doc. dr. vadimas starikovičius - techmat.vgtu.ltvs/lp/lygiagretusis_programavimas_1.pdf ·...
TRANSCRIPT

Lygiagretusis programavimas
doc. dr. Vadimas Starikovičius
http://www.techmat.vgtu.lt/~vs
VGTU Matematinio modeliavimo katedra

Studijų dalyko kodas – FMMMB16603.
Studijų dalyko apimtis – 3 kreditai.
Mokymo metodai:
• Paskaitos – 24 val. per semestrą.
• Laboratoriniai darbai – 24 val. per semestrą.
• Konsultacijos – 2 val. per semestrą.
Galutinis įvertinimas G:
G = Egzaminas (50%) +
+ Kolokviumas (20%) +
+ 3 × Laboratoriniai darbai (3 × 10%)

Studijų dalyko aprašas• Lygiagrečiųjų kompiuterių architektūra. Pagrindinės
klasifikacijos. Pagrindiniai tinklų tipai ir jų savybės.
• Pagrindiniai lygiagrečių algoritmų sudarymo būdai.
Duomenų lygiagretumas. Funkcinis lygiagretumas.
• Bendrosios atminties lygiagretusis programavimas. Gijų
valdymas ir sąveika. Gijų programavimo bibliotekos.
• OpenMP programavimo standartas: pagrindiniai principai ir
konstrukcijos.
• Paskirstytosios atminties lygiagretusis programavimas. MPI
biblioteka. Pagrindinės MPI funkcijos.
• Lygiagrečiųjų algoritmų analizė. Algoritmo spartinimo ir
efektyvumo vertinimas.
• Grafinių procesorių panaudojimas bendros paskirties
skaičiavimuose. GPGPU koncepcijos. GPU architektūros.
SIMT. Atminties hierarchija. CUDA. OpenCL.

Literatūra
• R. Čiegis. Lygiagretieji algoritmai ir tinklinės technologijos. Vilnius, Technika. 2005.
• M. Ben-Ari. Principles of Concurrent and Distributed Programming. Addison-Wesley Publishing Company, 2006.
• V. Eijkhout. Introduction to High Performance Scientific Computing. 2015.
• J. J. Dongarra, I. Foster, G. C. Fox, W. Gropp, K. Kennedy, L. Torczon, A. White. Source Book of Parallel Computing. Morgan Kaufmann, 2003.
• D. Storti, M. Yurtoglu. CUDA for Engineers: An Introduction to High-Performance Parallel Computing. Addison-Wesley Professional, 1st Edition, 2015.

Kompiuterių architektūra.
• Įvadas. Istorinė apžvalga.
• Von Neumann’o architektūra.
• Instrukcijų lygio lygiagretumas:
o konvejeriai,
o vektoriniai procesoriai,
o ...

Kas yra lygiagretieji skaičiavimai (parallel computing)?
Nuoseklieji skaičiavimai (serial computing):
• Vykdomi viename kompiuteryje su vienu procesoriumi/vykdomuoju
įrenginiu.
• Problemą sprendžiantis programinis kodas yra sukompiliuojamas į
diskrečią instrukcijų seką.
• Instrukcijos yra vykdomos viena po kitos (nuosekliai).
• Bet kuriuo laiko momentu gali būti vykdoma tik viena instrukcija.

Lygiagretieji skaičiavimai (parallel computing):• Vykdomi naudojant keletą procesorių (branduolių, skaičiavimo įrenginių)
vienu metu.
• Sprendžiama problema programuotojo arba kompiliatoriaus yra išskaidoma į
atskiras dalis, kuriuos gali būti sprendžiamos lygiagrečiai.
• Kiekviena atskira dalis kompiliavimo metu yra užkoduojama kaip instrukcijų
seka.
• Skirtingų dalių instrukcijos yra vykdomos skirtinguose CPU tuo pačiu metu,
taikant įvairius koordinacijos, sinchronizacijos mechanizmus.
t.y. keletas procesorių (branduolių, įrenginių) kartu tuo pačiu metu
sprendžia vieną problemą.

Kam reikalingi lygiagretieji skaičiavimai?
• Įgauti didesnius kompiuterinius pajėgumus tam, kad greičiau
išspręsti vis didesnius uždavinius.
• Lygiagrečios technologijos yra natūralus kelias didinti
kompiuterių skaičiavimų greitį ir atminties resursus.
• Paskutiniųjų dešimtmečių patirtis rodo, kad šis kompiuterinių
technologijų vystymosi kelias yra ekonomiškai naudingiausias.
• Todėl šiuo metu ne tik patys galingiausi pasaulyje bet ir
personaliniai kompiuteriai yra lygiagretieji kompiuteriai.

Tradiciniai uždaviniai - "Grand Challenge Problems"
• Branduolinės reakcijos (branduoliniai ginklai, branduolinės
energijos gavyba).
• Orų prognozė ir klimato pokyčiai, ekologija.
• Kosmologija.
• Geologija, seismologija (žemės drebėjimai).
• Žmogaus genomas, genų inžinerija.
• Raketų, lėktuvų, automobilių projektavimas.
• ...
Istoriškai kompiuteriai atsirado ir buvo vystomi norint išspręsti
didžiųjų iššūkių uždavinius.

Tradicinis modeliavimo būdas moksle ir inžinerijoje:
1. Sukurti teoriją/modelį
2. Patikrinti ją/jį stebėjimuose arba eksperimentuose
Problemos:
• per ilgai (laukti klimato pakeitimų)
• per pavojinga (branduoliniai bandymai)
• per brangu (daryti eksperimentinius lėktuvus/automobilius)
• per sudėtinga (dideli vėjo tuneliai)
Sprendimas – kompiuterinė simuliacija (virtualus eksperimentas)
Tradiciniai uždaviniai - "Grand Challenge Problems"

Kompiuterių skaičiavimo greitis
• Kompiuterių skaičiavimo greitis matuojamas atliekamų
aritmetinių operacijų skaičiumi per sekundę:
– 1 FLOP/s;
– 103 FLOP/s, kiloscale;
– 106 FLOP/s, megascale;
– 109 FLOP/s, gigascale;
– 1012 FLOP/s, terascale;
– 1015 FLOP/s, petascale;
– 1018 FLOP/s, exascale.

Harvard Mark I (1944 m.)
• Elektromechaninis programuojamas kalkuliatorius IBM
ASCC (Automatic Sequence Control Calculator).
• 800 km. laidų, 3 ∙106 jungčių, 3500 relių, 72 sumavimo
įrenginių. 3 FLOP/s (+,-).
• Kariniai uždaviniai, Manheteno projektas.

Colossus (1943-1945 m.)
• Didžiosios Britanijos specialiosios paskirties kompiuteriai,
naudojantys vakuuminius vamzdžius (elektroninės
lempas).
• Buvo sprendžiami kriptografijos uždaviniai.
• Iki 5∙5∙103 simbolių per sekundę.

ENIAC (Electronic Numerical Integrator and Computer)
• 1946 m., JAV, vakuuminių vamzdžių technologija.
• $487.000 1946 m. ($6.740.000 pagal 2016 m.)
• 5∙103 FLOP/s, kiloscale.
• Nuo 1948 m. Von Neumanno architektūros.

CDC 6600 (1964 m.)
• Vienas pirmųjų komercinių tranzistorinių kompiuterių.
• Greičiausias pasaulyje kompiuteris nuo 1964 iki 1969.
• 3∙106 FLOP/s, megascale.

Gigascale, 109 FLOP/s
• 1∙109 ILLIAC IV. 1972 m. superkompiuteris.
– $31.000.000.
– NASA. Pirmas prijungtas prie ARPANet.
– Branduolinių bandymų simuliacija.
– Sprendė CFD uždavinius.
• 1.3∙109 Intel Pentium III, 1999 m.
• 147.6∙109 Intel Core i7-980X Extreme Edition, 2010 m.

Terascale, 1012 FLOP/s
• 1.34∙1012 Intel ASCI Red. 1997 m. superkompiuteris.
– 9298 Pentium Pro procesoriai.
– Atnaujintas 1999 m. Pentium II Xeon ptocesoriais
pasiekė 3.1 TeraFlops.
• 1.344∙1012 GeForce GTX 480, NVIDIA. 2010 m.
• 4.64∙1012 ir 1∙1012 Radeon HD 5970, ATI. 2010 m.
• 5∙1012 Paskirstytų skaičiavimų projektas
„VGTU project@Home“ https://boinc.vgtu.lt

Savanoriški paskirstyti skaičiavimai
“Volunteer computing“ – paskirstytų skaičiavimųrūšis, kai kompiuterių savininkai aukoja jų skaičiavimo resursus (procesorių laiką, diskinę atmintį) vienam ar keliems projektams.
Internetas
Projektas Savanoriai

Populiariausi BOINC-based projektai
SETI@home - U.C. Berkeley,
Search for ExtraTerrestrial Intelligence
Rosetta@home - U. Washington,
baltymų tyrimai
LHC@home - CERN,
accelerator simulation
World Community Grid - IBM,
daug įvairių projektų

Petascale, 1015 FLOP/s• 1.026∙1015 IBM Roadrunner superkompiuteris, 2009 m.

Petascale, 1015 FLOP/s• 8.1∙1015 Folding@home, 2012 m.
• 33.86∙1015 Tianhe-2 superkompiuteris, Linpack testas,
2013 m.
• 93.01∙1015 Sunway TaihuLight superkompiuteris.
Greičiausias pasaulyje nuo 2013 m. iki 2018 m.
– 10.649.600 branduolių.
– 15.371.00 kW.
• 143.5 Pflop/s Summit, an IBM-built system at the Oak
Ridge National Laboratory (ORNL) in Tennessee, USA.
HPL benchmark, https://www.top500.org/
4,356 nodes, each one housing two Power9 CPUs with
22 cores each and six NVIDIA Tesla V100 GPUs each
with 80 streaming multiprocessors (SM).

Perspektyvos• 1∙1018 exascale.
– 2020 m. Tianhe-3. Kinija.
– Atitinkamas programas turi JAV
ir ES.
• Bitcoin tinklo Hash Rate
pasiekė 1.5 Exahashes
(1.5∙1018) per sekundę
2016 m. viduryje.
• 1∙1021 zettascale.
Pagal Moore dėsnį tokios
skaičiavimų sistemos galėtų
atsirasti 2030 m.

Lygiagretieji skaičiavimai tik “turtingiems”?
Asmeninių kompiuterių bumas atpigino kompiuterines technologijas ir padarė lygiagrečias technologijas žymiai
prieinamesnėmis.
Pvz.:
• 2-4 SMP procesorių tarnybinės darbo stotys.
• PC klasteriai.
Atitinkamai auga poreikis programinėje įrangoje
(ypač komerciniams taikymams).

Dar daugiau:
• Nuo 2003 m. mes neturime procesorių greičių (pagal taktinį dažnį) augimo.
• Nors iki tol apie 30 metų kas 18 mėnesių jis maždaug dvigubėjo (G. Muro (G. Moore) dėsnis).
• Priežastis – šilumos išskyrimas (dar ne šviesos greičio riba!)
• Procesorių gamintoju (Intel, AMD, IBM, SUN) sprendimas: daugia-branduoliniai procesoriai (multi-core), t.y. “lygiagrečiai” yra ne tik greičiau bet ir pigiau!
• Nuoseklios programos (pvz. žaidimai, multimedia) “savaime” nebegreitės! (The Free Lunch Is Over: A Fundamental Turn Toward
Concurrency in Software)

Ar bet kokios problemos sprendimą galima
išlygiagretinti?
• Žmogaus vaiko problema (Human Baby Problem).
• Sugalvokite savo pavyzdžius.
vienas klausimas:Bet...

Nuosekliųjų kompiuterių architektūra
• Kompiuteryje yra atskiriami vykdantis įrenginys ir atminties blokas, kuriame yra saugomi ir programa (instrukcijų rinkinys) ir jai reikalingi duomenys.
• Programos instrukcijos yra užkoduotiduomenys, kurie pasako vykdančiam įrenginiui, ką reikia atlikti.
• Šie duomenys yra saugomi kompiuterio atmintyje lygiai taip pat kaip ir duomenys, kurie turi būti apdoroti.
• Vykdantis įrenginys – procesorius (central processing unit (CPU)) gauna (fetch) instrukcijas ir/arba duomenys iš atminties, dekoduoja instrukcijas ir nuosekliai jas vykdo.
• Pirmieji kompiuteriai turėjo fiksuotą programą (ENIAC).
• Von Neumann’o architektūra – “stored-program computer”:

Von Neumann’o kompiuteris
(žvilgsnis iš arčiau)

• Taigi kompiuterį sudaro procesorius, atmintis ir juos jungianti magistralė (bus, datapath).
• Kiekviena iš šitų komponenčių (priklausomai nuo uždavinio) gali tapti kompiuterio silpnąja vieta (performance bottleneck). Klasikinis pavyzdys - von Neumann bottleneck.
• Kadangi turime vis daugiau tranzistorių procesoriuose (Muro dėsnis), tai kaip geriausiai juos panaudoti?
• Šiuolaikiniai procesoriai naudoja šiuos resursus keliuosefunkcinėse įrenginiuose siekiant atlikti kuo daugiau instrukcijų per vieną taktą!
• Vienas iš būdų “instrukcijų lygio lygiagretumas”, kuriuo “pasirūpina” procesorius ir kompiliatorius, kuris pagamina programą (atitinkamą instrukcijų seką).
• Konkretūs būdai yra labai įvairūs: pipelining, superscalararchitektūra, VLIW, multithreading ir prefetching, ... . Naudojami jau ir asmeninių kompiuterių procesoriuose...

Konvejeris (pipelining). Bendras principas.
Konvejeris – darbo organizavimo
principas
(pvz. automobilių gamyklos)
• Užduotis yra padalinama į m použdavinių (subtasks) T1, ..., Tm.
• Kiekvienas iš jų gali būti vykdomas nepriklausomai.
• Tarkime (paprastumui), kad kiekvienas použdavinys įvykdomas per tą
patį laiką – τ.
• N uždavinių atlikimo laikas nuosekliuoju būdu –
TS(N) = N m τ.
• N uždavinių atlikimo laikas konvejerio būdu –
TP(N) = (m + N - 1)τ.
• Konvejerio spartinimo koeficientas -
.1/)1(
1
1)1()(
)()( m
Nmm
Nm
Nm
Nm
mN
NT
NTNS N
P
s
• T.y. kuo ilgesnis konvejeris, tuo didesnį pagreitėjimą mes gauname, jei
galime laikyti jį užpildytų uždavinių srautu.

Instrukcijų konvejeris• Konvejerio principas taikomas procesoriuose vykdant instrukcijas.
• Konvejeris nesumažina vienos atskiros instrukcijos atlikimo laiką, o padidina jų pralaidumą (angl. throughput), tuo pačiu padidindamas procesoriaus našumą.
• Pvz., IBM “Reduced Instruction Set Computer” (RISC) konvejeris naudoja rinkinį iš paprastesnių instrukcijų (m=5):– Instruction fetch
– Instruction decode
– Instruction execute
– Memory access
– Register write back
• Pavyzdžiui, Pentium 4 turi 35 instrukcijų konvejerį.
• Tam, kad konvejeris butų efektyvus jis turi būti užpildytas.
• Problema: kokį instrukcijų srautą vykdyti, kai programoje yra išsiša-kojimas (angl. branch) dėl tam tikros sąlygos tikrinimo (if ... else ...)? Stabdyti konvejerį ir laukti, kol bus iki galo įvykdyta sąlygos patikri-nimo instrukcija? Tokiu būdu prarandame procesoriaus ciklus–laiką!
• Sprendimas – „branch predicting“ įrenginys procesoriuje, kuris bando atspėti teisingą instrukcijų srauto šaką ir spekuliatyviai pradeda jos vykdymą konvejeryje. Jei jis atspėja neteisingai, konvejerio turinys turi būti išvalytas (angl. pipeline’s flush)...
• Kompiliatorių optimizavimas (instruction reordering, loop unrolling, etc.)irgi stengiasi padidinti procesoriaus konvejerių apkrovimą.

Aritmetinis konvejeris. Vektoriniai procesoriai.
• Konvejerio principas puikiai tinka aritmetiniams veiksmams, ypač veiksmams su vektoriais (kadangi veiksmus su atskiromis koordinatėmis galima atlikti nepriklausomai).
Pvz. ci = ai + bi, i=1,2,…,N.
• Atitinkami “vektoriniai procesoriai” realizuoja ne tik instrukcijų bet ir duomenų konvejerį. Specialios instrukcijos nusako procesoriui atlikti reikalingą veiksmą iškarto su tam tikrais atminties segmentai - vektoriais (vietoj N instrukcijų su atskirai gaunamais skaičiais).
• Sutaupomas laikas: adresų dekodavimas ir tik viena instrukcija!Nepamirškime: instrukcijos irgi saugomos atmintyje!
• Problemos: sudėtingas CPU dizainas ir sudėtingos instrukcijos (jų dekoderiai) sulėtina atskirų paprastų instrukcijų atlikimą (a+b). Efektyvumui reikia didelių N !
• Vektoriniai procesoriai dominavo superkompiuteriuose nuo 70-ų iki 90-ų metų. Dauguma šiuolaikinių procesorių turi vek-toriniųoperacijų įrenginius: VIS, MMX, SSE, AltiVec ir AVX.

Superscalar architektūra• Vektoriniai procesoriai dažniausiai turi nevieną konvejerį (CRAY X-MP, Cray-
Y-MP, Fujitsu, NEC)!
• Procesorius, įvykdantys daugiau negu vieną instrukciją per taktą, vadinamas superskaliariniu (superscalar). Jis turi turėti keletą vykdančių įrenginių (pvz. ALU, FPU, SIMD).
• Panagrinėkime (kokios instrukcijos gali būti vykdamos lygiagrečiai?):
1) a = b+c;
2) d = e*f;
3) g = a-d;
4) h = i*j;
• Taigi, be keleto funkcinių įrenginių tam reikalingi:
– galimybė išdavinėti keletą instrukcijų per taktą skirtingiems įrenginiams,
– “out of order” ir “speculative” instrukcijų vykdymas.
• Už tai atsako procesoriaus valdantysis įrenginys (angl. dispatcher), kuris nuskaito instrukcijas iš atminties, nusprendžia kurios iš jų gali būti vykdomos lygiagrečiai ir paskirsto jas tarp vykdančiųjų įrenginių.
• Akivaizdu, kad jis iš esmės apsprendžia CPU architektūros galingumą ir efektyvumą.
• CDC 6600 kompiuteris (1965 m.) laikomas pirmu superskaliarinės architektūros pavyzdžiu. Šiuolaikiniai CPU (kažkur nuo 1998) visi yra superskaliarinėsarchitektūros.

Very Long Instruction Word (VLIW) procesoriai
• “Dispatcher/Hardware scheduler” yra sudėtinga ir brangi
procesoriaus dalis.
• Kitas būdas: VLIW procesoriai naudoja kompiliavimo metu
(kompiliatoriaus) atliktą analizę: kokios instrukcijos gali būti
vykdamos lygiagrečiai.
• Šios instrukcijos yra supakuojamos ir paduodamos vykdymui
kartu, iš čia ir pavadinimas – “Very Long Instruction Word”.
• Taigi, paprastesnė techninė įranga (hardware), tačiau
sudėtingesnė programinė (software). Iš vienos pusės
kompiliatorius turi visą programą (didesnis kontekstas), iš kitos jis
neturi “runtime” informacijos.
• Pirmas VLIW pavyzdys - Multiflow Trace machine (apie 1987
m.). Šios koncepcijos variantai yra naudojami Intel Itanium IA64
procesoriuose.
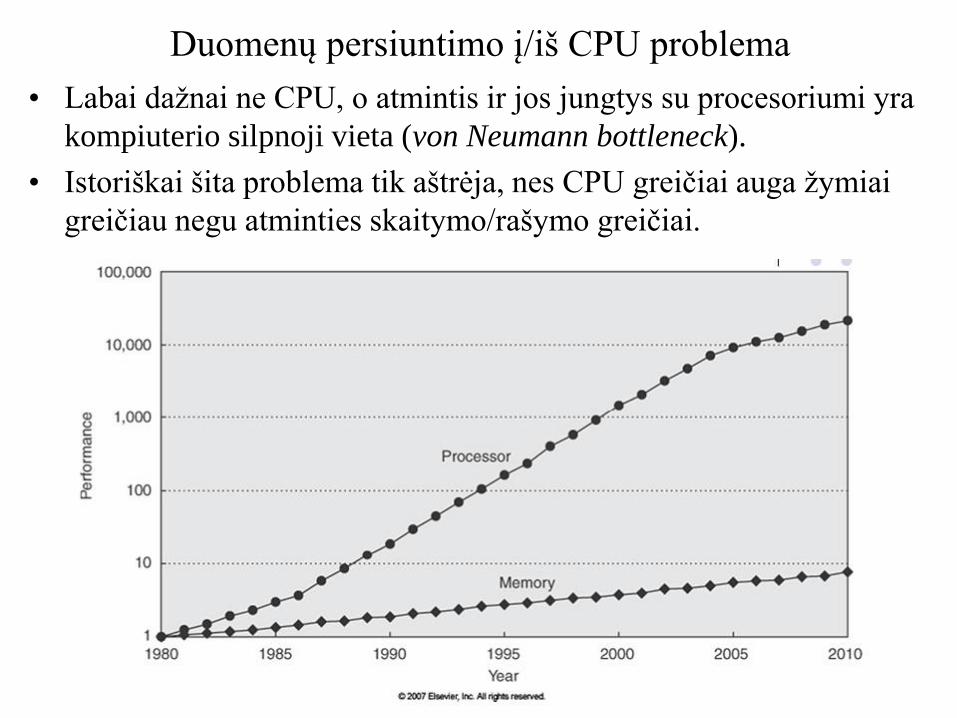
Duomenų persiuntimo į/iš CPU problema
• Labai dažnai ne CPU, o atmintis ir jos jungtys su procesoriumi yra
kompiuterio silpnoji vieta (von Neumann bottleneck).
• Istoriškai šita problema tik aštrėja, nes CPU greičiai auga žymiai
greičiau negu atminties skaitymo/rašymo greičiai.

Kompiuterio atminties darbo charakteristikos
• Pagrindinės atminties sistemos darbo charakteristikos yra uždelsimas (latency) ir pralaidumas (bandwidth).
• Uždelsimas (latency) – tai laikas nuo atminties užklausos iki laiko momento, kai pirmas duomuo pasieks procesorių.
• Pralaidumas (bandwidth) – tai greitis (pvz. baitai per sekundę), kuriuo duomenys iš atminties pasiekia procesorių.
• Gaminti greitą ir didelę pagal dydį atmintį yra sudėtinga ir brangu.
• Pralaidumą padidinti yra lengviau negu uždelsimą, didinant duomenų judėjimo kanalų skaičių.
• Šios problemos sprendimui šiuolaikiniuose kompiuteriuose naudojamos hierarchinės atminties “cache” sistemos.
• “Cache” – (buferinė / spartinančioji atmintinė) yra greitesnė atmintis, kurioje išsaugomos persiunčiamų duomenų iš pagrindinės atminties (RAM) kopijos, greitam jų pasiekimui pakartotinio panaudojimo atveju.
• Šiuolaikiniai procesoriai turi keletą hierarchinių „cache“ lygių pagal jų greitį ir dydį: L1, L2, L3.

Hierarchinė atminties sistema (CPU caches)
• Hierarchinės “cache” sistemos efektyvumas priklauso nuo duomenų erdvinio ir
laikinio lokališkumo (anlg. spatial and temporal locality). Programinis kodas turi siekti
kuo ilgiau naudoti tuos pačius duomenis, kitaip tariant kuo dažniau pataikyti į “cache”
(angl. “high cache hit ratio”).
• Nepataikymas į “cache”, t.y. kai reikalingų duomenų jame nėra (angl. “cache
misses”) netgi sulėtina programos vykdymą! (nes kompiuteris turi pakeisti visą
puslapį – “cache line/block”).
• Instrukcijų “prefetching” ir multithreading naudojami bandant sumažinti
procesoriaus “laukimo” laiką.
atminties lygių greičiai ir dydžiai