vasp:&some&accumulated&wisdom&people.bath.ac.uk/aw558/presentations/vasp_tips_2015.pdf ·...
TRANSCRIPT

VASP: Some Accumulated Wisdom
J. M. Skelton
WMD Group Mee<ng 21st September 2015

WMD Group Mee<ng, September 2015 | Slide 2
Convergence: Parameters
• Four key technical parameters in a VASP calcula<on:
o Basis set: ENCUT and PREC (or, alterna<vely, NGX, NGY, NGZ)
o k-‐point sampling: KPOINTS file and SIGMA
o [For certain types of pseudopoten<al.] Augmenta<on grid: ENAUG and PREC (or, alterna<vely, NGXF, NGYF, NGZF)
o Which space the projec<on operators are applied in (LREAL)
WMD Group Mee<ng, September 2015 | Slide 3
Convergence: Augmenta2on grid
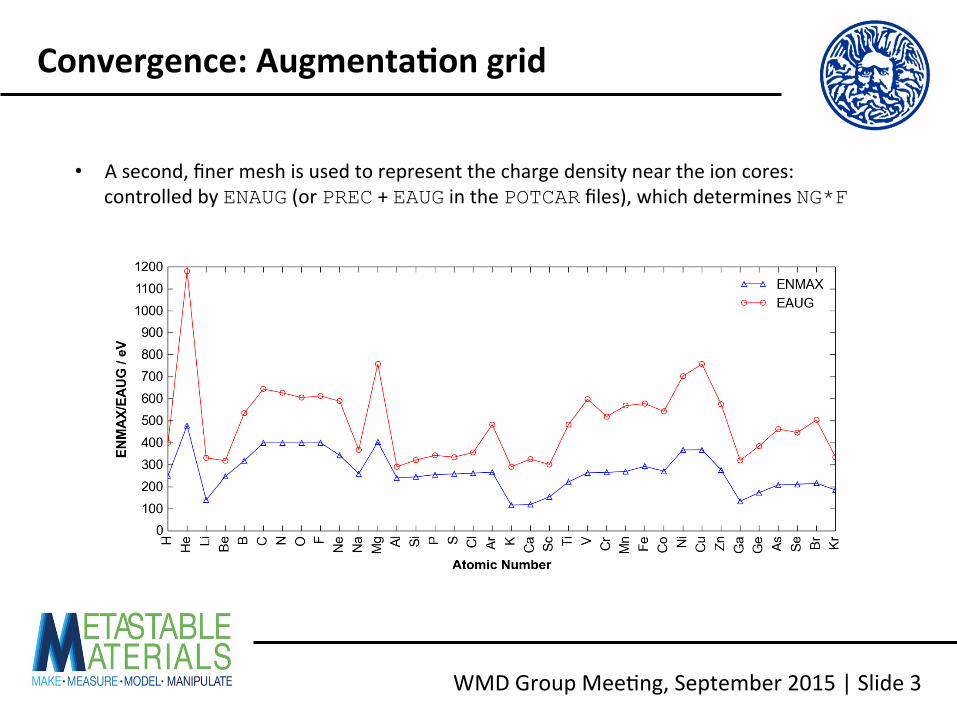
• A second, finer mesh is used to represent the charge density near the ion cores: controlled by ENAUG (or PREC + EAUG in the POTCAR files), which determines NG*F
WMD Group Mee<ng, September 2015 | Slide 4
Convergence: ZnS revisited
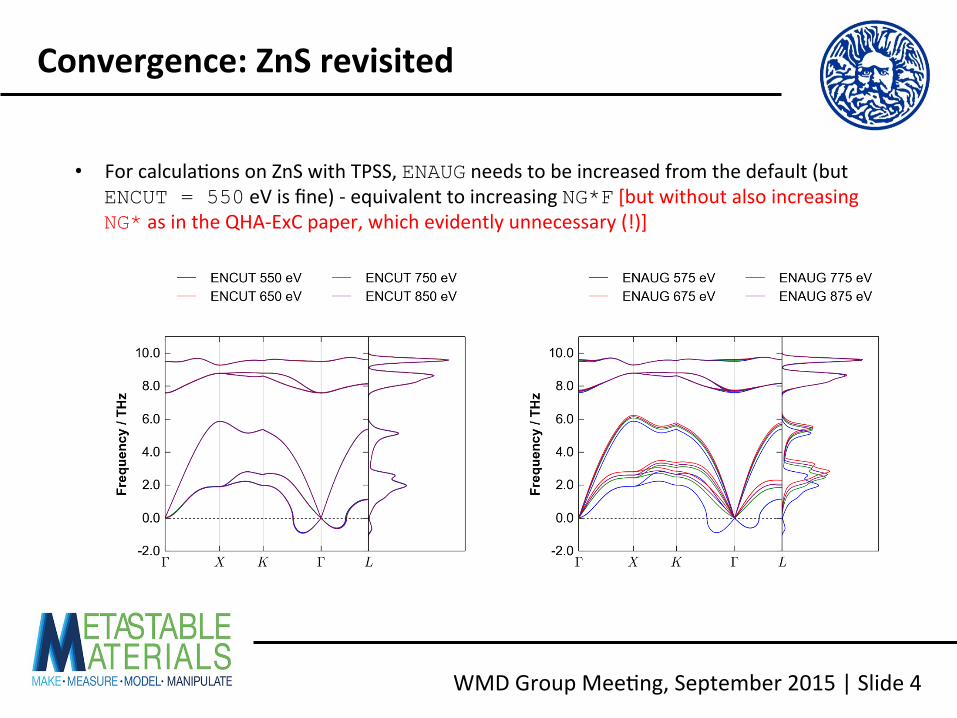
• For calcula<ons on ZnS with TPSS, ENAUG needs to be increased from the default (but ENCUT = 550 eV is fine) -‐ equivalent to increasing NG*F [but without also increasing NG* as in the QHA-‐ExC paper, which evidently unnecessary (!)]
WMD Group Mee<ng, September 2015 | Slide 5
Convergence: ZnS revisited
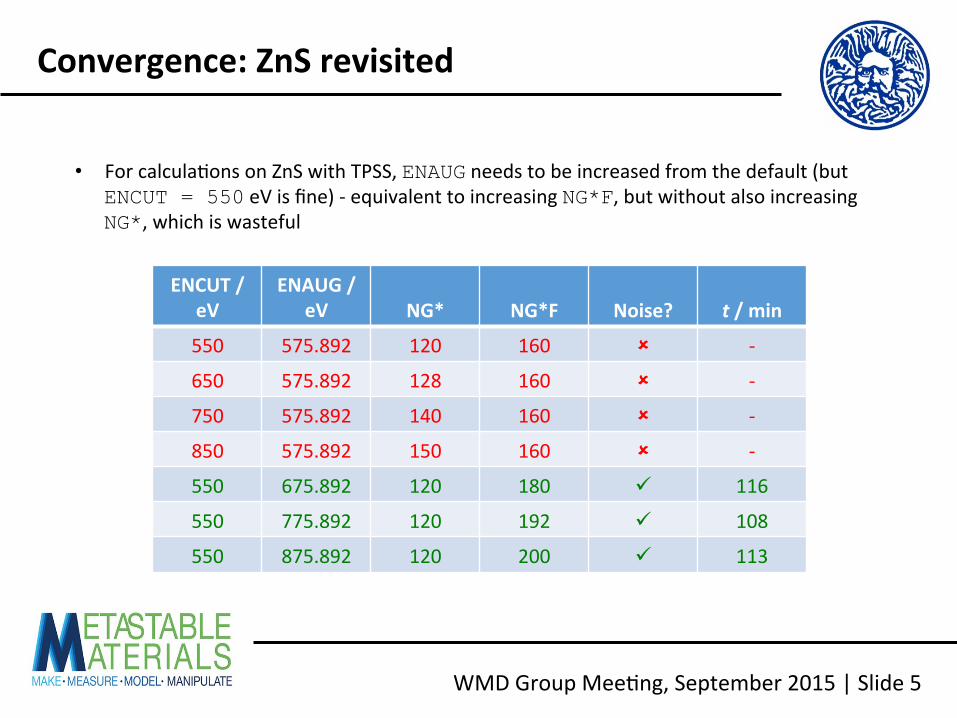
• For calcula<ons on ZnS with TPSS, ENAUG needs to be increased from the default (but ENCUT = 550 eV is fine) -‐ equivalent to increasing NG*F, but without also increasing NG*, which is wasteful
ENCUT / eV
ENAUG / eV NG* NG*F Noise? t / min
550 575.892 120 160 û -‐
650 575.892 128 160 û -‐
750 575.892 140 160 û -‐
850 575.892 150 160 û -‐
550 675.892 120 180 ü 116
550 775.892 120 192 ü 108
550 875.892 120 200 ü 113

WMD Group Mee<ng, September 2015 | Slide 6
The VASP SCF cycle
• The SCF cycle proceeds in two phases:
o The plane-‐wave coefficients are ini<alised randomly and “pre-‐op<mised” within a fixed poten<al given by the superposi<on of atomic densi<es (INIWAV, NELMDL)
o The wavefunc<ons and density are then op<mised self-‐consistently to convergence (EDIFF, NELMIN, NELM)
o If an ini<al charge density exists (e.g. from a previous SCF or converged CHGCAR/WAVECAR), the first step can be skipped (ISTART, ICHARG)
• To accelerate convergence, the output density from a step N is not fed directly into the next step N+1, but is mixed with the input density (IMIX, INIMIX, MIXPRE, MAXMIX, AMIX, AMIN, AMIX_MAG, BMIX, BMIX_MAG, WC)
• For the mathema<cally-‐minded: hhp://th.ii-‐berlin.mpg.de/th/Mee<ngs/DFT-‐workshop-‐Berlin2011/presenta<ons/2011-‐07-‐14_Marsman_Mar<jn.pdf
WMD Group Mee<ng, September 2015 | Slide 7
The VASP SCF cycle
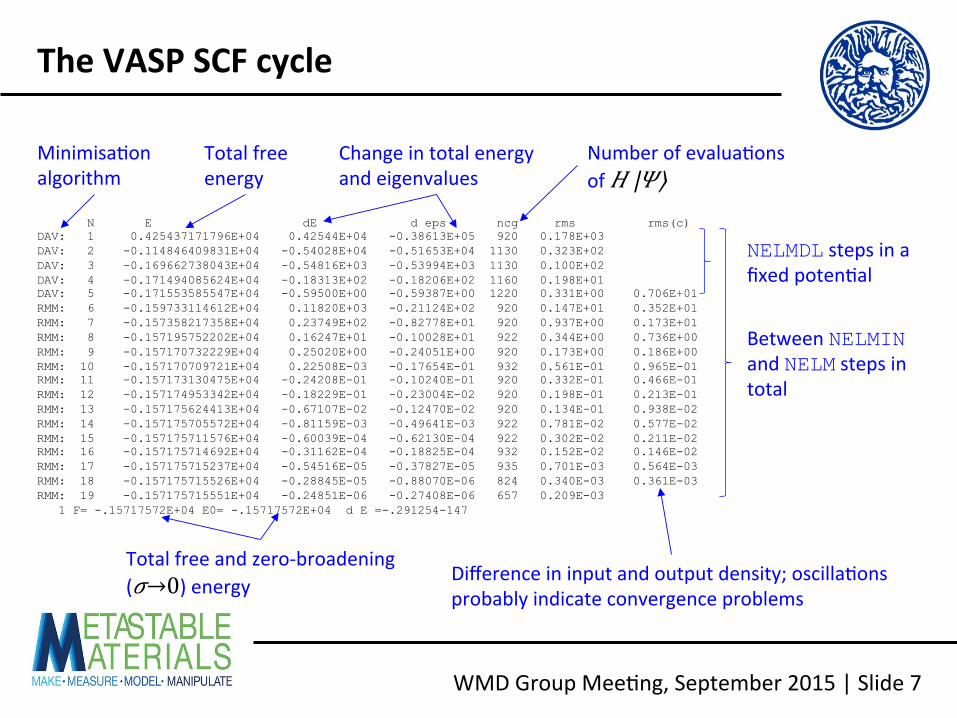
N E dE d eps ncg rms rms(c) DAV: 1 0.425437171796E+04 0.42544E+04 -0.38613E+05 920 0.178E+03 DAV: 2 -0.114846409831E+04 -0.54028E+04 -0.51653E+04 1130 0.323E+02 DAV: 3 -0.169662738043E+04 -0.54816E+03 -0.53994E+03 1130 0.100E+02 DAV: 4 -0.171494085624E+04 -0.18313E+02 -0.18206E+02 1160 0.198E+01 DAV: 5 -0.171553585547E+04 -0.59500E+00 -0.59387E+00 1220 0.331E+00 0.706E+01 RMM: 6 -0.159733114612E+04 0.11820E+03 -0.21124E+02 920 0.147E+01 0.352E+01 RMM: 7 -0.157358217358E+04 0.23749E+02 -0.82778E+01 920 0.937E+00 0.173E+01 RMM: 8 -0.157195752202E+04 0.16247E+01 -0.10028E+01 922 0.344E+00 0.736E+00 RMM: 9 -0.157170732229E+04 0.25020E+00 -0.24051E+00 920 0.173E+00 0.186E+00 RMM: 10 -0.157170709721E+04 0.22508E-03 -0.17654E-01 932 0.561E-01 0.965E-01 RMM: 11 -0.157173130475E+04 -0.24208E-01 -0.10240E-01 920 0.332E-01 0.466E-01 RMM: 12 -0.157174953342E+04 -0.18229E-01 -0.23004E-02 920 0.198E-01 0.213E-01 RMM: 13 -0.157175624413E+04 -0.67107E-02 -0.12470E-02 920 0.134E-01 0.938E-02 RMM: 14 -0.157175705572E+04 -0.81159E-03 -0.49641E-03 922 0.781E-02 0.577E-02 RMM: 15 -0.157175711576E+04 -0.60039E-04 -0.62130E-04 922 0.302E-02 0.211E-02 RMM: 16 -0.157175714692E+04 -0.31162E-04 -0.18825E-04 932 0.152E-02 0.146E-02 RMM: 17 -0.157175715237E+04 -0.54516E-05 -0.37827E-05 935 0.701E-03 0.564E-03 RMM: 18 -0.157175715526E+04 -0.28845E-05 -0.88070E-06 824 0.340E-03 0.361E-03 RMM: 19 -0.157175715551E+04 -0.24851E-06 -0.27408E-06 657 0.209E-03 1 F= -.15717572E+04 E0= -.15717572E+04 d E =-.291254-147
Between NELMIN and NELM steps in total
NELMDL steps in a fixed poten<al
Minimisa<on algorithm
Total free energy
Change in total energy and eigenvalues
Number of evalua<ons of 𝐻 |𝛹⟩
Difference in input and output density; oscilla<ons probably indicate convergence problems
Total free and zero-‐broadening (𝜎→0) energy

WMD Group Mee<ng, September 2015 | Slide 8
The ALGO tag
• ALGO is the “recommended” tag for selec<ng the electronic-‐minimisa<on algorithm
• Most of the algorithms have “subswitches”, which can be selected using IALGO
• I tend to use one of four ALGOs:
• RMM-‐DIIS (ALGO = VeryFast): fastest per SCF step, best parallelised, and converges quickly close to a minimum, but can struggle with difficult systems
• Blocked Davidson (ALGO = Normal): slower than RMM-‐DIIS, but usually stable, although can s<ll struggle with difficult problems (e.g. magne<sm, meta-‐GGAs and hybrids)
• Davidson/RMM-‐DIIS (ALGO = Fast): Uses ALGO = Normal for the “pre-‐op<misa<on”, then switches to ALGO = VeryFast; a good default choice
• All-‐band conjugate gradient (ALGO = All): Slow, but very stable; use as a fallback when ALGO = Normal struggles, and for hybrids
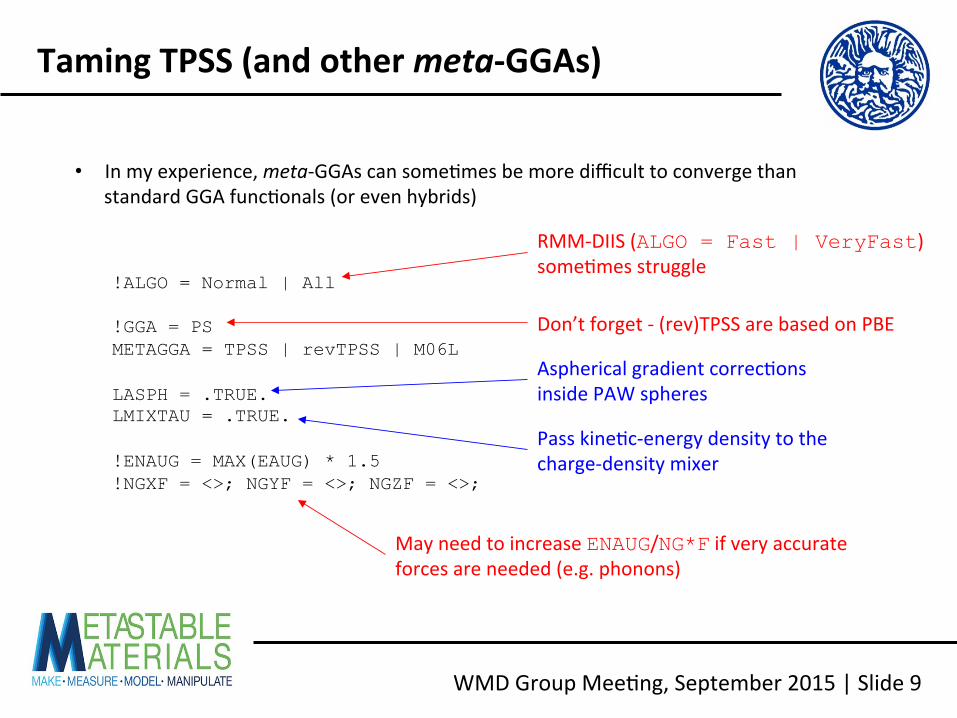
WMD Group Mee<ng, September 2015 | Slide 9
Taming TPSS (and other meta-‐GGAs)
!ALGO = Normal | All !GGA = PS METAGGA = TPSS | revTPSS | M06L LASPH = .TRUE. LMIXTAU = .TRUE. !ENAUG = MAX(EAUG) * 1.5 !NGXF = <>; NGYF = <>; NGZF = <>;
• In my experience, meta-‐GGAs can some<mes be more difficult to converge than standard GGA func<onals (or even hybrids)
RMM-‐DIIS (ALGO = Fast | VeryFast) some<mes struggle
Don’t forget -‐ (rev)TPSS are based on PBE
Aspherical gradient correc<ons inside PAW spheres
Pass kine<c-‐energy density to the charge-‐density mixer
May need to increase ENAUG/NG*F if very accurate forces are needed (e.g. phonons)

WMD Group Mee<ng, September 2015 | Slide 10
Parallelisa2on
• The newest versions of VASP implement four levels of parallelism:
o k-‐point parallelism: KPAR
o Band parallelism and data distribu<on: NCORE and NPAR
o Parallelisa<on and data distribu<on over plane-‐wave coefficients (= FFTs; done over planes along NGZ): LPLANE
o Parallelisa<on of some linear-‐algebra opera<ons using ScaLAPACK (no<onally set at compile <me, but can be controlled using LSCALAPACK)
• Effec<ve parallelisa<on will…:
o … minimise (rela<vely slow) communica<on between MPI processes, …
o … distribute data to reduce memory requirements…
o … and make sure the MPI processes have enough work to keep them busy
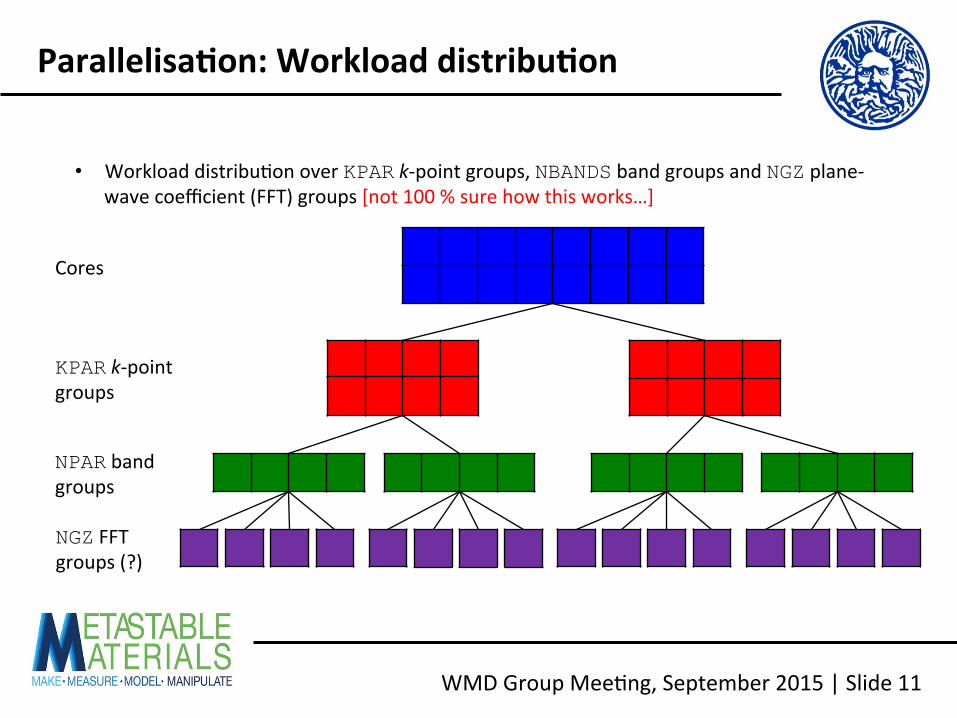
WMD Group Mee<ng, September 2015 | Slide 11
Parallelisa2on: Workload distribu2on
Cores
KPAR k-‐point groups
NPAR band groups
NGZ FFT groups (?)
• Workload distribu<on over KPAR k-‐point groups, NBANDS band groups and NGZ plane-‐wave coefficient (FFT) groups [not 100 % sure how this works…]
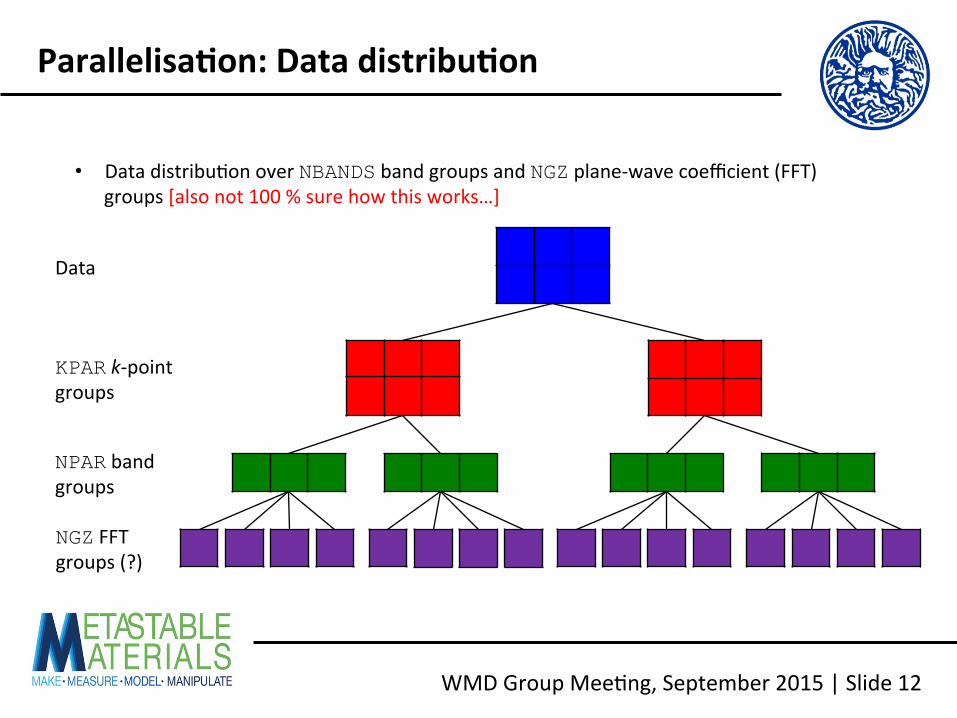
WMD Group Mee<ng, September 2015 | Slide 12
Parallelisa2on: Data distribu2on
Data
KPAR k-‐point groups
NPAR band groups
NGZ FFT groups (?)
• Data distribu<on over NBANDS band groups and NGZ plane-‐wave coefficient (FFT) groups [also not 100 % sure how this works…]
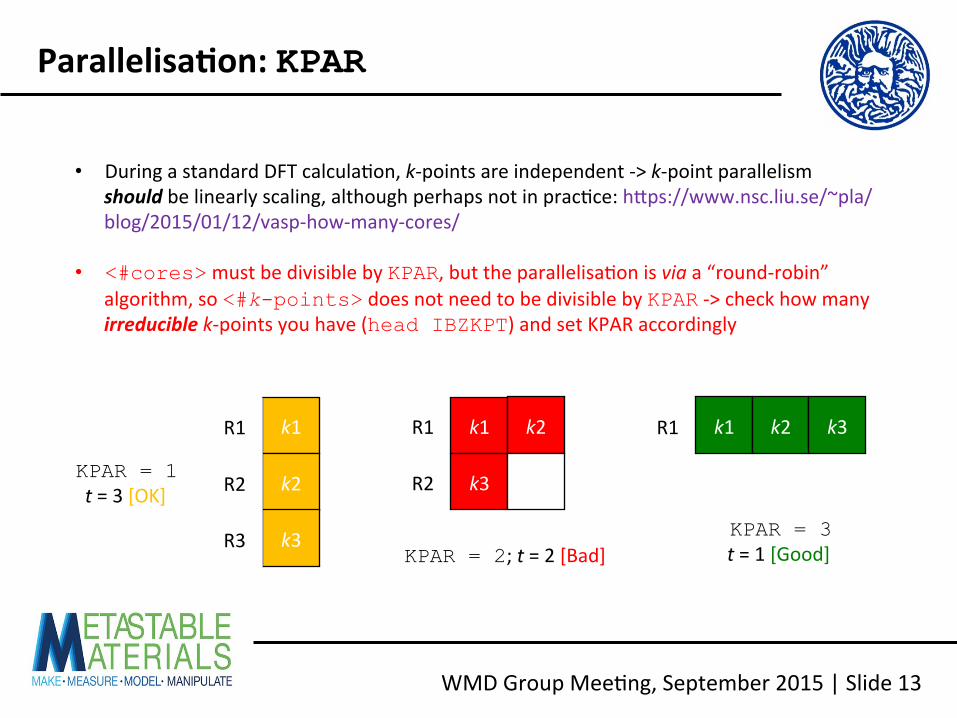
WMD Group Mee<ng, September 2015 | Slide 13
Parallelisa2on: KPAR
• During a standard DFT calcula<on, k-‐points are independent -‐> k-‐point parallelism should be linearly scaling, although perhaps not in prac<ce: hhps://www.nsc.liu.se/~pla/blog/2015/01/12/vasp-‐how-‐many-‐cores/
• <#cores> must be divisible by KPAR, but the parallelisa<on is via a “round-‐robin” algorithm, so <#k-points> does not need to be divisible by KPAR -‐> check how many irreducible k-‐points you have (head IBZKPT) and set KPAR accordingly
k1
k2
k3
k1 k2
k3
k1 k2 k3
KPAR = 1 t = 3 [OK]
KPAR = 2; t = 2 [Bad] KPAR = 3 t = 1 [Good]
R1
R2
R3
R1
R2
R1
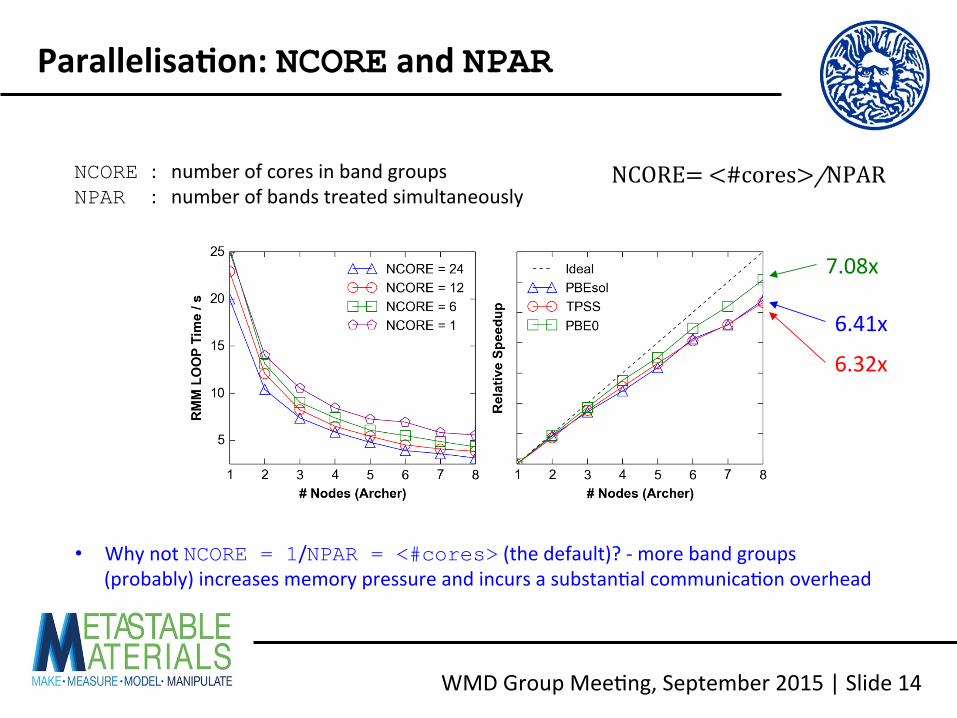
NCORE : number of cores in band groups NPAR : number of bands treated simultaneously
WMD Group Mee<ng, September 2015 | Slide 14
Parallelisa2on: NCORE and NPAR
NCORE= <#cores>/NPAR
• Why not NCORE = 1/NPAR = <#cores> (the default)? -‐ more band groups (probably) increases memory pressure and incurs a substan<al communica<on overhead
7.08x
6.41x
6.32x

WMD Group Mee<ng, September 2015 | Slide 15
Parallelisa2on: NCORE and NPAR
• WARNING: VASP will increase the default NBANDS to the nearest mul<ple of the number of groups
• Since the electronic minimisa<on scales as a power of NBANDS, this can backfire in calcula<ons with a large NPAR (e.g. those requiring NPAR = <#cores>)
Cores
NBANDS
Default Adjusted
96 455 480
128 455 512
192 455 576
256 455 512
384 455 768
512 455 512
NBANDS= NELECT/2 + NIONS/2
Example system:
• 238 atoms w/ 272 electrons
• Default NBANDS = 455
NBANDS= 3/5 NELECT+NMAG

WMD Group Mee<ng, September 2015 | Slide 16
Parallelisa2on: Memory
• KPAR: current implementa<on does not distribute data over k-‐point groups -‐> KPAR = N will use N x more memory than KPAR = 1
• NPAR/NCORE: data is distributed over band groups -‐> decreasing NPAR/increasing NCORE by a factor of N will reduce memory requirements by N x
• NPAR takes precedence over NCORE -‐ if you use “master” INCAR files, make sure you don’t define both
• The defaults for NPAR/NCORE (NPAR = <#cores>, NCORE = 1) are usually a poor choice for both memory and performance
• Band parallelism for hybrid func<onals has been supported since VASP 5.3.5; for memory-‐intensive calcula<ons, it is a good alterna<ve to underpopula<ng nodes
• LPLANE: distributes data over plane-‐wave coefficients, and speeds things up by reducing communica<on during FFTs -‐ the default is LPLANE = .TRUE., and should only need to be changed for massively-‐parallel architectures (e.g. BG/Q)
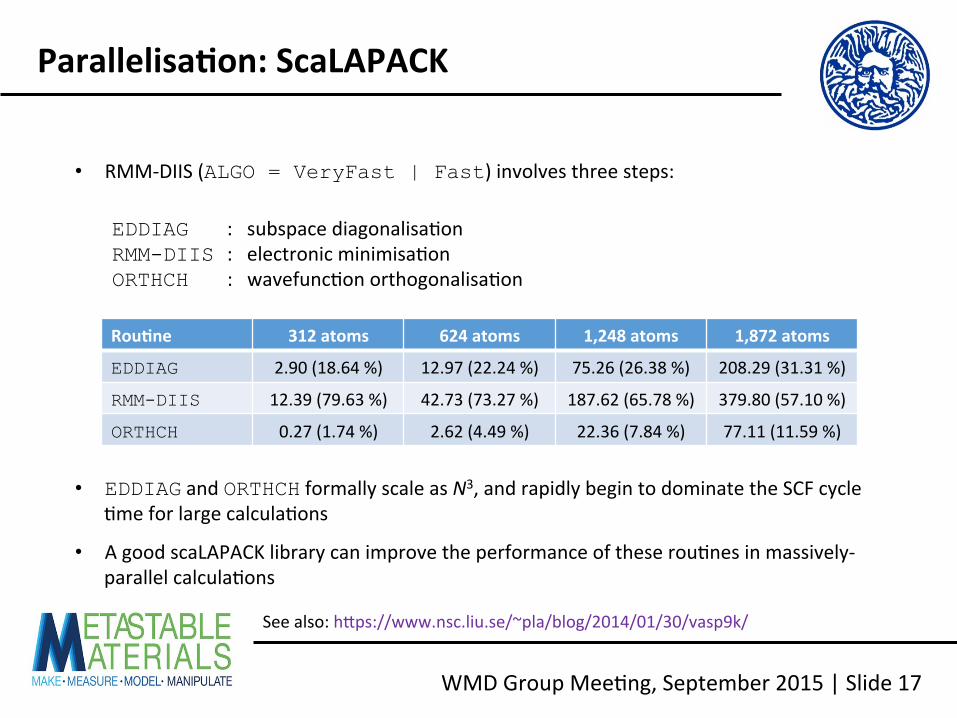
WMD Group Mee<ng, September 2015 | Slide 17
Parallelisa2on: ScaLAPACK
• RMM-‐DIIS (ALGO = VeryFast | Fast) involves three steps:
EDDIAG : subspace diagonalisa<on RMM-DIIS : electronic minimisa<on ORTHCH : wavefunc<on orthogonalisa<on
Rou2ne 312 atoms 624 atoms 1,248 atoms 1,872 atoms
EDDIAG 2.90 (18.64 %) 12.97 (22.24 %) 75.26 (26.38 %) 208.29 (31.31 %)
RMM-DIIS 12.39 (79.63 %) 42.73 (73.27 %) 187.62 (65.78 %) 379.80 (57.10 %)
ORTHCH 0.27 (1.74 %) 2.62 (4.49 %) 22.36 (7.84 %) 77.11 (11.59 %)
• EDDIAG and ORTHCH formally scale as N3, and rapidly begin to dominate the SCF cycle <me for large calcula<ons
• A good scaLAPACK library can improve the performance of these rou<nes in massively-‐ parallel calcula<ons
See also: hhps://www.nsc.liu.se/~pla/blog/2014/01/30/vasp9k/

WMD Group Mee<ng, September 2015 | Slide 18
Parallelisa2on: My “rules of thumb”
• For x86_64 IB systems (Archer, Balena, Neon…):
o Use KPAR in preference to NPAR
o Set NPAR = (<#nodes>/KPAR) or NCORE = <#cores/node>
o 1 per node/band group per 50 atoms; may want to use 2 nodes/50 atoms for hybrids, or decrease to ½ node per band group for < 10 atoms
o ALGO = Fast is a usually a good choice, except for badly-‐behaved systems
o Leave LPLANE at the default (.TRUE.)
o For the IBM BG/Q (STFC Hartree):
o The Hartree machine currently uses VASP 5.2.x -‐> no KPAR
o Try to choose a square number of cores, and set NPAR = sqrt(<#cores>)
o Consider se}ng LPLANE = .FALSE. if <#cores> ≥ NGZ