20150309 iscover challange_twitter_bot
TRANSCRIPT

I-Scover チャレンジ 2014論文紹介 Twitter bot
鈴木 英友

Page 2
「より効率的で多角的な論文探しのサポート」
コンセプト

Page 3
作品概要
目的- 本 bot のツイートを見る人に対して以下を提供
- 新たな知見の獲得
- 有益な論文の発見
形態- Twitter bot
- アカウント: @research_friend
機能- 毎日1件論文をランダムに紹介する
- フォローされた場合自動でフォローする
- 毎週1件論文をレコメンドする(いずれかのツイートをリツイートしたフォロワーのみ)
基本情報

Page 4
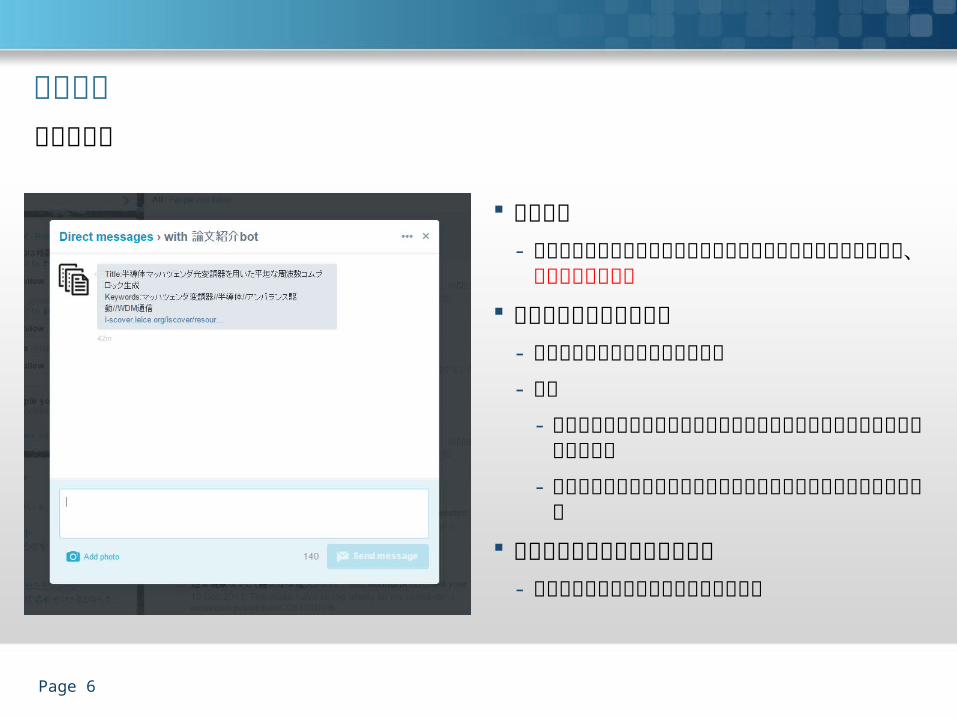
機能説明
機能目的- ランダムに提示される論文から気になっ
たものを読むことによる、新たな知見の獲得
頻度- 毎日1件
使用データセット- I-Scover データセット
( articles_all.xml 、 articlekw_all.xml )
ツイート内容- タイトル(日本語優先)
- キーワード
- I-Scover 上の URL
ランダム紹介

Page 5
機能説明
機能目的- 機械的なレコメンドにより従来の調べ方
では見つけられなかった、有益な論文の発見
頻度- 毎週月曜日1件
(デイリーツイートをリツイートしたフォロワーのみ)
使用データセット・ツイート内容- 「ランダム紹介」機能と同じ
レコメンド
Page 6
機能説明
機能目的- 機械的なレコメンドにより従来の調べ方
では見つけられなかった、有益な論文の発見
レコメンドアルゴリズム- ハイブリッド協調フィルタリング
- 理由
- フォロワー嗜好データが十分に集まらなくてもある程度のレコメンドが可能
- フォロワー嗜好データが集まれば集まるほどレコメンド性能が向上
フォロワー嗜好データ取得方法- ランダム紹介ツイートのリツイート情報
レコメンド

Page 7
レコメンド
アイテム(論文)間の評価- 非負値行列因子分解 (NMF) により論文をソフトクラスタリングすることで計算
- D. D. Lee and H. S. Seung Learning the parts of objects by non-negative matrix factrization, Nature, Vol. 401, No. 6755, pp. 788-791, 1999.
- NMF に利用する行列は論文とタイトル・キーワード・要旨にある単語ベクトル
ユーザ間の評価- ユーザがリツイートした論文の集合を元にマッチ率が高いユーザを類似しているユーザ
とみなす
アルゴリズム

システム構成
Page 8
フォロー情報リツイート情報( デイリー )
ランダムツイート(デイリー)レコメンドメッセージ(週1) スコアリング
( デイリー )
データ蓄積( 初回時 )

システム構成 – レコメンド
Page 9
① 各種情報取得フォロー情報リツイート情報
⑥ レコメンドメッセージ
② リフォロー
④ 論文間のスコアを取得
③ リツイート情報解析
⑤ レコメンド情報生成

実際のアカウント確認
Page 10
https://twitter.com/research_friend

Page 11
展望
レコメンドアルゴリズムの向上 更なるフォロワー嗜好データの取得方法の検討
- フォロワーのプロファイル、ツイート、フォロー情報など アルゴリズムの選択とチューニング
- 類似度計算の検討・ A/B テスト実施- 別のアルゴリズムフレームワークの検討・ A/B テスト実施
論文・フォロワー嗜好データの統計情報のツイート
チューニング・機能追加
キーワードごとの論文数・自動ジャンル分類結果を定期的にツイート 人気論文・ジャンルあるいはキーワードトレンドを定期的にツイート

終わりに
ご静聴ありがとうございました。
Page 12