description and analysis of multipliers using lava
TRANSCRIPT

Description and Analysis ofMULTIPLIERS
usingLAVA

Today:
Describe the most common multiplier circuits In general As Lava descriptions
Analyze them using Lava Self optimizing descriptions Time and size estimations

Lava advantages
Efficient description of very complex structured circuitsAutomatically generic description (in contrast to e.g VHDL)Efficient use of formal verificationInheritance of the power of Haskell

Binary multiplication
All algorithms use the ”sum of partial products” method:
Possible trade-off: Many PPs – Easier generation Fewer PPs – Complex generation
NMMMNM m 110 ...NMNMNM m 110 ...

Binary multiplication
Decomposition of the multiplier:
0 1 10 0 100 0 0000 0 10000 10 100000 0100 0000000 110000 + 00000000 + 00000000 00110110 00110110
Grouping: 00110110
00 11 01 10

Binary multiplication
Partial product selection method: Pi = Si N (shifted to the same position
as Si )
Example:Multiplicand (N): 1001 (9) Multiplier (M): * 0110 (6)
0000 1001 1001 + 0000 p
Product: 00110110 (54)
Partial products

Binary multiplicationTwo basic steps:
1. Generation of partial products (PPG)2. Summation of partial products
Several methods exitst for each step
Famous: Booth, Wallace…
Goal: To be able to combine any method for
the first step with any method for the second step

Interface
All PPs start from position 0 (shift by padding zeroes)Use adders whose result has the same length as the longest input (no carry-out) When carry-out is needed (only 1-bit
selection), pad with one zero after

Simple PPG (1-bit selection)
ppgSimple (as,bs) = ppgSimpleHelp 0 (as,bs) where ppgSimpleHelp i ([],bs) = [] ppgSimpleHelp i (a:as,bs) = p:ps where p = (zeroList i) ++ (bitMulti (a,bs)) ++ [low] ps = ppgSimpleHelp (i+1) (as,bs)

Bit multiplier distributeLeft (a,[]) = [] distributeLeft (a, b:bs) = (a,b):(distributeLeft (a,bs))
bitMulti = distributeLeft ->- map and2
m P = m N 0 0 1 N
m
nn
nn-1
n1
n0
n2
pn
pn-1
p1
p0
p2
&
&
&
&
&
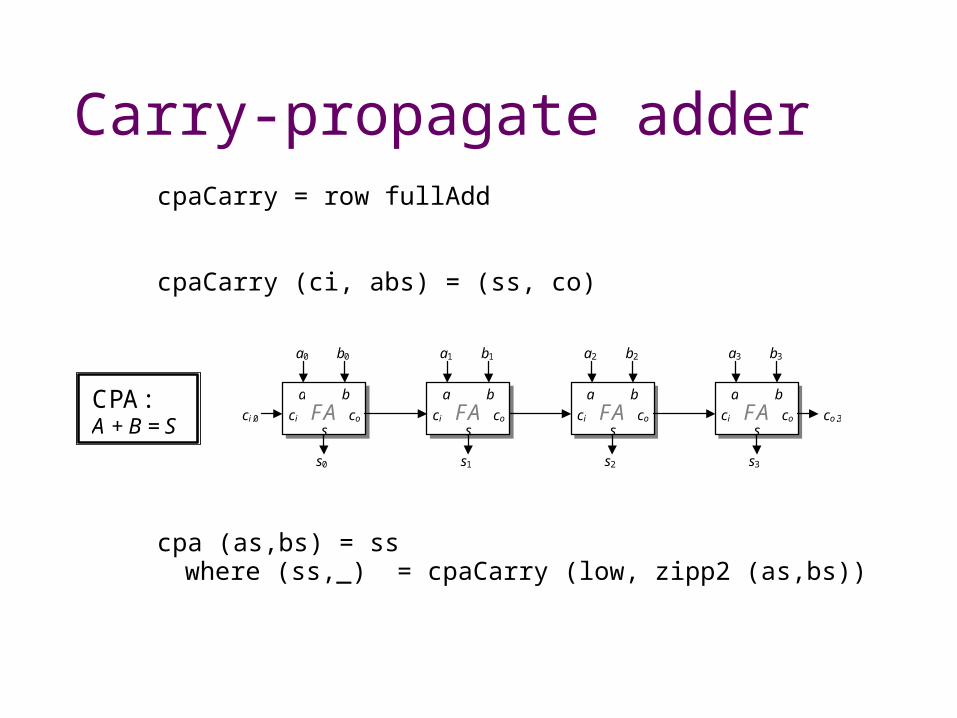
Carry-propagate adder
cpaCarry = row fullAdd cpaCarry (ci, abs) = (ss, co)
cpa (as,bs) = ss where (ss,_) = cpaCarry (low, zipp2 (as,bs))
CPA: A + B = S
FA a b
co ci
s
a0 b0
s0
FA a b
co ci
s
a1 b1
s1
FA a b
co ci
s
a2 b2
s2
FA a b
co ci
s
a3 b3
s3
ci,0 co,3
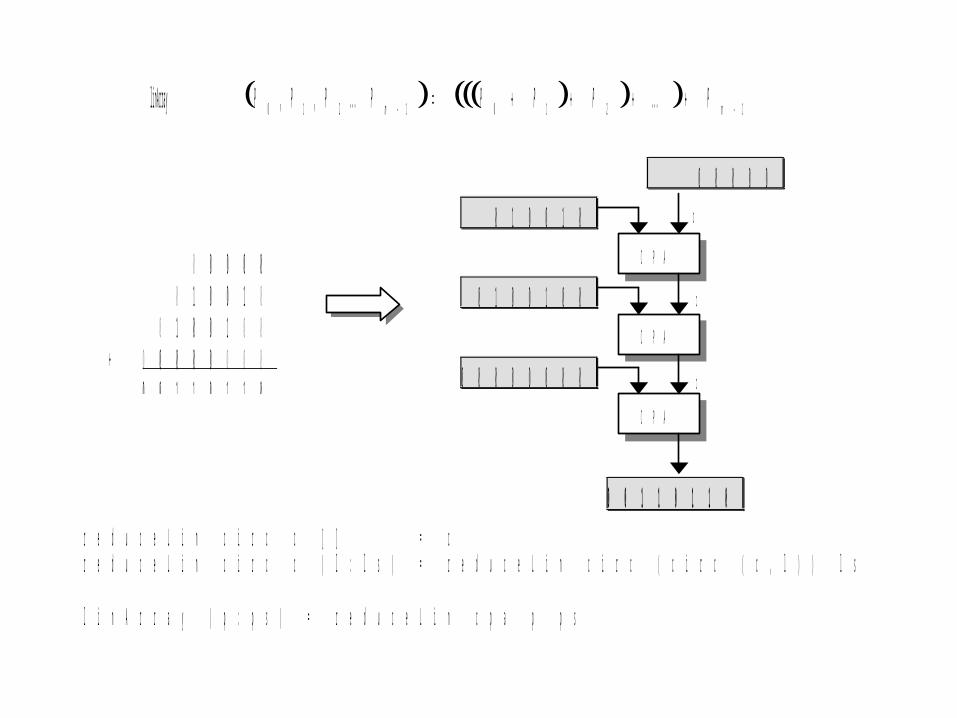
12101210 . . .. . .,,l in Array mm PPPPPPPP
r e d u c e L i n c i r c c [ ] = c r e d u c e L i n c i r c c ( l : l s ) = r e d u c e L i n c i r c ( c i r c ( c , l ) ) l s l i n A r r a y ( p : p s ) = r e d u c e L i n c p a p p s
0 0 0 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 + 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 0
C P A
C P A
C P A
0 0 0 0 0
0 0 0 0 0 0 0 0
0 1 0 0 1 0 0
0 1 0 0 1 0
0 0 1 1 0 1 1 0
c
c
c

Linear array summation
FA a b
co ci
s
FA FA FA FA
FA FA FA FA
FA FA FA FA FA FA
FA FA
FA FA
FA
FA
FA
P0,0 P1,0 P0,1 P1,1 P0,2 P1,2 P0,3 P1,3 P0,4 P1,4 P1,5
P2,0 P2,1 P2,2 P2,3 P2,4 P2,5 P2,6
P3,0 P3,1 P3,2 P3,3 P3,4 P3,5 P3,6 P3,7
S0 S1 S2 S3 S4 S5 S6 S7

Adder tree summationbinTree circ [p] = p binTree circ ps = (halveList ->- (binTree circ -|- binTree circ) ->- circ) ps addTree = binTree cpa
CPA CPA CPA CPA CPA CPA
CPA
CPA
CPA
CPA
CPA
P0 P1 P2 P3 P4 P5 P6 P7 P8 P9 P10 P11

Simple multipliersmult1 = ppgSimple ->- linArray mult2 = ppgSimple ->- addTree
Main> simulate mult1 ([low,high,high,low],[high,low,low,high]) [low,high,high,low,high,high,low,low] Main> simulate mult2 ([low,high,high,low],[high,low,low,high]) [low,high,high,low,high,high,low,low]
Main> verif mult1 4 Vis: ... (t=0.6) Valid. Main> verif mult2 8 Vis: ... (t=2.0) Valid.

Booth’s algorithm (s-bit selection)
boothBasic s (as,bs) = boothBasicHelp 0 (as,bs) where boothBasicHelp i ([],bs) = [] boothBasicHelp i (as,bs) = p:ps where (ss,as2) = splitAt s as p = (zeroList (s*i)) ++ (mult1 (ss,bs)) ps = boothBasicHelp (i+1) (as2,bs)
The number of PPs is m/ss-1 adders are used in the selection

Improved Booth 2
Booth 2 selects part. prod. values from {0,N, 2N, 3N}BUT, 3N = 4N – NSo, instead of 3N, select –NThe next part. prod. selection has to compensate for this

New selection method
Multiplier M
Groups
0010011010001101110 001 011 100 110 110 100 101 001 011
Multiplier bits Selection
000 + 0
001 + N
010 + N
011 + 2N
100 - 2N
101 - N
110 - N
111 - 0
MSB LSB
SBoothTabSBoothTab

Improved Booth s
The number of PPs is m/s+1s-2 adders are usedThe negation of PPs can easily be integrated into the selection procedure
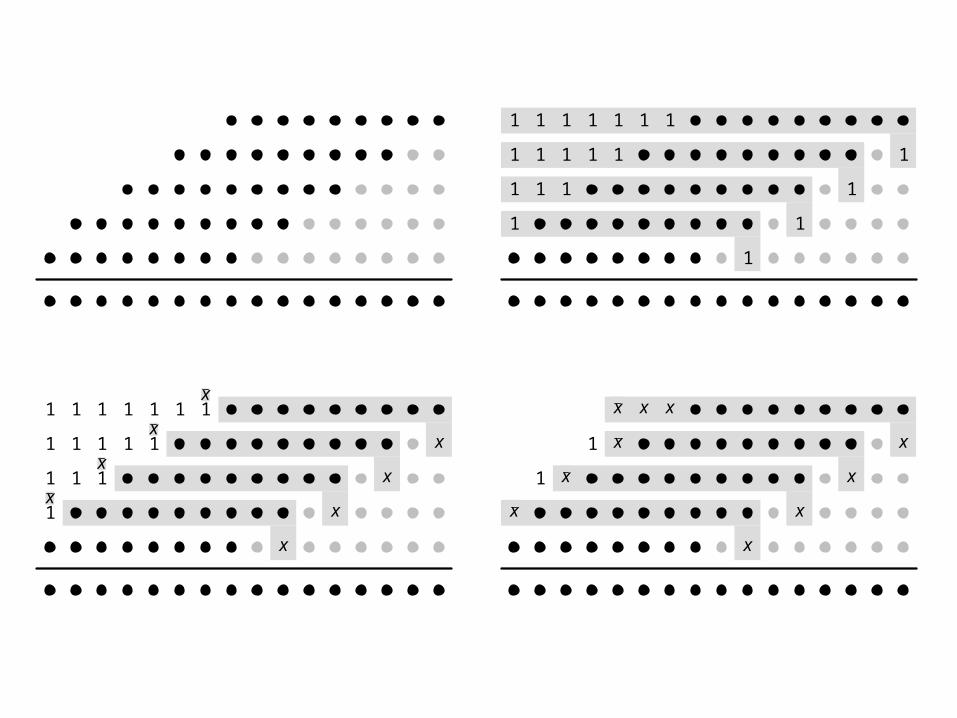
1 1 1 1 1 1 1
1
1 1 1 1 1 1 1
1 1 1 1 1
1 1 1
1
x
x
x
x
x
x
x
x
x x x
x
x
x
1
1
x
x
x
x
1
1
1
1
1 1 1 1
1 1
1
1

Improved Booth s
booth s (as,bs) = boothHelp 0 low (as,bs) where len = (length as) + (length bs) -- boothHelp i sp (as,bs) | (length as >= s) = p:ps where (ss, sign:as2) = splitAt s ([sp] ++ as) signInv = invCond sign x = (improved_sel (signInv ss) ->- signInv) bs (start, end) = boothBits s (s*i) sp sign p = trim len (start ++ x ++ end ++ [low]) ps = boothHelp (i+1) sign (as2,bs)
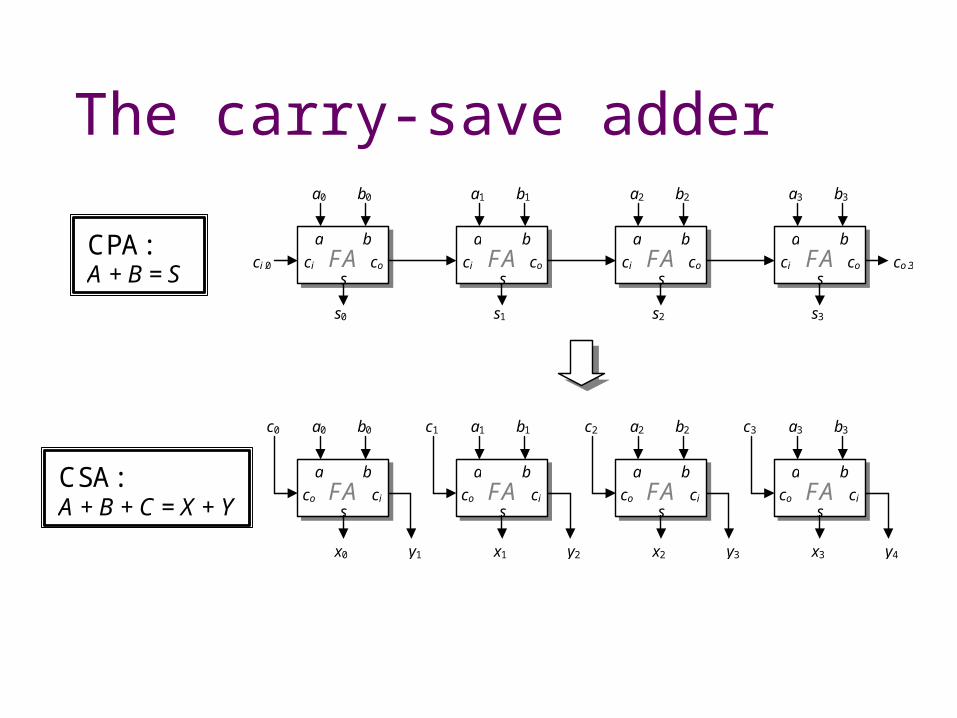
The carry-save adder
FA a b
ci co
s
a0 b0
x0
FA a b
ci co
s
a1 b1
x1
FA a b
ci co
s
a2 b2
x2
FA a b
ci co
s
a3 b3
x3
CSA: A + B + C = X + Y
c3
y4
c2
y3
c1
y2
c0
y1
CPA: A + B = S
FA a b
co ci
s
a0 b0
s0
FA a b
co ci
s
a1 b1
s1
FA a b
co ci
s
a2 b2
s2
FA a b
co ci
s
a3 b3
s3
ci,0 co,3
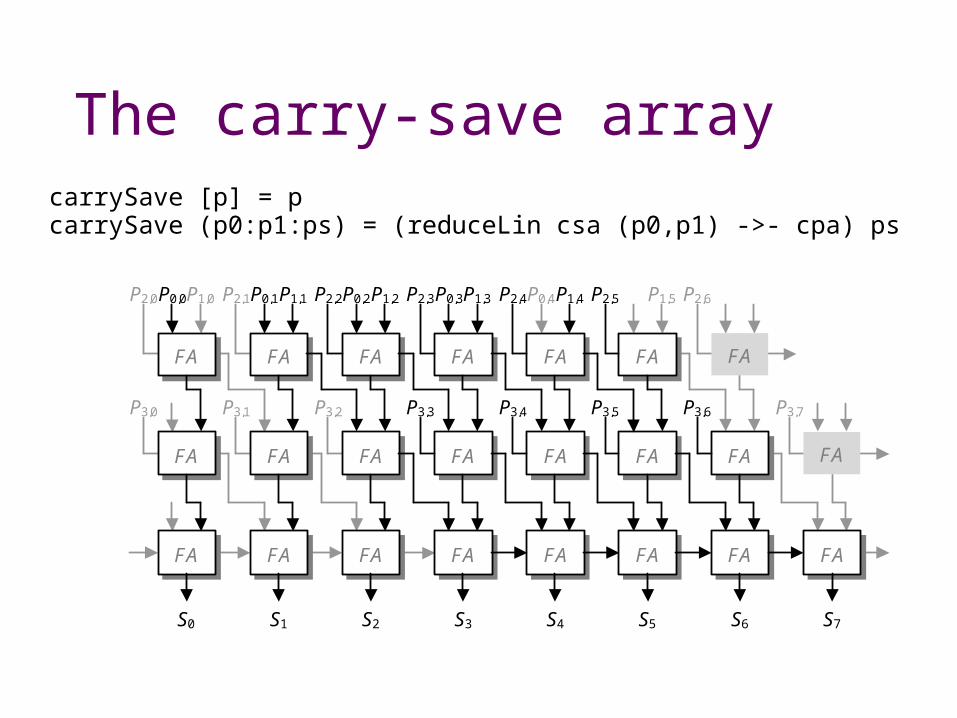
The carry-save arraycarrySave [p] = p carrySave (p0:p1:ps) = (reduceLin csa (p0,p1) ->- cpa) ps
FA FA FA FA FA FA
P0,0 P1,0 P0,1 P1,1 P0,2 P1,2 P0,3 P1,3 P0,4 P1,4 P1,5 P2,0 P2,1 P2,2 P2,3 P2,4 P2,5 P2,6
P3,0 P3,1 P3,2 P3,3 P3,4 P3,5 P3,6 P3,7
FA
FA FA FA FA FA FA FA FA
FA FA FA FA FA FA FA FA
S0 S1 S2 S3 S4 S5 S6 S7

Speed up summation with faster adders (logarithmic)
Linear array has several equal-length critical paths All adders need to be replacedThe carry-save array has only ONE critical path Replace only the final CPA

Logarithmic adder (Ladner – Fisher)logAdd (as,bs) = ss where gs = (zipp2 ->- map and2) (as,bs) ps = (zipp2 ->- map xor2) (as,bs) cps = zipp (gs,ps) cs = (unzipp ->- first ->- skipLast) (carryGen cps) ss = (zipp ->- map xor2) (ps, [low]++cs) -- first (g,p) = g -- carryGen [cp] = [cp] carryGen cps = cps1 ++ map (dotOp (last cps1)) cps2 where (cps1,cps2) = (halveList ->- (carryGen -|- carryGen)) cps -- dotOp (g',p') (g,p) = (or2 (g, and2 (p,g')), and2 (p,p'))
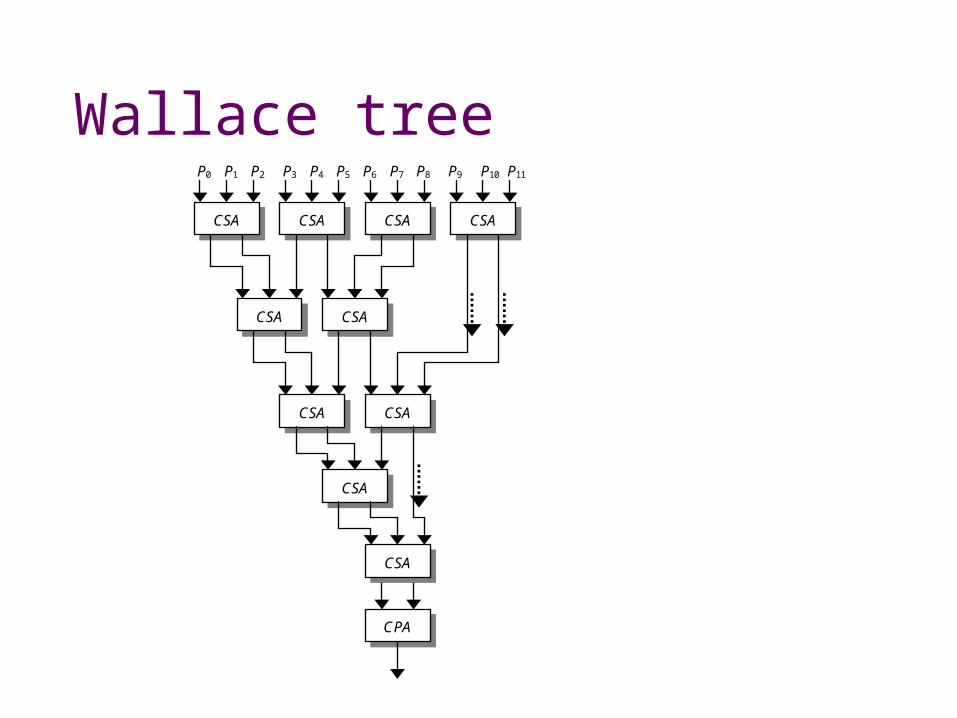
Wallace tree
CPA
CSA
P0 P1 P2 P3 P4 P5 P6 P7 P8 P9 P10 P11
CSA CSA CSA
CSA CSA
CSA CSA
CSA
CSA

Wallace tree
Sums in O(log m) steps
group3 [] = [] group3 [a] = [(a,[],[])] group3 [a,b] = [(a,b,[])] group3 (a:b:c:ds) = [(a,b,c)] ++ (group3 ds) csaWallace (a,[],[]) = (a,[]) csaWallace (a,b,[]) = (a,b) csaWallace (a,b,c) = csa ((a,b),c) unpairWallace [] = [] unpairWallace ((a,[]):as) = [a] ++ (unpairWallace as) unpairWallace ((a0,a1):as) = [a0,a1] ++ (unpairWallace as) wallace ps | ((length ps) <= 2) = carrySave ps | otherwise = wallace s where s = (group3 ->- map csaWallace ->- unpairWallace) ps

Reducing hardware
All circuits have used lots of constant bits, which need unnecessary hardwareCircuits operating on constant bits can be reducedSufficient to make the reduction in the basic gates (inv, and, nand, or, nor, xor, xnor)The reduction of the larger circuits follows automatically

Interpretations
Standard:
Symbolic:
Non-standard…
Main> simulate and2 (low,high) low Main> and2 (var “a”, var “b”) andl[a,b] Main> and2 (2, 3) 10

Self-reducing gates
and2NS (a,b) | (a == low || b == low) = low | (a == high) = b | (b == high) = a | otherwise = and2 (a,b)
Constant bits: low, highEverything else is variable var ”a” inv high

Reduction of larger circuits
HA FA FA
HA FA FA
HA FA FA
FA
HA
FA
P0,0 P0,1 P1,1 P0,2 P1,2 P0,3 P1,3 P1,4
P2,2 P2,3 P2,4 P2,5
P3,3 P3,4 P3,5 P3,6
S0
S1
S2
S3 S4 S5 S6 S7

Time estimationand2NS ((aTime,a), (bTime,b)) | (a == low || b == low) = (0,low) | (a == high) = (bTime,b) | (b == high) = (aTime,a) | otherwise = (outTime, and2 (a,b)) where outTime = maximum [aTime,bTime] + 2
Main> and2NS ((3,var"a"), (0,low)) (0,low) Main> and2NS ((0,high), (12,var"b")) (12,b) Main> and2NS ((3,var"a"), (4,var"b")) (6,andl[a,b])

Size estimation
and2NS (((aSize,aTime),a), ((bSize,bTime),b)) | (a == low || b == low) = ((0,0),low) | (a == high) = ((bSize,bTime),b) | (b == high) = ((aSize,aTime),a) | otherwise = ((outSize,outTime), and2 (a,b)) where outTime = maximum [aTime,bTime] + 2 outSize = aSize + bSize + 2
Problem with sharing:
halfAdd (a,b) = (s,co) where s = xor2 (a,b) co = (resSizePair ->- and2) (a,b)

Redifinition of basic gatesimport Lava hiding (high, low, inv, and2, nand2, or2, nor2, xor2, xnor2, mux, zeroList) import Arithmetic hiding (halfAdd, fullAdd, bitMulti) type Bittime = Integer type Bitsize = Integer type Info = (Bittime, Bitsize) type Infobit = (Info, Signal Bool) type Infonumber = [Infobit] low :: Infobit low = ((0,0), Lava.low) high = ((0,0), Lava.high) zeroList :: Int -> Infonumber zeroList n = replicate n low

Redefinition of ANDinvDelay = 1 invSize = 1 andDelay = 3 andSize = 3 inv a | (a == low) = high | (a == high) = low | otherwise = (incTime invDelay ->- incSize invSize) (infoB a, Lava.inv (valueB a)) and2 (a,b) | (a == low || b == low) = low | (a == high) = b | (b == high) = a | otherwise = (incTime andDelay ->- incSize andSize) (info, Lava.and2 (valueB a, valueB b)) where info = mergeInfos (infoB a, infoB b)

Estimation functionsvalueB :: Infobit -> Signal Bool valueB (info,a) = a value :: Infonumber -> Normnumber value = map valueB timeB :: Infobit -> Bittime timeB ((time,size),a) = time time :: Infonumber -> Integer time = (map timeB) ->- maximum sizeB :: Infobit -> Bitsize sizeB ((time,size),a) = size size :: Infonumber -> Bitsize size as = sum (map sizeB as)
how_fast circ n = (n2iPair ->- circ ->- time) ((replicate n (var "a")),(replicate n (var "a"))) how_fast2 circ m n = (n2iPair ->- circ ->- time) ((replicate m (var "a")),(replicate n (var "a"))) how_big circ n = (n2iPair ->- circ ->- size) ((replicate n (var "a")),(replicate n (var "a"))) how_big2 circ m n = (n2iPair ->- circ ->- size) ((replicate m (var "a")),(replicate n (var "a"))) measure circ n = (how_fast circ n, how_big circ n) measure2 circ m n = (how_fast2 circ m n, how_big2 circ m n)

EstimationsMain> measure (ppgSimple ->- addTree) 24 (267,9924) Main> measure (ppgSimple ->- carrySave) 24 (237,10287) Main> measure (booth 2 ->- carrySave) 24 (154,12937) Main> measure (booth 2 ->- wallace) 24 (100,12940) Main> measure (ppgSimple ->- wallace) 24 (102,10980)

Results
300
320
340
360
380
400
420
1-bit 2-bit 3-bit 4-bit 5-bit 6-bit 7-bit
Selection group length
Tim
e un
its
boothBasic
boothppgSimple
Different selection group lengths with linearArray summation:

Results
Wallace summation instead:
0
50
100
150
200
250
1-bit 2-bit 3-bit 4-bit
Selection group length
Tim
e un
its
boothBasic
booth
ppgSimple
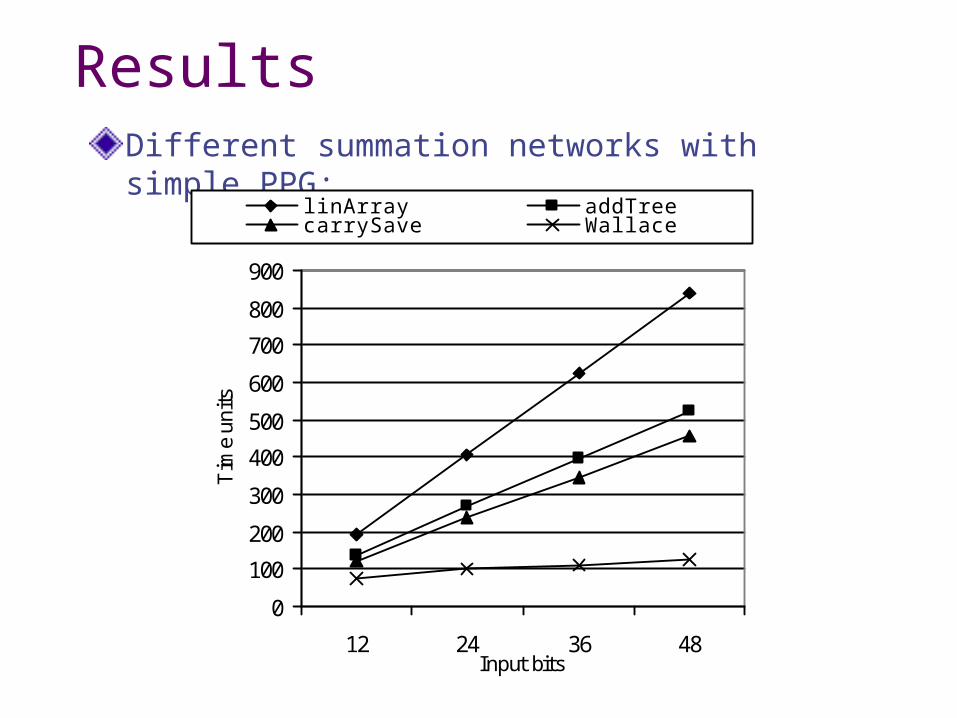
ResultsDifferent summation networks with simple PPG:
0
100
200
300
400
500
600
700
800
900
12 24 36 48Input bits
Tim
e un
itslinArray addTreecarrySave Wallace

Results
Regular summation networks:
250
255
260
265
270
275
280
285
290
1-bit 2-bit 3-bit 4-bitSelection group length
Tim
e un
its
boothBasic booth
ppgSimple
0
50
100
150
200
250
300
1-bit 2-bit 3-bit 4-bit 5-bit
Selection group length
Tim
e un
its
ppgSimple
addTree carrySave

Limitations of the estimations
Wiring delays Needs layout information
Fan-out Several inputs connected to the same
output slower signal
Only standard gates are used Better techniques exist for e.g full
adders