script independent keyword spotting using moment...
TRANSCRIPT

Jan 11, 2008
Script Independent Keyword Spotting Using Moment Features
Venu Govindaraju

Jan 11, 2008
Keyword Spotting for Multi-script Documents
Image – Based
Query Image
Provided OR
Rendered
OCR - Based
Match in Feature Space

Jan 11, 2008
Multi-script Documents
Challenge: Script Invariant Word Image Representation
Jan 11, 2008
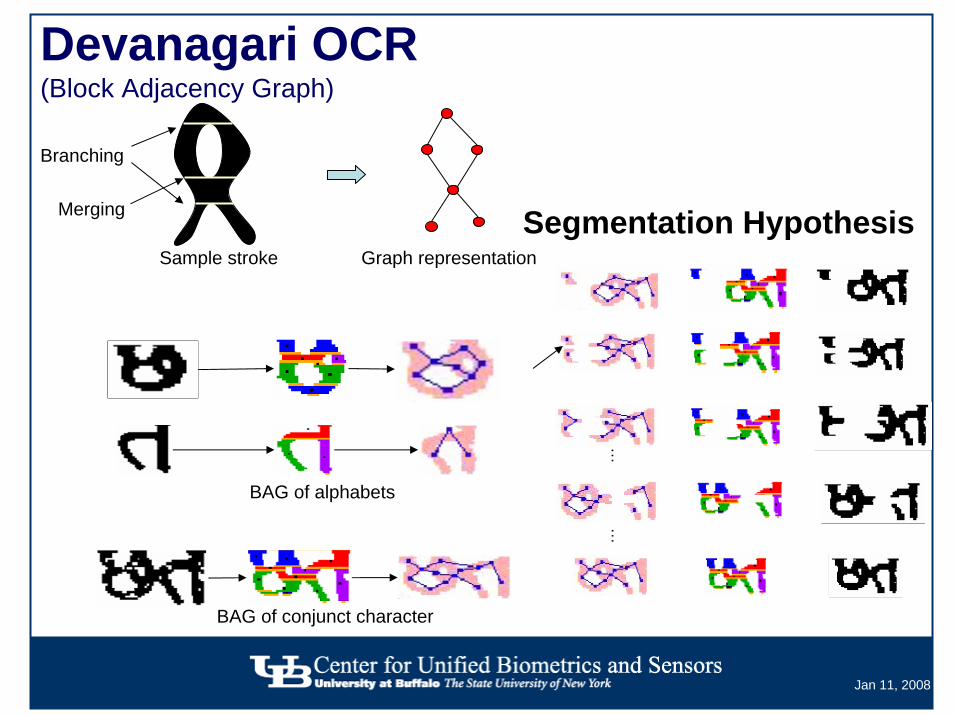
Devanagari OCR(Block Adjacency Graph)
Branching
Merging
Sample stroke Graph representation
BAG of conjunct character
BAG of alphabets
……
Segmentation Hypothesis

Jan 11, 2008
Recognition Methodology
Words
….
• Language model to choose path - results:– Script writing grammar rules eliminate two choices:
– Phonetic n-gram constraints remove another choice:
Jan 11, 2008
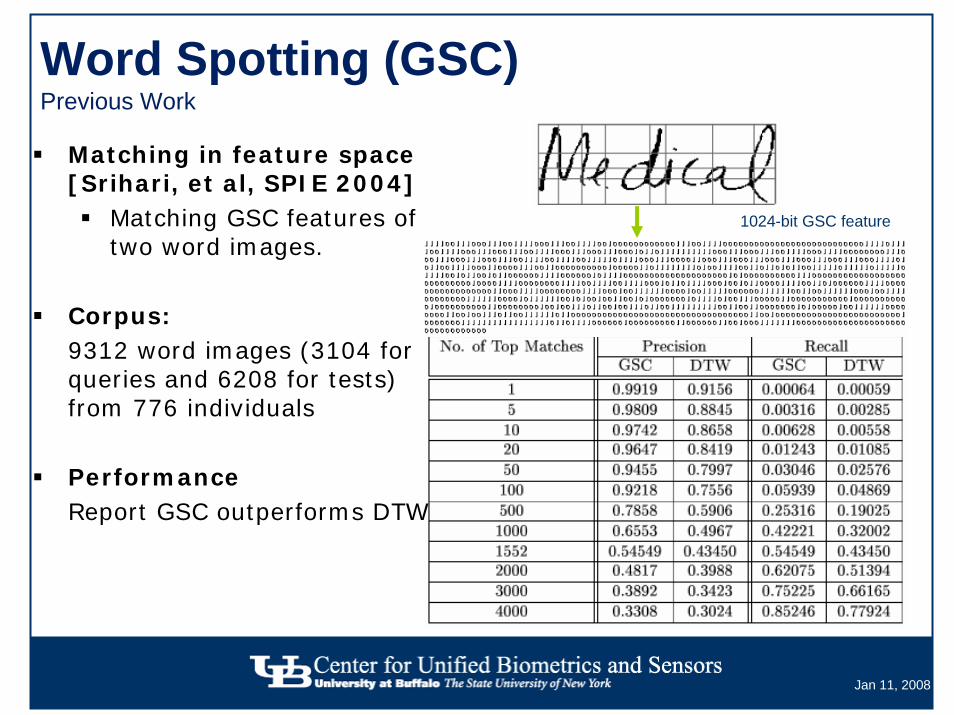
Word Spotting (GSC)Previous Work
Matching in feature space [Srihari, et al, SPIE 2004]
Matching GSC features of two word images.
Corpus: 9312 word images (3104 for queries and 6208 for tests) from 776 individuals
PerformanceReport GSC outperforms DTW
1024-bit GSC feature

Jan 11, 2008
Word Spotting (DTW)Previous Work
Word image
Upper/ lower
profile features
Observdensity ),Pr( fvwrd
Word recogn
Prob ∑=
wrdfvwrd
fvwrdfvwrd
),Pr(),Pr(
)|Pr(
Word recognition probability• Sequential Profile and DTW
[Rath et al, CVPR 2003]
CorpusWashington’s manuscripts
PerformanceAverage precision: 67.92%QueryImage and Text

Jan 11, 2008
Word Spotting (Gabor)Previous Work
Template Free Word Spotting in low-quality manuscripts [Huaigu, et al, ICAPR 2007]
Matching Gabor features of two word images. Corpus:
12 medical forms containing 5295 character images.
PerformanceReport probabilistic similarity performs better than Euclidean
similarity and WMR.
Feature Extraction
V1 V2 V3 V4
Vw = [V1T V2T V3T V4T]T
))|(ln(1),(1∑=
=
−=ni
iiP vcP
nVwwC i
Probabilistic Similarity

Jan 11, 2008
Issues• Deal with
– Complex characters (Devanagari)– Scale and translation– Multiple scripts
• Structural Features (GSC)– Script specific therefore ineffective
(Srihari et al)
– Profile features applicable only on long components (Manmatha et al)
Ascenders
Descenders
Core
Shirorekha
Base line

Jan 11, 2008
Moment Features Geometric Moments
Center of Gravity
Central Moments
Variance

Jan 11, 2008
Moment Features• Pre-processing of document images
• Moments (up to 7th order) extracted from normalized word images
• Invariant to scale and translations
Feature vector = [
230.045291568.635182-10.828037
-3200.1645835531.698681
-23057.359438202901.278885
-42801047.364910-28009097.448910755255816.89022
….….
]Feature vector consists of 30 moment values Construct for each word image and store in the index

Jan 11, 2008
4 6 8 10 12 14 160.7
0.72
0.74
0.76
0.78
0.8
0.82
0.84
0.86
Moment Order
Avg
Prec
.
Avg. Precision Vs Moment Order
Noise Sensitivity-High Order MomentsHindi Dataset
Average Precision vs higher order moments, Apply relevance feedback to re-rank word images

Jan 11, 2008
Corpus
Hindi : 763 machine print word images extracted from Million Book Project documents.
English : 707 handwritten word images extracted from IAM database and George Washington’s historical manuscripts.
Sanskrit : 693 machine print word images extracted from 5 documents downloaded from the URL : http://sanskrit.gde.to/

Jan 11, 2008
Corpus
• The test corpus consists of 5780 word images extracted from Million Book Project Documents.

Jan 11, 2008
Keyword Spotting• ja.ngal [ -3060.48 , 710.86 , 480388.32 , -43156.29 , ]
• kabUtar [ 31000.55 , 2774.74 , 496660.19 , 7229.75 , -]
• Vachan [ 8208.35 , -2379.97 , 146283.25 , 4141.59 , ]

Jan 11, 2008
Cosine Similarity
English Hindi
Pair A B CA 1 0.9867 0.9932B 0.9867 1 0.9467C 0.9932 0.9467 1
Pair D E FD 1 0.9662 0.9312E 0.9662 1 0.9187F 0.9312 0.9984 1
D
E scale
F Linear
A
B Scale
C Linear

Jan 11, 2008
Query OCR GSC Gradient GaborBaba 0.62 0.8 0.41 0.41
Bandar 1.0 0.092 1.0 1.0Bhakt 0.75 0.52 0.41 0.41Jungal 0.65 0.74 0.1 0.1Machali 0.79 0.93 0.89 0.89
Mata 0.63 0.35 0.38 1.0Naksha 1.0 0.77 1.0 0.41
Raat 0.70 0.72 0.41 0.38Ramkumar 1.0 0.89 0.22 0.24
Vachan 0.86 0.67 0.24 0.22
Mean for 10 0.80 0.65 0.50 0.50Mean for 20 0.67 0.60 0.29 0.29
Mean Average Precision

Jan 11, 2008
Relevance Feedback
Relevance
query
results
Query Feature
Word Features
Ranking
Feedback
INDEXINGDocImages

Jan 11, 2008
Relevance Feedback on Vector Space
R1 = [ 12333.37 , -12148.82 ]
Qnew = [ 1288.43 , -8450.10 ]
Q1 = [ -3060.48 , 710.86 ]M21
NR1 = [ 31000.55 , 2774.75 ]
NR2 = [ 8208.35 , -2379.98 ]
M12

Jan 11, 2008
Relevance Feedback
Q1 = [ -3060.48 , 710.86 ]
R1 = [ 12333.37 , -12148.82 ]
NR1 = [ 31000.55 , 2774.75 ]
NR2 = [ 8208.35 , -2379.98 ]
Qnew = Q1 + 0.75 * (R1) – (0.25/2) * (NR1 + NR2)
Qnew = [ 1288.43 , -8450.10 ]
Cosine Similarity (Q1 , R1 ) = - 0.8527
Cosine Similarity (Qnew , R1 ) = 0.8011
Jan 11, 2008
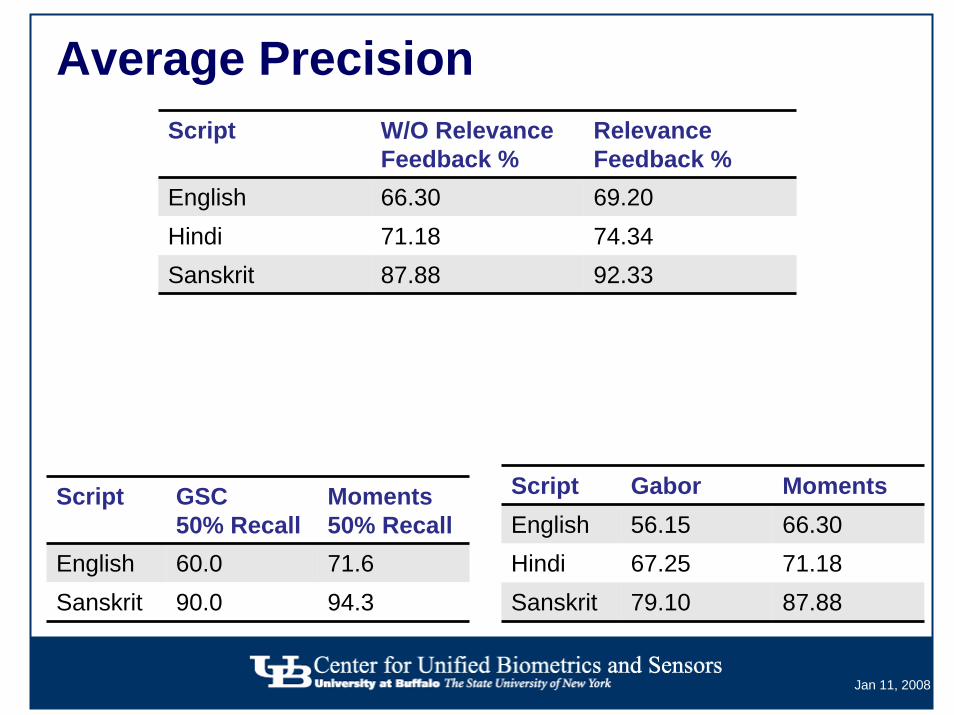
Average PrecisionScript W/O Relevance
Feedback %Relevance Feedback %
English 66.30 69.20Hindi 71.18 74.34Sanskrit 87.88 92.33
Script GSC50% Recall
Moments50% Recall
English 60.0 71.6Sanskrit 90.0 94.3
Script Gabor MomentsEnglish 56.15 66.30Hindi 67.25 71.18Sanskrit 79.10 87.88

Jan 11, 2008
Average Precision
1 2 3 4 5 6 7 80.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Query
Avg
Prec
isio
nAverage Precision Curve for few Queries English
0 10 20 30 40 50 600.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Queries
Aver
age
Prec
ision
Avg. Precision for few Queries
0 10 20 30 40 50 60 70 80 90 1000.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Queries
Aver
age
Prec
ision
Avg Precision for few Queries
SanskritHindi
8 queries
75 queries
100 queries

Jan 11, 2008
Summary
• Keyword Spotting Methods– OCR driven– Image based: Moments, GSC, Gabor
• Multi-script Documents– Moments– Relevance Feedback
• Future Work