8 - stima minimi quadrati -...
TRANSCRIPT

8 - STIMA MINIMI QUADRATI
8.1 Introduzione al problema Si misurano in modo indipendente i tre angoli di un triangolo
qualsiasi: 321 ,, ααα , ottenendo le seguenti osservazioni:
030201 ,, ααα .
Ogni misura i0α è una estrazione da una variabile casuale
con media iα e varianza 2
iσ , lo scarto ii0iv αα −= è un errore nella misura.
Se si considerano gli errori come accidentali, si può supporre che le medie iα delle
osservazioni angolari soddisfino la relazione caratteristica del triangolo:
πααα =++ 321
Si consideri ora la variabile casuale 0302010L ααα ++= , che per quanto detto a proposito
delle funzioni di variabili casuali, ha media e varianza:

8 – Stima minimi quadrati ________________________________________________________________________________________________
2
[ ] πααα =++= 3210LE
[ ] 2
3
2
2
2
10
2 L σσσσ ++=
Le osservazioni, dato che sono inficiate dagli inevitabili errori di misura, non soddisferanno
del tutto l’equazione di condizione, cioè si otterrà:
πααα ≠++= 0302010L .
La relazione di vincolo è un’informazione aggiuntiva ai dati numerici delle osservazioni dei
tre angoli: ovviamente è conveniente tenere conto di entrambe le informazioni nella ricerca
di una stima delle grandezze; del resto se volessimo fare dei calcoli coerenti con il
triangolo, per esempio calcolarne le coordinate dei vertici, si rende necessario che le
grandezze angolari siano compatibili con la relazione geometrica esprimente il vincolo.
Prendiamo in considerazione il caso in cui le misure abbiano la stessa precisione:
22
3
2
2
2
1 σσσσ ===
Dato l’errore di chiusura ∆:
3213213210302010 vvvvvvL ++=+++−++=−++=−=∆ παααπαααπ ,
poiché, in questo semplice caso gli errori hanno la stessa dispersione, risulta intuitivo
scegliere come stima degli scarti un terzo dell’errore di chiusura, per simmetria. Si ha:
3vvv 321
∆===
dove si definisce:
ii01 ˆv αα −= .
In modo che la stima della grandezza (l’osservazione stimata) sia:
3vˆ i01i0i
∆−=−= ααα .

8 – Stima minimi quadrati ________________________________________________________________________________________________
3
In tale maniera si distribuisce l’errore di chiusura in modo eguale sui tre angoli.
Con tale stima si continua a soddisfare il vincolo:
παααααα =∆−++=++ 302010321 ˆˆˆ .
Inoltre, si potrebbe dimostrare che le stime delle osservazioni sono meno disperse delle
osservazioni stesse:
22
ˆ 32
iσσ
α= .
La variabile casuale a tre dimensioni:
03
02
01
0
ααα
α =
é distribuita in uno spazio a tre dimensioni, e ha media:
3
2
1
ααα
α = .
Fig. 1
Poiché si deve rispettare il vincolo del triangolo, significa che il vettore media α deve
stare sul piano π, mentre il vettore delle osservazioni α0 non giace in quel piano. E’
intuitivo pensare che lo stimatore dovrà giacere sul piano, ma nella posizione il più vicino
possibile (secondo un determinato criterio di distanza) al vettore delle osservazioni α0. La
figura 2 illustra il concetto.

8 – Stima minimi quadrati ________________________________________________________________________________________________
4
Fig. 2
Si cerca a questo punto di minimizzare la distanza euclidea (la più tradizionale) e nello
stesso tempo si mantiene il vincolo: è noto che la ricerca del minimo vincolato si ottiene
applicando un moltiplicatore di Lagrange.
Se si introduce la distanza euclidea, si minimizza proprio una forma quadrata, da cui il
nome di stima minimi quadrati:
∑ −=−−=−3
1
2
ii0i0
T
0
2
0 )ˆ(min)ˆ()ˆmin(ˆmin αααααααα
vincolato alla condizione:
πα =∑3
1ii .
La funzione da minimizzare viene modificata con l’aggiunta della funzione di vincolo,
moltiplicata per il cosiddetto moltiplicatore di Lagrange:
.)ˆ(()ˆ( ii
2
ii0i ∑ −+∑ − παλαα
Differenziando rispetto ad iα , si ottiene dunque:
0)ˆ(2 i0 =+− λαα

8 – Stima minimi quadrati ________________________________________________________________________________________________
5
cioè:
2ˆ i0i
λαα −= .
Tenendo conto nuovamente del vincolo:
πλαα =−∑∑ =23ˆ i0iii
∆=⎥⎦⎤
⎢⎣⎡∑ −=
31
31
21
i0i παλ .
In conclusione, si ottiene lo stesso risultato ottenuto in modo intuitivo:
3ˆ i0i
∆−= αα .
Nei prossimi paragrafi vedremo l’uso più generale dei minimi quadrati.
8.2 Proiezioni ortogonali e minimi quadrati
Sappiamo che il prodotto interno di due vettori x ed y è xT y; esso è zero solo se x ed y
sono ortogonali.
Ricordiamo che la lunghezza di un vettore a n dimensioni è:
2
n
2
2
2
1
2 x...xxx +++=
(geometricamente significa applicare il teorema di Pitagora n-1 volte).
Supponiamo che dato un vettore (un punto) nello spazio a n dimensioni si ricerchi la
distanza (euclidea) da una data retta, in una direzione a: si cerca lungo la direzione a il
vettore (punto) p (secondo la norma euclidea) più vicino a b.
In questo caso la retta che congiunge p e b è ortogonale al vettore a.

8 – Stima minimi quadrati ________________________________________________________________________________________________
6
Fig. 3
Quello di cui abbiamo bisogno per il calcolo é solo la constatazione che la retta da b al più
vicino punto p=xa con x quantità incognita:
(b-xa) =⊥a,
ovvero:
aT (b-xa)=0,
da cui segue che:
aabax
T
T
= .
Questa formula porta, come conseguenza, un importante teorema dell’algebra lineare: la
diseguaglianza di Schwartz.
Infatti, se si calcola la distanza tra b e p, cioè il valore del segmento bp, si ottiene:
)aa()ba()aa)(bb(aa
aaba
aa)ba(2bba
aabab
T
2TTTT
T
T
T
2TT
2
T
T −=⎟
⎠⎞
⎜⎝⎛+−=− .
Questa distanza, e a maggior ragione il suo quadrato, non può che essere positiva, sicchè
il numeratore non può essere negativo:
0)ba()aa)(bb( 2TTT ≥− .
Aggiungendo a entrambi i membri (aTb)2 e estraendo la radice quadrata:
b
a p

8 – Stima minimi quadrati ________________________________________________________________________________________________
7
babaT ≤ .
La situazione è analoga quando invece di una retta consideriamo un piano o più in
generale un sottospazio S di Rn: anche in questo caso si tratta di trovare un vettore p nel
sottospazio il più vicino possibile (secondo la norma euclidea) a b, cioè la proiezione di b
in quel sottospazio.
Il problema descritto fino a questo punto in termini geometrici è un classico problema di
una soluzione ai minimi quadrati di un sistema sovradeterminato: il vettore b rappresenta i
dati ottenuti da serie di esperimenti o di questionari, le osservazioni, le misure, che
contengono errori che non permettono al vettore b di giacere nel sottospazio considerato:
in alternativa si sceglie allora il vettore p, in quanto giace nel sottospazio, ma è il più vicino
a b.
Dato un sistema Ax = b, a prima vista si dice che ha soluzione oppure no: se b non è nello
spazio delle colonne il sistema è incompatibile e la eliminazione di Gauss fallisce.
Prendiamo il caso di un sistema di m equazioni in una sola incognita:
2x= b1
3x= b2
4x= b3
esso è risolubile solo se i bi stanno nel rapporto 2:3:4, cioè la soluzione è unica ed esiste
solo se b è lungo la direzione determinata dal vettore a:
432
.
Spesso è comunque necessario cercare di dare una soluzione a questi sistemi
incompatibili; una possibilità potrebbe essere quella di trovare la soluzione per la parte del
sistema compatibile, e trascurare il resto, il che non ha giustificazione se le equazioni
(osservazioni) hanno la stessa validità, inoltre in questo caso alcune osservazioni non
avrebbero alcun errore e le altre errori di grande entità; una soluzione utilizzata
tradizionalmente è quella di mediare l’errore, distribuirlo, spalmarlo, su tutte le equazioni

8 – Stima minimi quadrati ________________________________________________________________________________________________
8
(osservazioni). Come si può immaginare esistono vari modi di ottenere questa
mediazione, tuttavia uno dei più noti è quello di minimizzare la somma dei quadrati degli
errori:
Σ2=(2x-b1)2+(3x-b2)2+(4x-b3)2
Solo se esiste una soluzione, Σ2=0, in caso contrario, che tra l’altro è quello più comune, è
necessario calcolare il minimo di tale funzione parabolica:
( ) ( ) ( )[ ] 04bx43bx32bx22dxd
321
2
=−+−+−=Σ
da cui la soluzione:
29b4b3b2x 321 ++
= .
Dato in generale un qualsiasi vettore non nullo a, ed un qualsiasi vettore b, la formula
generale prevede la minimizzazione dell’errore, cioè della lunghezza del vettore ax-b,
ovvero del suo quadrato:
( ) ( )[ ]( ) ( ) bbbxa2axabaxbax
bxa...bxabaxTT2TT2
2/12
mm
2
11
+−=−−=Σ
−++−=−=Σ
da cui si ottiene:
0ba2axa2dxd TT
2
=−=Σ
aabax
T
T
= .
Questa soluzione, dal punto di vista geometrico, è proprio la proiezione p=xa. Cioè il punto
più vicino a b sulla retta determinata da a.

8 – Stima minimi quadrati ________________________________________________________________________________________________
9
Supponiamo ora che le misure non siano ugualmente attendibili, cioè non siano affidabili
allo stesso livello, per esempio una misura sia migliore perchè ottenuta con maggiore
precisione strumentale oppure per un campione più grande, è intuitivo pensare che invece
di minimizzare il quadrato della lunghezza euclidea del vettore degli scarti:
( ) ( ) ( ) ( )2
4
2
3
2
2
2
1
2 bxbxbxbx −+−+−+−=Σ
4bbbbx 4321 +++
=
si minimizzi il quadrato di una lunghezza “pesata”:
( ) ( ) ( ) ( )2
44
2
33
2
22
2
11
2 bxpbxpbxpbxp −+−+−+−=Σ
( ) ( ) ( ) ( )[ ] 0bxpbxpbxpbxp2dxd
44332211
2
=−+−+−+−=Σ
4321
44332211
ppppbpbpbpbpx
++++++
= .
Esempio
Un paziente obeso viene pesato in quattro momenti diversi nelle stesse
condizioni, ottenendo le seguenti misure, espresse in kg:
b1=150, b2=153, b3=150, b4=151.
Qual è il valore migliore, nel senso dei minimi quadrati?
aabax
T
T
=
1111
a
151150153150
b ==
xm1514
151150153150x ==+++
=

8 – Stima minimi quadrati ________________________________________________________________________________________________
10
Si tratta dunque della già vista media ponderata nel caso di misure dirette.
Fig. 4
Nella figura 4, un vettore osservazioni è proiettato sul vettore colonna di A (media), mentre
nel secondo caso, in cui il valore di b1 è più affidabile dell’altro, il vettore osservazioni
viene proiettato sempre sul vettore colonna di A, ma poiché la media ponderata sarà più
piccola della media, è più vicina alla misura b1 e per visualizzare tale risultato, si può
immaginare il secondo asse stirato, in modo che abbia maggiore importanza.
Il passo successivo riguarda un sistema più generale del precedente, e una conseguente
variante dell’approccio geometrico.
Se la proiezione di un vettore su una retta corrisponde ad un sistema di m equazioni in
una incognita, vediamo di seguito a che cosa corrisponde un sistema a più variabili, cioè di
m equazioni in n incognite, dove m>n, cioè il sistema è incompatibile. E’ probabile che non
esista una scelta di x che verifichi i dati presenti nel vettore b, cioè è probabile che il
vettore b non sia una combinazione lineare dei vettori che costituiscono le colonne di A. Si
tratta anche in questo caso di rendere minimo l’errore nel senso della norma L2 (minimi
quadrati).
L’errore è la distanza tra b e p=Ax, che giace nello spazio delle colonne di A:
bAx −=Σ .
Dunque p deve essere la proiezione di b sullo spazio generato dalle colonne di A e il
vettore differenza bxA − deve essere perpendicolare a tale spazio.

8 – Stima minimi quadrati ________________________________________________________________________________________________
11
Fig. 5
Ogni vettore nello spazio di A è una combinazione lineare dei vettori colonna della matrice
A, è un vettore della forma Ay. Ma per ogni combinazione deve valere la condizione che
siano perpendicolari al vettore differenza (errore) bxA − .
Pertanto:
0)bxA()Ay( T =−
[ ] 0bAxAAy TTT =− .
Da cui si deduce la famosa soluzione ai minimi quadrati:
0bAxAA TT =− .
Si tratta delle cosiddette equazioni normali: se le colonne di A sono linearmente
indipendenti, allora la matrice ATA, detta matrice normale, è invertibile, e la soluzione
unica ai minimi quadrati è:
( ) bAAAx T1T −= .
La proiezione di b sullo spazio delle colonne di A è pertanto:

8 – Stima minimi quadrati ________________________________________________________________________________________________
12
( ) bAAAAxAp T1T −== .
Si tratta di costruire una retta perpendicolare da b allo spazio definito dalle colonne della
matrice A. La matrice che permette questa costruzione è la matrice cosiddetta proiezione
P:
( ) T1T AAAAP −= .
Tale matrice proietta, infatti, un vettore qualsiasi b sullo spazio delle colonne di A: sicché
p=Pb è la componente di b nello spazio delle colonne di A, mentre b-Pb è la componente
nel complemento ortogonale, ed è il vettore errore. La matrice proiezione ha due proprietà
fondamentali:
- è idempotente, nel senso che P2=P
- è simmetrica P=PT.
8.3 Regressione lineare Supponiamo di eseguire una serie di esperimenti e di avere ipotizzato il seguente modello:
b=C+Dt,
cioè una funzione lineare della variabile t.
Ad esempio si misura ad intervalli di tempo la distanza di un satellite da una certa
stazione: in questo caso t è il tempo e b la distanza; ovvero si misurano le deformazioni su
una struttura caricata in modo variabile: t è il carico e b la deformazione. Se la relazione è
lineare e non ci sono errori, già due sole misure di b a due diversi valori di t determinano la
retta: ma in genere ci sono errori e punti ulteriori non vanno a cadere sulla retta, sicché
siamo invogliati a cercare una qualche media dei vari esperimenti e a trovare una retta in
un certo senso ottimale, che non dobbiamo confondere con la retta su cui si proiettava il
vettore dei dati b.

8 – Stima minimi quadrati ________________________________________________________________________________________________
13
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=⎥⎦
⎤⎢⎣
⎡
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
m
2
1
m
2
1
b..
bb
DC
t1....t1t1
che è sintetizzabile in:
Ax=b.
Tale sistema non è in generale risolvibile.
Noi scegliamo ora C e D in modo che vengano minimizzati gli errori nel senso dei minimi
quadrati, cioè che venga minimizzata la somma dei quadrati degli errori, come nel caso
precedente, o per via geometrica o per via algebrica:
- nel primo caso, tutti i vettori Ax giacciono nel piano delle colonne di A e in questo
piano cerchiamo il vettore che sia il più vicino a b, che è la proiezione p=A x ,
rendendo minimo il vettore scarto v=b-p
- nel secondo, viene minimizzata la lunghezza al quadrato di Ax-b:
minbAx 2=− .
Poichè le colonne di A sono indipendenti, ricorriamo alla solita stima minimi quadrati e
normalizziamo il sistema:
⎥⎦
⎤⎢⎣
⎡∑∑∑
=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
⎥⎦
⎤⎢⎣
⎡⋅⋅⋅⋅⋅⋅
=2
ii
i
m
2
1
m1
T
tttm
t1....t1t1
tt11
AA
∑∑
=⋅⋅⋅
⎥⎦
⎤⎢⎣
⎡⋅⋅⋅⋅⋅⋅
=2
i
i
m
1
m1
T
bb
b
b
tt11
bA
∑∑
⎥⎦
⎤⎢⎣
⎡∑∑∑
==−
2
i
i
1
2
ii
i
bb
tttm
DC
x .

8 – Stima minimi quadrati ________________________________________________________________________________________________
14
Esempio
Si cerchi la retta che si avvicina di più ai tre punti: (0,6), (1,0), (2,0).
Stiamo cercando i valori di C e D che soddisfino le tre equazioni:
C+D*0=6
C+D*1=0
C+D*2=0
Tale sistema non ha soluzione, in quanto il secondo membro, il vettore b non
è combinazione lineare delle colonne di A:
006
b211101
A =⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
La necessaria stima minimi quadrati permette di ottenere:
t35b35
xbAxAA TT −=→=→=
12
1v
125
pb −=−
==
p1=5
b1=6 v1=1
v3=1
b3=0
p3=-1
v2=-2
p2=2
b2=0

8 – Stima minimi quadrati ________________________________________________________________________________________________
15
8.4 Trattazione algebrica della stima minimi quadrati
2.4.1 Minimi quadrati con equazioni di condizione Nelle seguenti trattazioni algebriche, verranno usati i seguenti simboli:
.toapprossimavalore~stimatovaloreˆteoricovalore
osservatovalore0
====
αααα
αααα σ QC 2
0= é la matrice di varianza-covarianza delle osservazioni, in cui 2
0σ è una
costante di proporzionalità a priori incognita, che viene stimata a posteriori, mentre la ααQ
è detta matrice dei cofattori. Se le misure sono indipendenti, la matrice ααQ è diagonale e
PQ 1 =−
αα , dove P è la cosiddetta matrice dei pesi da attribuire alle osservazioni, alle misure.
Si imposta la relazione di minimi quadrati relativa agli scarti tra valori osservati e valori
stimati:
min)ˆ(Q)ˆ( 0
1T
0 =−− − αααα αα .

8 – Stima minimi quadrati ________________________________________________________________________________________________
16
Tale forma quadratica coincide con quella ad esponenziale della normale ad n dimensioni
che compare nella funzione di verosimiglianza (nell’ipotesi di distribuzione normale).
Si deve pertanto risolvere il problema di minimo vincolato:
min)ˆ(Q)ˆ( 0
1T
0 =−− − αααα αα
0Cˆ =+αβ .
Si opera con i moltiplicatori di Lagrange:
min)Cˆ()ˆ(Q)ˆ( T
0
1T
0 =++−− − λαβαααα αα .
Per comodità si utilizza la funzione seguente:
Φ=++−−=Φ − min)Cˆ()ˆ(Q)ˆ(2/1 T
0
1T
0 λαβαααα αα .
Si calcolano e si pongono uguali a zero le derivate parziali:
0Cˆ)Cˆ( T' =+=+=Φ αβαβλ
0)ˆ(Q T
0
1' =+−=Φ − λβααααα .
Dopo i seguenti passaggi elementari:
⎩⎨⎧
=+
=+− −−
0Cˆ0QˆQ T
0
11
αβλβαα αααα
⎩⎨⎧
=+−
−=
0C)Q(Qˆ
T
0
T
0
λβαβλβαα
αα
αα
⎩⎨⎧
=+−
−=
0CQQˆ
T
0
T
0
λβββαλβαα
αα
αα

8 – Stima minimi quadrati ________________________________________________________________________________________________
17
⎩⎨⎧
+−=
+=−
−
)C()Q(Qˆ)C()Q(
0
1TT
0
0
1T
βαβββααβαββλ
αααα
αα .
Si introduce anche la quantità seguente:
)C()Q(Qˆv 0
1TT
0 +−=−= − βαβββαα αααα .
Si può provare la correttezza delle stime. Inoltre la varianza delle stime è inferiore alla
varianza dei dati di partenza; questo significa che le stime sono migliori dei dati di
partenza, delle misure: la stima è efficiente. Tralasciamo la dimostrazione, che è analoga
a quella svolta per il caso dei minimi quadrati con parametri aggiuntivi incogniti.
2.4.2 Equazioni con parametri aggiuntivi incogniti Le equazioni risolventi con parametri aggiuntivi incogniti, sono del tipo:
CAx +=α ,
in cui α sono le osservazioni e x i parametri aggiuntivi incogniti.
Tali equazioni sono verificate nei valori medi:
CxA +=α .
Si vogliono trovare delle stime tali che si abbia:
( ) ( ) minˆQˆ 0
1T
0 =−− − αααα αα
e nello stesso tempo venga rispettato il modello:
CxAˆ +=α .

8 – Stima minimi quadrati ________________________________________________________________________________________________
18
Si opera con i moltiplicatori di Lagrange, imponendo la seguente condizione:
( ) ( ) ( ) minCxAˆˆQˆ2/1 T
0
1T
0 =−−+−−=Φ − λααααα αα .
L’espressione, qualora si scriva 0CxAv α−+= e si ipotizzino le osservazioni indipendenti
PQ 1 =−
αα e αααα σ QC 2
0
== , diventa:
( ) minCxAvvPv2/1 T
0
T =+−−+=Φ λα .
Si calcola dunque il minimo rispetto v,x, λ:
.0CxAv
0Ax'
0vPv'
0
'
T'
'
=+−−=Φ
=−=Φ
=+=Φ
α
λ
λ
λ
Ricavando dalla prima espressione v stimato e introducendolo nella terza si ricava:
).CxA(PCxAP
Pv
0
0
1
1
αλαλ
λ
−+−=
+−−−−=
−
−
Inserendo il valore diλ nella seconda espressione, si ottiene:
[ ] [ ].)C(PA)PAA()C(PA)PAA(x0)C(PAxPAA
0)CxA(PA
0
T1T
0
T1T
0
TT
0
T
−=−−=
=−+
=−+
−− ααα
α
Sostituendo la stima di x nell’espressione della stima di v:

8 – Stima minimi quadrati ________________________________________________________________________________________________
19
[ ]
[ ] .CPCA)PAA(APA)PAA(AICPCA)PAA(APA)PAA(A
C)C(PA)PAA(ACxAv
T1T
0
T1T
0
T1T
0
T1T
00
T1T
0
+−+−−=
=−+−=
=−+−=−+=
−−
−−
−
αααααα
Si prova la correttezza di x :
[ ] xxE = .
Poiché:
[ ] [ ][ ]
[ ][ ] 0xAEC
0xE)PAA()C(PA)C(PAxE)PAA(
)EC(PAxE)PAA()C(PAx)PAA(
TT
TT
0
TT
0
TT
=+−=+−
−=−
−=−
−=−
αα
αα
α
ma siccome sappiamo che
0CxA =−+ α
l’equazione precedente risulta verificata.
Si calcola la matrice di varianza-covarianza xxC con la legge di propagazione della
covarianza:
[ ][ ][ ][ ][ ] [ ].)PAA(ˆI)PAA(ˆ
)PAA(PAA)PAA(ˆ)PAA(IPAA)PAA(ˆ
)PAA(PAPPA)PAA(ˆ)PAA(PAPQA)PAA(ˆC
1T2
0
1T2
0
1TT1T2
0
1TT1T2
0
1T1T1T2
0
1TT1T2
0xx
−−
−−
−−
−−−
−−
==
==
=
==
==
σσσσσσ αα
Si prova la correttezza di v :
[ ] [ ] [ ] 0CxAECxAEvECxAˆv
0
00
=−+=−+=
−+=−=
ααααα
data la correttezza di x e il fatto che il modello lineare è verificato nei valori medi.
Si calcola la matrice di varianza–covarianza delle stime degli scarti:

8 – Stima minimi quadrati ________________________________________________________________________________________________
20
[ ] [ ][ ] [ ]
[ ][ ][ ][ ]
[ ][ ]
[ ][ ] [ ].AAQPˆA)PAA(APˆ
A)PAA(AA)PAA(A2PˆIA)PAA(AA)PAA(IAA)PAA(APˆ
A)PAA(PAA)PAA(AA)PAA(PAPA)PAA(APˆA)PAA(PAIIA)PAA(APˆA)PAA(PAIPPA)PAA(APˆA)PAA(PAIPPA)PAA(AIˆ
A)PAA(PAIQPA)PAA(AIˆC
T
xx
12
0
T1T12
0
T1TT1T12
0
T1TT1TT1T12
0
T1TT1TT1T1T1T12
0
T1TT1T12
0
T1T1T1T12
0
T1T1T1T2
0
T1TT1T2
0vv
−=−
=+−=
=+−−
=+−−
=−−=
=−−
=−−=
=−−=
−−−
−−−
−−−−
−−−−−−
−−−
−−−−
−−−
−−
σσσ
σσ
σσσσ αα
Si prova la correttezza di α :
[ ] αα =ˆE
[ ] [ ] .CxACxAEˆECxAˆ
ααα
=+=+=+=
Si calcola la matrice di varianza covarianza delle stime delle osservazioni αα ˆˆC :
αααα σσ ˆˆ2
0
T
xx
2
0ˆˆ QˆAAQˆC == .
Come si è visto:
[ ]vvˆˆ
ˆˆ
T
xx
12
0vv
CCCCCAAQPˆC
−=
−=−= −
αααα
αααασ
e per i termini in diagonale principale:
2v
22ˆ ii0i
σ−σ=σ αα
pertanto la stima di α è efficiente (ha una varianza minore di quella delle osservazioni.

8 – Stima minimi quadrati ________________________________________________________________________________________________
21
Calcoliamo infine la stima della varianza 2
0σ :
[ ] [ ][ ] [ ][ ] [ ][ ] [ ][ ] [ ][ ][ ] [ ] [ ] [ ] [ ][ ]
[ ] [ ][ ] [ ] [ ][ ] [ ]nmˆITrITrˆ)PAA(PAATrITrˆA)PAA(PATrITrˆA)PAA(PAITrˆPQTrˆPCTr
vvPETrvvPETrvvPTrEPvvTrEPvvETrPvvE
2
0nm
2
0
1TT
m
2
0
T1T
m
2
0
T1T
m
2
0vv
2
0vv
TTTTTT
−=−=−
=−=−=========
−
−−
σσσσσσ
[ ].nmvPvEˆ
T2
0 −=σ
Poichè la media non è effettuabile, si pone:
nmvPvˆ
T2
0 −=σ .
Si dimostra che tale stima è corretta:
[ ] [ ] 2
0
2
0T
2
0 nm)nm(
nmvPvEˆE σ
σσ =
−−
=−
= .
E’ da notare che se (m-n) tende ad infinito, la stima della varianza tende a zero: pertanto
le stime di v,ˆ,x α sono consistenti, in quanto la loro varianza va a zero, quando il numero
di osservazioni m tende ad infinito.
2.5 Applicazioni dei minimi quadrati Vi sono due applicazioni principali:
− L’interpolazione, ovvero l’adattamento di un modello ad un insieme di dati: il
modello è noto, ma non sono noti i suoi coefficienti che, pertanto, vengono stimati.
Come dato di partenza si hanno le osservazioni, le relative precisioni e le eventuali
correlazioni; il dato di arrivo consiste nelle stime dei coefficienti, con le relative
precisioni ed eventuali correlazioni. Osserviamo che un modello si dice “grigio” se
ha forma di legge, “nero” se non è nota la legge di tipo matematico seguita dagli
eventi, in tal caso non è definibile un modello teorico ma esso deve essere

8 – Stima minimi quadrati ________________________________________________________________________________________________
22
ipotizzato a priori (anche in questo caso, il modello di stima fornisce unicamente i
coefficienti e non il modello);
− Reti, ovvero tutto ciò che sia schematizzabile per mezzo di un grafo (insieme di
vertici collegati da lati). Dato di partenza sono le osservazioni sui lati, con le
precisioni e le correlazioni; dato di arrivo sono i parametri dei vertici (le coordinate
nelle reti topografiche) con le precisioni e correlazioni relative.
Esempio
Sia dato il circuito elettrico in figura, di cui sono note le resistenze R1 ed R2,
mentre sono state misurate con la stessa precisione ed in modo
indipendente le intensità di corrente I1 I2 ed I.
E’ possibile scrivere le equazioni di condizione e stimare ai minimi quadrati le
osservazioni, ma è anche possibile risolvere il problema con il metodo dei
parametri incogniti, in quel caso la stima delle osservazioni segue la stima
del parametro aggiuntivo incognito. R1
I A I1 B
Metodo delle equazioni di condizione I2
Le osservazioni siano: R2
001,1552,0443,0
0 =α espresse in [A].
Mentre i dati noti:
R1=50 Ω e R2=40 Ω.
Le equazioni di condizione esprimono le leggi della fisica:
2211
21
IRIRIII
⎪⎩
⎪⎨⎧
=
=+
cioè:
0C =+αβ .

8 – Stima minimi quadrati ________________________________________________________________________________________________
23
Nel caso in esame:
⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=
00
C04050111
β .
Il prodotto βα0:
∆=−
=07,0006,0
0βα
410010103
K T == ββ
000246,000082,000082,0336066,0
)(K 1T1
−−
== −− ββ
00082,033607,001066,0368852,0
011475,0295082,0K 1T
−−=−β
002074,000296,000097,0
K 1T −−
=∆−β
998926,05549590,04439670,0
Kˆ 1T
0 =∆−= −βαα
Osserviamo come si giunga allo stesso risultato con la stima minimi quadrati ai parametri incogniti. L’equazione alle osservazioni, in questo caso è:
CAx +=α
in cui:
000
C,Vx,
R/1R/11R/1R/1
A,III
21
2
1
2
1
=∆=
+
==α

8 – Stima minimi quadrati ________________________________________________________________________________________________
24
998926,0554959,0443967,0
ˆˆ
19836,22)(ˆˆ,067705,0
8689,327,00305,0,045,0025,002,0,045,0025,002,0
01
0
1
==
==∆==
=====
−
−
xA
AAAVxA
NAANAA
TTT
TT
α
αα
Esempio - Regressione lineare
Siano date le seguenti osservazioni α0 in corrispondenza delle variabili
indipendenti x1 ed x2:
α0 x1 x2 85,3 -1 -1 72,3 1 1 71,4 0 1,2154 72 0 -1,2154 87 -1 -1
55,6 1 1 85 0 0
70,9 1,2154 0 68 0 0
89,6 -1,2154 0 Si ipotizzi un modello lineare: α=b0+b1x1+b2x2 e si stimino i tre parametri
incogniti.
Scrittura del problema:
Matrice disegno A
1 -1 -1 1 1 1 1 0 1,2154 1 0 -1,2154 1 -1 -1 1 1 1 1 0 0 1 1,2154 0 1 0 0 1 -1,2154 0

8 – Stima minimi quadrati ________________________________________________________________________________________________
25
Matrice normale N
10 0 0 0 6,954394 4 0 4 6,954394
Matrice inversa N-1
0,1 0 0 0 0,214883 -0,1236 0 -0,1236 0,214883
Vettore dei termini noti normalizzati Tn
757,1 -67,128 -45,1292
Vettore delle soluzioni
40079,1b8469,8b
71,75b
2
1
0
−=−==
Vettore delle osservazioni stimate α
85,9576965,4623174,0074877,4125285,9576965,4623175,71 64,9574875,71 86,46252

8 – Stima minimi quadrati ________________________________________________________________________________________________
26
2.6 I problemi non lineari La trattazione, fin qui svolta, sui problemi minimi quadrati ha riguardato esclusivamente
l'ambito lineare di questi. D'altra parte, la maggior parte dei fenomeni e processi sono non-
lineari e tale caratteristica si ripercuote, inevitabilmente, nella loro modellazione. Pertanto
anche la trattazione dei problemi minimi quadrati deve potersi estendere in ambito non-
lineare, fornendo modelli adatti all'analisi dei dati di questi fenomeni e processi.
La non-linearità dei problemi minimi quadrati può interessare:
− il modello funzionale;
− il modello stocastico.
Vettore degli scarti stimati v
0,657688 -6,83769 2,60748 5,41252 -1,04231 9,862312 -9,29 -5,94252 7,71 -3,13748
Matrice di varianza-covarianza dei parametri incogniti xxC
5,321971 0 0 0 11,43602 -6,57772 0 -6,57772 11,43602
Pertanto le precisioni dei parametri risultano:
3817,3ˆˆ3070,2ˆ
2b1b
0b
==
=
σσ
σ

8 – Stima minimi quadrati ________________________________________________________________________________________________
27
Nel primo caso si ha, direttamente, la non-linearità delle equazioni di condizione pure,
osservazione, pseudo-osservazione, vincolo, ecc.; nel secondo caso la matrice di
varianza-covarianza delle osservazioni non è del tutto nota, solo a meno di una costante.
Lo schema generale per l'attuazione di detta procedura si compone dei seguenti passi:
1. inizializzazione del problema e preparazione dei dati di partenza, in base a
informazioni a priori di sufficiente approssimazione;
2. avvio di un contatore per il controllo delle iterazioni;
3. effettuazione di un passaggio in ambito lineare ed ottenimento di risultati intermedi;
4. calcolo di una norma sui risultati intermedi ottenuti per il controllo delle iterazioni;
5. esecuzione di un test d'arresto del ciclo iterativo, capace di valutare in alternativa il
contenimento della suddetta norma al di sotto di un'opportuna soglia prefissata,
oppure il superamento da parte del contatore di un numero massimo d'iterazioni
consentite;
6. arresto del ciclo iterativo ed ottenimento dei risultati definitivi, se il test d'arresto è
soddisfatto; oppure aggiornamento dei dati di partenza in base ai risultati intermedi
ottenuti, se il test d'arresto non è soddisfatto;
7. incremento del contatore per il controllo delle iterazioni;
8. ripetizione della procedura descritta, a partire dal passo 3.
Si osservi come tale procedura, perquanto del tutto generale, bene si presta alla soluzione
iterativa di tutti e tre i casi sopraccitati di non-linearità dei problemi minimi quadrati. Infatti,
nessuno di essi, pur nella sua specificità, presenta anomalie tali da dover far abbandonare
uno schema molto generale e, conseguentemente, molto collaudato e sicuro.
La figura 6 seguente illustra lo schema a blocchi della procedura iterativa appena esposta.

8 – Stima minimi quadrati ________________________________________________________________________________________________
28
vero falso
inizializzazione iter=0
sol. di un problema lineare
test di controllo
delle iterazioniarresto aggiornamento
iter=iter+1
Fig. 6
La non-linearità del modello funzionale si manifesta, come già detto, nelle equazioni
d'osservazione e pseudo-osservazione. Considerazioni analoghe valgono, ovviamente,
per le equazioni di condizione pure e per le equazioni di vincolo; tuttavia la trattazione a
seguire restringerà l'attenzione alle sole equazioni d'osservazione e pseudo-osservazione,
giudicando l'uso di equazioni di condizione pure estremamente raro e ricordando la
possibilità di passaggio dalle equazioni di vincolo (e da più generali equazioni di
condizione) alle equazioni di pseudo-osservazione.
Si consideri il seguente sistema non lineare:
( )( )
( )⎪⎪⎪⎪
⎩
⎪⎪⎪⎪
⎨
⎧
=
==
n211m
n2122
n2111
x....x,xf.........
x....x,xfx....x,xf
α
αα
Si linearizzi il sistema di equazioni alle osservazioni per mezzo di uno sviluppo in serie di
Taylor approssimato al primo ordine:

8 – Stima minimi quadrati ________________________________________________________________________________________________
29
( ) ( ) ( )
( ) ( ) ( )
( ) ( ) ( )⎪⎪⎪⎪⎪⎪
⎩
⎪⎪⎪⎪⎪⎪
⎨
⎧
−++−+=
−++−=
−++−+=
nn
n
m11
1
mn211m
nn
n
211
1
2n2122
nn
n
111
1
1n2111
x~xxf...x~x
xfx~....x~,x~f
...
...
...
x~xxf...x~x
xfx~....x~,x~f
x~xxf...x~x
xfx~....x~,x~f
δδ
δδα
δδ
δδ
α
δδ
δδ
α
Sia iii xx~x δ=− :
( ) ( )
( ) ( )
( ) ( )⎪⎪⎪⎪⎪⎪
⎩
⎪⎪⎪⎪⎪⎪
⎨
⎧
+++++++=
+++=+++=
+++=+++=
x~fxxf...x
xfx
xf...x
xfx~....x~,x~f
...
...
...
x~fxxf...x
xfx
xf...x
xfx~....x~,x~f
x~fxxf...x
xfx
xf...x
xfx~....x~,x~f
mn
n
m1
1
mn
n
m1
1
mn21mm
2n
n
21
1
2n
n
21
1
2n2122
1n
n
11
1
1n
n
11
1
1n2111
δδδδ
δδδ
δδδ
δδα
δδδδ
δδδ
δδδ
δδα
δδδδ
δδδ
δδδ
δδα
Pertanto dato un sistema d'equazioni non lineari d'osservazione e pseudo-osservazione:
( )xF=α ,
noto (o conosciuto per altra via) un vettore di opportuni valori approssimati dei parametri
x~ , il suo sviluppo in serie di Taylor, arrestato al 1° ordine, ha forma:
( ) ( )( ) ( )( )x~xx~J~x~xx~Fx~F x −+=−+= αα
essendo ( )x~J la matrice Jacobiano della funzione di più variabili F .

8 – Stima minimi quadrati ________________________________________________________________________________________________
30
Si tratta di un modello parametrico e non lineare, che può venire assimilato formalmente
ad un modello lineare, basta infatti porre:
( )xx)x~x(
Ax~JC~
==−
=
=
δ
α
e si ottiene il ben noto modello lineare:
α=Ax+C.
Il vettore α~ costituisce un vettore di costanti numeriche, da addizionarsi alle osservazioni,
per fornire il vettore termine noto.
Ad ogni iterazione, ottenuto il vettore delle nuove incognite ( )x~x − ed aggiornato il vettore
delle incognite originarie ( )x~xx~x −+= , quest'ultimo viene considerato un nuovo vettore di
più opportuni valori approssimati dei parametri, in base al quale effettuare una nuova
linearizzazione, punto di partenza di una nuova iterazione.
La procedura continua, iterativamente, fino ad ottenere la convergenza del metodo alla
soluzione cercata. In pratica, ad ogni iterazione, ne succede una nuova, finché le nuove
incognite sono abbastanza grandi da dare un qualche contributo, utile all'aggiornamento
delle incognite originarie.
Al contrario, quando questo contributo svanisce (cioè tutte le nuove incognite sono ormai
pressoché nulle), la procedura è arrestata, perché si è ottenuta la convergenza del metodo
alla soluzione cercata. La procedura è arrestata, altresì, nel caso sfavorevole in cui, dopo
un numero massimo d'iterazioni consentite, non si ha alcuna convergenza.
La norma calcolata sulle nuove incognite, in base alla quale giudicare l'utilità del contributo
all'aggiornamento delle incognite originarie, è largamente arbitraria.
Una norma dell'estremo superiore:
( )in,1i
x~xmax −==
può essere consigliabile, perché garantisce che, effettivamente, tutte le nuove incognite
siano, ormai, pressoché nulle.

8 – Stima minimi quadrati ________________________________________________________________________________________________
31
La procedura appena descritta, nota come metodo di Newton-Fourier (altrimenti detto, con
un'espressione più antica, degli iperpiani tangenti), può essere notevolmente semplificata
e sveltita scegliendo, ad ogni iterazione dopo la prima, di ricalcolare solo il vettore y~ (ed
adottando il metodo detto, dalle stesse più antiche espressioni, degli iperpiani paralleli),
anziché esso e la matrice Jacobiano. Come evidente, tutto ciò accelera, ad ogni
iterazione, il calcolo della soluzione, in generale, senza arrecare alcun danno alla stessa
ed al solo prezzo di qualche veloce iterazione in più.
Esempio
Sia dato il modello non lineare: bxay +=
che si suppone adatto ad un determinato fenomeno: sono state eseguite con
la stessa precisione ed in modo indipendente le osservazioni yi in
corrispondenza delle variabili indipendenti xi :
x α 1 0,017 2 2,988 3 8,006 4 14,991
E si conoscano i valori approssimati:
999350,1b~;993841,0a~ =−= .
Si stimino i parametri aggiuntivi incogniti a e b.
Nella matrice disegno vengono inserite le derivate rispetto alle due incognite
(colonne) per ogni osservazione (riga), calcolate nei valori approssimati. (si
ricorda che la derivata della funzione y è: y’=xblogx).
Matrice disegno A (ovvero J):
1 0 1 2,7725 1 9,8875 1 22,1807

8 – Stima minimi quadrati ________________________________________________________________________________________________
32
Matrice trasposta AT:
1 1 1 1 0 2,7725 9,8875 22,1807
Matrice normale N :
4 34,8407 34,8407 597,4329
Matrice inversa N-1:
0,508083 -0,02963 -0,02963 0,003402
Vettore dei termini noti :
991,1400614,0
988,2017,0
009,0006,0012,0
017,0
15830
)x~(f0 =
−
−−=−α
Vettore dei termini noti normalizzati:
0,17357-0,002
))x~f(-(A 0
T =α
La soluzione è dunque:
00065,0006159,0
))x~(f(ANx 0
T1
−=−= − αδ .
Sicché, la stima dei parametri incogniti alla prima iterazione è:
99935,1b
99384,0a
=
−=
8 – Stima minimi quadrati ________________________________________________________________________________________________
33
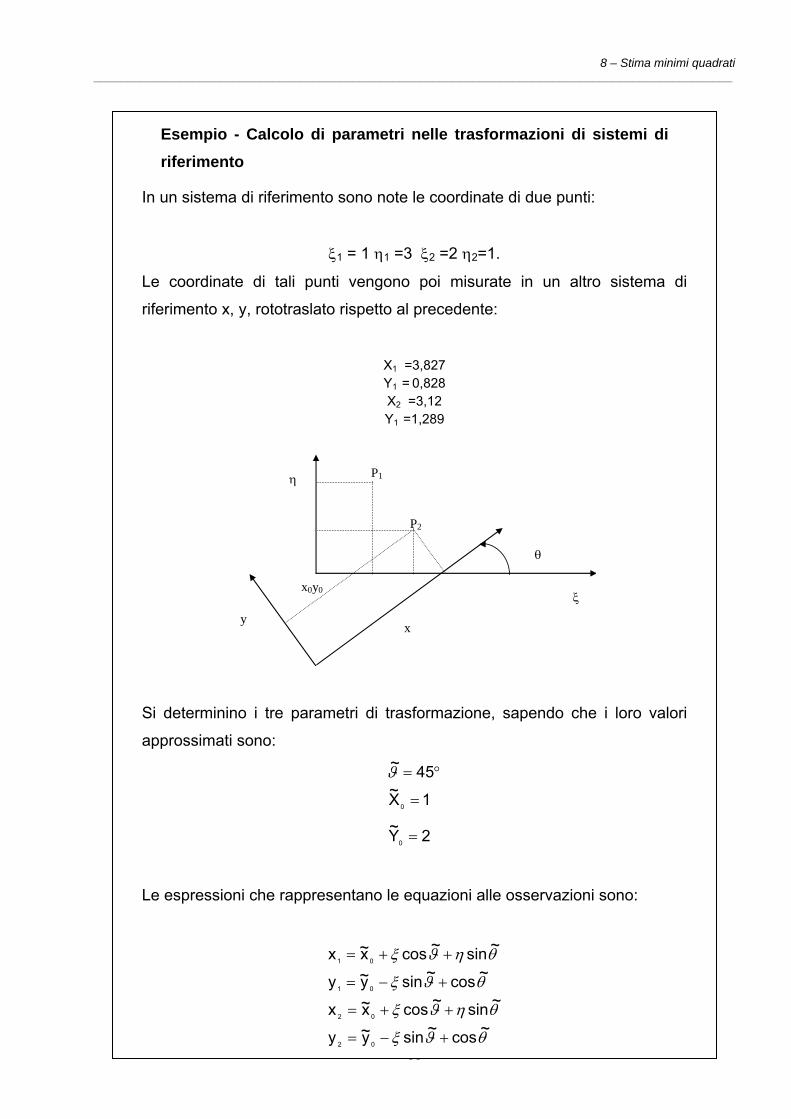
Esempio - Calcolo di parametri nelle trasformazioni di sistemi di riferimento
In un sistema di riferimento sono note le coordinate di due punti:
ξ1 = 1 η1 =3 ξ2 =2 η2=1.
Le coordinate di tali punti vengono poi misurate in un altro sistema di
riferimento x, y, rototraslato rispetto al precedente:
X1 =3,827 Y1 = 0,828 X2 =3,12 Y1 =1,289
x y
ξ
η
x0y0
θ
P1
P2
Si determinino i tre parametri di trasformazione, sapendo che i loro valori
approssimati sono:
2Y~
1X~45~
0
0
=
=
°=ϑ
Le espressioni che rappresentano le equazioni alle osservazioni sono:
θϑξ
θηϑξ
θϑξ
θηϑξ
~cos~siny~y
~sin~cosx~x
~cos~siny~y
~sin~cosx~x
02
02
01
01
+−=
++=
+−=
++=

8 – Stima minimi quadrati ________________________________________________________________________________________________
34
Il sistema minimi quadrati comporta la scritture dello Jacobiano e la
risoluzione dei vari noti passi.
Il vettore delle osservazioni α0 è noto:
289,11289,3828,0827,3
04
03
02
01
====
αααα
Il vettore C delle osservazioni approssimate è:
2928,1C1213,3C8284,0C8284,3C
4
3
2
1
====
La matrice disegno A (ovvero lo Jacobiano) è data da:
1 0 1,4142140 1 2,8284271 0 0,7071070 1 2,12132
La soluzione prevede, come al solito, i seguenti passi:
Calcolo della matrice normale N:
2 0 2,121320 2 4,949747
2,12132 4,949747 15
Calcolo della matrice inversa N-1
2,75 5,25 -2,121325,25 12,75 -4,94975
-2,12132-4,94975 2
Calcolo dei termini noti normalizzati:
( )01209,00042,00027,0
CAT 0
T
n −−−
=−= α

8 – Stima minimi quadrati ________________________________________________________________________________________________
35
Appendice
Statistica computazionale: i metodi diretti I metodi diretti raggruppano tutti quegli algoritmi della statistica computazionale capaci di
pervenire, in modo esatto, al calcolo della soluzione di sistemi in un solo passo. I più noti e
comunemente impiegati fra questi, sono gli algoritmi di Gauss, quelli Cholesky e di
Householder. Nel prosieguo, si illustrano gli algoritmi di Cholesky, perché maggiormente
flessibili e passibili di generalizzazioni ed estensioni, (l’algoritmo di Gauss è ben noto,
mentre gli algoritmi di Householder sono propedeutici agli algoritmi sequenziali, non trattati
in questa sede).
1. Gli algoritmi di Cholesky (algoritmi di base) Le compensazioni ai minimi quadrati richiedono la costruzione e la soluzione di un sistema
lineare, il sistema normale. Il metodo di Cholesky si applica alla soluzione di tale sistema:
0dCx =+
in cui C= ATA è la matrice normale e d =AT(C-α0) è il vettore dei cosiddetti termini noti
normalizzati.
Come abbiamo visto, esso deve essere preceduto, in una compensazione, dalla
normalizzazione del sistema di m equazioni d'osservazione, con n parametri incogniti
vbAx =+ .
Questo metodo consiste nella fattorizzazione della matrice normale, seguito dalla
soluzione del sistema; dalla matrice fattorizzata si calcola anche l'inversa della matrice
normale data.
Fattorizzazione
Calcolo delle soluzioni:
99995,4400051,2
000051,1
xx~x =+= δ

8 – Stima minimi quadrati ________________________________________________________________________________________________
36
Data una matrice C, simmetrica e definita positiva come è ovviamente la matrice normale,
si vuole calcolare una matrice T, triangolare superiore che soddisfi la relazione (fig. A.1):
CTTT = . (A.1)
Esplicitando in termini scalari si ottiene:
( )
( )
( )1jttttc
1ittttc
1jttcttc
kj
1i
1kkiijiiij
ki
1i
1kkiiiiiii
j111j1
111111
⟩⋅∑+⋅=
≠⋅∑+⋅=
⟩⋅=
⋅=
−
=
−
=
Da queste espressioni si ottengono immediatamente quelle effettivamente usate per il
calcolo degli elementi di T:
( )
( )
( )( )1j
t
ttct
1itct
1jtc
t
ct
ii
kj
1i
1kkiij
ij
1i
1k
2
kiiiii
11
j1
j1
1111
⟩⋅∑−
=
≠∑−=
⟩=
=
−
=
−
=
(A.2)
E' da notare che la matrice T può essere calcolata sia per righe che per colonne a partire
dall'elemento tii.
Soluzione del sistema
Si deve risolvere il sistema:
0dCx =+ (A.3)

8 – Stima minimi quadrati ________________________________________________________________________________________________
37
di n equazioni in n incognite, avendo a disposizione la fattorizzazione della matrice C .
Il sistema (A.3) si scompone come segue:
dxTTT −= (A.4)
dyTT = (A.5)
yxT −= (A.6)
La risoluzione in successione dei sistemi (A.5) e (A.6) fornisce la soluzione di (A.4) che,
per la (A.1) è equivalente a (A.3). La soluzione di (A.5) e (A.6) è immediata, essendo
triangolari le matrici T e TT.
La prima equazione di (A.5) è:
1111 dyt =
e si può immediatamente risolvere:
11
11 t
dy = .
La seconda equazione è:
2222112 dytyt =+
e da essa si può ricavare y2, essendo noto y1:
22
11222 t
ytdy −= .
Proseguendo dalla prima all'ultima incognita si ha in generale:
11
11 t
dy =
( )1it
ytdy
ii
k
1i
1kkii
i ≠∑−
=
−
= (A.7)
La soluzione di (A.6) è del tutto analoga, ma si inizia dall'ultima equazione, che contiene
solo l'ultima incognita:

8 – Stima minimi quadrati ________________________________________________________________________________________________
38
nn
nn t
yx −=
( )nit
xtyx
ii
k
n
1ikiki
i ≠∑+
−= += (A.8)
La soluzione del sistema (A.3) si ottiene dunque applicando in successione le espressioni
(A.2), (A.7), (A.8).
Inversione
Si deve calcolare l'inversa C-1 della matrice C, di cui è disponibile una fattorizzazione
(A.1). Dalla (A.1). si ottiene:
( ) ( ) 1T11T1 TTTTC −−−− == (A.9)
da cui:
( ) 1T1 TCT −− = . (A.10)
Queste formule sono entrambe immediatamente operative per il calcolo della matrice
inversa. Si ricordi che nella soluzione a minimi quadrati del sistema di equazioni alle
misure la matrice inversa ha significato statistico: essa, infatti, è proporzionale alla matrice
di varianza - covarianza delle incognite, da cui si ricavano immediatamente gli s.q.m. delle
incognite.
Nelle figure (A.2) e (A.3).si illustrano gli schemi corrispondenti alle formule. Si indicano con
tij gli elementi di T-1 , anch'essa triangolare superiore.
Indicando con cij gli elementi di C-1 dalla (A.10). si ottiene:
( )ij0t
t1t
jk
n
ikik
ii
ik
n
ikik
>=∑
=∑
=
=
γ
γ
Si riportano le espressioni per il calcolo della matrice inversa C-1, modificate per operare
solo nel triangolo superiore, essendo la matrice inversa, come noto, simmetrica:

8 – Stima minimi quadrati ________________________________________________________________________________________________
39
( )( )
( )
( )nit
tt1
ijt
tt
t
t
t1
ii
ik
n
1ikik
iiii
ii
jk
n
1jkikkj
n
1ikik
ii
kjsejkkjsekj
n
1ikik
ij
2
nn
nn
≠∑−
=
>∑+∑
−=
=∑
−=
=
+=
+=+=
<≥
+=
γγ
γγ
γγ
γ
(A.11)
Fig. A.1
Fig. A.2
Fig. A.3
Si noti che è necessario utilizzare un vettore di servizio che contenga volta a volta gli
elementi extradiagonali (cij-1
) di una riga della matrice inversa aventi proprio gli stessi

8 – Stima minimi quadrati ________________________________________________________________________________________________
40
indici i, j degli elementi extradiagonali (tij ) di una riga della matrice triangolare superiore,
ed entrambe necessarie per il calcolo dell'elemento diagonale (cii-1
) della matrice inversa.
2. Considerazioni sull'occupazione di memoria e modalità di memorizzazione
compatta delle matrici I problemi di interpolazione sono caratterizzati da molte osservazioni e relativamente pochi
parametri; ogni equazione alle osservazioni coinvolge in generale tutti i parametri.
Pertanto la matrice disegno A e la matrice normale C sono quasi completamente piene.
Nelle questioni di reti, il numero di osservazioni è in generale di poco superiore al numero
di parametri; ogni equazione alle osservazioni coinvolge pochi parametri (quelli relativi ai
vertici del lato del grafo su cui si sono operate le osservazioni).
Le matrici disegno A e normale C sono, in generale, matrici sparse, cioè con una piccola
quantità di elementi non-nulli rispetto al numero totale di elementi, a causa della struttura
topologica dei problemi reticolari, per esempio nei problemi geodetici e fotogrammetrici.
L'uso delle macchine da calcolo automatiche, piccole o grandi, nell'eseguire
compensazioni pone spesso il problema di economizzare la memoria occupata. E' perciò
necessario disporre di tecniche per memorizzare in modo compatto le matrici A e C,
trattandole poi nel calcolo mantenendo tale forma.
La matrice disegno A può essere memorizzata compatta registrando:
- per ogni equazione (riga) il numero dei coefficienti non-nulli ed i coefficienti stessi,
accompagnati dal numero d'ordine dell'incognita (colonna) cui si riferiscono;
- per ogni incognita (colonna) il numero dei coefficienti non-nulli ed i coefficienti
stessi, accompagnati dal numero d'ordine dell'equazione (riga) cui si riferiscono.
La matrice normale C può essere memorizzata compatta registrando il suo triangolo
superiore essendo, come noto, simmetrica:
- in forma rettangolare, se tutti gli elementi non-nulli sono contenuti in una banda,
ovvero se sono abbastanza vicini alla diagonale principale;
- "a elementi isolati", cioè per ogni colonna il numero dei coefficienti non-nulli ed i
coefficienti stessi, accompagnati dal numero di riga;
- "a profilo", cioè per ogni colonna il numero di tutti i coefficienti, nulli o non-nulli, a
partire dal primo non-nullo, ed i coefficienti stessi.

8 – Stima minimi quadrati ________________________________________________________________________________________________
41
Si osservi che la memorizzazione della matrice normale "a elementi isolati" serve
particolarmente quando si vuole eseguire la soluzione del sistema con metodi iterativi, di
cui non si occupa il presente paragrafo, mentre quello "a profilo", è utile quando si vuole
utilizzare un metodo esatto che richiede la fattorizzazione della matrice normale prima
della soluzione del sistema.
Nelle tre memorizzazioni per colonna sovraesposte, essendo variabile la lunghezza di ogni
colonna, è necessario registrare sequenzialmente tutti gli elementi di un vettore; inoltre per
facilitare l'accesso ad ogni singola colonna è conveniente sostituire al numero che
rappresenta la lunghezza di una colonna un puntatore che indirizzi direttamente al primo
od all'ultimo elemento della colonna stessa.
Nelle figure A.4, A.5, A.6, A.7 e A.8 si esemplificano gli schemi di memorizzazione delle
matrici disegno e normale.
Fig. A.4
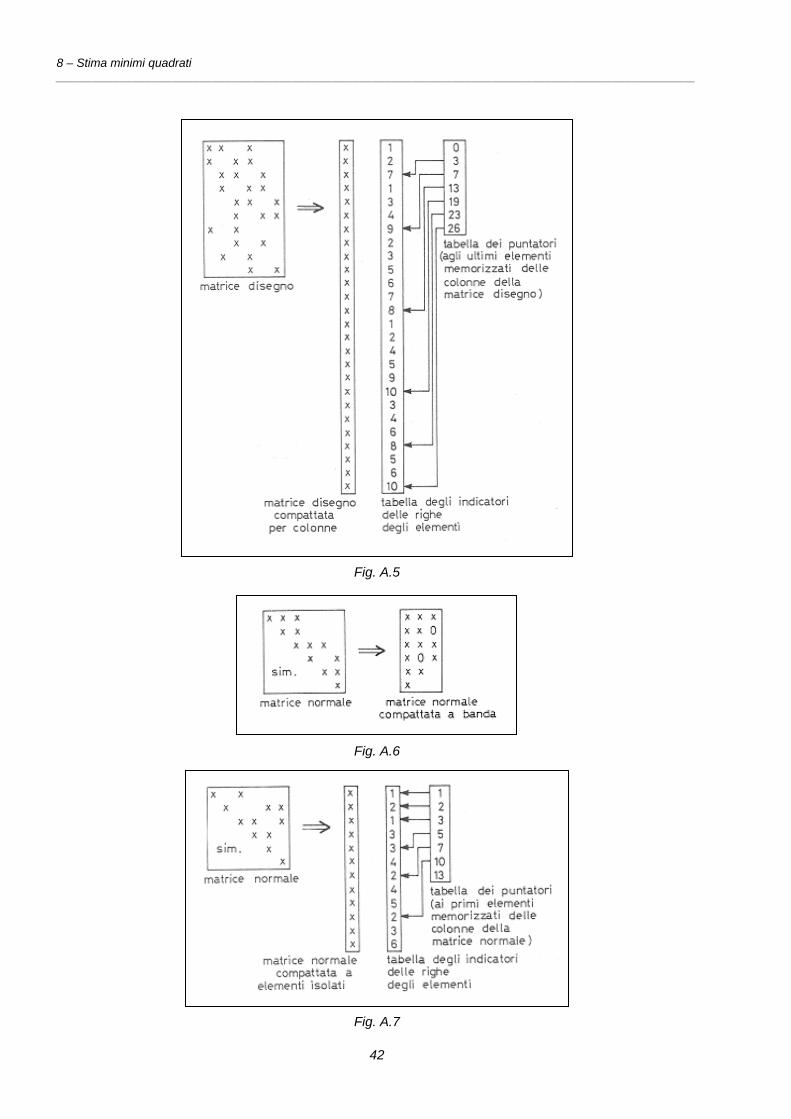
8 – Stima minimi quadrati ________________________________________________________________________________________________
42
Fig. A.5
Fig. A.6
Fig. A.7

8 – Stima minimi quadrati ________________________________________________________________________________________________
43
Fig. A.8