cloud-enabled privacy-preserving collaborative learning ... · and storage costs are small,...
TRANSCRIPT

Cloud-Enabled Privacy-Preserving Collaborative Learning forMobile Sensing∗
Bin Liu, Yurong Jiang, Fei Sha, Ramesh GovindanDepartment of Computer ScienceUniversity of Southern California
{binliu, yurongji, feisha, ramesh}@usc.edu
AbstractIn this paper, we consider the design of a system in which
Internet-connected mobile users contribute sensor data astraining samples, and collaborate on building a model forclassification tasks such as activity or context recognition.Constructing the model can naturally be performed by a ser-vice running in the cloud, but users may be more inclinedto contribute training samples if the privacy of these datacould be ensured. Thus, in this paper, we focus onprivacy-preserving collaborative learningfor the mobile setting,which addresses several competing challenges not previ-ously considered in the literature: supporting complex clas-sification methods like support vector machines, respectingmobile computing and communication constraints, and en-abling user-determined privacy levels. Our approach, Pickle,ensures classification accuracy even in the presence of sig-nificantly perturbed training samples, is robust to methodsthat attempt to infer the original data or poison the model,and imposes minimal costs. We validate these claims usinga user study, many real-world datasets and two different im-plementations of Pickle.
Categories and Subject DescriptorsI.1.2 [Computing Methodologies]: Symbolic and Al-
gebraic Manipulation—Algorithms; K.4.1 [Computers andSociety]: Public Policy Issues—Privacy
General TermsAlgorithms, Human Factors, Security
Keywordsprivacy, mobile sensing, support vector machines∗ This research was partially sponsored by National Science Founda-
tion grant CNS-1048824 and CNS-0121778. Any opinions, findings andconclusions or recomendations expressed in this material are those of theauthor(s) and do not necessarily reflect the views of the National ScienceFoundation (NSF).
Permission to make digital or hard copies of all or part of this work for personal orclassroom use is granted without fee provided that copies are not made or distributedfor profit or commercial advantage and that copies bear this notice and the full citationon the first page. To copy otherwise, to republish, to post on servers or to redistributeto lists, requires prior specific permission and/or a fee.
SenSys’12,November 6–9, 2012, Toronto, ON, Canada.Copyright c© 2012 ACM 978-1-4503-1169-4 ...$10.00
1 IntroductionAs smartphones proliferate, their sensors are generating a
deluge of data. One tool for handling this data deluge is sta-tistical machine classification; classifiers can automaticallydistinguish activity, context, people, objects, and so forth.We envision classifiers being used extensively in the futureinmobile computing applications; already, many pieces of re-search have used standard machine learning classifiers (Sec-tion 5).
One way to build robust classifiers is throughcollabora-tive learning[42, 8, 5], in which mobile users contribute sen-sor data as training samples. For example, mobile users maysubmit statistical summaries (features) extracted from audiorecordings of their ambient environment, which can be usedto train a model to robustly recognize the environment that auser is in: a mall, an office, riding public transit, and so forth.Collaborative learning can leverage user diversity for robust-ness, since multiple users can more easily cover a wider va-riety of scenarios than a single user.
We envision that collaborative learning will be enabledby a software system that efficiently collects training sam-ples from contributors, generates statistical classifiers, andmakes these classifiers available to mobile users, or softwarevendors. In this paper, we address the challenges involved indesigning a system for collaborative learning. Such a systemmust support the popular classifiers (such as Support-VectorMachines or SVMs and k-Nearest Neighbors or kNNs), mustscale to hundred or more contributors, and must incentivizeuser contribution (Section2). To our knowledge, no priorwork has discussed the design of a collaborative learning sys-tem with these capabilities.
An impediment to scaling collaborative learning is thecomputational cost of constructing the classifier from train-ing data. With the advent of cloud computing, a natural wayto address this cost is to let mobile users submit their sensordata to a cloud service which performs the classifier con-struction. In such a design, however, to incentivize usersto participate in collaborative learning it is essential toen-sure the privacy of the submitted samples. Training sam-ples might accidentally contain sensitive information; fea-tures extracted from audio clips can be used to approximatelyreconstruct the original sound [41, 18], and may reveal over70% of the words in spoken sentences (Section4.1).
In this paper, we present Pickle, a novel approach toprivacy-preserving collaborative learning. Pickle is based

on the following observation: the popular classifiers relyon computing mathematical relationships such as the innerproducts and the Euclidean distances between pairs of sub-mitted training samples. Pickle perturbs the training dataon the mobile device using lightweight transformations topreserve the privacy of the individual training samples, butregresses these mathematical relationships between trainingsamples in a unique way, thereby preserving the accuracy ofclassification. Beyond addressing the challenges discussedabove, Pickle has many desirable properties: it requires nocoordination among users and all communication is betweena user and the cloud; it allows users to independently tunethe level of privacy for perturbing their submitted trainingsamples; finally, it can be made robust to poisoning attacksand is collusion-resistant. Pickle’s design is heavily influ-enced by the requirements of mobile sensing applications,and occupies a unique niche in the body of work on privacy-preserving methods for classifier construction (Section5).
A user study demonstrates that Pickle preserves privacyeffectively when building a speaker recognition classifier(Section4.1); less than 2% of words in sentences recon-structed by attacking Pickle transformations were recogniz-able, and most of these were stop words. Results froma prototype (Section4.2) show that Pickle communicationand storage costs are small, classification decisions can bemade quickly on modern smartphones, and model train-ing can be made to scale using parallelism. Finally, usingseveral datasets, we demonstrate (Section4.3) that Pickle’sprivacy-preserving perturbation is robust to regression at-tacks in which the cloud attempts to reconstruct the origi-nal training samples. The reconstructed samples are signif-icantly distributionally-different from the original samples.Despite this, Pickle achieves classification accuracy thatiswithin 5%, in many cases, of the accuracy obtained withoutany privacy transformation.
2 Motivation and ChallengesModern phones are equipped with a wide variety of sen-
sors. An emerging use of this sensing capability iscollabo-rative learning, where multiple users contribute individuallycollected training samples (usually extracted from raw sen-sor data) so as to collaboratively construct statistical modelsfor tasks in pattern recognition. In this paper, we explore thedesign of a system for collaborative learning.
What is Collaborative Learning? As an example of col-laborative learning, consider individual users who collect au-dio clips from their ambient environments. These users maybe part of a social network. Alternatively, they may haveno knowledge of each other and may have volunteered toprovide samples, in much the same way as volunteers signup for distributed computing efforts like SETI@HOME; inthis sense, we focus onopencollaborative learning. Train-ing samples extracted from these clips are collected and usedto build a classifier that can determine characteristics of theenvironment: e.g., determine whether a user is at home, ona bus, in a mall, or dining at a restaurant, etc. As anotherexample, consider a mobile health application that collectspatient vital signs to build a model for classifying diseases.
Collaborative learning results in classifiers of activity,orof environmental or physiological conditions etc. Manyproposed systems in the mobile sensing literature (e.g.,[35, 8, 10, 43, 4]) have used machine-learning classifiers, of-ten generated by using training samples from asingleuser.Due to the diversity of environments or human physiology,classifiers that use data from a single user may not be robustto a wide range of inputs. Collaborative learning overcomesthis limitation by exploiting the diversity in training samplesprovided by multiple users. More generally, collaborativelearning is applicable in cases, such as human activity recog-nition or SMS spam filtering, where a single user’s data is farfrom being representative.
Designing a system for collaborative learning sounds con-ceptually straightforward, but has many underlying chal-lenges. Before we describe these challenges, we give thereader a brief introduction to machine-learning classifiers.
The Basics of Classification. The first step in manymachine-learning algorithms isfeature extraction. In thisstep, the raw sensor data (an image, an audio clip, or othersensor data) are transformed into a vector of features thatare most likely to be relevant to the classification task athand. Examples of features in images include edges, con-tours, and blobs. For audio clips, the fundamental frequency,the spreads and the peaks of the spectrum, and the numberof harmonics are all examples of features.
Classifiers are first trained on a set of training samplesdenoted by:D = {(xxx1,y1),(xxx2,y2), . . . ,(xxxN,yN)} wherexxxi ∈R
P is the i-th training feature vector, andyi is a categoricalvariable representing the class to whichxxxi belongs. For ex-ample,xxxi may be a list of spectral features of an audio clip,andyi may identify this audio clip as “bus” (indicating theclip was recorded in a bus). In what follows, we useXXX todenote the data matrix withxxxi as column vectors, andU orV to refer to users.
The goal of classification is to construct a classifier usingD such that when presented with a new test feature vectorxxx, the classifier outputs a labely that approximatesxxx’s trueclass membership.
One popular, yet simple and powerful, classifier is the k-Nearest-Neighbor (kNN) classifier. Given a feature vectorxxxand a training setD, kNN finds thek training feature vectorswhich are the closest toxxx, in terms of the Euclidean distancebetween them:
‖xxx− xxxi‖22 = xxxTxxx−2xxxTxxxi + xxxT
i xxxi . (1)
The classifier then outputs the majority of all the nearestneighbors’ labels as the label forxxx (ties broken arbitrarily).
Support Vector Machine (SVM) is another popular andmore sophisticated classifier. It leverages a non-linear map-ping to mapxxx into a very high-dimensional feature space.In this feature space, it then seeks a linear decision bound-ary (i.e., a hyperplane) that partitions the feature space intodifferent classes [16]. For the purposes of this paper, twocomputational aspects of this classifier are most relevant:
• The training process of SVMs rely on computing either theinner productxxxT
i xxx j or the Euclidean distance‖xxxi −xxx j‖22 be-
tween pairs of training feature vectors.

• The resulting classifier is composed of one or more of thesubmitted training samples — support vectors.
Design Goals and Challenges.A system for open collabo-rative learning must support three desirable goals.
First, it mustsupport the most commonly-used classifierssuch as the Support Vector Machine (SVM) classifier and thek-Nearest Neighbor (kNN) classifier described above. Thesepopular classifiers are used often in the mobile sensing lit-erature for logical localization [7], collaborative video sens-ing [8], behavioral detection of malware [10], device iden-tification [40] and so on. Other pieces of work, such asCenceMe [43], EEMSS [4], and Nericell [44] could haveused SVM to get better classification performance.
Second, the system mustscaleto classifiers constructedusing training samples from 100 or more users. At this scale,it is possible to get significant diversity in the training sam-ples in order to enable robust classifiers. A major hurdle forscaling is computational complexity. Especially for SVM,the complexity of constructing the classifier is the dominantcomputational task, and using the classifier against test fea-ture vectors (i.e.,xxx above) is much less expensive. As we dis-cuss later, it takes a few hours on a modern PC to constructa classifier using data from over 100 users; as such, this isa task well beyond the capabilities of smartphones today. Aless crucial, but nevertheless important, scaling concernisnetwork bandwidth usage.
Third, the system must have the rightadoption incentivesto enable disparate users to contribute training samples: (1)The system must ensure theprivacy of the submitted sam-ples, as we discuss below; (2) It must be robust todatapoisoning, a legitimate concern in open collaborative learn-ing; (3) It must enable users who have not contributed tothe model to use the classifier, but must dis-incentivizefree-riderswho use classifiers directly obtained from other users.Of these, addressing the privacy goal is most intellectuallychallenging, since the construction of many popular classi-fiers, like SVM or kNN, requires calculations using accuratefeature vectors which may reveal privacy (Section3).
Consideration of economic incentives for collaborativelearning is beyond the scope of this paper; we assume thatcrowd sourcing frameworks like Amazon Mechanical Turk1
can be adapted to provide appropriate economic incentives.Cloud-Enabled, Privacy-Preserving Classification. Wepropose to use an approach in which mobile users submittraining samples (with associated labels) to a cloud, possiblyat different times over a period of hours or days; the cloudcomputes the classifier; the classifier is then sent to mobilephones and used for local classification tasks.
Using the cloud addresses the computational scaling chal-lenge, since classifier construction can be parallelized totakeadvantage of the cloud’s elastic computing capability. Thecloud provides a rendezvous point for convenient trainingdata collection from Internet-connected smartphones. Fi-nally, the cloud provides a platform on which it is possibleto develop a service that provides collaborative learning ofdifferent kinds of models (activity/context recognition,im-age classification, etc.). Indeed, we can make the following
1https://www.mturk.com/mturk/welcome
claim: to conveniently scale open collaborative learning,anInternet-connected cluster isnecessary, and the cloud infras-tructure has the right pay-as-you-go economic model sincedifferent collaborative learning tasks will have different com-putational requirements.
However, using the cloud makes it harder to achieve animportant design goal discussed above,privacy.
Privacy and the Threat Model. In cloud-enabled open col-laborative learning, users contribute several training samplesto the cloud. Each sample consists of a feature vectorxxx andthe associated labely. Both of these may potentially leakprivate information to the cloud (as we discuss below, in ourapproach we assume the cloud is untrusted), and we considereach in turn. Before doing so, we note thatusingthe classi-fier itself poses no privacy threat2, since smartphones haveenough compute power to perform the classification locally(Section4.2).
Depending upon the kind of classifier that the user is con-tributing to, the labely may leak information. For example,if the model is being used for activity recognition, a labelmay indicate that the user was walking or running at a giventime. In this paper, we do not consider label privacy becausethe userwillingly contributes the labeled feature vectors andshould have no expectation of privacy with regard to labels.
However, users may (or should, for reasons discussed be-low) have an expectation of privacy with respect to infor-mation that may be leaked by the feature vectors. Featurevectorsxxx often consist of a collection of statistical or spec-tral features of a signal (e.g., the mean, standard deviation orthe fundamental frequency).
Some features can leak private information. Consider fea-tures commonly used to distinguish speech from music ornoise [35]: the Energy Entropy, Zero-Crossing Rate, Spec-tral Rolloff, or Spectral Centroid etc. These statistics ofthespeech signals may, unintentionally, reveal information thatcan be used to extract, for example, age, gender or speakeridentity. In experiments we have conducted on audio clipsfrom the TIMIT dataset [20] (details omitted for brevity),female voices tend to have higher average spectral rolloffand average spectral centroid than male voices, while voicesof younger individuals have higher average energy entropyand lower average zero-crossing rate than voices of the aged.Similar age-related differences in measures of repeated ac-tivity have also been observed elsewhere [6].
Worse yet, a relatively recent finding has shown that,in some cases, feature vectors can be used to reconstructthe original raw sensor data. Specifically, a commonlyused feature vector in speech and music classification isthe Mel-frequency cepstrum coefficients (MFCC), whichare computed by a sequence of mathematical operations onthe frequency spectrum of the audio signals. A couple ofworks [41, 18] have shown that it is possible to approxi-mately reconstruct the original audio clips, given the MFCCfeature vectors. In Section4.1, we present the results of anexperiment that quantifies information leakage by MFCC re-construction.
2Assuming the user can trust the phone software; methods for ensuringthis are beyond the scope of this paper.

In the context of collaborative learning, this is an alarmingfinding. When a user submits a set of feature vectors andlabels them as being in a cafe (for example), the cloud maybe able to infer far more information than the user intendedto convey. When the original audio clips are reconstructed,they may reveal background conversations, the identity ofpatrons, and possibly even the location of the specific cafe.A recent, equally alarming, finding is that original imagesmay be reconstructed from their feature vectors [54].
Given these findings, we believe it is prudent to ensure theprivacy of feature vectors. The alternative approach, avoid-ing feature vectors that are known or might be suspected toreveal private information, can affect classification accuracyand may not therefore be desirable.
One way to preserve the privacy ofxxx is to generatexxx fromxxx and send onlyxxx the cloud, with the property that, with highlikelihood, the cloud cannot reconstructxxx from xxx. Our ap-proach randomly perturbs the feature vectors to generatexxx,but is able to reconstruct some of the essential properties ofthese feature vectors that are required for classifier construc-tion, without significantly sacrificing classifier accuracy. Aswe show later, approaches that use other methods like ho-momorphic encryption, secure multi-party communicationor differential privacy make restrictive assumptions thatdonot apply to our setting.
We make the following assumptions about the threatmodel. The user trusts the software on the mobile device tocompute and perturb feature vectors correctly, and to trans-mit only the perturbed feature vectors and the associated la-bels. The user does not trust other users who participate inthe collaborative learning, nor does she trust any componentof the cloud (e.g., the infrastructure, platforms or services)The cloud has probabilistic polynomial-time bounded com-puting resources and may attempt to reconstruct the originalfeature vectors. Servers on the cloud may collude with eachother, if necessary, to recontruct the original feature vectors.Moreover, the cloud may collude with userA to attempt to re-construct userB’s original feature vectors by directly sendingB’s perturbed feature vectors toA. Also, userB’s perturbedfeature vectors may be included in the classifiers sent toA,andA may try to reconstructB’s original feature vectors.
Given that the cloud is untrusted, what incentive is therefor the cloud to build the classifier correctly (i.e., why shouldusers trust the cloud for developing accurate classifiers)?Webelieve market pressures will force providers of the collab-orative learning “service” to provide accurate results, espe-cially if there is a revenue opportunity in collaborative learn-ing. Exploring these revenue opportunities is beyond thescope of this work, but we believe therewill be revenue op-portunities, since a service provider can sell accurate clas-sifers (of, for example, context) to a large population (e.g.,all Facebook users who may be interested in automaticallyupdating their status based on context).
3 Privacy-Preserving Collaborative LearningIn this section, we discuss a novel approach to preserving
the privacy of collaborative learning, called Pickle.
Training Data Training Data Training Data
1
Sta
tist
ics
Pu
blic V
ecto
rs
1 12
Pe
rtu
rbe
d D
ata
Pe
rturb
ed
Mo
de
l
2 2
1
2
Regression Phase
Training Phase
USER SIDE
CLOUD SIDE
Figure 1—Illustrating Pickle.
3.1 Pickle OverviewIn Pickle (Figure1), each user’s mobile phone takesN
training feature vectors, where each vector hasP elements,and pre-multiplies the resultingP×N matrix by aprivate,randommatrixRRR, whose dimensionality isQ×P. This mul-tiplication randomly perturbsthe training feature vectors.Moreover, we setQ < P, so thisreduces the dimensional-ity of each feature vector. A dimensionality-reducing trans-formation is more resilient to reconstruction attacks thanadimensionality preserving one [32]. In Pickle,RRR is private toa participant, so is not known to the cloud, nor to other par-ticipants (each participant generates his/her own privateran-dom matrix). This multiplicative perturbation by a private,random matrix is the key to achieving privacy in Pickle.
A dimensionality-reducing transformation does not pre-serve important relationships between the feature vectors,such as Euclidean distances and inner products. For instance,the inner product between two data pointsxxxi andxxx j now be-comesxxxT
i RRRTRRRxxx j . This is not identical toxxxTi xxx j unlessRRR is
an orthonormal matrix which necessarily preserves dimen-sionality. A dimensionality-reducing transformation canap-proximatelypreserve Euclidean distances [25], but even thisproperty is lost when different participants use differentpri-vate random matrices; in this case, the Euclidean distancesand inner products for perturbed feature vectors fromdif-ferent usersis no longer approximately preserved. Distor-tion in these relationships can significantly degrade classi-fication accuracy when used directly as inputs to classifiers(Section4.3).
In this paper, our focus is on methods that maintain highclassification accuracy while preserving privacy. The centralcontribution of this paper is the design of a novel approach toapproximately reconstruct those relationships using regres-sion, without compromising the privacy of the original fea-ture vectors, while still respecting the processing and com-munication constraints of mobile devices.
To do this, Pickle learns a statistical model to compen-sate for distortions in those relationships, then approximatelyreconstructs distance or inner-product relationships between

the users’ perturbed feature vectors, before finally construct-ing the classifier. Conceptually, here is how Pickle works.1. Users generate labeled raw data at their convenience: for
example, Pickle software on the phone may collect audioclips, then prompt the user to label the clips.
2. Once a piece of raw data is labeled, the software will ex-tract feature vectors, perturb them usingRRR, and uploadthem, along with the corresponding label, to the cloud;as an optimization, the software may batch the extractionand upload. (In what follows, we use the termuser, forbrevity, to mean the Pickle software running on a user’smobile device. Similarly, we use the termcloud to meanthe instance of Pickle software running on one or moreservers on a public cloud.)
3. When the cloud receives a sufficient number of labeledperturbed feature vectors from contributors (the numbermay depend on the classification task), it constructs theclassifier and sends a copy to each user.Before the classifier is generated, the cloud learns a model
to compensate for the distortion introduced by perturbation.Specifically, in thisregression phase:1. The cloud sends to each participating user a collection of
public feature vectors.2. The user perturbs the cloud-generated feature vectors us-
ing its private transformation matrix and returns the resultto the cloud.
3. The cloud employs regression methods to learn approx-imate functions for computing the desired mathematicalrelationships between feature vectors.
The key intuition behind our approach is as follows. Pat-tern classifiers can effectivelydiscriminatebetween differentclasses by leveraging the most important covariance struc-tures in the underlying training data. Our regression phaselearns these structures from the transformed representationson public data. However, our privacy transformation suffi-ciently masks the less important components that would berequired togeneratethe original feature vectors. This is whywe are able to build accurate classifiers even without beingable to regenerate the original feature vectors.
3.2 The Regression PhaseStep 1: Randomly Generate Public Feature Vectors.Inthis step, the cloud randomly generatesM (in our paper, wesetM to 3P) public feature vectors as aP×M matrixZZZ andsends this matrix to each user. The random public featurevectors have the same dimensionality as true feature vectors.In Pickle, the cloud synthesizes random public feature vec-tors using summary statistics provided byU users. In thismethod, each user sends to the cloud the mean and the co-variance matrix of its private training data, derived from afixed number (in our paper, 4P) of its feature vectors. Thecloud generates aZZZ thatapproximates the statistical charac-teristics of the training feature vectors ofall theU users; thismatrix, generated using an equally-weighted Gaussian mix-ture model that simulates the true distribution of user data, isused in the next two steps to learn relationships between thefeature vectors and arenot used to build classifiers.
This method never transmits actual private feature vec-tors to the cloud, so preserves our privacy goal. Moreover,
although the cloud knows the mean and the covariance, thisinformation is far from sufficient to generate accurate indi-vidual samples since two random draws from the same con-tinuous distribution have zero probability of being identical.Despite this, it is possible that sample statistics of the fea-ture vectors may leak some private information; to limit this,Pickle generates sample statistics from a very small number(4P) of data samples. Finally, in this step, the public featurevectors need not be labeled.Step 2: Perturb the Public Feature Vectors. The high-level idea in this step is to perturbZZZ in exactly the sameway as users would perturb the actual training feature vec-tors. Concretely, a userU generates a private random matrixRRRu
3, computes the perturbed public feature vectorsRRRuZZZ, andsendsRRRuZZZ to the cloud.
However, this approach has the following vulnerability. IfZZZ is invertible, the privateRRRu can be recovered by the cloudwhen it receives the perturbed vectorsRRRuZZZ: the cloud simplycomputesRRRuZZZZZZ−1.
To raise the bar higher, Pickle computes and sendsRRRu(ZZZ+εεεu) to the cloud, whereεεεu is an additive noise matrix. Thecloud would then need to knowRRRuεεεu in order to apply theinversion to obtain an accurateRRRu. Unlike the public featurevectorsZZZ, however,εεεu is private to the user. The elementsof RRRu are drawn randomly from either a Gaussian or a uni-form distribution.εεεu has the distribution ofN (εεεu;000,αuΣΣΣZ),whereΣΣΣZ is the (sample) covariance matrix ofZZZ. αu is tun-able, controlling theintensityof the additive noise [11]. Aswe show in Section4.3, higher privacy can be obtained byusing smaller values ofQ (i.e., greater reductions in dimen-sionality) or bigger values ofαu.Step 3: Regress. The regression step is executed on thecloud. We describe it for two users; extending it to multipleusers is straightforward. Assume usersU andV have chosenrandom matricesRRRu, εεεu andRRRv, εεεv respectively. The cloudreceivesZZZu = RRRu(ZZZ+ εεεu) and ZZZv = RRRv(ZZZ+ εεεv). The keyidea is to useZZZu andZZZv to approximate quantities which arepertinent to classification.
Concretely, letµ and ν be two indicator variables thatµ,ν ∈ {u,v}. Also, let zzzi stand for thei-th public featurevector andzzzµi the i-th transformed feature vector byRRRµ. Inother words,zzzi andzzzµi are thei-th columns ofZZZ andZZZµ.
Intuitively, we would like the cloud to be able to recoverthe original relationships from the perturbed feature vectors.For this, we learn four functions (fuu, fuv, fvu and fvv) in theform of fµν(zzzµi,zzzν j ;θθθµν) that can approximate well a certainfunction f (zzzi ,zzzj) of (particularly, the distances or the innerproducts between)zzzi andzzzj . θθθµν is the parameter vector ofthe function. Once these functions are learnt, they are ap-plied to actual training data sent by users (Section3.3).
The parameter vectorsθθθµν are thus of critical importance.To identify the optimal set of parameters, we have used lin-ear regression (LR). We now show how to approximately re-cover the concatenation of public feature vectorszzzi andzzzj
(i.e., f (zzzi ,zzzj) = [zzzTi ,zzz
Tj ]
T) using LR. The models then can be
3The user can choose a task-specificRRRu. However, once chosen, thematrix is fixed, though private to the user. A dynamically varying RRRu willincur high computational cost, due to the Regress phase in the next step.

used to compute inner products and distancesapproximatelyon transformed actual training feature vectors from users4.The approximated quantities will then be supplied to learn-ing algorithms to construct classifiers (Section3.3).
For each pair ofµ and ν, let QQQµν be the matrix whosecolumns are concatenatedzzzµi andzzzν j with M2 columns (thenumber of total possible concatenations isM2, since thereareM public feature vectors). Also, letZZZC denote the matrixwhose columns are concatenatedzzzi andzzzj . Note thatQQQµν has2Q rows, whereQ is the row-dimensionality of each user’sprivate transformation matrixRRRµ or RRRν (for simplicity of de-scription, we assume the dimensionality is the same for thetwo users; Pickle allows different users to choose differentQ). ZZZC has 2P rows, whereP is the row-dimensionality ofthe public or original feature vectors.
For linear regression, we use this equation to obtainθθθµνfor fµν
ZZZC = θθθµνQQQµν (2)
where the parameterθθθµν is a matrix with the size of(2P×2Q). The optimal parameter set is thus found in closed formasθθθµν = ZZZCQQQ+
µν, where+ denotes the pseudo-inverse.Our implementation of Pickle uses one optimization,
called iPoD. In iPoD, the cloud can avoid calculating theregression functionsfuu and fvv (i.e., whenµ = ν) by ask-ing users directly for the corresponding inner products cal-culated from their own feature vectors. These inner productsdo not reveal the individual feature vectors. This trades off alittle communication overhead (quantified in Section4.2) forimproved accuracy.
Instead of linear regression, we could have used GaussianProcess Regression (GPR). We have found in preliminary ex-periments that GPR marginally improves accuracy over LRbut is significantly more compute-intensive, so we omit a de-tailed description of GPR.
Finally, all the schemes described above extend to mul-tiple users naturally: Pickle simply computes 4 (or 2 whenusingiPoD) regression functions for every pair of users.3.3 Model Generation and ReturnBuilding the Classifier. After the cloud learns the functionsfµν with the procedure in the previous section, it is readyto construct pattern classifiers using training samples con-tributed by users. In this step of Pickle, each userU col-lects its training feature vectorsXXXu (in which each column isone feature vector), then perturbs these feature vectors withits privateRRRu. Each perturbed feature vector, together withits label, is then sent to the cloud. Using perturbed featurevectors from each user, the cloud generates the classificationmodel.
Let xxxui denote the unperturbedi-th feature vector fromuserU and likewisexxxv j for the userV . Moreover, let
xxxui = RRRuxxxui, xxxv j = RRRvxxxv j (3)
denote the perturbed feature vectors. Using the regressionparameters obtained from Equation (2), the cloud first at-
4It is also possible to directly regress inner products and distances us-ing the functions but we have experimentally found that directly regressingthese quantities does not result in improved accuracy over the methods de-scribed.
tempts to reconstruct the concatenation ofxxxui andxxxv j,[
xxxuixxxv j
]
≈ fuv(xxxui,xxxv j;θθθuv) = θθθuv
[
xxxuixxxv j
]
,
[
rrru jrrrv j
]
whererrru j andrrrv j areP-dimensional vectors. The cloud thenapproximates the inner product with the reconstructed fea-ture vectors,xxxT
uixxxv j ≈ rrrTuirrrv j. Similarly, to approximate the
distance between two feature vectors, we use5
‖xxxui − xxxv j‖22 ≈ rrrT
uirrrui −2rrrTuirrrv j + rrrT
v jrrrv j (4)
Once inner products or distances are approximated, thecloud can build SVM or kNN classifiers using the follow-ing simple substitution: whenever these algorithms need thedistances or inner products of two feature vectors, the ap-proximated values are used.
Model Return. In this step, the cloud returns the model tousers, so that classification may be performed on individualphones; for the details of the classification algorithms, werefer the interested reader to [16]. The information returneddepends upon the specific classifier (e.g., when using SVM,the support vectors must be returned), but must include allfunctionsfµν and associatedθθθµν parameters for every pair ofusers. These are required because the classification step inmany classifiers also computes distances or inner productsbetween the test feature vectors and training feature vectorspresented in the model (e.g., the support vectors in SVM);all of these vectors are perturbed so their distances and innerproducts must be estimated using thefµν functions.
3.4 Privacy AnalysisRecall that the privacy goal in Pickle is to ensure the com-
putational hardness of de-noising user contributions by thecloud (either by itself, or in collaboration with other users)and thereby inferringXXX. We now show a userU who fol-lows the steps of the protocol does not leak vital informationwhich can be used to de-noise user contributions. In the pro-tocol,U sends data to the cloud in Steps 1, 2 and 4only.
In Step 1,U sends the mean and covariance matrix of asmall number of its private training samples. Using this, thecloud can construct synthetic vectors whose first and second-order statistics match that ofU’s private data, but clearlycannot reconstructXXXuuu.
In Step 2,U sendsRRR(ZZZ+ εεε) to the cloud. One might as-sume that the cloud can filter out the additive noiseRRRεεε andthen recoverRRR by using the knownZZZ−1. However, exist-ing additive noise filtering techniques (such as spectral anal-ysis [26], principal component analysis, and Bayes estima-tion [22]) need to know at least the approximate mean andthe approximate covariance of the additive noise. In Pickle,the cloud cannot know, or estimate with any accuracy, the co-variance ofRRRεεε, since that depends uponRRR, a quantity privateto the user.
Finally, in Step 4,U sendsRRRXXX to the cloud. The pri-vacy properties of this dimensionality-reducing transformare proven in [32], which shows thatXXX cannot be recovered
5 In the iPoD optimization, the first and last terms of the RHS in (4) canbe obtained directly from the users.

without knowingRRR — that is because there are infinite fac-torizations ofXXX in the form of RRRXXX. In fact, even ifRRR isknown, because the resulting system of equations is under-determined, we can only reconstructXXX in the sense of mini-mum norm.
Given this, usingεεεu provides an additional layer of pri-vacy. εεεu is a random matrix with real-valued elements, soit is highly infeasible for an adversary to guess its valuessuccessfully using brute force. The adversary may attemptto find approximate values forεεεu, but would still be facedwith the challenge of determining whether the resulting ap-proximate value forRRRu is correct; the only way to do this isto attempt to reconstruct the original feature vectors and seeif they reveal (say) meaningful human speech or other rec-ognizable sounds, and this is also computationally hard, asdescribed above.
However, it may be possible for an attacker toapproxi-mate XXX using areconstruction attacks. In Section4.3, weshow that Pickle is robust to these attacks as well.
Finally, Pickle is robust to collusion between the cloudand users. Since each userU independentlyselects a secretRRR, and since its feature vectors are encoded using this secret,another user cannot directly compute any ofU’s original fea-ture vectors from perturbed feature vectors it receives fromthe cloud (for the same reason that the cloud itself cannotcompute these). A similar robustness claim holds for collu-sion between cloud servers.
3.5 Other Properties of PickleBesides ensuring the privacy of its training feature vec-
tors, Pickle has several other properties.Pickle iscomputationally-efficienton mobile devices, and
incurs minimal communication cost. It requires two matrixmultiplications (one for the regression stage and the otherduring training); classification steps require computing dis-tances or inner products. It transmits a few matrices, and aclassification model over the network. All of these, as weshall validate, require minimal resources on modern phones,and modest resources on the cloud infrastructure.
Pickle requires no coordinationamong participants andprovides flexible levels of privacy. Each user can indepen-dently choose the privacy transformation matrixRRR, and com-municates only with the cloud. Users can also independentlyset the level of desired privacy by selecting the dimensionsof RRR or the intensity of the additive noise matrixεεε. In Sec-tion 4.3, we explore the implications of these choices.
Pickledisincentivizes free-riding. A userU who does notcontribute training samples, can get the model from otherusers, but, to use it, must also participate in at least the re-gression phase so that the cloud can computefuv and fvu forall other usersV whose vectors are included in the classifier.
Although we have discussed Pickle in the context of clas-sification, it extends easily to other tasks like non-linearre-gression and estimating distributions; these tasks arise in thecontext of participatory sensing [1, 12, 23, 17, 5, 46].
Beyond SVM and kNN, Pickle can be applied to all ker-nel based classification and regression methods that use dis-tances or inner-products to establish relationships betweentraining samples. One can simply replace these distances
or inner products with approximations derived by applyingPickle’s regression functions.
Finally, Pickle can bemade robust to poisoning attacksin which a fewmalicious users attempt to inject bogus datain order to render the model unusable.6 For classificationalgorithms which build robust statistical models, attackersmust inject distributionally different feature vectors inorderto succeed. Prior work has examined these kinds of attacksand have proposed a distance-based approach, called Orca,to detecting poisoning attacks [9]. Because Pickle can ap-proximately preserve distances, the cloud can run Orca eventhough it receives only perturbed data, as shown in Sec-tion 4.3.
4 Evaluation of PickleIn this section, we perform three qualitatively different
kinds of evaluation: auser-studywhich brings out the bene-fits of Pickle, especially for applications like speaker recog-nition where the un-perturbed feature vectors are known toleak privacy;measurements on a prototypethat quantify theresource cost of Pickle; and an extensive characterizationof the privacy-accuracy tradeoffs in Pickle, together withacomparison of alternatives, using anevaluation on publicdata-sets.
4.1 Pickle Privacy: A User StudyIn a previous section, we asserted that a commonly used
feature vector for acoustic applications, MFCC, could beused to approximately reconstruct original audio clips. Inthis section, we demonstrate this using a small-scale user-study on acoustic data, and show that: a) a scheme like Pickleis necessary, since without it, almost the entire audio clipcan be reverse-engineered from unperturbed MFCC featurevectors; b) Pickle can mitigate this privacy leakage withoutsignificant loss in classification accuracy.
MFCC is widely used in acoustic mobile applications,like [35, 8, 34, 36, 42]. In particular, MFCC can be usedto recognize speakers [42, 34] or their genders [36]; collab-orative learning can be used to build models for both theseapplications. To quantify the efficacy of Pickle in MFCCfor speaker recognition, we used spoken sentences from fourvolunteers (two men and two women) in the TIMIT dataset[20], and trained SVM (with RBF) models by extracting thestandard 13-dimensional MFCC feature vectors from the au-dio clips, with and without Pickle. For Pickle feature vectorswith a 50% dimensionality reduction and a 0.3 intensity ofadditive noise (denoted by(50%,0.3)), recognition accuracyis degraded only by 4.32%! We leave a more detailed discus-sion of Pickle’s impact on accuracy for a later section, butnow demonstrate how, with minimal accuracy loss, Picklecan greatly reduce privacy leakage.
To this end, we conducted a user study which used eighttesting sentences (81 words) from the training set used toconstruct the classifier. For each sentence, users were asked
6 Attacks in which a majority of contributors poison the modelrequireother mechanisms. Such attacks can render a model completely useless forthe corresponding classification task. In that case, a company that sells thesecollaboratively-designed models may offer monetary incentives to contrib-utors, but only if the resulting model is shown to be accurate. Discussion ofsuch mechanisms is beyond the scope of the paper.

to listen to three versions of this sentence in the followingor-der: (i) aPickle-MFCCaudio clip generated by first applyinga reconstruction attack (Section4.3.3) to (50%,0.3) Pickle-transformed MFCC feature vectors7, and then applying [18]to reverse-engineer the audio clip from the estimated featurevector; (ii) anMFCC audio clip generated directly from theMFCC feature vectors using the method described in [18];and (iii) theoriginal audio clip. Users were asked to writedown all the words they recognized in each of the clips. Sev-enteen users participated in the study, having varying levelsof proficiency in English.
For each participant, we calculated twoRecognition Ra-tios (RRs)for each sentence: Pickle-MFCC RR, is the ratioof the number of words recognized from thePickle-MFCCclip divided by the number of words recognized in the origi-nal clip; and MFCC RR, is the ratio of the number of wordsrecognized in theMFCC clip to that recognized in the orig-inal clip. As Figure4.1 shows, Pickle offers very good pri-vacy protection; averaged across all sentences, Pickle hasan RR of only 1.75%, while the MFCC-reconstructed clipshave an RR of 73.88%. Of the words recognized in Pickle-ed clips, most were articles, prepositions or linking verbs,but three users recognized the phrase “below expectations”in one sentence, and one user recognized the words “infor-mative prospective buyer” in another sentence. These wordsprovide minimal information about the original sentences,since they lack vital context information.
While a more extensive user study is the subject of futurework, our study shows that, without Pickle, a collaborativelearning task for speaker recognition can leak a majority ofwords in audio clips when MFCC is used as a feature vector;using Pickle, a negligible minority is leaked.4.2 Pickle Resource Costs: Prototype Evalua-
tionPrototype System. We have implemented a prototype ofPickle (Figure4) which consists of two components: soft-ware forAndroid 2.3.4(about 8K lines of Java code, abouthalf of which is the Pickle-SVM engine) andWindows Mo-bile 6.5(about 11K lines of C# code, about 40% of which isthe Pickle-SVM engine), and software forthe cloud, writ-ten with .Net 4.0 framework (about 8K lines of code inC#, of which the Pickle-SVM engine is shared with thephone code). The prototype supports all functions requiredby Pickle, including regression parameter construction andinteraction, raw data collection, feature vector generation,transformation, upload and classification, user labeling,out-lier detection, model training, and model return. The phonesoftware supports the collection and processing of acceler-ation and acoustic data, and the cloud component builds aPickle-SVM classifier with four optional kernels. Supportfor other sensors and other classifiers is left to future work.Experimental Methodology.Using this prototype, we havecollected 16,000 accelerometer-based feature vectors, col-lected using smartphones, for the purpose of evaluating theresource costs for collaborative learning. For evaluatingcol-laborative training, we cluster these feature vectors among
7The MFCC feature vectors were generated using 25ms overlappingframes with an inter-frame “hop” length of 10ms
5 20 40 60 80 100 120 140 1600
100
200
300
400
500
600
700
The number of users
File
siz
e (
KB
)
Regression file size per user
Pickle-SVM model file size
SVM model file size
(a) Communication Cost
5 20 40 60 80 100 120 140 1600
2
4
6
8x 10
6
The number of users
Tim
e C
ost
(ms)
SVM Tr. - 1 core
Pickle-SVM Tr. - 1
Pickle-SVM Tr. - 2
Pickle-SVM Tr. - 4
Pickle-SVM Tr. - 8
Regression
(b) Processing CostFigure 5—Processing and Communication Cost
160 users each of whom submits, on average, 100 trainingsamples. As shown in Figure3, when each feature vec-tor has 16 dimensions, the resulting classifier has an accu-racy of over 97% even when feature vectors are perturbed by(50%,0.3). A more detailed analysis of classifier accuracyis discussed in Section4.3. Our data set is adversariallychosen; prior work on mobile-phone based sound classifi-cation [35] has used half the number of dimensions and anorder of magnitude smaller training data set. Thus, from ourexperiments, we hope to understand how high Pickle’s re-source costs can be in practice.
We report on experiments conducted on both a Nexus Oneand an HTC Pure phone and our “cloud” is emulated by acluster of four Intel(R) Core(TM)2 Duo 2.53 GHz PCs, with3GB RAM, running Windows 7.Communication Overhead. In Pickle, each user needs tosend the perturbed data,RRRuXXXu, and inner products calculatedfrom her own feature vectors,XXXT
u XXXu to the cloud, whichincurs communication overhead. (The overhead of send-ing the public feature vectorsZZZ and having each user returnRRRu(ZZZ+ εεεu) to the cloud is relatively small since the num-ber of feature vectors is small (Section3.2), so we do notreport the cost of this operation). Since our privacy transfor-mation reduces dimensionality, the communication cost ofsending the perturbed data is actually lower than the cost ofthe original data. In our experiment, we use a privacy trans-formation, with relatively higher communication cost, whichreduces dimensionality by only 25%, and adds 0.3 intensityadditive noise. In our implementation, each user’s perturbedtraining samples only requires 15KB for the transformed fea-ture vectors with labels and 94KB for the inner products. Forcomparison, the original training samples without perturba-tion require 21KB.
The final component of the communication cost is thesize of the returned model. This cost has two componentsfor Pickle-SVM: the set of model parameters and perturbedsupport vectors, and the collection of regression coefficients(each user needs to download only her own regression coef-ficients, not the entire set of coefficients). For 160 users, theformer is 222 KB (Figure5(a)), and the latter is 585 KB peruser. For comparison, the model size for 160 users withoutPickle is 264 KB. Pickle’s dimensionality-reduction resultsin a smaller model size.
Overall, these numbers are well within the realm of practi-cality, especially because our evaluation setting is adversarialand our implementation is un-optimized. For example, sim-ply compressing the data, a factor of 2-3 reduction in transferoverhead can be obtained.

0
0.2
0.4
0.6
0.8
1
#1 #2 #3 #4 #5 #6 #7 #8
RR
Sentence number
Pickle MFCC RR MFCC RR
Figure 2—User Study Results
0.95
0.96
0.97
0.98
0.99
1
4 8 16
Dimensionality
Accuracy
real (25%, 0.3) (50%, 0.3)
Figure 3—Accuracy of accelerometer-based classifier construction
WindowbasedFraming
WindowbasedFraming
Store andProcessingStore andProcessing
Pickle
Perturbation
Pickle
Perturbation
FeatureExtractionFeatureExtraction
LocalClassification
LocalClassification
StoreStoreOutlier
Detection andPre processing
OutlierDetection andPre processing
Cross Validationand Parameter
Search
Cross Validationand Parameter
Search
FourOptionalKernels
FourOptionalKernels
Mobile Phone Processing
CloudProcessin
g
Acceleration/AcousticWaveform
Other Use
LabelsProvided
Perturbed Datafrom other Users Feedback
Pickle RegressionParameters Obtained fromUser Cloud Interactions
Model
+
PerturbedData
Figure 4—Architecture of the prototype system
Computational Cost. On the mobile phone, it takes on av-erage (over 50 runs) of less than 1 ms on both the NexusOne and the HTC Pure to multiplicatively transform a featurevector. Classifying a test vector on large model constructedfrom 160 users takes on average 266.7 ms and 477.6 ms onthe two phones respectively. For comparison, classifying ona model generated from pure SVM (without perturbation)takes on average 128.1 ms and 231.6 ms on the two phones.The main overhead of Pickle comes from using the regres-sion coefficients to estimate distances from the vector to beclassified to the support vectors. Both of these numbers arereasonable, especially since our dataset is large.
On the cloud, the processing of outlier detection is veryfast – only 10.55 ms on average (all numbers averaged over10 runs). Computing regression coefficients for pairs ofusers is shown in Figure5(b), the average cost increasingfrom 0.55 s to 723s as the number of users increases from 5to 160. However, the cost of model generation on the cloudis significantly higher, on average about 2.13 hours on a sin-gle core. Without Pickle, model generation is a factor of 2faster (Figure5(b)). Again, Pickle’s overhead mainly comesfrom the regression calculations.
However, a major component of model generation, per-forming a grid search to estimate optimal parameters forPickle-SVM, can be parallelized, and we have implementedthis. As shown in Figure5(b), as the number of cores in-creases, an almost linear speed-up can be obtained; with 8cores, model generation time was reduced to 0.26 hours. De-vising more efficient parallel algorithms for model genera-tion is left to future work.
Finally, as discussed in Section3, a user who has not con-tributed feature vectors can use the generated model, but thecloud needs to compute regression coefficients for this newuser, relative to other users whose vectors are included in theclassifier model. This computation can be performed incre-mentally, requiring only 8.71s in our 160 users experiment,and adding 160 regression coefficient entries (222 KB) thatneed to be downloaded only by the new user.
4.3 Accuracy/Privacy Tradeoffs and Compar-isons: Dataset Evaluation
In this section, we evaluate Pickle’s ability to preserve pri-vacy without sacrificing classification accuracy by analyzingpublic datasets. We also explore the sensitivity of our resultsto the different design choices presented in Section3.
4.3.1 MethodologyData Sets. We use four datasets to validate Pickle:Iris,Pima Indians Diabetes, Wine, andVehicle Silhouettes. Thedatasets are from the UCI Machine Learning Repository8,and are some of the most widely-used datasets in themachine-learning community. All the feature values in eachdataset are scaled between 0 and 1.
Users.We partition each data set into several parts to simu-late multiple users with private data. To do this, we clusteredthe feature vectors in each data set using the standard K-means clustering algorithm and assigned each cluster to one“user”. (Random partitions would not have been adversarialenough as our main goal is to collaboratively learn from datawith disparatestatistics.) Using this method, the number ofusers is 2, 5, 2, 5 for the four datasets respectively.
Although these numbers of users are small relative to ourtargeted scale, we note that the level of privacy and the clas-sification accuracy arenot likely to become worse with moreusers. If anything, classification accuracy will improve withmore users since one has more and diverse training data.
In our experiments, we use all four datasets to evaluatethe performance with 2 users, and also use the Diabetes andVehicle datasets to test the performance with 5 users. Afterpartitioning the data across users, we randomly select 80%of the labeled feature vectors from each user as thetrainingdata, and use the remaining fortesting.
Classifiers. We evaluate the effectiveness of Pickle usingtwo common pattern classifiers: Support Vector Machine(SVM) and k-Nearest Neighbor (kNN). We experiment SVMwith the most widely-used RBF kernel as well as the Lin-ear kernel and tune SVM parameters using standard tech-niques like cross-validation and grid-search. We use a moreaccurate variant of kNN called LMNN [53] which uses Ma-halonobis distances instead of Euclidean distances.
4.3.2 Evaluation MetricsWe use two metrics to evaluate the effectiveness of Pickle.
The first assesses how much privacy is preserved and howlikely users’ private data are to be compromised. The sec-ond measures how much Pickle’s accuracy is affected by itsprivacy transformations.
The Privacy Metric. Pickle distorts feature vectors to“hide” them. One way to measure privacy is to quantify theextent of this distortion. We use a slightly more adversar-ial privacy metric from prior work [2, 49], which measures
8http://archive.ics.uci.edu/ml

0.3
0.4
0.5
0.6
0.7
Privacy
Diabetes Iris Wine Vehicle
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.1 0.2 0.3 0.4 0.5 0.1 0.2 0.3 0.4 0.5 0.1 0.2 0.3 0.4 0.5
25% 50% 75%
Privacy
Diabetes Iris Wine Vehicle
Figure 6—Effect of reconstruction attack on privacy
the “distance” between the original feature vector and an es-timate for that vector derived by mounting areconstructionattack. Specifically, letxxxd
u stand for thed-th dimension ofthe feature vectorxxxu, andhhhd
u be the corresponding dimen-sion in the reconstructed vector. Then, we can defineℓud(0≤ ℓud ≤ 1) to be the difference in thedistributionsof thesetwo quantities, and the privacy metricℓ (0≤ ℓ≤ 1) asℓud av-eraged over all users and dimensions.
Intuitively, the larger theℓ, the more confident we are thatprivacy is preserved. Whenℓ is zero, we are less confident.Note that we cannot infer directly that privacy is violatedwhen ℓ = 0, as the metric only measuresdifferencein ex-pectation. Furthermore, the metric is not perfect, since iftheoriginal and reconstructed vectors are distributionally differ-ent then, regardless of the magnitude of this difference,ℓ is1. Finally, we emphasize thatℓ is defined with respect to aspecific attack on the perturbed feature vectors.Classification Accuracy. A privacy transformation can ad-versely affect the classification accuracy, so we are interestedin measuring classification accuracy under different privacylevels. We compute the accuracy in a standard way, as thepercentage of correctly classified test feature vectors amongall test feature vectors. All reported results are averagedover20 random splits of training, validation and testing data sets.4.3.3 Attack models and Privacy
In Section3, we had already discussed a few attack strate-gies, to which Pickle is resilient. We now discuss some-what more sophisticated attacks that are based on an intimateknowledge of how Pickle works.The Reconstruction Attack. Dimensionality-reductiontechniques can be attacked byapproximatereconstruction.By reconstructing original data to the extent possible, theseattacks function as a preprocessing step to other types of at-tacks. In Pickle, the cloud sends the public dataZZZ to a userU and receives transformed onesZZZu = RRRu(ZZZ+ εεεu). Whilethe cloud cannot decipherRRRu andεεεu, can the cloud use itsknowledge to infer important statistical properties of thesevariables to approximatelyreconstructthe user’s data whenshe sends actual training vectors for building classifiers?Onepossible approach is to build a regression model such thatZZZ ≈ hu(ZZZu;βββ). When the user sendsRRRuXXXu, the cloud appliesthe regression model and tries to recoverHHHu ≈ hu(RRRuXXXu;βββ).
Figure6 shows that, even when this attack uses GaussianProcess Regression, Pickle still provides significant privacy.To generate the plot, we computeℓ for this attack, for variouscombinations of multiplicative and additive transformations:reducing the dimensionality for the multiplicative transformby 25%, 50% and 75% of the original dimensionality, and
adding noise with intensities (Section3.2) ranging from 0.1to 0.5 in steps of 0.1. The figure shows the resulting privacy-level metric for each combination of additive and multiplica-tive transforms under the attack; the resulting privacy levelsrange from 0.1-0.7. Thus, depending on the degree to whichthe training data have been transformed, Pickle can be sig-nificantly robust to this attack.
The intuition for why Pickle is robust to this reconstruc-tion attack is as follows. Pickle’s regression phase learnsabout relationships between users enough todiscriminateamongst them. However, the regression is not powerfulenough togeneratethe original samples; intuitively, muchmore information is necessary for generation than for dis-crimination.Followup ICA Attack. The cloud can also improve its es-timateHHHu with a followup strategy. For example, ICA canbe used for this purpose [32, 15]. However, we have ex-perimentally verified that this strategy is unsuccessful withPickle – the ICA algorithm fails to converge to meaningfulsolutions.4.3.4 Classifier Accuracy
In this section, we discuss results for the classification ac-curacy of SVM (with RBF and Linear kernels) and LMNN,using Pickle for 2 users from each dataset. Results for Di-abetes and Vehicle with 5 users are omitted but are qual-itatively similar except that they have higher classificationaccuracy because they have a larger training set. These ex-periments on each of our four data sets use abaseline con-figurationwhich uses synthesized public feature vectors andiPoD. In subsequent sections, we deviate from this baselineconfiguration to examine different design choices.
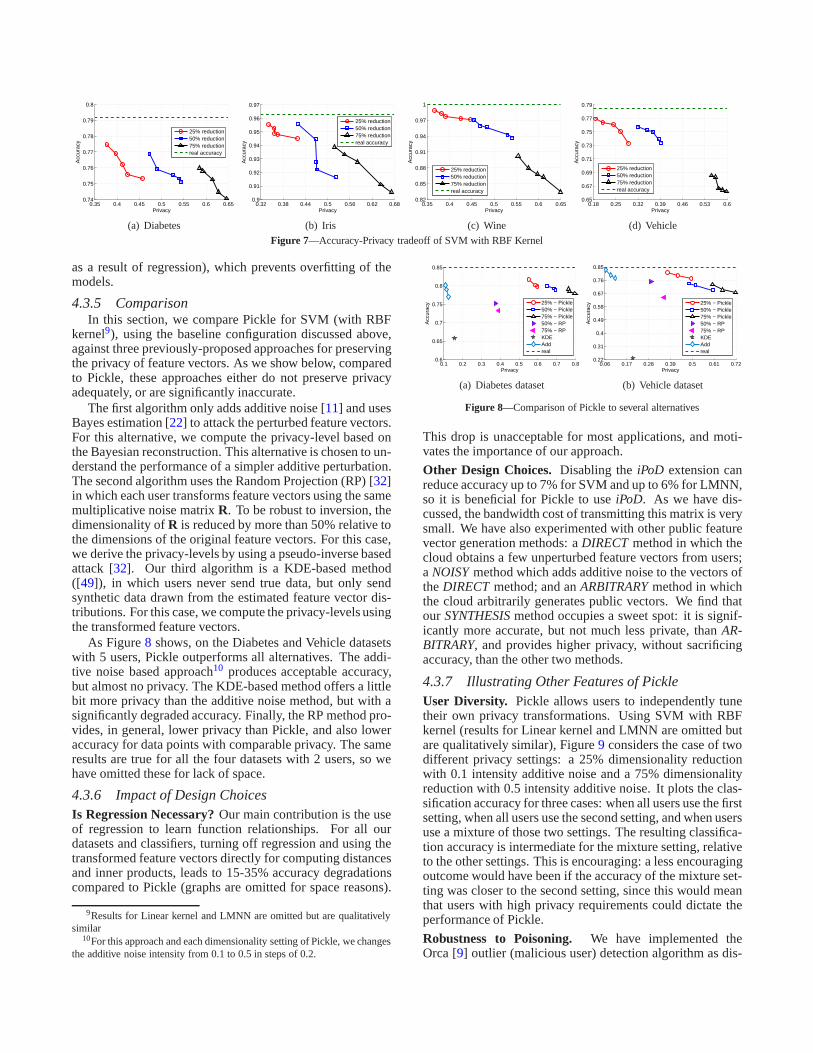
Figure 7 plots the classification accuracy for each dataset as a function of the privacy-level, for the SVM classifierwith the RBF kernel. In this plot, the horizontal line showsthe classification accuracy without Pickle. For this classifier,across all four data sets, the loss in classification accuracy isless than 6% for privacy levels up to 0.5; in the worst case(Wine) classification accuracy drops by 15% for a privacy-level of 0.65. This is an important result of the paper:evenwhen Pickle transforms data so that reconstructed featurevectors are distributionally different from the original ones,classification accuracy is only modestly affected.
Other features are evident from this figure. In general,classification accuracy drops with privacy-level, but the re-lationship is non-monotonic: for example, for the Diabetesdataset, 50% reduction with 0.1 intensity of additive noisehas higher privacy, but also higher accuracy than 25% with0.5 intensity. Second, the RBF kernel outperforms the Lin-ear kernel (graphs are omitted to save space) for which a 0.5privacy-level results in a 10% reduction in classification ac-curacy over all datasets, and nearly 20% in the worst case.
Finally, Pickle performs well even for nearest neighborclassification (figures omitted for space reasons). For LMNNwith k = 5, Pickle is within 5% of the actual classificationaccuracy for each data set for privacy levels to 0.5, and inthe worst case incurs a degradation of about 15%. Moreover,for LMNN, in some cases Pickle is even more accurate thanwithout any privacy transformations. This is likely due tothe regularization effect caused by noise (either additiveor
0.35 0.4 0.45 0.5 0.55 0.6 0.650.74
0.75
0.76
0.77
0.78
0.79
0.8
Privacy
Acc
urac
y
25% reduction50% reduction75% reductionreal accuracy
(a) Diabetes
0.32 0.38 0.44 0.5 0.56 0.62 0.680.9
0.91
0.92
0.93
0.94
0.95
0.96
0.97
Privacy
Acc
urac
y
25% reduction50% reduction75% reductionreal accuracy
(b) Iris
0.35 0.4 0.45 0.5 0.55 0.6 0.650.82
0.85
0.88
0.91
0.94
0.97
1
Privacy
Acc
urac
y
25% reduction50% reduction75% reductionreal accuracy
(c) Wine
0.18 0.25 0.32 0.39 0.46 0.53 0.60.65
0.67
0.69
0.71
0.73
0.75
0.77
0.79
Privacy
Acc
urac
y
25% reduction50% reduction75% reductionreal accuracy
(d) Vehicle
Figure 7—Accuracy-Privacy tradeoff of SVM with RBF Kernel
as a result of regression), which prevents overfitting of themodels.
4.3.5 ComparisonIn this section, we compare Pickle for SVM (with RBF
kernel9), using the baseline configuration discussed above,against three previously-proposed approaches for preservingthe privacy of feature vectors. As we show below, comparedto Pickle, these approaches either do not preserve privacyadequately, or are significantly inaccurate.
The first algorithm only adds additive noise [11] and usesBayes estimation [22] to attack the perturbed feature vectors.For this alternative, we compute the privacy-level based onthe Bayesian reconstruction. This alternative is chosen toun-derstand the performance of a simpler additive perturbation.The second algorithm uses the Random Projection (RP) [32]in which each user transforms feature vectors using the samemultiplicative noise matrixR. To be robust to inversion, thedimensionality ofR is reduced by more than 50% relative tothe dimensions of the original feature vectors. For this case,we derive the privacy-levels by using a pseudo-inverse basedattack [32]. Our third algorithm is a KDE-based method([49]), in which users never send true data, but only sendsynthetic data drawn from the estimated feature vector dis-tributions. For this case, we compute the privacy-levels usingthe transformed feature vectors.
As Figure8 shows, on the Diabetes and Vehicle datasetswith 5 users, Pickle outperforms all alternatives. The addi-tive noise based approach10 produces acceptable accuracy,but almost no privacy. The KDE-based method offers a littlebit more privacy than the additive noise method, but with asignificantly degraded accuracy. Finally, the RP method pro-vides, in general, lower privacy than Pickle, and also loweraccuracy for data points with comparable privacy. The sameresults are true for all the four datasets with 2 users, so wehave omitted these for lack of space.
4.3.6 Impact of Design ChoicesIs Regression Necessary?Our main contribution is the useof regression to learn function relationships. For all ourdatasets and classifiers, turning off regression and using thetransformed feature vectors directly for computing distancesand inner products, leads to 15-35% accuracy degradationscompared to Pickle (graphs are omitted for space reasons).
9Results for Linear kernel and LMNN are omitted but are qualitativelysimilar
10For this approach and each dimensionality setting of Pickle, we changesthe additive noise intensity from 0.1 to 0.5 in steps of 0.2.
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.80.6
0.65
0.7
0.75
0.8
0.85
Privacy
Acc
urac
y
25% − Pickle50% − Pickle75% − Pickle50% − RP75% − RPKDEAddreal
(a) Diabetes dataset
0.06 0.17 0.28 0.39 0.5 0.61 0.720.22
0.31
0.4
0.49
0.58
0.67
0.76
0.85
Privacy
Acc
urac
y
25% − Pickle50% − Pickle75% − Pickle50% − RP75% − RPKDEAddreal
(b) Vehicle dataset
Figure 8—Comparison of Pickle to several alternatives
This drop is unacceptable for most applications, and moti-vates the importance of our approach.
Other Design Choices. Disabling theiPoD extension canreduce accuracy up to 7% for SVM and up to 6% for LMNN,so it is beneficial for Pickle to useiPoD. As we have dis-cussed, the bandwidth cost of transmitting this matrix is verysmall. We have also experimented with other public featurevector generation methods: aDIRECTmethod in which thecloud obtains a few unperturbed feature vectors from users;a NOISYmethod which adds additive noise to the vectors oftheDIRECTmethod; and anARBITRARYmethod in whichthe cloud arbitrarily generates public vectors. We find thatour SYNTHESISmethod occupies a sweet spot: it is signif-icantly more accurate, but not much less private, thanAR-BITRARY, and provides higher privacy, without sacrificingaccuracy, than the other two methods.
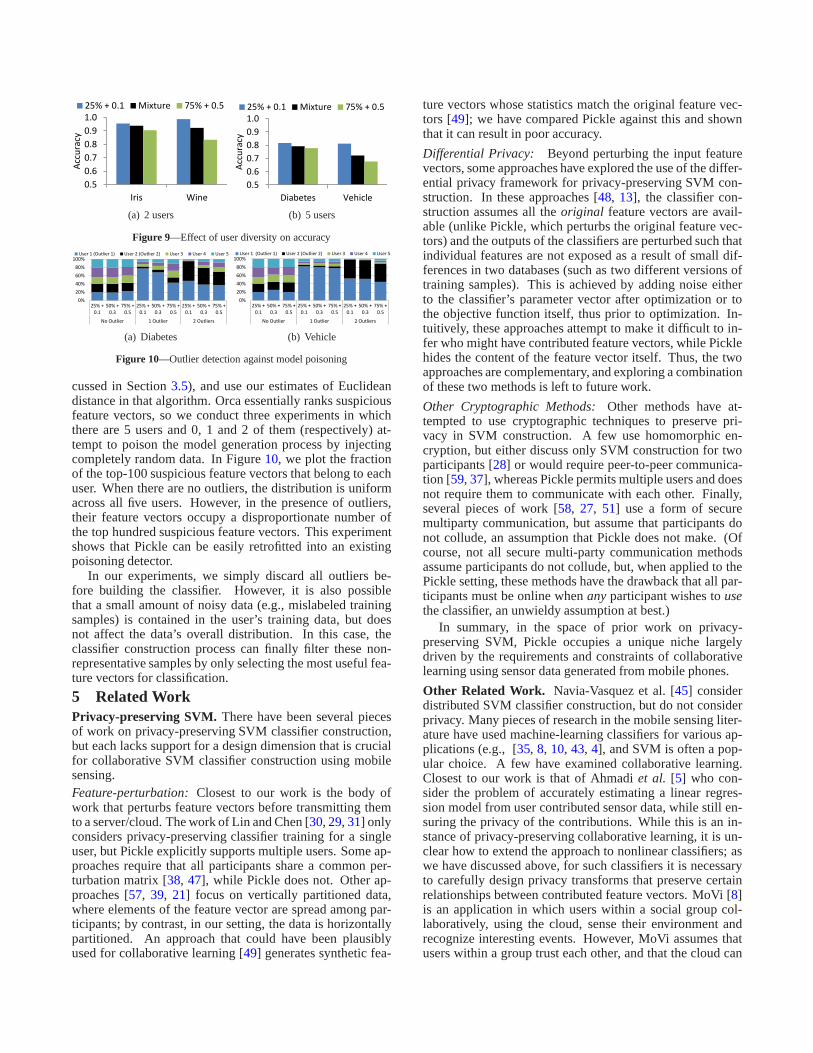
4.3.7 Illustrating Other Features of PickleUser Diversity. Pickle allows users to independently tunetheir own privacy transformations. Using SVM with RBFkernel (results for Linear kernel and LMNN are omitted butare qualitatively similar), Figure9 considers the case of twodifferent privacy settings: a 25% dimensionality reductionwith 0.1 intensity additive noise and a 75% dimensionalityreduction with 0.5 intensity additive noise. It plots the clas-sification accuracy for three cases: when all users use the firstsetting, when all users use the second setting, and when usersuse a mixture of those two settings. The resulting classifica-tion accuracy is intermediate for the mixture setting, relativeto the other settings. This is encouraging: a less encouragingoutcome would have been if the accuracy of the mixture set-ting was closer to the second setting, since this would meanthat users with high privacy requirements could dictate theperformance of Pickle.
Robustness to Poisoning. We have implemented theOrca [9] outlier (malicious user) detection algorithm as dis-
0.5
0.6
0.7
0.8
0.9
1.0
Iris Wine
Acc
ura
cy
25% + 0.1 Mixture 75% + 0.5
(a) 2 users
75% + 0.5
0.5
0.6
0.7
0.8
0.9
1.0
Diabetes Vehicle
Acc
ura
cy
25% + 0.1 Mixture 75% + 0.5
(b) 5 users
Figure 9—Effect of user diversity on accuracy
0%
20%
40%
60%
80%
100%
25% +
0.1
50% +
0.3
75% +
0.5
25% +
0.1
50% +
0.3
75% +
0.5
25% +
0.1
50% +
0.3
75% +
0.5
No Outlier 1 Outlier 2 Outliers
User 1 (Outlier 1) User 2 (Outlier 2) User 3 User 4 User 5
(a) Diabetes
User 5
0%
20%
40%
60%
80%
100%
25% +
0.1
50% +
0.3
75% +
0.5
25% +
0.1
50% +
0.3
75% +
0.5
25% +
0.1
50% +
0.3
75% +
0.5
No Outlier 1 Outlier 2 Outliers
User 1 (Outlier 1) User 2 (Outlier 2) User 3 User 4 User 5
(b) Vehicle
Figure 10—Outlier detection against model poisoning
cussed in Section3.5), and use our estimates of Euclideandistance in that algorithm. Orca essentially ranks suspiciousfeature vectors, so we conduct three experiments in whichthere are 5 users and 0, 1 and 2 of them (respectively) at-tempt to poison the model generation process by injectingcompletely random data. In Figure10, we plot the fractionof the top-100 suspicious feature vectors that belong to eachuser. When there are no outliers, the distribution is uniformacross all five users. However, in the presence of outliers,their feature vectors occupy a disproportionate number ofthe top hundred suspicious feature vectors. This experimentshows that Pickle can be easily retrofitted into an existingpoisoning detector.
In our experiments, we simply discard all outliers be-fore building the classifier. However, it is also possiblethat a small amount of noisy data (e.g., mislabeled trainingsamples) is contained in the user’s training data, but doesnot affect the data’s overall distribution. In this case, theclassifier construction process can finally filter these non-representative samples by only selecting the most useful fea-ture vectors for classification.
5 Related WorkPrivacy-preserving SVM. There have been several piecesof work on privacy-preserving SVM classifier construction,but each lacks support for a design dimension that is crucialfor collaborative SVM classifier construction using mobilesensing.Feature-perturbation:Closest to our work is the body ofwork that perturbs feature vectors before transmitting themto a server/cloud. The work of Lin and Chen [30, 29, 31] onlyconsiders privacy-preserving classifier training for a singleuser, but Pickle explicitly supports multiple users. Some ap-proaches require that all participants share a common per-turbation matrix [38, 47], while Pickle does not. Other ap-proaches [57, 39, 21] focus on vertically partitioned data,where elements of the feature vector are spread among par-ticipants; by contrast, in our setting, the data is horizontallypartitioned. An approach that could have been plausiblyused for collaborative learning [49] generates synthetic fea-
ture vectors whose statistics match the original feature vec-tors [49]; we have compared Pickle against this and shownthat it can result in poor accuracy.
Differential Privacy: Beyond perturbing the input featurevectors, some approaches have explored the use of the differ-ential privacy framework for privacy-preserving SVM con-struction. In these approaches [48, 13], the classifier con-struction assumes all theoriginal feature vectors are avail-able (unlike Pickle, which perturbs the original feature vec-tors) and the outputs of the classifiers are perturbed such thatindividual features are not exposed as a result of small dif-ferences in two databases (such as two different versions oftraining samples). This is achieved by adding noise eitherto the classifier’s parameter vector after optimization or tothe objective function itself, thus prior to optimization.In-tuitively, these approaches attempt to make it difficult to in-fer who might have contributed feature vectors, while Picklehides the content of the feature vector itself. Thus, the twoapproaches are complementary, and exploring a combinationof these two methods is left to future work.
Other Cryptographic Methods:Other methods have at-tempted to use cryptographic techniques to preserve pri-vacy in SVM construction. A few use homomorphic en-cryption, but either discuss only SVM construction for twoparticipants [28] or would require peer-to-peer communica-tion [59, 37], whereas Pickle permits multiple users and doesnot require them to communicate with each other. Finally,several pieces of work [58, 27, 51] use a form of securemultiparty communication, but assume that participants donot collude, an assumption that Pickle does not make. (Ofcourse, not all secure multi-party communication methodsassume participants do not collude, but, when applied to thePickle setting, these methods have the drawback that all par-ticipants must be online whenanyparticipant wishes tousethe classifier, an unwieldy assumption at best.)
In summary, in the space of prior work on privacy-preserving SVM, Pickle occupies a unique niche largelydriven by the requirements and constraints of collaborativelearning using sensor data generated from mobile phones.
Other Related Work. Navia-Vasquez et al. [45] considerdistributed SVM classifier construction, but do not considerprivacy. Many pieces of research in the mobile sensing liter-ature have used machine-learning classifiers for various ap-plications (e.g., [35, 8, 10, 43, 4], and SVM is often a pop-ular choice. A few have examined collaborative learning.Closest to our work is that of Ahmadiet al. [5] who con-sider the problem of accurately estimating a linear regres-sion model from user contributed sensor data, while still en-suring the privacy of the contributions. While this is an in-stance of privacy-preserving collaborative learning, it is un-clear how to extend the approach to nonlinear classifiers; aswe have discussed above, for such classifiers it is necessaryto carefully design privacy transforms that preserve certainrelationships between contributed feature vectors. MoVi [8]is an application in which users within a social group col-laboratively, using the cloud, sense their environment andrecognize interesting events. However, MoVi assumes thatusers within a group trust each other, and that the cloud can

be trusted not to reveal data from one group to third parties.Finally, Darwin [42] directly addresses collaborative learn-ing, but does not address privacy and assumes a trustworthycloud.
Privacy-preservation has, in general, received much moreattention in the data mining community which has consid-ered cryptographic methods (e.g., [50, 24]) for clusteringand other mining operations. In general, these methodsdo not scale to many users and require computationally-intensive encoding and decoding operations. That commu-nity has also considered anonymization of structured data(such as relational tables) to ensure privacy of individualen-tries without significantly compromising query results. Bynow, it is well known that anonymization is vulnerable tocomposition attacks using side information [19].
Preserving privacy throughperturbationor randomiza-tion is most relevant to our work. One body of work has con-sidered data perturbation techniques for datasets using vari-ous methods [56, 52, 55, 33] for dataset exchange betweentwo parties; it is unclear how to extend this body of work toPickle’s multi-party setting where the parties are assumedtobe able to collude. Additive-noise based randomization per-turbs the original data with additive noise (e.g., [3, 2]), butis susceptible toreconstruction attacks, in which the spec-tral properties of the perturbed data can be used to filter theadditive noise and recover the original data [26]. Multiplica-tive noise based perturbation (e.g., [14, 32]) can be robustto these reconstruction attacks. In some approaches (e.g.,[14]), the multiplicative noise is dimensionality-preservingwhile in others [32], it is not. Dimensionality-preservingtransformations can preserve inner products and Euclideandistances. Unfortunately, a dimensionality-preserving mul-tiplicative transformation is susceptible toapproximate re-construction[32]. Furthermore, if this method is applied tocollaborative learning, then participants must agree uponthematrix RRR, and collusion attacks may succeed. It is for thisreason that Pickle uses a dimensionality-reducing transfor-mation using per-user private matrices, and then uses a re-gression phase to recover inter-user relationships so thatitcan approximately infer Euclidean distances and inner prod-ucts.
6 ConclusionsIn this paper, we have described Pickle, an approach to
preserving privacy in mobile collaborative learning. Pickleperturbs training feature vectors submitted by users, but usesa novel regression technique to learn relationships betweentraining data that are required to maintain classifier accuracy.Pickle is robust, by design, to many kinds of attacks includ-ing direct inversion, collusion, reconstruction, and poison-ing. Despite this, Pickle shows remarkable classification ac-curacy for the most commonly used classifiers, SVM andkNN. Finally, Pickle requires minimal computing resourceson the mobile device, and modest resources on the cloud.Many avenues for future work remain, including an explo-ration of more sophisticated regression methods and otherclassifiers, an extension of applying Pickle to participatory
sensing, a more extensive and refined design of user study,and a cryptanalysis of our dimensionality-reduction.
Acknowledgements.We thank the anonymous referees andour shepherd Srdjan Capkun for their comments. We aregrateful to members of the Embedded Networks Laboratorywho participated in the user study.
7 References[1] T. Abdelzaher, Y. Anokwa, P. Boda, J. Burke, D. Estrin, L.Guibas,
A. Kansal, S. Madden, and J. Reich. Mobiscopes for human spaces.IEEE Pervasive Computing, 6(2), 2007.
[2] D. Agrawal and C. Aggarwal. On the design and quantification ofprivacy preserving data mining algorithms. InProceedings of the20th ACM SIGMOD-SIGACT-SIGART Symposium on Principles ofDatabase Systems (PODS ’01), 2001.
[3] R. Agrawal and R. Srikant. Privacy-preserving data mining. In Pro-ceedings of the 2000 ACM Special Interest Group on Management OfData (SIGMOD ’00), 2000.
[4] H. Ahmadi, N. Pham, R. Ganti, T. Abdelzaher, S. Nath, and J. Han.A framework of energy efficient mobile sensing for automatichumanstate recognition. InProceedings of the 7th International Conferenceon Mobile Systems, Applications, and Services (MobiSys ’09), 2009.
[5] H. Ahmadi, N. Pham, R. Ganti, T. Abdelzaher, S. Nath, and J. Han.Privacy-aware regression modeling of participatory sensing data. InProceedings of the 8th ACM Conference on Embedded Network Sen-sor Systems (SenSys ’10), 2010.
[6] M. Almeida, G. Cavalheiro, A. Pereira, and A. Andrade. Investiga-tion of age-related changes in physiological kinetic tremor. Annals ofBiomedical Engineering, 38(11), 2010.
[7] M. Azizyan, I. Constandache, and R. Choudhury. Surroundsense: mo-bile phone localization via ambience fingerprinting. InProceedings ofthe 15th Annual International Conference on Mobile Computing andNetworking (Mobicom ’09), 2009.
[8] X. Bao and R. Choudhury. Movi: mobile phone based video highlightsvia collaborative sensing. InProceedings of the 8th International Con-ference on Mobile Systems, Applications, and Services (MobiSys ’10),2010.
[9] S. Bay and M. Schwabacher. Mining distance-based outliers in nearlinear time with randomization and a simple pruning rule. InProceed-ings of the 9th ACM Special Interest Group on Knowledge Discoveryand Data mining (SIGKDD ’03), 2003.
[10] A. Bose, X. Hu, K. Shin, and T. Park. Behavioral detection of malwareon mobile handsets. InProceedings of the 6th International Confer-ence on Mobile Systems, Applications, and Services (MobiSys ’08),2008.
[11] R. Brand. Microdata protection through noise addition. InferenceControl in Statistical Databases, 2002.
[12] J. Burke, D. Estrin, M. Hansen, A. Parker, N. Ramanathan, S. Reddy,and M. Srivastava. Participatory sensing. InProceedings of the 2006World Sensor Web Workshop, 2006.
[13] K. Chaudhuri, C. Monteleoni, and A. Sarwate. Differentially privateempirical risk minimization.Journal of Machine Learning Research,12, 2011.
[14] K. Chen and L. Liu. Privacy-preserving data classification with rota-tion perturbation. InProceedings of the 5th IEEE International Con-ference on Data Mining (ICDM ’05), 2005.
[15] K. Chen and L. Liu. Towards attack-resilient geometricdata perturba-tion. In SIAM International Conference on Data Mining (SDM ’07),2007.
[16] C. Cortes and V. Vapnik. Support-vector network.Machine Learning,20(3):273–297, 1995.
[17] S. Eisenman, E. Miluzzo, N. Lane, R. Peterson, G. Ahn, and A. Camp-bell. The bikenet mobile sensing system for cyclist experience map-ping. In Proceedings of the 5th ACM Conference on Embedded Net-work Sensor Systems (SenSys ’07), 2007.
[18] D. Ellis. PLP and RASTA (and MFCC, and inversion) in Matlab,2005. online web resource.

[19] S. Ganta, S. Kasiviswanathan, and A. Smith. Composition attacksand auxiliary information in data privacy. InProceedings of the 14thACM SIGKDD International Conference on Knowledge Discoveryand Data Mining (SIGKDD ’08), 2008.
[20] J. Garofolo, L. Lamel, W. Fisher, J. Fiscus, D. Pallett,andN. Dahlgren. Darpa timit acoustic phonetic continuous speech cor-pus cdrom, 1993.
[21] Y. Hu, F. Liang, and G. He. Privacy-preserving svm classification onvertically partitioned data without secure multi-party computation. InProceedings of the 5th International Conference on NaturalCompu-tation (ICNC ’09), 2009.
[22] Z. Huang, W. Du, and B. Chen. Deriving private information fromrandomized data. InProceedings of the 2005 ACM Special InterestGroup on Management Of Data (SIGMOD ’05), 2005.
[23] B. Hull, V. Bychkovsky, Y. Zhang, K. Chen, M. Goraczko, A. Miu,E. Shih, H. Balakrishnan, and S. Madden. Cartel: a distributed mobilesensor computing system. InProceedings of the 4th ACM Conferenceon Embedded Network Sensor Systems (SenSys ’06), 2006.
[24] G. Jagannathan and R. Wright. Privacy-preserving distributed k-means clustering over arbitrarily partitioned data. InProceedings ofthe 11th ACM Special Interest Group on Knowledge Discovery andData mining (SIGKDD ’05), 2005.
[25] W. Johnson and J. Lindenstrauss. Extensions of lipshitz mapping intohilbert space.Contemp. Maths., 26, 1984.
[26] S. Kargupta, S. Datta, Q. Wang, and K. Sivakumar. On the privacypreserving properties of random data perturbation techniques. InPro-ceedings of the 3rd IEEE International Conference on Data Mining(ICDM ’03), 2003.
[27] D. Kim, M. Azim, and J. Park. Privacy preserving supportvectormachines in wireless sensor networks. InProceedings of the 3rd In-ternational Conference on Availability, Reliability and Security (ARES’08), 2008.
[28] S. Laur, H. Lipmaa, and T. Mielikainen. Cryptographically privatesupport vector machines. InProceedings of the 12th ACM SIGKDDInternational Conference on Knowledge Discovery and Data Mining(SIGKDD ’06), 2006.
[29] K. Lin and M. Chen. Releasing the svm classifier with privacy-preservation. InProdeedings of the 8th IEEE International Confer-ence on Data Mining (ICDM ’08), 2008.
[30] K. Lin and M. Chen. Privacy-preserving outsourcing support vectormachines with random transformation. InProceedings of the 16thACM SIGKDD International Conference on Knowledge Discoveryand Data Mining (SIGKDD ’10), 2010.
[31] K. Lin and M. Chen. On the design and analysis of the privacy-preserving svm classifier.IEEE Transactions on Knowledge and DataEngineering, 23(11), 2011.
[32] K. Liu, H. Kargupta, and J. Ryan. Random projection-based multi-plicative data perturbation for privacy preserving distributed data min-ing. IEEE Trans. on Knowledge and Data Engineering, 18(1), 2006.
[33] L. Liu, J. Wang, and J. Zhang. Wavelet-based data perturbation for si-multaneous privacy-preserving and statistics-preserving. In Proceed-ings of the 8th IEEE International Conference on Data MiningWork-shops, 2008.
[34] H. Lu, B. Brush, B. Priyantha, A. Karlson, and J. Liu. Speakersense:Energy efficient unobtrusive speaker identification on mobile phones.In Proceedings of the 9th International Conference on Mobile Sys-tems, Applications, and Services (MobiSys ’11), 2011.
[35] H. Lu, W. Pan, N. Lane, T. Choudhury, and A. Campbell. Sound-sense: scalable sound sensing for people-centric applications on mo-bile phones. InProceedings of the 7th International Conference onMobile Systems, Applications, and Services (MobiSys ’09), 2009.
[36] T. Maekawa, Y. Yanagisawa, Y. Kishino, K. Ishiguro, K. Kamei,Y. Sakurai, and T. Okadome. Object-based activity recognition withheterogeneous sensors on wrist. 2010.
[37] E. Magkos, M. Maragoudakis, V. Chrissikopoulos, and S.Gritzalis.Accurate and large-scale privacy-preserving data mining using theelection paradigm.Data and Knowledge Engineering, 68(11), 2009.
[38] O. Mangasarian and E. Wild. Privacy-preserving classification of hori-zontally partitioned data via random kernels. InProdeedings of the 8thIEEE International Conference on Data Mining (ICDM ’08), 2008.
[39] O. Mangasarian, E. Wild, and G. Fung. Privacy-preserving classifica-
tion of vertically partitioned data via random kernels.ACM Transac-tions on Knowledge Discovery from Data, 2(3), 2008.
[40] S. Mathur, W. Trappe, N. Mandayam, C. Ye, and A. Reznik. Radio-telepathy: extracting a secret key from an unauthenticatedwirelesschannel. InProceedings of the 14th ACM International Conferenceon Mobile Computing and Networking (Mobicom ’08), 2008.
[41] B. Milner and X. Shao. Clean speech reconstruction fromMFCC vec-tors and fundamental frequency using an integrated front-end. SpeechCommunication, 48(6), 2006.
[42] E. Miluzzo, C. Cornelius, A. Ramaswamy, T. Choudhury, Z. Liu, andA. Campbell. Darwin phones: the evolution of sensing and inferenceon mobile phones. InProceedings of the 8th International Conferenceon Mobile Systems, Applications, and Services (MobiSys ’10), 2010.
[43] E. Miluzzo, N. Lane, K. Fodor, R. Peterson, H. Lu, M. Musolesi,S. Eisenman, X. Zheng, and A. Campbell. Sensing meets mobilesocial networks: the design, implementation and evaluation of thecenceme application. InProceedings of the 6th ACM Conference onEmbedded Network Sensor Systems (SenSys ’08), 2008.
[44] P. Mohan, V. Padmanabhan, and R. Ramjee. Nericell: Richmonitor-ing of road and traffic conditions using mobile smartphones.In Pro-ceedings of the 6th ACM Conference on Embedded Network SensorSystems (SenSys ’08), 2008.
[45] A. Navia-Vazquez, D. Gutierrez-Gonzalez, E. Parrado-Hernandez,and J. Navarro-Abellan. Distributed support vector machines. IEEETransactions on Neural Networks, 2006.
[46] N. Pham, R. Ganti, Y. Uddin, S. Nath, and T. Abdelzaher. Privacy-preserving reconstruction of multidimensional data maps in vehicularparticipatory sensing. InWireless Sensor Networks, 2011.
[47] J. Qiang, B. Yang, Q. Li, and L. Jing. Privacy-preserving svm of hor-izontally partitioned data for linear classification. InProdeedings ofthe 4th International Congress on Image and Signal Processing (CISP’11), 2011.
[48] B. Rubinstein, P. Bartlett, L. Huang, and N. Taft. Learning in alarge function space: Privacy-preserving mechanisms for svm learn-ing. Arxiv Preprint arXiv:0911.5708, 2009.
[49] V. Tan and S. Ng. Privacy-preserving sharing of horizontally-distributed private data for constructing accurate classifiers. InPro-ceedings of the 1st ACM SIGKDD International Conference on Pri-vacy, Security, and Trust in KDD, 2007.
[50] J. Vaidya and C. Clifton. Privacy-preserving k-means clustering oververtically partitioned data. InProceedings of the 9th ACM SpecialInterest Group on Knowledge Discovery and Data mining (SIGKDD’03), 2003.
[51] J. Vaidya, H. Yu, and X. Jiang. Privacy preserving svm classification.Knowledge and Information Systems, 14(2), 2008.
[52] J. Wang and J. Zhang. Nnmf-based factorization techniques for high-accuracy privacy protection on non-negative-valued datasets. InPro-ceedings of the 6th IEEE International Conference on Data MiningWorkshops, 2006.
[53] K. Weinberger and L. Saul. Distance metric learning forlarge mar-gin nearest neighbor classification.Journal of Machine Learning Re-search, 10(2), 2009.
[54] P. Weinzaepfel, H. Jegou, and P. Perez. Reconstructingan image fromits local descriptors. InProceedings of the 24th IEEE Conference onComputer Vision and Pattern Recognition (CVPR ’11), 2011.
[55] S. Xu and S. Lai. Fast fourier transform based data perturbationmethod for privacy protection. InIEEE Intelligence and Security In-formatics, 2007.
[56] S. Xu, J. Zhang, D. Han, and J. Wang. Singular value decompositionbased data distortion strategy for privacy protection.Knowledge andInformation Systems, 10(3), 2006.
[57] H. Yu, J. Vaidya, and X. Jiang. Privacy-preserving svm classificationon vertically partitioned data. InProceedings of the 10th Pacific-AsiaConference on Knowledge Discovery and Data Mining (PAKDD ’06),2006.
[58] H. Yu, J. Vaidya, and X. Jiang. Privacy-preserving svm using nonlin-ear kernels on horizontally partitioned data. InProceedings of the 21stAnnual ACM Symposium on Applied Computing (SAC ’06), 2006.
[59] J. Zhan, L. Chang, and S. Matwin. Privacy-preserving support vectormachines learning. InProceedings of the 2005 International Confer-ence on Electronic Business (ICEB ’05), 2005.