statistische versuchsplanung design of experiments (dox) · i taguchi: robuste designs (insbes....
TRANSCRIPT

Statistische Versuchsplanung –Design of Experiments (DOX)
Markus Pauly
Institute of StatisticsUniversity of Ulm
Sommersemester 2015
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

RegularienVorlesung: Di 14:00–16:00 Uhr in Hörsaal H12
Übung: Mi 14:00–16:00 in Hörsaal H12 (Start: Morgen)
Homepage mit Materialien:uni-ulm.de/mawi/statistics/courseslehre/summer-semester-2015/statistische-versuchsplanung.html
Übungsaufgaben:– Abgabe jeweils am Mittwoch vor Beginn der Übung nach upload
eine Woche zuvor– Korrigierte Rückgabe eine Woche später– Zulassung zur Prüfung: 40% der Punkte– Tipp: Arbeiten in Kleingruppen von 2-3 Personen– Gemeinsame Abgaben (maximal 3 Personen) erlaubt und
empfohlen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Regularien
Prüfung:I Prüfung: 14.7. 2015
– Klausur oder mündliche Prüfung?
– Hilfsmittel bei Klausur: Ein selbstbeschriebenes DIN A4 Blatt (Vor-und Rückseite) sowie ein Taschenrechner
Prüfungsvorbereitung:– Teilnahme und rege Beteiligung in der Übungsstunde (Vorrechnen
bringt Bonuspunkte)
– Regelmässige Bearbeitung und Abgabe der Übungsblätter
– Diskutieren der Übungsaufgaben in Kleingruppen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Ankündigung
Am Mittwoch, 1.7, 14-16 trägtTina Müller (Schering, Berlin)
in HE20 zum (vorläufigen) ThemaApplied Statistics in the Pharmaceutical Industry
vor.Zuhörer sind herzlich eingeladen!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

LiteraturBandemer und Bellmann: Statistische Versuchsplanung, Teubner,1994.
Brunner: Statistische Modellierung. Vorlesungskript, UniversitätHeidelberg, 2009.
Montgomery: Design and Analysis of Experiments, Wiley, 2013.
Oehlert: A First Course in Design and Analysis of Experiments,New York: WH Freeman, 2000.
Müller: Grundlagen der Versuchsplanung. Vorlesungsskript,Universität Dortmund, 2014.
Siebertz: Statistische Versuchsplanung – Desgin of Experiments,Springer, 2010.
TUD: http://elearning.tu-dresden.de/versuchsplanung/
Ünlü: Grundlagen der Versuchsplanung. Vorlesungsskript,Universität Dortmund, 2011.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Ziele der Vorlesung
Vorstellung der grundlegenden Verfahren und Modelle für diePlanung von Experimenten
Vermeidung typischer Fehler, die hierbei auftreten können, umsystematischen Verzerrungen entgegen zu wirken,
Statistische Analysemethoden nach Durchführung derExperimente für die wichtigsten Modelle einführen
Entwicklung von Guidelines zur Planung von Experimenten und
Sensibilisierung gegenüber PARC1
(Planning After the Research is Complete; J. Stuart Hunter)
1Bitte 1x rückwärts lesen!Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 1:
Ein paar einleitende Worte zur Statistik

Eine Auswahl von Statistikprogrammen
Rfreie Software(GNU GPL),
Programmiersprache, kann mittels eines Editors komfortabel verwendet werden,
erhältlich unter http://www.r-project.org,Editoren/graphische Oberfläche unter http://www.sciviews.org/rgui/
häufige Verwendung an Hochschulen.
SPSSkommerzielles Programm,
(meist) Menü-basierte Steuerung,
weit verbreitet, z.B. in der Medizin, Psychologie und in denSozialwissenschaften,
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Eine Auswahl von Statistikprogrammen
SASkommerzielles Programm
eigene Programmiersprache
Menü-basierte Steuerung möglich (Enterprise Guide),
weit verbreitet, z.B. in der Medizin, Biometrie, erfüllt industrielleStandards,
Alle Statistikprogramme verfügen über umfangreiche Bibliotheken.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Ablauf einer statistischen Untersuchung
1 Datenerhebung: (Zufalls-)Experiment (Daten werden z.B. durchBeobachten oder Befragung erhoben)
2 Deskriptive Statistik: Datenaufbereitung und -darstellung (z.B.durch Tabellen und Grafiken) sowie Datenauswertung (z.B. durchBerechnung von Maßzahlen wie etwa Häufigkeiten, Mittelwertenund Streuungen)
3 Induktive oder schließende Statistik: Statistische Analyse (z.B.durch Schätzen, Testen oder Entscheidungen unter Unsicherheit)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Zufallsexperiment
Ein Zufallsexperiment ist ein realer Vorgang,– der verschiedene Ergebnisse haben kann, von denen genau
eines eintritt,
– dessen Ausgang vor Ablauf ungewiss ist,
– der (prinzipiell) unter den gleichen Bedingungen beliebig oftwiederholt werden kann.
Beispiele:Münzwurf, Würfeln, Zahlenlotto (Modellexperimente mit festenRegeln)Aber z.B. in der Pharma-Industrie auch: Qualitätskontrolle,Analyseergebnisse etc.=⇒ Zulassung von Medikamenten
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistik
In einem Gedankenexperiment werden im Vorfeld,(optimalerweise!!!) vor der Datenerhebung, alle möglichenSzenarien eines Zufallsexperiments durchgespielt,bewertet und wahrscheinlichkeitstheoretisch modelliert.Das Studium dieser Theorie und deren Gesetzmäßigkeiten lieferndie Basis für die Analyse der Ergebnisse von Zufallsexperimenten.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Studie in der Pharma-Industrie (stark vereinfacht)
Vermutung (Hypothesengenerierung): Medikament A wirktbesser als Medikament B.
Durchführung einer Studie (Zufallsexperiment): Patienten mitder Krankheit werden (zufällig) in zwei Gruppen eingeteilt: Eineerhält Medikament A, die andere Medikament B.
Vergleich Theorie vs. Wirklichkeit: Ist Medikament A wirklichbesser als Medikament B?
Induktive Statistik: Vergleich der Verbesserung desGesundheitszustands der Patienten.
⇒ Die Wahl des Auswertungsverfahrens hängt dabei von derBeziehung aller beteiligten Größen ab. Diese Struktur heißtVersuchsplan.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 2:
Motivation und Grundbegriffe derVersuchsplanung

Historisches vorweg
Ursprung: Agrarwissenschaften (1908 - 1940)I W.S. Gossett und der t-test (1908)I R. A. Fisher und Co-Autoren (Faktorielles Prinzip)⇒ Starken Einfluß auf die AgrarwissenschaftenI ANOVA, Factorial designs etc.
Die erste industrielle Ära (1951 - 1970)I Box and Wilson: Response surface Methode (RSM)⇒ Anwendung in der chemischen und anderen Prozessindustrien
Die zweite industrielle Ära (1970 - 1990)I Taguchi: Robuste Designs (insbes. fraktionelle faktorielle Designs),
Prozessrobustheit⇒ Qualitätsverbesserung in vielen Firmen
Seit 1990: Die moderne ÄraSchwerpunkt der VL eher auf biometrischen Anwendungen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Allgemeines
Die statistische Versuchsplanung ist eine natürliche Erweiterungdes naturwissenschaftlichen Vorgehens zum Erkenntnisgewinnüber reale Prozesse.Wesentlichen Schritte dabei: Planen, Experimentieren,Beobachten und Auswerten.Nur durch Experimentieren unter kontrollierten Bedingungenkönnen gesicherte Erkenntnisse über reale Prozesse gewonnenwerden.Mögliche Probleme
I Nicht alle für das Ergebnis wesentlichen Faktoren werden inrelevanten Bereichen variiert und die Ergebnisse einzelnerVersuche können widersprüchlich sein.
I Wesentliche Effekte können sich überlagern und damit nichtunterscheidbar sein bzw. sich abschwächen/aufheben oderverstärken (Antagonismen, Confounding, Synergien).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

ZufallsexperimentExperiment = Frage an die Natur im weitesten Sinne?
I Ist das neue Medikament A besser als ein etabliertes?I Ist Fernsehen für Kinder schädlich?
Die Frage sollte so genau wie möglich und eindeutig formuliertwerden, damit eine Lösung in einer für andere nachvollziehbarenWeise möglich ist.
I Unter welchen gesundheitlichen, physischen und sozialenVoraussetzungen liefert das neue Medikament eine höhereHeilwahrscheinlichkeit als das etablierte?
I Fünfjährige Kinder aus Ulm, die pro Woche mehr als fünfActionfilme sehen, zeigen im Kindergarten mehr aggressiveVerhaltensweisen als gleichaltrige Kinder aus Ulm, die überhauptnicht fernsehen.
Problem: Es ist (i.d.R.) unmöglich alle Bedingungen für einenVersuch im Vorfeld festzulegen!
I Beispiele...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Zufallsexperiment
Problem: Es ist (i.d.R.) unmöglich alle Bedingungen für einenVersuch im Vorfeld festzulegen!
I Naturgegebene Schwankungen⇒ Z.B. sind Schädigungen von Nadelbäumen in einem Wald auch für
Bäume gleichen Alters und gleicher Wachstumsbedingungenunterschiedlich. Ähnliche Beobachtungen gibt es auch fürunterschiedliche Krankheiten bei eineiigen Zwillingen
I Aufwand zu groß⇒ Auch bei einfachen Messungen (Gewicht o. Länge) haben
Umweltbedingungen (Temperatur, Luftfeuchtigkeit etc.) einenEinfluss auf die Messung.
⇒ (Fast) alle Experimente sind Zufallsexperimente!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Ziel- und Einflussgrößen
Definition 2.1 (Ziel- und Einflussgrößen):1 Die in einem Versuch beobachteten Zufallsvariablen, über die man bestimmte
Aussagen treffen möchte, heißen in der Versuchsplanung Zielgrößen,-variablen oder auch abhängige Variablen bzw. Endpunkt.
2 Diejenigen Größen, welche den Wert einer Zielgröße beeinflussen, nennt manEinflussgrößen oder unabhängige Variablen. Hierbei unterscheidet mannochmals:
3 Einflussgrößen, die im Versuch mit erfasst, beobachtet oder auch gezielt variiertwerden können heißen Faktoren.
4 Die übrigen Einflussgrößen, welche man wegen ihrer Vielzahl oder austechnischen Gründen nicht im Versuch beobachten, variieren oder mit erfassenkann oder möchte, werden zum sogenannten Versuchsfehlerzusammengefasst. Dieser wird durch eine Zufallsvariable beschrieben.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele für Ziel- und Einflussgrößen
Einfluss der Behandlungsform einer Krankheit (EG) auf die Rückfallquoten (ZG),
Auswirkung der Änderung der “Prozesstemperatur” (F) auf die “Festigkeit” (ZG),
Schizophrenie (ZG) als Reaktion auf Umweltfaktoren (EG),
Einfluss von Alkoholkonsum (F) auf die Reaktionszeit (ZG).
Vorsicht: Man kann einer Variablen i.a. nicht ansehen, ob sie eine EG oder ZGist. Erst durch Kenntnis der Versuchsanordnung, kann man darüber Auskunftgeben.
⇒ BSP: Die obige Variable Alkoholkonsum könnte in einer anderen Untersuchungauch ZG sein, wenn z.B. die Auswirkung von Reizentzug (EG) auf das Ausmaßdes Alkoholkonsums geprüft werden soll.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beobachtungs- vs. experimentelle Studien
Definition 2.2 (Beobachtungsstudien und experimentelle Studien):1 In einer Beobachtungsstudie (Feldexperimente) werden die Werte von
Einfluss- und Zielgrößen beobachtet, ohne die Einflussgrößen zu kontrollieren.2 Bei experimentellen Studien (Laborexperimente) werden die Faktporen
kontrolliert und die zugehörigen Werte der Zielgrößen beobachtet.
⇒ Auswertungen von Beobachtungsstudien leiden typischerweise unter denanfangs angedeuteten Problemen.
⇒ Experimentelle Studien mit statistischer Versuchsplanung vermeiden diese i.a.durch die systematische Auswahl von Versuchen, so dass alle interessierendenEffekte unabhängig voneinander geschätzt werden können, wobei zusätzlich diezur Verfügung stehenden Mittel optimal genutzt werden.
Ziel: Sinnvolle, maximale Interpretierbarkeit der Ergebnisse mit minimalemAufwand.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Störfaktoren und Stufen
Definition 2.3 (Störfaktoren und Stufen):1 Die Faktoren, deren Einfluss im Versuch nicht interessiert und die
nur unter Versuchskontrolle gebracht wurden, um dieVersuchsfehlerstreuung gering zu halten, nennt manStörfaktoren.
2 Im Gegensatz dazu bezeichnet man deshalb die interessierendenFaktoren auch manchmal als Einflussfaktoren
3 Die verschiedenen Ausprägungen eines Faktors heißen Stufen.Diese Ausprägungen können qualitativ oder quantitativ (metrischskaliert) sein.
Die Faktorstufen selber sind in der Versuchsplanung i.d.R. qualitativ.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mögliche StörfaktorenUmwelteinflüsse (Temperatur, Druck etc.)Zeiteinflüsse (Messungen zu verschiedenen Zeitpunkten) und in dem Zshg auch:Reifung der Versuchseinheit (Lern- und Alterungseffekte)Veränderung der Messinstrumente (Verschleiß etc.)Versuchsleitereffekte (Steigung von Sensititvität aber auch Müdigkeit im Verlauf;Wechsel des Versuchsleiters)Auswahlverzerrung (selection bias; Unterscheidung von Versuchsgruppenbereits vor Manipulation der Einflussfaktoren)
Testeffekte:I BSP: Erhöht autogenes Training die Intelligenz?
Versuch: Testpersonen machen IQ-Test vor Versuchsbeginn und nachAbsolvierung von fünf Trainingsstunden. Ergebnis: Anstieg desdurchschnittlichen IQs von 104 auf 112 Punkte (über die Testpersonenhinweg gemittelt).Aus diesem Ergebnis zu folgern, dass autogenes Training die Intelligenzerhöht, ist keineswegs zwingend. Es ist natürlich zu erwarten, dass man inIntelligenztests besser abschneidet, wenn man diese Tests schon einmaldurchgeführt/geübt hat.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015
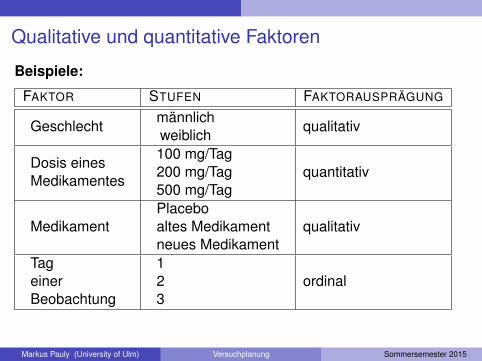
Qualitative und quantitative Faktoren
Beispiele:
FAKTOR STUFEN FAKTORAUSPRÄGUNG
Geschlechtmännlichweiblich
qualitativ
Dosis einesMedikamentes
100 mg/Tag200 mg/Tag500 mg/Tag
quantitativ
MedikamentPlaceboaltes Medikamentneues Medikament
qualitativ
TageinerBeobachtung
123
ordinal
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Erinnerung: Skalenniveaus und AusprägungVariablen nehmen unterschiedliche Ausprägungen an, die sich im Hinblick auf ihreMessung und erlaubten Operationen unterschieden.Definition 2.4 (Skalenniveaus):
1 Nominalskalenniveau: Keine Anordnung auf einer Dimension möglich.Erlaubte mathematische Operationen: =, 6=Beispiele: Geschlecht, Staatsangehörigkeit, Konfession
2 Ordinalskalenniveau: Rangreihung (Ordnung) auf einer Dimension nachgrößer - kleiner, besser - schlechter etc. möglich; über Abstände zwischendiesen benachbarten Urteilsklassen ist jedoch nichts ausgesagtErlaubte mathematische Operationen: =, 6=, <,>Beispiele: Schulnoten, Rangplätze beim Sport
3 Intervallskalenniveau: Ordnung auf einer Dimension möglich; die Abständezwischen den Skalenpunkten sind gleich.Erlaubte mathematische Operationen: =, 6=, <,>,+,−Beispiele: Zeitskala (Datum), Temperaturskalen (Celsius, Fahrenheit), IQ-Werte
4 Verhältnisskalenniveau: Intervallskala mit einem festen, nicht willkürlichenNullpunkt. Verhältnisse (halb oder doppelt so viel etc.) sind sinnvoll.Erlaubte mathematische Operationen: =, 6=, <,>,+,−, ∗, \Beispiele: Reaktionszeit, Lebensalter (0–150 Jahre), Fläche, Volumen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Erinnerung: Skalenniveaus und AusprägungHäufig werden die beiden letzten Skalenniveaus (Intervall- und Verhältnisskala) zumKardinalskalenniveau zusammengefasst.Eine verwandte Einteilung erfolgt hinsichtlich einer qualitativ/quantitativenMerkmalsausprägung.Definition 2.5 (Ausprägungen):
1 Eine Variable heißt qualitativ, wenn sie eine (höchstens ordinalskalierte)Eigenschaft der Untersuchungseinheit bezeichnet.
2 Eine Variable heißt quantitativ oder metrisch, wenn ihre (mindestensintervallskalierten) Ausprägungen “echt” gemessen oder gezählt wurden. DieMerkmalsausprägungen werden i.d.R. als Zahlenwerte plus Einheit angegeben.
3 Diskrete (quantitative) Variable haben höchstens abzählbar unendlich vieleAusprägungen.
4 Stetige (quantitative) Variable können prinzipiell überabzählbar viele Werteannehmen, z.B. jede reelle Zahl in einem Intervall.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Variation und CoBemerkung 2.1 (Abhängige und unabhängige Variable):
Die Zielgrößen sind abhängige Zufallsvariablen (abhängig von den Faktoren undVersuchsfehlern)
Die interessierenden Faktoren sollten durch den Versuchsleiter kontrolliertgeändert werden können und sollten unabhängig sein.
Definition 2.6 (Variation der Zielgröße):
Primärvariation: Systematische Variation der Zielgröße hervorgerufen nuraufgrund der interessierenden Faktoren
Sekundärvariation: Systematische Variation der Zielvariable hervorgerufendurch die Störfaktoren (nicht durch die interessierenden Faktoren)
Fehlervariation: Unsystematische Variation der Zielvariable, die weder auf denEinfluss von (identifizierbaren) Stör- noch auf die Manipulation derinteressierenden Einflussfaktoren zurückzuführen ist
Die Trennung in Sekundär- und Fehlervariation ist in der Praxis i.d.R. nichtnotwendig und eher konzeptueller Natur.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kontrolle von Sekundär- und FehlervariationEliminierung (z.B. Lärm)Konstanthaltung (z.B. Licht)Verblindung. Beispiel: Doppelblindstudien, bei denen sowohl derbehandelnde Arzt als auch der Patient nicht wissen, welchesMedikament der Patient bekommen hatUmwandlung der Störfaktoren in Einflussfaktoren→ zwei- odermehrfaktorielle PläneBlockbildung/Parallelisierung, Zuordnung zu Blöcken mittelsRangfolgenbildung (blocking)Randomisierung/zufällige Reihenfolge (randomization)Wiederholungsmessungen (repetition, repeated measurements)...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Feste und zufällige FaktorenZur Interpretation eines Versuchs und zur Verallgemeinerung derVersuchsergebnisse ist es nötig, zwei Arten von Faktoren zuunterscheiden: feste Faktoren und zufällige Faktoren.
Definition 2.7 (Feste und zufällige Faktoren):(a) Ein Faktor heißt fest (fixed factor), wenn seine Stufen eindeutigdefinierte, wiederholbare Ausprägungen (des Faktors) sind.
WIEDERHOLUNGSREGEL: Ein fester Faktor ist dadurchcharakterisiert, dass bei einer eventuellen Versuchswiederholungdieselben Faktorstufen verwendet werden würden wie imvorangegangenen Versuch.VERALLGEMEINERUNGSREGEL: Die Aussagen, die auf Grundeines Versuchs mit festen Faktorstufen gemacht werden, geltennur für die im Versuch verwendeten festen Faktorstufen.Beispiele: Geschlecht, Behandlung, Wochentag
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Feste und zufällige Faktoren(b) Ein Faktor heißt zufällig (random factor), wenn seine Stufen einezufällige Auswahl aus der Grundgesamtheit aller möglichen Stufendieses Faktors darstellen (Realisationen des zufälligen Faktors). DieStufen dieses Faktors sind nicht beobachtbare Zufallsvariable(unobservable random variables).
WIEDERHOLUNGSREGEL: Ein zufälliger Faktor ist dadurchcharakterisiert, dass bei einer Versuchswiederholung erneutzufällig ausgewählte Stufen des Faktors verwendet werden.VERALLGEMEINERUNGSREGEL: Die Aussagen, die auf Grundeines Versuchs mit zufälligen Faktorstufen gemacht werden,beziehen sich auf die Grundgesamtheit, aus der die im Versuchverwendeten Faktorstufen zufällig ausgewählt wurden.Beispiele: Patient, Labortier, Interviewer
⇒ Mehr hierzu: Später; insbes. im Abschnitt über Randomisierungund bei den auftretenden Random Effects Modellen!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

FaktorenerfassungFür eine gute Versuchsplanung ist es wichtig alle möglichenEinflußgrößen der Zielvariablen zu erfassen
Neben Expertenwissen (Befragung und Diskussion) könnenhierfür
auch sog. Cause-Effect- bzw. Fishbone-Diagramme hilfreichsein.
Weitere typische Hilfsmittel sind screening Pläne wie 2k -Pläne(kommen später) für erste Versuche.
Im nächsten Schritt sind diese nach interessierenden undStörfaktoren sowie Versuchsfehlern zu ordnen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Cause-Effect- bzw. Fishbone-Diagramme
(Quelle: http://tipqc.org/qi/jit/tools/cause-and-effect-diagram/)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kontrolle der Einflüsse
In einem aussagefähigen Versuch sollten alle Einflussgrößenunter Kontrolle sein
1 Faktoren: Unter Versuchskontrolle→ mit erfassen,2 Versuchsfehler: Unter statistischer Kontrolle→ randomisieren,
zufällig im gesamten Versuch verteilen.
Ist der Versuchsfehler nicht unter statistischer Kontrolle, dann istder Versuch verzerrt, das Versuchsergebnis ist nichtreproduzierbar und daher ist ein solcher Versuch in den meistenFällen nicht zu interpretieren.Deshalb versucht man bei einer Versuchsplanung die Faktorenvor der ersten Ergebnisregistrierung derart zu definieren,anzuordnen, zu kombinieren oder zu erfassen, dass die Streuungdes Versuchsfehlers möglichst klein wird.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele zu schlechter Versuchs- bzw.StudienplanungBeispiel 2.1 (Studie zu Kopf-Hals-Tumoren):
In einer Studie zu Kopf-Hals-Tumoren2 sollte untersucht werden,ob bestimmte genetische (und klinische) Faktoren einen Einflussauf das Krebsrisiko im Kopf-Hals-Bereich haben.Dabei wurde angenommen, dass dieses Risiko mit dem Altersteigt und Männer (im Alter) stärker betrifft als Frauen.So waren die meisten Patienten in dieser Studie Männer über 40.Um nun Risikofaktoren zu identifizieren, werden in solchenFall-Kontroll-Studien neben den Daten von Patienten (Fälle) auchdieselben Daten an Personen, die die Krankheit nicht zeigenKontrollen), erhoben, und die beiden Gruppen miteinanderverglichen.
2berichtet von einem mir bekannten StatistikerMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele zu schlechter Versuchs- bzw.Studienplanung
Da Alter und Geschlecht bekannte Risikofaktoren sind, solltendiese in dieser Studie neben den genetischen Faktoren mit in dasstatistische Modell aufgenommen werden.Die statistische Analyse dieser Daten führte zu einem Modell, dasziemlich gut zwischen Fällen und Kontrollen trennt (viel besser alsman es in solchen Studien erwarten würde).
Grund: Da es schwer (und kostspielig) ist, Kontrollen zurekrutieren, wurde das Krankenhauspersonal als Kontrollenverwenden – also hauptsächlich Frauen unter 30(Krankenschwestern).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele zu schlechter Versuchs- bzw.Studienplanung
Beispiel 2.2 (Aushärten von Aluminiumlegierung):Ein metallurgischer Ingenieur möchte den Effekt von zweiverschiedenen Aushärtungstechniken für eineAluminiumlegierung überpüfen: (1) Abschrecken mit Öl bzw. (2)Abschrecken mit SalzwasserDazu wählt er Proben aus zwei verschiedenen Öfen, schreckt dieProben aus Ofen i mit Methode (i) ab, i = 1,2, und misst imAnschluss die Härtegrade der LegierungenGute Idee?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele zu schlechter Versuchs- bzw.Studienplanung
Problem: Beim Vergleich der Mittelwerte aus beiden Gruppenkann der Ingenieur hier nicht mehr schließen, ob Unterschiedeaufgrund der unterschiedlichen Aushärtungstechnik oder aufgrundder unterschiedlichen Öfen (u.u. mit verschiedenenTemperaturen) auftreten
⇒ Man sagt: Er hat die Faktoren “Aushärtungstechnik” und “Ofen”confounded, d.h. Effekte dieser Faktoren können nicht mehrgetrennt werden!Außerdem sollten selbst bei einem so einfachen Experiment vieleFragen vorher beantwortet werden:
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele zu schlechter Versuchs- bzw.StudienplanungBeispielfragen
Sind obige Aushärtungstechniken die einzigen von Interesse?Welche anderen Faktoren (Temperatur des Mediums etc.) könnenden Härtegrad beeinflussen?Sollten diese im Experiment als Faktoren mit aufgenommen oderwenigstens kontrolliert (gleich gehalten) werden?Bei Mitaufnahme: Wie sollen die Faktoren angeordnet werden?Wie viele Proben sollen getestet werden (Fallzahlplanung) undwie sollen diese auf die verschiedenen Techniken aufgeteiltwerden ? (Wahl des Designs; balanciert hat oft Vorteile; aber:Kosten, Aufwand...)Welcher Unterschied zwischen den Härtegraden gilt als relevantMit welchem statistischen Verfahren sollten die Daten analysiertwerden?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beliebte (schlechte) Studienplanungsstrategien
Auffinden guter FaktorstufenkombinationenBest-Guess approach: Der Wissenschaftler (im letzten BeispielIngenieur) wählt aus Erfahrung die wichtigen Faktoren in einerbestimmten Kombinationsstufe aus (best-guess), um einenerwarten/erhofften Effekt auf die Zielgröße zu bekommen undführt damit das Experiment (mehrfach) durch.
⇒ Aufgrund seiner Erfahrung kann dies ganz gut funktionieren, aber:
I Bleibt das erhoffte Resultat aus, muss er nochmals eineFaktorstufenkombi wählen etc.Dies kann sehr viel Zeit in Anspruch nehmen.
I Ist das Ergebnis zufriedenstellend, so wird u.U. sofort gestoppt.I.d.R. gibt es aber noch andere Kombinationen, die zu besserenErgebnissen/Effekten führen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beliebte (schlechte) Studienplanungsstrategien
One-factor-at-a-time approach (OFAT):Für jeden Faktor wird eine Stufenbaseline festgelegt und dannjeder Faktor sukzessive, bei fest halten der anderen Faktoren aufder baseline, in Experimenten variiert.
⇒ Größtes Problem hierbei:I Mögliche Interaktionen zwischen den einzelnen Faktoren werden
komplett missachtet!I Häufig sehr ineffizient (im Bezug auf Stichprobengröße)
Besser: Statistische Versuchsplanung!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 3:
Grundprinzipien der Versuchsplanung

VorbemerkungenEin Experiment / Versuch wird typischerweise charakterisiertdurch die betrachteten
Versuchseinheiten und
Behandlungen sowie
deren Zuordnung und
den gemessenen Größen. BeispieleBehandlung Versuchseinheit ZielgrößeSchlafmittel Proband SchlafdauerFuttermittel Kuh MilchertragTumorart Labormaus ÜberlebenszeitWeizensorte Feld Ernteertrag
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

VariationenErinnerung:
Primärvariation: Systematische Variation der Zielgröße hervorgerufen nuraufgrund der interessierenden Faktoren
Sekundärvariation: Systematische Variation der Zielvariable hervorgerufendurch die Störfaktoren (nicht durch die interessierenden Faktoren)
Fehlervariation: Unsystematische Variation der Zielvariable, die weder auf denEinfluss von (identifizierbaren) Stör- noch auf die Manipulation derinteressierenden Einflussfaktoren zurückzuführen ist.
Was Primär- und Sekundärvariation ist wird im Vorfeld durch Festlegung derinteressierenden Faktoren/Einflussgrößen bestimmt!
Wir fassen die letzten beiden meistens zur Fehlervariation (im weitesten Sinne)zusammen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

PrimärvariationBemerkung 3.1 (Zur Primärvariation ):
Das Auftreten eines Effekts stellt man fest, indem man prüft, obdurch die Veränderung der Einflussgröße tatsächlich eineVeränderung der Zielgröße eingetreten istBeispiel: Verringert sich die Leistung beim Basketball (Veränderung ZG) durchVerabreichung einer höheren Dosis Alkohol (Veränderung EG)
Diese Unterschiede in den Messwerten der Zielgröße, nach denenwir eigentlich suchen, stellen idealerweise die Primärvariation dar.Leider kann nun aber die Variation der Einflussgröße auch durchStörfaktoren oder Versuchsfehler zu Stande gekommen sein.Diese ungewollte Variation (Fehlervariation) muss man kennen,um sie der eigentlich interessierenden Variation (Primärvariation)gegenüberstellen zu können.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Grundprinzipien der VersuchsplanungDas Hauptprinzip einer guten Versuchsplanung heißt i.d.R. auchMax-Kon-Min-Prinzip:
I Maximiere die Primärvariation!I Kontrolliere die Sekundärvariation!I Minimiere die Fehlervariation!
Für die letzten beiden Regeln verwendet man dabeitypischerweise eine der folgenden DoX Grundprinzipien:
Randomisierung
Wiederholungen
Blocking
Faktorielles Prinzip
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bermerkungen zu Max-Kon-MinVeranschaulichung von Max-Kon-Min-Prinzip: Sie sitzen in einerBar und nehmen ein tolles Lied aus der Musikanlage war. Umdieses besser zu hören, können Sie entweder die anderen Gästebitten, leiser zu sein (Reduzierung der Fehlervariation), oder dieAnlage lauter aufdrehen (Erhöhung der Primärvariation).
Die unerwünschte Fehlervariation (auch “Rauschen”) solltemöglichst gering gehalten werden, damit die zu erwartendePrimärvariation (auch “Signal”) das Rauschen deutlich überwiegt.
Falls die Fehlervariation jedoch nicht weiter verringert werdenkann, und die Gefahr besteht, dass die Manipulation derEinflussfaktoren im Vergleich zu Störfaktoren und Versuchsfehlereinen zu geringen Einfluss haben könnte, müssen Maßnahmenergriffen werden, um den Einfluss der interessierenden Faktorenzu erhöhen (Erhöhung der Primärvariation).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Maximierung der PrimärvariationAuswahl von extremen Werten: Damit die Primärvariationmöglichst groß wird, sollten möglichst unterschiedliche Werte derinteressierenden Faktoren verwenden werden.Grund: Effekt der Änderung sollte das Rauschen überwiegen.Beispiele: Behandlungsdauer (kurz, lang), Temperatur eines Prozesses (tief,hoch)Diese Methode ist nur sinnvoll, wenn eine einfache monotoneBeziehung zwischen ZG und EFen zu erwarten ist.
Wahl möglichst “optimaler” Stufen der Einflussfaktoren. In derPraxis ist dies aber i.d.R. vorab nicht möglich. Deshalb:
Auswahl möglichst vieler Stufen der Einflussfaktoren, denn: Jemehr Stufen wir untersuchen, um so genauer können wir dieBeziehung zwischen Zielgröße und Einflussfaktoren (Quelle fürdie Primärvariation) beschreiben.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kontrolle der Fehlervariation (im weitesten Sinne)Eliminierung (z.B. Lärm)Konstanthaltung (z.B. Licht)Verblindung. Beispiel: Doppelblindstudien, bei denen sowohl derbehandelnde Arzt als auch der Patient nicht weiß, welchesMedikament der Patient bekommen hatRandomisierung/zufällige Reihenfolge (randomization)Blockbildung/Parallelisierung, Zuordnung zu Blöcken mittelsRangfolgenbildung (blocking)Wiederholungsmessungen (repetition, repeated measurements)Umwandlung der Störfaktoren in Einflussfaktoren→ zwei- odermehrfaktorielle Pläne
BEM: In der Regel werden Kombinationen obiger Techniken (abhängigvon der Fragestellung) verwendet.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Eliminierung und Verblindung
Untersuchungen werden oft in Laboratorien und nicht in der alltäglichenUmgebung durchgeführt, da sich dort Störfaktoren besser eliminieren lassen.Eine vollständige Eliminierung aller Störfaktoren ist jedoch i.a. nicht möglich.
Beispiel 3.1 (Der Störfaktor Versuchsleitereffekt und Möglichkeiten derEliminierung): Untersuchung von Rosenthal und Fode (1961): Studentischen“Versuchsleitern” wurde die Aufgabe gegeben, einer Gruppe vonVersuchspersonen jeweils 10 Portraitfotos vorzulegen und anhand einer20stufigen Skala (plus dem Wert 0 als Mitte) einschätzen zu lassen, wieerfolgreich die portraitierten Personen wären (+10 = extrem erfolgreich, -10 =extrem erfolglos). In einem Vorversuch mit anderen Versuchspersonen (und den10 Fotos) war der Mittelwert der Einschätzungen exakt 0 gewesen. In derHauptuntersuchung wurde eine Gruppe der Versuchsleiter dahingehendinstruiert, dass der Mittelwert im Vorversuch -5 gewesen sei. Der anderenVersuchsleitergruppe wurde der Wert +5 als Vorinformation gegeben.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Eliminierung und Verblindung
⇒ Ergebnis: Wie erwartet erzielten die Versuchsleiter jeweilsErgebnisse, die deutlich vom Wert 0 abwichen und dabei jeweilsin der Richtung der Vorinformation lagen
⇒ Eliminierung z.B. durch Verblindung!Bei einem sog. “Doppelblindversuch” weiss weder dieVersuchsperson noch der eingesetzte Versuchsleiter, welcheexperimentelle Behandlung gerade abläuft. Übliches Vorgehen inder Biometrie.Erweiterung hiervon→ Trippelblindversuch in der Biometrie:Auch das sog. monitoring committee (u.a. Auswertungsinstanz)bekommt nur die Daten ohne weitere Kenntnisse
I Vorteil: ObkektivitätI Möglicher Nachteil: Bei ethischen Verpflichtungen ggü Patienten in
Arzneimittelstudien!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Konstanthaltung
Manche Variablen, die sich z.B. in unkontrollierter Weise auf dieFehlervariation auswirken können, kann man nicht eliminieren.Beispiele:
I das AlterI die NationalitätI die bisherige Erfahrung von PersonenI die Beleuchtungsart und -stärke, wenn es darum geht, etwas zu
sehenAnstelle der Eliminierung, versucht man hier die Größen(prinzipiell) konstant zu halten, indem man z.B.
I Personen ein und desselben Alters untersucht oderI darauf achtet, dass immer dieselbe Beleuchtung vorhanden ist.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

KonstanthaltungBeispiel 3.2 (Konstanthaltung): In einer Studie von Mayo (1950) wurdeuntersucht, ob eine Verbesserung der Arbeitsplatzbeleuchtung (Einflussgröße)zu einer Steigerung der Produktion (Zielgröße) in einem Industriebetrieb führt.Vorgehen:
I Vor Versuchsbeginn wurden die Produktionsleistungen an einerKontrollgruppe unter “normalen” Beleuchtungsbedingungen erhobenenund anschliessend
I mit denen einer Experimentalgruppe verglichen, die besonders gutbeleuchtete Arbeitsplätze erhalten hatte.
I Erstaunliches Ergebnis: Die Experimentalgruppe zeigte sowohl währenddes Experiments als auch nach dessen Abschluss (d.h. wieder unter“normaler” Beleuchtung) höhere Produktionsleistungen als dieKontrollgruppe!
⇒ Wahrscheinlicher Grund: Das Wissen um die Teilnahme an dem Versuchhat in der Experimentalgruppe zu (störenden) Motivationseffekten geführt!
⇒ Dieser Effekt hätte vermieden werden können, wenn man auch dieKontrollgruppe mit in den Versuch aufgenommen, d.h. das Wissen um das“Gemessenwerden” konstant gehalten hätte.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Randomisierung
Ein Experiment heißt randomisiert, wenn die Zuordnung derVersuchseinheit zur Behandlung einem bekannten (festen)Zufallsmechanismus unterliegt.Dieser Zufallsmechanismus heißt Randomisierung.Gründe:
I Durch die zufällige Zuteilung verhalten sich die Versuchseinheiteninnerhalb einer Behandlung gleich(rechtfertigt die beliebte i.i.d. Annahme)
I Schutz vor Confounding (Mehr dazu gleich)
⇒ Randomisierung ist eines der wichtigsten Grundprinzipien einerguten VersuchsplanungEin nicht-randomisierter Versuch heißt manchmal auchQuasi-Experiment.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

BeispielBeispiel 3.3 (Zur Randomisierung):
Ordne 4 verschiedene Behandlungen3 (I)-(IV) 16 VUen zu1 Verwende 16 verschiedene Blätter Papier; markiere 4 mit (I), 4 mit
(II) etc., mische diese 16 Blätter und ziehe für jede VU zufällig einPapier ohne Zurücklegen.
2 “Markiere” die VUen von 1, . . .16 und nehme die Einteilung nachder Realisierung einer multinomial-Mult4(16, 1
4 , . . . ,14 )-verteilten
Zufallszahl vor.3 Die ersten 4 VUen bekommen Behandlung (I), die nächsten 4
Behandlung (II) etc.4 Der Versuchsleiter entscheidet über die Zuteilung (ohne
zusätzlichen Mechanismus)
Was ist randomisiert?Erkennen Sie Unterschiede zwischen den Randomisierungen?
3Faktor “Behandlung” hat 4 StufenMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

BeispielDie letzten 2 Methoden sind nicht-randomisiert! Die Zuordnunghängt hier von einer (nicht-zufälligen) Reihenfolge der VUen oderdem (nicht-zufälligen) Bauchgefühl des Versuchsleiters ab!
⇒ Ich kann die zugehörigen Experimente nicht adäquat wiederholen,weil ich die VUen anders ordne oder ein anderes Bauchgefühl alsder Versuchsleiter habe
Die anderen beiden Methoden verwenden ein klar definiertesprobabilistisches Modell und sind somit randomisiert.
⇒ Ich kann die zugehörigen Experimente statistisch äquivalent durchVerwendung derselben Randomiserungstechnik wiederholen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fragen und Bemerkungen zum BeispielBemerkung 3.2 (zum Beispiel): Unterschied zwischen Methode1 und 2:
I Bei der ersten Methode ist die Anzahl der VUen in den Gruppenjeweils 4 (fest)
I bei der zweiten Methode ist diese zufällig!I Verschiedene Randomisierungen⇒ Verschiedenen Designs!
Übungsaufgabe: Wie erzeugen Sie die Realisierung einerMultinomial-Multk (n,p1, . . . ,pk )-Verteilung, k ,n ∈ N, k ≤ n,pi ≥ 0,
∑ki=1 pi = 1? Erinnerung: (xi ≥ 0,
∑i xi = n)
Multk (n,p1, . . . ,pk )(x1, . . . , xk ) = n!k∏
i=1
pxii
xi !(3.1)
Diskussion: Ist es nicht pervers dem Experiment durchRandomisierung noch mehr Zufall einzuimpfen? Wir wollen denVersuchsfehler doch eigentlich klein halten!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Randomisierung und Lottozahlen
1 2 3 4 5 6 78 9 10 11 12 13 14
15 16 17 18 19 20 2122 23 24 25 26 27 2829 30 31 32 33 34 3536 37 38 39 40 41 4243 44 45 46 47 48 49
In der ersten Stundesollten Sie zufälligLottozettel ankreuzen.Wir haben insgesamt106 Lottotipps erhalten,die wir (vereinfacht) alsunabhängige Tippsansehen wollen.
Frage von Interesse: Haben Sie die Zahlen wirklich zufälliggeneriert?Falls ja, so sollte die Anzahl der Kreuze auf dem äußeren Ringeiner hypergeometrischen-h(24,25,6)-Verteilung folgen.
⇒ Da Sarah und ich dies im Vorfeld bereits angezweifelt haben,testen wir nun H0 : {P = h(24,25,6)}, wobei P “Ihre” Verteilungbezeichnet.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Randomisierung und LottozahlenHistogram of Data
Data
Freq
uenc
y
0 1 2 3 4 5 6 7
05
1015
2025
30
Histogram of Zähldichte
Zähldichte
Freq
uenc
y
0 1 2 3 4 5 6 7
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015
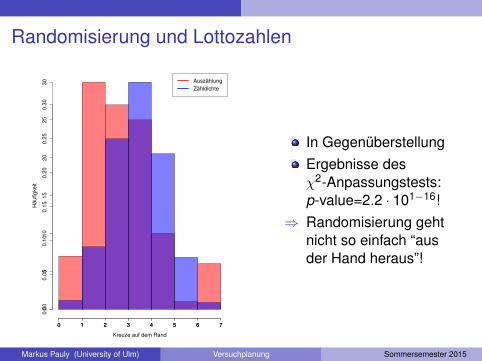
Randomisierung und Lottozahlen
Kreuze auf dem Rand
Häu
figke
it
0 1 2 3 4 5 6 7
05
1015
2025
30
0 1 2 3 4 5 6 7
0.00
0.05
0.10
0.15
0.20
0.25
0.30
AuszählungZähldichte
In GegenüberstellungErgebnisse desχ2-Anpassungstests:p-value=2.2 · 101−16!
⇒ Randomisierung gehtnicht so einfach “ausder Hand heraus”!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Randomisierung schützt vor ConfoundingErinnerung: Confounding = Der Effekt eines Faktors auf dieZielgröße kann nicht mehr von dem Effekt eines anderen Faktorsunterschieden werden.
Beispiel 3.4 (Koronare Herzkrankheit (KHK)4):I Man möchte ein neues Medikament für KHK mit der
kostspieligeren, invasiven Bypass-Operation vergleichen.I Zielgröße: Überlebenszeit (nach 5 Jahren; z.B.)I 100 Probanden haben ihr Einverständins zur Teilnahme gegeben.I Was kann passieren, wenn wir nicht randomisieren?I Der Gesundheitszustand der Patienten ist i.d.R. nicht homogen.⇒ Durchführende Ärzte sind verleitet den “schwächeren” Patienten
das Medikament zu geben und die “stärkeren” zu operieren.⇒ Die Faktoren Behandlung und Gesundheitszustand werden
confounded!I Wahrscheinliches Ergebnis: Schlechtere Überlebensrate in der
Medikamentgruppe4Sehr Vereinfacht nach Oehlert (2000)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mehr zur RandomisierungOben: Vereinfachte Sicht des Experiments als Zuordnung vonVUen zu Behandlungen und Messung von Zielgrößen.
Dies versteckt eine Vielzahl an zu beachtenden Punkten undEntscheidungen. Beispiele:
I Werden die VUen innerhalb der Behandlungen nicht gleichzeitigverwendet, so kann man jeweils auch derenVerwendungsreihenfolge randomisieren
I Werden verschiedene Messinstrumente zur Bestimmung derZielgröße verwendet, so kann man zusätzlich die Zuordnung zuden Messinstrumenten randomisieren.
I Werden die VUen an verschiedenen Orten verwendet, so kannman auch diese randomisieren!
⇒ Kann z.T. unübersichtlich werden!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mehr zur RandomisierungAndere Möglichkeit: Wird vermutet, dass einer dieser Punkte dieZielgröße beeinflusst, so kann dies auch im Design des Versuchsberücksichtigt werden! Beispiel hierfür später: Blocking!
⇒ Typisches Vorgehen: Designe das Experiment im Hinblick aufbekannte Probleme und randomisiere den Rest.
“Randomization generally costs little in time and trouble, but it cansave us from disaster.”
Gary W. Oehlert
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Durchführung einer RandomisierungFrage: Wie führt man die Randomisierung durch?
Physisch?I Münz- oder Würfelwurf (Manipulierte Größen?!)I Ziehen von durchgemischten Blättern/Karten (Gut durchmischt?)I “Ziehen” von VUen (Ganz schlecht wegen Inhomogenität der VUen)
Numerisch?I Mit (Pseudo)-Zufallszahlengeneratoren (deterministisch!)I Die heutzutage verwendeten (in SAS oder R) besitzen aber eine
sehr lange Periodizität und sind (aus statistischer Sicht) unkritisch!
Später: In Kombination mit Blockbildung führen verschiedeneRandomisierungen zu unterschiedlich “guten” Designs
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

BlockbildungManchmal ist es schwierig, den Einfluss von Störfaktoren zueliminieren oder konstant zu halten.Man kann dann durch Blockbildung versuchen, die Gleichheit vonVersuchsbedingungen bezüglich eines Störfaktors herzustellen.
⇒ Typisches Vorgehen:I Zuweisung der Versuchseinheiten zu “homogenen” Blöcken, so
dass die Variation der Einheiten bzgl. eines Störfaktors innerhalbjedes Blocks kleiner ist als die jeweilige Variation zwischen denBlöcken.
I Innerhalb jedes Blocks werden die Stufen der Einflussfaktoren perZufall auf die experimentellen Einheiten verteilt
Beispiele zur Blockbildung:I Parallelisierung (Matching) oderI Repeated Measurements oder sogarI eineiige Zwillinge (oder auch Drillinge, Vierlinge etc.) als Blöcke (da
genetisch homogen)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Parallelisierung (Matching)Zunächst werden die Personen einer Stichprobe aufgrund von Messwerten einesals relevant erachteten Störfaktors in eine Reihenfolge (Rangreihe) gebracht.Danach werden aus je 2 Personen mit “benachbarten” Rangplätzen paralleleBlöcke gebildet und die Behandlung innerhalb des Blocks zufällig bestimmt.Beispiel 3.5 (zur Parallelisierung5): Eine Psychologiestudentin möchteuntersuchen, wie sich die Konzentration auf die prospektivenGedächtnisleistungen auswirkt.Die Probanden werden durch Ablenkung oder keine Ablenkung (zweifachgestufter EF) in einen unkonzentrierten oder konzentrierten Zustand versetzt.Da das Alter einen zentralen Einfluss auf Gedächtnisleitungen hat, bringt sie dieProbanden dem Alter nach in eine Rangreihe und bildet daraufhin Paare. Mansagt, dass das Alter eine blockbildende Variable bildet. Die Personen aus denPaaren werden dann jeweils zufällig einer der beiden Bedingungen (abgelenktvs. nicht abgelenkt) zugeordnet.
⇒ Damit verteilt sich der Einfluss des Störfaktors “Alter” gleichmäßig auf diebeiden Bedingungen und führt nicht zu systematischer Verzerrung derMesswerte der Zielgröße.
5Quelle: TUD E-Learning
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015
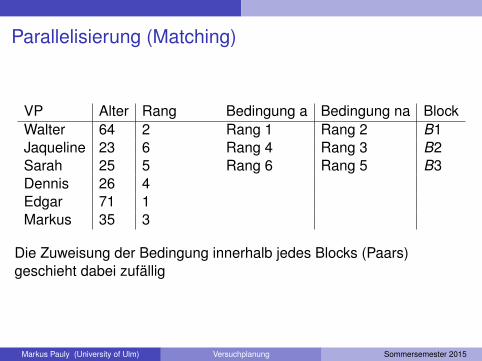
Parallelisierung (Matching)
VP Alter Rang Bedingung a Bedingung na BlockWalter 64 2 Rang 1 Rang 2 B1Jaqueline 23 6 Rang 4 Rang 3 B2Sarah 25 5 Rang 6 Rang 5 B3Dennis 26 4Edgar 71 1Markus 35 3
Die Zuweisung der Bedingung innerhalb jedes Blocks (Paars)geschieht dabei zufällig
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Repeated MeasurementsHierbei werden an jeder Versuchseinheit (jedem Individuum) wiederholteMessungen (Repeated Measures) unter allen Bedingungen durchgeführt. JedeVE ist also ein eigener Block!BSP: Messung einer Konzentration im Blut zu verschiedenen Zeitpunkten beiBehandlung und nicht Behandlung
Vorteile:
I Einfluss von Störfaktoren gleich für alle VersuchseinheitenI Kein Vortest zur Parallelisierung der Gruppe nötigI Häufig: Relativ geringe interindividuelle Variation zwischen den
Gruppen⇒Weniger Versuchseinheiten zur Feststellung eines Effekts nötig
Nachteil:
I Es können ungewünschte Übertragungseffekte (carry-overeffects) auftreten; z.B. durch Lernen der VE oder Zerstörung einesVersuchsobjektes, die den eigentlichen Effekt von Interesseüberlagen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Wiederholungen
Neben Randomisierung und Blocking zählt auch die Anzahl derunabhängigen Wiederholungen eines Versuchs mit den gleichenFaktorkombinationen zu den wichtigsten Grundprinzipien von DoXGründe:
I Schätzungen (Effekte, Fehlervarianz etc.) werden genauer mitwachsender Fallzahl n (LLN)
I Bei Tests: Güte hängt von n ab (Fallzahlplanung)Zu unterscheiden von Repeated Measurements (Blockbildungdurch Wiederholungsmessungen)⇒ Obige Unabhängigkeitsforderung verletzt
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Faktorielles Prinzip
Beispiel 3.6 (Basketball):Ich spiele gerne Basketball und liebe StatistikenNehmen wir an, ich würde in jedem Training 100 Würfe (je 50 FWeund 3er) nehmen und meine erzielten Punkte (score) notierenFrage: Welche Faktoren haben “wirklich” Einfluss auf meinenscore?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Faktorielles Prinzip
Beispiel 3.6 (Basketball)Ich spiele gerne Basketball und liebe StatistikenNehmen wir an, ich würde in jedem Training 100 Würfe (je 50 FWeund 3er) nehmen und meine erzielten Punkte (score) notierenFrage: Welche Faktoren haben “wirklich” Einfluss auf meinenscore?(A) Schuhe: Basketballschuhe vs. Laufschuhe(B) Ball: Profiball (Naturledergemisch) vs. Streetball (Gummigemisch)(C) Getränk: Wasser vs. Bier
I Untergrund, Wind, Temperatur,
Der Einfachheit halber betrachten wir nur die ersten 2 Faktoren Aund B (mit je 2 Stufen)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Faktorielles Prinzip
Angenommen ich habe noch keine Ahnung von DoX und wähle dieOFAT-Strategie:
Wähle baseline: Laufschuhe (=A+) und Streetball (=B+)Aus Zeitgründen wollen wir nur 4 Beobachtungen jeFaktorkombination wählen12 Beobachtungen
Faktorkombi A+B+(baseline) A+B− A−B+
Scores 93,90,92,93 92,94,91,91 95,92,93,91
Schätzung des Effekts von A durch A−B+ − A+B+; hier:
95 + 92 + 93 + 914
− 93 + 90 + 92 + 934
= 0.75
Schätzung des Effekts von B durch A+B− − A+B+; hier: 0
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Faktorielles PrinzipAngenommen ich hätte vorher doch ein Buch über DoX gelesen⇒ Die Kombination A−B− ist auch zu schätzen
Aus Zeitgründen wähle ich hier sogar “nur” 2 Beobachtungen jeFaktorkombination8 Beobachtungen in diesem faktoriellen 22-Design (StufenFaktoren):
Faktorkombi A+B+(baselie) A+B− A−B+ A−B−
Scores 93,90 92,91 95,92 100,97
Schätzung des Effekts von A durch A−B± − A+B±; hier:
95 + 92 + 100 + 974
− 93 + 90 + 92 + 914
= 4.5
Schätzung des Effekts von B durch A±B− − A±B+; hier: 2.5Schätzung der Wechselwirkung von AB:A+B+ − A+B− − A−B+ + A−B−; hier 2.5.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Faktorielles Prinzip
Fazit:Die Berücksichtigung aller Faktorkombinationen kann sehr wichtigsein!Insbesondere können Wechselwirkungen geschätzt (und späterauch getestet) werdenBemerke: Die Effekte von A und B werden sowohl bei OFAT alsauch beim faktoriellen Ansatz jeweils aufgrund von 8Beobachtungen geschätzt
⇒ OFAT benötigt aber insgesamt 12 Beobachtungen anstelle von 8bei obigen 22-Design zur Schätzung beider Effekte!Faktorieller Ansatz viel effizienter!Man sagt auch: Die relative Effizienz von OFAT im Vergleich zumfaktoriellen Ansatz ist 12/8 = 1.5
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Regression to the mean
Zu guter Letzt gehen wir noch auf einen weiteren Effekt ein, der dieGültigkeit von Untersuchungen beeinflussen kann.
Mit Regression to the mean muss man immer dann rechnen,wenn man Untersuchungen an so genannten Extremgruppendurchführt. Häufige Versuchsanordnung dabei:
1 Bildung der zu untersuchenden Extremgruppe auf Grund einerVorhermessung (Vortest) gebildet.
2 Danach erhält diese Extremgruppe die experimentelle Bedingung(Behandlung).
3 Im Anschluss daran wird ein Nachtest der Extremgruppe (vomähnlichen Typ wie der Vortest) durchgeführt. Hierbei nimmt manan, dass der Vortest den Nachtest nicht beeinflusst, d.h. dass keinTesteffekt vorliegt.
Wir verdeutlichen dies an einemBeispiel 3.7 (Cambell und Stanley (1963)): ...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel zu Regression to the mean
Ein Sportpsychologe vermutet, dass schlechte Leistungen imHochsprung hauptsächlich durch die Angst vor dem Absprungbedingt sind. Zu diesem Zweck entwickelt er eine Methode zurReduktion dieser Angst.Um seine Hypothese und die Effektivität seinerAngstreduktionsmethode zu überprüfen, geht er in eine Schuleund führt dort zunächst eine Vorhermessung durch, indem er imSportunterricht bei insgesamt 58 Schülern des gleichenJahrgangs die Hochsprungleistung ermittelt:
Höhe in cm 120 130 140 150 160 170 180Anzahl Schüler 4 6 12 14 12 6 4
Es sind also vier Schüler 1,20 m hoch gesprungen,sechs Schüler 1,30 m hoch etc.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel zu Regression to the mean
Nun wählt der Sportpsychologe die vier6 schlechtestenHochspringer (Extremgruppe) aus (1.) undführt mit ihnen sein Verfahren zu Angstreduktion durch (2.).Im Anschluss daran lässt er diese vier Schüler wiederhochspringen (Nachhermessung) (3.) und findet dabei folgendeErgebnisse:
I Ein Schüler bleibt bei seiner Höhe von 1,20 m,I einer verbessert sich auf 1,30 m,I einer spring 1,40 m undI ein ander springt jetzt sogar 1,50 m hoch.
Die durchschnittliche Leistung dieser Gruppe verbessert sich alsovon 1,20 m auf 1,35 m.
6sowieso schon viel zu kleine FallzahlMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel zu Regression to the meanWie kann man sich diese Leistungssteigerung erklären, wenn man davonausgeht, dass
(a) der Vortest keinen bedeutsamen Einfluss auf den Nachhtest ausgeübt hatund
(b) die Variation des Einflussfaktors Angstreduktionsmethode, in Wahrheitkeinen Effekt gehabt hat?
⇒ Bekanntlich sind Leistungen im Sport (aber nicht nur dort) Schwankungenunterworfen.
Mögliche Erklärung also: Die schlechten Hochspringer hatten in obigem Beispieleinfach nur einen (unverhältnismäßig) schlechten Tag beim Vortest erwischt.
Das Ergebnis beim Nachtest hätte natürlich auch noch schlechter werdenkönnen; die Wahrscheinlichkeit hierfür ist jedoch geringer, da wir annehmen,
I dass die Wahrscheinlichkeitsverteilung der gesprungenen Höhen gleich istbei Vor- und Nachtestung,
I dass sich also an der Verteilung durch die (Angst-) Behandlung nichtsverändert hat ((b) oben).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel zu Regression to the meanDies wird noch klarer, wenn man sich folgende hypothetischen Ergebnisse deranderen Schüler anschaut:
Also: Die vier “Schlechtesten” aus dem Vortest verbessern ihre Leistung aufdurschnittliche 1,35 m,die sechs “1,30 m–Springer” verbessern sich im Durchschnitt auf 1,40 m (imNachtest);...die vier “Besten“ dagegen verschlechtern ihre Durchschnittsleistung auf 1,65 m(im Nachtest).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel zu Regression to the meanDieser Regressionseffekt zum Mittelwert ist typischerweise desto größer, jeextremer die Gruppen im Vortest waren, denn:Nimmt man vereinfacht an, dass die Ergebnisse aller Schüler i.i.d. sind, sovergleicht man die Verteilung extremer Orderstatistiken (Vortest) mit der derGrundgesamtheit (Nachtest).
Fazit fürs Beispiel:I Unser Sportpsychologe kann uns also nicht von der Effektivität seiner
Angstreduktionsmethode überzeugen.I Es lag hier wahrscheinlich nur ein Regressionseffekt vor:I Die vier schlechten Hochspringer haben vermutlich beim ersten Mal
überdurchschnittlich viel Pech gehabt. Dass sie dieses Pech beim zweitenMal noch einmal haben würden, war ziemlich unwahrscheinlich(Schwankungen).
I Für die guten Hochspringer beim Vortest gilt das Umgekehrte(Schwankungen in die andere Richtung).
I Der Sportpsychologe hätte besser daran getan, entweder sämtliche 58Schüler oder aber eine repräsentative Stichprobe dieser Schüler zubehandeln und dann nochmals zu untersuchen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische ModellierungBemerkung 3.3 (zur statistischen Modellierung):
Vor Versuchsdurchführung und -auswertung (hierzu später mehr) sollte man sichauch Gedanken über ein geeignetes Modell machen.
Bei einer Fragebogenerhebung zum Stress im Studium mit jeweils 4Antwortmöglichkeiten7 (2 = stimme vollständig zu, 1 = stimme eher zu, -1= lehneeher ab, -2= lehne vollständig ab) ist die Annahme normalverteilter Antworten(oder Summen) eher schlecht. Hier würde u.U. eine diskrete oder ganznichtparametrisch, ordinale Annahmen mehr Sinn machen.
Typische Modellannahmen: Lineare Modelle, GLMs, Regressionsmodelle etc.mit
I parametrischerI semiparametrischer oderI nichtparametrischer
Verteilungsannahmen.
7sog. Forced Choice da gerade Anzahl; oft ist aber eine weitere, neutraleAntwortmöglichkeit wie ”weder noch“ gegeben
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische ModellierungBeispiel 3.8 (zu Modellen): Beispiele für
ein parametrisches Modell:
Y = µ+ ε,
ε normalverteilt.ein semiparametrisches Modell:
Y = g(x) + ε,
g ∈ G Funktionenklasse, ε normalverteiltein nichtparametrisches Modell:
Y ∼ F ,
F unbekannte Verteilung
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bemerkung zur statistischen Modellierung
Auch bei idealer Studienplanung ist das Anpassen einesstatistischen Modells nur eine Approximation an die Realität, diesehr (viel zu) komplex ist.Wir wissen dabei nie mit Sicherheit, was das korrekte Modell ist.Wir können nur unser Bestes geben, dass das gefundene Modelleine angemessene Repräsentation der Realität ist.
“All models are wrong, but some are useful.”
George Box
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 4:
Erste Versuchspläne und statistischeAuswertung

Definition – VersuchsplanEin Versuchsplan gibt Auskunft über
I Anzahl und Stufen der Einflussfaktoren (kurz: Faktoren)I die Häufigkeit der Messungen der Zielgröße undI die vor Versuchsbeginn erfolgte Verteilung der Versuchseinheiten auf die
unterschiedlichen Versuchsbedingungen (Versuchsgruppen).
Definition 4.1 (Versuchsplan): Ein Versuchsplan gibt an, an wie vielenGruppen von Versuchseinheiten wie oft die Darbietung der Stufen der Faktoren(und deren Anzahl) vorgenommen und die Einflussgröße gemessen werdenmuss und welche Kontrolltechnik(en) verwendet werden sollen.
Versuchseinheiten können z.B. Menschen, Probanden, Tiere, Pflanzen,Zellkulturen, Felder, Materialproben jeglicher Art (Flüssigkeiten, Pulver,Einzelteile einer Massenproduktion etc.) sein.
Sie können entweder nur einfach aber auch mehrfach (unter derselben oderunter verschiedenen Stufenkombinationen) beobachtet werden.
Der Versuchsplan dient als Grundlage für die spätere Auswertung, da je nacheingesetztem Plan andere statistische Methoden zu verwenden sind.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Versuchsplan – BemerkungenIm Folgenden: Beispiele für erste einfache Versuchspläne
Terminologie:I Faktoren: A, B, C usw.I Stufen dieser Faktoren: i = 1, . . . ,a, j = 1, . . . ,b, k = 1, . . . , c, etc.I Versuchseinheiten: Vs, s = 1, . . . ,n (oder auch mehrfach indiziert)I Zugehörige Messwerte: Ys, s = 1, . . . ,n (auch mehrfach indiziert)I Art der Zuweisung der V ’s zu Faktoren-Stufen-Kombinationen; z.B.→ O: Die Versuchseinheiten werden ohne bestimmte Kontrolltechnik
(z.B. direkt durch den Versuchsleiter) zugeteilt→ R: Die Versuchseinheiten werden zufällig mittels Randomisierung
verteilt→ B: Die Versuchseinheiten werden mittels Blocking verteilt.→ RB: Randomized-Block-Design→ . . . später mehr.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 1-GruppenplanEin Faktor A mit einer Stufe und 1x-iger Messung pro(unabhängiger) Versuchseinheit.
Faktor AStufe 1Versuchseinheit 1 V1...
...Versuchseinheit n Vn
Zuweisung hier typischerweise O, da die Gruppe so untersuchtwurde wie sie in der Natur vorkommt.Obiges Vorgehen entspricht typischerweise demErkenntnisgewinn im alltäglichen Leben8....
8es darf auch n = 1 gelten :)Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 1-GruppenplanBeispiel 4.1 (Einfache 1-Gruppenpläne):
Familie Müller benutzt seit Jahren die Zahncreme Exonal und derZahnarzt hat seitdem nicht mehr gebohrt⇒ Erklärung im Alltag typischerweise: Die gute Zahncreme (EF)
erklärt die erfahrene Zahnbehandlungen (ZG).⇒ Eine andere plausible Erklärung: Bessere bzw. besonders gesunde
Ernährung (Störfaktor) seit Jahren.Der Fußballverein SSV hat seit seinem Aufstieg in die Bundesligaimmer noch denselben Trainer und jetzt die Meisterschafterrungen.⇒ Eine Alltagserklärung: Der Trainer (EF) hat die Meisterschaft (ZG)
gewonnen.⇒ Hier könnten aber auch andere Gründe (SF) wichtiger für den
Erfolg gewesen sein; z.B. der Torwart oder ein besonderer Spieleroder...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 1-GruppenplanProbleme dieses Versuchsplans:
I Fehlen einer Vergleichsmöglichkeit: Man kann quasi nur mit der(nicht genau gemessenen) Erinnerung vergleichen und damitEffekte nicht wirklich bestimmen
I Da weder Kontrollen (d.h. Kontrolltechniken) noch Vergleiche (d.h.Vergleichsgruppen) vorhanden sind, kann man z.B. nicht prüfen, obeine Gruppe ohne Behandlung vielleicht genau dieselbenMesswerte ergeben hätte.
⇒ Das “Ergebnis” (welches eigentlich keines ist) kann nicht aufandere Situationen übertragen (generalisiert) werden.Da man hierbei den Effekt nicht bestimmen kann, ist dieserVersuchsplan der einmaligen Untersuchung einer Gruppe (egalwie genau gemessen wird) für wissenschaftliche Untersuchungeni.d.R. ungeeignet und wertlos.Ausnahme: Man interessiert sich nur für das Schätzen (vonFunktionen) der Wahrscheinlichkeit p für das Auftreten einesbestimmten Ereignisses⇒ Tafel!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Paariger 1-GruppenplanEin Faktor A mit 2x-iger Messung pro (unabhängiger)Versuchseinheit. Typisch: Messung vor und nach Behandlung beije n Patienten.
Faktor AStufe 1 2Block 1 = Versuchseinheit 1 V1 V1...
......
Block n = Versuchseinheit n Vn Vn
Zuweisung hier in der Praxis leider häufig auch O, da nur eineGruppe vorliegt. Es gibt aber Möglichkeiten:Zwillingsforschung: Hier stellt ein Zwillingspaar als Block eine VEdar. Die Behandlung könnte dann nur an einem zufälligausgewählten Zwilling randomisiert durchgeführt werden;analog bei Körperhälften: z.B. rechtes Auge vs. linkes Auge
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Paariger 1-Gruppenplan
Faktor AFaktor Versuchseinheit 1 2
1 V1 V1...
......
n Vn Vn
Möchte man (wie häufig) Aussagen über die Grundgesamtheitaller Versuchseinheiten (Patienten) machen, so ist der obigepaarige 1-Gruppenplan genau genommen ein sog. Mischplan, beidem neben dem festen Faktors A mit 2 Stufen ein zufälliger Faktor(Patient) mit n Stufen vorliegt.Dabei sind die Stufen der beiden Faktoren jeweils komplettgekreuzt, d.h. die Stufen bilden ein kartesisches Produkt, bei demjede Stufe des einen Faktors mit jeder Stufe des anderen Faktorskombiniert ist.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Paariger 1-GruppenplanVorteile dieses Versuchsplans:
I Vergleichsmöglichkeit vorhanden: Es liegt ein echter (und kein„fiktiver“) Vergleich von zwei Messwerten, auf den sich unsereweiteren Überlegungen stützen können, vor.
I Typische Effektmessgröße: Differenz 1.Messung - 2.MessungI Bei Zwillingen: Anwendung von Kontrolltechniken möglich.
Mögliche Nachteile des Versuchsplans (bei O):I Aufgrund fehlender Kontrolltechniken können sich auch
rivalisierende Erklärungsmöglichkeiten für etwaige Effekteauszeichenen.
→ Mögliche Vermischung mit Störvariablen wieF ZeiteinflüsseF Testeffekte (auch Reihenfolge)F Veränderungen der MessinstrumenteF etc.
I Beispiel:...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Paariger 1-GruppenplanBeispiel 4.2 (Paariger 1-Gruppenplan): Einführung neuer Mathematik-Bücher fürdie Oberstufe.Im ersten Halbjahr wird der LK von Lehrer Müller nach dem alten Buch und im 2. nachdem neuen Buch unterrichtet. Im Anschluss stellt man fest, dass sich die Schüler im2. Halbjahr im Durchschnitt verbessert haben
⇒ Gewünschte Erklärung: Der Effekt ist auf das Lehrbuch zurückzuführen.Mögliche Probleme mit dieser Erklärung:
I Zeiteinflüsse: Noten können mit den Jahreszeiten schwanken(Versetzung!);der Stoff des 1. Halbjahres könnte schwerer sein als der des 2.
I Testeffekte: Motivation zu besserem Lernen durch schlechte Noten imersten Halbjahr.
I Versuchsleitereffekt: Lehrer hat durch den auch für ihn neuen Input mehrSpaß am Lernen und motiviert dadurch die Schüler besser als zuvor oder...
I benotet dadurch besser (Veränderungen der Messinstrumente)⇒ Beheben z.B. durch Unterrichten von 2 verschiedenen (1x nach altem und
1x nach neuem Buch) unabhängigen Kursen gleichzeitig (mit zufälligzugewiesenen Schülern)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 2-GruppenplanEin Faktor A mit zwei Stufen und 1x-iger Messung proVersuchseinheit. Der Faktor A beschreibt hierbei i.d.R. dieGruppenzugehörigkeit und es werden zusätzlich noch dieStichprobenumfänge mit angegeben.Typisches Beispiel: Vergleich mit einer Kontrollgruppe
Faktor AStufe (Gruppe) 1 2Stichprobenumfang n1 n2
V11 V21
Versuchseinheiten...
...V1n1 V2n2
BEM: Vij steht für VE j = 1, . . . ,ni in Gruppe i = 1,2.Die Güte dieses Versuchsplans hängt auch wieder von derZuweisung der VE ab!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 2-Gruppenplan – vorgegebene GruppenNehmen wir zunächst an, dass es sich um vorgegebene, d.h. nicht zufälligzusammengesetzte Versuchsgruppen handelt.
Beispiel 4.3 (Einfache 2-Gruppenpläne):I Forscher der Universität möchten den Effekt bestimmter indischer
Rechentechniken auf das Lösen von Rechenaufgaben bei Schülern der 4.Klasse untersuchen. Dafür werden 10 Schüler einer privaten Grundschuleausgewählt und über 4 Wochen nach der indischen Methode unterrichtet.Als Kontrollgruppe werden 10 Schüler einer städtischen Grundschuleherangezogen. Im Anschluss an die Intervention werden in beidenGruppen identische Mathematikests geschrieben und bewertet. Schneidetdie Interventionsgruppe besser ab als die Kontrollgruppe, so möchten dieForscher im Anschluss eine umfangreiche bundesweite Studiedurchführen.
I Matheson et al. (1978):9 Es soll der Effekt der Gefangenschaft auf dasVerhalten einer Antilopenart untersucht werden. Hierzu wird die Herdeeiner wild lebende Antilopenart (Versuchsgruppe) mit einer bereits längereZeit im Zoo lebenden Gruppe (Kontrollgruppe) verglichen. (Messung überein Score-System).
9Experimental psychology: Research design and analysis. 3rd edition. New York: Holt, Rinehart & Winston
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 2-Gruppenplan – vorgegebene GruppenDas zweite Beispiel hat dabei die zusätzliche Besonderheit, dassder Einflussfaktor nicht vom Versuchsleiter selbst manipuliertwerden kann!
Zwischenfragen: Was sind im Beispiel Ziel- und Einflussfaktor undwie sind diese skaliert?
ZF: Lösen von Rechenaufgaben (ordinal: Schulnote nachMathetest); EF: Unterrichtsmethode (nominal: indisch oderklassisch)
ZF: Verhalten (ordinal: Score-System zum Verhalten);EF: Gefangenschaft (nominal: ja oder nein)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 2-Gruppenplan – vorgegebene GruppenDas zweite Beispiel hat dabei die zusätzliche Besonderheit, dassder Einflussfaktor nicht vom Versuchsleiter selbst manipuliertwerden kann!
Genauer: Hier wird im Anschluss (ex post) an die – in Form einesNaturereignisses (Wildbahn) – auftretende bzw. bereitsvorliegende faktenschaffende Behandlung (facto) gemessen.
Anordnungen, in denen nur noch die Wirkung einer bereits zuvorstattgefundenen (nicht selbst herbeigeführte) Behandlunggemessen werden kann, heißen deshalb auchEx-post-facto-Anordnungen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 2-Gruppenplan – vorgegebene GruppenVorteile dieses Versuchsplans:
Vergleichsmöglichkeit vorhanden: Es liegt ein echter (und kein„fiktiver“) Vergleich von zwei Messwerten, auf den sich unsereweiteren Überlegungen stützen können, vor.Typische Effektmessgröße: Differenz Gruppe 1 - Gruppe 2Im Vergleich zum Paariger 1-Gruppenplan(Vorher-Nachher-Messung):
I Die StörvariablenF Testeffekte,F Veränderung der Messinstrumente undF Regression to the mean
treten hier typischerweise nicht auf.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 2-Gruppenplan – vorgegebene GruppenMögliche Nachteile des Versuchsplans (bei O):
Aufgrund fehlender Kontrolltechniken können sich auch rivalisierendeErklärungsmöglichkeiten für etwaige Effekte auszeichenen.
Auswahlverzerrungen: Unähnlichkeit der beiden vorgegebenenVersuchsgruppen bereits vor Durchführung des Experiments
→ Im ersten Beispiel könnten die Schüler der privaten Schulen vielleichtaufgrund der dort besseren Betreuungssituation schon zu Beginn überbessere Rechenkenntnisse verfügen.
Confounding: Wallin et al. (1985) haben die Verbesserung der Dehnfähigkeit derrückseitigen Oberschenkelmuskulatur durch verschiedene Dehnübungen(dynamisch vs. statisch) überprüft. Die dynamisch Gruppe dehnte durchRumpfbeugen; die statische durch auflegen des zu dehnenden Beines imStehen auf einen Tisch. Ergebnis: Statisches Dehnen ist effektiver. Allerdings sonicht haltbar, da hier zwei Faktoren confounded worden: Stretchingtechnik(statisch vs. dynamisch) und Ausführungsformen (Rumpfbeuge vs. Fuß auf demTisch). Man hätte identische Ausführungen wählen müssen!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Einfacher 2-Gruppenplan – vorgegebene GruppenMögliche Nachteile des Versuchsplans (bei O):
Aufgrund fehlender Kontrolltechniken können sich auch rivalisierendeErklärungsmöglichkeiten für etwaige Effekte auszeichenen.
Experimentelle Einbußen: Die Gruppen könnten zwar vor Beginn desExperiments ähnlich sein, sich während der Durchführung aber in ungleicherWeise dezimieren, so dass sie nicht mehr wirklich vergleichbar sind.
→ Im vorherigen Beispiel könnten sich die “unsportlichen” Teilnehmer beimDehnen je nach Technik in einer Gruppe häufiger verletzt haben, so dassin dieser nur Ergebnisse der sportlicheren Versuchspersonen vorliegen
⇒ Die obigen Probleme lassen sich i.d.R. durch geeignete Kontrolltechniken(insbes. randomisierte Zuweisung zu den Gruppen) und ausreichendeFallzahlplanung (kommt jetzt gleich) beheben.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Auswertung von verbundenen undunverbundenen 2-SPenproblemen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Das verbundene 2SPenproblem
NomenklaturI Beobachtungen Yk = (Y1k ,Y2k )′
F k = 1, . . . ,N unabhängige Wiederholungen
Statistisches ModellI Yk = µ + εkI µ = (µ1, µ2)′ = E(Y1) ErwartungswertvektorI Klassische Annahme:
εii.i.d.∼ N(0,Σ) 1 ≤ k ≤ N (4.1)
mit unbekannter, positiv definiter Kovarianzmatrix Σ (i.Z. Σ > 0)
Test für H0 : {µ1 ≤ µ2} (oder {µ1 = µ2}, {µ1 ≥ µ2}) ?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der verbundene 2SPen-t-Test
Einseitiges Testproblem: H0 : {µ1 ≤ µ2} vs. H1 : {µ1 > µ2}I Setze Dk = Y1k − Y2kI Teststatistik
T pair =DN
Spair/√
N(4.2)
F mit DN = N−1∑Nk=1 Dk
F S2pair = (N − 1)−1∑N
k=1(Dk − DN)2
= Statistik des 1-SPen-t-Tests in den Differenzen.I Paariger t-Test für H0: ϕN = 1{T pair > tν,α}, ν = N − 1,
tν,α = (1− α)-Quantil der tν-Verteilung
I Begründung und Eigenschaften?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der verbundene 2SPen-t-Test
Analog:Einseitiges Testproblem: H0 : {µ1 ≥ µ2} vs. H1 : {µ1 < µ2}
I Unterer paariger t-Test: ϕN = 1{T pair < −tν,α}
Zweiseitiges Testproblem: H0 : {µ1 = µ2} vs. H1 : {µ1 6= µ2}
I Zweiseitiger paariger t-Test: ϕN = 1{|T pair | > tν,α/2}
Konfidenzintervalle für δ = µ1 − µ2 (Übung!)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Allgemeinerer Fall – Nicht-Normalverteilte FehlerNeues Modell
εkstu∼ F , F unbekannte 2-dim Verteilung mit Σ = Σ(F ) > 0. (4.3)
Satz 4.0 (Asymptotik): Der paarige t-Test bleibt im Modell (4.3) asymptotischkorrekt, d.h. Eµ(ϕN)→ α1{µ1 = µ2}+ 1{µ1 > µ2}. (Beweis an der Tafel)
Allerdings: Finit nur Approximation; z.T. schlecht bei schiefen Verteilungen
Mögliche Verbesserung: Randomisierung→ Randomisations-t-TestI Vertausche für jede Beobachtung (Yk )k die Koordinaten zufällig→ (Y sign
k )k (randomisierter Vektor)I (Bedingte) Quantile von T ((Y sign
k )i,k ) als kritische WerteI EIG: Auch asymptotisch korrekt und sogar finit exakt bei 0-Symmetrie von
D1!I Details: Vorlesung “Asymptotische Statistik”
Andere Lösung (z.T. für ordinale Daten): (Wilcoxon-)Vorzeichen-Test oderpaariger Brunner-Munzel (besser)
Bei nominalen Daten: McNemar Test oder χ2-Test
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der verbundene 2SPen-t-Test – Fallzahlplanung
Ziel (Fallzahplanung): Wähle bei gegebenen Fehler 1.Art (i.d.R.α = 0.05 oder 0.01) die Stichprobe N so groß, dass ein klinischerrelevanter Effekt ∆ mind. mit WS 1− β erkannt wird (typischβ = 0.1 oder 0.2).Bem: Dies hängt stets vom Modell und Testverfahren ab!Hier betr. wir nur ϕN im Modell (4.3).Messung des Effektes durch µd = µ1 − µ2
Gründe für Fallzahlplanung:I Ethischer Natur (unnötige Belastung von Probanden verhindern)I Ökonomischer Natur (je größer die Fallzahl desto teurer die Studie)
Fallzahlplanung immer vor der Durchführung der Studie(mit ins Protokoll aufnehmen)Intuitiv klar: Je kleiner der zu erkennende Effekt ∆, desto größermuß N gewählt werden.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Weiter an der Tafel. . .
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der verbundene 2SPen-t-Test – Fallzahlplanung
σ = Vorschätzung der Varianz (z.B. aus Literaturstudium); wirdtypischerweise bei der Berechnung noch variiert (±ε)Approximative Lösung im Modell (4.3) für einseitigen Test ϕN :
N ≈(zα + zβ)2σ2
∆2 . (4.4)
Für den zweiseitigen Test 1{|T pair | > tν,α/2} erhält man analog:
N ≈(zα/2 + zβ)2σ2
∆2 . (4.5)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der verbundene 2SPen-t-Test – Fallzahlplanung
Beispiel 4.4 (Vorbeugung von Osteoporose): Zur Vorbeugung vonOsteoporose bei postmenopausalen Frauen wird empfohlen mitInterventionen bei Vorliegen von Osteopenie (Vorstufe) zu beginnen.Wir nehmen an, dass die erwartete Knochendichte vor Behandlung bei-2 PBM (peak bone mass) liegt. Als klinisch relevant wird eineVerbesserung auf mind. -1.5 PBM angesehen. Für α = 0.05, β = 0.2und eine Vorschätzung σ2 erhält man:
N ≈ (z0.05 + z0.2)2σ2
0.52 ≈ (1.645 + 0.842)2
0.52 σ2 ≈ 24,74σ2
Für eine Vorschätzung von σ2 = 1 würde man also N = 25 wählen.Häufig würde man aber konservativer planen...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der verbundene 2SPen-t-Test – FallzahlplanungEntstammt die Vorschätzung σ2 aus einer vorangegangenen Studie anm Patienten als zugehörige empirische Varianz s2
m, so ist(0,
(m − 1)s2m
χ2m−1,0.95
]
mit χ2m−1,α = (1− α)− Quantil der χ2
m-Verteilung, ein (approximatives)einseitiges 95% Konfidenzintervall für die wahre Varianz σ2 (ZurÜbung). Waren in der vorangegeangenen Studie also beispielsweisem = 50 Patienten und sm = 1, so könnte im Beispiel zurkonservativeren Fallzahlberechnung auch der rechte Endpunkt alsVorschätzung σ2 = 49/χ2
49,0.95 ≈ 1.44 gewählt werden. Dies würde auf
N ≈ d24,74 ∗ 1.44e = 36
führen.Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Wilcoxon-Vorzeichentest
Modellannahmen und NomenklaturI die Messwert-Paare Xi = (Xi1,Xi2), i = 1, . . . ,n, sind unabhängig
IdeeI Quantifizierung von besser bzw. schlechterI lineares Modell
Xij = µj + εijεij : i.i.d. mit E(εij ) = 0, 0 < Var(εij ) <∞
I Es reicht aus: Differenzen εi2 − εi1 sind 0-symmetrischEffekt
I µd = µ2 − µ1
HypotheseI H0 : µd = µ2 − µ1 = 0
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Wilcoxon-Vorzeichentest
Idee und Berechnung der StatistikI Differenzen Di = Xi2 − Xi1 bilden
(Vorsicht bei ordinalen Daten!!!)I Null-Differenzen Di = 0 weglassenI n∗ : Anzahl der Null-Differenzen Di = 0I n0 = n − n∗ Anzahl der Differenzen Di 6= 0I die Absolutbeträge der Differenzen |Di | = |Xi2 − Xi1| rangieren
d.h. den |Di | Ränge zuweisen → R+i
bei Bindungen → MittelrängeI R+: Summe der R+
i , die zu Di > 0 gehörenI R−: Summe der R+
i , die zu Di < 0 gehörenI R+ + R− = n(n + 1)/2I die Differenz R+ − R− beschreibt den Unterschied von µd zu 0.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Wilcoxon-Vorzeichentest
Ablaufschema
Indiv. Zeitpunkt Differenz Vor- Absolut- RängeNr. 1 2 Xi2 − Xi1 zeichen Betrag R+
i1 X11 X12 X12 − X11 |X12 − X11| R+
1...
......
......
......
i Xi1 Xi2 Xi2 − Xi1 |Xi2 − Xi1| R+i
......
......
......
...n Xn1 Xn2 Xn2 − Xn1 |Xn2 − Xn1| R+
n
Summen: R+ =∑
i:Xi2−Xi1>0
R+i , R− =
∑i:Xi2−Xi1<0
R+i
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Wilcoxon-VorzeichentestStatistik / große Stichproben, n0 ≥ 15
W+n =
R+ − R−√∑n0i=1
(R+
i
)2
.∼. N(0,1) unter H0 (n0 →∞)
keine Bindungen⇒
I
n0∑i=1
(R+
i
)2=
n0(n0 + 1)(2n0 + 1)
6
W+n =
R+ − R−√n0(n0 + 1)(2n0 + 1)/6
=R+ − n0(n0 + 1)/4√
n0(n0 + 1)(2n0 + 1)/24.∼. N(0,1) unter H0 (n0 →∞)
kleine Stichproben / n0 < 15I Permutationsverfahren
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Wilcoxon-Vorzeichentest
Voraussetzungen für die Anwendung des Tests
I Stichproben* verbunden* Messwertpaare unabhängig
I Daten* genau genommen metrisch!* lineares Modell (für eine gute Interpretation)* zu 0 symmetrische Verteilung der Fehler-Differenzen,
AnmerkungI Test ist empfindlich auf die Annahme, dass die Fehler-Differenzen
symmetrisch zu 0 verteilt sindI schwierig überprüfbare VoraussetzungI Wird oft falsch angewendet! Besser für ordinale Daten:
F Vorzeichentest mit Prüfgröße∑n
i=1 1{Xi1 < Xi2} − 1{Xi1 > Xi2}F oder paariger Brunner-Munzel-Test (wirft weniger “Info” weg)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Das unverbundene 2SPenproblem
NomenklaturI Beobachtungen Yik
F Zwei Gruppen: i = 1, 2 (= Ein Faktor A mit 2 festen Stufen)F k = 1, . . . , ni unabhängige WiederholungenF N = n1 + n2 Beobachtungen
Statistisches ModellI Yik = µi + εikI µi = E(Yik ) Erwartungswert in Gruppe iI Klassische Annahme: Versuchsfehler
εiki.i.d.∼ N(0, σ2) i = 1,2, 1 ≤ k ≤ ni (4.6)
mit unbekannter aber gleicher Varianz σ2 ∈ (0,∞)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der unverbundene 2SPen-t-Test
Einseitiges Testproblem: H0 : {µ1 ≤ µ2} vs. H1 : {µ1 > µ2}I Teststatistik:
T =Y 1· − Y 2·
SN
√1n1
+ 1n2
(4.7)
F mit Y i· = n−1i
∑nik=1 Yik
F S2N = (N − 2)−1∑2
i=1(ni − 1)σ2i gepoolter Varianzschätzer
F σ2i = (ni − 1)−1∑ni
k=1(Yik − Y i·)2 Varianzschätzer für Gruppe i
I Einseitiger (oberer) t-Test: ϕN = 1{T > tν,α}, ν = N − 2.
I Begründung und Eigenschaften?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der unverbundene 2SPen-t-Test
Analog:Einseitiges Testproblem: H0 : {µ1 ≥ µ2} vs. H1 : {µ1 < µ2}
I Einseitiger (unterer) t-Test: ϕN = 1{T < −tν,α}
Zweiseitiges Testproblem: H0 : {µ1 = µ2} vs. H1 : {µ1 6= µ2}
I Zweiseitiger t-Test: ϕN = 1{|T | > tν,α/2}
Konfidenzintervalle für δ = µ1 − µ2 (Übung!)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Allgemeinere Fälle – Heteroskedastizitätεik
stu∼ N(0, σ2i )
I Var(ε11) = σ21 6= Var(ε21) = σ2
2 (Behrens-Fisher)
⇒ t-Test nicht mehr valide→ Verwende Welch-Test10 mit
I Teststatistik
T Welch =Y 1· − Y 2·√σ2
1n1
+σ2
2n2
(4.8)
I geschätztem Freiheitsgrad
ν =(σ2
1n1
+σ2
2n2
)2
(σ21/n1)2
n1−1 +(σ2
2/n2)2
n2−1
(4.9)
Eigenschaften: Asymptotisch korrekt; finit nur eine Approximation!10z.B. ϕWelch
N = 1{T Welch > tν,α} im 1-seitigen-oberen FallMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Allgemeinere Fälle – Nicht-Normalverteilte Fehlerεik
stu∼ Fi , Fi unbekannte VerteilungsfunktionI Var(ε11) = σ2
1 6= Var(ε21) = σ22 ; beide in (0,∞)
SATZ: Welch-Test bleibt asymptotisch korrekt11 (Begründung?)I Funktioniert bei symmetrischen Verteilungen und leichter
Heteroskedastizität gut bei ni > 10 oder 20I Finit nur Approximation; z.T. schlecht bei schiefen Verteilungen und
negative Pairing
Mögliche Lösung: Randomisierung→Welch-PermutationstestI Permutiere die gepoolten Beobachtungen (Yik )i,k zufällig→ (Yπ
ik )i,k (permutierter Vektor)I (Bedingte) Quantile von T Welch((Yπ
ik )i,k ) als kritische WerteI EIG: Auch asymptotisch korrekt und sogar finit exakt für F1 = F2!I VORSICHT: Funktioniert i.a. nicht mit T (oft falsch in Literatur)I Details: Vorlesung “Asymptotische Statistik”
Andere Lösung (insbesondere für ordinale Daten): Wilcoxon-Test oderBrunner-Munzel-NeubertBei nominalen Daten: Exakter Test von Fisher oder χ2-Test
11d.h. im oberen 1-seitigen Fall: ϕWelchN → α1{µ1 = µ2}+ 1{µ1 > µ2}
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Odds-Ratio
Bezogen auf den letzten Punkt betrachten wir in diesem Exkursspeziell folgende Kontingenztafeln von 2 binären Variablen:
Anzahl mit Risiko ohne Risikokrank n11 n10gesund n01 n00
Y=1 Y=0X=1 n11 n10X=0 n01 n00
Neben einer Analyse mit Fisher’s exaktem Test wird insbesonderein der Epidemiologie und Medizin bei Fall-Kontroll-Studien dassog. Odds-Ratio zur Rate gezogen.Dieses wird aus der gemeinsamen Verteilung
Y=1 Y=0X=1 p11 p10X=0 p01 p00
mit Hilfe der sog. Odds bestimmt:
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Odds-RatioDas Odds-Ratio wird aus der gemeinsamen Verteilung
P(Y = i,X = j) Y=1 Y=0X=1 p11 p10
X=0 p01 p00
als Qoutient sog. Odds für Y (gegeben X ), d.h. P(Y = ·|X = x), bestimmt, dieman folgender Tabelle entnehmen kann
P(Y = i|X = j) Y=1 Y=0X=1 p11/(p11 + p10) p10/(p11 + p10)
X=0 p01/(p01 + p00) p00/(p01 + p00)
Das Odds-Ratio (oder cross-product ratio) erhält man schließlich als
OR =p11/(p11 + p10)
p10/(p11 + p10)/
p01/(p01 + p00)
p00/(p01 + p00)=
p11p00
p10p01.
Man erhält dieselbe Größe offenbar auch, wenn man die Odds für X (gegebenY ) zugrunde legt.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Odds-Ratio
OR =p11/(p11 + p10)
p10/(p11 + p10)/
p01/(p01 + p00)
p00/(p01 + p00)=
p11p00
p10p01.
Ein natürlicher Schätzer hierfür ist gegeben durch
OR =n11n00
n10n01.
und asymptotische (1− α)-Konfidenzintervalle erhält man z.B. mittelsδ-Methode (Übung) als sog. logit-Intervall[
exp
(log(OR)± zα/2
√1
n11+
1n10
+1
n01+
1n00
)]
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Exkurs: Odds-Ratio
Wir betrachten folgendes Beispiel einer Fall-Kontroll-Studie von Doll und Hill(1950), welches als erste Lungenkrebs mit Rauchen in Verbindung brachte:
Anzahl Patienten mit Lungenkrebs ohne Lungenkrebs (Kontrolle)die geraucht haben 688 650die noch nie geraucht haben 21 59
⇒ OR ≈ 2.973, d.h. die “Chance” (bzw. das Chancenverhältnis) an Lungenkrebszu erkranken ist unter Rauchern ungefähr 3x höher als unter Nichtrauchern. Alsasymptotisches 95%-KI erhält man hiermit [1.78, 4.95].
In der Praxis wird das (geschätzte) OR häufig mit dem (geschätzten) relativenRisiko verwechselt! Im oberen Fall ist dieses aber z.B. durch
RR =P(Ereignis unter Rauchern)
P(Ereignis unter Nichrauchern)=
6881338
/2180≈ 1.959
gegeben. Obwohl RR etwas intuitiver ist, ist OR aufgrund des Auftretens in derlogistischen Regression geläufiger.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der unverbundene 2SPen-t-Test – Fallzahlplanung
Back 2 Business: Fallzahlplanung im unverbnundenen Fall:Ziel (Fallzahplanung): Wähle bei gegebenen Fehler 1.Art (i.d.R.α = 0.05 oder 0.01) die Stichprobe (N = n1 + n2) so groß, dassein klinischer relevanter Effekt ∆ mind. mit WS 1− β erkannt wird(typisch β = 0.1 oder 0.2).Dies hängt wieder von Modell und Testverfahren ab!Hier betr. wir nur den t-Test unter Homoskedastitzität.Messung des Effektes wieder durch µd = µ1 − µ2
Zusätzliche Schwierigkeit im Vergleich zum paarigen Fall:κ := n1/n2 ist i.a. nicht 1.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der unverbundene 2SPen-t-Test – Fallzahlplanung
Überlegungen wie zuvor mit vorgeschätzter Varianz σ2 führen aufLösen von
Φ
∆
σ√
1n1
+ 1n2
− zα
!= 1− β.
Umformen wie zuvor und Einsetzen von
n1 = κn2 (4.10)
(für vorgegebenes κ) führt auf
n2 ≈(zα + zβ)2σ2(1 + 1/κ)
∆2 . (4.11)
“Effizienteste” Wahl: Balanciertes Design mit κ = 1, denn...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
...die Güte des Tests wird bestimmt durch (und ist wachsend in)
µd
σ√
1n1
+ 1n2
.
mit µd > ∆ > 0. Seien nun N, µd und σ fest. Dann wird die Güte(in Abhängigkeit von n1 = λN,n2 = (1− λ)N, λ ∈ (0,1)) maximiertdurch maximieren von(
1n1
+1n2
)−1
=n1n2
N= λ(1− λ)N.
Differenzieren nach λ und Gleichsetzen mit 0 ergibt das Maximum (dadie 2. Ableitung negativ ist) λ = 1/2, d.h. κ = 1.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Der unverbundene 2SPen-t-Test – Fallzahlplanung
Bei balancierte Planung erhält man somit
n1 = n2 ≈2 ∗ (zα + zβ)2σ2
∆2 .
⇒ Analoge Formel für den 2-seitigen Test zur Übung selbst herleitenBemerkung: Aus verschiedenen
I ökonomischen (teure Behandlung) oderI ethischen (Placebo für kranke Patienten) Gründen
kann aber auch ein unbalanciertes Design erwünscht sein!Bemerkung: Bei randomiserten VPs kann dies durch die Art derRandomisierung gesteuert werden
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Beispiel 4.5 (Vergleich zweier blutdrucksenkender Mittel12): Zweiblutdrucksenkende Mittel A und B sollen in einer klinischen Studie an Hypertonikernhinsichtlich (mittlerer) Senkung des Blutdrucks nach vier Wochen untersucht werden.Dazu sollen durch Randomiseriung der Probanden zwei gleichgroße, unabhängigeTherapiegruppen gebildet. Aus Literaturstudien sei bekannt, dass das Medikament Aden Blutdruck von Hypertonikern im Mittel um etwa 10 mm Hg senkt. Aufgrund vonVoruntersuchungen wird bei B mit einer stärkeren Senkung gerechnet. Als klinischrelevant wird eine Verbesserung um mind. 15 mm Hg angesehen. Aufgrundmedizinischer Einschätzung kann eine Standardabweichung von 5 mm Hg für beideMedikamente bei der Blutdrucksenkung sowie eine Normalverteilung der Senkung beiHypertoniker angenommen werden. Es sei α = 0.025 und β = 0.2.Ziel: Bestimmung von N!
⇒ Einseitiger oberer t-Test anwendbar; ∆ = 5:
n1 = n2 ≈2 ∗ (z0.025 + z0.2)252
52 ≈ 2 ∗ (1.96 + 0.84)2 ≈ 16.
⇒ Obige Fallzahlplanung ergibt N = 32.
12Quelle: Röhrig et al. (2010), Deutsches Ärzteblatt 107, 552-556
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Bemerkung zu den beiden 2SpenproblememBemerkung 4.1 (paarig vs. unpaarig):
Das paarige Desing beim verbundenen 2SPen-t-Test istSpezialfall eines randomisierten Block Designs
I Block = “Relativ” homogene VersuchseinheitI Hier: Ein Paar (Y1k ,Y2k )′= einem BlockI Beachte: Blocking hat u.U. Effekt auf Randomisierung!I Mehr zu Block-Designs später
Vorteile ggü dem unverbundenen Design+ Automatisch balanciert (hat Designvorteile)+ Eliminiert mögliche Blockeffekte! Genauer:
Betrachte allgemeineres Modell mit stu
Yk = µ + βk12 + εk , 12 = (1,1)′,1 ≤ k ≤ N (4.12)I βk = Effekt von Block k , βk ∈ R bei festem Blockfaktor oder sonst βk
i.i.d. mit E(β1) = 0,Var(β1) = σ2β <∞ und unabhängig von den εk .
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Bemerkung zu den beiden 2Spenproblemem
Blockeffekt in Yk = µ + βk12 + εkI ändert die Verteilung der Differenzen Dk = Y1k − Y2k nicht undI ändert die Verteilung der Statistik T pair nichtI Grund: S2
pair schätzt die Varianz von Dk immer noch korrektI Ganz anders bei der unverbundenen Statistik T (...Tafel?!)
- Nachteil ggü dem unverbundenen DesignI Kleinerer Freiheitsgrad (ν = 2N − 2 beim unverbundenen)→ Sind keine Blockeffekte vorhanden und die Daten unabhängig:
⇒ Schlechtere Power im Vergleich zum unverbundenen t-Test⇒ Größere Konfidenzintervalle im Vergleich zu unverbundenen
t-Intervallen
Bemerkung 4.2 (Blockeffekt): Der Fall stochastischer Blockeffektewird bei der Modellierung des zufälligen Faktors Versuchseinheitverwendet. Das zugehörige Modell Yk = µ + βk12 + εk heißt dannauch gemischtes 2-Stichprobenmodell.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Beispiel mit möglichem Blockeffekt
Beispiel 4.6 (CFU-Studie (1)):Bei 26 Patientinnen, die wegen eines Karzinoms in Behandlungsind wurden aus dem peripheren Blut sogenanntesStammzell-Konzentrat gewonnen und eingefrorenDies ist ein typisches Vorgehen bei Chemotherapie zurRegeneration des hämatologischen Systems nach BehandlungUm zu messen, ob durch das Einfrieren wesentlicheEigenschaften der Stammzellen verlorengehen, wurde vor undnach dem Auftauen die Anzahl der CFU-GM13 (colony formingunits) gemessen.Ergebnisse für Patientinnen mit hoher Vorbelastung...
13wesenlticher IndikatorMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Beispiel mit möglichem Blockeffekt
Ergebnisse:
Nr. Patient 1 2 3 4 5 6 7 8 9 10CFU-GM vor 1.6431 2.5143 3.2593 0.8671 0.2489 1.0408 0.2229 0.4363 0.5056 0.0167CFU-GM nach 0.0001 0.6760 0.3797 0.1769 0.7623 0.2102 0.2947 0.3503 0.0089 0.089Nr. Patient 11 12 13 14 15 16 17 18 19 20CFU-GM vor 0.4843 0.3092 0.0688 0.0666 0.6747 1.1980 0.7455 8.7576 4.4324 4.2018CFU-GM nach 0.5776 0.3048 0.0087 0.0142 0.0001 0.3697 0.2418 0.7576 0.4564 0.8875Nr. Patient 21 22 23 24 25 26CFU-GM vor 2.3906 0.5707 2.5430 1.4143 1.5365 0.5133CFU-GM nach 0.4021 0.0001 0.3114 0.0152 0.3466 0.1915
Für PARC passt Modell (4.12) mit “beliebigen’ Fehlern u.U. besser
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Inferenz für 2-SPenprobleme
Und ein weiteres BeispielBeispiel 4.7 (γ-GT-Studie (1)):
Bei 24 Patientinnen, denen wegen einer Gallenstein-Erkrankung (ohneVerschluss des Gallengangs) die Gallenblase entfernt wurde, hat man dieKonzentration des γ-GT-Enzyms im Blut14 jeweils am Tag vor der Operation undeine Woche nach der Operation bestimmt.
Nr. Patient 1 2 3 4 5 6 7 8 9 10 11 12γ-GT(Tag -1) 5 8 30 20 17 17 114 7 275 8 15 5γ-GT(Tag 7) 8 61 42 23 18 36 6 10 59 12 43 11
Nr. Patient 13 14 15 16 17 18 19 20 21 22 23 24γ-GT(Tag -1) 14 11 27 11 18 14 19 75 11 8 26 11γ-GT(Tag 7) 18 22 26 59 30 22 53 47 12 30 29 43
Für PARC passt Modell (4.12) hier auch nicht mehr so gut (außer zufälligerFaktor mit großer Streuung, da viel ±)
Weiter Möglichkeiten: Entweder id. Struktur anpassen, robuste Methode wählenoder...
Diskussion über andere Faktoren!14Ein hoher GGT-Blutwert weist auf eine Gallen- oder Lebererkrankung hin
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 5:
Randomisierte 1-faktorielle Designs

Hier behandeln wir zunächst einfache Versuchspläne mit nureinem variierenden Faktor A mit a ≥ 2 verschiedenen Stufen.Der Fall a = 2 führt auf den 2-Gruppenplan aus dem vorherigenKapitel. Um die dortigen Nachteile bei vorgegebenen Gruppen zuumgehen, wird hier Randomisieung als (zunächst15) einzigeKontrolltechnik verwendet.Erinnerung: Randomisierung soll
I die Versuchseinheiten zufällig den verschiedenen Stufen(Versuchsbedingungen) zuweisen, um so
I mit großer WS zu garantieren, dass sich Einflüsse vonStörvariablen zufällig verteilen, um
I schwerwiegende Fehlinterpretationen bei der anschließendenstatistischen Inferenz zu verhindern.
15Später: Andere Techniken + Kombinationen bei komplexeren AnlagenMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der einfaktorielle Plan (CR1F bzw. CRF-a)Die Abkürzung CR1F steht für ’Completely Randomized1-Factorial Design’. Die N Versuchseinheiten werden zufällig dena Faktorstufen zugeteilt (randomoisiert):
Faktor AStufe (Gruppe) 1 · · · aStichprobenumfang n1 · · · na
V11 Va1
Versuchseinheiten... · · ·
...V1n1 Vana
Klassische Anwendung z.B. (Diskussion!)
Behandlung Versuchseinheit EffektSchlafmittel Proband SchlafdauerFuttermittel Kuh MilchertragTumorart Labormaus ÜberlebenszeitWeizensorte Feld Ernteertrag
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

BeispieleBeispiel 5.1 (Anzahl der Corpora Lutea16): In einer Fertilitätsstudie an 92weiblichen Wistar-Ratten sollten unerwünschte Wirkungen einer Substanz (Verum)auf die Fertilität untersucht werden. Das Verum wurde in vier Dosisstufen gegebenund mit einem Placebo verglichen. Nach der Sektion der Tiere wurde unter anderemdie Anzahl der Corpora Lutea bestimmt. Die Ergebnisse für die n1 = 22 Tiere derPlacebo-Gruppe und die n2 = 17, n3 = 20, n4 = 16 und n5 = 17 Tiere der vierVerum-Gruppen entnehmen Sie der unteren Tabelle:
Substanz Anzahl der Corpora LuteaPlacebo 9, 11, 11, 11, 12, 12, 12, 12, 12, 12, 13
13, 13, 13, 13, 13, 14, 14, 14, 14, 15, 16Verum 9, 10, 11, 11, 11, 11, 11, 12, 12, 12, 13Dosis 1 13, 14, 14, 14, 15, 15Verum 9, 11, 12, 12, 13, 13, 13, 13, 13, 14, 14Dosis 2 14, 14, 14, 15, 15, 15, 15, 17, 17Verum 6, 10, 11, 12, 12, 12, 13, 13, 13, 13, 14Dosis 3 14, 14, 15, 15, 16Verum 9, 10, 11, 11, 11, 13, 13, 13, 13, 13, 14Dosis 4 14, 14, 14, 14, 15, 15
16vgl. Brunner (2009)Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele
Beispiel 5.2 (Dunkle Schokolade): In einer Studie von Serafini et al.(2003, Nature 424, 1013) wurde u.a. der Effekt von Schokolade auf dieGesundheit des Herz-Kreislauf-Systems gemessen. Hierzu wurde derGehalt an herzschützenden Antioxidantien der Versuchsperson eineStunde nach Verzehr von
(I) 100g dunkler Schokolade,(II) 100g dunkler Schokolade und 200ml Vollmilch oder(III) 200g Milchschokoladegemessen. Wir nehmen vereinfacht an, dass die Studie aus 36Teilnehmer bestand, die zufällig (aber balanciert) in eine der dreiVerzehrgruppen randomisert wurden und das folgende Ergebnissebeobachtet wurden:
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015
Boxplot Schokolade
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiele
Fragen von Interesse in beiden Beispielen (u.a.):Unterschieden sich die Gruppen signifikant?Und wenn ja, zwischen welchen Gruppen (Paarvergleiche)?
Unterschiede zwischen den Beispielen:Im ersten Beispiel treten Bindungen auf unddie Ausprägungen sind diskreter Natur.Dies ist im Schokoladenbeispiel jeweils nicht der Fall;hier könnte man die Annahme normalverteilter Datenrechtfertigen; im ersten auf keinen Fall
⇒ Man benötigt wieder unterschiedliche Auswertungsverfahren, aufdie wir im Folgenden näher eingehen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Erinnerung: Wahl des Auswertungsverfahrens
Die Wahl der statistischen Inferenzmethode wird i.d.R. im Vorfelddurch Beantwortung der folgenden Fragen festgelegt:
1 Wie viele Faktoren enthält die Untersuchung? (hier: nur einen)2 Wie viele Stufen hat (haben) der (die) Faktor(en)?3 Welches Skalenniveau hat (haben) der (die) Faktor(en)?4 Wie viele Zielgrößen sollen untersucht werden? (haüfig: nur eine)5 Welches Skalenniveau hat (haben) die Zielgröße(n)?6 Welche Kontrolltechnik soll im Versuch verwendet werden
(Anordnung der Versuchseinheiten zu den einzelnen Stufen derFaktoren)?
7 Welche Fragestellung(en) soll(en) beantwortet werden?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
One-Way ANOVA-Modell
Beobachtungen YikI i = 1, 2, . . . , a (= Ein Faktor A mit a festen Stufen)I k = 1, . . . , ni unabhängige Wiederholungen, N =
∑ai=1 ni Beobachtungen
Statistisches ModellI (Additives) Fixed Effects Modell:
Yik = µ+ αi + εik (5.1)
I µ = Globaleffekt; αi = Effekt von Stufe i ; εik zentrierte ZufallsfehlerI Klassische Annahme: Versuchsfehler
εiki.i.d.∼ N(0, σ2) i = 1, . . . ,a, 1 ≤ k ≤ ni (5.2)
mit unbekannter aber gleicher Varianz σ2 ∈ (0,∞)⇒ einfaches lineares Modell mit Normalverteilungsannahme
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
One-Way ANOVA-Fragestellung
Statistisches Modell in Matrixschreibweise (µ = (µ1, . . . , µa)′):
Y = (Y′1, . . . ,Y′a)′ = (Yik )′i,k =
(a⊕
i=1
1ni
)µ + ε =: X µ + ε
Wie der Name suggeriert, nehmen wir hier an, dass µ, αi ∈ R feste Effekte sind.Dann kann man folgende Hypothese testen
H0 : {µ1 = · · · = µa} vs. H1 : {µi 6= µj für mind. ein Paar (i, j), i 6= j}. (5.3)
Kann H0 signifikant abgelehnt werden, so würde man zusätzlich noch allePaarvergleich durchführen, d.h. Testen von
H(i,j)0 : {µi = µj} vs. H(i,j)
1 : {µi 6= µj}, 1 ≤ i < j ≤ a. (5.4)
Diskussion: Wie würden Sie (5.3) und dann (5.4) testen?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
One-Way ANOVA
Globaltest ist der ANOVA-F-test in der Statistik
F =1
a−1∑a
i=1 ni(Y i· − Y ··)2
1(N−a)
∑ai=1∑ni
k=1(Yik − Y i·)2≈ „Variance between”
„Variance within”
Diese besitzt im Fixed Effect Modell unter der Annahmeεik
i.i.d .∼ N(0, σ2) eine F (a− 1,N − a)-Verteilung unter derNullhypohtese.
⇒ F-Test ist ϕN = 1{F > Fα(a− 1,N − a)}, wobei Fα(a− 1,N − a)das zugehörige (1− α)−Quantil ist.ANOVA = Analysis of Variance.Ergebnis beim Schokoladenbeispiel: F = 67.75 undp − value = 2.07e − 12, d.h.?Heuristische Herleitung im Rahmen von linearen Modellen: gleich
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Bemerkung 5.1 (One-Way ANOVA):1 Besitzt der Faktor sehr viel Stufen von Interesse, so würde man
häufig nur eine Zufallsstichprobe der Größe a hieraus ziehen, umdarauf basierend Schlüsse über alle Stufen zu ziehen. In diesemFall würde man die Größen αi in (5.1) als zufällig modellieren(Random Effects Modell) und andere Nullhypothesen über derenVariabilität testen! → hierzu (wahrscheinlich) später mehr!
2 Zum Testen von (5.4) haben wir bereits verschiedeneInferenzverfahren kennengelernt. Das Problem hier ist jedoch dieMultiplizität (Addition des Fehler’s 1. Art).
3 Der Name ANOVA kommt von der folgenden Aufteilung derempirischen Gesamtvarianz (sum of squares):
a∑i=1
ni∑k=1
(Yik − Y ··)2
︸ ︷︷ ︸SStotal
±Y i·=a∑
i=1
ni(Y i· − Y ··)2
︸ ︷︷ ︸SStreat
+a∑
i=1
ni∑k=1
(Yik − Y i·)2
︸ ︷︷ ︸SSerror
.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Herleitung der One-Way-ANOVA
Ausführlicher: In Stochastik 3!Interpretation der Effekte: µ = µ·
I µi = µ· + αi , µ· = 1a
a∑i=1
µi = 1a 1′a µ
I αi = µi − µ· (Abweichungen vom Globaleffekt),∑
i αi = 0I α = (α1, . . . , αa)′ =
(Ia − 1
a Ja)µ = Pa µ, Pa = Ia − a−1Ja:
zentrierende MatrixI αi Effekt der Stufe i von A = Abweichung vom Mittelwert µ·
Äquivalente Formulierung der Hypothese H0:I αi = 0, i = 1, . . . ,a (kein Effekt des Faktors A)I Matrizenschreibweise: α = 0 oder Pa µ = 0
Erinnerung: Das Statistische Modell als Lineares Modell:
Y = (Y′1, . . . ,Y′a)′ = (Yik )′i,k =
(a⊕
i=1
1ni
)µ + ε =: X µ + ε
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Das Lineare Modell
Lineares Modell mit NVA
Y = Xb + ε, ε ∼ N(0, σ2IN) (5.5)
I Y Vektor der N BeobachtungenI b ∈ Rd ParametervektorI X ∈ RN×d Designmatrix
Beispiele:I Modell der One-Way-ANOVA mit b = µ Vektor der ErwartungswerteI Regressionsmodelle (X enthält die Regressoren)
F Einfache lineare Regression: Yi = β0 + β1xi + εi , i = 1, . . . ,N alslineares Modell: Y = Xb + ε, ε ∼ N(0, σ2IN)
→ b =
(β0
β1
)und X =
1 x1...
...1 xN
, r(X) = 2
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Schätzer für die Parameter im LM
Unbekannte ParameterI b = (β0, β1, . . . , βd )′ - RegressionsmodellI b = µ = (µ1, . . . , µd )′ - Faktorielles Modell (d = a)I σ2 = Var(εik ), i = 1, . . . ,d ; k = 1, . . . ,n
Schätzer b für bI b so schätzen, dass Y = Xb und Y minimalen Abstand habenI D = (Y− Y)′(Y− Y) =
∑Ni=1(Yi − Yi )
2 wird minimalI Prinzip: kleinste Summe der Quadrate (least squares)
D = (Y− Xb)′(Y− Xb) = Y′Y− 2b′X′Y + b′(X′X)b(∂
∂biD)d
i=1
= −2X′Y + 2(X′X)b = 0
I Normalgleichungen: (X′X)b = X′YI Lösung (falls X′X invertierbar ist): b = (X′X)−1X′Y
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Eigenschaften des Parameterschätzers b
Satz von Gauß-MarkovI Falls X′X invertierbar ist, dann gilt
1. E(b) = b (erwartungstreuer Schätzer für b)2. Unter allen erwartungstreuen Schätzern für b hat b minimaleVarianz (genauer: haben alle Komponenten von b minimaleVarianz).
Verteilung von bI Falls Y ∼ N(µ, σ2IN), mit µ = (µ1, . . . , µd )′, dann gilt
1. b ∼ N(b,Σ), mit Σ = σ2(X′X)−1
2. Hb ∼ N(Hb,V), mit V = HΣH′ = σ2H(X′X)−1H′
Spezialfall: Faktorielles Modell b = µ = (µ1, . . . , µd )′
I b = (µ1, . . . , µd )′
I µi = 1n
∑nk=1 Yik = Y i· (arithmetischer Mittelwert)
I b = (Y 1·, . . . ,Y d·)′
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Varianzschätzer für σ2 im LM
Modell: Y = Xb + ε, E(ε) = 0, Cov(ε) = σ2INSatz
I Der Schätzerσ2 =
1N − rg(X)
Y′[IN − X(X′X)−1X′]Y
ist erwartungstreu für σ2
I Falls ε ∼ N(0, σ2IN) ist, dann gilt für die quadratische Form
Qε =1σ2 Y′[IN − X(X′X)−1X′]Y =
N − rg(X)
σ2 σ2 ∼ χ2N−rg(x)(0)
I Weiter gilt: σ2 und b sind stochastisch unabhängig
Spezialfall: Faktorielles Modell: b = (Y 1·, . . . ,Y d ·)′
I σ2 =1
N − d
d∑i=1
n∑k=1
(Yik − Y i·)2 und
N − rg(X)
σ2 σ2 ∼ χ2N−d (0)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Hypothesen Hb = 0 im LM testen
Gedanken zur Herleitung eines Tests für H0(H) : Hb = 0, Hgeeignete Hypothesenmatrix (z.B. Pd )
I Formulierung der Hypothese Hb = 0 ist multivariatI Hb schätzt Hb ; ist aber auch multivariat→ nicht als Testgröße geeignet
I äquivalente Formulierung: (Hb)′(Hb) = b′H′Hb = 0⇐⇒ Hb = 0I die quadratische Form b′H′Hb ist eindimensionalI untersuche die Verteilung von Q = b′H′HbI Hb ∼ N(Hb,V), mit V = HΣH′ = σ2H(X′X)−1H′I wähle eine symmetrische Matrix A so, dass AV idempotent ist, so
folgt (zur Übung∗) QH = b′H′AHb ∼ χ2sp(AV)(λ), λ = b′H′AHb
I unter H0(H) : λ = 0′A0 = 0I wähle A = V+ = 1
σ2 [H(X′X)−1H′]+, [·]+: Moore-Penrose InverseI QH = 1
σ2 b′H′[H(X′X)−1H′]+Hb ∼ χ2rg(H)(0) unter H0(H) : Hb = 0
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Der F -Test für Hb = 0
Modell: Y = Xb + ε, ε ∼ N(0, σ2IN)
Satz vom F -Test (für das feste Modell)I 1. QH = 1
σ2 b′H′[H(X′X)−1H′]+Hb ∼ χ2rg(H)(λ), λ = 1
σ2 b′H′V+HbI 2. Unter H0(H) : Hb = 0 folgt QH ∼ χ2
rg(H)(0)
I 3. Qε = 1σ2 Y′[IN − X(X′X)−1X′]Y ∼ χ2
N−rg(x)(0)I 4. QH und Qε sind stochastisch unabhängig
I 5. FH =1σ2 QH/r(H)
1σ2 Qε/[N − r(X)]
=QH/r(H)
Qε/[N − r(X)]ist
F (rg(H),N − r(X) | λ)− verteiltI 6. Unter H0(H) folgt FH ∼ F (rg(H),N − rg(X))
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Der F -Test für Hb = 0
Spezialfall: Balanciertes faktorielles Modell:b = (Y 1·, . . . ,Y d ·)
′
FH =n
d−1∑d
i=1(Y i· − Y ··)2
1d(n−1)
∑di=1∑n
k=1(Yik − Y i·)2
H0(Pd )∼ F (d − 1,N − d)
Man kann zeigen: Der unter der Alternative auftretendeZentralitätsparameter λ = 1
σ2 b′H′V+Hb hängt nicht von derspeziellen Wahl der Hypothesenmatrix H ab!
⇒ Für festes N hängt die Güte “nur” von der Design Matrix X ab!Hierfür kann man zeigen: Der F -Test hat bei balancierterAufteilung von N die größte Power!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Varianzanalysetabelle bei der One-Way-ANOVA
Die auftretenden quadratischen Formen, Hypothesenmatrizenund Nichtzentralitätsparameter (hier im CRF-a Modell:Yik = µ+ αi + εik ) stellt man häufig in sog.Varianzanalyse-Tabellen zusammen (wieder d = a):
Faktor Matrix Quadratform Rang r E(Q/r)
A Pa
a∑i=1
ni(Y i· − Y ··
)2a− 1 σ2 + n · σ2
α
ε
a∑i=1
n∑j=1
(Yij − Y i·
)2N − a σ2
Dabei gilt σ2α =
1a− 1
a∑i=1
α2i mit σ2
α = 0 unter H0, d.h. die beiden
Quadratformen schätzen in diesem Fall die gleiche Varianz σ2.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Der ANOVA-F -Test – FallzahlplanungDiskussion: Was ist ein praktisch relevanter Effekt?Man behilft sich z.B. der Approximation (SLLN) unter Alternative17
FH ≈1
d−1∑d
i=1 n(Y i· − Y ··)2
σ2 ∼ χ2d−1(λ)
für λ = nσ−2∑di=1(µi − µ)2 = nσ−2∑d
i=1 α2i
Erinnerung: Xiind .∼ N(ai , σ
2)⇒ σ−2∑di=1 X 2
i ∼ χ2d (λ) für
λ = σ−2∑di=1 µ
2i .
⇒ Beschreibe relevanten Effekt durch ∆ = σ−2∑di=1(µi − µ)2 und
⇒ löse folgende approximative18 Gleichung nach n auf:
P(χ2d−1(n∆) > χ2
α,d−1) = 1− β.
17Wir betrachten hier zur Vereinfachung nur den balancierten Fall18Approximation auch für den kritischen Wert verwendet
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Der ANOVA-F -Test – Fallzahlplanung
Wird in der Praxis doch häufig nicht so gemacht!Effekt
∆ = σ−2d∑
i=1
(µi − µ)2 = σ−2d∑
i=1
α2i
ist nicht so schön aus Anwendern herauszukitzeln:I Kleiner Effekt von allen Gruppen oderI großer Effekt von nur einer Gruppe
führen bspsw. zum selben Effekt.Z.T. beobachtetes Vorgehen in der Praxis:
I Nur der Effekt für “den” relevanten 2-Gruppenvergleich wirdangegeben und hiernach die Fallzahl berechnet. F -Test läuft quasinur mit.
I Setze eine “konservative” minimale Differenz zwischen allenmöglichen Paaren von Erwartungswerten µi in der Gleichung an.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Grenzen der One-Way-ANOVA
Die One-Way-ANOVA beruht auf den sehr restriktiven Annahmen,dass
I die Varianzen innerhalb der Stufengruppen identisch sind, und dassI normalverteilte Beobachtungen vorliegen.
Bei der Auswertung des Schokoladenbeispiels sind wir vereinfachtdavon ausgegangen. Schaut man sich die geschätztenStandardabweichungen an, erhält man dort jedoch(σ1, σ2, σ3) = (3.53,3.34,4,24), d.h. eine heteroskedastischeTendenz, die auch signifikant nachgewiesen werden kann19
Genauso kann die Nullhypothese normalverteilter Datensignifikant verworfen werden20
Noch deutlicher im anderen Beispiel des Kapitels.
19Barlett’s Test verwirft die Nullhypothese gleicher Gruppenvarianzen zum Niveau2.2e − 16
20Der Shapiro-Wilk Test liefert einen p-Wert von 0.004129Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Grenzen der One-Way-ANOVADie One-Way-ANOVA beruht auf den sehr restriktiven Annahmen, dass
I die Varianzen innerhalb der Stufengruppen identisch sind.
Dies verursacht typischerweise die folgenden Probleme:I Bei positive Pairing21 ⇒ Der F -Test wird konservativer⇒ Verlust an GüteI Bei negative Pairing⇒ Der F -Test wird liberalI In balancierten Designs treten obige Probleme indes in abgeschwächter
Form auf!
Überprüfung in der PraxisI Schätzung der gruppenspezifischen Streuungen der Residuen
εik = Yik − Y i·.
I Testen der Nullhypothese gleicher Gruppenvarianzen {σ21 = · · · = σ2
a}mittels
F Bartlett’s Test bei normalverteilten DatenF modifizierten Levene-Test bei nicht-normalverteilten Daten.
21große Varianzen gehen einher mit großen Stichprobenumfängen und kleine mitkleinen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Grenzen der One-Way-ANOVA
Die One-Way-ANOVA beruht auf den sehr restriktiven Annahmen,dass
I normalverteilte Beobachtungen vorliegen.
Dies verursacht insbesondere bei stärkeren tails und (z.T. auchbei) schiefen Verteilungen größere Probleme, die durch dasAuftreten von Varianzheterogenität nur noch verstärkt werden!Überprüfung in der Praxis
I Graphisch durch Histogramm, QQ- oder PP-Plots der Beobachtungen,Residuen oder standardisierten Residuen
Yik − Y i·
σ.
I Testen der Nullhypothese normalverteilter Daten; z.B. mit demShapiro-Wilks Test
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Überprüfung der Normalität⇒ Quantil-Quantil-Plot:
Beim Quantil-Quantil-Plot (QQ-Plot) plottet man die geordnetenbeobachteten Werte x1:n ≤ x2:n ≤ . . . ≤ xn:n (bzw. genauer: dergeordneten standardisierten Residuen) gegen die zugehörigentheoretischen Quantile der N(0,1)-Verteilung, d.h. gegenΦ−1(i/n).Weichen die Punkte in einem QQ-Plot (stark) von einer Geradenab, dann spricht dies gegen die Normalverteilungsannahme.
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
−3 −2 −1 0 1 2 3
−2
−1
01
23
Normalverteilt
Theoretical Quantiles
Sam
ple
Qua
ntile
s
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
−2 −1 0 1 2
02
46
Nicht Normalverteilt
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Überprüfung der Normalität
⇒ σ-Regeln:Für X ∼ N
(µ, σ2) gilt
P(|X − µ| ≤ σ
)≈ 0.6827
P(|X − µ| ≤ 2σ
)≈ 0.9545
P(|X − µ| ≤ 3σ
)≈ 0.9973.
D.h. man könnte zur Überprüfung, ob Xi , i = 1, . . . ,n,normalverteilt sind, schauen, ob etwa 68%, 95% bzw. 99% derbeobachteten Werte n dem σ-, 2σ- bzw. 3σ-Intervallen liegen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Exkurs: Überprüfung der NormalitätAlternativ kann man sich auch ein Histogramm der Residuen ansehenund überprüfen, ob das Histogramm ungefähr normalverteilt aussieht.
Falls mehrere Gruppen betrachtet werden, deren Varianzen sich nichtunterscheiden, dann können die Residuen beider Gruppen gemeinsambetrachtet werden. Ansonsten sollten nach Gruppen getrennte Grafikengeneriert werden.
Man kann auch die geschätzte Schiefe E(
(Xk − µk )3/σ3k
)= 0 oder
Kurtosis E(
(Xk − µk )4/σ4k
)der Daten betrachten. Falls diese
normalverteilt sind, ist die geschätzte Schiefe ungefähr 0 und dieKurtosis ungefähr 3.
Es existieren auch Tests wie z.B. der Kolmogorow-Smirnow-Test oderShapiro-Wilk-Test zur Überprüfung der Normalität der Daten, wobei wirnochmal kurz auf Letzteren eingehen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Shapiro-Wilk-TestSeien x1:n ≤ . . . ≤ xn:n die geordneten beobachteten Werte undq =
(q1, . . . ,qn
)′=(E(Y1:n), . . . ,E(Yn:n)
)′ für Yi i.i.d. N(0,1). Dann istdie Statistik des Shapiro-Wilk-Tests zum Testen der NullhypotheseH0 : Die Daten sind normalverteilt. gegeben durch
SW =
(∑ni=1 aixi:n
)2∑ni=1 (xik − xk )2 .
Hierbei ist
a = (a1, . . . ,an)′ =(
q′V−1V−1q)−0.5
q′V−1.
Dabei bezeichnet V die n × n Kovarianzmatrix von(Y1:n, . . . ,Yn:n
)′.Zur Berechnung des p-Werts wird typischerweise entweder eineMonte-Carlo- (bei kleinem n) oder eine N(0,1)-Approximation (beigroßem n) verwendet.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Grenzen der One-Way-ANOVA
Problem der obigen Verfahren: Genauigkeit bzw. Power nur gutbei großem n. Die Normailitätsannahme ist jedoch nur beikleinerem n problematisch!Typischer Ansatz bei Anzeichen nicht-normalverteilter undheteroskedastischer Beobachtungen:(Varianzstabilisierende) Transformation der Daten!
I Z.B. durch Vorwissen aus vorangegangenen Untersuchungen oderI durch die üblichen Verdächtigen wie einer log-Transformation beim
“Hinweis” auf lognormalverteilte Beobachtungen oderI eine Box-Cox-Transformation.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Logarithmische TransformationZum Beispiel verwendet man bei Volumenmessungen (in denAgrarwissenschaften) häufig logarithmische Transformationen derDaten.Hier 1x biespielhaft für das Volumen von 31 schwarzenKirschbäumen (Datensatz “trees” aus R-Paket “datasets“)
Histogramm Originaldaten
Volumen
Häu
figke
it
10 30 50 70
02
46
810
Histogramm nach Trafo
log(Volumen)
Häu
figke
it
2.0 2.5 3.0 3.5 4.0 4.5
02
46
810
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Box-Cox-TransformationFalls die üblichen Transformationen nicht weiterhelfen, können dieBox-Cox-Transformationen
zi =
{xγi −1γ für γ 6= 0
ln(xi) für γ = 0
betrachtet werden.
Dabei kann γ mittels Maximierung der Likelihood
`(γ) = −n2
ln
(1n
n∑i=1
(zi − zn
)2)
+(γ + 1
) n∑i=1
ln(xi)
spezifiziert werden.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Grenzen der One-Way-ANOVA
Bei Transformationen der Daten muss man viele Punktebeachten:
I Das transformierte Modell muss dann ein Fixed Effects Modell seinund
I mögliche Schlüsse gelten auch nur hierfür (Addititvität geht i.d.R.bei Rücktransformation verloren)
⇒ Wird in der Praxis manchmal vergessen oder sogar missbraucht(Transformieren bis zur Signifikanz)
Deshalb lieber...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Alternativen zur One-Way-ANOVA
Andere Methoden, die im Fixed Effects Modell ohne Varianzhomogenitätund/oder Normalverteilungen auskommen sind beispielsweise die Tests von
I Welch-James,I Brunner, Dette und Munk (beides Approximationen) oderI Permutationstests vom Wald-Typ
Hiermit lässt sich die Nullhypothese H0 auch in heteroskedastischen FixedEffects Modellen (z.T. ohne NVA) testen.
Eine weitere Alternative (insbesondere im ordinalen Fall) stellen rangbasierteMethoden zum Testen von Gleichheit der Verteilungsfunktionen
HF0 : {F1 = · · · = Fa}
dar. Am bekanntesten ist dabei der Kruskal-Wallis-Test, der als Hauptannahmejedoch ein sog. Shift-Modell annimmt, das wiederum Homoskedastizitätimpliziert. Deshalb existieren auch hierfür Erweiterungen (z.B. auch vonBrunner, Dette und Munk22). Diskussion?!Für nominale Daten gibt es wieder einen χ2-Test.
22vgl. BDM.test im R-Paket asbio; ergibt p-Wert von 2.008027e − 07Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Back to business: Multiple Vergleiche
Im Schokoladenbeispiel konnten wir mittels ANOVA-F -Test dieGlobalhypothese µ1 = µ2 = µ3 signifikant zu α = 5% verwerfen.Frage: Sind die einzelnen Gruppen auch paarweise signifikantvoneinander verschieden?23 Teste also
I H(1,2)0 : µ1 = µ2
I H(1,3)0 : µ1 = µ3
I H(2,3)0 : µ2 = µ3
Problem: Multiplizität! Man möchte die Wahrscheinlichkeitirgendeiner falschen Ablehnungen (FWER) zum Niveau αkontrollieren!Beim einfachen Durchführen der Einzeltests (hier z.B. t-Tests)können sich die Fehler aber addieren.
23oder verwandt dazu: Many-to-one bei Vergleich mit einer KontrolleMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Multiple Vergleiche allgemeine Methoden
Ziel: Teste H0(1), . . . ,H0(m) zum multiplen Level α, d.h.FWER≤ αMultiple Vergleiche von m Hypothesen über p-Werte p1, . . . ,pm p:Erste Lösung Bonferroni
I Lehne H(`)0 , falls p` < α/m
I Kontrolliert die FWER zum Niveau αI Aber: α/m ist sehr striktI Resultiert in sehr konservativem Verfahren (geringe Güte)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
Verbesserung
Ordne die p-Werte der Größe nach: p(1) ≤ . . . ≤ p(m)
Bonferroni - Holm - MethodeI Start: p(1) ≤ α/m?I Ja: Lehne H(1)
0 ab! Nein: Stop und lehne keine Hypothese abI p(2) ≤ α/(m − 1)?I Ja: Lehne H(2)
0 ab! Nein: Stop und lehne keine Hypothese abI p(`) ≤ α/(m − `+ 1)?I Ja: Lehne H(`)
0 ab! Nein: Stop und lehne keine Hypothese abI Man kann zeigen: Dies kontrolliert die FWER und hat mehr Güte
als Bonferroni
Weitere Verbesserungen, Methoden und Beweise in derVorlesung Multiple Hypothesentests
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Auswertung – ANOVA für feste Faktoren
AnwendungBerechne die p-Werte der Einzeltests p1, . . . ,pm
Die R-Funktion p.adjust(...) berechnet hieraus sog. adjustiertep-Werte pad
i , die pi so erhöhen, dass man sie direkt mit αvergleichen kann (und die FWER erhalten bleibt).
I p.adjust(c(p1, . . . ,pm),”bonferroni”) 24
I p.adjust(c(p1, . . . ,pm),”holm”)
Im Schokoladenbeispiel erhält man (Gruppe 1 = dunkleSchokolade) mittels 2-seitiger t-Tests p-Werte
I p12 = 1.899e − 10I p13 = 4.607e − 09I p23 = 0.8391,
die auch nach Bonferroni-Adjustierung die gleichen Signifikanzenliefern (Die Dunkle Schokoladengruppe unterscheidet sich jeweilssignifikant von den anderen beiden Gruppen; analoge Ergebnissefür einseitige Tests und rangbasierte Versionen)
24= (max(1,mp1), . . . ,max(1,mpm))Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 6:
Einfaktorielle Experimente mitgeblockten Störfaktoren

VorwortWir haben Blocking beispielhaft in den Kapiteln 3-4 kennengelernt. Dabeiinsbesondere beim paarigen 1-Gruppenplan bzw. paarigen2-Stichprobenproblem.
Allgemein ist Blocking eine Technik zur Kontrolle von Störfaktoren
Erinnerung: Störfaktoren sind Faktoren, deren Einfluss im Versuch nichtinteressiert. Da sie jedoch Einfluss auf die Zielgröße nehmen können, soll ihreVariabilität möglichst gering gehalten/ kontrolliert werden
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

VorwortWir haben Blocking beispielhaft in den Kapiteln 3-4 kennengelernt. Hierinsbesondere beim paarigen 1-Gruppenplan bzw. 2-Stichprobenproblem.
Allgemein ist Blocking eine Technik zur Kontrolle von Störfaktoren
Bisher haben wir hauptsächlich Randomisierung als Kontrolltechnik aufgrundihrer einfachen und breiten Anwendungsmöglichkeit verwendet. Hiermit kanni.d.R. auch der Einfluss von nicht veränderbaren oder gar unbekanntenStörfaktoren auf die Zielgröße ausbalanciert werden.
Ist der Störfaktor allerdings bekannt und kann vom Versuchsleiter bewußtverändert werden, so bietet sich stattdessen zunächst Blocking an.
Grundidee bei der Blockbildung: Bilde homogene Blöcke/Gruppen, für die dieVariabilität des bekannten Störfaktors innerhalb eines Blocks sehr gering ist. DieVariabilität zwischen den Blöcken kann dabei groß sein.
Typisch: Block = Spezielle Stufe des Störfaktors
George Box:
“Block what you can, randomize what you cannot”
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Complete Randomized Block DesignWir betrachten zunächst ein sog. komplett randomisiertes Block-Design(RCBD) mit einem festen Faktor A mit a Stufen.
Dabei wird das Experiment in jedem Block komplett durchgeführt, d.h. jedeStufe des Faktors kommt genau 1x vor.
Blocking schränkt dabei das Randomisieren ein: Es wird jeweils nur dieStufenzuweisung innerhalb eines Blocks randomisiert.
Faktor AStufe 1 · · · aBlock 1 V11 · · · V1a...
......
...Block n Vn1 · Vna
Wie beim paarigen 1-Gruppenplan ist der Faktor Block typischerweise zufällig.
Es gibt aber auch Ausnahmen:I In der Landwirtschaft: Wenn man nur Aussagen über das Verhalten von
Getreidesorten (Faktor A) auf vorliegende Felder (= Blöcke) treffen möchteI Bei multizentrischen Studien mit verschiedenen Kliniken sollen die Kliniken
als feste Blöcke angesehen werden.Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel: Wasserdichtheitsprüfung
Beispiel 6.1 (Wasserdichtheitsprüfung): Um den Einfluß von 4verschiedenen Imprägniersprays auf die Wasserdichtheit von Textilienzu messen, wurde folgendes Experiment durchgeführt:
Von verschiedenen Textilien wurde zufällig ein Materialstreifenausgewählt und in vier gleich große Stoffstücke geteilt.Die Behandlungen mit den 4 verschiedenen Sprays wurdenanschließend zu jedem Stück zufällig randomisiert. Abschließendwurde in einem Experiment die Dichheit in mm Wassersäulen(mmWS) nacheinander mit dem selben Messinstrumentgemessen.Obiges Experiment wurde insgesamt 4x wiederholt⇒Verschiedene Textilien bilden die Blöcke
Die Zuweisungen und Beobachtungen entnehmen wir den folgendenTabellen:
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel: Wasserdichtheitsprüfung
Zuweisung SprayBlock 1 3 1 4 2Block 2 3 4 2 1Block 3 2 1 3 4Block 4 1 4 2 3
BeobachtungenBlock 1 892 895 908 896Block 2 874 880 870 876Block 3 939 903 912 947Block 4 789 801 793 799
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel: Proteinstudie
Beispiel 6.2 (Proteinstudie): Um den Einfluss von fünf verschiedenenextensiven Eiweißdiäten auf die Entwicklung der Gewichtszunahme zuuntersuchen wurde eine Studie mit 15 Wistar-Ratten durchgeführt.
Diese wurden vorher bereits nach verschiedenen, hier nichtinteressierenden Kriterien (wie z.B. Größe, Gewicht, Aktivität,Appetit etc.) in drei verschiedene homogene Blöcke vorsortiert.Die Diätbehandlungen wurden innerhalb der Blöcke randomisiertzugewiesen undnach 4 Wochen Behandlung wurde die Gewichtszu-bzw.abnahme (in Gramm) gemessen.
Die Zuweisungen und Beobachtungen entnehmen wir den folgendenTabellen:
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015
Beispiel: Proteinstudie
Zuweisung BehandlungBlock 1 5 3 2 1 4Block 2 4 1 2 5 3Block 3 1 3 5 4 2
BeobachtungenBlock 1 112 95 88 99 107Block 2 101 98 79 109 107Block 3 102 96 108 95 85
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Modellierung des RCBD
Klassisches Modell mit festem Blockfaktor:
Yik = µ+ αi + βk + εik (6.1)
I Beobachtungen Yik sind unabhängigI µ - GlobaleffektI αi ∈ R i = 1, . . . ,a - fester Behandlungseffekt (von Faktor A)I βk ∈ R, k = 1, . . . ,n - fester BlockeffektI εik
i.i.d.∼ N(0, σ2), VersuchsfehlerI Annahme:
∑i αi =
∑k βk = 0
Mittlerer Behandlungseffekt von Stufe i :I µi = n−1∑n
k=1 E(Yik ) = µ+ αi
Hypothese von Interesse:I H0 : {µ1 = · · · = µa} = {α1 = · · · = αa = 0}⇒ Wie zu testen?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

ANOVA im RCBD
In den Übungen zeigen Sie die folgende Aufteilung der empirischenGesamtvarianz
a∑i=1
n∑k=1
(Yik − Y ··)2 = n∑a
i=1(Y i· − Y ··)2 + a∑n
k=1(Y ·k − Y ··)2
+∑a
i=1∑n
k=1(Yik − Y i· − Y ·k + Y ··)2
bzw. symbolisch
SStotal = SStreat + SSblocks + SSerror.
Man kann zeigen (Stochastik 3), dass die 3 Summen auf der rechtenSeite dividiert durch σ2 jeweils stu. χ2- verteilt sind mit Freiheitsgraden(a− 1), (n − 1) bzw. (a− 1)(n − 1). Genauer folgt dies ausnachfolgendem Satz (Exkurs)...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Satz 6.3 (Cochran’s Theorem):
Es gelteY ∼ Nd (0,Σ),A,Ak , k = 1,2, . . . ,m seien Matrizen mit A =
∑nk=1 Ak , so dass
AΣ idempotent ist.Ist dann auch AkΣ idempotent für alle k und gilt AkΣAk ′ = 0 für allek 6= k ′, so folgt:
1 Y′AkY ∼ χ2tr(AkΣ) für alle k
2 Y′AkY und Y′Ak ′Y sind unabhängig für k 6= k ′.3 Y′AY ∼ χ2
tr(AΣ) für alle k
Ohne Beweis
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

ANOVA im RCBD
Berechnung von den Erwartungswerten der Varianzanteile zeigt
E(SStreat/(a− 1)) = σ2 +n∑a
i=1 α2i
a− 1
E(SSblocks/(n − 1)) = σ2 +a∑n
k=1 β2k
n − 1E(SSerror/[(a− 1)(n − 1)]) = σ2,
so dass zum Testen von H0 : {αi = 0 ∀i} wieder eine F -Statistik
F =SStreat/(a− 1)
SSerror/[(a− 1)(n − 1)]
H0∼ F (a− 1, (a− 1)(n − 1)) (6.2)
verwendet werden kann. Der zugehörige F -Test lehnt H0 ab, fallsF > Fα(a− 1, (a− 1)(n − 1)) gilt.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Grenzen der ANOVA
Die Annahmen sind auch hier wieder sehr restriktiv, was mitunterzu ähnlichen Problemen führen kann wie beim CRF-a.Deskriptiv kann dies z.B. wieder über Studium der Residuen
εik = Yik − Y i· − Y ·k + Y ··
geschehen. Diese können auch einen Hinweis auf möglicheInteraktionen geben:
I Ist εik negativ für kleine und große Beobachtungen, aber positiv fürmittlere, deutet dies u.U. auf Block-Faktor-Interaktionen hin!
⇒ Gleich mehr zu Interaktionen...Ansonsten existieren auch hier wieder verschiedenenichtparametrische Verfahren im ordinalen oder nominalen Fall.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistische Modellierung des RCBD – Teil IIGemischtes Modell mit zufälligem Blockfaktor:
Yik = µ+ αi + βk + εik
I Yk = (Y1k , . . . ,Yak )′, k = 1, . . . ,n - unabhängigeBeobachtungsvektoren
I αi ∈ R, s = 1, . . . ,a - fester Stufeneffekt von A (∑
i αi = 0)I βk
i.i.d.∼ N(0, σ2β), k = 1, . . . ,n - zufälliger Blockffekt
I εksi.i.d.∼ N(0, σ2), Versuchsfehler
I die zufälligen Komponenten βk und εks sind unabhängigKonsequenz
I E(Yik ) = µi = µ+ αi wie zuvorI Var(Y1k ) = · · · = Var(Yak ) = σ2
β + σ2 sind gleichI Cov(Yik ,Yi′k ) = σ2
β für alle Paare (i , i ′), i 6= i ′ = 1, . . . ,a innerhalbeines festen Blocks
I Cov(Ysk ,Ys′k ′) = 0 für Beobachtungen aus verschiedenenBlöcken k 6= k ′ = 1, . . . ,n
I die Kovarianzstruktur der Yk heißt Compound SymmetryMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

ANOVA im RCBD – Teil IIAnalog zum Modell mit festen Blockeffekten rechnet man hiermit direktnach
E(SStreat/(a− 1)) = σ2 +n∑a
i=1 α2i
a− 1E(SSblocks/(n − 1)) = σ2 + aσ2
β
E(SSerror/[(a− 1)(n − 1)]) = σ2,
so dass zum Testen von H0 : {αi = 0 ∀i} wieder die gleicheF -Statistik25
F =SStreat/(a− 1)
SSerror/[(a− 1)(n − 1)]
H0∼ F (a− 1, (a− 1)(n − 1)) (6.3)
verwendet werden kann. Der zugehörige F -Test lehnt H0 ab, fallsF > Fα(a− 1, (a− 1)(n − 1)) gilt.
25Verteilung mit Cochran’s TheoremMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Zufällige vs. feste Blöcke
Möchte man Interaktionen zwischen dem festen Faktor A und denBlöcken mitmodellieren, so gelangt man zu einem gemischtenModell mit Interaktion:
Yik = µ+ αi + βk + γik + εik
I Im Fall fester Blöcke wären γik ∈ R die Interaktionseffekte (mit∑i γik =
∑k γik = 0) und
I bei zufälligen Blöcken würde man zufällige Interaktionenγik
i.i.d.∼ N(0, σ2γ), die unabhängig von den β’s und ε’s sind,
modellieren.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Zufällige vs. feste Blöcke
Konsequenzen:I Im Fall zufälliger Blöcke erhält man hierfür
E(SStreat/(a− 1)) = σ2 + σ2γ +
n∑a
i=1 α2i
a− 1E(SSblocks/(n − 1)) = σ2 + aσ2
β
E(SSerror/[(a− 1)(n − 1)]) = σ2 + σ2γ ,
d.h. die F -Statistik (6.2) kann auch hier zum Testen von H0verwendet werden.
I Bei festen Blöcken kürzt sich der Interaktionseffekt in SStreat; inSSerror aber nicht, d.h. der F -Test wäre nicht anwendbar.
In der Praxis sind zufällige Blöcke die Regel, da man dieErgebnisse meistens auf die Grundgesamtheit verallgemeinernmöchte.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mehr zu RCBDMultiple Vergleiche:
I Mit ähnlichen Techniken wie beim 1-faktoriellen Modell.I Hier allerdings die Paarvergleiche zum Testen von
H(i,j)0 : {αi = αj}
mittels paarigem t-Test.Weitere Anwendungen:
I Repeated Measurements:F a = t verschiedene BehandlungenF Jede Behandlung wird bei allen n Patienten genau 1x durchgeführtF Behandlungsreihenfolge muss dabei für RCBM randomisiert sein.
I Erweiterungen:F In manchen Versuchen werden die Stufen des festen Faktors nicht
nur genau 1x sondern häufiger pro Block zugewiesen, um einegrößere Gesamtstichprobe zu erreichen. Kommen die Stufen dabei inallen Blöcken gleich oft vor und werden zufällig zugewiesen, sospricht man auch von einem RCBD (im weitesten Sinne).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

RCBD (im weitesten Sinne)Beispiel zu Letzterem: 2 Behandlungen werden in 2 Blöcken der Länge 4 jeweilsgleichhäufig und zufällig zugeteilt:
Zuweisung BehandlungBlock 1 1 2 2 1Block 2 1 2 1 2
Mögliches Problem an den bisherigen RCBDs mit vorgegebener Blocklänge:I Kennt das Studienpersonal die Blocklänge (hier: 4) und die ersten drei
Behandlungen, so können Sie direkt schließen, welche Behandlung/Stufedie letzte Person im Block bekommt!
⇒ Ein Teil der Randomisierung kann vorhergesagt werden⇒ Es kann zu selection bias kommen!
Mögliche Lösung (wenn durchführbar):I Verblindung des Studienpersonals (!) oder auchI Verwendung von variablen (zufällig zugeteilten) Blocklängen⇒ Für jeden Block werden nacheinander die Blocklängen zufällig zugeteilt (im
Beispiel könnte man z.B. zwischen 2, 4 und 8 wählen)⇒ Dies führt aber zu unbalancierten Designs und mitunter zu (leicht) anderen
Fallzahlen.⇒ Wenn möglich immer doppelt Entblinden!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Weitere Blockpläne
Das obige RCBD behandelt den Fall eines vollständigenBlockplans mit genau einem (interessierenden) Faktor und einemBlockfaktor.Der Fall mehrerer Faktoren wird sehr ausführlich in den nächstenKapiteln behandelt.Im Folgenden behandeln wir zunächst noch weitereBlock-Designs mit einem Faktor, bei denen entweder 2 odermehrere Blockfaktoren auftreten oder die Zuteilung nichtvollständig ist.Die genauen Vor- und Nachteile sowie deren Auswertung werdendabei aus Zeitgründen jedoch nicht genau diskutiert.Außerdem wird nur der Fall fester Blocklängen behandelt.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Latin-Square DesignBeispiel 6.4.: In einer Studie zur Bioäquivalenzprüfung zwischen zweiGenerika und dem Originator (Faktor mit 3 Stufen) soll jedem der drei(zur Vereinfachung!) Probanden (nach einer ausreichenden“Washout”-Periode) jedes Medikament an drei verschiedenenZeitpunkten verabreicht werden. Um hierbei etwaige Störfaktoren zublockieren, beschließt der Versuchsleiter neben dem “Probanden”auch den “Zeitpunkt” als Blockfaktor zu verwenden und verwendet einspezielles 3× 3 Latin Square Design, bei dem die Stufen desinteressierenden Faktors in jedem der Blöcke genau 1x vorkommen(d.h. hier also in jeder Zeile und Spalte):
Zeitpunkt1 2 3
Patient 1 Orig Gen 1 Gen 2Patient 2 Gen 2 Orig Gen 1Patient 3 Gen 1 Gen 2 Orig
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Latin-Square Design (Lateinische Quadrate)Allgemein bezeichnet ein p × p Latin-Square Design einenVersuchsplan mit einem interessierenden Faktor und 2Blockfaktoren, die alle jeweilse p Stufen besitzen und bei dem injeder Zeile und Spalte (d.h. in jedem Block) jede Stufe desEinflussfaktors genau 1x vorkommt.
⇒ Dadurch, dass wir hierbei in zwei Richtungen “blocken”, haben wirautomatisch noch mehr Restriktionen an das randomisiertezuteilen der Faktorstufen.Bemerkung: Bis heute ist keine einfache Formel für dieBerechnung der Anzahl verschiedener Lateinischen Quadrate derOrdnung p bekannt. Die Anzahl ist jedoch größer als (p!)2p/pp2
Für kleine p erhält man beispielsweise2(p = 2),12(p = 3),576(p = 4) bzw. 161280(p = 5)Kombinationsmöglichkeiten, aus denen man beim Randomisieren“zufällig” das Design ziehen würde.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Latin-Square Design
Der Name “Lateinische Quadrate” geht zurück auf Euler, derlateinische Buchstaben für die verschiedenen Symbole (hier:Stufen des Faktors) verwendet hat.
3× 3A B CB C AC A B
4× 4A B C DB C D AD A B CC D A B
5× 5A D C B EC E A D BE B D C AD A B E CB C E A D
Im obigen Beispiel würde man durch A = Orig, B = Gen 1 undC = Gen 2 ein anderes LQ erhalten.Wir folgen dieser Schreibweise jedoch i.d.R. nicht, da wir dieFaktoren bereits mit Großbuchstaben bezeichnen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Latin-Square Design
Statistisches Modell im einfachen p × p Latin-Square Design:
Yijk = µ+ αi + τj + βk + εijk 1 ≤ i , j , k ≤ p,
beschreibt den Eintrag in Zeile i und Spalte k unter Faktorstufe j(kurzzeitige Notationsänderung für die Faktoreffekte), wobei
I αi = i-ter Zeileneffekt (des Zeilenblocks)I τj = j-ter Behandlungs- bzw. Stufeneffekt (des Faktors)I βk = k -ter Spalteneffekt (des Spaltenblocks)I εijk = Zufallsfehler (typisch: i.i.d. N(0, σ2))
Wie beim RCBD erhält man F-Tests zum Testen von Hypothesenüber feste Effekte; allerdingssind die Freiheitsgrade dabei wegen N = p2 Beobachtungenhäufig sehr klein...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Latin-Square DesignDeshalb werden die Experimente mit Latin-Square-Designs häufign Mal wiederholt.Statistisches Modell im n-fach wiederholten p × p Latin-SquareDesign:
Yijk` = µ+ αi + τj + βk + εijk` 1 ≤ i , j , k ≤ p, ` = 1, . . . ,n,
beschreibt den Eintrag in Zeile i und Spalte k unter Faktorstufe jbei Wiederholung `Wie oben erhält man wieder F-Tests zum Testen von Hypothesenüber feste Effekte; wobeidie Freiheitsgrade aufgrund von N = p2n Beobachtungen nungrößer sind.Erweiterungen mit Interaktionen sind natürlich auch wiedermöglich.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Crossover Designs
Ist speziell p = 2 so spricht man bei einem 2× 2 Latin-SquareDesign mit n-facher Wiederholung auch von einem sog.(standard) Crossover-Design.Dieses wird standardmäßig bei Pharmakokinetischen Studien(PK-studies) oder auch Bioäquivalenz-Überprüfungen eingesetztBeispiel: In einer pharmakokinetischen Studie soll die Aufnahmevon Hydrocortison in den Körper bei Gabe vor (V) bzw. nach (N)dem Essen untersucht werden. Dazu wurden die 10 Probandenzufällig in 2 Gruppen randomisiert. Die Probanden in der erstenGruppe erhielten dabei die Behandlungsreihenfolge VN, die in derzweiten Gruppe die Reihenfolge NV, d.h. in Gruppe 1 wurde zumersten Zeitpunkt nach Einnahme nach dem Essen gemessen undin ausreichenden Abstand beim zweiten Zeitpunkt nach demEssen bei Einnahme vor dem Essen gemessen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Crossover DesignsVersuchsplan für das Beispiel mit n = 10:
Gruppe 1 Gruppe 2Proband 2 3 6 7 9 1 4 5 8 10Zeitpunkt 1 V V V V V N N N N N
↓ ↓ ↓ ↓ Washout ↓ ↓ ↓ ↓Zeitpunkt 2 N N N N N V V V V V
Die Probanden wurden dabei zufällig den beiden GruppenzugeteiltEine ausreichende Washout-Länge ist dabei wichtig, um möglicheÜbertragung- bzw. Residualeffekte auszuschließen.Zur Auswertung (sowohl mittels F -Test als auch mit Hilfe vonnichtparametrischen Methoden) in R können Sie hierbei das Paketbear verwenden, welches auch Designs mit mehr als 3 oder 4Zeitpunkten zulässt.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Graeco-Latin-Square Design
Der zuvor behandelte Versuchsplan der Lateinischen Quadrateerlaubt die Kontrolle von 2 verschiedenen Störfaktoren bzw. dasBlocken in 2 verschiedene Richtungen.Möchte man nun sogar in 3 Richtungen blocken, so wirdtypischerweise wie folgt vorgegangen:
I Man überlagert zwei p × p Latin-Square Designs derart,I dass jede Stufe des einen Lateinischen Quadrats genau einmal mit
jeder Stufe des anderen kombiniert auftritt(man sagt: die LQs liegen orthogonal zueinander)
Man kann zeigen: Solch ein Versuchsplan existiert für allep ≥ 3,p 6= 6.Der Name wird klar, wenn man die Stufen im ersten LQ mitlateinischen und im zweiten LQ mit griechischen Buchstabenbezeichnet:
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Graeco-Latin-Square DesignBeispiel für ein 4× 4 Graeco-Latin-Square Design:
Blockfaktor 11 2 3 4
Blockfaktor 2
1 aβ dα cδ bγ2 dγ aδ bα cβ3 cα bγ aγ dδ4 bδ cγ dβ aα
Als einfaches Statistisches Modell ohne Wechselwirkung (und1-facher Wiederholung) erhält man
Yijk` = µ+ αi + τj + βk + ω` + εijk` 1 ≤ i , j , k , ` ≤ p,
wobei τ und ω die Effekte der “lateinischen” bzw. “griechischen”Behandlung angeben.Bem: Die vier Einzeleffekte können dann jeweils aufgrund von pBeobachtungen geschätzt werden!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Balanced incomplete Block DesignZum Abschluss des Kapitels behandeln wir noch den Fall eineseinzelnen Blockfaktors, bei dem die Blöcke (aus Kosten-,physikalischen oder Zeitgründen) zu klein sind, um alle Stufen desinteressierenden Faktors “aufzunehmen”, d.h. nicht jede Stufekommt in jedem Block vor.Sind alle Stufen gleich wichtig, sollte man die Stufenzuweisung zuden Blöcken ausbalancieren.Dies führt zu sog. Balanced incomplete Block Designs (BIBD),bei dem alle Paare von Stufenkombinationen (d.h. 2verschiedenen Stufen) in gleich vielen Blöcken vorkommen.
Faktorstufen1 2 3 4
Block 1 x x − xBlock 2 − x x xBlock 3 x x x −Block 4 x − x x
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Balanced incomplete Block DesignIm Folgenden bezeichnen wir die Anzahl der Blöcke mit p und die Anzahl derStufen des Faktors mit a. Im Fall a = p spricht man von einem symmetrischenBIBD.Nehmen wir an, dass jeder Block genau k < a Stufen enthält und jede Stufeinsgesamt r ≤ b26 Mal zugewiesen wird (d.h. in r verschiedenen Blöckenvorkommt), so enthält der Versuchsplan genau N = ar = pk Beobachtungen.Außerdem kommen alle Behandlungspaare in genau27
λ = r(k − 1)/(a− 1)
Blöcken vor (Im obigen Beispiel ist λ = 2).Das Modell für die i−te Beobachtung in Block k ist analog zum RCBD (6.1)gegeben durch
Yik = µ+ αi + βk + εik ,
wobei hier nicht alle Kombinationen von i und k vorkommen.Beim zugehörigen F -Test muss man dann für die Unvollständigkeit geeignetadjustieren (vgl. Montgomery (Kapitel 4.4.1).
26Dies ist notwengig für die Existenz des BIBD27Kleine Kombinatorikübung
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Block Designs aus kombinatorischer Sicht
Um für Block-Designs und im Speziellen für BIBD fürvorgegebene Werte von a,p, r und k randomisiert Zuweisen zukönnen ist es wichtig Informationen über Existenz und Anzahl dermöglichen Versuchspläne zu besitzen.Dies kann im Rahmen von fortgeschrittenen Kombinatorikaufgabegelöst werden.Beispielsweise gibt das Bruck-Ryser-Chowla Theorem (hier ohneBeweis) notwendige Bedingungen für die Existenz einessymmetrischen BIBD mit Parametern (a, r , k , λ):
I Ist a gerade, so ist k − λ Quadrat einer natürlichen ZahlI Ist a ungerade, so existieren nicht-triviale Lösungen der
Diophantine Gleichung28 x2 − (k − λ)y2 − (−1)(a−1)/2λz2 = 0
Und unter der zusätzlichen Bedingung k = r erhält manZusammenhänge mit endlichen projektiven Ebenen.
28d.h. es interessieren nur ganzzahlige LösungenMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Block Designs aus kombinatorischer Sicht
In dem Zusammenhang findet man auch das SchulmädchenProblem von Kirkman29:“Fifteen young ladies in a school walk out three abreast for sevendays in succession: it is required to arrange them daily so that no
two shall walk twice abreast”welches sich mit Hilfe von BIBD lösen lässt.Viel Spaß beim Tüfteln!
Details zu Kombinatorik und Designs findet man z.B. in Hughesand Piper: Design Theory (1985).
29Quelle: Graham et al. (1995): Handbook of Combinatorics.Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 7:
Zwei- und Mehrfaktorielle Experimente

Mehrfaktorielle DesignsIn den bisherigen Kapiteln haben wir (im Prinzip) nur Situationenund Versuchspläne mit einem interessierenden Faktor untersuchtDies wird sich jetzt ändern, d.h. wir studieren Versuchspläne, mitdenen man die Wirkung von zwei oder mehreren Faktorengleichzeitig auf die Zielgröße untersuchen kann.Diese mehrfaktoriellen Versuchspläne sollte man von sog.multivariaten Versuchsplänen unterschieden können (diezunächst nicht thematisiert werden), bei denen mehrereZielgrößen auftreten (die allerdings auch wieder 1-2- odermehrfaktoriell sein können).Neben der Analyse der zugehörigen Haupteffekte der Faktoren isthier insbesondere die wechselseitige Interaktion von Interesse.Bevor wir dies systematisch angehen, geben wir zunächst einigeBeispiele für Fragestellungen, bei denen mehr als ein Faktorinteressiert.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel 7.1 (Studien von Schachter (1959)): In einer viel zitierten Arbeit vonSchachter (1959) sollte (vereinfacht dargestellt) die Wirkung von Angst- undHungergefühlen auf das Geselligkeitsbedürfnis untersucht werden. Dazu führte er 2getrennte Versuche durch: (a) Hungerstudie. Hierbei wurde der Faktor Hungergefühlin drei Stufen untersucht
starker Hunger (ca. 20 Stunden ohne Mahlzeit)
mittlerer Hunger (ca. 6 Stunden ohne Mahlzeit)
kein Hunger (Mahlzeit unmittelbar vor dem Versuch)
und die Zielgröße Geselligkeitsbedürfnis erfasste er durch Abfragen, ob man nunlieber “alleine” oder “zusammen mit anderen” wäre. Die Aufteilung in die drei Gruppenerfolgte dabei durch Randomisieren.Ergebnis: Die Vermutung, dass steigender Hunger das Geselligkeitsbedürfnis fördert,wurde bestätigt.(b) Angststudie. Hierbei wurde der Faktor Angst (im Bezug auf angedachteElektroschocks) in 5 Stufen angegeben: “Mir gefällt es gar nicht, geschockt zuwerden” bis “Ich freue mich darauf, geschockt zu werden” und auch die Zielgrößewurde genauer gemessen: Ich möchte die Elektroschocks - viel lieber allein, - lieberallein, - egal, - lieber mit anderen zusammen, - viel lieber mit anderen zusammen,bekommen.Ergebnis: Die Vermutung, dass steigende Angst das Geselligkeitsbedürfnis fördert,wurde bestätigt.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fragen:I Um was für ein Design handelt es sich bei den Experimenten?I Wie sind Zielgröße und Faktoren skaliert?I Welchen Test würden Sie zur Auswertung verwenden?
Im Zusammenhang mit den Studien von Schachter fallen unsdirekt weitere Fragen ein:
I Besteht das größte Bedürfnis nach Geselligkeit, wenn mangleichzeitig hungrig und ängstlich ist? oder
I Kann man überhaupt einen systematischen Einfluss auf dasGeselligkeitsbedürfnis feststellen, wenn Hunger und Angstgleichzeitig auftreten? oder
I Geht das Bedürfnis nach Geselligkeit bei extrem hohenBelastungen von Angst und Hunger wieder zurück? oder
I Wollen wenig hungrige, aber sehr ängstliche Personen eher mitanderen Personen zusammen sein als wenig ängstliche, aber sehrhungrige?
⇒ Diese lassen sich aus den Schachter-Experimenten nichtbeantworten! Die Faktoren müssten in neuen Versuchengemeinsam untersucht werden (⇒ 2-faktorieller Versuchsplan)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Weiteres BeispielBeispiel 7.2 (Toxizitätsstudie30): Es wurde die Toxizität einerSubstanz in 5 Dosis-Stufen bei männlichen und weiblichenWistar-Ratten untersucht. Die Zielgröße wurde dabei durch Messungder relativen Nierengewichte (Nierengewicht/Körpergewicht) bestimmt.
Wir werden später sehen, dass sich der optische Eindruck (Dosis- undGeschlechtereffekt; aber keine Interaktion) auch bei einer statistischenAuswertung bestätigt.
30Quelle: Brunner und Munzel (2013)Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Und noch ein Beispiel
Beispiel 7.3 (Stressstudie): Eine Psychologiestudentin möchte denEinfluss von Studienfach und Geschlecht auf den Stress während derExamensarbeit in den Naturwissenschaften untersuchen. Dazu stelltsie zufällig ausgewählten Probanden, die gerade an ihrerBachelor-Arbeit schreiben, sog. Stressverarbeitungsfragebogen.Neben der Frage nach Einzel- bzw. Haupteffekten der beiden Faktoren
Geschlecht (M/W) undStudienfach (Biologie/Chemie/Mathematik/Physik)
ist dabei auch von Interesse, ob Interaktionen vorliegen.
Im Zusammenhang mit mehreren Faktoren spielt auch derenAnordnung eine große Rolle. Hierauf gehen wir zunächst kurz ein.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Anordnung der Faktoren
Definition 7.1 (Faktorenanordnungen und erste Designs):(a) Zwei Faktoren heißen gekreuzt (Kreuzklassifikation), wenn ihreStufen ein kartesisches Produkt bilden.
(b) Wird jede Stufe eines Faktors mit jeder Stufe aller anderenFaktoren kombiniert, dann heißt der Versuch vollständig, andernfallsheißt er unvollständig.
Definition 7.2 (Interaktion/Wechselwirkung): Eine Interaktion bzw.Wechselwirkung zwischen Faktoren liegt vor, wenn der Effekt einesFaktors davon abhängt, welche Stufe auf einem anderen Faktorvorliegt.Deshalb gehen wir noch kurz auf Effektmessungen ein...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

EffekteHaupteffekt
I Effekte auf die Zielgröße, die auf das alleinige Wirken eines Faktorszurückzuführen sind, nennt man Haupteffekte.
WechselwirkungI Faktoren A und B gekreuzt→ Einflüsse nicht notwendig getrennt
voneinander zu beurteilenI Stufe von B kann den Einfluss von A auf die Zielgröße verändernI analog fur mehrere gekreuzte Faktoren
einfacher FaktoreffektI Einfluss eines Faktors innerhalb der Faktorstufen eines anderen
FaktorsI von Bedeutung, falls eine Wechselwirkung vorhanden ist
InterpretationI Haupteffekt eines Faktors lässt sich nur sinnvoll interpretieren,
wenn keine Wechselwirkungen mit anderen Faktoren vorliegenMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bemerkungen vorwegEinfaktorielle Versuchspläne können nur einen Haupteffektaufzeigen!In mehrfaktoriellen Plänen können dagegen Haupteffekte undWechselwirkungen effizient geschätzt und getestet werden!Allerdings: Je mehr Faktoren man aufnimmt, desto schwierigersind Ergebnisse interpretierbar!Beispielsweise gibt es bei mehr als 2 Faktoren nicht nurInteraktionen 1. Ordnung (AB) sondern auch Wechselwirkungenhöherer Ordnung (ABC, ABCD etc.). Hier hängt eine guteInterpretierbarkeit häufig auch vom Problem ab. Zudem werdendie Pläne natürlich auch immer unübersichtlicher.Wir starten zunächst mit einem 2-faktoriellen Plan...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der zweifaktorielle gekreuzte Plan (CR2F bzw.CRF-ab)Die Abkürzung CR2F steht für ’Completely Randomized 2-Factorial Design’. DieStufen der beiden Faktoren A und B sind dabei vollständig gekreuzt, wobei dieN =
∑i,j nij Versuchseinheiten zufällig den ab Faktorstufen zugeteilt/randomoisiert
werden:
Faktor BFaktor
A 1 · · · b
V111 V1b1
1...
......
V11n11 V1bn1b
......
......
Va11 Vab1
a...
......
Va1na1 Vabnab
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Allgemeines Two-Way Modell
Beobachtungen YijkI i = 1, 2, . . . , a (= Faktor A mit a Stufen)I j = 1, 2, . . . , b (= Faktor B mit b Stufen)I k = 1, . . . , nij unabhängige Wiederholungen pro Stufenkombination,
N =∑
i,j nij BeobachtungenI Zur Vereinfachung im Folgenden: nij ≡ n
Statistisches ModellI (Additives) Fixed Effects Modell:
Yijk = µij + εijk = µ+ αi + βj + γij + εijk (7.1)
I αi = µi· − µ·· = Haupteffekt A,βj = µ·j − µ·· = Haupteffekt B,γij = µij − µi· − µ·j + µ·· = Interaktionseffekt AB
I εijk u.i.v. für festes (i , j) mit E(εijk ) = 0, Var(εijk ) = σ2ij > 0.
Klassische ANOVA-Annahme: εijku.i.v .∼ N(0, σ2).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Hypothesen im CRF-abHypothesen von Interesse im CR2F sind
H0(A) : {αi = 0 für alle i = 1, . . . ,a}H0(B) : {βj = 0 für alle j = 1, . . . ,b}H0(AB) : {γij = 0 für alle i = 1, . . . ,a, j = 1, . . . ,b}.
Diese lassen sich mit µ = (µ11, . . . , µ1b, . . . , µab)′ wiederum mittelsgeeigneter Kontrastmatrizen31 umformulieren32:
H0(A) : {CA · µ = 0} = {Pa ⊗ 1b 1′b · µ = 0}
H0(B) : {CB · µ = 0} = {1a1′a ⊗ Pb · µ = 0}
H0(AB) : {CAB · µ = 0} = {Pa ⊗ Pb · µ = 0}.
Frage: Wie würden Sie diese Nullhypothesen testen?
31d.h. also hier C1ab = 0.32Zur Übung! Z.B. gilt Pa ⊗ 1
b 1′b · µ = (αi )i
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

F-Test für die Two-Way ANOVA
Im klassischen ANOVA-Modell mit εijku.i.v .∼ N(0, σ2) schreibt man
(7.1) wieder als Lineares Modell wie bei der One-Way-ANOVA mitKQS µ = (Y 11·, . . . ,Y ab·)
′
und erhält nach dem Satz vom F -Test ein Testverfahren in derStatistik
FC =1σ2 QC/r(C)
1σ2 Qε/[N − r(C)]
=QC/r(C)
Qε/[N − r(C)],
wobei C die Quadratform in der Kontrastmatrix C bezeichnet.Unter Cµ = 0 gilt im balancierten Fall FC ∼ F (r(C),N − r(C))
Die jeweiligen Freiheitsgrade sowie Quadratformen im Zähler(ersten drei Zeilen) bzw. Nenner (letzte Zeile mit ε) entnimmt manfolgender Tabelle
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle für den CRF-ab
Faktor Matrix Quadratform Rang r E(Q/r)
A Pa ⊗ 1b 1′b nb
a∑i=1
(Y i·· − Y ···
)2a− 1 σ2 + nb · σ2
α
B 1a 1′a ⊗ Pb na
b∑j=1
(Y ·j· − Y ···
)2b − 1 σ2 + na · σ2
β
AB Pa ⊗ Pb
a∑i=1
b∑j=1
(Y ij· − Y i·· − Y ·j· + Y ···
)2(a− 1)(b − 1) σ2 + n · σ2
γ
εa∑
i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2ab(n − 1) σ2
Dabei gilt σ2α =
1a− 1
a∑i=1
α2i , σ2
β =1
b − 1
b∑j=1
β2j und
σ2γ =
1(a− 1)(b − 1)
a∑i=1
b∑j=1
γ2ij
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bemerkungen
Unter den Hypothesen
H0(A) : Pa ⊗ 1b 1′bµ = 0 ist σ2
α = 0 ,
H0(B) : 1a1′a ⊗ Pbµ = 0 ist σ2
β = 0 ,
H0(AB) : Pa ⊗ Pbµ = 0 ist σ2αβ = 0
und die Quadratform in der jeweiligen Zeile der Tabelle schätztdann die gleiche Varianz σ2 wie die Quadratform in der letztenZeile der Tabelle.Die entsprechenden F -Tests kann man auch symbolischaufschreiben:
Quadratform(Faktor)/r(Matrix)
Quadratform( ε ) / (ab(n − 1))
H0(Matrix)∼ F (r(Matrix),ab(n − 1) )
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Alternativen zur Two-Way-ANOVAAuch die Two-Way-ANOVA beruht auf den sehr restriktiven Annahmen, dass
I die Varianzen innerhalb aller Stufenkombinationen identisch sind,und dass
I normalverteilte Beobachtungen vorliegen.I gleiche Stichprobenumfänge vorliegen (ungleiche müssen anders
behandelt werden)Andere Methoden, die ohne Varianzhomogenität und/oder Normalverteilungenauskommen sind auch hier die Tests von
I Welch-James,I Brunner, Dette und Munk (beides Approximationen) oderI Permutationstests vom Wald-Typ
Hiermit lassen sich alle Nullhypothesen H0 auch in heteroskedastischenModellen (z.T. ohne NVA) testen.
Als weitere Alternative existieren auch hier rangbasierte Methoden wie z.B. derBrunner, Dette und Munk Test für faktorielle Designs. Bei derHypothesenformulierung ersetzt man einfach die Erwartungswerte µij durch dieunbekannten Verteilungsfunktion Fij .
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Auswertung der ToxizitätsstudieWir betrachten nochmal die Situation aus der Toxizitätsstudie, wo dieBoxplots auf ungleiche Streuungen und möglicherweise nichtnormalverteilte Beobachtungen hinweisen:
Fallzahlen VarianzenP D1 D2 D3 D4 P D1 D2 D3 D4
W 8 9 10 7 11 0.65 0.54 0.68 0.68 0.43M 8 7 8 7 11 0.52 0.60 0.68 0.44 0.53
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Auswertung der ToxizitätsstudieDa die Haupteffekte stark ausgeprägt sind, erhält man hier mit denbetrachteten Tests vergleichbare Ergebnisse:
Hypothese Test p-WertH0(A) BDM < 0.0001
F -Test < 0.0001Wald-Perm < 0.0001
H0(B) BDM < 0.0001F -Test < 0.0001Wald-Perm < 0.0001
H0(AB) BDM 0.6078F -Test 0.6509Wald-Perm 0.6453
Dabei sollte klar sein: Die Anwendung von verschiedenen Tests warhier nur zur Illustration!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Gekreuzte höherfaktorielle Versuchspläne
Das obige Vorgehen lässt sich kanonisch auf mehr als 2 Faktorenerweitern.Hätte man im letzten Datensatz beispielsweise noch nach demFaktor C Altersklassen unterschieden, so würde ein 3-faktoriellesModell vorliegen.Hierfür erhält man durch erneutes Aufsplitten der Indizes einenkomplexeren Versuchsplan, in dem weitere Hypothesen vonInteresse sind (mit ähnlicher Formulierung wie zuvor).Für Anwendungen wird dabei klassischerweise empfohlen, dassjede Zelle des Versuchsplans mit mindestens 5 Versuchseinheitenbesetzt ist.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der gekreuzte dreifaktorielle VersuchsplanDen vollständig gekreuzten 3-faktoriellen CR3F bzw. CRF-abc Planmit Faktoren A,B und C sowie vollständig randomisierter Zuweisungder N =
∑i,j,r nijr Versuchseinheiten zu den abc Faktorstufen erhält
man als:
Faktor B j = 1 . . . j = bFaktor C . . . Faktor C
FaktorA r = 1 · · · r = c . . . r = 1 · · · r = c
V1111 V11c1 . . . V1b11 V1bc1
i = 1...
...... . . .
......
...V111n111 V11cn11c . . . V1b1n1b1 V1bcn1bc
......
...... . . .
......
...Va111 Va1c1 . . . Vab11 Vabc1
i = a...
...... . . .
......
...Va11na11 Va1cna1c . . . Vab1nab1 Vacbnabc
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Allgemeines Three-Way Modell
Statistisches ModellI (Additives) Fixed Effects Modell:
Yijrk = µijr + εijrk 1 ≤ i ≤ a,1 ≤ j ≤ b,1 ≤ r ≤ c,1 ≤ k ≤ nijr .
I εijrk u.i.v. für festes (i , j , r) mit E(εijrk ) = 0, Var(εijrk ) <∞.Hypothesen hierfür (mit µ = (µ111, . . . , µabc)′):
I für die HaupteffekteF H0(A) : {(Pa ⊗ 1
b 1′b ⊗ 1c 1′c) · µ = 0}
F H0(B) : {( 1a 1′a ⊗ Pb ⊗ 1
c 1′c) · µ = 0}F H0(C) : {( 1
a 1′a ⊗ 1b 1′b ⊗ Pc) · µ = 0}
I Interaktionen 1. OrdnungF H0(AB) : {(Pa ⊗ Pb ⊗ 1
c 1′c) · µ = 0}F H0(AC) : {(Pa ⊗ 1
b 1′b ⊗ Pc) · µ = 0}F H0(BC) : {( 1
a 1′a ⊗ Pb ⊗ Pc) · µ = 0}I Interaktionen 2. Ordnung
F H0(ABC) : {(Pa ⊗ Pb ⊗ Pc) · µ = 0}
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Abschlussbemerkungen
Wie man sieht, wird der Versuchsplan mit mehr Faktoren immerkomplizierter.Außerdem tritt ein genereller Nachteil von komplett randomisiertenVersuchsplänen auf: Man benötigt relativ viele Versuchseinheiten,da hier mindestens vier Gruppen gebildet werden müssen.Außerdem sollte man bei Randomisierung als einzigeKontrolltechnik auch auf homogene Versuchseinheiten achten, umkeine zu große Versuchsfehlerstreuung im Versuch zu habenSpäter werden wir auch mehrfaktorielle Blockpläne kennenlernen,bei denen analog zum RCBD mit einem Faktor, Blocking alsweitere Technik eingesetzt wird.Zunächst betrachten wir aber einge Spezialfälle desmehrfaktoriellen Modells von Interesse.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 8:
Faktorielle 2k Designs und verwandtePläne

2k ExperimenteDie allgemeinen mehrfaktoriellen Experimente des letztenKapitels beinhalten viele interessante SpezialfälleEiner der Wichtigsten ist dabei das sogenannte 2k Design mit kFaktoren, die alle nur 2 Stufen besitzenDiese Stufen können
I quantitativ (zwei Dosen eines Wirkstoff, Temperaturwerte oderZeitpunkte) oder
I qualitativ sein (Fall und Kontrolle, “hoch” und “niedrig”, zweiMaschinen).
Man kodiert diese dann häufig mittels “+/−”, “0/1” oder “+1/−1“.In jedem Fall benötigt eine einfache Durchführung dieses DesignsN = 2k BeobachtungenHäufigste Anwendung: In frühen Versuchsstadien, um (die)relevante(sten) Faktoren zu finden!Die Auswertung geschieht dabei analog zum mehrfaktoriellen Fall.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel 8.1 (Chemieherstellung): Ein chemisches Produkt wird ineinem Druckbehälter hergestellt. In einer Pilotanlage soll der Effekt derFaktoren
Temperatur (A),Druck (B) undRührgeschwindigkeit (C) (alle jeweils auf 2 Stufen)
auf die Filtrationsrate (diese soll maximiert werden) durch Kombinationaller möglichen Stufen untersucht werden. Aus Kostengründen wirddabei jeweils nur eine Messung pro Stufenkombination durchgeführt.⇒ Es handelt sich also um einen einfachen 23-Versuchsplan!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel 8.2 (Organisation und Lernen): Aus Ünlü (2011): Wennman eine Reihe von Wörtern, die man vorher gehört hat, wiedergebensoll, so neigt man dazu, die Begriffe, die in einem sinnvollenZusammenhang stehen, nacheinander zu reproduzieren. Die Begriffewerden dabei geordneter wiedergegeben als sie dargeboten wurden.Man bildet sogenannte Wörter - Cluster, die zu einem Oberbegriffgehören. Im Rahmen des “experimentalpsychologischen Praktikums”der Universität Frankfurt ging man von folgenden Überlegung aus:
Gibt man die Lernreihe geordnet an, müsste die Behaltensleistungder Probanden größer sein als bei einer ungeordneten Lernreihe.(Faktor A mit 2 Stufen)Gibt man zusätzlich noch an, dass sich die Wörter bestimmtenOberbegriffen zuordnen lassen, müssten auch mehr Wörterbehalten werden als wenn dieser Hinweis nicht gegeben wird.(Faktor B mit 2 Stufen)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fortsetzung des BeispielsDie Lernreihe bestand dabei aus 60 zweisilbigen Wörtern.
Die Wörter wurden auf einem Tonband mit einem Abstand von ca.drei Sekunden nacheinander abgespielt.Dabei ließen sich je 15 Wörter einer von vier Kategorien (Tiere,Vornamen, Nahrungsmittel, Werkzeuge) zuordnen.Die Wörter wurden einmal zufällig ungeordnet und einmal ingeordneter Reihenfolge (Faktor A) abgespielt.Als weitere Versuchsbedingung wurde vor Darbietung der Wörterein Hinweis auf die Kategorien gegeben, unter der anderenBedingung nicht (Faktor B).Das vorliegende Experiment wurde insgesamt 5x wiederholt, sodass der Stichprobenumfang insgesamt N = 20 betrug (22 = 4Versuchspersonen (eine Person für eine Bedingung) proDurchführung). Die Probanden wurden dabei zufällig denverschiedenen Bedingungskombinationen zugeteilt.
⇒ Es handelt sich also um einen wiederholten 22-Versuchsplan!Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel 8.3 (Kreditkartenmarketing): Im International Journal of Researchin Marketing erschien 2006 ein Artikel von Bell et al., der ein Experiment zurSteigerung der Kreditkartenabschlüsse einer Firma aus dem Finanzsektor beschreibt.Das Experiment lässt sich schematisch vereinfacht wie folgt darstellen:
Faktor Kontrolle (-) Neue Idee (+)A: Jahresbeitrag Aktueller Satz NiedrigerB: Beantragungsgebühr Nein JaC: Zinssatz in den ersten 6 Monaten Aktueller Satz NiedrigerD: Zinssatz danach Aktueller Satz Höher
Das Marketing-Team der Firma hat aus obigen Stufenkombinationen somit 24 = 16verschiedene Angebote erstellt. Diese wurden an mehr als 7000 Kunden gemailt.⇒ Es handelt sich also um einen wiederholten 24-Versuchsplan!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Effektschätzung im 22 DesignWir betrachten das Beispiel Organisation und Lernen mit denhypothetischen Versuchsergebnissen
Faktor DurchgangA B I II III IV V Summe- - 25 27 22 30 26 130+ - 29 38 29 30 34 160- + 31 26 27 34 32 150+ + 31 39 33 32 35 170
Wie schätzt man nun die Effekte der Faktoren undWechselwirkungen?
⇒ Wie beim Basketballbeispiel!Mögliches Modell:
Yijk = µ+ αxi + βxj + γxixj + εijk , 1 ≤ i , j ≤ 2,1 ≤ k ≤ n = 5
für εijki.i.d .∼ N(0, σ2) und xi = (−1)i .
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Effektschätzung im 22 DesignFaktor DurchgangA B I II III IV V Summe- - 25 27 22 30 26 130+ - 29 38 29 30 34 160- + 31 26 27 34 32 150+ + 31 39 33 32 35 170
Haupteffekt33 A:
α =(A+B+ − A−B+) + (A+B− − A−B−)
2n=
170− 150 + 160− 13010
= 5
Haupteffekt B:
β =(A+B+ − A+B−) + (A−B+ − A−B−)
2n=
170− 160 + 150− 13010
= 3
Wechselwirkung AB:
γ =A+B+ − A+B− − A−B+ + A−B−
2n=
170− 160− 150 + 13010
= −1
33n=Anzahl der Wiederholungen und 1/2 wegen Mittelung der beiden EffektanteileMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

BemerkungMan kann die obigen Effektschätzer im Rahmen eines Linearen Modells alsKontraste der Stufenkombis A±B± angeben:
StufenkombinationenEffekte A−B−(= 1) A+B−(= a) A−B+(= b) A+B+(= ab)
A -1 +1 -1 +1B -1 -1 +1 +1
AB +1 -1 -1 +1
Die Kontrastvektoren (in den Zeilen) sind orthogonal zueinander!⇒ Dies führt dazu, dass die zugehörigen Effekte unabhängig voneinander
geschätzt werden können (Beweis an Tafel?!)!In Klammern haben wir zusätzlich eine Kodierung verwendet, die anzeigt,welche Faktoren im Zustand “+” sind. Diese wird bei mehreren Faktoren hilfreich.Außerdem sieht man im Rahmen der Theorie über Lineare Modell leicht ein,dass die Effektschätzer KQS im obigen Modell sind, d.h. sie minimieren dieFehlerquadratesumme
2∑i,j=1
n∑k=1
(Yijk − µ− αxi − βxj − γxixj )2.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Effektschätzung im 2k DesignDa die Kontraste zur Effektschätzung bei mehren Faktoren schnellunübersichtlich werden, haben wir in auf der letzten Folie die obigeKurzschreibweise eingefügt (Vorsicht: Hier werden die Kleinbuchstabenausnahmsweise nicht für die Stufenanzahl verwendet!).Allgemein lässt sich im 2k Design der Effekt von ABC . . .K schätzen durchEntwicklung von
2n2k (a± 1)(b ± 1) · · · (k ± 1)
schätzen. In einem 23 Design erhält man beispielsweise für die WechselwirkungAC:
2n23 (a− 1)(b + 1)(c − 1) =
abc + 1c + b + 1− ab − bc − a− cn22
Die zugehörigen Kontrastvektoren erhält man dann wie oben. Diese sind auchim allgemeinen Fall wieder orthogonal (leichte Übung).
Wir halten fest: 2k Designs sindI sog. orthogonale Pläne, bei denenI jeder Haupteffekt und jede Wechselwirkung einzeln und unabhängig
voneinander geschätzt werden kann
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Effektschätzung im 23 Design
Im 23-Design erhält man z.B. die folgenden Kontraste alsSpaltenvektoren:
EffekteStufenkombinationen I A B AB C AC BC ABC
1 +1 -1 -1 +1 -1 +1 +1 -1a +1 +1 -1 -1 -1 -1 +1 +1b +1 -1 +1 -1 -1 +1 -1 +1ab +1 +1 +1 +1 -1 -1 -1 -1c +1 -1 -1 +1 +1 -1 -1 +1ac +1 +1 -1 -1 +1 +1 -1 -1bc +1 -1 +1 -1 +1 -1 +1 -1
abc +1 +1 +1 +1 +1 +1 +1 +1
Man sieht direkt, dass je 2 Spalten orthogonal zueinander sind.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Geometrische Veranschaulichung im 23 Design
Quelle: Montgomery (2013).Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Optimalität von 2k Designs
Man kann zeigen: 2k Designs erfüllen gewisseOptimalitätskriterien wie
I D-optimalityI G-optimalityI I-optimality
im einfachen Fixed Effects Modell mit Interaktionen.⇒ Exkurs an der Tafel....
Zuvor aber: Erinnerung an den F-Test Exkurs (Folie 147ff)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Optimalität von 2k Designs2k Pläne erfüllen also gewisse Optimalitätskriterien.Der Stichprobenumfang für einen Durchgang kann für großes kallerdings sehr groß werden; z.B. benötigt die einfacheDurchführung eines Plans mit 10 Faktoren bereits 1024Beobachtungen.Lösung: Häufig ist man in der Screening-Phase nur an denHaupteffekten (k Stück) und gar nicht an den Wechselwirkungeninteressiert. In diesem Fall können andere (unvollständige) Plänegewählt werden, die mit einem geringeren Stichprobenumfangauskommen.Dies führt auf
I Placket-Burman- undI fraktioniert faktorielle 2k−p-Designs
Man muss hierbei allerdings beachten, dass vorhandeneWechselwirkungen in den Haupteffekten confounded werden.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Screening-Pläne – Schätzung ohneWechselwirkungen
Diese Problemstellung zielt darauf ab alle Haupteffekte imlinearen Fixed Effects Modell mit k Faktoren ohneWechselwirkungen und je 2 Stufen mit möglichst wenigenStufenkombinationen zu schätzen, d.h. der Erwartungswertvektordes LM besteht (bei einem Durchgang) aus den folgendenEinträgen:
β0 + β1x1 + · · ·+ βkxk , xi ∈ {−1,+1} für i = 1, . . . , k .
Ein zugehöriger Versuchsplan mit ortogonalen Kontrasten heißtdann auch Screening-Plan.Wir betrachten zunächst den Placket-Burman-Plan; bei dem man(leider) voraussetzen muss, dass k + 1 ein Vielfaches von 4 ist.Die Anzahl der Stufenkombinationen (pro Versuchsdurchgang) istdann auch ein Vielfaches der 4.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Placket-Burman-Designs
Placket-Burman-Designs lassen sich wie folgt konstruieren:1 Man wählt einen Zeilenvektor der Länge k + 1, der (k + 1)/2 mal
die +1 und (k − 1)/2 mal die −1 enthält2 Weitere Zeilenvektoren erhält man durch zyklisches Permutieren,
d.h. man schiebt die vorherige Zeile um eine Position nach rechtsund fügt den “verloren gegangenen” Wert an der ersten Stellehinzu.
3 Zum Abschluss wird dann noch ein Zeilenvektor mit den Einträgen-1 hinzugefügt.
Der Versuchsplan ergibt sich dann aus den Zeilen in obiger-1/+1-Kodierung, wobei die Spalten wiederum die Kontraste zumSchätzen der Haupteffekte widerspiegeln.Je zwei Spalten dieser Planungsmatrix sind dabei wieder orthogonal.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Placket-Burman-Designs – Beispiele
Beispiele für k = 3 und k = 7 Faktoren
FaktorenZeilennr. A B C
1 −1 +1 +12 +1 +1 −13 +1 −1 +14 −1 −1 −1
FaktorenZeilennr. A B C D E F G
1 −1 −1 +1 −1 +1 +1 +12 −1 +1 −1 +1 +1 +1 −13 +1 −1 +1 +1 +1 −1 −14 −1 +1 +1 +1 −1 −1 +15 +1 +1 +1 −1 −1 +1 −16 +1 +1 −1 −1 +1 −1 +17 +1 −1 −1 +1 −1 +1 +18 −1 −1 −1 −1 −1 −1 −1
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fraktioniert faktorielle 2k−p-Designs
Sog. fraktioniert faktorielle 2k−p-Designs sind unvollständigeVersuchspläne mit insgesamt 2k−p verschiedenen Versuchen(Stufenkombinationen/Beobachtungen).Man erhält diese durch Entfernen verschiedenerKontraste/Stufenkombinationen aus dem zugehörigenvollständigen 2k -DesignIm Fall
I p = 1 spricht man von einem One-Half-Fraction eines 2k -DesignsI p = 2 spricht man von einem One-Quarter-Fraction eines
2k -Designs
Hierbei können für p < k − 1 nicht nur die Haupteffekte sondernauch bestimmte Wechselwirkungen mit untersucht werden.Mehr Details und Theorie u.U. in späteren Teilen der Vorlesung.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fraktioniert faktorielle 2k−p-Designs – Beispiel
Beispiel für k = 3 und p = 1. Es werden die roten Kontraste des 2k
Designs entfernt,
EffekteStufenkombinationen I A B AB C AC BC ABC
1 +1 -1 -1 +1 -1 +1 +1 -1a +1 +1 -1 -1 -1 -1 +1 +1b +1 -1 +1 -1 -1 +1 -1 +1ab +1 +1 +1 +1 -1 -1 -1 -1c +1 -1 -1 +1 +1 -1 -1 +1ac +1 +1 -1 -1 +1 +1 -1 -1bc +1 -1 +1 -1 +1 -1 +1 -1
abc +1 +1 +1 +1 +1 +1 +1 +1
d.h. man verwendet nur die Kontraste a,b,c und abc (d.h. die mit einer“+1” in der ABC-Spalte)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fraktioniert faktorielle 2k−p-Designs – Beispiel
Im obigen Beispiel schätzt man also den Effekt von A durch
a− b − c + abc2
.
Dies ist für die vorliegenden vier Stufenkombinationen auchgleichzeitig ein Schätzer für die Wechselwirkung BC(Spaltenvergleich!)Man schätzt hier also eigentlich den (confounded) Effekt A + BC!Bemerkung: Führt man 2 verschiedene Hälften eines2k−1-Designs hintereinander durch, so kann man diese zumSchätzen aller Effekte wie im 2k -Design zusammenlegen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

3k und qk Designsqk Designs sind Versuchspläne mit k Faktoren, die alle genau qStufen besitzen.Als wichtiger Spezialfall ist hierbei q = 3 geläufig, bei dem manzusätzlich zu zwei extremen Stufen (“hoch” und “niedrig”) nocheine mittlere Stufe verwendet.Da man hierfür bei einem vollständigen Plan für eine einfacheDurchführung dieses Designs N = qk Beobachtungen benötigt,sind auch hier wieder fraktionierte qk−p Pläne geläufig.Ist q eine Primzahl, so lassen sich diese auch sehr leicht aus denvollständigen qk -Pläne wie im Fall q = 2 erzeugen.
⇒ Verwendung bei Modellen mit quadratischen (q = 3) Termen odernoch höheren Potenzen.Die Auswertung geschieht dabei wieder analog zummehrfaktoriellen Fall.Mehr Details u.U. in späteren Teilen der Vorlesung.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 9:
Mehrfaktorielle Experimente mitgeblockten Störfaktoren

VorwortAllgemein ist Blocking eine Technik zur Kontrolle von Störfaktoren
Blocking in einfaktoriellen Experimenten hatten wir in Kapitel 6 besprochen.
Dabei haben wir verschiedene Pläne kennengelernt, die im Hinblick auf einenoder mehrere Störfaktoren blocken können
Erinnerung aus Kapitel 6:I Störfaktoren sind Faktoren, deren Einfluss im Versuch nicht interessiert.
Da sie jedoch Einfluss auf die Zielgröße nehmen können, soll ihreVariabilität möglichst gering gehalten/ kontrolliert werden
I Grundidee bei der Blockbildung: Bilde homogene Blöcke/Gruppen, für diedie Variabilität des bekannten Störfaktors innerhalb eines Blocks sehrgering ist. Die Variabilität zwischen den Blöcken kann dabei groß sein
Blocking erfolgt dabei z.B. nach Zeit oder physikalischen Gründen
In diesem Abschnitt betrachten wir nun analog Blockpläne bei zwei und mehrFaktoren von Interesse, wobei wir nur von einem Blockfaktor ausgehen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel 9.1 (Organisation und Lernen): Aus Ünlü (2011): Wir greifennochmal Beispiel 8.2. eines wiederholten 22-Versuchsplans auf, bei dem man eineReihe von Wörtern, die man vorher gehört hat, wiedergeben soll. Die Lernreihebestand dabei aus 60 zweisilbigen Wörtern.
Die Wörter wurden auf einem Tonband mit einem Abstand von ca. dreiSekunden nacheinander abgespielt.
Dabei ließen sich je 15 Wörter einer von vier Kategorien (Tiere, Vornamen,Nahrungsmittel, Werkzeuge) zuordnen.
Die Wörter wurden einmal zufällig ungeordnet und einmal in geordneterReihenfolge (Faktor A) abgespielt.
Als weitere Versuchsbedingung wurde vor Darbietung der Wörter ein Hinweisauf die Kategorien gegeben, unter der anderen Bedingung nicht (Faktor B).
Das vorliegende Experiment wurde insgesamt 5x wiederholt, so dass derStichprobenumfang insgesamt N = 20 betrug (22 = 4 Versuchspersonen (einePerson für eine Bedingung) pro Durchführung). Die Probanden wurden dabeizufällig den verschiedenen Bedingungskombinationen zugeteilt.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fortsetzung des Beispiels
Bei dieser kleinen Stichprobengröße (5 Versuchspersonen proFaktorkombination) kann es natürlich passieren, dass in einerGruppe (5 Personen mit der gleichen Faktorkombination) durchZufall vier der fünf Personen ein überdurchschnittlich gutesGedächtnis hatten, in einer anderen dagegen genau umgekehrt.Diese interindividuellen Unterschiede (Störfaktor) könnennatürlich die Ergebnisse verfälschen.Als Lösung könnte man entweder die Stichprobengröße erhöhen,oder aber (effizienter) eine Blocktechnik verwenden, die dieVergleichbarkeit (Homogenität) der Versuchsgruppen vergrößert.Wir diskutieren dies im Folgenden am vorliegenden Beispiel...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fortsetzung des Beispiels – Parallelisierung
Eine einfache Möglichkeit bestünde darin, in Vortests dieGedächtnisleistung aller 20 Teilnehmer zu überprüfen.Vorsicht: Dieser Vortest sollte sich sehr deutlich vomHauptversuch unterscheiden, damit mögliche Testeffekte (alsneuer Störfaktor) vernachlässigbar sind!Basierend auf den Vortest Ergebnissen könnte man dann eineReihenfolge (Ränge/Platzierungen) der 20 Versuchspersonenfestlegen und aus je 4 benachbarten Rängen die 5 Blöcke bilden.Die Faktorkombination würde man innerhalb jedes Blocksrandomisiert zuweisen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fortsetzung des Beispiels – Wiederholungsmessung
Wir hatten auch Wiederholungsmessung (an den Personen) als Form derBlockbildung kennengelernt.
Wäre das im vorliegenden Beispiel sinnvoll?
Eher nicht, denn dies würde genau genommen bedeuten, dass alleVersuchspersonen alle vier Faktorkombinationen “ausprobiert” hätten; und zwarjedes Mal mit der gleichen Wortreihe!
⇒ Hier treten enorme Übertragungseffekte (carry-over effects) bzw. Lerneffekteauf, die sich sicherlich auch nicht durch Variation der Reihenfolge o.ä.ausschalten ließen.
Nichtsdestotrotz stellen Wiederholungsmessungen eine sinnvolle Technik beimehrfaktoriellen Versuchsanlagen (mit anderer Fragestellung) dar; insbesondereaufgrund der relativ geringen Anzahl an benötigten Versuchspersonen imVergleich zum Versuch ohne Blockbildung. Dieser Vorteil verstärkt sich noch mitder Anzahl an Stufen und Faktoren.
In dem Fall kann Parallelisierung eher zu umständlich sein.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Fortsetzung des Beispiels – VersuchsplanDer Versuchsplan des Beispiels mit den fünf Blöcken a vier Versuchseinheitenließe sich nun so darstellen:
Faktor BBlock Faktor A 1 2
1 1 V111 V121
2 V211 V221
......
......
5 1 V115 V125
2 V215 V225
Dabei wird die Zuweisung zu den Faktorstufenkombinationen innerhalb jedesBlocks randomisiert. Für den Fall der Parallelisierung gehören die Einträgeinnerhalb eines Blocks zu einer jeweils anderen Versuchseinheit; in einem Planmit Wiederholungsmessungen würden die Einträge zu derselbenVersuchseinheit gehören.
Analog ergibt sich der Versuchsplan für 2 Faktoren A und B mit a bzw. b Stufenund n homogenen Blöcken als...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Versuchsplan im 2-faktoriellen BlockdesignFaktor B
Block Faktor A 1 · · · b
11 V111 · · · V1b1...
......
...a Va11 · · · Vab1
......
......
......
......
......
n1 V11n · · · V1bn...
......
...a Va1n · · · Vabn
Der letzte Index der VE gibt dabei die Blockzugehörigkeit an; die anderen beidendie Stufe der Faktoren A bzw. B.
Die Zuweisung innerhalb der Blöcke erfolgt wiederum randomisiert⇒ Completely Randomized 2-Factorial Block Design (RCBD-ab).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Modellierung im 2-faktoriellen BlockdesignWir betrachten zunächst das Modell eines balancierten randomisierten2-faktoriellen Designs mit unabhängigen Beobachtungen:
Yijk = µ+ αi + βj + γij + εijk 1 ≤ i ≤ a, 1 ≤ j ≤ b, 1 ≤ k ≤ n.
Beispiel: Wir wollen an einem bestimmten Materialblock jeweils n Experimentemit allen Faktorkombinationen durchführen. Leider stellen wir fest, dass nichtgenügend Blöcke aus derselben Charge vorhanden sind, um alle abn Versuchedurchzuführen; allerdings können an einem Block ab Versuche durchgeführtwerden. Aus diesem Grund ordern wir jeweils einen Materialblock von nverschiedenen Chargen und führen an jedem Block die ab Faktorkombinationendurch.
Dies führt auf ein RCBD-ab mit zugehörigem statistischen Modell
Yijk = µ+ αi + βj + γij + δk + εijk 1 ≤ i ≤ a, 1 ≤ j ≤ b, 1 ≤ k ≤ n,
in dem δk ∼ N(0, σ2δ) den Effekt des k -ten Blocks beschreibt und wir implizit
angenommen haben, dass keine Blockinteraktionen vorliegen. Der Blockeffektwird typischerweise zufällig und unabhängig von den εijk ∼ N(0, σ2) modelliert.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Hypothesen im RCBD-abHypothesen von Interesse sind genau dieselben wie im CR2F:
H0(A) : {αi = 0 für alle i = 1, . . . ,a}H0(B) : {βj = 0 für alle j = 1, . . . ,b}H0(AB) : {γij = 0 für alle i = 1, . . . ,a, j = 1, . . . ,b}.
Diese testet man wiederum mittels entsprechender F -Tests, wobeisich die Freiheitsgrade durch den Blockfaktor leicht ändern wie diefolgende Varianzanalyse-Tabelle für den RCBD-ab zeigt 34...
34Eine ganz kurze Herleitung erfolgt später im Rahmen der gemischten ModelleMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle für den RCBD-ab
Faktor Quadratform Rang r E(Q/r)
Block abn∑
k=1
(Y ··k − Y ···
)2n − 1 σ2 + ab · σ2
δ
A nba∑
i=1
(Y i·· − Y ···
)2a− 1 σ2 + nb · σ2
α
B nab∑
j=1
(Y ·j· − Y ···
)2b − 1 σ2 + na · σ2
β
ABa∑
i=1
b∑j=1
(Y ij· − Y i·· − Y ·j· + Y ···
)2(a− 1)(b − 1) σ2 + n · σ2
γ
εa∑
i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2(ab − 1)(n − 1) σ2
Dabei gilt wieder σ2α = 1
a−1∑a
i=1 α2i , σ
2β = 1
b−1∑b
j=1 β2j und
σ2γ = 1
(a−1)(b−1)∑a
i=1∑b
j=1 γ2ij .
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

BemerkungenUnter den Hypothesen H0(A), H0(B) bzw. H0(AB) schätzen dieQuadratformen für die Faktoren A, B bzw. AB wieder dieselbeVarianz σ2 wie die Quadratform der Residuen in der letzten Zeileder Tabelle.Die entsprechenden F -Tests zum Testen vonH0(C),C ∈ {A,B,AB} kann man wiederum symbolischaufschreiben:
Quadratform(C)/r(C)
Quadratform( ε ) / (ab(n − 1))
H0(C)∼ F (r(C), (ab − 1)(n − 1) )
Die einzige Änderungen bei der Auswertung im Vergleich zumCRF-ab liegt also im zweiten Freiheitsgrad.Voraussetzung hierbei war stets, dass die Faktoreffekte fest sind;der Blockeffekt zufällig; und dass keine Blockinteraktionenvorliegen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Auf analoge Art und Weise erhält man Versuchspläne mit einemBlockfaktor und deren Auswertung auch für höherfaktorielleBlockdesigns.Ein Beispiel für den RCBD-abc gibt es zum Abschluss auf dernächsten FolieMöchte man wie bei Lateinischen Quadraten oder GraecoLateinischen Quadraten in mehr als eine Richtung blocken,Blockinteraktionen und zufällige Faktoreffekte zulassen, so erhältman weitere Versuchspläne, auf die wir aber hier nicht mehr nähereingehen.Zum Teil werden diese später im Rahmen von Linearen Modellenmit gemischten und zufälligen Faktoren (Mixed and RandomEffects Models) abgedeckt.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Versuchsplan im 3-faktoriellen Blockdesign
Faktor CBlock Faktor A Faktor B 1 · · · c
1
1
1 V1111 · · · V111c...
.
.
....
.
.
.b V11b1 · · · V11bc
.
.
....
.
.
....
.
.
.
a
1 V1a11 · · · V1a1c...
.
.
....
.
.
.b V1ab1 · · · V1abc
.
.
....
.
.
....
.
.
....
n
1
1 Vn111 · · · Vn11c...
.
.
....
.
.
.b V11b1 · · · V11bc
.
.
....
.
.
....
.
.
.
a
1 Vna11 · · · Vna1c...
.
.
....
.
.
.b Vnab1 · · · Vnabc
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 10:
Hierarchische und Split-Plot Designs

In diesem Abschnitt lernen wir zwei weitere, fortgeschrittenereVersuchspläne kennen, die häufig angewendet werden
I Hierarchische bzw. verschachtelte bzw. nested Designs undI Split-Plot Designs
Vorwort: In den meisten, der bisher betrachteten Versuchsplänen,waren die Stufen der interessierenden Faktoren untereinander(vollständig35) gekreuzt.In vielen Fällen ist dies aber gar nicht möglich. Möchte manbeispielsweise die Länder (Faktor A) Deutschland und Österreichmiteinander vergleichen, so sollte man als weiteren Faktorwenigstens auf die zugehörigen Bundesländer (Faktor B)schauen, um genauere lokale Unterschiede zu berücksichtigenIn diesem Fall können nicht alle 25 (=16+9) Stufen des Faktors Bmit den Stufen des Faktors Land kombiniert werden. Man sagt Bist unter A verschachtelt.
35Ausnahme hierbei war z.B. das Incomplete Block Design.Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Anordnung der FaktorenDefinition 10.1 (Faktorenanordnungen und erste Designs):(a) Die spezielle unvollständige Anordnung, die als
’Kronecker-Summe’ der Kombinationen der Faktorstufendarstellbar ist, heißt hierarchische Anordnung oder auchSchachtel-Modell (hierarchische Klassifikation). Hierbei heißt einFaktor verschachtelt unter einem anderen Faktor, wenn jedeseiner Stufen genau einer Stufe des anderen Faktors zugeordnetist
(b) Versuchsanlagen, bei denen zwei (oder mehrere) Faktorenuntereinander gekreuzt sind und ein weiterer Faktor (oder auchmehrere) mit einem Teil dieser Faktoren ebenfalls gekreuzt, unterden anderen Faktoren aber verschachtelt ist, heißen partiellhierarchisch.
Wir betrachten zuerst Teil (a) und greifen (b) im Rahmen derSplit-Plot-Designs wieder auf.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Übersicht: Gekreuzt und verschachtelte Faktoren
Anordnung der Faktorengekreuzte Faktoren (Kreuzklassifikation)
I Kombination der Stufen bildet kartesisches ProduktI vollständig gekreuzt = alle Kombinationen kommen vorI unvollständig = sonstI männliche und weibliche Patienten erhalten Verum und PlaceboI in jedem Zentrum (Schicht) Standardtherapie und neue Therapie
verschachtelte Faktoren (hierarchische Klassifikation)I jede Stufe des verschachtelten Faktors kann genau einer Stufe des
anderen Faktors zugeordnet werdenI Landkreis ist unter Bundesland verschachteltI Versuchstiere sind unter der Behandlung verschachteltI Doppelmessungen sind unter den Patienten verschachtelt
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel: KnochenschraubenBeispiel 10.1 (Knochenschrauben-Studie): Ein Unternehmen besitzt fünfverschiedene Langdrehautomaten (Faktor A) zur Herstellung von Knochenschraubenaus Titan. Jede dieser Maschinen wird von zwei verschiedenen Mechanikern 36
(Faktor B) betrieben. Die folgende Tabelle erhält die Durchmesser von jeweils einererstellten Schraube (Norm: 12mm)
Maschine Mechaniker Beobachtung in mm
1 1 12.52 12.6
2 3 11.84 12.1
3 5 12.06 11.9
4 7 12.88 12.7
5 9 12.510 12.6
361x Tag- und 1x NachtschichtMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel: Oberflächen-Volumen-Verhältnis
Beispiel 10.2 (OVV-Studie): Zur Untersuchung des protektivenEffektes der Bretschneiderschen HTK-Lösung37 wurden bei 10Hunden die AV-Knoten des Herzens untersucht. Fünf Herzen wurdenunter reiner Ischämie (Kontrolle) untersucht, die fünf anderen Herzenwurden mit der HKT-Lösung perfundiert; bei randomisierter ZuordnungEin wichtiger Parameter bei diesem Experiment ist dasOberflächen-Volumen-Verhältnis (SV R) der Mitochondrien imAV-Knoten des Herzens. Zur genaueren Bestimmung diesesVerhältnisses wurden bei jedem Knoten drei Schnitte im Abstand von50µm angefertigt und SV R nach der Methode von Weibel bestimmt.Die Ergebnisse entnehmen wir der folgenden Tabellen:
37Kardioplegischer Lösung, die u.a. bei Organtransplanatationen und zurkünstlichen Herbeiführtung eines Herzstillstand bei bestimmten Operationenverwendet wird
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel: Oberflächen-Volumen-VerhältnisOberflächen-Volumen-Verhältnis (SV R) [µm2/µm3]
Reine Ischämie HTK-LösungHund Schnitt SV R Hund Schnitt SV R
1 8.19 1 9.061 2 8.23 6 2 9.38
3 7.91 3 9.271 7.47 1 9.13
2 2 8.20 7 2 9.393 7.93 3 9.221 7.46 1 9.24
3 2 7.89 8 2 9.183 7.86 3 9.841 8.71 1 9.64
4 2 7.90 9 2 9.363 8.49 3 9.691 7.65 1 9.90
5 2 7.98 10 2 9.863 8.03 3 9.77
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bemerkungen
Dies sind beides hierarchische Designs mit 2 Faktoren (B ist unterA verschachtelt) bzw. zweifaktorielle hierarchische Pläne(CRHF-b(a)).Im ersten Beispiel sind die Mechaniker unter den Maschinenverschachtelt! Bemerke: Wenn uns der Effekt der Schichtinteressieren würde, hätten wir ein gekreuztes 2-faktoriellesDesign!Im zweiten Beispiel ist der Hund unter der Behandlungverschachtelt.Diskussion: Welche Faktoren sind fest, welche zufällig?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der zweifaktorielle hierarchische Plan (CRHF-b(a))Die Abkürzung CRH2F steht für ’Completely RandomizedHierarchical 2-Factorial Design’.
Wir sehen die Versuchseinheiten als Stufen des Faktors B an.
Da man in der Regel die Aussagen des Versuchs nicht nur für dieim Versuch verwendeten Versuchseinheiten (Mechaniker/Hunde)treffen möchte sondern auf die Grundgesamtheit derVersuchseinheiten verallgemeinern möchte, wird man den Faktor‘Versuchseinheit’ häufig als zufällig ansehen. In diesem Fallwerden von den ab möglichen Versuchseinheiten beimCRHF-b(a) zufällig b ausgewählt und den a Stufen des Faktors A(zufällig) zugeteilt.
Dies führt auf den folgenden balancierten Versuchsplan
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der zweifaktorielle hierarchische Plan (CRHF-b(a))Faktor B
FaktorA 1 · · · b b + 1 · · · 2b · · · (a− 1)b + 1 · · · ab
1 V11 · · · V1b2 V21 · · · V2b...
. . .a Va1 · · · Vab
Der Faktor B ist unter dem Faktor A verschachtelt.Analog erhält man unbalancierte CRHF-b(a) Pläne, bei denenunter Stufe i von Faktor A u.U. verschieden viele Stufen bi desFaktors B verschachtelt sind. Im obigen Plan gilt bi ≡ b.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Modell für den zweifaktoriellen hierarchischen Plan(feste Faktoren)
CRHF-b(a) im balancierten Fall bei zwei festen Faktoren:
Yijk = µij + εijk i = 1, . . . ,a; j = 1, . . . ,b; k = 1, . . . ,n= µ+ αi + βj(i) + εijk .
Wie üblich nehmen wir dabei an, dass εijki.i.d∼ N(0, σ2) sowie∑a
i=1 αi = 0.Für den Effekt βj(i) gilt in diesem Fall
I∑b
j=1 βj(i) = 0 , i = 1, . . . ,a (da B fester Faktor).
Bemerke: Da B unter A verschachtelt ist, treten hierbei keineInteraktionen zwischen den Faktoren auf!Im unbalancierten Fall läuft der Index j(i) = 1, . . . ,bi inAbhängigkeit von i und man erhält das Modell...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der CRHF-b(a) unbalanciert
Statistisches Modell
Yijk = µij + εijk = µ+ αi + βj(i) + εijk
I mit µij = E(Yijk ), εijki.i.d∼ N(0, σ2)
I Faktor A: i = 1, . . . ,a StufenI Faktor B: j = 1, . . . ,bi Stufen in Stufe i des Faktors AI Versuchsfehler: k = 1, . . . ,nij unabhängige WiederholungenI N =
∑ai=1∑bi
j=1 nij gesamte Anzahl der Versuchseinheiten
Matrizenschreibweise
I Y =
a⊕i=1
bi⊕j=1
1nij
µ + ε = X µ + ε
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der zweifaktorielle hierarchische Plan (CRHF-b(a))Interpretation
I Komponentenschreibweiseµij = µ·· + αi + βj(i), i = 1, . . . ,a, j = 1, . . . ,bi
αi = µi· − µ··, i = 1, . . . ,aβj(i) = µij − µi· j = 1, . . . ,bi und i = 1, . . . ,a
Hypothesen (bei zwei festen Faktoren)I kein Kategorie-Effekt38 H0(A) :
{αi = 0, i = 1, . . . ,a} = {Pa diag(b−11 1′b1
, . . . ,b−1a 1′ba
)µ = 0}
I kein Subkategorie-Effekt H0(B(A)) :
{βj(i) = 0,∀1 ≤ i ≤ a,1 ≤ j ≤ bi} = {diag(Pb1 , . . . ,Pba )µ = 0}
AnmerkungI es gibt keinen Haupteffekt des Faktors BI es gibt keine Wechselwirkung zwischen A und B
38mit µ = (µ11, . . . , µ1b1 . . . , µa1, . . . µaba )′
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle für den CRHF-b(a)
Varianztabelle für den balancierten39 CRHF-b(a) (feste Faktoren)
Faktor Matrix Quadratform Rang E(Q/r)
A Pa ⊗ 1b Jb ⊗ 1
n Jn nba∑
i=1
(Y i·· − Y ···
)2a− 1 σ2 + nb · σ2
α
B(A) Ia ⊗ Pb ⊗ 1n Jn n
a∑i=1
b∑j=1
(Y ij· − Y i··
)2a(b − 1) σ2 + n · σ2
β(α)
ε Ia ⊗ Ib ⊗ Pn
a∑i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2ab(n − 1) σ2
Dabei gilt
σ2α =
1a− 1
a∑i=1
α2i und σ2
β(α) =1
a(b − 1)
a∑i=1
b∑j=1
β2i(j)
39ähnliche Größen im unbalancierten mit obigen Matrizen zur ÜbungMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Modell für den zweifaktoriellen hierarchischen Plan(mixed model)
CRHF-b(a) im balancierten Fall bei festem Faktor A undzufälligem Faktor B
Yijk = µ+ αi + βj(i) + εijk , 1 ≤ i ≤ a; 1 ≤ j ≤ b; 1 ≤ k ≤ n.
Annahmen:I∑a
i=1 αi = 0, µi = µ+ αi = E(Yijk ), i = 1, . . . ,a - fester EffektI βj(i)
i.i.d∼ N(0, σ2β) zufälliger Faktor
I εijki.i.d∼ N(0, σ2) unabhängige Versuchsfehler
I die Zufallsvartiablen βj(i) und εijk sind unabhängigSpezialfall Repeated Measures oder auch Clusterdaten:
I mehrere Messungen an derselben VersuchseinheitI hier: unter gleichen Bedingungen / Behandlungen i = 1, . . . ,a
(um z.B. genauere Messungen zu erhalten)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Hierarchisches Versuchsschema bei RepeatedMeasures
Faktor A fest, Faktor B zufällig - B unter A verschachtelt: B(A)
BeispielI Zwei unverbundene Stichproben (balanciert) mit je 3
Messwiederholungen:
1 2x x
V11 x V21 xx xx x
V12 x V22 xx x
......
......
x xV1n x V2n x
x x
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle für den CRHF-b(a)
Varianztabelle für den balancierten CRHF-b(a) (mixed model)
Faktor Quadratform Rang E(Q/r)
A nba∑
i=1
(Y i·· − Y ···
)2a− 1 σ2 + nb · σ2
α + n · σ2β
B(A) na∑
i=1
b∑j=1
(Y ij· − Y i··
)2a(b − 1) σ2 + n · σ2
β
ε
a∑i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2ab(n − 1) σ2
Dabei gilt wieder σ2α = 1
a−1∑a
i=1 α2i und Var(βj(i)) = σ2
β.Bem: Zum Testen von H0(A) : {αi = 0, i = 1, . . . ,a} kann hier derQuotient von Q(A) und Q(B(A)) verwendet werden! Details undH0(B(A)) im mixed model im nächsten Kapitel.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle für den CRHF-b(a)Für Situationen, in denen der Faktor A auch noch zufällig ist,modelliert man diesen als αi
i.i.d .∼ N(0, σ2α) und erhält eine
Varianztabelle für den balancierten CRHF-b(a) (random model)
Faktor Quadratform Rang E(Q/r)
A nba∑
i=1
(Y i·· − Y ···
)2a− 1 σ2 + nb · σ2
α + n · σ2β
B(A) na∑
i=1
b∑j=1
(Y ij· − Y i··
)2a(b − 1) σ2 + n · σ2
β
ε
a∑i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2ab(n − 1) σ2
In diesem Fall testet man typischerweise Nullhypothesen über dieVarianzen der Faktoren; Details im nächsten Kapitel.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der Split-Plot Plan (SP-a.b)Dies ist ein partiell hierarchischer Plan.
Die Faktoren A und C sind mit dem Faktor B gekreuzt, der FaktorC ist unter dem Faktor A verschachtelt.
Jede Versuchseinheit ist eine Stufe des Faktors C
⇒ C ist hier typischerweise zufällig (Probanden etc.)
Die zugehörigen N =∑a
i=1 ni Versuchseinheiten werden zufälligden a Stufen von A zugeteilt
Einsatz in der Biometrie (u.a.): Man untersucht die Zeitverläufevon 1 ≤ i ≤ a unabhängigen Stichproben mit jeweils k = 1, . . . ,niunabhängigen Individuen mit je 1 ≤ j ≤ b Repeated Measures
Versuchsplan...Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Der Split-Plot Plan (SP-a.b)Anschaulich mit ni ≡ n
Faktor BFaktor
AFaktor
C 1 · · · b
1 V11 · · · V11
1...
......
...n V1n · · · V1n
......
......
...(a− 1)n + 1 Va1 · · · Va1
a...
......
...an Van · · · Van
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bemerkungen
Die Bezeichnung Split-Plot-Design hat ihren Ursprung in denAgrarwissenschaften.Hier treten in den Experimenten häufig Faktoren auf (wie bspsw.Bewässerungsmethode), die in der Regel nur für große Teile derLändereien (Böden), genannt whole plot, angewendet werden.Der zugehörige Faktor heißt deshalb auch whole plot factor(oder main treatment).Innerhalb eines whole plots wird dann ein weiterer Faktor (wieGetreidesorte) auf verschiedene, kleinere Teile des Landesaufgeteilt, indem man die whole plots in kleinere Teile; sog.subplots (oder split-plots) aufteilt (englisch: splitted). Derhierzugehörige Faktor heißt dann subplot factor
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel
Zur Überprüfung der Atmungsaktivität von Leukozyten wurde an insgesamt 44Laborratten folgender Versuch durchgeführt:
I 22 Ratten wurden mit einem Placebo und 22 mit einer Substanz zurStärkung der Abwehrkräfte behandelt. (whole-plot Faktor “Behandlung”)
I In weiteren (hier nicht detailliert erklärten) Schritten wurden von jedem Tierein leukozythaltiger Versuchsansatz entnommen und
I einer Hälfte des Ansatzes inaktivierte Staphylokokken zugesetzt; dieandere Hälfte blieb unbehandelt (sub-plot Faktor “Staphylokokken”)
I Im Anschluss wurde der O2-Verbrauch von Leukozyten nach 6, 12 und 18Minuten gemessen. Die gemittelten Werte entnehmen wir folgenderTabelle
Mittlerer O2-Verbrauch [µ`]Staphylokokken
mit ohneZeit [in Min] Zeit [in Min]
6 12 18 6 12 18Placebo 1.618 2.434 3.527 1.322 2.430 3.425Verum 1.656 2.799 4.029 1.394 2.57 3.677
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Split-Plot Plan – Klassisches Statistisches ModellFaktoren A und B fest, C zufällig - A× B, C × B, C(A)
Statistisches Modell: Yijk = µij + βk(i) + εijkI Yik = (Yik1, . . . ,Yikb)′, - k = 1, . . . ,n unabhängige ZVektorenI µij = E(Yijk ), i = 1, . . . ,a; j = 1, . . . ,b - feste EffekteI βk(i)
i.i.d∼ N(0, σ2β), k = 1, . . . ,an - zufälliger Effekt
I εijki.i.d∼ N(0, σ2), i , j , k Versuchsfehler
I Die Zufallsvariablen βk(i) und εijk sind unabhängigKonsequenz
I Var(Yijk ) = σ2β + σ2 für alle i , j , k Behandlungen und VE gleich
I Cov(Yijk ,Yij′k ) = σ2β für alle Paare (j , j ′), j 6= j ′ = 1, . . . ,b
I Cov(Yijk ,Yij′k ′) = 0 für verschiedene Versuchseinheiten k 6= k ′I diese Kovarianzstruktur heißt Compound Symmetry und tauchte
auch schon beim RCBD aufI Diese Kovarianzstruktur ist plausibel, wenn man die
Versuchseinheiten physikalisch aufteilen kann; für Verlaufsdatenjedoch eher unangemessen. Deshalb...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Split-Plot Plan – Allgemeineres Statistisches ModellFaktoren A und B fest, C zufällig - A× B, C × B, C(A)
Statistisches Modell: Yik = (Yik1, . . . ,Yikb)′ ∼ Nb(µi ,Vi),I 1 ≤ i ≤ a, 1 ≤ k ≤ n unabhängige ZVektoren mitI Erwartungswertvektor µi undI unstrukturierter Kovarianzmatrix Vi in Gruppe i .
Beispiele für Kovarianzstrukturen für ViI V = σ2Ib unabhängige homoskedastische Beobachtungen,
I V =b⊕
i=1
σ2i unabhängige heteroskedastische Beobachtungen,
I V = σ2Ib + ρJb Compound Symmetry / CS⇒ Klassisches Modell als Spezialfall mit ρ = σ2
β
I V = (cij )i,j=1,...,d , cii = σ2, cij = σ2ρ|i−j| Autoregressive StrukturI . . .
Sinnhaftigkeit von Strukturannahmen hängen vom Problem ab!Deshalb bevorzuge ich das Arbeiten ohne spezifische Annahmen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bemerkungen zu Repeated Measures (RM)Generelle Gesichtspunkte
I man unterscheidetF Messwiederholungen unter der gleichen Bedingung
(hierarchisches Design; linker Versuchsplan)F Messwiederholungen unter verschiedenen Bedingungen
(Block-Design, Verlaufskurven; rechter Versuchsplan))I beides wird in der Literatur als Clusterdaten bezeichnet
1 2x x
V11 x V21 xx xx x
V12 x V22 xx x
......
......
x xV1n1 x V2n2 x
x x
BehandlungVE 1 2 · · · a
x x · · · xV1 x x · · · x
x x · · · x...
......
......
x x · · · xVn x x · · · x
x x · · · x
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Allgemeineres Statistisches Modell – Sonderfälle
Unabhängigkeit / UnkorreliertheitKovarianzmatrix
V =
σ2
1 0 · · · 00 σ2
2 · · · 0...
......
0 0 · · · σ2b
Beispiel
I Für a = 1:I unabhängige strukturierte BeobachtungenI verschiedene Varianzen in den b unabhängigen Versuchsgruppen
zugelassen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Allgemeineres Statistisches Modell – Sonderfälle
Compound Symmetry (CS) - StrukturKovarianzmatrix
V =
σ2 + ρ % · · · %% σ2 + ρ · · · %...
......
% % · · · σ2 + ρ
= σ2Ib + ρJb
Beispiel: Klassisches Modell mit additivem Blockeffekt⇒ Ist praktisch nicht für Zeitverläufe/longitudinalen Daten geeignet,
da zeitlich benachbarte Beobachtungen höhere Korrelationenaufweisen als weiter auseinanderliegende.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Allgemeineres Statistisches Modell – Sonderfälle
Autoregressive (AR) Kovarianz-StrukturKovarianzmatrix
V = σ2
1 % %2 · · · %a−1
% 1 % · · · %a−2
%2 % 1 · · · %a−3...
......
...%a−1 %a−2 %a−3 · · · 1
I Varianz: σ2
I Kovarianz: %i,i+s = σ2%s, ρ < 1
ist eine sog. Toeplitz-MatrixBeispiel
I Messungen zu äquidistanten Zeitpunkten bei Zeitverläufen
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle SP-a.b – klassisches ModellErinnerung: A und B sind feste Faktoren und C(Versuchseinheiten) ein zufälliger Faktor. Dann liegt imklassischen Modell für die BeobachtungsvektorenYik = (Yik1, . . . ,Yikb)′ eine compound symmetry Struktur vor.Zum Testen von Nullhypothesen über die Faktoren A und B (dieEffekte sind wieder in µij versteckt), behilft man sich dannmeistens asymptotischer Verfahren. Hierzu müssen dieunbekannten Varianzen σ2 und σ2
β konsistent geschätzt werden:
Für Yi· = (Y i·1, . . . ,Y i·b)′ definiert man Kovarianzmatrixschätzer
V i =1
n − 1
n∑k=1
(Yik − Yi·)(Yik − Yi·)′, i = 1, . . . ,a, V =
1a
a∑i=1
V i
und erhält konsistente40 Schätzer für die unbekannten Varianzen:
σ2 =1
b − 1Sp(PbV ), σ2 + b · σ2
B =1b
1′bV1b.
40ohne BeweisMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle SP-a.b – klassisches Modell
Insgesamt erhält man im klassischen Modell eine “asymptotische”
Varianztabelle für den balancierten SP-a.b (compound symmetry)
Faktor Hypothesen- Quadratform QH GrenzverteilungMatrix H unter H0 : Hµ = 0
A Pa ⊗ 1b 1′b
bnσ2 + σ2
B
a∑i=1
(Y i·· − Y ···)2 χ2a−1
B 1a 1′a ⊗ Pb
anσ2
b∑s=1
(Y ··s − Y ···)2 χ2b−1
AB Pa ⊗ Pbnσ2
a∑i=1
b∑s=1
(Y i·s − Y i·· − Y ··s + Y ···)2 χ2(a−1)(b−1)
Hierbei ist µ = (µ11, . . . , µab) und man testet H0 : Hµ = 0 durchVergleich von QH mit (1− α)-Quantilen der jeweiligen Grenzverteilung
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle SP-a.b – allgemeineres ModellIn diesem Fall mit unbekannten und unstrukturiertenKovarianzmatrizen behilft man sich auch mit asymptotischenMethoden.Neben den empirischen Kovarianzmatrizen V i (als Schätzer fürVi = Cov(Yik )) von oben definiert man hier zudem
Σ =a⊕
i=1
Nni
Vi
als konsistenten Schätzer von41Cov(√
N Y·) =⊕r
i=1Nni
Vi undverwendet zum Testen von H0 : Hµ = 0 eine Statistik vomWald-Typ
QH = N · Y′·H′[HΣH′]+HY·Man kann zeigen, dass diese unter H0 asymptotisch χ2
r(H) verteiltist und erhält so...
41Y· = (Y′1·, . . . ,Y
′a·)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle SP-a.b – allgemeineres Modell
Varianztabelle für den balancierten SP-a.b (allgemeineres Modell)
Faktor Hypothesen- Quadratform QH GrenzverteilungMatrix H unter H0 : Hµ = 0
A Pa ⊗ 1b 1′b N · Y′·H′[HΣH′]+HY· χ2
a−1
B 1a 1′a ⊗ Pb N · Y′·H′[HΣH′]+HY· χ2
b−1
AB Pa ⊗ Pb N · Y′·H′[HΣH′]+HY· χ2(a−1)(b−1)
Hierbei ist wieder µ = (µ11, . . . , µab) und man testet H0 : Hµ = 0durch Vergleich von QH mit (1− α)-Quantilen der jeweiligenGrenzverteilungAllerdings benötigt man große Stichprobenumfänge, damit derTest nicht zu liberal wirdBesseres Verfahren: Sarahs Permutationstest :)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Erweiterungen
Erweiterungen von Split-Plot Designs sindSplit-Plot Designs mit mehr als zwei Faktoren: Dies tritt z.B. dannauf, wenn der whole plot und/oder sub-plot Faktor selber nocheine faktorielle Struktur besitzen. Beispiel: Tageszeiten beiMessungen über verschiedenen Tage hinweg.Split-Split-Plot Designs: Hier treten neben whole plot und sub-plotnoch sog. sub-sub-plot Faktoren aufStrip-Split-Plot Designs: Hier tritt ein Faktor in sog. orthogonalenStrips auf
Die genaue Definition und Behandlung ist aber nicht Teil dieserVorlesung :)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 11:
Random Effects und Mixed Models

Vorwort
Wir haben bei den bisherigen statistischen Modellen zwar immerzwischen den folgenden Designs
I mit ausschließlich festen Faktoren (Fixed Effects Model)I mit festen und zufälligen Faktoren (Mixed (Effects) Model)I mit ausschließlich zufälligen Faktoren (Random Effects Model)
unterschieden; allerdings dann auch immer nur Tests für(Nullhypothesen in) feste(n) Faktoren diskutiert.Zufällige Faktoren traten z.B. in natürlicher Weise bei RCBD,RCBD-ab, CRHF-b(a) und SP-a.b auf.In diesem Kapitel gehen wir zum einen etwas genauer auf diezugehörigen Modelle ein und diskutieren hierin zum anderenMöglichkeiten zum Testen von Hypothesen über zufälligeFaktoren.Wir starten mit einer einfachen Wiederholung
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Feste und zufällige Faktoren
Ein Faktor heißt fest (fixed factor), wenn seine Stufen eindeutigdefinierte, wiederholbare Ausprägungen (des Faktors) sind.
WIEDERHOLUNGSREGEL: Ein fester Faktor ist dadurchcharakterisiert, dass bei einer eventuellen Versuchswiederholungdieselben Faktorstufen verwendet werden würden wie imvorangegangenen Versuch.VERALLGEMEINERUNGSREGEL: Die Aussagen, die auf Grundeines Versuchs mit festen Faktorstufen gemacht werden, geltennur für die im Versuch verwendeten festen Faktorstufen.Beispiele: Geschlecht, Behandlung, Wochentag
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Feste und zufällige Faktoren
Ein Faktor heißt zufällig (random factor), wenn seine Stufen einezufällige Auswahl aus der Grundgesamtheit aller möglichen Stufendieses Faktors darstellen (Realisationen des zufälligen Faktors). DieStufen dieses Faktors sind nicht beobachtbare Zufallsvariable(unobservable random variables).
WIEDERHOLUNGSREGEL: Ein zufälliger Faktor ist dadurchcharakterisiert, dass bei einer Versuchswiederholung erneutzufällig ausgewählte Stufen des Faktors verwendet werden.VERALLGEMEINERUNGSREGEL: Die Aussagen, die auf Grundeines Versuchs mit zufälligen Faktorstufen gemacht werden,beziehen sich auf die Grundgesamtheit, aus der die im Versuchverwendeten Faktorstufen zufällig ausgewählt wurden.Beispiele: Patient, Labortier, Interviewer
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Random Effects Modelle – One Way CaseWir betrachten zunächst die Random Effects Modelle und startenmit dem einfaktoriellen Spezialfall, bei dem zufällig a Stufen desinteressierenden Faktors A (mit möglicherweise unendlich vielenStufen) ausgewählt werden.Dies führt auf das (klassische, additive) statistische Modell
Yik = µ+ αi + εik , 1 ≤ i ≤ a,1 ≤ k ≤ n (11.1)
I µ = GlobaleffektI εik
i.i.d.∼ N(0, σ2)= Versuchsfehler und davon unabhängigI αi
i.i.d.∼ N(0, σ2α) = Zufälliger Effekt von Stufe i ;
I mit unbekannten Varianzkomponenten σ2, σ2α ∈ (0,∞)
⇒ Var(Yik ) = σ2 + σ2α für alle Wahlen von i und k
⇒ Cov(Yik ,Yik ′) = σ2α für all k 6= k ′ und Cov(Yik ,Yi ′k ′) = 0 sonst.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Random Effects Modelle – One Way CaseDas Vorhandensein eines Faktoreffekts wird nun einfach durchdas Testproblem
H0 : {σ2α = 0} versus H1 : {σ2
α > 0} (11.2)
beschrieben.Wie bei der One-Way ANOVA im Fixed Effects Model lässt sichdie Gesamtfehlersumme aufschreiben als
SStotal = SStreat + SSerror = na∑
i=1
(Y i· − Y ··)2 +a∑
i=1
n∑k=1
(Yik − Y i·)2.
Unter H0 gilt αi = 0 f.s. und man erhält vollkommen analog zumModell mit festem Faktor als Teststatistik (N = an):
F =1
a−1SStreat1
(N−a)SSerror=:
MStreat
MSerror
H0∼ F (a− 1,N − a).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Random Effects Modelle – One Way Case
Begründung für das Letzte: Die Verteilungen der Beobachtungenunter den jeweiligen Nullhypothesen sind identisch!Man kann also denselben F -Test wie bei der One-Way ANOVA mitfesten Faktoren verwenden!Wir zeigen noch kurz auf, wie sich die unbekannten Varianz-komponenten erwartungstreu schätzen lassen. Sei dazu o.E.µ = 0, so gilt aufgrund der Zentriertheit aller Zufallsvariablen:
E(MStreat) =1
a− 1E
[1n
a∑i=1
(n∑
k=1
αi + εik )2 − 1N
(a∑
i=1
n∑k=1
αi + εik )2
]
=1
a− 1[Nσ2
α + aσ2 − nσ2α − σ2] = σ2 + nσ2
α.
Analog erhält man E(MSerror) = σ2.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Random Effects Modelle – One Way CaseSomit lassen sich die unbekannten Varianzkomponenten durch
σ2 = MSerror,
σ2α =
MStreat −MSerror
nerwartungstreu schätzen.(N − a)σ2/σ2 ist χ2
N−a-verteilt, so dass man 95%-KIs für σ2 wiedermittels {
σ2 :(N − a)MSerror
χ2N−a;.025
≤ σ2 ≤ (N − a)MSerror
χ2N−a;.975
}erhält.σ2α lässt sich jedoch “nur” als eine Linearkombination zweierχ2-verteilter Zufallsvariable schreiben, für die es keinegeschlossene Darstellung gibt. Zugehörige KI erhält manallerdings über Asymptotik
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel (Aus Montgomery)In einer Textilfabrik wird ein bestimmter Stoff auf einer großenAnzahl von Webmaschinen hergestellt.Damit der Stoff immer ungefähr die gleiche Stärke hat, sollten sichdie Webmaschinen homogen verhalten.Zur Überprüfung wurden deshalb zufällig vier Maschinenausgewählt und an jeweils vier, von diesen Maschinenhergestellten Stoffproben, die Stärke (in Gramm proQuadratmeter) gemessen. Die Ergebnisse entnehmen wir derfolgenden Tabelle
Webmaschinei=1 i=2 i=3 i=498 91 96 9597 90 95 9699 93 97 9996 92 95 98
y1· = 97.5 y2· = 91.5 y3· = 95.75 y4· = 97
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Beispiel– Ergebnisse
Nimmt man Modell(11.1) an, so erhalten wir als Schätzwerteσ2 = 1.9 sowie σ2
α = 6.96, d.h. die GesamtstreuungVar(Yik ) = 8.86 im Experiment wird hauptsächlich durch dieverschiedenen Webmaschinen getrieben und ist vermutlich nichtauf natürliche Schwankungen zurückzuführen.Diese Beobachtung wird durch die Teststatistik des F -Test auchsignifikant bestätigt: F = 15.68 > 3.490295 = F3,12;.05
Als 95%-KI für σ2 erhält man hier [0.977,5.1775] und ein 95%-KIfür den Globaleffekt lässt sich (zur Übung) auch leicht angebenmittels [
y ·· ∓ tn−1;.025
√MStreat
an
]= [92.78,98.1].
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Nachteile der Random One-Way ANOVASchätzen und Testen der Varianzkomponente σ2
α istproblematisch, da der Schätzer
σ2α =
MStreat −MSerror
n
auch negative Werte annehmen kann! Wähle z.B.Y11 = 1,Y12 = 5,Y21 = 4,Y22 = 2, so folgt σ2
α = −2.5Wie beim Fixed Effects Modell werden auch hier keine ungleichenVarianzen zugelassen und die Verteilungsannahmen derStatistikenberuhen alle auf einer Normalverteilungsannahme!Verbesserungen erhält man teilweise durch ML- und REML- (=restricted maximum likelihood) Schätzer.Obige Nachteile bleiben bei höherfaktoriellen Random EffectsModellen gültig! Wir gehen kurz auf den zweifaktoriellen Fall ein
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Random Two-Way Modell
Statistisches ModellI (Additives) Random Effects Modell:
Yijk = µ+ αi + βj + γij + εijk (11.3)
I αi = Zufälliger Haupteffekt von A, αiu.i.v .∼ N(0, σ2
α),1 ≤ i ≤ a,I βj = Zufälliger Haupteffekt B, βj
u.i.v .∼ N(0, σ2β),1 ≤ j ≤ b,
I γij = Zufälliger Interaktionseffekt AB, γiju.i.v .∼ N(0, σ2
γ),
I εijku.i.v .∼ N(0, σ2) Versuchsfehler, 1 ≤ k ≤ n.
Alle Zufallsvariablen sind unabhängigNullhypothesen von Interesse werden wieder über die Varianzender Komponenten aufgestellt.Wie oben berechnet man die Erwartungswerte der Quadratformenaus der Two-Way-ANOVA mit festen Effekten und erhält folgende
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Varianzanalyse-Tabelle für die Random Two-Way ANOVA
Faktor Matrix Quadratform Q(Faktor) Rang r E(Q/r)
A Pa ⊗ 1b 1′b nb
a∑i=1
(Y i·· − Y ···
)2a− 1 σ2 + nb · σ2
α + n · σ2γ
B 1a 1′a ⊗ Pb na
b∑j=1
(Y ·j· − Y ···
)2b − 1 σ2 + na · σ2
β + n · σ2γ
AB Pa ⊗ Pb
a∑i=1
b∑j=1
(Y ij· − Y i·· − Y ·j· + Y ···
)2(a− 1)(b − 1) σ2 + n · σ2
γ
εa∑
i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2ab(n − 1) σ2
Teststatistiken wählt man anhand der letzten Spalte aus, indem man schaut,welche Quadratformen unter der Nullhypothese die gleiche Varianz schätzen42:
I Für H0(A) : {σ2α = 0}: FA =
Q(A)/(a− 1)
Q(AB)/[(a− 1)(b − 1)]
H0(A)∼ F (a− 1, (a− 1)(b − 1)).
I Für H0(B) : {σ2β = 0}: FB =
Q(B)/(b − 1)
Q(AB)/[(a− 1)(b − 1)]
H0(B)∼ F (b − 1, (a− 1)(b − 1)).
I Für H0(AB) : {σ2γ = 0}: FAB =
Q(AB)/[(a− 1)(b − 1)]
Q(ε)/[ab(n − 1)]
H0(AB)∼ F ((a− 1)(b − 1), ab(n − 1)).
42Verteilung ohne BeweisMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Random Effects Modelle – Bemerkungen
Für andere Designs mit ausschließlich zufälligen Faktoren kannman häufig analog vorgehen.Beispielsweise funktioniert dieser Ansatz auch beim CRHF-b(a)mit zwei zufälligen Faktoren. Die zugehörigeVarianzanalysetabelle findet sich in Kapitel 9.Für höherfaktorielle Designs kann es jedoch vorkommen, dassman keine zwei Quadratformen findet, die unter der Nullhypothesedie gleiche Varianz schätzen.Dies ist bspsw. bei einer Random Three-Way-ANOVA für dieNullhypothese H0(A) der Fall.In solchen Fällen verwendet man sog. Quasi-F -Tests, bei denendie Quadratformen geeignet kombiniert werden.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mixed Two-Way Modell
Wir hatten gemischte Modelle im Rahmen von hierarchischenModellen mit einem festen Faktor A und einem darunterverschachtelten, zufälligen Faktor B kennengelernt. Daszugehörige Modell im balancierten Fall ist gegeben durch
Yijk = µ+ αi + βj(i) + εijk , 1 ≤ i ≤ a; 1 ≤ j ≤ b; 1 ≤ k ≤ n,
wobeiI∑a
i=1 αi = 0, µi = µ+ αi = E(Yijk ), i = 1, . . . ,a - fester EffektI βj(i)
i.i.d∼ N(0, σ2β) zufälliger Faktor
I εijki.i.d∼ N(0, σ2) unabhängige Versuchsfehler
I die Zufallsvariablen βj(i) und εijk sind unabhängigNullhypothesen von Interesse sind dann
I H0(A) : {αi = 0 für alle 1 ≤ i ≤ a} undI H0(B(A)) : {σ2
β = 0}
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Zum Testen geht man genauso vor wie zuvor und berechnet dieErwartungswerte der Quadratformen aus dem festen Modell wiefolgt (zur Übung)
Varianztabelle für den balancierten CRHF-b(a) (mixed model)
Faktor Quadratform Q(Faktor) Rang E(Q/r)
A nba∑
i=1
(Y i·· − Y ···
)2a− 1 σ2 + nb · σ2
α + n · σ2β
B(A) na∑
i=1
b∑j=1
(Y ij· − Y i··
)2a(b − 1) σ2 + n · σ2
β
ε
a∑i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2ab(n − 1) σ2
Dabei gilt wieder σ2α = 1
a−1∑a
i=1 α2i und Var(βj(i)) = σ2
β.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Tests im CRHF-b(a) (mixed model)
Durch Abgleich der letzten Spalte erhält man folgende Teststatistiken (Verteilungohne Beweis) für
H0(A) : {αi = 0 für alle 1 ≤ i ≤ a}:
FA =
ba∑
i=1
(Y i·· − Y ···
)2/(a− 1)
a∑i=1
b∑j=1
(Y ij· − Y i··
)2/[a(b − 1)]
H0(A)∼ F (a− 1, a(b − 1)).
H0(B(A)) : {σ2β = 0}:
FB(A) =
na∑
i=1
b∑j=1
(Y ij· − Y i··
)2/[a(b − 1)]
a∑i=1
b∑j=1
n∑k=1
(Yijk − Y ij·
)2/[ab(n − 1)]
H0(B(A))∼ F (a(b − 1), ab(n − 1)).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mixed Two-Way ModelGeläufig sind auch gemischte zweifaktorielle, vollständig gekreuzte Modelle derForm
Yijk = µ+ αi + βj + γij + εijk
I αi = Fester Haupteffekt von A,∑
i αi = 0, 1 ≤ i ≤ a,I βj = Zufälliger Haupteffekt B, βj ∼ N(0, σ2
β), 1 ≤ j ≤ b,I γij = Zufälliger Interaktionseffekt AB, γij ∼ N(0, σ2
γ),I εijk ∼ N(0, σ2) Versuchsfehler, 1 ≤ k ≤ n.
Hier gibt es jedoch diverse kontroverse Diskussionen über verschiedeneAnnahmen und VerfahrenBspsw. nimmt das sog. restriktive Modell an, dass σ2
γ von a abhängt, und dass∑i γij = 0 gilt, so dass die Zufallsvariablen γij nicht mehr unabhängig sind. Die
βj und εijk werden aber unabhängig modelliert.Dagegen nimmt das sog. uneingeschränkte Modell nur an, dass alle Variablenunkorreliert (bzw. unabhängig) sind.Diese führen zu verschiedenen Tests. In SAS z.B. ist das zweite Modellvoreingestellt, das sich auch im folgenden Rahmen herleiten lässt...
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Theorie - Exkurs (Mixed Models)
Zum Abschluss dieses Kapitels gehen wir noch ganz kurz auf dietheoretische Herleitung einÄhnlich wie bei den festen Faktoren betrachtet man das folgendestatistische Modell
Y = X1b + X2Z + ε.
I Y = (Y′1, . . . ,Y′n)′
I Yk = (Yk1, . . . ,Ykd )′, k = 1, . . . ,n, unabhängigI
I b : (feste) Parameter, z.B. Erwartungswerte; feste EffekteI X1 : Strukturmatrix für die festen EffekteI Z : zufällige Effekte (meist nicht beobachtbar)I X2 : Strukturmatrix für die zufälligen EffekteI ε : Vektor der Versuchsfehlerterme
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Theorie - Exkurs (Mixed Models)Idee: Schreibe die Zufallsfaktoren zu den Fehlertermen underhalte wieder ein Lineares Modell:
I Y = X1b + X2Z + ε︸ ︷︷ ︸η
= X1b + η
I η ∼ N(0,S), S = σ2I + X2 Cov(Z)X′2Nun kann man den Parametervektor b schätzen wie zuvor:
I Minimiere den Abstand von Y zu Y = X1b!I Allerdings: Abstand im gemischten Modell muss bezüglich der
Kovarianzstruktur adjustiert werdenI verwende den Mahalanobis-Abstand D = (Y− Y)′S−1(Y− Y)I minimiere D analog zur Vorgehensweise in Kapitel 5.
Lösung:I Normalgleichungen: X′1S−1X1Y = X′1S−1YI falls X′1S−1X1 invertierbar ist, gilt
b = (X′1S−1X1)−1X′1S−1YI b heißt Verallgemeinerter kleinste Quadrate Schätzer - GLSE
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Theorie - Exkurs (Mixed Models)Eigenschaften von b:
I erwartungstreu: E(b) = bI die Komponenten von b haben minimale Varianz
(unter allen erwartungstreuen linearen Schätzern)I b ist BLUE = best linear unbiased estimator
Zur Anwendung brauchen wir noch die Kovarianzmatrix von bI Cov(b) = (X′1S−1X1)−1
I Die Inverse enthält Linearkombinationen der auftretendenVarianzen σ2, σ2
α, σ2β , . . . der zufälligen Komponenten und des
FehlertermsI Zum Beispiel σ2 + nσ2
α
Die Quadratformen dividiert durch die zugehörigen Varianzen(z.B. σ2 + nσ2
α anstelle von nur σ2 bei festen Faktoren) sind dannwieder χ2-verteilt.Zum Testen von Hb = 0 sucht man deshalb zwei unabhängige (!)quadratische Formen, die unter der Nullhypothese die gleicheVarianz besitzen. Dies führt zu den oben angegebenen F -Tests
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Bemerkungen
Auf ähnliche Art und Weise geht man auch bei den RandomEffects Modellen vor.Allerdings sollte man nicht vergessen, dass die oben genanntenProbleme (Varianzhomogenität; u.U. negative Varianzschätzer)beim Testen der zufälligen Komponenten auftreten können.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Kapitel 12:
Spezielle Modelle und deren Auswertung

In diesem Kapitel betrachten wir einige spezielle Methoden, diebisher eher stiefmütterlich behandelt wurden.Hierzu zählen u.a.Binäre Zielgrößen
I logistische RegressionMehr als eine Zielgröße
I MANOVA undI Klassifikationsanalyse
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Motivierendes Beispiel: Challenger-UnglückAm 28.1.1986 explodierte das Space ShuttleChallenger kurz nach dem Start. Als Ursachewurde das Versagen der Dichtungsringe(O-Ringe), die zur Versiegelung derVerankerung der Feststoff-Booster dienen,ermittelt.
(Quelle: http://upload.wikimedia.org/wikipedia/commons/ e/e0/Challenger_STS_51_L_launch.JPG)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Motivierendes Beispiel: Challenger-UnglückBereits vor dem Start wurden in einer Telefonkonferenz starke Zweifel an derZuverlässigkeit der Dichtungsringe bei niedrigen Temperaturen geäußert, unddavor gewarnt, dass es beim Start zu Problemen mit den Dichtungsringenkommen könnte, da für diesen Tag eine Temperatur von 31 Grad Fahrenheit(−0.5◦C) vorhergesagt wurde.
●
●
●●● ● ●●
● ● ●
●●
●
● ●● ●● ●● ●
●
30 40 50 60 70 80
Temperatur (in Fahrenheit)
Min
d. e
in O
−R
ing
hat v
ersa
gt
Nein
Ja
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Statistisches Modell
Hier passt kein klassisches lineares Modell!Beliebte Wahl wäre sonst ja ein (multiples) linearesRegressionsmodell der Form
Y = β0 + β1X1 + β2X2 + . . .+ βpXp + ε,
bei dem Parameter βj ∈ R die j-te Einflussvariable Xj , j = 1, . . . ,pgewichtet.Begründung?
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Binäre ZielvariableHäufig ist die interessierende Zielvariable binär. Z.B.
I Person hat eine Krankheit vs. Person zeigt nicht dieseKrankheit,
I Kredit wird zurückgezahlt: ja vs. nein.
I Ausfall eines Dichtungsrings: ja vs. nein.Dabei werden die beiden Ausprägungen der Zielvariable Y durch0 und 1 kodiert.In solchen Fällen interessiert man sich üblicherweise für dieWahrscheinlichkeit, dass das interessierende Ereignis (z.B. krankoder Kredit wird zurückgezahlt) eintritt.Y nimmt also Werte zwischen 0 und 1 an.β0 + β1X1 + . . .+ βpXp + ε kann i.d.R. aber Werte in (−∞,∞)annehmen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Logistische Regression
Um ein ähnlich einfaches Modell wie das lineare Modell verwenden zukönnen, benötigen wir also eine Transformation von R auf [0,1].
Hierzu verwendet manüblicherweise die logistischeFunktion
h(η) =exp(η)
1 + exp(η)mit
η = β0 + β1X1 + . . .+ βpXp
= β0 + β′X (X = (X1, . . . ,Xp)′) −10 −5 0 5 100.
00.
20.
40.
60.
81.
0
η
h(η)
Deshalb wird dieses Modell logistisches Regressionsmodell genannt.Es ist ein Spezialfall der GLMs für binäre Zielvariablen.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Logistische Regression
Dies führt auf das einfache Modell
P(Y = 0|X = x) =1
1 + exp(β0 + β′x)
P(Y = 1|X = x) =exp(β0 + β′x)
1 + exp(β0 + β′x)
Der Quotient der beiden WSen wird mit Odds(Y1/0) bezeichnet,so dass das Modell wegen
Logit(Y1/0) = log(Odds(Y1/0)) = β0 + β′x
auch häufig als (binäres) Logit-Modell bezeichnet wird.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Zurück zum Beispiel: Challenger-UnglückAm 28.1.1986 explodierte das Space ShuttleChallenger kurz nach dem Start. Als Ursachewurde das Versagen der Dichtungsringe(O-Ringe), die zur Versiegelung derVerankerung der Feststoff-Booster dienen,ermittelt.
(Quelle: http://upload.wikimedia.org/wikipedia/commons/ e/e0/Challenger_STS_51_L_launch.JPG)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Challenger-UnglückVor dem Start: Mehrstündige Telefonkonferenz zwischen Experten desTriebwerkherstellers, der NASA und des Raumflughafens. Da hier nur dieAusfalldaten (rote Punkte) betrachtet wurden, kam man zu dem Schluss, dassdie Historie keinen Temperatureffekt belegen konnte.
●
●
●●● ● ●●
● ● ●
●●
●
● ●● ●● ●● ●
●
30 40 50 60 70 80
Temperatur (in Fahrenheit)
Min
d. e
in O
−R
ing
hat v
ersa
gt
Nein
Ja
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Challenger-Unglück – Modell
Wir wählen nun das einfache Logit-Modell mit
Y =
{1 Versagen mind. eines O-Rings0 Ordnungsgemäße Funktion aller O-Ringe
X = Außentemperatur in Grad Fahrenheit
P(Y = 0|X = x) =1
1 + exp(β0 + β1x)
P(Y = 1|X = x) =exp(β0 + β1x)
1 + exp(β0 + β1x)
Gesucht: Schätzer für β = (β0, β1).
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Challenger-Unglück – MLE
Idee: Wähle das β, das den Beobachtungen y1, . . . , yn die höchste WSzuordnet. Betr. dazu:
l(x ,β) = logn∏
i=1
P(Yi = yi |X = xi)
=n∑
i=1
(β0 + β1xi)yi − log(1 + exp(β0 + β1xi))
Einsetzen der Beobachtungen zeigt eine negativ definite Hesse-Matrixund Lösen von
∇l(x ,β) = ( ∂∂β0
l(x ,β), ∂∂β1
l(x ,β))′!
= 0
liefert den MLE β = (β0, β1) = (15.0429,−0.2322)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Challenger-Unglück – WSen
Basierend auf diesem Modell erhält man, dass die WS, dass bei 31Grad Fahrenheit mind. einer der Dichtungsringe versagt, bei ca.99.9996% liegt!
0.0
0.2
0.4
0.6
0.8
1.0
Temperatur (in Fahrenheit)
Wah
rsch
einl
ichk
eit,
dass
min
d. e
in O
−R
ing
vers
agt
●
●
●●● ● ●●
● ● ●
●●
●
● ●● ●● ●● ●
●
31 40 50 60 70 80
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Challenger-Unglück – Erweitert
Der Ausfall eines Dichtungsrings bedeutet noch nicht, dass es zueinem Unglück kommt.Zu jedem primären gehört nämlich auch ein sekundärerDichtungsring.D.h. man interessiert sich für die WS, dass mind. eineDichtungsringkombination versagt!
AußerdemDichtungsringe können aus verschiedenen Gründen ausfallen(in den Daten: Erosion oder Blow-by43)Diese sollten getrennt voneinander modelliert werdenZusätzlich könnte man noch weitere erklärende Variablen wiebspsw. Luftdruck mit aufnehmen unduntersuchen, ob das Modell “vernünftig” fitted.
43durch zu hohe Temperaturen oder vorbeiströmende GasenMarkus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Challenger-Unglück – Erweitert
Dies wurde von Dalal et al. (1989, JASA, 84, 945-957) unterVerwendung komplexerer logistischer Regressionsmodelledurchgeführt.Ergebnis: Bei einer Temperatur von 31 Grad Fahrenheit und 200psi Luftdruck ist die WS, dass mind. eineDichtungsringkombination versagt im angepassten Modell≈ 13%.Bei einer Verschiebung auf 60 Grad Fahrenheit und gleichemLuftdruck beträgt die WS dafür ≈ 1.9%.
⇒ Dies hätte im Vorfeld berechnet werden können!
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

PrognosenAllerdings sind üblicherweise Prognosen (weit) außerhalb desBereichs der bisher beobachteten Werte (äußerst) problematisch undsollten (wenn überhaupt, dann) nur mit großer Vorsicht betrachtetwerden.
Theoretisch könnte z.B. auch folgendes Verhalten der Werte vorliegen:
●
●
●●● ● ●●
● ● ●
●●
●
● ●● ●● ●● ●
●
30 40 50 60 70 80
Temperatur (in Fahrenheit)
Min
d. e
in V
ersa
gen
Nein
Ja ●● ●● ●●●●
●● ●● ●● ●●
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Lustige verwandte Beispiele– Liegende Kühe
Nehmen wir an, wir möchten herausfinden, ob dieWahrscheinlichkeit, dass sich eine Kuh hinlegt, mit der Zeit, diesie schon steht, steigt.Zur Analyse dieser Frage beobachten wir eine Reihe von Kühenund erheben deren Liege- sowie Stehzeiten.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Lustige verwandte Beispiele– Liegende KüheDie Analyse dieser Daten führte zuder Erkenntnis, dass je länger eineKuh liegt, desto eher steht siewieder auf. Wenn sie dann aberwieder aufgestanden ist, ist esnicht möglich vorherzusagen, wannsie sich wieder hinlegen wird.
Are cows more likely to lie down the longer they stand? B J Tolkamp, M J Haskell, C A Morgan, S P Turner
Scottish Agricultural College, Edinburgh, United Kingdom
Introduction Information on (changes in) standing and lying behaviour can be used for oestrus detection and early
093 Are cows more likely to lie down the longer they stand? B J Tolkamp, M J Haskell, C A Morgan, S P Turner Scottish Agricultural College, Edinburgh, United Kingdom Email: [email protected]
Introduction Information on (changes in) standing and lying behaviour can be used for oestrus detection and early diagnosis of health problems, to evaluate welfare consequences of changes in housing and management and to investigate the underlying animal motivation for these behaviours. A data set on lying and standing behaviour was collected from cows with IceTag™ sensors (IceRobotics, South Queensferry, UK) fitted to their legs. Our aims were (a) to investigate whether this behaviour was bouted, (b) to estimate bout criteria if required and (c) to test the hypotheses that (i) the probability of cows standing up would increase with lying time and (ii) the probability of cows lying down would increase with standing time.
Materials and methods Data were obtained from IceTag™ sensors fitted to 10 late-pregnant indoor-housed beef cows for periods up to 16 days. During part of the experiment, video recordings were made to validate the sensor records. The sensors produced one record per cow per min with an estimate of the percentage of standing and lying time, from which uninterrupted standing and lying episodes were calculated. The structure of standing and lying behaviour was investigated first by analysing log-survivorship plots and frequency distributions of (log-transformed) standing and lying episode lengths. The probability of cows standing up (Pstand) in the next 15 min at lying time t was calculated as 1 – (the number of lying bouts > t + 15 min divided by the number of lying bouts > t min). The same method on the basis of standing bout lengths was used to calculate the probability of cows lying down (Plie) within 15 min. Effects of lying time on Pstand and of standing time on Plie were estimated using linear regression. Only probabilities based on at least 100 observations were included in the regression analyses to avoid effects of data points based on few observations only.
Results A total of 10,814 lying episodes were recorded. Analyses of the (cumulative) frequency distributions of (log-transformed) lying episode lengths suggested that standing bouts were interrupted by an excessive number of short lying episodes (i.e. < 4 min). Comparison of IceTag™ records with video recordings showed that lying episodes > 4 min did correspond with lying behaviour, but episodes < 4 min did not (these tended to occur e.g. when a cow was displaced at a feeder). In contrast, short standing episodes recorded by the sensors did correspond to actual standing behaviour. Lying and standing bouts were, therefore, calculated by ignoring all lying episodes < 4 min. This decreased the number of episodes by 88%, but it had only minor effects on estimated total daily lying time (- 3%). The mean individual daily number of lying bouts ranged from 7.9 to 15.4 (mean 10.0, SE 0.7). Individual mean daily lying time varied from 10.2 to 13.0 h (mean 11.6, SE 0.33 h). The probability of cows standing up increased linearly with lying time (Fig. 1a), as hypothesized. The probability of cows lying down was, however, entirely unaffected by standing time (Fig. 1b), which contradicted our hypothesis. Disaggregation of the data in subsets showed that the absence of any effect of standing time on Plie was not caused by the pooling of data obtained during the day and the night or across individuals with different behavioural strategies.
Figure 1 The probability of cows standing up (Pstand) within 15 min in relation to time lying (a) and the probability of cows lying down (Plie) within 15 min in relation to time standing (b). Regression lines were fitted to the data indicated by the solid symbols. The regression line in graph (a) was highly significant (R2 = 0.98, P < 0.001, RSD = 0.021). The regression line in graph (b), however, was not (R2 = 0.003, P = 0.83, RSD = 0.033).
Conclusions Sensors can give relevant information on cows’ standing and lying behaviour but the type of sensor used here recorded an excessive number of short lying episodes which must be adjusted for. Determination of a bout criterion that distinguishes between actual lying bouts and sensor settings suggesting short lying episodes but caused by other factors, such as sudden leg movements, then allows a meaningful interpretation of the data. The increase in the probability of cows standing up with lying time was as expected. Cows were, however, not more likely to lie down the longer they were standing, thereby refuting our second hypothesis. This suggests that the increase in motivation to lie down that has been observed after lying deprivation (Metz 1985; Munksgaard et al., 2005) may have limited relevance for cows that are not deliberately lying-deprived.
Acknowledgements SAC receives support from Scottish Government, Rural and Environment Research and Analysis Directorate.
References Metz, J.H.M. 1985. Applied Animal Behaviour Science 13, 301-307. Munksgaard, L. Jensen, M.B., Pedersen, L.W, Hansen, S.J., Mathews, L. 2005. Applied Animal Behaviour Science 92, 3-14.
Für diese wichtige Erkenntnis erhielten Tolkamp et al. 2013 denalternativen Nobelpreis für Wahrscheinlichkeitstheorie.
“Cows can be really boring.”
Bert Tolkamp
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mehr als eine Zielgröße
In vielen Fällen wird nicht nur eine Zielgröße von Interessegemessen!Es liegen dann multivariate Daten vor, die mit Methoden derMultivariaten Analysis ausgewertet werden müssen.Verfahren, die in diesen Bereich fallen sind beispielsweise
I Hotelling’sT 2-TestI Wilk’s MANOVAI PCAI KorrelationsanalysenI Klasssifikation und DiskriminanzanalysenI etc.
Wir betrachten zur Veranschaulichung ein schönes Beispiel
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Entdeckung einer neuen Unterart des Possums
Ross Cunningham
Trichosurus cunninghamii
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Entdeckung einer neuen Unterart des Possums
Zoologen wollten die Hundskusus(Possums) in Australien genaueruntersuchen.
Für die Erhebung der Daten führte einStatistiker (Ross Cunningham) dieStudienplanung durch.
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Entdeckung einer neuen Unterart des PossumsBei der explorativen Analyse der Daten fiel Ross Cunningham auf,dass bei manchen gemessenen Größen zwei Gruppen zu sehenwaren.
Kopf− länge
50 60
●●
●●●
●●●
●●
●● ●●
●●
●●●●●●
●●
●●
●
●●●●●
●●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●●
●
●
●●●
●
●●
●
●
●
●●●
●● ●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●●
●●
●●● ●
●●●
●●
●●●
●●
●●●●●
●●●● ●●
●●
●●
●
●●● ●●
●●
● ●
●
●
●
●●
●
●
●
● ●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●● ●
●
● ●
●
●
●
●●●
●● ●
●
●
●● ●
●
●
●
●
●
●
●●
● ●
●
●● ●
●●
●●●
32 38
●●
●●●
●●●
●●
●●●●
●●
●●● ● ●●
●●
●●
●
●●● ●●
●●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●● ●
●
● ●
●
●
●
●●●
●● ●
●
●
●● ●
●
●
●
●
●
●
●●
● ●
●
●● ●
● ●
●●● ●
●●●
●●
●●●
●●
●● ●●
●
●●●● ●●
●●
●●
●
●●●●●
● ●
● ●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●●●
●
●●
●
●
●
●●●
●●●
●
●
●● ●
●
●
●
●
●
●
●●●●
●
●●●
●●
●●●
40 50
●●●●
●●
● ●●●
●●● ●●●
● ●●●●●
●●
● ●
●
●●●●●●●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
● ●
●
●
●●●
●
●●
●
●
●
●●●
●●●
●
●
●●●●
●
●
●
●
●
●●●●
●
●●●
●●
●●● ●
●●●
●●●●
●●
●●●●
●●
● ●●●● ●
●●
●●
●
●●●●●●●
●●
●
●
●
●●
●
●
●
●● ●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●● ●
●
● ●
●
●
●
●●●
● ●●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●●
●●
● ●●
22 26 30
8595●
●●●
●●●●
●●
●●●●●●
●●●● ●●
●●
●●
●
●●● ●●
● ●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●●●
●
●●
●
●
●
●●●
●● ●
●
●
●● ●
●
●
●
●
●
●
●●
●●
●
●●●
● ●
●●●
5060 ●
●●
●●●
●●●
●●●
●●●
●
●
●●●●●
●●
●●
●●●
●●●
●●
●●
●●
●
●●
●●
●
●●●
●
●
●
●●
●
● ●●
●
●●
●●●
● ●●●
●● ●●
●
●● ●
●●●
●●●
●● ●●
●
●
●● ●
●
●
●●
●● ●●
●
●●● ●●
●Schädel−
breite●
●●
●●●
●●●
●●●
●●●
●
●
●●●●●
●●
●●
●●●
● ●●
●●●
●
●●
●
●●
●●
●
●● ●
●
●
●
●●
●
●●●●
●●
●● ●
●●●●●
●●●●
●●●
●●●
●●●
●●●●
●
●
●●●
●
●
●●
● ●●●
●
●●● ●●
● ●
●●
●●●
●●●● ●
●
●●●
●
●
●● ●●●
●●
●●
●●●
● ●●
●●
●●
●●
●
●●
●●
●
●● ●
●
●
●
●●
●
●●●
●
●●
●●●●●●●
●●●●
●
● ● ●
●●●
●●●
●●●●
●
●
●●●
●
●
●●
● ●●●
●
●●●●●
● ●
●●
●●●
●●●
● ●●
●●●
●
●
●●●●●
●●
●●
●●●
●●●
●●
●●
●●
●
●●●
●
●●●
●
●
●
●●
●
●●●
●
●●
●● ●●● ●
●●●●●●
● ●●
●●●
●●●
●●●●
●
●
●●●
●
●
●●
●●●●
●
●●●●●
● ●
●●
●●●
● ●●●●
●
●●●
●
●
●●●●●●●
● ●
●●●
●●●●
●●
●
●●
●
●●
●●
●
●●●
●
●
●
●●
●
●●●
●
●●
●●●
●●●●●
● ●●●
● ●●
●●●
●●●
●●●●●
●
●● ●
●
●
●●
●● ●●
●
● ●●●●
● ●
●●
●●●
●●●
●●●
●● ●
●
●
●●●● ●
●●
●●
●●●
●●●●
●●
●
●●
●
●●
●●
●
●● ●
●
●
●
●●
●
●●●
●
●●
●● ●● ●●
●●
●●●●
● ●●
●●●
● ●●
●●● ●
●
●
●●●
●
●
●●
●●●●
●
● ●●● ●
● ●
●●
●●●
●●●
● ●●
●●●●
●
●●●●●
●●
●●
●●●
● ●●
●●
●●
●●
●
●●
●●
●
●●●
●
●
●
●●
●
●●●
●
●●
●●●
●● ●●
●● ●●●
●● ●
●●●
●●●
●●●●
●
●
●● ●
●
●
●●
●●●●
●
●●●●●
●
●●
●
●
●
●●●●
●●●●●
●●
●●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●● ● ●●●●
●
●●
●● ●●
● ●
● ●●●
●● ●
●●
●●●●
●
● ●●
●
●
●
●●●
●
●●
●
●
●●
●●
●●
●
●
● ●●
●
●
●
● ●●●●●
●●
●
●●
●●●●
●
●●
●
●●
●●●
●
● ●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●● ●●
●●●
●
●●
●●●●●●
●●●●
●●●
●●
●●●
●●
●●●
●
●
●
●●●
●
●●
●
●
●●
●●
●●
●
●
● Körper− größe
●●
●
●
●
●●●●● ●
●●●
●●
●●●●
●
●●
●
●●
●●●
●
● ●
●
●●●
●●
●
●●
●
●
●
●●
●
● ●●
●
●● ●●● ●
●
●
●●
●●●●
●●
●●●●
●● ●
● ●
●●●
●●
●●●
●
●
●
●● ●
●
●●
●
●
●●
●●
● ●
●
●
● ●●
●
●
●
●●●●
● ●●
●●
● ●
●●●●
●
●●
●
●●
●●●
●
● ●
●
●●●
●●
●
●
●
●
●
●●
●
● ●●
●
●● ●●●●
●
●
●●
●●● ●
●●
●●●●
●●●
●●
●●●
●●
●●●
●
●
●
●● ●
●
●●●
●
●●
●●
●●
●
●
● ●●
●
●
●
●●●●●●
●●
●
●●
● ●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●●●
● ●●●
●
●●
●●●●
●●
● ●●●
●●●
●●
●●●●
●
●●●
●
●
●
●●●
●
●●●
●
●●
●●
●●
●
●
● ●●
●
●
●
●●● ●●●
●●
●
●●
● ●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●● ●●●●
●
●
●●
●● ●●
● ●
●●●●
●●●
● ●
●● ●
●●
●● ●
●
●
●
●●●
●
●●
●
●
●●●
●
●●
●
●
●
7585
95
●●
●
●
●
●●●●
● ●●
●●
●●
●●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
● ●●●
●● ●●
● ●●
●
●●
●●● ●
●●
● ●●●
●● ●
●●
●●●●
●
●●●
●
●
●
●●●
●
●●
●
●
●●
●●
● ●
●
●
●
3238
●●
●●
●●●●●●
●
●●●
●●
●●●
●●●
●
●●●● ●●
●
●
●
●●●●● ●
●
●●
● ●
●●●
●
●
●●
●
●
●
●
●●
●
●●
●●
●● ●●
● ●● ●●
●
●●
● ●
●
●●●● ●● ●●
●
●
●
●
●
● ●●
●
●
● ●●
●
●
●
●●
●
●
●●
●●
●● ●●●●●
● ●●
●●
●●●
●●●
●
●●●● ●●
●
●
●
●●●●●●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●●●●●●●●●
●
●●● ●
●
●●●● ●
●●●
●
●
●
●
●
● ●●
●
●
●●●
●
●
●
●●●
●
● ●
●●
● ●●●●●
●
●●●
●●
●●●
●●●
●
●●●
●●●●
●
●
●●● ●●●
●
●●
● ●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●●●●
●●●●●
●
●●● ●
●
●●●●●
●●●
●
●
●
●
●
● ●●
●
●
●● ●
●
●
●
●●
●
●Schwanz−
länge ●●
●●
● ●●●●●
●
●● ●
● ●
●●●
●●●
●
●●●
● ●●●
●
●
● ●● ●●●
●
●
● ●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●●● ●
●●●●●
●
●●
● ●
●
●●●● ●
●●●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●●●
●
●●
●●
●●●●●●
●
●● ●
●●
● ●●
●●●
●
●● ●
● ●●●
●
●
●●●●●●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
● ●
●
●●
●●
●●●●
●●● ●●
●
●●
●●
●
●●●●●
●●●
●
●
●
●
●
● ●●
●
●
● ●●
●
●
●
●●●
●
● ●
●●
●●●● ●●
●
●●●
●●
● ●●
●● ●
●
●●●● ●●
●
●
●
●●●●● ●
●
● ●
●●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●● ●●
● ●●●●
●
●●
● ●
●
●● ●● ●
●● ●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●●
●
●
●●
●●
● ●●●●●
●
●●●
●●
●●●
●●●
●
●●●
● ●●●
●
●
● ●●● ●●
●
●●
● ●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●●
●● ●●●● ●●
●
●●
●●
●
●●●● ●
●●●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●●●
●
●●
●●
●●
●●●
●
●
●●
●
●
● ●●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
● ●●
● ●
●●
●●
●●●
●
● ●●●
●
●
●●● ●●●
●
●
●
●●●●●●
●
●●●
●
●
●
●●
●
●●
● ●●●
●●●
●● ●●
●
●●
●●
●●
●●●●
●
● ●
●
●
● ●●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
● ●●
● ●
●●
●●
●● ●
●
●●●
●●
●
●●
●●●●
●
●
●
●●●●● ●
●
●●●
●
●
●
●●
●
●●
● ●●●
●●●
●●●●
●
●●
●●
●●
●●●
●
●
●●
●
●
● ●●●●
●
●●●
●●
●
●●
●●
●
●●●
●
●
●●
●
●
●●
●●
●●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
●●● ●
●
●
●
●●
●●● ●
●
●●●
●
●
●
●●
●
●●
●● ●●
●● ●
●● ●●
●
●●
●●
●●●
●●●
●
●●
●
●
● ●●● ●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
●●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
●●● ●
●
●
●
●●
●●● ●
●
●●●
●
●
●
●●
●
●●
●● ●●
●● ●
●●●●
●
Pfoten− länge
●●
●●
●●
●●●●
●
●●
●
●
●● ●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
● ●
●
●
●●
●●
●●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
● ●●●
●
●
●
●●
●●●●
●
●●●
●
●
●
●●
●
●●
●●●●
●●●
●●●●
●
●●
●●
●●●● ●●
●
●●
●
●
●● ●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●●
●
● ●●
● ●
● ●
●●
●●●
●
● ●●
●●
●
●●
●●● ●
●
●
●
●●
●● ●●
●
●● ●
●
●
●
●●
●
●●
● ●●●
●●●●
●● ●
●
6070
●●
●●
●●●
●●●
●
●●
●
●
●●●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
● ●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
● ●●●
●
●
●
●●
●●● ●
●
●●●
●
●
●
●●
●
●●
● ●●●
●●●
●●●●
●
4050
●
●●●●●
●●
●●●●
●
●●●
●●●●●●
●●●
●
●●
●●●●●
●
●
●●
●
●●
●
●●
●●
●
● ●●●
●●● ●
●●
●●
●
●●
●
●●
●
● ●●
●●●●
●● ●●
●●●●
●● ●●●●
●
●
●●
●●
● ●●●
●●●
●●
●●●
●
● ●●●●
●●
●●●●
●
●●●
●●●●●●●●
●
●
●●
●●● ●●
●
●
●●
●
●●
●
●●
●●
●
● ●●●
●●● ●
●●
●●
●
●●
●
●●
●
●●●
●●●●
●● ●●
●●
●●
●●●●●●
●
●
●●
●●
● ●●●
●●●
●●
●● ●
●
● ●●● ●
●●●●
● ●●
●●●
●●●
● ●●●●
●
●
●●●
●●●●
●
●
●●
●
●●
●
●●
●●
●
●●●●
● ●●●
●●●
●●
●●
●
●●
●
●●●
●●
●●●● ●●
●●●
●
●●●● ●●
●
●
●●
●●
●● ●●
●● ●
●●
●● ●
●
● ●●●●●
●●●
●●●
●●●
●●
●● ●●
●●●
●
●●●
●● ●●
●
●
●●
●
●●
●
●●
●●
●
●● ●●
● ●● ●●●
●●
●
●●
●
●●
●
●●●
●●
●●●
●● ●
●●●
●
●●●● ●●
●
●
●●
●●
●● ●●●
● ●
●●
●● ●
●
● ●●● ●●●●●
●●●
●● ●
●●●● ●●
● ●●
●
●●
●●
● ●●●
●
●●
●
●●●
●
●●
●
●● ●●
● ●● ●
●●
●●
●
●●
●
●●
●
●●●
●●●●●
● ●●
●●●●
●●●● ●●
●
●
●●
●●
●●●●
●●●
●●
●● ●
Ohr− länge
●
●●●●●
●●
●●●●
●
●●●
●●●●● ●● ●
●
●
●●
●●●●●●
●
●●
●
●●
●
●●
●●
●
● ●●●
●●● ●●●
●●●
●●
●
●●
●
● ●●
●●
●●●
● ● ●
●●
●●
●●● ●●●
●
●
●●
●●
● ●●●
●●●
●●
● ●●
●
● ●●● ●
●●
●●●●
●
●●●
●●●
● ●●●●
●
●
●●
●●
●●●●
●
● ●
●
●●
●
●●
●●
●
● ● ●●
●●● ●
●●
●●
●
●●
●
●●
●
●●●
●●●●
●●●●
●●
●●
●●●● ●●
●
●
●●
●●
● ●●●●
●●
●●
●● ●
●
●●
●●
●●●
●
●●
●●●
●
●●
●●●
●
●
●
●
●●
●
●
●●●
●●●
●
●
●
●
●●
●
●●
● ●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●●
●
●
●
●
●●
●
●●
●●
● ●●
●
●●
●●
●●
●●
●●●
●
●
●
●
●●
●
●
●●●
●●●
●
●
●
●
●●
●
●●
● ●●●
●
●
●
●
●●
●
●●
● ●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●● ●
●
●
●
●
●●
●
●●
●●
●●●
●
●●
●●
●●
●●●●
●
●
●
●
●
●●
●
●
●● ●
●●●
●
●
●
●
●●
●
●●
● ● ●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●●●
●
●
●
●●
●
●●
●●
●●●
●
●●
●●●
●
●●
●●●
●
●
●
●
●●
●
●
●● ●
●●●
●
●
●
●
●●
●
●●
●●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
● ●●
●
●
●●
●●●●
●
●
●
●●
●
●●●●
●●●
●
●●
●●
●●
●●●●●
●
●
●
●
●●
●
●
●●●
●●●
●
●
●
●
●●●
●
●●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●●
●
●
●●
●●●●
●
●
●
●●
●
●●●●
●●●
●
●●●
●●
●
●●
●●●
●
●
●
●
● ●
●
●
●●●
●●●
●
●
●
●
●●
●
●●
●●●●
●
●
●
●
●●
●
● ●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●●
●
●
●
●
●●
Augen− größe
1315
17
●
●●
●●
●●●
●
●●
●●
●●
●●
●●●
●
●
●
●
●●
●
●
●● ●
●●●
●
●
●
●
●●
●
●●
● ●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●● ●
●
●
●
●
●●
85 95
2226
30
●●
●
●●
●●●
●●
●
●●●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
● ●●
●
● ●
●
●●
●
● ●●
● ●
●
●●●
●
●●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
●●
●●
●
● ●●
● ●●
●
●●
● ●●
●●
●
●●
●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
● ●●
●
●●
●
● ●
●
●●●
●●
●
●●●
●
●●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
●●
●●
●
●●●
●
75 85 95
● ●
●
●●
●●●●●
●
●●
●●●●●●
●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
● ●
●
●
●● ●
●
●●
●
●●
●
●● ●
●●
●
●● ●
●
● ●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
● ●
● ●
●
● ●●
● ●●
●
●●
●●●●●
●
●●●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
● ●
●
●
●● ●
●
●●
●
●●
●
●●●
●●
●
●● ●
●
● ●
●
●
●● ●●
●●
●
●
●●●
●● ●●
●
●●●
●
●
●
●●
● ●
●
●●●
●
60 70
●●
●
●●
●●●●●
●
●●
●● ●●●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●● ●
●
●●
●
●●
●
●●●
●●
●
●●●
●
●●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
●● ●
●
●
●
●●
●●
●
●●●
● ●●
●
●●
●●●
●●
●
●●
●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●●●
●
●●
●
●●
●
●●●
●●
●
●●●
●
●●
●
●
●●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
●●
●●
●
●●●
●
13 15 17
● ●
●
●●
●●●
●●
●
●●
● ●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
● ●
●
●
●
●
● ●
●
●
● ●●
●
●●
●
●●
●
● ● ●
● ●
●
●● ●
●
● ●
●
●
● ● ●●
●●
●
●
●● ●
●● ● ●
●
●●●
●
●
●
●●
●●
●
●● ●
● Brust− umfang
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Entdeckung einer neuen Unterart des PossumsBei genauerer Betrachtung stellte sich heraus, dass Possums imSüden / in Victoria (rot) größere Ohren, längere Pfoten und kürzereSchwänze als an anderen Standorten (blau) haben.
Kopf− länge
50 60
●●
●●●
●●●
●●
●● ●●
●●
●●●●●●
●●
●●
●
●●●●●
●●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●●
●
●
●●●
●
●●
●
●
●
●●●
●● ●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●●
●●
●●● ●
●●●
●●
●●●
●●
●●●●●
●●●● ●●
●●
●●
●
●●● ●●
●●
● ●
●
●
●
●●
●
●
●
● ●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●● ●
●
● ●
●
●
●
●●●
●● ●
●
●
●● ●
●
●
●
●
●
●
●●
● ●
●
●● ●
●●
●●●
32 38
●●
●●●
●●●
●●
●●●●
●●
●●● ● ●●
●●
●●
●
●●● ●●
●●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●● ●
●
● ●
●
●
●
●●●
●● ●
●
●
●● ●
●
●
●
●
●
●
●●
● ●
●
●● ●
● ●
●●● ●
●●●
●●
●●●
●●
●● ●●
●
●●●● ●●
●●
●●
●
●●●●●
● ●
● ●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●●●
●
●●
●
●
●
●●●
●●●
●
●
●● ●
●
●
●
●
●
●
●●●●
●
●●●
●●
●●●
40 50
●●●●
●●
● ●●●
●●● ●●●
● ●●●●●
●●
● ●
●
●●●●●●●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
● ●
●
●
●●●
●
●●
●
●
●
●●●
●●●
●
●
●●●●
●
●
●
●
●
●●●●
●
●●●
●●
●●● ●
●●●
●●●●
●●
●●●●
●●
● ●●●● ●
●●
●●
●
●●●●●●●
●●
●
●
●
●●
●
●
●
●● ●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●● ●
●
● ●
●
●
●
●●●
● ●●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●●
●●
● ●●
22 26 30
8595●
●●●
●●●●
●●
●●●●●●
●●●● ●●
●●
●●
●
●●● ●●
● ●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●●●
●
●●
●
●
●
●●●
●● ●
●
●
●● ●
●
●
●
●
●
●
●●
●●
●
●●●
● ●
●●●
5060 ●
●●
●●●
●●●
●●●
●●●
●
●
●●●●●
●●
●●
●●●
●●●
●●
●●
●●
●
●●
●●
●
●●●
●
●
●
●●
●
● ●●
●
●●
●●●
● ●●●
●● ●●
●
●● ●
●●●
●●●
●● ●●
●
●
●● ●
●
●
●●
●● ●●
●
●●● ●●
●Schädel−
breite●
●●
●●●
●●●
●●●
●●●
●
●
●●●●●
●●
●●
●●●
● ●●
●●●
●
●●
●
●●
●●
●
●● ●
●
●
●
●●
●
●●●●
●●
●● ●
●●●●●
●●●●
●●●
●●●
●●●
●●●●
●
●
●●●
●
●
●●
● ●●●
●
●●● ●●
● ●
●●
●●●
●●●● ●
●
●●●
●
●
●● ●●●
●●
●●
●●●
● ●●
●●
●●
●●
●
●●
●●
●
●● ●
●
●
●
●●
●
●●●
●
●●
●●●●●●●
●●●●
●
● ● ●
●●●
●●●
●●●●
●
●
●●●
●
●
●●
● ●●●
●
●●●●●
● ●
●●
●●●
●●●
● ●●
●●●
●
●
●●●●●
●●
●●
●●●
●●●
●●
●●
●●
●
●●●
●
●●●
●
●
●
●●
●
●●●
●
●●
●● ●●● ●
●●●●●●
● ●●
●●●
●●●
●●●●
●
●
●●●
●
●
●●
●●●●
●
●●●●●
● ●
●●
●●●
● ●●●●
●
●●●
●
●
●●●●●●●
● ●
●●●
●●●●
●●
●
●●
●
●●
●●
●
●●●
●
●
●
●●
●
●●●
●
●●
●●●
●●●●●
● ●●●
● ●●
●●●
●●●
●●●●●
●
●● ●
●
●
●●
●● ●●
●
● ●●●●
● ●
●●
●●●
●●●
●●●
●● ●
●
●
●●●● ●
●●
●●
●●●
●●●●
●●
●
●●
●
●●
●●
●
●● ●
●
●
●
●●
●
●●●
●
●●
●● ●● ●●
●●
●●●●
● ●●
●●●
● ●●
●●● ●
●
●
●●●
●
●
●●
●●●●
●
● ●●● ●
● ●
●●
●●●
●●●
● ●●
●●●●
●
●●●●●
●●
●●
●●●
● ●●
●●
●●
●●
●
●●
●●
●
●●●
●
●
●
●●
●
●●●
●
●●
●●●
●● ●●
●● ●●●
●● ●
●●●
●●●
●●●●
●
●
●● ●
●
●
●●
●●●●
●
●●●●●
●
●●
●
●
●
●●●●
●●●●●
●●
●●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●● ● ●●●●
●
●●
●● ●●
● ●
● ●●●
●● ●
●●
●●●●
●
● ●●
●
●
●
●●●
●
●●
●
●
●●
●●
●●
●
●
● ●●
●
●
●
● ●●●●●
●●
●
●●
●●●●
●
●●
●
●●
●●●
●
● ●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●● ●●
●●●
●
●●
●●●●●●
●●●●
●●●
●●
●●●
●●
●●●
●
●
●
●●●
●
●●
●
●
●●
●●
●●
●
●
● Körper− größe
●●
●
●
●
●●●●● ●
●●●
●●
●●●●
●
●●
●
●●
●●●
●
● ●
●
●●●
●●
●
●●
●
●
●
●●
●
● ●●
●
●● ●●● ●
●
●
●●
●●●●
●●
●●●●
●● ●
● ●
●●●
●●
●●●
●
●
●
●● ●
●
●●
●
●
●●
●●
● ●
●
●
● ●●
●
●
●
●●●●
● ●●
●●
● ●
●●●●
●
●●
●
●●
●●●
●
● ●
●
●●●
●●
●
●
●
●
●
●●
●
● ●●
●
●● ●●●●
●
●
●●
●●● ●
●●
●●●●
●●●
●●
●●●
●●
●●●
●
●
●
●● ●
●
●●●
●
●●
●●
●●
●
●
● ●●
●
●
●
●●●●●●
●●
●
●●
● ●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●●●
● ●●●
●
●●
●●●●
●●
● ●●●
●●●
●●
●●●●
●
●●●
●
●
●
●●●
●
●●●
●
●●
●●
●●
●
●
● ●●
●
●
●
●●● ●●●
●●
●
●●
● ●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
●●●
●
●● ●●●●
●
●
●●
●● ●●
● ●
●●●●
●●●
● ●
●● ●
●●
●● ●
●
●
●
●●●
●
●●
●
●
●●●
●
●●
●
●
●
7585
95
●●
●
●
●
●●●●
● ●●
●●
●●
●●●●
●
●●
●
●●
●●●
●
●●
●
● ●●
●●
●
●●
●
●
●
●●
●
● ●●●
●● ●●
● ●●
●
●●
●●● ●
●●
● ●●●
●● ●
●●
●●●●
●
●●●
●
●
●
●●●
●
●●
●
●
●●
●●
● ●
●
●
●
3238
●●
●●
●●●●●●
●
●●●
●●
●●●
●●●
●
●●●● ●●
●
●
●
●●●●● ●
●
●●
● ●
●●●
●
●
●●
●
●
●
●
●●
●
●●
●●
●● ●●
● ●● ●●
●
●●
● ●
●
●●●● ●● ●●
●
●
●
●
●
● ●●
●
●
● ●●
●
●
●
●●
●
●
●●
●●
●● ●●●●●
● ●●
●●
●●●
●●●
●
●●●● ●●
●
●
●
●●●●●●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●●●●●●●●●
●
●●● ●
●
●●●● ●
●●●
●
●
●
●
●
● ●●
●
●
●●●
●
●
●
●●●
●
● ●
●●
● ●●●●●
●
●●●
●●
●●●
●●●
●
●●●
●●●●
●
●
●●● ●●●
●
●●
● ●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●●●●
●●●●●
●
●●● ●
●
●●●●●
●●●
●
●
●
●
●
● ●●
●
●
●● ●
●
●
●
●●
●
●Schwanz−
länge ●●
●●
● ●●●●●
●
●● ●
● ●
●●●
●●●
●
●●●
● ●●●
●
●
● ●● ●●●
●
●
● ●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●●● ●
●●●●●
●
●●
● ●
●
●●●● ●
●●●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●●●
●
●●
●●
●●●●●●
●
●● ●
●●
● ●●
●●●
●
●● ●
● ●●●
●
●
●●●●●●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
● ●
●
●●
●●
●●●●
●●● ●●
●
●●
●●
●
●●●●●
●●●
●
●
●
●
●
● ●●
●
●
● ●●
●
●
●
●●●
●
● ●
●●
●●●● ●●
●
●●●
●●
● ●●
●● ●
●
●●●● ●●
●
●
●
●●●●● ●
●
● ●
●●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●● ●●
● ●●●●
●
●●
● ●
●
●● ●● ●
●● ●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●●
●
●
●●
●●
● ●●●●●
●
●●●
●●
●●●
●●●
●
●●●
● ●●●
●
●
● ●●● ●●
●
●●
● ●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●●●
●● ●●●● ●●
●
●●
●●
●
●●●● ●
●●●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●●●
●
●●
●●
●●
●●●
●
●
●●
●
●
● ●●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
● ●●
● ●
●●
●●
●●●
●
● ●●●
●
●
●●● ●●●
●
●
●
●●●●●●
●
●●●
●
●
●
●●
●
●●
● ●●●
●●●
●● ●●
●
●●
●●
●●
●●●●
●
● ●
●
●
● ●●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
● ●●
● ●
●●
●●
●● ●
●
●●●
●●
●
●●
●●●●
●
●
●
●●●●● ●
●
●●●
●
●
●
●●
●
●●
● ●●●
●●●
●●●●
●
●●
●●
●●
●●●
●
●
●●
●
●
● ●●●●
●
●●●
●●
●
●●
●●
●
●●●
●
●
●●
●
●
●●
●●
●●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
●●● ●
●
●
●
●●
●●● ●
●
●●●
●
●
●
●●
●
●●
●● ●●
●● ●
●● ●●
●
●●
●●
●●●
●●●
●
●●
●
●
● ●●● ●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
●●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
●●● ●
●
●
●
●●
●●● ●
●
●●●
●
●
●
●●
●
●●
●● ●●
●● ●
●●●●
●
Pfoten− länge
●●
●●
●●
●●●●
●
●●
●
●
●● ●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
● ●
●
●
●●
●●
●●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
● ●●●
●
●
●
●●
●●●●
●
●●●
●
●
●
●●
●
●●
●●●●
●●●
●●●●
●
●●
●●
●●●● ●●
●
●●
●
●
●● ●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●●
●
● ●●
● ●
● ●
●●
●●●
●
● ●●
●●
●
●●
●●● ●
●
●
●
●●
●● ●●
●
●● ●
●
●
●
●●
●
●●
● ●●●
●●●●
●● ●
●
6070
●●
●●
●●●
●●●
●
●●
●
●
●●●●●
●
●●●
●●
●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●●
● ●●
●●
●●
●●
●●●
●
●●●
●●
●
●●
● ●●●
●
●
●
●●
●●● ●
●
●●●
●
●
●
●●
●
●●
● ●●●
●●●
●●●●
●
4050
●
●●●●●
●●
●●●●
●
●●●
●●●●●●
●●●
●
●●
●●●●●
●
●
●●
●
●●
●
●●
●●
●
● ●●●
●●● ●
●●
●●
●
●●
●
●●
●
● ●●
●●●●
●● ●●
●●●●
●● ●●●●
●
●
●●
●●
● ●●●
●●●
●●
●●●
●
● ●●●●
●●
●●●●
●
●●●
●●●●●●●●
●
●
●●
●●● ●●
●
●
●●
●
●●
●
●●
●●
●
● ●●●
●●● ●
●●
●●
●
●●
●
●●
●
●●●
●●●●
●● ●●
●●
●●
●●●●●●
●
●
●●
●●
● ●●●
●●●
●●
●● ●
●
● ●●● ●
●●●●
● ●●
●●●
●●●
● ●●●●
●
●
●●●
●●●●
●
●
●●
●
●●
●
●●
●●
●
●●●●
● ●●●
●●●
●●
●●
●
●●
●
●●●
●●
●●●● ●●
●●●
●
●●●● ●●
●
●
●●
●●
●● ●●
●● ●
●●
●● ●
●
● ●●●●●
●●●
●●●
●●●
●●
●● ●●
●●●
●
●●●
●● ●●
●
●
●●
●
●●
●
●●
●●
●
●● ●●
● ●● ●●●
●●
●
●●
●
●●
●
●●●
●●
●●●
●● ●
●●●
●
●●●● ●●
●
●
●●
●●
●● ●●●
● ●
●●
●● ●
●
● ●●● ●●●●●
●●●
●● ●
●●●● ●●
● ●●
●
●●
●●
● ●●●
●
●●
●
●●●
●
●●
●
●● ●●
● ●● ●
●●
●●
●
●●
●
●●
●
●●●
●●●●●
● ●●
●●●●
●●●● ●●
●
●
●●
●●
●●●●
●●●
●●
●● ●
Ohr− länge
●
●●●●●
●●
●●●●
●
●●●
●●●●● ●● ●
●
●
●●
●●●●●●
●
●●
●
●●
●
●●
●●
●
● ●●●
●●● ●●●
●●●
●●
●
●●
●
● ●●
●●
●●●
● ● ●
●●
●●
●●● ●●●
●
●
●●
●●
● ●●●
●●●
●●
● ●●
●
● ●●● ●
●●
●●●●
●
●●●
●●●
● ●●●●
●
●
●●
●●
●●●●
●
● ●
●
●●
●
●●
●●
●
● ● ●●
●●● ●
●●
●●
●
●●
●
●●
●
●●●
●●●●
●●●●
●●
●●
●●●● ●●
●
●
●●
●●
● ●●●●
●●
●●
●● ●
●
●●
●●
●●●
●
●●
●●●
●
●●
●●●
●
●
●
●
●●
●
●
●●●
●●●
●
●
●
●
●●
●
●●
● ●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●●
●
●
●
●
●●
●
●●
●●
● ●●
●
●●
●●
●●
●●
●●●
●
●
●
●
●●
●
●
●●●
●●●
●
●
●
●
●●
●
●●
● ●●●
●
●
●
●
●●
●
●●
● ●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●● ●
●
●
●
●
●●
●
●●
●●
●●●
●
●●
●●
●●
●●●●
●
●
●
●
●
●●
●
●
●● ●
●●●
●
●
●
●
●●
●
●●
● ● ●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●●●
●
●
●
●●
●
●●
●●
●●●
●
●●
●●●
●
●●
●●●
●
●
●
●
●●
●
●
●● ●
●●●
●
●
●
●
●●
●
●●
●●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
● ●●
●
●
●●
●●●●
●
●
●
●●
●
●●●●
●●●
●
●●
●●
●●
●●●●●
●
●
●
●
●●
●
●
●●●
●●●
●
●
●
●
●●●
●
●●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●●
●
●
●●
●●●●
●
●
●
●●
●
●●●●
●●●
●
●●●
●●
●
●●
●●●
●
●
●
●
● ●
●
●
●●●
●●●
●
●
●
●
●●
●
●●
●●●●
●
●
●
●
●●
●
● ●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●●
●
●
●
●
●●
Augen− größe
1315
17
●
●●
●●
●●●
●
●●
●●
●●
●●
●●●
●
●
●
●
●●
●
●
●● ●
●●●
●
●
●
●
●●
●
●●
● ●●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●● ●
●
●
●
●
●●
85 95
2226
30
●●
●
●●
●●●
●●
●
●●●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
● ●●
●
● ●
●
●●
●
● ●●
● ●
●
●●●
●
●●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
●●
●●
●
● ●●
● ●●
●
●●
● ●●
●●
●
●●
●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
● ●●
●
●●
●
● ●
●
●●●
●●
●
●●●
●
●●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
●●
●●
●
●●●
●
75 85 95
● ●
●
●●
●●●●●
●
●●
●●●●●●
●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
● ●
●
●
●● ●
●
●●
●
●●
●
●● ●
●●
●
●● ●
●
● ●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
● ●
● ●
●
● ●●
● ●●
●
●●
●●●●●
●
●●●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
● ●
●
●
●● ●
●
●●
●
●●
●
●●●
●●
●
●● ●
●
● ●
●
●
●● ●●
●●
●
●
●●●
●● ●●
●
●●●
●
●
●
●●
● ●
●
●●●
●
60 70
●●
●
●●
●●●●●
●
●●
●● ●●●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●● ●
●
●●
●
●●
●
●●●
●●
●
●●●
●
●●
●
●
● ●●●
●●
●
●
●●●
●● ●●
●
●● ●
●
●
●
●●
●●
●
●●●
● ●●
●
●●
●●●
●●
●
●●
●●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●●●
●
●●
●
●●
●
●●●
●●
●
●●●
●
●●
●
●
●●●●
●●
●
●
●●●
●● ●●
●
● ●●
●
●
●
●●
●●
●
●●●
●
13 15 17
● ●
●
●●
●●●
●●
●
●●
● ●●●
●●●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
● ●
●
●
●
●
● ●
●
●
● ●●
●
●●
●
●●
●
● ● ●
● ●
●
●● ●
●
● ●
●
●
● ● ●●
●●
●
●
●● ●
●● ● ●
●
●●●
●
●
●
●●
●●
●
●● ●
● Brust− umfang
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Entdeckung einer neuen Unterart des PossumsSein Klassifikationsmodell:
T = 24− 0.571×Ohrlänge
− 0.149× Pfotenlänge
+ 0.341× Schwanzlänge
Falls T < 0 gilt, so kommt das Possumaus Victoria; ansonsten von einem deranderen Standorte.
Genetische Untersuchungenbestätigten später diese Entdeckungeiner neuen Unterart.
Quelle: P. Hall (2003). A Possum’s Tale – How Statistics
Revealed a New Mammal Species. Chance, 16, 8-13.
T. caninus T. cunninghamii
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015

Mehr Details zu multivariaten Fragestellungen – an der Tafel :)
Markus Pauly (University of Ulm) Versuchplanung Sommersemester 2015