intelligent chatbot on wechaton-demand.gputechconf.com/gtc/2017/presentation/s7630... ·...
TRANSCRIPT

Intelligent Chatbot on WeChat
WeChat AI NLP
2017.05.09

889 million monthly active users
600 million WeChat Pay users
10 million Official Accounts
200 thousand developers
WeChat is the leading mobile social network in China. In 6
years, WeChat has gained…
Data: Tencent Financial Reports

3
50% of users spend more
than 1 hour on WeChat
every day
Data: Penguin Intelligence

WeChat is not just a mobile messaging app.
It’s a new lifestyle, connecting people with
people, services, devices and more.
WeChat OverviewThe WeChat Lifestyle

Red Pocket
Jan 27 – Feb 01
46 BillionEmoji
Jan 27 – Feb 01
16 Billion
Voice Call
Jan 27 – Jan 28
2.1 Billion minutes
Chinese New Year 2017

6
The new way for businesses to
interact with their customers.
Powered by WeChat

7
Messaging
(Can be automated)Account management
Service AccountsChina Merchant Bank case
China Merchants Bank
Over 10 million followers
Open an account
Pay bill/loan
Receive payment notifications
Receive CRM promotions
Powered by WeChat

8
Messaging Account management
Service AccountsChina Southern Airlines case
China Southern Airlines
Buy Tickets
Check-in
Choose seats
Flight status update
Frequent flyer services
Powered by WeChat

… 4.3
2012.10
Voice Search
4.5
2013.2
Voice Reminder
Shake Music
5.0
2013.8
Voice Input
Scan
Cover/Word
5.2
2013.10
Voice to Text
5.3
2014.1
Shake TV
5.4
2014.6
Scan Cards
Smart Open
Platform
6.0
2014.12
Voice Print
6.2
2015.4
Data Mining
Now
Amber Platform
BOTs Platform
WeChat AIGrowth in 6 years

WeChat Amber Platform
Highlights
Applications
• Data/model parallelism
• Flexible resource management and scheduling
• Compile the graphs
• Best-effort concurrent operations
• Limited memory reuse
• Consistent data streaming
• Kernels merge
• Machine Learning
• Deep Learning
• Data Mining
Experiments – Google Net

Speech Recognition
Features
Applications
• End-to-end deep learning
• Above 95% accuracy
• Cloud based & embedded ASR
• User defined vocabulary and
grammar
• WeChat voice input
• Keyword spotting
• Speech retrieval
• Large vocabulary continuou
s speech recognition
Infrastructure
• Clusters+CUDA+MPI
• Latency control with infiniband
• Training with Tesla M40
• Inference with Tesla P4

Image Recognition
• OCR
• Identity Card Recognition
– Key personal information
extraction and verification
• Image Understanding
– Classify tens of millions of
images daily
– Supports 3 levels and 1,000
categories
– CNN/RNN/LSTM
– End-to-end deep learning
Applications
Algorithms

Chatbot
Examples
• WeBank
• WeChat official account
• Tencent games
• Xiao‘er Mechanical Monk
Chatbot on WeChat
• Natural to server customers
• Powerful for users to acquire
service, information, knowledge,
etc.
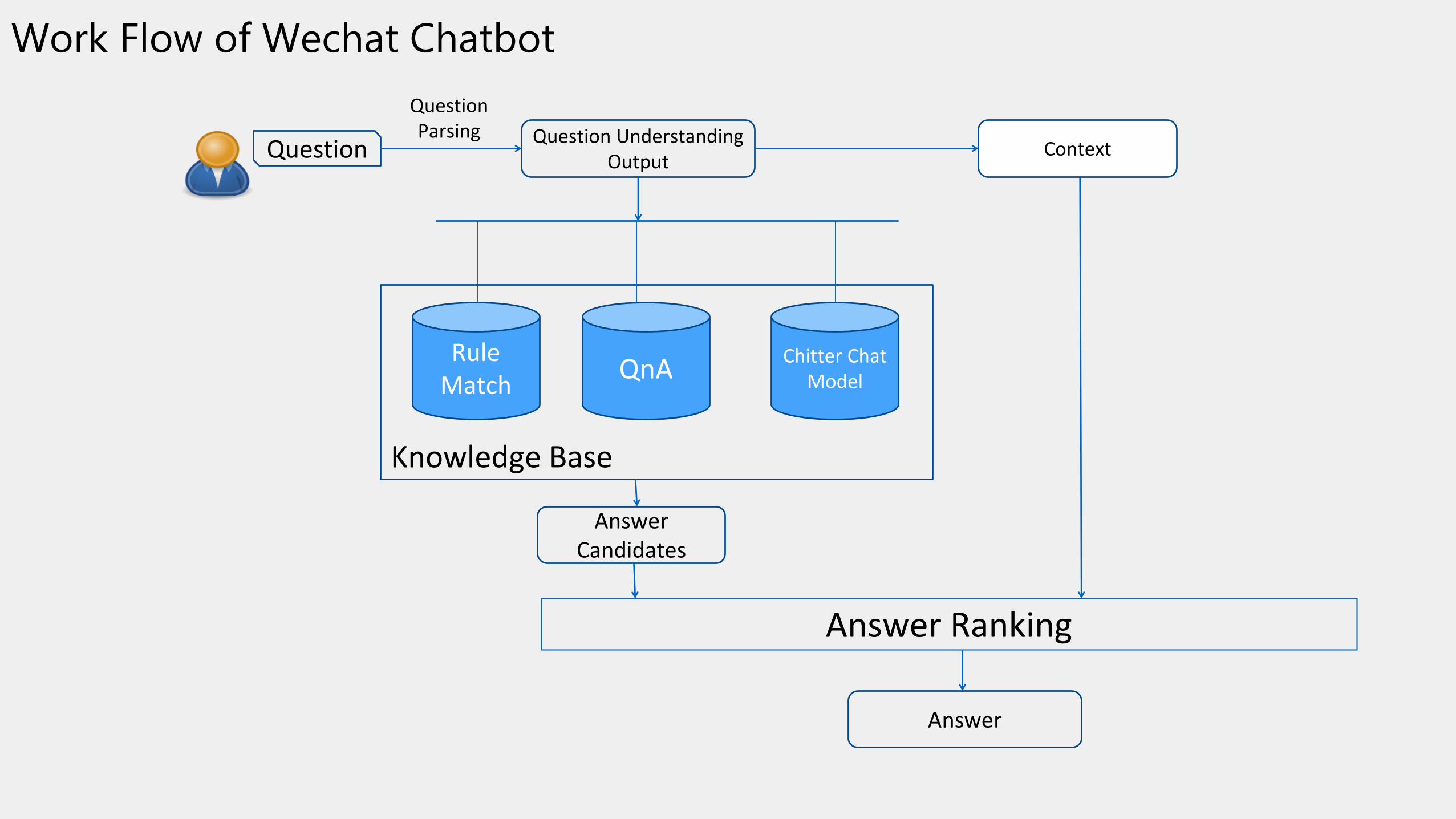
Work Flow of Wechat Chatbot
Question
QuestionParsing Question Understanding
Output
Rule Match
QnAChitter Chat
Model
Answer Ranking
Answer
Context
Answer Candidates
Knowledge Base

Chatbot Architecture in Progress
Question
QuestionParsing Question Understanding
Output
Rule Match
QnADocument
ContentChitter Chat
Model
Answer Ranking
Answer
Sentiment Analysis
Sentiment Analysis Output Context
Answer Candidates
Personalization
Knowledge Graph
Under development
• Sentiment analysis
• Knowledge graph
• Doc-chat
• Personalization
• Expose the platform to public

Conversational Chatbot
How can be happy? Why I’m so busy?

Hard Problems for Conversational Chatbot
Question Understanding:
• 干啥呐?(what are you doing?)
• 干啥的?(what is your job?)
• 你哪里好?(why you think you are good?)
• 你在哪里? (where are you?)
• 你师父呢?(where is your master?)
• 师父在忙 (master is busy)
• 他在忙啥? (what is he doing?)
• 闻何法啊? (how do you practice Dharma?)
• 破除我执 (being not obsessive)
• 如何破除呢? (how?)
Knowledge Representation:
• Notarial certificates, executed in the mainland,
and to be used in Hong Kong Special
Administrative Region, shall be acknowledged by
the Consular Department of the Ministry of
Foreign Affairs of the People's Republic of China
• 转心 (transform the heart),就是心里要去拿起一个正确的东西,否则心在烦恼(affliction)中时是很难转动的。要不断培养自己的发心(bodhicitta-
samutpada) ,让它越来越宽广,越来越清净,烦恼自然就越来越少。恨(hatred)也好,念(obsession)也好,都是妄想(delusion) ,消耗心力、迷障未来。
Answer Generation: avoid trivial and boring
answers
• 忙呢 (busy now)
• 你忙 (take your time)
• 再见 (see you later)
• 狗狗很可爱 (dogs are cute)是很可爱 (yes, they are cute)
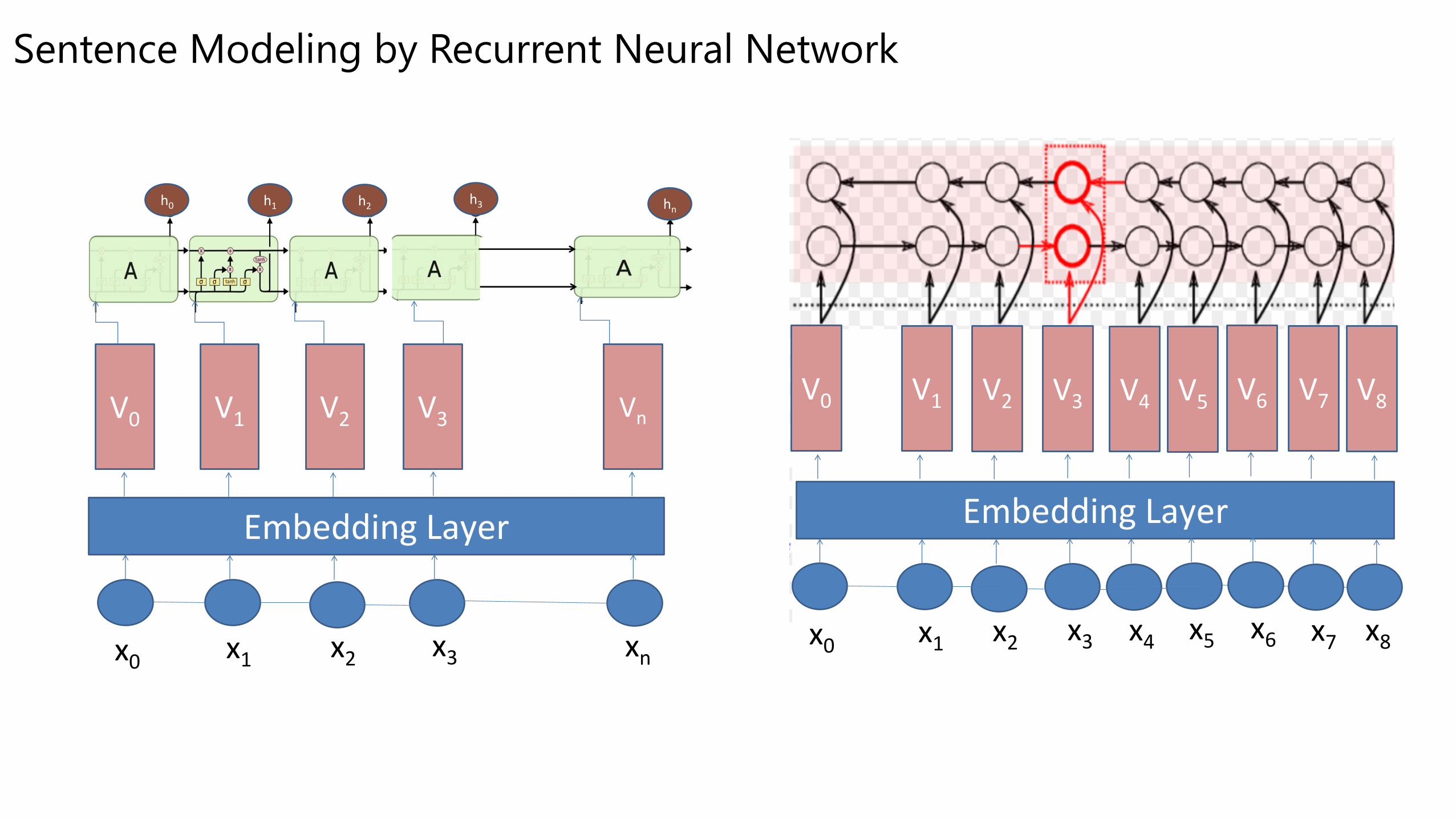
Sentence Modeling by Recurrent Neural Network
x0 x1 x2 x3 xn
Embedding Layer
V0 V1 V2 V3 Vn
h0 h1 h2 hnh3
V0 V1 V2 V3 V4 V5 V6 V7 V8
x0 x1 x2 x3 x8
Embedding Layer
x4 x5 x6 x7

Anaphora Resolution
Input:
q: current query
c: contenxt
Output:
q': current query after anaphora resolution
H: replace pronouns in the current query with noun
phrases in the context
About 5% of the total queries
Examples:
C1: 你是陈奕迅粉丝吗? (are you a fan of Eason Chan? )
C2: 更喜欢张学友 (I like Jacky Cheung more)
q : 为什么更喜欢他? (Why like him more?)
q ‘: 为什么更喜欢张学友 (Why like Jacky Cheung more?)
q'= H(q,C)
C1 : 你住哪儿? (where do you live? )
C2 : 不二寺。 (Bu’er Temple )
q : 那在哪儿? (Where is it? )
q ‘ : 不二寺在哪儿? (Where is Bu’er Temple ? )

模型建立代消解
Context Query陈奕迅 粉丝 更 喜欢 张学友 为什么 更 喜欢 他
)|(max 为什么更喜欢他张学友PP
“他”(him) “张学友”(Jacky Chueng)
q' = 为什么更喜欢张学友
RNN for Anaphora Resolution
Example:
C1: 你是陈奕迅粉丝吗?
C2: 更喜欢张学友
q : 为什么更喜欢他?
q ‘: 为什么更喜欢张学友
• 100K training data
• Accuracy: 90%
• Majority of the errors are
caused by the mistakes of entity
tagging
A bad case:
C1: 你认识贤三吗?
C2: 当然认识。
q : 他是你什么人?
q ': 三是你什么人?

Query Complement
Input:
q: current query
c: context
Output:
q': current query after query complement
H: complete the current query with information in the
context
About 15% of the total queries
Examples:
C1: 那你会发表情包吗? (can you send emojis? )
C2: 一般不发 (usually I don’t send emojis)
q :为什么? (Why?)
q ‘: 为什么不发表情包 (Why not send emojis?)
q'= H(q,C)
C1 :讲个故事给我听 (tell me a story )
C2 :等我学会了给你讲哦 。 (I’ll tell you a story once I learn how to)
q :我等着 (I’m waiting)
q ‘ :我等着听故事 (I’m waiting for the story)

模型建立代消解RNN for Query Completiontt
Training Sample:
C1:讲个故事给我听
C2:等我学会了给你讲哦 。
q :我等着
q ‘:我等着听故事
• 100,000 training instances
• Accuracy: 70%
• Increased the engagement of
Xian’er Mechanical Monk by 11%
我 等 着 听 故
我 等 着 听
讲 个 故 事 给 我 听 _E_ 等 ...
... ...
x
y

部分结果展示
你去问问师父喜欢你吗
不会的,问你师父去
什么时候问必要
Query Completion Results in Real Dialogs
Does your master like you?
Need to ask him
ask
Ask your master if he likes you

部分结果展示Sentence Similarity Computation
Unsupervised word embedding approach is not good enough
Sentence 0 Sentence 1 Similarity based on Word
Embedding
Similar Enough?
你是谁 (who are you) 我是谁 (who am I) 0.93 No
我爱你 (I love you) 你爱我 (you love me) 0.89 No
吃饭了吗 (Do you have lunch?) 吃饭了 (just had lunch) 0.84 No
你干嘛的 (what is your job?) 你干嘛呢 (who are you doing?) 0.93 No
有轮回吗? (Isreincarnation true?)
轮回有结束吗 (will the cycle of
life end?)
0.73 No
会不会轮回 (will reincarnation
happen?)
会不会轮回结束 (Will
reincarnation end?)
0.84 No
随喜您 (you did it well) 您做的很好 (you did it well) 0.20 Yes

Supervised Learning for Sentence Similarity
Feature Embedding Model• Sentence features
unigrams
bi-grams
• Comparison Features
word pairs from two sentences each
edit operations
什么 含义 vs. 什么 意思match-什么-什么replace-含义-意思
RNN for sentence similarityQuestion 0 Question 1
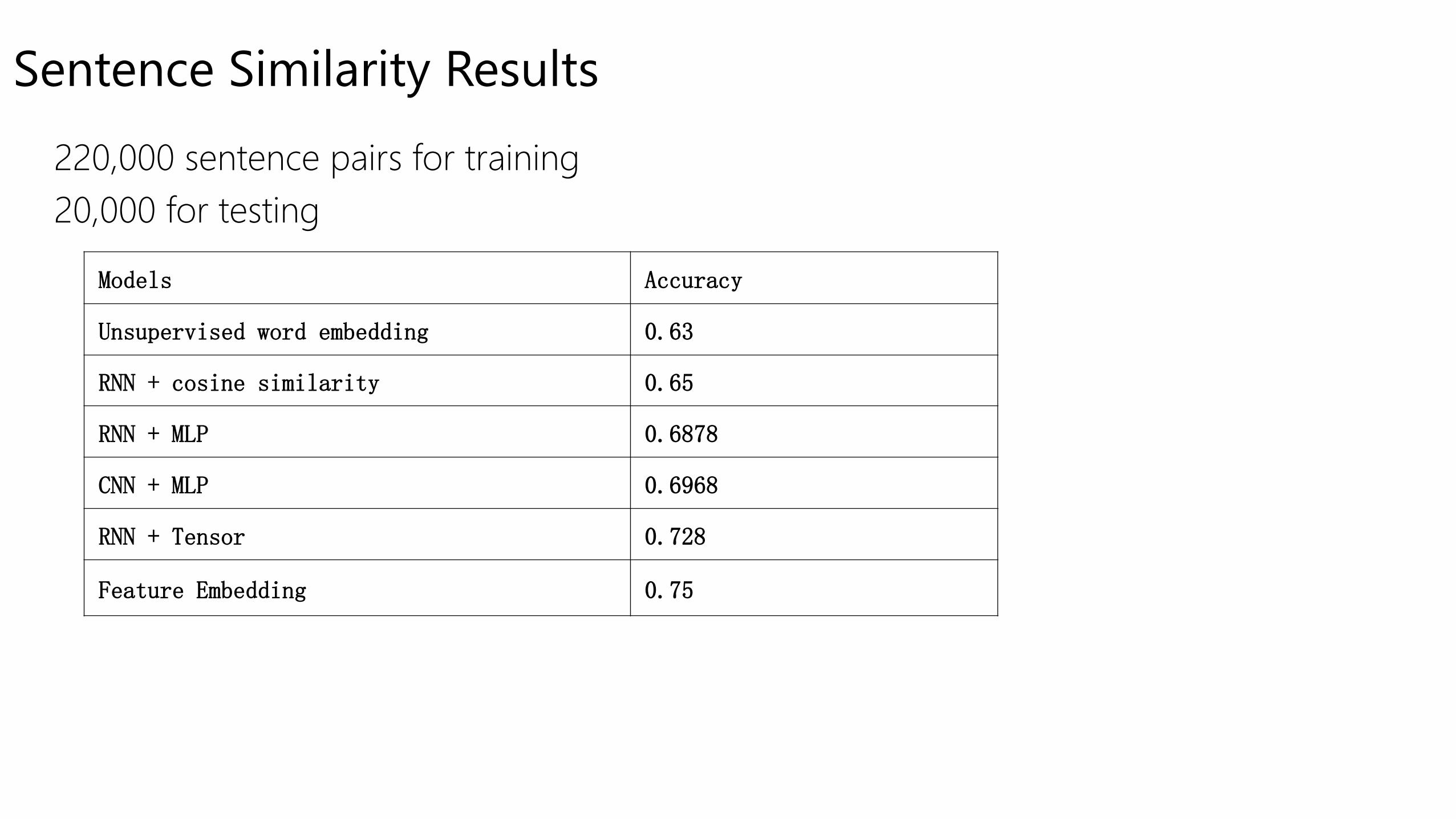
Sentence Similarity Results
Models Accuracy
Unsupervised word embedding 0.63
RNN + cosine similarity 0.65
RNN + MLP 0.6878
CNN + MLP 0.6968
RNN + Tensor 0.728
Feature Embedding 0.75
220,000 sentence pairs for training
20,000 for testing

Response Generation
• Generative model is used if no match from knowledge base
• Neural Network based methods for response generation
28
• Motivated by neural network based methods for translation
One sentence in Language A One sentence in Language B
Input Sentence Response Sentence
Translation
Response Generation

Neural Network based Methodsfor Response Generation
• Motivated by neural network based methods for translation
29
Training data:
Objective:
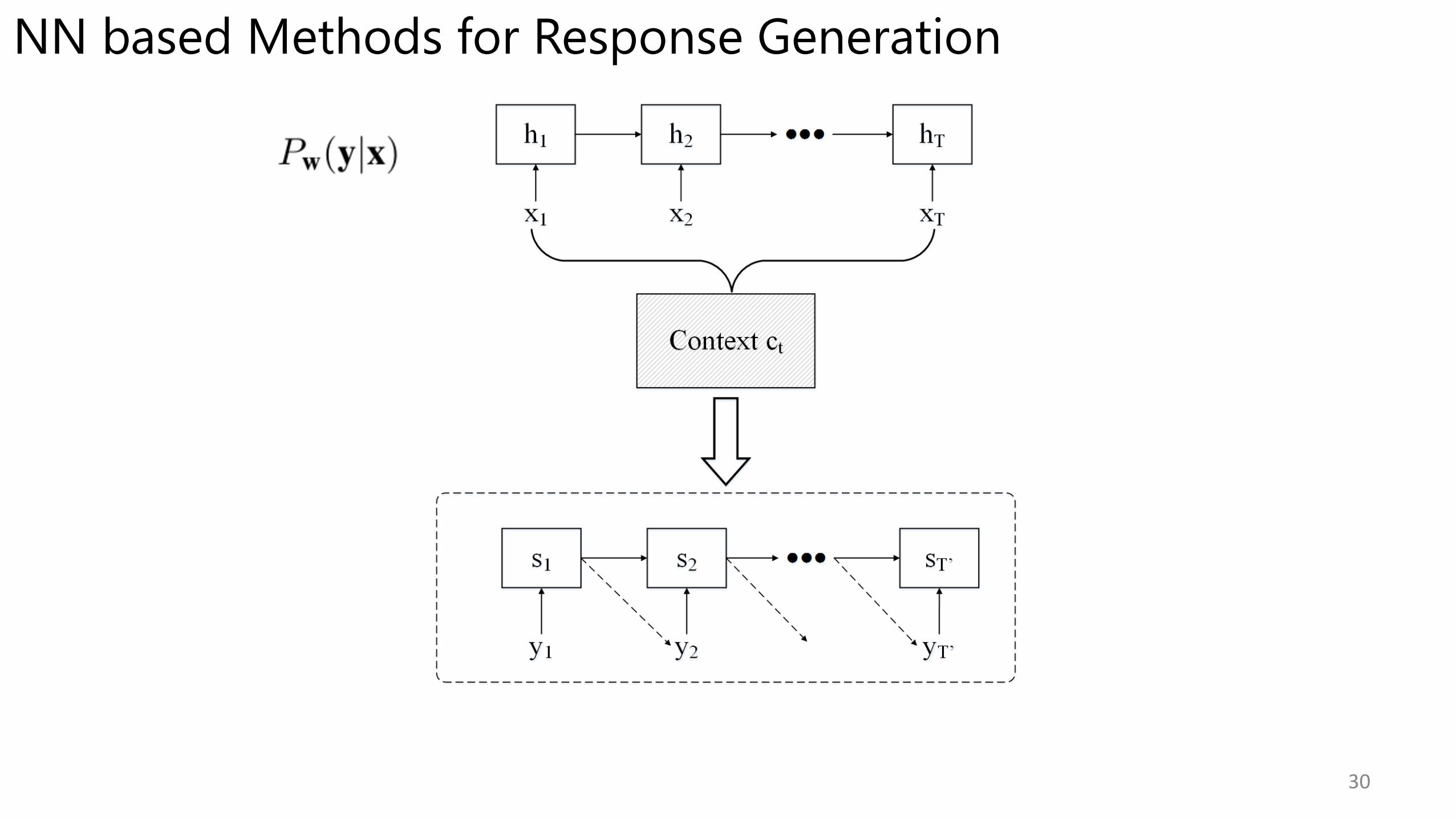
NN based Methods for Response Generation
30

Dialogue vs. Translation
31
•Dialogue corpus is different from translation corpus
•The response diversity problem exists in dialogue
corpus

Diversity
32
For question: What's up?The normal
I am OK.
I am fine.
Mr. SheltonBazinga!
Mr. TrumpYou are fired!

•In our experimental corpus, more than 60 different responses
exist to the post “You are so silly”
•No!
•You are!
•Why?
•Don’t say that
•Many different responses usually correspond to the same post
Diversity

Issues on Response Diversity
• Only return the safe and generic answers, i.e. the one with the
highest probability
• Cannot recognize good but low probability answers
34
Responses with high probabilities
Good responses,but occur not frequently
Bad responses

Response-Style Modeling
36

37A diverter is developed to generate the mechanism distribution of an input post
Encoder-Diverter-Decoder

39
•Training
•815, 852 pairs of post and response•775, 852 are for training,
•40, 000 are for model validation.
•Testing
•We randomly select 300 posts from about 15 million posts
•Every baseline model generates 5 response
•Use human judgment the evaluate the model performance
Experiment

41
the diversity of the response is increased by 1.7 times, and the accuracy is
increased by 9.8%
Experiment Results

42
Example Output

Future Work
• Making use of more knowledge sourcesknowledge grapharticle content
• Unsupervised machine learning
• Open the service to the publicknowledge managementmodel tuningchatbot customization
43

Voice & Audio Natural Language
ProcessingMachine LearningImage & Video
WeChat AI are hiring now!
[email protected] [email protected]
Beijing, Guangzhou, Shenzhen, Palo Alto
Machine
Translation
/通用格式
/通用格式
/通用格式
/通用格式
/通用格式
/通用格式 /通用格式 /通用格式 /通用格式 /通用格式sam
ple
s/se
c
batch_size
speed, 4 gpus
amber mxnet tf
Thanks
WeChat A.I. NLP