discovery and verification documentation
TRANSCRIPT

Discovery and Verification of Neighbor Positions in
Mobile Ad Hoc Networks
Abstract
A growing number of ad hoc networking protocols and location-aware
services require that mobile nodes learn the position of their neighbors. However,
such a process can be easily abused or disrupted by adversarial nodes. In absence
of a priori trusted nodes, the discovery and verification of neighbor positions
presents challenges that have been scarcely investigated in the literature. In this
paper, we address this open issue by proposing a fully distributed cooperative
solution that is robust against independent and colluding adversaries, and can be
impaired only by an overwhelming presence of adversaries. Results show that our
protocol can thwart more than 99 percent of the attacks under the best possible
conditions for the adversaries, with minimal false positive rates.

An NPV Scheme to identify Neighbors in Mobile
Networks
Modified Abstract
Location awareness has become an asset in mobile systems, where a wide
range of protocols and applications require knowledge of the position of the
participating nodes. In absence of a priori trusted nodes the discovery and
verification of neighbor positions becomes particularly challenging in the presence
of adversaries aiming at harming the system. In this paper, we address this open
issue by proposing a fully distributed cooperative solution that is robust against
independent and colluding adversaries, and can be impaired only by an
overwhelming presence of adversaries.

Introduction
Wireless ad hoc network
A wireless ad hoc network is a decentralized type of wireless network.[1]
The network is ad hoc because it does not rely on a pre existing infrastructure, such
as routers in wired networks or access points in managed (infrastructure) wireless
networks. Instead, each node participates in routing by forwarding data for other
nodes, so the determination of which nodes forward data is made dynamically on
the basis of network connectivity. In addition to the classic routing, ad hoc
networks can use flooding for forwarding data. An ad hoc network typically refers
to any set of networks where all devices have equal status on a network and are
free to associate with any other ad hoc network device in link range. Ad hoc
network often refers to a mode of operation of IEEE 802.11 wireless networks. It
also refers to a network device's ability to maintain link status information for any
number of devices in a 1-link (aka "hop") range, and thus, this is most often a
Layer 2 activity. Because this is only a Layer 2 activity, ad hoc networks alone
may not support a routeable IP network environment without additional Layer 2 or
Layer 3 capabilities.
An ad hoc network is made up of multiple “nodes” connected by
“links.” Links are influenced by the node's resources (e.g., transmitter power,
computing power and memory) and behavioral properties (e.g., reliability), as well
as link properties (e.g. length-of-link and signal loss, interference and noise). Since
links can be connected or disconnected at any time, a functioning network must be
able to cope with this dynamic restructuring, preferably in a way that is timely,
efficient, reliable, robust, and scalable. The network must allow any two nodes to
communicate by relaying the information via other nodes. A “path” is a series of

links that connects two nodes. Various routing methods use one or two paths
between any two nodes; flooding methods use all or most of the available paths.
Mobile ad hoc network
A mobile ad hoc network (MANET) is a self-configuring infrastructure less
network of mobile devices connected by wireless. Ad hoc is Latin and means "for
this purpose".[1] Each device in a MANET is free to move independently in any
direction, and will therefore change its links to other devices frequently. Each must
forward traffic unrelated to its own use, and therefore be a router. The primary
challenge in building a MANET is equipping each device to continuously maintain
the information required to properly route traffic. Such networks may operate by
themselves or may be connected to the larger Internet. MANETs are a kind of
Wireless ad hoc network that usually has a routable networking environment on
top of a Link Layer ad hoc network. The growth of laptops and 802.11/Wi-Fi
wireless networking have made MANETs a popular research topic since the mid-
1990s. Many academic papers evaluate protocols and their abilities, assuming
varying degrees of mobility within a bounded space, usually with all nodes within
a few hops of each other. Different protocols are then evaluated based on measures
such as the packet drop rate, the overhead introduced by the routing protocol, end-
to-end packet delays, network throughput etc.
MANETS can be used for facilitating the collection of sensor data for data
mining for a variety of applications such as air pollution monitoring and different
types of architectures can be used for such applications.[2] It should be noted that a
key characteristic of such applications is that nearby sensor nodes monitoring an
environmental feature typically register similar values. This kind of data
redundancy due to the spatial correlation between sensor observations inspires the

techniques for in-network data aggregation and mining. By measuring the spatial
correlation between data sampled by different sensors, a wide class of specialized
algorithms can be developed to develop more efficient spatial data mining
algorithms as well as more efficient routing strategies.[3] Also researchers have
developed performance models[4][5] for MANET by applying Queueing Theory.
These attacks on MANETs challenge the mobile infrastructure in which
nodes can join and leave easily with dynamics requests without a static path of
routing. Schematics of various attacks as described by Al-Shakib Khan [1] on
individual layer are as under: Application Layer: Malicious code, Repudiation
Transport Layer: Session hijacking, Flooding Network Layer: Sybil, Flooding,
Black Hole, Grey Hole. Worm Hole, Link Spoofing, Link Withholding, Location
disclosure etc. Data Link/MAC: Malicious Behavior, Selfish Behavior, Active,
Passive, Internal External Physical: Interference, Traffic Jamming, Eavesdropping
Vehicular ad hoc network
A vehicular ad hoc network (VANET) uses cars as mobile nodes in a
MANET to create a mobile network. [1] A VANET turns every participating car
into a wireless router or node, allowing cars approximately 100 to 300 metres of
each other to connect and, in turn, create a network with a wide range. As cars fall
out of the signal range and drop out of the network, other cars can join in,
connecting vehicles to one another so that a mobile Internet is created. It is
estimated that the first systems that will integrate this technology are police and
fire vehicles to communicate with each other for safety purposes.
Most of the concerns of interest to mobile ad hoc networks (MANETs) are
of interest in VANETs, but the details differ. Rather than moving at random,
vehicles tend to move in an organized fashion. The interactions with roadside

equipment can likewise be characterized fairly accurately. And finally, most
vehicles are restricted in their range of motion, for example by being constrained to
follow a paved highway. In addition, in 2006 the term MANET mostly described
an academic area of research, and the term VANET an application. Such a network
might pose safety concerns (for example, one cannot safely type an email while
driving). GPS and navigation systems might benefit, as they could be integrated
with traffic reports to provide the fastest route to work. It was also promoted for
free, VoIP services such as GoogleTalk or Skype between employees, lowering
telecommunications costs.
MAC
A medium access control (MAC) protocol coordinates actions over a shared
channel. The most commonly used solutions are contention-based. One general
contention-based strategy is for a node which has a message to transmit to test the
channel to see if it is busy, if not busy then it transmits, else if busy it waits and
Tries again later. After colliding, nodes wait random amounts of time trying to
avoid re-colliding. If two or more nodes transmit at the same time there is a
collision and all the nodes colliding try again later. Many wireless MAC protocols
also have a doze mode where nodes not involved with sending or receiving a
packet in a given timeframe go into sleep mode to save energy. Many variations
exist on this basic scheme.
In general, most MAC protocols optimize for the general case and for
arbitrary communication patterns and workloads. However, a wireless sensor
network has more focused requirements that include a local uni-or broad-cast,
traffic is generally from nodes to one or a few sinks (most traffic is then in one
direction),have periodic or rare communication and must consider energy
consumption as a major factor. An effective MAC protocol for wireless sensor

networks must consume little power, avoid collisions, be implemented with a small
code size and memory requirements, be efficient for a single application, and be
tolerant to changing radio frequency and networking conditions.
One example of a good MAC protocol for wireless sensor networks is B-
MAC. B-MAC is highly configurable and can be implemented with a small code
and memory size. It has an interface that allows choosing various functionality and
only that functionality as needed by a particular application. B-MAC consists of
four main parts: clear channel assessment (CCA), packet back off, link layer acks,
and low power listening. For CCA, B-MAC uses a weighted moving average of
samples when the channel is idle in order to assess the background noise and better
be able to detect valid packets and collisions. The packet backoff time is
configurable and is chosen from a linear range as opposed to an exponential
backoff scheme typically used in other distributed systems. This reduces delay and
works because of the typical communication patterns found in a wireless sensor
network. B-MAC also supports a packet by packet link layer acknowledgement. In
This way only important packet need pay the extra cost. A low power listening
scheme is employed where a node cycles between awake and sleep cycles. While
awake it listens for a long enough preamble to assess if it needs to stay awake or
can return to sleep mode. This scheme saves significant amounts of energy. Many
MAC protocols use a request to send (RTS) and clear to send (CTS) style of
interaction. This works well for ad hoc mesh networks where packet sizes are large
(1000s of bytes). However, the overhead of RTS-CTS packets to set up a packet
transmission is not acceptable in wireless sensor networks where packet sizes are
On the order of 50 bytes. B-MAC, therefore, does not use a RTS-CTS scheme.

Recently, there has been new work on supporting multi-channel wireless
sensor networks. In these systems it is necessary to extend MAC protocols to
multi-channel MACs. One such protocol is MMSN. These protocols must support
all the features found in protocols such as B-MAC, but must also assign
Frequencies for each transmission. Consequently, multi-frequency MAC protocols
consist of two phases: channel assignment and access control. The details for
MMSN are quite complicated and are not described here. On the other hand, we
expect that more and more future wireless sensor networks will employ multiple
Channels (frequencies). The advantages of multi-channel MAC protocols include
providing greater packet throughput and being able to transmit even in the
presence of a crowded spectrum, perhaps arising from competing networks or
commercial devices such as phones or microwave ovens.
MD5 Hash Algorithm
The MD5 message-digest algorithm is a widely used cryptographic hash
function producing a 128-bit (16-byte) hash value, typically expressed as a 32 digit
hexadecimal number. MD5 has been utilized in a wide variety of security
applications. It is also commonly used to check data integrity.
MD5 digests have been widely used in the software world to provide some
assurance that a transferred file has arrived intact. For example, file servers often
provide a pre-computed MD5 (known as Md5sum) checksum for the files, so that a
user can compare the checksum of the downloaded file to it. Most unix-based
operating systems include MD5 sum utilities in their distribution packages;
Windows users may install a Microsoft utility, or use third-party applications.
Android ROMs also utilize this type of checksum.

However, now that it is easy to generate MD5 collisions, it is possible for
the person who created the file to create a second file with the same checksum, so
this technique cannot protect against some forms of malicious tampering. Also, in
some cases, the checksum cannot be trusted (for example, if it was obtained over
the same channel as the downloaded file), in which case MD5 can only provide
error-checking functionality: it will recognize a corrupt or incomplete download,
which becomes more likely when downloading larger files. MD5 can be used to
store a one-way hash of a password, often with key stretching. Along with other
hash functions, it is also used in the field of electronic discovery, in order to
provide a unique identifier for each document that is exchanged during the legal
discovery process. This method can be used to replace the Bates stamp numbering
system that has been used for decades during the exchange of paper documents.
MD5 processes a variable-length message into a fixed-length output of 128
bits. The input message is broken up into chunks of 512-bit blocks (sixteen 32-bit
words); the message is padded so that its length is divisible by 512. The padding
works as follows: first a single bit, 1, is appended to the end of the message. This is
followed by as many zeros as are required to bring the length of the message up to
64 bits fewer than a multiple of 512. The remaining bits are filled up with 64 bits
representing the length of the original message, modulo 264. The main MD5
algorithm operates on a 128-bit state, divided into four 32-bit words, denoted A, B,
C and D. These are initialized to certain fixed constants. The main algorithm then
uses each 512-bit message block in turn to modify the state. The processing of a
message block consists of four similar stages, termed rounds; each round is
composed of 16 similar operations based on a non-linear function F, modular
addition, and left rotation.

Public-key cryptography
Public-key cryptography, also known as asymmetric cryptography, refers to
a cryptographic algorithm which requires two separate keys, one of which is secret
(or private) and one of which is public. Although different, the two parts of this
key pair are mathematically linked. The public key is used to encrypt plaintext or
to verify a digital signature; whereas the private key is used to decrypt ciphertext
or to create a digital signature. The term "asymmetric" stems from the use of
different keys to perform these opposite functions, each the inverse of the other –
as contrasted with conventional ("symmetric") cryptography which relies on the
same key to perform both. Public-key algorithms are based on mathematical
problems which currently admit no efficient solution that are inherent in certain
integer factorization, discrete logarithm, and elliptic curve relationships. It is
computationally easy for a user to generate his or her public and private key-pair
and to use them for encryption and decryption. The strength lies in the fact that it is
"impossible" (computationally infeasible) for a properly generated private key to
be determined from its corresponding public key. Thus the public key may be
published without compromising security, whereas the private key must not be
revealed to anyone not authorized to read messages or perform digital signatures.
Public key algorithms, unlike symmetric key algorithms, do not require a secure
initial exchange of one (or more) secret keys between the parties. Message
authentication involves processing a message with a private key to produce a
digital signature. Thereafter anyone can verify this signature by processing the
signature value with the signer's corresponding public key and comparing that
result with the message. Success confirms the message is unmodified since it was
signed, and – presuming the signer's private key has remained secret to the signer –
that the signer, and no one else, intentionally performed the signature operation. In

practice, typically only a hash or digest of the message, and not the message itself,
is encrypted as the signature.
Public-key encryption, in which a message is encrypted with a recipient's
public key. The message cannot be decrypted by anyone who does not possess the
matching private key, who is thus presumed to be the owner of that key and the
person associated with the public key. This is used in an attempt to ensure
confidentiality. Digital signatures, in which a message is signed with the sender's
private key and can be verified by anyone who has access to the sender's public
key. This verification proves that the sender had access to the private key, and
therefore is likely to be the person associated with the public key. This also ensures
that the message has not been tampered, as any manipulation of the message will
result in changes to the encoded message digest, which otherwise remains
unchanged between the sender and receiver. An analogy to public-key encryption
is that of a locked mail box with a mail slot. The mail slot is exposed and
accessible to the public – its location (the street address) is, in essence, the public
key. Anyone knowing the street address can go to the door and drop a written
message through the slot. However, only the person who possesses the key can
open the mailbox and read the message. An analogy for digital signatures is the
sealing of an envelope with a personal wax seal. The message can be opened by
anyone, but the presence of the unique seal authenticates the sender. A central
problem with the use of public-key cryptography is confidence/proof that a
particular public key is authentic, in that it is correct and belongs to the person or
entity claimed, and has not been tampered with or replaced by a malicious third
party. The usual approach to this problem is to use a public-key infrastructure
(PKI), in which one or more third parties – known as certificate authorities –
certify ownership of key pairs. PGP, in addition to being a certificate authority

structure, has used a scheme generally called the "web of trust", which
decentralizes such authentication of public keys by a central mechanism, and
substitutes individual endorsements of the link between user and public key. To
date, no fully satisfactory solution to this "public key authentication problem" has
been found.
Some encryption schemes can be proven secure on the basis of the presumed
difficulty of a mathematical problem, such as factoring the product of two large
primes or computing discrete logarithms. Note that "secure" here has a precise
mathematical meaning, and there are multiple different (meaningful) definitions of
what it means for an encryption scheme to be "secure". The "right" definition
depends on the context in which the scheme will be deployed. The most obvious
application of a public key encryption system is confidentiality – a message that a
sender encrypts using the recipient's public key can be decrypted only by the
recipient's paired private key. This assumes, of course, that no flaw is discovered in
the basic algorithm used. Another type of application in public-key cryptography is
that of digital signature schemes. Digital signature schemes can be used for sender
authentication and non-repudiation. In such a scheme, a user who wants to send a
message computes a digital signature for this message, and then sends this digital
signature (together with the message) to the intended receiver. Digital signature
schemes have the property that signatures can be computed only with the
knowledge of the correct private key. To verify that a message has been signed by
a user and has not been modified, the receiver needs to know only the
corresponding public key. In some cases (e.g. RSA), a single algorithm can be used
to both encrypt and create digital signatures. In other cases (e.g. DSA), each
algorithm can only be used for one specific purpose.

Objective
The scope of this project is to identify the neighbor positions nodes to
enhance lightweight NPV procedure that enables each node to acquire the locations
advertised by its neighbors, and assess their truthfulness and allows a node to
perform all verification procedures autonomously. This approach has no need for
lengthy interactions,, making our scheme suitable for both low- and high mobility
environments.
Problem Statement
The correctness of node locations is therefore an important issue in mobile
networks, and it becomes particularly challenging in the presence of adversaries
aiming at harming the system. In these cases, we need solutions that let nodes 1)
correctly establish their location in spite of attacks feeding false location
information, and 2) verify the positions of their neighbors, so as to detect
adversarial nodes announcing false locations.

Architecture Diagram

Abbreviations
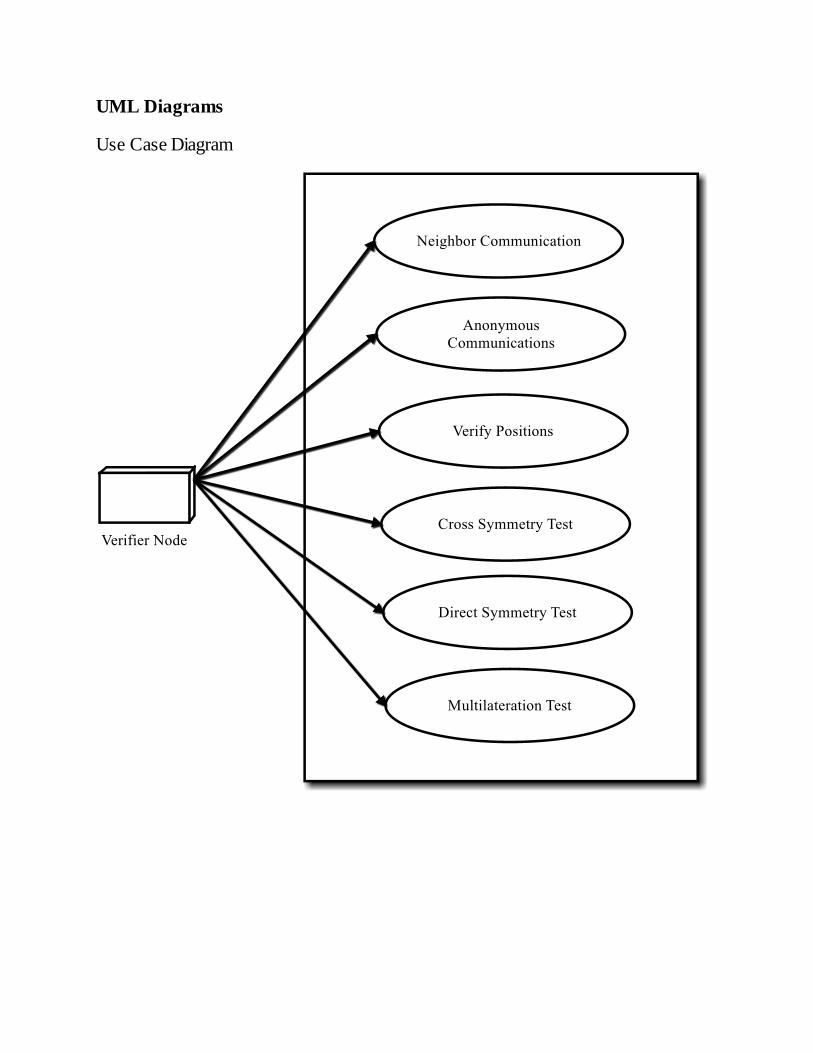
UML Diagrams
Use Case Diagram
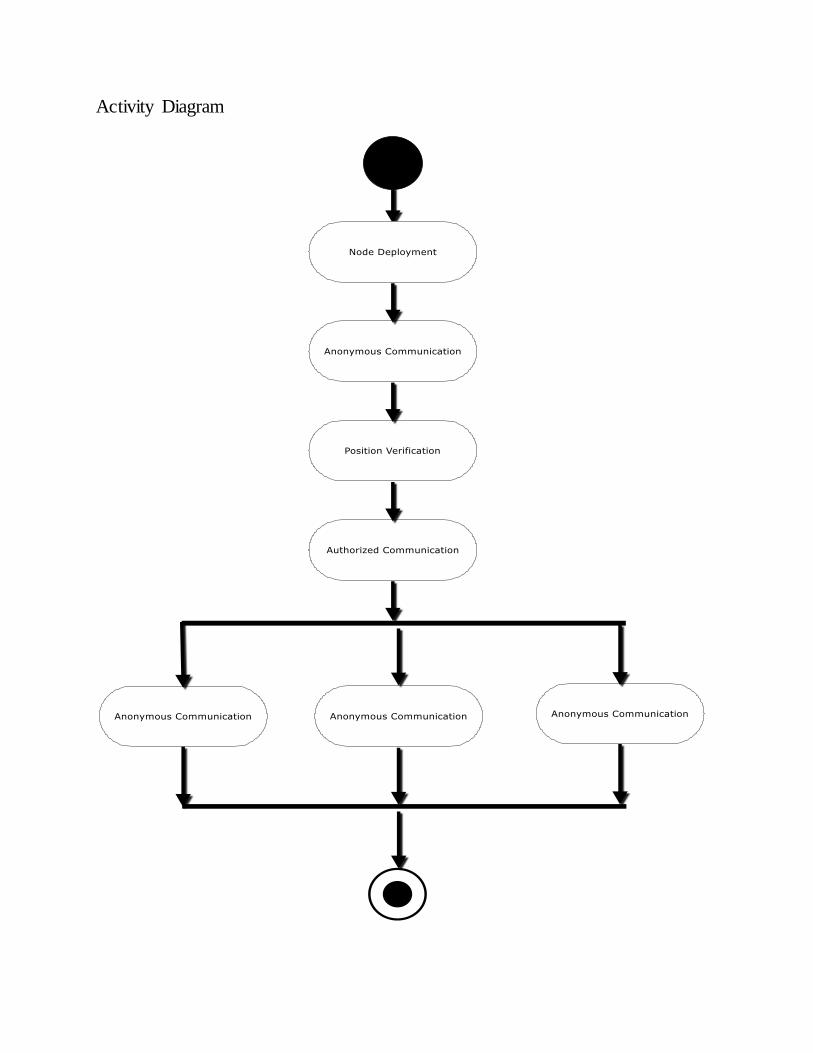
Activity Diagram

Literature Survey
GNSS-based Positioning: Attacks and Countermeasures
Concept
The contribution of this paper consists of three mechanisms that allow
receivers to detect forged GNSS messages and fake GNSS signals. The
countermeasures rely on in- formation the receiver obtained before the onset of an
attack, or more precisely, before the suspected onset of an attack. The mechanisms
rely on own (i) location information, calculated by GNSS navigation messages, (ii)
clock readings, without any re-synchronization with the help of the GNSS or any
other system, and (iii) received GNSS signal Doppler shift measurements. Based
on those different types of information, our mechanisms can detect if the received
GNSS signals and messages originate from adversarial devices. If so, location
information induced by the attack can be rejected and manipulation of the location-
aware functionality be avoided.
Algorithm
Location Inertial Test At the transition to alert mode, the node utilizes own
location information obtained from the PVT solution, to predict positions while in
attack mode. If those positions match the suspected as fraudulent PVT ones, the
receiver returns to normal mode. We consider two approaches for the location
prediction: (i) inertial sensors and (ii) Kalman filtering. Inertial sensors, i.e.,
altimeters, speedometers, odometers, can calculate the node (receiver) location
independently of the GNSS functionality.4 However, the accuracy of such (electro-
mechanical) sensors degrades with time. One example is the low-cost inertial
MEMS Crista IMU-15 sensor (Inertial Measurement Unit).

Doppler Shift Test (DST)
Based on the received GNSS signal Doppler shift, with respect to the nominal
transmitter frequency (ft = 1.575GHz), the receiver can predict future Doppler
Shift values. Once lock to GNSS signals is obtained again, predicted Doppler shift
values are compared to the ones calculated due to the received GNSS signal. If the
latter are different than the predicted ones beyond a threshold, the GNSS signal is
deemed adversarial and rejected. What makes this approach attractive is the
smooth changes of Doppler shift and the ability to predict it with low, essentially
constant errors over long periods of time. This in dire in contrast to the inertial test
based on location, whose error grows exponentially with time. The Doppler shift is
produced due to the relative motion of the satellite with respect to the receiver. The
satellite velocity is computed using ephemeris information and an orbital model
available at the receiver. The received frequency, fr, increases as the satellite
approaches and de- creases as it recedes from the receiver; it can be approximated
by the classical Doppler equation
Advantages
Secure mobile systems from location information manipulation via attack.
Secures GNSS Signals
Disadvantage
The effect of counter-measures that only partially limit the attack impact.
Increases Cost.

Secure Vehicular Communication Systems: Implementation, Performance, and
Research Challenges
Concept
In this paper component-based security architecture for VC systems, which
allows adding, replace, and reconfigure components (for example, substitute
cryptographic algorithms) throughout the life cycle of the vehicle is proposed. The
large number and the variety of vehicles have to be taken into account. Even for a
single car type, different production and equipment lines lead to many distinct
versions and variants. Nonetheless, it should be possible to integrate a security
system into all those platforms. In addition, the communication stack and security
measures might be designed by different teams or vendors; a situation that clearly
requires well-defined but still flexible interfaces. These reasons led to the
development of the so called “hooking architecture”, which introduces special
hooks at the interface between every layer of the vehicular communication system.
The hooking architecture introduces an event-callback mechanism into the
communication stack which allows adding security measures without the need to
change the entire communication system. The security system in a vehicle has to
fulfill real-time or near real-time requirements. For the underlying cryptographic
primitives, this implies optimized cryptographic hardware, in order to guarantee
the near real-time performance.
Algorithm
Baseline Architecture Deployment View
The SeVeCom baseline architecture addresses different aspects, such as
secure communication protocols, privacy protection, and in-vehicle security. As
the design and development of VC protocols, system architectures, and security

mechanisms is an ongoing process, only few parts of the overall system are yet
finished or standardized. As a result, a VC security system cannot be based on a
fixed platform but instead has to be flexible, with the possibility to adapt to future
VC applications or new VC technologies. To achieve the required flexibility, the
SeVeCom baseline architecture consists of modules, which are responsible for a
certain system aspect, such as identity management. The modules, in turn, are
composed of multiple components each handling a specific task. For instance, the
Secure Communication Module is responsible for implementing protocols for
secure communication and consists of several components, each of them
implementing a single protocol. Components are instantiated only when their use is
required by certain applications, and they use well-defined interfaces to
communicate with other components. Thus, they can be exchanged by more recent
versions, without other modules being affected. It instantiates and configures the
components of all other security modules and establishes the connection to the
Cryptographic Support Module. To cope with different situations, the Security
Manager maintains different policy sets.
Advantages
Identifies pertinent threats and models for adversaries
Enhances security and privacy for communication protocols.
Robust
Disadvantages
lets a node assess whether another node is an actual neighbor
does not verify the location

A Graph Theoretic Framework for Preventing the Wormhole Attack in Wireless
Ad Hoc Networks
Concept
These papers presents a graph theoretic framework for modeling of the
wormhole attack and state the necessary and sufficient conditions for any candidate
solution to prevent such an attack. We show that any previously proposed methods
or future solutions have to satisfy our conditions in order to prevent wormholes. In
addition, we also propose a cryptographic mechanism based on keys only known
within each neighborhood, which we call local broadcast keys (LBKs), in order to
secure the network from wormhole attacks and show that our solution satisfies the
conditions of the graph theoretic framework. We present a centralized method for
establishing LBKs, when the location of all the nodes is known to a central
authority (base station). Furthermore, we propose a decentralized mechanism for
LBK establishment that defends against wormholes with a probability very close to
unity. This solution does not require any time synchronization or highly accurate
clocks. In addition, our method requires only a small fraction of the network nodes
to know their location. Finally, our approach is based on symmetric cryptography
rather than expensive asymmetric cryptography and hence is computationally
efficient, while it requires each node to broadcast only a small number of messages
thus having a small communication overhead. Due to its efficiency, our method is
applicable to ad hoc networks with very stringent resource constraints, such as
wireless sensor networks.
Algorithms
Guard ID authentication: The use of a global symmetric key K0 does not provide
any authentication on the source of the message. Hence, any guard or node holding

the global key can broadcast fractional keys encrypted with K0. Though we have
assumed that the global symmetric key K0 is not compromised and that network
entities do not operate maliciously, in order to allow nodes to authenticate the
guards within one-hop, we provide a lightweight authentication mechanism4. Our
scheme is based on efficient one-way hash chains that have also been used
extensively in broadcast authentication protocols. In addition, due to the one-way
property of the hash chain, it is computationally infeasible for an adversary to
derive values of the hash chain that have not been already published by the guard
[26]. Each node is preloaded with a table containing the Id of each guard and the
corresponding hash value Hn(PWi). For a network with 200 guards, we need 8 bits
to represent node Ids. In addition, hash functions such as SHA-1 [45] have a 128-
bit output.
Advantages
Locating the origin point of the attack
Detection of the wormhole attack
Disadvantages
Does not securely determine the neighbor positions and time reference.
HiRLoc: High-resolution Robust Localization for Wireless Sensor Networks
Concept
A novel localization scheme for WSN called High resolution Range-
independent Localization (HiRLoc) that allows sensors to passively determine their
location with high accuracy. The increased localization accuracy is the result of
combination of multiple localization information over a short time period, and does
not come at the expense of increased hardware complexity or deployment of

reference points with higher density. Since our method does not perform any range
measurements to estimate the sensors location, it is not susceptible to any range
measurement alteration attacks. Furthermore, sensors do not rely on other sensors
to infer their location and hence, the robustness of our localization method does not
rely on the easily tampered sensor devices. Finally, we show that our method is
robust against well-known security threats in WSN, such as the wormhole attack,
the Sybil attack and compromise of network entities.
Algorithm
There are two different ways of computing the region of intersection. We can
collect all beacons over several transmission rounds and compute the intersection
of the all sector areas or estimate ROI after every round of transmissions and
intersect it with the previous estimate of the ROI: We will refer to the HiRLoc-I
and HiRLoc-II algorithm.
HIRLOC-I ALGORITHM
HiRLoc-I algorithm is Computing the intersection of all sector areas.
HiRLoc the estimation of the ROI is computed by collecting all beacons
transmitted by each locator over time, intersecting all sectors of each locator and
then intersecting the outcome.
Step 1: Initial estimate of the ROI.
Step 2: Beacon collection.
Option A: Antenna orientation variation.
Option B: Communication range variation.
Option C: Combination of options A, B.

Step 3: Determination of the ROI.
HIRLOC-II ALGORITHM
HiRLoc-II is computing the sector intersection at each transmission round.
The sensor computes the ROI by intersecting all collected information at each
transmission round. HiRLoc-II can be seen as an iterative application of SeRLoc ,
with sensors using SeRLoc at each transmission round to estimate ROI and
intersecting it with the previous one.
Advantages
HiRLoc localizes sensors with significantly higher accuracy.
Requiring fewer hardware resources.
HiRLoc allows the robust location computation even in the presence of
security threats in WSN.
The wormhole attack, the Sybil attack and compromise of network entities.
Disadvantages
Enabling nodes of a WSN to compute a high-resolution estimate of their
location even in the presence of malicious adversaries.
Secure localization for wireless sensor networks is not context of,
(a) Decentralized and scalable implementation,
(b) Resource efficiency in computation, communication and storage,
(c) range-independence,
(d) Robustness against security threats in WSN.
Secure Neighbor Discovery in Mobile Ad Hoc Networks
Concept

To address the aforementioned challenges, we present Mobile Secure
Neighbor Discovery (MSND), which allows neighbors to verify that they are
speaking directly with each other. A wormhole can be detected due to the fact that
the path traveled by a ranging signal varies from expected values when a wormhole
is present. Instead of traveling directly to the remote node, the ranging signal must
travel to one end of the wormhole, transit the wormhole, and then exit to arrive at
the destination node. In the case of a static network, this variation is difficult to
detect because, for a single node, it is constant.
• A protocol (MSND) for detecting the presence of wormholes when mobile nodes
participate.
• Security analysis and correctness of MSND.
• Performance evaluation through simulations, demonstrating accurate wormhole
detection with low false negatives.
• A real system evaluation employing Epic motes and iCreate robot hardware,
demonstrating the performance of our proposed solution.
Algorithm
MSND Protocol.
Verification.
MSND Protocol
MSND executes in two phases. First, NR ranging operations are conducted
and the resulting ranges and travel distances are sent to Verification. The execution
of MSND between two mobile nodes in a network with no wormhole. Node A
initiates ranging operations. Node B will become a neighbor of A if it can be

verified. A key requirement of the ranging phase is that each ranging node must
travel along a describable path. For the purposes of this paper, nodes move in
straight lines until either enough ranges are collected or it is no longer possible to
range. Ranging operations stop before completion of the protocol when nodes are
no longer in contact or when a node is forced to turn.
Verification
Verification uses preliminary checks, metric multidimensional scaling
(MDS) and knowledge of node movement to detect distortions caused by a
wormhole. Verification is used to analyze ranges and traveled distances to
determine if a wormhole has affected the results. Successful verification confirms
that the two nodes are neighbors.
Verification begins with preliminary checks that include a check for ranges
that are too long, adjoining ranges whose length differs by more than the combined
distances traveled by the participating nodes, and degenerate configurations.
Successful preliminary checks are followed by a loop that performs distance
analysis using MDS and a test of the fit of the resulting coordinates .The output is
analyzed and the best two outcomes are used to make a decision about the
presence/absence of a wormhole.
Advantages
The ability to securely determine valid neighbors is an important part of
many network functions.
Wormholes failure to protect neighbor discovery could lead to information
disclosure, incorrect localization, routing problems, and adversary control of
the network at any time.

MSND leverages graph rigidity to aid in the verification of network
neighbors.
Disadvantages
Neighbor discovery fails, communications and protocols performance
deteriorate.
In networks affected by relay attacks, also known as wormholes, the failure
may be more subtle.
The wormhole may selectively deny or degrade communications.

Existing System
An autonomous sensor is proposed in the existing system that allows nodes
to validate the position of their neighbors through local observations only. This is
performed by checking whether subsequent positions announced by one neighbor
draw a movement over time that is physically possible. The approach forces a node
to collect several data on its neighbor movements before a decision can be taken,
making the solution unfit to situations where the location information is to be
obtained and verified in a short time span.

Demerits:
Adversary can fool the protocol by simply announcing false positions.
These sensor can be attacked by using fake id nodes.
Another drawback of the presented solution is that each node has only a
local view that might not be enough to reliably identify all position faking
node

Proposed System
In this paper fully distributed cooperative scheme for NPV, which enables a
node, hereinafter called the verifier, to discover and verify the position of its
communication neighbors is proposed. This paper deals with a mobile ad hoc
network, where a pervasive infrastructure is not present, and the location data must
be obtained through node-to-node communication. Such a scenario is of particular
interest since it leaves the door open for adversarial nodes to misuse or disrupt the
location-based services. The proposed approach is designed for spontaneous ad hoc
environments, and, as such, it does not rely on the presence of a trusted
infrastructure or of a priori trustworthy nodes and it also leverages cooperation but
allows a node to perform all verification procedures autonomously.
A fully distributed cooperative scheme for NPV, which enables a node,
hereinafter called the verifier, to discover and verify the position of its
communication neighbors. For clarity, here we summarize the principles of the
protocol as well as the gist of its resilience analysis. Detailed discussions of
message format, verification tests, and protocol resilience are provided in Sections
5 and 6. A verifier, S, can initiate the protocol at any time instant, by triggering the
4-step message exchange depicted in Fig. 1, within its 1-hop neighborhood. The
aim of the message exchange is to let S collect information it can use to compute
distances between any pair of its communication neighbors. To that end, POLL
and REPLY messages are first broadcasted by S and its neighbors, respectively.
These messages are anonymous and take advantage of the broadcast nature of the
wireless medium, allowing nodes to record reciprocal timing information without
disclosing their identities. Then, after a REVEAL broadcast by the verifier, nodes
disclose to S, through secure and authenticated REPORT messages, their identities
as well as the anonymous timing information they collected. The verifier S uses

such data to match timings and identities; then, it uses the timings to perform ToF-
based ranging and compute distances between all pairs of communicating nodes in
its neighborhood. Once S has derived such distances, it runs several position
verification tests in order to classify each candidate neighbor as either: 1. Verified,
i.e., a node the verifier deems to be at the claimed position; 2. Faulty, i.e., a node
the verifier deems to have announced an incorrect position; 3. Unverifiable, i.e., a
node the verifier cannot prove to be either correct or faulty, due to insufficient
information. Clearly, the verification tests aim at avoiding false negatives (i.e.,
adversaries announcing fake positions that are deemed verified) and false positives
(i.e., correct nodes whose positions are deemed faulty), as well as at minimizing
the number of unverifiable nodes. We remark that our NPV scheme does not target
the creation of a consistent “map” of neighborhood relations throughout an
ephemeral network: rather, it allows the verifier to independently classify its
neighbors.There, M is a malicious node announcing a false location M0, so as to
fraudulently gain some advantage over other nodes. The figure portrays the actual
network topology with black edges, while the modified topology, induced by the
fake position announced by M, is shown with gray edges. It is evident that the
displacement of M to M0 causes its edges with the other nodes to rotate, which, in
turn, forces edge lengths to change as well. The tests thus look for discrepancies in
the node distance information to identify incorrect node positions.

Merits:
robust against independent and colluding adversaries
lightweight, as it generates low overhead traffic
does not require any infrastructure or a priori trusted neighbors
suitable for both low and high mobile environments

Data Flow Diagram

System Requirements
Hardware
System : Dual core Processor
Hard Disk : 80 GB
Monitor : 15 VGA color
Mouse : Logitech.
RAM : 1 GB.
Software
Operating System : Windows XP.
Language : Java.
IDE : Net Beans 6.9.1.
Database : MySQL.

Modules
Network Construction
Anonymous communication
Position Verification
Cross verification and Multilateration verification

Modules Description
Network Construction
The entire set of interdependent relationships is examined. Network with
fixed number of nodes or agents. Every agent has a utility function and their
possible actions are to form links between each other. Usually forming or
maintaining links has a cost and having connected to other nodes has benefits. The
question of this method is that given some initial setting and parameter values what
network structure will emerge. One way of network formation modeling,
something usually pursued by physicists, or biologists, is to start from a small
network - or even a single node; and then design a usually randomized rule on how
newly-arrived nodes form their links. The aim is to see what properties the network
may have when it grows in size. In this way, researchers try to reproduce
properties common in most real networks, such as the small world network
property or the scale-free network property.
Anonymous communication
The verifier starts the protocol by broadcasting a POLL whose transmission time
tS it stores locally (Algorithm 1, lines 2-3). The POLL is anonymous, since 1) it
does not carry the identity of the verifier, 2) it is transmitted employing a fresh,
software-generated MAC address, and 3) it contains a public key K0S taken from
S’s pool of anonymous one-time use keys that do not allow neighbors to map the
key onto a specific node. We stress that keeping the identity of the verifier hidden
is important in order to make our NPV robust to attacks (see the protocol analysis
in Section 6). Since a source address has to be included in the MAC-layer header
of the message, a fresh, software-generated MAC address is needed; note that this
is considered a part of emerging cooperative systems [2], [25]. Including a one-

time key in the POLL also ensures that the message is fresh (i.e., the key acts as a
nonce).
A communication neighbor X 2 INS that receives the POLL stores its
reception time tSX, and extracts a random wait interval TX 2 ½0; (Algorithm 2,
lines 2-4). After TX has elapsed, X broadcasts an anonymous REPLY message
using a fresh MAC address, and locally records its transmission time tX
(Algorithm 2, lines 5-9). For implementation feasibility, the physical layer
transmission time cannot be stamped on the REPLY, but it is stored by X for later
use. The REPLY contains some information encrypted with S s public key (K0S ),
specifically the POLL reception time and a nonce X used
to tie the REPLY to the next message sent by X: we refer to these data as X’s
commitment, Cj X (Algorithm 2, line 7). The hash hK0 S , derived from the public
key of the verifier, K0S , is also included to bind POLL and REPLY belonging to
the same message exchange. Upon reception of a REPLY from a neighbor X, the
verifier S stores the reception time tXS and the commitment Cj X (Algorithm 1,
lines 4-5). When a different neighbor of S, e.g., Y , Y 2 INS \ INX, broadcasts a
REPLY too, X stores the reception time tYX and the commitment Cj Y (Algorithm
2, lines 10-11). Since REPLY messages are anonymous, a node records all
commitments it receives without knowing their originators.
Position Verification
Then the verifier broadcasts a REVEAL message using its real MAC address
accounts for the propagation and contention lag of REPLY messages scheduled at
time. Once the REPORT message is broadcast and the identity of the verifier is
known to the neighbor nodes. Once the message exchange is concluded, S can
decrypt the received data and acquire the position of all neighbors that participated

in the protocol. The verifier S also knows the transmission time of its POLL and
learns that of all subsequent REPLY messages, as well as the corresponding
reception times recorded by the recipients of such broadcasts. Applying a ToF-
based technique, S thus computes its distance from each communication neighbor,
as well as the distances between all neighbor pairs sharing a link. More precisely,
by denoting with c the speed of light, the verifier computes, for any
communicating pair from the timing information related to the broadcast message
sent by X from the information related to the broadcast message by Y .Once such
distances have been computed, S can run the following three verification tests The
Direct Symmetry Test (DST), The Cross-Symmetry Test and The Multilateration
Test. The DST, S verifies the direct links with its communication neighbors. To
this end, it checks whether reciprocal ToF-derived distances are consistent 1) with
each other, 2) with the position advertised by the neighbor, and 3) with a proximity
range R. The latter corresponds to the maximum nominal transmission range, and
upper bounds the distance at which two nodes can communicate. More
specifically, the first check verifies that the distances, obtained from ranging, do
not differ by more than twice the ranging error plus a tolerance value, accounting
for node spatial movements during the protocol execution. The second check
verifies that the position advertised by the neighbor is consistent with such
distances, within an error margin.
Cross verification and Mulilateration verification
In Algorithm 4, implements cross verifications, i.e., it checks on the
information mutually gathered by each pair of communication neighbors. The CST
ignores nodes already declared as faulty by the DST (Algorithm 4, line 5) and only
considers nodes that proved to be communication neighbors between each other,
i.e., for which ToF-derived mutual distances are available (Algorithm 4, line 6).

However, pairs of neighbors declaring collinear positions with respect to S are not
taken into account (Algorithm 4, line 7, where lineðpX; pY Þ is the line passing by
points pX and pY ). As shown in the next section, this choice makes our NPV
robust to attacks in particular situations. For all other pairs ðX; Y Þ, the CST
verifies the symmetry of the reciprocal distances (Algorithm 4, line 9), their
consistency with the positions declared by the nodes (Algorithm 4, line 10), and
with the proximity range (Algorithm 4, line 11). For each neighbor X, S maintains
a link counter lX and a mismatch counter mX. The former is incremented at every
new crosscheck on X, and records the number of links between X and other
neighbors of S (Algorithm 4, line 8). The latter is incremented every time at least
one of the cross-checks on distance and position fails and identifies the potential
for X being faulty.
Once all neighbor pairs have been processed, a node X is added to the
unverifiable set UUS if it shares less than two non-collinear neighbors with S
(Algorithm 4, line 14). Indeed, in this case, the information available on the node is
considered to be insufficient to tag the node as verified or faulty (see Section 6 for
details). Otherwise, if S and X have two or more noncollinear common neighbors,
X is declared as faulty, unverifiable, or conditionally verified, depending on the
percentage of mismatches in the crosschecks it was involved in (Algorithm 4, lines
15-18). Specifically, X is added to IFS or UUS, depending on whether the ratio of
the number of mismatches to the number of checks is greater or equal to a
threshold
. If such a ratio is less than
, X is added to a temporary set WWS for conditionally verified nodes.

MLT, in Algorithm 5, ignores nodes already tagged as faulty or unverifiable and
looks for suspect neighbors in WWS. For each neighbor X that did not notify about
a link reported by another node Y , with X; Y 2 WWS, a curve LXðS; Y Þ is
computed and added to the set ILX (Algorithm 5, lines 5-7). Such a curve is the
locus of points that can generate a transmission whose Time Difference of Arrival
(TDoA) at S and Y matches that measured by the two nodes, i.e., jtXS
tXY j. It is easy to verify that such a curve is a
hyperbola, with foci in pS and pY , and passing through the actual position of X.
Once all couples of nodes in WWS have been checked, each node X for which two
or more unnotified links, hence two or more hyperbolas in ILX, exist is considered
as suspect (Algorithm 5, line 9). In such a case, S exploits the hyperbolae in ILX to
multilaterate X s position, referred to as pML X , similarly to what is done in [17]
(Algorithm 5, line 10). Note that ILX must include at least two hyperbolae for S to
be able to compute pML X , and this implies the presence of at least two shared
neighbors between S and X. pML X is then compared with the position advertised
by X, pX (Algorithm 5, line 11). If the difference exceeds an error margin 2p, X is
moved to the faulty set IFS. At the end of the test, all nodes still in WWS are
tagged as verified and moved to jVS

Algorithms Used
Message Exchange Protocol Verifier
Message exchange protocol: any neighbor
Direct Symmetry Test (DST)

Cross Symmetry Test
Multilateration Test

FEASIBILITY STUDY
Feasibility studies aim to objectively and rationally uncover the strengths and
weaknesses of the existing business or proposed venture, opportunities and threats
as presented by the environment, the resources required to carry through, and
ultimately the prospects for success. In its simplest term, the two criteria to judge
feasibility are cost required and value to be attained. As such, a well-designed
feasibility study should provide a historical background of the business or project,
description of the product or service, accounting statements, details of the
operations and management, marketing research and policies, financial data, legal
requirements and tax obligations. Generally, feasibility studies precede technical
development and project implementation.
Economical Feasibility
This study is carried out to check the economic impact that the system will
have on the organization. The amount of fund that the company can pour into the
research and development of the system is limited. The expenditures must be
justified. Thus the developed system as well within the budget and this was
achieved because most of the technologies used are freely available. Only the
customized products had to be purchased.
Technical Feasibility
Technical feasibility study is carried out to check the technical feasibility,
that is, the technical requirements of the system. Any system developed must not
have a high demand on the available technical resources. This will lead to high
demands on the available technical resources. This will lead to high demands being

placed on the client. The developed system must have a modest requirement, as
only minimal or null changes are required for implementing this system.
Operational Feasibility
The aspect of study is to check the level of acceptance of the system by the
user. This includes the process of training the user to use the system efficiently.
The user must not feel threatened by the system, instead must accept it as a
necessity. The level of acceptance by the users solely depends on the methods that
are employed to educate the user about the system and to make him familiar with
it. His level of confidence must be raised so that he is also able to make some
constructive criticism, which is welcomed, as he is the final user of the system.

Software Specification
Os -Windows Xp
Windows XP is nothing but an entire line of operating systems, which has
been initiated and developed, by Microsoft and it can be used on several computer
systems that are general-purpose, including desktops at home and business, media
centers and notebook computers. Windows XP was codenamed "Whistler", after
Whistler British Columbia, and the letters "XP" stand for experience. The two
words were combined together to form "Windows XP". Windows XP was released
in the year 2001 on October 25 and by January 2006 above 350 million copies was
being used all over. People used Windows 2000 and Windows Me before
Microsoft has developed Windows XP. Windows XP is the first operating system
which is consumer based produced by Microsoft, which is to be built on the
Windows NT kernel and architecture. Microsoft Windows XP is the most
commonly used and supported operating system today. Windows Vista, which is
now a successor of Windows XP, was released worldwide on January 30, 2007.
The minimum requirements specified by Microsoft for Windows XP are 233MHz
processor, 1.5GB of available hard drive space, an SVGA-capable video card and
64MB of RAM. Although it is strongly recommended by UITS that any system
running XP should have a CPU which is faster than 400MHz and at least 256MB
of RAM.
Front-End:
Java:-
Java is a programming language expressly designed for use in the distributed
environment of the Internet. It was designed to have the "look and feel" of the C++
language, but it is simpler to use than C++ and enforces an object-oriented

programming model. Java can be used to create complete applications that may run
on a single computer or be distributed among servers and clients in a network. It
can also be used to build a small application module or applet for use as part of a
Web page. Applets make it possible for a Web page user to interact with the page.
The major characteristics of Java are:-
The programs you create are portable in a network. Your source program is
compiled into what Java calls byte code, which can be run anywhere in a network
on a server or client. That has a Java virtual machine. The Java virtual machine
interprets the byte code into code that will run on the real computer hardware. This
means that individual computer platform differences such as instruction lengths
can be recognized and accommodated locally just as the program is being
executed. Platform-specific versions of your program are no longer needed.
The code is robust, here meaning that, unlike programs written in C++ and
perhaps some other languages, the Java objects can contain no references to data
external to themselves or other known objects. This ensures that an instruction
cannot contain the address of data storage in another application or in the operating
system itself, either of which would cause the program and perhaps the operating
system itself to terminate or "crash." The Java virtual machine makes a number of
checks on each object to ensure integrity.
Java is object-oriented, which means that, among other characteristics, an
object can take advantage of being part of a class of objects and inherit code that is
common to the class. Objects are thought of as "nouns" that a user might relate to
rather than the traditional procedural "verbs." A method can be thought of as one
of the object's capabilities or behaviors.

Java was introduced by Sun Microsystems in 1995 and instantly created a
new sense of the interactive possibilities of the Web. Both of the major Web
browsers include a Java virtual machine. Almost all major operating system
developers (IBM, Microsoft, and others) have added Java compilers as part of their
product offerings.The Java virtual machine includes an optional just-in-time
compiler that dynamically compiles byte code into executable code as an
alternative to interpreting one byte code instruction at a time. In many cases, the
dynamic JIT compilation is faster than the virtual machine interpretation.
IDE:
NetBeans 6.9.1:
The NetBeans Platform is a reusable framework for simplifying the
development of Java Swing desktop applications. The NetBeans IDE bundle for
Java SE contains what is needed to start developing NetBeans plugins and
NetBeans Platform based applications; no additional SDK is required.
Applications can install modules dynamically. Any application can include
the Update Center module to allow users of the application to download digitally-
signed upgrades and new features directly into the running application.
Reinstalling an upgrade or a new release does not force users to download the
entire application again.
The platform offers reusable services common to desktop applications,
allowing developers to focus on the logic specific to their application. Among the
features of the platform are:
• User interface management (e.g. menus and toolbars)

• User settings management
• Storage management (saving and loading any kind of data)
• Window management
• Wizard framework (supports step-by-step dialogs)
• NetBeans Visual Library
• Integrated Development Tools
Netbeans IDE is a free, open-source, cross-platform IDE with built-in-support
for Java Programming Language.
Integrated modules
NetBeans have three Integrated Modules
• NetBeans Profiler
• GUI design tool
• NetBeans JavaScript editor
Back-End
MySQL:-
MySQL is the world's most used relational database management system
(RDBMS) [4] that runs as a server providing multi-user access to a number of
databases. It is named after developer Michael Widenius' daughter, my. [5] The
SQL phrase stands for Structured Query Language.The MySQL development
project has made its source code available under the terms of the GNU General
Public License, as well as under a variety of proprietary agreements. MySQL was
owned and sponsored by a single for-profit firm, the Swedish company
MySQLAB, now owned by Oracle Corporation.

Free-software-open source projects that require a full-featured database
management system often use MySQL. For commercial use, several paid editions
are available, and offer additional functionality. Applications which use MySQL
databases include: TYPO3, Joomla, Word Press, phpBB, Drupal and other
software built on the LAMP software stack. MySQL is also used in many high-
profile, large-scale World Wide Web products, including Wikipedia, Google,
Facebook, and Twitter.
MySQL is a database management system.
A database is a structured collection of data. It may be anything from a simple
shopping list to a picture gallery or the vast amounts of information in a corporate
network. To add, access, and process data stored in a computer database, you need
a database management system such as MySQL Server. Since computers are very
good at handling large amounts of data, database management systems play a
central role in computing, as standalone utilities, or as parts of other applications.
MySQL is a relational database management system.
A relational database stores data in separate tables rather than putting all the data
in one big storeroom. This adds speed and flexibility. The SQL part of “MySQL”
stands for “Structured Query Language.” SQL is the most common standardized
language used to access databases and is defined by the ANSI/ISO SQL Standard.
The SQL standard has been evolving since 1986 and several versions exist. In this
manual, “SQL-92” refers to the standard released in 1992, “SQL: 1999” refers to
the standard released in 1999, and “SQL: 2003” refers to the current version of the

standard. We use the phrase “the SQL standard” to mean the current version of the
SQL Standard at any time.
TESTING
SYSTEM TESTING
System testing is the stage of implementation, which aimed at ensuring that
the system works accurately and efficiently before the live operation commences.
Testing is the process of executing a program with the intent of finding an error. A
good test case is one that has a high probability of finding a yet undiscovered error.
A successful test is one that answers a yet undiscovered error.
UNIT TESTING
Unit testing is the testing of each module and the integration of the overall
system is done. Unit testing becomes verification efforts on the smallest unit of
software design in the module. This is also known as ‘module testing’. The
modules of the system are tested separately. This testing is carried out during the
programming itself.
INTEGRATION TESTING
Data can be lost across an interface, one module can have an adverse effect on
the other sub function, when combined, may not produce the desired major
function. Integrated testing is systematic testing that can be done with sample
data. The need for the integrated test is to find the overall system performance.
There are two types of integration testing. They are:
i) Top-down integration testing.

ii) Bottom-up integration testing.
WHITE BOX TESTING
White Box testing is a test case design method that uses the control structure of
the procedural design to drive cases. Using the white box testing methods, we
derived test cases that guarantee that all independent paths within a module have
been exercised at least once.
BLACK BOX TESTING
Black box testing is done to find incorrect or missing function
Interface error
Errors in external database access
Performance errors
Initialization and termination errors
In ‘functional testing’, is performed to validate an application conforms to its
specifications of correctly performs all its required functions. So this testing is also
called ‘black box testing’. It tests the external behavior of the system. Here the
engineered product can be tested knowing the specified function that a product has
been designed to perform, tests can be conducted to demonstrate that each function
is fully operational.

Conclusion
We presented a distributed solution for NPV, which allows any node in a
mobile ad hoc network to verify the position of its communication neighbors
without relying on a priori trustworthy nodes. Our analysis showed that our
protocol is very robust to attacks by independent as well as colluding adversaries,
even when they have perfect knowledge of the neighborhood of the verifier.
Simulation results confirm that our solution is effective in identifying nodes
advertising false positions, while keeping the probability of false positives low.
Only an overwhelming presence of colluding adversaries in the neighborhood of
the verifier, or the unlikely presence of fully collinear network topologies, can
degrade the effectiveness of our NPV.
Future Enhancement
Future work will aim at integrating the NPV protocol in higher layer
protocols, as well as at extending it to a proactive paradigm, useful in presence of
applications that need each node to constantly verify the position of its neighbors.

References
[1] 1609.2-2006: IEEE Trial-Use Standard for Wireless Access in Vehicular Environments -
Security Services for Applications and Management Messages, IEEE, 2006.
[2] P. Papadimitratos, L. Buttyan, T. Holczer, E. Schoch, J. Freudiger, M. Raya, Z. Ma, F. Kargl,
A. Kung, and J.-P. Hubaux, “Secure Vehicular Communications: Design and Architecture,”
IEEE Comm. Magazine, vol. 46, no. 11, pp. 100-109, Nov. 2008.
[3] P. Papadimitratos and A. Jovanovic, “GNSS-Based Positioning: Attacks and
Countermeasures,” Proc. IEEE Military Comm. Conf. (MILCOM), Nov. 2008.
[4] L. Lazos and R. Poovendran, “HiRLoc: High-Resolution Robust Localization for Wireless
Sensor Networks,” IEEE J. Selected Areas in Comm., vol. 24, no. 2, pp. 233-246, Feb. 2006.
[5] R. Poovendran and L. Lazos, “A Graph Theoretic Framework for Preventing the Wormhole
Attack,” Wireless Networks, vol. 13, pp. 27-59, 2007.
[6] S. Zhong, M. Jadliwala, S. Upadhyaya, and C. Qiao, “Towards a Theory of Robust
Localization against Malicious Beacon Nodes,” Proc. IEEE INFOCOM, Apr. 2008.
[7] P. Papadimitratos, M. Poturalski, P. Schaller, P. Lafourcade, D. Basin, S.
Capkun, and J.-P. Hubaux, “Secure Neighborhood
Discovery:AFundamental Element for Mobile Ad Hoc Networks,” IEEE Comm. Magazine, vol.
46, no. 2, pp. 132-139, Feb. 2008.
[8] Y.-C. Hu, A. Perrig, and D.B. Johnson, “Packet Leashes: A Defense against Wormhole
Attacks in Wireless Networks,” Proc. IEEE INFOCOM, Apr. 2003.
[9] J. Eriksson, S. Krishnamurthy, and M. Faloutsos, “TrueLink: A Practical Countermeasure to
the Wormhole Attack in Wireless Networks,” Proc. IEEE 14th Int’l Conf. Network Protocols
(ICNP), Nov. 2006.
[10] R. Maheshwari, J. Gao, and S. Das, “Detecting Wormhole Attacks in Wireless Networks
Using Connectivity Information,” Proc. IEEE INFOCOM, Apr. 2007.