rozpoznawanie emocji na podstawie mowy naturalnej · do walki o przetrwanie jednostki gatunku....
TRANSCRIPT

POLITECHNIKA ŁÓDZKA
Wydział Elektrotechniki, Elektroniki,Informatyki i Automatyki
mgr inz. Dorota Kaminska
Streszczenie rozprawy doktorskiej na temat:
Rozpoznawanie emocji na podstawie mowy naturalnej
Promotordr hab. inz. Adam Pelikant
Łódz 2014

1. Wprowadzenie
Komunikacja interpersonalna to nieodzowny element ludzkiego zycia. Rozmowa dostarcza
słuchaczowi zarówno informacji lingwistycznych, jak i okresla charakterystyke biologiczno -
psychologiczna mówcy. Wydobycie obu rodzajów informacji poprawia jakosc komunikacji.
Waznym elementem konwersacji jest ocena stanu emocjonalnego rozmówcy, który mozemy
równiez z niej odczytac.
W dzisiejszych czasach, kiedy komputery sa czescia naszego zycia, poszukuje sie rozwiazan
majacych na celu polepszenie komunikacji człowiek-komputer/człowiek-robot (HCI/HRI).
Dlatego tez powstaja nowoczesne technologie rozpoznawania ludzkiej mowy. Systemy,
które dodatkowo rozpoznawałyby stany emocjonalne uzytkownika, byłyby bardziej naturalne
i wiarygodne. Totez komputerowe rozpoznawanie emocji stało sie istotnym trendem
badawczym.
Odczucia wyrazane sa zarówno poprzez procesy werbalne jak i niewerbalne. Sygnały
takie jak mowa [1], mimika twarzy [2], kontakt wzrokowy, gesty [3] oraz stan fizjologiczny
organizmu (elektroencefalografia EEG, elektromiografia EMG, reakcja skórno-galwaniczna
GSR, temperatura skóry, rytm i długosci wydechów czy cisnienie tetnicze) [4] stanowia wejscie
systemów rozpoznawania emocji. Ludzki głos, najłatwiej dostepny z wyzej wymienionych
sygnałów, jest równiez szeroko stosowany jako zródło informacji na temat stanu emocjonalnego
mówcy.
Niniejsze rozwazania dotycza rozpoznawania stanów emocjonalnych wyrazanych głosem.
Autorka skupiła sie głównie na mowie spontanicznej, dotychczas powszechnie zastepowanej
mowa odegrana. Na potrzeby zrealizowanych badan zgromadzone zostały nagrania audio
z nosnikiem emocjonalnym, stanowiace kompleksowa baze wejsciowa. Opierajac sie na
kole Roberta Plutchika stworzono modele emocji podstawowych oraz wtórnych, bedacych
wariacjami stanów podstawowych. Autorka przedstawiła nowatorski sposób klasyfikacji
emocji spontanicznych stosujac przy tym zarówno powszechnie znane deskryptory sygnału
1

mowy jak i percepcyjne współczynniki hybrydowe, dotychczas nie wykorzystywane do opisu
emocji. Ponizej przedstawione tezy badawcze, scisle powiazane z zagadnieniami klasyfikacji
mowy emocjonalnej, zostana zweryfikowane w toku pracy.
Teza 1: Wykorzystanie hybrydowych współczynników percepcyjnych w procesie
klasyfikacji dokonywanym przy uzyciu komitetu klasyfikatorów pozwala na uzyskanie
wysokiej skutecznosci rozpoznawania emocji na podstawie mowy naturalnej.
Teza 2: Opierajac sie na teorii emocji Plutchika mozna dokonac klasyfikacji emocji
wtórnych.
Teza 3: Istnieje mozliwosc zwiekszenie dokładnosci rozpoznawania emocji zawartych w
głosie poprzez minimalizacje cech osobniczych mówcy.
2. Psychoewolucyjna teoria Roberta Plutchika
W latach 1960-1980 amerykanski psycholog Robert Plutchik [5] opracował teorie, w
której wyodrebnił osiem pierwotnych emocji stanowiacych prototyp: radosc, akceptacja,
strach, zdziwienie, smutek, gniew, obrzydzenie oraz oczekiwanie. Stany te sa wrodzone,
odnosza sie do zachowan adaptacyjnych, które maja na celu pomoc w przetrwaniu. Stanowia
one hipotetyczne konstrukty, swojego rodzaju stany idealne, których własciwosci i cechy sa
wnioskowane intuicyjnie. Wszystkie inne emocje sa stanami pochodnymi, wystepuja jako
kombinacje, mieszaniny lub zwiazki stanów podstawowych. Swoje przemyslenia Plutchik
zobrazował przy pomocy koła emocji, przedstawionego na rysunku 1.
Diagram reprezentuje stopien podobienstwa pomiedzy poszczególnymi stanami. Emocje
podstawowe rozmieszczone sa na kole jako pary biegunów przeciwstawnych, których nie
mozna doswiadczyc w tym samym czasie, gdyz sie wzajemnie wykluczaja. Przykładowo
radosc stanowi przeciwienstwo smutku. Emocje sasiadujace na diagramie, gdy sa odczuwane
jednoczesnie, mieszajac sie tworza nowe stany. Mieszanina dwóch pierwotnych emocji jest
nazywana przez Plutchika diada. Na przykład, diada radosci i zaufania to miłosc. Diady z
2

Rysunek 1. Koło emocji Plutchika
przeciwstawnych emocji nie wystepuja, gdyz zachodzi miedzy nimi konflikt. Poparcie tego
strukturalnego modelu stanowia badania empiryczne [5].
3. Parajezyk
Juz Arystoteles twierdził, ze poszczególny stan emocjonalny wiaze sie z okreslonym
tonem głosu. Jednakze to dopiero Darwin dokonał pierwszego opisu dzwieków zwiazanych
z stanami emocjonalnymi mówcy. Na podstawie badan róznych gatunków zwierzat oraz
ludzi, doszedł do wniosku, ze istnieje bezposredni zwiazek miedzy sygnałem akustycznym,
a stanem wewnetrznym jednostki, natomiast zmiana tonu, głosnosci czy intonacji sygnalizuje
zmiane nastroju. Zaobserwował równiez, ze sygnały akustyczne moga wywoływac reakcje
emocjonalne u słuchacza.
Aby lepiej zobrazowac wpływ emocji na ludzka mowe, nalezy przyjrzec sie modelowi
narzadu głosu, na który składaja sie: przestrzenie rezonacyjne (nagłosnia, gardło, jama nosowa,
jama ustna), generator energii akustycznej (głosnia) oraz zbiornik powietrza (płuca i oskrzela).
Strumien powietrza, konieczny do fonacji, wytwarzany jest w płucach z drzewem
oskrzelowym. Głosnia jest generatorem tonu podstawowego (krtaniowego), zas
3

precyzyjne drgania fałdów głosowych przekształcaja energie wyrazona wektorem cisnienia
podgłosniowego w energie akustyczna [6]. Czestotliwosc tych drgan tzw. czestotliwosc
podstawowa (F0) jest cecha osobnicza, wynika z rozmiaru krtani oraz napiecia i rozmiaru
strun głosowych, jest zalezna od płci oraz wieku. Przykładowo dla mezczyzn zawiera sie w
przedziale od 80 do 480 Hz, natomiast dla kobiet w przedziale od 160 do 960 Hz. Jest zatem
odpowiedzialna za skale głosu. Podczas rozmowy, zakres jej zmian zwiazany jest głównie
z intonacja, która odgrywa ogromna role w ekspresji emocji, dlatego tez deskryptory zródła
dzwieku sa powszechnie stosowane w badaniach nad tym zagadnieniem.
Struktura harmoniczna dzwieku podstawowego zmienia kształt pod wpływem działania
rezonatorów (filtrów akustycznych) traktu głosowego. Okreslone składowe pierwotnego tonu
ulegaja wzmocnieniu, inne natomiast osłabieniu. Maksima wzmocnionych czestotliwosci
nazywane sa formantami. Ich wartosci zaleza od cech osobniczych (długosc przewodu
głosowego), ale równiez od sposobu artykulacji (ułozenie jezyka i ust, ruchomosc zuchwy)
[6]. Deskryptory traktu głosowego sa rzadziej stosowane w badaniach, aczkolwiek niosa ze
soba istotne informacje emocjonalne, majace swoje odzwierciedlenie w mimice np. ułozenie
ust. Jest bowiem oczywiste, ze zdanie wypowiadane z usmiechem brzmi inaczej, niz to samo
zdanie wypowiadane z odmiennym wyrazem twarzy.
Podejscie teoretyczne oraz praktyczne do rozpoznawania stanów emocjonalnych sugeruje,
ze okreslone wzorce wyrazen wokalnych sa specyficzne dla konkretnego stanu. Emocje moga
powodowac zmiany w sposobie oddychania, fonacji czy artykulacji, co z kolei ma swoje
odzwierciedlenie w sygnale mowy. Poza wyzej wymienionymi deskryptorami zródła oraz
traktu głosowego, inne cechy takie jak postrzegana głosnosc czy tempo wypowiedzi maja
wpływ na percepcje emocji. Przykładowo stany takie jak gniew i strach charakteryzuja
sie szybkim tempem mowy, wysokimi wartosciami F0, szerokim zakresem intonacji, co
spowodowane jest pobudzeniem układu współczulnego, nagłym przyspieszeniem akcji serca,
zwiekszeniem cisnienia krwi, czemu czasem moze towarzyszyc suchosc w ustach i drzenie
miesni. Zupełnie odwrotnie jest w przypadku smutku oraz znudzenia, kiedy to mowa jest wolna,
monotonna, F0 obnizone, bez wiekszych zmian intonacji. Spowodowane jest to miedzy innymi
pobudzeniem układu przywspółczulnego, zwolnieniem rytmu serca, spadkiem cisnienia krwi,
zwiekszeniem ilosci wydzielanej sliny.
4

Istnieja przesłanki wskazujace na niezaleznosc prozodiów od rasy, kultury, religii, a takze
od jezyka natywnego mówcy. Liczne badania wskazuja, ze korelaty emocji podstawowych
w róznych kulturach sa podobne ze wzgledu na uniwersalne zjawiska fizjologiczne [7].
Aczkolwiek wielu naukowców neguje teze uniwersalnosci mowy emocjonalnej. W badaniach
[8] przeprowadzonych na grupie wolontariuszy z Hiszpanii i Szwecji udowodniono, jak trudno
jest rozpoznac emocje w głosie mówcy innej narodowosci. Najlepsze wyniki osiagnieto dla
smutku i wyniosły one zaledwie 53%, inne emocje rozpoznawane były z dokładnoscia nizsza
niz 30%. Nalezy przy tym podkreslic, ze wyniki badan tego samego spektrum emocji u
osób tej samej narodowosci, srednio wahaja sie w granicach 55 - 60% [8]. Stosunkowo
niska rozpoznawalnosc wiaze sie z wystepowaniem podobnych zjawisk fizjologicznych dla
danych stanów, co prowadzi do podobienstw cech akustycznych. Nalezy dodatkowo wziac
pod uwage, ze na ludzka ocene wypływa równiez kontekst wypowiedzi. Dlatego, przy analizie
komputerowej dokonywanej wyłacznie na podstawie cech akustycznych, nie nalezy oczekiwac
lepszych rezultatów. Mimo to, w zwiazku z szeroka dostepnoscia sygnału mowy równiez przy
duzej odległosci oraz przy komunikacji za pomoca urzadzen teleinformatycznych, jest to wazny
element tego typu rozwazan.
4. Projekt systemu rozpoznawania stanów emocjonalnych
Automatyczne rozpoznawanie to proces klasyfikacji analizowanych danych (wzorców),
w oparciu o wiedze zgromadzona w systemie informatycznym, bazujac na narzuconych lub
odkrytych przez ten system regułach [9]. Wspólnym mianownikiem problemów tej dziedziny
jest algorytm obejmujacy pewne zasadnicze fazy (rys. 2). Poniewaz rozpoznawanie emocji
jest tematem wpisujacym sie w schemat ogólnej metodologii automatycznego rozpoznawania,
algorytm ten jest wykorzystywany w podjetych badaniach.
Rysunek 2. Algorytm rozpoznawania wzorców
Pierwszy krok algorytmu to akwizycja danych, która w przypadku niniejszej pracy stanowi
baza mowy emocjonalnej. Nastepny krok to przygotowanie danych do dalszej analizy, czyli tzw.
5

wstepna obróbka. Trzecia faze rozpoznawania stanowi ilosciowy opis przedmiotu. Obejmuje
on identyfikacje takich własciwosci obiektu, które niosa informacje wystarczajace do realizacji
zadania. Ostatni etap stanowi proces klasyfikacji, czyli kategoryzowanie przedmiotu badan,
na podstawie wczesniej utworzonego opisu ilosciowego. Ponizszy opisano kolejne kroki
algorytmu.
4.1. Korpus mowy emocjonalnej
Percepcja naturalnych emocji jest procesem złozonym, subiektywnym i bardzo czesto
zdarza sie, ze człowiek jedna sytuacje potrafi ocenic na kilka sposobów. Dlatego tez poszukuje
sie rozwiazan, w których mozna uniknac zdeterminowanego etykietowania, wskazujac jedynie
wystepowanie lub absencje konkretnych stanów podstawowych (np. tworzac tzw. profil
emocjonalny), a nastepnie pomiar stopnia nasilenia kazdego z nich [10]. Podejscie to moze
okazac sie pomocne w rozpoznawaniu niejednoznacznie okreslonych emocji, które pojawiaja
sie w spontanicznych dialogach.
Aby dokładniej zrozumiec problem niejednoznacznosci emocji, przytoczona zostanie
ponizsza definicja: emocje prototypowe (podstawowe) to stany majace znaczenie adaptacyjne
do walki o przetrwanie jednostki gatunku. Według Plutchika wyróznia sie osiem stanów
podstawowych: gniew, wyczekiwanie, radosc, ufnosc, strach, zaskoczenie, smutek oraz odraza.
Oprócz prototypowych mozna wyróznic szereg emocji wtórnych, bedacych kombinacjami
tych podstawowych. W 2009 roku na konferencji ACII (Affective Computing and Intelligent
Interaction) odbyła sie specjalna sesja poswiecona rozpoznawaniu emocji z niejednoznacznie
okreslonych wypowiedzi. Konferencja ta rozpoczeła lawine pytan dotyczacych badan
mowy spontanicznej, a naukowcy zaczeli porzucac analize nagran odgrywanych. Ponizej
przedstawiono główne zjawiska składajace sie na niejednoznacznosc stanu psychicznego
mówcy oraz percepcji słuchaczy:
• mieszanina emocji – dwa lub wiecej stanów emocjonalnych wystepuje w tym samym
momencie; według teorii Plutchika mozemy przezywac mieszanine pierwotnych emocji;
polega to na łaczeniu poszczególnych stanów pierwotnych w jeden stan wtórny (emocje
lezace obok siebie na kole Plutchika rys. 1);
6

• maskowanie emocji – ukrywanie przez mówce przezywanego stanu emocjonalnego innym
stanem (np. maskowanie smutku radoscia);
• przyczynowo-skutkowy konflikt ekspresji – konkretny stan emocjonalny okazywany jest w
ten sam sposób, jak stan całkowicie przeciwny (np. płacz ze szczescia);
• podobienstwo stanów emocjonalnych – granice pomiedzy poszczególnymi stanami sa
niejednoznacznie okreslone, nakładaja sie wzajemnie (emocje lezace obok siebie na kole
Plutchika rys. 1);
• sekwencja emocji – konsekutywnie okazywanie kolejnych stanów w trakcie wypowiedzi.
Zastosowanie techniki tworzenia profili jest pomocne w okresleniu najbardziej
prawdopodobnego stanu psychicznego mówcy, zbadaniu ewolucji tego stanu trakcie
wypowiedzi (wzrost lub spadek natezenia) oraz interpretacji wypowiedzi, na które nakłada sie
kilka emocji na raz.
Zadanie rozpoznawania wzorców wymaga zgromadzona odpowiednich danych
wejsciowych (zbiór treningowy i testowy). W przypadku niniejszych badan dane te stanowia
próbki mowy nacechowanej emocjonalnie. Biorac pod uwage teorie Roberta Plutchika,
stworzono korpus emocji podstawowych, lecz w szerszym zakresie niz przedstawiaja to
dotychczasowe badania. Pierwszym krokiem było zgromadzenie próbek mowy w siedmiu
podstawowych (według Plutchika) stanach emocjonalnych: gniew, wyczekiwanie, radosc,
strach, zaskoczenie, smutek oraz odraza. Z powodu niedostatecznej ilosci próbek ze zbioru
wykluczono ufnosc. Wszystkie próbki zostały ocenione przez grupe ekspertów oraz nadano
im etykiety odpowiadajace wyzej opisanym stanom emocjonalnym. Nastepnie najbardziej
charakterystyczne emocje (gniew, zadowolenie, starach i smutek) zostały poddane badaniu
intensywnosci. W ten sposób otrzymano pietnascie stanów emocjonalnych, których zestawienie
przedstawiono w tabeli 3.
Metodyka doboru zródeł nagran
Badania statystyczne, które stanowia integralna czesc tworzenia korpusu mowy
emocjonalnej, powinny spełniac okreslone kryteria. Jednym z nich jest zachowanie
prawidłowego rozkładu parametrów (cech) podmiotu badan, majacych znaczenie dla
wnioskowania, a wpływajacych na jego wiarygodnosc. Wykorzystywany w niniejszych
badaniach korpus stanowi zbiór wypowiedzi emocjonalnych w jezyku polskim, jedynym
7

Rysunek 3. Zestawienie materiału badawczego
ograniczeniem próby jest natywna znajomosc jezyka polskiego. Zakres przestrzenny, czas,
miejsce oraz cechy personalne próby nie stanowiły obostrzen.
Dobór próby reprezentatywnej w trakcie gromadzenia nagran jest jednym z kluczowych
elementów badan wpływajac na ich wiarygodnosc. Zakłada sie, ze próba jest reprezentatywna,
kiedy wystepuja w niej wszystkie wartosci zmiennej, mogace miec wpływ na wyniki badan.
Poniewaz proces ekspresji emocji jest subiektywny, zalezny przede wszystkim od płci, wieku
oraz pochodzenia osoby badanej, to własnie te zmienne społeczno-demograficzne zostały
wziete pod uwage w procesie tworzenia korpusu. Przy wyborze zródeł kierowano sie
zatem dostepem do wyzej wymienionych informacji, a przy tworzeniu korpusu zachowano
odpowiednie proporcje tych zmiennych. Załozenie to w znacznym stopniu ograniczyło
8

mozliwosci gromadzenia materiału (brak danych personalnych w nagraniach radiowych).
Najistotniejsza cecha próbek miała byc autentycznosc prezentowanych emocji, co równiez
zaweza obszar poszukiwan. Autorka głównie skupiła sie na materiałach prezentowanych
na zywo oraz programach typu reality show. Prezentowane tam uczucia wydaja sie byc
spontaniczne, prowokowane wydarzeniami oraz dyskusja. Przykładowo do prezentacji złosci
wybrano programy prezentujace problemy polityczne i społeczne (np. Panstwo w Panstwie
telewizji Polsat). Załozenie autentycznosci okazywanych uczuc moze byc błedne i jest
zwiazane z subiektywna ocena autorki oraz wolontariuszy bioracych udział w ocenie próbek.
Nalezy równiez wspomniec, ze zgromadzone nagrania czesto zawierały zakłócenia, co równiez
moze miec wpływ na ocene.
Stan emocjonalny mówcy moze zostac rozpoznany juz na podstawie krótkich wypowiedzi
typu Tak lub Nie. Dzieki temu krótkie zdania, a takze same słowa sa takze odpowiednie do
analizy. Czasem o stanie emocjonalnym mówcy informuja dodatkowe dzwieki takie, jak krzyk,
pisk, smiech czy płacz. Dlatego tez oprócz pełnych wypowiedzi, na baze emocji składaja sie
równiez pojedyncze słowa i dzwieki, takie, które pojawiaja sie w codziennej komunikacji.
Dodatkowo do celów badawczych stworzono model mowy neutralnej (bez zabarwienia
emocjonalnego). Został on złozony z wypowiedzi z bazy opisanej w podrozdziale ??
uzupełnionej wypowiedziami dziennikarzy zazwyczaj neutralnie komentujacych wydarzenia.
Model ten składa sie z 235 wypowiedzi i nie został poddany etykietowaniu przez wolontariuszy.
Etykietowanie mowy emocjonalnej
Proces etykietowania zgromadzonych nagran podzielono na dwie czesci. Pierwsza z nich
została przeprowadzona przez autorke oraz studentów psychologii Uniwersytetu Łódzkiego. Na
podstawie pełnych nagran wideo, a wiec majac do dyspozycji zarówno głos, semantyke, jak i
obraz, nagrania zostały podzielone na osiem grup (emocje podstawowe). Biorac pod uwage,
ze w pierwszym kroku eksperci mogli korzystac z dodatkowych bodzców (gesty, mimika),
etykietowanie nagran, pomijajac czasochłonnosc, nie stanowiło wiekszego wyzwania. Dopiero
krok drugi, w którym nagrania etykietowane były przez wolontariuszy wyłacznie na podstawie
głosu, pokazał jak subiektywnym procesem jest percepcja emocji.
Odsłuch wstepnie zakwalifikowanych próbek przeprowadzono w celu przetestowania, czy
słuchacz jest w stanie zidentyfikowac emocjonalna zawartosc nagrania. W badaniu tym
9

brało udział pietnascie prawidłowo słyszacych osób róznej płci, w wieku od 21 do 58 lat.
Zadaniem uczestników badania było dokonanie oceny nagrania i zakwalifikowanie do jednej
z wybranych grup (klas). Proces ten odbywał przy pomocy stworzonego do tego celu
oprogramowania. Osoba oceniajaca odsłuchiwała nagrania jedno po drugim i dokonywała
wyboru, który kolejno zapisywany był w bazie danych. Kazda z próbek mozna było odtworzyc
dowolna ilosc razy przed dokonaniem ostatecznej oceny, jednakze po dokonaniu wyboru,
nie było mozliwosci powrotu do danego nagrania. Na tej podstawie sporzadzono wyniki
rozpoznawania poszczególnych emocji przez kazda z osób. Srednie rozpoznawanie wyniosło
82,6% w zakresie od 63% do 93%. Nalezy jednak podkreslic, ze wzór stanowiły próby ocenione
przez autorke i studentów psychologii, a ocena ta równiez jest subiektywna. Dlatego tez próbki,
które wielokrotnie etykietowano niezgodnie z ocena ekspertów, zostały właczone do zbioru
stanowiacego niejednoznacznie okreslone stany. Emocje ocenione zgodnie przez co najmniej
dziesiec osób, zostały sklasyfikowane jako czyste stany prototypowe. Czesc z nich stanowi
zbiór treningowy, czesc zbiór testowy niniejszych badan. Podczas procesu etykietowania
wolontariusze zostali poproszeni dodatkowo o oznaczenie intensywnosci (natezenia) czterech
podstawowych stanów emocjonalnych (gniew, radosc, strach i smutek) w skali od jednego
(najnizsze natezenie) do 3 (najwyzsze natezenie). W ten sposób uzyskano etykiety diad
emocjonalnych.
4.2. Deskryptory sygnału mowy
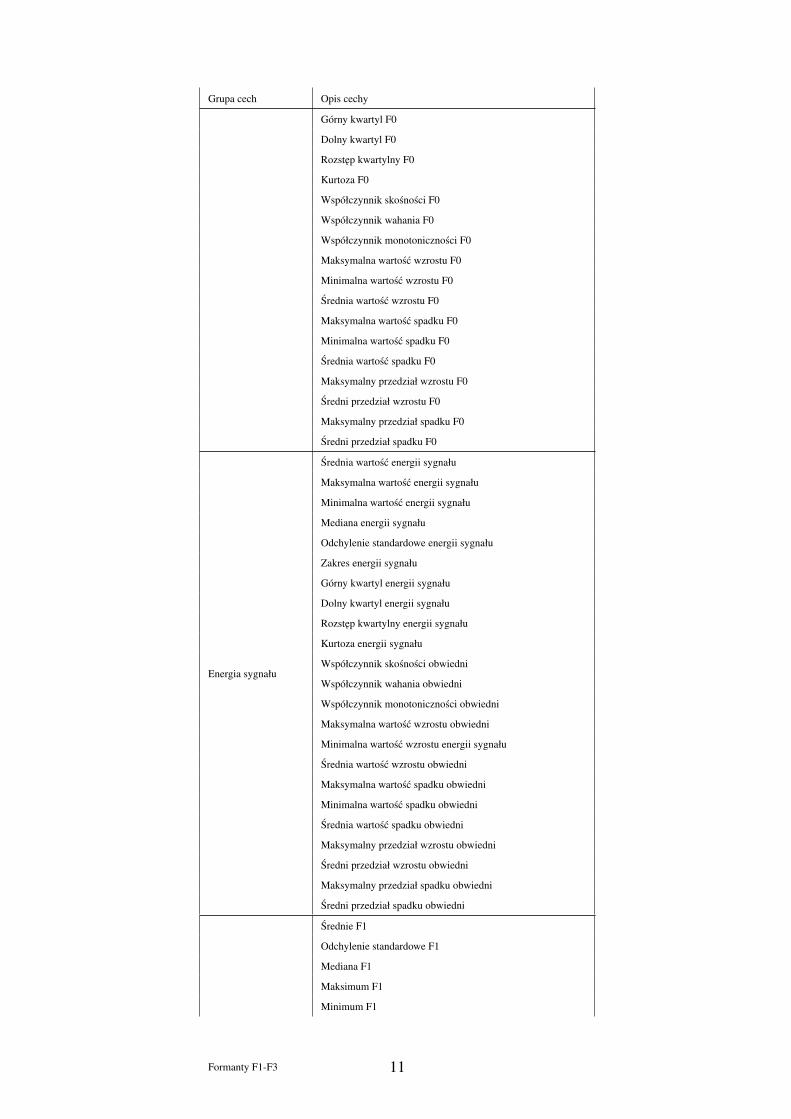
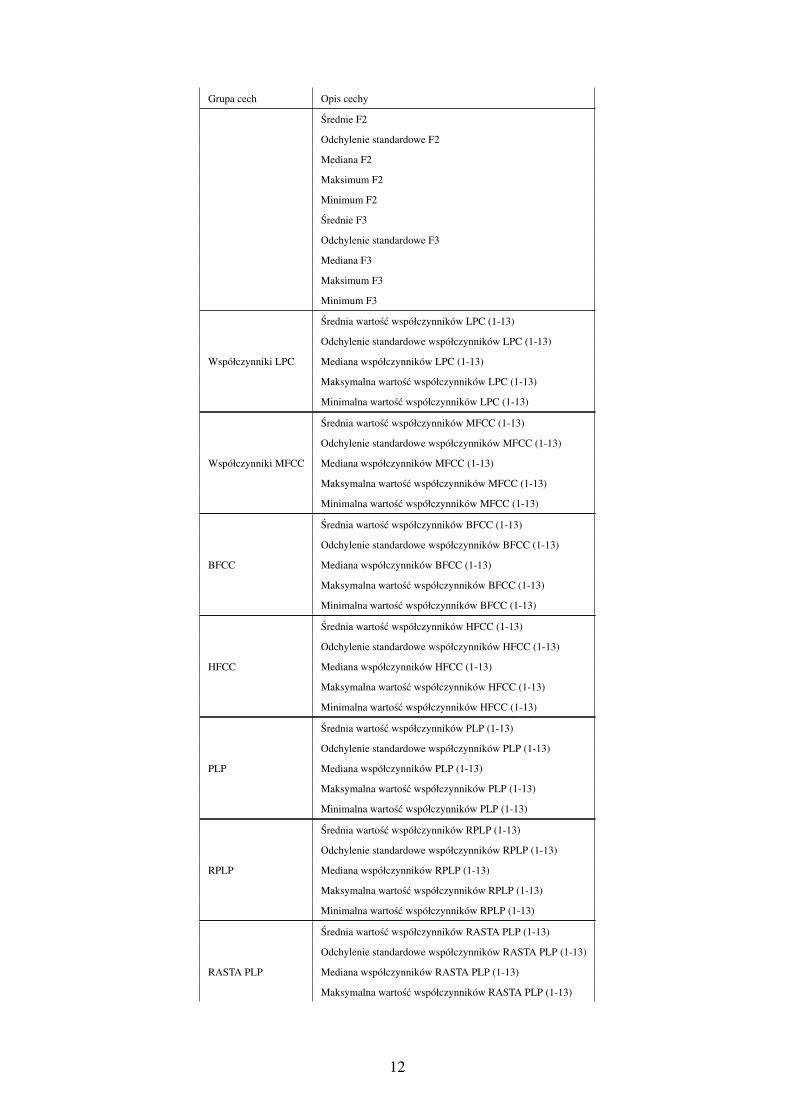
Jednym z najistotniejszych kroków jest ilosciowy opis przedmiotu badan, czyli identyfikacja
cech obiektu, które niosa informacje, wystarczajace do efektywnej klasyfikacji. W
ponizszej tabeli dokonano zestawienia deskryptorów sygnału mowy wykorzystanych podczas
prowadzonych badan.
Zestawienie deskryptorów mowy wykorzystanych w niniejszych badaniach
Grupa cech Opis cechy
Czestotliwosc F0
Srednia wartosc F0
Maksymalna wartosc F0
Minimalna wartosc F0
Mediana F0
Odchylenie standardowe F0
Zakres F0
10
Grupa cech Opis cechy
Górny kwartyl F0
Dolny kwartyl F0
Rozstep kwartylny F0
Kurtoza F0
Współczynnik skosnosci F0
Współczynnik wahania F0
Współczynnik monotonicznosci F0
Maksymalna wartosc wzrostu F0
Minimalna wartosc wzrostu F0
Srednia wartosc wzrostu F0
Maksymalna wartosc spadku F0
Minimalna wartosc spadku F0
Srednia wartosc spadku F0
Maksymalny przedział wzrostu F0
Sredni przedział wzrostu F0
Maksymalny przedział spadku F0
Sredni przedział spadku F0
Energia sygnału
Srednia wartosc energii sygnału
Maksymalna wartosc energii sygnału
Minimalna wartosc energii sygnału
Mediana energii sygnału
Odchylenie standardowe energii sygnału
Zakres energii sygnału
Górny kwartyl energii sygnału
Dolny kwartyl energii sygnału
Rozstep kwartylny energii sygnału
Kurtoza energii sygnału
Współczynnik skosnosci obwiedni
Współczynnik wahania obwiedni
Współczynnik monotonicznosci obwiedni
Maksymalna wartosc wzrostu obwiedni
Minimalna wartosc wzrostu energii sygnału
Srednia wartosc wzrostu obwiedni
Maksymalna wartosc spadku obwiedni
Minimalna wartosc spadku obwiedni
Srednia wartosc spadku obwiedni
Maksymalny przedział wzrostu obwiedni
Sredni przedział wzrostu obwiedni
Maksymalny przedział spadku obwiedni
Sredni przedział spadku obwiedni
Formanty F1-F3
Srednie F1
Odchylenie standardowe F1
Mediana F1
Maksimum F1
Minimum F1
11
Grupa cech Opis cechy
Srednie F2
Odchylenie standardowe F2
Mediana F2
Maksimum F2
Minimum F2
Srednie F3
Odchylenie standardowe F3
Mediana F3
Maksimum F3
Minimum F3
Współczynniki LPC
Srednia wartosc współczynników LPC (1-13)
Odchylenie standardowe współczynników LPC (1-13)
Mediana współczynników LPC (1-13)
Maksymalna wartosc współczynników LPC (1-13)
Minimalna wartosc współczynników LPC (1-13)
Współczynniki MFCC
Srednia wartosc współczynników MFCC (1-13)
Odchylenie standardowe współczynników MFCC (1-13)
Mediana współczynników MFCC (1-13)
Maksymalna wartosc współczynników MFCC (1-13)
Minimalna wartosc współczynników MFCC (1-13)
BFCC
Srednia wartosc współczynników BFCC (1-13)
Odchylenie standardowe współczynników BFCC (1-13)
Mediana współczynników BFCC (1-13)
Maksymalna wartosc współczynników BFCC (1-13)
Minimalna wartosc współczynników BFCC (1-13)
HFCC
Srednia wartosc współczynników HFCC (1-13)
Odchylenie standardowe współczynników HFCC (1-13)
Mediana współczynników HFCC (1-13)
Maksymalna wartosc współczynników HFCC (1-13)
Minimalna wartosc współczynników HFCC (1-13)
PLP
Srednia wartosc współczynników PLP (1-13)
Odchylenie standardowe współczynników PLP (1-13)
Mediana współczynników PLP (1-13)
Maksymalna wartosc współczynników PLP (1-13)
Minimalna wartosc współczynników PLP (1-13)
RPLP
Srednia wartosc współczynników RPLP (1-13)
Odchylenie standardowe współczynników RPLP (1-13)
Mediana współczynników RPLP (1-13)
Maksymalna wartosc współczynników RPLP (1-13)
Minimalna wartosc współczynników RPLP (1-13)
RASTA PLP
Srednia wartosc współczynników RASTA PLP (1-13)
Odchylenie standardowe współczynników RASTA PLP (1-13)
Mediana współczynników RASTA PLP (1-13)
Maksymalna wartosc współczynników RASTA PLP (1-13)
12

Grupa cech Opis cechy
Minimalna wartosc współczynników RASTA PLP (1-13)
4.3. Klasyfikacja hierarchiczna
Ostatni krok zadania rozpoznawania wzorców stanowi proces klasyfikacji. W procesie tym
okresla sie przynaleznosc nieznanego obiektu, opisanego za pomoca wektora atrybutów, do
jednej ze zdefiniowanych wczesniej klas. Mimo, iz metody klasyfikacji to raczej standardowe
narzedzia automatycznego rozpoznawania, obejmujace szereg podejsc (systemy ekspertowe,
drzewa decyzyjne, logika rozmyta, sieci neuronowe i inne) [11], to niejednokrotnie zdarza
sie, ze narzedzia te nie daja oczekiwanych rezultatów. Klasyfikacja emocji na podstawie
mowy, a w szczególnosci mowy spontanicznej, jest zadaniem trudnym, zaleznym od wielu
czynników, i mimo szeroko eksploatowanych badan, wciaz natrafia na powazne przeszkody.
Dlatego tez poszukuje sie nowych rozwiazan, poprzez tworzenie innowacyjnych algorytmów
badz klasyfikatorów hybrydowych, bazujacych na współdziałaniu istniejacych rozwiazan.
Jednym z obiecujacych podejsc w uczeniu maszynowym wydaje sie byc stosowanie
komitetów klasyfikujacych (ang. Ensemble, Committee, Multiple Classifier Systems - MCS),
bazujacych na zasadzie dziel i zwyciezaj. W tym celu dokonuje sie dekompozycji złozonego
problemu na kilka mniej złozonych [12]. Tworzone w ten sposób rozwiazanie składa sie z
wielu prostych (łatwych do zbudowania) modeli (wezłów) o relatywnie niskiej skutecznosci, a
ich koncowe wyniki sa łaczone (np. metoda głosowania, przypisujac obiekt do klasy, na która
głosuje najwiecej sposród klasyfikatorów bazowych).
Biorac pod uwage wysokie rezultaty rozpoznawania emocji na podstawie mowy w
powyzszych pracach oraz niejednoznacznosc stanów oraz rozmycie granic miedzy nimi w
mowie spontanicznej, niniejsze badania stanowia próbe opracowania skutecznego klasyfikatora
hierarchicznego. Proces jego tworzenia rozpoczyna sie od Podstawowego Algorytmu
Rozpoznawania Emocji PAKEmo, opartego na horyzontalnym podziale problemu na
podproblemy wzgledem wektora cech. Nastepnie algorytm rozbudowywany był poprzez
dodawanie kolejnych wezłów, majacych za zadanie zwiekszyc wydajnosc systemu. Ostateczny
algorytm stanowi wielopoziomowy, hierarchiczny klasyfikator, który na kolejnych poziomach
zawiera takie elementy jak: rozpoznawanie płci, budowa profili emocjonalnych, zaleznosc
emocji od długosci wypowiedzi oraz badanie natezenia emocji. Wszystkie wyzej wymienione
podproblemy zostały kolejno przedstawione w ponizszych podrozdziałach.
13

Algorytm bazowy
Wektory cech opisujacych obiekty ze zbioru uczacego oraz wektor opisujacy nieznany
obiekt zostały podzielone na podwektory konkretnych grup cech (przedstawione w załaczniku
A niniejszej pracy). W ten sposób otrzymano m oddzielnych podwektorów, przykładowo
wektor deskryptorów czestotliwosci podstawowej czy współczynników MFCC. Na poziomie
zerowym algorytmu PAKEmo (rys. 4) znajduje sie zespół m klasyfikatorów. W kazdym z
nich podejmowana jest decyzja dm przy uzyciu algorytmu k-NN. Kazdy z m klasyfikatorów
dokonuje oddzielnej klasyfikacji na podstawie okreslonej grupy cech, a zatem wykonywanych
jest m testów. Na poziomie pierwszym otrzymujemy m decyzji, gdzie liczby k, l..., s
reprezentuja ilosc głosów oddanych na konkretna klase. Na tej podstawie, wykorzystujac
głosowanie równoprawne, wybierana jest ostateczna klasa nieznanego obiektu.
Rysunek 4. Schemat podstawowego algorytmu klasyfikacji emocji
Problemy pojawiaja sie w przypadku, gdy na podstawie głosowania równoprawnego nie
da sie wyłonic jednego zwyciezcy (jednej klasy). W takim przypadku sprawdzane zostaje
połozenie obu klas na kole emocji Plutchika. Jesli obie zwycieskie klasy leza na kole
obok siebie, zachodzi podejrzenie, ze granice miedzy nimi sa na tyle niejednoznaczne, ze
nie jest mozliwe podjecie jednej, konkretnej decyzji. Wypowiedz klasyfikowana jest jako
niejednoznaczna i opatrzona dwoma etykietami. Jesli jednak połozenie zwycieskich klas
na kole jest przeciwstawne, co dyskwalifikuje (wg Plutchika) mozliwosc wystepowania obu
14

emocji jednoczesnie, za zwycieska uznaje sie te klase, która wskazywały grupy cech uznane za
najefektywniejsze według selekcji grupowej (tabela ??).
Minimalizacja cech osobniczych mówcy
Oczywistym jest fakt, ze rozpoznawanie emocji uzaleznione od mówcy daje duzo
lepsze rezultaty niz rozpoznawanie niezalezne. Aczkolwiek system, który miałby działac
w naturalnych warunkach, powinien byc uniwersalny, omijajac cechy osobnicze głosu w
klasyfikacji emocji. Dlatego tez budujac tego typu systemy dazy sie do ich minimalizacji.
Powszechnie uwaza sie, ze kobiety lepiej niz mezczyzni rozpoznaja emocje w tonie głosu,
a przekonanie to potwierdzono badaniami. Samo okazywanie emocji równiez jest odmienne
dla obu płci. Ponadto czestotliwosc drgan fałdów głosowych, a zatem czestotliwosc krtaniowa
(podstawowa), zalezy od masy, długosci i napiecia tych fałdów. Poniewaz u mezczyzn długosc
fałdów wynosi około 15-20 mm, zas u kobiet 8-12 mm, głos kobiecy jest około oktawe wyzszy
od meskiego [6]. Widoczny jest zatem wpływ płci na mowe, co moze przekładac sie równiez
na proces rozpoznawania.
Widoczny jest równiez wpływ wieku na głos mówcy. Mowa młodych chłopców
charakteryzuje sie znacznie wyzsza czestotliwoscia podstawowa, niz dorosłych mezczyzn. Tej
róznicy nie widac w sposób tak istotny jak w przypadku kobiet. Mozna takze zauwazyc, ze z
wiekiem głos staje sie coraz bardziej zachrypniety, a mowa spowolniona.
Poniewaz elementy społeczno-demograficzne ciezko okreslic na podstawie klasyfikacji
opartej o mowe, totez sama konstrukcja korpusu powinna zakładac prawidłowy rozkład tych
parametrów. Przykładowo, w zbiorze treningowym powinny znajdowac sie próbki mowy
osób wywodzacych sie z róznych czesci Polski, a ich rozkład powinien byc proporcjonalny.
W ten sposób, bazujac na odpowiednich przykładach, klasyfikator jest w stanie rozpoznac
odpowiednia próbke.
Pomimo, iz w korpusie zapewniono prawidłowy rozkład płci i wieku mówców,
zdecydowano sie na wprowadzenie dodatkowego elementu. Zbiór treningowy podzielono na
dwie grupy: meska i zenska, a do klasyfikatora dodano moduł rozpoznawania płci. Wezeł
odpowiedzialny za rozpoznawanie płci umieszczono tuz nad algorytmem PAKEmo. W
zaleznosci od płci badanego mówcy, zbiór treningowy PAKEmo stanowi teraz odpowiednio
zbiór wypowiedzi kobiet badz mezczyzn. Rozpoznawanie płci dokonano na podstawie wartosci
sredniej czestotliwosci podstawowej F0.
Klasyfikacja w wykorzystaniem wag
Majac na uwadze nierównomierny wpływ deskryptorów mowy na rozpoznawanie
stanów emocjonalnych, zdecydowano sie na zastapienie metody głosowania równoprawnego
głosowaniem wazonym. W takim przypadku decyzja podejmowana jest równiez na zasadzie
15

głosowania, ale nie kazdy głos jest liczony jednakowo. Dla kazdego ucznia (klasyfikator
konkretnej grupy cech) okresla sie wagi w1, w2, ..., wm, co pozwala nadac priorytet lepszym
uczniom. Decyzja podejmowana jest wtedy na podstawie równania ??.
ri =m∑j=1
wjdji (1)
Z = argl
maxi=1
[ri] (2)
Problem stanowi sposób dobierania własciwych wag, podejscie to wymaga umiejetnosci
ocenienia (albo przynajmniej porównania) klasyfikatorów bazowych. W niniejszej pracy wagi
zostały dobrane doswiadczalnie, na podstawie błedu poszczególnych klasyfikatorów.
Segmentacja mowy
Biorac pod uwage załozenie zmiennosci stanów emocjonalnych w trakcie wypowiedzi
zastosowano segmentacje mowy. Załozono bazowa długosc fragmentu 3 s - w tym czasie
stan nie powinien ulec zmianie. Podobne podejscie autorka zastosowała w [13], gdzie
wypowiedz dzielona była na trzy fragmenty o równej długosci: poczatek, srodek i koniec
wypowiedzi. Nastepnie dokonywana była oddzielna klasyfikacja kazdego z fragmentów,
a wynik rozpoznawania uzyskiwano za pomoca głosowania równoprawnego. Poniewaz w
wykorzystywanym w niniejszej pracy korpusie mowy zdarzaja sie równiez krótsze fragmenty
mowy (krótkie wypowiedzi, pojedyncze słowa), a niekiedy tylko dzwieki (smiech, krzyk, pisk),
tego typu segmentacja nie moze zostac wykorzystana. Dlatego tez zastosowano podział na
3-sekundowe fragmenty. W przypadku, gdy wypowiedz jest krótsza niz 3 s, pozostaje ona
niepodzielona. Jesli jednak wypowiedz jest dłuzsza, całosc zostaje podzielona na fragmenty
3-sekundowe oraz fragment dopełniajacy (majacy co najmniej 500 ms). Jesli fragment koncowy
jest krótszy niz 500 ms, zostaje on dodany do ostatniego fragmentu 3-sekundowego. Nastepnie
kazdy z nich zostaje poddany indywidualnej klasyfikacji przy uzyciu algorytmu k-NN.
Rozpoznawanie intensywnosci emocji podstawowych
Ostatni poziom klasyfikatora stanowi algorytm rozpoznawania intensywnosci emocji
podstawowych. Jak juz wczesniej wspominano, według Plutchika kazda z pierwotnych emocji
moze byc odczuwana w trzech stopniach natezenia (np. gniew: irytacja, gniew, furia).
Intuicyjna zaleznosc podobienstwa mowy neutralnej i emocjonalnej stanowi hipoteze, na
podstawie której opracowano algorytm rozpoznawania natezenia emocji. Mozna zauwazyc, ze
wraz ze wzrostem natezenia konkretnej emocji, podobienstwo głosu do mowy neutralnej spada.
Zaleznosc te autorka prezentowała miedzy innymi w [1]. Zauwazona została proporcjonalna
zmiana konturu czestotliwosci podstawowej wzgledem mowy neutralnej.
16

Bazujac na tych obserwacjach stworzono algorytm rozpoznawania natezenia emocji
podstawowej. Wejscie algorytmu stanowia: obiekty zbioru treningowego danej klasy CUk,
model mowy neutralnej (centroid) Xn oraz nieznany obiekt z okreslona klasa podstawowa
xn. Nastepnie obliczane sa odległosci d pomiedzy centroidem mowy neutralnej, a kazdym
obiektem ze zbioru treningowego CUk. Odległosci te sa sortowane malejaco. Bazujac na nich,
zbiór dzielony jest na trzy podzbiory intensywnosci. Podzbiór, którego odległosc centroidu od
centroidu mowy neutralnej jest najwieksza, uznawany jest za zbiór najwyzszych intensywnosci,
podzbiór z najmniejsza odległoscia, jako intensywnosc najnizsza, zas podzbiór przejsciowy,
jako emocja podstawowa. Dla kazdego podzbioru wyznaczany jest centroid według wzoru 3:
µk =1
Nk
k3Nk∑
k−13
Nk+1
xi dla k = {1, 2, 3} (3)
gdzie: µk - centroid podzbioru k, Nk - licznosc podzbioru k.
Zastosowanie metody najblizszej sredniej (ang. nearest mean), której istota jest zastapienie
wszystkich próbek konkretnej klasy ich wartoscia srednia (centroidem), ogranicza przede
wszystkim czasochłonnosc obliczen. Teraz nieznany obiekt xn porównywany jest tylko z
centroidami konkretnych podzbiorów, a zatem wykonywane sa tylko trzy operacje obliczania
odległosci. Nieznany obiekt przypisywany jest do klasy intensywnosci na podstawie
najmniejszej odległosci od centroidu.
Algorytm wyjsciowy
W poprzednich podrozdziałach szczegółowo opisane zostały kolejne elementy finalnego
algorytmu rozpoznawania mowy emocjonalnej. Składa sie on z pieciu modułów, tworzacych
kolejne poziomy struktury hierarchicznej:
1. Poziom zerowy – wejscie modułu stanowi wypowiedz emocjonalna (wektor cech), która
nastepnie podlega procesowi klasyfikacji okreslajacej płec mówcy. Wyjscie modułu stanowi
wypowiedz z okreslona płcia (meska, zenska).
2. Poziom pierwszy – wejscie modułu stanowi wypowiedz okreslonej płci, która nastepnie
poddawana jest segmentacji. Kazda wypowiedz trwajaca dłuzej niz 3s dzielona jest na
3-sekundowe segmenty.
3. Poziom drugi – wejscie modułu stanowia fragmenty wypowiedzi, które nastepnie
poddawane sa osobnej klasyfikacji z wykorzystaniem klasyfikatora k-NN, a dodatkowo
liczba klasyfikatorów, przypadajaca na jeden fragment uzalezniona jest od liczby grup cech
wykorzystywanych w badaniach.
17

4. Poziom trzeci – stanowi głosowanie wazone na poziomie konkretnych grup cech (np. F0,
LPC, PLP). Wyjsciem modułu sa klasy, których licznosc jest równa liczbie grup cech
wykorzystanych w badaniach.
5. Poziom czwarty – stanowi go głosowanie równoprawne na poziomie konkretnych
fragmentów. Wyjsciem modułu sa klasy, których licznosc jest równa liczbie fragmentów,
na jakie została podzielona wypowiedz.
6. Poziom piaty – konkretna emocja jest badana pod katem jej natezenia. Na podstawie
autorskiego algorytmu porównujacego badana wypowiedz z modelem mowy neutralnej,
okreslana jest jako emocja podstawowa, badz dwie jej diady (najwyzsza intensywnosc,
najnizsza intensywnosc). Krok ten konczy działanie algorytmu.
Profile emocjonalne
Aby lepiej zobrazowac zagadnienie niejednoznacznosci emocji autorka postanowiła
skorzystac z definicji profili emocjonalnych w celu przedstawienia zawartosci danych stanów
w wypowiedzi. Według [10] profil emocjonalny jest to sa wektor wyrazajacy stopien
obecnosci lub nieobecnosci emocji podstawowych w danej wypowiedzi. Mozna w ten sposób
uniknac sztywnej klasyfikacji (ang. hard labeling), zastepujac ja etykietowaniem wielokrotnym
(ang. multiple labeling). Tego typu klasyfikacja moze wskazywac na zawartosc kilku
stanów emocjonalnych w danej wypowiedzi, ich mieszanine czy tez ewolucje emocjonalna
wypowiedzi. Mozliwe jest równiez zastosowanie etykietowania rozmytego, w którym
dodatkowo okresla sie funkcje przynaleznosci do kazdego ze stanów.
Algorytm podstawowy PAKEmo stanowi szereg klasyfikatorów tego samego poziomu,
uwzgledniajacych rozkład grup deskryptorów mowy. Poszerzenie tego modułu o kolejny,
dokonujacy segmentacji mowy, tworzy hierarchiczna strukture klasyfikatorów k-NN, a na
podstawie ich odpowiedzi dokonuje sie głosowania. Zastapienie głosowania analiza odpowiedzi
pozawala na stworzenie profilu emocjonalnego poszczególnych próbek mowy. Poprzez zliczane
kolejnych wyników dla danej emocji budowany jest histogram, przedstawiajacy zawartosc
danych stanów w konkretnej wypowiedzi. Podejscie to nie zastepuje klasyfikacji, a jest jedynie
jej rozszerzeniem, i w szczególnosci ma zadanie zobrazowanie wypowiedzi niejednoznacznie
okreslonych.
5. Podsumowanie
Głównym załozeniem prezentowanych badan było stworzenie systemu pozwalajacego na
automatyczne rozpoznawanie stanów emocjonalnych na podstawie mowy naturalnej. W tym
celu stworzono polska baze emocji spontanicznych, na która składa sie ponad siedemset próbek,
podzielonych na siedem podzbiorów reprezentujacych stany podstawowe. Ponadto w celach
18

porównawczych dokonano równiez analizy emocji odegranych przez profesjonalnych aktorów.
Ilosciowy opis problemu stanowia powszechnie uzywane w tego typu badaniach deskryptory
mowy, które zestawiono z hybrydowymi współczynnikami percepcyjnymi (uzywanymi w
rozpoznawaniu mowy, aczkolwiek pomijanymi w rozpoznawaniu emocji). Jak wykazały
badania, atrybuty te okazały sie silnie dyskryminatywne, co uzasadnia ich uzycie. W
trakcie klasyfikacji porównano algorytm k-NN z autorskim podejsciem opartym na zbiorze
klasyfikatorów (komitecie), majacym zapewnic lepsze wyniki rozpoznawania. Analiza
wyników potwierdziła poczatkowe załozenia autorki.
5.1. Korpus mowy spontanicznej i jego wpływ na rozpoznawanie emocji
Badania nad rozpoznawaniem emocji prowadzone sa na całym swiecie w wielu osrodkach
badawczych. Niestety wiekszosc analiz prowadzona jest na prywatnych korpusach, których
z przyczyn prawnych autorzy zazwyczaj nie moga udostepniac. W niniejszej pracy analize
przeprowadzono na dwóch bazach, porównujac emocje odegrane z naturalnymi. Badania
wykazały jak duzy wpływ na wyniki klasyfikacji maja korpusy tworzace wzorce, co istotnie
utrudnia porównywanie skutecznosci róznych, zaproponowanych dotychczas podejsc. Duze
znaczenie ma przede wszystkim licznosc wzorców. Odpowiednia liczba i róznorodnosc
przykładów moze w znacznym stopniu zwiekszyc jakosc rozpoznawania. Liczba próbek obu
wykorzystanych korpusów rózni sie zasadniczo, co odbija sie równiez na jakosci klasyfikacji.
W przypadku bazy mowy odegranej dysponujemy 40 próbkami danej emocji, zas w przypadku
mowy spontanicznej liczba ich jest co najmniej dwukrotnie wieksza. Dodatkowo, w drugim
przypadku róznorodnosc próbek (płec oraz wiek mówcy) moze miec wpływ na lepsze
wyniki klasyfikacji. Poprzez wykorzystanie wypowiedzi róznego typu, ograniczany jest
wpływ cech osobniczych na rozpoznawanie. Dodatkowo, uwzgledniajac róznice w sposobie
ekspresji emocji przez kobiety i mezczyzn, wprowadzono moduł rozpoznawania płci. W
przypadku mowy spontanicznej spowodowało to poprawe wyników rozpoznawania. Obnizenie
wydajnosci klasyfikatora w przypadku mowy odegranej moze wiazac sie z ograniczeniem
licznosci wzorców po podziale na płec.
W badaniach dokonano równiez klasyfikacji natezen mowy emocjonalnej. Zaprezentowano
autorski algorytm okreslenia intensywnosci danej emocji na podstawie stopnia jej podobienstwa
do mowy neutralnej. Zadanie to równiez wydaje sie byc istotnym: rozróznienie, czy mówca jest
lekko podirytowany, czy tez rozwscieczony, ma znaczenie, w szczególnosci w zastosowaniach
aplikacyjnych. Biorac pod uwage rozmyte granice miedzy konkretnymi natezeniami danej
emocji, w przyszłych badaniach nalezałoby przetestowac róznego typu funkcje przynaleznosci
do rozpoznania konkretnego natezenia.
19

Niewatpliwym atutem bazy mowy spontanicznej sa próbki, których stan emocjonalny
jest niejednoznacznie okreslony. Przeprowadzona analiza pokazuje złozonosc mechanizmów
powstawania emocji, ich percepcji i ekspresji. W naturalnym srodowisku mówca moze
byc targany róznymi emocjami w tym samym momencie, a słuchacz moze róznie odbierac
wysyłane przez niego sygnały. Dlatego tez wzorce mowy odegranej moga nie sprawdzic sie
przy klasyfikacji emocji w warunkach naturalnych. Przeprowadzone badania wskazuja, ze
zaproponowany algorytm radzi sobie równiez z próbkami niejednoznacznie okreslonymi, co
moze wskazywac na to, ze niektórych parametrów głosu człowiek nie jest w stanie zmienic
nawet celowo.
5.2. Deskryptory mowy emocjonalnej
Proces wyznaczania odpowiednich atrybutów, które trafnie opisuja przedmiot analizy, ma
ogromne znaczenie w zadaniach rozpoznawania wzorców. A zatem algorytm klasyfikacji musi
byc poprzedzony procesem doboru wydajnych zestawów cech oraz procesem ich ewentualnej
selekcji. Do ilosciowego opisu problemu autorka posłuzyła sie grupami deskryptorów
mowy powszechnie stosowanymi w badaniach nad rozpoznawaniem emocji: czestotliwosc
podstawowa, formanty, cechy energetyczne, współczynniki LPC, MFCC oraz PLP. Dodatkowo
zaproponowano uzycie deskryptorów, które mimo istotnego wkładu w rozpoznawanie mowy,
pomijane sa w zadaniach rozpoznawania emocji: współczynniki BFCC, HFCC, RPLP oraz
RASTA PLP. Wstepne badania przeprowadzone na konkretnych podzbiorach cech wskazuja,
ze w przypadku obu korpusów najwyzsze wyniki rozpoznawania osiagana sa własnie przy
uzyciu zaproponowanych atrybutów. I tak dla bazy mowy odegranej najlepsze rozpoznawanie
uzyskano na zbiorze współczynników BFCC (64,4%), nieco nizej, aczkolwiek takze wysoko
plasuja sie współczynniki RPLP (58,6%). Dla bazy mowy naturalnej najwyzsze wyniki
otrzymano równiez przy uzyciu współczynników BFCC (77,7%), tuz za nimi plasuja sie
współczynniki MFCC (74%) i HFCC (72,9%). Liczna reprezentacja tych atrybutów po
wykonaniu selekcji metoda SFS na całym zbiorze cech dodatkowo potwierdza siłe owych
deskryptorów. W trakcie badan dokonano równiez redukcji wymiarowosci konkretnych
podzbiorów cech, dzieki czemu udało sie zwiekszyc wyniki rozpoznawania: przykładowo w
przypadku mowy odegranej dla całej puli współczynników BFCC osiagnieto 55,7%, tak po
selekcji 64,4%. W przypadku mowy naturalnej dokładnosc rozpoznawania po zastosowaniu
selekcji równiez uległa zwiekszeniu na kazdym podzbiorze cech.
5.3. Klasyfikacja
Mimo, iz proces klasyfikacji opiera sie na standardowych narzedziach rozpoznawania,
wraz z rosnaca złozonoscia zadan pojawia sie potrzeba nowych rozwiazan, majacych na celu
20

zapewnienie lepszej skutecznosci. W tym celu tworzone sa całkowicie nowe klasyfikatory,
metody hybrydowe, łaczace poszczególne algorytmy, a takze metody usprawniajace istniejace
rozwiazania. Zaproponowany w niniejszej pracy algorytm oparto o teorie tzw. komitetów,
które pracujac wspólnie, osiagaja wyniki lepsze niz pojedyncze modele. Podejscie oparte
na komitetach było wczesniej zastosowane w kilku pracach poswieconych rozpoznawaniu
emocji na podstawie mowy. Jednakze zaleta tego typu klasyfikacji jest mozliwosc
stworzenia róznego rodzaju struktur dostosowanych do konkretnego problemu. Dlatego
tez przedstawione rozwiazanie jest całkowicie innowacyjnym podejsciem w omawianym
zagadnieniu. Zastosowanie komitetu do niniejszych rozwazan wydawało sie byc słuszne
z dwóch powodów. Modele oparte na atrybutach wybranych do reprezentacji emocji
popełniaja rózne błedy dla nowych danych, a zatem mozemy mówic o róznorodnosci
komitetu. Dodatkowo w trakcie badan zauwazono, ze dla okreslonych podzbiorów najlepsze
wyniki osiagane sa przy uzyciu roznych wartosci liczby k algorytmu k-NN. A zatem
zastosowanie rozbicia pojedynczego modelu na zbiór klasyfikatorów, z którego kazdy dokonuje
rozpoznawania na podstawie innego podzbioru atrybutów, a ostateczna decyzja podejmowana
jest na podstawie głosowania, powinno prowadzic do zwiekszenia jakosci rozpoznawania.
Badania udowodniły teze postawiana przez autorke. I tak w przypadku bazy mowy odegranej
wyniki wzrosły ponad 5%. W przypadku bazy mowy naturalnej wyniki równiez wzrosły,
aczkolwiek wzrost ten wynosi jedynie 2,7%. W zwiazku z tym, ze kazdy z podzbiorów
atrybutów ma inny wkład w rozpoznawanie, nastepnym krokiem było zastapienie głosowania
równowaznego wazonym. Wagi dobrano na podstawie błedu konkretnego modelu, a ich
wprowadzenie do algorytmu głosowania ostatecznie uzasadnia uzycie zaproponowanego
rozwiazania.
6. Dalsze prace rozwojowe, potencjał zaprezentowanego rozwiazania
Naturalnym kierunkiem kontynuacji przedstawionych w niniejszej rozprawie badan wydaje
sie byc przede wszystkim sprawdzenie mozliwosci innych algorytmów klasyfikacji jako
modeli bazowych komitetu. Nalezy tutaj podkreslic, ze mozliwe jest zastosowanie komitetów
heterogenicznych, dopasowujac odpowiedni algorytm rozpoznawania do konkretnego
podzbioru cech. Dodatkowo nalezy przetestowac inne kombinacje komitetu stosujac inne
warunki podziału modelu bazowego. Kolejnym kierunkiem rozwoju algorytmu jest okreslenie
dodatkowych cech opisujacych przedmiot analizy. Algorytm mozna poszerzyc o dodatkowe
modele, przykładowo bazujace na prozodiach sygnału (tempo, pauzy) czy tez atrybutach
wyznaczanych na podstawie opisu sygnału metodami zaczerpnietymi z analizy układów
21

nieliniowych. A zatem zastosowane podejscie daje szeroka game mozliwosci dalszego rozwoju
i optymalizacji.
Potrzeba rozszerzenia korpusu mowy o dodatkowe próbki tworzace wzorce oraz
kolejne stany emocjonalne wydaje sie byc oczywista. Jest to niezbedne w szczególnosci
do zastosowania algorytmu rozpoznawania natezenia równiez na pozostałych stanach
podstawowych, nie uwzglednionych w niniejszej analizie. Mozna takze pokusic sie
o poszerzenie korpusu o próbki wypowiedzi dzieci, których ekspresja emocji moze
zaburzyc jakosc rozpoznawania. Waznym kierunkiem rozwoju jest rozpoznawanie stanów
niejednoznacznie okreslonych, a zaproponowana w niniejszej rozprawie metoda etykietowania
poprzez tworzenie profili moze w znacznym stopniu to ułatwic.
Podsumowujac, powyzej zaprezentowane potencjalne mozliwosci rozwoju pozwalaja na
dalsza prace nad rozpoznawaniem stanów emocjonalnych na podstawie sygnału mowy.
Obiecujacym zdaje sie takze byc tworzenie dodatkowych modeli bazujacych na innych
sygnałach: obraz (mimika oraz gesty), sygnały EEG czy analiza obrazu w podczerwieni.
Komitet stworzony na podstawie dodatkowych przesłanek moze w znacznym stopniu poprawic
klasyfikacje.
Analiza emocji znajduje zastosowanie w syntezatorach głosu oraz jako system
wspomagajacy rozpoznawanie mowy. Dodatkowo istotna dziedzina zastosowan jest medycyna,
a w szczególnosci diagnoza zaburzen psychologicznych i neurologicznych, objawiajacych
sie nieprawidłowa percepcja i ekspresja emocji (autyzm, schizofrenia, depresja, stres) oraz
wspomaganie terapii behawioralnej.

Bibliografia
[1] Kaminska D. , Pelikant A. Recognition of Human Emotion from a Speech Signal Based on
Plutchik’s Model. International Journal of Electronics and Telecommunications, 58(2):165–171,
2012.
[2] Kaliouby R., Robinson P. Mind Reading Machines Automated Inference of Cognitive Mental
States from Video. IEEE International Conference on Systems, Man and Cybernetics, pages
682–688, The Hague, Netherlands, 2004.
[3] Silva P.R., Madurapperuma A.P., Marasinghe A., Osano M. A multi-agent based interactive system
towards childs emotion performances quantified through affective body gestures. International
Conference on Pattern Recognition, pages 1236–1239, 2006.
[4] Garay N., Cearreta I., López J.M., Fajardo I. Assistive Technology and Affective Mediation. An
Interdisciplinary Journal on Humans in ICT Environments, 2(1):55–83, 2006.
[5] Plutchik R. Emotion A Psychoevolutionary Synthesis. New York Harper and Row, 1980.
[6] Obrebowski A. Narzad głosu i jego znaczenie w komunikacji społecznej. Uniwersytet Medyczny
im. Karola Marcinkowskiego w Poznaniu, 2008.
[7] Abelin A. Anger or Fear? Cross-Cultural Multimodal Interpretations of Emotional Expressions.
Plural Publishing, 2007.
[8] Izdebski K. Emotions in the Human Voice Volume I Foundations. Plural Publishing, 2007.
[9] Slot K. Wybrane zagadnienia biometrii. Wydawnictwa Komunikacji i Łacznosci WKŁ, 2008.
[10] Mower E., Mataric M.J., Narayanan S.S. A Framework for Automatic Human Emotion
Classification Using Emotional Profiles. IEEE Transactions on Audio, Speech and Language
Processing, 19(5):1057 – 1070, 2011.
[11] Slot K. Rozpoznawanie biometryczne Nowe metody ilosciowej reprezentacji obiektów.
Wydawnictwa Komunikacji i Łacznosci WKŁ, 2010.
[12] Cichosz P. Systemy uczace sie. Wydawnictwa Naukowo-Techniczne, 2007.
[13] Kaminska D., Pelikant A. Rozpoznawanie Stanów Emocjonalnych na Podstawie Analizy Mowy
Spontanicznej. Informatyka, Automatyka Pomiary w Gospodarce i Ochronie Srodowiska, 3, 2012.
23