statystyczna analiza danych funkcjonalnych. funkcjonalny ... · słowa kluczowe: dane funkcjonalne,...
TRANSCRIPT

Politechnika GdańskaWydział Fizyki Technicznej i Matematyki Stosowanej
Anna Wieżel
Statystyczna analiza danych funkcjonalnych.Funkcjonalny model liniowy.
Praca magisterskana kierunku MATEMATYKA
Praca wykonana pod kierunkiemdra hab. Karola Dziedziula
styczeń 2016


Streszczenie
Celem pracy jest przedstawienie pewnych zagadnień statystyki matematycznej na nie-skończenie wymiarowych funkcyjnych przestrzeniach Hilberta. Przedstawiony jest pełenliniowy model funkcjonalny postaci Y = ΨX + ε oraz test jego istotności zaproponowa-ny przez Kokoszkę i innych. Test bada zanikanie operatora Hilberta-Schmidta Ψ , któreimplikuje brak liniowej zależności między X a Y . Teoretyczną część pracy kończy wyka-zanie zbieżności statystyki testowej do rozkładu chi-kwadratu z zastosowaniem rozkładuna główne składowe. Tematyka ta nie posiada do tej pory kompleksowego przedstawieniaw polskiej literaturze.W dalszej części pracy test jest wykorzystany do analizy danych o polu magnetycznymze stacji badawczych na różnych szerokościach geograficznych. Wyniki wykazują liniowązależność składowych horyzontalnych indukcji magnetycznej obserwowanych w stacjachna wysokich szerokościach geograficznych z indukcją obserwowaną w stacjach na średnichoraz niskich szerokościach z jedno- lub dwudniowym opóźnieniem, lecz przeczą liniowejzależności między danymi z większym opóźnieniem.
Słowa kluczowe: dane funkcjonalne, analiza danych funkcjonalnych, funkcjonalny modelliniowy, test istotności, statystyka na przestrzeniach Hilberta.
Dziedzina nauki i techniki, zgodnie z wymogami OECD: 1.1 Matematyka.
3

Abstract
The paper’s motivation is to present some aspects of mathematical statistics on infinitedimensional function Hilbert spaces. The author presents the fully functional linear modelin form Y = ΨX+ε and its significance test proposed by Kokoszka et al. The test detectsvanishing of Hilbert-Schmidt operator Ψ , which implies the lack of linear dependence be-tween X and Y . Using the principal component decomposition it is concluded with teststatistic convergent by distribution to chi-squared. These topics have not been fully cove-red in Polish literature yet.The test is further used for magnetic field data collected in some stations in different lati-tudes. The results show linear dependence between horizontal intensities of the magneticfield in high-latitude stations with mid- and low-latitude station data with a day or twodelay but they contradict the linear dependence between data with more than a two-daylag.
Keywords: functional data, functional data analysis, functional linear model, significancetest, statistics on Hilbert spaces.
4

Spis treści
Wstęp 7
1 Preliminaria 91.1 Klasyfikacja operatorów liniowych . . . . . . . . . . . . . . . . . . . . . . . 91.2 L2-elementy losowe. Pojęcie funkcji średniej i operatora kowariancji . . . . . 141.3 Estymacja średniej, funkcji kowariancji i operatora kowariancji. FPC . . . . 19
2 Test istotności w funkcjonalnym modelu liniowym 232.1 Funkcjonalny model liniowy . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.2 Test istotności . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.3 Rozkład statystyki testowej . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3 Przykład zastosowania testu istotności 353.1 Opis danych oraz procedury testowej . . . . . . . . . . . . . . . . . . . . . . 353.2 Zastosowanie testu dla danych magnetometrycznych . . . . . . . . . . . . . 37
A Kod w R 45
Bibliografia 51
5

6

Wstęp
Praca dotyczy tzw. funkcjonalnej analizy danych (ang. Functional Data Analysis, FDA),czyli zagadnień statystycznych, gdy badane obiekty są funkcjami. Z teoretycznego punk-tu widzenia będziemy operować na zmiennych funkcjonalnych przyjmujących wartości wośrodkowej przestrzeni Hilberta. Przedstawimy podstawowe definicje i własności takichzmiennych, a także opiszemy test istotności w funkcjonalnym modelu liniowym (wraz zdowodami asymptotycznych własności odpowiedniej statystyki). Pracę kończy przykładzastosowania przedstawionego testu do danych magnetometrycznych.
W pierwszym rozdziale, oprócz niezbędnych preliminariów z teorii operatorów liniowychoraz teorii miary, znajdują się podstawy formalizmu zmiennych losowych o wartościach wnieskończenie wymiarowych ośrodkowych przestrzeniach Hilberta. Wprowadzone zostanąpojęcią wartości oczekiwanej oraz operatora kowariancji dla zmiennych funkcjonalnych. Wpracy szczególnie zainteresowani będziemy przypadkiem, gdy rozważaną przestrzenią Hil-berta będzie L2(T ), gdzie T ⊂ R jest przedziałem. Ponieważ elementy przestrzeni L2(T ) sąformalnie klasami abstrakcji funkcji równych prawie wszędzie, to powyższe podejście unie-możliwia rozważanie wartości obserwacji elementu losowego w ustalonym punkcie t ∈ T .Z kolei w praktyce mamy do dyspozycji dane historyczne będące wartościami wylosowa-nej funkcji w pewnej liczbie punktów z przedziału T . Dlatego naturalne jest rozważaniejako wyjściowego obiektu procesu stochastycznego Xtt∈T , a następnie związanie z nimL2(T )-elementu losowego. Rozdział kończy się krótkim opisem sposobu estymacji wartościoczekiwanej, funkcji i operatora kowariancji oraz wartości i wektorów własnych operatorakowariancji metodą FPC.
Treścią drugiego rozdziału jest przedstawienie oraz analiza testu istotności w pełnymfunkcjonalnym modelu liniowym. Przedstawiamy postać oraz założenia tego modelu, anastępnie statystykę testową będącą podstawą testu. Pozostała część rozdziału poświęco-na jest dowodom asymptotycznego rozkładu statystyki testowej, gdy hipoteza zerowa obraku zależności liniowej jest spełniona bądź nie.
Trzeci rozdział opisuje przykład zastosowania powyższego testu do wnioskowania o cha-rakterze zależności liniowej między danymi magnetometrycznymi pochodzącymi ze stacjibadawczych na różnych szerokościach geograficznych (rozważamy także przypadek, gdydane są przesunięte w stosunku do siebie o dzień, dwa lub trzy). Prezentowana jest wyko-rzystywana w praktyce procedura testowa, a także opis wykorzystanych danych. Ponieważdane są w postaci dyskretnej, analizę modelu funkcjonalnego poprzedzono interpolacją da-nych za pomocą bazy B-splajnów, aby uzyskać dane funkcjonalne. Przeprowadzono szeregtestów, których wyniki przedstawione są w pracy.
W załączniku na końcu pracy załączony został kod napisany w języku R na potrzebyprzykładu zaprezentowanego w pracy. W programie wykorzystane pakiet fda, którego opismożna znaleźć w [R: fda 1].Praca opiera się głównie na artykule [Kokoszka et al.], który został rozwinięty w książce
7

[Horvath, Kokoszka]. Więcej na temat funkcjonalnej analizy danych można znaleźć takżew pracach [Bosq], [Ferraty, Vieu], [Hsing, Eubank], [R: fda 2], [Ramsay, Silverman] oraz[Maslova et al.].Ze względu na fakt, że analiza danych funkcjonalnych jest stosunkowo nowym działemstatystyki i jest wciąż mało popularna w polskiej literaturze, wiele pojęć czy określeń za-wartych w pracy nie posiada jeszcze ogólnie przyjętych polskich odpowiedników. Dlategozostały one przetłumaczone przez autora według własnego uznania, przytaczając orygi-nalne (angielskie) nazwy.
W pracy wykorzystano dane o polu magnetycznym Ziemi publikowane na stronie programuINTERMAGNET oraz organizacji SuperMAG. Załączam zatem specjalne podziękowania:
ACKNOWLEDGEMENTS
The results presented in this paper rely on data collected at magnetic observatories. Wethank the national institutes that support them and INTERMAGNET for promoting highstandards of magnetic observatory practice (www.intermagnet.org).
For the ground magnetometer data we gratefully acknowledge: Intermagnet; USGS, JeffreyJ. Love; CARISMA, PI Ian Mann; CANMOS; The S-RAMP Database, PI K. Yumoto andDr. K. Shiokawa; The SPIDR database; AARI, PI Oleg Troshichev; The MACCS program,PI M. Engebretson, Geomagnetism Unit of the Geological Survey of Canada; GIMA; ME-ASURE, UCLA IGPP and Florida Institute of Technology; SAMBA, PI Eftyhia Zesta; 210Chain, PI K. Yumoto; SAMNET, PI Farideh Honary; The institutes who maintain theIMAGE magnetometer array, PI Eija Tanskanen; PENGUIN; AUTUMN, PI Martin Con-nors; DTU Space, PI Dr. Juergen Matzka; South Pole and McMurdo Magnetometer, PI’sLouis J. Lanzarotti and Alan T. Weatherwax; ICESTAR; RAPIDMAG; PENGUIn; Bri-tish Artarctic Survey; McMac, PI Dr. Peter Chi; BGS, PI Dr. Susan Macmillan; PushkovInstitute of Terrestrial Magnetism, Ionosphere and Radio Wave Propagation (IZMIRAN);GFZ, PI Dr. Juergen Matzka; MFGI, PI B. Heilig; IGFPAS, PI J. Reda; University ofL’Aquila, PI M. Vellante; SuperMAG, PI Jesper W. Gjerloev.
8

Rozdział 1
Preliminaria
Niech (Ω,F , P ) będzie przestrzenią probabilistyczną. Ω jest zatem zbiorem scenariuszy ω,F jest σ-algebrą podzbiorów Ω, a P miarą probabilistyczną na F .
Definicja 1.1 Niech B będzie przestrzenią Banacha. σ-ciałem zbiorów borelowskichna B nazywamy σ-ciało B(B) generowane przez rodzinę zbiorów otwartych w normieprzestrzeni B.
Definicja 1.2 Niech B będzie przestrzenią Banacha, zaś (Ω,F , P ) przestrzenią probabi-listyczną. Odwzorowanie X : Ω → B nazywamy B-elementem losowym, gdy X jestmierzalne, tzn. dla każdego zbioru borelowskiego A ∈ B(B) zachodzi X−1(A) ∈ F .
W pracy skupimy się na elementach losowych przyjmujących wartości w nieskończeniewymiarowej ośrodkowej (rzeczywistej) przestrzeni Hilberta. W środowisku statystykówprzyjęło się aby, w przypadku gdy X(ω) jest funkcją (lub ogólnie krzywą), taką zmiennąnazywać zmienną funkcjonalną (ang. functional variable), zaś obserwację χ zmiennejX nazywać daną funkcjonalną (ang. functional data). Statystyki takich obiektów sąbardziej skomplikowane niż dla zmiennych losowych przyjmujących wartości w R lub Rn(n ∈ N), dlatego aby zbudować pojęcia funkcji średniej oraz operatora kowariancji dlazmiennych tego typu, wprowadzimy najpierw niezbędne pojęcia z dziedziny operatorówliniowych.
1.1 Klasyfikacja operatorów liniowych
Rozważmy ośrodkową nieskończenie wymiarową rzeczywistą przestrzeń Hilberta H z ilo-czynem skalarnym 〈·, ·〉 zadającym normę ‖·‖. Przez L oznaczmy przestrzeń ograniczonych(ciągłych) operatorów liniowych w H, tj.
Ψ ∈ L ⇐⇒ ∃C>0 ∀x∈H ‖Ψx‖ ¬ C ‖x‖ .
Każdy operator Ψ ∈ L posiada operator sprzężony Ψ∗, zdefiniowany następująco
〈Ψ∗x, y〉 = 〈x,Ψy〉.
Przestrzeń L z normą
‖Ψ‖L := sup‖Ψ(x)‖ : ‖x‖ ¬ 1 = minC > 0 : ‖Ψx‖ ¬ C ‖x‖ , x ∈ H, Ψ ∈ L
jest przestrzenią Banacha.
9

Definicja 1.3 [Horvath, Kokoszka]Operator Ψ ∈ L nazywamy operatorem zwartym, jeśli istnieją dwie ortonormalne bazyw H υj∞j=1 i fj∞j=1, oraz ciąg liczb rzeczywistych λj∞j=1 zbieżny do zera, takie że
Ψ(x) =∞∑j=1
λj〈x, υj〉fj , x ∈ H. (1.1)
Klasę operatorów zwartych oznacza się przez C.
Bez straty ogólności możemy założyć, że w przedstawionej reprezentacji λj są wartościamidodatnimi, w razie konieczności wystarczy fj zamienić na −fj .Równoważną definicją operatora zwartego jest spełnienie przez Ψ następującego warunku:zbieżność 〈y, xn〉 → 〈y, x〉 dla każdego y ∈ H implikuje ‖Ψ(xn)−Ψ(x)‖ → 0.
Kolejną klasą operatorów są operatory Hilberta-Schmidta, którą oznaczać będziemy przezS.
Definicja 1.4 [Bosq]Operatorem Hilberta-Schmidta nazywamy taki operator zwarty Ψ ∈ L, dla któregociąg λj∞j=1 w reprezentacji (1.1) spełnia
∑∞j=1 λ
2j <∞.
Przytoczymy teraz tożsamość Parsevala, z której wielokrotnie będziemy korzystać w pracy.
Lemat 1.1 (Tożsamość Parsevala)Niech ej∞j=1 będzie bazą ortonormalną w przestrzeni Hilberta H. Wtedy dla każdego x ∈H mamy ‖x‖2 =
∑∞j=1 |〈x, ej〉|2.
Uwaga 1.1 [Bosq], [Horvath, Kokoszka]Klasa S jest przestrzenią Hilberta z iloczynem skalarnym
〈Ψ1,Ψ2〉S :=∞∑j=1
〈Ψ1(ej),Ψ2(ej)〉, (1.2)
gdzie ej∞j=1 jest dowolną bazą ortonormalną w H.Powyższy iloczyn skalarny zadaje normę
‖Ψ‖S :=
( ∞∑j=1
λ2j
)1/2, (1.3)
co wynika z szeregu równości
‖Ψ‖2S = 〈Ψ ,Ψ〉S =∞∑n=1
⟨ ∞∑j=1
λj〈en, υj〉fj ,∞∑k=1
λk〈en, υk〉fk⟩
=∞∑n=1
∞∑j=1
∞∑k=1
λjλk〈en, υj〉〈en, υk〉〈fj , fk〉 =∞∑n=1
∞∑j=1
λ2j 〈en, υj〉2
=∞∑j=1
λ2j
∞∑n=1
〈en, υj〉2tożsamośćParsevala=
∞∑j=1
λ2j‖υj‖2 =∞∑j=1
λ2j .
Definicja 1.5 [Bosq]Zwarty operator liniowy nazywamy operatorem śladowym (ang. nuclear operator), jeślirówność (1.1) spełniona jest dla ciągu λj∞j=1 takiego, że
∑∞j=1 |λj | <∞.
10

Uwaga 1.2 [Bosq]Klasa operatorów śladowych N z normą ‖Ψ‖N :=
∑∞j=1 |λj | jest przestrzenią Banacha.
Uwaga 1.3 [Bosq]Prawdziwe są inkluzje: N ⊂ S ⊂ C ⊂ L.
Definicja 1.6 [Horvath, Kokoszka]Operator Ψ ∈ L nazywamy symetrycznym, jeśli
〈Ψ(x), y〉 = 〈x,Ψ(y)〉, x, y ∈ H,
oraz nieujemnie określonym (lub połowicznie pozytywnie określonym, ang. positive se-midefinite), jeśli
〈Ψ(x), x〉 0, x ∈ H.
Uwaga 1.4 [Horvath, Kokoszka]Symetryczny nieujemnie określony operator Hilberta-Schmidta Ψ możemy przedstawić wpostaci
Ψ(x) =∞∑j=1
λj〈x, υj〉υj , x ∈ H, (1.4)
gdzie ortonormalne υj są funkcjami (wektorami) własnymi Ψ, a λj odpowiadającymiim wartościami własnymi, tj. Ψ(υj) = λjυj. Funkcje υj mogą być rozszerzone do bazy,przez dodanie bazy ortonormalnej dopełnienia ortogonalnego podprzestrzeni rozpiętej przezoryginalne υj. Możemy zatem założyć, że funkcje υj w (1.4) tworzą bazę, a pewne wartościλj mogą być równe zero.
W dalszej części pracy ograniczymy się do przypadku H = L2(T,A, µ), gdzie (T,A, µ) jestprzestrzenią z miarą σ-skończoną. Przestrzeń L2(T,A, µ) jest zbiorem mierzalnych funkcjirzeczywistych całkowalnych z kwadratem określonych na T , tj.
x ∈ L2(T,A, µ) ⇐⇒ x : T → R ∧∫T
x2(t)dµ(t) <∞,
z utożsamieniem funkcji równych prawie wszędzie. Jeśli x, y ∈ L2(T,A, µ), równość x = yzawsze oznaczać będzie
∫T [x(t)− y(t)]2 dµ(t) = 0. Przestrzeń L2(T,A, µ) jest przestrzenią
Hilberta z iloczynem skalarnym
〈x, y〉 :=∫T
x(t)y(t)dµ(t), x, y ∈ L2(T,A, µ),
wyznaczającym normę
‖x‖2 = 〈x, x〉 =∫T
x2(t)dµ(t), x ∈ L2(T,A, µ).
Ważną klasę operatorów liniowych na przestrzeni L2(T,A, µ) stanowią operatory całko-we. Przedstawimy pomocnicze definicje i twierdzenia, a następnie twierdzenie opisującewarunki, które powinny być spełnione, aby taki operator był dobrze określony.
Definicja 1.7 [Beśka]Niech (T,A) i (S, C) będą przestrzeniami mierzalnymi. σ-algebra produktowa na T × Sjest określona jako
A⊗ C = σ(A× C : A ∈ A, C ∈ C).
11

Twierdzenie 1.1 [Beśka]Niech (T,A, µ) i (S, C, ν) będą przestrzeniami z miarami σ-skończonymi. Wówczas istniejejedyna miara na A⊗ C oznaczana symbolem µ× ν taka, że
(µ× ν)(A× C) = µ(A)ν(C), A ∈ A, C ∈ C.
Taką miarę nazywamy miarą produktową.
Twierdzenie 1.2 [Billingsley] (Twierdzenie Fubiniego)Niech (T,A, µ) i (S, C, ν) będą przestrzeniami z miarami σ-skończonymi. Niech f : T×S →R będzie funkcją mierzalną względem σ-algebry produktowej A⊗ C.
(a) Załóżmy, że całka∫Sf(t, s)dν(s) istnieje dla każdego t ∈ T oraz całka
∫Tf(t, s)dµ(t)
istnieje dla każdego s ∈ S. Wówczas funkcja T 3 t 7→∫Sf(t, s)dν(s) ∈ R jest A-
mierzalna i funkcja S 3 s 7→∫Tf(t, s)dµ(t) ∈ R jest C-mierzalna.
(b) Załóżmy, że przynajmniej jedna z całek jest skończona:
∫T×S
|f |dµ⊗ ν,∫T
∫S
|f(t, s)|dν(s)
dµ(t),∫S
∫T
|f(t, s)|dµ(t)
dν(s).
Wtedy dla µ-prawie wszystkich t ∈ T funkcja f(t, ·) : S → R jest ν-skończenie cał-kowalna i dla ν-prawie wszystkich s ∈ S funkcja f(·, s) : T → R jest µ-skończeniecałkowalna. Ponadto, funkcja T 3 t 7→
∫Sf(t, s)dν(s) ∈ R jest µ-skończenie całko-
walna i funkcja S 3 s 7→∫Tf(t, s)dµ(t) ∈ R jest ν-skończenie całkowalna. Prawdziwe
są poniższe równości
∫T×S
fdµ⊗ ν =∫T
∫S
f(t, s)dν(s)
dµ(t) =∫S
∫T
f(t, s)dµ(t)
dν(s).
Uwaga 1.5 [Beśka]Zauważmy, że funkcje T 3 t 7→
∫Sf(t, s)dν(s) ∈ R, S 3 s 7→
∫Tf(t, s)dµ(t) ∈ R mogą
nie być poprawnie określone dla wszystkich t ∈ T oraz s ∈ S. Są one zdefiniowane µ- iν-prawie wszędzie, co wystarcza, aby poprawnie zdefiniować ich całki.
Lemat 1.2 [Hsing, Eubank]Niech (T,A, µ) będzie przestrzenią z miarą σ-skończoną. Dla funkcji ψ ∈ L2(T × T,A ⊗A, µ× µ) zdefiniujmy
Ψx(t) =∫T
ψ(t, s)x(s)dµ(s), x ∈ L2(T,A, µ), t ∈ T. (1.5)
Wówczas Ψ : L2(T,A, µ) → L2(T,A, µ) jest ograniczonym operatorem liniowym spełnia-jącym
‖Ψ‖L ¬(∫T
∫T
|ψ(t, s)|2dµ(t)dµ(s))1/2
= ‖ψ‖L2(T×T ).
12

Dowód. Pokażemy, że dla x ∈ L2(T,A, µ) zachodzi Ψx ∈ L2(T,A, µ).
Oznaczmy M :=( ∫T
∫T |ψ(t, s)|2dµ(t)dµ(s)
)1/2. Mierzalność funkcji Ψx wynika z twier-
dzenia Fubiniego. Z nierówności Cauchy’ego-Schwarza mamy
‖Ψx‖2 =∫T
|Ψx(t)|2dµ(t) =∫T
∣∣∣ ∫T
ψ(t, s)x(s)dµ(s)∣∣∣2dµ(t)
ºT
(∫T
|ψ(t, s)|2dµ(s) ·∫T
|x(s)|2dµ(s))dµ(t)
=∫T
∫T
|ψ(t, s)|2dµ(s)dµ(t) ·∫T
|x(s)|2dµ(s) = M2‖x‖2,
więc Ψx ∈ L2(T,A, µ) oraz Ψ jest operatorem ograniczonym z normą ‖Ψ‖L ¬M . Linio-wość operatora wynika z liniowości całki.
Tak określony operator Ψ (wzór (1.5)) nazywamy operatorem całkowym, zaś funkcjęψ nazywamy jądrem całkowym operatora Ψ .
Od tego miejsca, interesować nas będzie tylko przypadek L2(T,A, µ) = L2(T,B(T ), λ),gdzie T ⊂ R jest przedziałem, B(T ) σ-algebrą zbiorów borelowskich na T , zaś λ jest mia-rą Lebesgue’a. Przestrzeń L2(T,B, λ) jest ośrodkową przestrzenią Hilberta z iloczynemskalarnym
〈x, y〉 :=∫T
x(t)y(t)dt, x, y ∈ L2,
wyznaczającym normę
‖x‖2 = 〈x, x〉 =∫x2(t)dt, x ∈ L2.
Tak jak zwyczajowo zapisujemy L2(T ) lub L2 zamiast L2(T,B, λ), tak w przypadku sym-bolu całki bez wskazania obszaru całkowania będziemy mieć na myśli całkowanie po całymprzedziale T . Operator całkowy przedstawia się teraz następująco
Ψ(x)(t) =∫ψ(t, s)x(s)ds, x ∈ L2, t ∈ T.
Uwaga 1.6 [Horvath, Kokoszka]Operator całkowy Ψ jest operatorem Hilberta-Schmidta. Ponadto zachodzi
‖Ψ‖2S =∫∫
ψ2(t, s)dtds.
Twierdzenie 1.3 [Horvath, Kokoszka] (Twierdzenie Mercera)Niech operator Ψ będzie operatorem całkowym. Jeśli jądro całkowe ψ spełnia ψ(s, t) =ψ(t, s) oraz
∫∫ψ(t, s)x(t)x(s)dtds 0, to operator Ψ jest symetryczny i nieujemnie okre-
ślony, zatem z Uwagi 1.4 mamy
ψ(t, s) =∞∑j=1
λjυj(t)υj(s) w L2(T × T ),
gdzie λj, υj są odpowiednio wartościami własnymi i funkcjami własnymi operatora Ψ.Jeżeli ponadto funkcja ψ jest ciągła, powyższe rozwinięcie jest prawdziwe dla wszystkicht, s ∈ T i szereg jest zbieżny jednostajnie.
13

1.2 L2-elementy losowe. Pojęcie funkcji średniej i operatorakowariancji
W pracy przedstawiona zostanie teoria estymacji elementów losowych przyjmujących war-tości w ośrodkowej (rzeczywistej) przestrzeni Hilberta L2(T ), gdzie T ⊂ R jest przedzia-łem. Ponieważ elementy przestrzeni L2(T ) są formalnie klasami abstrakcji funkcji równychprawie wszędzie, to powyższe podejście uniemożliwia rozważanie wartości obserwacji ele-mentu losowego w ustalonym punkcie t ∈ T . Z kolei w praktyce mamy do dyspozycji danehistoryczne będące wartościami wylosowanej funkcji w pewnej liczbie punktów z przedzia-łu T . Dlatego naturalne jest rozważanie jako wyjściowego obiektu procesu stochastycznegoXtt∈T , a następnie związanie z nim L2(T )-elementu losowego. W tym celu potrzebujemywarunku który zagwarantuje, że odwzorowanie Ω 3 ω 7→ X(ω, ·) będzie L2(T )-elementemlosowym.
Lemat 1.3 [Hsing, Eubank]Niech (Ω,F , P ) będzie przestrzenią probabilistyczną, a H ośrodkową przestrzenią Hilberta.Odwzorowanie X : Ω→ H jest H-elementem losowym wtedy i tylko wtedy, gdy dla każdegoy ∈ H odwzorowanie Ω 3 ω 7→ 〈y,X(ω)〉 ∈ R jest mierzalne (rozważając na R σ-ciałozbiorów borelowskich).
Dowód. Załóżmy najpierw, że X jest H-elementem losowym. Ponieważ dla dowolnegoy ∈ H odwzorowanie H 3 x 7→ 〈y, x〉 ∈ R jest ciągłe, to jest także mierzalne (rozpatrującσ-ciała borelowskie zarówno na H oraz R). W takim razie odwzorowanie ω 7→ 〈y,X(ω)〉jest mierzalne jako złożenie odwzorowań mierzalnych.Aby przeprowadzić dowód w drugą stronę wystarczy pokazać, że przeciwobrazy kul do-mkniętych w H są mierzalne (ponieważ generują one B(H)). Ustalmy w tym celu h ∈ Horaz ε > 0 oraz bazę ortonormalną ej∞j=1 przestrzeni H. Z tożsamości Parsevala mamy
x ∈ H : ‖x− h‖ ¬ ε = x ∈ H : ‖x− h‖2 ¬ ε2 = x ∈ H :∞∑j=1
〈ej , x− h〉2 ¬ ε2
=x ∈ H :
∞∑j=1
(〈ej , x〉 − 〈ej , h〉
)2 ¬ ε2.Podobnie
X−1(x ∈ H : ‖x− h‖ ¬ ε
)= ω ∈ Ω : ‖X(ω)− h‖ ¬ ε
=ω ∈ Ω :
∞∑j=1
(〈ej , X(ω)〉 − 〈ej , h〉
)2 ¬ ε2Ponieważ wszystkie odwzorowania ω 7→ 〈ej , X(ω)〉 są mierzalne z założenia, a skończonesumy oraz granice funkcji mierzalnych są mierzalne, to mierzalne jest także odwzorowanie
ω 7→∞∑j=1
(〈ej , X(ω)〉 − 〈ej , h〉
)2, więc (na mocy powyższej równości) zbiór X−1(x ∈ H :
‖x− h‖ ¬ ε)
jest mierzalny.
Definicja 1.8 [Hsing, Eubank]Niech T ⊂ R będzie przedziałem, a (Ω,F , P ) przestrzenią probabilistyczną. Proces stocha-styczny Xtt∈T nazywamy mierzalnym, gdy jest mierzalny jako odwzorowanie z prze-strzeni mierzalnej (Ω× T,F ⊗ B(T )) w przestrzeń (R,B(R)).
Podamy teraz kryterium gwarantujące, że proces stochastyczny zada L2-element losowy.
14

Lemat 1.4 [Hsing, Eubank]Niech Xtt∈T będzie mierzalnym procesem stochastycznym. Jeśli dla każdego ω ∈ Ω funk-cja X(ω, ·) jest całkowalna z kwadratem (względem miary Lebesgue’a na T ), to odwzoro-wanie Ω 3 ω 7→ X(ω, ·) ∈ L2(T ) jest L2-elementem losowym (gdzie X(ω, ·) rozumiemy jużjako klasę abstrakcji funkcji równych prawie wszędzie).
Dowód. Założenie o całkowalności z kwadratem gwarantuje, że funkcja X(ω, ·) rzeczywiścienależy do L2(T ). Wystarczy zatem wykazać mierzalność odwzorowania. Skorzystamy wtym celu z Lematu 1.3. Weźmy y ∈ L2(T ). Ponieważ odwzorowanie ω 7→ 〈X(ω, ·), y〉 =∫X(ω, t)y(t)dt nie zmieni się gdy funkcje podcałkowe zmienimy na zbiorze miary zero,
to y możemy traktować jako reprezentanta klasy abstrakcji. Skoro X : Ω × T → R jestmierzalne względem σ-ciała produktowego F⊗B(T ), a y : T → R jest mierzalne względemB(T ), to odwzorowanie Ω × T 3 (ω, t) 7→ X(ω, t)y(t) także jest mierzalne względemF ⊗B(T ). Z twierdzenia Fubiniego (Twierdzenie 1.2) wynika teraz, że odwzorowanie ω 7→∫X(ω, t)y(t)dt = 〈X(ω, ·), y〉 jest mierzalne. Z Lematu 1.3 otrzymujemy, że odwzorowanie
ω 7→ X(ω, ·) ∈ L2(T ) jest L2-elementem losowym.
Definicja 1.9 [Horvath, Kokoszka]Niech X będzie L2(T )-elementem losowym. Mówimy, że X jest całkowalny, jeśli E ‖X‖ =E[∫X2(t)dt
]1/2<∞.
Zauważmy, że jeśli X jest L2-elementem losowym, to odwzorowanie ω 7→ ‖X(ω)‖ jestmierzalne (gdyż odwzorowanie L2 3 h 7→ ‖h‖ jest ciągłe), więc można rozważać powyższąwartość oczekiwaną. Wprowadzimy teraz pojęcie wartości oczekiwanej dla L2-elementulosowego.
Definicja 1.10 [Horvath, Kokoszka]Niech X będzie całkowalnym L2(T )-elementem losowym. Jedyny element µ ∈ L2 taki, że〈y, µ〉 = E〈y,X〉 dla dowolnego y ∈ L2 nazywamy wartością oczekiwaną (funkcjąśredniej) elementu losowego X. Ozn. EX := µ.
Aby uzasadnić powyższa definicję, zauważmy najpierw, że odwzorowanie ω 7→ 〈y,X(ω)〉jest zmienną losową na mocy Lematu 1.3. Odwzorowanie f : L2 → R zadane jakof(y) := E〈y,X〉 jest ograniczonym funkcjonałem liniowym na L2. Liniowość wynika zliniowości wartości oczekiwanej oraz iloczynu skalarnego, zaś ograniczoność z nierównościCauchy’ego-Schwarza:
|f(y)| = |E〈y,X〉| ¬ E|〈y,X〉| ¬ E‖y‖‖X‖ = ‖y‖ · E[∫
X2(t)dt]1/2
= E ‖X‖ · ‖y‖.
Istnienie i jednoznaczność funkcji µ ∈ L2 takiej, że f(y) = 〈y, µ〉 wynika teraz z twierdze-nia Riesza o reprezentacji funkcjonału liniowego ciągłego na przestrzeni Hilberta.
Wartość oczekiwana jest przemienna z operatorami ograniczonymi, tj. jeśli X jest cał-kowalna oraz Ψ ∈ L, to Ψ(X) także jest całkowalna (gdyż E‖Ψ(X)‖ ¬ E‖Ψ‖‖X‖ =‖Ψ‖·E‖X‖ <∞) oraz mamy EΨ(X) = Ψ(EX). Istotnie, niech µ = EX oraz ν = EΨ(X).Wówczas dla dowolnego y ∈ L2 mamy
〈y, ν〉 = E〈y,Ψ(X)〉 = E〈Ψ∗y,X〉 = 〈Ψ∗y, µ〉 = 〈y,Ψµ〉,
gdzie Ψ∗ oznacza operator sprzężony do operatora Ψ . W takim razie Ψ(EX) = Ψµ = ν =EΨ(X).
Jeśli dodatkowo założymy, że Xtt∈T jest mierzalnym procesem stochastycznym o całko-walnych z kwadratem trajektoriach (więc, z Lematu 1.4 zadaje L2-element losowy) oraz
15

takim, że∫|EX(t)|2dt < ∞, to funkcję średniej zadanego przez niego L2-elementu loso-
wego możemy znaleźć wprost jako µ(t) = EX(t) dla prawie wszystkich t ∈ T . Po pierwszezauważmy, że dodatkowe założenie gwarantuje, że funkcja t 7→ EX(t) należy do L2(T ) (wszczególności wartość oczekiwana EX(t) istnieje dla prawie każdego t ∈ T ). Dla dowolnegoy ∈ L2 zachodzi (na mocy tw. Fubiniego, 1.2)∫
y(t)EX(t)dt = E∫y(t)X(t)dt = E〈y,X〉,
więc funkcja t 7→ EX(t) spełnia definicję bycia wartością oczekiwaną elementu losowegoω 7→ X(ω, ·). Z uwagi na jednoznaczność wartości oczekiwanej zachodzi µ(t) = EX(t). Nakoniec zauważmy, że jeśli proces Xtt∈T spełnia E‖X‖2 < ∞ (założenie to będzie obo-wiązywało w dalszej części pracy), to spełnia także
∫|EX(t)|2dt <∞, gdyż (z nierówności
Jensena oraz ponownie twierdzenia Fubiniego)∫|EX(t)|2dt ¬
∫ (E|X(t)|
)2dt ¬
∫E(|X(t)|2
)dt = E
∫|X(t)|2dt = E‖X‖2 <∞.
Definicja 1.11 [Bosq]Operator kowariancji całkowalnego L2(T )-elementu losowego X o funkcji średniej µXspełniającego E ‖X‖2 <∞ definiujemy jako ograniczony operator liniowy według wzoru
CX(x) := E[⟨X − µX , x
⟩(X − µX)
], x ∈ L2.
Jeśli Y jest L2(T )-elementem losowym o funkcji średniej µY spełniającym powyższe warun-ki, wtedy operator kowariancji między zmiennymi X i Y (ang. cross-covariance operator)przedstawiamy jako
CX,Y (x) := E[⟨X − µX , x
⟩(Y − µY )
], x ∈ L2,
orazCY,X(x) := E
[⟨Y − µY , x
⟩(X − µX
)], x ∈ L2.
Uzasadnimy, że powyższe operatory są dobrze określonymi operatorami ograniczonymina L2. Wystarczy to zrobić dla CX,Y , gdyż CX = CX,X . W pierwszej kolejności należysprawdzić, że Z := 〈X − µX , x〉(Y − µY ) jest L2-elementem losowym. Z Lematu 1.3wystarczy sprawdzić, że dla każdego z ∈ L2 funkcja ω 7→ 〈Z(ω), z〉 jest zmienną losową.Mamy
〈Z, z〉 = 〈〈X − µX , x〉(Y − µY ), z〉 = 〈X − µX , x〉〈Y − µY , z〉
= 〈X,x〉〈Y, z〉 − 〈X,x〉〈µY , z〉 − 〈µX , x〉〈Y, z〉+ 〈µX , x〉〈µY , z〉.
Skoro X oraz Y są L2-elementami losowymi, to 〈X,x〉 oraz 〈Y, z〉 są zmiennymi loso-wymi. Pozostałe wyrażenia są stałe, więc ostatecznie 〈Z, z〉 jest zmienną losową. Z jestcałkowalny, gdyż (z nierówności Cauchy’ego-Schwarza)
E‖Z‖ = E‖〈X − µX , x〉(Y − µY )‖ ¬ E[|〈X − µX , x〉| · ‖(Y − µY )‖
]¬ ‖x‖ · E
[‖X − µX‖ · ‖(Y − µY )‖
]¬ ‖x‖ · E
[(‖X‖+ ‖µX‖
)(‖Y ‖+ ‖µY ‖
)]¬ ‖x‖ ·
[E‖X‖‖Y ‖+ ‖µX‖E‖Y ‖+ ‖µY ‖E‖X‖+ ‖µX‖‖µY ‖
].
Skoro E‖X‖2, E‖Y ‖2 < ∞, to także E‖X‖‖Y ‖, E‖X‖, E‖Y ‖ < ∞, więc zachodzi teżE‖Z‖ <∞. W takim razie, CX,Y (x) = EZ istnieje i należy do L2(T ). Powyższy rachunekpokazuje także, że operator CX,Y jest ograniczony, zaś jego liniowość wynika z liniowościiloczynu skalarnego oraz wartości oczekiwanej (liniowość wartości oczekiwanej dla L2-elementów losowych wynika wprost z definicji).
16

Twierdzenie 1.4 (Własności operatora kowariancji)Załóżmy, że Xtt∈T jest mierzalnym procesem stochastycznym takim, że E‖X‖2 < ∞ zfunkcją średniej µX ∈ L2(T ). Wówczas operator kowariancji CX elementu losowego Xwprowadzony w Definicji 1.11 posiada następujące własności:
(i) jest operatorem całkowym z jądrem całkowym c(t, s):
c(t, s) = E[(X(t)− µX(t)
)(X(s)− µX(s)
)]nazywanym też funkcją kowariancji,
(ii) jest operatorem Hilberta-Schmidta,
(iii) jest operatorem symetrycznym i nieujemnie określonym,
(iv) posiada on reprezentację
CX(x) =∞∑j=1
λj〈x, υj〉υj , x ∈ L2,
gdzie λj są wartościami własnymi operatora CX (lub zerami), a υj odpowiadającymiim wektorami własnymi tworzącymi bazę ortonormalną przestrzeni L2(T ),
(v) jego wartości własne λj i funkcje własne υj spełniają równość: λj = E〈X−µX , υj〉2,
(vi) jest operatorem śladowym.
Dowód.
(i) Zauważmy, że mierzalność procesu implikuje, że funkcja c(t, s) jest mierzalna naprodukcie T×T (twierdzenie Fubiniego). Najpierw pokażemy, że jądro c(t, s) podanejpostaci rzeczywiście zadaje ograniczony operator liniowy na L2. W tym celu, na mocyLematu 1.2, wystarczy sprawdzić, że c ∈ L2(T × T ) . Mamy∫∫
|c(t, s)|2dtds =∫∫ ∣∣∣E(X(t)− µX(t)
)(X(s)− µX(s)
)∣∣∣2dtds¬∫∫ (
E∣∣X(t)− µX(t)
∣∣∣∣X(s)− µX(s)∣∣)2dtds = (∗).
Zauważmy, że dla prawie każdego t ∈ T zmienna losowa X(t) jest całkowalna zkwadratem, tzn. X(t) ∈ L2(Ω,F , P ). Wynika to z faktu, że∫
EX2(t)dt = E∫X2(t)dt = E‖X‖2 <∞,
więc funkcja t 7→ EX2(t) musi być skończona prawie wszędzie. W takim razie tak-że(X(t) − µX(t)
)∈ L2(Ω,F , P ) i możemy skorzystać z nierówności Cauchy’ego-
Schwarza:
(∗) ¬∫∫
E∣∣X(t)− µX(t)
∣∣2E∣∣X(s)− µX(s)∣∣2dtds =
(∫E|X(t)− µX(t)|2dt
)2
=(E∫|X(t)−µX(t)|2dt
)2=(E‖X−µX‖2
)2¬(E‖X‖2+‖µX‖E‖X‖+‖µX‖2
)2<∞.
Pokażemy teraz, że przy powyższych założeniach operator kowariancji istotnie jestoperatorem całkowym z jądrem c. Ponieważ mamy do czynienia z L2-elementem
17

losowym pochodzącym od mierzalnego procesu stochastycznego, to wartość oczeki-waną elementu losowego Z :=
⟨X − µX , x
⟩(X − µX) możemy liczyć punktowo (por.
uwaga po Definicji 1.10), czyli dla x ∈ L2(T ) zachodzi dla prawie wszystkich t ∈ T :
CX(x)(t) = E⟨X − µX , x
⟩(X(t)− µX(t))
= E[ ∫ (
X(s)− µX(s))x(s)ds
](X(t)− µX(t)
)= E
[ ∫ (X(s)− µX(s)
)(X(t)− µX(t)
)x(s)ds
]=∫ [
E(X(s)− µX(s)
)(X(t)− µX(t)
)]x(s)ds
=∫c(t, s)x(s)ds,
zatem funkcja c jest jądrem operatora CX .
(ii) Na mocy Uwagi 1.6, jako operator całkowy, operator kowariancji jest operatoremHilberta-Schmidta.
(iii) Oczywistym jest, że c(t, s) = c(s, t) i mamy∫∫c(t, s)x(t)x(s)dtds =
∫∫E[(X(t)− µX(t)
)(X(s)− µX(s)
)]x(t)x(s)dtds
= E[(∫ (
X(t)− µX(t))x(t)dt
)2] 0.
Zatem operator kowariancji CX jest symetryczny oraz nieujemnie określony (spełniazatem założenia Twierdzenia 1.3).
(iv) Teza wynika bezpośrednio z powyższych własności oraz z Uwagi 1.4.
(v) Spełnione jest
λj = λj‖υj‖2 = 〈λjυj , υj〉 = 〈CXυj , υj〉 =⟨E〈X − µX , υj〉(X − µX), υj
⟩=∫
E[( ∫ (
X(s)− µX(s))υj(s)ds
)(X(t)− µX(t)
)]υj(t)dt
= E∫∫ ((
X(s)− µX(s))υj(s)
)((X(t)− µX(t)
)υj(t)
)dsdt
= E[(∫ (
X(t)− µX(t))υj(t)dt
)2]= E〈X − µX , υj〉2.
(vi) Korzystając z powyższych równości zauważamy, że wartości własne operatora kowa-riancji są nieujemne oraz tożsamość Parsevala pokazuje, że
∞∑j=1
λj =∞∑j=1
E〈X − µX , υj〉2 = E∞∑j=1
〈X − µX , υj〉2 = E‖X − µX‖2 <∞.
Zatem operator CX spełnia definicję operatora śladowego (Definicja 1.5).
Uwaga 1.7 Operatorem sprzężonym do CX,Y jest CY,X .
18

Dowód. Wystarczy sprawdzić, że dla dowolnych x, y ∈ L2 zachodzi 〈CX,Y (x), y〉 = 〈x,CY,X(y)〉.Dla uproszczenia załóżmy, że EX = EY = 0. Korzystając z definicji wartości oczekiwanejdla elementu losowego mamy
〈CX,Y (x), y〉 = 〈E〈X,x〉Y, y〉 = E〈〈X,x〉Y, y〉 = E〈X,x〉〈Y, y〉
= E〈〈Y, y〉X,x〉 = E〈x, 〈Y, y〉X〉 = 〈x,E〈Y, y〉X〉 = 〈x,CY,X(y)〉.
W dalszej części pracy będziemy skupiać się na scentrowanych elementach losowych X,tj. takich że EX = 0, dlatego operator kowariancji przyjmować będzie postać
CX(x) = E[⟨X,x
⟩X], x ∈ L2.
Niezależność elementów losowych przyjmujących wartości w przestrzeni Hilberta definiujesię dokładnie tak samo jak w przypadku niezależności zmiennych losowych. W pracy wie-lokrotnie korzystać będziemy z założenia o niezależności oraz z następującej konsekwencji:
Lemat 1.5 [Horvath, Kokoszka]Jeśli X i Y są niezależnymi L2-elementami losowymi takimi, że EX = 0 i E‖X‖2 < ∞oraz E‖Y ‖2 <∞, to E[〈X,Y 〉] = 0.
1.3 Estymacja średniej, funkcji kowariancji i operatora ko-wariancji. FPC
Naturalnym problemem pojawiającym się przy L2-elementach losowych jest wnioskowanieo obiektach nieskończenie wymiarowych na podstawie skończonej próbki danych. Ze wzglę-du na fakt, że w statystyce ograniczamy się głównie do przypadku, w którym elementylosowe to funkcje gładkie lub krzywe, to nazywa się je także zmiennymi funkcjonalnymi,zaś obserwacje zmiennej funkcjonalnej - danymi funkcjonalnymi.
Z punktu widzenia analizy danych funkcjonalnych parametrami koniecznymi do estymacjisą funkcja średniej, funkcja kowariancji oraz operator kowariancji. Przypomnijmy określo-ne w Definicji 1.10 oraz Definicji 1.11 (i w Twierdzeniu 1.4) pojęcia:
funkcja średniej: µ(t) = E[X(t)],funkcja kowariancji: c(t, s) = E[(X(t)− µ(t)(X(s)− µ(s))],operator kowariancji: C = E[〈(X − µ), ·〉(X − µ)].
Funkcję średniej µ estymujemy średnią z funkcji z próby (długości N)
µ(t) =1N
N∑n=1
Xn(t), t ∈ T,
funkcję kowariancji ze wzoru
c(t, s) =1N
N∑n=1
(Xn(t)− µ(t)
)(Xn(s)− µ(s)
), t, s ∈ T,
zaś operator kowariancji estymujemy
C(x)(t) =1N
N∑n=1
〈Xn − µ, x〉(Xn(t)− µ(t)), x ∈ L2, t ∈ T. (1.6)
19

Powyższe estymatory są dobrze określone, a estymator funkcji średniej jest estymatoremnieobciążonym. Dowody poprawności tych estymatorów można znaleźć w Rozdziale 2 wksiążce [Horvath, Kokoszka].
W dalszej części pracy istotne będzie dla nas oszacowanie również wartości i funkcji wła-snych operatora kowariancji C. W szczególności interesować nas będzie p największychwartości własnych λj spełniających
λ1 > λ2 > ... > λp > λp+1 0. (1.7)
Funkcje własne υj zdefiniowane są przez równanie Cυj = λjυj . Zauważmy, że (z definicjioperatora liniowego), jeśli υj jest funkcją własną, to również aυj jest funkcją własną, gdziea 6= 0 jest skalarem. Funkcje własne υj są zazwyczaj normalizowane, tak aby ‖υj‖ = 1.Przy estymacji może pojawić się problem ze znakiem υj , dlatego wprowadzamy dodatkoweparametry cj = sign(〈υj , υj〉) tak aby cj υj były możliwie blisko υj . Niemniej jednak cj niesą możliwe do uzyskania z danych, dlatego sposób estymacji funkcji własnych nie powinienzależeć od cj . Wartości własne λj i funkcje własne υj estymujemy zatem według wzoru∫
c(t, s)υj(s)ds = λj υj(t), j 1.
Podamy teraz (bez dowodu) podstawową własność przyjętego sposobu estymacji warto-ści oraz wektorów własnych operatorów kowariancji - średniokwadratowy błąd estymacjimaleje do zera szybciej niż liniowo:
Twierdzenie 1.5 [Kokoszka et al.], [Bosq]Według powyższych oznaczeń, jeżeli dla pewnego p > 0 prawdziwe jest (1.7), to spełnionesą nierówności
lim supN→∞
NE ‖υj − cj υj‖2 <∞, lim supN→∞
NE[∣∣∣λj − λj∣∣∣2] <∞,
dla j ¬ p.
Realnym przedmiotem funkcjonalnej analizy danych jest seria prób losowych x1, ..., xN ,gdzie każdy xn jest wektorem o wielkim wymiarze. Dane te przekształcamy w taki sposób,aby były one realizacjami ciągu niezależnych danych funkcjonalnych X1, ..., XN w L2(T ) ojednakowym rozkładzie jak zmienna funkcjonalna X ∈ L2 spełniająca założenie E‖X‖2 <∞. Przekształcenia tego dokonuje się w oparciu o układ bazowy fjJj1 w L2, gdzie Jjest odpowiednio dużą liczba naturalną. Układ bazowy oznacza w tym przypadku zbiórniezależnych liniowo funkcji. Mamy zatem
Xn(t) ≈J∑j=1
αjnfj(t), n = 1, ..., N,
gdzie αjn można znaleźć metodą najmniejszych kwadratów lub metodą interpolacji da-nych. Dla uproszczenia obliczeń najlepiej, kiedy układ fkJj=1 jest ortonormalny, jak np.baza Fouriera, ale możemy wykorzystać nawet bazę nieortogonalną, np. bazę tworzonąprzez B-splajny. W Rozdziale 3 przedstawiony przykład ilustruje interpolację kubicznymiB-splajnami w zależności od wyboru J (Rysunek 3.2).W tym realnym przypadku, funkcjonalny odpowiednik analizy głównych składowych (ang.principal components analysis, PCA) przedstawia się następująco. Funkcje własne υjJj=1operatora kowariancji z próby C nazywamy empirycznymi funkcjonalnymi głów-nymi składowymi (ang. empirical functional principal components, EFPC’s) danychfunkcjonalnych X1, ..., XN . Tworzą one bazę ortonormalną w przestrzeni rozpiętej przez
20

układ bazowy fjJj=1 i baza ta jest bazą optymalną do rozwinięcia danych funkcjonalnychX1, ..., XN . Zatem
Xn(t) ≈J∑j=1
ξjnυj(t), n = 1, ..., N.
Jeśli X1, ..., XN mają taki sam rozkład co L2-element losowy X (całkowalny z kwadratem,tj. spełniający E‖X‖2 < ∞), to funkcje własne operatora C nazywamy funkcjonalny-mi głównymi składowymi (FPC’s), które estymujemy przez EFPC z dokładnością doznaku. Iloczyny skalarne 〈Xi, υj〉 =
∫Xi(t)υj(t)dt odpowiadają wadze zmienności Xi opi-
sanej przez υj i nazywane są w angielskiej literaturze j-tymi (functional) principalcomponent scores.
21

22

Rozdział 2
Test istotności w funkcjonalnymmodelu liniowym
W tym rozdziale opiszemy funkcjonalny odpowiednik mieszanego modelu liniowego, a na-stępnie test na jego efektywność, tj. sprawdzenie, czy operator stojący przy zmiennejobjaśniającej jest istotnie różny od zera.
2.1 Funkcjonalny model liniowy
Załóżmy, że mamy dane scentrowane L2-elementy losowe Y oraz X takie, że E‖X‖2 <∞, E‖Y ‖2 < ∞ dla których chcemy zbudować funkcjonalny model liniowy w którymY jest zmienną objaśnianą a X zmienną objaśniającą. Obserwujemy próbę długości N ,tzn. mamy dane ciągi YnNn=1, XnNn=1, εnNn=1 takie że kolejne trójki (Yn, Xn, εn) sąniezależne, Xn oraz εn są niezależne dla każdego n ∈ 1, ..., N, Eεn = 0. Pełen modelfunkcjonalny (ang. fully functional model) przyjmuje postać
Yn = ΨXn + εn, n = 1, 2, ..., N, (2.1)
gdzie operator Ψ : L2 → L2 jest całkowym operatorem Hilberta-Schmidta, a zatem jądrocałkowe ψ(t, s) jest funkcją całkowalną z kwadratem na T × T . Równość (2.1) rozumiemyzatem następująco
Yn(t) =∫ψ(t, s)Xn(s)ds+ εn(t), n = 1, 2, ..., N. (2.2)
Nazwa powyższego modelu wynika z faktu, że zarówno zmienne objaśniane Yn jak i zmien-ne objaśniające Xn są zmiennymi funkcjonalnymi. Niewielkim uproszczeniem są pozostałetypy funkcjonalnych modeli liniowych, tj.
- model z odpowiedzią skalarną (ang. scalar response model) postaci
Yn =∫ψ(s)Xn(s)ds+ εn, n = 1, 2, ..., N,
w którym tylko zmienne objaśniające Xn są zmiennymi funkcjonalnymi,
- model z odpowiedzią funkcyjną (ang. functional response model) postaci
Yn(t) = ψ(t)xn + εn(t), n = 1, 2, ..., N,
w którym zmienne objaśniające xn są deterministycznymi skalarami.
23

Naturalnym problemem pojawiającym się przy funkcjonalnym modelu liniowym jest es-tymacja operatora Ψ należącego do nieskończenie wymiarowej przestrzeni na podstawieskończonej próbki danych. Możliwym jest znalezienie operatora Ψ metodą najmniejszychkwadratów (jak jest to zrobione w pakiecie fda, do programu R-project), ale przypominaon biały szum i jego interpretacja jest często problematyczna i niepraktyczna. Jednymze sposobów na rozwiązanie tego problemu jest poszukiwanie operatora należącego dopodprzestrzeni generowanej przez funkcje własne operatorów kowariancji danych z próby,nazywane empirycznymi funkcjonalnymi głównymi składowymi (EFPC’s), które zostałyopisane w podrozdziale 1.3. Główne składowe odpowiadają istotnym czynnikom zmienno-ści zmiennych, dobrze służą zatem do przybliżania ich wartości.
Niech X i Y będą scentrowanymi L2-elementami losowymi o rozwinięciach
X(s) =∞∑i=1
ξiυi(s), Y (t) =∞∑j=1
ζjuj(t), (2.3)
gdzie υi są funkcjami własnymi operatora kowariancji X (czyli funkcjonalnymi głównymiskładowymi), uj są funkcjami własnymi operatora kowariancji Y , zaś ξi oraz ζj są principalcomponent scores, czyli
ξi = 〈X, υi〉, ζj = 〈Y, uj〉,
gdzie Cυi = λiυi oraz Γuj = ζjuj , oznaczając przez C operator kowariancji X, zaś przezΓ operator kowariancji Y .
Lemat 2.1 [Horvath, Kokoszka]Niech X,Y, ε będą scentrowanymi L2-elementami losowymi. Załóżmy, że ε jest niezależneod X i niech spełnione będzie równanie liniowe
Y (t) =∫ψ(t, s)X(s)ds+ ε(t) (2.4)
z jądrem ψ(·, ·) takim, że ∫∫ψ2(t, s)dtds <∞. (2.5)
Wtedy
ψ(t, s) =∞∑k=1
∞∑l=1
E[ξlζk]E[ξ2l ]
uk(t)υl(s),
gdzie zbieżność jest w L2(T × T ).
Dowód. Skoro υii1 i ujj1 są bazami w L2, to ciąg funkcji υi(s)uj(t), s, t ∈ Ti,j1tworzy bazę w L2(T × T ). Korzystając z założenia (2.5) oraz z Uwagi 1.6 zauważmy,że operator Ψ jest operatorem Hilberta-Schmidta. Zatem jądro ψ posiada jednoznacznąreprezentację
ψ(t, s) =∞∑k=1
∞∑l=1
ψkluk(t)υl(s), (2.6)
a na mocy założenia (2.5) współczynniki ψkl spełniają
∞∑k=1
∞∑l=1
ψ2kl =∫∫
ψ2(t, s)dtds <∞.
24

Podstawiając (2.3) i (2.6) do (2.4) oraz korzystając z ortonormalności υii1, otrzymu-jemy
∞∑j=1
ζjnuj(t) =∫ [ ∞∑
k=1
∞∑l=1
ψkluk(t)υl(s)∞∑i=1
ξiυi(s)]ds+ ε(t)
=∞∑k=1
∞∑l=1
ψkluk(t)∞∑i=1
ξi
∫υl(s)υi(s)ds+ ε(t)
=∞∑k=1
∞∑l=1
ψkluk(t)∞∑i=1
ξi〈υl(s), υi(s)〉+ ε(t)
=∞∑k=1
∞∑i=1
ψkiξiuk(t) + ε(t).
Mnożąc powyższe wyrażenie obustronnie przez ul(t), a następnie całkując po t otrzymu-jemy kolejne równości
∫ul(t)
∞∑j=1
ζjuj(t)dt =∫ul(t)
( ∞∑k=1
∞∑i=1
ψkiξiuk(t) + ε(t))dt
∞∑j=1
ζj
∫uj(t)ul(t)dt =
∞∑k=1
∞∑i=1
ψkiξi
∫uk(t)ul(t)dt+
∫ul(t)ε(t)dt
∞∑j=1
ζj〈uj , ul〉 =∞∑k=1
∞∑i=1
ψkiξi〈uk, ul〉+ 〈ul, ε〉
ζl =∞∑i=1
ψliξi + 〈ul, ε〉.
Wystarczy teraz pomnożyć obustronnie przez ξk, nałożyć wartość oczekiwaną na obiestrony powyższej równości i skorzystać z Lematu 1.5, żeby otrzymać
E[ζlξk] = E∞∑i=1
ψliξiξk + Eξk〈ul, ε〉 =∞∑i=1
ψliEξiξk = (∗).
Rozpiszemy tylko wyrażenie Eξiξk
Eξiξk = E〈X, υi〉〈X, υk〉 = E〈〈X, υi〉X, υk〉 = 〈E〈X, υi〉X, υk〉 = 〈Cυi, υk〉
= λi〈υi, υk〉 = λiδi,k.
Zatem dla i 6= k wyrażenie to zeruje się, a w przypadku gdy i = k wynosi λk. Podstawiającznowu do (∗)
(∗) = ψlkλk = ψlkE[ξ2k]
co kończy dowód.
Zauważmy, że E[ξ2l ] = λl, gdzie λl jest wartością własną odpowiadającą funkcji własnejυl. Bez zmiany reprezentacji (2.3) możemy pominąć z niej funkcje własne odpowiadającezerowym wartościom własnym i dzięki temu założyć, że E[ξ2l ] > 0 dla każdego l 1. Zatemw Lemacie 2.1 warunek (2.5) można zastąpić przez
∞∑k=1
∞∑l=1
(E[ξlζk])2
λ2l<∞.
25

Powyższe rozważania prowadzą do estymatora
ψKL(t, s) =K∑k=1
L∑l=1
λ−1l σlkuk(t)υl(s),
gdzie K i L są odpowiednio małymi liczbami wybranymi do wygładzenia przybliżenia Xi Y , zaś σlk jest estymatorem E[ξlζk], czyli np.
σlk =1N
N∑i=1
〈Xi, υl〉〈Yi, uk〉.
2.2 Test istotności
Jednym z podstawowych testów na efektywność modelu jest test istotności zmiennychobjaśniających. Badamy zatem zerowanie się operatora Ψ , tj. hipotezy
H0 : Ψ = 0 przeciw HA : Ψ 6= 0.
Zauważmy, że przyjęcie H0 nie oznacza braku związku między zmienną objaśnianą a ob-jaśniającą. Prowadzi jedynie do stwierdzenia braku zależności liniowej.
Kontynuując wcześniej wprowadzone założenia, niech Yn ma taki sam rozkład jak Y , zaśXn ma taki sam rozkład jak X. Dla zmiennych Y oraz X mamy zadane operatory kowa-riancji:
C(x) = E[〈X,x〉X], Γ(x) = E[〈Y, x〉Y ], ∆(x) = E[〈X,x〉Y ], x ∈ L2. (2.7)
Przez C, Γ, ∆ oznaczamy ich estymatory (zgodnie z (1.6)), tj.
C(x) =1N
N∑n=1
〈Xn, x〉Xn, Γ(x) =1N
N∑n=1
〈Yn, x〉Yn, ∆(x) =1N
N∑n=1
〈Xn, x〉Yn, x ∈ L2.
Definiujemy również wartości i wektory własne C i Γ
C(υk) = λkυk, Γ(uj) = γjuj , (2.8)
których estymatory będziemy oznaczać (λk, υk), (γj , uj).
Poniższe rozważania są heurystycznym uzasadnieniem wzoru na statystykę testową (2.11).Test obejmuje obcięcie powyższych operatorów na podprzestrzenie skończenie wymia-rowe. Podprzestrzeń Vp = spanυ1, ..., υp zawiera przybliżenia X1, ..., XN , które są li-niowymi kombinacjami pierwszych p głównych składowych (FPC’s). Analogicznie Uq =spanu1, ..., uq zawiera przybliżenia Y1, ..., YN .
Z ogólnej postaci funkcjonalnego modelu liniowego
Y = ΨX + ε
możemy wyprowadzić kolejne równości
〈X,x〉Y = 〈X,x〉(ΨX + ε) = 〈X,x〉ΨX + 〈X,x〉εE [〈X,x〉Y ] = E [〈X,x〉ΨX] + E [〈X,x〉ε] .
Korzystając z definicji operatorów C oraz ∆ (2.7), założenia, że Ψ jest operatorem ogra-niczonym (więc komutuje z wartością oczekiwaną) oraz z założenia o niezależności międzyX a ε zachodzi
∆(x) = E[〈X,x〉Y ] = E [〈X,x〉ΨX] + E [〈X,x〉ε]
26

= E [Ψ(〈X,x〉X)] = Ψ(E [〈X,x〉X]
)= ΨC(x).
W szczególności, dla funkcji własnych υk, k ¬ p prawdziwa jest równość
∆(υk) = ΨC(υk) = Ψ(λkυk) = λkΨ(υk).
Skoro λk 6= 0 to możemy napisać
Ψ(υk) = λ−1k ∆(υk). (2.9)
Stąd, Ψ zeruje się na spanυ1, ..., υp wtedy i tylko wtedy, gdy ∆(υk) = 0 dla każdegok = 1, ..., p. Przypomnijmy, że
∆(υk) ≈ ∆(υk) =1N
N∑n=1
〈Xn, υk〉Yn.
Skoro zatem Y1, ..., YN są dobrze aproksymowane przez Uq, to możemy ograniczyć się dosprawdzania czy ⟨
∆(υk), uj⟩
= 0, k = 1, ..., p, j = 1, ..., q. (2.10)
Statystyka testowa powinna zatem sumować kwadraty iloczynów skalarnych (2.10). Wpraktyce υk i uj zastępujemy υk oraz uj . Celem kolejnego podrozdziału jest udowodnienieTwierdzenia 2.1 stanowiącego, że przy H0 statystyka
TN (p, q) = Np∑k=1
q∑j=1
λ−1k γ−1j
⟨∆(υk), uj
⟩2, (2.11)
zbiega według rozkładu do rozkładu χ2 z pq stopniami swobody. Zauważmy, że zachodzi
⟨∆(υk), uj
⟩=⟨
1N
N∑n=1
〈Xn, υk〉Yn, uj⟩
=1N
N∑n=1
〈Xn, υk〉 〈Yn, uj〉 (2.12)
oraz λk = E 〈X, υk〉2 i γj = E 〈Y, uj〉2 (por. Rozdział 1.2). Jeśli TN (p, q) > χ2pq(1 − α), toodrzucamy hipotezę zerową o braku liniowej zależności. W przeciwnym razie nie mamypodstaw do odrzucenia H0.
Uwaga 2.1 Oczywistym jest, że jeśli odrzucamy H0, to Ψ(υk) 6= 0 dla pewnego k 1.Jednak ograniczając się do p największych wartości własnych, test jest skuteczny tylkojeśli ψ nie zanika na którymś wektorze υk, k = 1, ..., p. Takie ograniczenie jest intuicyjnieniegroźne, ponieważ test ma za zadanie sprawdzić czy główne źródła zmienności Y mogąbyć opisane przez główne źródła zmienności zmiennych X.
Przedstawiony test można stosować już do prób wielkości 40, co pokazują autorzy pozy-cji [Horvath, Kokoszka] w Rozdziale 9.3. Szczegółowy schemat przebiegu testu zostaniezaprezentowany w Rozdziale 3.
2.3 Rozkład statystyki testowej
Założenie 2.1 Trójka (Yn, Xn, εn) tworzy ciąg niezależnych zmiennych funkcjonalnych ojednakowym rozkładzie, ponadto εn jest niezależne od Xn oraz
EYn = 0, EXn = 0, Eεn = 0,
E‖Yn‖2 <∞, E‖Xn‖4 <∞ i E‖εn‖4 <∞.
27

Założenie 2.2 Wartości własne operatorów C oraz Γ spełniają, dla pewnych p > 0 i q > 0
λ1 > λ2 > ... > λp > λp+1 0, γ1 > γ2 > ... > γq > γq+1 0.
Twierdzenie 2.1 [Kokoszka et al.], [Horvath, Kokoszka]
Jeśli spełnione są powyższe Założenia 2.1, 2.2 oraz H0, to TN (p, q) d−→ χ2pq przy N →∞.
Twierdzenie 2.2 [Kokoszka et al.], [Horvath, Kokoszka]
Przy Założeniach 2.1, 2.2 oraz jeśli 〈Ψ(υk), uj〉 6= 0 dla k ¬ p oraz j ¬ q, to TN (p, q) P−→∞ przy N →∞.
Dowody powyższych twierdzeń rozbijemy na kolejne lematy i wnioski. Najpierw jednakzauważmy, że konsekwencją prawdziwości H0 i przyjęcia modelu postaci Yn = ΨXn + εnjest równość Yn = εn.
Będziemy korzystać z wielowymiarowej wersji Centralnego Twierdzenia Granicznego:
Twierdzenie 2.3 [Billingsley]Niech Xn = (Xn,1, Xn,2, ..., Xn,k) będzie ciągiem niezależnych k-wymiarowych wektorówlosowych o tym samym rozkładzie. Załóżmy, że EX2n,j < ∞ dla każdego j = 1, ..., k orazoznaczmy wektor średnich jako µ = (µ1, ..., µk) := (EXn,1, ...,EXn,k), oraz macierz kowa-riancji jako Σ = [σij ]ki,j=1, σij = Cov(Xn,i, Xn,j) = E(Xn,i−µi)(Xn,j−µj). Wówczas ciągwektorów losowych
X1 + ...+Xn − nµ√n
zbiega według rozkładu do k-wymiarowego rozkładu normalnego o wektorze średnich µ imacierzy kowariancji Σ.
Pierwszym krokiem będzie zbadanie asymptotyki składowych statystyki, gdy estymujemytylko operator ∆, zaś wartości i funkcje własne C oraz Γ przyjmujemy za znane.
Lemat 2.2 [Kokoszka et al.], [Horvath, Kokoszka]Jeśli spełnione są Założenia 2.1, 2.2 i H0, to zachodzi zbieżność według rozkładu pq-wymiarowych wektorów losowych
√N〈∆υk, uj〉, 1 ¬ k ¬ p, 1 ¬ j ¬ q d−→ ηkj
√λkγj , 1 ¬ k ¬ p, 1 ¬ j ¬ q, (2.13)
gdzie ηkj ∼ N(0, 1) oraz ηk,j oraz ηk′j′ są niezależne dla (k, j) 6= (k′, j′).
Dowód. Przy H0 mamy
√N〈∆υk, uj〉 =
√N⟨ 1N
N∑n=1
〈Xn, υk〉Yn, uj⟩
=1√N
N∑n=1
〈Xn, υk〉〈Yn, uj〉
=1√N
N∑n=1
〈Xn, υk〉〈εn, uj〉.
Skoro (Xn)n1 oraz (εn)n1 są niezależnymi po współrzędnych ciągami niezależnych L2-elementów losowych składających się z elementów o tych samych rozkładach, to takżeciągi wektorów losowych (〈Xn, υk〉, 1 ¬ k ¬ p)n1 oraz (〈εn, uj〉, 1 ¬ j ¬ q)n1są niezależne po współrzędnych i składają się z niezależnych wektorów losowych o tychsamych rozkładach. W takim razie (〈Xn, υk〉〈εn, uj〉, 1 ¬ k ¬ p, 1 ¬ j ¬ q)n1 także jestciągiem niezależnych wektorów losowych o tym samym rozkładzie. Zauważmy, że powyższe
28

zmienne losowe mają skończony drugi moment, gdyż (z nierówności Cauchy’ego-Schwarzaoraz niezależności Xn i εn)
E|〈Xn, υk〉〈εn, uj〉|2 ¬ ‖υk‖2‖uj‖2 · E‖Xn‖2‖εn‖2
= ‖υk‖2‖uj‖2 · E‖Xn‖2E‖εn‖2.
ZachodziE〈Xn, υk〉〈εn, uj〉 = E〈Xn, υk〉E〈εn, uj〉 = 0
orazE(〈Xn, υk〉〈εn, uj〉
)2 = E〈Xn, υk〉2 · E〈Yn, uj〉2 = λkγj .
Wielowymiarowe Centralne Twierdzenie Graniczne (Twierdzenie 2.3) pokazuje teraz, żewektor losowy
√N〈∆υk, uj〉, 1 ¬ k ¬ p, 1 ¬ j ¬ q =
1√N
N∑n=1
〈Xn, υk〉〈εn, uj〉, 1 ¬ k ¬ p, 1 ¬ j ¬ q
zbiega do pq-wymiarowego rozkładu normalnego, w którym współrzędne mają rozkładnormalny o średniej 0 i wariancji λkγj . Aby zakończyć dowód twierdzenia należy wyka-zać, że współrzędne wektora granicznego są niezależne, czyli (wobec normalności rozkła-du łącznego) nieskorelowane. Wystarczy pokazać, że dla (k, j) 6= (k′, j′), zmienne losowe〈Xn, υk〉〈εn, uj〉 i 〈Xn, υk′〉〈εn, uj′〉 są nieskorelowane. Wynika to z faktu że mają one śred-nią zero oraz z poniższych przekształceń:
E〈Xn, υk〉〈εn, uj〉〈Xn, υk′〉〈εn, uj′〉 = E〈Xn, υk〉〈Xn, υk′〉E〈εn, uj〉〈εn, uj′〉
= E〈Xn, υk〉〈Xn, υk′〉E〈Yn, uj〉〈Yn, uj′〉 = E〈〈Xn, υk〉Xn, υk′〉E〈〈Yn, uj〉Yn, uj′〉
= 〈E〈Xn, υk〉Xn, υk′〉〈E〈Yn, uj〉Yn, uj′〉 = 〈Cυk, υk′〉〈Γυj , υj′〉
= λk〈υk, υk′〉γj〈υj , υj′〉 = λkγjδk,k′δj,j′ .
Normę Hilberta-Schmidta operatora Hilberta-Schmidta Ψ zdefiniowaliśmy wzorem (1.3),który jest równoważny ‖Ψ‖2S =
∑∞j=1 ‖Ψ(ej)‖2, gdzie ciąg ejj1 stanowi bazę ortonor-
malną. Norma ta jest nie mniejsza od normy operatorowej, tj. ‖Ψ‖L ¬ ‖Ψ‖S .
Lemat 2.3 [Kokoszka et al.], [Horvath, Kokoszka]Przy założeniach Twierdzenia 2.1 mamy
E∥∥∥∆∥∥∥2
S= N−1E ‖X‖2 E ‖ε1‖2 .
Dowód. Zauważmy, że
∥∥∥∆(ej)∥∥∥2 = 〈∆(ej), ∆(ej)〉 =
⟨ 1N
N∑n=1
〈Xn, ej〉Yn,1N
N∑n′=1
〈Xn′ , ej〉Yn′⟩
= N−2N∑
n,n′=1
〈Xn, ej〉〈Xn′ , ej〉〈Yn, Yn′〉.
Stąd, przy założeniu H0, mamy
E∥∥∥∆∥∥∥2
S= E
∞∑j=1
∥∥∥∆(ej)∥∥∥2 =
∞∑j=1
E∥∥∥∆(ej)
∥∥∥2 = N−2∞∑j=1
N∑n,n′=1
E[〈Xn, ej〉〈Xn′ , ej〉〈Yn, Yn′〉
]
29

= N−2∞∑j=1
N∑n,n′=1
E[〈Xn, ej〉〈Xn′ , ej〉〈εn, εn′〉
]
= N−2∞∑j=1
N∑n,n′=1
E[〈Xn, ej〉〈Xn′ , ej〉
]E〈εn, εn′〉 = (∗).
Ponieważ dla n 6= n′ elementy losowe εn oraz εn′ są niezależne oraz Eεn = 0, to z Lematu1.5 mamy E〈εn, εn′〉 = 0, więc
(∗) = N−2∞∑j=1
N∑n=1
E[〈Xn, ej〉〈Xn, ej〉
]E‖εn‖2 = N−1
∞∑j=1
E〈X, ej〉2E‖ε1‖2 =
= N−1E∞∑j=1
〈X, ej〉2E‖ε1‖2 = N−1E‖X‖2E‖ε1‖2.
Lemat 2.4 [Kokoszka et al.], [Horvath, Kokoszka]Załóżmy, że Un∞n=1 oraz Vn∞n=1 są ciągami elementów losowych z przestrzeni Hilberta
takich, że ‖Un‖P→ 0 i ‖Vn‖ = OP (1), tj.
limC→∞
lim supn→∞
P (‖Vn‖ > C) = 0.
Wtedy zachodzi
〈Un, Vn〉P−→ 0.
Dowód. Ustalmy dowolnie C > 0. Należy wykazać, że limn→∞
P (|〈Un, Vn〉| > C) = 0. Weźmydowolne ε > 0. Korzystając z nierówności Cauchy’ego-Schwarza mamy
lim supn→∞
P (|〈Un, Vn〉| > C) ¬ lim supn→∞
P (‖Un‖‖Vn‖ > C)
= lim supn→∞
(P (‖Un‖‖Vn‖ > C, ‖Un‖ > ε) + P (‖Un‖‖Vn‖ > C, ‖Un‖ ¬ ε)
)¬ lim supn→∞
P (‖Un‖ > ε) + lim supn→∞
P (ε‖Vn‖ > C, ‖Un‖ ¬ ε) ¬ lim supn→∞
P
(‖Vn‖ >
C
ε
).
Ponieważ nierówność jest prawdziwa dla dowolnego ε, to możemy przejść do granicy:
lim supn→∞
P (|〈Un, Vn〉| > C) ¬ limε→0
lim supn→∞
P
(‖Vn‖ >
C
ε
)= 0.
Pokażemy teraz, że zbieżność w Lemacie 2.2 zachodzi także, gdy wektory własne operato-rów kowariancji zastąpimy ich estymatorami.
Lemat 2.5 [Kokoszka et al.], [Horvath, Kokoszka]Jeśli spełnione są Założenia 2.1, 2.2 i H0, to zachodzi zbieżność według rozkładu pq-wymiarowych wektorów losowych
√N⟨∆(υk), uj
⟩, 1 ¬ k ¬ p, 1 ¬ j ¬ q d−→ ηkj
√λkγj , 1 ¬ k ¬ p, 1 ¬ j ¬ q, (2.14)
gdzie ηkj ∼ N(0, 1) oraz ηk,j oraz ηk′j′ są niezależne dla (k, j) 6= (k′, j′).
30

Dowód. Na mocy Lematu 2.2, wystarczy pokazać, że dla dowolnych 1 ¬ k ¬ p, 1 ¬ j ¬ qzachodzi √
N⟨∆(υk), uj
⟩−√N⟨∆(υk), uj
⟩ P−→ 0, (2.15)
gdyż zbieżność według prawdopodobieństwa jest mocniejsza od zbieżności według rozkła-du. Ponieważ √
N⟨∆(υk), uj
⟩−√N⟨∆(υk), uj
⟩=
√N⟨∆(υk), uj
⟩−√N⟨∆(υk), uj
⟩+√N⟨∆(υk), uj
⟩−√N⟨∆(υk), uj
⟩=⟨
∆(υk),√N(uj − uj)
⟩+√N⟨∆(υk − υk), uj
⟩,
to wystarczy wykazać ⟨∆(υk),
√N(uj − uj)
⟩ P−→ 0 (2.16)
i √N⟨∆(υk − υk), uj
⟩ P−→ 0. (2.17)
Aby udowodnić zbieżność (2.16), zauważmy, że z Twierdzenia 1.5 oraz nierówności Cze-byszewa dla dowolnego C > 0 mamy
limC→∞
lim supN→∞
P (‖√N(uj − uj)‖ > C) = lim
C→∞lim supN→∞
P(‖(uj − uj)‖2 >
C2
N
)¬ limC→∞
lim supN→∞
N
C2E‖(uj − uj)‖2 ¬ lim
C→∞
1C2
lim supN→∞
NE‖(uj − uj)‖2 = 0,(2.18)
czyli ‖√N(uj − uj)‖ = OP (1). Z kolei na mocy Lematu 2.3 mamy
P (‖∆(υk)‖ > C) ¬ 1CE‖∆(υk)‖ ¬
1CE‖∆‖L‖υk‖ ¬
1C
(E‖∆‖2L
)1/2(E‖υk‖2)1/2=
1C
(E‖∆‖2S
)1/2 =1
C√N
(E ‖X‖2 E ‖ε1‖2
)1/2 N→∞−→ 0,(2.19)
czyli ‖∆(υk)‖P−→ 0. Stąd zbieżność (2.16) wynika z Lematu 2.4.
Aby wykorzystać takie samo uzasadnienie dla (2.17) (skorzystać z Twierdzenia 1.5 orazLematu 2.4), zauważmy, że
√N⟨∆(υk − υk), uj
⟩=⟨√N(υk − υk), ∆∗(uj)
⟩.
Fakt, że ‖√N(υj −υj)‖ = OP (1) dowodzimy identycznie jak w (2.18). Ponieważ ‖∆∗‖L =
‖∆‖L ¬ ‖∆‖S oraz supN1
E‖uj‖2 < ∞ (gdyż E‖uj − uj‖2 → 0) to możemy powtórzyć
rozumowanie z (2.19) aby otrzymać ‖∆∗(uj)‖P−→ 0.
Z Twierdzenia 1.5 oraz nierówności Czebyszewa mamy λkP→ λk oraz γj
P→ γj , gdyż
P (|λk − λk| > C) ¬ 1C2
E|λk − λk|2 =1
NC2NE|λk − λk|2
N→∞−→ 0.
Lemat 2.5 daje teraz zbieżność także wtedy, gdy wartości własne zastąpimy ich estyma-torami.
Wniosek 2.1 [Kokoszka et al.], [Horvath, Kokoszka]Jeśli spełnione są Założenia 2.1, 2.2 i H0, to zachodzi zbieżność według rozkładu pq-wymiarowych wektorów losowych
√Nλk
−1/2γj−1/2 ⟨∆(υk), uj
⟩, 1 ¬ k ¬ p, 1 ¬ j ¬ q d−→ ηkj , 1 ¬ k ¬ p, 1 ¬ j ¬ q,
(2.20)gdzie ηkj ∼ N(0, 1) oraz ηk,j oraz ηk′j′ są niezależne dla (k, j) 6= (k′, j′).
31

Korzystając z tego wniosku jesteśmy w stanie łatwo udowodnić Twierdzenie 2.1.
Dowód Twierdzenia 2.1. Z Wniosku 2.1 mamy
TN (p, q) = Np∑k=1
q∑j=1
λ−1k γ−1j
⟨∆(υk), uj
⟩2
=p∑k=1
q∑j=1
(√Nλ−1/2k γ
−1/2j
⟨∆(υk), uj
⟩ )2 d−→p∑k=1
q∑j=1
η2kj .
Skoro ηkj są niezależne oraz mają rozkład N(0, 1), top∑k=1
q∑j=1
η2kj ma rozkład χ2pq.
W celu udowodnienia Twierdzenia 2.2 potrzebujemy kolejnych lematów pomocniczych,analogicznych do lematów służących do dowodu Twierdzenia 2.1. Ponieważ jednak niezakładamy hipotezy H0, to pewne fragmenty rozumowania muszą być zmodyfikowane.
Lemat 2.6 Jeśli spełnione są Założenia 2.1, 2.2, to zachodzi
E‖∆‖L ¬(E‖X‖2E‖Y ‖2
)1/2.
Dowód. Dla dowolnego u ∈ L2 takiego, że ‖u‖ ¬ 1, mamy
‖∆u‖ =∥∥∥∥ 1N
N∑n=1
〈Xn, u〉Yn∥∥∥∥ ¬ 1
N
N∑n=1
|〈Xn, u〉|‖Yn‖ ¬1N
N∑n=1
‖Xn‖‖Yn‖,
więc
E‖∆‖L ¬1N
N∑n=1
E‖Xn‖‖Yn‖ ¬1N
N∑n=1
(E‖Xn‖2E‖Yn‖2
)1/2=(E‖X‖2E‖Y ‖2
)1/2.
Twierdzenie 2.4 [Billingsley] (Mocne Prawo Wielkich Liczb, wersja Chinczyna)Niech Xnn1 będzie ciągiem niezależnych zmiennych losowych o jednakowym rozkładzietakich, że EXn = m. Wtedy mamy
1N
N∑n=1
Xnp.n.−→ m.
Lemat 2.7 [Kokoszka et al.], [Horvath, Kokoszka]Jeżeli spełnione jest Założenie 2.1, to dla dowolnych funkcji υ, u ∈ L2
〈∆(υ), u〉 P−→ 〈∆(υ), u〉.
Dowód. Tezę otrzymujemy korzystając z Mocnego Prawa Wielkich Liczb (zbieżność prawiena pewno implikuje zbieżność według prawdopodobieństwa) zauważając
〈∆(υ), u〉 =1N
N∑n=1
〈Xn, υ〉〈Yn, u〉
orazE[〈Xn, υ〉〈Yn, u〉
]= E
[〈〈Xn, υ〉Yn, u〉
]= 〈∆(υ), u〉.
32

Lemat 2.8 [Kokoszka et al.], [Horvath, Kokoszka]Jeżeli spełnione są Założenia 2.1 oraz 2.2, to
〈∆(υk), uj〉P−→ 〈∆(υk), uj〉, dla k ¬ p, j ¬ q.
Dowód. Na mocy Lematu 2.7 wystarczy pokazać
〈∆(υk), uj〉 − 〈∆(υk), uj〉P−→ 0.
W tym celu pokażemy, że
〈∆(υk), uj − uj〉 =⟨ 1√
N∆(υk),
√N(uj − uj)
⟩P−→ 0
i〈∆(υk)− ∆(υk), uj〉 =
⟨√N(υk − υk),
1√N
∆∗(uj)⟩P−→ 0,
korzystając z Lematu 2.4. ‖√N(uj − uj)‖ = OP (1) oraz ‖
√N(υk − υk)‖ = OP (1) pokaza-
liśmy już w (2.18). Z nierówności Czebyszewa i z Lematu 2.6 zachodzi
P
(∥∥∥ 1√N
∆(υk)∥∥∥ > C
)¬ 1
C√N
E‖∆(υk)‖ ¬1
C√N
(E‖X‖2E‖Y ‖2
)1/2 N→∞−→ 0,
czyli ‖ 1√N
∆(υk)‖P−→ 0. Tak samo jak w dowodzie Lematu 2.5 korzystamy z faktów, że
‖∆∗‖ = ‖∆‖ oraz supN1
E‖uj‖2 <∞, aby uzasadnić ‖ 1√N
∆∗(uj)‖P−→ 0.
Dowód Twierdzenia 2.2. Z założenia mamy 〈Ψ(υk), uj〉 6= 0 dla pewnych 1 ¬ k ¬ p, 1 ¬j ¬ q. Korzystając z równości (2.9) otrzymujemy
〈∆(υk), uj〉 = λk〈Ψ(υk), uj〉 6= 0, więc 〈∆(υk), uj〉2 > 0.
Wprowadźmy oznaczenia
SN (p, q) =p∑k=1
q∑j=1
λ−1k γ−1j 〈∆(υk), uj〉2,
S(p, q) =p∑k=1
q∑j=1
λ−1k γ−1j 〈∆(υk), uj〉2.
Pokazaliśmy już (korzystając z Twierdzenia 1.5), że
λ−1k γ−1jP−→ λ−1k γ−1j .
Z Lematu 2.8 mamy〈∆(υk), uj〉2
P−→ 〈∆(υk), uj〉2,
więc ostatecznieSN (p, q) P−→ S(p, q) > 0.
StądTN (p, q) = NSN (p, q) P−→∞.
33

34

Rozdział 3
Przykład zastosowania testuistotności
W tym rozdziale przedstawimy przykładowe zastosowanie testu istotności w funkcjonal-nym modelu liniowym z użyciem programu R-project. Celem poniższej analizy jest jedyniezaprezentowanie procedury testowej, bez wnikliwej analizy wyników testu.Podobnie jak w artykule [Kokoszka et al.] oraz książce [Horvath, Kokoszka] rozważać bę-dziemy kilka funkcjonalnych modeli liniowych z użyciem danych opisujących indukcję po-la magnetycznego Ziemi. Zmienną objaśniającą X będą obserwacje zanotowane w ciągujednego dnia w obserwatorium geofizycznym znajdującym się na wysokich szerokościachgeograficznych. Zaś zmienna objaśniana Y będzie różna dla kolejnych modeli: zmienne Ybędą dziennymi obserwacjami z wybranego obserwatorium znajdującego się na odpowied-nio niższej szerokości geograficznej - wybrano obserwatoria ulokowane na średnich i niskichszerokościach geograficznych (Tabela 3.1).
3.1 Opis danych oraz procedury testowej
Mianem pogody kosmicznej nazywamy charakteryzację zjawisk w przestrzeni międzypla-netarnej oddziałujących na atmosferę ziemską. Głównym źródłem jej zmian są wahaniaaktywności słonecznej. Słońce stale emituje naładowane cząsteczki, które docierają doZiemi w postaci tzw. wiatrów słonecznych i mogą powodować pewne anomalie w magne-tosferze i jonosferze ziemskiej, które są najbardziej odczuwalne w okolicach biegunów ma-gnetycznych. Do najważniejszych konsekwencji wzmożonej aktywności słonecznej należąburze i subburze magnetyczne (ang. magnetic substorms), które w szczególności skutkująpojawianiem się zórz polarnych. Pogoda kosmiczna wpływa na działanie satelitów, pro-mów kosmicznych, komunikację radiową i telefoniczną, loty samolotowe, na funkcjonowanieelektrowni, możliwe że także na klimat na Ziemi oraz na życie zwierząt oraz roślin. Zatemobserwacja i zrozumienie jej procesów, w tym subburz, jest niezwykle istotne do kontro-lowania i przewidywania jej skutków. Przedstawiona poniżej analiza polega na zbadaniuistnienia zależności liniowej pomiędzy zmianami indukcji magnetycznej w czasie subburzna wysokich szerokościach geograficznych a indukcją magnetyczną na średnich i niskichszerokościach geograficznych.Parametry pola magnetycznego, generowanego przez prąd elektryczny przepływający przezziemską magnetosferę i jonosferę, rejestrowane są za pomocą tzw. magnetometru. To na-ziemne urządzenie odczytuje kilka składowych indukcji pola magnetycznego, nas intere-sować będzie składowa horyzontalna (H, Horizontal), która wskazuje na wielkość induk-cji magnetycznej skierowanej w stronę magnetycznej północy1. Przykładowe obserwacje1Jednostką indukcji magnetycznej jest tesla. W naszym przypadku dane będą podawane zawsze w
nanoteslach [nT].
35

przedstawiają wykresy na Rysunku 3.2 (niebieska linia).Dane o polu magnetycznym Ziemi zbierane są przez stacje geofizyczne i publikowane są np.w ramach międzynarodowego programu INTERMAGNET na stronie internetowej projek-tu ([INTERMAGNET]). Do programu należy obecnie 129 naziemnych obserwatoriów, wtym dwie stacje znajdujące się w Polsce (mapa stacji na Rysunku 3.1). Ze strony progra-
Rysunek 3.1: Mapa stacji geofizycznych należących do programu INTERMAGNET, źró-dło: strona internetowa projektu [INTERMAGNET].
mu INTERMAGNET można pobrać dane dokładne: w odstępach jednosekundowych lubuproszczone: w odstępach jednominutowych (obserwacja jest średnią z 60 sekund). W pra-cy wykorzystano dane uproszczone, mamy zatem 1440 punktów z każdego dnia, przypisa-nych według czasu centralnego, które posłużą nam do stworzenia danych funkcjonalnych.Tym sposobem jeden dzień stanie się jedną obserwacją. Informacje o zaobserwowanychsubburzach pobrano ze strony programu SuperMAG ([SuperMAG1]), którzy wykorzystu-je dane ze strony INTERMAGNET oraz z wielu innych źródeł.Ze względu na częściowe braki danych w obserwacjach musieliśmy przyjąć pewne założe-nia odnośnie ich traktowania. W przypadku niektórych dni brakuje tylko jednej czy dwóchobserwacji, niekiedy jednak luki w zapisie danych dotyczą przynajmniej kilku godzin. Od-setek dni z brakami danych jest na tyle duży, że niewskazane jest odrzucanie bezwzględniewszystkich dni z niedoborem danych. Przyjęliśmy zatem następujące podejście: w przy-padku braku więcej niż 10 wartości (10 minut) dzień zostaje odrzucony z analiz, jeślijednak brakuje nie więcej niż 10 punktów w ciągu dnia obserwacje zostają zachowane przydopełnieniu braków danych ostatnią znaną wartością (w przypadku braku wartości po-czątkowych bierzemy pierwszą znaną wartość). Dopiero po oczyszczeniu próby z brakówdanych możemy przystąpić do dalszej analizy.Kolejnym krokiem jest stworzenie danych funkcjonalnych na podstawie danych dyskret-nych. W tym celu skorzystamy ze specjalnego pakietu do programu R-project : pakietu fda([R: fda 1]), który zawiera ponad 150 poleceń (funkcji oraz zbiorów danych) ułatwiają-cych analizę danych funkcjonalnych, w tym komendy generujące układy bazowe o zada-nym rodzaju i liczbie funkcji. W przedstawionym przykładzie korzystać będziemy z bazytworzonej przez B-splajny (kubiczne, tj. trzeciego stopnia). Tak przygotowane dane po-
36

służą nam do zobrazowania testu zależności liniowej między nimi. Poniżej przedstawiamykolejne kroki procedury testowej.
Schemat przebiegu testu
1. Wybieramy liczbę głównych składowych p i q korzystając z kryterium osypiska Cat-tela (ang. scree test) oraz wskaźnika CPV (ang. cumulative percentage of total va-riance).
2. Sprawdzamy założenie o liniowości metodą FPC score predictor-response plots.
3. Wyliczamy wartość statystyki TN (p, q) (2.11).
4. Jeśli TN (p, q) > χ2pq(1−α), to odrzucamy hipotezę zerową o braku liniowej zależności.W przeciwnym razie nie mamy podstaw do odrzucenia H0.
Ad.1. W procesie analizy głównych składowych dokonujemy scentrowania danych funk-cjonalnych (tak aby spełniały założenia modelu) oraz redukcji wymiaru danych. Kry-terium osypiska to prosta metoda graficzna polegająca na analizie zmniejszających siękolejnych wartości własnych przez obrazowanie ich na wykresie według kolejnych funkcjiwłasnych (głównych składowych, PC’s). Wyboru liczby głównych składowych dokonujesię przez zidentyfikowanie wartości własnej od której różnice pomiędzy kolejnymi warto-ściami własnymi są znacząco niższe od poprzednich i kolejne wartości własne utrzymująsię na podobnym poziomie. Wskaźnik CPV p-tej głównej składowej określa procent całko-witej wariancji elementu losowego wyjaśnionej przez p pierwszych głównych składowych.Wyznacza go wzór
CPV (p) =∑pk=1 λk∑∞k=1 λk
,
gdzie λk są kolejnymi wartościami własnymi elementu losowego. W praktyce suma w mia-nowniku jest skończona, ponieważ górną granicę stanowi moc wykorzystanego systemubazowego. Wybieramy takie p dla którego CPV (p) > 80%.Ostateczne liczby głównych składowych są znacznie mniejsze od początkowo wybranejliczby funkcji w bazie (zazwyczaj p, q < 10).
Ad.2. Metoda FPC score predictor-response plots to graficzna metoda przedstawiona wartykule [Chiou, Muller], która bada, czy reszty liniowego modelu (Y (t)− Y (t)) nie podą-żają według jakiegoś trendu. Test polega na analizie tzw. score plots, tj. wykresów wartościprincipal component scores kolejnych głównych składowych X na jednej osi i scores Y nadrugiej osi. Należy stworzyć pq takich wykresów, aby uzyskać wartości score wszystkichkombinacji kolejnych głównych składowych X oraz Y . Jeśli już na tym etapie zauważamy,że score plots cechuje jakiegoś rodzaju trend i punkty na wykresie nie są na pierwszy rzutoka losowe, powinniśmy odrzucić hipotezę o liniowej zależności między X a Y .
Ad.3 i 4. Statystykę obliczymy ze wzoru (2.11) korzystając z równości (2.12).
Zauważmy, że w procedurze testowej nie jest nam potrzebna dokładna postać operatoraΨ , dlatego nie będziemy jej wskazywać w przykładzie.
3.2 Zastosowanie testu dla danych magnetometrycznych
W kręgu zainteresowań autorów artykułu [Kokoszka et al.] leżą dane pochodzące z obser-watoriów Ameryki Północnej, będziemy zatem analizować podobne dane.
Wybraliśmy dane z pięciu obserwatoriów przedstawionych w Tabeli 3.1. Dane z jedynegoobserwatorium ulokowanego na wysokiej szerokości geograficznej (College, Alaska) tworzyć
37
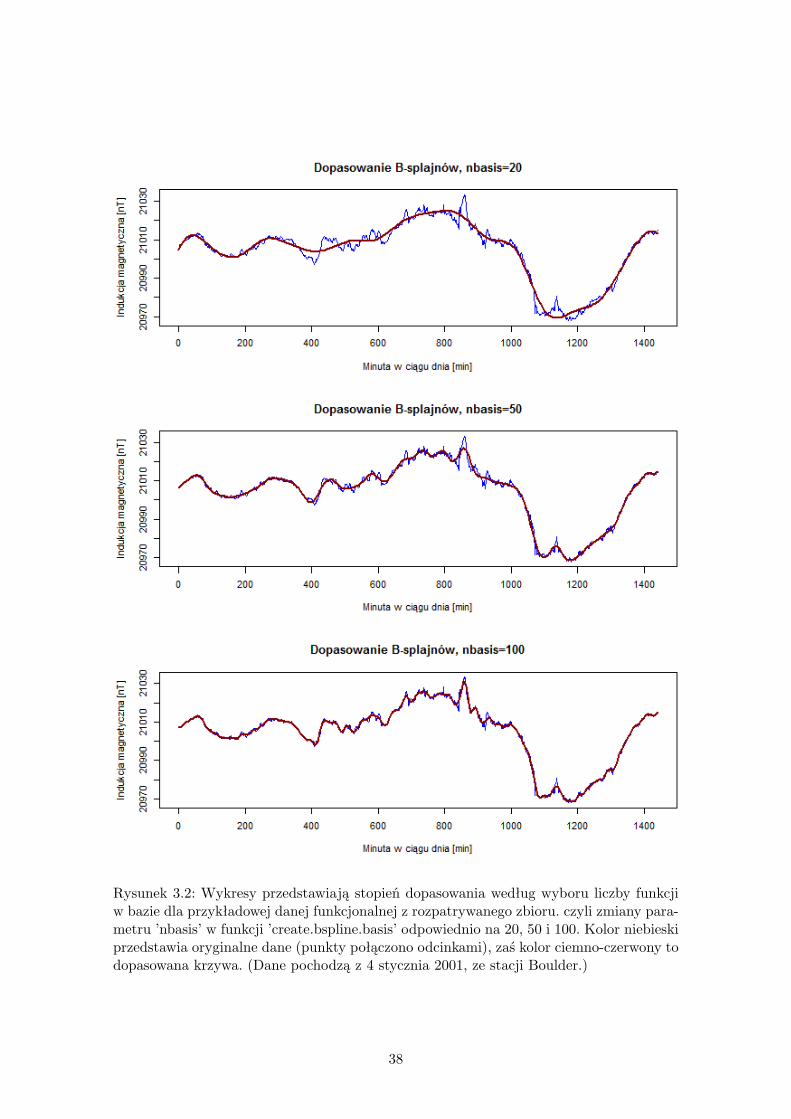
Rysunek 3.2: Wykresy przedstawiają stopień dopasowania według wyboru liczby funkcjiw bazie dla przykładowej danej funkcjonalnej z rozpatrywanego zbioru. czyli zmiany para-metru ’nbasis’ w funkcji ’create.bspline.basis’ odpowiednio na 20, 50 i 100. Kolor niebieskiprzedstawia oryginalne dane (punkty połączono odcinkami), zaś kolor ciemno-czerwony todopasowana krzywa. (Dane pochodzą z 4 stycznia 2001, ze stacji Boulder.)
38
będę zmienną objaśniającą X. Dane z pozostałych czterech obserwatoriów tworzyć będąkolejne zmienne objaśniane Y , będziemy zatem badać zależność 4 par zmiennych funkcjo-nalnych. Wykorzystamy obserwacje pochodzące z roku 2001. Według danych pobranych zestrony SuperMAG, obserwacje ze stacji College wskazują na 87 subburz, jednak w drodzeeliminacji braków danych liczba obserwacji wykorzystanych w testach waha się między 50a 60 dla kolejnych par obserwatoriów.
Szerokość geograficzna Stacja Oznaczenie (Szer., Wys.)Wysoka College CMO (64°87’ N, 147°86’ W)
ŚredniaBoulder BOU (40°14’ N, 105°24’ W)Fredericksburg FRD (38°20’ N, 77°37’ W)
NiskaHonolulu HON (21°32’ N, 158°00’ W)San Juan SJG (18°11’ N, 66°15’ W)
Tabela 3.1: Lista wykorzystanych stacji geofizycznych w podziale na szerokości geograficz-ne wraz ze stosowanymi skrótami.
Dla każdej pary zmiennych X i Y analizować będziemy obserwacje w dniach w którychzidentyfikowano subburze, ale rozważać będziemy też modele, w których obserwacje Ysą przesunięte o jeden dzień lub dwa dni. Wprowadzimy zatem dodatkowe oznaczenieprzesunięcia obserwacji Y : dopisek do oznaczenia wyboru stacji ”0” oznaczać będzie brakprzesunięcia, dopisek ”1” oznaczać będzie obserwacje przesunięte o jeden dzień, zaś ”2”oznaczać będzie przesunięcie o 2 dni. Jeśli nie będzie wskazane inaczej, brak dopisku ozna-czać będzie dane z całego roku (lub miesiąca), bez wyszczególnienia dni z i bez subburz.Wybór liczby funkcji bazowych do estymacji danych funkcjonalnych nie ma istotnego wpły-wu na wynik testu, ważne żeby otrzymana dana funkcjonalna była dobrze dopasowana dooryginalnych punktów, ale z wyeliminowaniem szumu. Stopień dopasowania według wybo-ru liczby funkcji w układzie bazowym przedstawia Rysunek 3.2. Ostatecznie wybraliśmysystem bazowy o mocy 100.Wymagamy, aby dane funkcjonalne były scentrowane, co można wykonać jednym polece-niem pakietu fda ’center.fd’. Dane przed i po scentrowaniu ilustrują Rysunki 3.3 i 3.4.
Możemy teraz przystąpić do badania liniowej zależności pomiędzy kolejnymi parami da-nych funkcjonalnych. Przejdziemy przez procedurę testową krok po kroku według sche-matu przebiegu testu przedstawionego w poprzednim podrozdziale. Na początku jednakzauważmy, że ze względu na to, że w różnych stacjach możemy mieć braki danych w in-nych dniach, każdy test (każda kombinacja stacji) może wykorzystywać inne dni, a tymsamym dla każdego z nich zmieniać się będą wyniki analizy głównych składowych - nawetdla niezmiennego elementu X (stacja College). Różnice są jednak niewielkie i nie mająwpływu na wybór liczby składowych.
1. Wybieramy liczbę głównych składowych p i q korzystając z kryterium osypiska Cattela(ang. scree test) oraz wskaźnika CPV (ang. cumulative percentage of total variance).
Rysunek 3.5 przedstawia wykresy do analizy liczby głównych składowych metodą osypi-ska dla wybranych dwóch stacji. Dla obu stacji obserwujemy wyraźny spadek wielkościwartości własnych. Na podstawie tego kryterium, dla obserwacji z Boulder możemy ogra-niczyć się już do 4 głównych składowych, zaś dla obserwacji z College należałoby wybrać9 EFPC’s. Rysunek 3.6 przedstawia 4 pierwsze główne składowe dla stacji w Boulder.Zestawienie wskaźnika CPV dla kolejnych 12 głównych składowych obserwacji dla stacjiw College (w parze ze stacją Boulder) przedstawia Tabela 3.2. Pierwszą wartością własną,dla której wskaźnik CPV przyjmuje wartość powyżej 80% jest wartość ósma. Biorąc poduwagę wykres na Rysunku 3.5 wybieramy p = 9.Przedstawione metody posłużyły do wyznaczenia liczby głównych składowych również
39
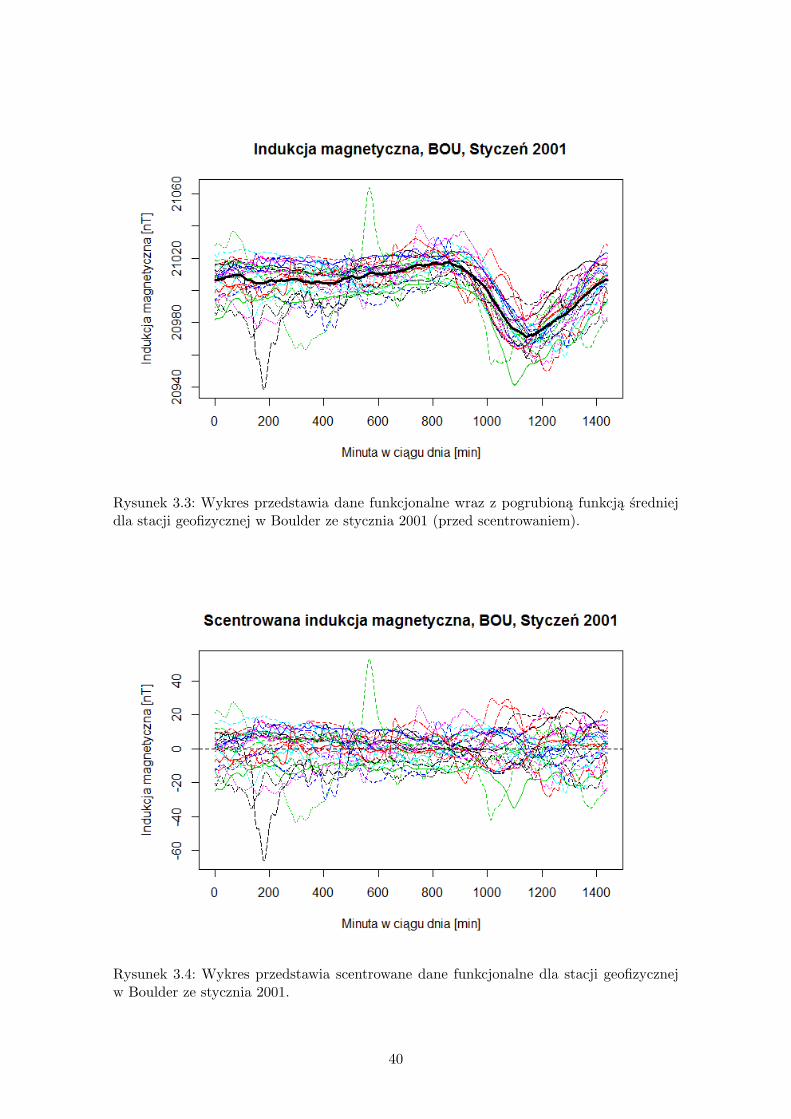
Rysunek 3.3: Wykres przedstawia dane funkcjonalne wraz z pogrubioną funkcją średniejdla stacji geofizycznej w Boulder ze stycznia 2001 (przed scentrowaniem).
Rysunek 3.4: Wykres przedstawia scentrowane dane funkcjonalne dla stacji geofizycznejw Boulder ze stycznia 2001.
40
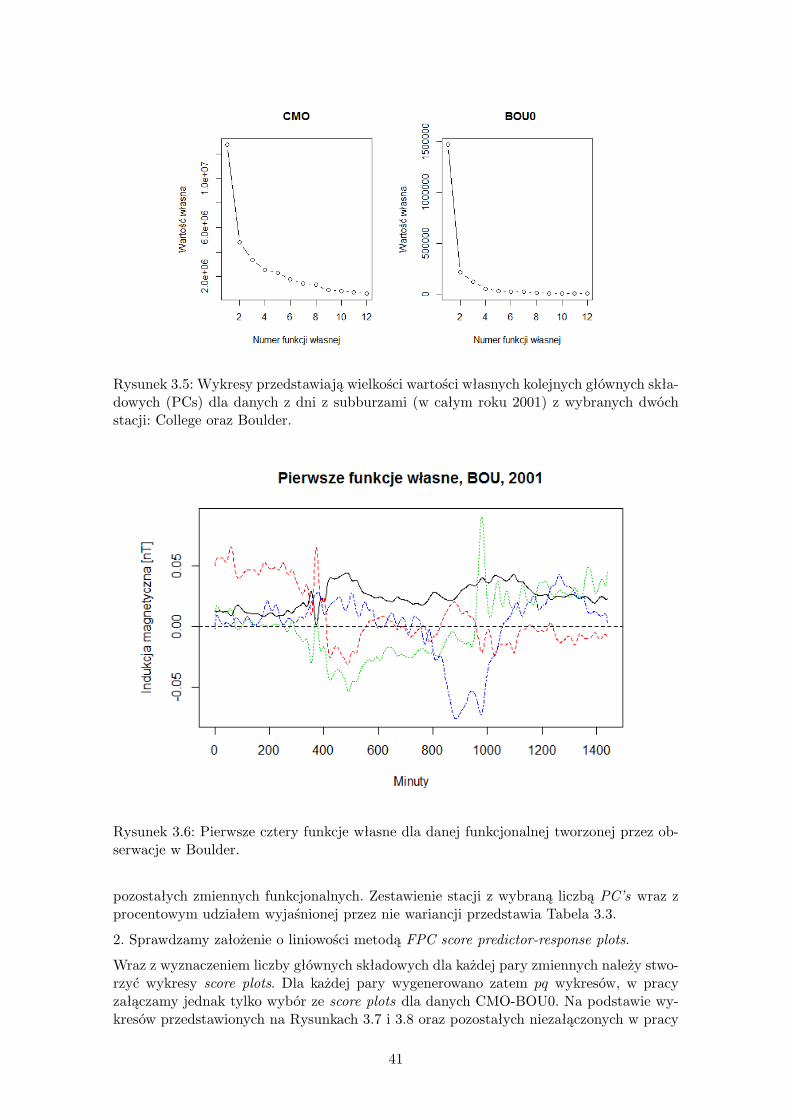
Rysunek 3.5: Wykresy przedstawiają wielkości wartości własnych kolejnych głównych skła-dowych (PCs) dla danych z dni z subburzami (w całym roku 2001) z wybranych dwóchstacji: College oraz Boulder.
Rysunek 3.6: Pierwsze cztery funkcje własne dla danej funkcjonalnej tworzonej przez ob-serwacje w Boulder.
pozostałych zmiennych funkcjonalnych. Zestawienie stacji z wybraną liczbą PC’s wraz zprocentowym udziałem wyjaśnionej przez nie wariancji przedstawia Tabela 3.3.
2. Sprawdzamy założenie o liniowości metodą FPC score predictor-response plots.
Wraz z wyznaczeniem liczby głównych składowych dla każdej pary zmiennych należy stwo-rzyć wykresy score plots. Dla każdej pary wygenerowano zatem pq wykresów, w pracyzałączamy jednak tylko wybór ze score plots dla danych CMO-BOU0. Na podstawie wy-kresów przedstawionych na Rysunkach 3.7 i 3.8 oraz pozostałych niezałączonych w pracy
41

CMOp CPV1 34,15%2 46,96%3 56,00%4 62,88%5 69,07%6 73,80%7 77,67%8 81,31%9 83,71%10 85,96%11 87,92%12 89,55%
Tabela 3.2: Wskaźniki CPV dla kolejnych głównych składowych zmiennej z danymi zestacji College.
Stacja PC CPV Stacja PC CPVCMO 9 83,71%BOU0 4 91,55% FRD0 5 93,63%BOU1 3 98,90% FRD1 5 94,03%BOU2 3 95,00% FRD2 1 99,99%BOU3 2 97,38% FRD3 5 92,50%HON0 4 96,96% SJG0 4 96,49%HON1 4 99,98% SJG1 4 97,99%HON2 3 93,31% SJG2 4 98,75%HON3 3 95,50% SJG3 4 97,29%
Tabela 3.3: Liczby wykorzystanych głównych składowych dla poszczególnych stacji, wy-znaczone za pomocą kryterium osypiska oraz procentowego udziału wyjaśnionej wariancji(wskaźnika CPV ).
wykresów tego typu nie mamy podstaw do doszukiwania się trendu między FPC scoreszmiennej X a scores zmiennych Y .
3 i 4. Wyliczamy wartość statystyki TN (p, q) (2.11). Jeśli TN (p, q) > χ2pq(1−α), to odrzu-camy hipotezę zerową o braku liniowej zależności. W przeciwnym razie nie mamy podstawdo odrzucenia H0.
Wyniki przedstawione zostały w Tabeli 3.4. Dla danych bez opóźnienia wszystkie paryzmiennych objaśnianych ze zmienną objaśniającą wykazują wzajemną zależność liniową.Jednak wraz ze wzrostem odstępu czasu między danymi zależność liniowa znika. Ponadto,zgodnie z intuicją, zależność jest słabsza dla bardziej odległych stacji.
Na pierwszy rzut oka przedstawiona procedura testowa może wydawać się skomplikowa-na, jednak dzięki dostępności pakietu fda do programu R-projekt, zaimplementowanie iużycie testu staje się bardzo proste. Przedstawione w tym rozdziale dane stanowią dobryprzykład danych funkcjonalnych, świetnie sprawdzają się jako zbiór do ćwiczenia intuicjio zmiennych funkcjonalnych oraz - podobnych jak ta - analiz teoretycznych.
Wykorzystany w tym podrozdziale kod do programu R-project został zmieszczony w Do-datku.
42
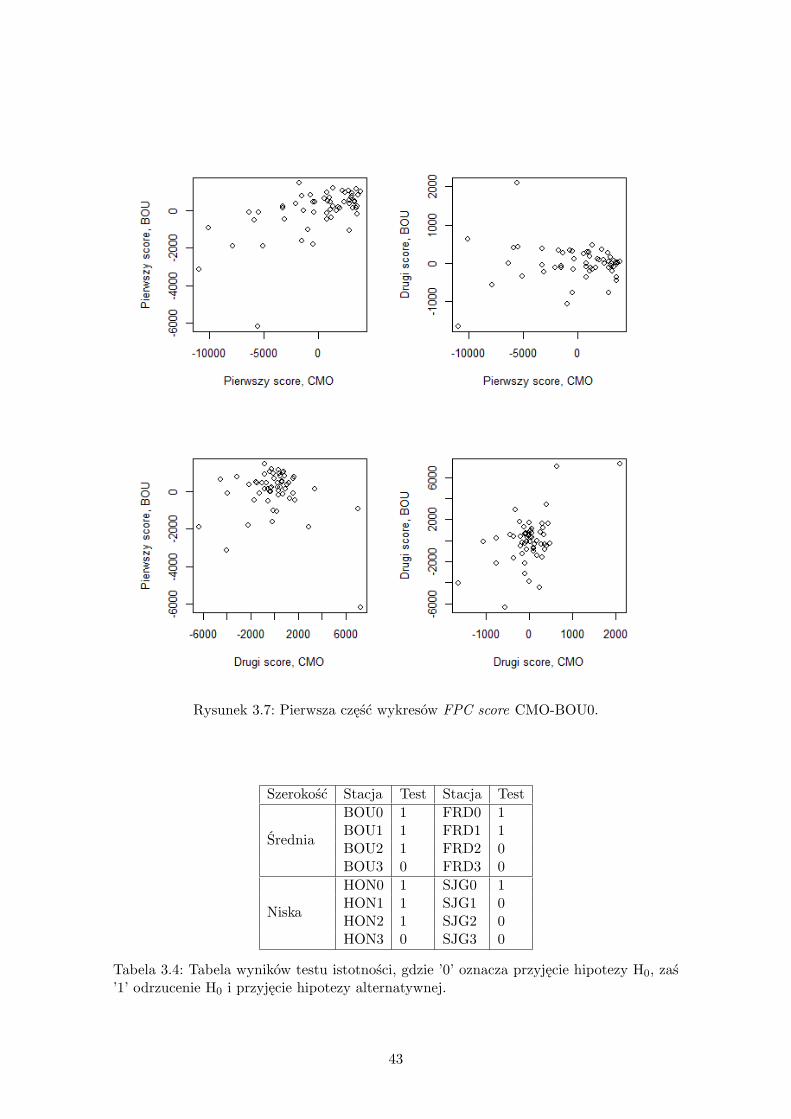
Rysunek 3.7: Pierwsza część wykresów FPC score CMO-BOU0.
Szerokość Stacja Test Stacja Test
Średnia
BOU0 1 FRD0 1BOU1 1 FRD1 1BOU2 1 FRD2 0BOU3 0 FRD3 0
Niska
HON0 1 SJG0 1HON1 1 SJG1 0HON2 1 SJG2 0HON3 0 SJG3 0
Tabela 3.4: Tabela wyników testu istotności, gdzie ’0’ oznacza przyjęcie hipotezy H0, zaś’1’ odrzucenie H0 i przyjęcie hipotezy alternatywnej.
43
Rysunek 3.8: Druga cześć wykresów FPC score CMO-BOU1.
44

Dodatek A
Kod w R
Poniżej załączony jest kod napisany w języku R wykorzystany w przedstawionym wyżejprzykładzie.
#-------------------------------------------------------------------------# WCZYTYWANIE DANYCH BEZPOŚREDNIO Z PLIKÓW .min#-------------------------------------------------------------------------# BOU - STYCZEŃBOU.1.1<-t(matrix(as.numeric(array(scan(file="D:/.../bou20010101dmin.min",what="list", skip=26), dim=c(7,1440))[3:4,]),nrow=2,ncol=1440))BOU.1.2<-t(matrix(as.numeric(array(scan(file="D:/.../bou20010102dmin.min",what="list", skip=26), dim=c(7,1440))[3:4,]),nrow=2,ncol=1440))...#BOU.1<-cbind(BOU.1.1[,2],BOU.1.2[,2],...,BOU.1.30[,2],BOU.1.31[,2])...#BOU<-cbind(BOU.1,BOU.2,BOU.3,...,BOU.10,BOU.11,BOU.12)...##-------------------------------------------------------------------------# USUNIĘCIE BRAKÓW DANYCH#-------------------------------------------------------------------------# braki danych = 99999 lub 88888## ZLICZANIE BRAKÓW DANYCHzlicz.braki<-function(zbior)braki<<-c()n<-dim(zbior)for (i in 1:n[2])braki<<-c(braki,length(which(zbior[,i]>80000)))brakizlicz.braki(BOU.1)length(which(braki>0))
# ZAMIANA ZBIORU - USUNIĘCIE/PODMIANA BRAKÓW DANYCHzmien.braki<-function(zbior)n<-dim(zbior)
45

zbior2<<-zbiorbraki<<-c()for (i in 1:n[2])b1<<-which(zbior[,i]>80000)b2<<-length(b1)braki<<-c(braki,b2)if (b2>0 & b2<11)if(b1[1]==1 & b2==1)zbior2[1,i]<<-zbior2[2,i]else if(b1[1]==1 & b2>1 & b1[2]!=2)zbior2[1,i]<<-zbior2[2,i]for (j in b1[-1]) zbior2[j,i]<-zbior2[j-1,i]else if(b1[1]==1 & b1[2]==2)pierwsza<<-which(b1[-b2]!=b1[-1]-1)if (length(pierwsza)<1) pierwsza<<-b1[b2]zbior2[1:pierwsza,i]<<-zbior2[pierwsza+1,i]else zbior2[1:pierwsza[1],i]<-zbior2[pierwsza[1]+1,i]for (j in b1[pierwsza[1]+1:(b2-pierwsza[1])]) zbior2[j,i]<-zbior2[j-1,i] else if(b1[1]>1) for (j in b1) zbior2[j,i]<-zbior2[j-1,i]usun<<-which(braki>10)zbior2<<-zbior2## BOULDER#styczeńzmien.braki(BOU.1)BOU.1b<-usunBOU.1bb<-zbior2# cały rokzmien.braki(BOU)BOU.b<-usunBOU.bb<-zbior2...##-------------------------------------------------------------------------# PREZENTACJA DANYCH#-------------------------------------------------------------------------# INSTALACJA I ZAŁADOWANIE PAKIETU ’fda’install.packages("fda", dependencies =TRUE)library(fda)## TWORZENIE BAZY B-SPLAJNÓW DLA WYBRANEJ LICZBY FUNKCJI = PARAMETRU ’nbasis’bspline.basis<-create.bspline.basis(c(0,1440),100)# TWORZENIE DANEJ FUNKCJONALNEJ NA PODSTAWIE ZBIORU DANYCH = ESTYMACJA# WSPÓŁCZYNNIKÓW W KOMBINACJI Z WYBRANĄ BAZĄBOU.1.fd<-Data2fd(seq(1,1440),BOU.1bb,bspline.basis)## WYKRES DANYCH WEJCIOWYCH
46

plot(x=1:1440,y=BOU.1.4[,2],type="l",col="blue",xlab="Minuta w ciągu dnia [min]",ylab="Indukcja magnetyczna [nT]",main="Dopasowanie B-splajnów, nbasis=50")# DODANIE PRZYBLIŻONEJ DANEJ FUNKCJONALNEJlines(BOU.1.fd[4],col="dark red",lw=2)...##-------------------------------------------------------------------------#bspline.basis<-create.bspline.basis(c(0,1440),100)BOU.1.fd<-Data2fd(seq(1,1440),BOU.1bb,bspline.basis)plot.fd(BOU.1.fd, xlab="Minuta w ciągu dnia [min]",ylab="Indukcja magnetyczna [nT]",main="Indukcja pola magnetycznego, BOU, Styczeń 2001")# TWORZENIE FUNKCJI ŚREDNIEJ DANYCH FUNKCJONALNYCHmean.BOU.1.fd<-mean.fd(BOU.1.fd)lines(mean.BOU.1.fd,lw=3)## CENTROWANIE DANYCH FUNKCJONALNYCHBOU.1.fdc<-center.fd(BOU.1.fd)plot.fd(BOU.1.fdc)...##-------------------------------------------------------------------------# FPCA#-------------------------------------------------------------------------# BUDOWANIE ’nharm’ LICZBY PIERWSZYCH FUNKCJI WŁASNYCHpca<-pca.fd(BOU.1.fd, nharm=3, centerfns = TRUE)
# WYKRESY PIERWSZYCH ’nharm’ FUNKCJI WŁASNYCHplot.fd(pca$harmonics,main="Pierwsze funkcje własne")# PIERWSZE WARTOŚCI WŁASNEpca$values[1]pca$values[2]pca$values[3]
# SCORE-PLOTSpar(mfrow=c(1,3))plot(pca$scores[,1],pca$scores[,2],xlab="Pierwszy score",ylab="Drugi score")plot(pca$scores[,1],pca$scores[,3],xlab="Pierwszy score",ylab="Trzeci score")plot(pca$scores[,2],pca$scores[,3],xlab="Drugi score",ylab="Trzeci score")par(mfrow=c(1,1))
#-------------------------------------------------------------------------# TEST - SUBSTORMS#-------------------------------------------------------------------------# pakiety niezbędne do wczytania pliku Excelinstall.packages("rJava", dependencies =TRUE)library(rJava)install.packages("XLConnectJars", dependencies =TRUE)library(XLConnectJars)
47

install.packages("XLConnect", dependencies =TRUE)library(XLConnect)
# lista subburz ze strony SuperMAG - wybór dla stacji w Collegepath_substorms<-"D:/.../supermag-stations.xlsx"file_substorms<-loadWorkbook(path_substorms)substorms<-t(as.vector(readWorksheet(file_substorms,sheet="Substorms_College2",header=FALSE,startRow=2,startCol=9,endRow=88,endCol=9)))length(substorms)
# DEFINIOWANIE ZMIENNYCH X I YX<-"CMO"X.bb<-CMO.bbX.b<-CMO.b#Y<-"BOU"Y.bb<-BOU.bbY.b<-BOU.b#Y<-"FRD"Y.bb<-FRD.bbY.b<-FRD.b#Y<-"HON"Y.bb<-HON.bbY.b<-HON.b#Y<-"SJG"Y.bb<-SJG.bbY.b<-SJG.b
#NO LAGcomb1<-setdiff(substorms,c(X.b,Y.b))#comb1<-setdiff(1:365,c(X.b,Y.b))comb2<-comb1##LAG1comb1<-setdiff(substorms,c(X.b,Y.b+1))comb2<-comb1+1#LAG2comb1<-setdiff(substorms,c(X.b,Y.b+2))comb2<-comb1+2#LAG3comb1<-setdiff(substorms,c(X.b,Y.b+3))comb2<-comb1+3
(N<-length(comb1))
X.fd.Y<-Data2fd(seq(1,1440),X.bb[,comb1],bspline.basis)Y.fd.X<-Data2fd(seq(1,1440),Y.bb[,comb2],bspline.basis)
48

#-------------------------------------------------------------------------# 1. WYBÓR LICZBY PCA ’p’ I ’q’#pca.X.Y.test<-pca.fd(X.fd.Y, nharm=12, centerfns = TRUE)par(mfrow=c(1,2))plot(1:12,pca.X.Y.test$values[1:12],"b",xlab="Numer funkcji własnej",ylab="Wartość własna",main=X)
pca.Y.X.test<-pca.fd(Y.fd.X, nharm=12, centerfns = TRUE)plot(1:12,pca.Y.X.test$values[1:12],"b",xlab="Numer funkcji własnej",ylab="Wartość własna",main=Y)par(mfrow=c(1,1))
# PROCENT WYJAŚNIONEJ WARIANCJI PRZEZ ’i’-TĄ GŁÓWNĄ SKŁADOWĄpca.Y.X$varprop
# CVP DLA KOLEJNYCH LICZB GŁÓWNYCH SKŁADOWYCH ’q’total<-sum(pca.Y.X.test$values[1:100])for(i in 1:12)procent<-sum(pca.Y.X.test$values[1:i])/totalcat(i, procent, "\n")
#CMO: 9p<-9pca.X.Y<-pca.fd(X.fd.Y, nharm=p, centerfns = TRUE)#BOU0: 4, FRD0: 5, HON0: 4, SJG0: 4q<-4pca.Y.X<-pca.fd(Y.fd.X, nharm=q, centerfns = TRUE)
# CPV(q)total<-sum(pca.Y.X.test$values[1:100])(procent<-sum(pca.Y.X.test$values[1:q])/total)
#-------------------------------------------------------------------------# 2. SCORE PLOTS
par(mfrow=c(2,2))plot(pca.X.Y$scores[,1],pca.Y.X$scores[,1],xlab=paste0("Pierwszy score, ", X),ylab=paste0("Pierwszy score, ", Y))plot(pca.X.Y$scores[,1],pca.Y.X$scores[,2],xlab=paste0("Pierwszy score, ", X),ylab=paste0("Drugi score, ", Y))plot(pca.X.Y$scores[,2],pca.Y.X$scores[,1],xlab=paste0("Drugi score, ", X),ylab=paste0("Pierwszy score, ", Y))plot(pca.Y.X$scores[,2],pca.X.Y$scores[,2],xlab=paste0("Drugi score, ", X),ylab=paste0("Drugi score, ", Y))par(mfrow=c(1,1))...
#-------------------------------------------------------------------------# 3. STATYSTYKA TESTOWA
49

temp2<-0for(k in 1:p)for(j in 1:q)scores<-0for(n in 1:N)scores<-scores+pca.X.Y$scores[n,k]*pca.Y.X$scores[n,j]scores<-1/N*scorestemp2<-temp2+(1/pca.X.Y$values[k])*(1/pca.Y.X$values[j])*scores^2(T<-N*temp2)
#-------------------------------------------------------------------------# 4. PORÓWNANIE Z ROZKŁADEM CHI-KWADRAT
alpha<-0.05qchisq(1-alpha,df=p*q)if(T>qchisq(1-alpha,df=p*q)) cat("Odrzucamy H_0 na rzecz H_A:Operator Psi jest istotnie większy od zera") else cat("Przyjmujemy H_0:Operator Psi nie jest istotnie większy od zera")
#-------------------------------------------------------------------------
50

Bibliografia
[Beśka] M. Beśka, Wstęp do teorii miary (skrypt do zajęć dydaktycznych).
[Billingsley] P. Billingsley, Prawdopodobieństwo i miara, Wydawnictwo Naukowe PWN2009, s. 231, 288, 383.
[Bosq] D. Bosq, Linear Processes in Function Spaces, Springer 2000.
[Chiou, Muller] J-M. Chiou, H-G. Muller, Diagnostics for functional regression via resi-dual processes. Computational Statistics and Data Analysis, 51 (2007), s. 4849-4863.
[SuperMAG3] EMMA: Lichtenberger J., M. Clilverd, B. Heilig, M. Vellante, J. Manninen,C. Rodger, A. Collier, A. Jørgensen, J. Reda, R. Holzworth, and R. Friedel (2013),The plasmasphere during a space weather event: first results from the PLASMONproject, J. Space Weather Space Clim., 3, A23 (www.swsc-journal.org/articles/swsc/pdf/2013/01/swsc120062.pdf).
[Ferraty, Vieu] F. Ferraty, P. Vieu, Nonparametric Functional Data Analysis. Theory andpractice, Springer 2006.
[Horvath, Kokoszka] L. Horvath, P. Kokoszka, Interference for Functional Data with Ap-plications, Springer 2012.
[Hsing, Eubank] T. Hsing, R. Eubank, Theoretical Foundations of Functional Data Ana-lysis, with an Introduction to Linear Operators, Wiley 2015.
[SuperMAG4] IMAGE Chain: Tanskanen, E.I. (2009), A comprehensive high-throughputanalysis of substorms observed by IMAGE magnetometer network: Years 1993-2003examined, 114, A05204, doi:10.1029/2008JA013682.
[INTERMAGNET] INTERMAGNET http://www.intermagnet.org/index-eng.php
[Johnson, Wichern] R.D. Johnson, D.W. Wichern, Applied Multivatiate Statistical Analy-sis (6th edition), Pearson 2007.
[Kokoszka et al.] P. Kokoszka, I. Maslova, J. Sojka, L. Zhu, Testing for lack of dependencein the functional linear model, Canadian Journal of Statistics, 36 (2008), s. 207-222.
[SuperMAG5] MACCS: Engebretson, M. J., W. J. Hughes, J. L. Alford, E. Zesta, L. J.Cahill, Jr., R. L. Arnoldy, and G. D. Reeves (1995), Magnetometer array for cusp andcleft studies observations of the spatial extent of broadband ULF magnetic pulsationsat cusp/cleft latitudes, J. Geophys. Res., 100, 19371-19386, doi:10.1029/95JA00768.
[SuperMAG6] MAGDAS / 210 Chain: Yumoto, K,. and the CPMN Group (2001), Cha-racteristics of Pi 2 magnetic pulsations observed at the CPMN stations: A review ofthe STEP results, Earth Planets Space, 53, s. 981-992.
51

[Maslova et al.] I. Maslova, P. Kokoszk, J. Sojka and L. Zhu, Statistical significance testingfor the association of magnetometer records at high–, mid– and low latitudes duringsubstorm days. Planetary and Space Science, 58 (2010), s. 437–445.
[SuperMAG5] McMAC Chain: Chi, P. J., M. J. Engebretson, M. B. Moldwin, C. T. Rus-sell, I. R. Mann, M. R. Hairston, M. Reno, J. Goldstein, L. I. Winkler, J. L. Cruz-Abeyro, D.-H. Lee, K.Yumoto, R. Dalrymple, B. Chen, and J. P. Gibson (2013),Sounding of the plasmasphere by Mid-continent MAgnetoseismic Chain magnetome-ters, J. Geophys. Res. Space Physics, 118, doi:10.1002/jgra.50274.
[R: fda 1] J.O. Ramsay, H. Wickham, S. Graves, G. Hooker, Package ’fda’, wersja 2.4.4.On-line: https://cran.r-project.org/web/packages/fda/fda.pdf
[R: fda 2] J.O. Ramsay, G. Hooker and S. Graves, Functional Data Analysis with R andMatlab, Springer 2009.
[Ramsay, Silverman] J.O. Ramsay, B.W. Silverman, Functional Data Analysis, Springer2005.
[SuperMAG1] SupeMAG http://supermag.jhuapl.edu/
[SuperMAG2] SuperMAG: Gjerloev, J. W. (2012), The SuperMAG data processing tech-nique, J. Geophys. Res., 117 , A09213, doi:10.1029/2012JA017683.
52