4. das preference sql - system · preference sql = standard sql + präferenzen per default...
TRANSCRIPT

© Prof. Kießling 2015 4 - 1
4. Das Preference SQL - System
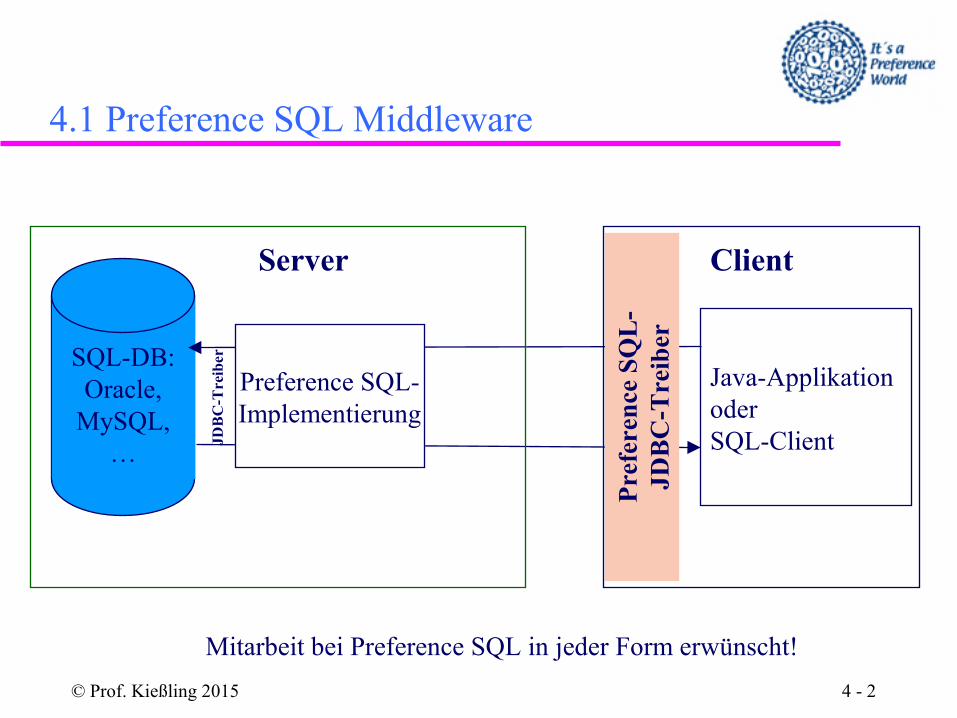
4.1 Preference SQL Middleware
4.2 Preference SQL Syntax
4.2.1 Präferenz-Konstruktoren
4.2.2 Qualitätsfunktionen für Bewertung
4.2.3 Top-k Schnittstelle zum Auffüllen
4.2.4 BUT ONLY als Nachfilter
4.3 Anwendungsbeispiele
4.4 Erweiterung um GROUPING
© Prof. Kießling 2015 4 - 2
4.1 Preference SQL Middleware
SQL-DB:Oracle,
MySQL,…
Preference SQL-Implementierung
Java-Applikationoder SQL-Client
Client
Pre
fere
nce
SQ
L-
JDB
C-T
reib
er
Server
Mitarbeit bei Preference SQL in jeder Form erwünscht!
JDB
C-T
reib
er
© Prof. Kießling 2015 4 - 3
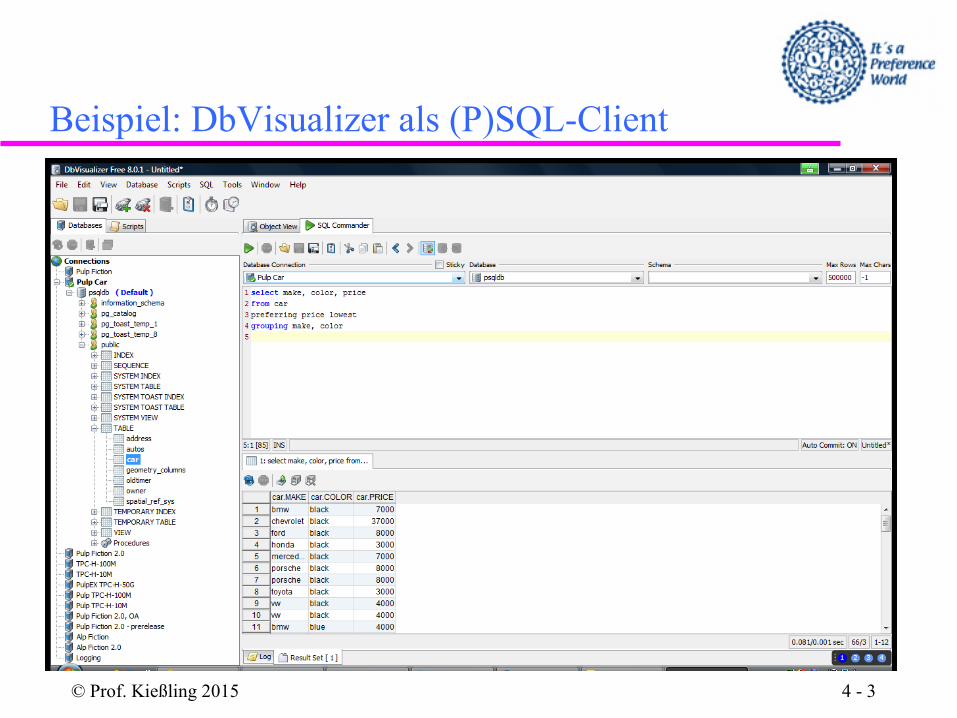
Beispiel: DbVisualizer als (P)SQL-Client

© Prof. Kießling 2015 4 - 4
Benötigte Daten für Treiber-Konfiguration:
Preference SQL-JDBC-Treiber:
PreferenceSQLJDBCClient.jar (per Download von Homepage)Driver:
psql.connector.client.PSQLDriver
URL:
jdbc:psql://[email protected]::
jdbc:oracle:thin:@gemini.informatik.uni-augsburg.de:1521:db
Login: Näheres dazu auf Übungsblatt

© Prof. Kießling 2015 4 - 5
4.2 Preference SQL Syntax
Vorbemerkungen:
Preference SQL = Standard SQL + Präferenzen
Per Default verwendet Preference SQL reguläre SV-Semantik.
Bei jeder numerischer Präferenz ist der d-Parameter (im Folgenden d) optional.
Dokumentation findet sich unter www.trial.preferencesql.com.

© Prof. Kießling 2015 4 - 6
Preference SQL-Abfrageblock:
10. SELECT <projection_list>
1. FROM <table_references>
2. WHERE <hard_conditions>
3. - 5. PREFERRING <pref_constructor>
6. GROUP BY <attribute_list>
7. HAVING <hard_conditions>
8. ORDER BY <attribute_list>
9. LIMIT <number>;

© Prof. Kießling 2015 4 - 7
Auswertungsreihenfolge
1. R := R1 x … x Rn kartesisches Produkt
2. T1 := σH (R) H ist eine harte Bedingung auf dem kart. Produkt.
3. - 5. T4:= ...σ [P] (T1) Präferenzauswertung auf dem Ergebnis der harten
Selektion; Verfeinerung auf der nachfolgenden Folie;
6. T5 := ΓAGG (T4) Gruppierung nach Aggregationsattributen
7. T6 := σHAVING (T5) Selektion pro Gruppe durch Agg.attribut / Agg.funktion
8. T7 := SORTA (T6) Sortierung nach Attributen
9. T8 := LIMITn (T7) Begrenzung der Ergebnismenge
10. T9 := πA (T8) Projektion von Attributen, Präferenzauswertung stellt
weitere Funktionen für Projektion zur Verfügung!

© Prof. Kießling 2015 4 - 8
Bemerkungen:
In SQL gruppiert GROUP BY … HAVING die Ergebnismenge nach der harten Selektion in Partitionen, die durch die Gruppierungsattribute charakterisiert sind und den HAVING-Bedingungen genügen müssen.
In Preference SQL gruppiert GROUP BY … HAVING die BMO-Menge, die durch die Präferenzauswertung resultiert, nach den Gruppierungsattributen. Zudem gelten die HAVING-Bedingungen.

© Prof. Kießling 2015 4 - 94 - 9
Präferenz-Selektion:
3. PREFERRING <soft_conditions>
4. TOP <number>
5. BUT ONLY <but_only_conditions>
3. T2 := σ [P] (T1) Präferenzauswertung nach harter
Selektion
4. T3 := TOPk (T2) Top-k Schnittstelle, siehe später
5. T4 := σBO (T3) BO ist eine harte Bedingung (Nachfilter).
Beachte: Die gleichzeitige Verwendung von TOP K und BUT ONLY sollte semantisch durch Anwendung begründbar sein!

© Prof. Kießling 2015 4 - 10
Mit Hilfe von Basispräferenzen, die sich aufteilen in
Kategorielle Präferenzen und Numerische Präferenzen
werden induktiv komplexe Präferenzen aufgebaut.
4.2.1 Präferenz-Konstruktoren

© Prof. Kießling 2015 4 - 11
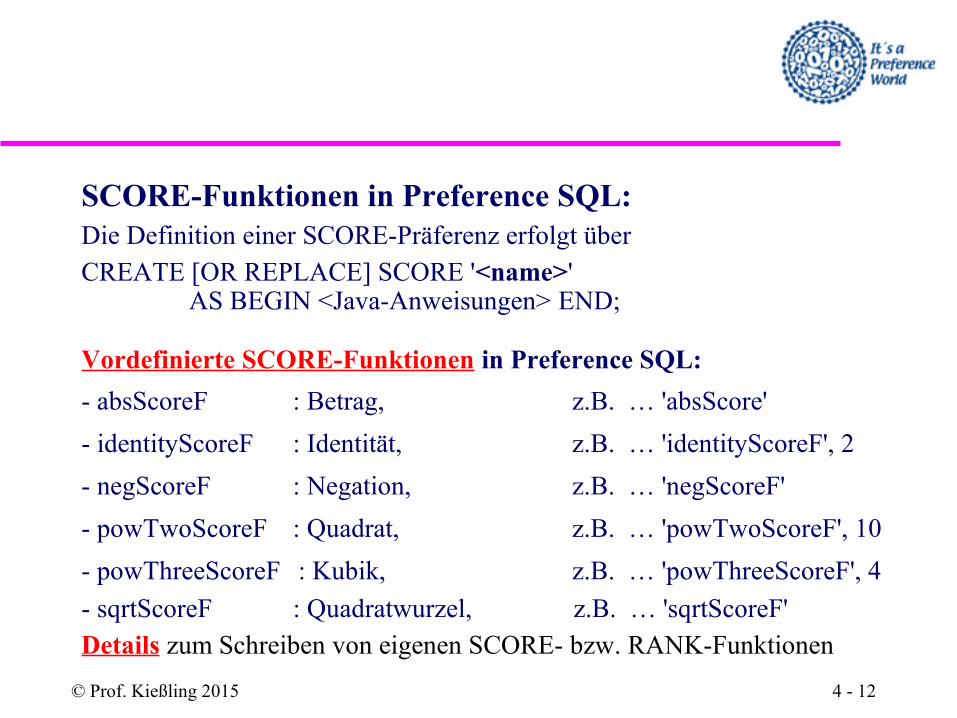
1.) SCORE (A, f, d, SV)
Preference SQL-Syntax:<column> SCORE <string_literal>
[ , <number> ] [<SV-Relation>]
Beispiele:
alter SCORE 'sqrtScoreF'
preis SCORE 'preisFunktion' , 5
4.2.1.1 Numerische Basispräferenzen
© Prof. Kießling 2015 4 - 12
SCORE-Funktionen in Preference SQL:Die Definition einer SCORE-Präferenz erfolgt über CREATE [OR REPLACE] SCORE '<name>'
AS BEGIN <Java-Anweisungen> END;
Vordefinierte SCORE-Funktionen in Preference SQL:
- absScoreF : Betrag, z.B. … 'absScore'
- identityScoreF : Identität, z.B. … 'identityScoreF', 2
- negScoreF : Negation, z.B. … 'negScoreF'
- powTwoScoreF : Quadrat, z.B. … 'powTwoScoreF', 10
- powThreeScoreF : Kubik, z.B. … 'powThreeScoreF', 4
- sqrtScoreF : Quadratwurzel, z.B. … 'sqrtScoreF'Details zum Schreiben von eigenen SCORE- bzw. RANK-Funktionen

© Prof. Kießling 2015 4 - 13
2.) BETWEEN (A, [low, up], d, SV)
Preference SQL-Syntax:
PREFERRING <column>
BETWEEN <low>, <up> [, <number> ]
[<SV-Relation>]
Beispiele: alter BETWEEN 10, 16
preis BETWEEN 5000, 6000, 100

© Prof. Kießling 2015 4 - 14
3.) AROUND (A, z, d, SV)
Preference SQL-Syntax:
<column> AROUND <number> [, <number> ][<SV-Relation>]
Beispiele:
leistung AROUND 90
verbrauch AROUND 6.5 , 0.5

© Prof. Kießling 2015 4 - 15
4.) HIGHEST (A, d, SV)
Preference SQL-Syntax:
<column> HIGHEST [<number> , <number> ] [<SV-Relation>]
Das 1. <number>-Element ist das Supremum.
Das 2. <number>-Element ist der d-Parameter.
Beispiele:
leistung HIGHEST
jahresgehalt HIGHEST 100000 , 1000

© Prof. Kießling 2015 4 - 16
5.) LOWEST (A, d, SV)
Preference SQL-Syntax:
<column> LOWEST [<number> , <number> ] [<SV-Relation>]
Das 1. <number>-Element ist das Infimum.
Das 2. <number>-Element ist der d-Parameter.
Beispiele:
preis LOWEST
verbrauch LOWEST 2.0 , 0.5

© Prof. Kießling 2015 4 - 17
1.) LAYEREDm (A, L, SV)
Preference SQL-Syntax:
PREFERRING
<column> LAYERED ( ( (<string_literal> [, <string_literal>]* )
| OTHERS)
[, (<string_literal> [, <string_literal>]* )
|, OTHERS ]* ) [<SV-Relation>]
Zudem gilt: es darf nur ein OTHERS geben.
Beispiel:
farbe LAYERED ( ('blau', 'gelb'), ('weiß', 'schwarz'), OTHERS,
('lila', 'rosa') )
4.2.1.2 Kategorielle Basispräferenzen

© Prof. Kießling 2015 4 - 18
2.) POS/POS (A, POS1-set, POS2-set, SV)
Preference SQL-Syntax:
PREFERRING
<column> IN (<string_literal> [, <string_literal>]* )
ELSE (<string_literal> [, <string_literal>]* )
[<SV-Relation>]
Beispiele:
modell IN ('Kombi', 'Limousine') ELSE ('SUV', 'Van')
farbe IN ('blau', 'gelb') ELSE ('rot', 'grün')

© Prof. Kießling 2015 4 - 19
3.) POS (A, POS-set, SV)
Preference SQL-Syntax:PREFERRING <POS> [<SV-Relation>]<POS> ::= <column> = <string_literal> |
<column> IN (<string_literal> [, <string_literal>]* )
Beispiele:farbe IN ('gelb', 'grün', 'blau') amtsbezeichnung = 'Bundespräsident' modell = 'Kombi'

© Prof. Kießling 2015 4 - 20
4.) POS/NEG (A, POS-set, NEG-set, SV)
Preference SQL-Syntax:
PREFERRING
<column> IN (<string_literal> [, <string_literal>]* )
NOT IN (<string_literal> [, <string_literal>]* )
[<SV-Relation>]
Beispiele:
modell IN ('Kombi', 'Limousine') NOT IN ('SUV', 'Van')
farbe IN ('blau', 'gelb') NOT IN ('pink', 'rosa', 'lila')

© Prof. Kießling 2015 4 - 21
5.) NEG (A, NEG-set, SV)
Preference SQL-Syntax:PREFERRING <NEG> [<SV-Relation>]<NEG> ::=
<column> != <string_literal> <column> <> <string_literal> |
<column> NOT IN (<string_literal> [, <string_literal>]* )
Beispiele:farbe NOT IN ('gelb', 'grün', 'blau')
amtsbezeichnung <> 'Bundespräsident' modell != 'Kombi'

© Prof. Kießling 2015 4 - 22
6.) EXPLICIT (A, E-Graph)
Preference SQL-Syntax:PREFERRING <column> EXPLICIT ( <string_literal> < <string_literal> [, <string_literal> < <string_literal> ]* )
Die Implementierung sichert Zyklenfreiheit im E-Graph zu. Die Explicit-Präferenz hat keinen SV-Parameter. Es gilt triviale SV-Semantik.
Beispiel:
modell EXPLICIT ( 'LKW' < 'Van', 'Van' < 'Kombi',
'Van' < 'Limousine',
'Kombi' < 'Limousine' )

© Prof. Kießling 2015 4 - 23
Folgende Produktionen gelten für SV-Relation:<SV-Relation> ::=
∅ | // Default-SV-Relation, siehe unten
REGULAR | // Reguläre SV-Semantik
TRIVIAL | // Triviale SV-Semantik
// benutzerdefiniert
// Implementierung sichert disjunkte SV-// Mengen zu
SV ( (<string_literal> [, <string_literal>]*) [, (<string_literal> [, <string_literal> ]*) ]* )
Für SCORE und Subkonstruktoren ist reguläre SV-Semantik der Default.Für EXPLICIT (und später GROUPING) gilt triviale SV-Semantik als Default.

© Prof. Kießling 2015 4 - 24
Beispiel für benutzerdefinierte SV-Semantik:
SELECT id FROM carPREFERRING color
IN ('blue', 'yellow' , 'white') ELSE ('green', 'red' , 'pink') SV ( ('blue', 'yellow'), ('green', 'red') )AND price LOWEST;

© Prof. Kießling 2015 4 - 25
Beispiele zu Preference SQL-Anfragen: (elementare Präferenzkonstruktoren)
SELECT * FROM trips
PREFERRING duration AROUND 14, 1;
SELECT * FROM apartmentsPREFERRING area HIGHEST 400, 10;
SELECT * FROM programmersPREFERRING experience IN ('java', 'C++');
SELECT * FROM hotelsPREFERRING location <> 'downtown';

© Prof. Kießling 2015 4 - 26
SELECT make, age FROM car
PREFERRING age AROUND 5, 2;
-- Gruppierung obiger BMO-Tupel nach Marke SELECT make, count(*) FROM carPREFERRING age AROUND 5, 2GROUP BY make;
-- zusätzliche Anforderung: Mindestanzahl pro GruppeSELECT make, count(*) FROM carPREFERRING age AROUND 5, 2GROUP BY makeHAVING count(*) > 2;

© Prof. Kießling 2015 4 - 27
4.2.1.3 Komplexe Präferenzen
Komplexe Präferenzen setzen sich aus den bereits bekannten Basispräferenzen zusammen.
1.) Pareto ({A1, A2}, <P1 ⊗ P2)
Preference SQL-Syntax:
PREFERRING
<preference> AND <preference>
Beispiel:
preis AROUND 5000, 500 AND farbe = 'blau'

© Prof. Kießling 2015 4 - 28
2.) Priorisierung ({A1, A2}, <P1 & P2)
Preference SQL-Syntax:
PREFERRING
<preference> PRIOR TO <preference>
Beispiele:
price AROUND 5000 PRIOR TO color = 'blue'
price AROUND 5000, 100
PRIOR TO (color IN ('blue', 'green', 'red') SV( ('blue', 'green') ) )
© Prof. Kießling 2015 4 - 29
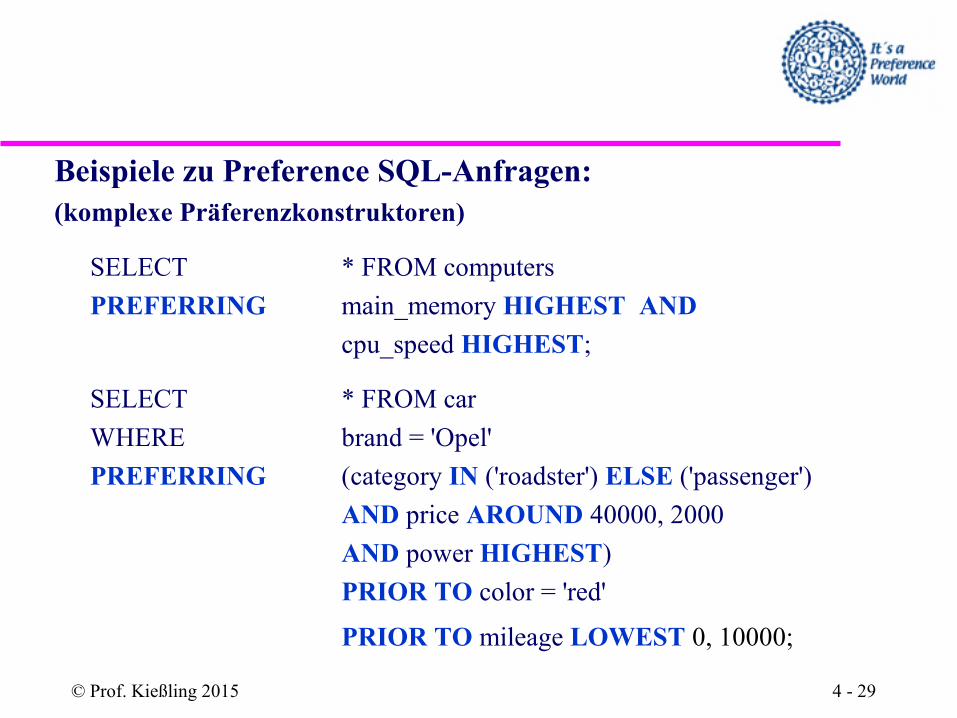
Beispiele zu Preference SQL-Anfragen: (komplexe Präferenzkonstruktoren)
SELECT * FROM computers
PREFERRING main_memory HIGHEST AND
cpu_speed HIGHEST;
SELECT * FROM car
WHERE brand = 'Opel'
PREFERRING (category IN ('roadster') ELSE ('passenger')
AND price AROUND 40000, 2000
AND power HIGHEST)
PRIOR TO color = 'red'
PRIOR TO mileage LOWEST 0, 10000;

© Prof. Kießling 2015 4 - 30
3.) Numerisches Ranking ({A1, A2}, <rankF, d)
Preference SQL-Syntax:PREFERRING
( <score_preference> | <rank_preference>
[ | <score_preference> | <rank_preference > ]* )
RANK <string_literal> [ <string_literal> ] [ <number> ]
Die Definition einer RANK-Präferenz erfolgt analog zu SCORE über CREATE [OR REPLACE] RANKFUNCTION '<name>'
AS BEGIN <Java-Anweisungen> END;
Details zur Einbindung von Java-Code für RANK-Präferenzen
© Prof. Kießling 2015 4 - 31
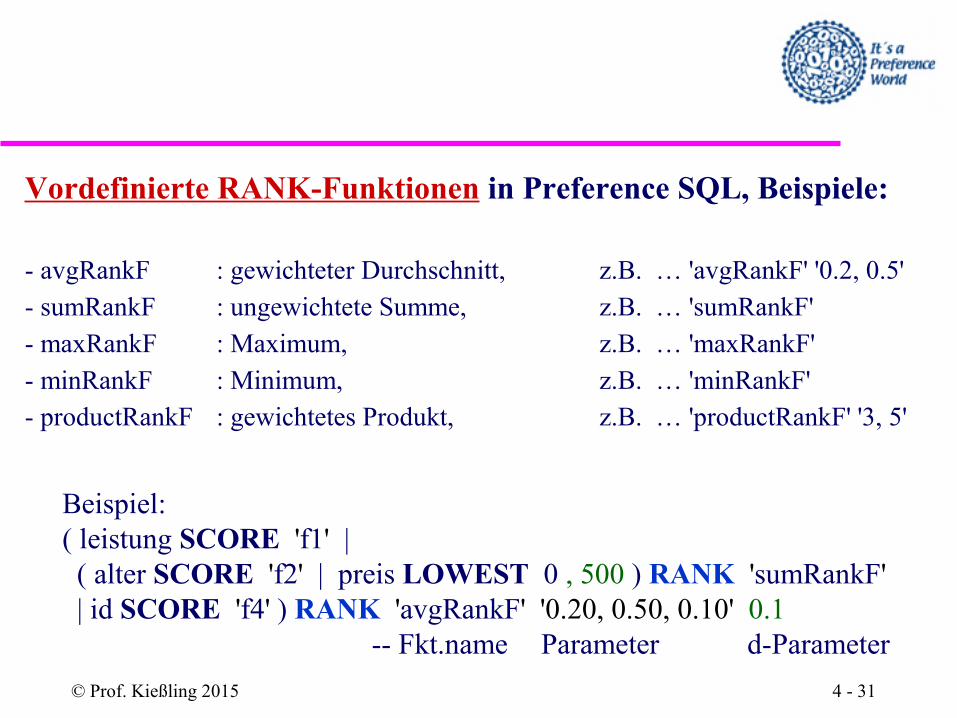
Vordefinierte RANK-Funktionen in Preference SQL, Beispiele:
- avgRankF : gewichteter Durchschnitt, z.B. … 'avgRankF' '0.2, 0.5'- sumRankF : ungewichtete Summe, z.B. … 'sumRankF' - maxRankF : Maximum, z.B. … 'maxRankF'- minRankF : Minimum, z.B. … 'minRankF'- productRankF : gewichtetes Produkt, z.B. … 'productRankF' '3, 5'
Beispiel:( leistung SCORE 'f1' | ( alter SCORE 'f2' | preis LOWEST 0 , 500 ) RANK 'sumRankF' | id SCORE 'f4' ) RANK 'avgRankF' '0.20, 0.50, 0.10' 0.1
-- Fkt.name Parameter d-Parameter

© Prof. Kießling 2015 4 - 32
4.2.1.4 Qualitätsfunktionen
DISTANCE (<preference_alias>)
berechnet die Distanz zwischen einem Attributwert v und den perfekten Treffern bezüglich einer numerischen Basispräferenz über der Domäne von A.
DISTANCE : dom(A) → ℝ0
+
DISTANCE (v, [low, up]) :=
if v ∈ [low, up] then 0 else if v < low then low - v else v - up
Beispiel:SELECT id, DISTANCE(p_age) FROM carPREFERRING (age AROUND 40 AS p_age)

© Prof. Kießling 2015 4 - 33
LEVEL (<preference_alias>)
berechnet das Level eines Attributwerts v einer diskretisierten Basispräferenz über der Domäne von A.
Perfekte Attributwerte haben das Level 0.
LEVEL : dom(A) → 0+
Numerische Domäne A mit d-Parameter:
LEVEL (v, [low, up]) := ⎡DISTANCE (v, [low, up]) / d⎤
Kategorielle Domäne A:
LEVEL (v) = layerm (v)

© Prof. Kießling 2015 4 - 34
Qualitätsfunktionen können benutzt werden
in der Projektion wie Attribute
z.B. SELECT id, LEVEL(p_age), DISTANCE(p_price) FROM car PREFERRING (age LOWEST 0, 2 AS p_age) AND
(price LOWEST AS p_price)
in der BUT ONLY-Klausel als boolescher Ausdruck
z.B. … wie oben
BUT ONLY DISTANCE(p_price) < 5000 AND LEVEL(p_age) < 5

© Prof. Kießling 2015 4 - 35
Hinweis:
Bezeichne pref_alias eine Basispräferenz P über einem Attribut A. Mit Hilfe der booleschen Ausdrücke
LEVEL(pref_alias) = 0 DISTANCE(pref_alias) = 0.0
kann überprüft werden, ob ein Tupel einen perfekten Attributwert bezüglich P(A) hat.
© Prof. Kießling 2015 4 - 36
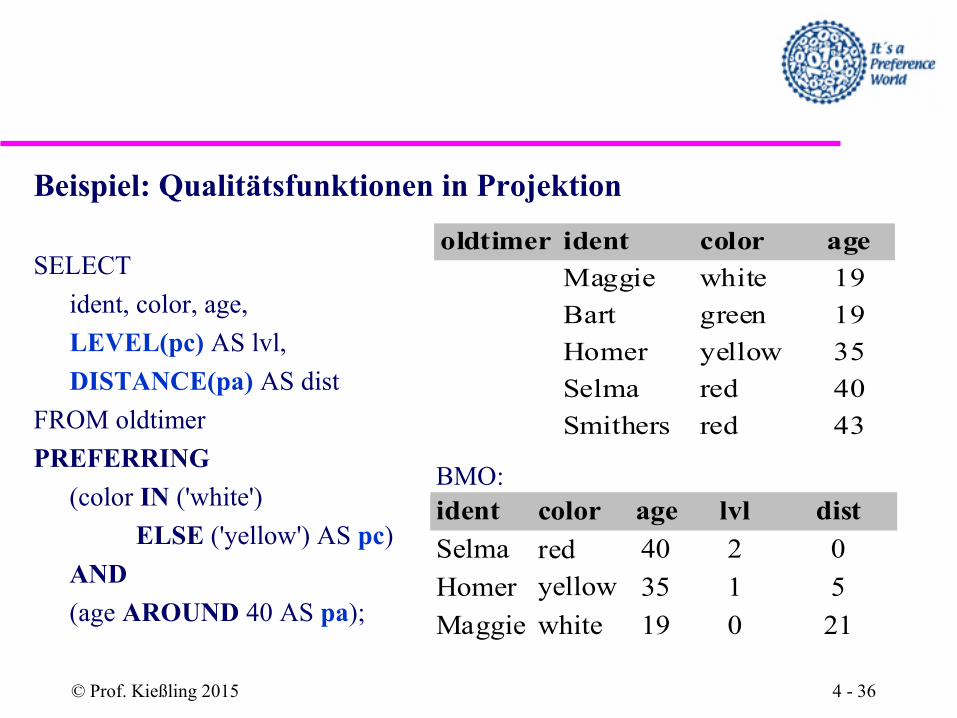
Beispiel: Qualitätsfunktionen in Projektion
SELECT
ident, color, age,
LEVEL(pc) AS lvl,
DISTANCE(pa) AS dist
FROM oldtimer
PREFERRING
(color IN ('white')
ELSE ('yellow') AS pc)
AND
(age AROUND 40 AS pa);
oldtimer ident color age
Maggie white 19
Bart green 19
Homer yellow 35
Selma red 40
Smithers red 43
color lvl
Selma 40 2 0
Homer 35 1 5
Maggie 19 0 21
ident age dist
redyellow
white
BMO:

© Prof. Kießling 2015 4 - 37
Motivation
Das BMO-Query-Modell liefert die bestmögliche Ergebnismenge. Vorab ist aber unbekannt, wie groß die Menge ist.
Das Top-k-Query-Modell soll genau k beste Ergebnisse liefern. k < | BMO | zufällige Auswahl der BMO-Ergebnisse k >= | BMO | BMO-Ergebnisse und weitere nächstbeste
Ergebnisse, so dass k Ergebnisse zurückgeliefert werden.
Eine Erweiterung des BMO-Modells zu einem Multi-Level-BMO-Modell liefert pro Schicht die nächstbesten Ergebnisse.
4.2.1.5 Top-k Schnittstelle

© Prof. Kießling 2015 4 - 38
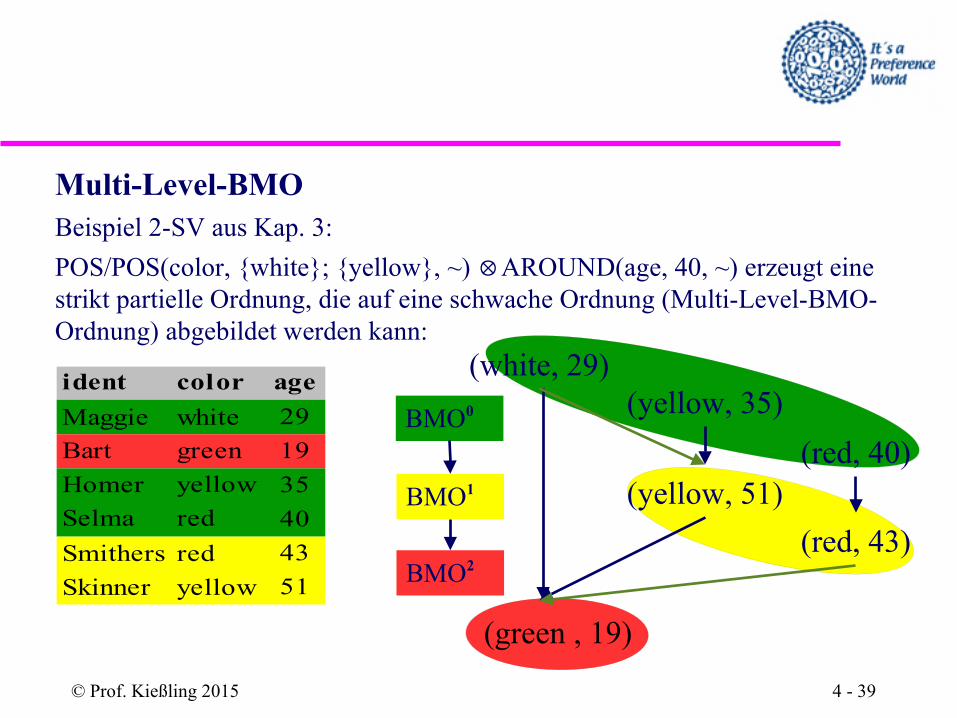
Theorem
Jede strikt partielle Ordnung lässt sich auf eine spezielle schwache Ordnung, die sogenannte Multi-Level-BMO-Ordnung abbilden.
Diese Ordnung wird durch die iterierte Anwendung der Präferenzselek-tion, der jeweils ihre iterationsspezifisches BMOi-Menge zugeordnet ist, generiert.
© Prof. Kießling 2015 4 - 39
Multi-Level-BMOBeispiel 2-SV aus Kap. 3:
POS/POS(color, {white}; {yellow}, ~) ⊗ AROUND(age, 40, ~) erzeugt eine strikt partielle Ordnung, die auf eine schwache Ordnung (Multi-Level-BMO-Ordnung) abgebildet werden kann:
(red, 40)
(red, 43)
(white, 29)
(green , 19)
(yellow, 35)
(yellow, 51)
29
Bart 19
Homer 35
40
43
51
ident color age
Maggie white
green
yellow
Selma red
Smithers red
Skinner yellow
BMO0
BMO1
BMO2

© Prof. Kießling 2015 4 - 40
color
Maggie 19
Bart 19
Homer 35
Selma 40
Smithers 43
oldtimer ident age
whitegreen
yellow
redred
Ergebnis:
Beispiel:
SELECT *
FROM oldtimer
PREFERRING
color IN ('red') AND
age BETWEEN 40, 45, 5
TOP 3
BMO1 := σ[P](oldtimer \ BMO0) =
BMO0 := σ[P](oldtimer) =
ident color age
Selma red 40
Smithers red 43
Homer yellow 35

© Prof. Kießling 2015 4 - 41
Kontrolle der Qualität der Ergebnismenge:
BUT ONLY schränkt durch harte Bedingungen das bisherige Ergebnis ein. Dabei können auch die Qualitätsfunktionen für Präferenzen als Qualitätsfilter eingesetzt werden.
Die Verwendung von anderen booleschen Ausdrücken als Selektion auf den Tupeln der Ergebnismenge - syntaktisch analog zur WHERE-Klausel - verursacht eine Nachfilterung der BMO-Menge.
Bemerkung:
Bei Verwendung des gleichen booleschen Ausdrucks kann die Ergebnismenge unterschiedlich sein, je nachdem ob der Ausdruck in der Vorfilterung (WHERE) bzw. in der Nachfilterung (BUT ONLY) verwendet wird.
4.2.1.6 BUT ONLY

© Prof. Kießling 2015 4 - 42
Beispiel zum Unterschied zwischen Vorfilterung und Nach-filterung durch gleichen booleschen Ausdruck:
id
1 85000 3
2 12000 6
3 6000 7
4 42000 5
5 84000 5
car price ageSELECT id FROM carWHERE price < 20000PREFERRING age AROUND 5, 2
➞ {2, 3}
SELECT id FROM carPREFERRING age AROUND 5, 2BUT ONLY price < 20000
➞ { }

© Prof. Kießling 2015 4 - 43
Beispiel: Qualitätsfunktionen in BUT ONLY
SELECT t.*, LEVEL (p_start_day) AS delta_start, DISTANCE (p_duration) AS delta_duration
FROM trips t
PREFERRING (start_day AROUND date '1999-07-03',INTERVAL '1' DAY AS p_start_day)
AND
(duration AROUND 14 AS p_duration)
BUT ONLY DISTANCE (p_duration) <= 2 AND
LEVEL (p_start_day) < 3;
Hinweis: Datentypen und Preference SQL

© Prof. Kießling 2015 4 - 44
4.3 AnwendungsbeispieleDesignhinweise für personalisierte Suchmaschinen:
Harte Selektionen (WHERE) gegen weiche (PREFERRING)? Welche Kontrolle bzgl. der Qualität der Ergebnismenge
(BUT ONLY-Einschränkung)? Bedeutung von Multi-Attribut-Präferenzen
(AND contra PRIOR TO contra RANK)? Präsentation der Ergebnismenge
(Einsatz von LEVEL(p_alias), DISTANCE(p_alias))?
Woher stammen Präferenzen? Fest verbunden mit der Suchmaske durch den Bereitsteller des E-
Services (Benutzermodell)? Explizit eingegeben von den E-Business-Kunden? Implizit eingetragene Verkäufer-Präferenzen? Implizit eingetragenes anwendungsspezifisches Domänen- / Kontext-
wissen?
© Prof. Kießling 2015 4 - 45
4.3.1 Gebrauchwagenhandel

© Prof. Kießling 2015 4 - 46
SELECT *, LEVEL(p_manu), LEVEL(p_model), LEVEL(p_price), LEVEL(p_mileage), LEVEL(p_regyear), LEVEL(p_diesel), LEVEL(p_airbag), LEVEL(p_autotransmission), LEVEL(p_aircondition) FROM used_cars PREFERRING ((manufacture = 'BMW' AS p_manu) AND
(model = '7' AS p_model)) PRIOR TO
((price BETWEEN 0, 75000, 7500 AS p_price)
AND (mileage BETWEEN 0, 30000, 3000 AS p_milage)
AND (regyear BETWEEN 1997, 1999, 2 AS p_regyear) AND (diesel = 'yes' AS p_diesel) AND (airbag = 'yes' AS p_airbag) AND (autotransmission = 'yes' AS p_autotransmission) AND (aircondition = 'yes' AS p_aircondition));

© Prof. Kießling 2015 4 - 47

© Prof. Kießling 2015 4 - 48
4.4 Gruppierende Präferenzen
Präferenzen lassen sich gruppieren mit dem Schlüsselwort GROUPING, wodurch ausgedrückt wird, dass die Präferenz pro Gruppe ausgewertet werden soll.
Wie von „GROUP BY“ gewohnt, können auch Aggregatsfunk-tionen in der Projektion bzw. in der HAVING-Klausel verwendet werden.
Bemerkung:
Die SQL-Schlüsselwörter „GROUP BY … HAVING“ und die Preference-SQL-Schlüsselwörter „GROUPING … HAVING“ dürfen nur exklusiv genutzt werden!

© Prof. Kießling 2015 4 - 49
Deklarative Semantik der gruppierenden Präferenz-Selektion:
Gegeben seien eine Relation R, eine Menge von Attributen
G ⊆ attrib(R) und eine Äquivalenz-Relation (als Spezialfall: SV-
Relation) ≅G auf dom(G).
Die gruppierende Präferenzselektion bezüglich ≅G ist definiert als:
σ[P GROUPING ≅G](R) :=
{t ∈R | ¬ v ∃ ∈R: t[G] ≅G v[G] t[A] ∧ <P v[A]}
Die Präferenzselektion wird also jeweils pro Gruppe ausgewertet.

© Prof. Kießling 2015 4 - 50
Gruppierender Preference SQL-Abfrageblock:
9. SELECT <projection_list>
1. FROM <table_references>
2. WHERE <hard_conditions>
3'. - 6'. PREFERRING <group_pref_constructor>
7. ORDER BY <attribute_list>
8. LIMIT <number>;

© Prof. Kießling 2015 4 - 51
Syntax der gruppierenden Präferenz-Selektion:
3'. PREFERRING <soft_conditions>
4'. TOP <number>
5'. BUT ONLY <but_only_conditions>
3'. GROUPING <grouping_attributes>
6'. HAVING <having_condition>
Der Default der SV-Relation ≅G ist TRIVIAL.

© Prof. Kießling 2015 4 - 52
Verarbeitungsreihenfolge der gruppierenden Präferenz-Selektion:
3'. T2 := σ [P GROUPING ≅G] (T1) Präferenzauswertung pro Gruppe
4'. T3 := σTOP (T2) Top-k Schnittstelle
5'. T4 := σBO (T3) BO ist eine harte Bedingung (Nachfilter).
6'. T5 := σHAVING (T4) HAVING ist eine harte Bedingung für
Gruppen mittels Gruppierungsattribute
oder Aggregationsfunktionen.

© Prof. Kießling 2015 4 - 53© Prof. Kießling 2012 4 - 53
Bemerkungen:
„GROUPING … HAVING“ verhält sich wie „GROUP BY … HAVING“: Nur Gruppierungsattribute und Aggregatsfunktionen sind in dieser Klausel zulässig und schließen ganze Gruppen aus.
Aliase, die in der GROUPING-Klausel definiert werden, dürfen in der Projektion und in Aggregatsfunktionen benutzt werden.
„TOP“ erzeugt die gewünschte Mengengröße pro Gruppe (Multimengensemantik).
Nicht aggregierte Attribute können nur durch „BUT ONLY“ nachgefiltert werden, wodurch Tupel evtl. gelöscht werden.
Qualitätsfunkionen können in „BUT ONLY“ verwendet werden.
© Prof. Kießling 2015 4 - 54
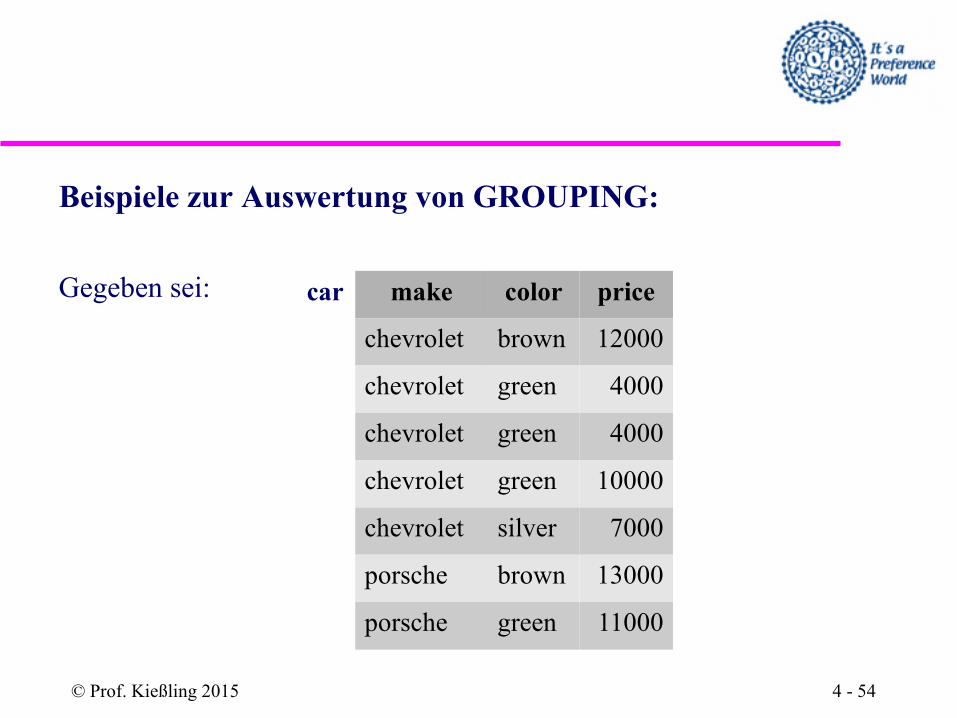
Beispiele zur Auswertung von GROUPING:
Gegeben sei: car make color price
chevrolet brown 12000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
chevrolet silver 7000
porsche brown 13000
porsche green 11000
© Prof. Kießling 2015 4 - 55
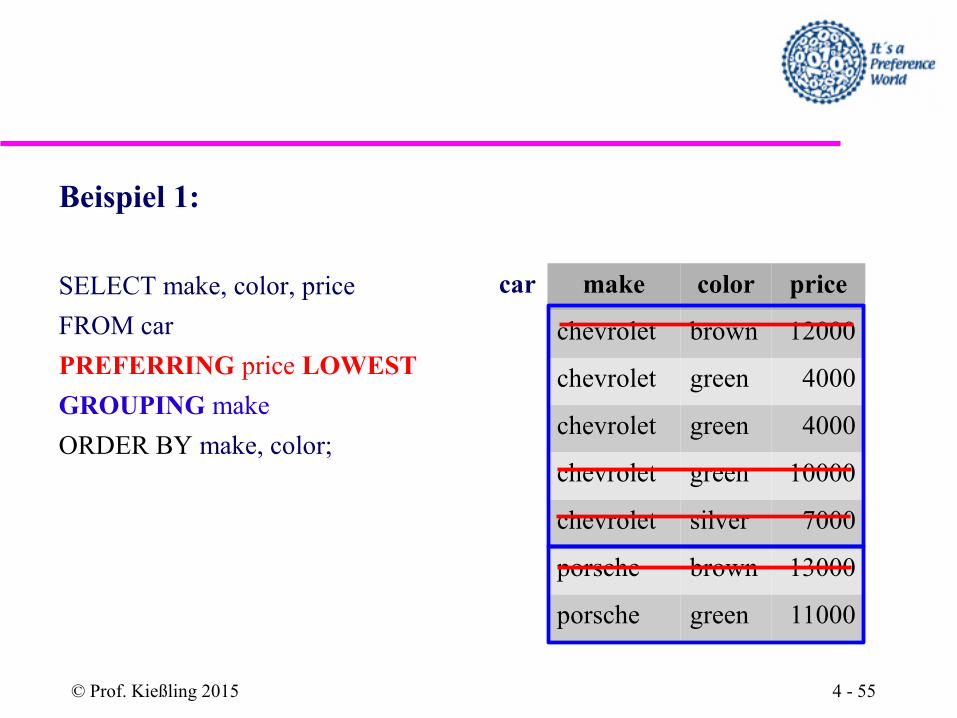
Beispiel 1:
SELECT make, color, price
FROM car
PREFERRING price LOWEST
GROUPING make
ORDER BY make, color;
car make color price
chevrolet brown 12000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
chevrolet silver 7000
porsche brown 13000
porsche green 11000

© Prof. Kießling 2015 4 - 56
Beispiel 2:
SELECT make, color, price
FROM car
PREFERRING price LOWEST
GROUPING color
ORDER BY color, make;
car make color price
chevrolet brown 12000
porsche brown 13000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
porsche green 11000
chevrolet silver 7000
© Prof. Kießling 2015 4 - 57
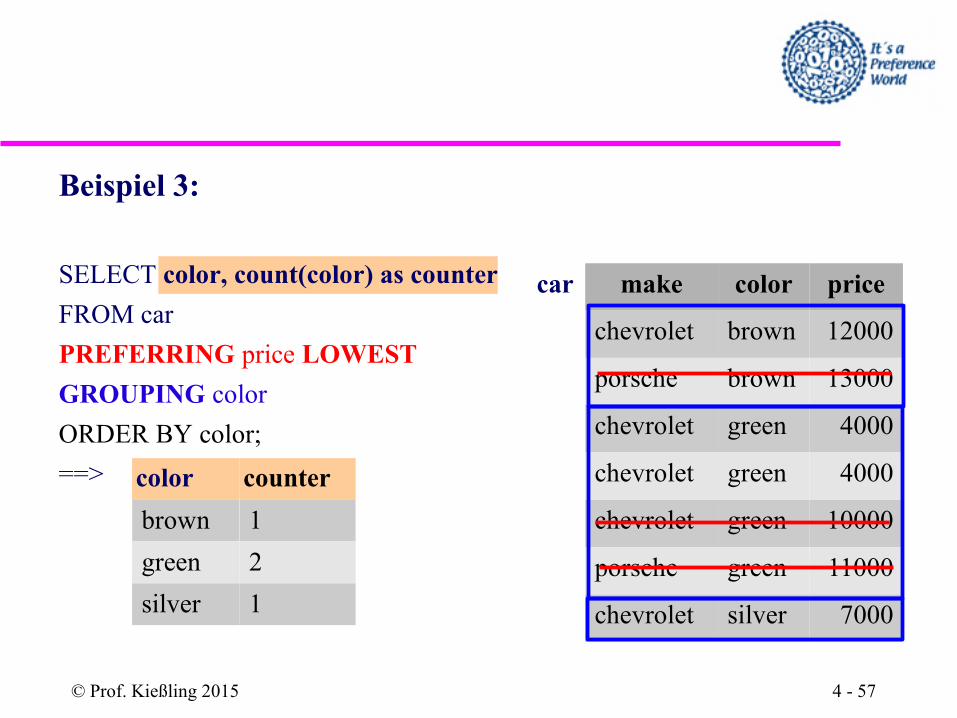
Beispiel 3:
SELECT color, count(color) as counter
FROM car
PREFERRING price LOWEST
GROUPING color
ORDER BY color;
==> color counter
brown 1
green 2
silver 1
car make color price
chevrolet brown 12000
porsche brown 13000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
porsche green 11000
chevrolet silver 7000
© Prof. Kießling 2015 4 - 58
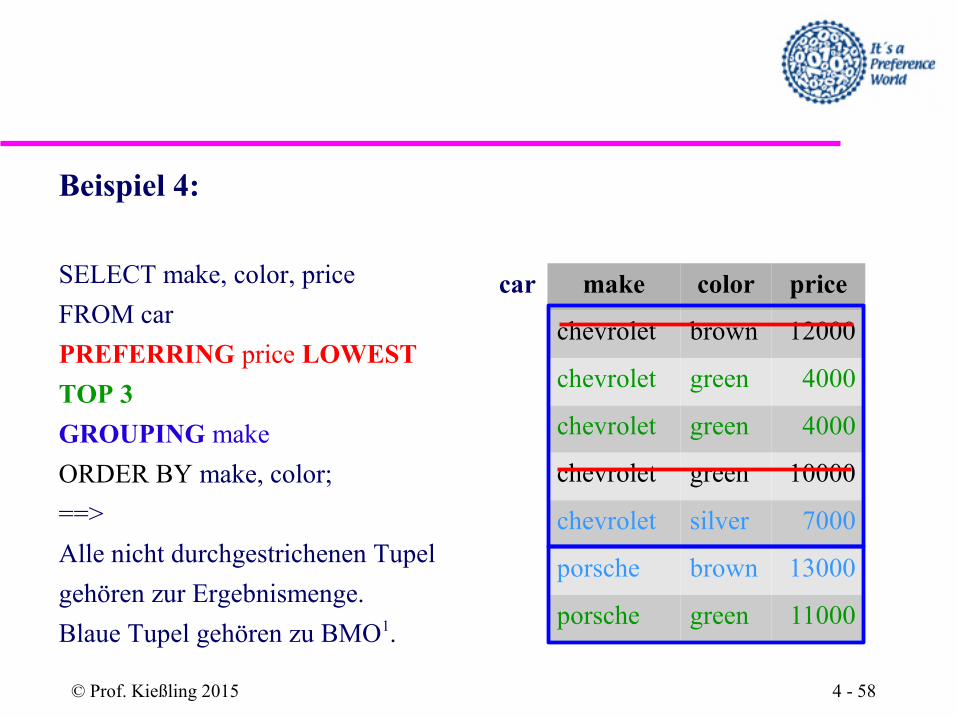
Beispiel 4:
SELECT make, color, price
FROM car
PREFERRING price LOWEST
TOP 3
GROUPING make
ORDER BY make, color;
==>
Alle nicht durchgestrichenen Tupel
gehören zur Ergebnismenge.
Blaue Tupel gehören zu BMO1.
car make color price
chevrolet brown 12000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
chevrolet silver 7000
porsche brown 13000
porsche green 11000
© Prof. Kießling 2015 4 - 59
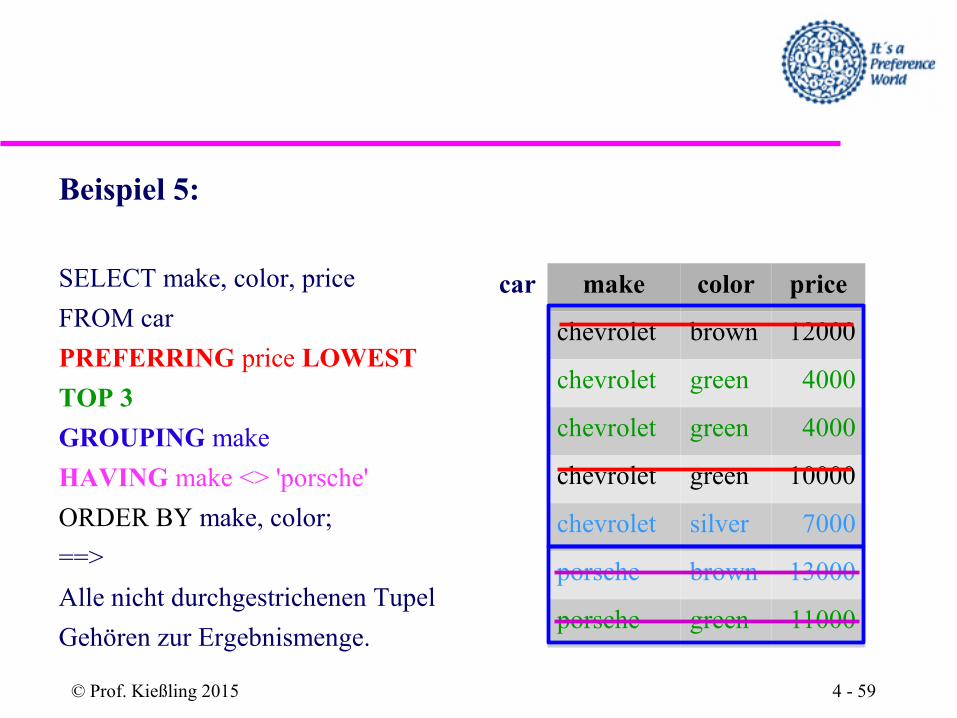
Beispiel 5:
SELECT make, color, price
FROM car
PREFERRING price LOWEST
TOP 3
GROUPING make
HAVING make <> 'porsche'
ORDER BY make, color;
==>
Alle nicht durchgestrichenen Tupel
Gehören zur Ergebnismenge.
car make color price
chevrolet brown 12000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
chevrolet silver 7000
porsche brown 13000
porsche green 11000
© Prof. Kießling 2015 4 - 60
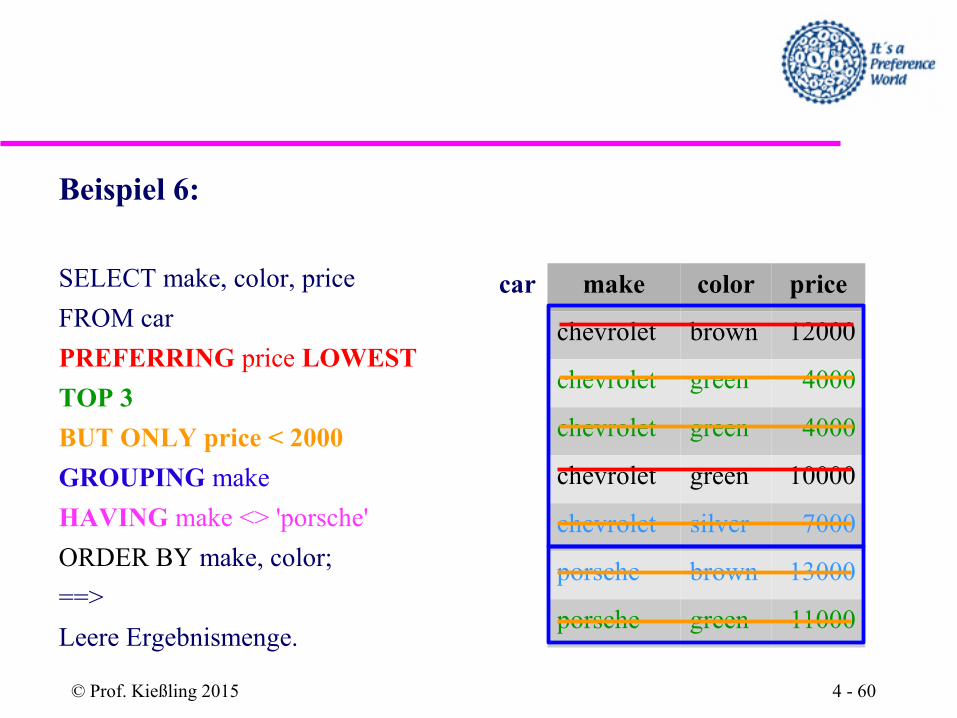
Beispiel 6:
SELECT make, color, price
FROM car
PREFERRING price LOWEST
TOP 3
BUT ONLY price < 2000
GROUPING make
HAVING make <> 'porsche'
ORDER BY make, color;
==>
Leere Ergebnismenge.
car make color price
chevrolet brown 12000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
chevrolet silver 7000
porsche brown 13000
porsche green 11000
© Prof. Kießling 2015 4 - 61
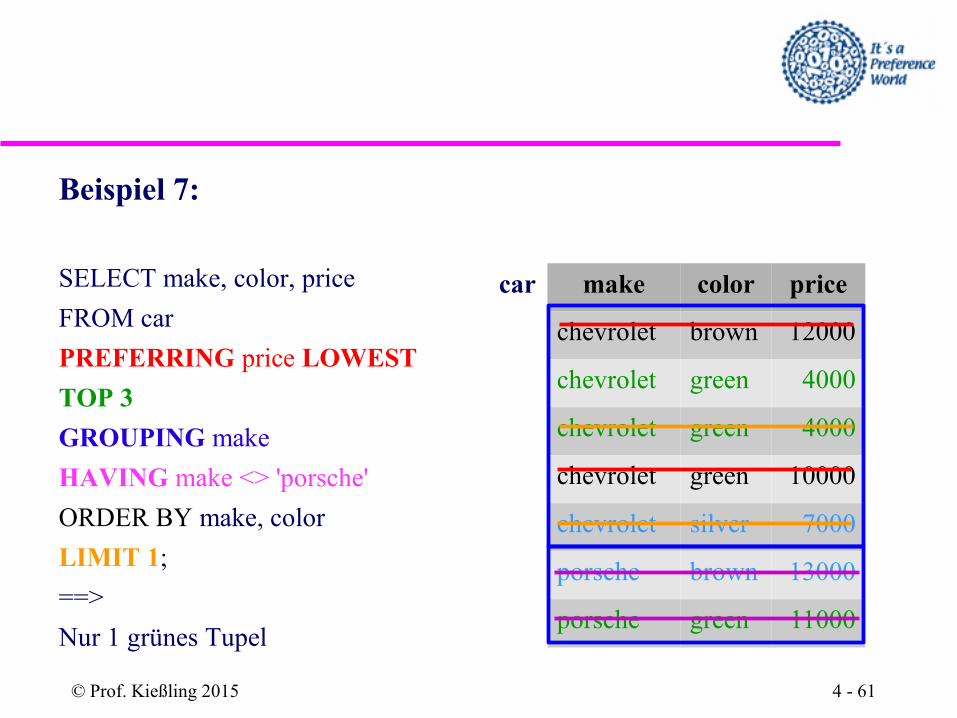
Beispiel 7:
SELECT make, color, price
FROM car
PREFERRING price LOWEST
TOP 3
GROUPING make
HAVING make <> 'porsche'
ORDER BY make, color
LIMIT 1;
==>
Nur 1 grünes Tupel
car make color price
chevrolet brown 12000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
chevrolet silver 7000
porsche brown 13000
porsche green 11000

© Prof. Kießling 2015 4 - 62
GROUPING mit benutzerdefinierter SV-Semantik:A, B, … seien Attribute einer Relation R, wobei ai, bi, … deren
Domänenwerte seien. In der GROUPING-Klausel steht für benutzerdefinierte SV-Semantik folgende Syntax zur Verfügung:
GROUPING A SV ((a1, a2, …) [AS 'KlasseA1'], … ,
[OTHERS [AS ...]]) [AS A-Alias]],
B SV ((b1, b2, …) [AS 'KlasseB1'], … ,
[OTHERS [AS ...]]) [AS B-Alias]], …
Bei fehlenden Klassennamen wird ein Default-Name generiert wie '(a1, a2)'
bzw. 'OTHERS'.
© Prof. Kießling 2015 4 - 63
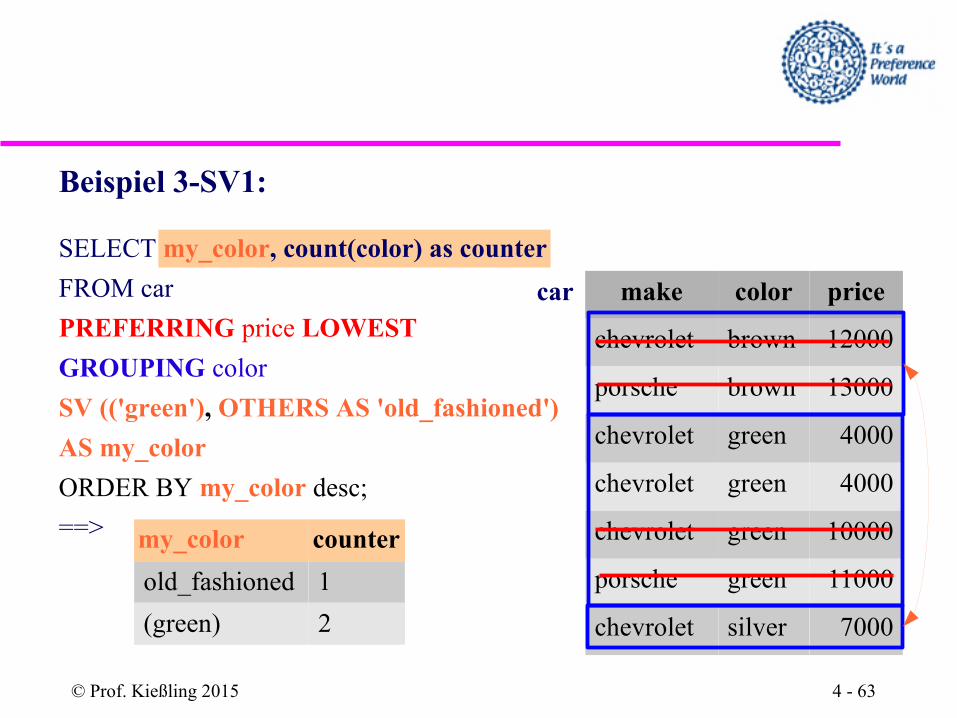
Beispiel 3-SV1:
SELECT my_color, count(color) as counter
FROM car
PREFERRING price LOWEST
GROUPING color
SV (('green'), OTHERS AS 'old_fashioned')
AS my_color
ORDER BY my_color desc;
==> my_color counter
old_fashioned 1
(green) 2
car make color price
chevrolet brown 12000
porsche brown 13000
chevrolet green 4000
chevrolet green 4000
chevrolet green 10000
porsche green 11000
chevrolet silver 7000
© Prof. Kießling 2015 4 - 64
car make color price
chevrolet brown 12000
porsche brown 13000
vw green 4000
chevrolet green 4000
chevrolet green 10000
porsche green 11000
chevrolet silver 7000
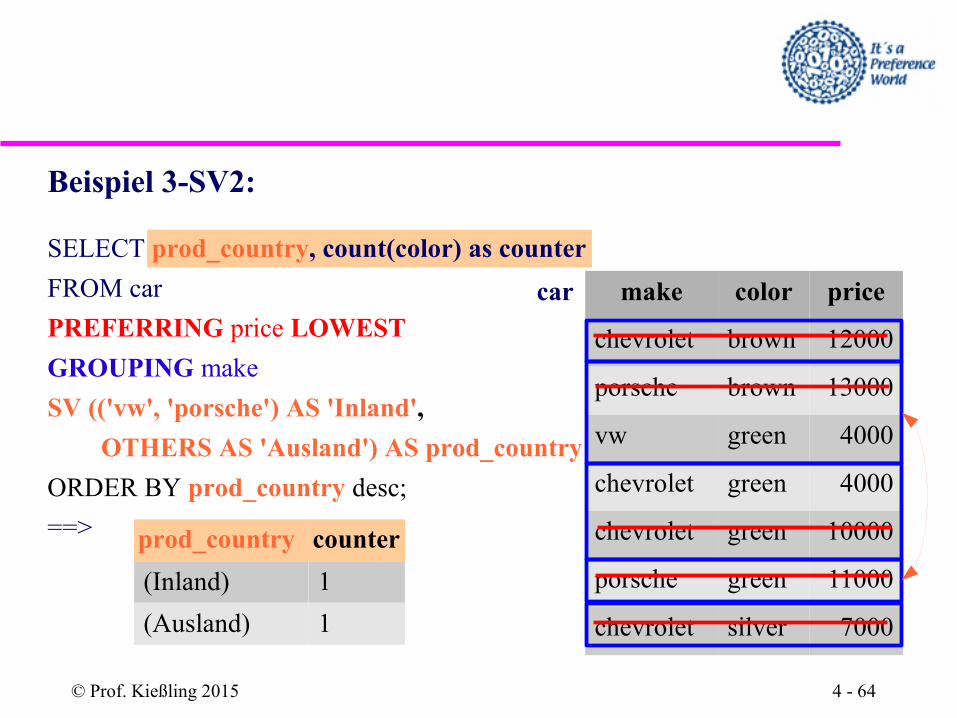
Beispiel 3-SV2:
SELECT prod_country, count(color) as counter
FROM car
PREFERRING price LOWEST
GROUPING make
SV (('vw', 'porsche') AS 'Inland',
OTHERS AS 'Ausland') AS prod_country
ORDER BY prod_country desc;
==> prod_country counter
(Inland) 1
(Ausland) 1

© Prof. Kießling 2015 4 - 65
Beispiel zu unterschiedlichen Ergebnissen von GROUP BY im Vergleich zu GROUPING:
„Anzahl der möglichst billigen
Autos, aufgeschlüsselt nach Marke“
SELECT make, count(*)
FROM car
PREFERRING price LOWEST
GROUP BY make;
==>
car make color price
chevrolet brown 12000
porsche brown 13000
vw green 4000
chevrolet green 4000
chevrolet green 10000
porsche green 11000
chevrolet silver 7000
;
make count(*)
vw 1
chevrolet 1

© Prof. Kießling 2015 4 - 66
Beispiel zu unterschiedlichen Ergebnissen von GROUP BY im Vergleich zu GROUPING:
„Marke und Anzahl der marken-
spezifisch möglichst billigen Autos“
SELECT make, count(*)
FROM car
PREFERRING price LOWEST
GROUPING make;
==>
car make color price
chevrolet brown 12000
porsche brown 13000
vw green 4000
chevrolet green 4000
chevrolet green 10000
porsche green 11000
chevrolet silver 7000
;
make count(*)
vw 1
chevrolet 1
porsche 1

© Prof. Kießling 2015 4 - 67
Beispiele zu Preference SQL-Anfragen mit GROUPING
(GROUPING mit Aggregation in Projektion oder HAVING)
SELECT make, count(*) AS best_model FROM car
PREFERRING price LOWEST AND age LOWEST
GROUPING make;
SELECT make, count(*) AS best_model FROM car
PREFERRING price LOWEST AND age LOWEST
GROUPING make
HAVING count(*) > 5 AND make <> 'chevrolet';

© Prof. Kießling 2015 4 - 68
Beispiel zu Preference SQL-Anfragen mit GROUPING:
(GROUPING mit Vorfilterung und Nachfilterung)
SELECT make, count(*) AS best_model
FROM car
WHERE age < 10 -- Vorfilterung
PREFERRING price LOWEST AND age LOWEST
BUT ONLY color <> 'red' -- Nachfilterung
GROUPING make
HAVING count(*) > 5 and make <> 'chevrolet';