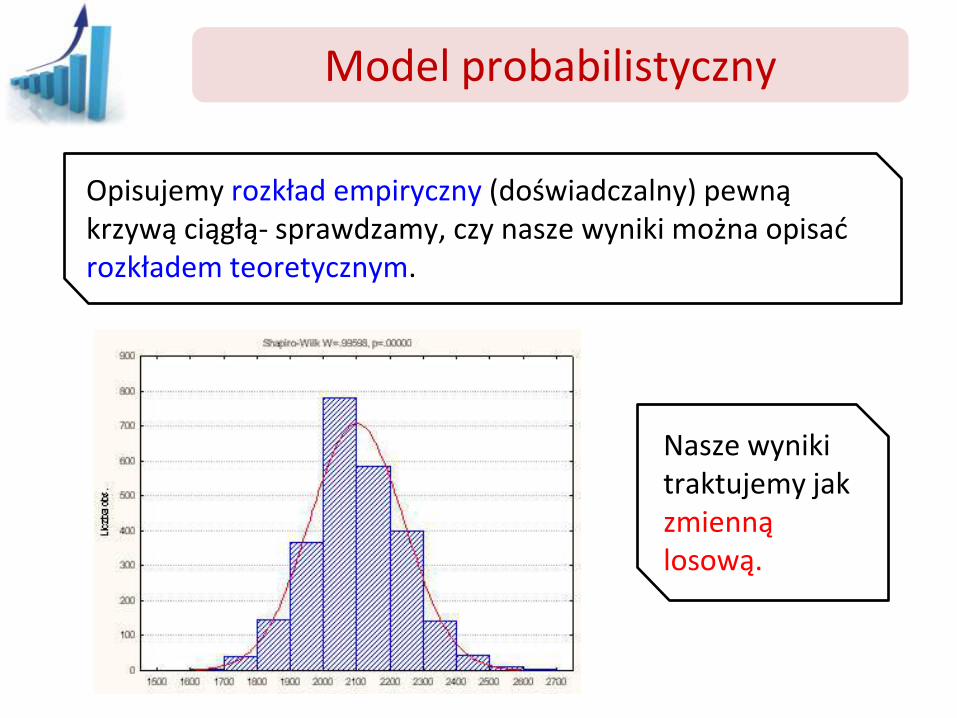
Model probabilistyczny
Opisujemy rozkład empiryczny (doświadczalny) pewną krzywą ciągłą- sprawdzamy, czy nasze wyniki można opisać rozkładem teoretycznym.
Nasze wyniki traktujemy jak zmienną losową.
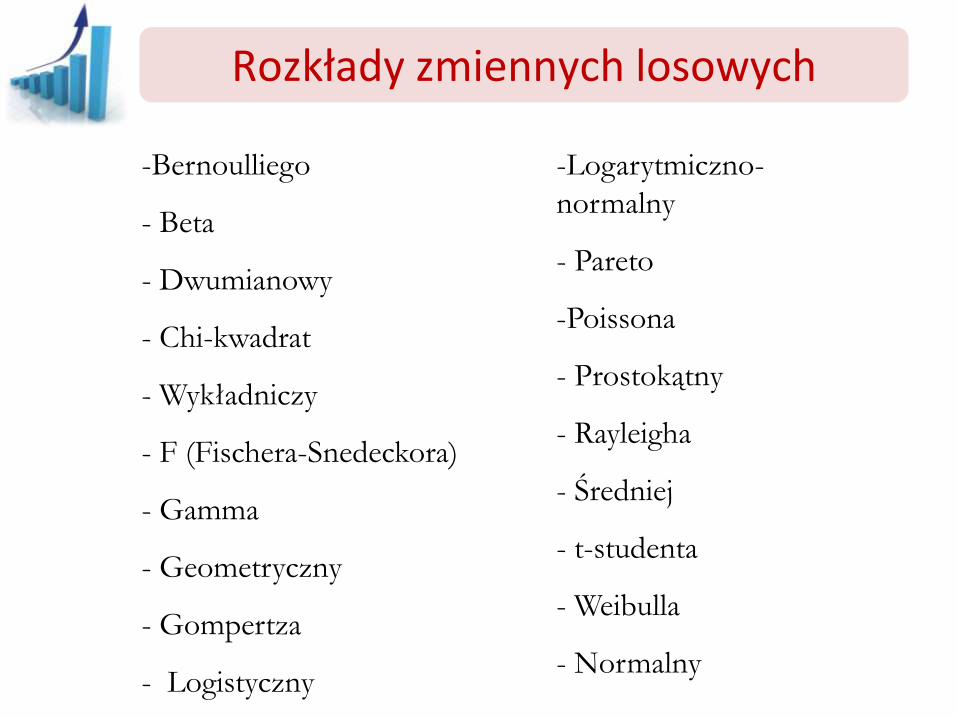
Rozkłady zmiennych losowych
-Bernoulliego
- Beta
- Dwumianowy
- Chi-kwadrat
- Wykładniczy
- F (Fischera-Snedeckora)
- Gamma
- Geometryczny
- Gompertza
- Logistyczny
-Logarytmiczno-
normalny
- Pareto
-Poissona
- Prostokątny
- Rayleigha
- Średniej
- t-studenta
- Weibulla
- Normalny
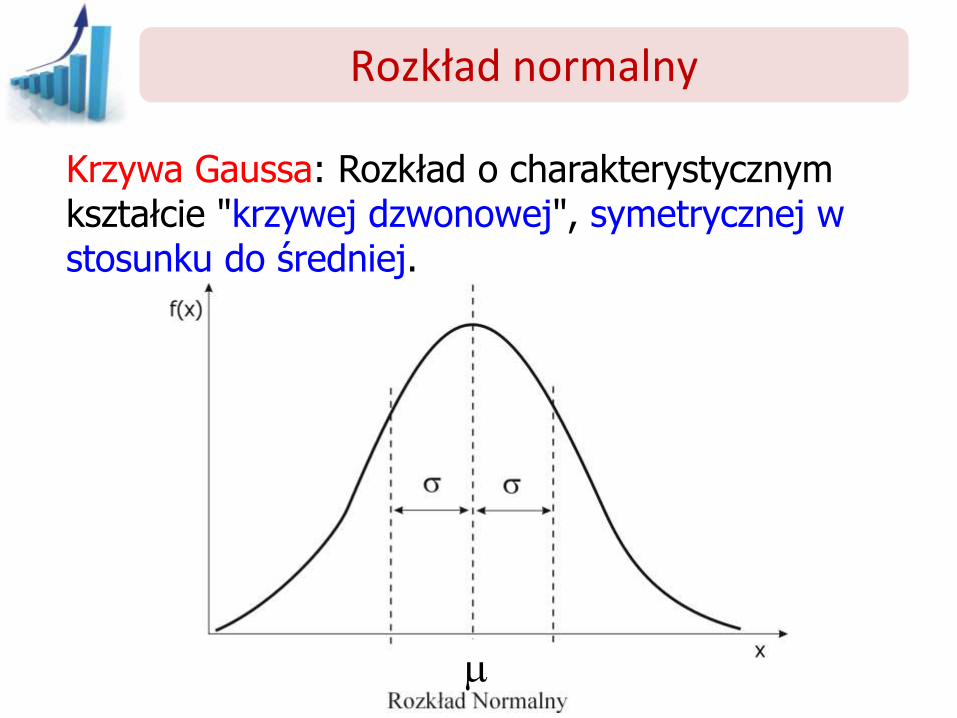
Rozkład normalny
Krzywa Gaussa: Rozkład o charakterystycznym kształcie "krzywej dzwonowej", symetrycznej w stosunku do średniej.
m
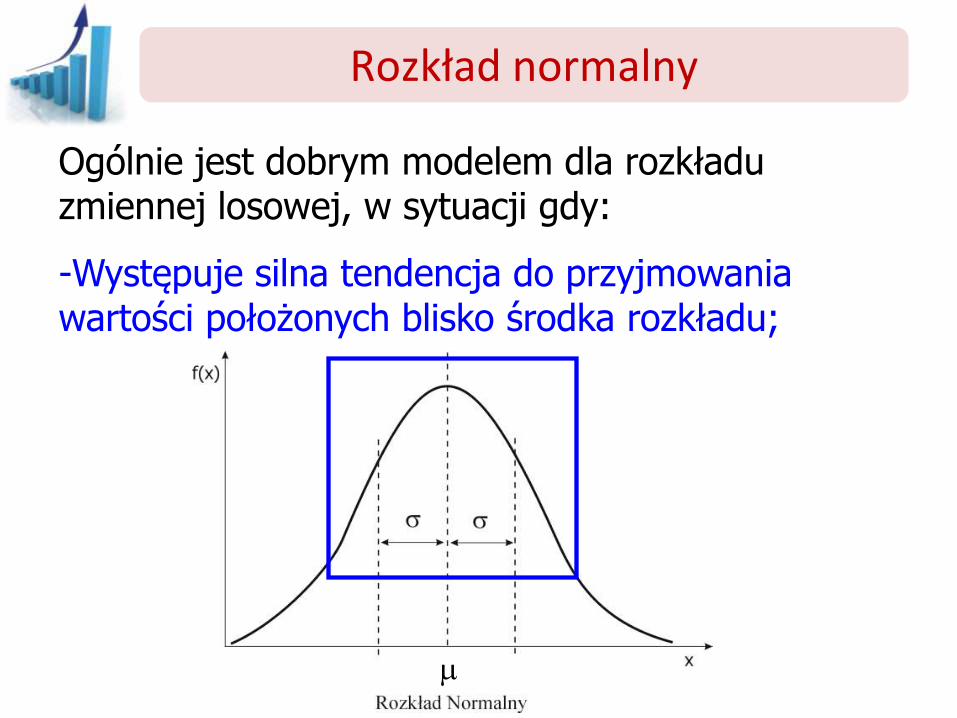
Rozkład normalny
Ogólnie jest dobrym modelem dla rozkładu zmiennej losowej, w sytuacji gdy:
-Występuje silna tendencja do przyjmowania wartości położonych blisko środka rozkładu;
m
Rozkład normalny
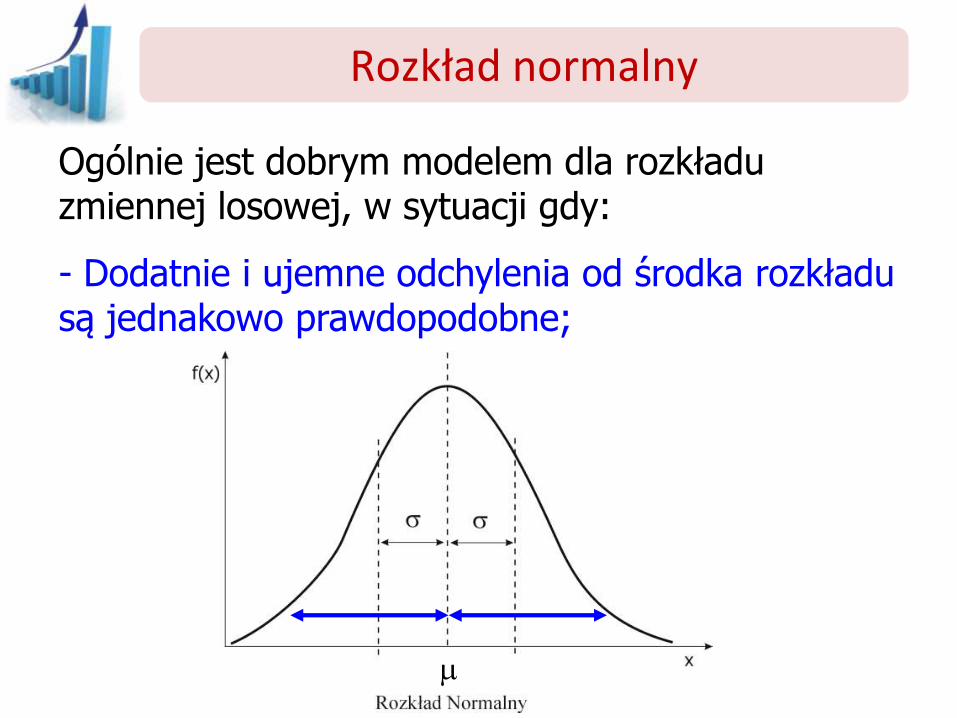
Ogólnie jest dobrym modelem dla rozkładu zmiennej losowej, w sytuacji gdy:
- Dodatnie i ujemne odchylenia od środka rozkładu są jednakowo prawdopodobne;
m
Rozkład normalny
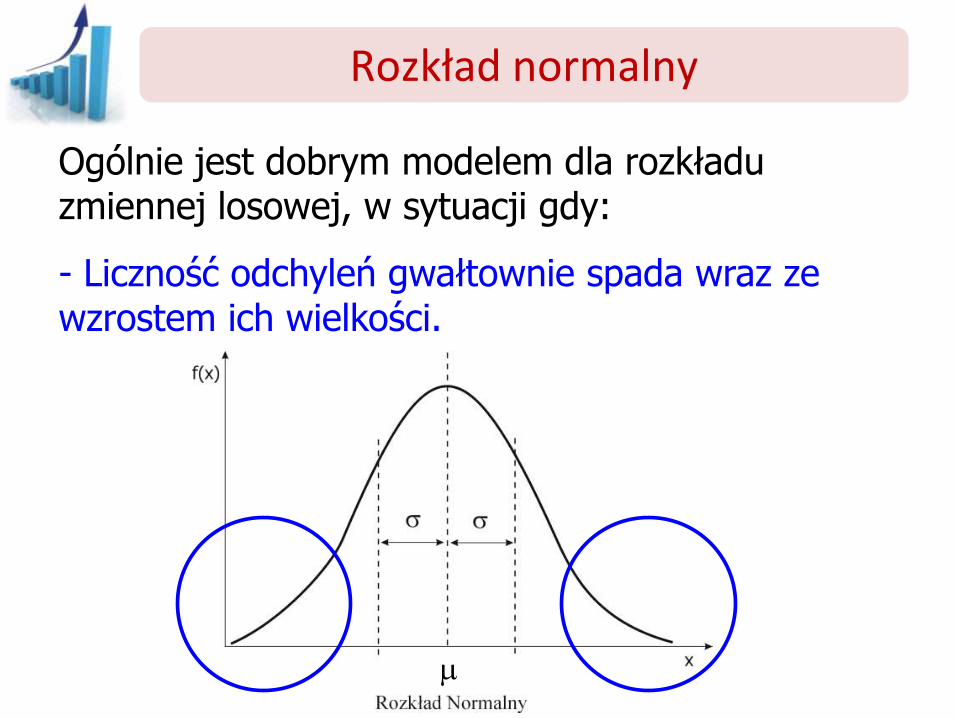
Ogólnie jest dobrym modelem dla rozkładu zmiennej losowej, w sytuacji gdy:
- Liczność odchyleń gwałtownie spada wraz ze wzrostem ich wielkości.
m
Rozkład normalny
Podstawowy mechanizm tworzący rozkład normalny: nieskończoną liczbę niezależnych zdarzeń losowych które generują wartości danej zmiennej.
m
Rozkład normalny
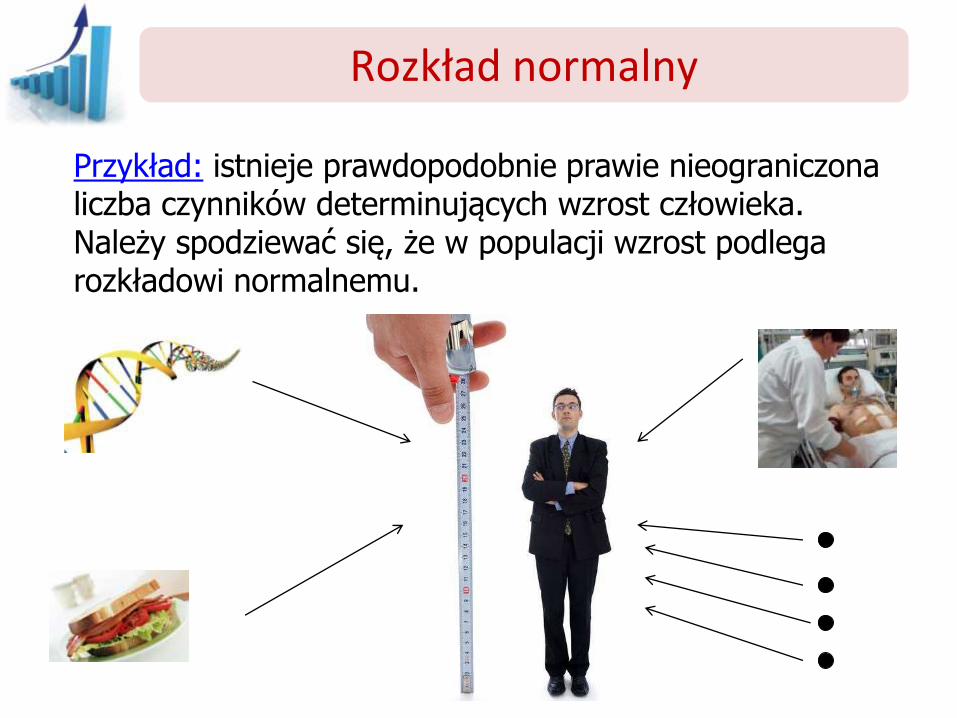
Przykład: istnieje prawdopodobnie prawie nieograniczona liczba czynników determinujących wzrost człowieka. Należy spodziewać się, że w populacji wzrost podlega rozkładowi normalnemu.

Rozkład normalny
Najważniejszy rozkład zmiennej losowej ciągłej, ponieważ
• przy nieograniczonym wzroście l-by niezależnych doświadczeń statystycznych WSZYSTKIE znane teoretyczne rozkłady zmiennych losowych ciągłych i dyskretnych są SZYBKO ZBIEŻNE do rozkładu normalnego
•w badaniu prób losowych popełniane są błędy przypadkowe, których rozkład jest normalny lub zbliżony do normalnego

Rozkład normalny
Gęstość prawdopodobieństwa
𝑓 𝑥 =1
𝜎 2𝜋exp(−
𝑥 − 𝜇 2
2𝜎)
m i to parametry rozkładu (mając ich wartości uzyskamy gotową krzywą Gaussa)
Rozkład ten jest określony w przedziale (-,+ )
𝑓 𝑥 =1
𝜎 2𝜋exp(−
𝑥 − 𝜇 2
2𝜎)

Rozkład normalny
Gęstość prawdopodobieństwa
𝑓 𝑥 =1
𝜎 2𝜋exp(−
𝑥 − 𝜇 2
2𝜎)
m
m=E(X) - wartość oczekiwana (średnia arytm.)
=D(X) - odchylenie standardowe
𝑓 𝑥 =1
𝜎 2𝜋exp(−
𝑥 − 𝜇 2
2𝜎)
Rozkład normalny
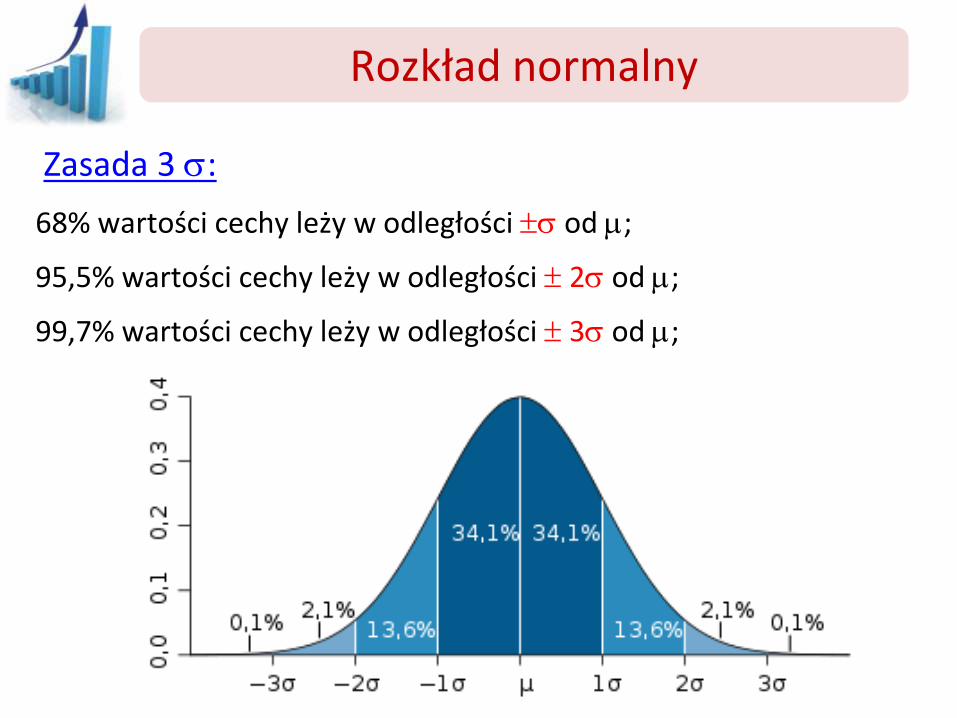
Zasada 3 :
68% wartości cechy leży w odległości od m;
95,5% wartości cechy leży w odległości 2 od m;
99,7% wartości cechy leży w odległości 3 od m;

Tablice- standaryzowany R.N.
W TABLICACH rozkład normalny sprowadza się do standaryzowanego rozkładu normalnego.
u =x − μ
σ
Wtedy gęstość rozkładu:
f u =1
2πexp −
μ2
2
Tablice- standaryzowany R.N.
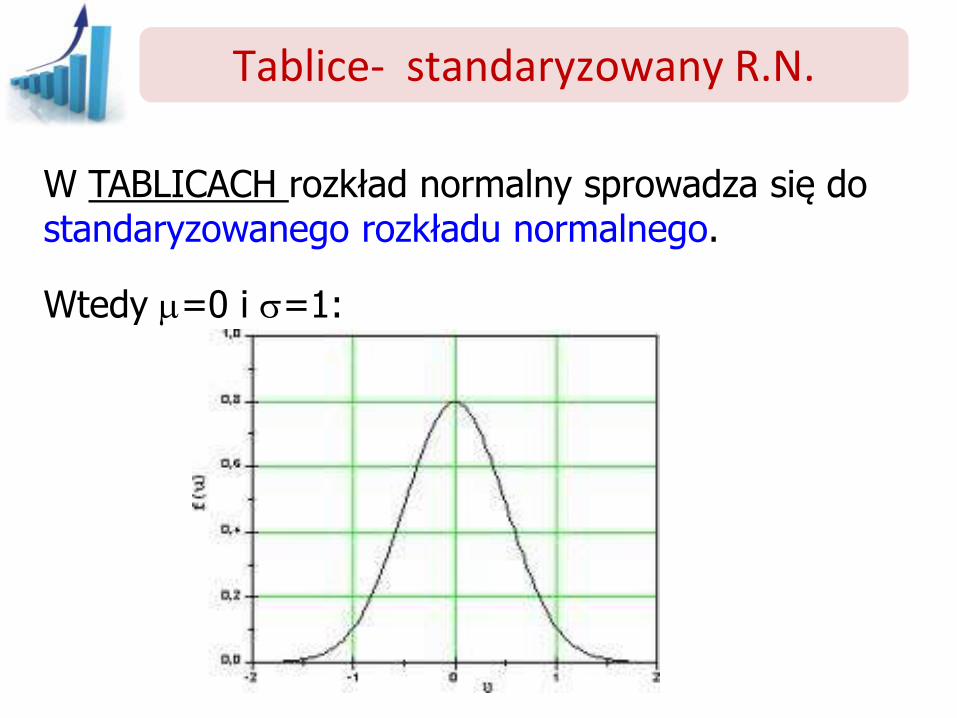
W TABLICACH rozkład normalny sprowadza się do standaryzowanego rozkładu normalnego.
Wtedy m=0 i =1:
Tablice- standaryzowany R.N.
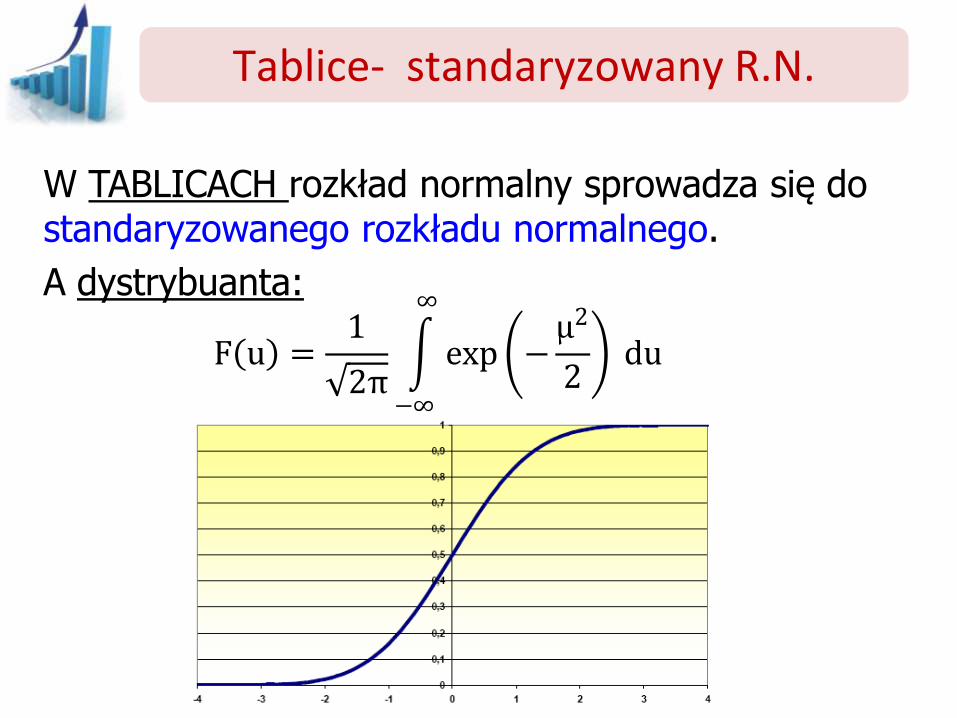
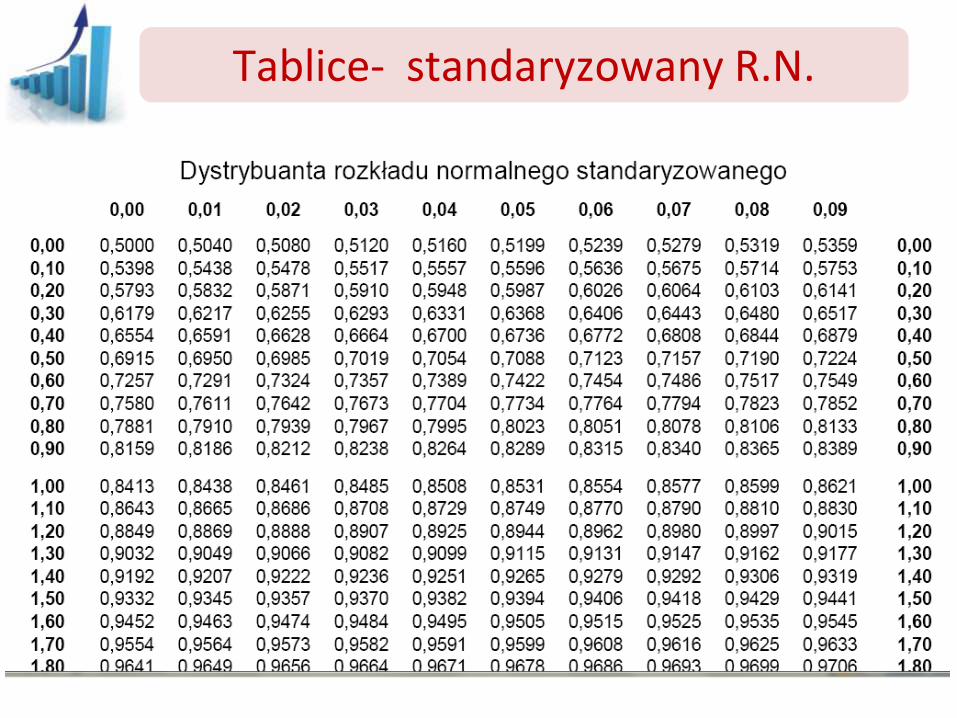
W TABLICACH rozkład normalny sprowadza się do standaryzowanego rozkładu normalnego.
A dystrybuanta:
F u =1
2π exp −
μ2
2
∞
−∞
du

Tablice- standaryzowany R.N.
Jeśli poszukujemy p-stwa znalezienia wyników w przedziale (x1,x2) to:
u1 =x1 − μ
σ u2 =
x2 − μ
σ
P(x1<x<x2)=F(x2)-F(x1)=F(u2)-F(u1)
Po co jest potrzebna operacja standaryzacji?
Tablice- standaryzowany R.N.

Estymatory
Jeżeli nie wiemy, ile naprawdę wynosi m rozkładu normalnego i (dla całej populacji) a jedynie liczymy średnią arytmetyczną i odchylenie z pomiarów, to wyliczone przybliżone parametry są obarczone błędem.
E(x) = m x
D(x) = 𝜎
E(x)- wartość oczekiwana rozkładu teoretycznego D(x)- odchylenie standardowe rozkładu teoretycznego

Estymatory
Błąd standardowy średniej:
𝜎𝑥 =𝜎
𝑛
Przedział, gdzie znajduje się wartość oczekiwana:
𝜇 = 𝑥 ± 𝜎𝑥
(𝑥 − 𝜎𝑥 ; 𝑥 + 𝜎𝑥 )

Rozkład t-studenta
Definicja zmiennej losowej t-studenta
Gdzie:
𝑡 =𝑥 − 𝜇
𝜎 ∙ 𝑛
𝜎

Rozkład t-studenta
Lub inaczej:
Gdzie:
𝑡 =𝑥 − 𝜇
𝜎 𝑥 =𝑥 − 𝜇
𝜎∙ 𝑛 − 1
𝜎 = 1
𝑛 𝑥𝑖 − 𝑥 2
𝑛
𝑖=1

Rozkład t-studenta
Rozkład t-studenta ma jeden parametr – liczbę stopni swobody – od niego zależy kształt rozkładu
f=df=n-1
𝑡 =𝑥 − 𝜇
𝜎 𝑥 =𝑥 − 𝜇
𝜎∙ 𝑛 − 1
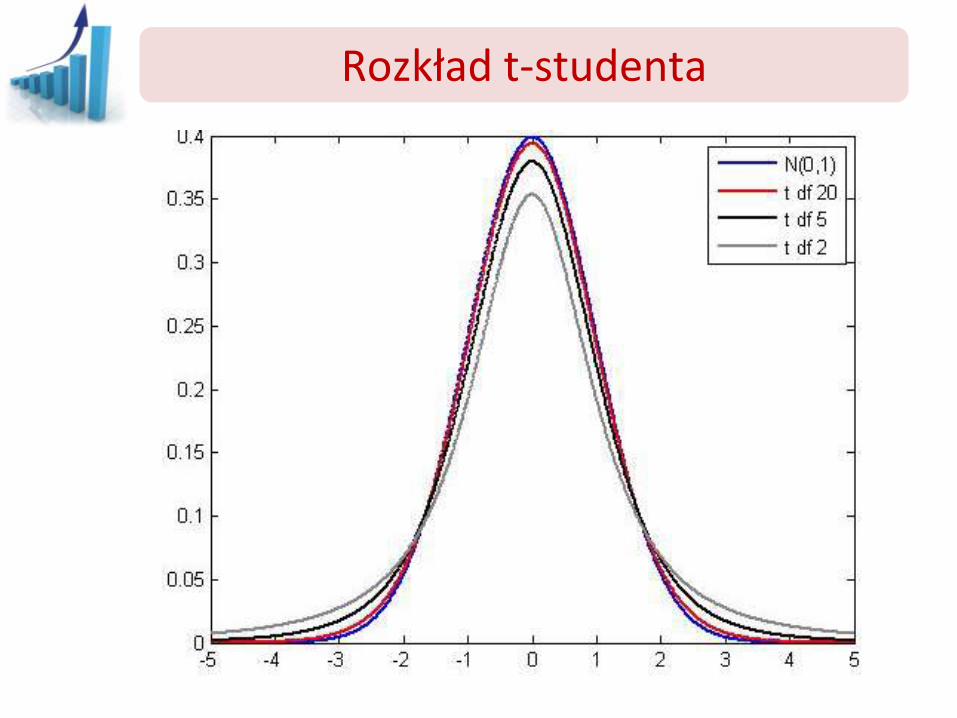
Rozkład t-studenta
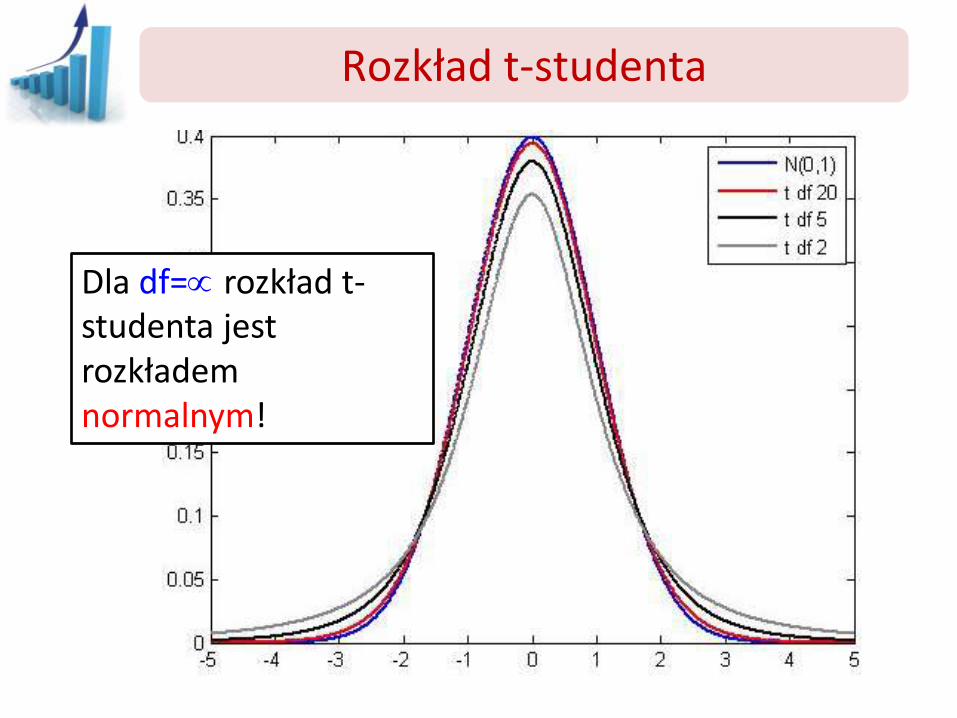
Rozkład t-studenta
Dla df= rozkład t-studenta jest rozkładem normalnym!
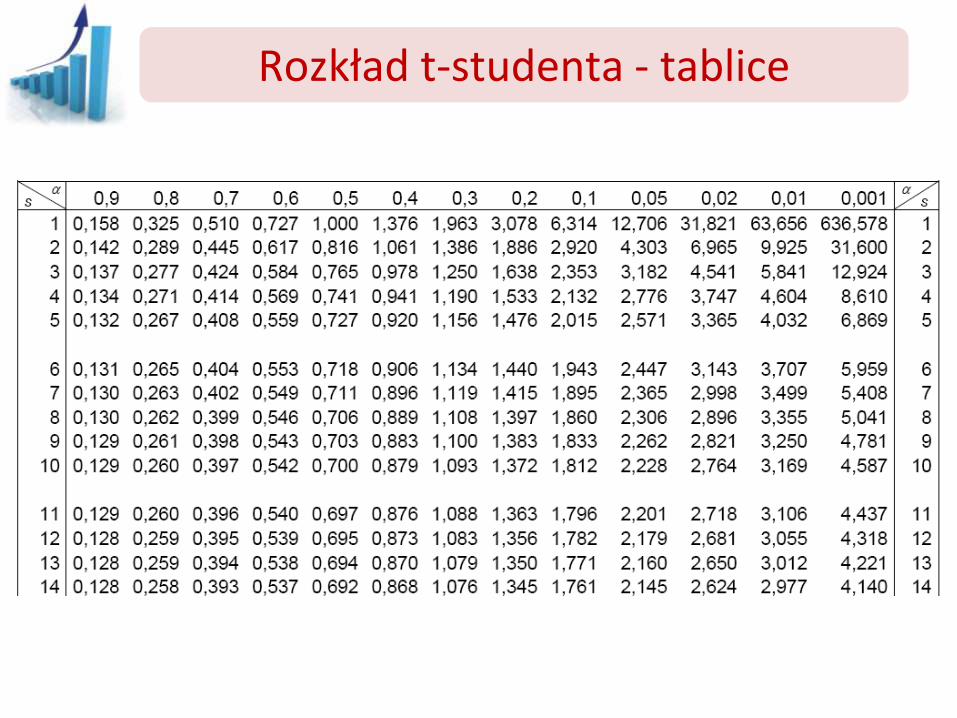
Rozkład t-studenta - tablice

Przedział ufności
Definicja: Niech cecha X ma rozkład w populacji z nieznanym parametrem θ. Z populacji wybieramy próbę losową (X1, X2, ..., Xn).
Przedziałem ufności (θ - θ1, θ + θ2) o współczynniku ufności 1 - α nazywamy taki przedział (θ - θ1, θ + θ2), który spełnia warunek:
P(θ1 < θ < θ2) = 1 − α gdzie θ1 i θ2 są funkcjami wyznaczonymi na podstawie próby losowej.

Przedział ufności
Definicja:
Definicja pozwala na dowolność wyboru funkcji z próby
ALE
zazwyczaj będziemy poszukiwać przedziałów najkrótszych.

Przedział ufności
Współczynnik ufności 1-a: Prawdopodobieństwo wyznaczenia takiego przedziału, że rzeczywista wartość parametru θ w populacji znajdzie się w tym przedziale. Im większa wartość tego współczynnika, tym szerszy przedział ufności, a więc mniejsza dokładność estymacji parametru. Im mniejsza wartość 1 - α, tym większa dokładność estymacji, ale jednocześnie tym węższy przedział ufności.

Przedział ufności
Współczynnik ufności 1-a:
Wybór odpowiedniego współczynnika jest więc kompromisem pomiędzy dokładnością estymacji a ryzykiem błędu. W praktyce przyjmuje się zazwyczaj wartości 1-a:
0,99; 0,95 lub 0,90 WTEDY a (poziom ufności):
0,01; 0,05; 0,1

Przedział ufności
Współczynnik ufności 1-a:
0,95 oznacza to, że średnio na każde 100 przedziałów ustalonych na 100 prób losowych, w 95 przypadkach prawdziwa wartość parametru znajduje się wewnątrz przedziału, natomiast w 5 przypadkach znajduje się poza przedziałem
Przedział ufności
Ponieważ szukamy jak najkrótszych przedziałów ufności, to przy wyznaczaniu przedziału staramy się wykorzystać jak najwięcej dostępnych informacji o rozkładzie cechy w populacji.

Przedział ufności
• Najlepiej, gdy zmienna ma rozkład normalny z odchyleniem standardowym σ – wzór na najdokładniejszy przedział ufności
• Przy nieznanym σ – wzór wtedy stosowany daje przedział szerszy, czyli mniej dokładny
• Wzory ogólniejsze, np. dla nieznanego rozkładu, często korzystają z rozkładów granicznych estymatorów i dlatego wymagają dużej liczebności próby.
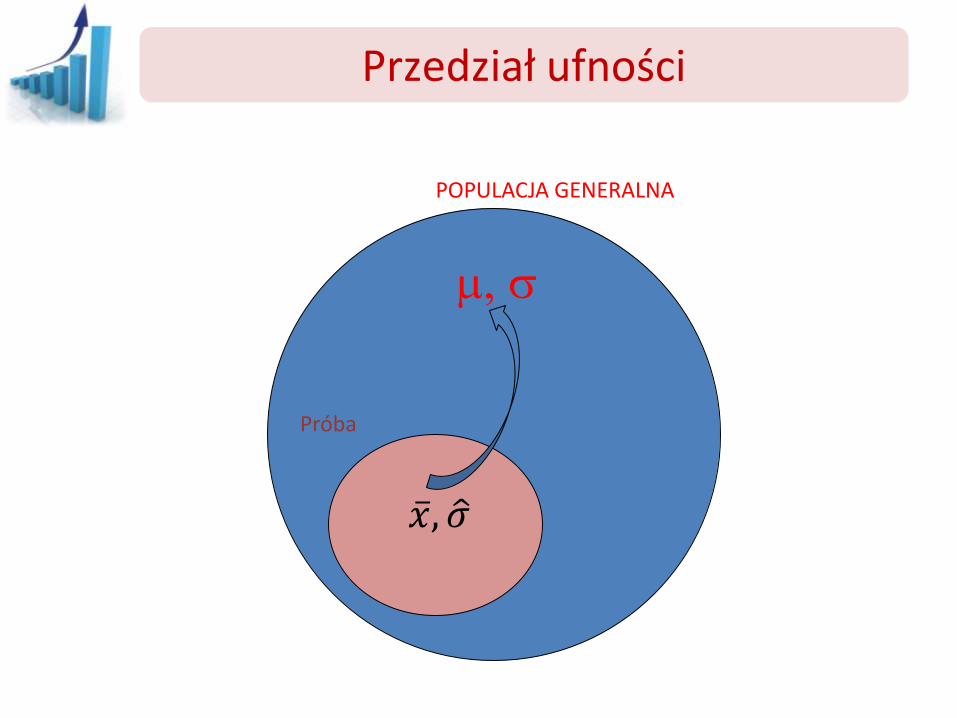
Przedział ufności
POPULACJA GENERALNA
m,
Próba
𝑥 ,𝜎
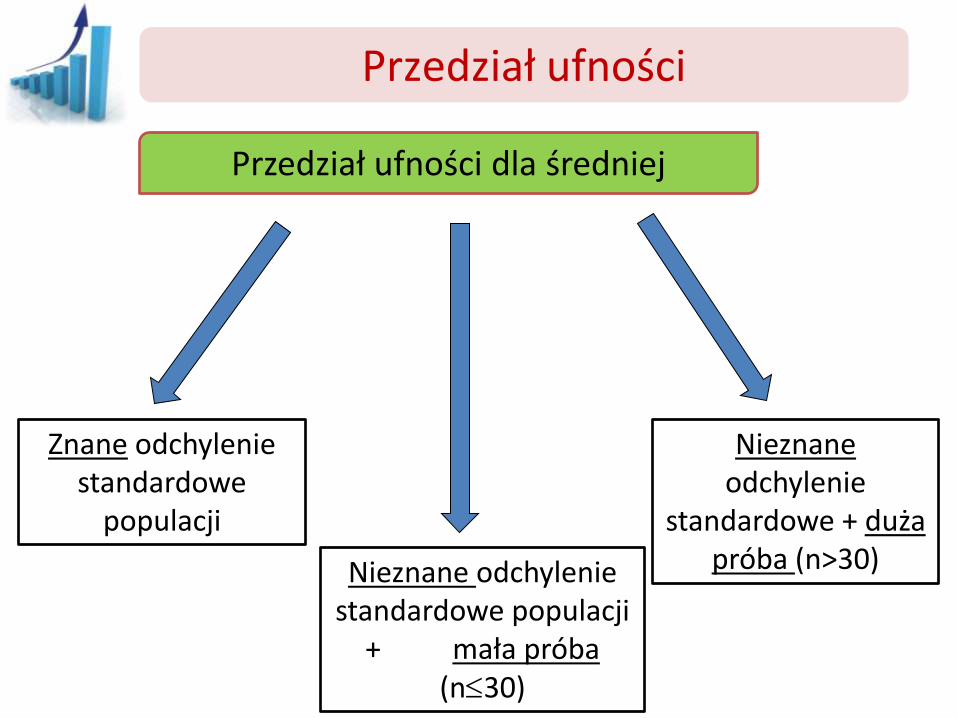
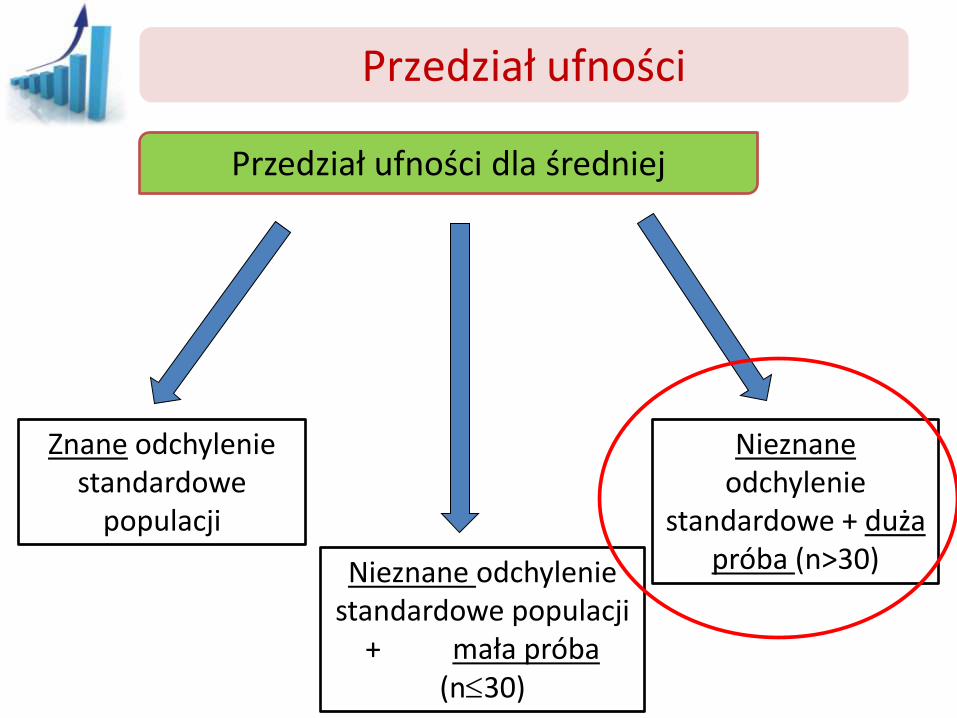
Przedział ufności
Przedział ufności dla średniej
Znane odchylenie standardowe
populacji
Nieznane odchylenie standardowe populacji
+ mała próba (n30)
Nieznane odchylenie
standardowe + duża próba (n>30)
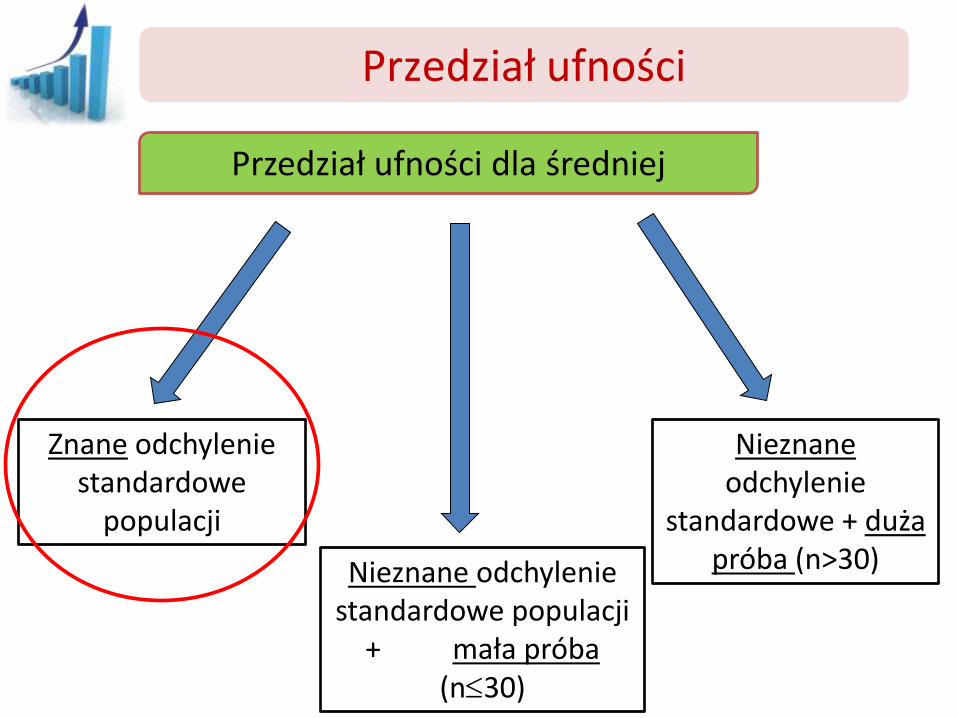
Przedział ufności
Przedział ufności dla średniej
Znane odchylenie standardowe
populacji
Nieznane odchylenie standardowe populacji
+ mała próba (n30)
Nieznane odchylenie
standardowe + duża próba (n>30)
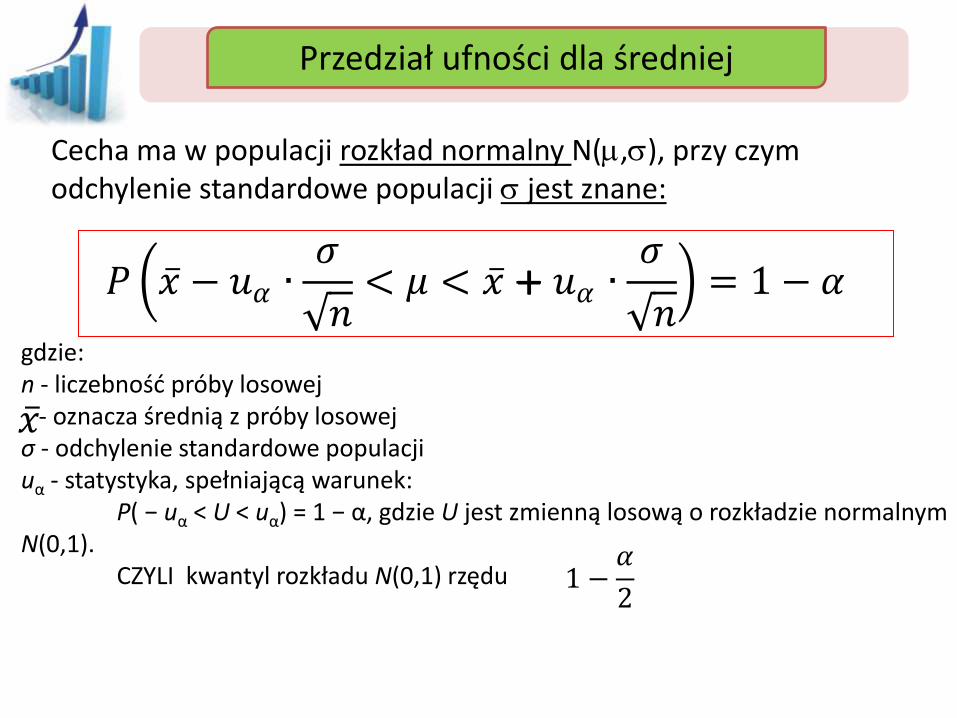
Przedział ufności Przedział ufności dla średniej
Cecha ma w populacji rozkład normalny N(m,), przy czym odchylenie standardowe populacji jest znane:
gdzie: n - liczebność próby losowej - oznacza średnią z próby losowej σ - odchylenie standardowe populacji uα - statystyka, spełniającą warunek: P( − uα < U < uα) = 1 − α, gdzie U jest zmienną losową o rozkładzie normalnym N(0,1). CZYLI kwantyl rozkładu N(0,1) rzędu
𝑃 𝑥 − 𝑢𝛼 ∙𝜎
𝑛< 𝜇 < 𝑥 − 𝑢𝛼 ∙
𝜎
𝑛 = 1 − 𝛼
𝑃 𝑥 − 𝑢𝛼 ∙𝜎
𝑛< 𝜇 < 𝑥 − 𝑢𝛼 ∙
𝜎
𝑛 = 1 − 𝛼
1 −𝛼
2
+

Przedział ufności Przedział ufności dla średniej
P( − uα < U < uα) = 1 − α, gdzie U jest zmienną losową o rozkładzie normalnym N(0,1). CZYLI ua to kwantyl rozkładu N(0,1) rzędu
1 −𝛼
2
Niech a=0,05
P( − u0,05 < U < u0,05) = 1 − 0,05 = 0,95
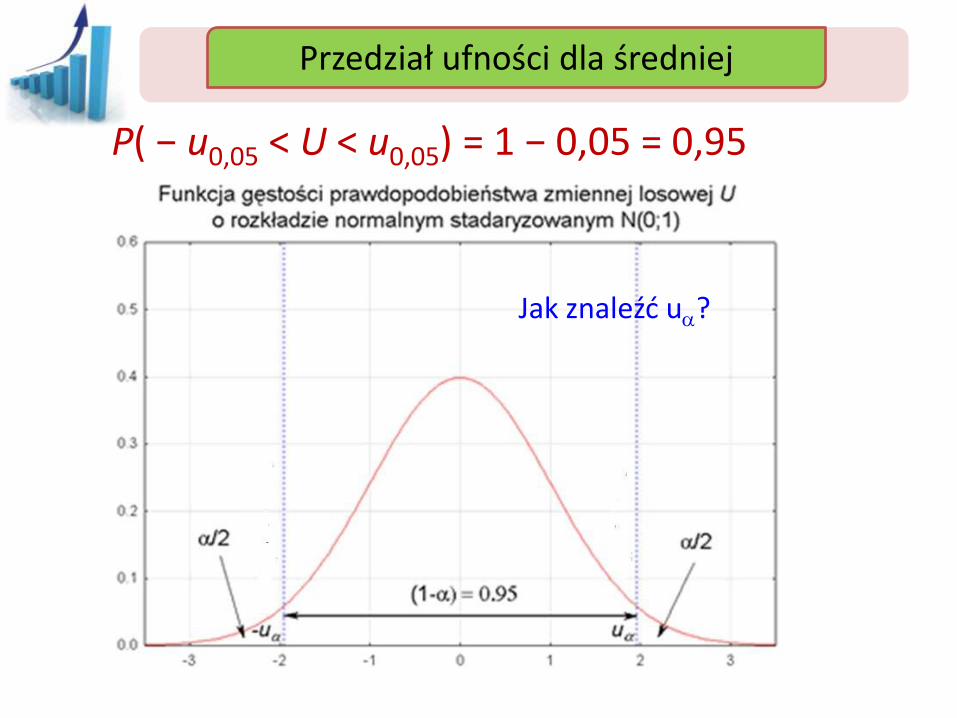
Przedział ufności Przedział ufności dla średniej
P( − u0,05 < U < u0,05) = 1 − 0,05 = 0,95
Jak znaleźć ua?
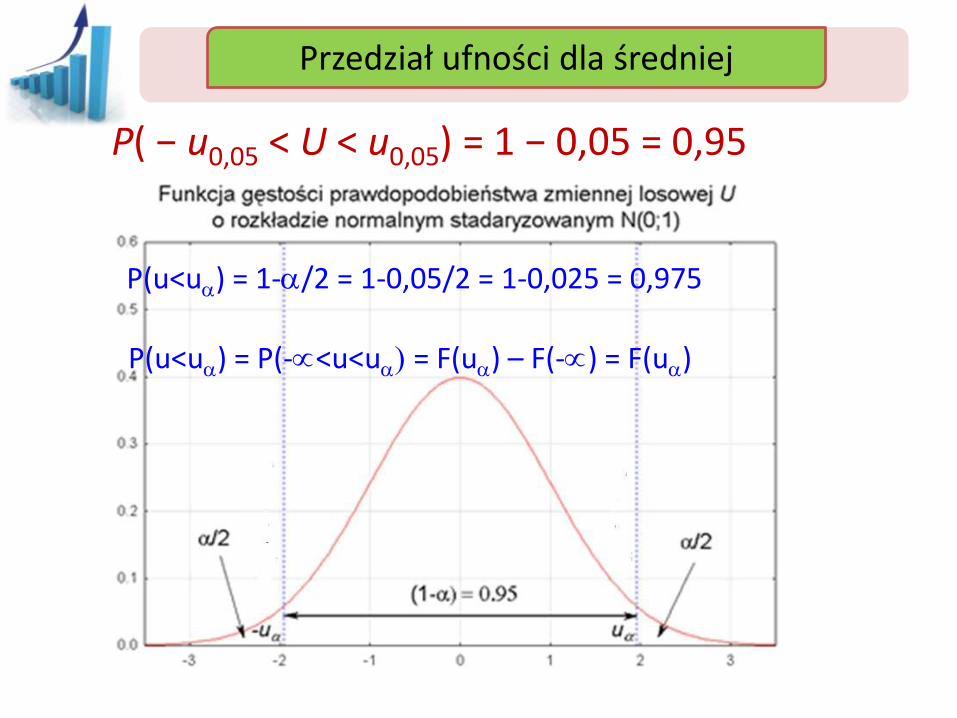
Przedział ufności Przedział ufności dla średniej
P( − u0,05 < U < u0,05) = 1 − 0,05 = 0,95
P(u<ua) = 1-a/2 = 1-0,05/2 = 1-0,025 = 0,975
P(u<ua) = P(-<u<ua) = F(ua) – F(-) = F(ua)
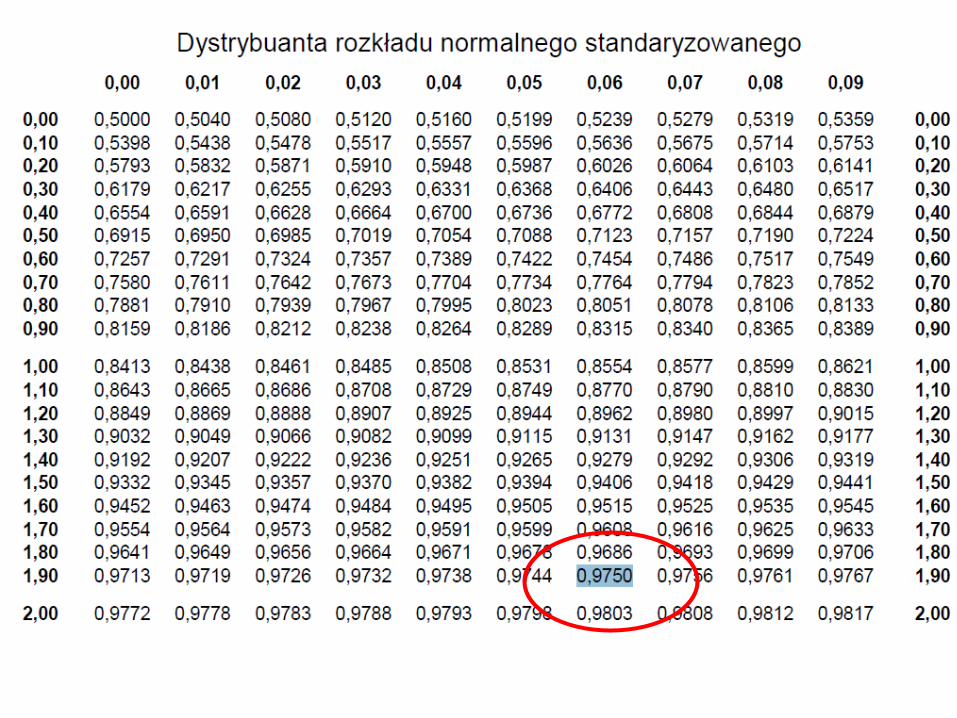
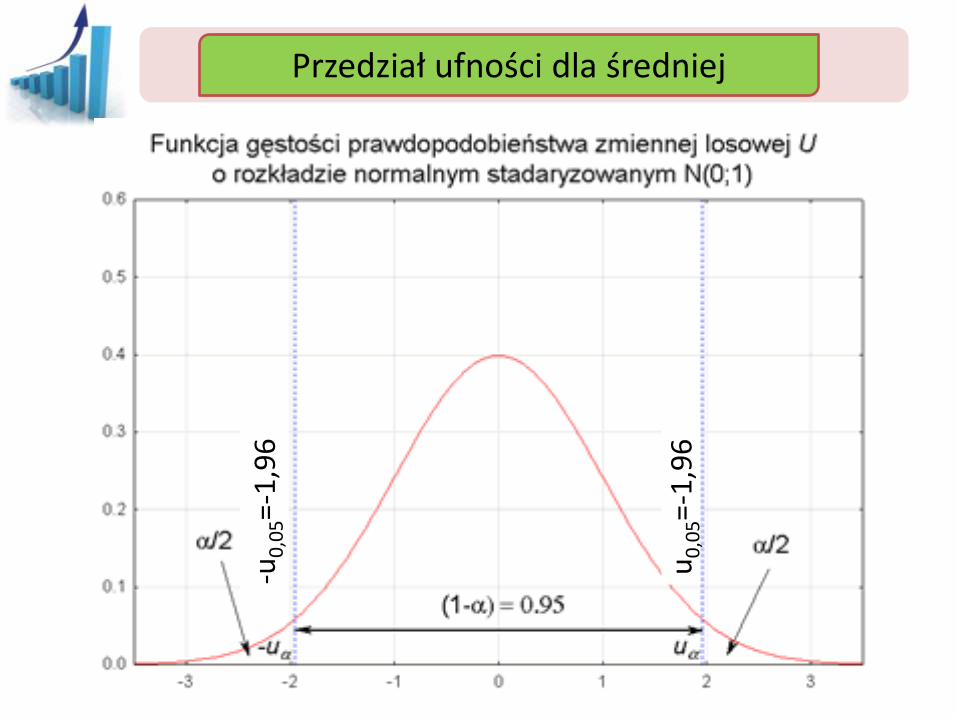
Przedział ufności Przedział ufności dla średniej
-u0
,05=-
1,9
6
u0
,05=-
1,9
6
Przedział ufności Przedział ufności dla średniej
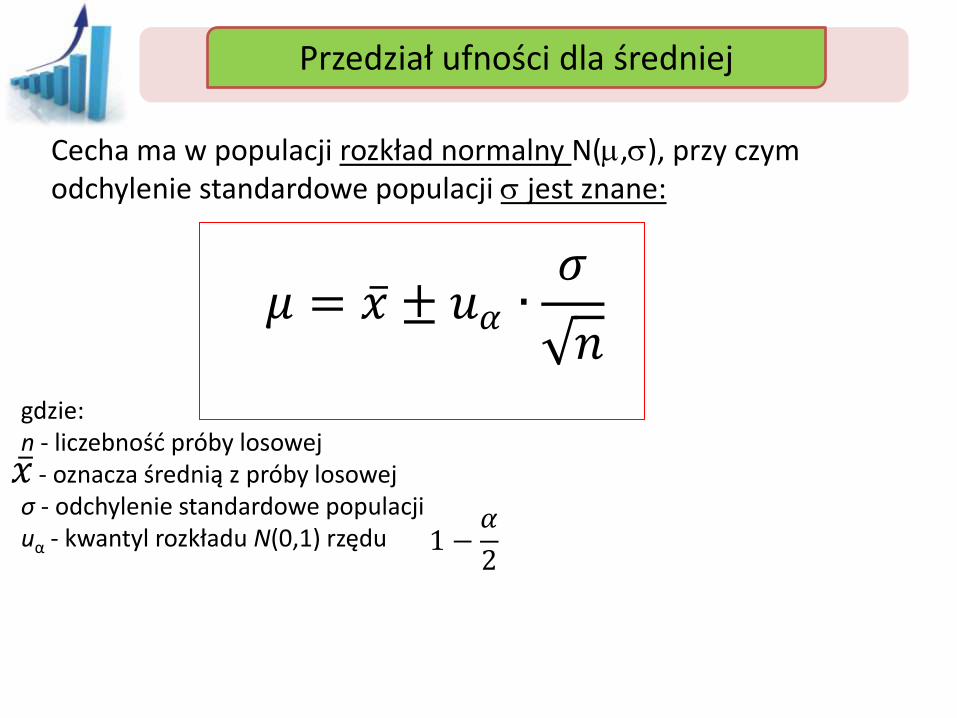
Cecha ma w populacji rozkład normalny N(m,), przy czym odchylenie standardowe populacji jest znane:
gdzie: n - liczebność próby losowej - oznacza średnią z próby losowej σ - odchylenie standardowe populacji uα - kwantyl rozkładu N(0,1) rzędu
𝑃 𝑥 − 𝑢𝛼 ∙𝜎
𝑛< 𝜇 < 𝑥 − 𝑢𝛼 ∙
𝜎
𝑛 = 1 − 𝛼
1 −𝛼
2
𝜇 = 𝑥 ± 𝑢𝛼 ∙𝜎
𝑛

Przedział ufności Przedział ufności dla średniej
Cecha ma w populacji rozkład normalny N(m,), przy czym odchylenie standardowe populacji jest znane:
Taka sytuacja występuje bardzo rzadko (musieli byśmy zbadać CAŁĄ populację generalną)
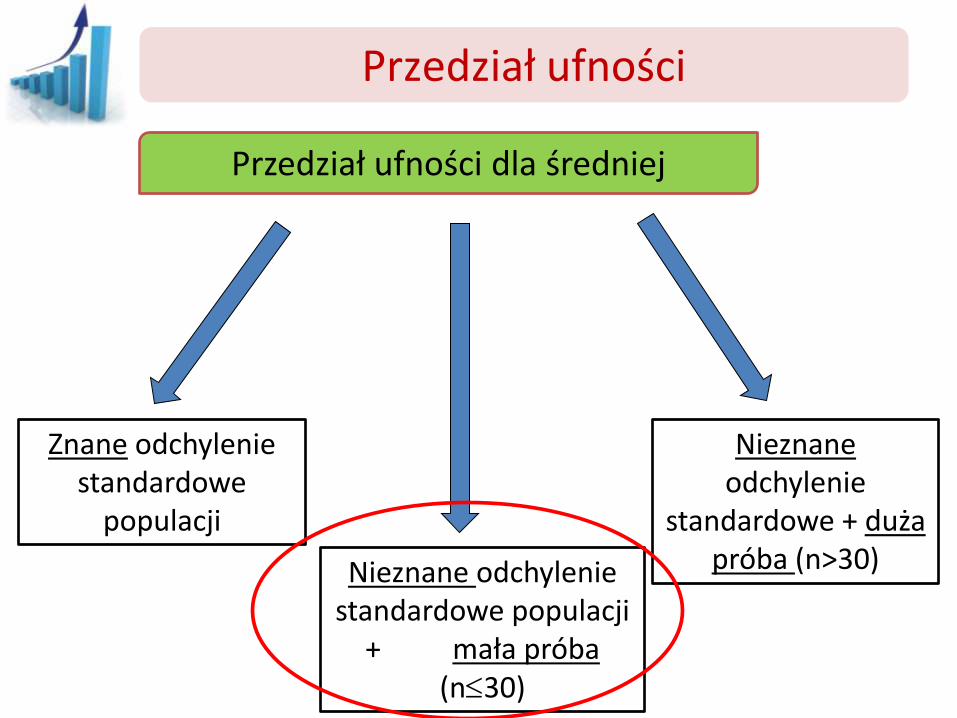
Przedział ufności
Przedział ufności dla średniej
Znane odchylenie standardowe
populacji
Nieznane odchylenie standardowe populacji
+ mała próba (n30)
Nieznane odchylenie
standardowe + duża próba (n>30)

Przedział ufności Przedział ufności dla średniej
Cecha ma w populacji rozkład normalny N(m,), przy czym odchylenie standardowe jest nieznane a znamy tylko odchylenie stand, próbki (n30):
gdzie: n - liczebność próby losowej X - średnia z próby losowej σ - odchylenie standardowe z próby t(a,f) – kwantyl rzędu 1 - a/2 rozkładu t-studenta z df=f=n-1 stopniami swobody
𝜎
𝜎
𝑃 𝑥 − 𝑡 𝛼,𝑓 ∙𝜎
𝑛 − 1< 𝜇 < 𝑥 + 𝑡(𝛼,𝑓) ∙
𝜎
𝑛 − 1 = 1 − 𝛼

Przedział ufności Przedział ufności dla średniej
Cecha ma w populacji rozkład normalny N(m,), przy czym odchylenie standardowe jest nieznane a znamy tylko odchylenie stand, próbki (n30):
gdzie: n - liczebność próby losowej X - średnia z próby losowej σ - odchylenie standardowe z próby t(a,f) – kwantyl rzędu 1 - a/2 rozkładu t-studenta z df=f=n-1 stopniami swobody
𝜎
𝜎
𝜇 = 𝑥 ± 𝑡(𝑃 = 1 − 𝛼,𝑓) ∙𝜎
𝑛 − 1
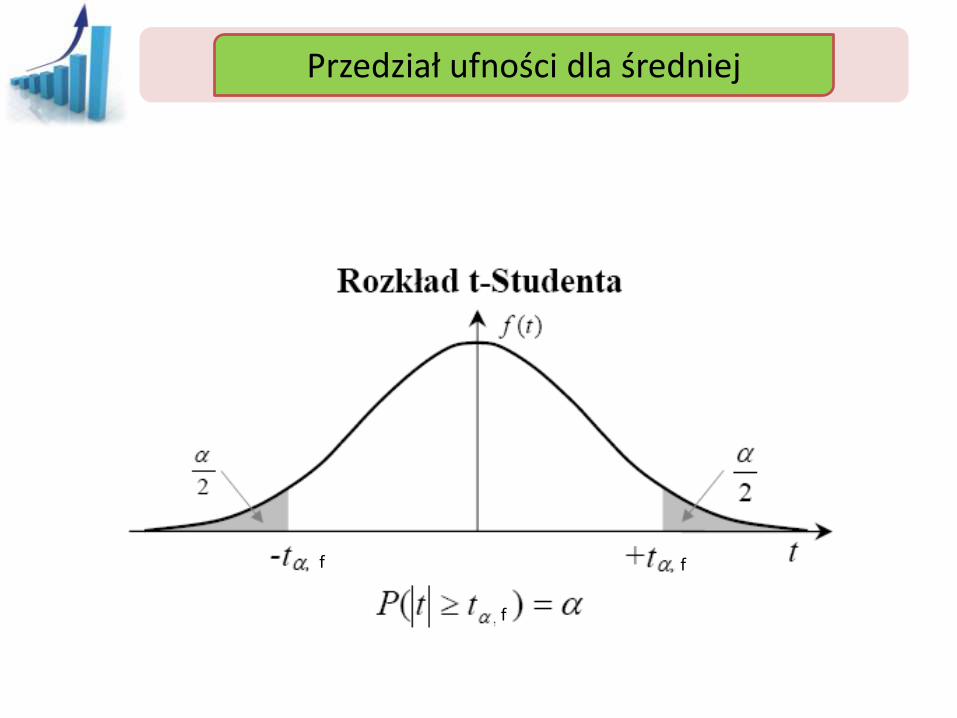
Przedział ufności Przedział ufności dla średniej
f
f
f
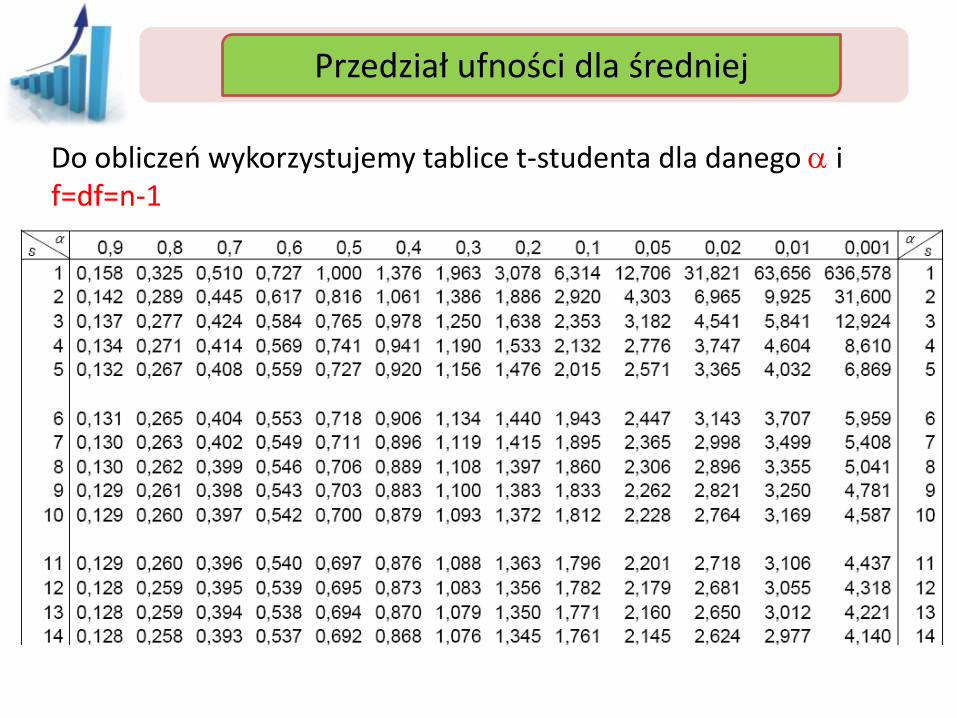
Przedział ufności Przedział ufności dla średniej
Do obliczeń wykorzystujemy tablice t-studenta dla danego a i f=df=n-1

Przedział ufności Przedział ufności dla średniej
𝜇 = 𝑥 ± 𝑡(𝑃 = 1 − 𝛼,𝑓) ∙𝜎
𝑛 − 1
Zwykle stosuje się ten wzór dla małej próby (n<30). Tak naprawdę działa on dla każdej wielkości próby, jednak dla dużych prób można przybliżyć rozkład t Studenta rozkładem normalnym, co jest łatwiejsze do wyliczenia a dające niemal takie same wartości
Przedział ufności
Przedział ufności dla średniej
Znane odchylenie standardowe
populacji
Nieznane odchylenie standardowe populacji
+ mała próba (n30)
Nieznane odchylenie
standardowe + duża próba (n>30)

Przedział ufności Przedział ufności dla średniej
Cecha ma w populacji rozkład normalny N(m,), przy czym odchylenie standardowe jest nieznane (znamy tylko próby) a próba jest duża (n>30):
gdzie: n - liczebność próby losowej X - oznacza średnią z próby losowej σ - odchylenie standardowe z próby ua - kwantyl rzędu 1 – a/2 standaryzowanego rozkładu normalnego N(0,1)
𝜎
𝜎
𝑃 𝑥 − 𝑢𝛼 ∙𝜎
𝑛< 𝜇 < 𝑥 + 𝑢𝛼 ∙
𝜎
𝑛 = 1 − 𝛼

Przedział ufności Przedział ufności dla średniej
Cecha ma w populacji rozkład normalny N(m,), przy czym odchylenie standardowe jest nieznane (znamy tylko próby) a próba jest duża (n>30):
Czyli: 𝜇 = 𝑥 ± 𝑢(𝑃 = 1 − 𝛼) ∙ 𝜎 𝑥
𝜎
gdzie: n - liczebność próby losowej X - oznacza średnią z próby losowej – błąd standardowy średniej u(P=1-a) - kwantyl rzędu 1 – a/2 standaryzowanego rozkładu normalnego N(0,1)
𝜇 = 𝑥 ± 𝑢(𝑃 = 1 − 𝛼) ∙ 𝜎 𝑥
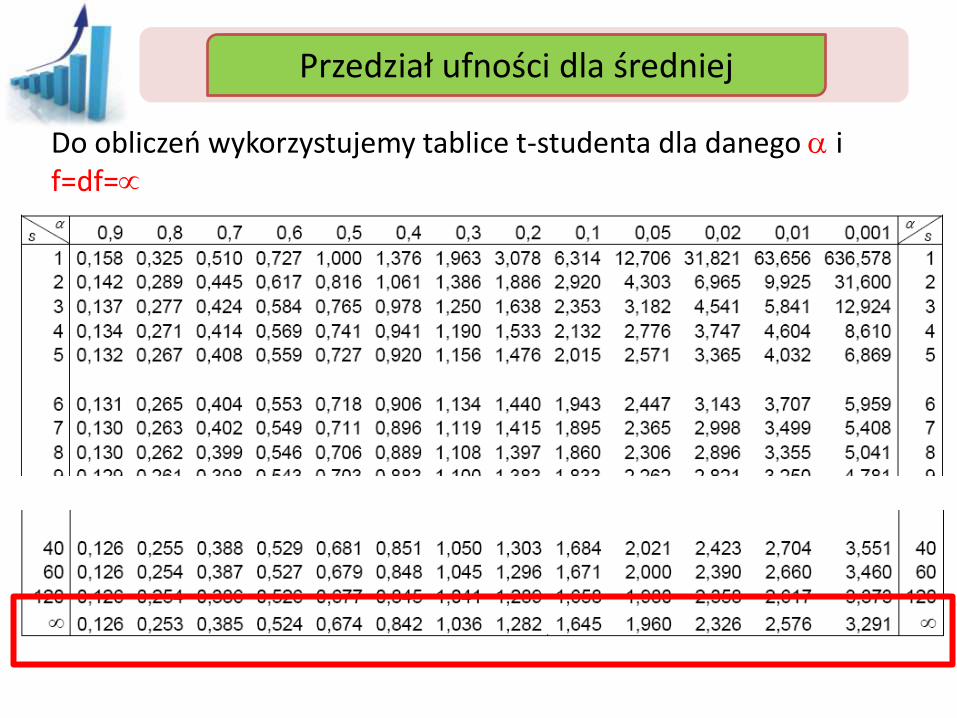
Przedział ufności Przedział ufności dla średniej
Do obliczeń wykorzystujemy tablice t-studenta dla danego a i f=df=

Rozkład chi-kwadrat
Definicja zmiennej losowej 2
Gdy Xi są zmiennymi losowymi losowanymi z rozkładu normalnego N(0,1), to ma rozkład chi-kwadrat o f stopniach swobody. Gdy losowanie odbywa się z rozkładu normalnego N(m,), to:
1 parametr rozkładu: f=n-1 (liczba stopni swobody)
f
i
iX1
2
)
f
i
iX
12
2
2
m

Rozkład chi-kwadrat
Definicja zmiennej losowej 2
00
0
22
1
)(
21
2
2
xdla
xdlaexkxf
xf
f
- funkcja gamma Eulera f – liczba stopni swobody
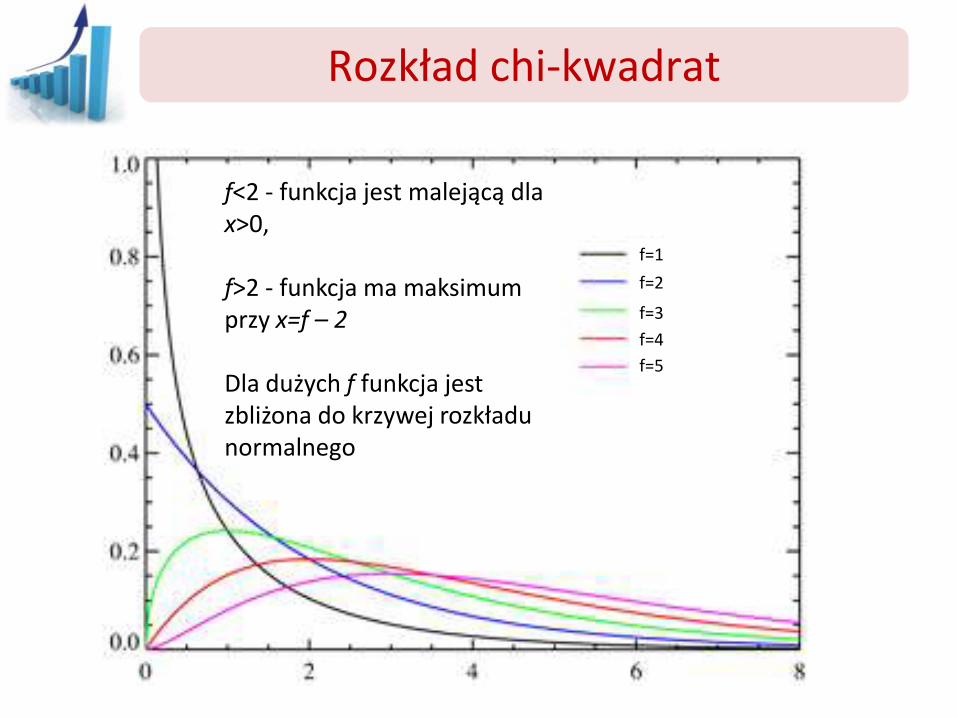
Rozkład chi-kwadrat
f=1
f=2
f=3
f=4
f=5
f<2 - funkcja jest malejącą dla x>0, f>2 - funkcja ma maksimum przy x=f – 2 Dla dużych f funkcja jest zbliżona do krzywej rozkładu normalnego
Rozkład chi-kwadrat
Przedział ufności
Przedział ufności dla wariancji
Mała próba n30 Duża próba n>30
Przedział ufności
Przedział ufności dla wariancji
Mała próba n<30 Duża próba n>30
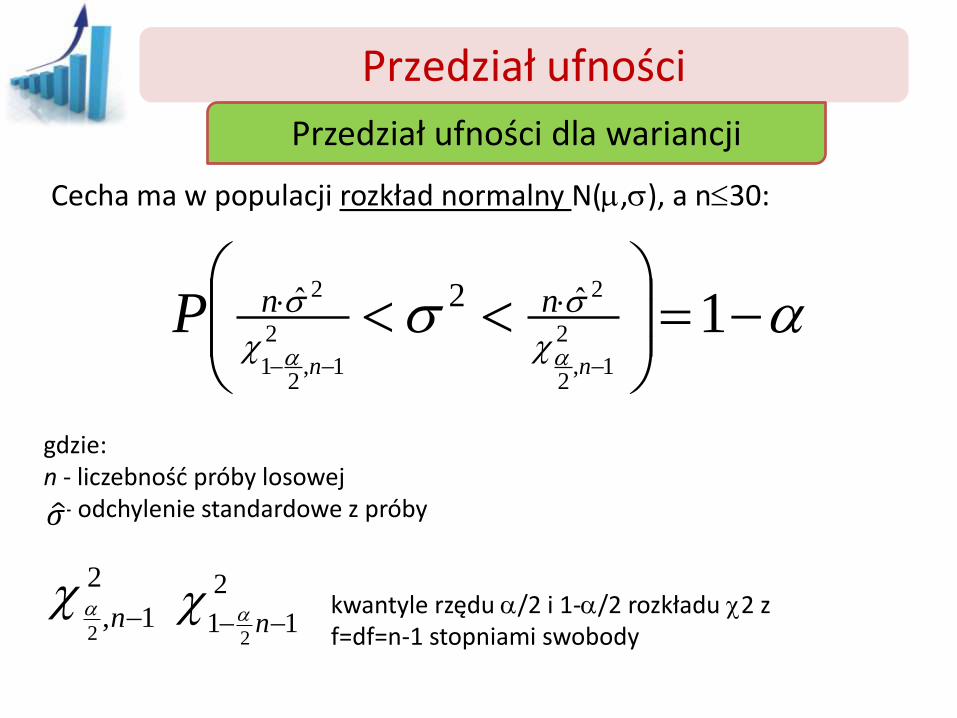
Przedział ufności
Przedział ufności dla wariancji
Cecha ma w populacji rozkład normalny N(m,), a n30:
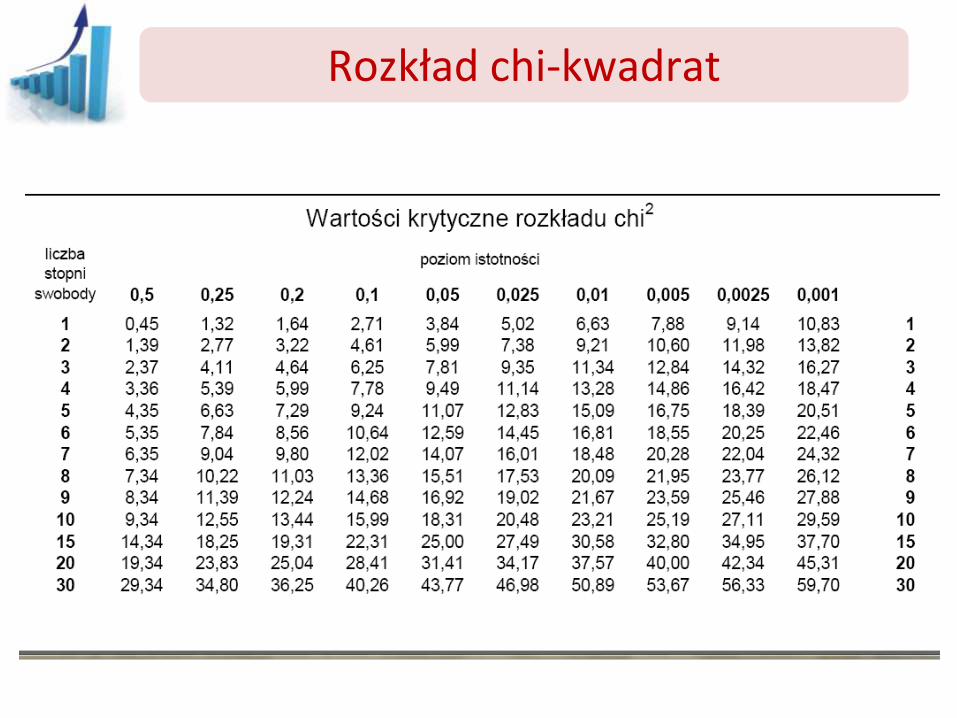
gdzie: n - liczebność próby losowej σ - odchylenie standardowe z próby kwantyle rzędu a/2 i 1-a/2 rozkładu 2 z f=df=n-1 stopniami swobody
𝜎
aaa
12
1,2
2
2
1,2
1
2 ˆ2ˆ
nn
nnP
2
1,2
na 2
112
na

Przedział ufności
Przedział ufności dla wariancji
𝜎2𝑑 =
𝑛 ∙ 𝜎 2
𝜒2(𝑃 = 1 − 𝛼,𝑓 = 𝑛 − 1)
Czyli:
𝜎2𝑔 =
𝑛 ∙ 𝜎 2
𝜒2(1 − 𝑃,𝑓 = 𝑛 − 1)
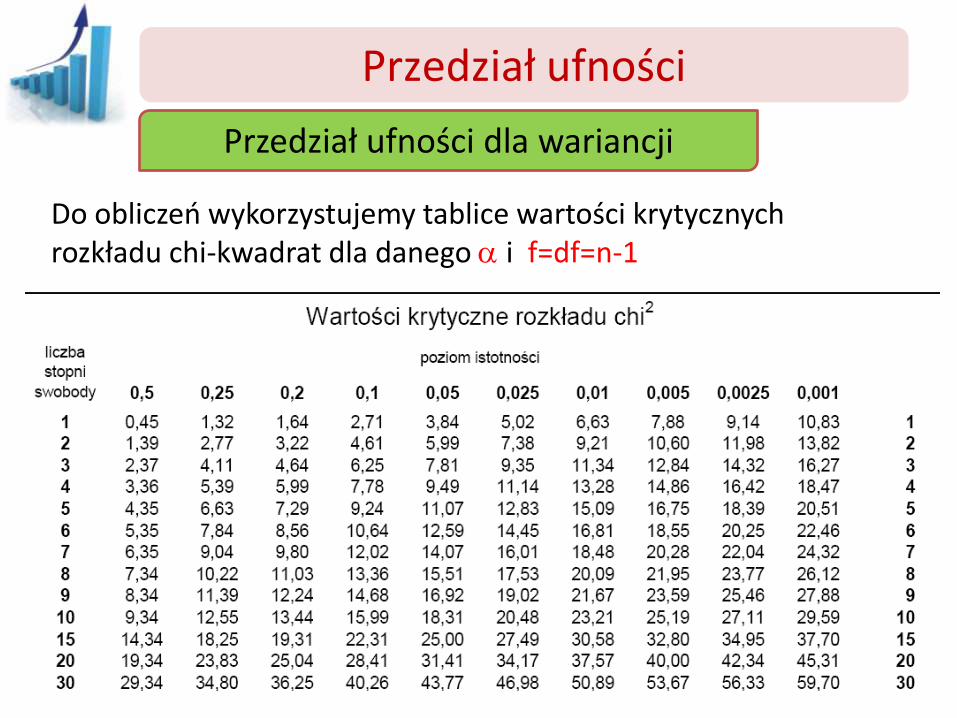
Przedział ufności
Przedział ufności dla wariancji
Do obliczeń wykorzystujemy tablice wartości krytycznych rozkładu chi-kwadrat dla danego a i f=df=n-1

Przedział ufności
Przedział ufności dla odchylenia standardowego
Cecha ma w populacji rozkład normalny N(m,), a n30:
aaa
12
1,2
2
2
1,2
1
2 ˆˆ
nn
nnP
Przedział ufności
Przedział ufności dla wariancji
Mała próba n<30 Duża próba n>30

Przedział ufności
Przedział ufności dla odch. stand, (wariancji)
Cecha ma w populacji rozkład normalny N(m,), a n>30:
gdzie: n - liczebność próby losowej σ - odchylenie standardowe z próby uα – kwantyl rzędu 1-a/2 standaryzowanego rozkładu normalnego N(0,1)
𝜎
aaa
122
1
ˆ
1
ˆ
n
u
n
uP
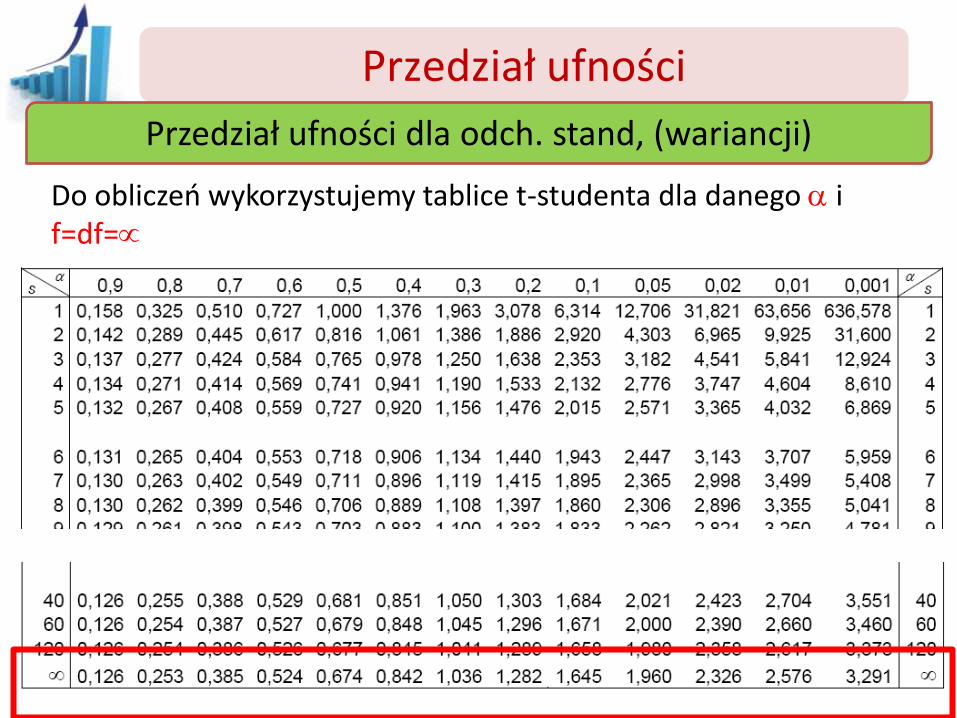
Przedział ufności
Do obliczeń wykorzystujemy tablice t-studenta dla danego a i f=df=
Przedział ufności dla odch. stand, (wariancji)