signal processing on gpus for radio telescopes | gtc...
TRANSCRIPT

March 18-21, 2013March 18-21, 2013 1GTC'13GTC'13
Signal Processing on GPUsfor Radio Telescopes
Signal Processing on GPUsfor Radio Telescopes
John W. RomeinJohn W. Romein
Netherlands Institute for Radio Astronomy (ASTRON)Dwingeloo, the Netherlands

March 18-21, 2013March 18-21, 2013 2GTC'13GTC'13
Overview
radio telescopes motivation processing pipelines signal-processing algorithms
filter, correlator, beam forming, etc. performance

March 18-21, 2013March 18-21, 2013 3GTC'13GTC'13
The LOFAR Radio Telescope

March 18-21, 2013March 18-21, 2013 4GTC'13GTC'13
The LOFAR Radio Telescope
largest low-frequency telescope
no dishes
distributed sensor network
~85.000 receivers

March 18-21, 2013March 18-21, 2013 5GTC'13GTC'13
LOFAR: A Software Telescope
all-sky view antennas ➜ new science opportunities different observation modes require flexibility
digitally steered concurrent observations supercomputer real time
standard imaging
pulsar survey
known pulsar
epoch of re-ionization
transients
ultra-high energy particles
...

March 18-21, 2013March 18-21, 2013 6GTC'13GTC'13
LOFAR SuperTerp

March 18-21, 2013March 18-21, 2013 7GTC'13GTC'13
What's Next? The Square Kilometre Array
world-wide effort unprecedented size
3,000 dishes + aperture array South Africa + Australia
2016‒2019: 10% SKA 2020‒2023: 100% SKA
exascale computing; petascale I/O O(104)‒O(105) > LOFAR
many challenges!

March 18-21, 2013March 18-21, 2013 8GTC'13GTC'13
Our Efforts
build/maintain/operate current telescopes (LOFAR, WSRT) research for SKA

March 18-21, 2013March 18-21, 2013 9GTC'13GTC'13
Motivation
1)bring GPU technology to LOFAR
2)do accelerator research for the SKA

March 18-21, 2013March 18-21, 2013 10GTC'13GTC'13
ASTRON/IBM Dome
P1 algorithms & machines
P2 nano-photonics
P3 access patterns
P4 microservers
P5 accelerators
P6 compressed sampling
P7 real-time communication
research technologies to develop the SKA green computing nano-photonics data & streaming

March 18-21, 2013March 18-21, 2013 11GTC'13GTC'13
Accelerator Research
accelerators for (radio-astronomical) signal processing GPUs, Xeon Phi, BG/Q, FPGAs, ...
fundamental understanding of accelerators which properties make architecture (in)efficient? I/O-compute balance? energy efficiency? programmability? architecture-(in)dependent optimizations? devise new algorithms? generic approach to program accelerators, or ad-hoc?
applications:
1) LOFAR2) SKA

March 18-21, 2013March 18-21, 2013 12GTC'13GTC'13
LOFAR Data Processing
developing new GPU-based system

March 18-21, 2013March 18-21, 2013 13GTC'13GTC'13
Correlator Processing Overview
March 18-21, 2013March 18-21, 2013 14GTC'13GTC'13
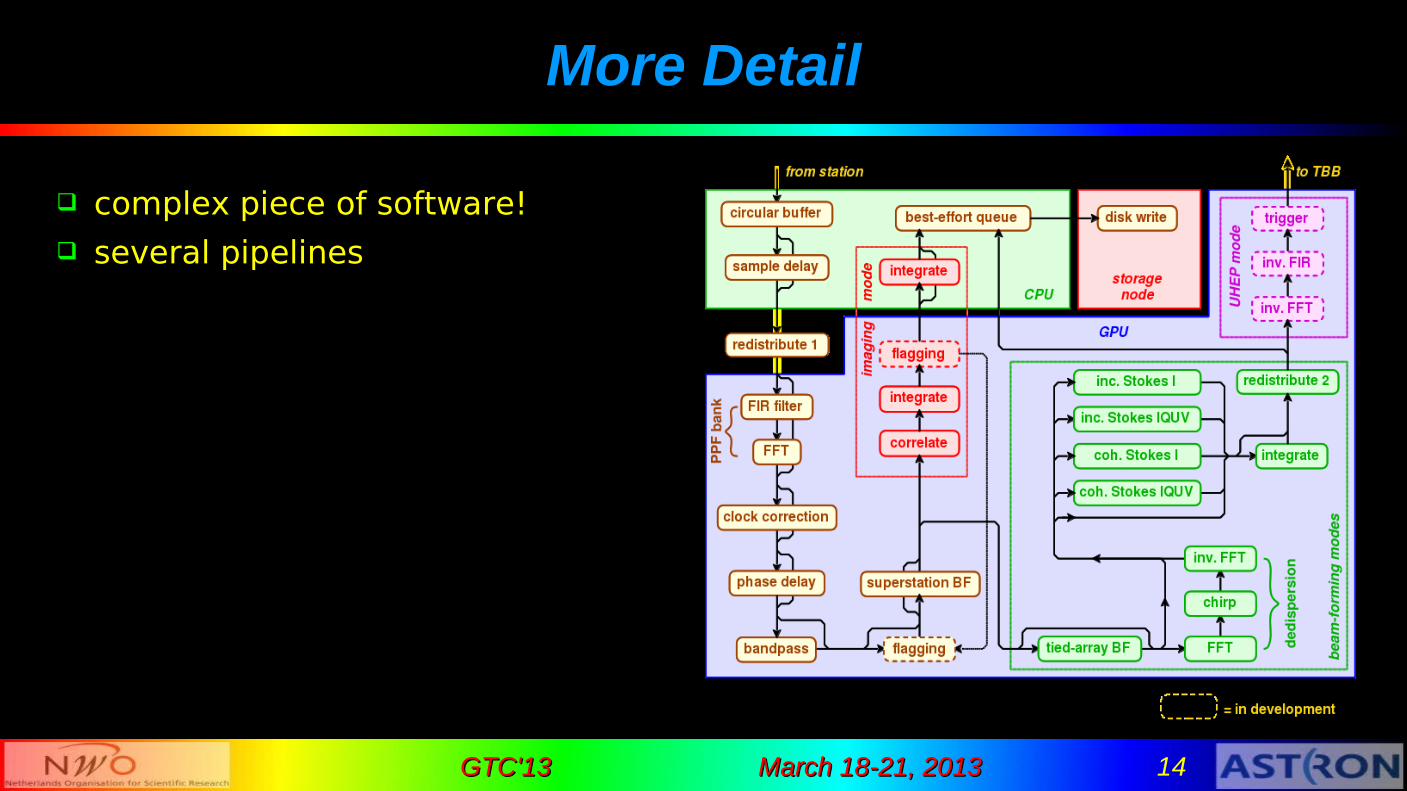
More Detail
complex piece of software! several pipelines

March 18-21, 2013March 18-21, 2013 15GTC'13GTC'13
Implement GPU Kernels
killing two birds
1) develop new LOFAR correlator2) code base for accelerator research

March 18-21, 2013March 18-21, 2013 16GTC'13GTC'13
Why We Use OpenCL
OpenCL advantages disadvantagesvendor independent poor library support (e.g., FFT)GPU: runtime compilation cannot use all GPU features (e.g., GPUdirect)GPU: float8, float16, swizzlingCPU: nice C++ interface (exceptions)
float2 input_samples[NR_STATIONS][NR_CHANNELS][NR_TIMES][NR_POLARIZATIONS];
float16 sums, weights;…sums += weights.s3456789ABCDEF012 * sample;

March 18-21, 2013March 18-21, 2013 17GTC'13GTC'13
Why We Are Disappointed
OpenCL advantages disadvantagesvendor independent poor library support (e.g., FFT)GPU: runtime compilation cannot use all GPU features (e.g., GPUdirect)GPU: float8, float16, swizzlingCPU: nice C++ interface (exceptions)
float2 input_samples[NR_STATIONS][NR_CHANNELS][NR_TIMES][NR_POLARIZATIONS];
float16 sums, weights;…sums += weights.s3456789ABCDEF012 * sample;❑ NVIDIA dropped OpenCL support in
development tools
❑ visual profiler

March 18-21, 2013March 18-21, 2013 18GTC'13GTC'13
GPUs
NVIDIA Tesla K10 AMD FirePro S10000 Intel Xeon Phi
3072 3584 976 FPUs
4.58 5.91 2.14 SP TFLOPS
320 (ECC off) 480 352 GB/s
225 375 300 W
FirePro S10000:
driver/VBIOS/hardware (?) issues cannot always overlap compute‒PCIe I/O
Xeon Phi:
immature results

March 18-21, 2013March 18-21, 2013 19GTC'13GTC'13
From Feasibility Study to Production Software
concentrated mostly on GPU kernels CPU parts: now/later

March 18-21, 2013March 18-21, 2013 20GTC'13GTC'13
Implemented Kernels
most important: filter correlator beam former

March 18-21, 2013March 18-21, 2013 21GTC'13GTC'13
Processing Pipelines
imaging mode
sky images pulsar modes
in development UHEP mode
detect Ultra-High Energy Particles experimental

March 18-21, 2013March 18-21, 2013 22GTC'13GTC'13
Processing Pipelines
imaging mode
sky images pulsar modes
in development UHEP mode
detect Ultra-High Energy Particles experimental

March 18-21, 2013March 18-21, 2013 23GTC'13GTC'13
Processing Pipelines
imaging mode
sky images pulsar modes
in development UHEP mode
detect Ultra-High Energy Particles experimental

March 18-21, 2013March 18-21, 2013 24GTC'13GTC'13
Imaging (Correlator) Pipeline

March 18-21, 2013March 18-21, 2013 25GTC'13GTC'13
Imaging (Correlator) Pipeline
four GPU kernels
March 18-21, 2013March 18-21, 2013 26GTC'13GTC'13
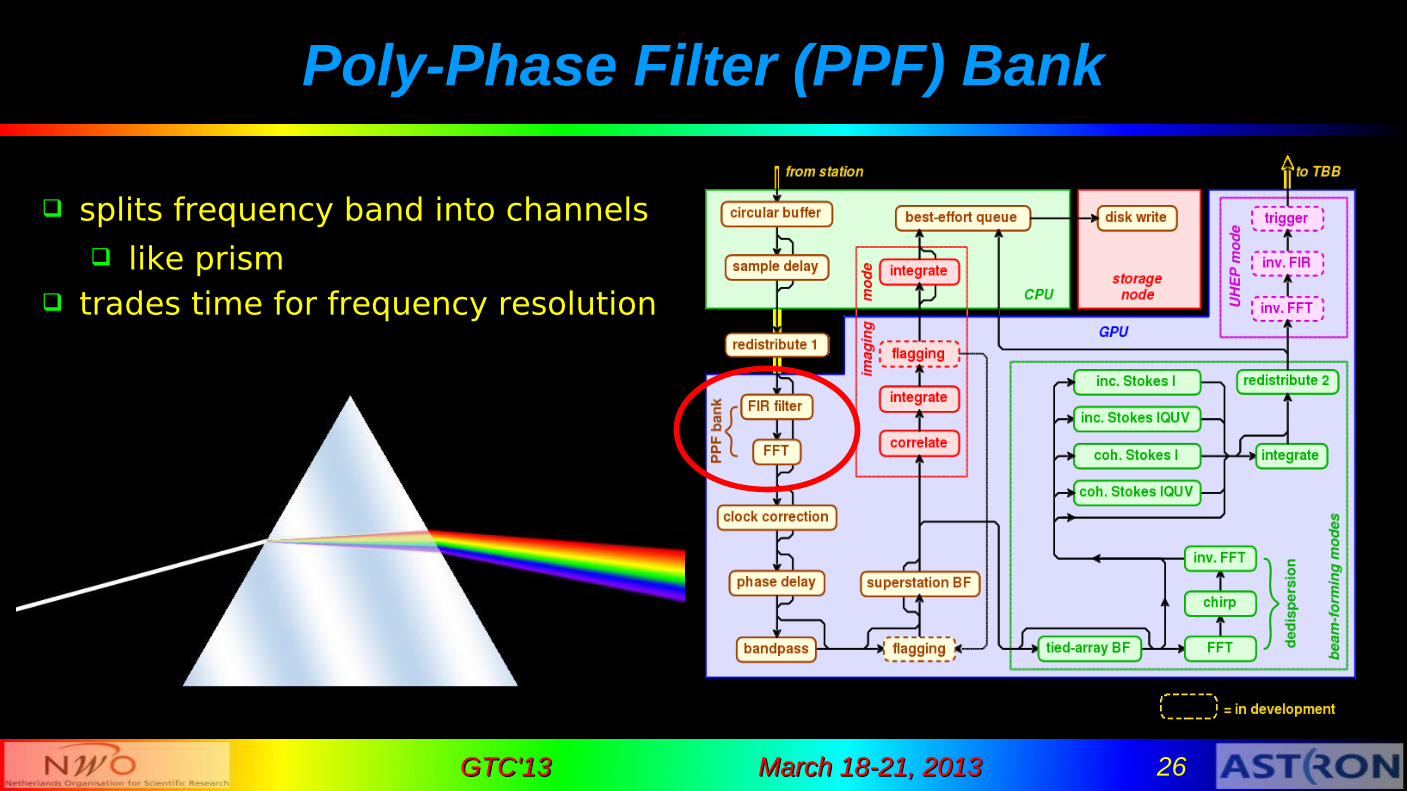
Poly-Phase Filter (PPF) Bank
splits frequency band into channels like prism
trades time for frequency resolution

March 18-21, 2013March 18-21, 2013 27GTC'13GTC'13
Poly-Phase Filter (PPF) Bank
FIR filter + FFT

March 18-21, 2013March 18-21, 2013 28GTC'13GTC'13
1) Finite Impulse Response (FIR) Filter
history & weights (in registers)
no physical shift reorder output for next kernel
uncoalesced writes many FMAs
operational intensity = 6.4 FLOPs / byte

March 18-21, 2013March 18-21, 2013 29GTC'13GTC'13
FIR Filter Performance
0 20 40 60 800
0.5
1
1.5
2 FirePro S10000Tesla K10
#stations
TF
LO
PS
0 20 40 60 800
100
200
300
400
FirePro S10000Tesla K10
#stations
GB
/s
K10: drop @41 stations ➜ small #threads

March 18-21, 2013March 18-21, 2013 30GTC'13GTC'13
2) FFT
1D complex ➜ complex typically: 64‒256 tweaked “Apple” FFT library

March 18-21, 2013March 18-21, 2013 31GTC'13GTC'13
2) FFT Performance
0 20 40 60 800
0.5
1
1.5
2 FirePro S10000Tesla K10
#stations
TF
LO
PS
0 20 40 60 800
100
200
300
400
FirePro S10000Tesla K10
#stations
GB
/s
memory I/O bound

March 18-21, 2013March 18-21, 2013 32GTC'13GTC'13
combined kernel: clock correction delay compensation bandpass correction transpose
reduces #device memory accesses
3) Phase & BandPass Correction

March 18-21, 2013March 18-21, 2013 33GTC'13GTC'13
3a) Clock Correction
stations: shared clock corrects cable length errors merge with next step (phase delay)

March 18-21, 2013March 18-21, 2013 34GTC'13GTC'13
3b) Delay Compensation (a.k.a. Tracking)
track observed source delay telescope data
delay varies due to earth rotation shift samples remainder: rotate phase (= cmul)
0.75 FLOPs / byte

March 18-21, 2013March 18-21, 2013 35GTC'13GTC'13
3c) BandPass Correction
0 64 128 192 2560.0
0.5
1.0
frequency channel
po
we
r
powers in channels unequal
artifact from station processing multiply by channel-dependent weight
0.125 FLOPs / byte

March 18-21, 2013March 18-21, 2013 36GTC'13GTC'13
Phase & BandPass Correction
0 20 40 60 800
0.5
1
1.5
2 FirePro S10000Tesla K10
#stations
TF
LO
PS
0 20 40 60 800
100
200
300
400
FirePro S10000Tesla K10
#stations
GB
/s
☹ 0.75 FLOPs / byte memory I/O bound

March 18-21, 2013March 18-21, 2013 37GTC'13GTC'13
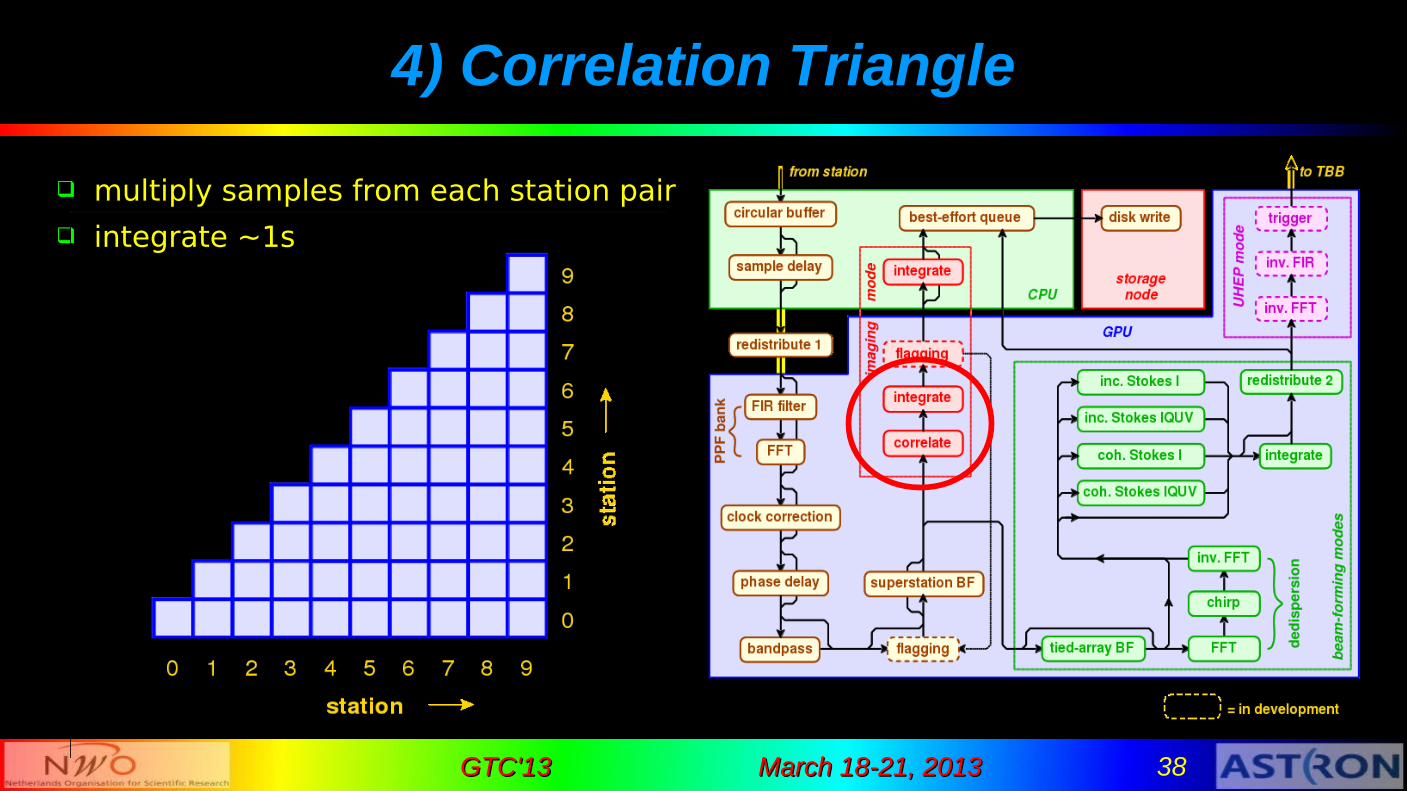
4) Correlator Kernel
multiply samples from each station pair
integrate ~1s
March 18-21, 2013March 18-21, 2013 38GTC'13GTC'13
4) Correlation Triangle
multiply samples from each station pair
integrate ~1s

March 18-21, 2013March 18-21, 2013 39GTC'13GTC'13
4) Correlator Implementation
global memory ➜ local memory 1 thread per station pair (dual pol)
1 FLOP / byte (local mem)

March 18-21, 2013March 18-21, 2013 40GTC'13GTC'13
4) Optimized Correlator Implementation
increase register reuse 1 thread: 2x2 stations (dual pol)
2 FLOPs / byte (local mem) also: 3x3, 4x4

March 18-21, 2013March 18-21, 2013 41GTC'13GTC'13
Correlator Register Usage
3x3 on K10: excessive spilling
max. registers/thread
Tesla K10 63
FirePro S10000 256
#accumulator registers
1x1 8
2x2 32
3x3 72

March 18-21, 2013March 18-21, 2013 42GTC'13GTC'13
Correlator #Threads
cannot use all threads in last warp too few threads ➜ low occupancy too many threads ➜ multiple passes
multiple thread blocks
0 20 40 60 800
256
512
768
1024
#stations
#th
rea
ds
1x12x23x3
max #threads
Tesla K10 1,024
FirePro S10000 256

March 18-21, 2013March 18-21, 2013 43GTC'13GTC'13
1x1 vs. 2x2 and 3x3 (FirePro S10000)
0 20 40 60 800
0.5
1
1.5
2 1x12x23x3
#stations
TF
LO
PS
0 20 40 60 800
100
200
300
400 1x12x23x3
#stations
GB
/s
use whichever performs best

March 18-21, 2013March 18-21, 2013 44GTC'13GTC'13
Correlator Performance
0 20 40 60 800
0.5
1
1.5
2 FirePro S10000Tesla K10
#stations
TF
LO
PS
0 20 40 60 800
100
200
300
400
FirePro S10000Tesla K10
#stations
GB
/s
compute bound S10000: multiple passes

March 18-21, 2013March 18-21, 2013 45GTC'13GTC'13
Combined Pipeline
#pragma omp parallel num_threads(2 * nrGPUs) { cl::CommandQueue queue(...); cl::Buffer input(...), output(...), ...; #pragma omp for schedule(dynamic) for (int subband = 0; subband < nrSubbands; subband ++) { receive(input, subband); queue.enqueueWriteBuffer(input, ...); queue.enqueueNDRangeKernel(FIR_filter, ...); queue.enqueueNDRangeKernel(FFT, ...); queue.enqueueNDRangeKernel(delay_bandpass, ...); queue.enqueueNDRangeKernel(correlator, ...); queue.enqueueReadBuffer(output, ...); send(output, subband); } }
2 queues/GPU: overlap I/O & computations
1 host thread/queue: easy model

March 18-21, 2013March 18-21, 2013 46GTC'13GTC'13
Correlator PipelineTesla K10 Performance Breakdown
1 10 20 30 40 50 60 70 800
2
4
6
8
10?CorrelatePhase & BandPass CorrectionFFTFIR filter
#stations
#G
PU
s
most challenging observation mode 8-bit samples
488 subbands (95.3 MHz)
correlations most expensive
need ~11 Tesla K10s

March 18-21, 2013March 18-21, 2013 47GTC'13GTC'13
Large #Stations
➜ different approach
#stations #correlations #threads #thread blocks (K10)
LOFAR ~80 ~12,960 ~820 1
SKA ≤3,000 ≤18,000,000 ≤1,125,000 ≤1,000
LOFAR SKA

March 18-21, 2013March 18-21, 2013 48GTC'13GTC'13
Large #Stations: Another Strategy
32x32 stations(16x16 threads)
2x2 stations (dual pol)1 thread
192x192 stations(squares + rectangles)
read samples 32+32 stations
☺ 32 FLOPs / byte

March 18-21, 2013March 18-21, 2013 49GTC'13GTC'13
Large #Stations: Correlator Performance
0 128 256 384 512 640 768 8960
1
2
3
4
FirePro S10000Tesla K10
#stations
TF
LO
PS
0 128 256 384 512 640 768 8960
100
200
300
400
FirePro S10000Tesla K10
#stations
GB
/s
to do: Tesla K20X possibly faster

March 18-21, 2013March 18-21, 2013 50GTC'13GTC'13
Pulsar Pipelines

March 18-21, 2013March 18-21, 2013 51GTC'13GTC'13
Pulsar Pipelines
1)search unknown pulsars
2)observe known pulsar many narrow beams
credit: Jason Hessels

March 18-21, 2013March 18-21, 2013 52GTC'13GTC'13
Pulsar Pipelines
in development

March 18-21, 2013March 18-21, 2013 53GTC'13GTC'13
Coherent Beam Forming
CV beam=∑stat
W beam ,stat∗Sstat
add stations
> sensitivity weighed
compensate Δt change phase different Δt ➜ different beam
many beams from same input

March 18-21, 2013March 18-21, 2013 54GTC'13GTC'13
Coherent Beam Forming Implementation
CV beam=∑stat
W beam ,stat∗Sstat
global memory ➜ local memory each thread:
1 beam, 1 polarization station-dependent weights in registers
2 passes of 24 stations
☺ 48 stations, 128 beams ➜ 14.2 FLOPs / byte

March 18-21, 2013March 18-21, 2013 55GTC'13GTC'13
Coherent Beam Forming Performance
0 32 64 96 1280
0.5
1
1.5
2
2.5 FirePro S10000Tesla K10
#beams
TF
LO
PS
0 32 64 96 1280
100
200
300
400 FirePro S10000Tesla K10
#beams
GB
/s
48 stations sawtooth caused by unused threads

March 18-21, 2013March 18-21, 2013 56GTC'13GTC'13
Ultra-High Energy Particle (UHEP) Pipeline
March 18-21, 2013March 18-21, 2013 57GTC'13GTC'13
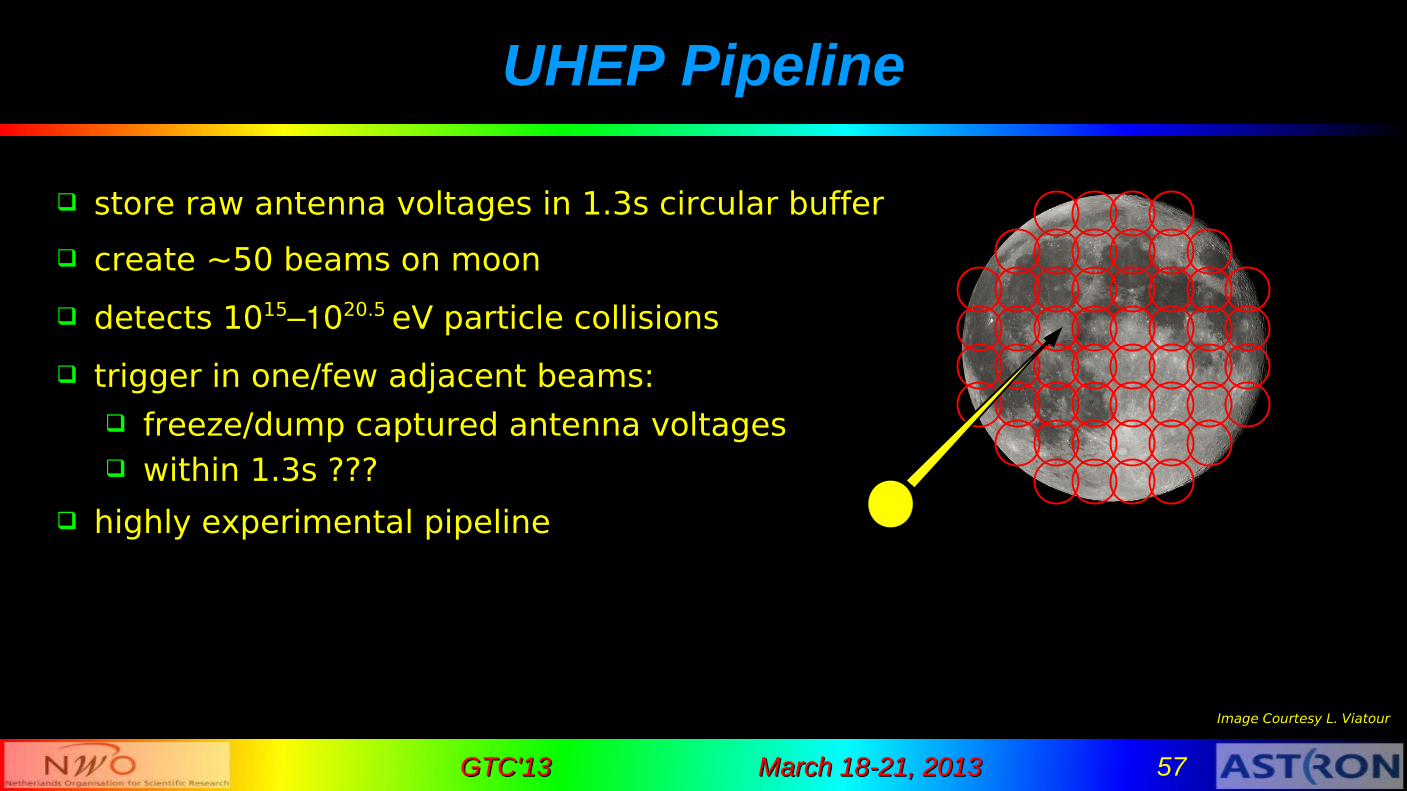
UHEP Pipeline
store raw antenna voltages in 1.3s circular buffer
create ~50 beams on moon
detects 1015‒1020.5 eV particle collisions
trigger in one/few adjacent beams: freeze/dump captured antenna voltages within 1.3s ???
highly experimental pipeline
Image Courtesy L. Viatour

March 18-21, 2013March 18-21, 2013 58GTC'13GTC'13
UHEP Pipeline
create ~50 beams on moon inverse filter for high time resolution trigger
peak detection anti-coincidence check
freeze raw antenna data buffer max 1.3s latency!

March 18-21, 2013March 18-21, 2013 59GTC'13GTC'13
UHEP Pipeline
create ~50 beams on moon inverse filter for high time resolution trigger
peak detection anti-coincidence check
freeze raw antenna data buffer max 1.3s latency!

March 18-21, 2013March 18-21, 2013 60GTC'13GTC'13
UHEP Pipeline
create ~50 beams on moon inverse filter for high time resolution trigger
peak detection anti-coincidence check
freeze raw antenna data buffer max 1.3s latency!

March 18-21, 2013March 18-21, 2013 61GTC'13GTC'13
UHEP Pipeline
create ~50 beams on moon inverse filter for high time resolution trigger
peak detection anti-coincidence check
freeze raw antenna data buffer max 1.3s latency!

March 18-21, 2013March 18-21, 2013 62GTC'13GTC'13
UHEP Performance Breakdown
48 stations, 64 beams
Beam Forming Transpose Inverse FIR Inverse FFT Trigger0
1
2
3 Tesla K10FirePro S10000
TF
LO
P/s
Beam Forming Transpose Inverse FIR Inverse FFT Trigger0
100
200
300
400Tesla K10FirePro S10000
GB
/s

March 18-21, 2013March 18-21, 2013 63GTC'13GTC'13
UHEP Performance Breakdown
3.93 ms data, 48 stations, 488 subbands
most time spent in beam former
I/O overlap
latency ≪ 100 ms
Tesla K10 FirePro S100000
20
40
60
Input (Beam Former Weights)Input (Samples)?TriggerInv. FFTInv. FIRTransposeBeam Forming
ms

March 18-21, 2013March 18-21, 2013 64GTC'13GTC'13
A Wild Idea

March 18-21, 2013March 18-21, 2013 65GTC'13GTC'13
OpenCL on Top of CUDA Driver API
fool CUDA RTS
CPU: implement our own “platform” (ICD)
OpenCL library calls ➜ CUDA Driver API Calls limited subset (proof of concept)
GPU: use OpenCL ➜ PTX compiler (clc/clang/llvm)
☺ efficient
☹ does not support full language can use:
☺ visual profiler
☺ cuFFT, GPUdirect

March 18-21, 2013March 18-21, 2013 66GTC'13GTC'13
OpenCL on Top of CUDA Driver API

March 18-21, 2013March 18-21, 2013 67GTC'13GTC'13
Future Work

March 18-21, 2013March 18-21, 2013 68GTC'13GTC'13
To Do (LOFAR Correlator)
GPU kernels: dedispersion, flagging pulsar pipelines CPU code:
work distribution network reordering (FDR IB)
>240 Gb/s optimizations monitoring & control ...

March 18-21, 2013March 18-21, 2013 69GTC'13GTC'13
To Do (SKA Research)
Xeon Phi OpenCL on FPGA energy efficiency fully understand all results

March 18-21, 2013March 18-21, 2013 70GTC'13GTC'13
Conclusions
many signal-processing GPU kernels new LOFAR correlator research for SKA
OpenCL: vendor independent, elegant, but poor support NVIDIA FirePro S10000 faster then Tesla K10, but immature driver high efficiency on most important kernels

March 18-21, 2013March 18-21, 2013 71GTC'13GTC'13
Thanks
support: Intel, NVIDIA grants from Dutch national & province governments LOFAR GPU Correlator team: Alexander van Amesfoort, Wouter Klijn, Marcel
Loose, Jan David Mol