a probabilistic approach to melodic similarity · josé f. bernabeu, jorge calera-rubio, josé m....
TRANSCRIPT

A probabilistic approach to melodic similarity
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo
Dept. Lenguajes y Sistemas Informáticos, Universidad de Alicante, Spain{jfbernabeu,calera,inesta,drizo}@dlsi.ua.es
Sep 7, 2009
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity

Hypothesis
Probabilistic tree automata provide a way to assess similarityas a probability.Similarity between a sample and a class is in this waycomputed as the probability of the sample to belong to thatclass.We will apply this approach to the melody recognition task.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 2 / 21

Melody tree representation
A melody has two main dimensions: rhythm (duration) andpitch.In tree representations:
Only pitch codes are needed to be established.Trees are able to implicitly represent time in their structure.Less degrees of freedom for coding and testing.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 3 / 21
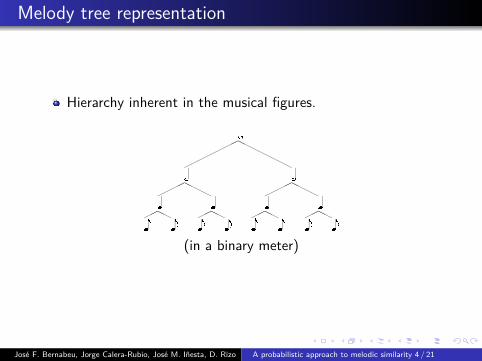
Melody tree representation
Hierarchy inherent in the musical figures.���������
HHHHHHHHH������
HHHHH���� HHH(� (� �
��� HHH(� (��
�����
HHHHH���� HHH(� (� �
��� HHH(� (�(in a binary meter)
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 4 / 21

Melody tree representationPitch descriptor selected in this work:
The interval from the tonic of the song modulo 12.The alphabet is Σp = {p ∈ N | 0 ≤ p ≤ 11} ∪ {′−′}.
Coding procedure:Each bar is represented independently and then linked to acommon root.First, leaf nodes are labeled.
11
42� � �
0
�2
� ��
�54
� �
5
11 5
2 4 0
— 0
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 5 / 21

Melody tree representation
A bottom-up propagation of the pitch labels is performed tolabel all the internal nodes. Using melodic analysis rules:
Harmonic notes have always priority for propagation.When two harmonic notes share a common father node,priority depends on the metrical strength of the note.Rests never have more priority than notes.
4
4 7
- 4 5 7 4 5
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 6 / 21

Melody tree representation
After all the bars have been coded, they are linked to acommon root, building up a forest.This will be the input for the algorithm.
t1 t|M|t2 t3 t4 t5 t6 t7
σ
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 7 / 21

Locally Testable Languages
The stochastic extension of k-testable languages is equivalentto k-grams models.k-testable tree languages can be defined using subtrees ofdepth ≤ k in a similar way that substrings are taken fromstrings.A deterministic tree automata can be inferred from a positivesample of trees.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 8 / 21

Stochastic extension
The likelihood of a stochastic sample is maximized if thestochastic model assigns to every tree a probability equal toits relative frequency in the sample.So, we only need to count the number of k-forks (that playthe role of substrings), (k − 1)-subtrees (prefixes) and(k − 1)-roots (suffixes).If we store the probabilities as the quotient of two counters,the automaton can be updated incrementally.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 9 / 21

Deterministic Tree Automata (DTA)
A = (Q,Σ,∆,F )
where Q: states, Σ: alphabet, ∆: transitions, F : accepting states.Example:Q = {q1, q2}Σ = {a, b}∆ = {
δ0(a) = q1,δ0(b) = q2,δ1(a, q2) = q1,δ2(a, q1, q2) = q2
}F = {q2}
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 10 / 21

Deterministic Tree Automata (DTA)
A = (Q,Σ,∆,F )
where Q: states, Σ: alphabet, ∆: transitions, F : accepting states.Example:Q = {q1, q2}Σ = {a, b}∆ = {
δ0(a) = q1,δ0(b) = q2,δ1(a, q2) = q1,δ2(a, q1, q2) = q2
}F = {q2}
a
a
a
a b
b
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 10 / 21

Deterministic Tree Automata (DTA)
A = (Q,Σ,∆,F )
where Q: states, Σ: alphabet, ∆: transitions, F : accepting states.Example:Q = {q1, q2}Σ = {a, b}∆ = {
δ0(a) = q1,δ0(b) = q2,δ1(a, q2) = q1,δ2(a, q1, q2) = q2
}F = {q2}
a
a
a
a b
b
q1 q2
q2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 10 / 21

Deterministic Tree Automata (DTA)
A = (Q,Σ,∆,F )
where Q: states, Σ: alphabet, ∆: transitions, F : accepting states.Example:Q = {q1, q2}Σ = {a, b}∆ = {
δ0(a) = q1,δ0(b) = q2,δ1(a, q2) = q1,δ2(a, q1, q2) = q2
}F = {q2}
a
a
a
a b
b
q2
q1 q2
q2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 10 / 21

Deterministic Tree Automata (DTA)
A = (Q,Σ,∆,F )
where Q: states, Σ: alphabet, ∆: transitions, F : accepting states.Example:Q = {q1, q2}Σ = {a, b}∆ = {
δ0(a) = q1,δ0(b) = q2,δ1(a, q2) = q1,δ2(a, q1, q2) = q2
}F = {q2}
a
a
a
a b
b q1
q2
q1 q2
q2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 10 / 21

Deterministic Tree Automata (DTA)
A = (Q,Σ,∆,F )
where Q: states, Σ: alphabet, ∆: transitions, F : accepting states.Example:Q = {q1, q2}Σ = {a, b}∆ = {
δ0(a) = q1,δ0(b) = q2,δ1(a, q2) = q1,δ2(a, q1, q2) = q2
}F = {q2}
a
a
a
a b
b
q2
q1
q2
q1 q2
q2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 10 / 21

Stochastic DTA
A = (Q,Σ,∆,P, ρ)
where P: probabilities, ρ: probabilities of the root.Example:Q, Σ, and ∆ like before,but nowP = {
p0(a) = 0.5,p0(b) = 0.3,p1(a, q2) = 0.5,p2(a, q1, q2) = 0.7
}ρ(q2) = 1
a q2
a q1
a q2
a q1 b q2
b q2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 11 / 21

Stochastic DTA
A = (Q,Σ,∆,P, ρ)
where P: probabilities, ρ: probabilities of the root.Example:Q, Σ, and ∆ like before,but nowP = {
p0(a) = 0.5,p0(b) = 0.3,p1(a, q2) = 0.5,p2(a, q1, q2) = 0.7
}ρ(q2) = 1
a q2
a q1
a q2
a q1 b q2
b q2
P = 0.3× 0.3× 0.5× 0.7× 0.5× 0.7× 1
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 11 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 1/1
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 1/1 b, a, b 1/1
a 0
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 1/1 b, a, bb
1/21/2
a 0 a 1/1
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 2/2 b, a, bb
1/21/2
a 0 a 1/1
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 2/2 b, a, bb
2/31/3
a 0 a 1/1
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 2/2 b, a, bb
2/31/3
a 0 aa, a, b
1/21/2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 2/2 b, a, bb
3/41/4
a 0 aa, a, b
1/21/2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Example: k = 2 (Inference probabilistic DTA)
b
a b
b
a
a b
b
a b
q ρ(q) δ p(δ)
b 2/2 b, a, bb
3/63/6
a 0 a, a, ba
1/43/4
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 12 / 21

Multilevel smoothing
The problem occurs when parsing a tree the system finds atransition not seen in the training set, therefore with a zeroprobability.We follow a backing-off scheme similar to the standard forstrings.To discount some probability mass to the seen events anddistribute it among the unseen events.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 13 / 21

Multilevel smoothing
Models with 1 ≤ k ≤ K are built.The aim is always to compute the probability of a transitionwith the K model. If it does not have the needed transitionthen the k − 1 model is utilized. If necessary, this process isrepeated until the k = 1 model is used.This model that never assigns null probabilities and thereforeis able to recognize any tree through its component nodes.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 14 / 21

Classification
Once the probabilistic DTAs for the different classes havebeen inferred and the probabilities estimated, a melody M isclassified in the class C that maximizes the likelihood
C = argmaxj
l(M|Cj)
where the likelihood of the melody for each class is computedwith
l(M|Cj) = ρ[2](σ|Cj)|M|∏i=1
π[k](ti |Cj)
where ρ[2](σ|Cj) is the probability of the root of the forest andthe other term in the equation is the conditional probability ofthe new melody for class Cj .
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 15 / 21

Experiments
420 monophonic variations played by musicians.Themes (8-12 bars) of 20 worldwide well-known tunes ofdifferent musical genres.Musicians played the songs using MIDI controllers, real-timesequencing them.21 different variations were obtained for each song.The goal is to select the correct song a given variation belongsto, using the proposed maximum likelihood technique.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 16 / 21

Experiments
A 3-fold cross-validation scheme was carried out to performthe experiments, obtaining average success rates anddispersions ((max−min)/4) .The results were compared to those obtained for the samedata using the tree edit distance using the Selkow’s (1977)algorithm.
Tree edit dist. K = 2 K = 3 K = 482.0± 0.2 85.7± 0.5 93.3± 0.5 86± 2
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 17 / 21
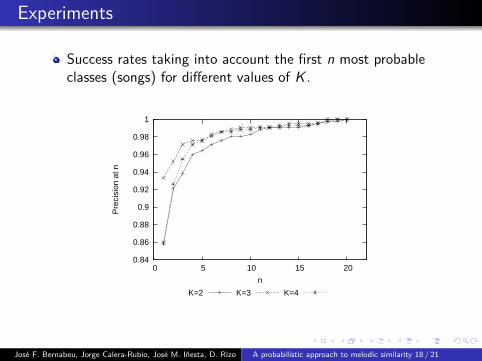
Experiments
Success rates taking into account the first n most probableclasses (songs) for different values of K .
0.84
0.86
0.88
0.9
0.92
0.94
0.96
0.98
1
0 5 10 15 20
Pre
cisi
on a
t n
n
K=2 K=3 K=4
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 18 / 21

Conclusions
Stochastic k-testable tree-models are able to compute thesimilarity between two melodies represented by trees.This similarity is given as the probability of a song to belongto a class made up of different variations of that song.The results improved those obtained using a classical tree editdistance, showing that this probabilistic models are suitablefor the classification of tree-represented music data.The high degree of variations may lead the edit distance towrong decisions, but this probabilistic models seem to dealbetter with noisy data.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 19 / 21

Conclusions
This is an initial attempt, so we are persuaded that thesepromising results can be improved by adjusting discountparameters of the back-off model or using different and moresophisticated discount methods.Also other music categorization problems like genre or styleclassification might be explored.
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity 20 / 21

A probabilistic approach to melodic similarity
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo
Dept. Lenguajes y Sistemas Informáticos, Universidad de Alicante, Spain{jfbernabeu,calera,inesta,drizo}@dlsi.ua.es
Sep 7, 2009
José F. Bernabeu, Jorge Calera-Rubio, José M. Iñesta, D. Rizo A probabilistic approach to melodic similarity