handout 5: summarizing numerical datacourse1.winona.edu/thooks/media/handout 5 - stat 100...
TRANSCRIPT
Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
1
In this handout, we will consider methods that are appropriate for summarizing a single set of
numerical measurements.
Definition
Numerical Data: A set of measurements that are recorded on a naturally numeric scale.
Example: Typical Household Income
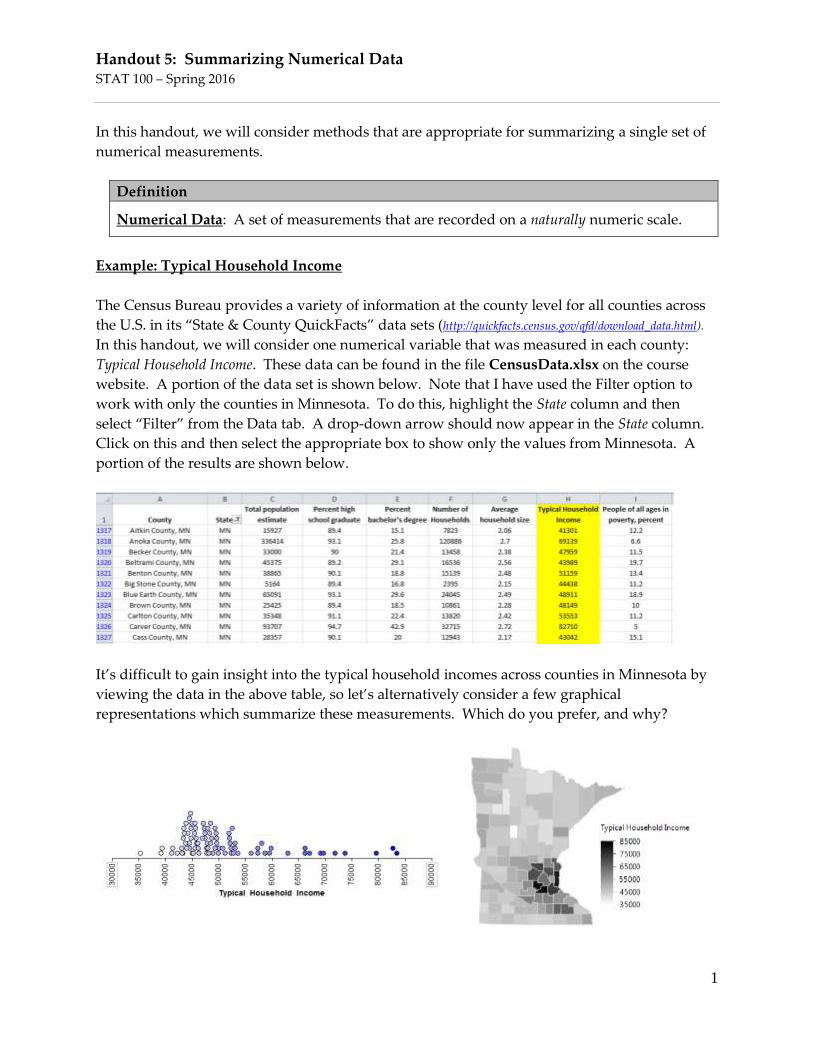
The Census Bureau provides a variety of information at the county level for all counties across
the U.S. in its “State & County QuickFacts” data sets (http://quickfacts.census.gov/qfd/download_data.html).
In this handout, we will consider one numerical variable that was measured in each county:
Typical Household Income. These data can be found in the file CensusData.xlsx on the course
website. A portion of the data set is shown below. Note that I have used the Filter option to
work with only the counties in Minnesota. To do this, highlight the State column and then
select “Filter” from the Data tab. A drop-down arrow should now appear in the State column.
Click on this and then select the appropriate box to show only the values from Minnesota. A
portion of the results are shown below.
It’s difficult to gain insight into the typical household incomes across counties in Minnesota by
viewing the data in the above table, so let’s alternatively consider a few graphical
representations which summarize these measurements. Which do you prefer, and why?

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
2
MEASURES OF LOCATION: CENTER
Suppose we wanted to summarize the “location” (on a number line) of the data that were
measured on typical household incomes in Minnesota counties. The most common measures of
location summarize the center of a data set: the mean and the median.
Definitions
Mean: The arithmetic average of all values. This is calculated by adding up all of the
values and dividing by the total number of measurements.
Median: This is the middle value of a data set, after the numerical values have been put in
order. If the data set contains an even number of observations, then the median is the
average of the middle two observations.
Getting these Summaries in Excel:
In Excel, you can calculate the mean and median using the following functions:
Summary Excel Function
Mean =AVERAGE( )
Median =MEDIAN( )
Enter the following in your Excel spreadsheet to calculate these summaries:
Write the values that Excel returns in Column N on the spreadsheet shown below.

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
3
Excel Tip
You can name a range of cells to be referenced later in a formula. Do this by highlighting the
data values in a specific range (in this case, highlight the Typical Household Income values for
Minnesota counties) and then giving the data range a name in the box just above the column
labels.
For example, I chose to name the range of data containing Typical Household Income for
Minnesota counties MN_Income in the worksheet shown below.
This range can now be referenced in a formula using only its name:

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
4
The mean (or average) is the balance point in the distribution.
The median is the middle value. Since there are 87 measurements in this data set, the middle
value would be the 44th of the ordered measurements.
Questions:
1. Does the mean necessarily have to be a value in the data set? Explain.
2. Does the median necessarily have to be a value in the data set? Explain.
3. In Minnesota, the typical household income is highest in Scott County ($83,415).
Suppose this data value was replaced by a value that was even larger (say $90,000).
What effect would this have on the mean Typical Household Income across Minnesota
counties? What about the median?
4. Note that in our data set, each county is represented by a single value for Typical
Household Income. How do you think the U.S. Census Bureau came up with this one
measurement for each county? Discuss.

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
5
MEASURES OF LOCATION: PERCENTILES
In addition to the mean and/or median, summaries called percentiles are also used to describe a
set of measurements. These percentiles give us insight into the entire spectrum of data values.
Definition
Percentile: The pth percentile of a set of measurements is defined to be the point in the data
set where p% of the measurements fall at or below that value.
To see how percentiles are calculated, consider the county level Typical Household Income in
Minnesota counties. A graph of these values is shown below.
One way to understand percentiles is to find the percentage of observations that fall at or below
a particular point in the data set. For example, note that about 3% of the counties in Minnesota
have typical income levels below $40,000. So, the 3rd percentile of this data set is about $40,000.
Typical
Household
Income Percentiles
$35,000 0%
$40,000 3%
$45,000 26%
$50,000 64%
$55,000 79%
$60,000 87%
$65,000 89%
$70,000 94%
$75,000 97%
$80,000 98%
$85,000 100%

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
6
A cumulative density function (CDF) plot can be used to display all of these percentiles. To
create a CDF plot on the graph below, plot the typical household income levels from the
preceding table on the x-axis and their respective percentiles on the y-axis.
Next, instead of first selecting a Typical Household Income value and then calculating the
percentage of data points at or below that point, we could work backwards. In other words, we
could define certain percentiles and then determine the Typical Household Income level for that
percentile. For example, the bottom 10% of the incomes falls at or below $43,285. So, the 10th
percentile for this data set is $43,285.
Income per
household Percentiles
$35,307 0%
$43,285 10%
$44,472 20%
𝑄1- $44,820 25%
$45,475 30%
$46,960 40%
Median - $47,959 50%
$49,420 60%
$51,987 70%
𝑄3 - $52,598 75%
$55,590 80%
$66,208 90%
$83,415 100%

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
7
Percentiles can be calculated in Excel using the =PERCENTILE( ) function. For example, in the
worksheet shown below, I entered the following formulas in Column N so that Excel would
return those percentiles in Column N.
Excel returns the percentiles as shown below:

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
8
Note that the CDF plot based on the table we just obtained in Excel is equivalent to the one
sketched earlier.
Questions: Use the preceding table of percentiles and/or the corresponding CDF plot to answer
the following questions.
1. What is the median Typical Household Income for MN counties?
2. How could you determine the median from the CDF plot? Discuss.
3. What is the minimum Typical Household Income in MN? What is the maximum? How
could you identify these from the CDF plot? Discuss.
4. The CDF plot has a “longer tail” on the upper-end than on the lower-end. What does
this imply about Typical Household Income across the 87 counties in MN? Discuss.
5. The CDF plot is fairly steep between $45,000 and $55,000. What does this imply about
Typical Household Income across the 87 counties in MN? Discuss.

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
9
IS A MEASURE OF CENTER ENOUGH?
Note that by calculating a summary such as a mean or median for a data set, we condense
information from all of the measurements down to a single value. For example, consider the
Typical Household Income across counties for three different states (Minnesota, Wisconsin, and
Virginia):
The following picture shows the average for each state.
Questions:
1. What differences exist in the Typical Household Income values across these three states?
Discuss.
2. Suppose that your friend tries to summarize the differences across these three states
using only the mean (i.e., average) from each state. Do you think that this single
summary (the mean) tells the whole story well? Why or why not?

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
10
Note that instead of simply comparing only the the means from each state, we could have also
considered percentiles. Putting the CDF plots for all three states on the same graph allows us to
make very rich comparisons across states.
Questions:
1. Consider the poorest people in each state. In which state do the county-level typical
household incomes tend to be the lowest? Likewise, consider the richest people in each
state. In which state are the county-level typical household incomes the highest?
2. Which state seems to have the most problems with income inequality? Discuss.
3. How do the income levels of MN and WI compare?
4. What is an advantage to using the CDF plot to make comparisons across states?

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
11
MEASURES OF VARIABILITY
As noted above, describing an entire data set well involves more than simply summarizing its
center with a mean or a median. We should also consider the amount of variability in the data
set (i.e., a measure of how different the measurements are from one another).
Several quantities exist for summarizing the amount of variability. A few of them are discussed
below.
Definition
Range: The difference between the largest and smallest measurements in a data set.
For example, consider the Minnesota counties’ Typical Household Incomes:
In Excel, you can calculate this using the =MAX( ) and =MIN( ) functions:
Write the value that Excel returns on the spreadsheet below:

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
12
Definition
Mean Absolute Deviation:
For each measurement, calculate how far away that measurement is from the mean of the
data set. The mean absolute deviation is the average of these absolute distances.
n
mean the to DistanceMAD
To see how this is calculated, first consider the mean for Minnesota:
Then, consider the distance between each measurement and the mean:
Next, we consider the length of each of these distances (also called the absolute value of the
residuals) on the following plot. The average of this data set is the mean absolute deviation.
Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
13
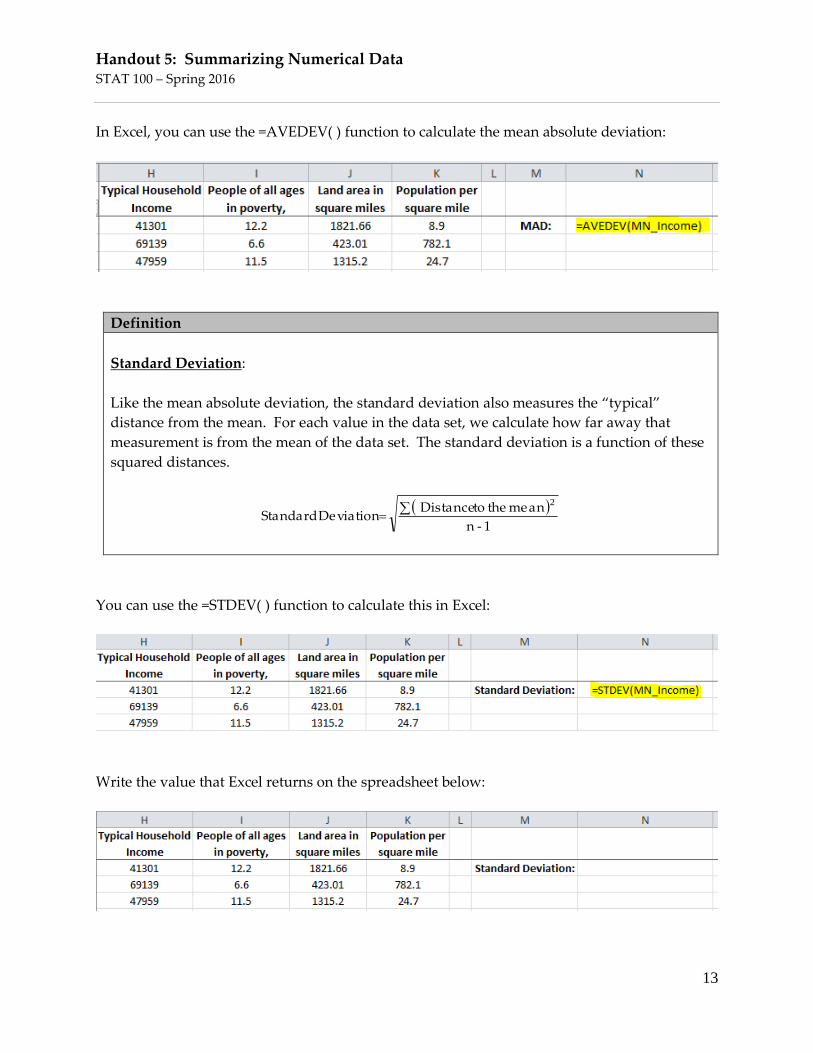
In Excel, you can use the =AVEDEV( ) function to calculate the mean absolute deviation:
Definition
Standard Deviation:
Like the mean absolute deviation, the standard deviation also measures the “typical”
distance from the mean. For each value in the data set, we calculate how far away that
measurement is from the mean of the data set. The standard deviation is a function of these
squared distances.
1-n
mean the to Distance DeviationStandard
2
You can use the =STDEV( ) function to calculate this in Excel:
Write the value that Excel returns on the spreadsheet below:

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
14
Use Excel to compute the following summaries for each of the three states listed below. Then,
answer the questions that follow the table.
Virginia Wisconsin Minnesota
Mean
Minimum
25th percentile
Median
75th percentile
Maximum
Range
MAD
Standard Deviation

Handout 5: Summarizing Numerical Data STAT 100 – Spring 2016
15
Questions:
1. In which state does the Typical Household Income of counties tend to be the highest? The
lowest? Discuss.
2. Which state appears to have the most problems with income inequality? Which state
appears to have the least problems with income inequality? How did you decide this?
3. Virginia’s data set consists of 134 counties, while Wisconsin’s consists of only 72. Your
friend argues that there is less variability (and therefore less income inequality) in
Wisconsin’s data set simply because it has a smaller number of measurements. Why is
this reasoning incorrect? What is the real reason there is less variability in Wisconsin
than in Virginia?