technische universität dortmund automatic mapping to tightly coupled memories and cache locking...
TRANSCRIPT

Technische Universität Dortmund
Automatic mapping to tightly coupled memories and cache locking
Peter Marwedel1,2, Heiko Falk1, Robert Pyka1, Lars Wehmeyer2
1TU Dortmund2Informatik Centrum Dortmund (ICD)
http://ls12-www.cs.uni-dortmund.de, http://www.icd.de
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 2 -
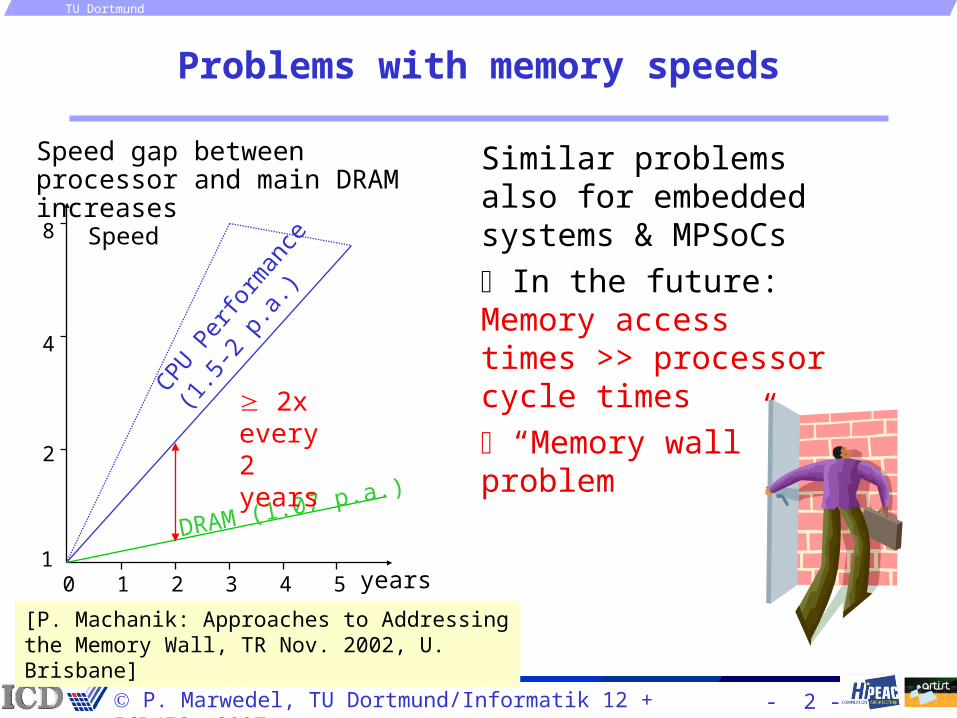
Problems with memory speeds
Speed gap between processor and main DRAM increases
[P. Machanik: Approaches to Addressing the Memory Wall, TR Nov. 2002, U. Brisbane]
2
4
8
2 4 5
Speed
years
CPU Per
form
ance
(1.5
-2 p
.a.)
DRAM (1.07 p.a.)
31
2x every 2 years
10
Similar problems also for embedded systems & MPSoCs
In the future:Memory access times >> processor cycle times
“Memory wall” problem
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 3 -
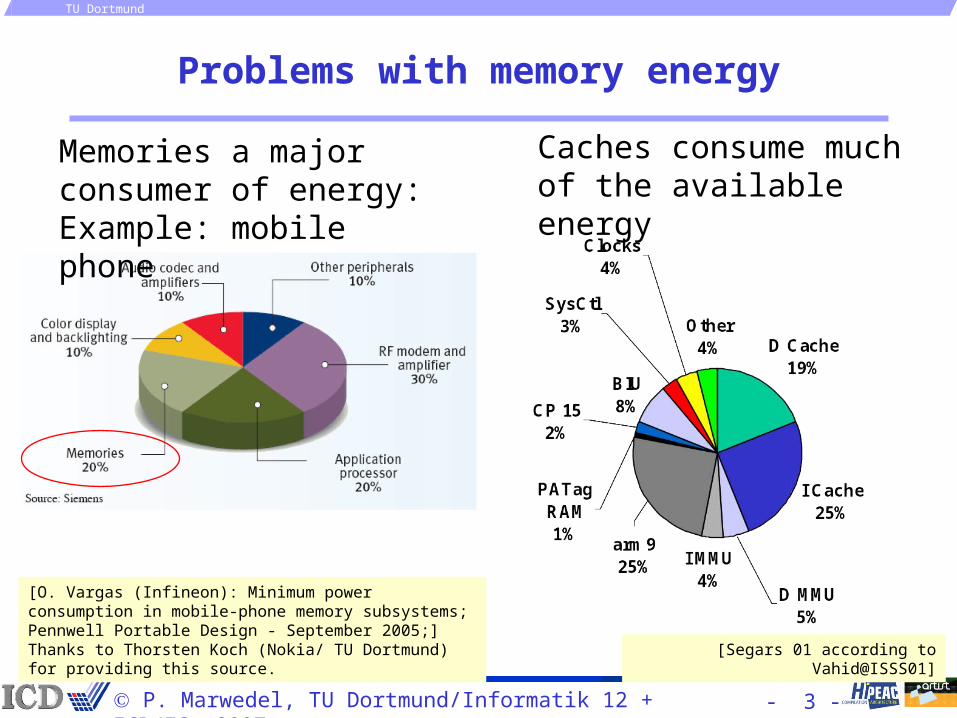
Problems with memory energy
[Segars 01 according to Vahid@ISSS01]
Caches consume muchof the available energy
[O. Vargas (Infineon): Minimum power consumption in mobile-phone memory subsystems; Pennwell Portable Design - September 2005;] Thanks to Thorsten Koch (Nokia/ TU Dortmund) for providing this source.
Memories a major consumer of energy: Example: mobile phone

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 4 -
Tightly coupled memories/Scratch pad memories (SPM): Fast, energy-efficient, timing-predictable
Address space
ARM7TDMI cores, well-known for low power consumption
scratch pad memory
0
FFF..
ExampleExample
Small; no tag memory
TCM/SPMs are small, physically separate memories mapped into the address space;
Selection is by an appropriate address decoder (simple!)
SPM
select
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 5 -
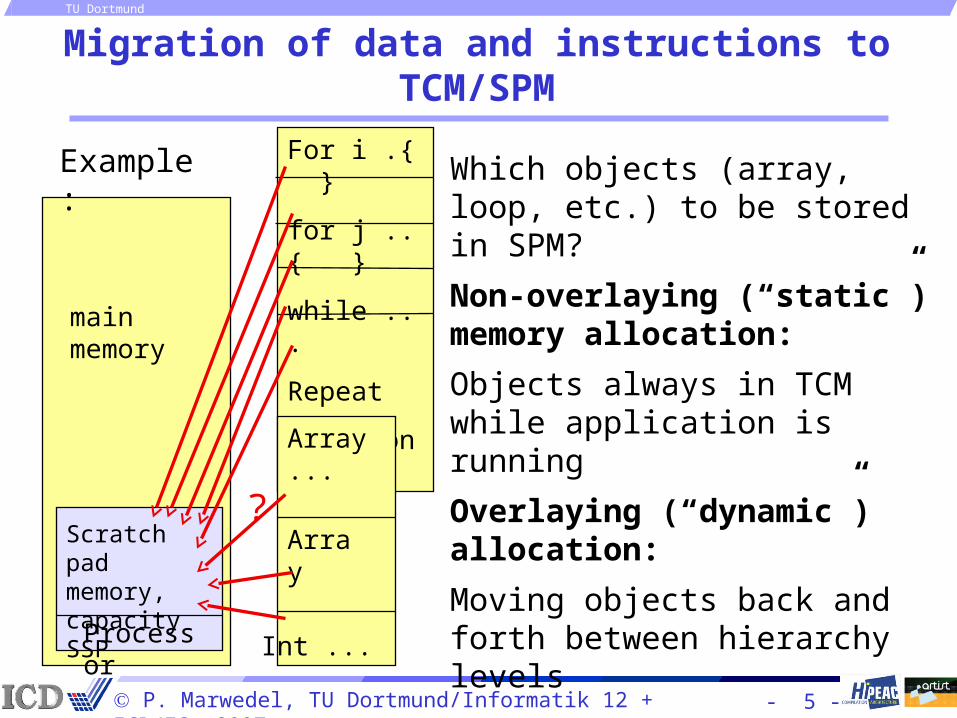
Migration of data and instructions to TCM/SPM
Which objects (array, loop, etc.) to be stored in SPM?
Non-overlaying (“static”) memory allocation:
Objects always in TCM while application is running
Overlaying (“dynamic”) allocation:
Moving objects back and forth between hierarchy levels
Processor
Scratch pad memory,capacity SSP
main memory
?
For i .{ }
for j ..{ }
while ...
Repeat
function ...
Array ...
Int ...
Array
Example:

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 6 -
A survey of algorithms for scratchpad allocation
Non-overlaying (“static”) approachesGain gk & size sk for each object k.Maximise gain G = gk, respecting SSP sk. Knapsack
• Code, static data, stack, heap,• Partitioning, handling large arrays
Overlaying (“dynamic”) approaches• single/multiple hierarchy levels• for single process• for static number of multiple processes• for dynamic number of multiple processes• not using/using MMU
Survey of algorithms: http://ls12-www.cs.uni-dortmund.de/publications/ papers/2007-marwedel-acaces.zip
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 7 -
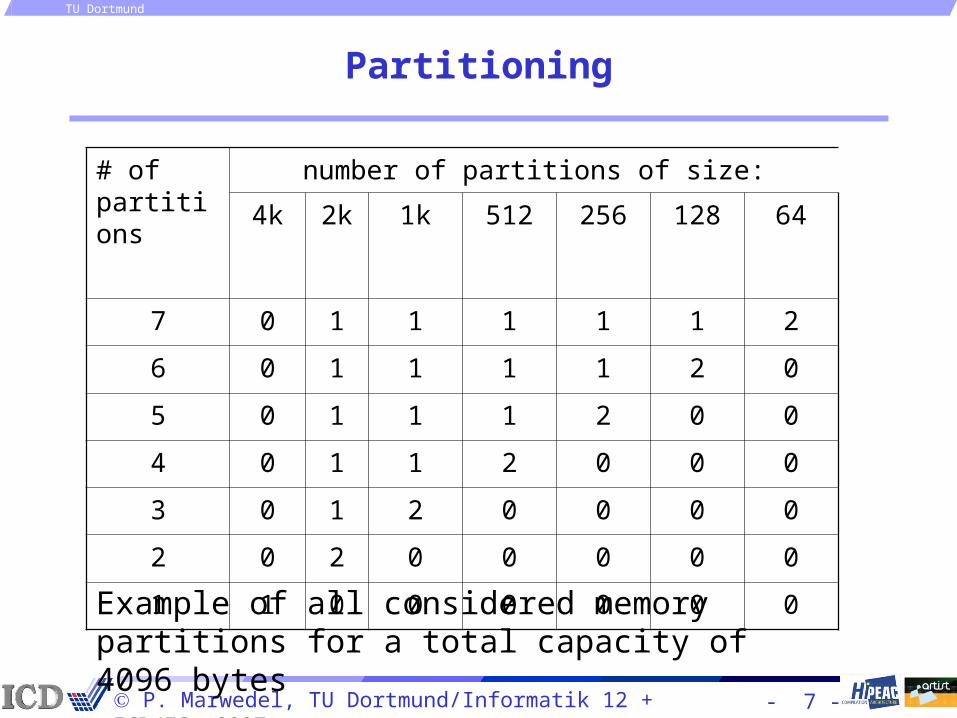
Partitioning
# of partitions
number of partitions of size:
4k 2k 1k 512 256 128 64
7 0 1 1 1 1 1 2
6 0 1 1 1 1 2 0
5 0 1 1 1 2 0 0
4 0 1 1 2 0 0 0
3 0 1 2 0 0 0 0
2 0 2 0 0 0 0 0
1 1 0 0 0 0 0 0
Example of all considered memory partitions for a total capacity of 4096 bytes
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 8 -
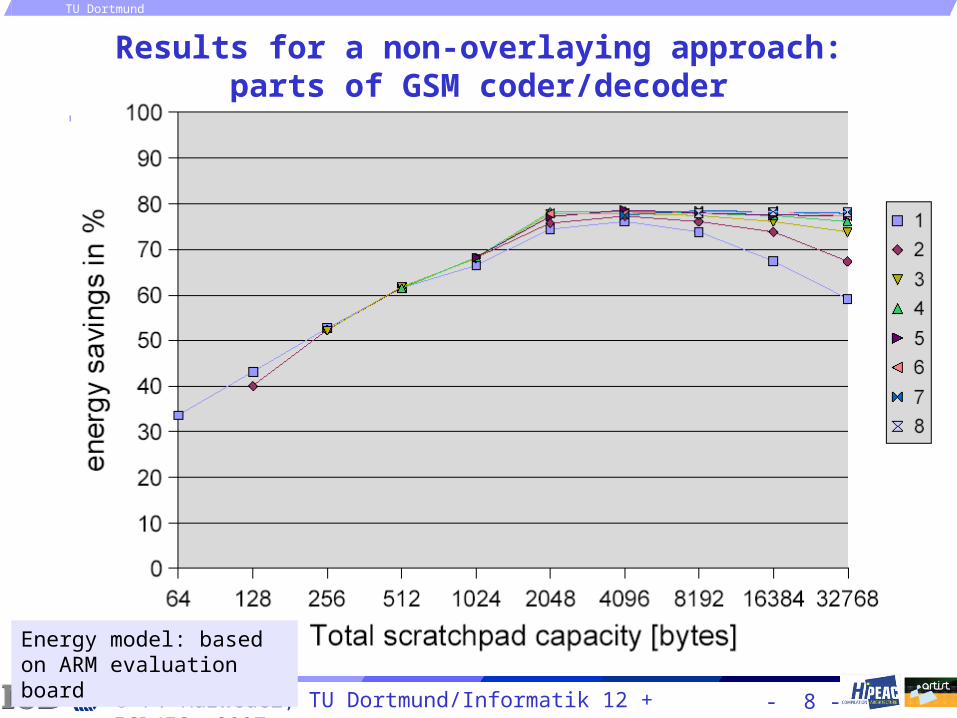
Results for a non-overlaying approach:parts of GSM coder/decoder
Energy model: based on ARM evaluation board
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 9 -
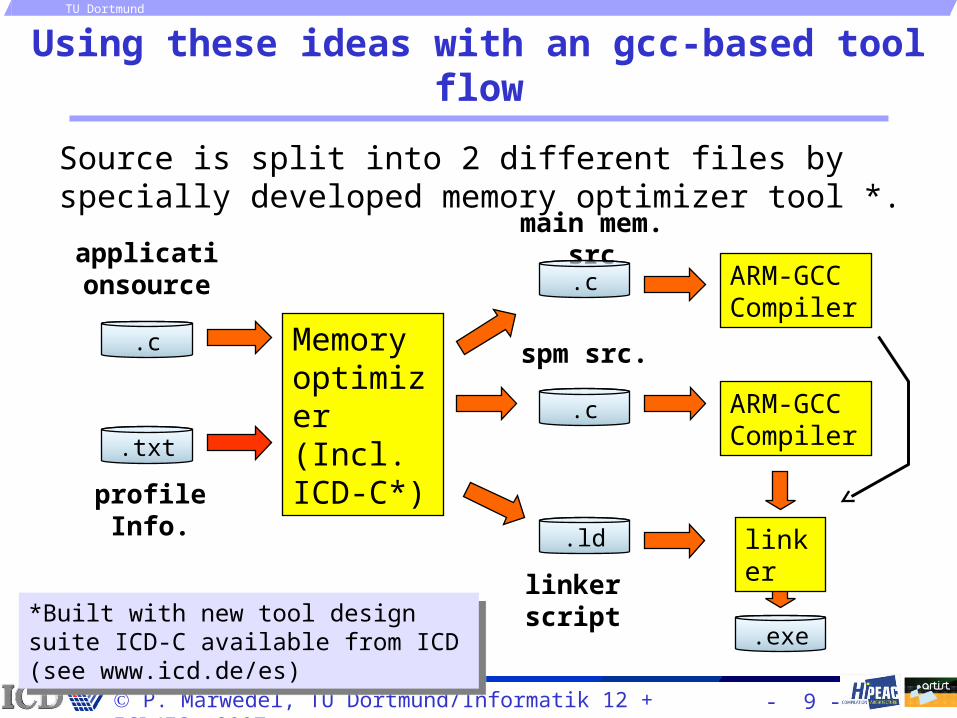
Using these ideas with an gcc-based tool flow
Source is split into 2 different files by specially developed memory optimizer tool *.
applicationsource
profile Info.
main mem. src
spm src.
linker script*Built with new tool design suite ICD-C available from ICD (see www.icd.de/es)
*Built with new tool design suite ICD-C available from ICD (see www.icd.de/es) .exe
.ld linker
ARM-GCCCompiler
ARM-GCCCompiler
.c
.c
.c
.txt
Memory optimizer(Incl. ICD-C*)
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 10 -
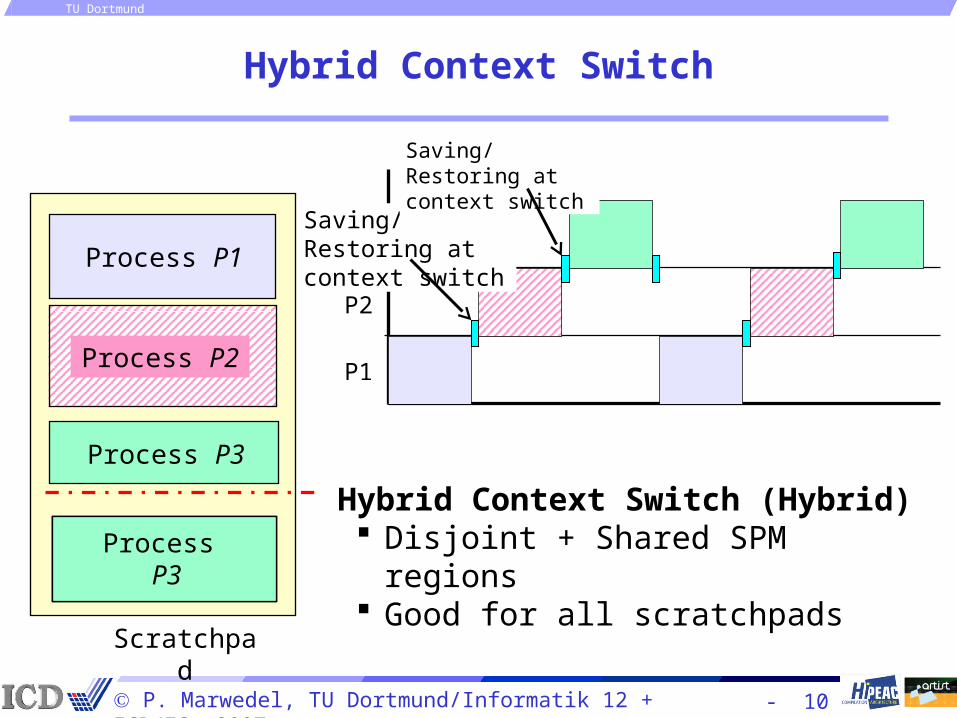
Hybrid Context Switch
Hybrid Context Switch (Hybrid) Disjoint + Shared SPM regions Good for all scratchpads
Scratchpad
Process P1,P2, P3
Process P1
Process P2
Process P3
Process P1Process P2Process P3
P1
P2
P3Saving/Restoring at context switch
Saving/Restoring at context switch

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 11 -
Multi-process Scratchpad Allocation: Results
For small SPMs (64B-512B) Saving is better For large SPMs (1kB- 4kB) Non-Saving is better Hybrid is the best for all SPM sizes. Energy reduction @ 4kB SPM is 27% for Hybrid approach
80
90
100
110
120
130
140
150
160
64 128 256 512 1024 2048 4096
Scratchpad Size (bytes)
En
erg
y C
on
sum
ptio
n (
mJ)
Energy (SPA) Energy (Non-Saving)
Energy (Saving) CopyEnergy (Saving)
Energy (Hybrid) CopyEnergy (Hybrid)
27%
SPA: Single Process Approach
edge detection,
adpcm, g721, mpeg
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 12 -
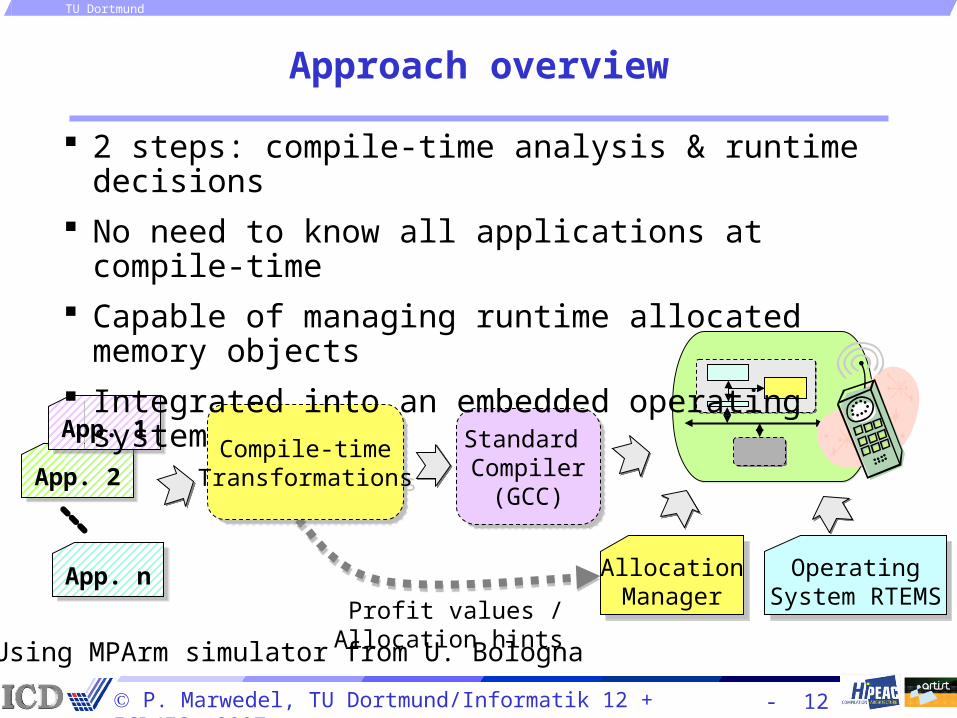
Approach overview
App. 2App. 2
App. 1App. 1
App. nApp. n AllocationManager
AllocationManager
Standard Compiler(GCC)
Standard Compiler(GCC)
OperatingSystem RTEMS
OperatingSystem RTEMS
Compile-timeTransformations
Compile-timeTransformations
Profit values / Allocation hints
2 steps: compile-time analysis & runtime decisions
No need to know all applications at compile-time
Capable of managing runtime allocated memory objects
Integrated into an embedded operating system
Using MPArm simulator from U. Bologna

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 13 -
Comparison of SPMM to Caches for SORT
Baseline: Main memory only SPMM peak energy reduction by
83% at 4k Bytes scratchpad Cache peak: 75% at 2k 2-way
cache
SPMM capable ofoutperforming caches
OS and libraries are not considered yet
Chunk allocation results:
SPM Size Δ 4-way
1024 74,81%
2048 65,35%
4096 64,39%
8192 65,64%
16384 63,73%

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 14 -
Worst case timing analysis using aiT
C program
SPM size
executable
Actualperformance
Worst caseexecution time
memory-awarecompiler
ARMulator
aiT
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 15 -
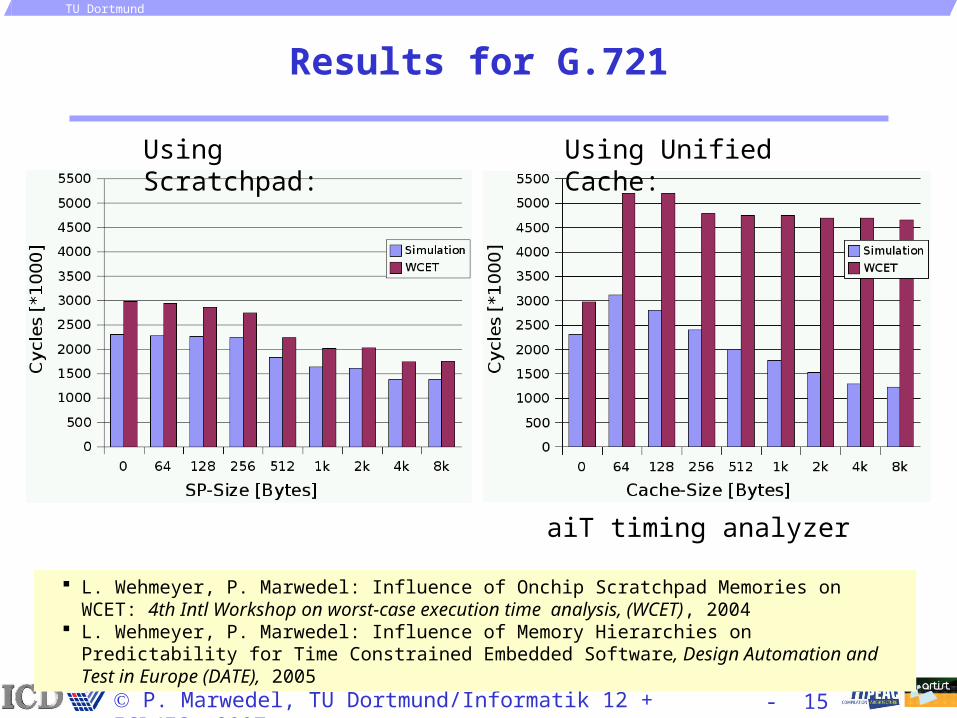
Results for G.721
L. Wehmeyer, P. Marwedel: Influence of Onchip Scratchpad Memories on WCET: 4th Intl Workshop on worst-case execution time analysis, (WCET), 2004
L. Wehmeyer, P. Marwedel: Influence of Memory Hierarchies on Predictability for Time Constrained Embedded Software, Design Automation and Test in Europe (DATE), 2005
Using Scratchpad: Using Unified Cache:
aiT timing analyzer
P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 16 -
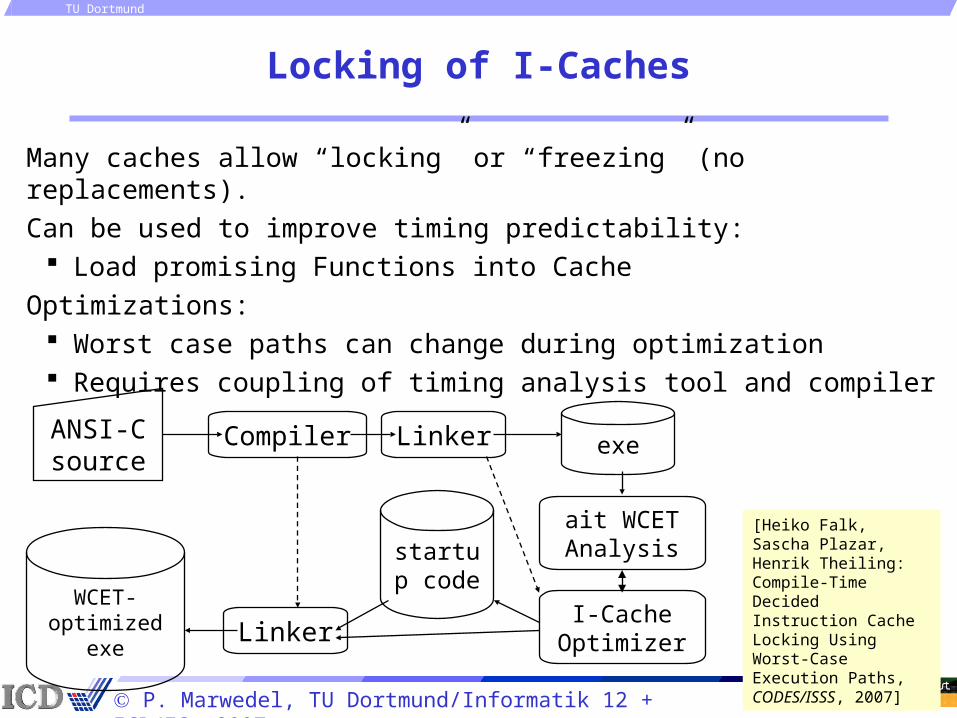
Locking of I-Caches
Many caches allow “locking” or “freezing” (no replacements).
Can be used to improve timing predictability: Load promising Functions into Cache
Optimizations: Worst case paths can change during optimization Requires coupling of timing analysis tool and compiler
[Heiko Falk, Sascha Plazar, Henrik Theiling: Compile-Time Decided Instruction Cache Locking Using Worst-Case Execution Paths, CODES/ISSS, 2007]
ANSI-C source
Compiler Linker
LinkerWCET-
optimized exeI-Cache
Optimizer
ait WCET Analysis
exe
startup code

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 17 -
Relative WCETs after I-Cache Locking
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
110%
64 128 256 512 1024 2048 4096 8192 16384
Cache Size [bytes]
Re
l. W
CE
T [
%]
ADPCM G723 Statemate Compress MPEG2
(ARM920T)

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 18 -
More information
2006
• http://ls12-www.cs.uni-dortmund.de/publications/papers/2007-marwedel-acaces.zip
• http://ls12-www.cs.uni-dortmund.de/publications/global_index.html
• http://ls12-www.cs.uni-dortmund.de/publications/papers/2007-marwedel-acaces.zip
• http://ls12-www.cs.uni-dortmund.de/publications/global_index.html
2007

P. Marwedel, TU Dortmund/Informatik 12 + ICD/ES, 2007
TU Dortmund
- 19 -
Conclusion
Major impact of the memory system on system speed, energy consumption and timing predictability.
Memory hierarchies comprising TCMs/SPMs are fast, energy-efficient and timing predictable.
Algorithms have been designed for• Code, static data, stack, heap• Single and multiple memory hierarchy levels• non-overlaying and overlaying allocation• saving, non-saving and hybrid context switches• mono- and multiprocessor systems.
Very large improvements in terms of the considered figures of merit.
Compatible with existing tool flows