structure of chick chromosomal genes for calbindin and calretinin
TRANSCRIPT

J. Mol. Biol. (1988) 200, 615625
Structure of Chick Chromosomal Genes for Calbindin and Calretinin
P. W. Wilson’, J. Rogers’, M. HardingI, V. Poh13 G. Pattyn3 and D. E. M. Lawson’
‘A FRC Institute of Animal Physiology and Genetics Research Babraham, Cambridge CB2 4AT, England
2MRC Laboratory of Molecular Biology Hills Road, Cambridge, England
3Laboratoire d’tlistologie, Universit6 Libre de Bruxelles Brussels, Belgium
(Received 14 September 1987, and in revised form 9 December 1987)
The chick chromosomal gene for calbindin (the 28,000 M, intestinal calcium-binding protein) was cloned, and all the exons and flanking regions were sequenced. The promoter region contains typical ATAAA and GGGCGG boxes, the latter being unusual in “non- housekeeping” genes. Three polyadenylation signals are found in the calbindin gene that correspond to the three known mRNAs. Transcription termination is not efficient because homology with consensus sequences found downstream from the polyadenylation signal is weak.
There are ten introns, most of which do not fall at homologous positions, neither with respect to the sixfold repeating structure of the calbindin protein, nor with respect to previously sequenced genes for calmodulin and other calcium-binding proteins. The gene for the related protein calretinin was cloned and partially sequenced. The introns are in the same positions in the calretinin and calbindin genes. The introns have apparently been inserted during the divergence of the calcium-binding protein superfamily.
1. Introduction
Calbindint is a calcium-binding protein present’ in all classes of vertebrates and in a wide range of t,issues (Norman et al., 1982). It binds four atoms of calcium per mole. As the name implies, the protein binds calcium with high affinity, K, = lo6 M-l
(Bredclerman & Wasserman, 1974), but its role within the cell is unknown. In mammalian intestine and kidney, the 28,000 M, calbindin is replaced by a smaller pro&n, 8600 M,, which is the product of a distantly related gene and will not be further discussed in this paper. 1,25Dihydroxyvitamin D stimulates the synthesis of intestinal calbindin by inducing the synthesis of its mRNA (Emtage et al., 1974).
A number of cDNA clones for chick calbindin have been prepared, sequenced, and used to
t Calbindin was previously called vitamin II-dependent calcium-binding protein (Wasserman, 1985). The larger form (28,000 M, calbindin-D) is that referred to in this paper.
examine the kinetics of its mRNA synthesis (Hunziker et al., 1983; Wilson et al., 1985; Hunziker, 1986; Theophan & Norman, 1986; Wood et al., 1987). The cDNA sequences gave the protein’s amino acid sequence for the first time (Wilson et al., 1985; Hunziker, 1986; Yamakuni et al., 1986), a result later confirmed from the calbindin amino acid sequence directly established (Takagi et al., 1986; Fullmer & Wasserman, 1987). Sequence homologies indicate that calbindin is a member of the calmodulin/troponin C superfamily of calcium- binding proteins. The calcium-binding domains of these proteins have characteristic structures con- sisting of 29 amino acid residues arranged in a helix-loop-helix conformation (Kretsinger, 1980). As expected from its biochemistry, calbindin contains four canonical calcium-binding domains. but it also has two other homologous domains, which are probably ineffective due to mutations at critical positions (Hunziker, 1986; Lawson et al., 1987).
A cDNA for a related calcium-binding protein, named calretinin, has been isolated from chick
615 0 1988 Academic Press Limited

616 P. W. Wilson et al.
retina (Rogers, 1987). Calretinin is more closely related to calbindin (58% homology) than to any other members of the superfamily. Unlike calbindin, calretinin appears to be expressed only in neurones; in chick brain, calbindin and calretinin are generally in different neurones (Rogers, 1987).
Calbindin mRNA exists in three forms of different size; namely, 2.1, 2.8 and 3.1 kbt, all of which are 1,25dihydroxyvitamin D-dependent in chick intestine but not in brain (Hunziker et al., 1983; Taylor, 1974). Calretinin mRNA exists in two forms, of 1.4 kb and 1.2 kb (Rogers, 1987). To study the regulatory events responsible for the accumula- tion of these mRNAs, we have isolated and characterized several recombinant chick genomic clones. The use of these clones in transfection studies of suitable cell lines may aid the identifica- tion of calbindin’s function.
2. Materials and Methods
(a) Materials
Amersham International supplied [32P]dCTP (3000 Ci/mmol), [35S]dATP (410 Ci/mmol) and Nick Translation kits. Restriction endonucleases and DNA- modifying enzymes were obtained from Anglian Biotech- nology Ltd., BRL (UK) Ltd.. Boehringer-Mannheim, P and S Biochemicals, PL Biochemical Inc., and Pharmacia. Stratagene supplied Bluescript KS, Ml3 + phagemid. Oligonucleotide probes and primers were prepared by the Microchemical Facility. AFRC Babraham. Nitrocellulose filters BA-85 (0.45 pm) came from Schleicher and Schuell.
(b) Screening the chick genomic libraries
The calbindin gene was isolated from a chick genomic library obtained from Dr J. D. Engel (Northwestern University, Evanston, IL). The library was prepared by incorporating MboI partial digests of chick DNA, average size 21 kb. into the BamHI *site of EMBLS phage. Following transfection of Escherichia coli Q358, high- density screening of lo6 plaques was performed with a 32P-labelled, nick-translated calbindin cDNA clone. pWHl1 (Wilson et al., 198.5). as described by Maniatis et al. (1982) using duplicate nitrocellulose filters. Positive plaques were rescreened several times for purity.
The calretinin gene was isolated from a chick genomic library made in exactly the same way by Dr M. Goedert. (Goedert. 1986), and screened with a “P-1abelled insert’ from calretinin cDNA clone RU37 (Rogers, 1987). One positive clone, lCGl1, was recovered.
(c) Subcloning of the calbindin gene
Restriction fragments spanning the complete calbindin gene were subcloned into pUC plasmids (Fig. 1). The fragments and the subclone name were as follows: SalI- EcoRI, pWH3T; SalI-HindIII, pWH5T; BarnHI-EcoRI,
pWH4; BarnHI-HindIII, pWH6; BgZII fragment, pWH7. The 5’ end of the genomic insert was sequenced by subcloning the HindIII-Sal1 and HindIII-EcoRI fragments of pWH5T in opposite orientations into Bluescript KS, Ml3 + to give p5HS and p5HE.
t Abbreviation used: kb, lo3 bases or base-pairs.
To sequence the 3’ end of (‘CB2, subclones p4HA. p4HB and p4HC were constructed with the 3 Hind111 genomic fragments from pWH4; as appropriate restricx- tion sites were available, both st’rands could be sequenced without oppositely orientated inserts being required.
(d) Sequencing of the calbindin gene
Progressive, unidirectional overlapping deletions were prepared from p5H8, p5HE, p4HA, p4HB, p4HC and pWH3T by digestion with exonuclease TIT (Henikoff. 1984) and blunting of the single-stranded protruding ends with mung bean nuclease. The plasmids were religated with bacteriophage T4 DNA ligase and used to transform competent E. coli JM109 cells (Hanahan. 1983). Appro- priate size-selected plasmids were sequenced by double- stranded techniques (Hattori & Sakaki, 1986). modified by the removal of the denaturing alkali by a Sepharose CL6B spin column. Sequencing was carried out, according to the Sanger dideoxy chain termination procedures (Sanger et aZ., 1977) using [35S]dATP. In this way, 3 kb at both the 5’ end and the 3’ end of the gene were sequenced in both directions.
Double-stranded sequencing of the exons lying between both these 3 kb regions; and of the smaller introns when present, was carried out with pWH4. pWH6 and pWH7 by “exon walking” using specific 17-mer oligonucleotide primers. These regions were sequenced in both directions.
(e) Subcloning and sequencing of the calretink gem
A restriction map was made from the original XXI 1 and from plasmid subclones, and the calretinin gene was located by probing Southern-blotted digests with 32P- labelled probes representing various parts of the RIJ37 cDNA clone.
PstI fragments from lCGl 1 were subcloned into Ml3 mp18, the subclones were plaque-hybridized with nick- translated RU37 insert, and positive plaques were picked. DNA was prepared from these and a single sequence was read from each, using the “universal” primer, by the method of Sanger et al. (1977). The calretinin exons were located and put in order bv comparison with the RU37 cDNA sequence and the nCGl1 restriction map. The sequences are not reproduced here as they were done on only 1 strand. but there were no discrepancies with thta RU37 cDNA sequence (Rogers, 1987).
3. Results
(a) Isolation and mapping of overlapping calbindin genomic clones
The LVboI chick genomic library was screened with the cDNA clone pWH11. Twelve positive genomic clones were identified, isolated and charac- terized following restriction endonuclease digest,ion and hybridization of the fragments against t’wo [32P]cDNA fragments derived from each end of the cDNA. Two overlapping clones (CCBZ and CCBS) contained between them all of the calbindin aDNA within their 17 kb inserts.
In preliminary studies, the approximate locations of the calbindin exons within CCB2 and (Y%8 werr found by digesting the phages and subclones with the enzymes indicated in Figure I(c). (e) and (f). and the resulting fragments were Southern-blotted and hybridized against specific regions of pWHl1
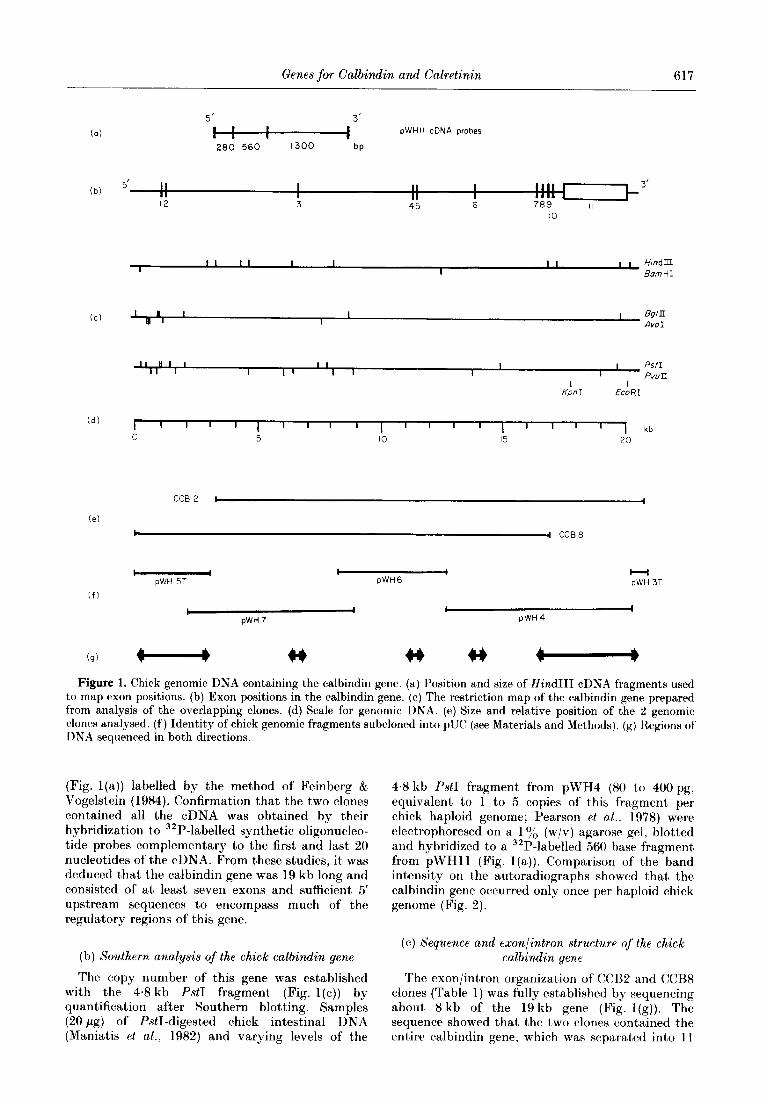
Genes for Calbindin and Calretinin 617
(b)
(C)
(d)
260 560
pWHll cDNA probes
I II II I I I I , , HmdlIl
I BGV?lHl
I 1 I 1 a 1
, EJgin I AVUI
II 111 I II I
I I I
I Pst1 I '
I I I I I PVUII
I KpnI EC&I
I ’ ’ ’ ’ I ’ ’ ’ I , I I I I , I I I I
0 1 kb
5 IO I5 20
CCB 2 I I
(e)
I 4 CCB8
I I H pWH 6 pWH 3T
I I t 4
pWH7 pWH 4
(9) 4 I) 4 I) Figure 1. Chick genomic DNA containing the calbindin gene. (a) Position and size of Hind111 cDNA fragments used
to map exon positions. (b) Exon positions in the calbindin gene. (c) The restriction map of the calbindin gene prepared from analysis of the overlapping clones. (d) Scale for genomic DNA. (e) Size and relative position of the 2 genomic clones analysed. (f) Identity of chick genomic fragments subcloned into pUC (see Materials and Methods), (g) Regions of DNA secluencaed in both directions.
(Fig. l(a)) labelled by the method of Feinberg & Vogelstein (1984). Confirmation that’ the two clones contained all the cDNA was obtained by their hybridization to 32P-labelled synthetic oligonucleo- tide probes complementary to the first and last 20 nucleotides of the cDNA. From these studies, it was deduced that the calbindin gene was 19 kb long and consisted of at, least seven exons and sufficient 5’ upstream sequences to encompass much of the regulatory regions of this gene.
4.8 kb PstI fragment from pWH4 (80 to 400 pg, equivalent to 1 to 5 copies of t’his fragment per chick haploid genome; Pearson et al.. 1978) were electrophoresed on a 1 y. (w/v) agarose gel, blotted and hybridized to a 32P-labelled 560 base fragment from pWHl1 (Fig. l(a)). Comparison of the band intensity on the autoradiographs showed that the calbindin gene occurred only once per haploid chick genome (Fig. 2).
(c) Sequence and exonlintron structwr of the chick (b) Southern analysis of the chick calbindin gene calbindin gene
The copy number of this gene was established The exon/intron organization of CCR2 and CCH8 with the 4.8 kb PstI fragment (Fig. l(c)) by clones (Table 1) was fully established by sequencing quantification after Southern blotting. Samples about 8 kb of the 19 kb gene (Fig. l(g)). The (20 pg) of PstI-digested chick intestinal DNA sequence showed that the two clones contained the (Maniatis et al., 1982) and varying levels of the entire calbindin gene, which was separated into 11
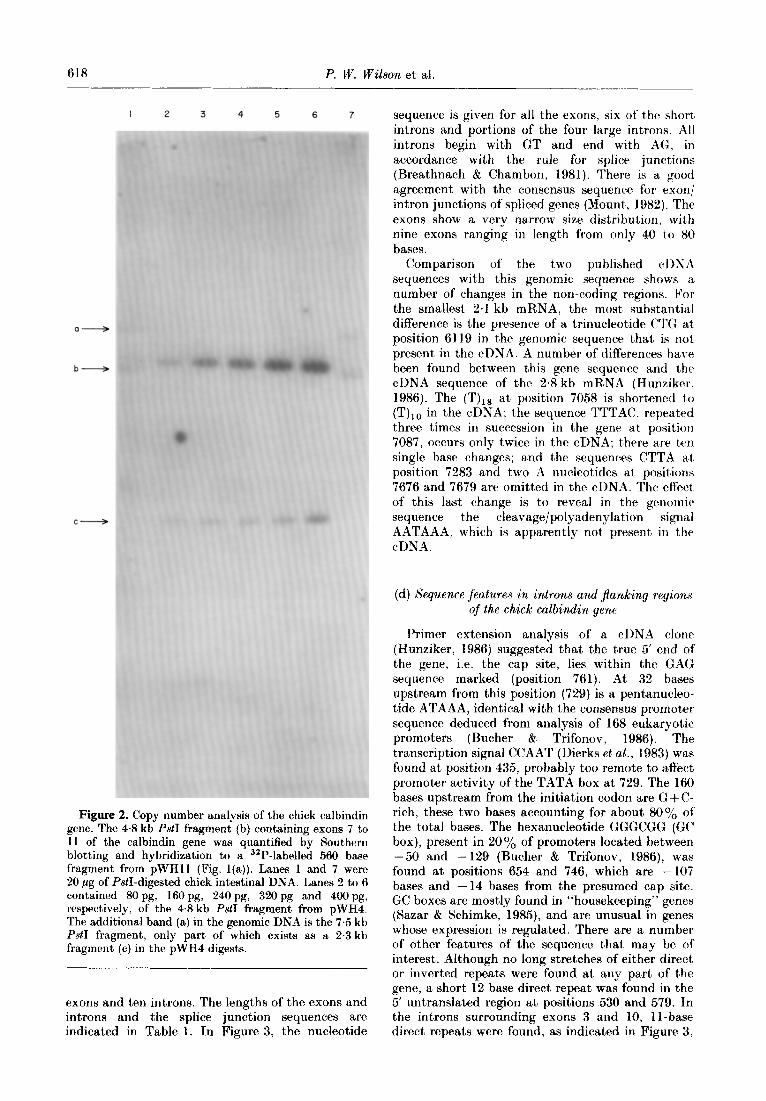
618 P. W. Wilson et al.
I 2 3 4 5 6 7
Figure 2. Copy number analysis of the chick calbindin gene. The 4% kb P&I fragment (b) containing exons 7 to 11 of the calbindin gene was quantified by Southern blotting and hybridization to a 32P-labelled 560 base fragment from pWHl1 (Fig. l(a)). Lanes 1 and 7 were 20 pg of P&I-digested chick intestinal DNA. Lanes 2 to 6 contained 80 pg, 160 pg, 24Opg, 320 pg and 4OOpg, respectively, of the 4.8 kb PstI fragment from pWH4. The additional band (a) in the genomic DNA is the 7.5 kb P&I fragment, only part of which exists as a 2.3 kb fragment (c) in the pWH4 digests.
exons and ten introns. The lengths of the exons and introns and the splice junction sequences are indicated in Table 1. In Figure 3, the nucleotide
sequence is given for all the exons, six of the short introns and portions of the four large introns. All introns begin with GT and end with AG, in accordance wit,h the rule for splice junctions (Breathnach & Chambon, 1981). There is a good agreement with the consensus sequence for exon/ intron junctions of spliced genes (Mount, 1982). The exons show a very narrow size distribution, with nine exons ranging in length from only 40 to 80 bases.
Comparison of the two published cl)NA sequences with this genomic sequence shows a number of changes in the non-coding regions. For the smallest 2.1 kb mRNA, the most substantial difference is the presence of a trinucleotide CTG at, position 6119 in the genomic sequence that is not present in the cDNA. A number of differences have been found between this gene sequence and the cDNA sequence of the 2.8 kb mRNA (Hunziker. 1986). The (T),, at position 7058 is shortened t,o (‘VI, in the cDNA; the sequence TTTAC, repeated three times in succession in the gene at position 7087, occurs only twice in the cDNA; there are ten single base changes; and the sequences CTTA a.t position 7283 and two A nucleotides at positions 7676 and 7679 are omitted in the cDNA. The effect of this last change is to reveal in the genomic sequence the cleavage/polyadenylation signal AATAAA, which is apparently not present, in the cDNA.
(d) Sequence features in introns and jlanking regions
of the chick calbindin gene
Primer extension analysis of a cDNA clone (Hunziker, 1986) suggested that the true 5’ end of the gene, i.e. the cap site, lies within the GAG sequence marked (position 761). At 32 bases upstream from this position (729) is a pentanucleo- tide ATAAA, identical with the consensus promoter sequence deduced from analysis of 168 eukaryotic promoters (Bucher & Trifonov, 1986). The transcription signal CCAAT (Dierks et al., 1983) was found at position 435, probably too remote to affect promoter activity of the TATA box at 729. The 160 bases upstream from the initiation codon are G + C- rich, these two bases accounting for about 80% of t,he total bases. The hexanucleotide GGGCGG (GC box), present in 20% of promoters located between -50 and -129 (Bucher & Trifonov, 1986), was found at positions 654 and 746, which are - 107 bases and - 14 bases from the presumed cap site. GC boxes are mostly found in “housekeeping” genes (Sazar & Schimke, 1985), and are unusual in genes whose expression is regulated. There are a number of other features of the sequence t’hat may be of interest. Although no long stretches of either direct or inverted repeats were found at any part of the gene, a short 12 base direct repeat was found in the 5’ untranslated region at positions 530 and 579. In the introns surrounding exons 3 and IO, II-base direct, repeats were found, as indicated in Figure 3,

Genes for Calbindin and Calretinin 619
Table 1 Sizes and splice junction sequences of calbindin exons and introns
Exon Exon no. size
1 187 2 77 3 75 4 84 5 57 6 78 7 56 8 40 9 54
10 72 11 1250$
Consensus sequence
Exon/intron sequence
ACG/GTGACT TTG/GTAGGT GAG/GTAAGA CAG/GTACAC AAGIGTAAGC ATGIGTAAGA CAG/GTATGC CAG/GTAAGA CAA/GTAAGT AAG/GTAATC
~AGIGTAAGT
No. linking nucleotides calbindin (calretinin)
236t 4500 4500 (112)
w (700) 2700 VW 2700 (128t)
5f-V (290) 7Ot Wt) w
388t
Intron/exon sequence
GTAG/G ACAG/G ACAGjC GCAG/A ACAG/A TCAGjC AAAG/G TTAG/G TCAG/G $TAG/G
Np/G
The size of partially sequenced calbindin introns found by electron microscopy (Pohl et al., 1987). Sizes of introns in the calretinin gene are given in parentheses where known.
t Tntrons completely sequenced; other introns are partially sequenced. $ Exon 11 is 1920 and 2260 bases long to give the 2.8 and 3.1 kb forms of calbindin mRNA.
and an 11 -base complementary repeat was found on either end of the first exon.
(e) Cleavage/polyadenylation signal
As there is only one copy of the calbindin gene per haploid genome, the nucleotide sequence of the gene was expected to provide an explanation of the origin and relative proportion of the three forms of calbindin mRNA. At position 7018, the hexanucleo- tide AATATA is found, which can form part of the recognition signal for 3’ end processing of the primary transcript (Gil & Proudfoot, 1987). In this case, the resulting mRNA would be of an appropriate length and the final 3’ nucleotide of the cDNA could be the polyadenylation site. The cDNA sequence of the 2.8 kb mRNA reported by Hunziker (1986) did not show an appropriate cleavage polyadenylation signal but the changes in the sequence of the gene show that the usual signal AATAAA is present at position 7676. This signal would give rise to an mRNA of appropriate size for the sequence shown by the cDNA. The next occurrence of this signal in the gene sequence is at position 8009, which would yield a mRNA of about 3.1 kb.
It has been shown that faithful and efficient 3’ end processing requires additional sequences, par- ticularly G+T-rich and T-rich elements in the 50 bases following the AATAAA sequence (Gil & Proudfoot, 1987). Of the three cleavage/poly- adenylation signals found in the calbindin gene, the first at position 7018 is followed by a T-rich sequence at position 7058, but there are only two occurrences of GT in this region. The next occurrence of AATAAA, at 7676, is followed by three repeats of the sequence TTTT but again there is no G +T-rich sequence. The third AATAAA sequence has neither T-rich nor G + T-rich motifs in the following 100 bases. Consequently, the three
calbindin mRNAs probably arise because there is only weak homology with consensus transcription termination signals, the best homology being at positions appropriate to produce the 2.1 kb mRNA. This is the mRNA present in highest, concentration.
(fJ Partial sequence and exonlintron structure of the calretinin gene
A genomic clone representing the calretinin gene, KG1 1, was identified by hybridization to cDNA clone RU37. The hybridizing sequences were confined to the right-hand 4.9 kb of the AGCll insert. Because the cDNA clone was not complete, this may not include the whole calretinin gene. A number of subcloned PstI fragments from lCGl1 were sequenced from the ends, and these gave the complete sequences of five successive exons of the calretinin gene and their flanking splice sites. Further sequencing located another two exons (Fig. 4). The introns were mostly short and some were sequenced completely (Table 1). The positions of the introns were unambiguous and are indicated in Figures 4 and 5. They exactly matched the positions of introns 2 to 9 of the calbindin gene.
4. Discussion
(a) Sizes of introns and exons
The calbindin gene is split by ten introns, and the calretinin gene, as far as has been sequenced, has introns in exactly the same places. The exons have a narrow size distribution; all except the first and last have lengths between 40 and 80 nucleotides. This uniformity of exon size is characteristic of many genes (Naora & Deacon, 1982).
The intron lengths, on the other hand, are extremely variable. The calbindin gene includes some of the shortest introns known from any

620 P. W. Wilson et al.
1
101
201
301
401
501
601
701
801
901
1001
1101
1201
1301
1401
1501
1601
1701
1801
1901
2001
2101
2201
2301
2401
2501
2601
2701
2801
2901
3001
3101
3201
3301
3401
3501
3601
3701
3801
3901
4001
4101
4201
4301
4401
4501
4601
TCTCACGCCTCTGCAGTG AAARAOAGTGAGCTTATGCGGTATTCCATTCCTACCTGCTGGGATG~TTAGGACC~TATTT~TATACCATCTCTGT
TCCAGGGCTGTGGATCCAGAAATGOCATGGCATGACC~GCAGATTCCTTGCACTCTACACACTGTTCCATATGGTTTTTCTTGCACTGGGATATCCTGCAGGG
CTTGGGCACCCAAGACTCTTTCCCAGGTGGMGCCAATGCCTGATCACCCACCATCCTCTGCATCTCATGGGCACACTCTACCA
CGGCGAGGGGCCCATAACAACTTCTCTCT CCAAACGAGTACCCCTCACCTCGTACTGAGAGGCAGCTGCCCGGGGG~GGGATGACT
GGCGAGGACTCGGGGCCCCAGCCGCCGGCGGGAGACTCC TACCCCGCGC~~AGGTAGCGCCGAGGCCCGCGGAGAGGGAGGGGAGCGCCGG l ** ---------------------------------
GGGGGAGTG~CCGTGCCG~GCCAGCCCCATAAATAGCCCTCGGC~~~GGCGGGAGGAGCCCTCGGAGTCGTCGTCGCCGCAGCTGCCGCCGTCGC
MetThrAlaGluThrIiisLeuGlnGlyValGl ------------------------------------------------------------C--------------------------------------- CGCTCCGGCCGCGGGCACAGTCAGCACCGCGGACAGCGCCCCCGCTGAGCCCCCTCTGCAGCCCCATCATGACGGCGGAGACGCACCTGCAGGGCGTGGA
uIleSerAlaAlaGlnPhePheGluIl~TrpHiSHiSTyrAspS~rAsp -------_------------------------------------------ GATCTCGGCCGCCCAGTTCTTCGAGATCTGGCACCACTACGACTCCGACGGTGACTCCTTTCCCCTCCCCGGGGTGGCGGGGGGCGGCTGGCGGCTGGCG
GGGGTTATGCGAGGGGGAGGCTGGGGGTCCCACMCTCCTTGGCCGCCATTCCACAG CACGGCTGGGTTTCAGGTCGGGCGAGGAGTG
CGGGAGCAGCTCCGCCGGGAGMCACGGGCTAGAGACATCCCTGGCAGCGCTGMGAGTGGTGAGAGTTTGGAGGGAGCGGTGACACCAGGCATMCTCT
GlyAsnGlyTyrMetAspGlyLysGluLeuGlnAsnPheIleGlnGluLeuGlnGlnAlaArgLysLysAlaGlyLeu ___---________---__------~-~------------~--~~~~~~-------------~---~---~~~~~~~ TTTTATTGTAGGCMTGGGTACATGGATGGGMGGAGCTAC~CTTCATCCAGGAGCTGCAGCAGGCGCGGMGMGGCAGGCTTGGTAGGTTMCCA
TTCACCCCACTTCTTTCATCTCCTCTGG~G~GAGTTTTCTTGAGC~CTCCAGTGCCTTGGTTCCTTCTGTTCCTAGTTGCCTTCACACAGTTCA
TGCACTAGCCTCACGAGGCAGAGAAGTAGATGGGTAGATGGGTTAG~TMGCAGGTTTT~CATGTCCTCTGCTTTGG~GGTAGAGTCAGGGGTGTCCATTCA
GCTGGAGAGCAGGTCTTGTTCACATCTCACCAGACTGTGAGCTGAT~TGCTC~CGGCTTAATAAGARAAGTCAGRGCATCGACATTATCCTTTT
GTCATGGGTGGACTTTATCCTACTGCMCCTGATCCAGATATGCACAGATACTTT~ TAAATAAATTTATTTTAAAAGAGAGAAAATAGAAAAGM
AACCTAAGTCTTCAAGTTAGTTGCGCTCTTTTAATTTCATTGCATTCCTGCCCCTTGGTGGTCAGTAAATAGATC
TGCAGATGACTGCTAAACACTTTTTGCCCTTTGCCAGTGTTGCACACCAGGAATATGAGTGCCAAATCCTAGTAGTTCAGATTGCTAACAGAGACAGCAA
CGTTTTTGACAGTGTTGTCAGCMTGCTATGCATGAGCTATTMTGTTTTMTTAC~TTTCTTCCGMCTATACCCACTTGGGG~GAGAG
AGTGCGGAGAGMGGAGAGATGGAGAAAGRGAGAGAAATATATGGG
TMTTGGTTTCTAAAGCAGGCTACTTAGCACCAAGTTCAATTATA
GMGGAAAAAAAAATATCTGATTAGCATGTGTGGTTATTACTTTATATTA CCCTCTGAATTGAGCAATAACCTT
TCAATAACTGACTTTAATATTGCTGTATATTTTAGAAGCA CAACAATCATATGCTTARATTTTOTGGAAAATCTTCTT
GTGGTTATCTTCTTAGTAGTTCCATGAGTGCAGGCTTCACACACGTGAAAATCTGTCTGTCTCCCAGCATGCTTCATTTCTACAGTCTTAGTATCAGTTACGTC
TTACAGCATCTGCTGTAGATGCTCATTTTCATGAGTTATTC AAAAAGCCTCAAAAACCCAAACAGAAAATTGGTTTTCAG
AGGGAATAGGTGGTTTTTTTTCTTTCTTTTTATGCAGAAAATCTCTGTTCTGTAG
AGAAGTGCAGGAAACTTATGTTTGTTTGTTAGAAAGAAGATATT
TAGGAATTTGAAAAA TGAATTAGCAGCTTGAAGGATACTAGTTACTTTAAA
TAGAGCTTGCTCAAAGTGACACGAACTTTTGCAG~CTGTTCTTATCTGCTGCATTTCATCATTCATTATGTTTTTTGAGT~CCTCTTCCTGTATCTCAC
ACTGTTTTGAAAATACACAGGTGCTTMTTA------ 2.6kb ------ATCACATGATATTATCCACCC AAAAAMATTACTCAATTTCACTTCAAC
TTGAGGMTCTCGCTAAAATTMGTGTGMTATTTCATC~TGTAGT~TTTATTGACMCTMTAGMTATTTMGTACTTTGCATA~TGTTTCTCTG
AspLeUThrProGluMetLysAlaPheValASpGlnTyrGlyLysAl~ThrAspGlyLysIl -_---_--------_____-____________________---------------------- CATCTGARAAATATGATTCTCTCATTGTMCTTTACAGGACTTMCACCTG~TG~GCTTTTGTGGACCAGTATGGCMGGCCACTGATGG~T
eGlyIleValGlu ------------- AGGRATCGTTGAGGTAAGATAGTTACCCT~C~TGACT~CACATTTACTTACAG~TGCATTTAGCACAG~CTGTATGGGCGTATTTGT~
TAGGCTGGATTTTTAGTACTGAAAATTTTATTTCTCTGAG~TCTTTAGTGTTTTTTTCACT~TGATCTTTTTCCTTACCCC~GC~TATCCC
TTACCCTTTGCCAGATATTTCACTAAACTTCGTTTAACTTCGTTT~CTTTGCATA*TTTGTTTCAGTATAACA------ 4.3kb ------AGAAGTCTTTCAGAGGC
ATCATCCTGATGTTTGGACTTATGGGATGMGGTTCCTGTGAGGCTACATTAGGACAGTAGGACCATGMGMTTTCACACTCTTTTAG~GTGTCATAC
LeUAlaGlnValLeuProThrGluGluAsn -__________---__-___---------- TCATTCAAAAGCTCATCTCATCTAATGGAAAATCAGAATTTCTGTCACAGCTTGCTCAGGTGTTGCCGACGGAGGAGAAT
PheLeuLeuPhePheArgCysGlnGlnLeuLysSerSerGluAspPheMetGln __-_--_____------_______________________--------~~~~-~ TTCCTGTTGTTCTTTAGGTGCCAGCAGCTAAAGTCAAGTCMGTGMGACTTCATGCAGGTACACTGTGAAAATTTTCCTTCTGTAAAATCATCATCCMGACCTGAT
ThrTrpArgLysTyrAspSerAspHisSerGlyPheIleAspSerGluGluLeuLy~ ____----_____------------~~~~-------~~~~~~~~~-~~~~~~~~~~~
TGCCATAAATTCATTATCAACTTATCTGGTTGCAGACATGGAG~TATGACAGTGACCACAGTGGTTTCATTGATTCTGAGG~CTT~GGT~GCTG
ATACTTATGAGTGTGCGCAAAATGAGATTGGAGATTGGATTAC------ 2‘5kb ------AAATGTTACAGACCTAACTGTTAATGCTATGCCTTTT
CTTACTTATTCTGAACTGCAC~T~TTAAATGAGAGAGCAAAGTAGTATTTCCCATTACTTTAATTTTG~GATAGCAAGTCAAGCAAAAATA~TACG
SerPheLeuLysAspLeuLeuGlnLysAlaAsnLysGlnIleGluAspSerLysLeuTh~G _-__-------_____________________________---------------------
GAT~AAAATTCACCTGTTATACTCTCTTTATTTTRACAGAGCAAATAAGCAGATTGRAGACTCAAAGCTAACAG
1uTyrThrGluIleMet -------_--__----- AATATACAGAAATAATGGTAATTATATAAAGGCGTATTTTGTCAAGACTGTGTTTATCTTCAGCTGCTAGAAGGTTCCAAATTAGTTGGGCCCCACTA
AGTCATMCCAGGCCAAATCAGGCTGCTGCATCATTGCAGCACAGAGATGGTATCMGCACTGCMGTACTCCTGTAGCTGTGTAGTTTTCAGTGTTGcT
ACAGAAATGCCCAGGMTTTTGMCCTTCTTGGTGCTTATTAAACAGTAGGCCCTGTCACAGTGTGGTGCAAAGATTCCCATT
CTGTTAGGGGTA------ 2.3 kb ------AAACCTGGGCCATCACTTCAGTGTTAAATAerAGT
Fig. 3.

Genes for Calbindin and Calretinin 621
4701
4801
4901
5001
5101
5201
5301
5401
5501
5601
5701
5801
5901
6001
6101
6201
6301
6401
6501
6601
6701
6801
6901
7001
7101
7201
7301
7401
7501
7601
7701
7801
7901
8001
8101
8201
8301
8401
8501
8601
LeuArgMetPheAspAlaAsnAsnAspGlyLysLeuGluLe ---------------_-------------------------
GTTTTCTTCACTATGTTATTTMTTGCAATTAGTAATGT AAAAATATGTACTCTTTCAGCTCAGGATGTTTGATOCAAATTGGAGCT
uThrGluLeuAlaArg Le _-_--___------- --- TACTGMCTGGCCAGGTATGCCTTCGGTCTTTTTTCACMCAAATATCATGTATCATGTACCMTTACAGTAGACATGTTGACCTTTGTTTTTTGTCTCCAGCT
uLeuProValGlnGluAsnPheLeuIleLysPheGln ________-----__---_---~---~-~~~----~~ ACTCCCAGTACAGGAAAATTTTCTTATTllAATTTCAGGT~G~TATTCATTGTCTTATGGTTAAACTCTTAGTATTACACATACTCAGTGTTATATATC
GlyValLysMetCysAlaLysGluPheAsnLysAlaPheGluMetTyrAspGln --__-----__---_-__------------------------------------
MTATTTTTTCTTTTCCTTTTGGTGTTTAGGGTGTCAAAAGAGTTCMTAAAGCCTTTGAGATGTACGATCMGTMGTGTTTAG~G
CCCTTAGGGATTAGATTTATTGGATTTTMGGACCTGGCA
CAACTARAAATCTTGGCAGATCATAGCACTGTAAAGCCCTTGCTTATGAGACATCA
GCTCTCAGCAGTCTAACATAAGCCTATACTCGGATCATGTATCAATGTGTTACTGTTACAAAGGCTGAGAG~CATCTTTTTTTTTCCCCCTCCTTATTTT
GluLeuAspIleAsnAsnLeuAlaThr ---------------------------
CTGCCATTGGCAGCAAACTTGCTGATGCTGGTMCTAAACAGGATTATAAAGCATTATTATCTGTTCTTT~TAGGMTTAGACATTMCMCCTTGCGACA
TyrLysLysSerIleMetAlaLeuSerAspGlyGlyLysLeuTyrArgAlaGluLeuAlaLeuIleLeuCysAlaGluGluAsn _______________-________________________------------------------------------------------------------ TACMGAAAAGCATCATGGCCTTGTCTGATGGAGGGMGCTTTACCGAGCAGMCTGGCTCTCATTCTCTGTGCTGAGG-TT-CTCTTCTCTCA
________-______---_--------------------------------------------------------------------------------- TGTCCACTTMCTAGTGATGTATTCTATCTACACMTMCTGTGCACTATMGGGAGTAGGCTGTATTTTT~CTGCATATAG-TTAGCCAGGATG
-------------------------------------------------------------------2-------------------------------- TATATTCAAAAOAAACTACATGTTGGGGTTGGATTTTTTTTTTTTTTTTTGGCTTTTTTGGCTCTTTTTTTTTGCTTTCATG~CATGCCTG~ ------------------lll--T---T----------------------------------------------------A--------------------- AAATTACACCTGCTGATGCTGTTGTGGTCATCATATCCTTTGACACTTGCMCATTTTTCCTTGTTGATCTACATMCG~GGCCTAG~TCTCTCTC ------------------A--C-----------------------G------------------------------------------------------ CCACTTACAACTACACACGTTTGGGTTTTTTTGTTTGGGTTGTTGTTTTTTTTTT~TGTATGATAC~TTCAG~G~TATGATTTAGGTTGT~TA ---------------------------------------G--------------------------C--------------------------------- GGATAAAGMGTAGGCATGTTTACACTCCAAAAGGTACCACCACTCACTTACAGGTCTGTGCTCTCTGTAGTTTTTCA
-----C---------------------------------------------------------------------------------------------- GGATGTTCTTTTCTGTACCATGTAAAGGACAAAAC-CAGTTATTTTG~TTGTGCCTCCTTGGATCTTACACTGAGTTATTMTCTGTMTMTACTM
---------------------------------------------------------------------------------------------------- T-GGTMCACT-TACACMGACCTAGT~GATTTTATMCAGTTTAGTMTTCGGTTTACCAGTGCTCTGCTTTTTATTMGCTAGAGAGG --------A---------------------------=====================l1111111==========~==========11111========~ TATTTTTTTAAATGTGAAATATMTATGGMCMGCTCTTTCTTCTTCCCGTCTTCCTTTTTTTTTTTTTTTTTTGGCCTGGTTCTTTTACTTTACTTTA
====A=======T========L===================~C~======~=================================================== CACCGTCTTTGTACCAGCACCTCCATG~CATCCAGGCCATCATCGCACTCAGTATATACTGGTGTAGGAAGGAAATTGGGCTGTOTA
======C=E=================I=============================================~======-======llll=========~==== AATCTGTGTTGCTTCCATACACAGAAAGCTATTTTCAGMGCAGGTTAGMGATTAGCTTTATATMCTTCTC~TGCATCTCTTACTTMCMGCAGM
============---------======E====================== --------- iE====-- --E===---------------- ----------------===== ------__---_-_ s==== 'GGAAATGCATTTTATTTGAGTATCTCMGCMTGAGGCTCAGATCCTTCMGATTATTTTGGCACTGAAATCCCACTGARATTAATCCGTOACCTCCGTGACCTCA
========~============r===============================================T=========================l====== ';GTGAACTCAGGCRACTAGTCATTTCAGAAACAGCCCCTTGGCCTTGGCATGTTATGGAGTGCAGGATGGGGCCT
=I==C===E============I================================================================================ ‘TGCTGMGAAAGGCACACTGMCTGAGATTTACTCGTTCCCATGGCTTTACTTCCACTCCACACAGTGATTTMCTTCTCACCTGCTTGTT
============================================4========================4=====~==1===================== CGCTCTATGCMTGTGAAATACMTTGTGTATGTAAAGTGAAGGAATAGGATTGATATTGTTCATCT
,z===== TGTGCAGCTGMGCCCTGGATTTTGCCTTATTTTMGATTTTMCAGTGTAAATGTT AAAAAAAAAATTGTATGCGAAATATGATGTMCCTGAATGTTT
OCTARRATCACTACAGTGGAAGATAAGGTAAAGTGTTTTATGCCTTCTTTAGTATGAGCAAAGTTACTTGTC
AAAGGCTTGTTCTGAAGTCACTATGCTCCACTGCTGGCMTTCTCTCCCTCCATACMCAGTTCTCAGCTACCTGCAGGGCAAATGTTTCTTCCAGTATC
TTCGCATGAAT-CTTGAATT-GACAATAATTTAACAACACCATTCT AAAAAAGATGTCTATTATATCAATGAAUGCTAAATTTATAGCAAATA
I-AGCTAAGTCAAAGCTGGTGTAATCTCCATGTTTTCAAATCGCTCCTGAACAGAGCTCTTAGAACTGTCAGGGTTGGGGCTGAACAAGGG
'PTAGGTCAGTAAGAGAGGTGATGTTGAGG~GACTGC~GCTTCTTTCTTCTGGTAGGCATTCAGT~CAGATTTTCT~TTATTTTACAGTAG~GG
I-AGCARRAGTTTCCTMTTCTCAAAGAAAACAAAAATGCAGTAAATATTTGGCCCTTTTRAAGACCTTTGACCTTTGACAT~TGCCTCATCTGCTMTGT~CC
'PCAGCAGMTTCAGACGCCATTAGCACACCTCAGGGCATCTCACTG~TTGCMGTCATCMCCACTGMGTTTTGATAC~CTCATCACCC~~~~T~~~
~;MGAGCMGTGMGTTTCACTTATGATTTTATCMGAGCAAACACAGGCTTTGMGCACMTTTAGCTTACATTTTCTGCTGTACATTTCTACCCTG
MCAGATCGTGTTCACAGCATCACTGCTGTGGTCTAATCGCCATAGATCGCAATTAGTAATCACGCATATTCGCAAGATACCTGGCAAGCTTCAGAAGTC
Figure 3. Partial nucleotide sequence of the chick calbindin gene. Homology with cDNA sequence of Wilson et al.
( 198.5) is indicated by dashes and with that of Hunziker (1986) by double dashes. The amino acid sequence is given above the cDXA nucleotide sequence. The probable cap site is indicated by ***; the putative TATA promoter at 729 is over-lined and the 3 polyadenylation/cleavage signals are underlined. Direct repeats are indicated by +; complementary repeats by +--+. The 2 GGCGGG sequences are boxed. 1. Genomic bases not present in cDNA. Bases in cDNA before posit,ion marked: 2, extra T; 3, extra C; 4. extra A. EMBL accession nos. X06629, X06630, X06631, X06632. X06633.

622 P. W. Wilson et al.
+-.p - - - - - _ _ - _ - - _ -I*; - _ - 23;
* ScYlI t
Figure 4. Map of the right-hand 2.2 kb of llCGl1, showing the central part of’ the calretinin gene. Arrows indicate regions sequenced. Axons of the calretinin gene are numbered as in calbindin. The sequences of exons 3 to 8 confirm t,he cDNA sequence (Rogers, 1987). The sequence of exon 9 is:
ag/GGGATGAAGCTGTCCTCGGAGGAATTCAACGCGATTTTTGCTTTTTATGACAAG/gt.
At t,he site marked with an asterisk, there could be another small PstI fragment. t, P&I and Sal1 polylinker sites.
vertebrate gene (56 and 60 nucleotides), as well as some very long ones (2.7 to 4.5 kb). Remarkably, three of these long introns in calbindin correspond to very short ones in calretinin, while an intron that is only 60 nucleotides long in calbindin is about 700 nucleotides long in calretinin (Table 1).
(b) Intron distribution in the calmodulin superfamily: evidence for intron insertion
Figure 5 shows the positions of the introns in all relevant, members of the calmodulin superfamily of calcium-binding proteins. The calcium-binding domains are aligned. It is evident that introns do not typically fall between domains, nor even in the same places in different domains (Hardin et al.. 1985). Clearly, this superfamily is not one of those in which units of protein structure are encoded in separate exons, even though genetically these units were derived by duplication of a common ancestral gene specifying a calcium-binding domain.
Three possible explanations can be considered for such a chaotic intron distribution. First, the introns may be in ancestral positions, modified only by removal of some introns. This cannot be generally true, as the introns occur at too many positions relative to the canonical calcium-binding domain sequence, several only one to four nucleotides apart. Moreover, very few of them are shared between different domains or different gene families. If the present arrangement was due to random removal from an original set, which would have to have contained at least ten introns per domain, far more coincidences between different domains would be expected. Second, the introns may have moved. While this could be true for some introns that are in the same phase of the reading frame (see the legend to Fig. 5), it cannot be generally true, because an intron cannot be moved by a non-integral number of codons, or moved across a conserved coding sequence, without damaging the gene or invoking vanishingly improbable coincidences of mutations (Rogers, 1986). Third, the introns may have been inserted since the genetic duplications of the domains and the genes, as has occurred in other genes and gene families (Rogers, 1985, 1986). This is the most likely history of the calcium-binding
protein genes. Moreover, the weak clustering of intron positions into four regions of the calcium- binding domain sequence (Fig. 5) is consistent with the evidence for preferential insertion into certain regions in other gene families (Rogers, 1985, 1986).
The genes in Figure 5 can be assigned to three families by sequence homology and by intron distribution. The probable evolution of each family. as discussed below (Fig. 6), is consistent with the evolutionary tree proposed from comparison of the homologies in amino acid sequence of the calcium- binding domains (Parmentier et al., 1987).
The first family includes calmodulin, Specl, and the myosin alkali light chain. These genes have four introns in common. Three of these a.re phase I introns, in domains 1, II and IV, respectively. But they can never have been in homologous positions. nor can they have separated the domains, as they map within different conserved positions of the calcium-binding domain. Each gene also has a unique intron in domain III, in a different position and a different phase in each gene. These must have been inserted after the three genes separated. near the middle of what would then have been the longest exon. This provides a graphic example of how selective intron insertion leads to uniformity of exon size. Parvalbumin is a member of t,his faiily, and shows the same pattern of evolution, although it has no domain I and a variant, domain Tl (Berchtold et al., 1987).
Two members of this family have been sequenced from Drosophila, and all four common introns nrr present in one or both genes, as is the gene-specific intron in domain III of the myosin alkali light chain. This shows that all these insertions preceded the separation of vertebrates from inserts. How ever, the common introns are lacking from domain I of Drosophila calmodulin (Smith et al.. 1987) and from domains IT and IV of the Drosophila myosin alkali light, chain (Falkenthal et al., 1985). This shows that introns have been removed from the insect genes, consistent with the fact that insect genes, in general, contain fewer introns in different places from those of plants or vertebrates.
The second family consists of the calpain gene (Emori et al.; 1986). These authors noted that the introns do fall more or less between the calpain

Genes for Cal&din and Calretinin 623
1 CALM V v MADQL--TEEQIAEFKEAFSL-FDKDGDGTITTKEL-GTVMRSL---.----
SPEC V v MAAQLLFTDEEVTEFKRRFKN-KDTDKSKSITAEEL-GEFFKST---.----
MALCl... V v K---IEFSKEQQDDFKEAFLL-FDRTGDAKITLSQV-GDIVRAL-------
MALC3 V v M----SFSPDEIN/
CALP.... v V RHKDLKTDGFSLDSCRNMVNL-MDKDIGSARLGLVEF-QILWNKI-------
CALB
n PARV
CALM
SPEC
MALC
CALP
CALB
CALR
v MSMTDLLSAEDIKKAIGA-FT--AADSFDHKKF-FQMVGLK-------- v -- --GQNPTEAELQDMINE-VDADGNGTIDFPEF-LTMMARKM------- v --GKSYTDKQIDKMISD-VDTDESGTIDFSEM-LMGIAEQM-------
--- v -GQNPTNAEINKILGN-PSKEoAKKITFEEF-LPMLQAAAN------
,g:::I: V v --RSWLTIFRQ-YDLDKSGTMSSYEM-RMALESA--------
V LTPEMKAFVDQ-YGKATDGKIGIVEL-AQVLPTEENFLLFFR
. . .G V DSKRDSLGDKMKEFMHK-YDKNADGKIEKAEL-AQILPTEENFLLCFR
III PARV
CALM
SPEC
MALC
CALP
CALB
CALR
--- v KKSADDVKKVFHI-LDKDKSGFIEEDEL-GSILKGFSSD----- V -KDTDSEEEIREAFRV-FDKDGNGYISAAEL-RHVMTNL--------
0 VKWTWKEEHYTKAFDD-MDKDGNGSLRPQEL-REALSAS-------- v NKDQGTFEDFVEGLRV-FDKEGNGTVMGAEL-RHVLATL--------
v GFKLNNKLHQVVVARY-ADAE-TG-VDFDNF-VCCLVKL--------
CQQLKSSEDFMQ z
V WRK-YDSDHSGFIDSEEL-KSFLKDLLQKANKQI
-QHVGSSSEFMEAWRR-YDTDRSGYIEANEL-KFFLSDLLKKANRPY
m PARV
CALM
SPEC
MALC
CALP
CALB
CALR
P CALB
CALR
m CALB
v ARDLSAKETKTLMAA-GDKDGDGKIGVEEF-STLVAES* 7 GEKLTDEEVDEMIRE-ADIDGDGQVNYEEF-VQMMTAK* v KPPMKRKKIKAIIQK-ADANKDGKIDREEF-MKLIKSC"
v v GEKMTEEEVEELMKG--QEDSNGCINYEAF-VKHIMSV* ------ v ETMFRFFHS-MDRDGTGTAVMN-L-A ~$~LLLTMcG* v
EDSKLTEYTEIMLRM-FDANNDGKLELTEL-ARLLPVQENFLIKFQ ; v V DEAKLQEYTQTILRM-FDMNGDGKLGLSEM-SRLLPVQENFLLKFQ
V V V GVKMCAKEFNKAFEM-YDQDGNGYIDENEL-DALLKDLCEKNKK V V GMKLSSEEFNAIFAF-YDK...
V ELDINNLATYKKSIM-ALSDG-GKLYRAEL-ALILCAEEN*
A A* *
A A.. AfA A AA YY (O=EMN)
Figure 5. Positions of introns in genes of the calcium-binding protein superfamily. Sequences and intron positions are shown for those members of the calmodulin superfamily for which substantial genomic sequence is available from deuterostome species. The calcium-binding domains are aligned, with the central conserved calcium-binding loop of each one set off by dashes. Intron positions are coded according to the phase of the reading frame: V. phase 0 (between codons), v, phase I (after 1st nucleotide of codon); 8, phase II (after 2nd nucleotide of codon). At the bottom is a plot of all intron positions, with the larger dots representing the shared introns of calmodulin, Specl, and the myosin alkali light chain. Genes listed are: PARV, parvalbumin (rat: Berchtold et al., 1987). CALM, calmodulin (chick: Simmen et al., 1987); SPEC, Specl (sea urchin: Hardin et al., 1985); MALC, myosin alkali light chain (chick: Nabeshima et al., 1984); CALP, calpain (chick: Emori et aZ., 1986); CALB, calbindin (chick: this paper); CALR, calretinin (chick: this paper, incomplete). The arrangement of introns in calmodulin domains II to IV is identical in the rat (Nojima & Sokabe, 1986). The myosin alkali light chain has 2 alternative pairs of 5’ exons, producing MALCl and MALC3, and the arrangement is identical in the mouse (Robert et al., 1984) and rat (Strehler et al., 1985). In addition to the genes shown here, the gene for myosin regulatory light chain LC, (Nude1 et al., 1984) contains 5 introns that are again at different positions from those in other superfamily members.
domains; but they nevertheless represent indepen- dent insertions, as they fall in different phases of the reading frame. Calpain “domain III”, which has essentially no homology to the canonical calcium- binding domain, is encoded in a separate exon and may exemplify the complete replacement of an exon in evolution.
The third family consists of calbindin and calretinin. Three of the ten introns (introns 2, 8 and
10) are in phase 0 and fall between domains (preceding domains II, V and VI). Two others (introns 4 and 6), also in phase 0, fall 11 or 12 codons into domains III and IV, and they could have moved from the inter-domain junctions, as the sequences in between are not strongly conserved. It is therefore possible that these five mtrons are all descended from one intron preceding an ancestral domain. However, there is no evidence of such an

624 P. W. Wilson et al.
4- DomaIn ancestor
Delete donun I \
Colmodulln
Speci
MALC
+6 Introns Substitute exon for domoln III
Co-bandIng E-Domam domom - ancestor
4-Domoln \ , j - ancestor l Calpot”
\
/ , 4-domom -- __+ z,i;“,“Jn < :I:,:
o”ceS’or /” ‘2: +I Intro” Duplvxte f7
exons I”irO”s
Figure 6. Probable evolutionary history of the calcium-binding protein genes. In the calbindin/calretinin lineage, it is not clear whether 1 intron was inserted before some of the domain duplications (as shown here) or whether all IO introns were inserted into the 6-domain gene. All these events occurred before the separation of mammals from birds, and in the calmodulin/MALC family, before the separation of vertebrates from insects. In insect) genes for calmodulin and the myosin alkali light chain, some of the inserted introns have subsequently been removed.
ancestral intron in the other calcium-binding protein genes. And this interdomain region, particu- larly the coding sequence for Gly-X-Lys-Leu/Met, may be favoured for intron insertion, since phase T introns have been inserted here preceding the myosin alkali light chain domain IV (a gene-specific insertion; see above) and preceding domain TTT of calpain (otherwise non-homologous; see above).
The other five introns of the calbindin gene are all in three phases of the reading frame, and fall within conserved regions of the calcium-binding domains. Three (introns 3, 5 and 7, in domains II, III and IV) fall within an 11-nucleotide span that has been subject to intron insertion in other genes; all these introns are in different positions. Two (introns 1 and 9, in domains I and V) fall in positions four nucleotides apart, and the same positions contain introns in calmodulin domains II and III, respec- tively, the latter apparently being a gene-specific insertion (see above). Although such coincidences could indicate that the introns concerned are survivors from an ancestral gene, it is at least as likely that they have been introduced indepen- dently into different domains of the calmodulin and calbindin genes. This is one of the four clusters of intron positions in calcium-binding domain sequences, and these clusters may represent regions favoured for intron insertion.
In conclusion, the calmodulin and calbindin gene families have acquired introns independently since their original four-domain structures were created. Introns have been inserted preferentially in certain regions, and have tended to divide the genes into exons of uniform size. The result has been approximately one intron per domain in calmodulin, and two per domain in calbindin, but
these distributions do not reflect any ancestral arrangement. In fact, they demonstrate the fallacy of inferring ancestral arrangements from apparent, regularities in present-day intron distributions.
References Berchtold, M., Epstein, P., Beaudet, A. I,.. Payne, M. E..
Heizmann. (1. W. & Means. A. R. (1987). ,I. Biol. Chem. 262, 8696-8701,
Breathnach, R. & Chambon, P. (1981). Annuc. KU.. B&hem. 50, 349-383.
Breddermann, P. B. & Wasserman, It. H. (1974). Biochemistry, 13, 1687-1691.
Bucher, P. & Trifonov. E. N. (1986). Nucl. Acids Ile,u. 14. looO9-10026.
Dierks, P.. van Oyen, A.. Cochran. M. I)., Dobkin, (‘.. Reiser, J. & Weissmann, C. (1983). Cell, 32, 695-706.
Emori, Y.. Ohno, S., Tobita, M. & Suzuki, K. (1986). FEBS Letters, 194, 249-252.
Emtage, J. S., Lawson, D. E. M. & Kodicek. E. (1974). Nature (London), 246, 100-103.
Falkenthal, S., Parker, V. P. & Davidson. N. (1985). Proc. Nat. Acad. Sci., 1J.S.A. 82, 449-4.53.
Feinberg, A. P. & Vogelstein, B. (1984). Anal. Bioche,m. 137, 266-267.
Fullmer, C. S. & Wasserman, R. H. (1987). Proc. iVat. Acad. A%%., U.S.A. 84, 4772-4776.
Gil, A. & Proudfoot, N. ,J. (1987). Cell, 49. 399. 406. Goedert, M. (1986). B&hem. Bi0ph:y.s. Res. Pomrnun. 141,
1116-1122. Hanahan, D. (1983). J. Mol. Biol. 166, 557-580. Hardin, S. H., Carpenter, C. D., Hardin, P. E., Briskin.
A. M. & Klein, W. H. (1985). J. Mol. Biol. 186, 243% 255.
Hattori, M. & Sakaki. Y. (1986). Anal. Niorhem. 152. 232-238.
Henikoff, S. (1984). Gene, 28, 351-359.

Genes for Calbindin and Calretinin 625
Hunziker, W. (1986). Proc. Nut. Acad. Sci., U.S.A. 83, Garner, I., Guenet, J.-L. & Buckingham, M. (1984). 7578-7582. Cell, 39, 129-140.
Hunziker, W., Siebert, P. D., King, M. W., Stucki, P., Dugaiczyk, A. & Norman, A. W. (1983). Proc. Nut. Acad. Sci., fi.S.A. 80, 4228-4232.
Kretsinger. R. H. (1980). Ann. N. Y. Acad. Sci. 356, 14- 19.
Lawson, I). E. M., Harding, M., Wilson, P. W., Pohl, V., Pattyn. G. & Pasteels, J. L. (1987). In Calcium Binding Proteins in Health and Disease (Norman, A. W., Vanaman, T. C. & Means, A. R., eds), pp. 217-226, Academic Press, New York.
Maniatis, T., Frisch. E. F. & Sambrook, J. (1982). Editors of Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY.
Rogers, J. (1985). Nature (London), 315. 458-459. Rogers, J. (1986). Trends Genet. 2, 223. Rogers, J. (1987). J. Cell Biol. 105. 1343-1353. Sanger, F., Nicklen, S. & Coulson, A. R. (1977). Proc. Nat.
Acad. Sci., IJ.S.A. 74, 5463-5467. Sazar, S. & Schimke, R. T. (1985). J. Biol. Chem. 261,
4685-4690.
Mount. S. M. (1982). ,Vucl. Acids Res. 10, 459-472. Nabeshima. Y.. Fujii-Kuriyama, Y., Muramatsu, M. &
Oga,ta. K. (1984). Nature (London), 308, 333-338. Naora, H. & Deacon, N. J. (1982). Proc. Nat. Acad. Sri.,
I:.S.A. 79, 6196-6200.
Simmen, R. C. M., Tanaka, T., Tsui, K. F., Putkey, J. A., Scott, M. J., Lai, E. C. & Means. A. R. (1987). J. Biol. Chem. 262, 4928-4929.
Smith, V. L., Doyle, K. E., Maune, J. F., Munjaal, R. P. & Beckingham, K. (1987). J. Mol. Biol. 196,471-485.
Strehler, E. E., Periasamy, M., Strehler-Page, M. A. & Nadal-Ginard. B. (1985). Mol. Cell Biol. 5, 3168- 3182.
Takagi. T., Nojiri. M. & Konishi. K. (1986). FEBS Letters, 201, 41-46.
Taylor, A. N. (1974). Arch. Biochem. Biophys. 161, 100- 106.
Nojima, H. & Sokabr, H. (1986). J. Mol. Biol. 190, 391- 400.
Theophan, G. & Norman, A. W. (1986). J. Hiol. Chem. 261, 731-735.
Norman. A. W., Roth, J. & Orci, L. (1982). Endocrinol. Rev. 3, 331L366.
Nudel. I!., Calve, ,J. ICI., Shani, M. & Levy. Z. (1984). Nucl. Acids Res. 12. 7175-7186.
Parmentier. M.. Lawson, D. E. M. 19, Vassant, G. (1987). Eur. J. Biochpm. 170, 207-215.
Pearson, W. R., Wu, J. R. & Bonner, J. (1978). Biochemistry, 17, 51-59.
Pohl. V., Pattvn, G. & Lawson, D. E. M. (1987). In Calcium knding Proteins in Health and Disease (Norman. A. W., Vanaman, T. C. & Means, A. R., eds). pp. X27-229. Academic Press, New York.
Robert. B.. Daubas. P., Akimenko, M.-A.. Cohen, A..
Wasserman, R. H. (1985). In Vitakn D. Chemical Biochemical and Clinical Update (Norman, A. W., ed.), pp. 321-322, De Gruyter. Berlin.
Wilson. P. W., Harding, M. & Lawson, 1). E. M. (1985). Nucl. Acids Res. 13, 8867-8881.
Wood, T.. Tobin, A. J., Varghese, S., Huang, Y. C. & Christakos, S. (1987). In Calcium Binding Proteins in Hea.lth and Disease (Norman, A. W., Vanaman, T. C. 8: Means, A. R.. eds), pp. 276-284. Academic Press, New York.
Yamakuni, T., Kuwano, R., Odami, S., Miki, N., Yamaguchi. Y. & Takahashi. Y. (1986). ,Vucl. Acids Res. 14, 6768.
Edited by B. Mach