horatiuvlad.com formale...horatiuvlad.com
TRANSCRIPT

CONF. DR. DANIELA MARINESCU
REPROGRAFIA UNIVERSITĂŢII “TRANSILVANIA” DIN BRAŞOV


CUPRINS
Capitolul I. .. ....…………………………………………………………………………….1
§ 1.1 Noţiunea de limbaj ................................ ................................ .......................... …1
§ 1.2 Gramatici generative ................................ ................................ ......................... ..4
§ 1.3 Operaţii cu limbaje ................................ ................................ .......................... …7
§ 1.4 Exercitii…….. ................................ ................................ ................................ ... ..8
Capitolul II.………………………………………………………………………………..9
§ 2.1 Automate finite…………………………………………………………………9
§ 2.2 Legătura dintre gramaticile regulate şi automatele finite ........................... ..….12
§ 2.3 Minimizarea automatului finit..……………………………………………….16
§ 2.4 Algoritmi pentru minimizarea automatului finit ................................ .......... ….17
§ 2.5 Lema de pompare pentru mulţimi regulate ................................ ................... …22
§ 2.6 Gramatici regulate şi expresii regulate................................ ........................ …..22
§ 2.7 Algoritm de transformare a unei gramatici regulate într-o expresie regulată…24
§ 2.8 Echivalenţa dintre expresiile regulate şi automatele finite nedeterministe……27
§ 2.9 Proprietăţi ale limbajelor de tip 3 ................................ ................................ …..30
§ 2.10 Exercitii………………………………………………………………………..35
Capitolul III…...………………………………………………………………………….37
§ 3.1 Arbori de derivaţie pentru gramaticile I.D.C. ................................ ............. .….37
§ 3.2 Forme normale ................................ ................................ ............................ .….40
§ 3.3 Teorema de pompare pentru limbaje I.D.C.(lema Bar-Hillel).................... .….40
§ 3.4 Automate Push-down ................................ ................................ ................. ..….44
§ 3.5 Legătura dintre automatele push-down nedeterministe şi limbajele
independente de context ................................ ................................ .......................... ….47
§ 3.6 Proprietăţi de închidere pentru limbaje I.D.C. ................................ ............ …..48
§ 3.7 Exerciţii ................................ ................................ ................................ ....... …..54
BIBLIOGRAFIE ...............................................................................................................56

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 1 -
Introducem, în acest capitol, o serie de noţiuni folosite în teoria limbajelor formale cum ar fi:
alfabet, simbol, cuvânt, subcuvânt, prefix, suffix, cuvânt vid. Noţiunea de limbaj formal se defineşte apoi în
mai multe feluri, echivalente între ele, pornind de la sisteme de rescriere, pînă la gramatici generative şi
analitice. În continuare se prezintă o ierarhizare a gramaticilor, numită Ierarhia lui Chomsky, şi se
definesc operaţiile cu limbaje. Capitolul I se încheie cu probleme propuse spre rezolvare.
§ 1.1 Noţiunea de limbaj Noţiunea de limbaj se întâlneşte atât în lingvistică, unde se referă la limbajele naturale, cât şi în
informatică, unde se referă la limbajele de programare.
O limbă naturală se defineşte, conform dicţionarului, ca o mulţime de cuvinte şi de metode de
combinare a lor, folosită şi înţeleasă de o comunitate umană considerabilă.
Un limbaj de programare se defineşte ca o mulţime de programe scrise în acel limbaj.
O limbă naturală sau un limbaj de programare pot fi considerate ca mulţimi de secvenţe, adică şiruri
finite de elemente ale unui anumit vocabular de bază.
Pentru a putea studia proprietăţile acestor limbaje a fost necesară formalizarea noţiunii de limbaj,
construirea unei teorii matematice riguroase a limbajelor. O astfel de teorie este suficient de generală pentru
a include şi limbajele naturale şi limbajele de programare, precum şi o mulţime de alte limbaje, formând la
un loc aşa numitele limbaje formale.
Pentru a putea defini noţiunea de limbaj formal vom introduce o serie de noţiuni şi notaţii folosite
frecvent în această teorie.
Definiţia 1.1.1 Un alfabet sau vocabular, V, este o mulţime finită, nevidă de elemente.
Definiţia 1.1.2 Un element al alfabetului V se numeşte literă sau simbol.
În cele ce urmează vom folosi ca simboluri cifrele, literele latine şi greceşti mari şi mici şi simboluri
speciale cum ar fi $, #.
Exemplul 1.1.1 Exemple de alfabete sunt:
-alfabetul latin: {A, B, C, ..., Z}
-alfabetul grecesc: {, , , ..., }
-alfabetul binar: {0, 1}.
Definiţia 1.1.3 Un cuvânt peste alfabetul V este un şir finit constând din zero sau mai multe simboluri ale
lui V, unde un acelaşi simbol poate să apară de mai multe ori.
Notăm cu sau , cuvântul vid, format din zero simboluri.
Dacă V este un alfabet atunci prin V* vom nota mulţimea tuturor cuvintelor peste V, inclusiv
cuvântul vid , iar V+= V* - .
Exemplul 1.1.2 Dacă V = 0, 1 atunci
V*=, 0, 1, 00, 01, 10, 11, . ..
şi
V+=0, 1, 00, 01, 10, 11, 000 , ....
Evident V* şi V+ sunt mulţimi infinite deoarece ele conţin cuvinte de lungime oricât de mare.
Definiţia 1.1.4 Un limbaj este o mulţime de cuvinte peste un alfabet.

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 2 -
Exemplul 1.1.3 Într-un limbaj natural alfabetul, în sensul definiţiilor de mai sus, este dicţionarul limbii
respective, cuvintele sunt frazele, iar limbajul este mulţimea tuturor frazelor. Într-un limbaj de programare
simbolurile sunt instrucţiunile limbajului, cuvintele sunt programele iar limbajul este mulţimea tuturor
programelor.
În mulţimea cuvintelor se introduce o operaţie numită concatenare:
Definiţia 1.1.5 Dacă u şi v sunt două cuvinte din V* atunci concatenarea uv este tot un cuvânt din V*, care
se obţine prin alăturarea simbolurilor lui v după ultimul simbol al lui u.
Observaţia 1.1.1 Evident operaţia de concatenare este asociativă, u(vw)=(uv)w, dar nu este comutativă (în
general uvvu) iar cuvântul vid este element neutru relativ la operaţia de concatenare: u=u=u.
Definiţia 1.1.6 Puterea a i-a a cuvântului u, notată ui, este definită recursiv astfel:
(1) u0 =
(2) ui+1
= uiu
Definiţia 1.1.7 Lungimea unui cuvânt u, notată lg(u) sau |u|, este numărul de simboluri ale cuvântului u şi
este o aplicaţie lg: V* N .
Prin definiţie lg() = 0, fiind cuvântul format din zero simboluri.
Definiţia 1.1.8 Un cuvânt u este subcuvânt al lui v dacă şi numai dacă există cuvintele şi astfel încât v =
u. Dacă = atunci u se numeşte prefix al lui v iar dacă = atunci u se numeşte sufix al lui v. Un
subcuvânt u al lui v se numeşte subcuvânt propriu al lui v numai dacă u{,v}.
Majoritatea limbajelor care ne interesează vor conţine o mulţime infinită de cuvinte. Se pun atunci
trei chestiuni importante:
1. Cum se poate reprezenta un limbaj?
Dacă limbajul este finit atunci el s-ar putea reprezenta prin enumerarea cuvintelor sale, deşi la un
număr mare de cuvinte enumerarea poate fi complicată. Dacă însă limbajul este infinit apare problema
găsirii unei reprezentări finite pentru limbaj.
Apare atunci o altă problemă:
2. Există o reprezentare finită pentru orice limbaj?
Evident mulţimea V* a tuturor cuvintelor peste un alfabet finit V este o mulţime numărabilă. Un
limbaj este o submulţime a lui V*, deci mulţimea tuturor limbajelor peste V este mulţimea părţilor lui V*,
adică o mulţime nenumărabilă.
Deşi nu am definit încă o reprezentare finită a unui limbaj, se pare că mulţimea reprezentărilor finite
este numărabilă [4] deci ar rezulta că există mai multe limbaje decât reprezentări finite ale limbajelor.
3. Ce se poate spune despre structura acelor clase de limbaje care admit reprezentări finite? Aceasta este una din principalele problemele de care ne vom ocupa în continuare.
Să considerăm acum câteva limbaje peste alfabetul {a, b}.
L1={ }
L2={ a, ba, aaba, bbbb }
L3={ ap | p număr prim }
L4={ ai b
i | i număr natural }
L5={ u *,ba | Na(u)=Nb(u) }
unde Na (u) este numărul de apariţii ale simbolului a în cuvântul u. Considerăm şi limbajul vid , care nu
conţine nici un cuvânt. Se observă că {} pentru că limbajul { } conţine un cuvânt şi anume .
Limbajele L1 şi L2 fiind finite se pot reprezenta prin enumerarea cuvintelor lor pe când limbajele L3, L4 şi L5 sunt infinite şi au fost caracterizate de o proprietate pe care trebuie să o satisfacă toate cuvintele
limbajului. O astfel de proprietate specifică este un mijloc de bază de definire a unui limbaj infinit.
Un alt mod de a defini un limbaj infinit este de a introduce un mecanism generativ şi de a considera
cuvintele produse de acest mecanism.
Se poate, de asemenea, construi un mecanism analitic, de recunoaştere. Astfel un limbaj se poate
defini ca mulţimea tuturor cuvintelor recunoscute de un astfel de mecanism.
Mecanismele generative şi analitice se pot defini în termenii unui sistem de rescriere.

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 3 -
Să considerăm câteva moduri de definire ale unor limbaje în exemplele următoare.
Exemplul 1.1.4 Fie L un limbaj peste alfabetul {a, b} definit după cum urmează:
(i) λ L
(ii) Dacă x L atunci axb L
(iii) Nici un alt cuvânt nu aparţine lui L.
Se poate demonstra prin dublă incluziune că limbajul L construit conform acestor reguli este chiar
limbajul L4 = { ai b
i | i număr natural }.
Se observă că (i)-(iii) constituie un mecanism generativ pe când L4 este definit de o proprietate
specifică.
Exemplul 1.1.5 Fie L’ definit după cum urmează :
(i) L’
(ii) Dacă xL’, atunci axbL’ şi bxaL’
(iii) Dacă x1L, x2L’ atunci x1x2L’
(iv) Nici un alt cuvânt nu aparţine lui L’.
Si aici se poate demonstra că L’=L5.
Exemplul 1.1.6 Fie L” un limbaj constând din toate cuvintele care se pot reduce la prin înlocuirea
subcuvintelor ab prin .
Astfel cuvintele , ab, abab şi aabbab L”. Evident L”L5 dar L”L5 pentru că, de exemplu,
baL”. Definiţia aceasta poate fi considerată ca un mecanism de recunoaştere sau analitic.
În exemplele date anumite subcuvinte sunt rescrise. În conformitate cu definiţia următoare, o
mulţime finită de reguli de rescriere determină un sistem de rescriere.
Definiţia 1.1.9 Un sistem de rescriere este o pereche ordonată SR=(V, F), unde V este un alfabet şi F o
mulţime finită de perechi ordonate de cuvinte peste V. Elementele (α,β) ale lui F sunt numite reguli de
rescriere sau producţii şi se notează αβ.
Un cuvânt x peste V generează direct cuvântul y (xSR y) dacă şi numai dacă există cuvintele u, v, α ,
β astfel încât: x=uαv, y=uβv, iar α1β1 F, adică subcuvântul α al lui x este înlocuit prin subcuvântul β.
Un cuvânt α peste V generează β (în mai mulţi paşi) (α*
β) dacă şi numai dacă există un şir finit de
cuvinte α0, α1 , ..., αk, k 0, unde α0=α, αk=β şi αi αi+1, pentru 0 i k-1. Secvenţa α0 α1... αk se
va numi derivaţie a lui β din α în conformitate cu sistemul de rescriere, SR.
α= α0 α1 α2.... αk=β
Astfel relaţia este o relaţie binară pe V* iar *
este închiderea reflexivă şi tranzitivă a relaţiei .
Numărul k se numeşte lungimea derivaţiei sau număr de paşi.
Un sistem de rescriere poate fi transformat într-un mecanism generativ prin specificarea unei
submulţimi Ax V*, numită mulţimea de axiome, şi considerând limbajul
(1) Lg(SR, Ax)={ β | α*
β, αAx }
Similar un sistem de rescriere poate fi privit ca un mijloc analitic sau de recunoaştere, considerând
limbajul (2) La(SR, Ax)={ α | α*
β, βAx }
Formula (1) reprezintă limbajul generat de perechea (SR, Ax), iar formula (2) reprezintă limbajul
recunoscut sau acceptat de perechea (SR, Ax).
Observaţia 1.1.3 De cele mai multe ori mulţimea Ax este formată dintr-un singur simbol (simbolul iniţial)
sau are o structură foarte simplă.
Observaţia 1.1.4 De cele mai multe ori V se împarte în două submulţimi:VT, mulţimea terminalelor, VN
mulţimea neterminalelor sau a variabilelor şi limbajul se defineşte ca o submulţime a lui VT *.
Revenind la exemplele anterioare, în exemplul 1.1.6, L” se poate defini, în termenii unui sistem de
rescriere ca L” = La(SR,{}), unde V={a,b} iar F={ab}.
În exemplul 1.1.4, L=Lg(SR,{x}){a,b}*, unde SR=({a,b,x}, {x, xaxb}).

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 4 -
Limbajul L’ din exemplul 1.1.5 este definit acum :
L’ = Lg(SR,{x}){a,b}*,
Unde SR=({a,b,x}, {x, xaxb, xbxa, xxx}).
Sistemele de rescriere sunt de asemenea denumite sisteme semi - Thue.
Dintre cele mai cunoscute sisteme de rescriere fac parte: algoritmul normal în sens Markov[16], sistemele
normale Post si gramaticile generative.
§ 1.2 Gramatici generative Vom defini un tip de mecanism care joacă un rol important în teoria limbajelor formale.
Definiţia 1.2.1 O gramatică generativă este un quadruplu ordonat G=(VN, VT,S,P), unde VN şi VT sunt
alfabete finite disjuncte SVN şi P este o mulţime finită de perechi ordonate (u,v), astfel încât v este un
cuvânt din V*, unde V=VNVT şi u este un cuvânt din V* care conţine cel puţin o literă din VN.
Elementele lui VN formează mulţimea neterminalelor sau variabilelor, iar cele ale lui VT formează
mulţimea terminalelor; S se numeşte simbolul iniţial, iar P sunt reguli de rescriere, producţii. De fapt o
gramatică este un sistem de rescriere (V, P) numit sistem de rescriere indus de G.
Noţiunile de derivare directă sau derivare corespund celor introduse în cadrul unui sistem de
rescriere.
Limbajul L(G) generat de G este definit de:
L(G)={ w| wV *, S*
w }
Definiţia 1.2.2 Două gramatici, G şi G1, se numesc gramatici echivalente atunci şi numai atunci când
L(G)=L(G1).
Exemplul 1.2.1 Limbajul L = { aib
i | iN } este generat de gramatica generativă
G = ({S}, {a,b}, S, {S, SaSb})
Exemplul 1.2.2 Limbajul L = { w | w{a,b}*, Na(w)=Nb(w) } este generat de gramatica generativă
G = ({S}, {a,b}, S, {S, Sasb, SbSa, SSS})
Vom da în continuare câteva exemple de gramatici conform cu [21].
Exemplul 1.2.3 [21].
G = ({S, B, C}, {a, b, c}, S, P}) , unde mulţimea P este formată din:
SaSBC
SaBC
CBBC
bBbb
bCbc
cCCc
aBab
Să încercăm o derivaţie în gramatica G:
S aSBC aaSBCBC aaaSBCBCBC aaaaBCBCBCBC aaaaBBCCBCBC
* aaaaBBBBCCCC aaaabBBBCCCC aaaabbBBCCC aaaabbbBCCCC
aaaabbbbCCCC aaaabbbbcCCC aaaabbbbccCC aaaabbbbcccC aaaabbbbcccc
Se poate demonstra că L(G)={anb
nc
n | n1}
Exemplul 1.2.4. [21] Fie limbajul L={ ww | w{0,1}* }. Gramatica G definită de: G=({x0, x1, x2, x3},
{0,1}, x0, P}), unde P este:
P : x0x1x2x3
x1x2
x3
x1x2ix1yi
yijjyi
yix3x2ix3
ix2x2i
pentru fiecare i şi j din {0,1}
Această gramatică generează limbajul L. Să încercăm o derivaţie în această gramatică:
x0 x1x2x3 0x1y0x3 0x1x20x3 01x1y10x3 01x10y1x3 01x10x21x3

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
5
01x1x201x3 0101x3 0101
Exemplul 1.2.5[21] Pentru limbajul L={an² | n1} vom avea următoarele reguli gramaticale care se
bazează pe identitatea n2=1+3+...+(2n-1), unde toate simbolurile cu excepţia lui a sunt simboluri
neterminale:
P : x0a
x0axx2z
x2zaa
xaaa
yaaa
x2zy1yxz
xx1x1yx
yx1y1yx
xy1x1y
yy1y1y
ax1axxyx2
x2yxy2
y2yyy2
y2xyx2
Să încercăm şi aici câteva derivaţii:
x0 axx2z axaa aaaa
x0 axx2z axy1yxz ax1yyxz axxyx2yyxz axxyxy2yxz
axxyxyy2xz axxyxyyx2z axxyxyyaa axxyxyaaa
axxyxaaaa axxyaaaaa axxaaaaaa axaaaaaaa
aaaaaaaaa = a9
= a3².
Exemplul 1.2.6. [21] Pentru generarea limbajului L = { a2ⁿ
| n0 }vom avea următoarele reguli:
P : x0yxy
yxyz
zxxxz
zyxxy
xa
y
Vom construi o derivaţie în aceasta gramatică pentru n = 2, pornind de la simbolul iniţial x0
x0 yxy yzy yxxy yzxy yxxzy yxxxxy xxxy axxxy
aaxxy aaaxy aaaay aaaa
Exemplul 1.2.7 Fie G=({S,B}, {0,1}, S, P) unde
P:
1B
S1B
0BS
Limbajul generat de G este L(G) = {(01)n
| n>0}. Exemplificăm derivaţia unui cuvânt din limbaj pentru
n = 3. S 0B 01S 010B 0101S 01010B 010101 = (01)3
Exemplul 1.2.8 Fie gramatica G=({S,A,B},{a,b},S,P), unde mulţimea regulilor P={SaSb, Sab}.
Este uşor de demonstrat că limbajul generat de gramatica G este L(G) = {anb
n | n>0}.
Pentru n = 4 obţinem următoarea derivaţie:
S aSb aaSbb aaaSbbb aaaabbbb = a4b
4
Gramaticile generative pot fi clasificate prin impunerea de restricţii asupra form ei regulilor.
Definiţia 1.2.4 (Ierarhia lui Chomsky) Pentru i{0,1,2,3}, o gramatică generativă, G=(VN, VT, S, P)
este de tip i dacă şi numai dacă regulile de rescriere din P îndeplinesc restricţiile de tip (i):
(0) Nici o restrictie.
(1) Reguli dependente de context (DC): Fiecare regulă din P este de forma u1Au2u1wu2 ,
unde u1, u2V*, AVN şi wV+ cu o singură excepţie posibilă S, care poate să apară
dacă S nu apare în dreapta nici unei reguli din P.
(2) Reguli independente de context (IDC): Fiecare regulă din P este de forma
A w cu A VN şi w V+.
(3) Reguli regulate (R): Fiecare regulă este de una din următoarele două forme A aB sau A
a , unde A, BVN şi aVT*.

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 6 -
Gramaticile de tip 1 se numesc dependente de context sau contextuale, gramaticile de tip 2 se
numesc independente de context, iar gramaticile de tip 3 se mai numesc şi regulate sau cu număr finit de
stări.
Evident că orice gramatică de tip 3 este şi de tip 2, orice gramatică de tip 2 este şi de tip 1, şi orice
gramatică de tip 1 este de tip 0.
Dacă notăm cu Li familia limbajelor de tip (i) avem, evident, următoarea incluziune între
familiile de limbaje:
L3 L2 L1 L0
Se va demonstra ulterior că incluziunea este proprie, deci că prin restricţiile (0)-(3) se obţine într-
adevăr o ierarhizare a familiilor de limbaje.
Definiţia 1.5 O gramatică este cu lungime crescătoare sau monotonă dacă şi numai dacă regula uv
satisface condiţia |u| |v| cu o singură excepţie posibilă S, care, dacă apare în mulţimea regulilor,
atunci S nu apare în partea dreaptă a nici unei reguli.
Observaţia 1.2.2 Gramaticile dependente de context sunt gramatici cu lungime crescătoare. Se poate
demonstra că gramaticile cu lungime crescătoare şi gramaticile dependente de context sunt echivalente.
Observaţia 1.2.3 Gramaticile din exemplele 1.2.3, 1.2.4, şi 1.2.6 sunt gramatici monotone deci, conform
observatiei 1.2.2, limbajele generate sunt dependente de context. Gramatica din exemplul 1.2.5 este o
gramatică de tip 0 (există reguli care nu sunt monotone, ca de exemplu regula x1x2), gramatica din
exemplul 1.2.8 este independentă de context iar cea din exemplul 1.2.7 este regulată sau de tip 3.
Exemplul 1.2.10 Din punct de vedere lingvistic, gramaticile sunt folosite pentru analiza frazelor. Să
considerăm următoarea gramatică analitică IDC unde VN = { F, A, V, Pn, S, Sn}, (variabile care
reprezintă, respective: fraza, articol, verb, predicat nominal, substantiv, subiect), VT = {o, fata, este,
laboranta}, unde fiecare din aceste cuvinte ale limbii române reprezintă un simbol al alfabetului
terminalelor. Regulile gramaticii sunt:
{ A o,S fată, S laborantă, V este, Sn AS, Pn VS, F SnPn }
Frazele generate sunt :
o fata este laborantă
o laborantă este fată
o fată este fată
o laborantă este laborantă
Fiecare din fraze este corectă gramatical dar unele s-ar putea să nu aibă nici un înţeles.
Exemplul 1.2.11 Se numeşte palindrom un cuvânt, care este identic când este citit de la stânga la dreapta
sau de la dreapta la stânga. Astfel în limba româna există palindroamele: capac, coc, cuc, lupul, ele, etc.
Notăm cu y~ reflectatul sau oglinditul unui cuvânt y, adică cuvântul ale cărui simboluri sunt în ordine
inversă faţă de y. Limbajul { yy~ | y VT* } este în mulţimea palindroamelor cu VT={a1, ..., an} şi poate fi
generat de gramatica:
G=({S}, VT, S, {S, Sa1Sa1, Sa2Sa2, ..., SanSan}).
În exemplul anterior există regula S iar S apare şi în dreapta altor reguli. Vom arăta că există
ca pentru orice astefel de gramatică există o gramatică echivalentă în care S nu apare în dreapta nici unei
reguli.
Teorema 1.2.1. Dacă G = (VN, VT, S, P) este o gramatică DC, atunci există altă gramatică DC, G1, care
generează acelaşi limbaj cu G, pentru care simbolul initial (de start) nu apare în dreapta nici unei
reguli ale lui G1. Dacă G este IDC sau R atunci şi G 1 este IDC, respectiv R.
▼ Demonstraţie :
Fie S1VNVT. Construim gramatica G1={VN{S1}, VT, S1, P1 }, unde P1 conţine toate regulile
din P şi în plus toate regulile de forma S1 unde S P :
P1=P{S1 │ S P }
Observăm că S1VNVT deci nu apare în dreapta nici unei producţii din G şi nici în dreapta
vreunei producţii noi adăugate în P.

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 7 -
Să demonstrăm acum că L(G)=L(G1).
a) Presupunem că wL(G), deci există o derivaţie în gramatica G de forma S*
w. Atunci prima
regulă folosită este de forma S deci derivaţia va fi : SG
*
Gw
Prin definiţia lui P1 avem : S1 P1 şi deci: S11G
Pentru că toate regulile lui P sunt în P1 rezultă că orice derivaţie din G este şi o derivaţie în gramatica
G1 deci *
1G w
Combinând cele două derivaţii se obţine: S11G
*
1G w ,
Deci w L(G1), de unde rezultă că L(G)L(G1).
b) Presupunem acum că wL(G1), deci există derivaţia S1
*
w în gramatica G1. Prima regulă folosită
este de forma S1, pentru un anume . Rezultă din construcţia gramaticii G1 că S este o regulă din
P şi deci S, în gramatica G. Acum *
w este o derivaţie în gramatica G1 dar nu poate avea simbolul
S1, căci foloseşte numai regulile din P1 care sunt şi în P. Rezultă că *
w este o derivaţie în gramatica
G şi atunci SG
*
Gw, adică wL(G).
Evident că regulile adăugate la P pentru a obţine P1 sunt de acelaşi tip cu regulile lui P deci dacă
G este DC (IDC sau R) atunci şi G1 este DC (IDC sau R). ▲
Teorema 1.2.2. Dacă L este un limbaj DC, IDC sau R, atunci şi L şi L\{} sunt limbaje DC, IDC
respectiv R.
▼Demonstraţie : Dacă L este un limbaj DC, IDC sau R, din teorema 1.2.3 rezultă că există o gramatică
G, care poate fi DC, IDC sau R, în care simbolul iniţial, S, nu apare în partea dreaptă a nici unei reguli
de rescriere. În plus singura regulă în care membrul drept poate fi λ este de forma S→λ.
Atunci pentru limbajul L\{} se scoate regula S→λ, iar pentru limbajul L se adugă tot regula S→λ.
Toate aceste modificări nu au nici o influenţă asupra restului cuvintelor generate de G pentru că
simbolul iniţial S nu mai apare în partea dreaptă a nici unei reguli de rescriere . ▲
§1.3 Operaţii cu limbaje Pentru că limbajele sunt mulţimi, rezultă că se pot folosi toate operaţiile cu mulţimi cunoscute.
Reuniunea a două limbaje L1L2={ w | wL1 sau wL2 }
Intersecţie a două limbaje L1L2={ w | wL1 şi wL2 }
Diferenţa a două limbaje L1\L2={ w | wL1 şi wL2 }
Complementara unui limbaj relativ la un alphabet V CV(L)=V*\L
În afară de aceste operaţii se pot introduce o serie de opera ţii specifice limbajelor :
Concatenarea a două limbaje L1L2={uv | uL1, vL2
Limbajele Φ şi {} reprezintă elementul zero şi respectiv elementul unitate relativ la concatenarea
limbajelor: L Φ = Φ L= Φ L{}={}L=L
Concatenarea se mai numeşte şi produs.
Puterea unui limbaj se defineşte recursiv prin:
L0
= {}
Li+1
= Li L .
Produsul Kleene (sau Închiderea Kleene) este definit prin reuniunea tuturor puterilor lui L:

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 8 -
0i
i* LL
Închiderea Kleene - liberă este
1i
iLL
Câtul stâng a două limbaje este limbajul format din sufixele cuvintelor din L1 care au prefixul în L2:
L2\L1={v |uvL1, uL2}
Derivata stângă a unui limbaj relativ la cuvântul v este s
v L={u |vuL} adică câtul stâng al
limbajelor {v}\L.
Câtul drept a două limbaje este limbajul format din prefixele cuvântelor din L1 cu sufixul în L:
L1/L2 = { v| vuL1 pentru uL2 }
Derivata dreaptă a unui limbaj relativ la cuvântul u este udL= {v |vuL} adică câtul drept al
limbajelor L/{u}.
Reflectatul sau oglinditul unui limbaj L~
= { u~ | uL }.
Substituţia unui limbaj se defineşte astfel:
aV definim (a) un limbaj peste Va iar apoi se aplică proprietăţile:
()=,
(uv)=(u)(v) u, v V*
deci este o aplicaţie : V* P(V’*), unde V’=
Va
aV
.
Substituţia unui limbaj L este atunci:
(L)={ v | v(u) pentru uL }
Dacă (a) este un singur cuvânt ua, atunci substituţia se numeşte homomorfism h:V*V’*. Un
homomorfism se numeşte -liber dacă nici unul din cuvintele (a)=ua nu este .
Una din problemele pe care le vom studia în capitolele următoare este problema închiderii
familiilor de limbaje de tip i, Li (i = 0, 1, 2, 3), relative la operaţiile introduse.
§1.4 Exerciţii
1.Să se construiască o derivaţie în gramatica din exemplul 1.2.3 pentru:
a. n = 2;
b. n = 3;
c. n = 4.
d. n = 5.
2. Să se construiască o derivaţie în gramatica din exemplul 1.2.4 pentru cuvintele:
a. 0001100011;
b. 10101010;
c. 1111011110.
3. Să se construiască o derivaţie în gramatica din exemplul 1.2.5 pentru:
a. n = 1;
b. n = 2;
c. n = 4;

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 9 -
Capitolul II este dedicat limbajelor de tip 3, numite şi limbaje regulate. Se prezintă trei moduri
de reprezentare ale limbajelor regulate: gramaticile de tip 3, automatele finite (deterministe şi
nedeterministe) şi expresiile regulate. Pentru automatele finite deterministe se prezintă un algoritm de
minimizare. Se demonstrează că cele trei moduri de reprezentare sunt echivalente şi se studiază
proprietăţile familiei limbajelor de tip 3, dintre care fac parte: lema de pompare şi proprietăţile de
închidere ale familiei limabjelor regulate la operaţiile introduse în capitolul I. Capitolul II se încheie cu
probleme propuse spre rezolvare.
În capitolul anterior am definit noţiunea de limbaj regulat sau limbaj de tip 3, ca fiind limbajul generat
de o gramatică de tip 3, adică de o gramatică G=(VN,VT,S,P), unde regulile din P sunt de forma :
A→aB sau A→a
Aici A şi B, sunt simboluri neterminale iar a este un symbol terminal.
Vom defini în cele ce urmează un sistem analitic pentru limbajele regulate ş i anume automatele finite.
§ 2.1 Automate finite Din punct de vedere istoric, automatele finit au fost introduse pentru a modela reţelele neuronale
dar au o mulţime de aplicaţii şi în alte domenii cum ar fi: analiza lexicala (faza iniţială a unui
compilator), descrierea editoarelor de texte şi a altor programe de procesare a textelor, modelarea
circuitelor logice şi altele.
Automatul finit este un bun model pentru un calculator cu o cantitate extreme de limitată de
memorie. Vom vede că, deşi are o memorie foarte mică, un astfel de calculator poate sa facă o serie de
lucruri utile cum ar fi cele enumerate mai sus.
Definiţia 2.1.1 Un automat finit determinist, notat M=(Q, Σ, δ, q0, F), este format din:
Q - o mulţime finită nevidă (mulţimea stărilor);
Σ - un alfabet finit de intrare;
- o aplicaţie numită funcţie de tranziţie, care ataşează fiecărei combinaţii <stare, simbol de
intrare> o nouă stare QΣQ:δ ;
Qq0 starea iniţială;
QF mulţimea stărilor finale.
Din punct de vedere practic un automat finit este format dintr-un control finit, care se poate afla într-una
din stările mulţimii Q, dintr-o bandă de intrare împărţită în celule în care sunt scrise un număr finit de
simboluri din Σ, şi un cap de citire care se mişcă pe banda de intrare secvenţial de la stânga la dreapta
(de fapt banda de intrare se mişcă în dreptul capului de citire de la dreapta la stânga ).
a0 a1 … ai … an …
Figura 2.1.1
CONTROL FINIT

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 10 -
Iniţial controlul finit se află în starea q0 iar capul de citire analizează cel mai din stânga simbol scris pe
banda de intrare. Interpretarea lui pa)δ(q, pentru q,pєQ şi aєΣ, este aceea că automatul M, aflat în
starea q şi analizând simbolul a pe banda de intrare, îşi schimbă starea în p şi îşi mută capul de citire cu
o celulă la dreapta.
S-ar putea ca funcţia de tranziţie δ să nu fie peste tot definită, adică să existe p P şi a astfel încât
δ(p,a)=. În cazul în care automatul se află în această stare p şi capul de citire vizează simbolul a pe
banda de intrare se spune că automatul se blochează fiindca nu este definită mişcarea următoare.
Aplicaţia δ se poate extinde la *ΣQ , prin δ̂ :
, Σa ,Σ x a)x),(q,δ̂ δ(xa)(q,δ̂
qλ)(q,δ̂
*
semnificaţia lui px)(q,δ̂ fiind aceea că M, pornind să analizeze secvenţa x din starea q, ajunge în
starea p în momentul în care capul de citire depăşeşte secvenţa x.
Observaţia 2.1.1 În continuare vom folosi notaţia δ şi pentru ̂ .
Definiţia 2.1.2 Un cuvânt x este acceptat sau recunoscut de un automat finit M, dacă, px),δ(q0
pentru Fp .
Limbajul acceptat de automatul M se notează Fx),δ(qxT(M)0
.
Definiţia 2.1.3 Numim configuraţie instantanee perechea (q,x), formată din starea Qq în care se
află automatul finit şi şirul de caractere *Σx rămas necitit pe banda de intrare, unde capul de citire
vizează cel mai din stânga simbol al lui x.
Dacă automatul finit foloseşte tranziţia pa)δ(q, , atunci vom nota modificarea configuraţiei
astfel: )a(q, ├ ),p( .
Exemplul 2.1.1 Specificarea unui automat finit M se poate face prin definirea funcţiei δ (într-un tabel)
sau printr-o diagramă de stare sau de tranziţie. Diagrama de tranziţie este un graf orientat în care
nodurile sunt stările automatului iar arcele (q,p) sunt etichetate cu a dacă δ(q,a)=p este o tranziţie din
automatul M.
▼Fie, de exemplu, automatul finit }{qF , }q,q,q,{qQ , }1,0{
F),qδ,Σ,(Q,M
03210
0
Fie şirul de intrare 10110010; atunci putem urmări execuţia automatului astfel:
, Fq,0)δ(q,10)δ(q,010)δ(q,0010)δ(q
,10010)δ(q,110010)δ(q,0110010)δ(q,10110010)δ(q
01323
1320
deci 10110010 T(M) .
În mod echivalent, într-un calcul de configuraţii se scrie:
Σ δ
0 1
q0 q1 q2
q1 q0 q3
q2 q3 q0
Q
q3 q2 q1
sau:
Figura 2.1.2
q0 q1
q2 q3
Start 0
0
0
0
1 1 1 1

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 11 -
(q0,10110010) ├ (q2,0110010) ├ (q3,110010) ├ (q1,10010) ├ (q3,0010) ├ (q2,010)
├ (q3,10) ├ (q1,0) ├ (q0,λ) unde q0 F,
deci s-a obţinut din nou că 10110010 T(M) .
Se poate demonstra că automatul finit M de mai sus acceptă şirurile cu număr par de 0 şi număr
par de 1.▲
Definiţia 2.1.4 Un automat finit nedeterminist, notat M=(Q, Σ, δ’,q0, F), este format din Q, Σ, q0, F –
prezentate în definiţia 2.1.1, dar funcţia de tranziţie este aici
Q)(ΣQ:δ' P .
Deci a)(q,δ' este o mulţime de stări şi nu o singură stare.
Şi aici δ’ se poate extinde la ΣQ astfel:
. a ,Σx , a)(p,δ'xa)(q,δ'
{q}λ)(q,δ'
x)(q,δ'p
Acum δ’ se poate extinde la Q)(P astfel:
k
1iik21
x),(pδ'x)},p,...,p,({pδ'
Definiţia 2.1.5 Un cuvânt x este acceptat sau recunoscut de un automat finit nedeterminist M dacă
Fx),δ(q0
, adică dacă M pornind din starea q0 şi analizând cuvântul x poate ajunge într-o stare
finală.
Limbajul acceptat de un automat finit nedeterminist este format din mulţimea cuvintelor
acceptate T(M) pentru care există o secvenţă care conduce la acceptare:
T(M) = {w | ’(q,w) ∩ F }
Exemplul 2.1.2 Fie automatul finit descris în figura 2.1.3 cu ajutorul diagramei de tranziţie; în acest
caz T(M) este mulţimea cuvintelor care au sau doi de zero consecutivi sau doi de unu consecutivi.
▼
Să urmărim funcţionarea acestui automat pentru câteva situaţii diferite:
a) Dacă şirul de intrare este 0101, automatul va face toate încercările de tranziţii posibile, înainte de a
trage concluzia că acest cuvânt nu e recunoscut (nu duce automatul într-o stare finală):
(q0,0101)├ (q0,101)├ (q0,01)├ (q0,1)├ (q0,λ) , Fq0
(q0,0101)├ (q0,101)├ (q0,01)├ (q0,1)├ (q1,λ) , Fq1
(q0,0101)├ (q0,101)├ (q0,01)├ (q3,1)├ blocare ( )1,(q3
)
Figura 2.1.3
q0 Start q3 q4
q1
q2 0,1
0,1 0,1
1
1
0 0

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 12 -
(q0,0101)├ (q0,101)├ (q1,01)├ blocare ( )1,(q1
)
(q0,0101)├ (q3,101)├ blocare ( )1,(q3
)
b) Dacă şirul de intrare este 0110, automatul va accepta acest cuvînt în momentul depistării unui calcul
de configuraţii ce duce automatul într-o stare finală (indiferent câte încercări nereuşite face, automatul
acceptă şirul de intrare la înregistrarea unui succes):
(q0,0110)├ (q0,110)├ (q0,10)├ (q0,0)├ (q0,λ) , Fq0
(q0,0110)├ (q0,110)├ (q0,10)├ (q0,0)├ (q3,λ) , Fq3
(q0,0110)├ (q0,110)├ (q0,10)├ (q1,0)├ blocare ( )1,(q1
)
(q0,0110)├ (q0,110)├ (q1,10)├ (q2,0)├ (q2,λ) , Fq2 succes !
(q0,0110)├ (q3,110)├ blocare ( )1,(q3
)
c) Configuraţiile instantanee ce determină acceptarea în cazul cuvântului de intrare 010011 sunt:
(q0,010011)├ (q0,10011)├ (q0,0011)├ (q3,011)├ (q4,11)├ (q4,1)├ (q4,λ)
şi
(q0,010011)├ (q0,10011)├ (q0,0011)├ (q0,011)├ (q0,11)├ (q1,1)├ (q2,λ)
Ambele arată faptul că şirul de intrare poate fi citit de pe bandă ajungând într-o stare finală (q2 sau q4),
fiind deci recunoscut. Este suficientă găsirea uneia dintre ele, când se stabileşte acceptarea cuvântului de
către automat.
Pentru aceeaşi intrare propusă anterior, pot fi “încercate” şi alte posibile transformări de configuraţii, dar
care nu termină citirea într-o stare finală sau nici măcar nu permit finalizarea citirii benzii (ajung la
blocare, când simbolul de pe bandă şi starea automatului finit nu sunt compatibile d.p.d.v. al funcţiei de
tranziţie, cum ar fi cazul citirii simbolului 0 într-un moment în care automatul se află în starea q1,
deoarece se observă că ,0)δ(q1
).▲
§ 2.2 Legătura dintre gramaticile regulate şi automatele finite
Vom demonstra în cele ce urmează că limbajele de tip 3 sunt echivalente cu limbajele
recunoscute de automatele finite (numite şi mulţimi regulate).
Teorema 2.2.1 Fie L o mulţime de cuvinte acceptate de un automat finit nedeterminist. Atunci există un
automat finit determinist care acceptă L.
▼ Demonstraţie:
Fie F),qδ,Σ,(Q,M0
un automat finit nedeterminist care acceptă L, adică L=T(M).
Definim )F',q',δ'Σ,,(Q'M'0
un automat finit determinist după cum urmează:
Q' ≈P(Q) noile stări (M’ păstrează urma stărilor în care poate fi M la un moment dat)
card(Q)k0 Q,q ]q,...,q,[q Q'ik21
;
]q[q00
;
,F' ,Q'F' conţine cel puţin o stare finală din F;
şi definim tranziţiile:
}p,...,p,p{a)},q,...,q,δ({q ]p,...,p,p[a)],q,...,q,([qδj21t21j1t21
Deci dacă δ’ este aplicat unui element Z=[q1, q2,....,qk ] din Q', rezultatul este calculat prin aplicarea lui
δ la fiecare stare a lui Q din Z=[q1,q2,. . . ,qk ]:
j1,l ,a),δ(qp
]p,...,p,p[a)],q,...,q,([qδk
1iil
j21k21
Se arată prin inducţie asupra lungimii şirului de intrare x că :

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 13 -
(2.2.1) }q,...,q,{qx),δ(q ]q,...,q,[qx),q(δi210i210
- pentru |x|=0, ]q[q00
afirmaţia (2.2.1) este adevărată;
- presupunem că (2.2.1) este adevărată pentru |x| t ; să studiem atunci intrarea “xa”, unde Σa şi deci
|xa| t+1 : a)x),,q(δ(δxa),q(δ00
Conform ipotezei inducţiei, }p,...,p,{px),δ(q ]p,...,p,[px),q(δj210j210
Prin definiţie, }r,...,r,r{a)},p,...,p,δ({p ]r,...,r,[ra)],p,...,p,([pδk21j21k21j21
Astfel, }r,...,r,r{xa),δ(q ]r,...,r,[rxa),q(δk210k210
Pentru a completa demonstraţia mai avem de adăugat că Fx),q(δ0
exact când x),δ(q0
conţine o
stare a lui Q care este în F.
Aşadar T(M)=T(M’). ▲
Exemplul 2.2.1 Considerăm automatul finit }){q ,q δ, {0,1}, },q,({qM1010
,
}q,{q,1)δ(q
,0)δ(q
}{q,1)δ(q
}q,{q,0)δ(q
101
1
10
100
Să se construiască automatul finit determinist M’, echivalent cu M.
▼
Să reprezentăm automatul M sub formă de diagramă de tranziţie :
Construim M’ conform Teoremei 2.2.1 : ) ]}q,[q],{[q , ][q , δ , {0,1} , ]}q,[q],[q],{[q (M 10101010
]q,[q],1)q,([qδ
]q,[q],0)q,([qδ
]q,[q],1)([qδ
Φ],0)([qδ
][q],1)([qδ
]q,[q],0)([qδ
1010
1010
101
1
10
100
Deci automatul M’ va avea diagrama tranziţiilor ca în figura 2.2.2:▲
Figura 2.2.1
q0 q1 Start
0 1
0,1
1
Figura 2.2.2
[q0] [q1]
[q0,q1]
Start
0,1
1
0 1

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 14 -
Teorema 2.2.2 Fie G=(VN, VT, S, P) o gramatică de tip 3. Atunci există un automat finit nedeterminist
F),qδ,Σ,(Q,M0
cu T(M)=L(G).
▼ Demonstraţie:
Construim NN VT {T},VQ ; Sq0 ;
Dacă PλS , atunci T}{S,F şi S nu apare la dreapta nici unei reguli; dacă
PλS , atunci {T}F ;
TVa ,a)δ(T, ;
Dacă a)δ(B,T atunci VB , Va
PaB
NT
;
Dacă a)δ(B,C atunci VCB, , Va
PaCB
NT
;
Dacă există N
VB care nu apare în membrul stâng al nici unei reguli din P, atunci
TVa ,a)δ(B, .
Atunci M simulează derivaţiile în G. Să arătăm că, într-adevăr, T(M)=L(G):
a) Fie L(G)...aaaxn21 , 1n . Atunci:
n1n211n1n2111a...aaaA...aaa...AaS
pentru anumite variabile Ai din VN. Din construcţia automatului M avem:
)aδ(S,A11
)a,δ(AA212
…
)a,δ(AAn1-n
Aşadar:
(S, a1a2…an)├ (A1, a2…an)├ …├ (An-1, an) ├ (A,λ)
Adică cuvântul T(M)...aaa n21 x .
Pentru că x a fost din L(G) T(M)L(G)
b) Fie T(M)x , 1|| x există stările S,A1,…,An-1,T astfel încât:
)a,δ(AT
...
)a,δ(AA
)aδ(S,A
n1n
212
11
PaA
...
PAaA
PAaS
1n
221
11
deci are loc derivaţia:
n1n211n1n2122111a...aaaA...aaa...AaaAaS
De aici L(G)T(M) L(G) x
Din (a) şi (b) L(G)T(M) . ▲
Teorema 2.2.3 Fiind dat un automat finit determinist M, există o gramatică G de tip 3 astfel încât
L(G)=T(M).
▼ Demonstraţie:
Presupunem F),qδ,Σ,(Q,M0
- automat finit determinist.
Definim o gramatică de tip 3, P),qΣ,(Q,G0
astfel încât:
(i) q → ap (q,a) = p
(ii) q → a (q,a) = p F


LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 16 -
0B][A,, 1[S]B][A,, B]0[A,B][A,
0[B], 1[S][B], B]0[A,[B]
0[B][S]
:P
▲
Observaţia 2.2.2 Gramatica G’ este mult mai complicată decât gramatica G iniţială, deşi ele sunt
echivalente şi evident că dacă pornim de la ea se poate construi un automat finit şi mai complicat,
echivalent cu automatele de mai sus.
Se pune atunci problema dacă pornind de la un automat finit nu putem micşora numărul de stări
sau dacă atunci când se implementează un automat finit nedeterminist se poate obţine o reprezentare în
memorie optimală. Această ultimă problemă este de mare importanţa in construcţia compilatoarelor şi
este abordată în [12], [14]. În continuare nu vom ocupa de prima dintre aceste probleme, şi anume de
micşorarea numărului de stări ale unui automat fin it determinist.
§ 2.3 Minimizarea automatului finit Definiţia 2.3.1 O relaţie binară R pe mulţimea S se numeşte relaţie de echivalenţă dacă ea este:
1) Reflexivă S)x (xRx,
2) Simetrică yRx) (xRy
3) Tranzitivă xRz) yRz(xRy,
O relaţie de echivalenţă peste S împarte mulţimea S în clase de echivalenţă, submulţimi disjuncte Si
astfel încât
ii
i
SS
xRySyx,.
Observaţia 2.3.3 Se poate construi un cel mai mic automat care acceptă un limbaj T(M), prin
eliminarea stărilor inaccesibile şi comasarea celor redundante. Stările redundante sunt determinate prin
partiţionarea stărilor automatului în clase de echivalenţă astfel încât fiecare clasă conţine stări care nu se
pot distinge între ele şi este atât de mare cât este posibil.
Definiţia 2.3.4 Fie F),qδ,Σ,(Q,M0
un automat finit determinist şi q1,q2 două stări distincte.
Spunem că Σx distinge q1 de q2 dacă:
x),(q1
├* λ),(q
3
x),(q2
├*
λ),(q4
şi una şi numai una dintre stările q3 şi q4 este stare finală adică:
q3 F q4 F
şi q4 F q3 F.
Definiţia 2.3.5 Spunem că q1 şi q2 sunt k-nedistinctibile (2
k
1qq ) dacă şi numai dacă nu există x,
cux k, astfel încât x distinge q1 de q2.
Definiţia 2.3.6 Spunem că q1 si q2 sunt nedistinctibile (q1q2) dacă sunt k-nedistinctibile pentru k0.
Definiţia 2.3.7 O stare q este inaccesibilă dacă nu există x astfel încât x),(q0
├ λ)(q, .
Definiţia 2.3.8 M este un automat redus dacă nici o stare nu este inaccesibilă şi nu există două stări
nedistinctibile.
Teorema 2.3.3 Fie F),qδ,Σ,(Q,M0
un automat finit determinist cu n stări. Stările q1 şi q2 sunt
nedistinctibile dacă şi numai dacă sunt (n-2)-nedistinctibile.
▼ Demonstraţie:
Implicaţia directă )"(" este evidentă; să demonstrăm implicaţia inversă )"(" :

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 17 -
a) Dacă F are 0 sau n stări demonstraţia este imediată.
b) Presupunem că 0 card(F) n.
Vom demonstra că 013n2n
...
.
Observăm că pentru q1,q2Q avem:
a),δ(qa),δ(q ,a qq qq (2)
F respectiv, sau, Fq,q F\Qsau Fλ),δ(q λ),,δ(q qq (1)
2
1-k
12
1-k
1
k
1
2121
0
1
Relaţia 0
partiţionează Q în două clase de echivalenţă: F şi K\F.
Dacă k1k
atunci 1
k
este o rafinare a lui k
şi conţine cel puţin o clasă de echivalenţă în plus.
Pentru că sunt cel mult n-1 stări în F sau Q\F , cel mult n-2 rafinări a lui 0
. Aşadar, este prima
relaţie k
pentru care k1k
.▲
Observaţia 2.3.4 Două stări sunt distinctibile dacă ele se pot distinge pe un şir de intrare de lungime
mai mică decât numărul stărilor.
§ 2.4 Algoritmi pentru minimizarea automatului finit
(A) Algoritm de minimizare[1]
Fie M=(Q,,,q0,F). Se construieşte M’ redus parcurgând următorii trei paşi:
A.1 Se elimină întâi nodurile inaccesibile (conform algoritmului (B))
A.2 Se construiesc relaţiile de echivalenţă ,...,10
până când relaţia se stabilizează adică 1kk
.
Alegem k
.
A.3 Se construieşte M’=(Q’, , ’, q0, F’) unde Q’ e mulţimea claselor de echivalenţă ale lui Q,
astfel:
’([q],a)=[p] dacă (q,a)=p
q 0’=[q0]
F’= [q] qF
(B) Algoritm de eliminare a stărilor inaccesibile. Pentru eliminarea stărilor inaccesibile se poate
folosi orice algoritm din teoria grafurilor de eliminare a nodurilor inaccesibiel din nodul reprezentând
starea iniţială, unde avem:
Intrare - Graful (Q,) cu (q,p)=a (q,a)=p
- q0Q
Ieşire Mulţimea de noduri Q’Q astfel încât există un drum de la q0 la pQ’.
Algoritmul marchează succesiv nodurile accesibile din q0 printr-un drum. Astfel, găseşte nodurile
accesibile şi le elimină pe celelalte. Prezentăm în continuare două variante ale aces tui algoritm:
Varianta I BI.1 Iniţializează Q’={q0} şi marchează q0 cu 0.
BI.2 Pentru qQ’ caută pQ astfel încât există un arc (q,p); marchează p cu 1+ marca lui q
(dacă p nu e marcat) şi adaugă pe q la Q’; reia pasul BI2.
Dacă qQ’ şi p astfel încât (q,p), p este marcat atunci stop.
Sau:

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 18 -
Varianta a II-a
BII.1 Iniţializează L=q0, marchează q0.
BII.2 Dacă L e vid stop .
Dacă nu, alege primul element q din L şi îl scoate din L.
BII.3 Pentru pQ astfel încât (q,p), dacă p nu e marcat, marchează p şi adaugă p în capul listei L.
Salt la pasul BII2.
Vom arăta în continuare că automatul obţinut prin algoritmul de minimizare este automatul cu număr
minim de stări.
Teorema 2.4.1. Automatul M’ definit de algoritmul de minimizare (A) este automatul cu cel mai mic
număr de stări acceptând L(M).
▼ Demonstraţie:
Presupunem că există un automat M’’, care are mai puţine stări decât M’ şi că L(M”)=L(M).
Pentru că fiecare clasă de echivalenţă indusă de relaţia de echivalenţă nedistinctibilitatea, , este nevidă,
rezultă că fiecare stare din M’ este accesibilă.
Pentru că M” are mai puţine stări decât M’ rezultă că w,x două cuvinte astfel încât:
w),q(0 ├
*M” λ)(q,
x),q(0 ├
*M” λ)(q,
unde 0
q este starea iniţială a lui M”.
Dar w şi x conduc M’ în stări diferite, deci w şi x conduc M în stări diferite, şi atunci:
w),(q0
├*
M λ)(p,
x),(q0
├*
M λ)(r,
stări care sunt distinctibile, adică y* astfel încât (p,y)F şi (r,y) F
(q0,wy)F şi (q0,xy)F
wyT(M) iar xyT(M), pe când ”(q0,wy)=”(q0,xy)
deci wy şi xy sunt deodată în T(M”)=T(M) contradicţie.
▲
Exemplul 2.4.1 Să se construiască automatul finit redus pentru automatul finit M din Figura 2.4.1 .
▼
Aplicăm algoritmul (A).
Pasul A.1 Toate nodurile sunt accesibile.
Pasul A.2 Construim relaţiile de echivalenţă.
Iniţializare ( 0-nedistinctibilitate ):
}q,q,q,{q},q,{q 0k432150
0
Analizăm 1-nedistinctibilitatea:
Start
Figura 2.4.1
q3
q0
q1
q5
q4
q2
a
a
a
b
b b
a
a
b
b
b
a

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 19 -
5
1
00
45
10
0
55
50
qb),δ(q
qb),δ(q
egale)(chiar qa),δ(q
qa),δ(q
(rămân în aceeaşi clasă)
2
1
10
52
31
0
22
41
qb),δ(q
qb),δ(q
qa),δ(q
qa),δ(q
(se vor separa în clase diferite)
3
1
10
03
31
0
33
41
qb),δ(q
qb),δ(q
qa),δ(q
qa),δ(q
(se vor separa în clase diferite)
Ştiind deja că q1 se separă de q2 şi de q3, trebuie văzut dacă q2 şi q3 rămân totuşi împreună:
3
1
20
03
52
0
33
22
qb),δ(q
qb),δ(q
qa),δ(q
qa),δ(q
(rămân în aceeaşi clasă de echivalenţă)
Ultima stare neanalizată este q4; din cele văzute deja, aceasta ar putea aparţine fie clasei care conţine pe
q1, sau celei care conţine pe q2 şi q3, sau unei clase noi. În următorul calcul se vede că prima este
varianta valabilă:
4
1
10
24
31
0
14
41
qb),δ(q
qb),δ(q
qa),δ(q
qa),δ(q
Aşadar, s-a obţinut:
}q,{q},q,{q},q,{q 1k324150
1
Să analizăm 2-nedistinctibilitatea:
5
2
01
45
10
1
55
50
qb),δ(q
qb),δ(q
qa),δ(q
qa),δ(q
4
2
11
24
31
1
14
41
qb),δ(q
qb),δ(q
qa),δ(q
qa),δ(q

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 20 -
3
2
21
03
52
1
33
22
qb),δ(q
qb),δ(q
qa),δ(q
qa),δ(q
Se observă că nici una dintre clasele 1-nedistinctibile nu s-a împărţit în subclase. Deci relaţia s-a
stabilizat şi s-a obţinut:
}q,{q},q,{q},q,{q 2k324150
2
Deoarece 21
, relaţia de echivalenţă este determinată.
Pasul A.3 Automatul redus are 3 stări (corespunzând celor trei clase de echivalenţă) reprezentate de
}q,q,{q210
şi este descris în Figura 2.4.2 .
▲
Observăm că modul în care se construiesc relaţiile de k-echivalenţă este destul de complicat. Prezentăm
acum o altă variantă [7] de algoritm de de minimizare.
(C) Algoritm de minimizare[7]
Fie M=(Q,,,q0,F). Algoritmul va marca perechile de strări (p,q.). O pereche (p,q) va fi marcată în
momentul în care se descoperă că p şi q nu sunt echivalente. Se construieşte M’ redus parcurgând
următorii cinci paşi:
C.1 Se elimină întâi nodurile inaccesibile (conform algoritmului (B))
C.2 Se scrie tabelul tuturor perechilor (p,q), iniţial nemarcate.
C.3 Se marcheză (p,q) dacă p F şi q F sau invers.
C.4 Se repetă următoarele până când nu se mai schimbă nimic în table:
Dacă există o pereche nemarcată (p,q) astfel încât ((p,a), (q,a)) este marcată pentru un a ,
atunci marchează perechea (p,q).
C.5 Perechile nemarcate (p,q) sunt perechile echivalente.
Exemplul 2.4.1 Să minimizăm automatul definit de următorul tabel al funcţiei de tranzitie, unde stările
finale sunt 1, 2, şi 5:
a b
0 1 2
1 3 4
Start
Figura 2.4.2
q0
q1
q2 a
a
a b
b
b

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 21 -
2 4 3
3 5 5
4 5 5
5 5 5 C1. Toate nodurile sunt accesibile deci trecem la :
C2. Tabelul iniţial este cu toate perechile nemarcate.
0 _ 1
_ _ 2
_ _ _ 3
_ _ _ _ 4
_ _ _ _ _ 5
C3. Marcheză perechile: (stare finală, stare nefinală) .
0
X 1
X _
2 _ X X 3
_ X X
_ 4
X _
_ X X 5
C4. (i) Alegem acum o pereche nemarcată, (0,3). Pentru intrarea a, 0 şi 3 trimit automatul în 1 şi 5,
notat (0,3) → (1,5). Deoarece perechea (1,5) nu este marcată, nu vom marca nici (0,3). Cu intrarea b,
avem (0,3) → (2,5), care tot nemarcată estedeci nu vom marca perechea (0,3) nici acum. Continuam să
verificăm perechile şi observăm că pentru perechea (1,5) simbolul a realizează
(1,5) → (3,5), unde perechea (3,5) este marcată., deci marcăm perechea (1,5).
Verificând toate perechile nemarcate se obţine tabelul următor:
0
X 1
X _
2 _ X X 3
_ X X
_ 4
X X X X X 5
(ii) Acum mai facem o trecere prin tabel fiindcă s -a modificat linia stării 5. Vom obţine:
0
X 1
X _
2
X X X 3
X X X _ 4
X X X X X 5
Tabel care nu se mai modifică.
C5. Stările echivalente sunt date de perechile nemarcate: (1,2) şi (3,4), deci automatul redus va fi:
a b
0 1 1
1 3 3
3 5 5
5 5 5

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 22 -
§ 2.5 Lema de pompare pentru mulţimi regulate
Această lemă dă o caracterizare a mulţimii regulate şi anume fiind dată o mulţime şi un cuvânt
suficient de lung, se poate găsi un subcuvânt nevid al acestui cuvânt care se poate repeta de oricâte ori
astfel încât cuvântul obţinut prin repetare rămâne în mulţimea regulată dată.
Teorema 2.5.1. Fie L o mulţime regulată . Atunci există o constantă p , astfel încât dacă un cuvânt wL
şi |w|p atunci w poate fi scris w=xyz, unde:
- 0 |y| p
- xyizL, i0.
▼ Demonstraţie:
Fie M=(Q,,,q0,F) un automat finit cu n stări astfel încât T(M)=L. Fie p=n.
Dacă wT(M) şi w n, atunci considerăm configuraţiile succesive ale lui M, în acceptarea lui w;
cel puţin n+1 configuraţii, deci trebuie să fie cel puţin două stări identice p = qi = qj astfel încât:
w),(q0
├* )w,(qi
├* z),(qj ├
* λ)(r,
De aici rezultă că w=xw’ şi w’=yz şi deci w=xyz.
Fie j cel mai mic indice pentru care qi = qj de unde şi 0 |y| n.
Dar atunci :
z)xy,(q i
0├
* z)y(p, i
├* z)y(p, 1-i
├* …├
* z)(p, ├
* λ)(r,
Deci xyizT(M), i0.
Pentru i = 0 :
xz),(q0
├* z)(p, ├
* λ)(r, . ▲
Pentru ca lema de pompare dă o caracterizare a mulţimilor regulate ea poate fi folosită şi pentru a
demonstra că limbajele care nu respectă lema de pompare nu sunt regulate.
Exemplul 2.5.1 Folosind teorema de pompare (2.5.1), să se arate că mulţimea aib
i i1 nu este o
mulţime regulată.
▼
Presupunem că p astfel încât pentru wL : |w| p, w=xyz, |y|) p şi w’=xyizL.
- dacă y=aj cu ji, atunci a
i+jb
iT(M) , ceeace contrazice structura limbajului deci este imposibil;
- dacă y=bj, atunci a
ib
j+iT(M) ceeace contrazice din nou structura limbajului deci este imposibil;
- dacă y=ajb
k cu ji şi ki, atunci a
ib
ka
jb
iT(M) din nou imposibil
aib
i i1 nu e o mulţime regulată pentru că nu respectă lema de pompare. ▲
§ 2.6 Gramatici regulate şi expresii regulate Să considerăm următorul exemplu în care folosim operaţiile cu limbaje definite în § 1.3:
Exemplul 2.6.1 Fie următoarele două alfabete:
L={A,B,…,Z,a,b,…,z}, alfabetul literelor mari şi mici
C={0,1,…,9}, alfabetul cifrelor din baza 10.
Cu aceste alfabete, pe care le putem chiar considera limbaje formate din cuvinte de lungime 1, putem
construi numeroase alte limbaje, cum ar fi:
(a) CL = mulţimea literelor şi a cifrelor;
(b) LC = mulţimea cuvintelor de lungime 2, formate din o literă urmată de o cifră;
(c) L4 = mulţimea cuvintelor formate din exact patru litere;
(d) L* = mulţimea cuvintelor formate din oricâte litere (inclusiv cuvântul vid);
(e) L( CL )* = mulţimea cuvintelor de lungime cel puţin 1, formate din litere şi cifre, primul
caracter fiind obligatoriu o literă;
(f) C+ = mulţimea şirurilor numerice formate din cel puţin o cifră.

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 23 -
Modul de reprezentare al limbajelor de mai sus sugerează un alt mod de descriere al limbajelor
de tip 3 şi anume cu ajutorul expresiilor regulate.
Definiţia 2.7.1 Se numeşte expresie regulată o expresie care poate fi construită cu următoarele reguli:
1. este o expresie regulată indicând mulţimea vidă.
2. λ este o expresie regulată indicând limbajul format doar din cuvântul vid, {λ}.
3. Dacă T
Va , atunci a este o expresie regulată indicând limbajul format dintr-un cuvânt
de lungime 1, construit cu simbolul a şi anume limbajul {a}.
4. Dacă e1 şi e2 sunt expresii regulate indicând limbajele L1 şi L2, atunci următoarele
expresii sunt regulate:
a) Alternarea (e1)|(e2), indicând 21
LL ;
b) Concatenarea (e1)(e2), indicând 21
LL ;
c) Închiderea Kleene (e1*), indicând
1L .
Observaţia 2.6.1 Parantezele ( ) pot fi eliminate în următoarele cazuri:
({ }) = { }
( | ) = |
(( )) = ( )
Observaţia 2.6.2 a) Operaţiile de alternare, |, concatenare, ., şi închidere, *, au precedenţa descrescând de la cea mai
mare , , la cea mai mică , | .
b) Toate operaţiile sunt asociative iar alternarea este şi comutativă.
Există un număr de reguli algebrice pentru expresii regulate care pot fi folosite pentru a le transforma
în alte expresii echivalente, conform tabelului următor.
Tabelul 2.6.1
Regulă Descriere
r|s=s|r Alternarea este comutativă
r|(s|t)=(r|s)|t Alternarea este asociativă
(rs)t=r(st) Concatenarea este asociativă
r(s|t)=(rs)|(rt)
(s|t)r=(sr)|(tr)
Concatenarea este distributivă la stânga
şi la dreapta faţă de alternare
λr=r
rλ=r
Cuvântul vid este element neutru pentru concatenare
r*=(r|λ)
*
r**
=r* Idempotenţa închiderii (produs Kleene)
Operatorii folosiţi pentru scrierea expresiilor regulate sunt analogi cu forma BNF de descriere a
limbajelor (sunt simboluri ale metalimbajului).
Exemplul 2.6.2 Exemple de expresii regulate:
a) Expresia 110 reprezintă limbajul format dintr-un singur cuvânt {110}.
b) Expresia 0|1 reprezintă limbajul {0,1}.
c) Expresia 1* reprezintă limbajul {1
i | i=0,1,2,…}.
d) a*b* reprezintă limbajul 0nm,ba nm ;
e) (ab)* reprezintă limbajul 0m(ab)m ;
f) (aa|ab|ba|bb)* reprezintă mulţimea şirurilor peste {a,b} de lungime pară.
Vom defini în continuare egalitatea a două expresii regulate.
Definiţia 2.6.3 Două expresii regulate sunt egale (=) sau echivalente dacă ele reprezintă acelaşi limbaj.
Exemplul 2.6.4 00* = 000*|0 (ele reprezintă acelaşi limbaj, al şirurilor peste alfabetul {0} formate din
cel puţin un simbol 0).

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 24 -
Exemplul 2.6.5 Elementele unui limbaj de programare pot fi definite atât în termenii gramaticilor
regulate cât şi în cei ai expresiilor regulate. Spre exemplu, un identificator format din litere mici şi cifre,
începând cu o literă, poate fi descris de gramatica regulată ale cărei reguli sunt:
9|...|1|0|z|...|c|b|a|9A|...|1A|0A|zA|...|cA|bA|aAAz|...|c|b|a|zA|...|cA|bA|aAS
şi de expresia regulată:
(a|b|c| . . . |z) (a|b|c| . . . |z|0|1| . . . |9)*
Putem folosi <literă> pentru a scurta reprezentarea lui z|...|c|b|a şi <cifră> pentru 9|...|1|0 ,
expresia putând fi scrisă în acest caz astfel:
<literă>(<literă>|<cifră>* .
§ 2.7 Algoritm de transformare a unei gramatici regulate într-o expresie regulată
Expresiile regulate pot fi utilizate în ecuaţii şi deci pot fi evaluate. De exemplu, A=aA|a este o
ecuaţie cu o expresie regulată validă.
Pentru a prezenta o metodă de a converti o gramatică regulată într-o expresie regulată,
considerăm gramatica regulată care generează limbajul 1mn,baa nm :
aCaCCbCBaBSaSS
Înlocuind operatorul de rescriere "" cu unul de echivalenţă (“=”) şi combinând toate regulile
care au acelaşi membru stâng într-o singură expresie prin folosirea operatorului de alternare, gramatica
poate fi scrisă ca o mulţime de ecuaţii:
a|aCCbCB
aB|aSS
Prin rezolvarea acestui sistem de ecuaţii, se obţine o expresie regulată cu un singur simbol
terminal, care reprezintă acelaşi limbaj ca şi cel generat de gramatica regulată.
Să rezolvăm mai întâi ecuaţiile definite doar prin ele însele. În acest sistem, ecuaţia pentru C are
soluţia: C= a*a. Verificăm prin înlocuirea acestei soluţii în ecuaţia pentru C. Se obţine
a*a = a a*a | a,
sau altfel scris
a*a = (a a* | λ) a,
dar a a* | λ = a* şi deci se verifică a*a = a*a.
Soluţia pentru C poate fi înlocuită în a doua ecuaţie, obţinând sistemul:
a*baB
B)|a(SS
Apoi B poate fi înlocuit în prima ecuaţie a)*ba|a(SS
sau expresia echivalentă:
S = aS | aba*a
şi se vede imediat că o soluţie a acestei ecuaţii este:
S= a*aba*a
care este o expresie regulată reprezentând acelaşi limbaj ca şi limbajul generat de gramatica iniţială.
Prezentăm în continuare algoritmul de trecere de la o gramatică regulată la o expresie regulată. Algoritm de transformare [EXPRESII REGULATE]

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 25 -
Intrare O gramatică regulată G, având regulile a},{aXψ ψ,Xji
, cu X1, simbol iniţial.
Ieşire Expresia regulată echivalentă cu G.
Pas 1. Transformarea în ecuaţii regulate:
- Pentru fiecare regulă ψXi a lui G, Execută:
- Dacă ecuaţia Xi nu a fost iniţializată
Atunci defineşte ψXi
Altfel schimbă ψ|αXprin αXii , unde α este partea definită anterior a lui X i)
Pas 2. Aducerea în formă intermediară a sistemului de ecuaţii:
- Pentru fiecare i=1,2,…,n-1, Execută:
- Transformă ecuaţia X i în forma iiii
ψ|XαX , unde i
ψ este de forma
nin,1ii1,ii0,
Xβ|...|Xβ|β
iar αi şi fiecare βj,i sunt expresii regulate peste VT.
- Pentru fiecare j=i+1,i+2,…,n, Execută:
- Înlocuieşte Xi cu ii ψ* în ecuaţia pentru X j.
Pas 3. Rezolvarea ecuaţiilor:
- Pentru fiecare i=n,n-1,…,2,1, Execută:
- Transformă ecuaţia X i din forma iiii
ψ|XαX , unde i
ψ este o expresie regulată peste
VT, în ii ψ*X i .
- Pentru fiecare j=i-1,i-2,…,2,1, Execută:
- Înlocuieşte soluţia iψ* i a lui Xi în ecuaţia pentru Xj.
Pas 4. Stabilirea soluţiei:
- Soluţia este 11 ψ*
Observaţia 2.7.1 a) Primul pas al algoritmului transformă gramatica regulată într-o mulţime de ecuaţii de forma:
llkkjjm21iXψ|...|Xψ|Xψ|δ|...|δ|δX ,
unde fiecare Tii
Vψ,δ .
b) Pasul al doilea al algoritmului transformă fiecare ecuaţie în forma:
nin,1ii1,ii0,iiiXβ|...|Xβ|β|XαX
,
lucru posibil efectuând o serie de transformări algebrice.
c) În pasul al treilea se face substituţia înapoi pentru a rezolva mulţimea de ecuaţii. Soluţia pentru Xn
este uşor de găsit pentru că această ecuaţie este de forma n0,nnn
β|XαX şi deci soluţia este
n0,nn β*αX . Această soluţie se poate înlocui apoi în fiecare din ecuaţiile precedente din sistem, acolo
unde apare Xn. În general, îndată ce ecuaţia pentru Xi a fost rezolvată şi înlocuită în ecuaţiile precedente
rezultă că este rezolvată şi ecuaţia pentru Xi-1, care are numai variabilele Xi şi Xi-1 în membrul drept, iar
Xi a fost înlocuit.
Exemplul 2.8.1 Folosind algoritmul [EXPRESII REGULATE], să transformăm în expresie regulată
gramatica: PS,,cb,a,,BA,S,G , unde P este formată din regulile:

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 26 -
cBbBBaAbBAaAA
aSaAS
▼
Pas 1.
c|bBBa|bB|aAA
a|aAS
Pas 2. Nu este necesar
Pas 3. c*bB 3i
{a}a|c*{a}bbA
a|c*bb|aAA 2i
a|a*aa|c*bb*aaS
a|a)*a|c*bb*a(aS 1i
Pas 4. Soluţie: S= aa*bb*c | aa*. Limbajul reprezentat de această expresie regulată este
1n|a1mn,|cba nmn .▲
Exemplul 2.8.2 Folosind algoritmul [EXPRESII REGULATE], să transformăm în expresie regulată
gramatica PS,,cb,a,,CB,A,S,G , unde P este formată din regulile:
cCcBCbCBaBAaAA
aAS
▼
Pas 1.
c|cBCbCB
aB|aAAaAS
Singura ecuaţie care nu este în formă intermediară este ecuaţia pentru variabila C şi anume C =
cB|c. Este necesar atunci pasul 2 pentru transfomarea în formă intermediară:
Pas 2.
c|cbCCbCB
aB|aAAaAS
Pas 3. c*cbC
c|cbCC 4i
c*cbbB 3i
c*ab(cb)*aA
{a}aBA 2i

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 27 -
c*ab(cb)*aaS
aAS 1i
Pas 4. Soluţie: S = aaa*b(cb)*c sau, echivalent, S = aaa*bc(bc)*. Limbajul reprezentat de această
expresie regulată este 1m2,n|(bc)a mn . ▲
§ 2.8 Echivalenţa dintre expresiile regulate şi automatele finite nedeterministe Expresiile regulate sunt importante pentru construirea unui generator de analizor lexical, care
foloseşte ca intrare expresii regulate.
Vom prezenta în cele ce urmează metode de generare a unui acceptor cu număr finit de stări
dintr-o expresie regulată sau generarea unei expresii regulate dintr-un automat finit nedeterminist. Vom
arăta deci că expresiile regulate şi mulţimile acceptate de automate finite nedeterministe sunt
echivalente, deci că mulţimile regulate şi expresiile regulate reprezintă aceleaşi mulţimi. Pentru
construcţiile ce vor urma, este necesară următoarea definiţie.
Definiţia 2.9.1 Un automat finit nedeterminist cu λ-tranziţii este un ansamblu M=(Q, Σ, δ, q0, F) ale
cărui componente au aceleaşi semnificaţii ca la un automat finit oarecare, doar că funcţia de tranziţie
este definită astfel:
Q)(PλΣQ:δ .
Avem o λ-tranziţie între două configuraţii w)(p, ├ w)(q, dacă şi numai dacă λ)δ(p,q ,
Σ wQ,p . În reprezentarea grafică, o astfel de tranziţie, practic fără citirea benzii de intrare la acel
pas, arată astfel:
Teorema 2.8.1. Mulţimea cuvintelor recunoscute de automatele finite cu λ-tranziţii este aceiaşi cu
mulţimea cuvintelor recunoscute de automatele finite nedeterministe.
▼Demonstratie
Se arată în [5] că automatele finite nedeterministe cu λ-tranziţii sunt echivalente cu cele fără λ-tranziţii.
Vom da aici un exemplu de utilizare a homomorfismului pentru a da o altă demonstraţie [7] a acestei
afirmaţii. Fie automatul finit cu λ-tranziţii M = (Q, Σ, δ, q0, F), unde considerăm λ un simbol care nu
este în Σ. Considerăm acum automatul finit nedeterminist M’, peste alfabetul Σ{λ}:
M’ = (Q, Σ{λ}, δ, q0, F) ,
Definim acum acceptarea pentru automatul cu cu λ-tranziţii după cum urmează: pentru orice x
din Σ*, automatul M acceptă x dacă există y în (Σ{λ})* astfel încât:
- M’ acceptă y relativ la definiţia acceptării unui automat finit nedeterminist;
- x este obţinut din y prin ştergerea tuturor apariţiilor simbolului λ; atunci x = h(y), unde:
h: (Σ{λ})* → Σ*,
este homomorfismul definit de :
h(a) = a pentru a
h(λ) = λ.
În acest fel L(M) = h(L(M’)). Dar mulţimea L(M’) este regulată şi conform teoremei 2.9.11 va
rezulta că şi L(M) este o muţime regulată.▲
Figura 2.9.1
p q
λ

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 28 -
Algoritmul de conversie a unei expresii regulate într-un AFN este următorul:
Algoritmul 2.8.1. Construcţia unui automat finit nedeterminist cu -tranziţii pentru o expresie regulată. Intrare: o expresie regulată r peste un alfabet , sub forma unui arbore sintactic.
Ieşire: un AFN, N pentru limbajul L(r)
Metodă: Construim N, parcurgând arborele sintactic de jos în sus, aplicând regulile (1) şi (2) şi
combinând automatele obţinute la fiecare nod, cu ajutorul regulei (3) unde:
1. pentru , construim automatul
cu i noua stare iniţială şi f noua stare finală. Automatul va recunoaşte limbajul {}.
2. pentru a, construim automatul
cu i noua stare iniţială şi f noua stare finală. Automatul va recunoaşte limbajul {a}.
3. dacă N(s) şi N(t) sunt AFN pentru expresiile regulate s şi t atunci:
a) Pentru expresia regulată s|t construim următorul automat N(s|t)
cu i noua stare iniţială a lui N(s|t) şi f noua stare finală. Avem _tranziţii de la i la fostele stări iniţiale
ale lui N(s) şi N(t) şi _tranziţii de la fostele stări finale ale lui N(s) şi N(t) la f. Astfel, automatul N(s|t)
recunoaşte L(s) U L(t).
b) Pentru expresia regulată st construim următorul automat N(st)
unde i, starea iniţială pentru N(s) a devenit starea iniţială pentru N(st) şi f starea finală pentru N(t) a
devenit starea finală pentru N(st). Starea finală pentru N(s) este identificată cu starea iniţială pentru N(t)
şi noua stare creată în N(st) îşi pierde statutul de stare iniţială sau finală. Astfel, automatul N(st)
recunoaşte limbajul L(s)L(t).
c) Pentru expresia regulată s* construim automatul N(s*)
start
N(t)
N(s)
start i f
a start i f
start i f
i
N(s) N(t)
f
start i N(s) f
LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 29 -
cu i noua stare iniţială şi f noua stare finală pentru N(s*). Stările iniţială şi finală pentru N(s) îşi pierd
acest statut. Astfel automatul N(s*) recunoaşte limbajul L(s)*.
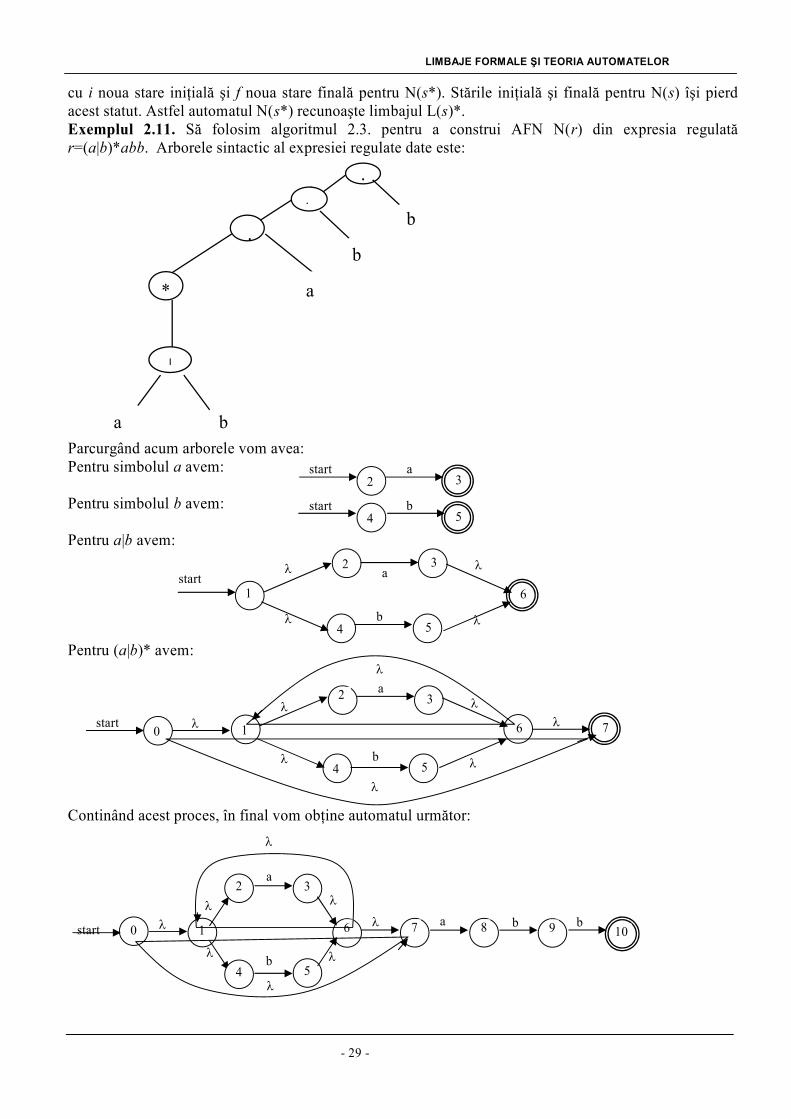
Exemplul 2.11. Să folosim algoritmul 2.3. pentru a construi AFN N(r) din expresia regulată
r=(a|b)*abb. Arborele sintactic al expresiei regulate date este:
Parcurgând acum arborele vom avea:
Pentru simbolul a avem:
Pentru simbolul b avem:
Pentru a|b avem:
Pentru (a|b)* avem:
Continând acest proces, în final vom obţine automatul următor:
a start 2 3
b start 4 5
a start 2 3
b 4 5
1 6
a 2 3
b 4 5
1 6 7 start 0
|
a *
b
.
.
b
. b
b a
b
b
a
start 0 1
2
10
3
4 5
6 7 8 9
.
.
.
b b
a
a

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 30 -
Toate automatele construite astfel sunt nedeterministe cu λ-tranziţii.
Teorema 2.8.1 Fiind dată o expresie regulată R, există un automat F cu număr finit de stări,
nedeterminist şi cu λ-tranziţii, care acceptă limbajul generat de R.
▼ Demonstraţie:
- se face prin inducţie în raport cu fiecare din cele trei operaţii ale expresiilor regulate. Construcţia
formală se deduce din diagramele de stare definite mai sus. ▲
Teorema 2.8.2. Fiind dat un automat cu număr finit de stări, determinist, care acceptă limbajul L, există
o expresie regulată care reprezintă limbajul L.
▼ Demonstraţie:
- se aplică algoritmul de transformare a automatului finit determinist într-o gramatică de tip 3, după
care se aplică acesteia algoritmul de determinare a expresiei regulate echivalente. ▲
§ 2.9 Proprietăţi ale limbajelor de tip 3 Vom studia o serie de proprietăţi ale limbajelor regulate dintre care o parte importantă o
formează proprităţile de închidere ale familiei limbajelor rwegulte la operatiile cu limbaje introduce în §
1.3. Pentru că limbajele de tip 3 pot fi generate de gramatici de tip 3, recunoscute de automatele finite
sau reprezentate de expresii regulate, în demonstraţii vom folosi oricare dintre aceste
Teorema 2.9.1 Clasa limbajelor de tip 3 este închisă în raport cu reuniunea.
▼ Demonstraţie:
Demonstraţia se poate face folosind automate finite nedeterministe sau folosind gramaticile generative
de tip 3. Alegem cea de a doua variantă (prima poate constitui un exerciţiu).
Fie L1, L2 două limbaje de tip 3 generate de gramaticile G1, G2:
)P,S,V,(VG
)P,S,V,(VG
22
(2)
T
(2)
N2
11
(1)
T
(1)
N1
, unde
λ \L)L(G
λ \L)L(G
22
11
Presupunem că (2)
N
(1)
NVV (în caz contrar, se poate face o redenumire a variabilelor astfel încât
condiţia să fie îndeplinită fiindcă variabilele nu apar în cuvintele limbajului) şi construim:
)P,S,VV,S V(VG33
(2)
T
(1)
T3
(2)
N
(1)
N3 ,
unde
22113213
(2)
N
(1)
N3
PαSsau PαS αS PPP
VVS
Dacă 21
LLλ (2211
PλSsau PλS ) atunci la mulţimea regulilor se adaugă λS3 .
Fie 1
Lw . Atunci:
33
*
G
*
GG11
PαS , wα wαS Lw311
.
Similar pentru 2
Lw .
Dacă wα*
G 3
,3
Sα , atunci wα*
G1
sau wα*
G 2
după cum *(1)
T
(1)
NVVα sau
*(2)
T
(2)
NVVα .▲
Teorema 2.9.2. Clasa limbajelor de tip 3 este închisă în raport cu complementarea.
▼ Demonstraţie:

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 31 -
Să arătăm această proprietate folosind automate finite deterministe. Fie F),qδ,Σ,(Q,M0
un
automat finit determinist, astfel încât T(M)=L. Fie ΣΣ1 şi s o nouă stare ( Qs ).
Construim {s})F)\(Q,q,δ,Σ{s},(QM0111
, unde:
11
11
1
Σapentru s,a)(s,δ
Σ\Σa Q,qpentru s,a)(q,δ
Σa Q,qpentru a),δ(q,a)(q,δ
M1 este construit adăugând o stare “capcană” la mulţimea stărilor, stare în care automatul intră pentru
orice simbol care nu e în Σ şi rămâne în ea indifferent de simbolul de intrare citit, iar apoi schimbând
stările finale cu cele nefinale.
Un cuvânt din T(M)\Σ*
1 este sau un cuvânt din Σ
* de la care M nu ajunge în stare finală, deci care nu e
acceptat de M, adică F\Qx),δ(q0
, sau este un cuvânt care conţine simboluri din Σ\Σ1
şi în
momentul depistării unui astfel de simbol M1 intră în starea s în care rămâne până analizează tot
cuvântul. ▲
Teorema 2.9.3 Clasa limbajelor de tip 3 este închisă în raport cu intersecţia.
▼ Demonstraţie:
Varianta 1.
Folosim pentru această demonstraţie una dintre relaţiile lui DeMorgan, din teoria mulţimilor:
2121LLLL ,
unde L reprezintă complementara lui L.
Din teoremele 2.6.1 şi 2.6.2 rezultă deci că dacă L1 şi L2 sunt limbaje regulate, atunci şi limbajul
21LL este regulat.
Sigur ca aceasta este o demonstraţie elegantă a teoremei dar ea nu ne furnizează nici un mijloc de
a construi gramatica sau automatul pentru 21
LL când cunoaştem gramaticile, respectiv automatele,
pentru L1 şi L2. Prezentăm in continuare o astfel de demonstraţie, care se poate face construind un
automat finit care să simuleze în paralel cele două automate M 1 si M2 astfel:
Varianta 2.
Fie )F,q,δ,Σ,(QM111111
şi )F,q,δ,Σ,(QM222222
două automate finite deterministe. Ele
acceptă mulţimile regulate T(M1) = L1, respectiv T(M2) = L2.
Presupunem că 21
QQ (dacă nu, se face o simplă redenumire a stărilor fiecăruia dintre ele, de
exemplu prin renumerotare). Putem presupune că ΣΣΣ21 (dacă nu, creăm
21ΣΣΣ ).
Construim automatul finit nedeterminist M3 care acceptă intersecţia 21
LL , după cum urmează:
M3 = (Q1 x Q2, , 3, [q0,q1], F1 x F2), unde 3 este definit de :
3([q,p], a) = [r,t] 1(p,a) = r şi 2(q,a) = t
Evident că automatul M3 intră într-o sare finală din F1 x F2 dacă şi M1 intră intr-o stare finală din F1 şi M2
intră intr-o stare finală din F2. ▲
Teorema 2.9.5 Toate mulţimile finite sunt limbaje de tip 3.
▼ Demonstraţie:
Dacă L este o mulţime finită de cuvinte, atunci }w,...,{wLn1
.
Arătăm întâi că pentru fiecare cuvânt Lwi , există Gi o gramatică de tip 3, astfel încât
ii
w)L(G . Fie wi= a1a2. . . an. Atunci mulţimea de reguli:
S → a1A1

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 32 -
A1 → a2A2
. . . . . . . . . . . . .
An-2 → an-1An-1
An-1 → an
generează cuvântul wi adică:
i
*
GwS
3
Deci limbajele n1,ii
w
sunt regulate.
Cum L este un limbaj finit, n
1ii
wL
, folosind Teorema 2.6.1 rezultă că L este un limbaj de tip 3.
O demonstraţie echivalentă se poate face şi construind un automat finit M, astfel încât T(M)=L.▲
Teorema 2.9.6. Clasa mulţimilor regulate este închisă în raport cu operaţia de oglindire.
▼ Demonstraţie:
Fie un automat finit F),qδ,Σ,(Q,M0
. Considerăm mulţimea regulată L=T(M).
Definim automatul finit nedeterminist M’ astfel încât să funcţioneze “invers” faţă de M:
)F,q,δΣ,},q{(QM00
, unde }{qF0
dacă T(M)λ sau }q,{qF00 dacă T(M)λ
având tranziţiile:
qa)(p,δ dac ă a)(q,δp
Fa)(p,δ dac ă a),q(δp0
Este uşor de demonstrat acum că L~
)MT( (vezi şi definiţia oglindirii unui limbaj, în capitolul I,
paragraful § 1.3). ▲
Teorema 2.9.7 Clasa mulţimilor regulate este închisă în raport cu operaţia de concatenare .
▼ Demonstraţie:
Fie )F,q,δ,Σ,(QM111111
şi )F,q,δ,Σ,(QM222222
două automate finite deterministe.
Ele acceptă mulţimile regulate T(M1), respectiv T(M2).
Presupunem că 21
QQ (dacă nu, se face o simplă redenumire a stărilor fiecăruia dintre ele, de
exemplu prin renumerotare). Putem presupune că ΣΣΣ21 (dacă nu, creăm
21ΣΣΣ ).
Construim automatul finit nedeterminist M3 care acceptă concatenarea ))T(MT(M21
după cum
urmează: )F,q,δΣ,,Q(QM313213
cu
pa)(q,δ iş Qpq, ădac , a)(q,δp
pa)(q,δ iş Fp ,Qq ădac , a)(q,δ p},{q
pa)(q,δ iş F\Qp ,Qq ădac , a)(q,δp
223
11132
11113
şi
212
22
3
Lλ ădac ,FF
Lλ ădac ,FF
Automatul finit M3 astfel construit va simula pe M1 până când acesta va intra într-o stare finală, moment
în care M3 poate intra în starea iniţială a lui M2 sau poate continua să simuleze M1. Atunci când M3
ajunge în starea iniţială a lui M2, îl va simula pe acesta din urmă până la oprire.
Se demonstrează uşor că )T(M)T(M)T(M213
. ▲

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 33 -
Teorema 2.9.8 Clasa mulţimilor regulate este închisă în raport cu închiderea Kleene.
▼ Demonstraţie:
Fie F),qδ,Σ,(Q,M0
un automat finit determinist acceptând limbajul regulat L=T(M).
Construim automatul finit nedeterminist:
})q{F,q,δΣ,},q{(QM000
{p}a)(q,δ atunci F,pa)(q,δ ăDac
}q{p,a)(q,δ atunci F,pa)(q,δ ăDac
{p}a),q(δ atunci F,pa),(qδ ăDac
}q{p,a),q(δ atunci F,pa),(qδ ăDac
0
00
000
Se adaugă astfel o nouă stare iniţială 0
q pentru că, dacă λ trebuie să aparţină lui T(M)*, nu putem forţa
q0 să aparţină lui F3 căci M ar putea intra în q0 şi pe parcursul acceptării unui cuvânt când Fq0 .
a) Dacă *Lx atunci λx şi
300Fqλ),qδ( sau x=x1x2…xn cu Lx
i , iar în acest caz sunt
posibile situaţiile:
a.1) (0
q ,x1x2…xn)├* (p, x2…xn), Fp (pentru că Lx
1 ) dar în continuare nu e sigur că
automatul va conduce la acceptare (pornind din starea p cu şirul rămas).
Alegem atunci a doua variantă:
a.2) (0
q ,x1x2…xn)├* (q0,x2…xn)├
* (q0,x3…xn)├
*…├
*(q0,xn) ├ (r,λ) unde Fr .
Aşadar )MT(x .
b) Dacă )MT(x şi x=a1a2…am , atunci există stările q1,q2,…,qm astfel încât:
Qq,...,q,q iş
Fq
)a,q(δq
)a,q(δq
m21
m
1ii1i
101
Atunci, pentru un anume i avem:
sau
F)a,(qδ
1ii
01i sau 1i1ii
q)a,δ(q
.
Deci x poate fi scris în forma x=x1x2…xn, unde Lxj ( F)x,δ(q
j0 ). ▲
Teorema 2.9.9 Clasa mulţimilor regulate este închisă relativ la substituţia cu mulţimi regulate.
▼ Demonstraţie:
Fie ΣR o mulţime regulată şi pentru fiecare Σa fie
ΔRa
o mulţime regulată.
Fie ΔΣ:f o substituţie regulată, f(a)=Ra. Pentru ca R şi Ra, pentru fiecare a din R, sunt mulţimi
regulate rezultă că există câte o expresie regulată care să le reprezinte, expresii care conţin un număr
finit de opratori *, . ,sau |.
Se observă ca substituţia unei reuniuni, a unei concatenări sau a unui produs Kleene este reuniunea,
concatenarea, respectiv produsul Kleene al substituţiilor:
)f(Rf(R)
)f(R)f(R)Rf(R
)f(R)f(R)Rf(R
2121
2121

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 34 -
Dar reuniunea concatenarea şi respectiv produsul Kleene sunt reprezentate de cei trei operatori ai unei
expresii regulate: *, . , | . Deci şi pentru două expresii regulate e 1 si e2 vom avea:
)f(ef(e)
)f(e)f(e)ef(e
)f(e|)f(e)e|f(e
2121
2121
Folosind inducţia relativ la numărul de operatori folosiţi de expresia regulată rezultă că: dacă r este o
expresie regulată atunci f(r) este tot o expresie regulată, ceea ce trebuia demonstrat. ▲
În capitolul I (paragraful § 1.3) s-a definit operaţia de homomorfism. Să introducem şi inversa acesteia:
Definiţia 2.9.1 Definim homomorfismul invers astfel:
1 h(a)
wh(x) x (w)h
wh(x) x (w)h
Lh(x) x (L)h
1
1
1
Teorema 2.9.10 Clasa mulţimilor regulate este închisă în raport cu homomorfismul şi cu
homomorfismul invers.
▼ Demonstraţie:
Deoarece h(a) e un caz particular de substituţie, Teorema 2.9.10 justifică prima cerinţă a acestei
teoreme.
Fie L un limbaj de tip 3 şi M automatul finit care recunoaşte L = T(M). Construim un automat
finit M’ pentru h-1
(L) care simulează în controlul său finit funcţionarea lui M corespunzător cu Fig.2.9.1.
Automatul M va fi un automat cu λ-tranziţii care citeşte câte un simbol ai de pe banda de intrare şi
generează pentru simbolul de intrare citi cuvântul h(ai) într-o zonă de memorie din controlul său finit.
Apoi efectuează o serie de λ-tranziţii în şirul de intrare, adică nu mai citeşte nici un simbol de intrare, şi
în acest timp simulează acţiunea automatului M în controlul său finit. Când M termină de citit h(ai) şi
starea sa este o stare finală (adică M acceptă h(ai)) atunci M’ işi goleşte zona sa de memorie în care
reprezenta h(ai) şi citeşte un nou simbol de intrare(această gilire se poate face şi pe parcurs reţinând în
zona de memorie numai partea necitită din h(ai)). M’ continuă de această manieră pînă când nu mai are
nici un simbol de intrare de citit şi zona sa de memorie este goală. Evident M’ termină de citit şirul său
de intrare numai dacă M a acceptat fiecare h(ai) pentru i de la 1 la n.
Pentru formalizare vom considera fiecare stare a lui M’ de forma [α,q]unde α este partea necitită din
h(ai) iar q este o stare a lui M. Funcţia de tranziţie, ’, a lui M’ se defineşte astfel:
a0 a1 … ai … an …
Fig.2.9.1
CF pt.M
h(ai)

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 35 -
’([λ,q],a) = [h(a),q] M’ generează h(a), în memoria lui ’([bα,q], λ) = [α, (b,q)] M’ simuleză,
funcţionarea lui M pe un sufix al lui h(a), în controlul său finit. ▲
§ 2.10 Exerciţii
1. Să considerăm automatele finite nedeterministe M1 şi M2, ale căror funcţii de tranziţie δ1 şi δ2
sunt definite în următoarele tabele:
Să se construiască automatele finite deterministe echivalente pentru fiecare dintre cele două automate.
2 Să considerăm automatul finit din figura următoare. El acceptă cuvintele cu număr par de 0 şi
număr par de 1. Să se construiască un automat finit care să accepte cuvintele cu:
a. Număr par de 0 şi impar de 1;
b. Număr par de 1 şi impar de 0;
c. Număr impar de 0 şi impar de 1;
3. Să se construiască automate finite deterministe pentru fiecare dintre mulţimile următoare:
a. Mulţimea cuvintelor peste alfabetul {0,1} care se termină în 010;
b. Mulţimea cuvintelor peste alfabetul {0,1} care conţin cel puţin trei apariţii consecutive ale lui 1;
c. Mulţimea cuvintelor peste alfabetul {0,1} pentru care fiecare apariţie a lui 1 este urmată de cel
puţin două apariţii ale lui 0:
d. Mulţimea cuvintelor peste alfabetul {0,1} care încep cu 1 şi, interpretate ca un număr în baza 2,
sunt divizibile prin 3;
e. Mulţimea cuvintelor peste alfabetul {0,1} pantru care al treilea simbol de la dreapta spre stânga
este 1.
4. Să se construiască automate finite nedeterministe pentru fiecare dintre mulţimile următoare:
a. Mulţimea cuvintelor peste {0,1} astfel încât să conţină doi de 0 separaţi de un număr par de 1;
b. Mulţimea cuvintelor peste alfabetul {a,b,c} astfel încât să conţină subcuvântul aba sau bab.
Σ δ1
0 1
q0 q0,q1 q0
q1 q2 q2
q2 q3 -
Q1
q3 q3 q3
Σ δ2
0 1
p q,s q
q r q,r
r s p
Q2
s - p
M1 = (Q1, Σ, δ1, q0, { q3}) M2 = (Q2, Σ, δ2, p, { q,s})
q0 q1
q2 q3
Start 0
0
0
0
1 1 1 1

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 36 -
5. Pornind de la automatul finit din exerciţiul 2 să se construiască o gramatică de tip 3 care să genereze
limbajul T(M).
6. Să se construiască un automat finit şi o gramatică de tip 3 pentru limbajul;
L = {a (a2b
3)i b | i > 0}
7. Se consideră gramatica G = ({S,A,B}, {a,b}, S, P) unde mulţimea P este formată din regulile:
S → aA, S → bB, A → aA, A → aB, B → bA, B → b
Să se construiască:
a. Un automat finit care să recumoască L(G);
b. O expresie regulată care să reprezinte L(G).
8. Să se construiască câte o expresie regulată peste alfabetul {0,1} pentru fiecare dintre limbajele
următoare:
a. Muţimea tuturor cuvintelor care conţin 1101;
b. Muţimea tuturor cuvintelor care nu conţin 101;
c. Mulţimea cuvintelor peste alfabetul {0,1} astfel încât să conţină trei de 0 separaţi de un număr
impar de 1;
d. Mulţimea cuvintelor peste alfabetul {0,1} pentru care fiecare apariţie a lui 1 este urmată de cel
puţin două apariţii ale lui 0:
e. Mulţimea cuvintelor peste alfabetul {0,1} care se termină în 111;
f. Mulţimea cuvintelor peste alfabetul {0,1} care conţin cel puţin două apariţii consecutive ale lui 0.
9. Să se construiască câte un automat finit pentru fiecare dintre limbajele descries de următoarele
expresii regulate:
a. (11|0)* (00|1)*;
b. (1|01|001)* (0|00)*;
c. (00|11|10|01)*.
10. Să se minimizeze automatele finite de la exerciţiul 3 a, b, c, d, e.

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 37 -
Capitolul III este dedicat limbajelor de tip 2 din ierarhia lui Chomsky, numite limbaje
independente de context. Se defineşte noţiunea de arbore de derivaţie, noţiune foarte importantă în
teoria compilării, iar apoi se introduc formele normale: Chomsky şi Greibach, pentru gramaticile
independente de context. Se introduce aici un nou tip de automat, numit automat push-down
nedeterminist, şi se demonstrează că acest automat recunoaşte limbajele independente de context. Se
studiază proprietăţile limbajelor independente de context t. Capitolul III se încheie cu probleme propuse
spre rezolvare.
§ 3.1 Arbori de derivaţie pentru gramaticile I.D.C.
Limbajele independente de context sunt generate de gramaticile de tip 2 din ierarhia lui
Chomsky, adică gramatici de forma: G = ( VN, VT, S, P),unde mulţimea regulilor P este de forma:
Aα,, cu A variabilă din VN, iar α un şir format din variabile şi terminale, adică α (VN VT)*.
Vom prezenta o metodă vizuală de descriere a oricărei derivaţii într-o gramatică I.D.C sub forma
unui arbore de derivaţie.
Definiţia 3.1.1 Un graf de tip arbore este un graf cu următoarele proprietăţi:
i) există un nod în care nu intră nici un arc, numit rădăcină;
ii) în oricare alt nod intră exact un arc;
iii) există un drum de la rădăcină către oricare nod (graf conex);
iv) nodurile din care nu pleacă nici un arc se numesc frunze.
Definiţia 3.1.2 Fie G= ( VN,VT,S,P) o gramatică I.D.C. Un arbore de derivaţie în G este un arbore în
care:
i) fiecare nod este etichetat cu un simbol din TN
VV ;
ii) eticheta rădăcinii este S;
iii) dacă nodul A are cel puţin un descendent atunci el are o etichetă din VN;
iv) dacă A1, A2, A3,….,Ak sunt toţi descendenţii direcţi ai lui A în ordine de la stânga spre dreapta
atunci : AA1A2…Ak este o regulă din P.
Exemplul 3.1.1
▼ Fie G = ({S,A,B},{a,b},S,P), unde mulţimea P conţine regulile:
AA1A2…Ak
A
A1 A2 Ak …

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 38 -
bSB
aSA
bS
bBAS
aS
aABS
Pentru această gramatică, un arbore
de derivaţie având frunzele a,a,b,b
şi a este cel din figura 3.1.1.
▲
Definiţia 3.1.3 Se numeşte rezultat al unui arbore cuvântul format din etichetele frunzelor citite de la
stânga spre dreapta.
Exemplul 3.1.2 Rezultatul arborelui de derivaţie din figura 3.1.1. este cuvântul aabba.
Vom arăta mai târziu că dacă α este rezultatul unui arbore de derivaţie, atunci S *
G α .
Definiţia 3.1.4 Se numeşte subarbore al unui arbore graful format dintr-un nod împreună cu toţi
descendenţii săi.
Exemplul 3.1.3
▼
(
A
ab)▲
Teorema 3.1.1 Fie G =(VN,VT,A,P ) o gramatică I.D.C. Atunci pentru λα , (S αG
) există un
arbore de derivaţie în gramatica G al cărui rezultat este α .
▼ Demonstraţie:
Vom demonstra că dacă GA=(VN,VT,A,P) atunci pentru orice A în VN avem (A
AG
α ) dacă şi
numai dacă există un subarbore cu rădăcina A al cărui rezultat este α .
Se observă că regulile din P sunt aceleaşi pentru orice gramatică GA, deci
( A αAG
) (A αBG
)
şi, pentru că G = GS, avem (A αAG
) (A αG
).
a) Presupunem că α este rezultatul unui arbore de derivare în gramatica GA; demonstrăm prin inducţie,
în raport cu numărul de noduri care nu sunt frunze , că A
AG
α :
Figura 3.1.1.
S
a A B
a S b S
b a
Figura 3.1.2.
A
a S
b

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 39 -
a1) Dacă există un singur nod care nu e frunză atunci arborele arată ca în
figura 3.1.3. Rezultă că α =A1A2…Ak şi, din definiţia arborelui de derivaţie, avem A α P, deci
A α
.
a2) Presupunem că α este rezultatul unui arbore A cu n noduri care nu sunt frunze şi că rezultatul
anterior este valabil pentru arbori cu cel mult n-1 noduri care nu sunt frunze.
Considerăm descendenţii direcţi ai lui A: A1,A2,…,Ak , deci (AA1….AkP).
Dacă Ai nu e o frunză, rezultă că Ai este o variabilă, rădăcină a unui subarbore cu rezultatul α i şi
cu cel mult n-1 noduri care nu sunt frunze.
Dacă Ai este o frunză, punem A i = α i.
Se observă că dacă j < i atunci nodul Aj şi toţi descendenţii săi se află la stânga lui Ai şi a tuturor
descendenţilor săi.
Rezultă că α = α 1 α 2…… α k .
Deoarece din ipoteza inducţiei α i este rezultatul unui subarbore cu rădăcina Ai şi cu cel mult n-1
noduri care nu sunt frunze, rezultă că (A i α*
G i).
Deci AGA1A2…Ak
G
α...αααk21 ,
adică (A α*
G ).
b) Presupunem acum că A αAG
. Vom arăta că există un arbore de derivaţie cu rezultatul α în GA, prin
inducţie relativ la numărul de paşi ai derivaţiei.
b1) Dacă A αAG într-un singur pas rezultă că ( A α P ) şi dacă α =A1A2…Ak rezultă din
definiţia arborelui de derivaţie că există un arbore cu rezultatul α :
Figura 3.1.3.
A
A1 A2 Ak …
Figura 3.1.4
A
A1 A2 Ak …

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 40 -
b2) Presupunem că A αAG
în n paşi şi că pentru orice derivaţie a lui β cu numărul de paşi mai
mic decât n există o derivaţie cu rezultatul β . Fie primul pas al derivaţiei αA*
de forma
AA1A2…Ak. Atunci orice simbol al lui α este sau unul dintre Ai sau derivat dintr-un Ai în cel mult n-1
paşi. Deci, există subarborii T1,T2,..,Tk de rădăcini A1,A2,…,Ak, cu rezultatele k21
α,...,α,α atunci când
Ai iG
αA
.
Deci dacă la arborele din Figura 3.1.4 adăugăm subarborii Ti, obţinem:
Rezultă că arborele din Figura 3.1.5 (în care câte un arbore Tj poate fi vid, dacă AjVT) are
rezultatul format din rezultatele subarborilor T1, …,Tk în ordine de la stânga α....αααk21 . ▲
§ 3.2 Forme normale
Se poate arăta că pentru orice gramatică independentă de context, există o gramatică echivalentă în care
regulile au forme particulare, forme uşor de utilizat în demonstraţii.
Forma normală Chomsky
Teorema 3.3.1 (Forma normală Chomsky) Orice limbaj I.D.C. poate fi generat de o gramatică în care
toate regulile sunt de forma ABC sau Aa, cu A,B,CVN şi aVT.
▼Demonstraţia se gaseste in [4]▲
Forma normală Greibach
În această formă normală fiecare regulă are membrul drept începând cu un terminal, eventual urmat de
variabile.
Teorema 3.3.2 (Forma normală Greibach) Fiecare limbaj I.D.C. poate fi generat de o gramatică
pentru care fiecare regulă este de forma A aα cu AVN, aVT, α N
V ( α un şir de variabile,
posibil vid).
▼Demonstraţia se gaseste in [4]▲
§ 3.3 Teorema de pompare pentru limbaje I.D.C.(lema Bar-Hillel)
Teorema 3.4.1 (lema de pompare Bar-Hillel ) Fie un limbaj I.D.C., notat L. Atunci există constantele
p şi q, depinzând de L, astfel încât: dacă Lz cu p | z| , atunci z poate fi scris sub forma:
F ig u ra 3 .1 .5
A
A 1 A 2 A k…
T 1 T 2 T k
α 1 α 2 α k…

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 41 -
z = uvwxy, unde
λ) ambelesunt nu x (v, 0 | vx |
q |vwx | astfel încât pentru fiecare întreg 0i ,
Lzwxuv ii .
▼Demonstraţie:
Fie G=(VN,VT,S,P) o gramatică I.D.C. în formă normală Chomsky, pentru L. Dacă G are k
variabile, atunci fie p=2k-1
şi q=2k. Este uşor de observat că, pentru o gramatică în formă normală
Chomsky, dacă un arbore de derivaţie nu are drumuri de lungime mai mare decât j, atunci cuvântul
derivat nu este mai lung decât 2j-1
, această valoare reprezentând maximul de frunze într-un astfel de
arbore (binar, datorită formei Chomsky).
Deci, dacă Lz şi p | z | , atunci arborele unei derivaţii a lui z în gramatica G conţine un
drum de lungime mai mare decât k. Să considerăm cel mai lung drum, R, cu lungimea mai mare decât k.
Atunci există două noduri n1 şi n2 în R astfel încât:
n1 şi n2 sunt etichetate identic;
n2 este subarborele lui n1;
subarborele n1 nu are drumuri de lungime mai mare decât k+1.
Pentru a arăta că n1 şi n2 pot fi astfel găsite, parcurgem drumul R de la frunză înspre rădăcină.
Din primele k+2 noduri, numai o frunză are ca etichetă un simbol terminal. Cele k+1 noduri rămase nu
pot avea etichete distincte.
Exemplu: G=({A,B,C},{a,b},A,P), unde
P={ bB a,A BA,C BA,B BC,A }
a)
Legendă:
drum R
z3=bb z2=a z4=λ z=bbbaba
b) c)
Figura 3.4.1
A
C B
B A
B C
B A
b
b
b a
B A
b a
n1
n2
A
B C
b B A
b a
n1
n2
A
a
n2

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 42 -
Subarborele T1, cu rădăcina n1, reprezintă derivaţia unui subcuvânt de lungime cel mult 2k (şi
deci de lungime cel mult q), pentru că în T1 nu există nici un drum de lungime mai mare decât k+1, din
cauză că R a fost drumul cel mai lung.
Fie z1 rezultatul subarborelui R. Dacă T2 este subarborele generat de nodul n2 şi z2 este rezultatul
lui T2, atunci z1 se poate scrie z3z2z4. În plus, z3 şi z4 nu pot fi ambele λ, pentru că prima regulă folosită în
derivaţia lui z1 e de forma BCA , unde B,CN
V . Subarborele T2 trebuie să fie completat în interior
sau de subarborele lui B sau de subarborele lui C.
Avem atunci 423
*
G43
*
GzzzAzzA , unde q |zzz | 423 . De aici rezultă că
i
2
i*
G
ii*
G 4343zzzAzzA pentru 0i .
Evident şirul z poate fi scris sub forma yzzuz423
, pentru anumiţi u şi y.
Vom pune acum v=z3, w=z2 şi x=z4, demonstraţia fiind astfel încheiată. ▲
Observaţia 3.4.1 Teorema 3.4.1 se poate aplica pentru a demonstra că L={akb
kc
k | k 0} nu este I.D.C.
▼Demonstraţie:
Să presupunem, prin absurd, că limbajul L este I.D.C., ceea ce ar însemna că sunt îndeplinite
consecinţele Teoremei 3.4.1., care permit "pomparea" anumitor subcuvinte din interiorul unor cuvinte
suficient de lungi ale limbajului L.
Se observă, însă, că indiferent de lungimea cuvintelor alese din L, ele fiind de forma z = akb
kc
k
(k 0), nu este posibilă alegerea vreunei descompuneri de forma z=uvwxy cu proprietăţile specificate în
teorema amintită şi astfel încât Lywxuv ii .
Să urmărim cazurile posibile. Fie m, n, p 0 , k 0). Atunci cuvintele v, w şi x pot fi de una
din următoarele forme:
z=u(vwx)y v w x Motiv Lzwxuv ii
I.
am
(an)a
k-m-nb
kc
k
1na
2na 3n
a Grupul de simboluri "a" se alungeşte
independent de grupurile "b" şi "c".
1na
2na nn
ba 3
Grupurile de simboluri "a" şi "b" se
alungesc în mod independent. În plus,
dacă n3,n 0 , simbolurile "a" şi "b" se
amestecă.
1na
32 nnba 4n
b Grupurile de simboluri "a" şi "b" se
alungesc în mod independent.
II.
am
(ak-m
bn)b
k-nc
k
21 nnba
3nb 4n
b
Grupul de simboluri "b" se alungeşte
independent de grupurile "a" şi "c". În
plus, dacă n1,n2 0 , simbolurile "a" şi
"b" se amestecă.
III.
akb
m(b
n)b
k-m-nc
k
1nb
2nb 3n
b Grupul de simboluri "b" se alungeşte
independent de grupurile "a" şi "c".
IV.
akb
m(b
k-mc
n)c
k-n
Similar cazului II. …
V.
akb
kc
m(c
n)c
k-m-n
1nc
2nc 3n
c Grupul de simboluri "c" se alungeşte
independent de grupurile "a" şi "b".
În concluzie, prin pompare se va afecta cel puţin una din proprietăţile limbajului considerat:
numărul de simboluri a, b, respectiv c este acelaşi (deci nu se pot multiplica subcuvinte formate dintr-

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 43 -
unul din cele trei simboluri), iar ordinea caracterelor în cuvânt este strict alfabetică (deci nu se pot
multiplica subcuvinte formate din "îmbinarea" a două simboluri distincte, ab sau bc, căci se amestecă).
Rezultă că {akb
kc
k | k 0} 1 2L L deci clasa limbajelor independente de context este diferită de
cea a limbajelor dependente de context: 1 2L L .▲
Teorema 3.4.3 Fiind dată o gramatică I.D.C., G1, se poate găsi o gramatică echivalentă G2, pentru
care, dacă A este o variabilă în G2 alta decât simbolul iniţial, atunci există o infinitate de cuvinte
iniţiale derivate din A.
▼Demonstraţie:
Dacă L(G1) este finit atunci L={u1,u2,…,un} şi putem considera G2 cu mulţimea regulilor
P2={Sui | i=1,n}.
Dacă L(G1) este infinit, G1=(VN,VT,S,P1), considerăm pentru fiecare AVN gramatica
GA=(VN,VT,S,P1). Prin Teorema 3.4.2 se poate determina dacă L(GA) este finit sau nu.
Presupunem că A1,A2,…,Ak sunt variabilele care generează o infinitate de cuvinte şi că
B1,B2,…,Bm sunt variabilele care generează un număr finit de cuvinte.
Creem mulţimea de reguli P2 din P1 în modul următor:
Presupunem că C0C1C2…Cr este o regulă din P1, iar C0{A1,A2,…,Ak}. Atunci regula
C0u1u2…un este o regulă din P2, unde:
1. Dacă CiVT ui=ci
2. Dacă Ci {A1,A2,…,Ak} ui=ci
3. Dacă Ci {B1,B2,…,Bm} ui este unul din cuvintele (în număr finit) generate de ci (ci
ui).
Rezultă că P2 nu conţine nici o regulă cu Bi la dreapta.
Considerăm acum G2=('
NV ,VT,S,P2) unde
'
NV ={A1,A2,…,Ak}. Observăm că S trebuie să aparţină
lui '
NV pentru că L(GS) este infinit.
a) Evident, dacă ( βα2G
*
) atunci β(α1G
) deci L(G1)L(G2).
b) Pentru a demonstra L(G2)L(G1), demonstrăm prin inducţie asupra numărului de paşi din derivaţie
că dacă Ai
1G
w 1 i k unde w*
TV atunci Ai
2G
w.
Rezultatul este evident pentru o derivaţie într-un pas. Presupunem că este adevărat pentru o
derivaţie în cel mult j paşi. Considerăm o derivaţie în j+1 paşi şi presupunem că prima regulă folosită
este AiC1C2…Cr .
Putem astfel scrie w sub forma w1w2…wr unde Ci
1G
wi , 1 i r.
Atunci există o regulă în G2 de forma Aiu1u2…ur,
unde
}A,...,{AC dac ă C
}B,...,{B VC dac ă wu
k1ii
m1Tii
i .
Dar ci
1G
wi în cel mult j paşi (Ci
G2
wi) .
Deci AG2 u1u2…ur
G2
w1w2…wr . ▲
Exemplul 3.4.1 Fie gramatica G=({S,A,B},{a,b,c,d},S,P), unde P={SASB, SAB, Aa, Ab,
Bc, Bd}). Să aplicăm Teorema 3.4.3.
▼Rezolvare:
Variabilele A şi B generează numai cuvintele a şi b respectiv c şi d, dar S generează o infinitate
de cuvinte. Atunci se construieşte G2=({S},{a,b,c,d},S,P2), mulţimea regulilor fiind:
P2: SaSc S ac SaSd S ad SbSc S bc SaSd S bd ▲

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 44 -
§ 3.5 Automate Push-down Vom introduce un nou tip de dispozitiv care să accepte limbajele I.D.C., numit automat push-
down.
Un automat push-down are, pe lângă o bandă de intrare, şi o stivă (o listă LIFO). Într-o astfel de
stivă, intrarea şi ieşirea unui simbol se face numai la capul stivei. Când un simbol intră în stivă, simbolul
care anterior a fost capul stivei devine al doilea, cel care a fost al doilea devine al treilea ş.a.m.d. În mod
similar, când un simbol este scos din stivă, simbolul care anterior acestei scoateri era al doilea, ajunge în
capul stivei, cel care era al treilea devine al doilea ş.a.m.d.
O astfel de stivă se poate compara cu un teanc de farfurii în care se ridică sau se pune o farfurie
deasupra teancului.
Exemplul 3.5.1 Să utilizăm o stivă de "farfurii", cuplată cu un control finit pentru a recunoaşte o
mulţime neregulată.
▼ Fie limbajul I.D.C. L={{0,1} w| w~wc }, care nu este regulat (posibil de demonstrat acest lucru
folosind lema de pompare) şi fie gramatica
G=({S},{0,1,c},S,P)
unde mulţimea regulilor este P= c}S1S1,S0S0,{S .
Pentru a recunoaşte limbajul L, vom utiliza un control finit cu două stări q1 şi q2 şi o memorie
push-down pe care vom plasa "farfurii" albastre, roşii şi verzi. Dispozitivul va opera după următoarele
reguli:
1) Maşina porneşte cu o farfurie roşie pe stivă şi cu controlul finit în starea q1.
2) Dacă simbolul de intrare este 0 şi starea este q1, dispozitivul plasează o farfurie albastră pe stivă,
iar dacă simbolul de intrare este 1 şi starea q1, atunci plasează o farfurie verde pe stivă şi, în ambele
cazuri, rămâne în starea q1.
3) Dacă intrarea este c şi starea q1, îşi schimbă starea în q2 fără a acţiona asupra stivei.
4) Dacă intrarea este 0, starea q2 şi pe stivă se află o farfurie albastră, scoate farfuria şi rămâne în q 2,
iar dacă este 1, starea q2 şi pe stivă este o farfurie verde, scoate farfuria şi rămâne tot în q 2.
5) Dacă dispozitivul este în starea q2 şi pe stivă este o farfurie roşie, scoate farfuria indiferent de
intrare.
6) În alte situaţii dispozitivul nu face nici o mişcare.
Dispozitivul acceptă şirul de intrare dacă, după citirea lui, stiva devine goală. ▲
Vom defini un automat push-down ca fiind un dispozitiv format din: bandă de intrare, control
finit şi memorie push-down (stivă), precum în Figura 3.5.1..
Dispozitivul este nedeterminist, având un număr finit de şanse de mişcare în fiecare situaţie.
Mişcările vor fi de două tipuri:
ai … Banda de intrare
Z
Capul stivei
Z0
Figura 3.5.1
CONTROL
FINIT (Q)

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 45 -
I. - tranziţie cu simbol de intrare: în funcţie de simbolul de intrare, de capătul stivei şi de starea
controlului finit, sunt posibile anumite mişcări care constau fiecare din: o nouă stare a controlului finit şi
un şir (posibil vid) de simboluri care înlocuieşte capul stivei. După alegerea unei mişcări posibile,
dispozitivul avansează cu un simbol pe banda de intrare.
II. - "λ-tranziţie" : este similară cu mişcarea tip I., dar nu e utilizat nici un simbol de intrare.
Limbajul acceptat de un automat push-down se poate defini în două moduri:
mulţimea şirurilor de intrare care conduc la golirea memoriei push -down sau
mulţimea şirurilor de intrare pentru care automatu l intră într-o stare finală.
Cele două tipuri de acceptări sunt echivalente.
Formal, un automat push-down se defineşte prin:
Definiţia 3.5.1 Un automat push-down nedeterminist, M, este un sistem format din:
M = F),Z,qδ,Γ,Σ,(Q,00
,
unde:
Q este o mulţime finită de stări
Σ este un alfabet finit al benzii de intrare
Γ este un alfabet finit al memoriei push-down
Qq0 stare iniţială
ΓZ0 simbol de start al memoriei push-down
QF mulţimea stărilor finale
)(Q)λ(ΣQ:δ * P
Interpretarea expresiei )}γ,(p),...,γ,(p),γ,{(pZ)a,δ(q,mm2211
, unde
m1,i ,Γ γΓ, ZΣ,a Q,pq, *
ii , este aceea că automatul push-down aflat în starea q, cu a pe
banda de intrare şi Z în capul stivei, poate trece într-una din stările pi înlocuind pe Z cu i
γ şi apoi
avansează cu un simbol pe banda de intrare.
Interpretarea expresiei )}γ,(p),...,γ,(p),γ,{(pZ)λ,δ(q,mm2211
, unde
m1,i ,Γ γΓ, ZQ,pq, *
ii , este aceea că automatul push-down aflat în starea q şi având pe Z
în capul stivei, indiferent de simbolul aflat pe banda de intrare îşi schimbă starea într-una din stările pi şi
înlocuieşte pe Z cu i
γ fără să avanseze pe banda de intrare.
Exemplul 3.5.2 În exemplul anterior, automatul push-down acceptă limbajul {{0,1} w| w~wc }
prin memorie vidă (v.definiţia 3.5.4). Să descriem formal acest automat.
▼
M=({q1,q2},{0,1,c},{R,A,V},δ,q1,R, )
λ)},{(qR)λ,,δ(qVV)},{(qV),1,δ(q
λ)},{(qV),1,δ(qVA)},{(qA),1,δ(q
λ)},{(qA),0,δ(qAV)},{(qV),0,δ(q
R)},{(qR)c,,δ(qAA)},{(qA),0,δ(q
V)},{(qV)c,,δ(qVR)},{(qR),1,δ(q
A)},{(qA)c,,δ(qAR)},{(qR),0,δ(q
2211
2211
2211
2111
2111
2111
▲
Observaţia 3.5.1 Automatul din Exemplul 3.5.2 este determinist pentru că are o singură posibilitate de
mişcare la fiecare pas.
Un astfel de automat, idiferent dacă este determinist sau nedeterminist, se poate şi el reprezenta
printr-o diagramă de tranziţie[23], similară cu cea pentru automatul finit, cu excepţia faptului ca una
dintre etichetele unui arc între starea p şi starea q, este de forma:

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 46 -
(a, A→ BC) dacă (q, BC) (p,a,A)
sau, folosind forma din [13]:
(a, A, BC) dacă (q, BC) (p,a,A)
Să considerăm automatul push-down, definit printr-o diagramă de tranziţie, din figura 2.3.2, care
recunoaşte cuvintele limbajului:
{anb
n | n ≥ 0}.
Definiţia 3.5.2 O configuraţie instantanee este o pereche γ)(q, , unde Qq şi *γ , unde cel mai
din stânga simbol al lui γ este vîrful stivei push-down, iar γ reprezintă conţinutul stivei.
Dacă λ}{Σa , γ, β*Γ , ΓZ şi Z)a,δ(q,β)(p, , atunci scriem:
a : (q,Zγ)├M
(p,βγ) (Intrarea "a" trece automatul M din (q,Zγ) în (p,βγ).)
Dacă pentru fiecare λ}{Σa...,an1 , Qq,...,q
1n1
şi şirurile
*
1n1Γγ,...,γ
, avem:
ai : (qi,γi)├ M (qi+1,γi+1) n1,i , atunci scriem: a1… an : (q1,γ1)├
*
M (qi+1,γi+1)
Similar, se poate folosi descrierea instantanee, constituită din tripletul Zαaw,q, şi atunci
scriem: Zαaw,q, ├M
(p,w,βα) dacă (p, β) Z)a,δ(q, .
Definiţia 3.5.3 Limbajul acceptat prin stări finale de către automatul M este
)Zw,,(q ,Σ w {wL(M)00
* ├*
M F}p ,Γ γ,γλ,p, * .
Definiţia 3.5.4 Limbajul acceptat prin stivă vidă de către automatul M este
)Zw,,(q ,Σ w {wN(M)00
* ├*
M Q}p ,λλ,p, .
Exemplul 3.5.3 Să construim automatul push-down care acceptă limbajul {{0,1} w|w~w }.
▼
M=({q1,q2},{0,1},{z0,A,B},δ,q1,Z0, )
λ)},(qBB),,{(qB),1,δ(q
λ)},{(q)Zλ,,δ(qBA)},{(qA),1,δ(q
λ)},{(q)Zλ,,δ(qAB)},{(qB),0,δ(q
λ)},(qAA),,{(qA),0,δ(q
λ)},{(qB),1,δ(q)}BZ,{(q)Z,1,δ(q
λ)},{(qA),0,δ(q)}AZ,{(q)Z,0,δ(q
211
20211
10111
211
220101
220101
Spre exemplu, şirul de intrare 001100 este acceptat de automatul push-down deoarece există un
calcul de configuraţii care se finalizează prin golirea memoriei push-down după citirea benzii de intrare:
)Z,001100,(q01
├M
)AZ,01100,(q01
├M
)AAZ,1100,(q01
├M
├M
)BAAZ,100,(q01
├M
)AAZ,00,(q02
├M
)AZ,0,(q02
├M
)Zλ,,(q02
├M
├M
λ)λ,,(q2
,
q p
q
0, A → AA
1, A → λ
s
r
p
q
r
p
q
1, A → λ λ, Z0 → λ
0, Z0 → AZ0
λ, Z0 → λ
Figura 3.2.2

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 47 -
deci 001100 N(M) .
Problema care apare în acest exemplu este de a determina mijlocul cuvântului de pe banda de
intrare. Pentru determinarea mijlocului, singura condiţie cunoscută este de a avea pe banda de intrare doi
de 0 consecutivi sau doi de 1 consecutivi. Însă această condiţie nu determină în mod precis mijlocul
cuvântului de intrare, situaţia nefiind unică. Astfel, automatul push-down poate "bănui" că a ajuns la
mijlocul cuvântului de intrare ori de câte ori apar doi de 0 sau doi de 1 consecutivi. Deci, de câte ori
automatul întâlneşte două simboluri identice pe banda de intrare, are de ales între două variante:
"bănuieşte" că aici este mijlocul şi trece în starea q2, care începe să şteargă stiva, sau "bănuieşte" că nu
este la mijloc şi continuă să memoreze în stivă. Dacă a "bănuit" corect atunci va reuşi să-şi golească
stiva. De aici apare nedeterminismul. ▲
Observaţia 3.5.2
a) Un automat push-down este determinist dacă sunt îndeplinite următoarele condiţii:
- pentru fiecare Γ Zşi Σa Q,q corespunzătoare, Z)a,δ(q, nu conţine mai mult de un element;
- pentru fiecare Zşi Qq , dacă Z)λ,δ(q, atunci ,Z)a,δ(q, a (aceste condiţii
evită situaţia în care ar fi posibile atât o λ-mutare cât şi o mutare nevidă, generând astfel nedeterminism).
b) Pentru automatele push-down în general, modelul determinist şi cel nedeterminist nu sunt
echivalente. Acest lucru se demonstrează în § 3.9., secţiune dedicată limbajelor independente de context
deterministe.
§ 3.6 Legătura dintre automatele push-down nedeterministe şi limbajele independente de context
În cele ce urmează vom discuta numai despre automate push-down nedeterministe, pe care le
vom numi simplu automate push-down, iar atunci când ele nu sunt nedeterministe vom preciza acest
lucru.
Teorema 3.6.1 Un limbaj L este acceptat prin stivă vidă de către un automat push-down M1, (L=N(M1))
dacă şi numai dacă el este acceptat prin stări finale de către un automat push-down M2, ( L=N(M2) ).
▼Demonstraţie:
I. Fie L=T(M2), unde M2= F),Z,qδ,Γ,Σ,(Q,00
.
Construim M1= )X,,q,δ{X},ΓΣ,},q,{q(Q00λ
, unde δ este definit după cum urmează:
1) X)λ,,q(δX)Z,(q000
2) Γ Z,λΣa Q,q , Z)a,(q,δZ)a,δ(q,
3) Pentru toţi Z)λ,(q,δλ,q {X}Γ ZF,qλ
4) Pentru toţi Z)λ,,(qδλ,q {X}ΓZλλ
Regula 1) îl face pe M1 să intre în configuraţia iniţială a lui M2, dar simbolul iniţial al stivei este
X. Regula 2) simulează pe M2 până când intră într-o stare finală. Regulile 3) şi 4) golesc stiva când M2
intră într-o stare finală.
Se observă că regulile 2) pot goli stiva lui M2 şi pentru un cuvânt care nu este în T(M2), iar acesta
este motivul pentru care M1 are propriul său simbol iniţial al stivei, X.
Să demonstrăm echivalenţa celor două automate:
a) Fie )T(Mw2
. Atunci:
00
Zw,,q ├*
M2(q,λ,γ) pentru q Q .
Fie acum w intrarea lui M1;
- conform regulei 1), rezultă că 00
Zw,,q ├*
M1(q0,w,Z0X)

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 48 -
- conform regulei 2), rezultă că XZw,,q00
├*
M1(q,λ,γX) (M1 simulează pe M2)
- conform regulilor 3) şi 4), rezultă în final că γXλ,q, ├*
M1(qλ,λ,λ)
Aşadar )N(M w1
.
b) Dacă )N(Mw1
, atunci se vede că stiva este complet ştearsă numai dacă sunt aplicate regulile 3)
şi 4), deoarece regulile lui M2 nu pot şterge pe X. Aşadar, este necesar ca M2 să intre într-o stare finală cu
aceeaşi intrare ca M1, ca să poată fi aplicate reguli de tip 3 şi 4.
II. Reciproc, fie M1= ),Z,qδ,Γ,Σ,(Q,00 astfel încât L=N(M1).
Definim M2= }){qX,,q,δ{X},ΓΣ,},q,q{(Qf0f0
, unde δ este definit după cum urmează:
1) X)λ,,q(δX)Z,(q000
2) Z)a,,q(δZ)a,δ(q, Γ Z,λΣa Q,q
3) X)λ,(q,δλ),(q Qqf
Regula 1) îl face pe M2 să intre în configuraţia iniţială a lui M1. Regula 2) simulează pe M1 până
îşi goleşte stiva la citirea intrării. Regula 3) îl determină pe M2 să intre într-o stare finală dacă M1 şi-a
golit stiva iar în stiva lui M2 este doar X.
Demonstraţia este similară cu I. ▲
Teorema 3.6.2 Dacă L este un limbaj independent de context, atunci există un automat push-down M
astfel încât L=N(M).
▼Demonstraţie:
Fie o gramatică independentă de context G=(VN,VT,S,P) în formă normală Greibach, astfel încât
L=L(G). Presupunem că λ L(G) (demonstraţia se poate adapta şi pentru cazul contrar).
Construim M= )S,,qδ,,V,V},({q1NT1
, unde A)a,,δ(q1
conţine γ),(q1
pentru fiecare
regulă PaγA .
Pentru a arăta că L(G)=N(M), observăm că:
xaα(xAβG β) Aβa,,q
1 ├
M αβλ,,q
1
Prin inducţie asupra numărului de paşi dintr-o derivaţie rezultă că:
)Vβα, ,VA ,Vypentru x, xyα(xAβ *
NN
*
T
*
G Aβy,,(q
1 )├
*
Mα)λ,,(q
1
Atunci : S)x,,(q x S1
*
G ├
*
Mλ)λ,,(q
1.
Se observă că M nu face λ-mutări.▲
Teorema 3.6.3 Dacă L este acceptat prin stivă vidă de către un automat push-down M (L=N(M)), atunci L
este un limbaj independent de context.
▼Demonstraţia se gaseste in [4]:
Observaţia 3.6.1 Din teoremele 3.6.1, 3.6.2 şi 3.6.3 rezultă că următoarele afirmaţii sunt echivalente:
i) L este un limbaj independent de context;
ii) L=N(M1) pentru un automat push-down M1 nedeterminist;
iii) L=T(M2) pentru un automat push-down M2 nedeterminist.
§ 3.7 Proprietăţi de închidere pentru limbaje I.D.C.
Vom considera anumite operaţii care păstrează limbajele I.D.C. Aceste operaţii se pot folosi atât
pentru a demonstra că un limbaj este I.D.C. cât şi pentru a demonstra că un limbaj nu este I.D.C.

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 49 -
Teorema 3.7.1 Limbajele independente de context sunt închise la reuniune, concatenare şi produs
Kleene.
▼Demonstraţie:
Fie L1 şi L2 generate de )P,S,T,(VG11111
şi )P,S,T,(VG22222
. Presupunem că
V1 V2= . Atunci putem realiza următoarele construcţii de gramatici I.D.C:
Limbajul 21
LL este generat de )P,S,TT},{SV(VG33213213
, unde
}SS,S{SPPP2313213
.
Să demonstrăm că )L(GLL321
:
Fie 21
LLw ; înseamnă că w aparţine cel puţin unuia din cele două limbaje:
iL w:{1,2}i , altfel spus )L(G w:{1,2}i
i . Există deci o derivare a lui w în una din cele
două gramatici date, Gi, pornind de la simbolul iniţial al respectivei gramatici: wSiG
i
. Deoarece toate
regulile din gramatica Gi sunt şi reguli ale gramaticii construite G3, înseamnă că aceeaşi derivare are loc
şi în gramatica G3. În plus, putem obţine simbolul Si printr-o derivare într-un pas pornind de la S3, şi
anume folosind una din cele două reguli nou adăugate la P 3, obţinând următoarea derivaţie în G3:
wSS :{1,2}i33 G
iG
3
, deci )L(G w 3 .
Rezultă că )L(GLL321
.
Fie )G(Lw3
; înseamnă că w poate fi generat cu regulile P3, pornind de la S3: wS 3G
3
.
Deoarece singurele S3-reguli sunt cele două redenumiri }SS,S{S2313
, rezultă că primul pas al
derivaţiei amintite nu poate fi decât rezultatul aplicării uneia d in aceste două reguli:
wSS :{1,2}i33 G
iG
3
, deci wS3G
i
.
Putem observa faptul că, în afară de primul pas al acestei derivări, toate regulile folosite în
obţinerea lui w pornind de la S3 sunt chiar reguli din Pi, {1,2}i , în funcţie de simbolul Si obţinut în
primul pas. Deoarece V1 V2= , rezultă că wSiG
i
, deci )L(Gwi
=Li.
S-a arătat astfel că 1
Lw sau 2
Lw , adică 21
LLw .
Rezultă că )L(GLL321
.
Ţinând cont de cele două implicaţii rezultă că limbajul 21
LL este generat de gramatica G3.
Următoarele construcţii se demonstrează în mod asemănător, constituind un bun exerciţiu:
a) Limbajul 21
LL este generat de )P,S,TT},{SV(VG44214214
, unde
}SS{SPPP214214
.
b) Limbajul *
1L este generat de )P,S,T},{S(VG
551515 , λ}S,SS{SPP
515515 .▲
Teorema 3.7.2 Familia limbajelor independente de context este închisă la substituţie.
▼Demonstraţie:
Fie L un limbaj I.D.C., *ΣL şi pentru fiecare Σa fie La un limbaj I.D.C.
Fie o gramatică G care generează limbajul iniţial, L=L(G). De asemenea, pentru fiecare simbol
Σa considerăm câte o gramatică astfel încât La=L(Ga).
Presupunem că variabilele lui G şi ale lui G a sunt distincte, oricare ar fi Σa .

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 50 -
Construim gramatica G I.D.C. în felul următor:
Variabilele lui G sunt variabilele lui G şi cele ale lui Ga, pentru Σa ;
Terminalele lui G sunt terminalele lui Ga;
Simbolul iniţial al lui G este simbolul iniţial al lui G;
Regulile lui G sunt cele ale lui Ga, pentru Σa , şi regulile lui G în care fiecare Σa se
înlocuieşte cu Sa (simbolul iniţial al Ga).
▲
Exemplul 3.7.1 Fie L limbajul cuvintelor cu număr egal de a şi b. Să urmărim aplicarea celor
demonstrate în teorema anterioară.
▼ Avem gramatica generativă P)S,b},{a,({S},G , unde mulţimea regulilor este
λ}SbSaS,SaSbS,{SP . Se poate verifica faptul că L=L(G). Să considerăm limbajele de
substituţie:
1}n|1{0L nn
a , generat de regulile P(Ga)= 01}S1,0S{S
aaa ;
}{0,2}w|w~{wL *
b , limbaj generat de mulţimea de reguli
P(Gb)= λ}S2,2SS0,0S{Sbbbbb .
Atunci, conform construcţiei efectuate în demonstraţia Teoremei 3.7.2, gramatica rezultată este
G= )PS,{0,1,2},},S,S({S,ba
, cu mulţimea de reguli:
, , , 0 1, 01, 0 0, 2 2, }a b b a a a a b b b b bP S S SS S S S SS S S S S S S S S S S
Să generăm un cuvânt la întâmplare cu aceste reguli:
a b b b b bS S SS S 01SS S 01S S 012S 2S 0120S 02S 012002S 01200 2 ▲
Observaţia 3.7.1 Teorema 3.7.1 se poate obţine folosind Teorema 3.7.2 şi ţinând cont că Σba,
avem:
b}{a, este I.D.C.
b}{a este I.D.C.
a este I.D.C.
Dacă acum f(a)=La şi f(b)=Lb, atunci, datorită proprietăţii de închidere la substituţie , rezultă că:
ba
LL este I.D.C.
ba
LL este I.D.C.
aL este I.D.C.
Pentru că homomorfismul este un caz special de substituţie, în care card(La)=1, obţinem şi
următorul corolar.
Corolar 3.7.1 Clasa limbajelor I.D.C. este închisă la homomorfism.
Teorema 3.7.3 Clasa limbajelor independente de context este închisă la homomorfismul invers.
▼Demonstraţie:
Fie ΔΣ:h un homomorfism şi L un limbaj I.D.C.; atunci există un automat push-down
F),Z,qδ,Γ,Δ,(Q,M00
astfel încât L=T(M).
Construim un automat push-down M care să accepte (L)h 1, astfel:
Cu intrarea a pentru automatul M', acesta generează h(a) şi simulează execuţia lui M cu această
intrare h(a). Dacă M' ar fi un automat cu număr finit de stări, atunci M' şi-ar schimba numai stările. În

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 51 -
cazul automatului push-down, M' poate şi să pună o mulţime de simboluri pe stivă şi, în plus, fiind
nedeterminist are o mulţime de posibilităţi de mişcare.
De aceea, dotăm M' cu un buffer (o zonă tampon) în care el poate să memoreze h(a). Atunci M'
poate să simuleze orice λ-mutare a lui M, dacă doreşte, şi să consume simbolurile lui h(a) câte unul la
fiecare moment, la fel cum face M. Pentru ca buffer-ul să fie o parte a controlului finit al lui M', el nu
poate fi oricât de lung. Se poate realiza asta permiţându-i lui M' să citească un simbol de intrare numai
când buffer-ul este gol. Astfel, în buffer este păstrat în fiecare moment un sufix al lui h(a), pentru un
anume a preluat de pe banda de intrare a lui M'.
Automatul push-down M' acceptă cuvântul de intrare w dacă buffer-ul este vid şi M este într-o
stare finală. În acest fel, M a acceptat h(a) pentru fiecare simbol de intrare a, deci a acceptat h(w).
Astfel, L(M')= L(M)}h(w) {w , adică: L(M')= (L(M))h 1
Construcţia formală este )λF,Zλ],,[q,δΓ,Σ,,Q(M00
, unde:
Q’ = {[q,x] | q Q, iar x este un suffix al lui h(a),a }
Funcţia de tranziţie δ :
1) Y)λ,x],([q,δγ)x],([p, pentru fiecare Y)λ,δ(q,γ)(p, .
Astfel, M' simulează λ-mutările lui M, indiferent de conţinutul din buffer.
2) Y)λ,ax],([q,δγ)x],([p, dacă Y)a,δ(q,γ)(p, .
Astfel, M' simulează mutările lui M pe intrarea a din Σ, eliberând a din capul buffer-ului.
3) Y)a,λ],([q,δY)h(a)],([q, pentru toţi Σa şi ΓY .
În acest mod, M' încarcă în buffer h(a), citind a de pe intrarea M', în timp ce starea şi stiva lui M rămân
neschimbate.
Să demonstrăm că L(M')= (L(M))h 1.
a) Mai întâi, să observăm că printr-o aplicare a regulii (3) urmată de o aplicare a regulilor (1) şi (2),
dacă α)h(a),(q, ├
Mβ)λ,(p, ,
atunci α)a,λ],([q, ├M α)λ,h(a)],([q, ├
Mβ)λ,λ],([p, .
Astfel, dacă M acceptă h(a), adică dacă )Zh(w),,(q00
├
Mβ)λ,(p, pentru Fp şi
Γβ , atunci
)Zw,λ],,([q00
├
Mβ)λ,λ],([p, ,
astfel încât M' acceptă w.
Deci L(M') (L(M))h 1 .
b) Reciproc, să presupunem că M' acceptă intrarea w=a1a2…an. Atunci, pentru că regula (3) poate fi
aplicată numai cu buffer-ul vid (precum arată a doua componentă a stării lui M), şirul de mişcări ale lui
M' ce conduc la acceptare poate fi scris ca:
h
Stiva lui
M şi M'
…
Figura 3.7.1
Intrarea lui M'
Controlul
lui M'
Buffer Controlul
lui M

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 52 -
)Z,...aaaλ],,([q0n210
├
M )α,...aaaλ],,([p
1n211├
M)α,...aa)],h(a,([p
1n211├
M
├
M)α,...aaλ],,([p
2n22├
M)α,...aa)],h(a,([p
2n322├
M. . .. . . .
├
M)α,aλ],,([p
nnn├
M)αλ,)],h(a,([p
nnn├
M)αλ,λ],,([p
1n1n , unde pn+1F.
Tranziţia din starea λ],[pi
în )]h(a,[pii
se face prin regula (3) iar celelalte tranziţii prin
regulile (1) şi (2).
Astfel, )Zλ,,δ(q)α,(p0011
şi )α),h(a,δ(p)α,(p :iiii1i1i
deci obţinem o recunoaştere şi din partea lui M:
)Z),...aah(a,(q0n210
├
M)α,...aaaλ],,([p
1n211├
M)α,...aaλ],,([p
2n22├
M…├
M
)α,aλ],,([pnnn
├
M )αλ,λ],,([p
1n1n , unde pn+1F.▲
Există câteva proprietăţi ale mulţimilor regulate care nu se păstrează la mulţimile I.D.C., şi
anume proprietăţile de închidere la intersecţie şi complementare.
Teorema 3.7.4 Clasa limbajelor I.D.C. nu este închisă relativ la intersecţie .
▼Demonstraţie:
Să presupunem, prin absurd, că intersecţia oricăror limbaje I.D.C. este tot un limbaj I.D.C. Să
construim un contraexemplu:
Am demonstrat că limbajul }1i cb{aL iii nu este independent de context (v. Observaţia
3.4.1). Considerăm acum două limbaje care sunt I.D.C.:
}1j1,i cb{aL jii
1
}1j1,i cb{aL jji
2
Pentru aceste limbaje este uşor să construim câte un automat push-down sau sau câte o gramatică I.D.C.;
spre exemplu, o gramatică pentru generarea limbajului L2 ar putea avea setul de reguli:
bc}BbBc,Ba,AaA,AAB,{S .
Dar 21
LLL şi L nu este I.D.C., ceea ce contrazice presupunerea făcută. ▲
Corolar 3.7.2 Clasa limbajelor I.D.C. nu este închisă relativ la complementare .
▼Demonstraţie:
Ştim că clasa limbajelor I.D.C. este închisă la reuniune. Presupunând că ar fi închisă şi la
operaţia de complementare, şi ţinând cont de relaţiile lui de Morgan privind complementarea reuniunii (
C(A B)=C(A) C(B) ), am obţine concluzia că are loc închiderea şi la intersecţie, ceea ce contrazice
Teorema 3.7.4. ▲
Teorema 3.7.5 Dacă L este un limbaj I.D.C. iar R este o mulţime regulată, atunci RL este un limbaj
I.D.C.
▼Demonstraţie:
Fie L=T(M), M fiind un automat push-down, )F,Z,q,δΓ,Σ,,(QMM00MM
Fie şi R=T(A), unde A este un automat finit nedeterminis, )F,p,δΣ,,(QAA0AA
Construim un automat push-down M' pentru limbajul RL , într-un mod care să simuleze
funcţionarea în paralel a lui M şi A: M' simulează mişcările lui M pe intrarea λ fără a schimba starea lui
A. Când M face o mişcare pe simbolul de intrare a, M' simulează această mişcare şi de asemenea
simulează schimbarea stării lui A pentru simbolul a. Automatul M' acceptă o intrare dacă şi numai dacă
atât A cât şi M o acceptă.
Construcţia formală a lui M' este următoarea: )FF,Z],q,[pδ,Γ,Σ,,Q(QMMA000MA
,

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 53 -
unde δ este definit astfel:
X)a,q],δ([p,γ)],q,p([ atunci când
X)a,(q,δγ),q(
pa)(p,δ
M
A
Desigur, dacă λa atunci pp .
Să demonstrăm acum faptul că RL =T(M')
a) Se demonstrează uşor prin inducţie relativ la i că dacă )Zw,],q,([p000
├i
M γ)λ,q],([p, , atunci
)Zw,,(q00
├i
Mγ)λ,(q,
şi w),(p0
├i
A
λ)(p,
pentru i=0 rezultatul e trivial, deoarece luăm p=p0, q=q0, γ=Z0 şi w=λ.
presupunem afirmaţia adevărată pentru i-1 şi fie
)Zxa,],q,([p000
├1-i
Mβ)a,],q',([p' ├
M γ)λ,q],([p, ,
unde w=xa şi Σa sau a=λ.
Conform ipotezei de inducţie, rezultă că:
px),(pδ0A
)Zx,,(q00
├
Mβ)λ,,q(
În plus, conform definiţiei,
pa),p(δA
şi β)a,,q( ├M
γ)λ,(q,
Utilizând toate acestea, obţinem:
pxa),(pδ0A
)Zxa,,(q00
├
Mγ)λ,(q,
sau, altfel scris,
T(M)xa
T(A)xa , ceea ce trebuia demonstrat.
b) Reciproc, se procedează într-o manieră similară, pentru a arăta că daca
)Zw,,(q00
├i
Mγ)λ,(q, şi w),(p
0├
i
A
λ)(p, atunci )Zw,],q,([p000
├
Mγ)λ,q],([p, ▲
Teorema 3.7.6 Clasa limbajelor independente de context este închisă în raport cu operaţia de oglindire.
▼Demonstraţie:
Fie G o gramatică independentă de context de forma:
Stiva lui
M şi M'
…
Figura 3.7.2
Intrarea lui A, M şi M'
Controlul
lui M' Controlul
lui A
Controlul
lui M

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 54 -
G = (VN, VT, S, P) şi L = L(G).
Construim o nouă gramatică G’ = (VN, VT, S, P”), în care fiecare regulă din mulţimea regulilor, P, este
înlocuită cu o regulă similară în care membrul drept este oglinditul membrului drep al regulei
corespunzătoare din P:
P’ = {A → u~ | A → u P}
Se observă că regulile din P’ sunt tot independente de context. Este uşor de demonstrat că:
L(G’) = L~
▲
Exemplul 3.7.2 Fie limbajul }b}{a,w{wwL . Să se exemplifice proprietăţile de închidere.
▼ Limbajul L este format din cuvintele ale căror jumătate stângă este identică cu jumătatea dreaptă.
Presupunem că acest limbaj ar fi I.D.C.
Din Teorema 3.7.5 rezultă că limbajul babaLL
1 ar fi şi el I.D.C.; dar
}1j1,i bab{aL jiji
1 nu este de acest tip, fapt ce se poate vedea cu ajutorul teoremei de
pompare:
Fie p,q N . Alegem z = qqqq baba = uvwxy, unde |v| + |x| > 0, |vwx| q. Posibilităţile de
alegere ale subcuvântului vwx sunt multiple (aib
j cu i+j q , b
i cu i q , b
j-ia
i cu i j q ), ele însă nu
permit crearea de cuvinte ywxuv ii care să fie tot din L1 (proprietatea egalităţii jumătăţilor nu se poate
păstra prin pompare).
Din contradicţia obţinută rezultă că limbajul L considerat iniţial nu este I.D.C.
Să mai observăm şi faptul că se poate demonstra că L1 nu este I.D.C. şi fără a folosi teorema de
pompare, reducând acest limbaj la limbajul
1}j,1idcb{aL jiji
2 .
Fie h(a)=h(c)=a şi h(b)=h(d)=b. Atunci )(Lh1
1 este format din toate cuvintele de forma
x1x2x3x4, unde x1 şi x3 au aceeaşi lungime în c}{a, , iar x2 şi x4 au aceeaşi lungime în
d}{b, .
Atunci 2
****
1
1 Ldcba)(Lh .
Dacă L1 ar fi I.D.C., atunci (din Teoremele 3.7.3 şi 3.7.5) rezultă că L2 ar fi şi el I.D.C., ceea ce
ştim că este fals.
Astfel s-a arătat, din nou, faptul că L1 nu este I.D.C. ▲
§ 3.7 Exerciţii
1. Să se construiască câte o gramatică independentă de context pentru fiecare din mulţimile următoare:
a. Mulţimea tuturor palindroamelor peste alfabetul {a,b}.
b. {an b
2n | n > 0}
c. {an+1
b3n
| n > 0}
d. {ai b
j | i j}
e. {ai b
j c
k | i j sau j k }
f. {u # u~ | u {a,b}* }
2. Considerăm gramatica:
G = ({S, T, L}, {a, b, +, -, x, /, [, ] }, S, P),
unde mulţimea P este formată din regulile:
S → T + S T → L x T L → [ S ]
S → T – S T → L / T L → a
S → T T → L L → b
Să se construiască o derivaţie şi un arbore de derivaţie pentru cuvântul: a + [a x b – b/a ]:

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 55 -
5. Să se construiască automate push-down pentru fiecare dintre mulţimile de la problema 1.
6. Să se construiască automate push-down pentru fiecare dintre mulţimile următoare:
d. {w | w {0,1}* N0(w) = N1(w)}, unde N0(w) reprezintă numărul de apariţii ale simbolului 0 în w;
e. {ai b
j | i ≤ j ≤ 2i}
f. Limbajul generat de gramatica G = ({S,A}, {a,b}, S, { S → aAA, A → bBS, A → aS, A → a})
7. Se consideră automatul push-down definit de M = ({q,p}, {0,1}, {Z,X}, , q, Z, ), unde este:
(q, 1, Z) = {(q, XZ)} (q, λ, Z) = {(q, λ)}
(q, 1, X) = {(q, XX)} (q, 0, X) = {(p, X)}
(p, 1, X) = {(p, λ)} (p, 0, Z) = {(q, Z)}
Să se construiască o gramatică independentă de context care să genereze N(M).
8. Se consideră limbajul L = {an b
n | n ≥ 1} {a
n b
2n| n ≥ 1}. Să se arate că L este un limbaj
independent de context (se construieşte un automat push-down nedeterminist).
Sfârşit

LIMBAJE FORMALE ŞI TEORIA AUTOMATELOR
- 56 -
BIBLIOGRAFIE
[1]. AHO, A.V., ULLMAN, J. D. “The theory of parsing, translation and compiling” Prentice Hall-
London, 1972.
[2]. AHO, A.V., SETHI, R., ULLMAN, J.D. “Compiling, Principles, Techniques and Tools”, Addison-
Wesley, Reading, Mass., 1988.
[3]. GRIES, D. “Compiler construction for digital computers”, New -York, John Weley, 1971.
[4]. HOPCROFT, J.E., ULLMAN, J. D. “Formal Languages and their relation to Automata” , Addison-
Wesley, Reading, Mass., 19769.
[5]. HOPCROFT, J.E., ULLMAN, J. D. “Introduction to automata theory, Languages and Computation” ,
Addison-Wesley, 1979.
[6]. IACOB P., MARINESCU D. "An Optimal Representation of the Nondeterministic Finite
Automaton by a Set - Union Knapsack Problem" Proceedings of the International Conference "Symetry
and Antisymetry in Mathematics, Formal Languages and Computer Science" Brasov 1996 pp 47-48.
[7]. KOZEN, D.C.,“ Automata and Computability”, Springer, 1997.
[8]. LIVOVSCHI, L. GEORGESCU, H. “Bazele informaticii”, Ed. Didactică şi Pedagogică, Bucureşti,
1985.
[9]. MARCUS, S. “ Lingvistica Matematică”, Ed. Didactică şi Pedagogică, Bucureşti, 1973.
[10]. MARINESCU D.,. “- “O masina Turing cu trei benzi universală pentru algoritmi normali” , Bul.
Univ. Braşov, seria C, Vol. XX – 1978, pp. 87 -100.
[11]. MARINESCU D., - “A bidimensional Turing machine for the cutting stock problem with quillotine
restrictions” - Proceeding of the scientific symposion with the contribution of teachers and researchers
from the Republic of Moldova , Brasov, 1991, pp 73 -83
[12]. MARINESCU D., - “Some Turing machines for the determination of the cuts in a cutting-stock
model” - Proceeding of the scientific symposion with the contribution of teachers and researchers from
the Republic of Moldova , Brasov 1991, pp 85 -96
[13]. MARINESCU D., " The Use of Didactic Software JFLAP for Formal Languages "Report TR--HH-
10-97 Restructuring of the (re)training of school teachers In Computer science- Computer Libris Agora,
ISBN 973-97515-1-2, Cluj-1997, pp.240-251.
[14]. MARINESCU D., IACOB P., VLADAREAN C.- “ An Algorithm for Optimal Representation of a
Nondeterministic Finite Automaton By a set-union Knapsack Problem”, Proceedings of the 2-th
International Conference "Symetry and Antisymetry in Mathematics, Formal Languages and Computer
Science"- Satelite Conference of 3 ECM- Brasov 2000, pp 199-206.
[15] MARINESCU, D. “Limbaje Formale si Teoria Automatelor”, Ed. Univ. Transilvania, Brasov, 2003.
[15]. MOLDOVAN, G., CIOBAN, V., LUPEA,M. “ Limbaje Formale şi Teoria Automatelor-
Culegere de probleme”, Ed. Mesagerul, Cluj-Napoca, 1997.
[16]. MARUŞCIAC, I. “Teoria Algoritmilor”, Ed. Didactică şi Pedagogică, Bucureşti, 1966.
[17]. ORMAN, G. “Limbaje Formale”, Ed. Tehnică, Bucureşti, 1982.
[18]. ORMAN, G. “Limbaje Formale şi acceptori”, Ed. Albastră, Cluj-Napoca, 2002.
[19]. PĂUN, GH. “ Gramatici matriceale”, Ed. Ştiinţufică şi Enciclopedică, Bucureşti, 1981.
[20]. PĂUN, GH. “ Mecanisme generative ale proceselor economice”, Ed. Tehnică, Bucureşti, 1982.
[21]. PĂUN, GH. “ Probleme actuale în Teoria Limbajelor Formale”, Ed. Ştiinţufică şi Enciclopedică,
Bucureşti, 1984.
[21]. SALOMAA, A. “Formal Languages”, Academic Press, New-York, 1973.
[22]. SIMOVICI, D. “Limbaje Formale şi Tehnici de compilare”, Ed. Didactică şi Pedagogică, Bucureşti,
1978.
[23]. SIPSER, M. ” Introduction to the theory of computation”, PWS publishing Company, Boston,
1996.