semantic web research anno 2006: main streams, popular falacies, current status, future challenges...
Post on 18-Dec-2015
214 views
TRANSCRIPT

Semantic Web research anno 2006:
main streams, popular falacies, current status, future challenges
Frank van HarmelenVrije Universiteit Amsterdam

2
This is NOT a Semantic Webevangelization talk
(I assume you are already converted)

This is a “topical” talk:
Webster: “referring to the topics of the day, of temporary interest”

Which Semantic Web are we talking about?
Semantic Web research anno 2006:
main streams, popular falacies, current status, future challenges
main streams

5
General idea of Semantic WebMake current web more machine accessible
(currently all the intelligence is in the user)
Motivating use-cases
Search engines• concepts, not keywords• semantic narrowing/widening of queries
Shopbots• semantic interchange, not screenscraping
E-commerce Negotiation, catalogue mapping, data-integration
Web Services Need semantic characterisations to find them
Navigation• by semantic proximity, not hardwired links
.....

6
General idea of Semantic Web(2)
Do this by:
1. Making data and meta-dataavailable on the Webin machine-understandable form (formalised)
2. Structure the data and meta-data in ontologies These are non-trivial
design decisions.Alternative would be:

7
“machine-understandable form” (What it’s like to be a machine)
<name>
<symptoms>
<drug>
<drugadministration>
<disease>
<treatment>
IS-A
alleviatesMETA-DATA
8
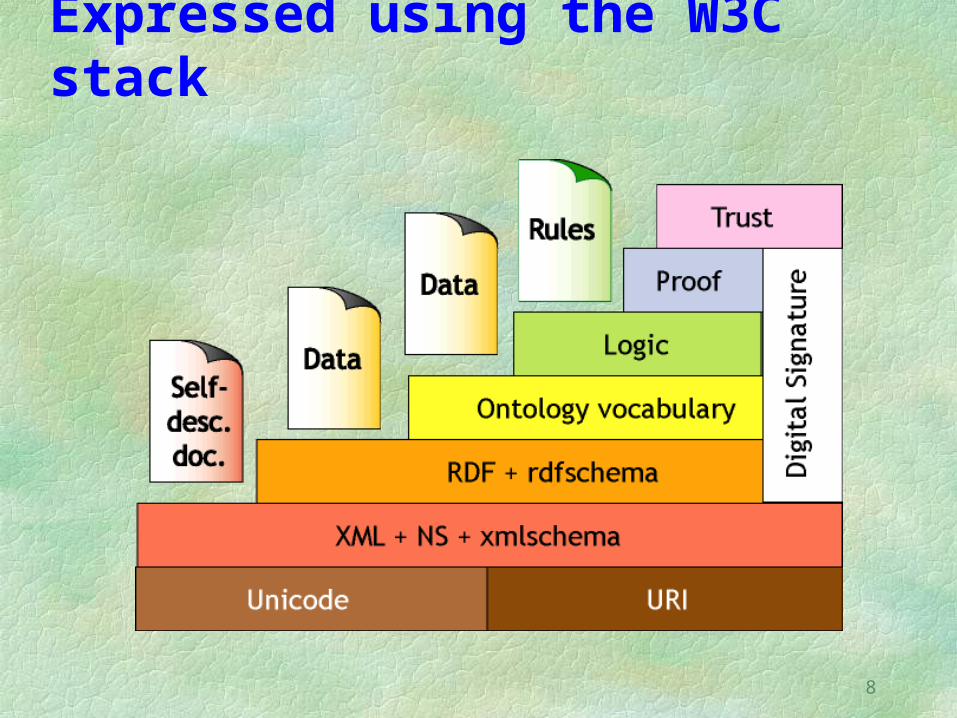
Expressed using the W3C stack

9
Which Semantic Web?Version 1:
"Semantic Web as Web of Data" (TBL)
recipe:expose databases on the web, use RDF, integrate
meta-data from: expressing DB schema semantics
in machine interpretable waysenable integration and unexpected re-
use

10
Which Semantic Web?Version 2:
“Enrichment of the current Web”
recipe:Annotate, classify, index
meta-data from: automatically producing markup:
named-entity recognition, concept extraction, tagging, etc.
enable personalisation, search, browse,..

11
Which Semantic Web?Version 1:
“Semantic Web as Web of Data”
Version 2:“Enrichment of the current Web”
Different use-cases Different techniques Different users

Four popular falacies about the Semantic Web
Semantic Web research anno 2006:
main streams, popular falacies, current status, future challenges
popular falacies

13
First: clear up some popular misunderstandingsFalse statement No :
“Semantic Web people try to enforce meaning from the top”
They only “enforce” a language.They don’t enforce what is said in that language
Compare: HTML “enforced” from the top,But content is entirely free.

14
First: clear up some popular misunderstandingsFalse statement No :
“The Semantic Web people will require everybody to subscribe to a single predefined "meaning" for the terms we use.”
Of course, meaning is fluid, contextual, etc.
Lot’s of work on (semi)-automatically bridging between different vocabularies.

15
First: clear up some popular misunderstandingsFalse statement No :
“The Semantic Web will require users to understand the complicated details of formalised knowledge representation.”
All of this is “under the hood”.

16
First: clear up some popular misunderstandingsFalse statement No :
“The Semantic Web people will require us to manually markup all the existing web-pages.”
Lots of work on automatically producing semantic markup:
named-entity recognition, concept extraction, etc.

The current state of Semantic Web
Semantic Web research anno 2006:
main streams, popular falacies, current status, future challengescurrent status

18
4 hard questions on the Semantic Web:
Q1: "where does the meta-data come from?” NL technology is delivering on concept-extraction Socially emerging (learning from tagging).Q2: “where do the meta-data-schema
come from?” many handcrafted schema hierarchy learning remains hard relation extraction remains hard.Q3: “what to do with many meta-data schema?” ontology mapping/aligning remains VERY hard.Q4: “where’s the ‘Web’ in the Semantic Web?” more attention to social aspects (P2P, FOAF) non-textual media remains hard deal with typical Web requirements.

19
Q1: Where do the ontologies come from?Professional bodies, scientific communities,
companies, publishers, ….
Good old fashioned Knowledge Engineering
Convert from DB-schema, UML, etc.
Learning remains very hard…

20
Q1: Where do the ontologies come from? handcrafted
music: CDnow (2410/5), MusicMoz (1073/7) community efforts
biomedical: SNOMED (200k), GO (15k), commercial: Emtree(45k+190k) ranging from lightweight (Yahoo)
to heavyweight (Cyc) ranging from small (METAR)
to large (UNSPC)
21
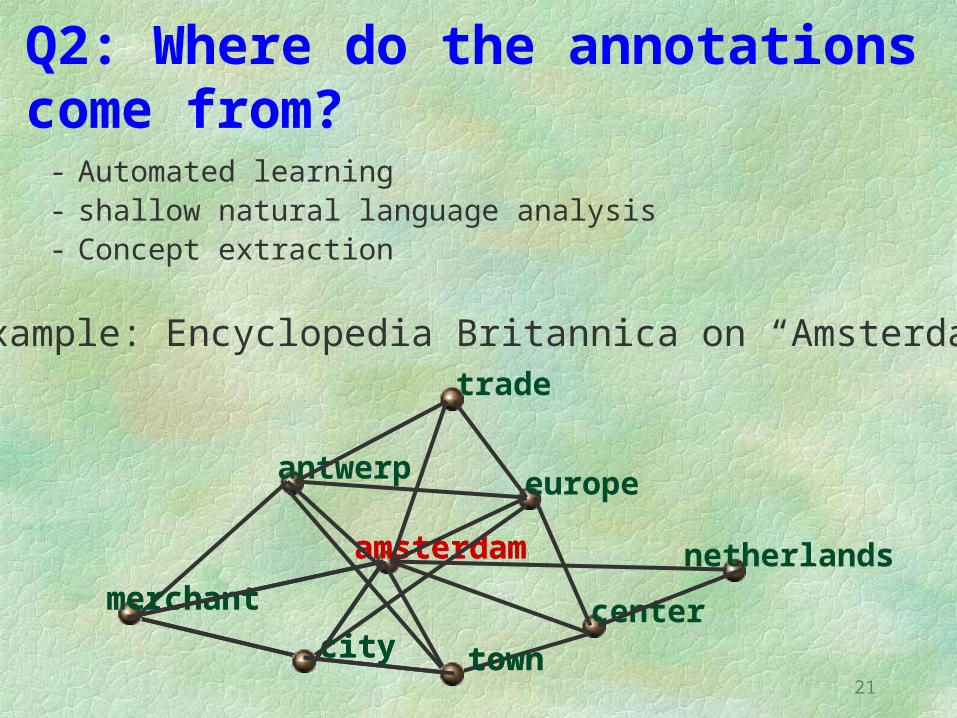
Q2: Where do the annotations come from?
- Automated learning- shallow natural language analysis- Concept extraction
amsterdam
trade
antwerp europe
amsterdam
merchant
city town
center
netherlandsmerchant
city town
Example: Encyclopedia Britannica on “Amsterdam”

22
lightweight NLP Dutch language semantic search engine
exploit existing legacy-data Amazon Lab equipment
side-effect from user interaction MIT Lab photo-annotator
NOT from manual effort
Q2: Where do the annotations come from?

23
Q3: What to do with many ontologies? Mesh
Medical Subject Headings, National Library of Medicine 22.000 descriptions
EMTREE Commercial Elsevier, Drugs and diseases 45.000 terms, 190.000 synonyms
UMLS Integrates 100 different vocabularies
SNOMED 200.000 concepts, College of American Pathologists
Gene Ontology 15.000 terms in molecular biology
NCI Cancer Ontology: 17,000 classes (about 1M definitions),

24
Q3: What to do with many ontologies?Stitching all this together by hand?

25
Q3: What to do with many ontologies?
Linguistics & structure
Shared vocabulary
Instance-based matching
Shared background knowledge

26
Where are we now: toolsLanguages are stableTooling is rapidly emerging
HP, IBM, Oracle, Adobe, … Parsers, Editors, visualisers, large scale storage and querying Portal generation, search

27
Where are we now: applications
healthy uptake in some areas: knowledge management / intranets data-integration life-sciences convergence with Semantic Grid cultural heritage
still very few applications in personalisation mobility/context awareness
Most applications for companies, few applications for the public

Future directions/challenges
Semantic Web research anno 2006:
main streams, popular falacies, current status, future challengesfuture challenges

29
Semantic Web as an integrator of many different subfields
DatabasesNatural Language ProcessingKnowledge RepresentationMachine LearningInformation RetrievalAgentsHCI….

30
Provocation…Ontology research is done……
We know how to make, maintain & deploy them
We have tools & methods forediting, storing, inferencing, visualising, etc
… except for two problems: Learning Mapping
Natural lang. technology is also done… at least it’s good enough

31
Large open questions Ontology learning & mapping emerging semantics (social &
statistical) Semantic Web services
discovery, composition: realistic? non-textual media
the semantic gap: text or social? Deployment:
1. data-integration2. search3. personalisation

32
Changing focus
centralised,
formalised, complete,
precisedistributed,
heterogeneous,
open, P2P, approximate,
lightweight
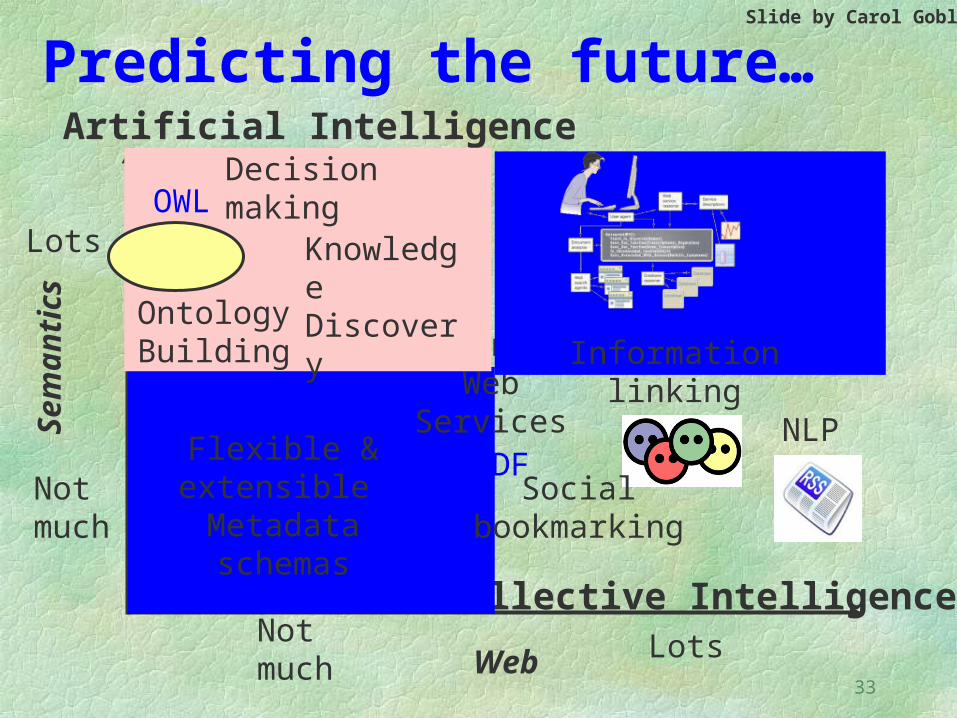
Web 3.0 = Web 2.0 + Semantic Web
33Web
Not much
Lots
Semantics
Lots
Not much
Artificial Intelligence
Collective Intelligence
RDFFlexible & extensible Metadataschemas
Semantic Web
Services
Ontology Building
OWL
KnowledgeDiscovery
SWRL
Decision making
FOAF
RSSSocial bookmarking
NLP
Information linking
Slide by Carol Goble
Predicting the future…