initial usage analysis of dbpedia's triple pattern fragments
TRANSCRIPT

Initial Usage Analysis of DBpedia'sTriple Pattern FragmentsRuben Verborgh, Erik Mannens & Rik Van de Walle


What role will the Semantic Web playfor the future generation?
Will it be remotely as important as the Web now is to us?

There used to be no applicationsbecause there was no data.
Linked Data more of less solved this chicken-and-egg problem.

There are no applications because data is not queryable.
SPARQL endpoints are unreliable. Data dumps are not live.

We analyzed DBpedia’s low-cost Triple Pattern Fragments interface between Nov 2014 and Feb 2015.
Over 4M requests were made. There was 1 minute of downtime.

Web interfaces to triples
Four months of fragments
Extending the analysis

Web interfaces to triples
Four months of fragments
Extending the analysis

Web interfaces act as gatewaysbetween clients and databases.
Database ClientWeb
interface
The interface hides the database schema.The interface restricts the kind of queries.

No sane Web developer or admin would give direct database access.
Database ClientWeb
interface
The client must know the database schema.The client can ask any query.
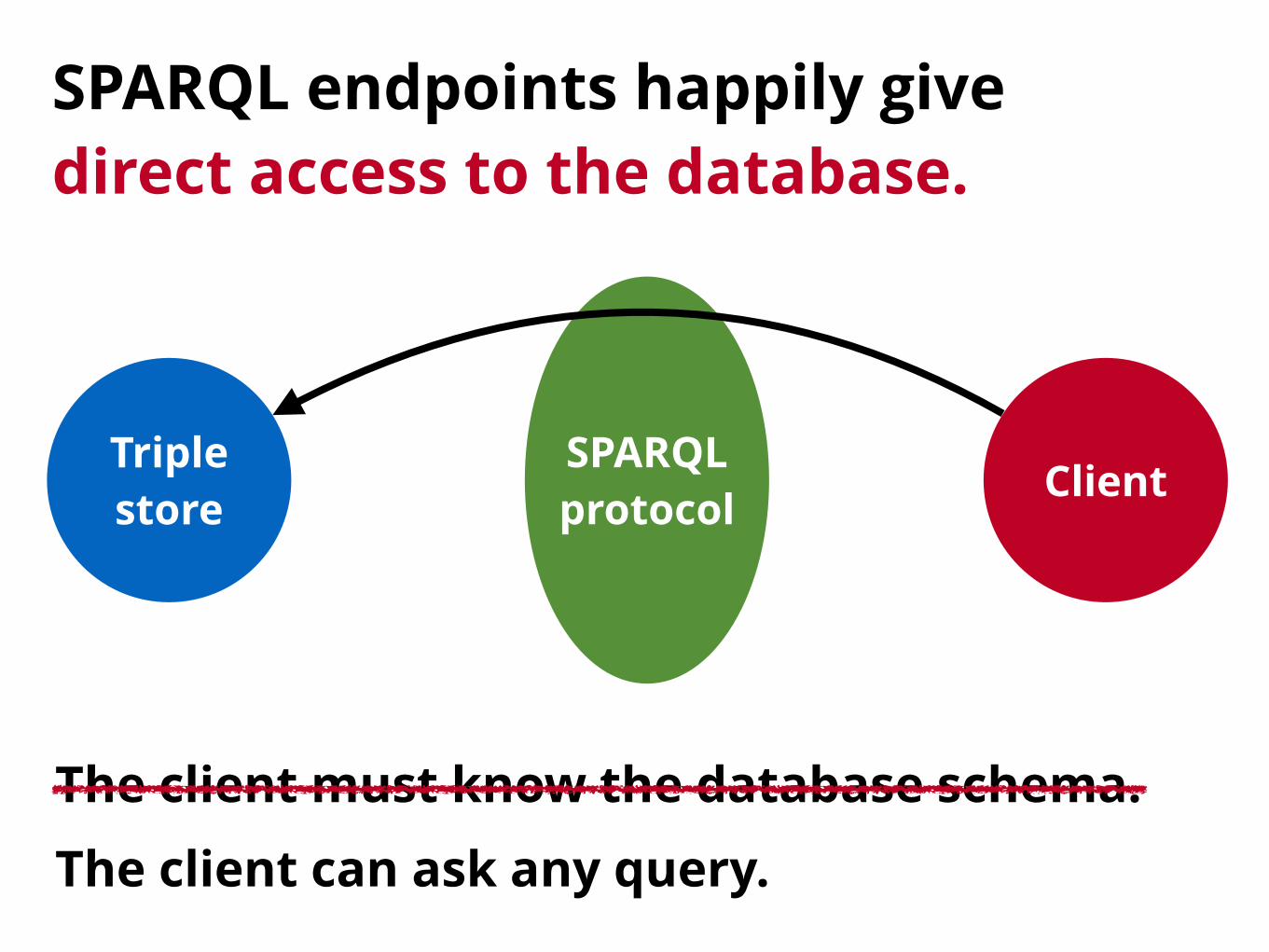
SPARQL endpoints happily givedirect access to the database.
Triplestore Client
SPARQL protocol
The client must know the database schema.The client can ask any query.

SPARQL interfaces are expensive, so we have an availability problem.
There are few SPARQL endpoints because hosting them is expensive.
Many of the endpoints that exist suffer from low availability.
You already give data for free. Do you have to pay for query time as well?

Data dumps allow you to set upyour own private SPARQL endpoint.
But then we no longer query the Web…
No usage statistics whatsoever.
Not everybody can do this: mobile devices, non-technical users, …
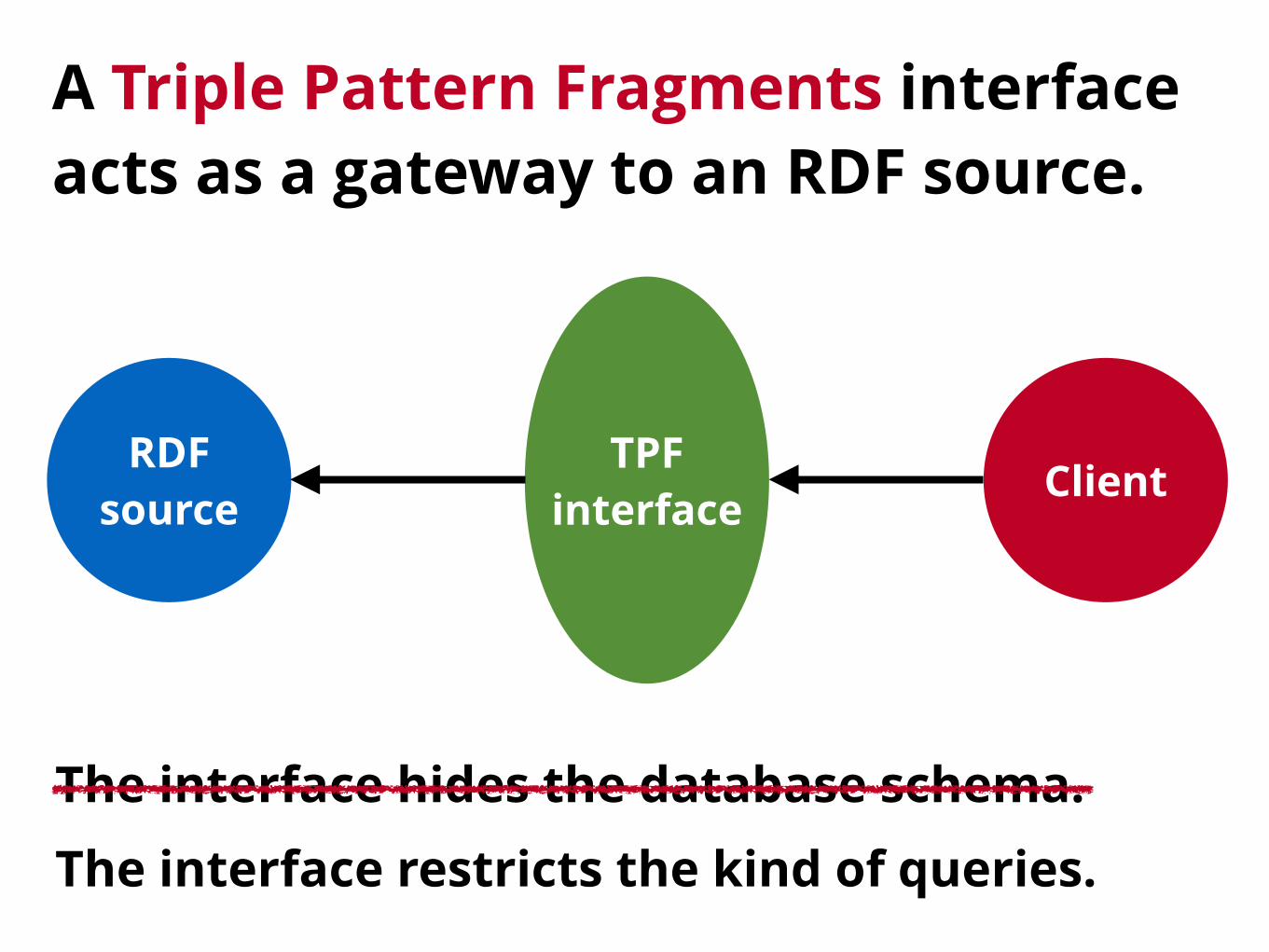
The interface hides the database schema.The interface restricts the kind of queries.
A Triple Pattern Fragments interfaceacts as a gateway to an RDF source.
RDFsource ClientTPF
interface

A Triple Pattern Fragments interfaceacts as a gateway to an RDF source.
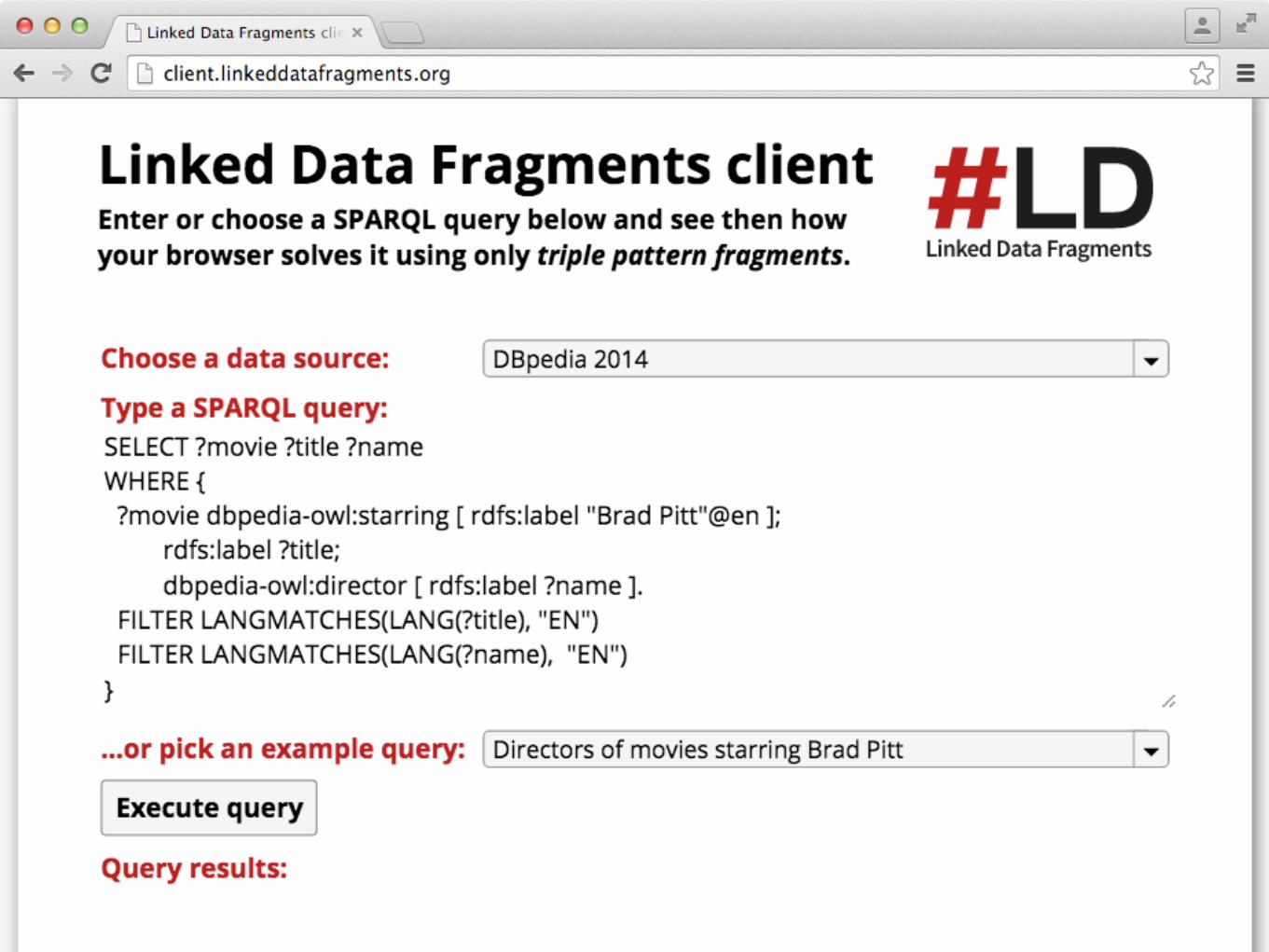
Client can only ask ?s ?p ?o patterns.
Decompose complex SPARQL querieson the client client-side.
Low server cost, highly cacheable, but higher bandwidth and query time.


Web interfaces to triples
Four months of fragments
Extending the analysis

In mid-October 2014, we startedan official TPF interface for DBpedia.
Will this interface be used?
How will clients use it?
Will the availability be sufficientfor live application usage?

The server is deployed virtually, availability monitored externally.
Amazon Elastic Compute Cloudc3.2xlarge machine (8 CPU, 15GB RAM)
Compressed HDT format as backend
Pingdom for analysis
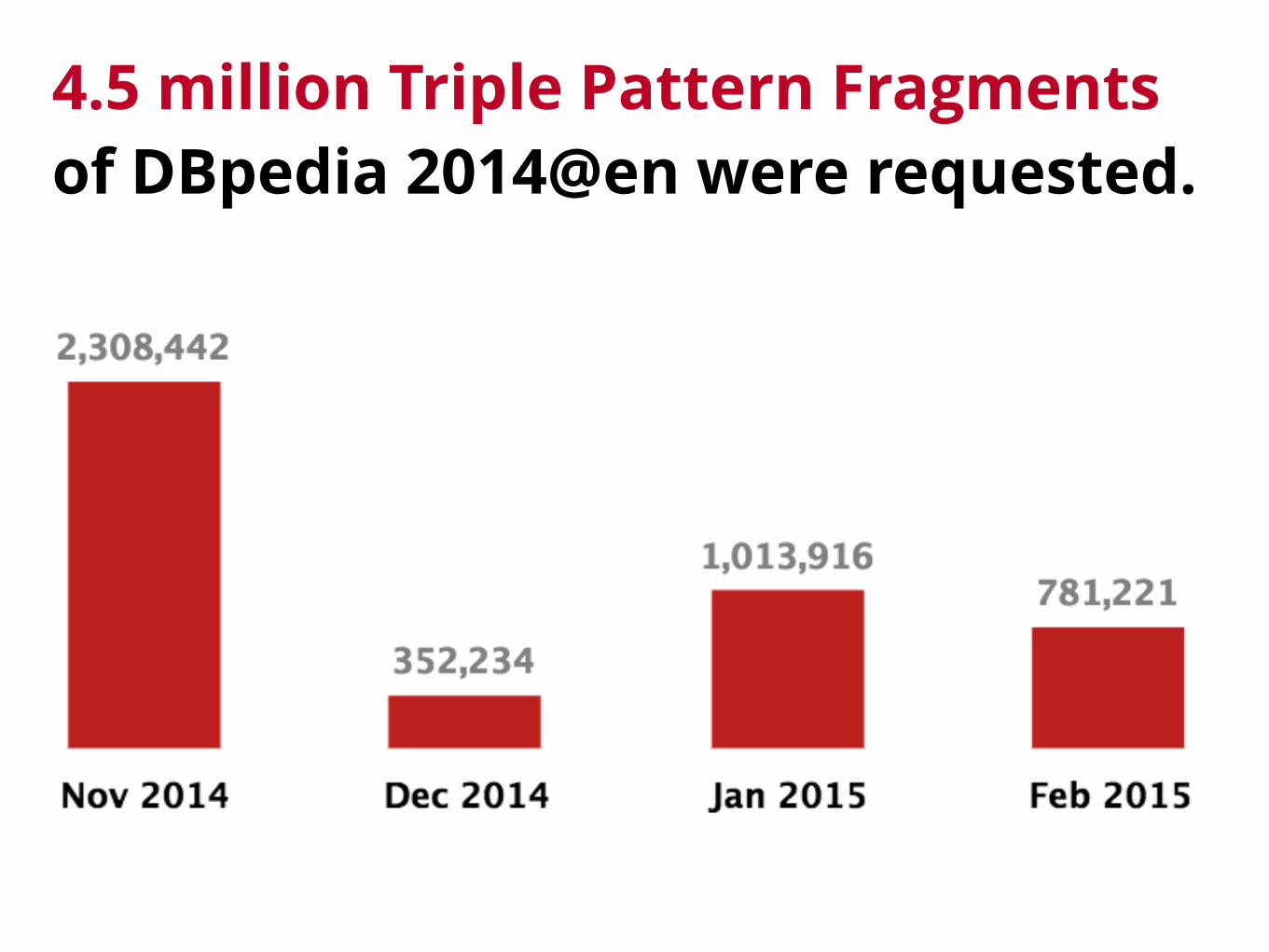
4.5 million Triple Pattern Fragments of DBpedia 2014@en were requested.

The TPF client library consumed most, followed by crawlers and Chrome.
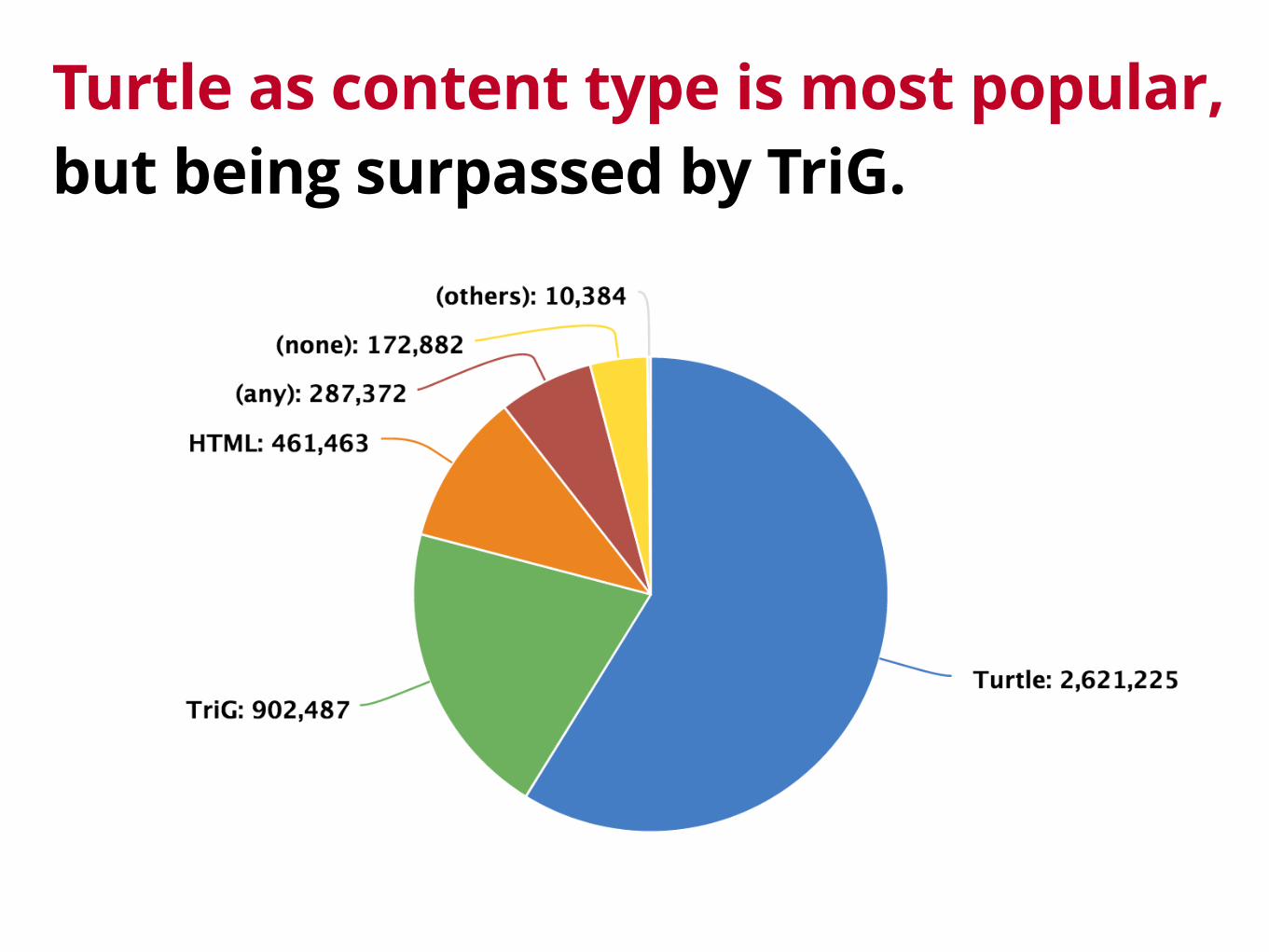
Turtle as content type is most popular,but being surpassed by TriG.
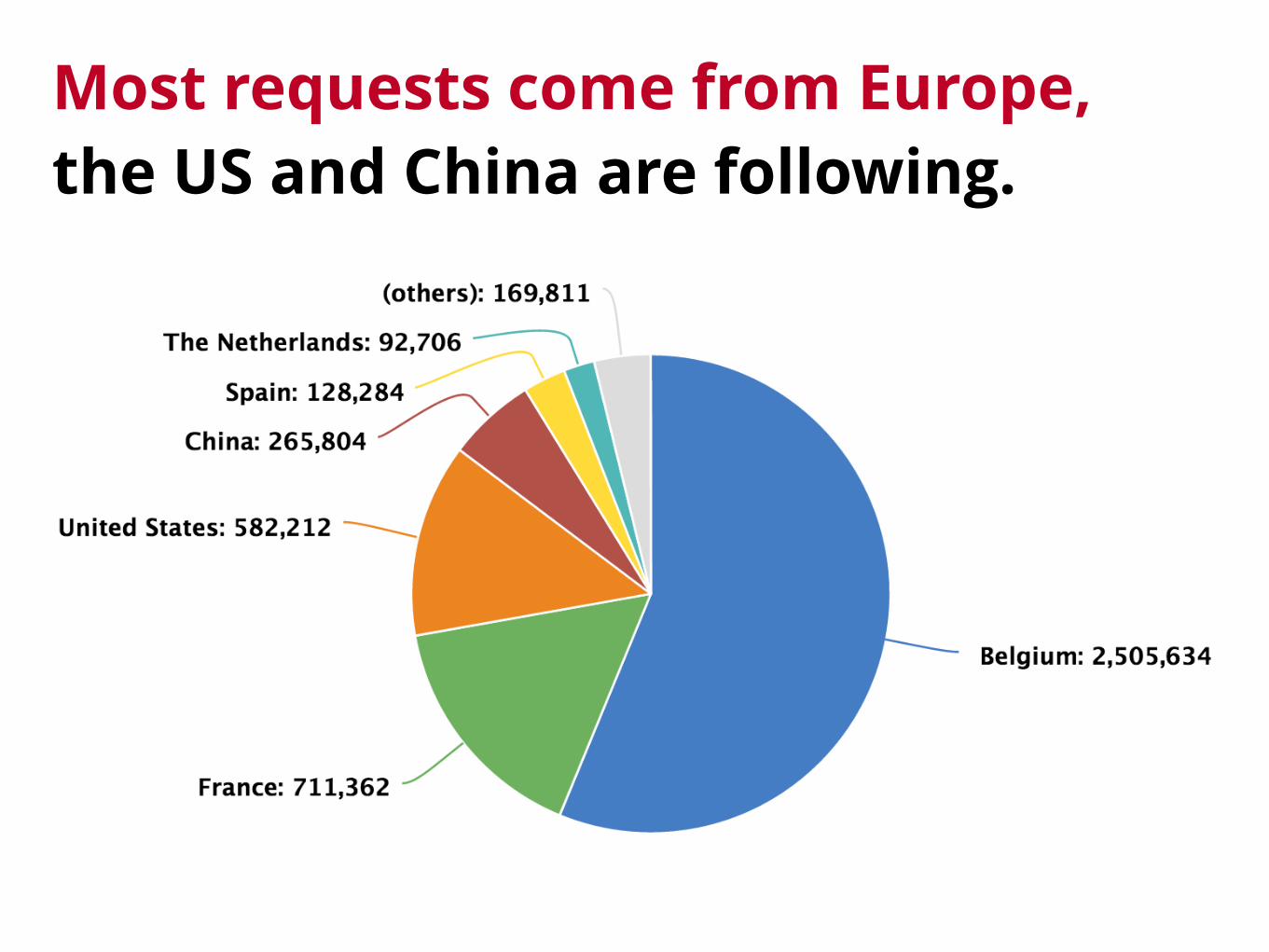
Most requests come from Europe, the US and China are following.

The “type” fragment was popular, but it’s hard to conclude anything.

A quarter of all requests was cached(but we could cache everything).

During four months,the API had 99.9994% availability.
We deeply apologize for that one minute of downtimein November.

Web interfaces to triples
Four months of fragments
Extending the analysis

We don’t know exactlywhich clients executed queries.
Was the TPF client used standalone?
As a library of another application?
Also hard for SPARQL endpoints.

The analysis did not give insights in which queries clients executed.
Good for privacy!
We can try reconstructing SPARQL queries,but maybe clients did something else.
We only know with SPARQL endpoints, not with data dumps or LD documents.

We could learn from the human Web: can clients give explicit feedback?
“This is the query I executed. It took me 5 seconds.”
Potential source of insights,but clients need a gain.
Will this be representative/truthful?

Web interfaces to triples
Four months of fragments
Extending the analysis

We have a >99.999% available API to the most popular RDF datasource.
No more excuses not to build apps.
So where are they?
Is something else holding us back?

We need to think differently on how to build Linked Data apps.
The paradigm of querying a databaseand waiting for the resultsdoes not scale to the Web.
Live data requires new interfacesand new visualizations.

We need developers to build bridges from data to end users.
Now that the chicken-and-egg problemand the availability problems are solved, we need to tackle fundamental questions.
Where are the killer apps the next generation is waiting for?

Initial Usage Analysis of DBpedia'sTriple Pattern Fragments@RubenVerborgh ruben.verborgh.orglinkeddatafragments.org