chip multiprocessor coherence and interconnect system design natalie enright jerger phd defense...
TRANSCRIPT

Chip Multiprocessor Coherence and Interconnect System Design
Natalie Enright Jerger
PhD DefenseOctober 20, 2008

Key Contributions – Interconnects (1) Trend: proliferation of architectures
requiring broadcast and multicast communication
Challenge: too expensive for on-chip
Solution: Virtual Circuit Tree Multicasting Improves throughput with low-
overhead routing tables
10/20/2008 2Natalie Enright Jerger - PhD Defense

Key Contributions – Interconnects (2) Trend: interconnect latency has a
significant impact on overall performance
Challenge: router overhead contributes substantially to total network latency
Solution: Hybrid Circuit Switching Circuit switching can be made fast
without sacrificing bandwidth
10/20/2008 3Natalie Enright Jerger - PhD Defense

Key Contributions – Cache Coherence Trend: Need for all cores to observe
coherence requests will be rare Challenge: low latency cache-to-
cache transfers without high bandwidth overhead
Solutions: leverage properties of interconnection network Virtual Tree Coherence
Efficient multicast Circuit-Switched Coherence
Optimized pair-wise sharing10/20/2008 4Natalie Enright Jerger - PhD
Defense

Outline Overview/Background
On-chip Networks Cache Coherence
Virtual Circuit Tree Multicasting Hybrid Circuit Switching Virtual Tree Coherence Circuit-Switched Coherence Conclusion/Future Work
10/20/2008 5Natalie Enright Jerger - PhD Defense

Communication system co-design
Communication consists of both How data is communicated (interconnect) What is communicated to whom and when
(coherence) Focus on co-design
Interconnect provides efficient multicasting design multicast coherence protocol
Interconnect optimizes pair-wise communication integrate pair-wise sharing into protocol
10/20/2008 6Natalie Enright Jerger - PhD Defense
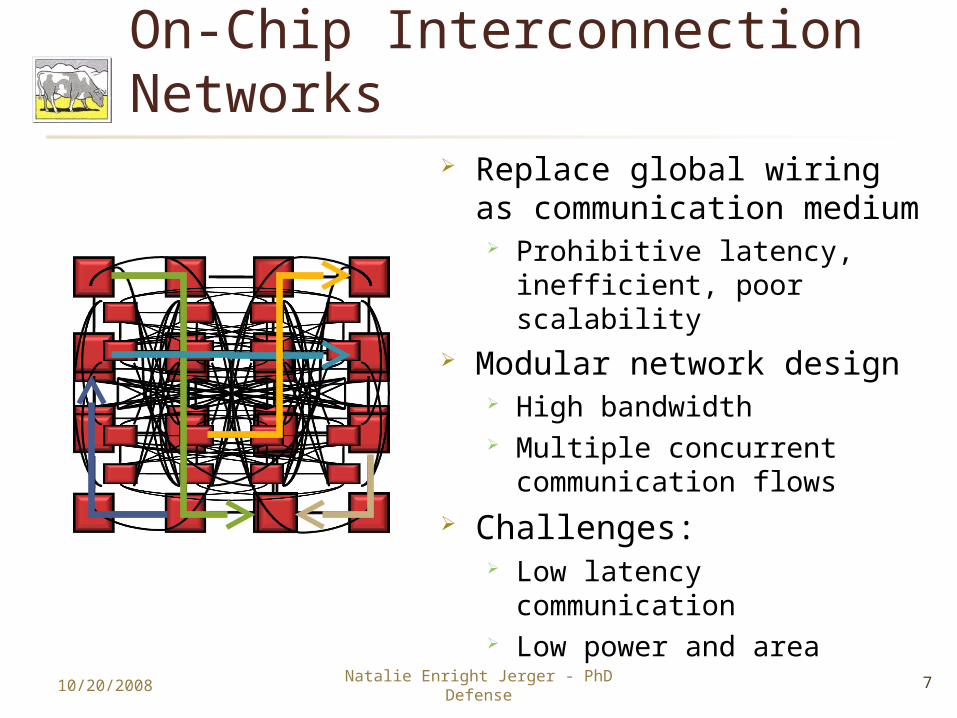
On-Chip Interconnection Networks
Replace global wiring as communication medium
Prohibitive latency, inefficient, poor scalability
Modular network design High bandwidth Multiple concurrent
communication flows Challenges:
Low latency communication Low power and area
10/20/2008 7Natalie Enright Jerger - PhD Defense
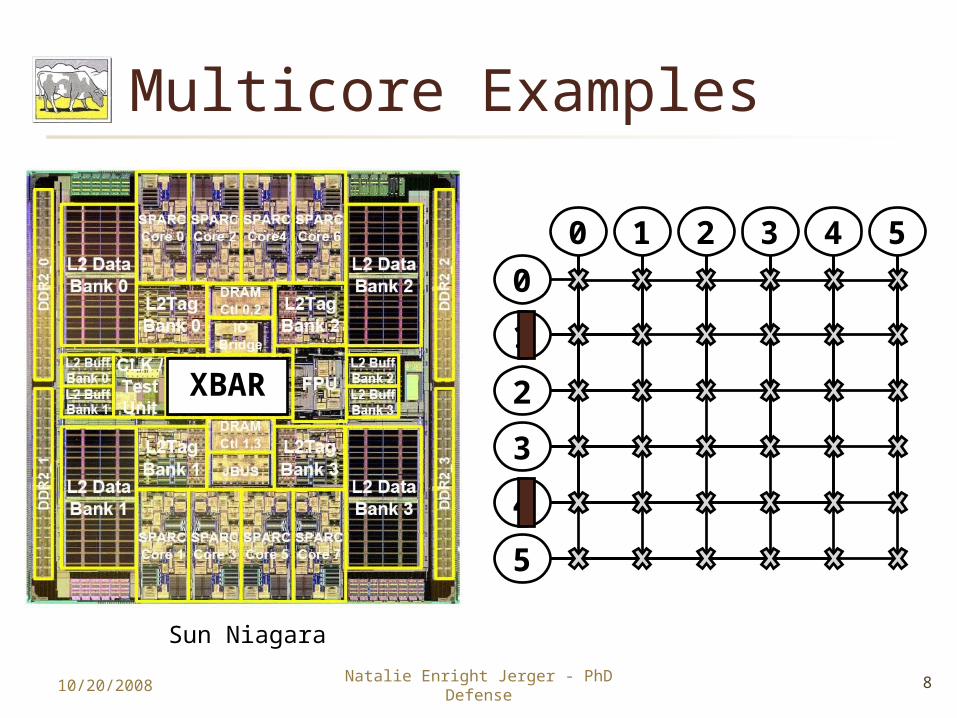
Multicore Examples
10/20/2008 8Natalie Enright Jerger - PhD Defense
Sun Niagara
XBAR
0
1
2
3
0 1 2 3
4
5
4 5
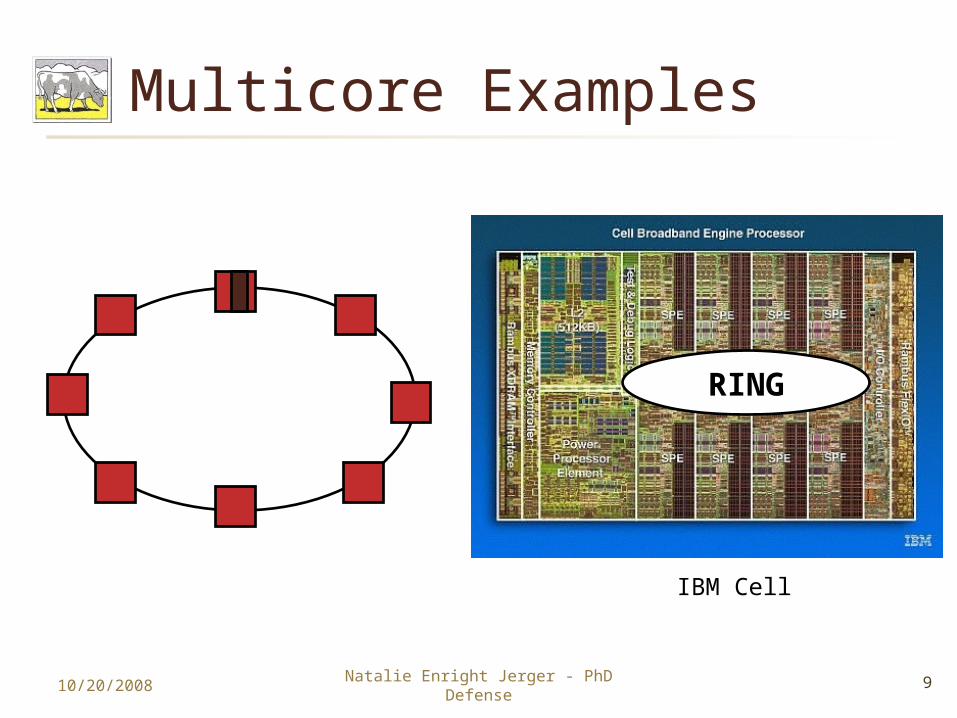
Multicore Examples
10/20/2008 9Natalie Enright Jerger - PhD Defense
IBM Cell
RING
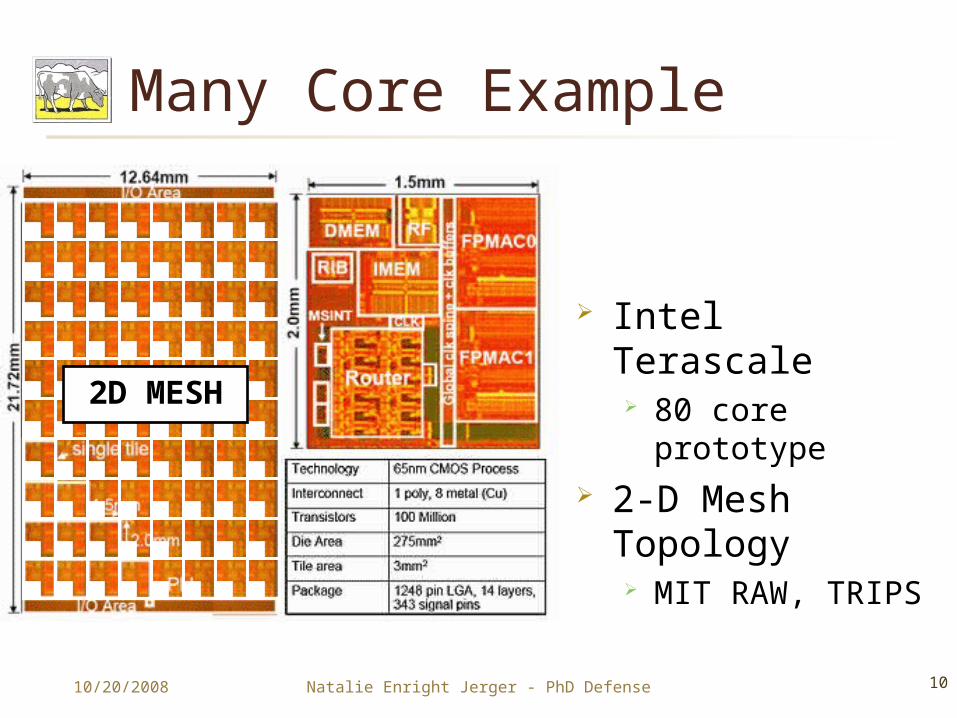
Many Core Example
Intel Terascale 80 core
prototype 2-D Mesh
Topology MIT RAW, TRIPS
10/20/2008 Natalie Enright Jerger - PhD Defense 10
2D MESH
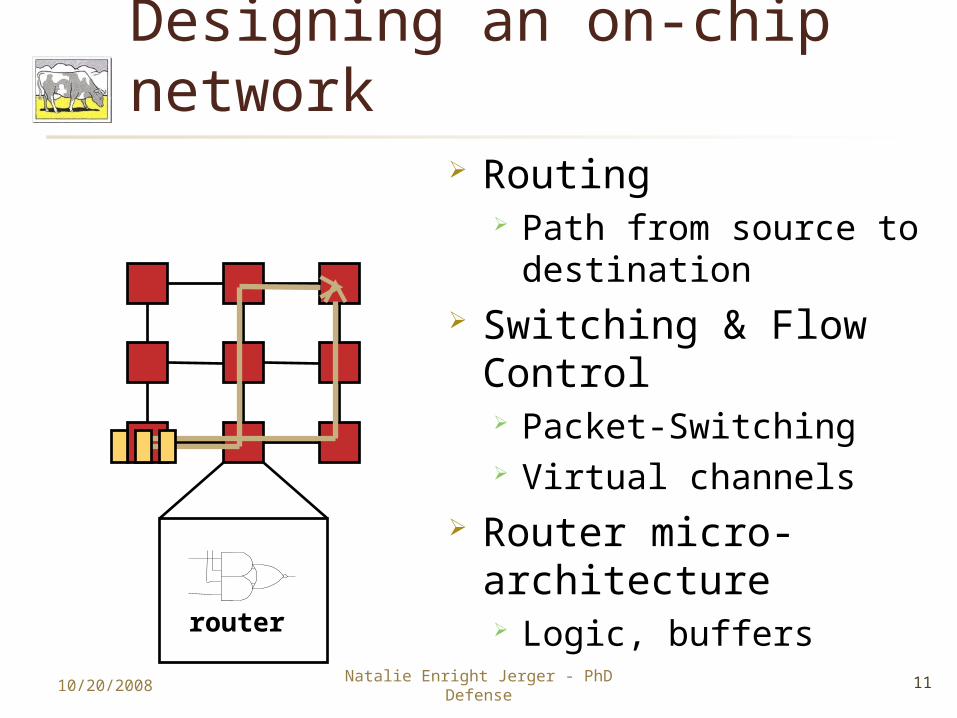
Designing an on-chip network
Routing Path from source to
destination Switching & Flow
Control Packet-Switching Virtual channels
Router micro-architecture Logic, buffers
10/20/2008Natalie Enright Jerger - PhD
Defense
router
11
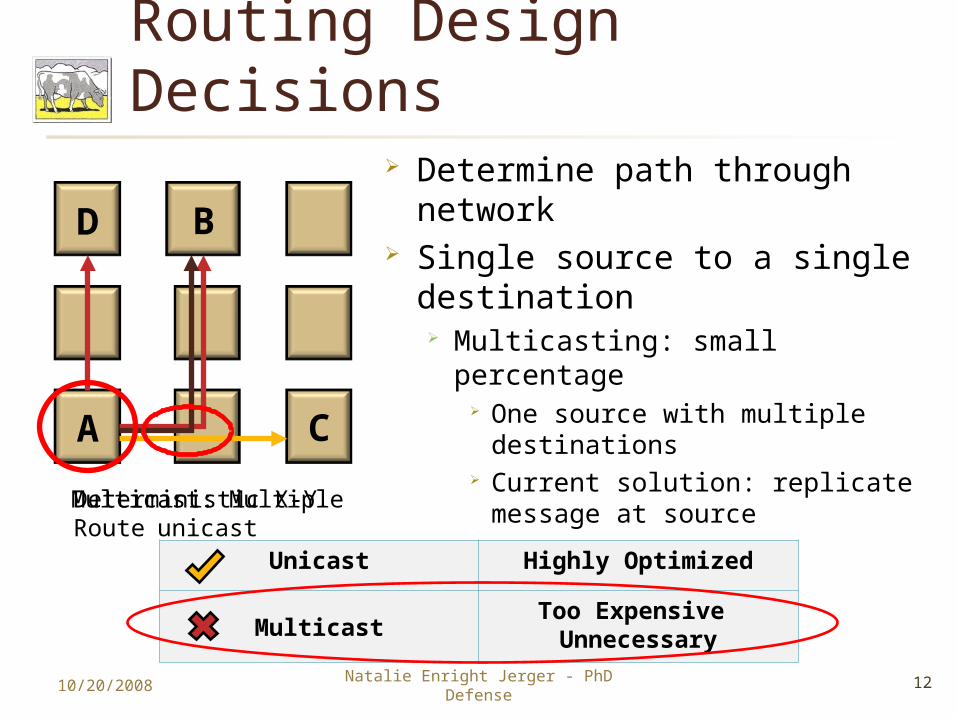
Routing Design Decisions Determine path through
network Single source to a single
destination Multicasting: small percentage
One source with multiple destinations
Current solution: replicate message at source
10/20/2008 12Natalie Enright Jerger - PhD Defense
B
A
Deterministic X-Y Route
C
D
Unicast Highly Optimized
MulticastToo Expensive Unnecessary
Multicast: Multiple unicast

Communication latency Network latency
Router overheads Network congestion due to inefficient
multicasting Coherence protocol
Cache-to-cache transfer latency Bandwidth requirements
10/20/2008 13Natalie Enright Jerger - PhD Defense

Existing Coherence Schemes Broadcast
Low latency Simple ordering (using bus) Single ordering point bottleneck Low bandwidth interconnect
High coherence traffic requirements Directory
Distributed ordering point Mostly unicast coherence traffic
Scalable topologies Indirection latency Storage overhead
10/20/2008 14Natalie Enright Jerger - PhD Defense

Full-chip Coherence: Broadcast
Too expensive Too much power, too much bandwidth Majority of cores do not need to see
broadcast10/20/2008 15Natalie Enright Jerger - PhD
Defense
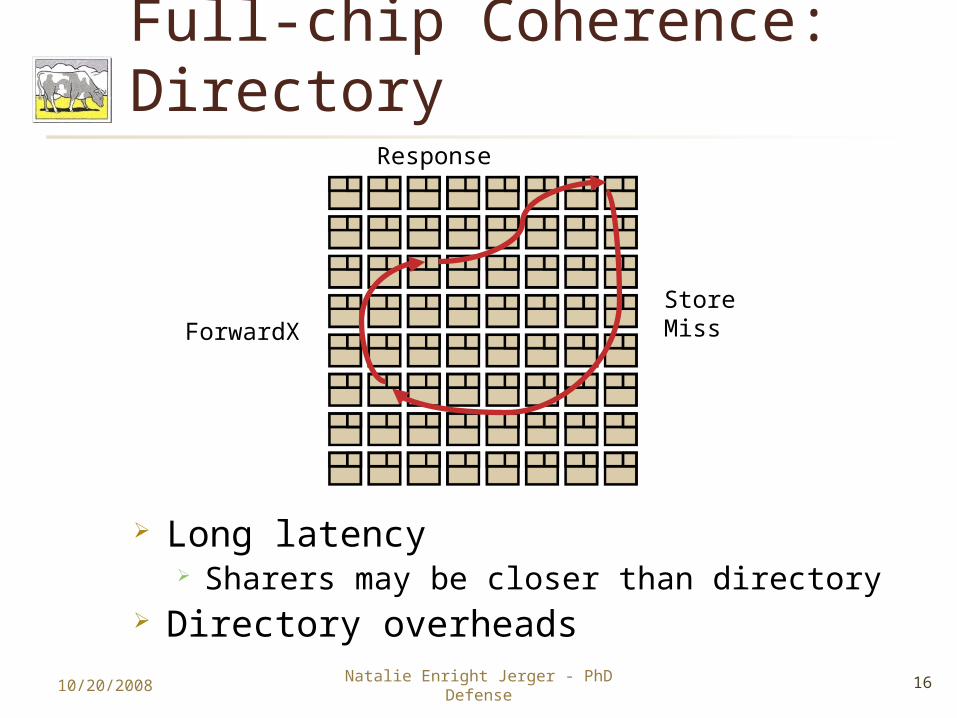
Full-chip Coherence: Directory
Long latency Sharers may be closer than directory
Directory overheads10/20/2008 16Natalie Enright Jerger - PhD
Defense
Store MissForwardX
Response

Hierarchical Coherence for CMPs Limit coherence actions to subset
Reduce bandwidth demands and power consumption
A multicast to active sharers
Fast cache-to-cache transfers Avoid indirection (directory)
Limited storage overhead Leverage coarse-grain information Efficient directories
10/20/2008 17Natalie Enright Jerger - PhD Defense

Workloads & Coherence Hierarchical coherence good
match to applications Server consolidation
Emerging class of workloads for many-core Limited global (inter-VM) communication
Communication and coherence dominated by intra-VM sharing
Traditional workloads Small number of sharers per cache line or
region (multiple cache lines)
10/20/2008 18Natalie Enright Jerger - PhD Defense

Outline Motivation Virtual Circuit Tree Multicasting
Baseline Inefficiencies Router Architecture Results
Hybrid Circuit Switching Virtual Tree Coherence Circuit-Switched Coherence Conclusion/Future Work
10/20/2008 19Natalie Enright Jerger - PhD Defense
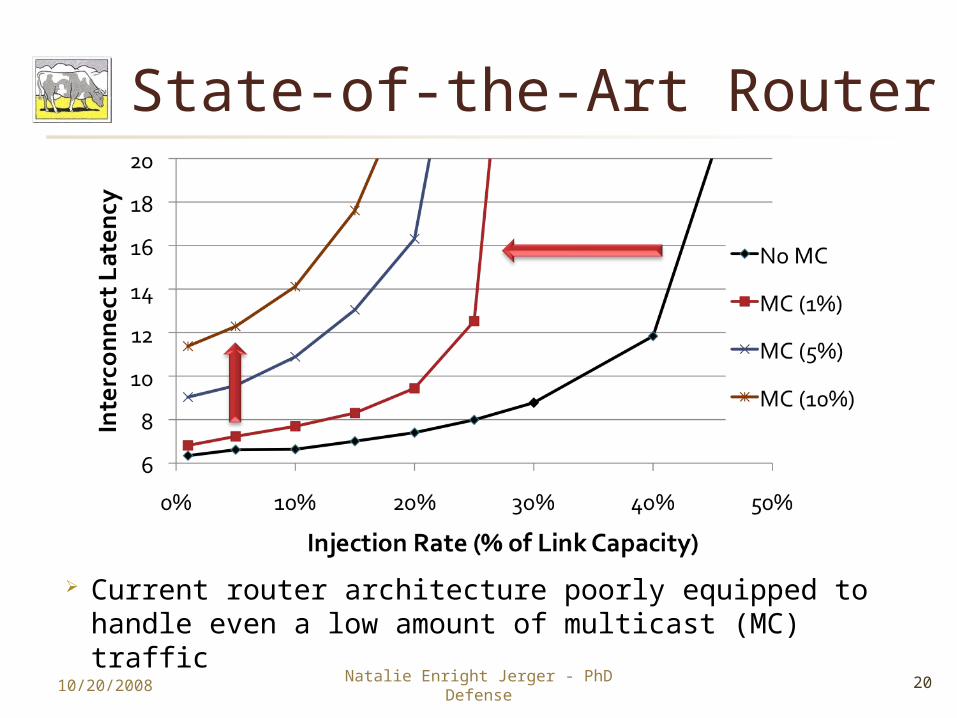
State-of-the-Art Router
Current router architecture poorly equipped to handle even a low amount of multicast (MC) traffic
10/20/2008 20Natalie Enright Jerger - PhD Defense

Packet-Switched Router 3 stage router with virtual channel flow
control Based on most aggressive recent proposals
Aggressive baseline not well matched all types of communication
Multicast is performed using multiple unicasts
10/20/2008 21Natalie Enright Jerger - PhD Defense
Buffer Write
Virtual Channel/Switch
Allocation
Switch Traversal
Link Traversal
Switch Traversal
Link Traversal
Link Traversal
Link Traversal
Router LinkLinkRouter
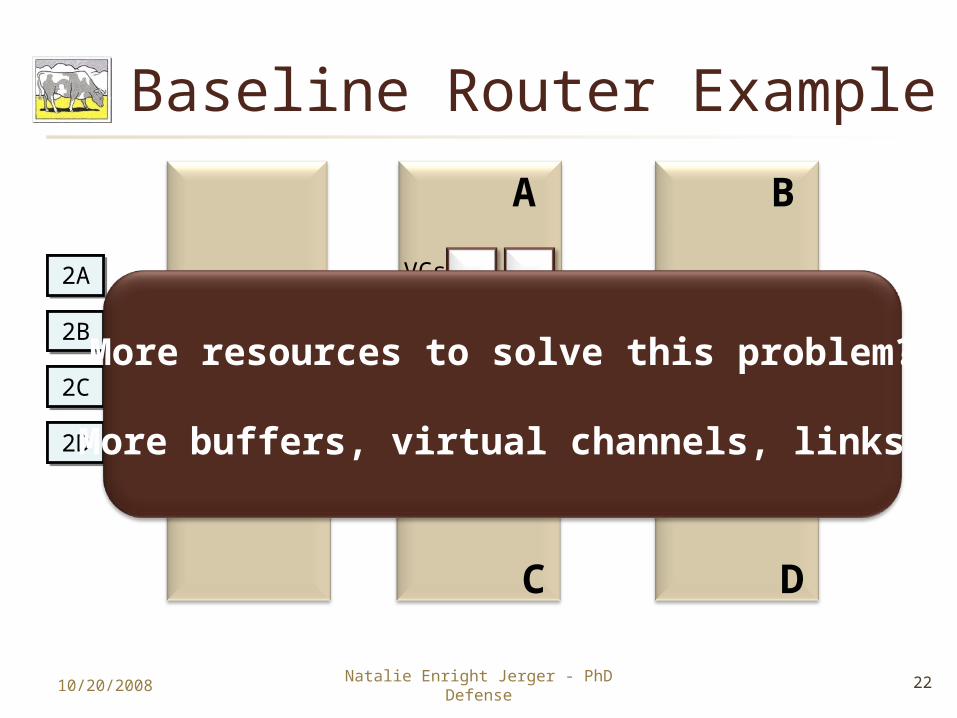
Baseline Router Example
10/20/2008 22Natalie Enright Jerger - PhD Defense
VCsVCs X
A B
DC
VCsBusy
VCs
VCs
1B1B
1A1A
1C1C
1D1D
2A2A
2B2B
2C2C
2D2D
More resources to solve this problem?
More buffers, virtual channels, links?
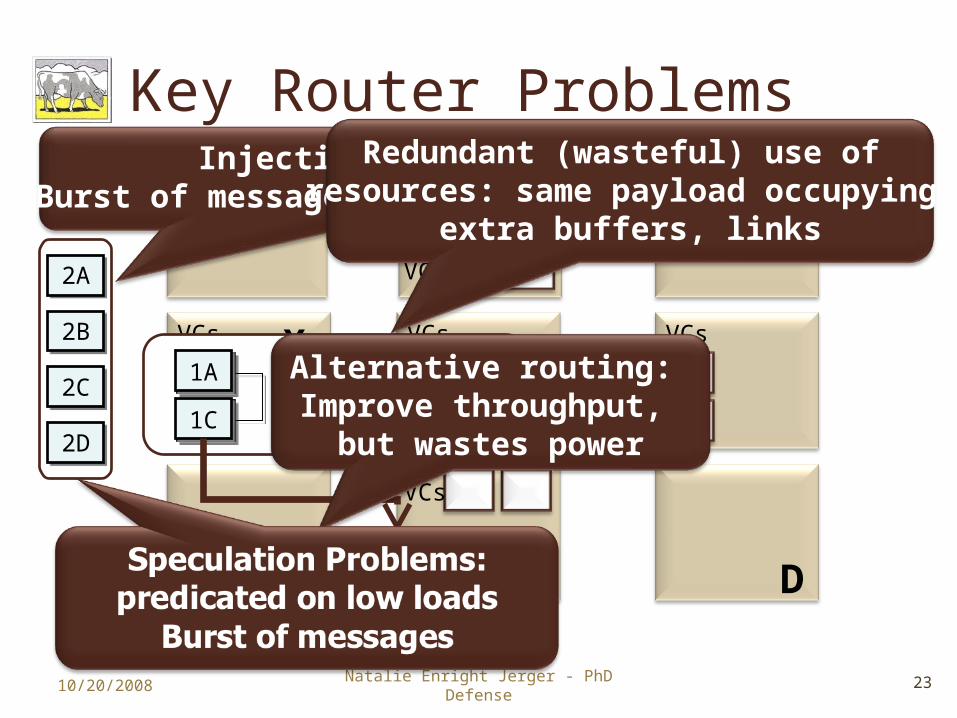
Key Router Problems
10/20/2008 23Natalie Enright Jerger - PhD Defense
VCsVCs X
A B
DC
VCsBusy
VCs
VCs
2A2A
2B2B
2C2C
2D2D
Injection Bandwidth: Burst of messages at network interface
1A1A
1C1C
1B1B
1D1D
Redundant (wasteful) use of resources: same payload occupying
extra buffers, links
Alternative routing: Improve throughput,
but wastes power
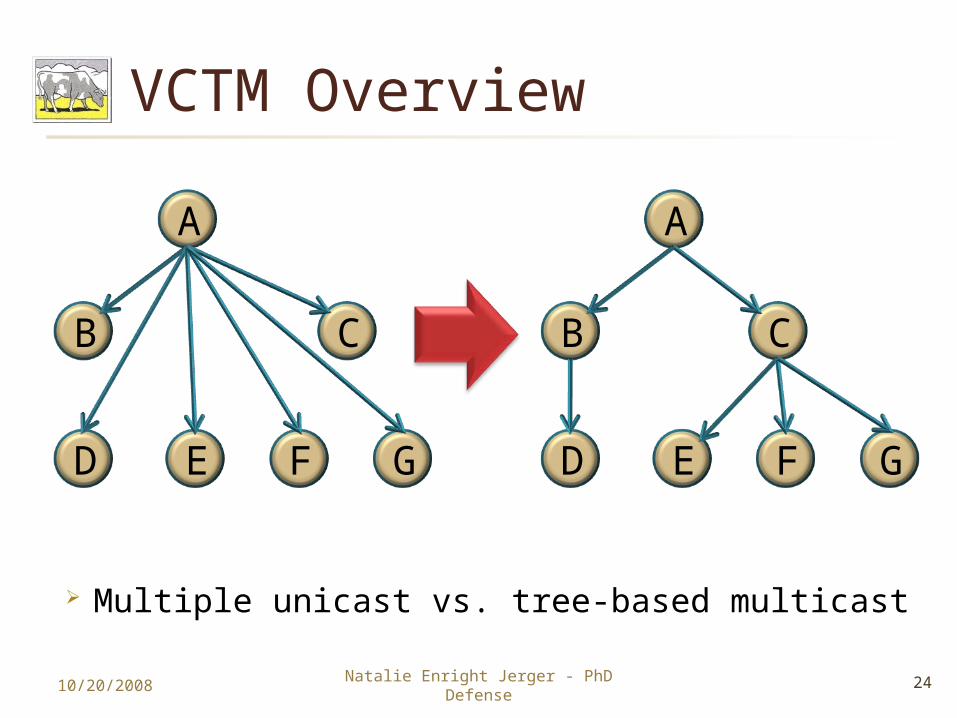
VCTM Overview
Multiple unicast vs. tree-based multicast
10/20/2008 24Natalie Enright Jerger - PhD Defense
A
B C
D E F G
A
B C
D E F G
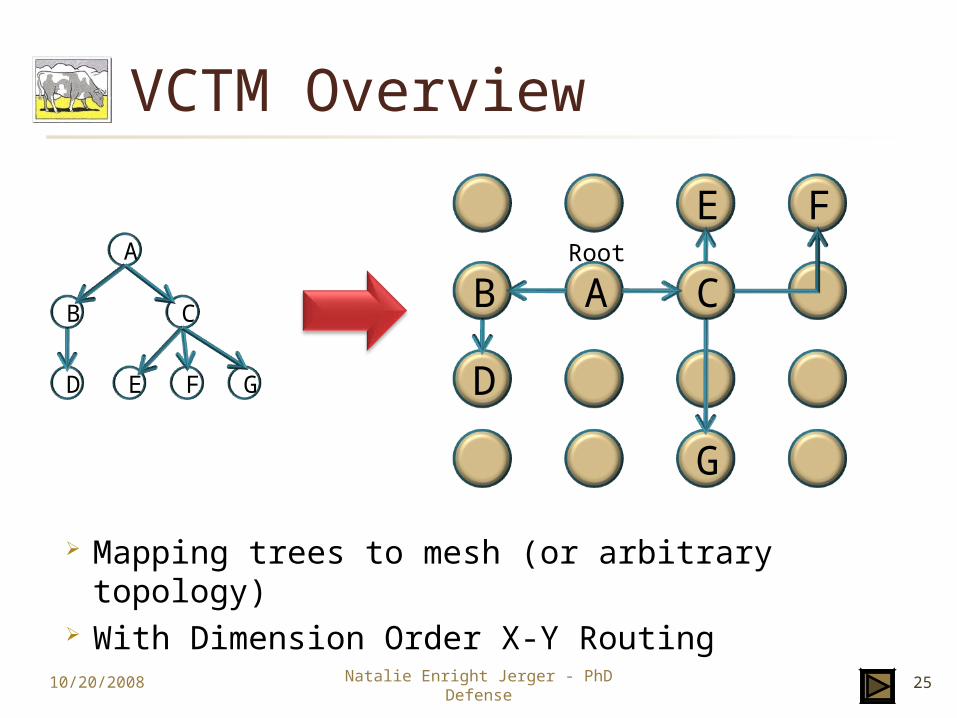
VCTM Overview
Mapping trees to mesh (or arbitrary topology) With Dimension Order X-Y Routing
A C
E F
G
D
BRoot
10/20/2008 25Natalie Enright Jerger - PhD Defense
A
B C
D E F G
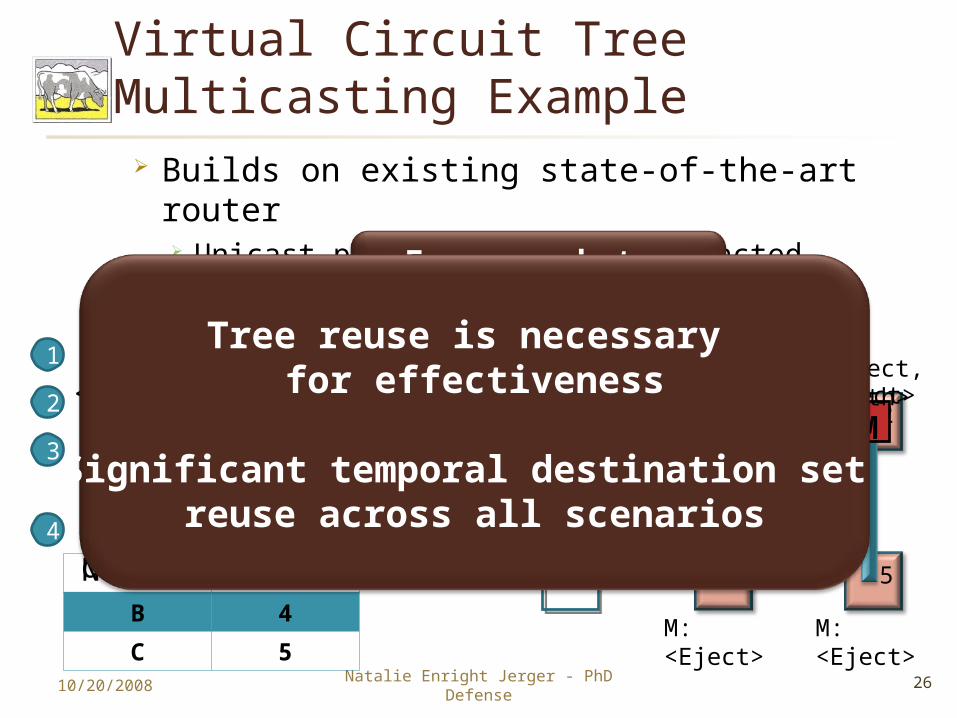
M: <Eject>
M: <Eject>
Multicast from 0 to <2,4,5> 1
Build Tree Incrementally (Tree M)2
3 Unicast Setup Packets (1 per destination)
3
0 1 2
3 4 5
3 Packets Injected into Network4
Virtual Circuit Tree Multicasting Example
Builds on existing state-of-the-art router Unicast performance is not impacted
Build multicast trees incrementally
10/20/2008 26Natalie Enright Jerger - PhD Defense
ABCM M M
A 2
B 4
C 5
M: <East> M: <Eject>
M: <East, South>
M: <Eject, South>
M: <East>
Injection problem solved
Link Redundancy Removed
Fewer packets improves speculation
Tree reuse is necessary for effectiveness
Significant temporal destination set reuse across all scenarios

VCTM Router Architecture
10/20/2008 27Natalie Enright Jerger - PhD Defense
VC 0
MVC 0
VC 0
VC x
MVC 0
VC 0
VC x
MVC 0
Src VCTnum
Virtual Circuit Tree Table
Switch Allocator
Virtual Channel Allocator
VC 0
VC xInput Ports
Id Ej N S E W
.
.
.
0 1 0 1 1 0
Routing Computation
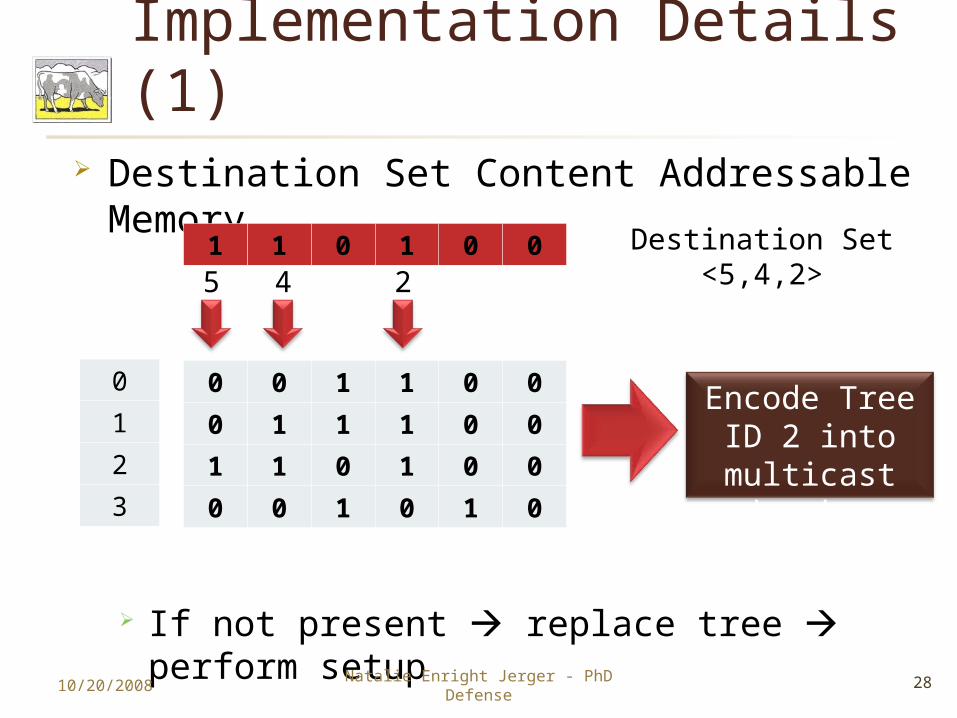
Implementation Details (1) Destination Set Content Addressable
Memory
If not present replace tree perform setup10/20/2008 28Natalie Enright Jerger - PhD
Defense
0 0 1 1 0 0
0 1 1 1 0 0
1 1 0 1 0 0
0 0 1 0 1 0
5 4 21 1 0 1 0 0
0
1
2
3
Encode Tree ID 2 into multicast header
Destination Set <5,4,2>

Implementation Details (2) VCTs provide routing not resources
Multicast arbitration same as unicast VCTs do not pre-allocate resources
Multiple arbitration steps at tree branch If one desired output is blocked, other tree
branch outputs can still proceed Longer buffer occupancy
VCT entries statically partitioned equally among nodes Dynamic partitioning explored
10/20/2008 29Natalie Enright Jerger - PhD Defense

TokenB
VTC
Characterizing Multicasts Unique Destination Sets: combination of
destinations in multicast Number of Destinations per multicast
10/20/2008 30Natalie Enright Jerger - PhD Defense
TokenB: 1 destination set for each node
VTC and Directory:Much larger variety of
destination sets
TRIPS and Directory:Small destination sets
TokenB and Opteron:Large destination sets
VTC:Wide variety of sizes
Up to 13% of traffic is multicast
VCTM is an inexpensive solution to support multicasting
VT
C
Tok
enB

Simulation Methodology Network traffic from 5 different
scenarios Detailed network simulator
Cycle-accurate modeling of router stages
Evaluate 5 Scenarios: TokenB, VTC, AMD Opteron, SGI Origin
Directory, TRIPS*
*Thanks to Niket Agarwal & Noel Eisley for TokenB, Opteron and TRIPS traces
10/20/2008 31Natalie Enright Jerger - PhD Defense

Network Configuration
10/20/2008 32Natalie Enright Jerger - PhD Defense
Topology 4-ary 2-mesh5-ary 2-mesh (TRIPS)
Routing Dimension Order: X-Y Routing
Channel Width 16 Bytes
Packet Size 1 flit (Coherence request = Address + Command)5 flits (Data)3 flits (TRIPS)
Virtual Channels 4
Buffers per port 24
Router ports 5
Virtual Circuit Trees
Varied from 16 to 4K(1 to 256 VCTs/core)

Power Savings On-chip networks consume up to ~36% of
chip power [Wang, 2002] Links, buffers and crossbars consume nearly
100% of network power Power saved through activity reduction
10/20/2008 33Natalie Enright Jerger - PhD Defense
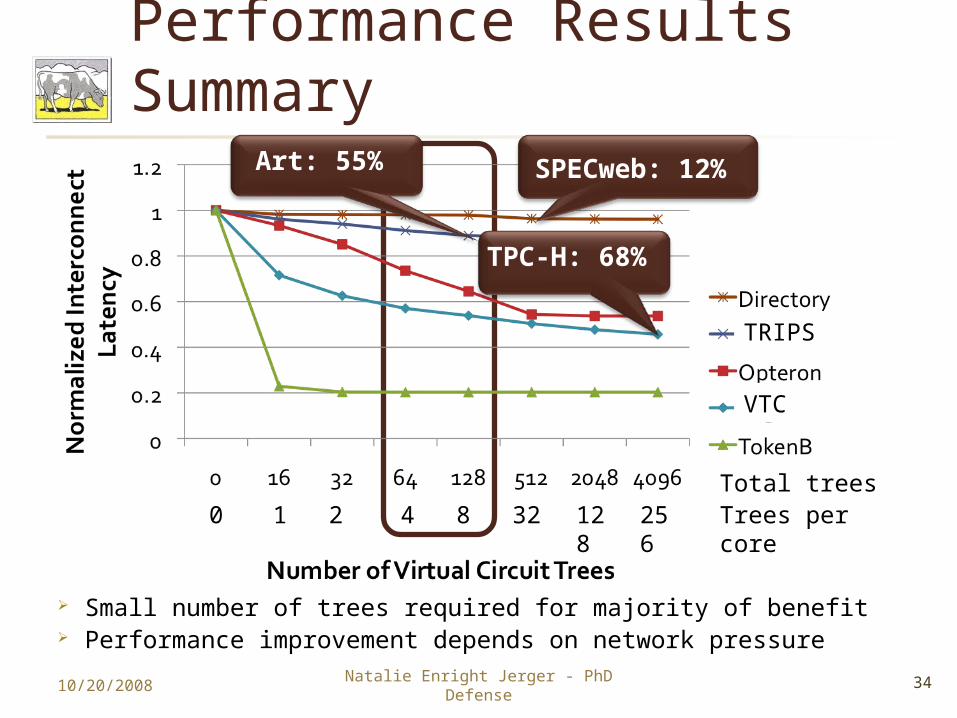
Performance Results Summary
Small number of trees required for majority of benefit Performance improvement depends on network pressure10/20/2008 34Natalie Enright Jerger - PhD
Defense
TPC-H: 68%
Art: 55% SPECweb: 12%
VTC
1 2 4 8 32
128
256
0 Trees per core
Total trees
TRIPS
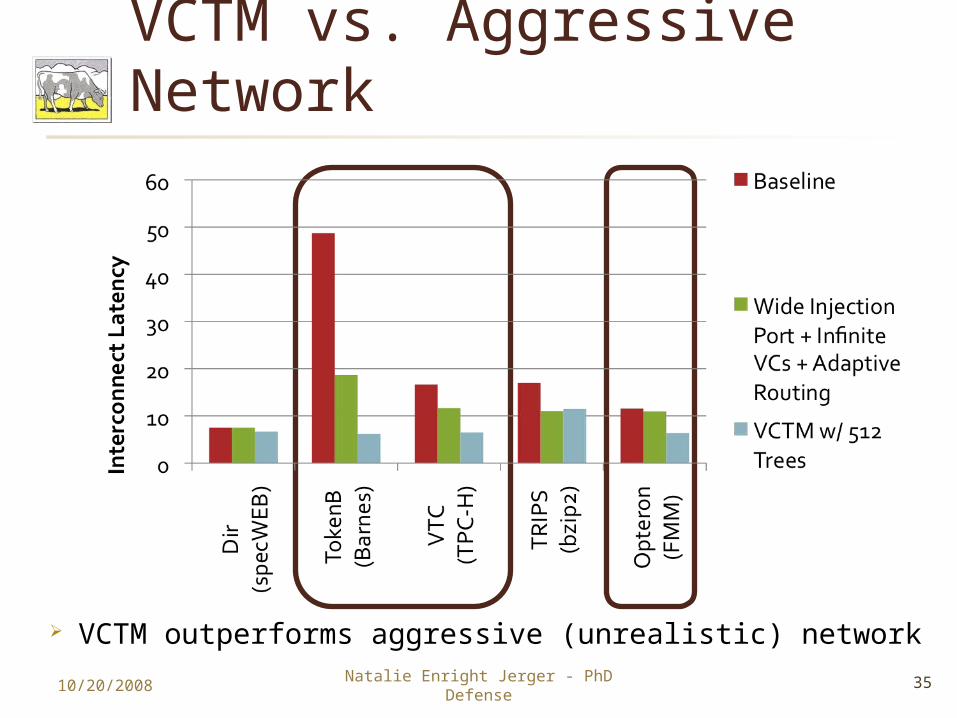
VCTM vs. Aggressive Network
VCTM outperforms aggressive (unrealistic) network10/20/2008 35Natalie Enright Jerger - PhD
Defense

Related Work Off-Chip Multicast Routers
[Sivaram, 99; Turner, 94; Stunkel, 99, Chiang, 95; Malumbres, 96]
Expensive: High Radix Routers Large Routing Tables Targeting Multi-stage networks
On-Chip Path-based, SOC [Lu, 06] D-NUCA cache [Jin, 07] Table-based [Rodrigo, 08]
10/20/2008 36Natalie Enright Jerger - PhD Defense

VCTM Summary Key contributions
Characterize multicasting: necessary VCTM improves throughput of network
Improves performance across a variety of scenarios Reduces interconnect latency by up to
90% Reduces switching activity by up to 53%
Small number of trees necessary (8/core)
10/20/2008 37Natalie Enright Jerger - PhD Defense

Outline Motivation Virtual Circuit Tree Multicasting Hybrid Circuit Switching
Brief (work presented at Prelim) (2 slides)
Extended (12 slides) Virtual Tree Coherence Circuit-Switched Coherence Conclusion/Future Work
10/20/2008 38Natalie Enright Jerger - PhD Defense

Hybrid Circuit Switching (1)
Latency is critical Utilize Circuit Switching for lower
latency A circuit connects resources across
multiple hops to avoid router overhead Traditional circuit-switching performs
poorly HCS Contributions
Novel setup mechanism Bandwidth stealing
10/20/2008Natalie Enright Jerger - PhD
Defense39

Hybrid Circuit Switching (2) Hybrid Network
Interleaves circuit-switched and packet-switched flits
Optimize setup latency Improve throughput over traditional
circuit-switching Packet-switched flits snoop idle
bandwidth Reduce interconnect delay by
average of 18% (up to 22%)
10/20/2008 40Natalie Enright Jerger - PhD Defense

Outline Motivation Virtual Circuit Tree Multicasting Hybrid Circuit Switching Virtual Tree Coherence
Hierarchical Coherence Coarse Grain Regions Ordering Results
Circuit-Switched Coherence Conclusion/Future Work
10/20/2008 41Natalie Enright Jerger - PhD Defense

Virtual Tree Coherence Local Coherence: Snoopy multicast
Root information present: send coherence request to tree root
Tree Root multicasts request to sharers using VCTM
Add requestor to sharing vector Sharers supply data (and invalidate if store)
Global Coherence No root information:
Request root from coarse directory –OR – broadcast for root
Then perform first level actions10/20/2008 42Natalie Enright Jerger - PhD
Defense

Coarse Grain Region Overview
Take a macro view of memory Better observe access patterns (1KB Regions) Use RegionTracker for efficient storage
[Zebchuk, 07] Region-based Optimizations
Coarse Grain Coherence Tracking [Cantin, 05] Eliminate unnecessary broadcasts
Track sharers and roots on coarse granularity Multicast to sharers for data Efficient upgrading for non-shared regions
10/20/2008 43Natalie Enright Jerger - PhD Defense

Selecting Root Node Root should be sharer fast
ordering First touch
Possibility of single node becoming root for many regions
Migration Migrate to more central location as
sharers are added Forces majority of roots onto center nodes
Forward in-flight requests to old root10/20/2008 44Natalie Enright Jerger - PhD
Defense

Global Coherence Trade-offs Global Coarse Directories
Storage overhead Unicast requests
Global Broadcast No storage overhead Broadcast traffic: expensive but rare
10/20/2008 45Natalie Enright Jerger - PhD Defense

Virtual Tree Coherence Ordering
Intra-region Order Ordering Point
Tree Root orders all messages to same address region
Multiple roots prevent ordering bottleneck Sharers
A multicast must contain all current sharers Too many false sharers wastes power Too few incorrect execution
10/20/2008 46Natalie Enright Jerger - PhD Defense

Preserving Network Order Arbitrary topology
Messages can become reordered either By virtual channel allocation By adaptive routing
Restrict virtual channel assignment to prevent re-ordering in the network
Tree must use the same VC throughout network traversal
Leaves (sharers) observe requests in same order that root processed them
10/20/2008 47Natalie Enright Jerger - PhD Defense
Disallow
Address
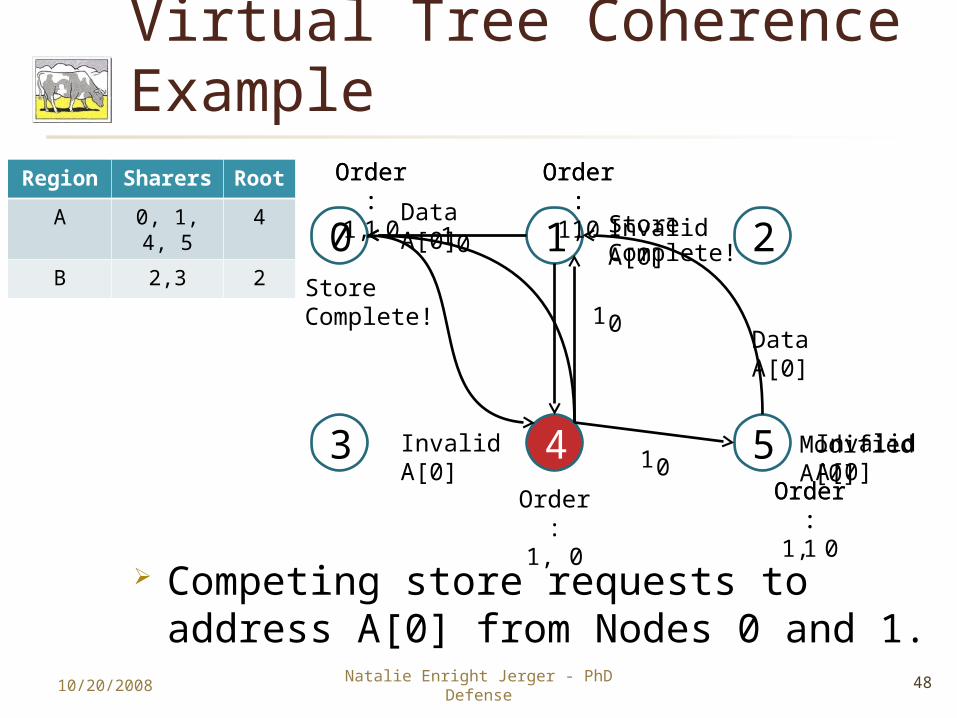
Virtual Tree Coherence Example
Competing store requests to address A[0] from Nodes 0 and 1.
10/20/2008 48Natalie Enright Jerger - PhD Defense
0 1 2
3 4 5
Region Sharers Root
A 0, 1, 4, 5
4
B 2,3 2
Order:1, 0
Order:1
Order:1
Order:1
Data A[0]1
1
1 StoreComplete!
0
0
0Data A[0]
Store Complete!
Order:1,0
Order:1, 0
Order:1, 0
Invalid A[0]Invalid A[0]
Invalid A[0]
Modified A[0]

Inter-Region Order (1) Safe to collect acknowledgments on every
store miss (Opteron-like) Given our intra-region tree order
Acknowledging every store miss overly conservative
Before a dirty block becomes visible to system (leaves the core) Must fence on all previous dirty/unfenced
regions A fence issued for each region on that region’s tree
Memory barrier requires that fences on all dirty/unfenced regions are complete (PowerPC consistency)
10/20/2008 49Natalie Enright Jerger - PhD Defense

Inter-Region Order (2) Write atomicity
Remote reads to dirty/unfenced regions initiate fence(s) and are deferred until fence(s) completes
Fence acks guarantee that all prior stores (invalidates) to that region have been sunk on all cores
Write serialization Writes within a region serialized through Tree
Order Serialize writes across region boundary with fence
(e.g. St A, St B) Fence occurs on tree of earlier store (A) Eager fence10/20/2008 50Natalie Enright Jerger - PhD
Defense

Simulation Methodology PHARMsim
Full-system multi-core simulator Detailed network level model with VCTM
Baseline: Directory Coherence
Workloads: Commercial: SPECjbb, SPECweb, TPC-H, TPC-
W Scientific: Barnes-Hut, Ocean, Radiosity,
Raytrace Server Consolidation
10/20/2008 51Natalie Enright Jerger - PhD Defense

Simulation Configuration
10/20/2008 52Natalie Enright Jerger - PhD Defense
Processors
Cores 16,64 in-order general purpose
Memory System
L1 I/D Caches 32 KB 2-way set associative1 cycle
Private L2 caches 1MB 8-way set associative, 6 cycles64 Byte lines
RegionTracker (associated with each L2)
1024 sets, 8 ways, 1KB regions
Interconnect: 4x4 2-D Mesh
Packet-switched baseline 3 router stages8 Virtual channels with 4 Buffers each
Virtual Circuit Tree Multicasting 64 Trees per source node1024, 4096 total trees
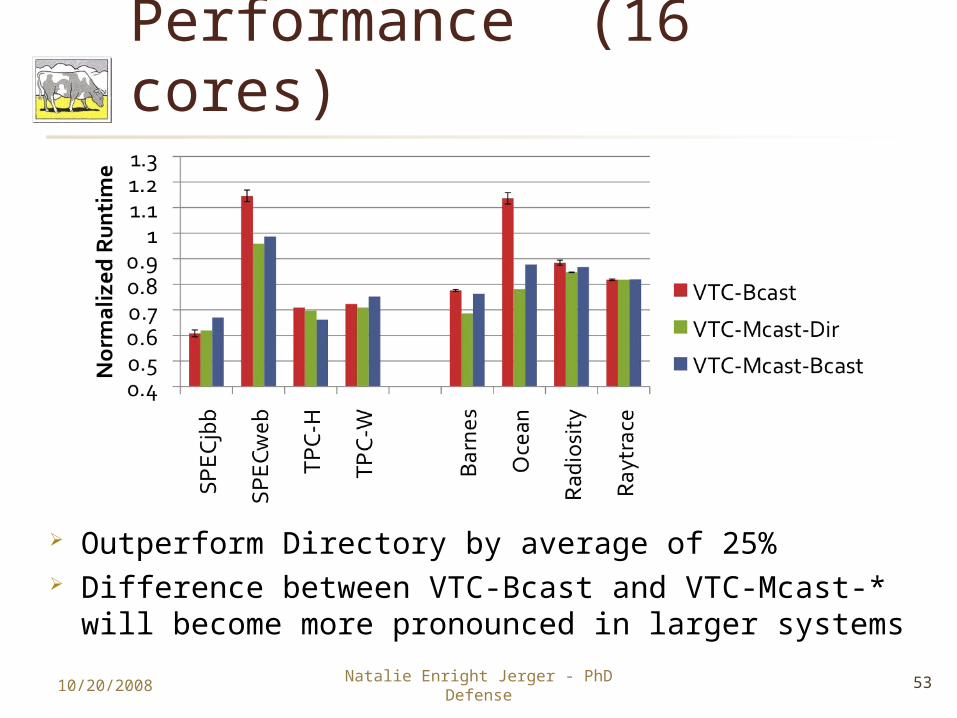
Performance (16 cores)
Outperform Directory by average of 25% Difference between VTC-Bcast and VTC-Mcast-* will
become more pronounced in larger systems
10/20/2008 53Natalie Enright Jerger - PhD Defense
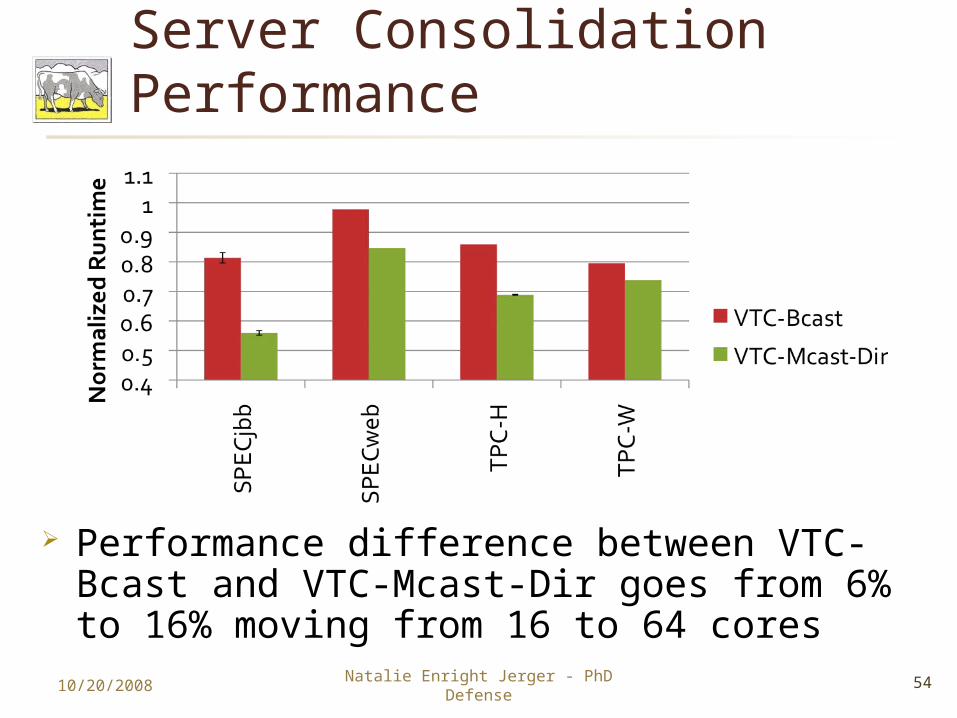
Server Consolidation Performance
Performance difference between VTC-Bcast and VTC-Mcast-Dir goes from 6% to 16% moving from 16 to 64 cores
10/20/2008 54Natalie Enright Jerger - PhD Defense
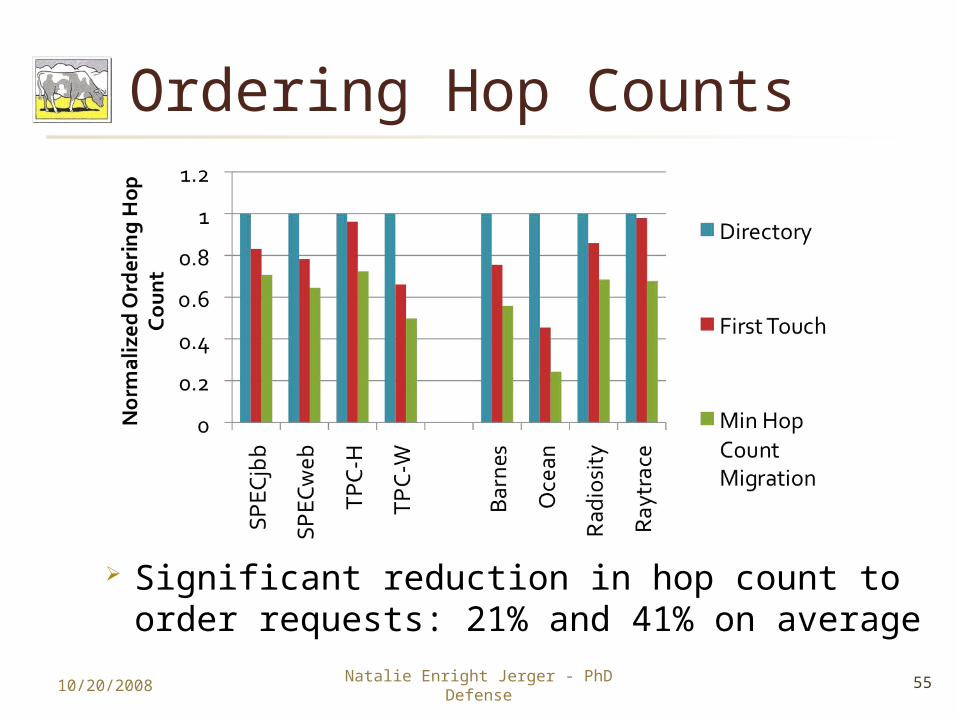
Ordering Hop Counts
Significant reduction in hop count to order requests: 21% and 41% on average
10/20/2008 55Natalie Enright Jerger - PhD Defense
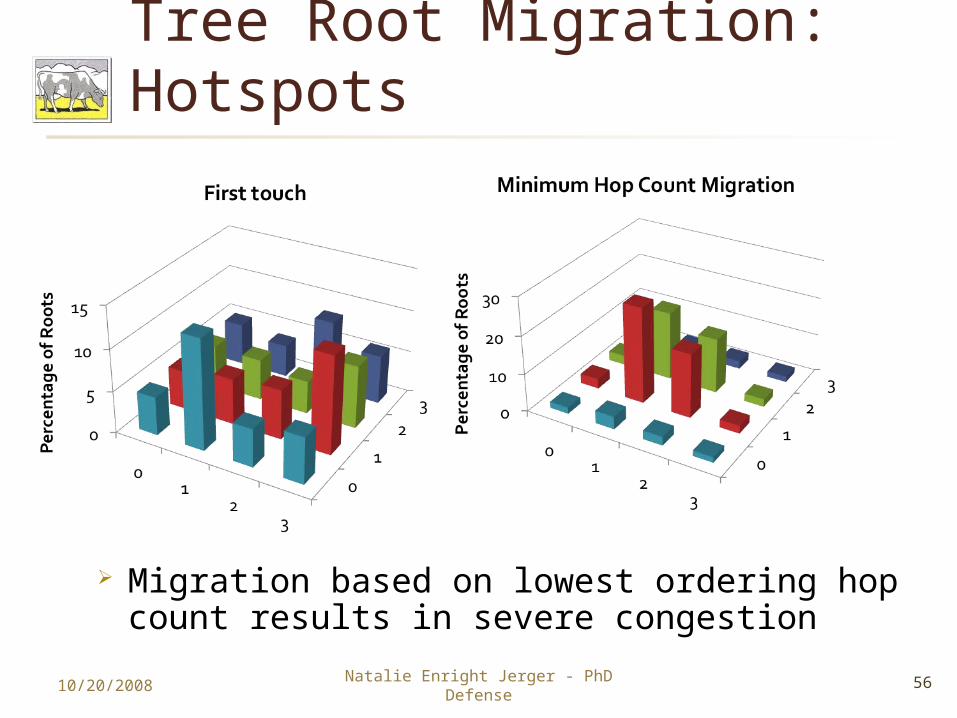
Tree Root Migration: Hotspots
Migration based on lowest ordering hop count results in severe congestion
10/20/2008 56Natalie Enright Jerger - PhD Defense
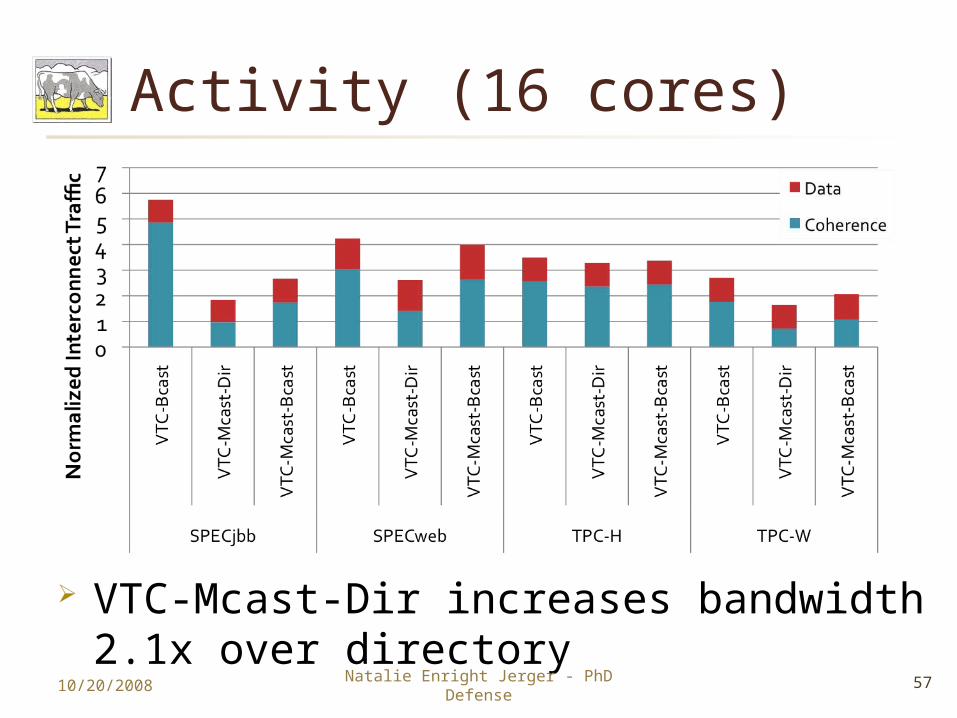
Activity (16 cores)
VTC-Mcast-Dir increases bandwidth 2.1x over directory
10/20/2008 57Natalie Enright Jerger - PhD Defense

Related Work Unordered Interconnects
Logical/Virtual Ordering: UnCorq [Strauss, 07] Token Counting: Token Coherence [Martin, 03]
Hierarchical Coherence Virtual Hierarchies [Marty, 07] Multiprocessors built out of SMP building
blocks [Laudon, 97; Lenoski, 90; Lovett, 96; Hagersten, 99]
Multicast coherence Multicast Snooping, Destination Set Prediction
[Bilir, 99; Martin, 03]
10/20/2008 58Natalie Enright Jerger - PhD Defense

Virtual Tree Coherence Summary High bandwidth, low latency
ordering substrate Fast cache-to-cache transfers
Efficient bandwidth utilization through multicasting Coarse-grain tracking of sharers
Scales well for server consolidation workloads
10/20/2008 59Natalie Enright Jerger - PhD Defense

Outline Motivation Virtual Circuit Tree Multicasting Hybrid Circuit Switching Virtual Tree Coherence Circuit-Switched Coherence
Brief (work presented at Prelim) (1 slide)
Extended (6 slides) Conclusion/Future Work
10/20/2008 60Natalie Enright Jerger - PhD Defense

Circuit-Switched Coherence
Goal: Better exploit circuits through coherence protocol
Observe pair-wise sharing Take Directory off critical path
Directory is sole ordering point Performance improvement increased
with HCS + Protocol Optimization Protocol Optimization drives up circuit
reuse, better utilizing HCS Performance improvement up to 18%
10/20/2008Natalie Enright Jerger - PhD
Defense61

Outline Motivation Virtual Circuit Tree Multicasting Hybrid Circuit Switching Virtual Tree Coherence Circuit-Switched Coherence Conclusion/Future Work
10/20/2008 62Natalie Enright Jerger - PhD Defense

Conclusion Communication behaviors must
influence interconnect design Coherence protocol dictates
interconnect traffic Designing networks solely for unicast
traffic problematic Protocol should take advantage of
interconnect properties If interconnect provides implicit
ordering use it
10/20/2008 63Natalie Enright Jerger - PhD Defense

Future Work Network Quality of Service/Fairness
Root selection results in potential for hotspots in network
Reduction/Collection Networks Reduce interconnect activity
Combine acknowledgments in network
Techniques to improve scalability of VCTM
10/20/2008 64Natalie Enright Jerger - PhD Defense

Thank you
10/20/2008 65Natalie Enright Jerger - PhD Defense

Extended Versions (HCS, CSC)
10/20/2008 66Natalie Enright Jerger - PhD Defense

Hybrid Circuit Switching (Extended) Latency is critical Utilize Circuit Switching for lower
latency A circuit connects resources across
multiple hops to avoid router overhead Traditional circuit-switching performs
poorly HCS Contributions
Novel setup mechanism Bandwidth stealing
10/20/2008Natalie Enright Jerger - PhD
Defense67
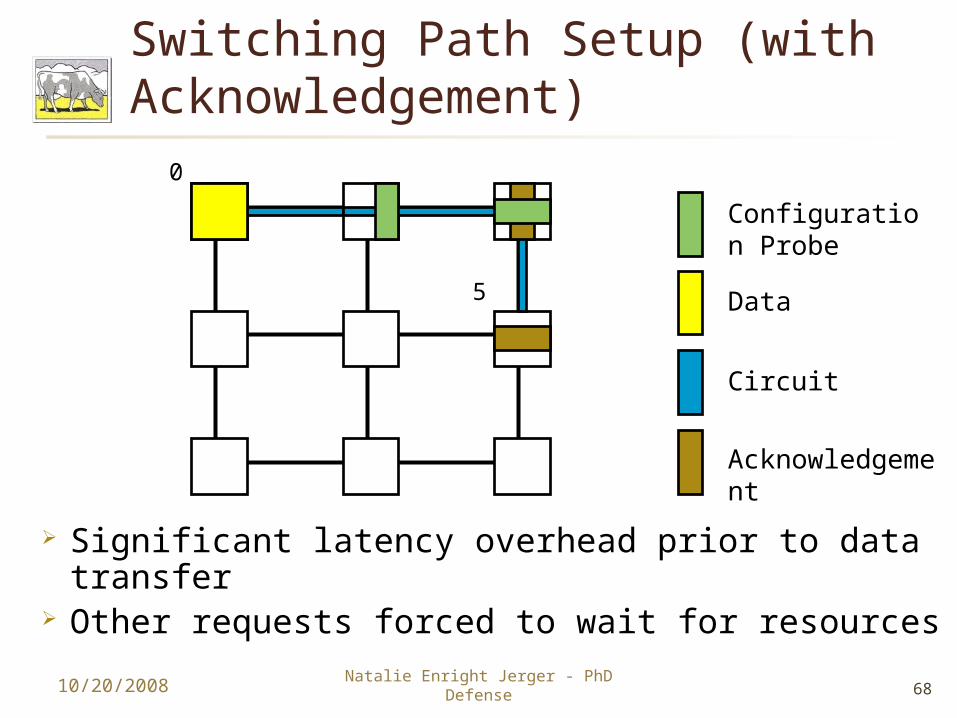
Traditional Circuit Switching Path Setup (with Acknowledgement)
Significant latency overhead prior to data transfer
Other requests forced to wait for resources10/20/2008 Natalie Enright Jerger - PhD
Defense
Acknowledgement
Configuration Probe
Data
Circuit
0
5
68
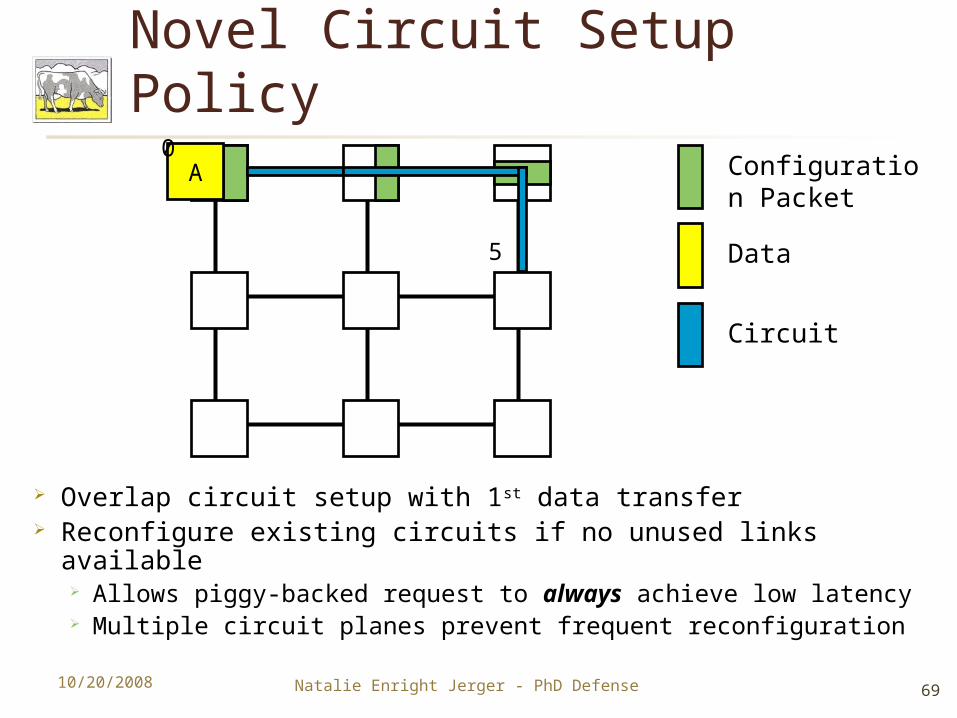
Novel Circuit Setup Policy
Overlap circuit setup with 1st data transfer Reconfigure existing circuits if no unused links available
Allows piggy-backed request to always achieve low latency Multiple circuit planes prevent frequent reconfiguration
Configuration Packet
Data
Circuit
A0
5
Natalie Enright Jerger - PhD Defense10/20/200869

Setup Network Light-weight setup network
Narrow Circuit plane identifier (2 bits) + Destination (4 bits)
Low Load No virtual channels small area footprint
Stores circuit configuration information Multiple narrow circuit planes prevent
frequent reconfiguration Reconfiguration
Buffered, traverses packet-switched pipeline
10/20/2008 70Natalie Enright Jerger - PhD Defense

Packet-Switched Bandwidth Stealing Remember: problem with traditional
Circuit-Switching is poor bandwidth Need to overcome this limitation
Hybrid Circuit-Switched Solution: Packet-switched messages snoop incoming links When there are no circuit-switched
messages on the link A waiting packet-switched message can
steal idle bandwidth
10/20/2008 71Natalie Enright Jerger - PhD Defense
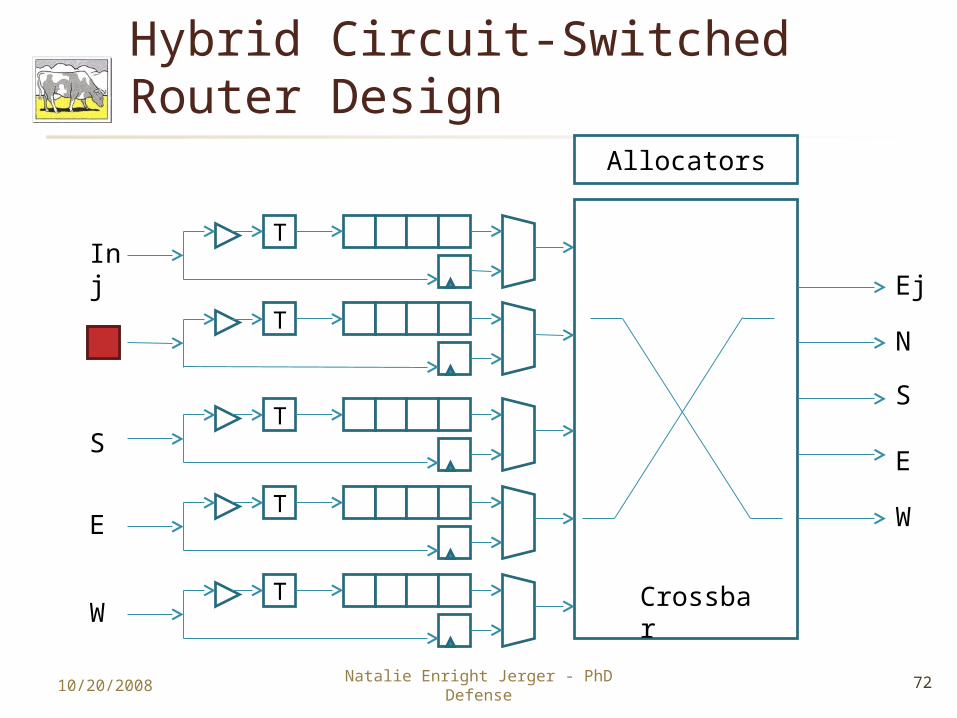
Hybrid Circuit-Switched Router Design
T
T
T
T
T
Allocators
Crossbar
Inj
N
S
E
W
W
E
S
N
Ej
10/20/2008Natalie Enright Jerger - PhD
Defense72
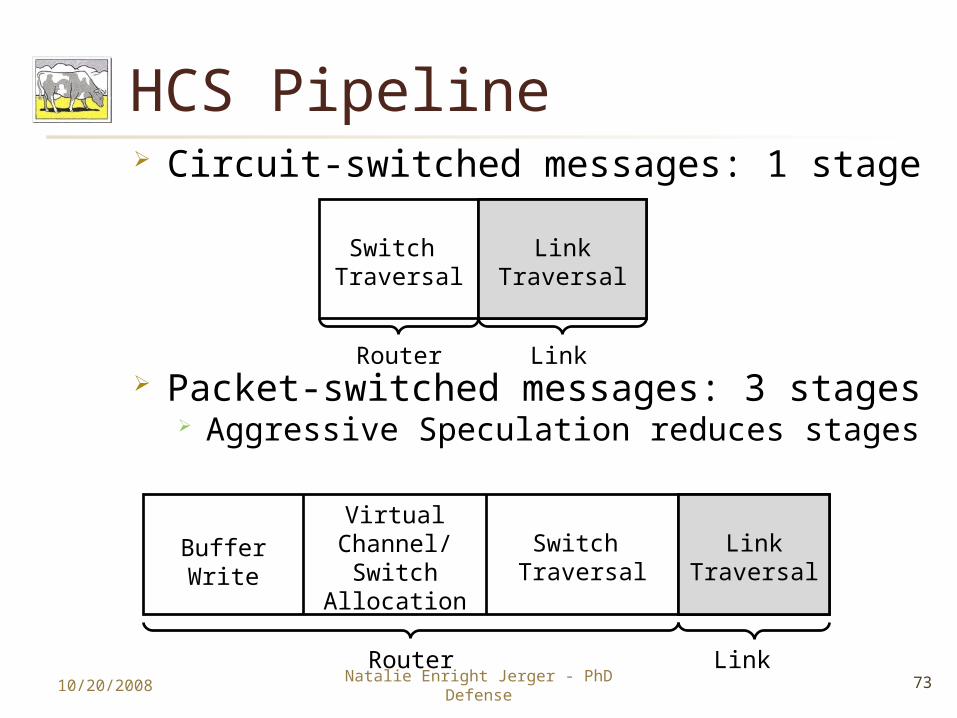
HCS Pipeline Circuit-switched messages: 1 stage
Packet-switched messages: 3 stages Aggressive Speculation reduces stages
Buffer Write
Virtual Channel/Switch
Allocation
Switch Traversal
Link Traversal
10/20/2008Natalie Enright Jerger - PhD
Defense
Switch Traversal
Link Traversal
73
Router Link
Router Link
Link Traversal
Link Traversal

Simulation Workloads
10/20/2008 74Natalie Enright Jerger - PhD Defense
Commercial
SPECjbb Java server workload24 warehouse, 200 requests
SPECweb Web server, 300 requests
TPC-W Web e-commerce, 40 transactions
TPC-H Decision support system
Scientific
Barnes-Hut 8k particles, full run
Ocean 514x514, parallel phase
Radiosity Parallel phase
Raytrace Car input, parallel phase
Synthetic
Uniform Random Destination select with uniform random distribution
Permutation Traffic
Each node communicates with one other node (pair-wise)

Simulation Configuration
Table with config parameters
10/20/2008 75Natalie Enright Jerger - PhD Defense
Processors
Cores 16 in-order general purpose
Memory System
L1 I/D Caches 32 KB 2-way set associative1 cycle
Private L2 caches 512 KB 4-way set associative6 cycles64 Byte lines
Shared L3 Cache 16 MB (1MB bank/tile)4-way set associative12 cycles
Main Memory Latency 100 cycles
Interconnect: 4x4 2-D Mesh
Packet-switched baseline Optimized 1-3 router stages4 Virtual channels with 4 Buffers each
Hybrid Circuit Switching 1 router stage2 or 4 Circuit planes

Network Results
Communication latency is key: shave off precious cycles in network latency
10/20/2008 76Natalie Enright Jerger - PhD Defense
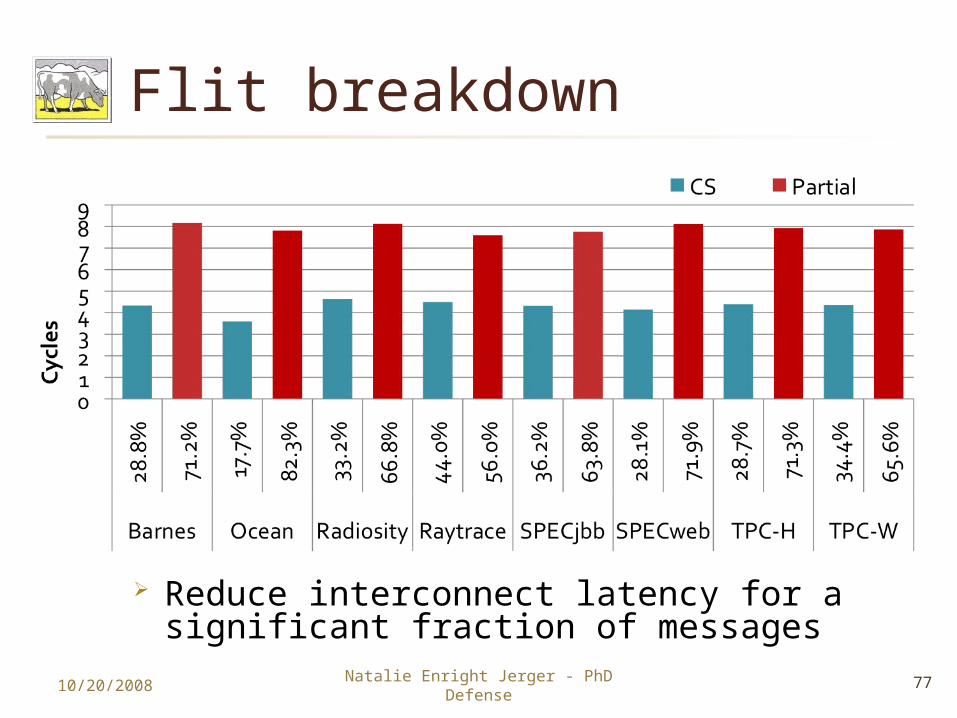
Flit breakdown
Reduce interconnect latency for a significant fraction of messages
10/20/2008 77Natalie Enright Jerger - PhD Defense

Uniform Random Traffic
HCS successfully overcomes bandwidth limitations associated with Circuit Switching
10/20/2008 78Natalie Enright Jerger - PhD Defense

HCS Conclusion Overcome the bandwidth limitations
of traditional circuit-switching Fast setup technique for low latency Improve performance
Network latency reduced by average of 18% (up to 22%)
Overall performance improvement: up to 7%
10/20/2008 79Natalie Enright Jerger - PhD Defense

Circuit-Switched Coherence (Extended)
Goal: Better exploit circuits through coherence protocol
Modifications: Allow a cache to send a request
directly to another cache Notify the directory in parallel Prediction mechanism for pair-wise
sharers Directory is sole ordering point
10/20/2008Natalie Enright Jerger - PhD
Defense80
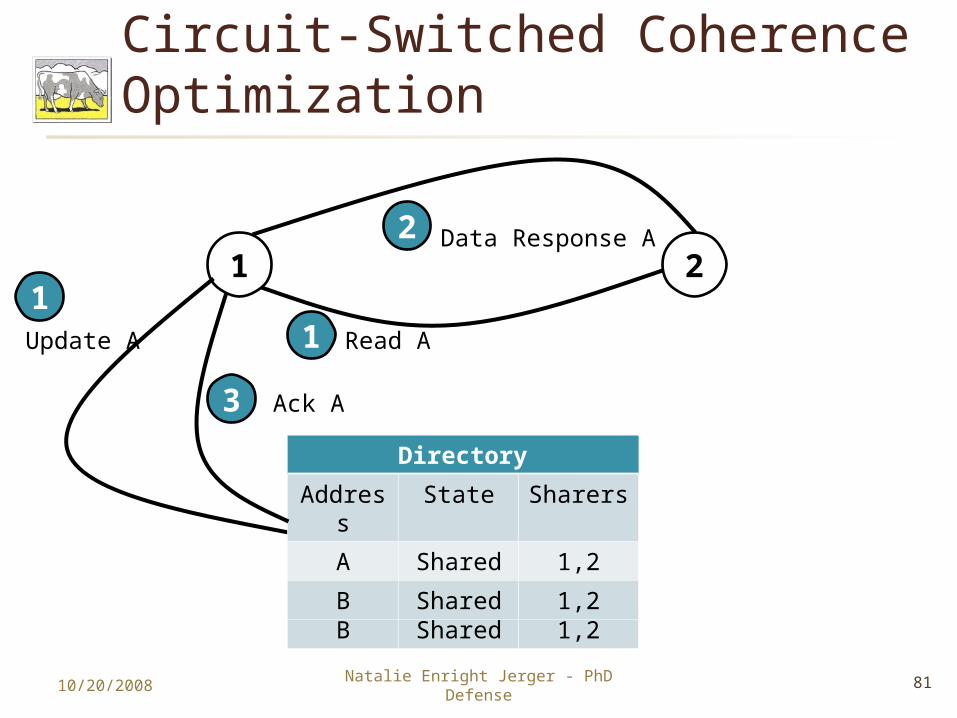
Circuit-Switched Coherence Optimization
10/20/2008 81Natalie Enright Jerger - PhD Defense
Directory
Address
State Sharers
A Exclusive
2
B Shared 1,2
1 2
Update A
1
Data Response A2
3
Directory
Address
State Sharers
A Shared 1,2
B Shared 1,2
Ack A
Read A1
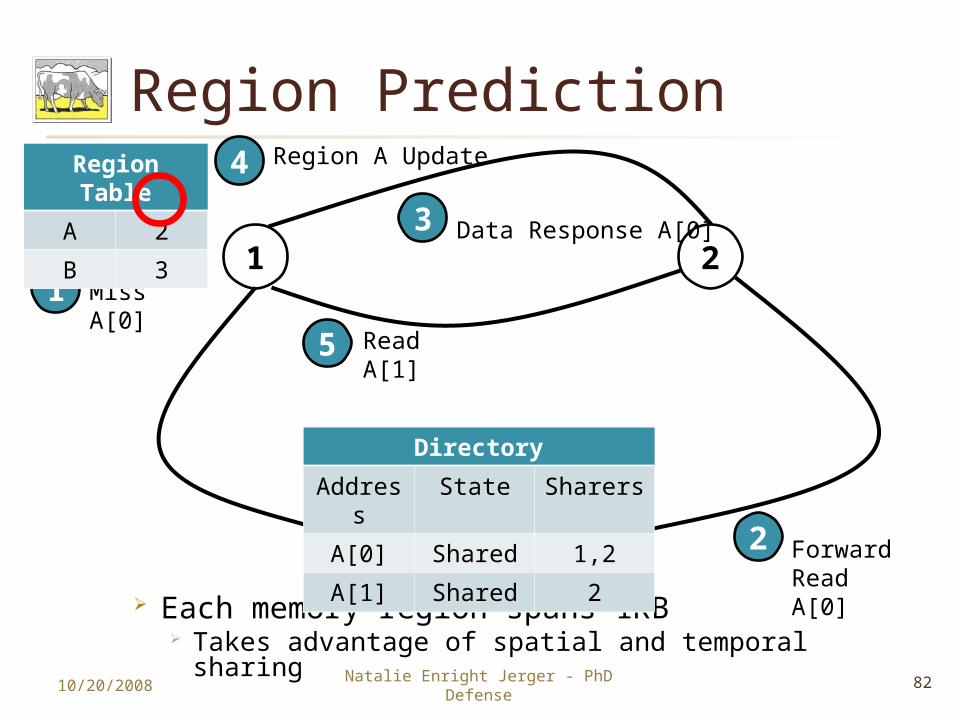
Region Prediction
Each memory region spans 1KB Takes advantage of spatial and temporal sharing
10/20/2008 82Natalie Enright Jerger - PhD Defense
Directory
Address
State Sharers
A[0] Shared 2
A[1] Shared 2
1 2Miss A[0]1
Forward Read A[0]
2
Data Response A[0]3
Region Table
A --
B 3
Region Table
A 2
B 3
Region A Update4
5 Read A[1]
Directory
Address
State Sharers
A[0] Shared 1,2
A[1] Shared 2

Simulation Configuration
Table with config parameters
10/20/2008 83Natalie Enright Jerger - PhD Defense
Processors
Cores 16 in-order general purpose
Memory System
L1 I/D Caches 32 KB 2-way set associative1 cycle
Private L2 caches 512 KB 4-way set associative6 cycles64 Byte lines
Shared L3 Cache 16 MB (1MB bank/tile)4-way set associative12 cycles
Main Memory Latency 100 cycles
Interconnect: 4x4 2-D Mesh
Packet-switched baseline Optimized 1-3 router stages4 Virtual channels with 4 Buffers each
Hybrid Circuit Switching 1 router stage2 or 4 Circuit planes

HCS + Protocol Optimization
Improvement of HCS + Protocol optimization is greater than the sum of HCS or Protocol Optimization alone.
Protocol Optimization drives up circuit reuse, better utilizing HCS
10/20/2008Natalie Enright Jerger - PhD
Defense84
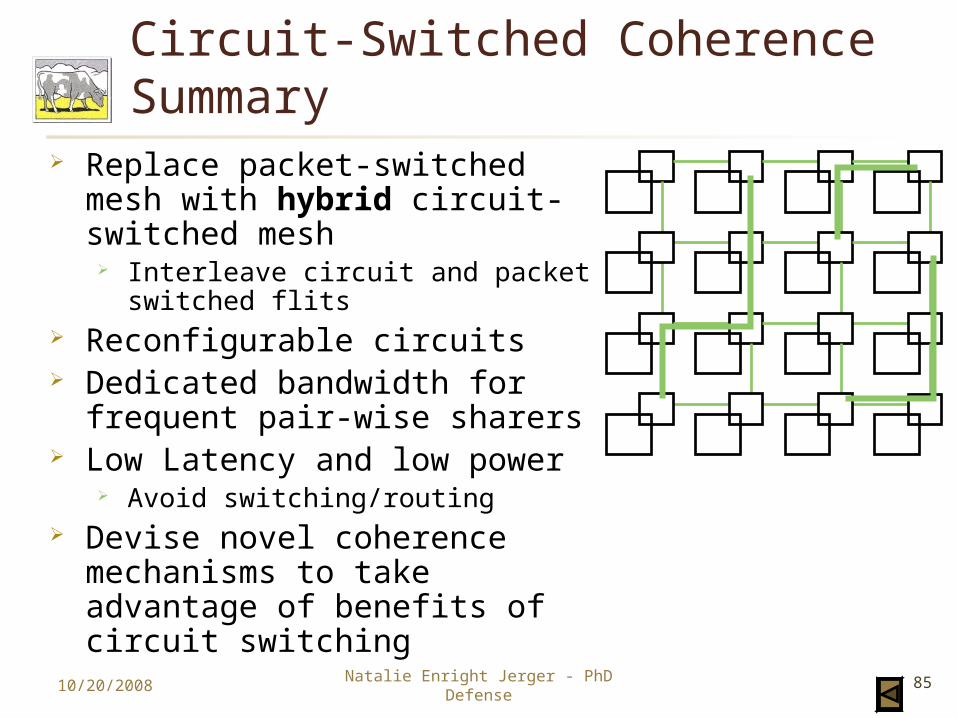
Circuit-Switched Coherence Summary
Replace packet-switched mesh with hybrid circuit-switched mesh
Interleave circuit and packet switched flits
Reconfigurable circuits Dedicated bandwidth for
frequent pair-wise sharers Low Latency and low power
Avoid switching/routing Devise novel coherence
mechanisms to take advantage of benefits of circuit switching
10/20/2008Natalie Enright Jerger - PhD
Defense85

Inter-Region Order (3)
Option 1: require acknowledgments from multicast sharers
Option 2: Coarse grain fences Fence between stores to different regions Significantly reduces acknowledgments Fence not required if previous region was held
in Exclusive10/20/2008 86Natalie Enright Jerger - PhD
Defense
P0 P1
Store A[0] Rd A[1]
Store A[1] Rd A[0]
If P1 observes the store to A[1], then it
has also observed A[0] because of tree
order
P0 P1
Store A Rd B
Store B Rd A
Delayed on Tree 1
Arrives quickly on Tree 2
Result: P1 reads new values of B and stale
value of A
Remote Reads to B cannot be satisfied
by P0 until acks collected for Fence
A, B
P0 P1
Store miss A Rd B
Implicit Fence A Rd A
Store miss B
Implicit Fence B

Inter-Region Order (4) Write Atomicity
10/20/2008 87Natalie Enright Jerger - PhD Defense
P0 P1 P2
A = 1 While (A == 0); While (B == 0);
B = 1 Rd A
A
P0 P1 P2
B
P2 reads B = 1, A = 0

Inter-Region Order (5) Write Atomicity
10/20/2008 88Natalie Enright Jerger - PhD Defense
Remote Reads to dirty/unfenced region
require fence to guarantee that store is visible to all
processors
P0 P1 P2
A = 1 While (A == 0); While (B == 0);
Remote Rd A Fence A
B = 1 Rd A
P1’s read of A cannot be satisfied until Fence A sunk
by everyoneP2 will Rd A = 1