harvesting metadata using oai-pmh roy tennant california digital library
TRANSCRIPT

Harvesting Metadata Using OAI-PMH
Roy TennantCalifornia Digital Library

Outline
The Open Archives InitiativeOAI-PMHThe Harvesting ProcessHarvesting ProblemsSteps to a Fruitful HarvestA Harvesting Service ModelThe OAI Future

Open Archives InitiativeAimed at making the large and growing number of repositories of freely available digital content interoperableProtocol for Metadata Harvesting (OAI-PMH) specifies how repositories can expose their metadata for others to harvestOver 800 repositories world-wide support the protocolOAIster.org has indexed nearly 6 million items from over 500 of those repositories

www.oaforum.org/tutorial/

OAI-PMHData providers (DP) — those with the stuffService providers (SP) — those who harvest metadata and provide aggregation and search servicesSoftware for both DPs and SPs readily available OAI-PMH verbs:
IdentifyListIdentifiersListMetadataFormatsListSetsListRecordsGetRecord

OAI Architecture
Source: Open Archives Forum Tutorial


IdentifyProvides basic information about a repository

ListMetadataFormatsLists available metadata formats

ListIdentifiersLists all identifiers (or only those of the optionally specified set)Must include metadataPrefix attribute
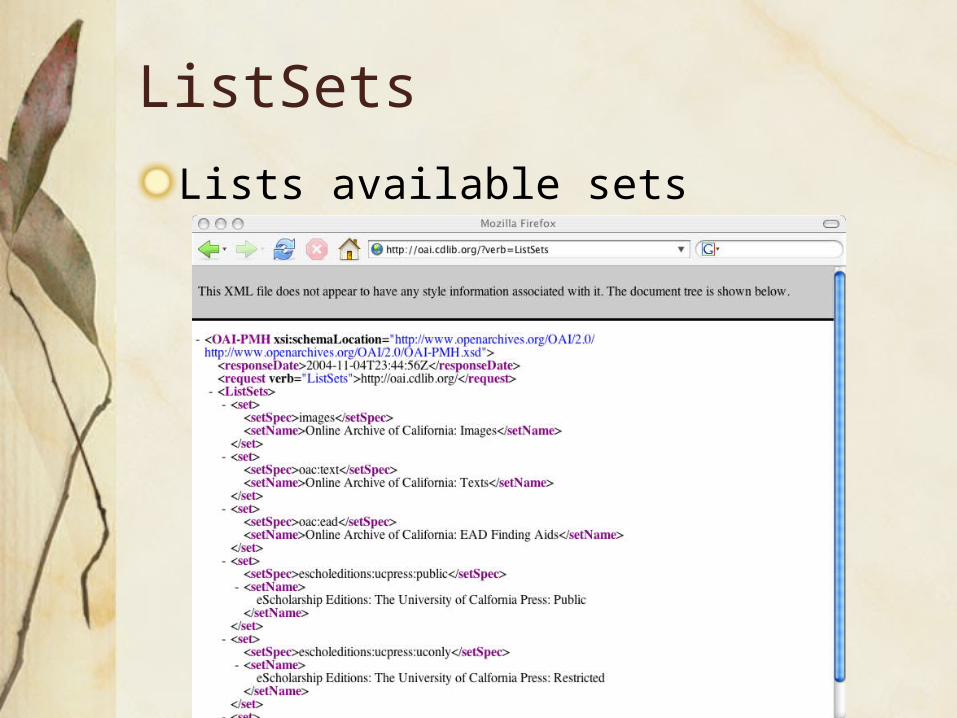
ListSets
Lists available sets
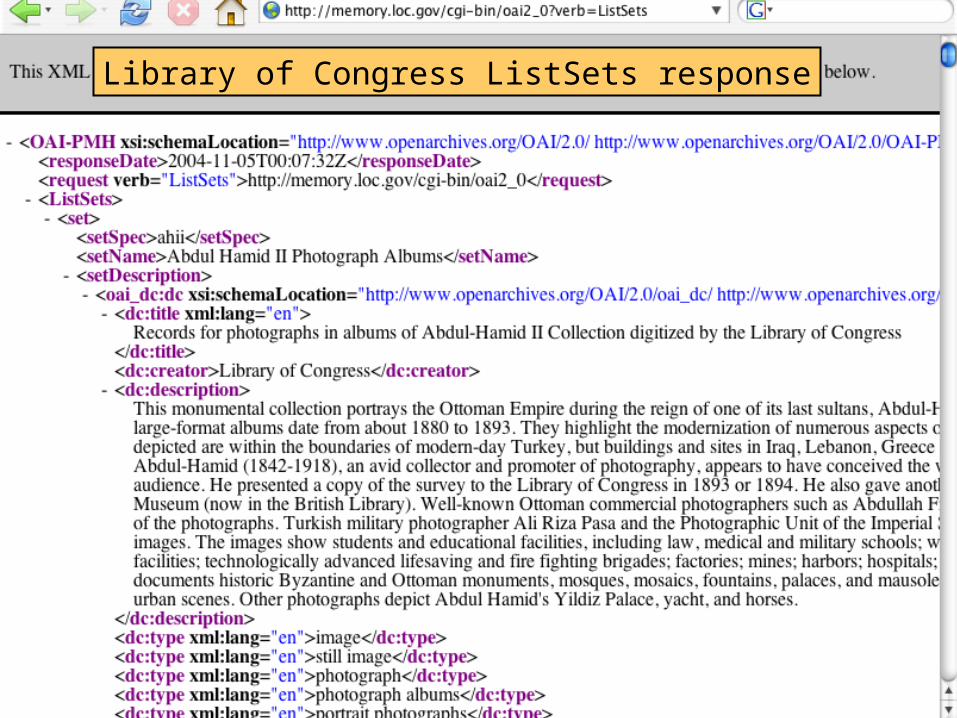
Library of Congress ListSets response

ListRecordsLists all records (or only those of the optionally specified set)Must include metadataPrefix attribute

GetRecordRetrieves a specific recordMust include metadataPrefix and identifier attributes

The Harvesting Process
Identifying SourcesSelecting SetsHarvestingMetadata ProcessingIndexingInterface

A Harvesting Service Model

gita.grainger.uiuc.edu/registry/

errol.oclc.org

Selecting Sets
Review the response to the ListSets verbMay be instructive to search the collection in the native interface, if possibleLook for descriptive pages on the site being harvested


Harvesting
Many harvesting applications are available, I will focus on:
Public Knowledge Project (PKP) Harvester Virginia Tech Perl Harvester
Library software vendors increasingly offer harvesting products (e.g., ExLibris’ MetaIndex)


+-----------------------------------------+| Harvester Sample Configurator |+-----------------------------------------+| Version 1.1 :: July 2002 || Hussein Suleman <[email protected]> || Digital Library Research Laboratory || www.dlib.vt.edu :: Virginia Tech |------------------------------------------+
Defaults/previous values are in brackets - press <enter> to accept thoseenter "&delete" to erase a default valueenter "&continue" to skip further questions and use all defaultspress <ctrl>-c to escape at any time (new values will be lost)
Press <enter> to continue
[ARCHIVES]Add all the archives that should be harvested
Current list of archives:No archives currently defined !
Select from: [A]dd [D]oneEnter your choice [D] : a{return}
[ARCHIVE IDENTIFIER]You need a unique name by which to refer to the archive youwill harvest metadata fromExamples: nsdl-380602, VTETD
Archive identifier [] : nsdl-380602{return}
Virginia Tech Perl Harvester

Let’s Harvest!

Indexing
Pick your favorite database/indexing software:
MySQLSWISH-EWhatever is lying around…
May need to specifically set up a method to search across the entire recordMay need different fields for indexing than for displayWill need to deal with element collision

Interface
Software interface (API) for other applications:
SRU/SRW?MXG?Arbitrary Web Services schema?
User interface:What functions do you want your users to be able to perform?What kinds of displays do you want?

Harvesting Problems
SetsMetadata FormatsMetadata ArtifactsGranularityMetadata Variances

Sets
Records are harvested in clumps, called “sets” created by DPsNo guidelines exist for defining setsExamples:
CollectionOrganizational structureFormat (but is a page image an image? See example)

Metadata Formats
Only required format is simple Dublin Core, although any format can be made available in additionFew DPs surface richer metadataSimple DC is simply too simple!Example (artifact vs. surrogate dates)

Metadata Artifacts
“unintended, unwanted aberrations”Sample causes:
Idiosyncratic local practicesAnachronismsHTML code
Examples: Circa = string of dates for searching purposes[electronic resource]

Granularity
Record Granularity: what is an “object”?
A book, or each individual page?Examples: CDL, Univ. of Michigan
Metadata Granularity: Multiple values in one fieldExample: Univ. of Washington

Metadata Variances
Subject terminology differencesDisparities in recording the same metadata
Example: date variances
Mapping oddities or mistakesExamples: 1) format into description, 2) description into subject

Steps to a Fruitful Harvest
Needs Assessment (it’s the user, stupid)DP Identification and CommunicationMetadata CaptureMetadata AnalysisMetadata SubsettingMetadata NormalizationMetadata EnrichmentIndexing & DisplayInterface (it’s still the user, stupid)

Needs Assessment
What are you trying to accomplish?What will your users want to be able to do?What metadata will you need, and what procedures will you need to set up to enable these activities?Which repositories have what you want?Is what they have (e.g., sets, metadata) usable as is, or ?

DP Identification & Communication
Identification:Use UIUC directory of DPs to identify potential sources
Communication:Not required to tell them you are harvesting, but may help establish a good relationshipMay want to request that they surface a richer metadata format and/or provide a different set

Metadata Capture
Sample questions to answer:Individual sets, or all?Richer metadata formats available?How frequently to reharvest?Start from scratch each time or update?
Many software options

Metadata Analysis
Finding out what you have (and don’t have)
Encoding practicesGap analysis (e.g., missing fields, etc.)Mistakes (e.g., mapping errors)
Software can helpCommercial software like SpotfireIn-house or open source software tools

Source: 2002 Master’s Thesis, Jewel Hope Ward, UNC Chapel Hill
Five elements are used 71% of the time





Metadata Subsetting
DP sets are unlikely to serve all SP uses wellSPs will need the ability to subset harvested metadata

Metadata Normalization
Normalizing: to reduce to a standard or normal statePrototype date normalization service screen

Metadata EnrichmentAdding fields and/or qualifiers may be useful or required, for example:
Metadata provider informationGeographic coverageSubject terms mapped to a different thesaurusAuthority control record
The enrichment process may be the same tool as the subsetting tool (i.e., find a cluster of records and perform an action)

Indexing & Display
Selected fields may need to be mapped to specific indexing and display elementsParticularly required if harvesting different metadata formatsBut also needs to be done with multiple, conflicting fields:
<date>1863.</date><date>[2001 or 2002.]</date>
<identifier>SHS 1,679</identifier><identifier>http://content.lib.washington.edu/cgi-bin/htmlview.exe?CISOROOT=/loc&CISOPTR=58</identifier><identifier>http://content.lib.washington.edu/loc/image/1679.jpg</identifier>

A Harvesting Service Model

The OAI Future
Further protocol developmentServices layered on top of OAI-PMHShared software toolsBest practices for both DPs and SPs
oai-best.comm.nsdl.org