technia international journal of computing science … of...keywords: gabor wavelet correlogram (g...
TRANSCRIPT

TECHNIA International Journal of Computing Science and Communication Technologies, VOL. 4, NO. 1, July 2011. (ISSN 0974-3375)
Optimization of Gabor Wavelet CorrelogramQuantization Thresholds Using
Genetic Algorithm1Subrahmanyam Murala, 2R.P. Maheshwari, 3R. Balasubramanian
Indian Institute of Technology Roorkee, Roorkee 247667, Uttarakhand, [email protected], [email protected], [email protected]
Abstractdrastically over the past decade, retrieval of images based oncontent, often referred as CBIR has gained a lot of researchinterests. The Gabor Wavelet Correlogram (GWC) method isbased on a combination of multi-resolution imagedecomposition and color correlation histogram. According toGWC algorithm, Gabor wavelet coefficients of the image arecomputed using a directional Gabor wavelets transform. Aquantization step is then applied before computing one-directional Auto-Correlogram of the Gabor waveletcoefficients. Finally, index vectors are constructed using thisone-directional Gabor Wavelet Correlogram. Thequantization step is more important for Gabor WaveletCorrelogram based image indexing and retrieval. A novelevolutionary method called Evolutionary Group Algorithm(EGA) is proposed in [1] for complicated time-consumingoptimization problems such as finding optimal parameters ofcontent-based image indexing algorithms. In the newevolutionary algorithm, the image database is partitionedinto several smaller subsets, and each subset is used by anupdating process as training patterns for each chromosomeduring evolution. This is in contrast to Genetic Algorithmsthat use the whole database as training patterns forevolution. The optimal quantization thresholds computed byEGA improved significantly all the evaluation measuresincluding average precision and average recall for the GaborWavelet Correlogram method.
Keywords: Gabor Wavelet Correlogram (GWC), GeneticAlgorithm (GA), Content Based Image Retrieval (CBIR).
I. INTRODUCTION
Recent years have seen a rapid increase in the size ofdigital image collections. Every day, both military andcivilian equipment generates Giga-bytes of images. Ahuge amount of information is out there. However, wecannot access or make use of the information unless it isorganized so as to allow efficient browsing, searching, andretrieval. Image retrieval has been a very active researcharea since the 1970s, with the thrust from two majorresearch communities, database management andcomputer vision. These two research communities studyimage retrieval from different angles, one being text-basedand the other visual-based. The text-based image retrievalcan be traced back to the late 1970s. Avery popularframework of image retrieval then was to first annotate theimages by text and then use text based database
management systems (DBMS) to perform image retrieval.Many advances, such as data modeling, multidimensionalindexing, and query evaluation, have been made along thisresearch direction. However, there exist two majordifficulties, especially when the size of image collectionsis large (tens or hundreds of thousands). One is the vastamount of workers required in manual image annotation.The other difficulty, which is more essential, results fromthe rich content in the images and the subjectivity ofhuman perception. That is, for the same image contentdifferent people may perceive it differently. Theperception subjectivity and annotation impreciseness maycause unrecoverable mismatches in later retrievalprocesses [2]. In the early 1990s, because of theemergence of large-scale image collections, the twodifficulties faced by the manual annotation approachbecame more and more acute. To overcome thesedifficulties, Content Based Image Retrieval was proposed.That is, instead of being manually annotated by text-basedkey words, images would be indexed by their own visualcontent, such as color and texture. Since then, manytechniques in this research direction have been developedand many image retrieval systems, both research andcommercial, have been built. Two major approachesincluding spatial and transform domain-based methods canbe identified in CBIR systems. The first approach usuallyuses pixel (or a group of adjacent pixels) features likecolor and shape. Among all these features, color is themost used signature for indexing. Color histogram [3] andits variations [4] were the first algorithms introduced in thepixel domain. Despite its efficiency, color histogram isunable to carry local spatial information of pixels.Therefore, in such systems retrieved images may havemany inaccuracies, especially in large image databases.For these reasons, two variations called image partitioningand regional color histogram were proposed to improvethe effectiveness of such systems [5, 6]. ColorCorrelogram is a different pixel domain approach whichincorporates spatial information with color [7, 8]. Colorspatial schemes like color Correlogram offer moreeffectiveness in comparison with color histogram methodswith little efficiency reduction. Despite the achievedadvantage, they suffer from sensitivity to scale, color andillumination changes. Edge orientation Auto-Correlogram[9] was an effort to reduce the sensitivity of color
668

TECHNIA International Journal of Computing Science and Communication Technologies, VOL. 4, NO. 1, July 2011. (ISSN 0974-3375)
Correlogram method to color and illumination variations.Shape-based and color shape- based systems using snakes[10], contour images, and other boundary detectionmethods [9, 11], were also proposed as pixel domainmethods. In the second approach, transformed data areused to extract some higher-level features. Wavelet-basedmethods, which provide better local spatial information inspatial domain, have been used [12]. The advances in thisresearch direction are mainly contributed by the computervision community. This approach has established a generalframework of image retrieval from a new perspective.However, there are still many open research issues to besolved before such retrieval systems can be put intopractice. Regarding content-based image retrieval, there isa need to survey what has been achieved in the past fewyears and what are the potential research directions whichcan lead to compelling applications [2].
The organization of the paper is as follows. In sectionII, a brief review of Gabor Wavelet Correlogram methodis given. Section III, presents a brief review of GWCquantization thresholds optimization using EGA.Experimental results and discussion are given in sectionIV. Finally, conclusions are presented in section V.
II. GABOR WAVELET CORRELOGRAM
One of the most important properties of wavelettransform is space-frequency decomposition of the inputsignal. This property enables us to apply pixel domaintools, such as color correlogram, to the waveletcoefficients of an image. A wavelet correlogram expresseshow the spatial correlation of pairs of wavelet coefficientschanges with distance. Therefore, the multiscalemultiresolution property of the wavelet transform andinvariancy of color correlogram are combined.Consequently, the image indexes obtained by the waveletcorrelogram method may have better discriminativeperformance. Among different wavelet decompositionalgorithms, the 2D Gabor wavelet has special properties,which make it an appropriate wavelet transform to be usedin the wavelet correlogram algorithm. The brief review ofthe 2D Gabor wavelet transform for implementation isavailable in [13]. Fig 1 shows the development of theGabor wavelet correlogram approach for image indexingand retrieval, the theoretical development GWC isavailable in [14].
Fig. 1: Gabor Wavelet Correlogram Algorithm [15]
In this paper Gabor wavelets in four directions (K=4)and three scales (S=3) are used as illustrated in Fig. 1.According to this figure, GWC first computes the waveletcoefficients using Gabor wavelets. The next block whosetask is to quantization of the coefficients are discretizedusing the quantization thresholds obtained experimentallyfor good performance as shown in Fig. 2.
Fig. 2: GWC Quantization Thresholds without Optimization
As illustrated in Fig. 2, small coefficients areconsidered as noise (and discarded) and the negativecoefficients are truncated to suppress the undesirableeffects of sinusoid oscillations of the Gabor wavelets.Finally, the autocorrelogram of the quantized coefficientsis computed along the direction normal to Gabor waveletorientation:
' ' ' ', 0 0 ,
,
,
( , ) ( , ) ; ( , )( , )
( , ) ( , )m mm n i m n k k i
m n
m n i
x y W x y c W x y ci i
x y W x y c (1)
Where, is the matrix of the quantized Gaborwavelet coefficients computed by indicates the
distance parameter of autocorrelogram and and aregiven by:
' ' Tk k
(2)
III. GWC QUANTIZATION THRESHOLDSOPTIMIZATION USING EGA
The quantization step is more important for GaborWavelet Correlogram. A novel evolutionary method calledEvolutionary Group Algorithm (EGA) is proposed [1] forcomplicated time-consuming optimization problems suchas finding optimal parameters of content-based imageindexing algorithms. In the new evolutionary algorithm,the image database is partitioned into several smallersubsets, and each subset is used by an updating process astraining patterns for each chromosome during evolution.This is in contrast to Genetic Algorithms that use thewhole database as training patterns for evolution.
The image database consists of image categories (A),and each category includes C images, i.e., |D| =A*C where|.| returns the cardinality of a set. The reference imagedatabase is partitioned into several subsets and the whole
669

TECHNIA International Journal of Computing Science and Communication Technologies, VOL. 4, NO. 1, July 2011. (ISSN 0974-3375)
database is used only once. In each evolution step, onlyone subset is indexed using each chromosome in thepopulation.
A. Reference Image Database Partitioning
All images of the reference image database arepartitioned to L different subsets according to Equation (3)and (4) such that each subset includes = C/L imagesfrom each similarity category.
L(3)
(4)
L (5)where ( , )i kI indicates the kth image in the
subset iD and LD is the total number of images in each
subset. The following equations are simply concluded:
(6)
B. Proposed Chromosomes
The chromosomes are defined as follows:' evn hisj j j j j ,
(7)
Where and jJ represent the age gene,evolutionary genes, history genes, and evaluation genes ofthe jth chromosome, respectively.
1. Evolutionary genes
As implied by their name, the evolutionary genesparticipate to evolution whose goal is their optimization.Indeed, evolutionary genes are the indexing parametersthat should be optimized during evolution.
,(8)
2. Age gene
For each chromosome, the age gene indicates thenumber of the image subsets that have already beenindexed during evolution. Using the age gene jg , we maywrite
( , ) ( , )j evni k i k j ,
j
L
(9)
where ( , )ji k indicates the index vector of the kth image
from the ith image subset that is computed by the indexingparameters of the jth chromosome. The age of each
chromosome is initially set to zero and obviously, it isalways between 0 and L.
3. History genes
For each chromosome, the history genes are the indexvectors of the previously indexed images.
(10)
During evolution, for each chromosome, the CBIRsystem retrieves the matched images using the above localfeaturebase. Therefore, for query image ( , )i kI , we have
'( , ) ( , )
( , )
ji k i k j
ji k j (11)
4. Evaluation genes
For the jth chromosome, the evaluation function isdefined as:
2 1'
( , ), ( , ),0 1 1 1
1( , ) ( , ),2
1,2,......., .
j j jLDg g gj j
j j i k p i k qi k p qj
LJ g y yC D g
j M (12)
Where ( , ),ji k py indicates the pth member of ( , )
ji k .
IV. MATURE AND IMMATURE CHROMOSOMES
For each chromosome, the cardinality of the local
larger than a threshold . We call this chromosome asmature and the chromosome whose age is smaller thanas immature.
V. UPDATING CHROMOSOMES
A chromosome updating process (CUP) is defined inGA in order to update the genes by indexing the newimages of the next image subsets. CUP proceeds asfollows.
S mature chromosomes, whose ages are smallerthan L, are randomly selected from the currentpopulation as well as all immature chromosomesto make a set P.The history genes of these chromosomes areextended as follows:
The evaluation genes are also extended asfollows:
Age genes of these chromosomes are increasedby one
Therefore, the age gene indicates the progress of theupdating process. In each stage of CUP, all immaturechromosomes are kept in the population and are updateduntil they become mature and generate offspring.
670

TECHNIA International Journal of Computing Science and Communication Technologies, VOL. 4, NO. 1, July 2011. (ISSN 0974-3375)
C. Fitness Function
In typical GA, the fitness function is defined as afunction of evaluation values for all chromosomes.
Chromosomes in different ages have local featureand image databases with different sizes.Consequently, their retrieval results are notcomparable.The retrieval results of the chromosomes withvarious ages have different dimensions.Older chromosomes are more valuable thanyounger ones, since they have been kept in thegroup for a longer duration and competed morewith other chromosomes during evolution.
In the proposed fitness function, the chromosomes arefirst classified into same-age classes. Then, the probabilityof selecting each class is computed.
D. Fitness Computation Algorithm
The immature chromosomes cannot be used asparents to generate new offspring during evolution fortheir imprecise evaluations. Therefore, their fitness shouldalways set to zero until they become mature. The proposedalgorithm for computing the chromosomes fitness (thefitness algorithm) is summarized as follows [1].
Fig. 3: Flowchart for the Ega
K is set to the threshold of . Also, the fitness ofall immature chromosomes is set to zero
' 'j k j
The fitness of all chromosomes that belong to thesame age class k is computedThe total fitness of the same-age class iscomputed.k=k+1.Steps 2 to 4 are repeated until the fitness of allchromosomes is computed (k= ).
Fig. 4: Optimized Quantization Thresholds for GWC [15]
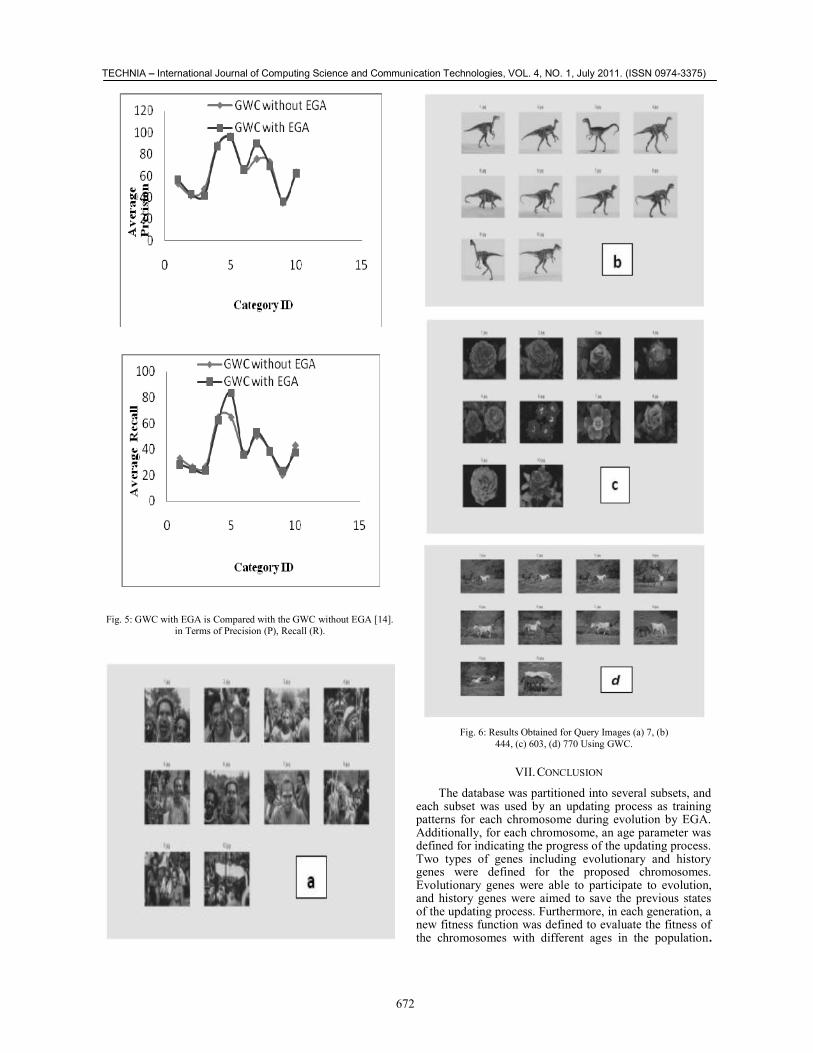
VI. RESULTS AND DISCUSSIONS
In this paper GWC is applied to a subset of CORELdatabase with 1000 images in 10 categories as listed inTable. 1 and Fig. 6 illustrate four query results usingGWC. A retrieved image has been considered a match if itbelongs to the same category of the query image. TheGWC with EGA results are compared with the GWCwithout EGA[14] results in terms of average precision,and recall. Precision (P), and recall (R) for query image
are defined as:
(13)Where, k represents the set of all matched images
with and ( )kA I gives the number of its members.The average precision for images belonging to the qth
category ( )qA has been computed by:
q
Finally, the average precision is given by:10
110q
qP P (14)
The average recall is also computed in the samemanner. The retrieval result of GWC with EGA iscompared with the GWC without EGA [14] are shown inthe following table.TABLE I: GWC WITH EGA IS COMPARED WITH THE GWC WITHOUT EGA
[14].
CategoryGabor Wavelet Correlogram
GWC without EGA [14] GWC with EGAPrecision (%)
(N=10)Recall (%) Precision
(%)(N=10)Recall (%)
Africans 52.9 33.2 56.90 28.38Beaches 42.0 26.2 43.10 24.75Buildings 47.8 26.5 41.90 23.87Buses 88.3 65.1 87.42 62.41Dinosaurs 96.2 65.0 96.00 83.34Elephants 65.9 37.0 65.91 35.85Flowers 75.5 50.4 89.94 53.14Hores 73.0 39.5 69.17 38.62Mountains 35.2 20.1 36.60 23.82Food 63.2 43.1 62.61 37.62Total 64.1 40.6 65.01 41.18
671
TECHNIA International Journal of Computing Science and Communication Technologies, VOL. 4, NO. 1, July 2011. (ISSN 0974-3375)
Fig. 5: GWC with EGA is Compared with the GWC without EGA [14].in Terms of Precision (P), Recall (R).
Fig. 6: Results Obtained for Query Images (a) 7, (b)444, (c) 603, (d) 770 Using GWC.
VII.CONCLUSION
The database was partitioned into several subsets, andeach subset was used by an updating process as trainingpatterns for each chromosome during evolution by EGA.Additionally, for each chromosome, an age parameter wasdefined for indicating the progress of the updating process.Two types of genes including evolutionary and historygenes were defined for the proposed chromosomes.Evolutionary genes were able to participate to evolution,and history genes were aimed to save the previous statesof the updating process. Furthermore, in each generation, anew fitness function was defined to evaluate the fitness ofthe chromosomes with different ages in the population.
672

TECHNIA International Journal of Computing Science and Communication Technologies, VOL. 4, NO. 1, July 2011. (ISSN 0974-3375)
The optimal quantization thresholds computed by EGAimproved significantly all the evaluation measuresincluding average precision and average recall for theGabor Wavelet-Correlogram method.
ACKNOWLEDGMENT
My sincere thanks to the Anil Balaji Gonde (ResearchScholar), Department of Electrical Engineering, IndianInstitute of Technology Roorkee for giving inspiration,moral support and encouragement throughout this work.
REFERENCES
[1]Approach for Optimizing Content Based Image Indexing
Cybernetics part b: Cybernetics, vol. 37, no. 1, pp. 139 153,February 2007.
[2] Y. Rui and T.Promising Directions, and Open IssueCommunication and Image Representation 10, pp. 39 62, 1999.
[3]pp.11 32, 1991.
[4] M. Flickner, H. Sawhney,W. Niblack, J. Ashley, Q. Hunag, B.Dom, M. Gorkani, J. Hafner, D. Lee, D. Petkovic, D. Steele, P.
IEEE Comput. 28 (9), pp. 23 32, 1995.[5] C. Carson, M. Thomas, S. Blongie, J.M. Hellerstine, J. Malik,
-based image indexing andretriNetherland, pp. 509 516, 1999.
[6]73, 1997.
[7] J. Huang, S.R. Kumar, M. Mitra, W.J. Zhu, R.
Conference on Computer Vision and Pattern Recognition, San Juan,pp. 762 768, 1997.
[8]. J. Comput. Vis. 35 (3), pp. 245
268, 1999.[9] F. Mahmoudi, J. Shanbehzadeh, A.M. Eftekhari-Moghadam, H.
Soltanian-edge orientation auto-1725 1736, 2003.
[10] H.H.S -invariant active contour model (AI-snake) for model-pp. 135 146, 1998.
[11]ultimedia Storage
Archiving Systems 29(4), pp. 131 140, 1997.[12] J.Z. Li, G.
Anal. Mach. Intell. 23(9), pp. 947 963, 2001.[13] S. Murala, A. B.
Advance Computing Conference (IACC 2009), Thapar University,Patiala, India, pp 1411-1416, 6-7 March 2009.
[14] M. Saadatmand-Tarzjan, H.A. Gabor Wavelet
Int. conf. On Pattern Recognition, 2(10), pp. 925 928, 2006.[15] S. Murala, Applications of Genetic Algorithm in Content Based
lEngineering, IIT Roorkee, Roorkee, India, pp. 1 47, 2009.
673