proximity-based ranking of biomedical texts rey-long liu * and yi-chih huang * dept. of medical...
DESCRIPTION
Research Background A Proximity-based Ranker Enhancer3TRANSCRIPT

Proximity-based Ranking of Biomedical
Texts
Rey-Long Liu* and Yi-Chih Huang*Dept. of Medical Informatics
Tzu Chi UniversityTaiwan

Outline
• Research background• Problem definition• The proposed approach: PRE• Empirical evaluation• Conclusion
A Proximity-based Ranker Enhancer 2

Research Background
A Proximity-based Ranker Enhancer 3

Biomedical Information Need
• Biomedical research requires relevant evidences in the huge and ever-growing biomedical literature
• Retrieval of the evidences requires a system that – Accepts a natural language query for a biomedical
information need, and – Ranks relevant texts higher for access or processing
A Proximity-based Ranker Enhancer 4

An Example Info Need• Query: urinary tract infection, criteria for treatment and admission (from OHSUMED) – A disease as the target concept (i.e., urinary tract infection)
– Two concepts about the scenario of the information need (i.e., treatment and admission)
• Neither special nor related to any disease
A Proximity-based Ranker Enhancer 5

Problem Definition
A Proximity-based Ranker Enhancer 6

Goals• Explore how text rankers may be improved by
considering the completeness of query concepts appearing in a nearby area of the text being ranked
• Develop a technique PRE (Proximity-based Ranker Enhancer) that – Measures contextual completeness of query
concepts appearing in a nearby area in the text– Serves as a supplement to improve existing rankers
A Proximity-based Ranker Enhancer 7

Related Work• Biomedical text ranking
– Using synonyms and considering diversity of passages, without considering term proximity
• Text ranking– Individual text scoring techniques (e.g., BM25)
and learning to rank techniques (e.g., Ranking SVM), without considering term proximity
• Improving ranking by term proximity– Term proximity is employed, but contextual
completeness was not consideredA Proximity-based Ranker Enhancer 8

The Proposed Approach: PRE
A Proximity-based Ranker Enhancer 9

System Overview
A Proximity-based Ranker Enhancer 10
Text Ranker Development
TrainingTesting
Underlying RankerPRE
Text Ranking TF in d
User
Query (q)
Text (d)
TF (Term Frequency) Assessment
Training Data
Ranked Texts

TF Assessment
A Proximity-based Ranker Enhancer 11
• Three types of term proximity– Overall proximity (QTermTF)– Individual proximity (IndiP)– Collective proximity (CollP)
• A term t may get a large TF increment in d, if – Many query terms appear frequently in d– Query terms are individually near to t at some
places, and– Query terms collectively appear at a place near to t

A Proximity-based Ranker Enhancer 12
•RTF(t,d,q) = TF(t,d)+TFincrement(t,d,q)•TFincrement(t,d,q) = QtermTF(d,q)IndiP(t,d,q)×CollP(t,d,q)•QtermTF(d,q) = Total TF of query terms in d•IndiP(t,d,q) =ΣmM -
{t}SigmoidWeight(Mindist(t,m))/ MaxIndiP•Mindist(x,y) = shortest distance between x and y in d•SigmoidWeight(dt) = 1/(1+e-((|q|-1)-dt))•CollP(t,d,q) = MaxkK{mM - {t}
SigmoidWeight(dist(t,k,m))}/MaxCollP, where K is the set positions at which t appears in d•dist(t,k,m) = Distance between t (at position k) and m

Empirical Evaluation
A Proximity-based Ranker Enhancer 13

Experimental Data• OHSUMED
– A popular database of biomedical queries and references
– 106 queries– 348,566 references– 16,140 query-reference pairs
• Definitively relevant• Possibly relevant• Not relevant
A Proximity-based Ranker Enhancer 14

Underlying Rankers
A Proximity-based Ranker Enhancer 15

Baseline Ranker Enhancer• Three state-of-the-art techniques that
enhanced text rankers by term proximity– The t-function
• t() by [Tao & Zhai, 2007]– The p-function
• p() by [Cummins & O’Riordan, 2009] – The proximity language model
• PLM by [Zhao & Yun, 2009].
A Proximity-based Ranker Enhancer 16

Evaluation Criteria• Evaluating how relevant references are
ranked higher for users to access– Mean average precision (MAP)– Normalized discount cumulative gain at x
(NDCG@X)
A Proximity-based Ranker Enhancer 17
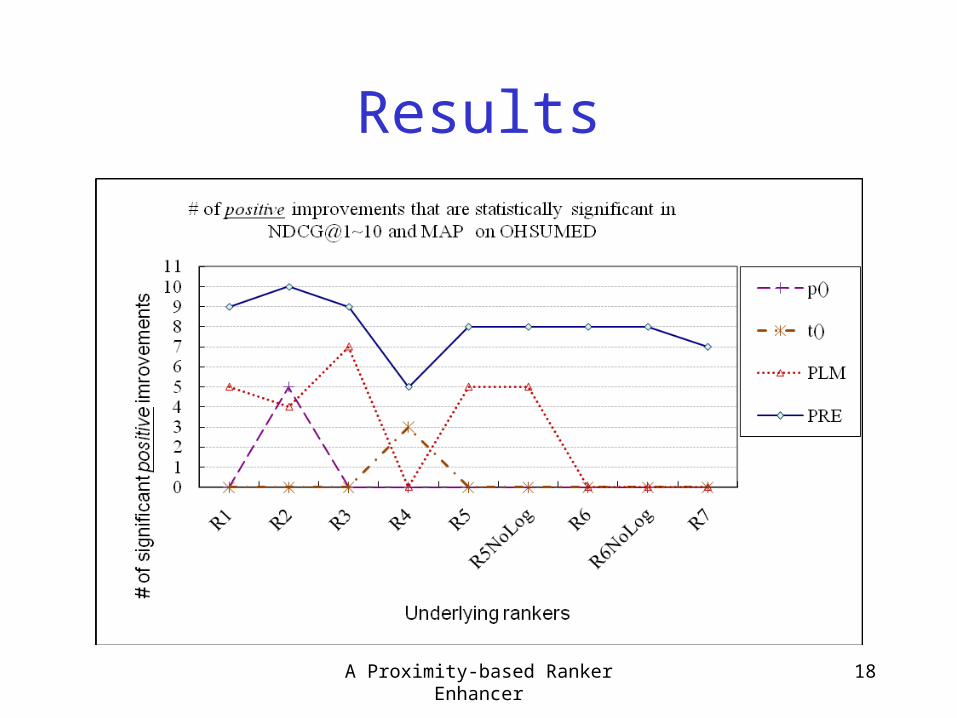
Results
A Proximity-based Ranker Enhancer 18

A Proximity-based Ranker Enhancer 19

Conclusion
A Proximity-based Ranker Enhancer 20

• Term proximity may be comprehensively applied to improving various kinds of text rankers
• It is helpful to integrate three types of term proximity– Overall proximity– Individual proximity– Collective proximity
• Term proximity information may be encoded to re-assess TF of each term
A Proximity-based Ranker Enhancer 21