week 5: value function approximation and deep q-learning
TRANSCRIPT

Week 5: Value Function Approximation and DeepQ-Learning
Bolei Zhou
The Chinese University of Hong Kong
October 3, 2021
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 1 / 68

Announcement
1 HW1 tutorial session at TA office hour this Thursday
2 TA hour office after every homework due will be homework tutorialsession
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 2 / 68

This Week’s Plan
1 Introduction on function approximation
2 Value function approximation for prediction
3 Value function approximation for control
4 Batch RL and least square prediction and control
5 Deep Q-Learning: Entering the modern RL world
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 3 / 68

Introduction: Scaling up RL
1 Previous lectures on small RL problems:1 Cliff walk: 4×16 states2 Mountain car: 1600 states3 Tic-Tac-Toe: 103 states
2 Large-scale problems:1 Backgammon: 1020 states2 Chess: 1047 states3 Game of Go: 10170 states4 Robot Arm and Helicopter have continuous state space5 Number of atomic in universe: 1080
3 Challenge: How can we scale up the model-free methods forprediction and control to large-scale problems?
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 4 / 68

Introduction: Scaling up RL
1 In tabular methods we represent value function by a lookup table:1 Every state s has an entry V (s)2 Every state-action pair s, a has an entry Q(s, a)
2 Challenges with large MDPs:1 too many states or actions to store in memory2 too slow to learn the value of each state individually
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 5 / 68

Scaling up RL with Function Approximation
1 How to avoid explicitly learning or storing for every single state:1 Dynamics or reward model2 Value function, state-action function3 Policy
2 Solution: Estimate with function approximation
v̂(s,w) ≈ vπ(s)
q̂(s, a,w) ≈ qπ(s, a)
π̂(a, s,w) ≈ π(a|s)
1 Generalize from seen states to unseen states2 Update the parameter w using MC or TD learning
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 6 / 68
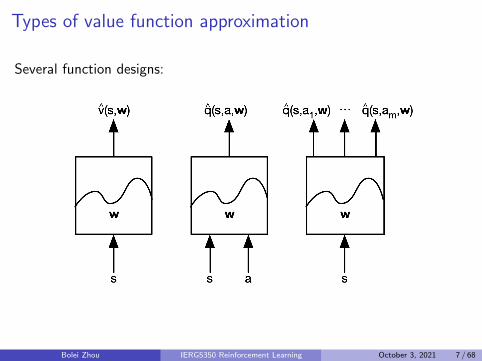
Types of value function approximation
Several function designs:
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 7 / 68

Function Approximators
1 Many possible function approximators:1 Linear combinations of features2 Neural networks3 Decision trees4 Nearest neighbors
2 We will focus on function approximators that are differentiable1 Linear feature representations2 Neural networks
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 8 / 68

Review on Gradient Descend
1 Consider a function J(w) that is a differentiable function of aparameter vector w
2 Goal is to find parameter w∗ that minimizes J3 Define the gradient of J(w) to be
∇wJ(w) =(∂J(w)
∂w1,∂J(w)
∂w2, ...,
∂J(w)
∂wn
)T4 Adjust w in the direction of the negative gradient, where α is step-size
∆w = −1
2α∇wJ(w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 9 / 68

Value Function Approximation with an Oracle
1 We assume that we have the oracle for knowing the true value forvπ(s) for any given state s
2 Then the objective is to find the best approximate representation ofvπ(s)
3 Thus use the mean squared error and define the loss function as
J(w) = Eπ
[(vπ(s)− v̂(s,w))2
]
4 Follow the gradient descend to find a local minimum
∆w =− 1
2α∇wJ(w)
wt+1 =wt + ∆w
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 10 / 68

Representing State with Feature Vectors
1 Represent state using a feature vector
x(s) =(x1(s), ..., xn(s)
)T2 For example:
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 11 / 68

Linear Value Function Approximation1 Represent value function by a linear combination of features
v̂(s,w) = x(s)Tw =n∑
j=1
xj(s)wj
2 The objective function is quadratic in parameter w
J(w) = Eπ
[(vπ(s)− x(s)Tw)2
]3 Thus the update rule is as simple as
∆w = α(vπ(s)− v̂(s,w))x(s)
Update = StepSize × PredictionError × FeatureValue4 Stochastic gradient descent converges to global optimum. Because in
the linear case, there is only one optimum, thus local optimum isautomatically converge to or near the global optimum.
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 12 / 68

Linear Value Function Approximation with Table LookupFeature
1 Table lookup is a special case of linear value function approximation
2 Table lookup feature is one-hot vector as follows
xtable(S) =(1(S = s1), ..., 1(S = sn)
)T3 Then we can see that each element on the parameter vector w
indicates the value of each individual state
v̂(S ,w) =(1(S = s1), ..., 1(S = sn)
)(w1, ...,wn
)T4 Thus we have v̂(sk ,w) = wk
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 13 / 68

Value Function Approximation for Model-free Prediction
1 In practice, no access to oracle of the true value vπ(s) for any state s2 Recall model-free prediction
1 Goal is to evaluate vπ following a fixed policy π2 A lookup table is maintained to store estimates vπ or qπ
3 Estimates are updated after each episode (MC method) or after eachstep (TD method)
3 Thus what we can do is to include the function approximationstep in the loop
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 14 / 68

Incremental VFA Prediction Algorithms
1 We assumed that true value function vπ(s) given by supervisor/oracle
∆w = α(vπ(S)− v̂(S ,w)
)∇wv̂(St ,w)
2 But in RL there is no supervisor, only rewards3 In practice, we substitute the target for vπ(s)
1 For MC, the target is the actual return Gt
∆w = α(Gt − v̂(St ,w)
)∇wv̂(St ,w)
2 For TD(0), the target is the TD target Rt+1 + γv̂(St+1,w)
∆w = α(Rt+1 + γv̂(St+1,w)− v̂(St ,w)
)∇wv̂(St ,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 15 / 68

Monte-Carlo Prediction with VFA
1 Return Gt is an unbiased, but noisy sample of true value vπ(St)
2 Why unbiased? E[Gt ] = vπ(St)
3 So we have the training data that can be used for supervised learningin VFA:
< S1,G1 >,< S2,G2 >, ..., < ST ,GT >
4 Using linear Monte-Carlo policy evaluation
∆w =α(Gt − v̂(St ,w)
)∇wv̂(St ,w)
=α(Gt − v̂(St ,w)
)x(St)
5 Monte-Carlo prediction converges, in both linear and non-linear valuefunction approximation.
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 16 / 68

TD Prediction with VFA
1 TD target Rt+1 + γv̂(St+1,w) is a biased sample of true value vπ(St)
2 Why biased? It is drawn from our previous estimate, rather than thetrue value: E[Rt+1 + γv̂(St+1,w)] 6= vπ(St)
3 We have the training data used for supervised learning in VFA:
< S1,R2 + γv̂(S2,w) >,< S2,R3 + γv̂(S3,w) >, ..., < ST−1,RT >
4 Using linear TD(0), the stochastic gradient descend update is
∆w =α(R + γv̂(S ′,w)− v̂(S ,w)
)∇wv̂(S ,w)
=α(R + γv̂(S ′,w)− v̂(S ,w)
)x(S)
This is also called as semi-gradient, as we ignore the effect ofchanging the weight vector w on the target
5 Linear TD(0) converges(close) to global optimum
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 17 / 68

Control with Value Function Approximation
Generalized policy iteration
1 Policy evaluation: approximate policy evaluation, q̂(., .,w) ≈ qπ
2 Policy improvement: ε-greedy policy improvement
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 18 / 68

Action-Value Function Approximation
1 Approximate the action-value function
q̂(s, a,w) ≈ qπ(s, a)
2 Minimize the MSE (mean-square error) between approximateaction-value and true action-value (assume oracle)
J(w) = Eπ[(qπ(s, a)− q̂(s, a,w))2]
3 Stochastic gradient descend to find a local minimum
∆w = α(qπ(s, a)− q̂(s, a,w))∇wq̂(s, a,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 19 / 68

Linear Action-Value Function Approximation
1 Represent state and action using a feature vector
x(s, a) =(x1(s, a), ..., xn(s, a)
)T2 Represent action-value function by a linear combination of features
q̂(s, a,w) = x(s, a)Tw =n∑
j=1
xj(s, a)wj
3 Thus the stochastic gradient descend update
∆w = α(qπ(s, a)− q̂(s, a,w))x(s, a)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 20 / 68

Incremental Control AlgorithmSame to the prediction, there is no oracle for the true value qπ(s, a), so wesubstitute a target
1 For MC, the target is the return Gt
∆w = α(Gt − q̂(St ,At ,w)
)∇wq̂(St ,At ,w)
2 For Sarsa, the target is the TD target Rt+1 + γq̂(St+1,At+1,w)
∆w = α(Rt+1 + γq̂(St+1,At+1,w)− q̂(St ,At ,w)
)∇wq̂(St ,At ,w)
3 For Q-learning, the target is the TD targetRt+1 + γmaxa q̂(St+1, a,w)
∆w = α(Rt+1 + γmax
aq̂(St+1, a,w)− q̂(St ,At ,w)
)∇wq̂(St ,At ,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 21 / 68

Semi-gradient Sarsa for VFA Control
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 22 / 68

Mountain Car Example
1 Control task: move the car up the hill with forward and backwardacceleration
1 Continuous state: [position of the car, velocity of the car]2 Action: [full throttle forward, full throttle backward, zero throttle]
2 Grid-tiling coding of the continuous 2D state space with 4 tilings
3 Q function approximator: q̂(s, a,w) = wTx(s, a) =∑4
i=1 wixi (s, a)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 23 / 68

Mountain Car Example
1 Visualization of cost-to-go function (−maxa q̂(s, a,w)) learned overepisodes
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 24 / 68

Mountain Car Example
1 Code example: https://github.com/cuhkrlcourse/RLexample/
blob/master/modelfree/q_learning_mountaincar.py
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 25 / 68

Convergence of Control Methods with VFA
1 For Sarsa,
∆w = α(Rt+1 + γq̂(st+1, at+1,w)− q̂(st , at ,w)
)∇wq̂(st , at ,w)
2 For Q-learning,
∆w = α(Rt+1 + γmax
aq̂(st+1, a,w)− q̂(st , at ,w)
)∇wq̂(st , at ,w)
3 TD with VFA doesn’t follow the gradient of any objective function
4 The updates involve doing an approximate Bellman backup followedby fitting the underlying value function
5 That is why TD can diverge when off-policy or using non-linearfunction approximation
6 Challenge for off-policy control: behavior policy and target policy arenot identical, thus value function approximation can diverge
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 26 / 68

The Deadly Triad for the Danger of Instability andDivergence
Potential problematic issues:
1 Function approximation: A scalable way of generalizing from a statespace much larger than the memory and computational resources
2 Bootstrapping: Update targets that include existing estimates (as indynamic programming or TD methods) rather than relying exclusivelyon actual rewards and complete returns (as in MC methods)
3 Off-policy training: training on a distribution of transitions otherthan that produced by the target policy
4 See details at Textbook Chapter 11.3
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 27 / 68

Convergence of Control Methods
Algorithm Table Lookup Linear Non-Linear
Monte-Carlo Control√
(√
) XSarsa
√(√
) XQ-Learning
√X X
(√
) moves around the near-optimal value function
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 28 / 68

Batch Reinforcement Learning
1 Incremental gradient descend update is simple
2 But it is not sample efficient
3 Batch-based methods seek to find the best fitting value function for abatch of the agent’s experience
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 29 / 68

Least Square Prediction1 Given the value function approximation v̂(s,w) ≈ vπ(s)
2 The experience D consisting of < state, value > pairs (may from oneepisode or many previous episodes)
D ={< s1, v
π1 >, ..., < sT , v
πT >
}3 Objective: To optimize the parameter w that best fit all the
experience D4 Least squares algorithms are used to minimize the sum-squared error
between v̂(st ,w) and the target values vπt
w∗ = arg minw
ED[(vπ − v̂(s,w)2]
= arg minw
T∑t=1
(vπt − v̂(st ,w))2
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 30 / 68

Stochastic Gradient Descent with Experience Replay1 Given the experience consisting of < state, value > pairs
D ={< s1, v
π1 >, ..., < sT , v
πT >
}2 Iterative solution could be to repeat the following two steps
1 Randomly sample one pair < state, value > from the experience
< s, vπ >∼ D
2 Apply the stochastic gradient descent update
∆w = α(vπ − v̂(s,w))∇wv̂(s,w)
3 The solution from the gradient descend method converges to the leastsquares solution
wLS = arg minw
T∑t=1
(vπt − v̂(st ,w))2
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 31 / 68

Solving Linear Least Squares Prediction
1 Experience replay finds least squares solution, but it may take manyiterations
2 Using linear value function approximation v̂(s,w) = x(s)Tw, we cansolve the least squares solution directly
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 32 / 68

Solving Linear Least Squares Prediction 2
1 At minimum of LS(w), the expected update must be zero
ED[∆w] = 0
2 thus
∆w = α
T∑t=1
x(st)(vπt − x(xt)Tw) = 0
T∑t=1
x(st)vπt =
T∑t=1
x(st)x(st)Tw
w =( T∑
t=1
x(st)x(st)T)−1 T∑
t=1
x(st)vπt
3 For N features, the matrix inversion complexity is O(N3)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 33 / 68

Linear Least Squares Prediction Algorithms
1 Again, we do not know the true values vπt2 In practice, the training data must use noisy or biased samples of vπt
1 LSMC: Least squares Monte-Carlo uses returnvπt ≈ Gt
2 LSTD: Least squares TD uses TD targetvπt ≈ Rt+1 + γv̂(St+1,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 34 / 68

Linear Least Squares Prediction Algorithms
LSMC 0 =T∑t=1
α(Gt − v̂(St ,w))x(St)
w =( T∑
t=1
x(St)x(St)T )−1
T∑t=1
x(St)Gt
LSTD 0 =T∑t=1
α(Rt+1 + γv̂(St+1,w)− v̂(St ,w))x(St)
w =( T∑
t=1
x(St)(x(St)− γx(St+1))T)−1 T∑
t=1
x(St)Rt+1
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 35 / 68

Least Square Control with Value Function Approximation
Generalized policy iteration
1 Policy evaluation: Policy evaluation by least squares Q-learning
2 Policy improvement: greedy policy improvement
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 36 / 68

Least Squares Action-Value Function Approximation
1 Approximate action-value function qπ(s, a)
2 using linear combination of features x(s, a)
q̂(s, a,w) = x(s, a)Tw ≈ qπ(s, a)
3 minimize least squares error between q̂(s, a,w) and qπ(s, a)
4 The experience is generate from using policy π, consisting of< state, action, action − value >
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 37 / 68

Least Squares Control
1 For policy evaluation we want to efficiently use all the experience
2 For control we want to improve the policy
3 The experience is generated from many policies (previous old policies)
4 So to evaluate qπ(s, a) we must learn off-policy5 We follow the same idea of Q-Learning:
1 Use the experience generated by old policy:
St ,At ,Rt+1,St+1 ∼ πold
2 Consider the alternative successor action A′ = πnew (St+1) using greedy3 Update q̂(St ,At ,w) towards value of alternative action
Rt+1 + γq̂(St+1,A′,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 38 / 68

Least Squares Q-Learning
1 Consider the following linear Q-learning update
δ =Rt+1 + γq̂(St+1, π(St+1),w)− q̂(St ,At ,w)
∆w =αδx(St ,At)
2 LSDQ algorithm: solve the total sum of the gradient = zero:
0 =T∑t=1
α(Rt+1 + γq̂(St+1, π(St+1),w) − q̂(St ,At ,w))x(St ,At)
w =( T∑
t=1
x(St ,At)(x(St ,At) − γx(St+1, π(St+1)))T)−1
T∑t=1
x(St ,At)Rt+1
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 39 / 68

Least Squares Policy Iteration Algorithm
1 Use LSDQ for policy evaluation
2 Repeatedly re-evaluate experience D with different policies
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 40 / 68

Convergence of Control Methods
Algorithm Table Lookup Linear Non-Linear
Monte-Carlo Control√
(√
) XSarsa
√(√
) XQ-Learning
√X X
LSPI√
(√
) -
(√
) moves around the near-optimal value function
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 41 / 68

Deep Q-Learning
1 DeepMind’s Nature paper: Mnih, Volodymyr; et al. (2015).Human-level control through deep reinforcement learning
1 Entering the period of modern RL: deep learning + reinforcementlearning
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 42 / 68

Review on Stochastic Gradient Descend for FunctionApproximation
1 Goal: Find the parameter vector w that minimizes the loss between atrue value function vπ(s) and its approximation v̂π(s,w) asrepresented with a particular function approximator parameterized byw
2 The mean square error loss function is as
J(w) = Eπ
[(vπ(S)− v̂(s,w))2
]3 Follow the gradient descend to find a local minimum
∆w =− 1
2α∇wJ(w)
wt+1 =wt + ∆w
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 43 / 68

Linear Function Approximation1 Represent value function by a linear combination of features
v̂(S ,w) = x(S)Tw =n∑
j=1
xj(S)wj
2 Objective function is J(w) = Eπ
[(vπ(S)− x(S)Tw)2
]3 Update is as simple as ∆w = α(vπ(S)− v̂(S ,w))x(S)4 But there is no oracle for the true value vπ(S), we substitute with the
target from MC or TD1 for MC policy evaluation,
∆w =α(Gt − v̂(St ,w)
)x(St)
2 for TD policy evaluation,
∆w =α(Rt+1 + γv̂(St+1,w)− v̂(St ,w)
)x(St)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 44 / 68

Linear vs Nonlinear Value Function Approximation
1 Linear VFA often works well given the right set of features
2 But it requires manual designing of the feature set
3 Alternative is to use a much richer function approximator that is ableto directly learn from states without requiring the feature design
4 Nonlinear function approximator: Deep neural networks
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 45 / 68

Deep Neural Networks
1 Multiple layers of linear functions, with non-linear operators betweenlayers
f (x; θ) = WTL+1σ(WT
L σ(...σ(WT1 x + b1) + ...+ bL−1) + bL) + bL+1
2 The chain rule to backpropagate the gradient to update the weights
using the loss function L(θ) = 1n
∑ni=1
(y (i) − f (x; θ)
)2Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 46 / 68

Convolutional Neural Networks
1 Convolution encodes the local information in 2D feature map
2 Layers of convolution, reLU, batch normalization, etc.
3 CNNs are widely used in computer vision (more than 70% topconference papers using CNNs)
4 A detailed introduction on CNNs:http://cs231n.github.io/convolutional-networks/
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 47 / 68

Deep Reinforcement Learning
1 Frontier in machine learning and artificial intelligence2 Deep neural networks are used to represent
1 Value function2 Policy function (policy gradient methods to be introduced)3 World model
3 Loss function is optimized by stochastic gradient descent (SGD)4 Challenges
1 Efficiency: too many model parameters to optimize2 The Deadly Triad for the danger of instability and divergence in
training
1 Nonlinear function approximation2 Bootstrapping3 Off-policy training
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 48 / 68

Deep Q-Networks (DQN)
1 DeepMind’s Nature paper: Mnih, Volodymyr; et al. (2015).Human-level control through deep reinforcement learning
2 DQN represents the action value function with neural networkapproximator
3 DQN reaches a professional human gaming level across many Atarigames using the same network and hyperparameters
4 Atari Games: Breakout, Pong, Montezuma’s Revenge, Private Eye
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 49 / 68

Recall: Action-Value Function Approximation
1 Approximate the action-value function
q̂(S ,A,w) ≈ qπ(S ,A)
2 Minimize the MSE (mean-square error) between approximateaction-value and true action-value (assume oracle)
J(w) = Eπ[(qπ(S ,A)− q̂(S ,A,w))2]
3 Stochastic gradient descend to find a local minimum
∆w = α(qπ(S ,A)− q̂(S ,A,w))∇wq̂(S ,A,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 50 / 68

Recall: Incremental Control Algorithm
Same to the prediction, there is no oracle for the true value qπ(S ,A), sowe substitute a target
1 For MC, the target is the return Gt
∆w = α(Gt − q̂(St ,At ,w)
)∇wq̂(St ,At ,w)
2 For Sarsa, the target is the TD target Rt+1 + γq̂(St+1,At+1,w)
∆w = α(Rt+1 + γq̂(St+1,At+1,w)− q̂(St ,At ,w)
)∇wq̂(St ,At ,w)
3 For Q-learning, the target is the TD targetRt+1 + γmaxa q̂(St+1, a,w)
∆w = α(Rt+1 + γmax
aq̂(St+1, a,w)− q̂(St ,At ,w)
)∇wq̂(St ,At ,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 51 / 68

DQN for Playing Atari Games
1 End-to-end learning of values Q(s, a) from input pixel frame
2 Input state s is a stack of raw pixels from latest 4 frames
3 Output of Q(s, a) is 18 joystick/button positions
4 Reward is the change in score for that step
5 Network architecture and hyperparameters fixed across all games
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 52 / 68

Q-Learning with Value Function Approximation
1 Two of the issues causing problems:1 Correlations between samples2 Non-stationary targets
2 Deep Q-learning (DQN) addresses both of these challenges by1 Experience replay2 Fixed Q targets
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 53 / 68

DQNs: Experience Replay
1 To reduce the correlations among samples, store transition(st , at , rt , st+1) in replay memory D
2 To perform experience replay, repeat the following1 sample an experience tuple from the dataset: (s, a, r , s ′) ∼ D2 compute the target value for the sampled tuple: r + γmaxa′ Q̂(s ′, a′,w)3 use stochastic gradient descent to update the network weights
∆w = α(r + γmax
a′Q̂(s ′, a′,w)− Q(s, a,w)
)∇wQ̂(s, a,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 54 / 68

DQNs: Fixed Targets
1 To help improve stability, fix the target weights used in the targetcalculation for multiple updates
2 Let a different set of parameter w− be the set of weights used in thetarget, and w be the weights that are being updated
3 To perform experience replay with fixed target, repeat the following1 sample an experience tuple from the dataset: (s, a, r , s ′) ∼ D2 compute the target value for the sampled tuple:
r + γmaxa′ Q̂(s ′, a′,w−)3 use stochastic gradient descent to update the network weights
∆w = α(r + γmax
a′Q̂(s ′, a′,w−)− Q(s, a,w)
)∇wQ̂(s, a,w)
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 55 / 68

Why fixed target
1 In the original update, both Q estimation and Q target shifts at eachtime step
2 Imagine a cat (Q estimation) is chasing after a mouse (Q target)
3 The cat must reduce the distance to the mouse
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 56 / 68

Why fixed target
1 Both the cat and mouse are moving,
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 57 / 68

Why fixed target
1 This could lead to a strange path of chasing (an oscillated traininghistory)
2 Solution: fix the target for a period of time during the training
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 58 / 68
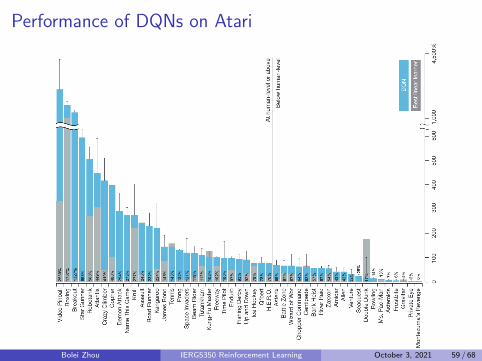
Performance of DQNs on Atari
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 59 / 68

Ablation Study on DQNs
1 Game score under difference conditions
Replay Replay No replay No replayFixed-Q Q-learning Fixed-Q Q-learning
Breakout 316.81 240.73 10.16 3.17Enduro 1006.3 831.25 141.89 29.1River Raid 7446.62 4102.81 2867.66 1453.02Seaquest 2894.4 822.55 1003 275.81Space Invaders 1088.94 826.33 373.22 301.99
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 60 / 68

Demo of DQNs
1 Demo of deep Q-learning for Breakout:https://www.youtube.com/watch?v=V1eYniJ0Rnk
2 Demo of Flappy Bird by DQN:https://www.youtube.com/watch?v=xM62SpKAZHU
3 Code of DQN in PyTorch: https://github.com/cuhkrlcourse/
DeepRL-Tutorials/blob/master/01.DQN.ipynb
4 Code of Flappy Bird:https://github.com/xmfbit/DQN-FlappyBird
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 61 / 68

Summary of DQNs
1 DQN uses experience replay and fixed Q-targets
2 Store transition (st , at , rt+1, st+1) in replay memory D3 Sample random mini-batch of transitions (s, a, r , s ′) from D4 Compute Q-learning targets w.r.t. old, fixed parameters w−
5 Optimizes MSE between Q-network and Q-learning targets usingstochastic gradient descent
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 62 / 68

Improving DQN
1 Success in Atari has led to a huge excitement of using deep neuralnetworks for value function approximation in RL
2 Many follow-up works on improving DQNs1 Double DQN: Deep Reinforcement Learning with Double Q-Learning.
Van Hasselt et al, AAAI 20162 Dueling DQN: Dueling Network Architectures for Deep Reinforcement
Learning. Wang et al, best paper ICML 20163 Prioritized Replay: Prioritized Experience Replay. Schaul et al, ICLR
2016
3 A nice tutorial on the relevant algorithms:https://github.com/cuhkrlcourse/DeepRL-Tutorials
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 63 / 68

Improving DQN: Double DQN
1 Handles the problem of the overestimation of Q-values
2 Idea: use the two networks to decouple the action selection from thetarget Q value generation
3 Vanilla DQN:
∆w = α(r + γmax
a′Q̂(s ′, a′,w−)− Q(s, a,w)
)∇wQ̂(s, a,w)
4 Double DQN:
∆w = α(r + γQ̂(s ′, arg max
a′Q(s ′, a′,w),w−)− Q(s, a,w)
)∇wQ̂(s, a,w)
5 Code: https://github.com/cuhkrlcourse/DeepRL-Tutorials/blob/
master/03.Double_DQN.ipynb
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 64 / 68

Improving DQN: Dueling DQN1 One branch estimates V (s), other branch estimates the advantage for
each action A(s, a). Then Q(s, a) = A(s, a) + V (s)
2 By decoupling the estimation, intuitively the DuelingDQN can learnwhich states are (or are not) valuable without having to learn theeffect of each action at each state
3 Code: https://github.com/cuhkrlcourse/DeepRL-Tutorials/
blob/master/04.Dueling_DQN.ipynb
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 65 / 68

Improving DQN: Prioritized Experience Replay1 Transition (st , at , rt+1, st+1) is stored in and sampled from the replay
memory D
2 Priority is on the experience where there is a big difference betweenour prediction and the TD target, since it means that we have a lot tolearn about it.
3 Define a a priority score for each tuple i
pi = |r + γmaxa′
Q(si+1, a′,w−)− Q(si , ai ,w)|
4 Code: https://github.com/cuhkrlcourse/DeepRL-Tutorials/
blob/master/06.DQN_PriorityReplay.ipynb
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 66 / 68

Improving over the DQN
1 Rainbow: Combining Improvements in Deep Reinforcement Learning.Matteo Hessel et al. AAAI 2018.https://arxiv.org/pdf/1710.02298.pdf
2 It examines six extensions to the DQN algorithm and empiricallystudies their combination
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 67 / 68

Homework
1 Go through the Jupytor tutorial and training your own gaming agent:https://github.com/cuhkrlcourse/DeepRL-Tutorials
2 Good resource for your course project1 Make sure it works for simple environment such as Pong
3 Assignment 2 is/will be out this week at https://github.com/cuhkrlcourse/ierg5350-assignment-2021
4 Next week: Policy-based RL
Bolei Zhou IERG5350 Reinforcement Learning October 3, 2021 68 / 68