sound-event partitioning and feature normalization for robust sound-event detection 2 department of...
TRANSCRIPT

Sound-Event Partitioning and Feature Normalization for Robust Sound-Event Detection
2Department of Electronic and Information EngineeringThe Hong Kong Polytechnic University, Hong Kong SAR, China
Baiying LEI1,2
Man-Wai MAK2
1Department of Biomedical Engineering, Shenzhen University, Shenzhen, China
Funding Sources: •Motorola Solutions Foundation•The Hong Kong Polytechnic University

2
Contents1. Motivations of Sound-Event Detection
2. Objectives
3. Methodology– System Architecture
– Acoustic Features and Fusion
– Sound Event Partitioning
4. Experiments and Results
5. Conclusions
2

• Under some situations (e.g., in a washroom), surveillance via video cameras is inappropriate. Audio is a viable alternative under such situations.
• With the high processing power of today’s smartphones, it becomes possible to turn a smartphone into a personal audio surveillance and monitoring system.
• Audio-based surveillance can make effective use of mobile devices, allowing the surveillance system to be moved from one place to another easily.
• Abnormal sound events such as screaming can be detected and emergency phone calls can be automatically made.
3
Motivation

1. Determining suitable acoustic features for scream sound detection
2. Addressing the data-imbalance problem (scream vs. non-scream) in training SVM classifiers
3. Implement the detection algorithm on mobile phones
4
Objectives of This Work

5
Methodology
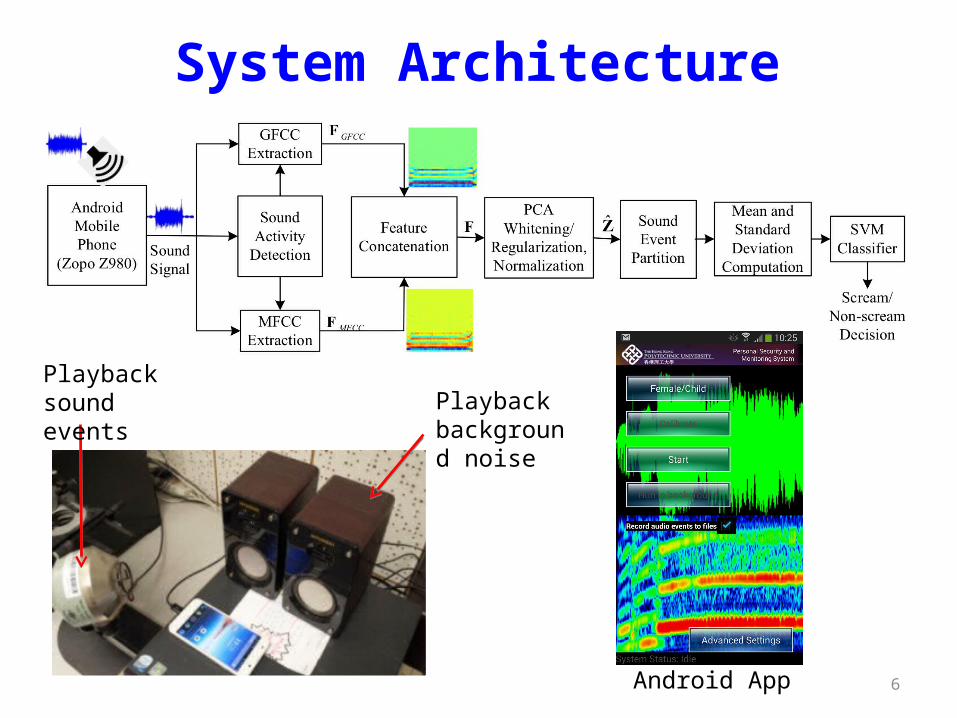
6
System Architecture
Android App
Playback background noise
Playback sound events

7
Feature Extraction and Fusion• Characteristics of scream sounds
– Almost impossible to detect them in the time domain– But their spectral characteristics are still visible in the
spectrogram under very noise condition

8
Feature Extraction and Fusion• Time-Frequency Acoustic Features
– MFCC (Mel-frequency cepstral coefficients)• Commonly used in speech and speaker recognition systems• Known to be not very noise robust
– GFCC (Gammatone frequency cepstral coefficients)• Based on auditory filtering and cepstral analysis• More noise robust than MFCC
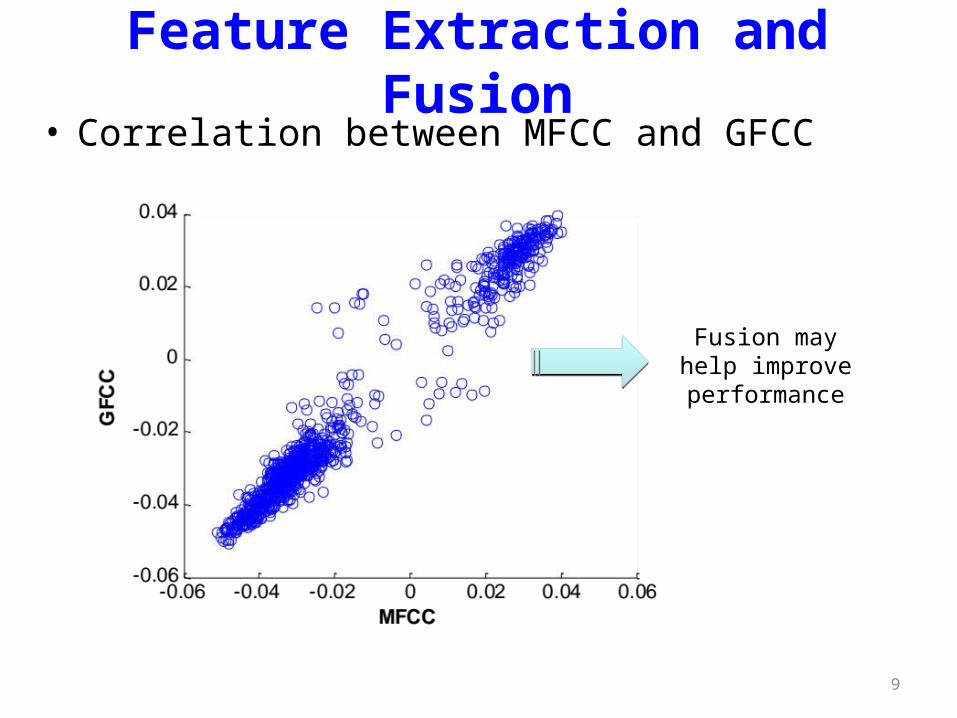
9
Feature Extraction and Fusion• Correlation between MFCC and GFCC
Fusion may help improve
performance
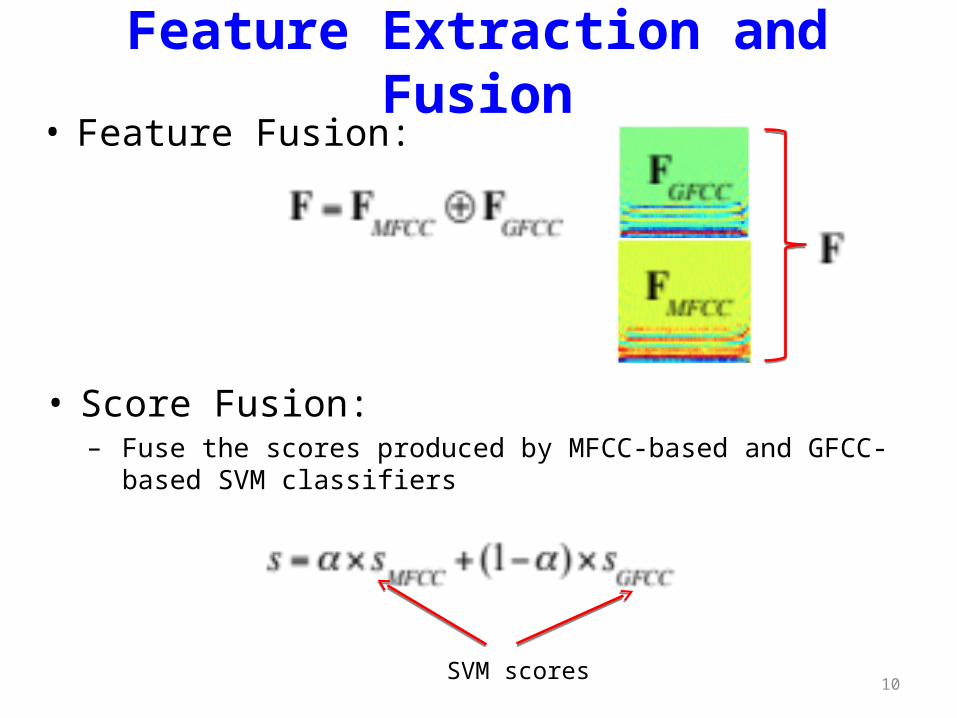
10
Feature Extraction and Fusion• Feature Fusion:
• Score Fusion:– Fuse the scores produced by MFCC-based and GFCC-based SVM
classifiers
SVM scores

Feature Extraction and Fusion• Feature Fusion + Score Fusion:
Score from feature-fusion
SVM
Score from score-fusion
SVM
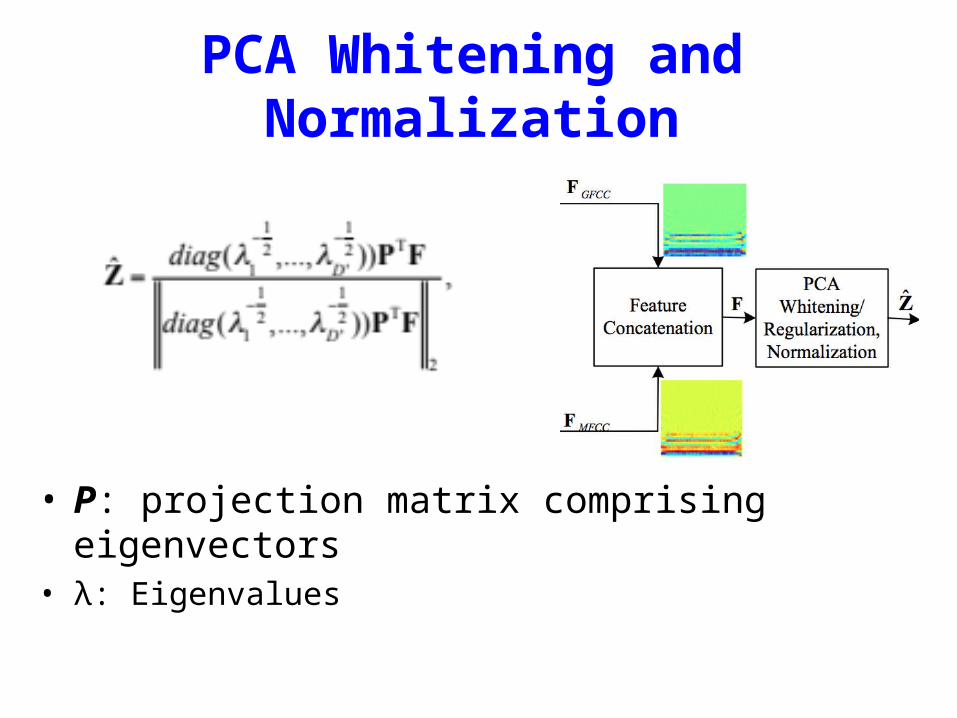
PCA Whitening and Normalization
• P: projection matrix comprising eigenvectors• λ: Eigenvalues
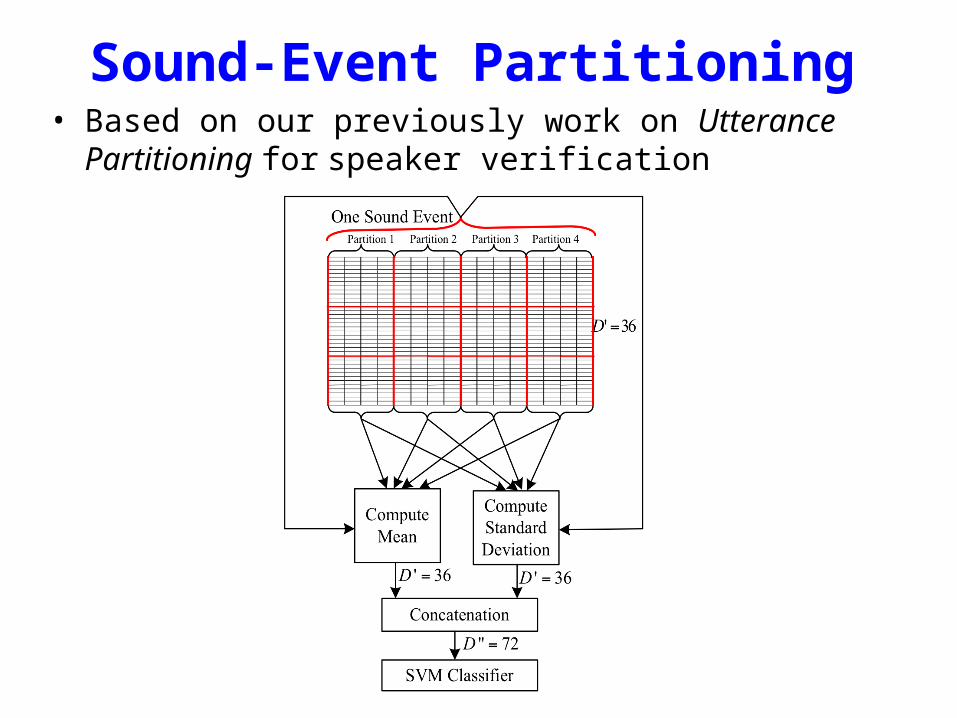
Sound-Event Partitioning• Based on our previously work on Utterance Partitioning for
speaker verification

14
Experiments and Results
15
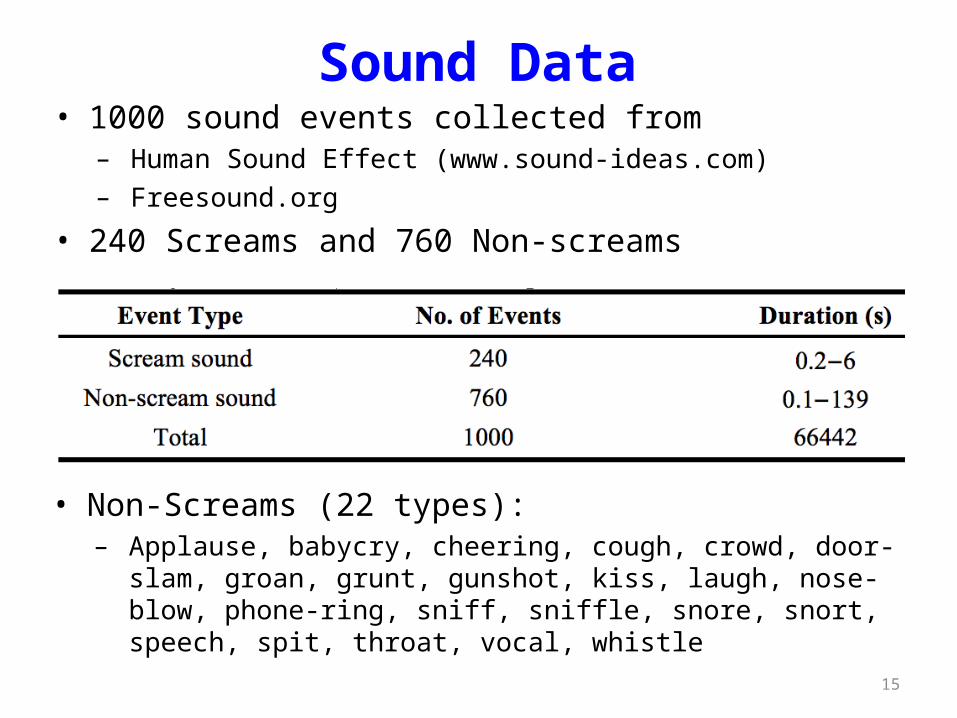
Sound Data• 1000 sound events collected from
– Human Sound Effect (www.sound-ideas.com)– Freesound.org
• 240 Screams and 760 Non-screams
• Non-Screams (22 types):– Applause, babycry, cheering, cough, crowd, door-slam, groan,
grunt, gunshot, kiss, laugh, nose-blow, phone-ring, sniff, sniffle, snore, snort, speech, spit, throat, vocal, whistle

16
Sound Data

17
Effect of Background Noise• Babble noise from NOISEX’92 was added to the sound
events so that the resulting noisy sound events have SNR of 10dB, 5dB, 0dB, and -5dB
• Performance (%EER, False Acceptance = False Rejection)
Perform better under matched conditions
18
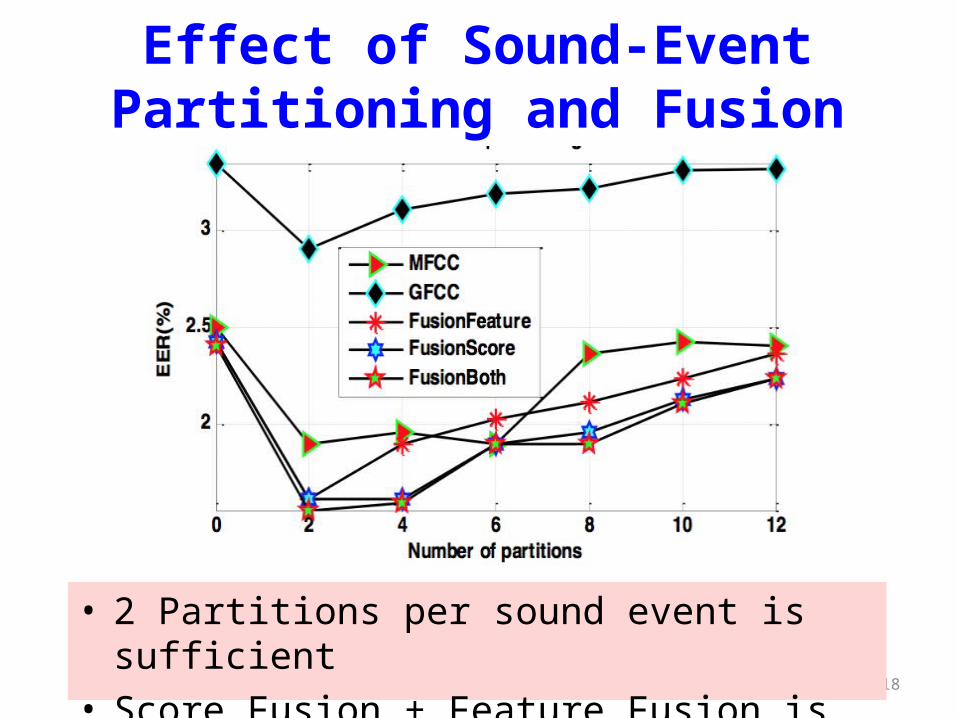
Effect of Sound-Event Partitioning and Fusion
• 2 Partitions per sound event is sufficient• Score Fusion + Feature Fusion is the best
19
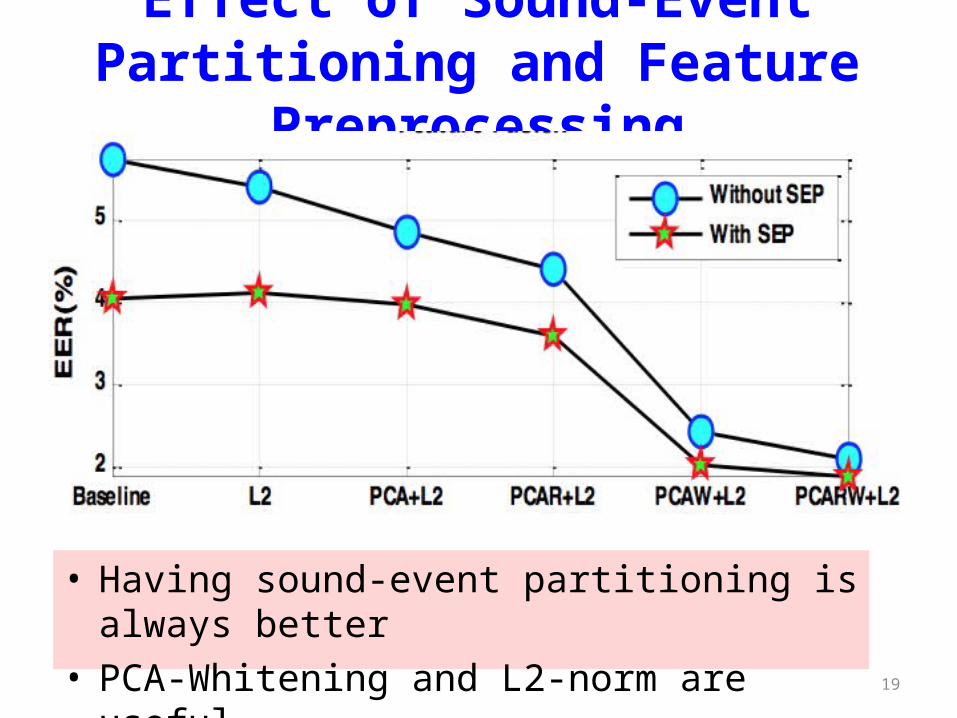
Effect of Sound-Event Partitioning and Feature Preprocessing
• Having sound-event partitioning is always better• PCA-Whitening and L2-norm are useful

20
Conclusion• Sound-event partitioning and feature pre-
preprocessing methods are proposed for scream sound detection.
• It was found that– Having sound-event partitioning is always better– PCA-Whitening and L2-norm are useful– Score fusion + feature fusion is effective
• Demo

21