spe 112246 rapid model updating with right-time data ... 112246 rapid model updating with right-time...
TRANSCRIPT

SPE 112246
Rapid Model Updating with Right-Time Data - Ensuring Models Remain Evergreen for Improved Reservoir Management Stephen J. Webb, David E. Revus, Angela M. Myhre, Roxar, Nigel H. Goodwin, K. Neil B. Dunlop, John R. Heritage, Energy Scitech Ltd.
Copyright 2008, Society of Petroleum Engineers This paper was prepared for presentation at the 2008 SPE Intelligent Energy Conference and Exhibition held in Amsterdam, The Netherlands, 25–27 February 2008. This paper was selected for presentation by an SPE program committee following review of information contained in an abstract submitted by the author(s). Contents of the paper have not been reviewed by the Society of Petroleum Engineers and are subject to correction by the author(s). The material does not necessarily reflect any position of the Society of Petroleum Engineers, its officers, or members. Electronic reproduction, distribution, or storage of any part of this paper without the written consent of the Society of Petroleum Engineers is prohibited. Permission to reproduce in print is restricted to an abstract of not more than 300 words; illustrations may not be copied. The abstract must contain conspicuous acknowledgment of SPE copyright.
Abstract History matching reservoir models to production data has been a challenge for asset teams since the early days of reservoir simulation. Keeping these models evergreen as production data continues to arrive, knowing when a re-history match is required and being able to re-history match easily and efficiently is also a major challenge which is often not addressed in a timely manner. This need is becoming even more pressing as real-time reservoir performance data is increasingly available. Decisions can now be made with the support of the good quality real-time data from the reservoir usually in the form of pressure data from downhole gauges and rate data from multiphase meters.
With the recent integration of existing technologies, a rapid model updating workflow is now possible. The history matching workflow that was once a discrete process can now be a computer assisted continuous process. Using statistically-based assisted history-matching technology in conjunction with real-time data acquisition, data monitoring, and reservoir simulation software, new production data can be quickly assimilated into the reservoir model. Real-time data from the field measurement devices is filtered for consumption by the reservoir modeling software and compared with the forecasts from the reservoir simulator to determine if re-history matching is required. The new data can be added to the history file and the model (revised if necessary) can be used in operational performance optimization.
This rapid model updating workflow can be run semi-automatically on a continuous basis as new production data is gathered, thereby keeping reservoir models
evergreen and providing the most up-to-date basis for the making of important reservoir management decisions. Introduction Since the early days of reservoir simulation, history matching has been identified1 as one of the best methods of validating a reservoir model’s predictive capabilities. Often long periods of time have been spent adjusting the reservoir description so that the reservoir simulator’s calculated results match the observed data from the reservoir. Unfortunately, due to limitations of data availability, computer hardware performance and mantime, history matching has been a discrete process which is performed only at certain stages in a reservoir’s life cycle rather than as a continuous process that updates the reservoir model as new data arrives. Although recent advances in assisted matching technology2 have shown there is potential to cut the time required to achieve history matches, often the reservoir model is out of date before the history matching process has been completed because the production data used in history matching is frozen in time when the process is started and is not updated over the often many months that history matching can take.
With the advent of digital oil field technology3,4,5, data is now available from the reservoir in real-time. In particular, downhole pressures6 and multiphase surface flow rates7 can now be measured directly and continuously. This real-time data is now routinely used for reservoir monitoring, flow assurance calculations, production optimization8,9,10 and for reservoir engineering analysis11. However, despite many good intentions12,13, reservoir modeling has been slow to take up the use of real-time production data to condition its models. While there have been some promising projects using Ensemble Kalman Filtering to update reservoir models14,15, these have mostly been research oriented and have not yet made it into mainstream use.
The approach taken in this paper is different from those reported previously in that it builds upon assisted history matching technology that is already in the commercial domain and is in widespread use. First, a process framework is established in which a history match of a reservoir model can be obtained. This process, which

2 SPE 112246
will be summarized in this paper and is described in detail elsewhere2,16, allows the engineer to chose parameters in the reservoir model that the assisted history matching software can sensitize so that it can explore which parameters need to be changed and how they need to be changed to achieve a history match. The process also produces an estimate of the uncertainty in the history match. While it is obtaining history matches, the process can be used to forecast reservoir performance and define confidence intervals in the forecast performance. These confidence intervals can then be used as a measure of the forecast’s accuracy as new reservoir performance data arrives. If the new data lies within the confidence intervals, the model is forecasting field performance to within the uncertainty of the modeling system. If the new data lies outside the confidence intervals, either the field is not being operated as forecast (and the simulator’s operating constraints need updating) or the model itself requires updating. The process framework provides an environment where this can be done in an almost automatic fashion.
This process will be illustrated by an example based on a large mature North Sea reservoir where the rapid model updating process is illustrated by repeatedly assimilating new production data into the history matching process, thereby keeping the model “evergreen” and as up to date as possible for field operating and development decisions.
Rapid Model Updating Process Components The rapid model updating process is comprised of the following components:
• Statistically-based assisted history-matching technology
• Robust full field black oil and compositional
reservoir flow simulator
• Real-time field monitoring and production data management system
These technology components are directly interfaced with each other to provide a comprehensive and integrated total system which is described in the subsequent sections of this paper. Assisted History Matching The availability of powerful and inexpensive computing hardware over the last decade has led to the development of software tools that can greatly help the history matching process. Additionally these tools allow for the inherent uncertainty in the reservoir description and indeed the production data, and reflect that uncertainty in the reservoir performance forecasts used for operational and field development decision-making. The technologies that have been employed are many, and include gradient methods, simulated annealing, evolutionary algorithms
and Bayesian response surface modeling2,16,17,18,19,20,21,22,23,24,25,26,27,28.
The technology used in this work is the advanced linear Bayesian tool, EnABLE™. It can be used with a number of different reservoir simulators and is designed to assist in the process of identifying multiple acceptable history matches by using a structured workflow process which allows many parameters to be automatically modified simultaneously. Advanced experimental design methods and linear Bayesian statistical routines are used which permit the use of objective data, subjective opinion and other indirect information in specifying a prior distribution29. A statistical estimator based on a response surface model (the Estimator) is created as a proxy for the full reservoir simulation model and is updated after each simulation run. By using the proxy to approximate the simulator, extensive exploration of the simulated responses across the solution space may be performed without the computational expense of making a complete simulator run in each evaluation. Starting with a set of scoping runs designed to broadly explore the entire solution space followed by additional “most informative runs” (whereby the regions of the parametric space where the proxy model has the greatest uncertainty are explored) a reasonably predictive estimator is built. A number of history match solutions are then obtained more rapidly than would be possible by simply running a large number of simulation cases. Fit for purpose history matching and confidence interval estimation using the workflow described here typically is accomplished with the use of a number of reservoir model runs of the order of 100 to 300 runs. Methods that do not employ an estimator are variously reported to require a thousand or more runs30. The workflow process is shown in Figure 1:
1. Identify study objectives. 2. Setup simulation model as usual. 3. Identify parameters (modifiers) for
investigation in the history match (and predictions and optimization31, if anticipated) and their ranges of investigation.
4. Make modifications to the simulator input data to sensitize these parameters.
5. Generate a set of ‘scoping runs’. These runs, made using an experimental design procedure, provide the initial basis for the Estimator model. Typically 25 runs are used for this step, although less may be sufficient for small numbers of modifiers. Multiple runs can be submitted for simultaneous computation, if multiple processors are available.
6. Import the historical data on well performance and production.
7. Validate: decide by inspection whether the model parameterization has the potential to lead to a history match of sufficient accuracy to meet project objectives.

SPE 112246 3
8. Identify the observed data that is considered to be most diagnostic of reservoir and flow physics and pick points for history matching.
9. Initialize the Estimator models using results from the scoping runs. The tool will select the most important modifiers for each match point and construct an initial statistical response surface model.
10. Generate additional runs to improve the Estimator model with a set of ‘most informative’ runs. This is a sequential experimental design approach. These runs explore where there is the most uncertainty about the simulation model. Each of these runs causes the tool to perform a Bayes update of the Estimator model using the new results.
11. Conduct a sequence of ‘best match’ simulation runs. Since each run updates the Estimator model, a sequence of best match runs is needed, where each run is using an improved Estimator model. The parameter values are chosen by the tool which performs an optimization that is informed by the Estimator model.
12. Evaluate the runs graphically using the tool’s built-in capabilities. Modify weighting of match objective function to steer match, ensuring that the phenomena expected to have the most impact on predictions are targeted. Repeat from 9 (or 10) until good matches are seen to be emerging.
Forecasting Under Uncertainty Once a set of acceptable history match runs has been obtained, uncertainty in the production forecasts can be explored. Simply by extending the simulated time period to include the chosen production forecast scenario, the range of expected production behavior can be explored. By repeating steps in the workflow above for a time period that includes the original history match period and the forecast period, confidence intervals in the production forecast can be generated. Rather than the Estimator just providing information about the quality of the history match, it is now providing details of the uncertainty in the production forecasts given the known quality of the associated history match. For simplicity, Figure 1 shows this as “Start forecasting”. The details of the workflow are:
13. Generate a number of scoping runs (typically 15) to scope the newly added forecast period. These runs scope the new solution space so that the new results in the forecast period following on from the history will be taken into account in the Estimator before starting the refinement runs.
14. Select forecast points. 15. Generate a series of most informative and
best match runs (e.g. 12 most informative runs followed by 3 best match runs). The most informative runs reduce the Estimator uncertainty in the simulator response at forecast points. The best matches ensure that there are forecasts that are associated with good history match runs. The Estimator is updated with the run modifiers and results at the end of each simulation run.
A further step that can be added is to optimize the operational plan of the reservoir. By adding controllable parameters that can be subjected to optimization to the set of modifiers that is being used (e.g. choke settings, workover scheduling, well placement, compression timing, etc.) recommendations for field operational and development optimization can be derived.
Regarding confidence intervals and estimated prediction uncertainty, the technology estimates the confidence associated with the set of results for the match point. This is a measure of the uncertainty in the value of the production at a future point in time. The measure of confidence takes the form of percentile values, and the confidence interval (CI) is the probability that a value is between an upper limit and a lower limit. The default confidence intervals used in this work were 80% intervals. Real-time Production Monitoring The real-time production system used in this workflow, and shown in Figure 2, consists of a specialized field monitoring system (at the local field level), and a comprehensive production data management system (at the office level). The real-time production system acquires, collects, and stores real-time and historical intelligent instrumentation data, and provides a common desktop for visualization, field monitoring, analysis, and interpretation.
It features “life of the field” storage capability at the office level with flexible sampling rates as low as per second with high precision. A broad range of specialized interpretation, analysis, monitoring, and diagnostics tools are available to streamline analyses, processes, daily operations, production optimization, and reservoir management.
Available configurations for the real-time production system include direct interface with intelligent instruments (downhole, subsea, and topside/surface), and/or instrument interface via the operator’s automated process control infrastructure of Distributed Control Systems (DCS), Supervisory Control and Data Acquisition (SCADA), Subsea Master Control Systems (MCS), Information Management Systems (IMS), Automated Systems, and third-party historians.

4 SPE 112246
The real-time production system utilizes the industry
standard network communications protocol, TCP/IP to connect the operator’s communications network, and to connect remote locations via a telecommunications provider, satellite services provider, over the internet, or via a wireless network for near proximity locations.
This availability of real-time pressure, temperature (topside, subsea or downhole) and multiphase rate data (topside or subsea) means that high quality reservoir performance data are now available to the reservoir engineer. While these data have been enthusiastically taken up and used by operations and production engineers for field monitoring, field surveillance, flow assurance and production optimization, the reservoir engineering community has been somewhat slower to react. Take up has been inhibited by the lack of tools to quickly assimilate this real-time data into reservoir models.
One issue is the challenge of timescales. Whereas real-time data arrives and can be stored on a second by second basis, for this workflow, the reservoir engineer is typically interested in daily, weekly, or monthly averaged production data (Figure 3). So for real-time production data to be ready for consumption by reservoir models, some form of data aggregation is generally needed, which may include filtering, interpolation, averaging, and other summarization methods, depending upon the characteristics of the data. This aggregated data may be provided to reservoir models in the form of ASCII, spreadsheet, or XML, using the emerging PRODML format32. This is often referred to as “in-time” or “right-time” data rather than real-time data.
Therefore, prior to consumption by the reservoir engineer, the real-time data used in this work were filtered using a custom formula defined by the user, or a default moving average smoothing algorithm supplied with the application. These formulae enable customised noise filtering to smooth extreme outliers without modifying the original real-time data. The calculation is performed automatically on the selected time span of real-time data. Once smoothed, the resulting filtered data are averaged and interpolated to produce data at any desired time period, and may then be exported into an appropriate format. Currently the export is a manual process whereby the averaged and interpolated data are exported, with the help of templates, in specialized ASCII format files that, may be directly inserted as Include Files to the reservoir flow simulator data deck, or imported as well history into the assisted history matching application. However, in the future it is anticipated that this data transfer will be in an XML format (PRODML) and that the rapid model update applications will receive the data when it becomes available using a publish and subscribe mechanism similar to that available with WITSML33 data.
Another issue that has inhibited the use of real-time
data in reservoir models is the lack of a robust automated
process for repeatedly including new production data in the history matching process. Because history matches have often taken so long, engineers are reluctant to repeat the process even though the models they are using for decision making purposes can be out of date. The next section addresses that challenge. Rapid Model Updating Workflow A process has been established whereby “right-time” data can be extracted from a real-time monitoring application in a suitably aggregated format and, employing the workflow described in the sections above, used to update reservoir flow simulation models that are interfaced to assisted history matching technology and potentially geological reservoir models. The key components of this workflow are illustrated in Figure 4. It should be noted that the rapid model update process and the individual component applications are capable of handling any desired time period, including intra-day production data.
This right-time data is then made available to the rapid
model updating workflow to append to the existing history that has been used in the assisted history matching process. The controls on the existing forecast runs are replaced with the newly observed production data controls and the confidence intervals around dependent aspects of the modeled production behavior re-calculated. This is achieved by rerunning steps 13 to 15 in the workflow. The model set up determines whether a production value is assigned or dependent; dependent values are typically phase rates and pressures but may include compositions and temperatures. New actual recorded values are compared with model generated values to determine where they lie with respect to the model’s confidence intervals. If the new data lies within the confidence intervals, then the field is operating within the limits of the model’s ability to forecast and the reservoir model is still capable of predicting field performance within the uncertainty of the model.
If, however, the new data lies outside the confidence intervals, then the reservoir model is no longer capable of forecasting the performance of the field and it needs updating. This can be achieved by rerunning steps 9 (or 10) to 12. If this automatic step does not lead to an acceptable match then human intervention is required. Action may be required of an engineer to steer the history match differently as in step 12. Or if the mismatch is sufficiently severe the process may need to start at steps 2 or 3 where new modifiers are introduced.
Once these steps have been performed the forecast workflow is repeated (steps 13 to 15) so that a new forecast and new confidence intervals are generated with the new model. This new model can also be used for optimization runs to re-evaluate and revise, if necessary, the field operating and development plans.
This whole process is repeated every time new data becomes available and is illustrated in Figure 5. In the

SPE 112246 5
reservoir management workflow this would normally not be more frequent than every month (see Figure 2) but could, if necessary be repeated on a more frequent basis if the field performance was changing quickly.
In summary, as new history data (recorded data and operational controls) are added they are checked to see if they are consistent with the forecast based on the existing history match (i.e. within the confidence intervals). If they are, new forecasts are made based on the augmented history. If not, a re-history match is required which includes all the previous history and the new data. This may be possible using the existing modifiers or new modifiers may have to be introduced. The new forecasts should be narrower than the previous forecasts from the new forecast point but may be offset from previous forecasts as operational controls have most likely been changed. Also, the modifier ranges which generate good history matches should be reduced. Therefore as time progresses and more and more production data is assimilated, both the history match and forecast are refined. New information reduces uncertainty in the geological and simulation models which results in the forecast being refined (a consequence of refining the history match). The new information may allow the selection of a narrower range of possible geological models.
Using this rapid model updating process to update the
history match as described above, the set of possible reservoir models is always kept up to date ensuring that the best possible set of models is used for operating and field development planning decision-making.
Finally, there is no inherent requirement that this rapid model updating procedure is performed only using the reservoir simulator. It has been shown that during the history matching process using assisted history matching tools, geological models and reservoir simulation models can be kept consistent by applying modifiers to the geological model as well as the simulation model34. By applying the rapid model updating workflow to the geological model as well as the simulation model, the geological model can be updated as new production data is assimilated thereby keeping both the simulation and geological models “evergreen”. Example An example of this workflow is based on a publicly available version35 of a simulation model of the Gullfaks field on the Norwegian Continental Shelf. The simulation model is of the eastern part of the Gullfaks field (Block 30/10) and models the field from startup in 1986 until the end of 1996. Although there are some 60 wells defined in the model only about a quarter are active early on in the production of the field. This workflow was executed by using the advanced linear Bayesian tool described above, together with the full physics reservoir flow simulator Tempest-MORE and real-time production monitoring software. The simulation recurrent data and historical
data were prepared from the actual field performance data on a monthly basis for this example case.
The objective of the example was to illustrate how a
reservoir model that is kept current can be an excellent reservoir surveillance tool, and thus improve the quality of reservoir management36. Water production was the focus of attention, because it was anticipated that this parameter would provide the greatest disparity between simulated and observed data. For the purposes of this example it was assumed that today’s date (“current date”) is the end of September 1989 and that everything prior to that date is “past” and everything after that date is “future”. The model was history matched up to September 30, 1989 using the workflow shown in Figure 1 and the cumulative water production results, for the well group of producers, are shown in Figure 6. Up until this point all the wells in the models were controlled on oil rate and water production was allowed to be predicted by the models. Forecasts were then run from October 1, 1989 until January 1991 with the wells on bottom-hole pressure control and a field oil production rate target (Figure 6). Confidence intervals for these forecasts were generated at approximately 3 month intervals, which was the planned time period for reservoir surveillance.
The “current date” was then advanced to the end of December 1989. The confidence intervals were compared with the actual water production observed (Figure 7). It can be seen that the actual water production rate was still within the confidence intervals set for the forecasts. Therefore, the models were still able to forecast performance of the field within the confidence intervals and no further adjustment of the models was required. Forecasts were then made from January 1990 onwards using the existing models.
The “current date” was then advanced to March 31,
1990 and the process repeated. Now the actual cumulative water production was outside the confidence intervals (Figure 8). The deviation between actual and forecast is seen even more dramatically in the water production rate (Figure 9). This meant that the models were no longer able to forecast field performance and needed to be adjusted to assimilate the new production data. The forecast field performance controls were replaced with the actual field performance controls and the models re-matched using the existing modifiers (as described above this may be achieved by re-running steps 9 to 12). The results of this re-match are shown in Figure 10. A comparison of the actual modifier values for the best match history runs to September 30, 1989 and the run closest to the actual history to March 31, 1990, indicated that the Kv/Kh ratio and aquifer strength were some of the key factors in achieving the re-history match. This match is not perfect, however, and had a more accurate re-history match have been required, the process could have been re-started at step 2 and new modifiers introduced. The re-history matching process (steps 2 through 12) would then have resulted in a modified set of models that

6 SPE 112246
could better have matched the production performance of the field and represented a better set of models to make forecasts for future performance of the field. However, for the purposes of this example, the re-matching workflow had been demonstrated and the process stopped here.
Conclusions A process has been described and illustrated whereby new production data can be quickly and continually assimilated into a set of history matched reservoir models. By extending the framework of an assisted history matching process, new production data can be added to the old production history and, if necessary, be used to update the existing history match. Confidence intervals from the reservoir performance forecasts are used as a guide to whether the existing reservoir models are capable of modeling the new production data. If they are, the performance forecasts are updated by simply introducing the new operating conditions. If not, the models are adjusted, repeating the history matching process which may, if necessary, include new history matching parameters.
As data continues to arrive, it is monitored against the
forecast performance and the associated confidence intervals. At discrete time intervals, new operational data replaces the forecast operational control and the rapid model updating process is repeated.
In this way, the set of history match models can
always be kept up to date or “evergreen” providing the most up to date models as a basis for important reservoir management and development decision making. Acknowledgements The authors would like to thank the management of Roxar for permission to publish this work and for the use of the EnABLE™ software, the Tempest-MORE reservoir simulator and Tempest simulation suite, and the Fieldwatch/Fieldmanager real-time monitoring and production data management software. They would also like to thank Bob Parish, Robert Frost and David Ponting for their useful contributions to this work. References
1. K.H. Coats, “Use and Misuse of Reservoir Simulation Models”, SPE2367 (1969), JPT November 1969
2. D.S. Bustamante, D.R. Keller and G.D. Monson, “Understanding Reservoir Performance and Uncertainty Using a Multiple History Matching Process” SPE95401 (2005) presented at SPE ATCE Dallas, TX, USA, October 2005.
3. T. Unneland and M. Hauser, “Real-Time Asset Management: From Vision to Engagement – An Operator’s Experience” SPE96390 (2005) presented at SPE ATCE Dallas, TX, USA, October 2005.
4. C. Reddick, “Field of the Future: Making BP’s Vision a Reality”, SPE99777 (2006) presented at
the Intelligent Energy Conference and Exhibition, Amsterdam, The Netherlands, April, 2006.
5. H. Potters, P. Kapteijn, “Reservoir Surveillance and Smart Fields”, IPTC11039 (2005) presented at the International Petroleum Technology Conference, Doha, Qatar, November, 2005.
6. T. Unneland and T. Haugland, “Permanent Downhole Gauges Use in Reservoir Management of Complex North Sea Oil Field”, SPE26781 (1994) SPE Production and Facilities, August, 1994.
7. K.H. Frantzen, M. Brandt, K, Olsvik, “Multiphase Meters – Operational Experience in the Asia-Pacific” SPE80502 (2003) presented at the SPE Asia Pacific Oil and Gas Conference and Exhibition, Jakarta, Indonesia, September, 2003
8. D. Reeves, R. Harvey, T. Smith, “Gas Lift Automation: Real Time Data to Desktop for Optimizing an Offshore GOM Platform”, SPE84166 (2003) presented at the SPE Annual Technical Conference and Exhibition held in Denver, Colorado, October 2003.
9. W.E.J.J.Van Zandvoord, A.A. Maskery, T. Schmid, “Application of Real Time Surveillance and optimization Tools on a Large Asset”, SPE100342 (2006) presented at the 2006 SPE Asia Pacific Oil & Gas Conference and Exhibition, Adelaide, Australia, September 2006.
10. L.A. Saputelli et al., “Promoting Real-Time Optimization of Hydrocarbon Producing Systems”, SPE83978 (2003) presented at Offshore Europe, Aberdeen, UK, September 2003.
11. A.G. Mezzatesta, D.C. Shaw, S.J. Webb, “Constant Reservoir Evaluation through Real-Time Data as a Service”, SPE109856 (2007) presented at the SPE ACTE Anaheim, CA, USA, November 2007.
12. D.J. Rossi, O. Gurpinar, R. Nelson, S. Jacobsen, “Discussion on Integrating Monitoring Data into the Reservoir Management Process”, SPE65150 (2000) presented at the SPE European Petroleum Conference in Paris, France, October, 2000.
13. O. Nygaard, C. Kramer, R. Kulkarni, J-E. Nordtvedt, “Development of a Marginal Gas-Condensate Field Using a Novel Integrated Reservoir and Production Management Approach”, SPE68734 (2001) presented at the SPE Asia Pacific Oil and Gas Conference and Exhibition in Jakarta, Indonesia, April 2001.
14. G. Naevdal, L. M. Johnsen, S. I. Aanonsen, E. H. Vefring, “Reservoir Monitoring and Continuous Model Updating Using Ensemble Kalman Filtering”, SPE84372 (2003) presented at the SPE ACTE, Denver, CO, USA, October 2003.
15. X.-H Wen, W.H. Chen, “Real-Time Reservoir Model Updating Using Ensemble Kalman Filtering”, SPE92991 (2005) presented at the

SPE 112246 7
SPE Reservoir Simulation Symposium, Houston, TX, February 2005.
16. A.J. Little, H.A. Jutila, A. Fincham, Energy Scitech Ltd. “History Matching With Production Uncertainty Eases Transition into Prediction” SPE100206 (2006) presented at the SPE Europec/EAGE Annual Conference in Vienna, Austria, 12-15 June 2006.
17. C.E. Romero, J.N. Carter, R.W. Zimmerman, A.C. Gringarten, “Improved Reservoir Characterization Through Evolutionary Computation”, SPE62942 (2000), presented at the SPE ACTE Dallas, TX, USA, October 2000.
18. Various Authors, “PUNQ. Production Forecasting with Uncertainty Quantification”. A research project funded in part by the European Commission under the Non-Nuclear Energy Programme (JOULE III), contract F3-CT95-0006, January 1996 – May 1999.
19. F. Bennett, T. Graf, “Use of Geostatistical Modeling and Automatic History Matching to Estimate Production Forecast Uncertainty - A Case Study” SPE74389 (2002) presented at the SPE International Petroleum Conference and Exhibition, Villahermosa, Mexico, February 2002.
20. M. Feraille, F. Roggero, E. Manceau, L.Y. Hu, I. Zabalza-Mezghani, L. Costa Reis, “Application of Advanced History Matching Techniques to an Integrated Field Case Study”, SPE84463 (2003) presented at the SPE ACTE Denver, CO, USA, October 2003.
21. G.J.J. Williams, M. Mansfield, D.G. MacDonald, M.D Bush, “Top-Down Reservoir Modelling”, SPE89974 (2004) presented at the SPE ACTE, Houston, TX, USA, September 2004.
22. M. Litvak, M. Christie, D. Johnson, J. Colbert, M. Sambridge, “Uncertainty Estimation in Production Predictions Constrained by Production History and Time-Lapse Seismic in a GOM Oil Field” SPE93146 (2005) presented at the SPE Reservoir Simulation Symposium, The Woodlands, TX, USA, February 2005.
23. Watkins A.J., Parish R.G., 1992. "A Stochastic Role For Engineering Input to Reservoir History Matching." SPE23738, LAPEC II; Caracas, Venezuela, March 1992.
24. Watkins A.J., Parish R.G., 1992. "Computational Aids to Reservoir History Matching." SPE24435. SPE Petroleum Computer Conference, Houston, Texas. July 1992.
25. Parish R.G., Watkins A. J., Muggeridge A., Calderbank V. J. 1993. “Effective History Matching: The Application of Advanced
Software Techniques to the History Matching Process“ SPE25250, 1993
26. A.J. Watkins, K.N.B. Dunlop, V.M. Alcobia, "The Stochastic Revision of Knowledge in Reservoir History Matching", 22nd Petr. Itinerary Congress of OMBKE, (Hungarian Mining & Mineral Society), Tihany Hungary, Oct. 6-9 1993.
27. Parish R.G. & Little A.J.H., 1994. “A Complete Methodology for History Matching Reservoirs” 6th ADIPEC, October 1994.
28. Parish R.G. & Little A.J.H., 1997. “Statistical Tools to Improve the Process of History Matching Reservoirs” SPE37730, MEOS, March 1997.
29. I. Miller and J. Freund, “Probability and Statistics for Engineers”, second edition, Prentice-Hall, Inc., Englewood Cliffs, NJ (1977).
30. J. Lach, K. McMillen, R. Archer, J. Holland, R. DePauw, B.E. Ludvigsen, “Integration of Geologic and Dynamic Models for History Matching, Medusa Field”, SPE95930 (2005) presented at the SPE ACTE, Dallas, TX, October, 2005.
31. H.A. Jutila, SPE, and N.H. Goodwin, Energy Scitech Ltd. “Schedule Optimization to Complement Assisted History Matching and Prediction Under Uncertainty”, SPE100253 (2006), Presented at the SPE Europec/EAGE Annual Conference in Vienna, Austria, 12-15 June 2006.
32. B. Weltevrede, A, Doniger, L. Ormerod, S, DeVries, “Second-Stage Callenge for the PRODML Standard: Adaptive Production Optimization”, SPE110907 (2007) presented at the SPE ACTE, Anaheim, CA, November, 2007.
33. M.A. Kirkman, M.E. Symmonds, S.W. harbinson, J.A. Shields, M.Will, A. Doniger, “Wellsite Information Transfer Standard Markup Language, WITSML, an Update”, SPE84066 (2003) presented at the SPE ACTE, Denver, CO, October, 2003.
34. S.J. Webb, J.S. Bayless, K.N.B. Dunlop, “Enabling the ‘Big Loop’- Ensuring Consistency of Geological and reservoir Simulation Models” paper presented at the 2007 AAPG Annual Convention and Exhibition, Long Beach, California, April, 2007.
35. Gullfaks Data released by Statoil is a selection of availiable petroleum technical data from the Gullfaks field, finalized before 01.01.1998
36. C. C. Mattax, R. L. Dalton, “Reservoir Simulation”, SPE Monograph Series Volume 13, SPE, 1990.

8 SPE 112246
Figure 1 Assisted history matching and forecasting workflow diagram
Geomodeling, gridding
Revise Geomodel
No
Identify modifiers & ranges
Import model into EnABLE
Revise modifiers or
Review/Revise tolerances
& match points
Scoping runs (Experimental design)
Import/Review Observed Data
Model validated?
Pick Estimator (match) Points
Informative Runs
Good matches emerging?
Best match runs
Start forecasting
Agree study objectives
Match, optimisation, forecasts complete?
No
Yes
Yes
Recommend Decision
No
Yes
No Yes
1
2,3
4,5
6
7
8,9
10
11
12
13,14,15

SPE 112246 9
On-shoreoffices
Topside
SubseaDownhole
Figure 2 Offshore real-time production system
Figure 3 Application of real-time data by duration and granularity10
Capacity Planning/Business Design
Seconds
Minutes
HoursDays
Months
Years
PID/Regulatory Control
Supervisory Control
Scheduling/Real-Time Optimization
Operational Planning
Data Collection Period
Reservoir Surveillance
Capacity Planning/Business Design
Seconds
Minutes
HoursDays
Months
Years
Seconds
Minutes
HoursDays
Months
Years
PID/Regulatory ControlPID/Regulatory Control
Supervisory ControlSupervisory Control
Scheduling/Real-Time Optimization
Operational Planning
Data Collection Period
Reservoir Surveillance

10 SPE 112246
P, TQo, Qw, QgSand rate
Qo, Qw, QgSand rate
Qo, Qw, QgSand rate
Real-TimeProduction System
Real-TimeProduction System
Data Historian
Field Controls
Reservoir Geologic Model
Reservoir Flow Simulation Model
Proxy Model for Uncertainty
Analysis
Assisted History Matching Workflow
ASCII,PRODML
Small Loop
Big Loop
Figure 4 Rapid Model Updating Workflow
Figure 5 Rapid Model Updating Flowchart
History match for (0, t0)
Predict for (t0, tend)
n = 0
Production model for (tn, tn+1) as expected?
Do (tn, tn+1) data fit predicted CIs ?
Change (t0, tn+1) to history and rematch, including prediction phase (tn+1, tend)
Record data from (tn, tn+1)
Remove runs covering original prediction phase (t0, tend)
Redo runs covering (t0, tend) using new schedule, treating (t0, tn) as history and (tn, tend) as prediction
n = n + 1
Yes
No
Yes
No
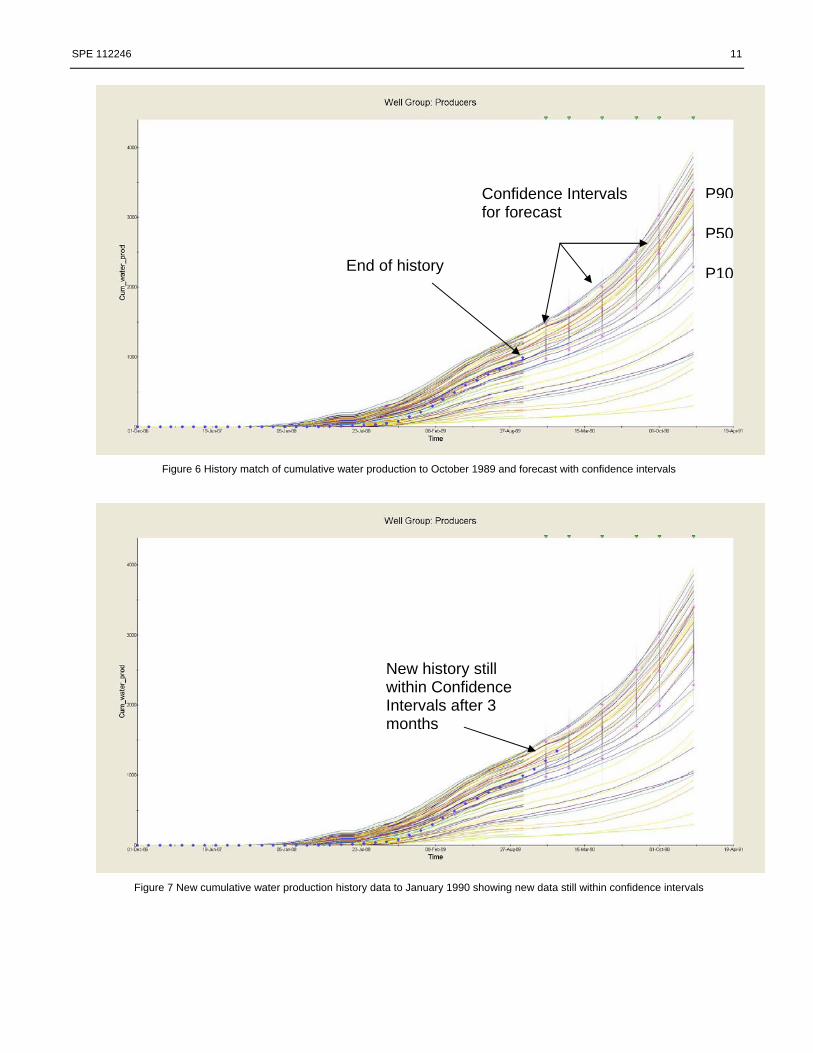
SPE 112246 11
Figure 6 History match of cumulative water production to October 1989 and forecast with confidence intervals
Figure 7 New cumulative water production history data to January 1990 showing new data still within confidence intervals
End of history
Confidence Intervals for forecast
P90
P50
P10
New history still within Confidence Intervals after 3 months
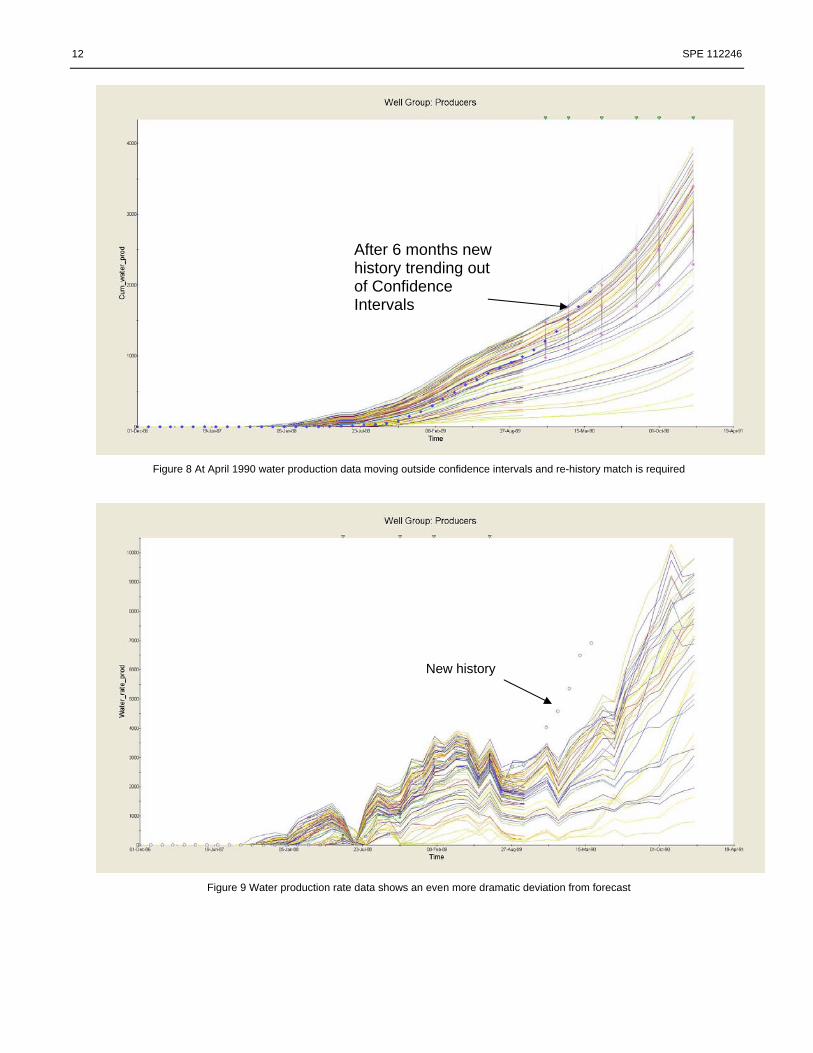
12 SPE 112246
Figure 8 At April 1990 water production data moving outside confidence intervals and re-history match is required
Figure 9 Water production rate data shows an even more dramatic deviation from forecast
After 6 months new history trending out of Confidence Intervals
New history

SPE 112246 13
Figure 10 Effect of re-history match to April 1990 and re-forecast on water production rate match
New re-matched run