screaming frog tricks | seokomm 2015
TRANSCRIPT

ScreamingFrogTricks,diedunochnichtkennst
DownloadVersion

WEBWORKS–IHREONLINEMARKETINGAGENTURFÜR
ONLINESHOPS

Vorstellung
MarioTrägeristPartnerderAgenturWebworks.WebworksunterstütztgroßeundmiIelständischeOnlineShopsbeimStart,AusbauundderOpPmierungdesOnlineMarkePngs.MarioTrägeristspezialisiertaufSEO-SuchmaschinenopPmierungundGooglePageSpeedOpPmierung.ErstudierteMedieninformaPkundInternetWeb-ScienceundbeschäSigtsichseit2007mitallenBereichenderSuchmaschinenopPmierung.Bis2014warerHeadofSEOundSocialMediaderWiIGruppe(memberoftheoIogroup).
www.webworks-agentur.de

MitHilfevonvierSEOAnwendungsfällenmöchteichdieMöglichkeitenmitScreamingFrogaufzeigenundeuch
neueDenkanstößefürdieVerwendunggeben

Themen
Indexierungskontrolle DuplicateContentfinden
Relaunchmeistern Backlinksbewerten

#1IndexierungskontrollemitScreamingFrog

WiekannichmehrKontrolleüberdieIndexierungmeinerWebseitebeiGooglebekommenundwieerhalteicheineÜbersichtnichtindexierterSeiten???

Indexierung mit Hilfe der Search Console
?

Überprüfung der Sitemap
§ Download der XML Sitemap
§ XML Sitemap in Screaming Frog importieren:
§ Crawling starten >

Überprüfung der Sitemap #Statuscodes
§ Status Code 5xx, 4xx, 3xx & blockierte Seiten ermitteln:
- 7.267 - 404 Fehlerseiten - 3.226 - 301 Weiterleitungen - 423 - 501 Fehlerseiten - 165 - blockierte Seiten
11.121 Seiten die in der XML Sitemap nichts zu suchen haben >

Überprüfung der Sitemap #Meta Robots
§ Seiten mit Noindex ermitteln:
- 3.399 Seiten sind auf Noindex
3.399 Seiten die in der XML Sitemap nichts zu suchen haben >

Überprüfung der Sitemap #Canonical
§ Seiten mit einem Canonical auf eine andere Seite ermitteln:
- 301 Seiten zeigen auf eine andere Seite
301 Seiten die in der XML Sitemap nichts zu suchen haben >

In99%derFällenisterstmaldieSitemapschuld!

Export aller zu indexierenden Seiten
§ URLs, welche aufgrund Statuscodes, Meta Robots usw. nicht ranken, können innerhalb von Screaming Frog entfernt werden
§ Liste an URLs als CSV Datei exportieren:

WelcheSeitensindnunnichtimIndexenthaltenundwarum?

Überprüfung auf Indexierung #GoogleCacheCrawl
§ Liste mit allen relevanten URLs + Webcache URL erstellen
- Speed: Max URIs/Sekunde auf 0,1 heruntersetzen
Google stoppt nach einer gewissen Zeit das Crawling durch einen Captcha >
http://webcache.googleusercontent.com/ search?q=cache:www.meinedomain.de/

Überprüfung auf Indexierung #GoogleCacheCrawl
§ Prüfung auf Indexierung mit Hilfe von URL Profiler:
- Das Tool URL Profiler ermittelt, welche Seiten unserer Sitemap nicht im Google Index enthalten sind
- Bei einer größeren Anzahl an Seiten ist die Verwendung von Proxys erforderlich

Überprüfung auf Indexierung #GoogleCacheCrawl
§ Prüfung auf Indexierung mit Hilfe von URL Profiler:

Gründe bei nicht indexierten Seiten finden
§ Liste aller nicht indexierten Seiten mit Crawl der Seite abgleichen
- Seiten haben Thin Content
Inhalt anreichern oder Seite auf Noindex >
- Seiten haben Duplicate Content
Unique Inhalte erstellen oder Noindex >
- Seiten werden zu schwach intern verlinkt
Interne Verlinkung / Seitenstruktur verbessern
>

#2DuplicateContentfindenmitScreamingFrog

WelcheInhaltemeinerWebseitegenerierenDuplicateContentundwelcheMustersindalsUrsachenerkennbar???

Einfache Möglichkeit über die Search Console
§ HTML Verbesserungen: Doppelte Title & Descriptions:
§ ABER: Daten meist nicht vollständig und veraltet

Bessere Möglichkeit durch vollständiges Crawling
§ Duplikate bei Page Titles und Meta Descriptions exportieren
§ Hiermit lässt sich jedoch nur Duplicate Content finden, wenn Seiten gleiche Meta Tags besitzen
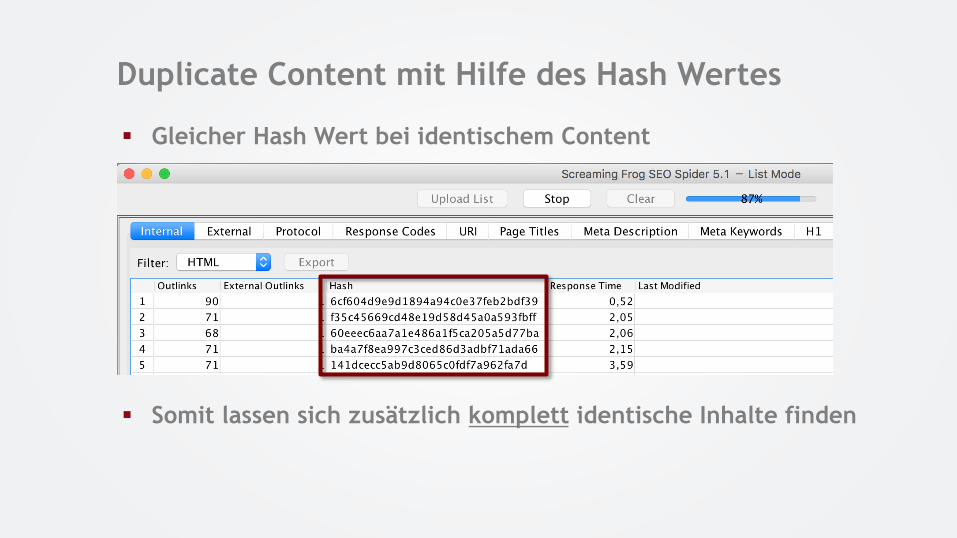
Duplicate Content mit Hilfe des Hash Wertes
§ Gleicher Hash Wert bei identischem Content
§ Somit lassen sich zusätzlich komplett identische Inhalte finden

Auffinden von doppelten Produkttexten #Shop
§ Auslesen von Texten mit Hilfe der Customer Extraktion:

Auffinden von doppelten Produkttexten #Shop
§ Auslesen von Texten mit Hilfe der Customer Extraktion:

Auffinden von doppelten Produkttexten #Shop
§ Auslesen von Texten mit Hilfe der Customer Extraktion:
§ Duplikate der Produkttexte mit Hilfe von Excel finden

Vermeidung von Mobile Duplicate Content
§ Überprüfung ob mobile Subdomain stets auf Desktop zeigt:

Vermeidung von Mobile Duplicate Content
§ Überprüfung ob mobile Subdomain stets auf Desktop zeigt:

#3RelaunchmeisternmitScreamingFrog

WiekannicheinenRelaunchausSEOSichtopEmalvorbereitenundwiefindeichnachdemRelaunchsofortFehler???

Crawling vor dem Relaunch
§ Erfassen aller relevanten Unterseiten & Weiterleitungsketten
- Aus dem Crawling kann ein Redirect Plan erstellt werden
- Zudem ist das Crawling nach dem Relaunch erforderlich um Fehler finden zu können

Crawling vor dem Relaunch
§ Meta Daten & SEO Content sichern
§ Im schlimmsten Fall lassen sich dadurch SEO Inhalte wieder herstellen und gehen nicht verloren

Crawling vor dem Relaunch
§ Meta Daten & SEO Content sichern

Crawling vor dem Relaunch
§ Meta Daten & SEO Content sichern
§ Im schlimmsten Fall lassen sich dadurch SEO Inhalte wieder herstellen und gehen nicht verloren

Nach dem Relaunch – Redirect Audit
§ Umfassende Liste mit vollständigem Crawling vor dem Relaunch hochladen und erneut crawlen lassen
§ Weiterleitungsketten auswerten und Statuscodes überprüfen

Waskannichtun,wennvordemRelaunchkeinCrawlingAbbilderstelltwurde?

Nach dem Relaunch – Wayback Machine hilft aus
§ Wayback Machine kann mit Hilfe der korrekten URL und den richtigen Screaming Frog Einstellungen gecrawlt werden
http://web.archive.org/web/*/www.meinedomain.de

Nach dem Relaunch – Wayback Machine hilft aus
§ Wayback Machine kann mit Hilfe der korrekten URL und den richtigen Screaming Frog Einstellungen gecrawlt werden
http://web.archive.org/web/*/www.meinedomain.de

Nach dem Relaunch – Wayback Machine hilft aus
§ Wayback Machine kann mit Hilfe der korrekten URL und den richtigen Screaming Frog Einstellungen gecrawlt werden
http://web.archive.org/web/*/www.meinedomain.de
§ Mit Hilfe von Excel müssen nun noch die URLs von der web.archive Adresse extrahiert werden

Google Tag Manager & Google Analytics Check
§ Nach dem Relaunch alle Seiten auf Trackingcodes prüfen:
§ Je nach Setup kann der Quelltext nach dem Tag Manager Code oder nach dem Analytics Code durchsucht werden

#4BacklinksbewertenmitScreamingFrog

WelcheLinkszeigenzumaktuellenZeitpunktwirklichnochaufmeineDomainundwelchedavonsollteichentwerten???

Sammlung von Daten aus verschiedensten Quellen
§ Linkdaten Export bspw. aus Sistrix, eig. Listen & Search Console
§ Vollständige Liste in Screaming Frog importieren:

Überprüfung der Links auf Aktualität / Bestehen
§ Crawl 1: Weiterleitungsketten und finales Linkziel ausfindig machen
- Alle Seiten mit 4xx & 5xx Statuscodes fliegen raus - Alle Seiten, welche den Link bereits entfernt haben, fliegen raus
- Viele Linkquellen haben sich durch die Umstellung von http auf https geändert und sollten daher berücksichtigt werden
§ Crawl 2: Linkquellen filtern, welche den Link im HTML enthalten:
§ Dadurch erhalten wir Seiten, welche tatsächlich einen Link setzen

Überprüfung bestehender Links auf SPAM/PORN...
§ Crawl 3: Content der Linkquellen auf Spam, Porn oder Paid Content Hinweise durchsuchen:

Finale Linkquellen mit Crawlingdaten anreichern
§ Crawl 4: Finale Liste mit zusätzlichen Crawlingdaten anreichern um leichter schlechte Links ausfindig machen zu können
Linkquellen mit minderwertigem Thin Content? >
Indiz für Linkfarmen? >

Zusammenfassung
Indexierungskontrolle DuplicateContentfinden
Relaunchmeistern Backlinksbewerten

Kontakt
mail:[email protected]:030–42804064mobile:015143132337xing:Mario_Traeger
www.webworks-agentur.de