s5230 - websphere extreme scale - ibm www page · pdf file · 2016-01-13websphere...
TRANSCRIPT

© 2009 IBM Corporation
Session 5230
WebSphereeXtreme Scale
SHARE Summer 2009Denver, COAugust 23 - 28, 2009
IBM Washington Systems Center

© 2009 IBM Corporation2 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Objective and Agenda
• Background on why the topic of “data grids” are being discussed in the first place
• A review of “eXtreme Scale” -- what it is, and how it works, and how it positions with WAS and WAS z/OS
• Some broad examples of usage
• Quick review of WebSphere Extended Deployment, of which eXtreme Scale one part
Objective: to speak in clear language what “eXtreme Scale” is and in so doing demystify the product and the
function of it. You should leave with a better understand what it is and how it’s used.

© 2009 IBM Corporation3 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Personal Disclaimer
I’m a pinch-hitter for this presentation … I do not claim deep expertise. But I believe I have the essential concepts well understood and delivering those is my objective
My presentation style involves intentionally omitting details that are distracting. There may well be subtle variations and exceptions, but
I’m choosing not to dwell on those so the key concepts come through

© 2009 IBM Corporation4 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
BackgroundAnswers the “Why are we talking about this?” question.

© 2009 IBM Corporation5 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Standard Online Transaction Processing Model
Here’s a model that’s commonly used for many applications
Presentation
Static(HTML, JPG, GIF)
Dynamic(Servlets, JSPs)
Logic
Java(Servlets, EJBs)
Traditional(COBOL, C/C++)
Data
Relational(DB2, etc.)
Non-Relational(CICS, IMS, etc)
Other(VSAM, etc)
Users
This is the “three tier” model you may have heard about
It may be physically three tier or physically one tier (on System z)
Logically it’s three tier … that’s the key
Works and works well as long as the demands placed on it don’t outstrip some element of this … which often happens when scaled up

© 2009 IBM Corporation6 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Internet Has Opened Up a World of Users
In “the old days” when the user base was limited to internal, the issue of scale was somewhat predictable and manageable. But the Internet changed that:
Users Compute Resources
Think about some of the very large models in today’s world:
• Online banking
• Online retailing
• Auction sites
• Social networking sites
Potentially multi-millions of simultaneous users
These numbers put enormous strain on the resources … need to scale
We’re using “very large” here to set the stage to explain why data grids came about. However, eXtreme Scale can provide cost saving value in any sized environment.

© 2009 IBM Corporation7 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Scaling the Presentation and Logic Layer
Here’s what we often see in response to work demands overwhelming some element of the design:
Data
Relational(DB2, etc.)
Non-Relational(CICS, IMS, etc)
Other(VSAM, etc)
Users
Presentation and Logic “Scaled Out”
Scaling out the presentation and logic layers spreads the work
The data layer is a another matter … more difficult to “spread out”
Logical three tier … physical one or many

© 2009 IBM Corporation8 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Scaling the Data Layer
Three general approaches to this
Users
Logical three tier … physical one or many
1. Share the data -- this is what Parallel Sysplex doesWorks well … proven technology. One physical copy shared between data resource engines with Sysplex management of the data locks
2. Mirror the data -- various data mirroring technologies do thisMultiple copies of the data … updates to one reflect over to the other
3. Partition the data -- split it across databasesSplit the data in some fashion and have application go to appropriate data partition
See
legend
below

© 2009 IBM Corporation9 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Caching Less-Volatile Data
When scaling limitations are felt one of the first things pursued is the caching of data that doesn’t change much. General principle: avoid data call if possible.
Users
Cached Data
Cached Data
Less I/O activity against the data subsystems
Example: basic user profile data for online banking customers. Or profile information for social networking site.
Doesn’t change much … but it does change sometimesSo the invalidation/update model has to be taken into account

© 2009 IBM Corporation10 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Issues with “Traditional” Caching
Caching in the application JVM tends to result in two issues:
Account:
11111111
Account:
22222222
Account:
33333333
Account:
99999999
Java Virtual
Machine
Application
Use of Heap
Account:
11111111
Account:
33333333
Account:
99999999
Java Virtual
Machine
Application
Use of Heap
Account:
11111111
Account:
22222222
Account:
33333333
Java Virtual
Machine
Application
Use of Heap
Over time cached data tends to be duplicated in each caching store
• Some duplication is desired for
availability; excessive duplication
is a bad thing.
• Uses heap inefficiently
• With millions of potential users the
scalability of this is limited
Coordination of invalidated or updated cache instances gets burdensome as number increases
• Some inter-cache communication
mechanism is required
• Coordination chatter can quickly
overwhelm the system
• Very much a function of the rate of
change of the cached data
Caching is an important part of high scaling, but the mechanism has to be different from a “everything cached everywhere” model

© 2009 IBM Corporation11 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Caching “Grids”
The idea here is to designate some number of JVMs as members of a logical “grid” and spread the cached data across the grid:
DB
Accounts:00000000
11111111
22222222
33333333
44444444
55555555
66666666
77777777
88888888
99999999
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Account:
44444444
Account:
99999999
Java Virtual
Machine
Account:
33333333
Account:
88888888
Account:
22222222
Account:
77777777
Account:
11111111
Account:
66666666
Account:
00000000
Account:
55555555
Get
11111111Get
77777777• How does the data get into the grid?
• How does an application get data from
the grid?
• Does it always imply “remote” access?
• How do the applications know where
cached data resides?
• What happens if a JVM is lost?
• How is availability maintained?
• What happens if a JVM joins the grid?
• What software allows a JVM to
participate in the grid?
• What happens if data changes?
• Is there a notion of “transactionality?”
“Grid”
Many questions
tumble out of this …
© 2009 IBM Corporation12 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
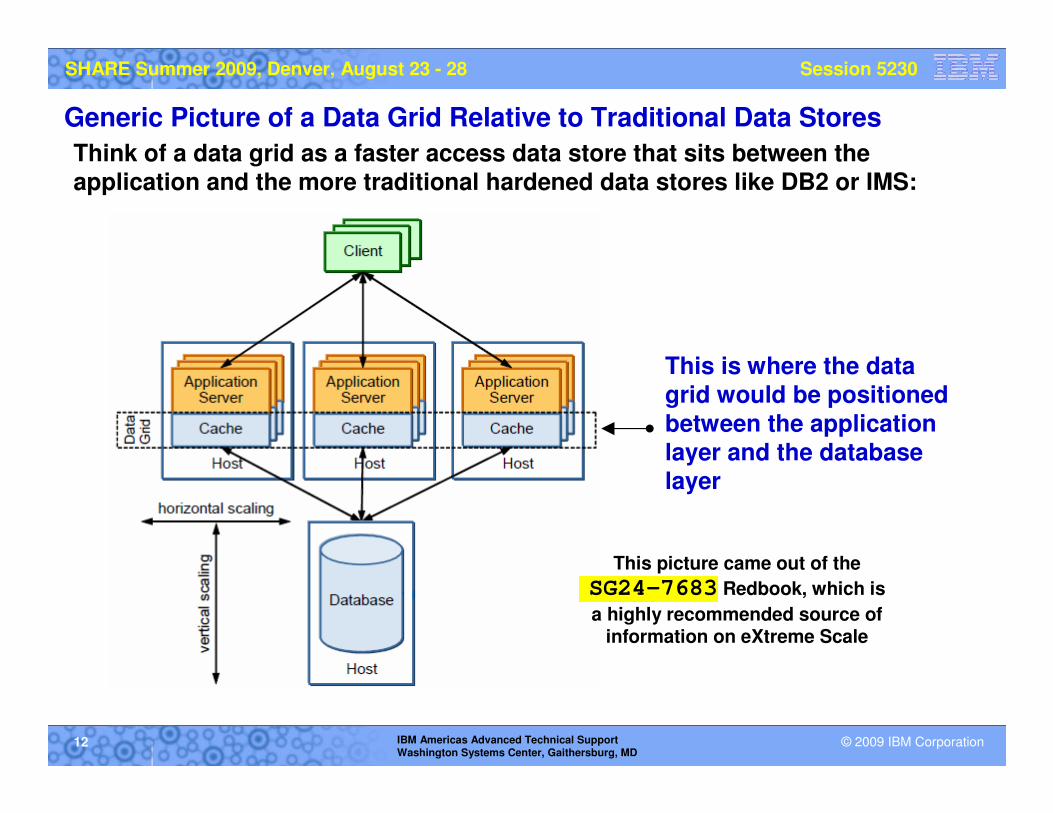
Generic Picture of a Data Grid Relative to Traditional Data Stores
Think of a data grid as a faster access data store that sits between the application and the more traditional hardened data stores like DB2 or IMS:
This is where the data grid would be positioned
between the application layer and the database layer
This picture came out of the
SG24-7683 Redbook, which is
a highly recommended source of information on eXtreme Scale

© 2009 IBM Corporation13 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Stage is Set: eXtreme Scale at a High Level
eXtreme Scale is a software solution that provides the functions to implement, use and maintain a highly scalable caching and data grid:
WebSphere eXtreme Scale
WebSphere Virtual Enterprise
WebSphere Compute Grid
WebSphere Extended
Deployment
Software Delivery Media
eXtreme Scale Grid Container(Any JSE environment)
JAR
• Grid Container framework
• Cached object facilities
• Grid Application APIs that
implement Java Persistence
Architecture (JPA)
eXtreme Scale Catalog Server(s)(Any JSE environment)
• Maintains awareness of grid
clients
• Generates and distributes
placement object map
• Rebalances data objects as
neededWith that we now dig deeper into what eXtreme Scale provides, a general sense for
how it works, and some discussion on
common usage patterns

© 2009 IBM Corporation14 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
eXtreme Scale BasicsProvides an understanding of the functionality

© 2009 IBM Corporation15 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
A Simple Starting Example
Imagine a hypothetical 1M account database. Imagine your topology has five grid containers. Imagine how the data records could be split across the grid:
Account Last First State Accounts
0000001 Aardvark Alan Wyoming 5
0000002 Abraham John Arkansas 1
0000003 Adamson Frank Montana 1
0000004 Atchinson Mary Alaska 3
:
:
0999997 Williamson Jill Michigan 12
0999998 Xavier George Virginia 4
0999999 Yelovick Cynthia Missouri 1
1000000 Zanzibar Dennis Arizona 8
1,000,000 records1,000 bytes per record===================1GB of data5 grid containers===================200MB per grid container JVM
x
÷
=
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Accounts:
0000001
to
0200000
Accounts:
0200001
to
0400000
Accounts:
04000001
to
0600000
Accounts:
0600001
to
0800000
Accounts:
0800001
to
1000000
This illustrates how a grid can spread the data out, requiring less of a footprint in any one instance
What happens if a grid container goes down … do we simply lose the data?
Container 001 Container 002 Container 003 Container 004 Container 005

© 2009 IBM Corporation16 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
“Shards” -- Primary and Replicas
A shard is chunk of data. Accounts 0000001 - 0200000 for example. We now introduce “primary” shards and “replica” shards:
We’ve doubled the JVM heap usage … per container and overall
We’ve also provided a duplicate copy of the “shard” within the grid for availability
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Java Virtual
Machine
Accounts:
0000001
to
0200000
Accounts:
0200001
to
0400000
Accounts:
04000001
to
0600000
Accounts:
0600001
to
0800000
Accounts:
0800001
to
1000000
Container 001 Container 002 Container 003 Container 004 Container 005
Accounts:
0400001
to
0600000
Accounts:
0800001
to
1000000
Accounts:
0200001
to
0400000
Accounts:
0000001
to
0200000
Accounts:
0600001
to
0800000
Primary
Replica
Replicated, but
not in the same
grid container

© 2009 IBM Corporation17 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Grid Clients, Grid Applications, Near Cache and the Grid
Applications can reside in the grid container JVM and take advantage of the possibility of cache hits locally; then grid; then actual data system:
Java Virtual
Machine
Accounts:
0000001
to
0200000
Container 001
Accounts:
0400001
to
0600000
JP
A F
ram
ew
ork
JAR
Application
grid.get(0200201)
Java Virtual
Machine
Java Virtual
Machine
Accounts:
0600001
to
0800000
Accounts:
0800001
to
1000000
Container 004 Container 005
Accounts:
0000001
to
0200000
Accounts:
0600001
to
0800000
Real Data Subsystem
Anything
accessible via
JDBC, JCA or
JMS
Grid Object Map
Access
Grid
Consult
Object Map
In Near
Cache?In Grid?
Access real data subsystem
and load into grid
Fetch Fetch across network
N N
YY
dd
© 2009 IBM Corporation18 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
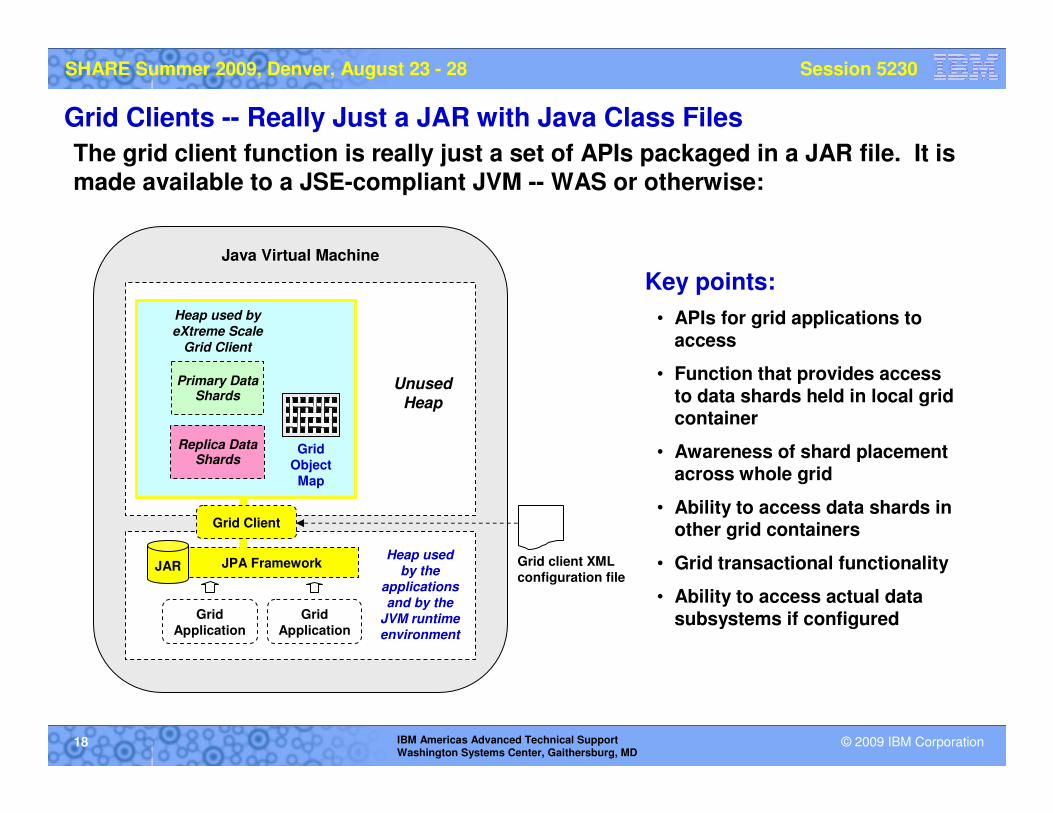
Grid Clients -- Really Just a JAR with Java Class Files
The grid client function is really just a set of APIs packaged in a JAR file. It is made available to a JSE-compliant JVM -- WAS or otherwise:
Key points:
• APIs for grid applications to access
• Function that provides access to data shards held in local grid container
• Awareness of shard placement across whole grid
• Ability to access data shards in other grid containers
• Grid transactional functionality
• Ability to access actual data subsystems if configured
Java Virtual Machine
Heap used
by the
applications
and by the
JVM runtime
environment
JPA FrameworkJAR
Grid
Application
Grid
Application
Primary Data Shards
Replica Data Shards
Heap used by
eXtreme Scale
Grid Client
Unused Heap
Grid Client
Grid client XML
configuration file
Grid
Object
Map

© 2009 IBM Corporation19 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
The Catalog Server Function
Something has to watch over all the “shards” in the grid. The Catalog Server function does that:
eXtreme Scale Catalog Server(s)(Any JSE environment)
• Maintains awareness of grid
clients
• Generates and distributes
placement object map
• Rebalances data objects as
needed Grid
Client
Grid
Client
Grid
Client
Grid
Client
Grid
Client
Grid Object Map
Catalog Server function updates and distributes Grid Object Map when …
• Grid container instances join or leave the grid
• Data is introduced to the grid
• Data is removed from the grid
• Data needs to be re-balanced in the grid
This is a hash table … not huge, but greater than 0
No, not a single point of failure
This brings up some interesting questions about the amount of re-shuffling that may take place
© 2009 IBM Corporation20 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
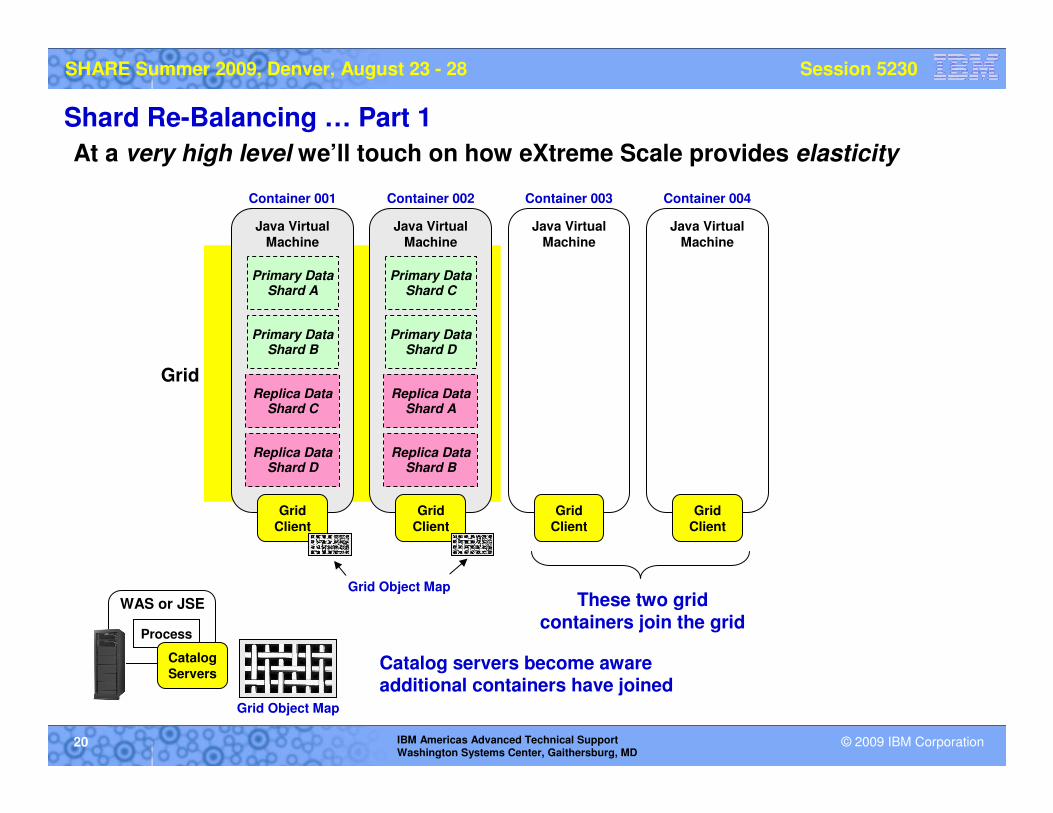
Shard Re-Balancing … Part 1
At a very high level we’ll touch on how eXtreme Scale provides elasticity
Java Virtual
Machine
Container 001
Primary Data Shard A
Replica Data Shard C
Primary Data Shard B
Replica Data Shard D
Java Virtual
Machine
Container 002
Primary Data Shard C
Replica Data Shard A
Primary Data Shard D
Replica Data Shard B
Java Virtual
Machine
Container 003
Java Virtual
Machine
Container 004
Process
WAS or JSE
Catalog
Servers
Grid Object Map
Grid
Client
Grid
Client
Grid
Client
Grid
Client
Grid
These two grid containers join the grid
Catalog servers become aware additional containers have joined
Grid Object Map

© 2009 IBM Corporation21 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Shard Re-Balancing … Part 2
More of the picture … again, at a high level:
Java Virtual
Machine
Container 001
Primary Data Shard A
Replica Data Shard C
Java Virtual
Machine
Container 002
Primary Data Shard B
Replica Data Shard D
Java Virtual
Machine
Container 003
Java Virtual
Machine
Container 004
Process
WAS or JSE
Catalog
Servers
Grid
Client
Grid
Client
Grid
Client
Grid
Client
Grid
Primary Data Shard C
Primary Data Shard D
Replica Data Shard A
Replica Data Shard B
Grid Object Map
Catalog servers recalculates shard placement and initiates the movement to the new containers. The object map is recalculated and redistributed to all the grid clients.

© 2009 IBM Corporation22 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Synchronous and Asynchronous Replications
It supports both … and manages that within “zones”
Java Virtual
Machine
Container 001
Primary Data Shard A
Replica Data Shard C
Java Virtual
Machine
Container 002
Primary Data Shard B
Replica Data Shard D
Java Virtual
Machine
Container 003
Java Virtual
Machine
Container 004
Process
WAS or JSE
Catalog
Servers
Grid
Client
Grid
Client
Grid
Client
Grid
Client
Grid
Primary Data Shard C
Primary Data Shard D
Replica Data Shard A
Replica Data Shard B
Grid Object Map
Assume data in one of the shards is updated. Means replica copies also need to be updated within the gridAnd to persisted storage, which the grid also handles
The two data centers are viewed as different zones … high-speed synchronous backplane replication within a data center,
asynchronous replication across data centers
Data Center B
Data Center A
Synchronous
Asynchronous
zone boundary

© 2009 IBM Corporation23 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Relationship of WAS to eXtreme Scale
WebSphere Application Server is not a requirement for eXtreme Scale, but it can be use as the JVM provider, or in association with a non-WAS grid:
CR SR
AppServer
CR
Node Agent
CR
Daemon
CR SR
DMGR
LPAR A
Node
Cell
Process
AppServer
Grid
Client
Grid
Client
Other non-WAS
JSE environment
Grid
Client
Grid
Client
Other non-WAS
JSE environment
Process
WAS or JSE
Catalog
Servers
Primary Data Shards
Replica Data Shards
eXtreme Scale Grid
Key points:
• WebSphere Application Server is not a pre-req for the use of eXtreme Scale
• However, WAS provides a rich deployment and management framework for Java applications
• So eXtreme Scale can be a mix of WAS and non-WAS JVMs; WAS providing key points of richer functionality
z/OS
Distributed and
Linux for System z

© 2009 IBM Corporation24 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
The Role of System z -- z/OS and Linux for System z
Here’s a picture that summarizes a lot of different things regarding eXtreme Scale and System z:
1. Hardware VirtualizationThe System z platform has outstanding
hardware virtualization capabilities (CPU,
memory, I/O, network)
2. Grid client in Linux for System zGrid clients may be placed on Linux for z
3. Use of HiperSockets across LPARsHiperSockets is a cross-memory networking
solution between LPARs on a System z frame.
4. Catalog server in Linux for System zThe catalog server is supported on Linux for
System z.
5. Grid client on z/OSGrid clients may be placed on z/OS. The catalog
server is not supported on z/OS.
6. Data systems in highly available data sharing configuration on Parallel Sysplex
Highly available data subsystems can be
configured using data sharing in a Parallel
Sysplex environment.
7. Use of local connectorsAccess to data subsystems can be
accomplished using efficient cross-memory
local connectors on z/OS.
Virtualized Hardware Resources
zLinux LPAR z/OS LPAR z/OS LPAR
Grid
Client
Grid
Client
Grid
Client
Grid
Client
zLinux LPAR
Catalog
Server
Catalog
Server
eXtreme Scale Grid
HiperSockets
DB2
IMS
CICS
MQ
DB2
IMS
CICS
MQ
CFData Sharing
2
3
4
5
6
7
1
The picture painted is one of efficient use of physical resources -- machine, space, cooling -- as well as
efficient cross-memory communications

© 2009 IBM Corporation25 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
eXtreme Scale Usage ConceptsGeneric representations … to give a sense for how it can be used

© 2009 IBM Corporation26 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Online Banking -- User Profiles in the Grid
Imagine a heavily used online banking system with some portion of user data being seen as fairly static. To reduce backend load, you cache those profiles.
CICS, IMS, DB2 and MQ
Data
Sysplex-Enabled
Traffic
Spraying
Appliances
Web
Server
Static
Cache
Web
Server
Static
Cache
App
Server
App
Server
Grid
Client
Grid
Client
3
4
2
1
Grid
Client
Presentation Logic Data
1. Web servers out front serve cached static objects such
as JPG and GIF files and some static HTML.
2. User profiles -- all, or some known subset of frequent
users -- are loaded into the grid. Additional profiles can
be added to the grid at any time.
3. When request hits logic layer and application needs to
access the user profile, it checks the grid. If there, it
pulls the data from the grid.
4. Application uses standard data query to get more volatile
information, such as account balances
Queries for stable data is kept off the backend systems, allowing them to dedicate energy to
processing more data-intensive requests

© 2009 IBM Corporation27 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
User State Data
Sometimes it’s necessary to maintain the current state of users -- some information they’ve entered. Caching in the grid is a good way to scale:
CICS, IMS, DB2 and MQ
Data
Sysplex-Enabled
Traffic
Spraying
Appliances
Web
Server
Static
Cache
Web
Server
Static
Cache
App
Server
App
Server
Grid
Client 2
6
1
Presentation Logic Data
User User
User 123
User User
User UserGrid
Client
5
1. User comes in and hits the top appserver first.
2. User logs in and the application creates session state
information for that logged-in user
3. The next request by the user gets sprayed to a different
front-end web server…
4. … which forwards it to a different application server
3
4
5. Application goes to grid to get state data
6. Other more data-intensive requests flow to backend data
subsystems
No affinity routing required. No cycles burned storing and retrieving state data.

© 2009 IBM Corporation28 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Bulk Data Analysis
Imagine doing low-intensity* analysis of historic user data. Bulk load the data into the grid during low CPU times and query against the grid:
* As compared to intense data mining, which has other techniques and products
CICS, IMS, DB2 and MQ
Data
Sysplex-Enabled
Grid
Client
Grid
Client
Grid
Client
Grid
Client
Grid
Client
Grid
Client
App Server
App Server
App Server
App Server
App Server
Large set of
queries and
analysis
If the nature of the analysis lends itself to breaking up and running in parallel, this provides an excellent way to do this without impact
production work

© 2009 IBM Corporation29 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
WebSphere Extended DeploymentExploring the product family and the other two products - Virtual Enterprise and Compute Grid

© 2009 IBM Corporation30 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
WebSphere Extended Deployment
What used to be one product is now offered as three separate functions:
WebSphere eXtreme Scale
WebSphere Virtual Enterprise
WebSphere Compute Grid
WebSphere Extended Deployment
Large scale caching gridWhat we just explored in some detail
Dynamic operations and health monitoringWe’ll cover: the On Demand Router and dynamic clusters
Batch processing frameworkA rich-function Java EE batch framework
Our objective here is to simply position and make aware … not enough time to go into full detail

© 2009 IBM Corporation31 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Virtual Enterprise
Is an extension to a WebSphere Application Server ND environment which provides:
• A greater awareness of the WAS cell environment with dynamic operations such as starting and stopping server clusters to expand capacity
It is true that WAS z/OS working in conjunction with zWLM does some of these features.
• The “On Demand Router” which is like the Proxy Server with additional capabilities to classify work, prioritize distribution and control dynamic operations within the cell
WAS z/OS with zWLM can control the classification and placement of work within a server on an LPAR. The ODR extends that and allows for work placement across LPARs with dynamic horizontal capacity expansion.
• Application “editions” which is a way to roll in new updates to applications in a more controlled and granular fashion
Unique to Virtual Enterprise … WAS z/OS ND does not have the features this provides
• Configuration checkpoints and fallback … the ability to maintain
checkpoints of configuration updates made to your cell environment, with the ability to have WAS rollback changes to a prior known state
Unique to Virtual Enterprise … WAS z/OS ND does not have the features this provides

© 2009 IBM Corporation32 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Compute Grid
Is an extension to a WebSphere Application Server ND environment which provides:
• A batch container framework that operates within the Java EE environment provided by WAS z/OS
• The batch container framework provides essential batch processing functions such as:
• Job submission capabilities integrated with commonly used platform scheduling tools such as Tivoli Scheduling Manager (TSM)
• Job checkpointing
• Multi-step job control XML with condition code processing
• Job pause and resume
• Integration with the clustering capabilities of WAS z/OS ND
• Integration with the zWLM exploitation that takes place with WAS z/OS ND
• Batch Data Streams (BSD), which provides a way to abstract large record input sources
• An Eclipse-based tooling environment
Provides a way to take Java batch processing to the a level pastJVM launching tools such as BPXBATCH or JZOS
Going from JZOS to Compute Grid is a natural growth path

© 2009 IBM Corporation33 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
WAS z/OS and the Three Components of Extended Deployment
Though they may be deployed separately, they can work in cooperation with one another:
CR SR
DMGR
LPAR A
AppServer
Compute
Grid
Virtual
Enterprise
CR SR
LPAR B
AppServer
Compute
Grid
Virtual
Enterprise
CR SR
Grid
Client
Grid
Client
CF
Parallel Sysplex
DB2,CICS,IMS,MQ
JES,RRS,WLM,SAF
DB2,CICS,IMS,MQ
JES,RRS,WLM,SAF
Grid
Client
Grid
Client
Other JVMs
Compute Grid• Providing Java batch framework within a managed Java EE
environment
• Taking advantage of WAS z/OS clustering across LPARs
• Taking advantage of proximity to data and Sysplex I/O capabilities
• Taking advantage of WAS z/OS WLM integration for intelligent
resource allocation and work placement
• Taking advantage of eXtreme Scale as highly available and fast access
data grid
• Taking advantage of Virtual Enterprise for application editions,
configuration checkpoints, dynamic horizontal operations and the
ODR for intelligent placement of incoming work
Virtual Enterprise• Providing dynamic operations and
autonomic functions
• Taking advantage z/OS qualities of service
• Providing a dynamic expansion of data grid
clients and batch containers in a Sysplex-
enabled runtime
eXtreme Scale• Providing a highly scalable data and object grid
• Taking advantage z/OS qualities of service
• Providing data services to Compute Grid and VE-enabled WAS
applications as noted above

© 2009 IBM Corporation34 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
Reference Information
http://www.ibm.com/software/webservers/appserv/extremescale/
Main product page, including a link to “Library”which has downloadable PDFs
http://www.redbooks.ibm.com/abstracts/sg247683.html?Open
http://en.wikipedia.org/wiki/IBM_WebSphere_eXtreme_Scale
Very good Redbook
WikiPedia article ☺☺☺☺
http://www.ibm.com/developerworks/
Considerable resources available through search on IBM developerWorks
© 2009 IBM Corporation35 IBM Americas Advanced Technical SupportWashington Systems Center, Gaithersburg, MD
SHARE Summer 2009, Denver, August 23 - 28 Session 5230
More on DeveloperWorks
PROVIDES DEVELOPERS WITH
Prescriptive guidance for top
scenarios.
Find latest news and collateral
such as articles, sample code,
tutorials and demos.
Direct access to our technical
evangelists and SMEs with
channels such as:
• Blogs
• Forum
• YouTube Channel
http://www.ibm.com/developerworks/spaces/xtp