universitatea politehnica din bucure şti -...
TRANSCRIPT

Web usage miningWeb usage mining
Prof.dr.ing. Florin Radulescu
Universitatea Politehnica din Bucureşti

�Objectives and approaches in weblog mining
�Web log formats
�Statistic approaches
Road Map
2
Florin Radulescu, Note de curs
DMDW-9
�Statistic approaches
�Data mining approaches
�Summary

�Weblog mining methods, techniques and algorithms are intended to discover patterns in clickstreams recorded by the web servers and also profiles of the users interacting with them.
Objectives
3
Florin Radulescu, Note de curs
DMDW-9
them.
�The input data are:1. Web server logs, and particularly the access
logs. A web server maintains other logs also (for example error logs) that are not discussed in this lesson

�The input data are – cont.:2. Site structure. The link structure of the site is
used to perform path completition. This means that pages seen in browser window but not requested from the web server due to caching
Objectives
4
Florin Radulescu, Note de curs
DMDW-9
requested from the web server due to caching (proxy or local) are determined using this structure
3. Site content. The content for each page can be used to attach different event labels (product view, buy/bid, etc) to different pages for better understanding of surfer behavior.

�The input data are – cont.:
4. Information on visitors – not always
available. If the users of a website are
authenticated and their account contains
Objectives
5
Florin Radulescu, Note de curs
DMDW-9
authenticated and their account contains
other profile information (age, sex, annual
revenue, etc), a data mining application use
this information for knowledge extraction.
5. Application data, specific to the particular
website.
�There are four types of tasks in web mining (see [Kosala, Blockeel, 2000]):
1. Resource finding: the task of retrieving intended Web documents.
2. Information selection and pre-processing:
Tasks in web mining
6
Florin Radulescu, Note de curs
DMDW-9
2. Information selection and pre-processing: automatically selecting and pre-processing specific information from retrieved Web resources.
3. Generalization: automatically discovers general patterns at individual Web sites as well as across multiple sites.
4. Analysis: validation and/or interpretation of the mined patterns.

� Three categories of tasks in web mining:
� Web content mining
� Web structure mining
� Web usage mining
Categories of tasks
7
Florin Radulescu, Note de curs
DMDW-9
� Web usage mining

�Web content mining is dedicated to the extraction and integration of data, information and knowledge from Web page contents, no matter the structure of the website.
�The hyperlinks contained in each page or the
Web content mining
8
Florin Radulescu, Note de curs
DMDW-9
�The hyperlinks contained in each page or the hyperlinks pointing to them are not relevant in that case, only the information content.
�In [Cooley et al, 97] web content mining is also split in two approaches: �the agent-based approach and �the database approach.

� The objective is to build intelligent tools for information retrieval:� Intelligent Search Agents. In this case, intelligent Web
agents are developed. These agents search for relevant information using domain characteristics and user profiles, then organize and interpret the discovered information.
� Information Filtering/Categorization. In this case, the
Agent based approach
9
Florin Radulescu, Note de curs
DMDW-9
� Information Filtering/Categorization. In this case, the agents use information retrieval techniques and characteristics of open hypertext Web documents to automatically retrieve, filter, and categorize them.
�Personalized Web Agents. In the third case, the agents learn about user preferences and discover Web information based on them (also preferences of similar users may used).

�The objectives involve improvements of the management for semi-structured data available on the Web.�Multilevel Databases. At the lowest level of the
database are semi-structured information stored in Web repositories (hypertext documents), and
Database approach
10
Florin Radulescu, Note de curs
DMDW-9
database are semi-structured information stored in Web repositories (hypertext documents), and at the higher levels meta data or generalizations are extracted and organized using relational or object-oriented model
�Web Query Systems. In this case, specialized query languages are used for querying the Web. Examples are W3QL, WebLog, Lorel, UnQL, etc.

�Web structure mining uses graph theory to analyze the node and connection structure of a web site (see also [Wikipedia]). The new research area emerged in the domain is called Link Mining.
�The following summarization of link mining is from
Web structure mining
11
Florin Radulescu, Note de curs
DMDW-9
�The following summarization of link mining is from [da Costa, Gong 2005]:
1. Link-based Classification. In this case the task is to focus on the prediction of the category of a web page, based on words that occur on the page, links between pages, anchor text, html tags and other possible attributes found on the web page.

�Summarization of link mining – cont.:2. Link-based Cluster Analysis. Cluster analysis finds
naturally occurring sub-classes. In that case the data is clustered with similar objects in the same cluster, and dissimilar objects in different clusters. Link-based cluster analysis is unsupervised so it can be
Web structure mining
12
Florin Radulescu, Note de curs
DMDW-9
based cluster analysis is unsupervised so it can be used to discover hidden patterns in data.
3. Link Type. The goal is to predict the existence of links, the type of link, or the purpose of a link.
4. Link Strength. In this approach links are weighted (importance, etc).
5. Link Cardinality. The goal ist o compute a prediction for the number of links between objects.

�The most known practical applications in this
area are Page Rank (used by Google) and Hubs
and Authorities.
�In the first case, the importance of a page is
Applications
13
Florin Radulescu, Note de curs
DMDW-9
�In the first case, the importance of a page is
computed based on the importance of its
ancestors (an ancestor is a page containing a
link to that page).
�In the second case, each page has a measure
for being a hub (or an index) and another
measure of being an authority.

�Authorities are pages containing information about a topic, and hubs are pages not containing actual information, but links to pages containing topic information.
�The measure of being hub or authority are
Applications
14
Florin Radulescu, Note de curs
DMDW-9
�The measure of being hub or authority are computed recursively: the authority measure is the sum of hub measures for the hubs pointing at it and the hub measure is the sum of the authority measures for the pages referred by that page.

� Web usage mining tries to predict user behavior when interacting with the Web. This is the main topic to be discussed in detail in this lesson.
� Data involved in web usage mining may be classified in four categories:
� Usage data. Here we have server, client and proxy logs. There are several problems encountered here in identifying users and
Web usage mining
15
Florin Radulescu, Note de curs
DMDW-9
several problems encountered here in identifying users and sessions based on their IP address (see [Srivastava et al., 2000]):
o Single IP address / Multiple Server Sessions: because several users access the web server via an ISP provider and the provider allow the access using some proxies, many users have the same IP address in the web server access log in the same period.

� Problems encountered - cont.:
o Multiple IP address / Single Server Session: also because of the ISP policy, accesses of the same user session can be assigned to different proxies, so having different IP addresses in the web server access log.
o Multiple IP address / Single User: the same user accessing the web from different computers will be
Web usage mining
16
Florin Radulescu, Note de curs
DMDW-9
o
accessing the web from different computers will be recorded with different IP addresses for different sessions.
o Multiple agent / Single User: The same user may use several browsers, even on the same computer, so will be recorded in the log files with different user agents.

� Content data. The website contains documents in HTML or other format or dynamic pages generated from scripts and related databases. The content of a page can be used for associating events or other semantic that can be used in the process of web usage mining. Webpages contains also meta data as descriptive keywords, document attributes, semantic tags, etc.
� Structure data. This data capture the link structure of the website. Links are between pages but also intra page links (from a position in
Web usage mining
17
Florin Radulescu, Note de curs
DMDW-9
Links are between pages but also intra page links (from a position in a document to another position in the same or other document), even for dynamically generated pages. This structure is used for example in path completition (see paragraph 5.4).
� User data. In some cases additional information on users is available: personal information about the user (sex, age, revenue), domain of interests, past activity (bids, purchases), past visits history, and so on. This information can also be used for the web usage mining process.
�Objectives and approaches in weblog mining
�Web log formats
�Statistic approaches
Road Map
18
Florin Radulescu, Note de curs
DMDW-9
�Statistic approaches
�Data mining approaches
�Summary

�There are several log file formats described in
the domain literature. The most known is the the
Common Logfile Format, described in [W3.org
1] as follows:
Web log formats
19
Florin Radulescu, Note de curs
DMDW-9
remotehost rfc931 authuser [date] "request" status bytes
�Example:127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET
/apache_pb.gif HTTP/1.0" 200 2326

� Elements from the previous definition:
What is everything
remotehost The remote hostname (or IP number if DNS hostname
is not available, or if DNSLookup is Off).
rfc931 The remote logname of the user
authuser The username as which the user has authenticated
20
Florin Radulescu, Note de curs
DMDW-9
authuser The username as which the user has authenticated
himself
[date] Represents the date and time of the request
"request" The request line exactly as it came from the client
status The HTTP status code returned to the client
bytes The content-length of the document transferred

� For the prefious example:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
�The remote host is 127.0.0.1, remote hostname is
What is everything
21
Florin Radulescu, Note de curs
DMDW-9
�The remote host is 127.0.0.1, remote hostname is unavailable (a hyphen indicates such a case), authuser is frank, the date is October 10, 2000, with the time indicated, the request is a GET for a gif file placed in Document Root, the status code is 200 – success and the document length (transfer length) is 2326.

� The Combined Log File Format adds some other information, most important being:
Combined Log File Format
referrer This gives the site that the client (user agent) reports
22
Florin Radulescu, Note de curs
DMDW-9
referrer This gives the site that the client (user agent) reports
having been referred from.
user-agent This is the identifying information that the client
browser reports about itself

127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
� The first seven fields are the same.
� The last two fields indicated the referrer as start.html
Example
23
Florin Radulescu, Note de curs
DMDW-9
� The last two fields indicated the referrer as start.html from www.example.com and the user agent as Netscape.
�Mozilla was originally the codename for the defunct Netscape Navigator software project, along with Netscape's mascot,a cartoon reptile inspired by Godzilla, - see [Wikipedia]
� There is also an Extended Log File Format.

�Objectives and approaches in weblog mining
�Web log formats
�Statistic approaches
Road Map
24
Florin Radulescu, Note de curs
DMDW-9
�Statistic approaches
�Data mining approaches
�Summary

�For obtaining statistics about a website there are two possibilities:
1. Local statistics: there are several packages that analyze the log file of the website and presents detailed statistics about the
Statistic approaches
25
Florin Radulescu, Note de curs
DMDW-9
presents detailed statistics about the accesses recorded in them. Some examples are: Analog, W3Perl, AWStats, Webalizer, etc.
2. External statistics. In this case behavioral information cannot be obtained, only statistics about visitors.
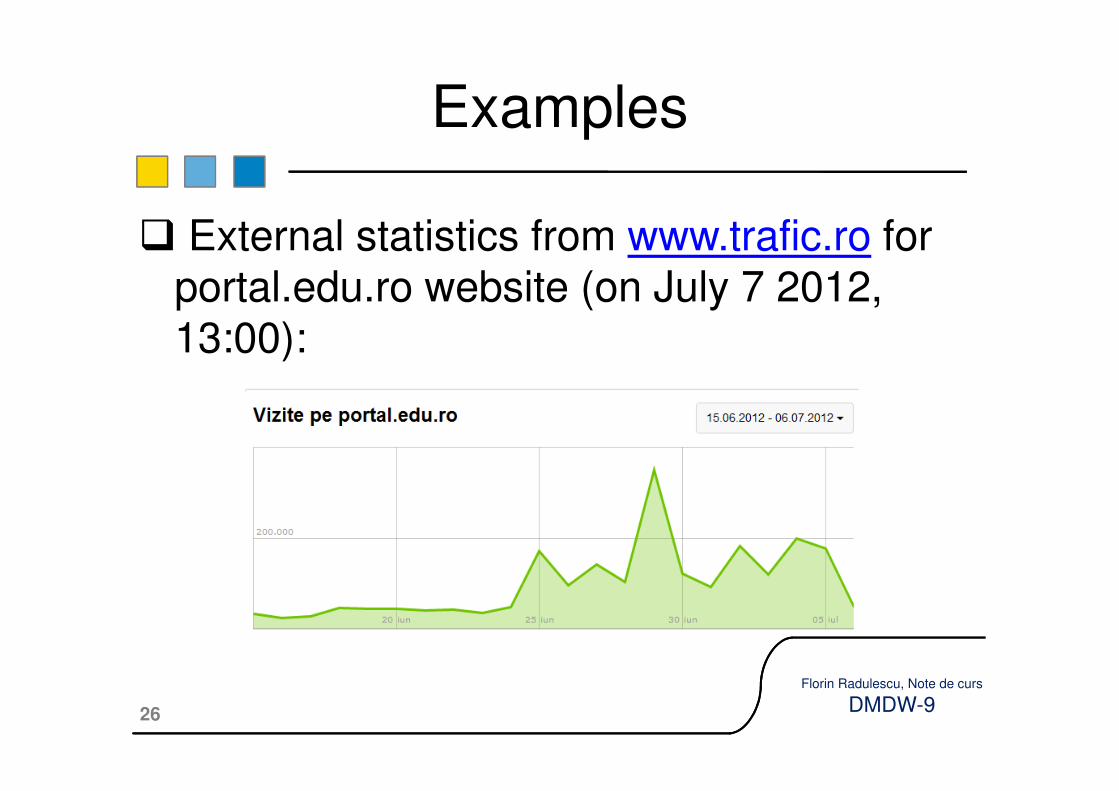
� External statistics from www.trafic.ro for portal.edu.ro website (on July 7 2012, 13:00):
Examples
26
Florin Radulescu, Note de curs
DMDW-9

Examples – cont.
27
Florin Radulescu, Note de curs
DMDW-9

Examples – cont.
28
Florin Radulescu, Note de curs
DMDW-9

�Objectives and approaches in weblog mining
�Web log formats
�Statistic approaches
Road Map
29
Florin Radulescu, Note de curs
DMDW-9
�Statistic approaches
�Data mining approaches
�Summary

� [Srivastava et al., 2000] describes the web usage mining process as having the following structure:
�Data preprocessing
Data mining approaches
30
Florin Radulescu, Note de curs
DMDW-9
�Data preprocessing
�Pattern discovery
�Pattern analysis

� Structure:
The web usage mining process
Site files
(site content)
31
Florin Radulescu, Note de curs
DMDW-9
Log
files
Preprocessed
clickstream
data
Rules,
Patterns,
Statistics
Interesting
Rules, Patterns,
Statistics
Preprocessing Pattern discovery
Pattern analysis

�This step includes:
�Data cleaning
�Pageview identification
�User identification
Data preprocessing
32
Florin Radulescu, Note de curs
DMDW-9
�User identification
�Session and event identification
(sessionization)
�Path completition
�Data integration, including event identification

�Data cleaning tasks includes:
�removal of unnecessary fields (the server
access logs contains fields that can be
removed in some cases being irrelevant for
Data cleaning
33
Florin Radulescu, Note de curs
DMDW-9
removed in some cases being irrelevant for
the intended analysis),
�removal of log entries coming from robots
(spider navigation) and
�removal of erroneous entries (status not
success).

• Pageview identification: A pageview is a collection of Web objects or resources representing a specific “user event,” e.g., clicking on a link, viewing a product page, adding a product to the shopping cart.
Pageview identification
34
Florin Radulescu, Note de curs
DMDW-9
adding a product to the shopping cart.
• In usual terms, a pageview is the collection of objects that can be materialized in what the browser window shows at a given moment.

• For a usual site, with static pages and no frames, each HTML file with all embedded objects (music, images, etc) is a pageview.
• Each pageview corresponds to several
Pageview identification
35
Florin Radulescu, Note de curs
DMDW-9
• Each pageview corresponds to several entries in the web log. These entries must be identified and treated as a single access to the web server.

� User identification. In a web server environment users can be identified by: � Authentication: many sites may be accessed only by
authenticated users and so the user is known from the beginning to the end of its activity on that site.
� Cookies: In the absence of authentication facilities, client side cookies may be used. A cookie is a unique piece of information
User identification
36
Florin Radulescu, Note de curs
DMDW-9
cookies may be used. A cookie is a unique piece of information (like a passport) issued by the web server and sent to the browser and subsequently used by the browser to access pages on that web server. In that way each cookie identifies that user session but the cookie can live beyond the session and be recognized in subsequent sessions of the same user.
� If cookie mechanism is not available, the users can be identified by their IP address and user-agent. Some problems in this case were listed at slides 15-16.

� An example is presented in the nextfigure. Based on the IP and user agent, three users can be distinguished:
� User1 with Chrome/Win7
Example
37
Florin Radulescu, Note de curs
DMDW-9
� User1 with Chrome/Win7
� User2 with FireFox/Win7
� User3 with IE9/WinXP SP1

Web server log
Time Client IP Req. URL Ref. URL User Agent
12:55 1.2.3.4 A - Chrome20;Win7
12:59 1.2.3.4 B A Chrome20;Win7
13:04 1.2.3.4 D B Chrome20;Win7
13:10 2.3.4.5 C - IE9;WinXP;SP1
13:13 1.2.3.4 E B Chrome20;Win7
13:14 1.2.3.4 B - FireFox9;Win7
13:15 2.3.4.5 F C IE9;WinXP;SP1
38
Florin Radulescu, Note de curs
DMDW-9
13:16 1.2.3.4 D B FireFox9;Win7
13:17 1.2.3.4 C A Chrome20;Win7
13:18 1.2.3.4 A - Chrome20;Win7
13:19 1.2.3.4 E B FireFox9;Win7
13:20 2.3.4.5 A C IE9;WinXP;SP1
13:21 1.2.3.4 C A Chrome20;Win7
13:22 1.2.3.4 A B FireFox9;Win7
13:23 2.3.4.5 B A IE9;WinXP;SP1
13:24 1.2.3.4 G C Chrome20;Win7
13:25 1.2.3.4 C A FireFox9;Win7
13:26 1.2.3.4 B A Chrome20;Win7
13:28 1.2.3.4 G C FireFox9;Win7
13:31 1.2.3.4 E B Chrome20;Win7

�User1:
User 1
Time Client IP Req. URL Ref. URL User Agent
12:55 1.2.3.4 A - Chrome20;Win7
12:59 1.2.3.4 B A Chrome20;Win7
13:04 1.2.3.4 D B Chrome20;Win7
13:13 1.2.3.4 E B Chrome20;Win7
13:17 1.2.3.4 C A Chrome20;Win7
39
Florin Radulescu, Note de curs
DMDW-9
13:17 1.2.3.4 C A Chrome20;Win7
13:18 1.2.3.4 A - Chrome20;Win7
13:21 1.2.3.4 C A Chrome20;Win7
13:24 1.2.3.4 G C Chrome20;Win7
13:26 1.2.3.4 B A Chrome20;Win7
13:31 1.2.3.4 E B Chrome20;Win7

� User2
User3
User2 and User3
Time Client IP Req. URL Ref. URL User Agent
13:14 1.2.3.4 B - FireFox9;Win7
13:16 1.2.3.4 D B FireFox9;Win7
13:19 1.2.3.4 E B FireFox9;Win7
13:22 1.2.3.4 A B FireFox9;Win7
13:25 1.2.3.4 C A FireFox9;Win7
13:28 1.2.3.4 G C FireFox9;Win7
40
Florin Radulescu, Note de curs
DMDW-9
� User3
Time Client IP Req. URL Ref. URL User Agent
13:10 2.3.4.5 C - IE9;WinXP;SP1
13:15 2.3.4.5 F C IE9;WinXP;SP1
13:20 2.3.4.5 A C IE9;WinXP;SP1
13:23 2.3.4.5 B A IE9;WinXP;SP1

� Session identification (sessionization): The web activity of a user is segmented in sessions.
�As a general idea, a user session begins when the opens the browser window and ends when that window is closed.
Sessionization
41
Florin Radulescu, Note de curs
DMDW-9
window is closed.
�A user session contains visits on several websites, on each website being recorded as a session in the web server log.
�From the point of view of a single web server, only pageviews from that server are known and represents the user session.

�There are several methods to identify user sessions:�Authentication and cookies, discussed earlier.
�Embedded session IDs: at the beginning of a new session the server generates a unique session ID. Web pages are dynamically generated and The ID is
Sessionization
42
Florin Radulescu, Note de curs
DMDW-9
Web pages are dynamically generated and The ID is contained in every link, so subsequent hits are recognized.
�Software agents: programs loaded into the browsers that send back usage data.
�Heuristics: when the above methods are not available, several heuristics may be used to split the activity of a user into sessions.

�Some known heuristics for sessionization are:
�Duration of a session is limited at a given amount of time (for example 20 minutes)
�Session ends when the time of stay on a webpage is above a given amount of time (for example, if
Euristics
43
Florin Radulescu, Note de curs
DMDW-9
above a given amount of time (for example, if between two successive hits there is more than 20 minutes, a new session begins there)
�Pageviews in a session are linked. If a pageview is not accessible from an open session, it starts a new session. Note that the same user may have several open sessions in the same time (several different browser windows pointing on the same web server).

Example
Time Client IP Req. URL Ref. URL User Agent
12:55 1.2.3.4 A - Chrome20;Win7
12:59 1.2.3.4 B A Chrome20;Win7 Session 1
13:04 1.2.3.4 D B Chrome20;Win7
13:13 1.2.3.4 E B Chrome20;Win7
13:17 1.2.3.4 C A Chrome20;Win7
44
Florin Radulescu, Note de curs
DMDW-9
13:17 1.2.3.4 C A Chrome20;Win7
13:18 1.2.3.4 A - Chrome20;Win7
13:21 1.2.3.4 C A Chrome20;Win7 Session 2
13:24 1.2.3.4 G C Chrome20;Win7
13:26 1.2.3.4 B A Chrome20;Win7
13:31 1.2.3.4 E B Chrome20;Win7

� Episode identification: An episode is a sequence of pageviews in a session that are related (semantically or functionally).
Episode identification
45
Florin Radulescu, Note de curs
DMDW-9

�Path completition: Because of the cachethat browsers and proxies implement, some pageviews are not requested from the web servers but are directly served by the proxy or the browser cache is used to display it.
Path completition
46
Florin Radulescu, Note de curs
DMDW-9
or the browser cache is used to display it.
�In that case the web server log do not containentries for that pageview.
�The obvious example for that situation is pressing the “Back” button of the browser. In that case the cached version of the previous page is displayed in most of the cases.
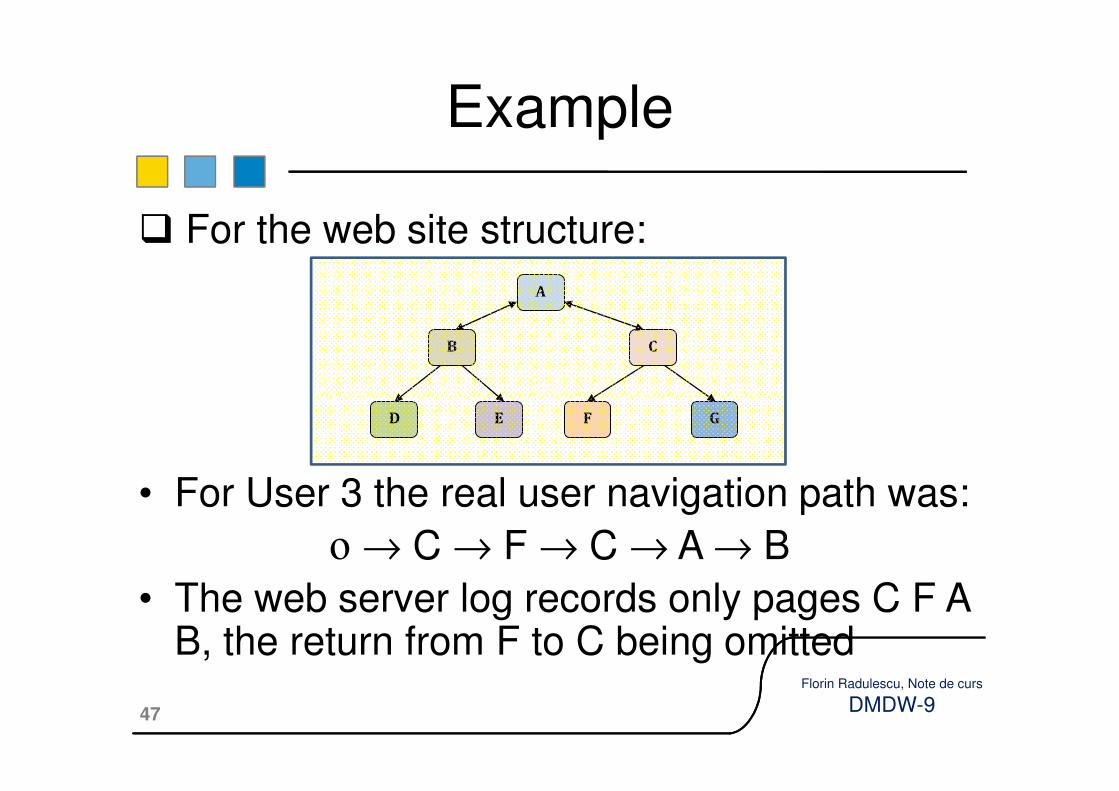
� For the web site structure:
Example
A
B C
47
Florin Radulescu, Note de curs
DMDW-9
• For User 3 the real user navigation path was:
ο → C → F → C → A → B
• The web server log records only pages C F A B, the return from F to C being omitted
D E F G
�Data integration and event identification: now users are identified, sessions are also identified, but for mining the data some other information must be integrated from various sources.
�For example in an e-commerce application other
Data integration and event identification
48
Florin Radulescu, Note de curs
DMDW-9
�For example in an e-commerce application other data may be:
�User data, if available: age, sex, revenue, previous products bought, domains of interest, products visualized in the past, and so on.
�Product information: category, price, fabric (for textile products), fat and sugar (for food products), etc.

�At this moment some pageviews or some successions of pageviews can be associated with specific events.
� Identifying events adds more semantic to the user sessions, semantic that may be used in further analysis process.
�Examples:
Events
49
Florin Radulescu, Note de curs
DMDW-9
�Examples:o Product view: a pageview where a product is displayed
o Product click-through: when the user clicks on a product to display more data about it
o Shopping cart change: when a user add or remove a product in the shopping cart
o Buy: when the shopping cart is validated and the customer finalize the buying transaction

�Summary list of types of algorithms andmethods ([Srivastava et al., 2000]):
�Statistical Analysis
�Association rules
Pattern discovery
50
Florin Radulescu, Note de curs
DMDW-9
�Association rules
�Clustering
�Classification
�Sequential patterns discovery
�Dependency modeling

�Statistical Analysis. This is the most simple
and common way to extract information and
knowledge about the visitors of a website.
�Statistical methods includes computing
Statistical Analysis
51
Florin Radulescu, Note de curs
DMDW-9
�Statistical methods includes computing
measures like frequency, mean, median,
generating reports with statistical information
and so on.
�Some examples are already presented in this
lesson (trafic.ro examples).

�Association rules. Obtaining association rules allow relating pages accessed together in the same session.
�This is important for marketing purposes,
Association rules
52
Florin Radulescu, Note de curs
DMDW-9
�This is important for marketing purposes, for future site restructuring and for generating recommendations.

� Clustering. Clustering algorithms can be used for discovering usage clusters and page clusters.
� In the first case users with similar surfing behavior are discovered (each cluster contains similar users).
�This may be used for market segmentation and
Clustering
53
Florin Radulescu, Note de curs
DMDW-9
�This may be used for market segmentation and personalization.
� In the second case, clusters contain similar web pages or related based on their content.
�These clusters can be used by the search engines for better results and also for recommendation purposes.

• Classification. Classification algorithms can be used for segmenting users in several classes or categories.
• Types of classification algorithms suitable
Classification
54
Florin Radulescu, Note de curs
DMDW-9
• Types of classification algorithms suitable for that are decision trees classifiers, Naïve Bayes classifiers, KNN or SVM.

• Sequential patterns discovery. The goal is to find frequent sequential patterns in sessions, so that the presence of some pageviews in a particular order may be
Sequential patterns discovery
55
Florin Radulescu, Note de curs
DMDW-9
pageviews in a particular order may be followed by another pageview.

• Dependency modeling. The goal of this method is to obtain a model for a particular object (for example a model for customers) including all significant dependencies among variable measures
Dependency modeling
56
Florin Radulescu, Note de curs
DMDW-9
dependencies among variable measures involved.
• Cited methods in this area are Hidden Markov Models and Bayesian Belief Models.

�An example of sequence mining algorithm is GSP.
�GSP stands for Generalized Sequential Pattern algorithm and is inspired from
The GSP algorithm
57
Florin Radulescu, Note de curs
DMDW-9
Pattern algorithm and is inspired from Apriori algorithm.
�The sketch of the algorithm is the following (see [Wikipedia]):
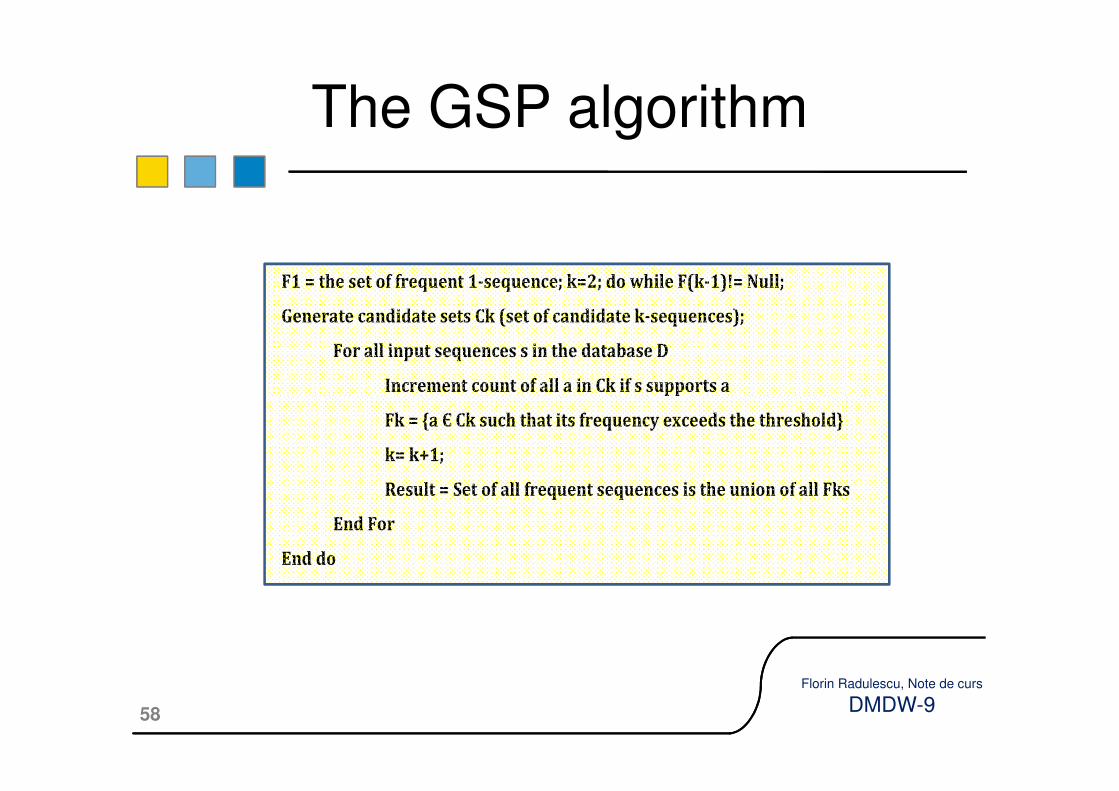
The GSP algorithm
F1 = the set of frequent 1-sequence; k=2; do while F(k-1)!= Null;
Generate candidate sets Ck (set of candidate k-sequences);
For all input sequences s in the database D
Increment count of all a in Ck if s supports a
58
Florin Radulescu, Note de curs
DMDW-9
Increment count of all a in Ck if s supports a
Fk = {a Є Ck such that its frequency exceeds the threshold}
k= k+1;
Result = Set of all frequent sequences is the union of all Fks
End For
End do

� The main difference between GSP and Apriori is at candidate generation step.
�If for example there are two frequent 2-
sequences, A→B and A →C, the Apriori
GSP vs. Apriori
59
Florin Radulescu, Note de curs
DMDW-9
sequences, A→B and A →C, the Apriori style generation produce A→B→C.
�In GSP three different candidate
sequences are generated: A→B→C, A→C→B and A→BC.

This course presented:
�Objectives and approaches in weblog mining
�Web log formats
�Statistic approaches
Summary
60
Florin Radulescu, Note de curs
DMDW-9
�Data mining approaches
Next week: Data warehousing - introduction

[Liu 11] Bing Liu, Web Data Mining, Exploring Hyperlinks, Contents, and Usage Data, Second Edition, Springer, 2011, chapter 12
[Wikipedia] Wikipedia, the free encyclopedia, en.wikipedia.org
[W3.org 1] Logging Control In W3C httpd, page visited June 1, 2012: http://www.w3.org/Daemon/User/Config/Logging.html
References
61
Florin Radulescu, Note de curs
DMDW-9
2012: http://www.w3.org/Daemon/User/Config/Logging.html
[W3.org 2] Extended Log File Format, page visited June 1, 2012: http://www.w3.org/TR/WD-logfile.html
[Apache.org 1] Apache HTTP Server Version 2.4, Log files, page visited June 1, 2012: http://httpd.apache.org/docs/2.4/logs.html

[Kosala, Blockeel, 2000] Raymond Kosala, Hendrik Blockeel, Web Mining Research: A Survey, ACM SIGKDD Explorations Newsletter, June 2000, Volume 2 Issue 1.
[Cooley et al, 97] Cooley, R.; Mobasher, B.; Srivastava, J.; Web mining: information and pattern discovery on the World Wide Web. Tools with Artificial Intelligence, 1997, Ninth IEEE International Conference.
References
62
Florin Radulescu, Note de curs
DMDW-9
Conference.
[da Costa, Gong 2005] Miguel Gomes da Costa Júnior ZhiguoGong, Web Structure Mining: An Introduction, Proceedings of the 2005 IEEE International Conference on Information Acquisition June 27 - July 3, 2005, Hong Kong and Macau, China
[Srivastava et al., 2000] J. Srivastava, R. Cooley, M.Deshpande, P.Tan, Web usage mining: discovery and applications of web usage patterns from web data, SIGKDD Explorations, Volume 1(2), 2000, available at http://www.sigkdd.org/explorations/