human genom project, ncbi, blast
DESCRIPTION
The goal of Human genome project and what happened during this processTRANSCRIPT


1956 The first physical map of the human genome is determined. Using light microscopy of stained tissue, JH Tjio and A Levan (Hereditas 42,
1-6) reveal that our cells normally contain 46 chromosomes and that there are 24 different types of human chromosome.
1977 Fred Sanger and colleagues publish the dideoxy DNA sequencing method (Proc. Nat! Acod. Sci. USA 74,5463-5467). With some further
re finement s (fluorescence labeling and automation) it will be the method used to sequence the human genome and many other
genomes.
1981 Sanger and colleagues publish the complete sequence of human mitochondrial DNA (Anderson S et al. Nature 290, 457-465).
1988 The US National Institutes of Health (NIH) sets up a dedicated Office of Human Genome Research (later renamed the National Center
for
Human Genome Research).
1990 The Human Genome Project (HGP) is launched officially after implementation of a $3 billion 15-year project in the USA.
1992 The first comprehensive human genetic linkage map, based on microsatellite markers (Weissenbach J et at Nature 359, 794-801).
1995 The first detailed physical map of the human genome is published, based on sequence-tagged sites (Hudson TJ et al. Science 270,
1999 The first essentially complete DNA sequence for a human chromosome is reported, for chromosome 22 (Dunham I et al. Nature 402,
489-495).
2001 Draft sequences of the human nuclear genome, comprising roughly 90% of the total euchromatic component, are published by the
International Human Genome Sequencing Consortium (IHGSC) (Nature 409,860-921) and by Celera (Science 291, 1304-1351).
2001/2 Publication of a draft sequence ofthe mouse nuclear genome (Waterson B et al. Nature 420, 520-562). Human-mouse comparisons
help
human gene identification/characterization.
2003/4 The essentially completed sequence (about 99%) of the euchromatic componel1t of the human genome is reported, comprising 2.85
Gb of
DNA, or roughly gook> of the total of 3.2 Gb (analyses published in 2004 by the IHGSC, Nature 431, 93 1-945).
2004 Over 21 ,000 human genes are validated by full-length cDNA clones (Imanishi T et al. PLoS BioI. 2, e1 62).
2005-7 The International HapMap Consortium reports increasingly detailed single nucleotide polymorphism (SNP) maps for the human
genome
in 2005 (Nature 437, 1299-1320) and 2007 (Nature 449,851-861). The latter map has more than 3.1 million SNPs, roughly one SNP per
kilobase.
2007-8 The age of personal genome sequencing begins with delivery of euchromatic gel10me sequences for James Watson and Craig
Venter and

• An important rationale of the HGP-and a major motivation for
privately funded genome sequencing. ( Started 1990 )
• The resulting gene map was published in (1998) and seemed to
identify the positions of 30,000 human genes.
• ((it was clear that human genes were not uniformly distributed
along or between chromosomes. Some chromosomes were rich
in genes and others were gene-poor))
Essentially devoid of genes and extraordinarily rich in repetitive DNA. which
would make mapping extremely difficult.

Sanger Institute for chromosome 1,
Washington University for
chromosome 2
To collect and managing HGP 7 University and Institute were joint to this
process

Celera company in 1999 announced that it intended to produce a draft human
genome sequence in 2 years and that it would do this by whole genome shotgun
sequencing.
International Human Genome Sequencing Consortium
IHGSC continued alone
By 2003, the lHGSC had produced an essentially complete sequence of the
euchromatic component of the human genome.
By 2004,. data became reedited and 2.85 Gb of sequence reported and The sequence
was interrupted by 341 gaps that remained. The gaps are of two types

• The final sequence was a composite one, representing various donor cells of
different genotypes. 2004
• 21,000 of human genes were confirmed but there are still considerable
uncertainties about exactly how many genes we have.
• The International 1000 Genomes Project that was launched in early 2008. The
aim is to obtain a detailed catalog of human genetic variation by sequencing the
genomes of at least 1000 individuals representing a variety of different ethnic
groups.

Genome projects have also been conducted for a variety of model organisms
Escherichia coli
Saccharomyces Cerevisiae
Caenorhabditis Elegance
Drosophila melanogaster

Mouse Genome Sequencing Consortium derived the genome
sequence of the widely used C57BLl6J mouse strain. The latest C57BLl6J
sequence update represents more than 90% of the total mouse genome
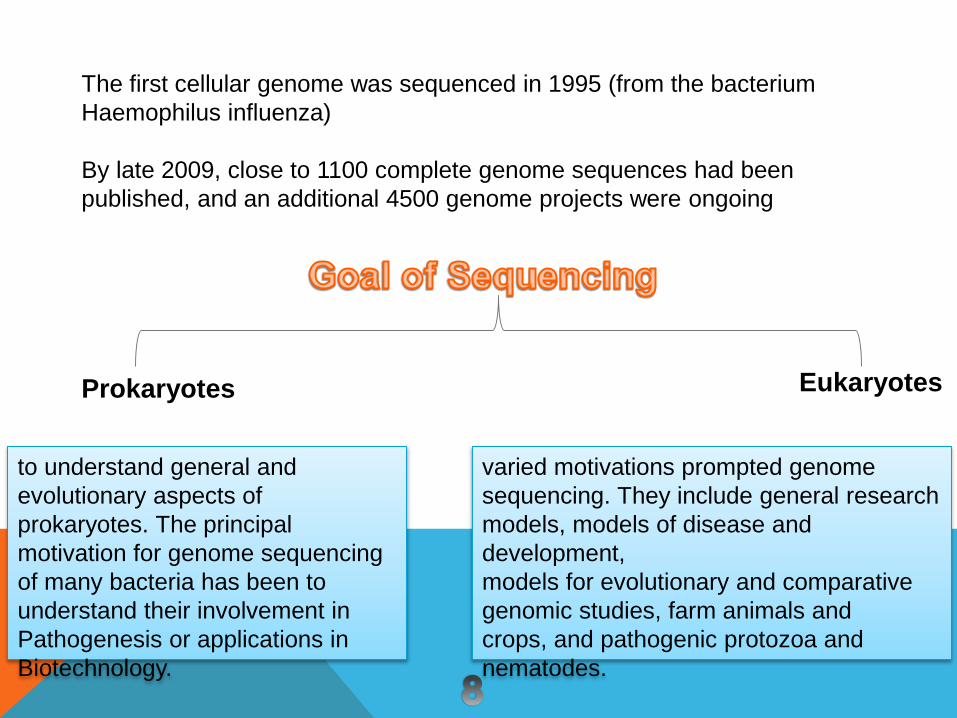
The first cellular genome was sequenced in 1995 (from the bacterium
Haemophilus influenza)
By late 2009, close to 1100 complete genome sequences had been
published, and an additional 4500 genome projects were ongoing
Prokaryotes Eukaryotes
varied motivations prompted genome
sequencing. They include general research
models, models of disease and
development,
models for evolutionary and comparative
genomic studies, farm animals and
crops, and pathogenic protozoa and
nematodes.
to understand general and
evolutionary aspects of
prokaryotes. The principal
motivation for genome sequencing
of many bacteria has been to
understand their involvement in
Pathogenesis or applications in
Biotechnology.


اطالعات موجود در پایگاه های اطالعاتی
پایگاه
اطالعات ژنوم
(Genome databases)
اطالعات مولکولی
(molecular databases)
اطالعات منابعی
(literature databases)

MEDLINE:اطالعات مقاالت چاپ شده
PubMed :دریافت خالصه مقاالت
PubMed Central:مقاالت رایگان بیولوژی و پزشکی
OMIM :اطالعات های ژن های انسانی و ناهنجاری ژنتیکی
(online Mendelian inheritance in man)
OMIA:اطالعات ژن ها و ناهنجاری ژنتیکی در حیوانات
(online Mendelian inheritance in animals)
Books:مجموعه ایی از کتابهای بیولوژی و پزشکی
Journals:دسترسی به عنوان،مخفف وISSN مجالت
MeSH: اطالعات واژگان و معادل تخصصی واژه های علمی
اطالعات منابعی

توالی های نوکلئوتیدی
توالی های پروتئینی
اطالعات ساختاری
اطالعات رده بندی
اطالعات ژن ها
اطالعات تظاهر ژن ها
(MOLECULAR DATABASES)اطالعات مولکولی

RefSeq : در مواردی که یک مولکول با چند توالی برای یک ارگانیسم درGenBank آورده شود
NCBI تالش می کند تا بهترین توالی را انتخاب کند و به عنوان رکوردRefSeq رکورد (معرفی نماید
RefSeqدتا حد امکان به دور از جهش، اشتباهات تعیین توال، تغییرات ناشی از کلونینگ می باش(
dbEST: توالی هایDNA باز دارند و از تعیین ترادف یک یا 500تا 300کوتاهی هستند که معموال بین
. هر دو انتهای بیان شونده ژن بوجود می آیند
ساخته می شود سپس کلون می شود CDNAابتدا mRNAاز روی
بدست می آیدEST’5یا EST’3توالی یابی شود cDNAبر حسب اینکه کدام انتهای
GSS: شبیهEST است تفاوتGSS باEST در این است که منشاءGSS ژنومی است در حالیکه
است mRNAمولکول ESTمنشاء
. بدست می آیندBACکوتاه و تصادفی و معموال از انتهای کلون های کاسمید و GSSتوالی های

:اطالعات این پایگاه بر اساس شش گروه موجودات طراحی شده
آرکئاها1.
باکتری ها2.
یوکاریوت ها 3.
ویروس ها4.
ویروئید ها5.
پالسمید ها6.
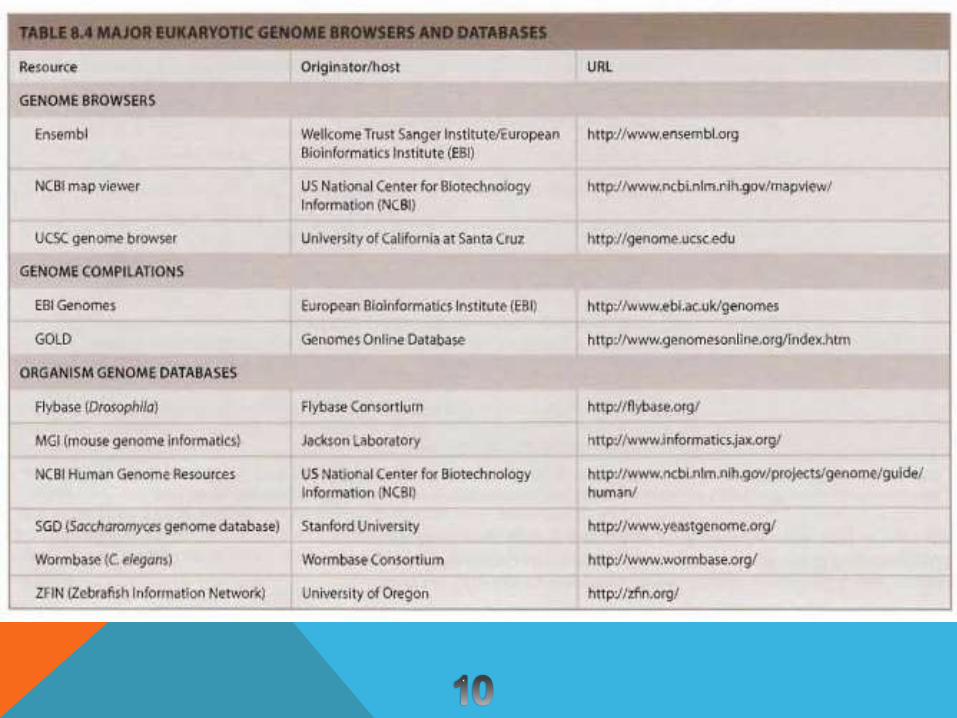
(GENOME DATABASES)پایگاه اطالعات ژنوم

BASIC LOCAL ALIGNMENT SEARCH
TOOLS
(BLAST)
ان تشابهبرنامه ایی است برای پیدا کردن همردیفی موضعی بدون فاصله و باالترین میز
ئیکسرعت باال ودقت زیاد درشناسایی تشابه بین توالی های پرتئین و اسیدنوکل
برای شناسایی تشابه بین توالی ها
Identity : (همسانی توالی ها)توالی هایی که از نظر یا بطور دقیق باهم شباهت دارند.
Similarity :(.هاشباهت توالی)توالی هایی که در برخی نقاط با هم همسانی داشته باشند
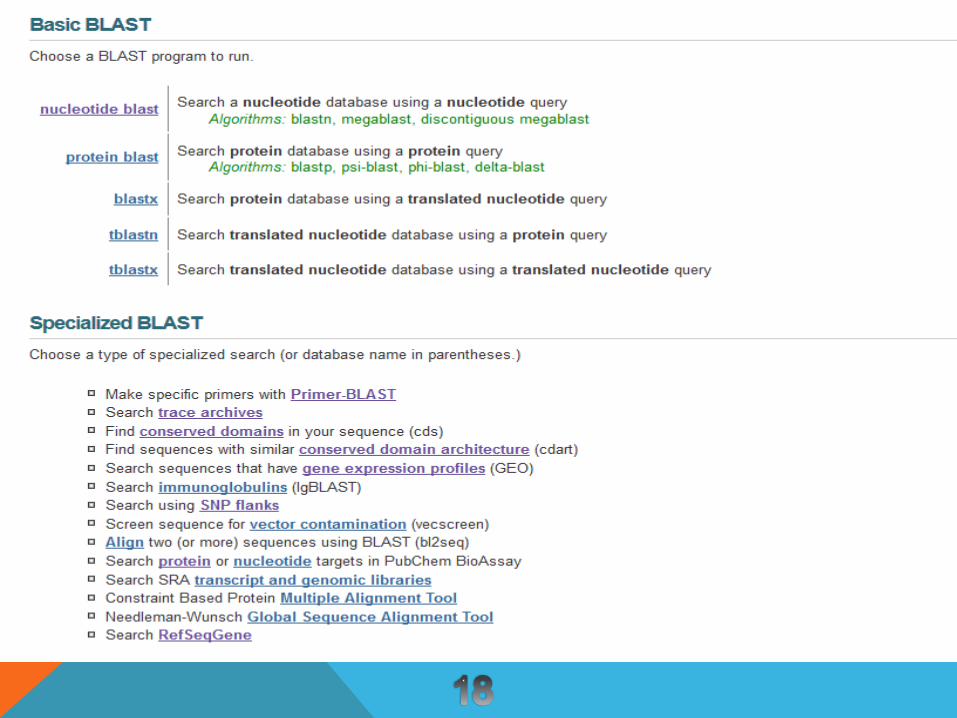

:BLASTPتئینی مقایسه یک توالی پروتئینی با یک توالی پرودر پایگاه اطالعات
:BLASTN مقایسه یک توالیDNA بایک توالیDNA موجود در پایگاه اطالعات
:BLASTX مقایسه یک توالیDNA مورد تفاضا بایک توالی)*(پروتئینی موجود در پایگاه اطالعات
:TBLASTNایک مقایسه یک توالی پروتئینی مورد تقاضا ب)**(توالی پروتئینی ترجمه شده موجود در پایگاه اطالعات
:TBLASTXایک مقایسه یک توالی پروتئینی مورد تقاضا ب)***(توالی پروتئینی ترجمه شده موجود در پایگاه اطالعات

در شش چارچوب خواندنی ترجمه DNAتوالی BLASTXدر * ( سه چارچوب برای رشته باال و سه چارچوب برای رشته پایین)
.مقایسه میشودProسپس با یک توالی
توالی ها در پایگاه اطالعات در شش چارچوب TBLASTNدر ** .قرائت ترجمه و مقایسه ها صورت میگیرد
هم توالی مورد تقاضا و هم توالی های موجود TBLASTXدر *** در در پایگاه اطالعات در شش چارچوب ترجمه میشوند و بعداز آن
.مقایسه ها در سطح اسیدآمینه صورت میگیرد


BLAST Output: Alignments
Identical match
positive score
(conservative)
Negative or zero
gap

REFERENCES
• http://www.ncbi.nlm.nih.gov/guide/sequence-analysis/#howtos_
• http://blast.ncbi.nlm.nih.gov/Blast.cgi
• http://blast.ncbi.nlm.nih.gov/Blast.cgi?CMD=Web&PAGE_TYPE=BlastDocs
• http://www.bio.davidson.edu/genomics/2008/Simpson/Tutorial.html
