neural machine translation by jointly learning to align...
TRANSCRIPT

Neural Machine Translation by Jointly Learning to Alignand Translate
Reporter: Fandong Meng
Institute of Computing TechnologyChinese Academy of Sciences
October 11, 2014
To appear in proceedings of NIPS 2014. [Download]
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 1 / 26

Overview
1 Motivation
2 RNN Encoder-Decoder
3 Learning to Align and TranslateDecoder: Gerenal DescriptionEncoder: Bidirectional RNN for Annotation SequencesHidden Unit that Adaptively Remembers and Forgets
4 Experiments
5 Conclusion
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 2 / 26

Motivation
Framework
Basic RNN encoder-decoder based machine translation.
Fit a parameterized model to maximize the conditional probability oftarget sentence y given a source sentence x , i.e., argmaxyp(y |x)using a training parallel corpus.
Compress all the necessary information of a source sentence into afixed-length vector.
Decode the vector into a variable-length target sentence.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 3 / 26

Motivation
Issues
Compressing all the necessary information of a source sentence into afixed-length vector may make it difficult for the neural network to copewith long sentences, especially those that are longer than the sentences inthe training corpus.
To address this issue, this paper introduces an extension to theencoder-decoder model which learns to align and translate jointly.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 4 / 26

Motivation
Distinguish from the basic encoder-decoder
It encodes the input sentence into a sequence of vectors and chooses asubset of these vectors adaptively while decoding.
To generate a word in a translation, the model searches for a set ofpositions in a source sentence where the most relevant information isconcentrated.
The model then predicts a target word based on the context vectorsassociated with these source positions and all the previous generatedtarget words.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 5 / 26
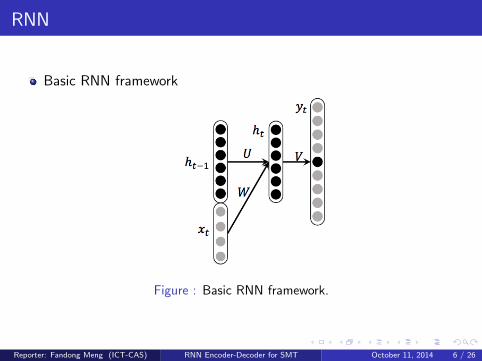
RNN
Basic RNN framework
Figure : Basic RNN framework.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 6 / 26

RNN Encoder-Decoder: Encoder
In the Encoder-Decoder framework, an encoder reads the inputsentence, a sequence of vectors x = (x1, ..., xTx ) into a vector c ,
Figure : Basic encoder-decoder framework.
where ht = f (xt , ht−1) and c = q(h1, ..., hTx ), f and q are somenonlinear functions.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 7 / 26

RNN Encoder-Decoder: Decoder
The decoder is often trained to predict the next word yt given thecontext vector c and all the previously predicted words {y1, ..., yt−1}.In other words, the decoder defines a probability over the translationy by decomposing the joint probability into the ordered conditionals:
p(y) =T∏t=1
p(yt |y1, ..., yt−1, c) (1)
where y = {y1, ..., yTy }. With an RNN, each conditional probability ismodeled as
p(yt |{y1, ..., yt−1}, c) = g(yt−1, st , c) (2)
where g is a nonlinear, potentially multi-layered, function thatoutputs the probability of yt , and st is the hidden state of the RNN.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 8 / 26

RNN Encoder-Decoder
Context vector c is a constant vector!
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 9 / 26

Learning to Align and Translate
Introduce two parts in detail.
Decoder: Gerenal Description
Encoder: Bidirectional RNN for Annotation Sequences
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 10 / 26

Decoder: Gerenal Description
Derived in steps.
The conditional probability is
p(yi |{y1, ..., yi−1}, x) = g(yi−1, si , ci ) (3)
where si is a RNN hidden state for time i , computed by
si = f (si−1, yi−1, ci ). (4)
Here the probability is conditioned on a distinct context vector ci foreach target word yi , which is different from basic RNN decoder.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 11 / 26

Decoder: Gerenal Description
Derived in steps.
In si = f (si−1, yi−1, ci ), the context vector ci depends on a sequenceof annotations (h1, ..., hTx) to which an encoder maps the inputsentence.
Each annotation hi contains information about the whole inputsequence with a strong focus on the parts surrounding the i − th wordof the input sequence.
How to compute ci?
ci =Tx∑j=1
aijhj (5)
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 12 / 26

Decoder: Gerenal Description
Derived in steps.
In ci =∑Tx
j=1 aijhj , the weight aij of each annotation hj is computedby
aij =exp(eij)∑Tx
k=1 exp(eik)(6)
where eij = a(si−1, hj), a is the so called alignment model, can bejointly trained with all the other components of the proposed system.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 13 / 26

Decoder: Gerenal Description
Derived in steps.
The probability aij , or its associated energy eij , reflects theimportance of the annotation hj with respect to the previous hiddenstate si−1 in deciding the next hidden state si and generating yi .
Figure : The graphical illustration of the proposed model trying to generate thet − th target word y given a source sentence (x1, ..., xT ).Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 14 / 26

Decoder: Gerenal Description
Derived from top to down.
p(yi |{y1, ..., yi−1}, x) = g(yi−1, si , ci )
si = f (si−1, yi−1, ci )
ci =∑Tx
j=1 aijhj
aij =exp(eij )∑Tx
k=1 exp(eik )
eij = a(si−1, hj)
What are left?
a(si−1, hj)
hj
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 15 / 26

Decoder: Gerenal Description
Alignment model
Use a single-layer multilayer perceptron.
a(si−1, hj) = vTa tanh(Wasi−1 + Uahj) (7)
where va,Wa,Ua are weight matrices, can be jointly trained with all theother components of the proposed system.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 16 / 26

Decoder: Gerenal Description
Derived from top to down.
p(yi |{y1, ..., yi−1}, x) = g(yi−1, si , ci )
si = f (si−1, yi−1, ci )
ci =∑Tx
j=1 aijhj
aij =exp(eij )∑Tx
k=1 exp(eik )
eij = a(si−1, hj)
a(si−1, hj) = vTa tanh(Wasi−1 + Uahj)
What is left now?
hj
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 17 / 26

Encoder: Bidirectional RNN for Annotation Sequences
A BiRNN consists of forward and backward RNNs.
The forward RNN−→f reads the input sequence as it is ordered (from
x1 to xTx ) and calculates a sequence of forward hidden states
(−→h 1, ...,
−→h Tx ).
The backward RNN←−f reads the input sequence as it is ordered (from
xTx to x1) and calculates a sequence of forward hidden states
(←−h 1, ...,
←−h Tx ).
Therefore, hj = [−→h T
j ;←−h T
j ]
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 18 / 26

Encoder: Bidirectional RNN for Annotation Sequences
Take a look at the annotation h again.
Figure : The graphical illustration of the proposed model trying to generate thet − th target word y given a source sentence (x1, ..., xT ).
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 19 / 26

Hidden Unit that Adaptively Remembers and Forgets
A new type of hidden unit.
In si = f (si−1, yi−1, ci ), f may be as simple as an element-wise logisticsigmoid function and as complex as a long short-term memory (LSTM)unit. This paper used a new type of hidden unit (Cho et al., 2014)) thathas been motivated by the LSTM unit but is much simpler to computeand implement. Let us describe how the activation of the jth hidden unitis computed:
The hidden state si of the decoder given the annotations from theencoder is computed by
si = (1− zi ) ◦ si−1 + zi ◦ s̃i (8)
where
s̃i = tanh(WEyi−1 + U[ri ◦ si−1] + Cci )zi = sigmod(WzEyi−1 + Uzsi−1 + Czci )ri = sigmod(WrEyi−1 + Ur si−1 + Crci )
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 20 / 26

Hidden Unit that Adaptively Remembers and Forgets
A new type of hidden unit.
Look at the follow example, we just take h as s and take X as Y .
si = f (si−1, yi−1, ci ) = (1− zi ) ◦ si−1 + zi ◦ s̃is̃i = tanh(WEyi−1 + U[ri ◦ si−1] + Cci )zi = sigmod(WzEyi−1 + Uzsi−1 + Czci )ri = sigmod(WrEyi−1 + Ur si−1 + Crci )
Figure : An illustration of the proposed hidden activation function. The updategate z selects whether the hidden state is to be updated with a new hidden stateh̃. The reset gate r decides whether the previous hidden state is ignored.Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 21 / 26

Experiments
Setup
Training Set
WMT 2014 English-French parallel corporahttp://www.statmt.org/wmt14/translation-task.html
Development Set
news-test-2012 and news-test-2013
Test Set
news-test-2014
Other Details
data selection30,000 most frequent wordsmap other words to [UNK]
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 22 / 26

Experiments
Results with respect to the lengths of the sentences.
Figure : The BLEU scores of the generated translations on the test set withrespect to the lengths of the sentences. The results are on the full test set whichincludes sentences having unknown words to the models.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 23 / 26

Experiments
Main Results
Figure : BLEU scores of the trained models computed on the test set. Thesecond and third columns show respectively the scores on all the sentences and,on the sentences without any unknown word in themselves and in the referencetranslations. Note that RNNsearch-50? was trained much longer until theperformance on the development set stopped improving. We disallowed themodels to generate [UNK] tokens when only the sentences having no unknownwords were evaluated (last column).Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 24 / 26

Conclusion
Extend the basic encoderCdecoder by letting a model search for a setof input words, or their annotations computed by an encoder, whengenerating each target word. This novel architecture makes it betterfor long sentence translation.
One of challenges left for the future is to better handle unknown, orrare words.
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 25 / 26

The End! Thanks!
Reporter: Fandong Meng (ICT-CAS) RNN Encoder-Decoder for SMT October 11, 2014 26 / 26