skynet project: monitor, analyze, scale, and maintain a system in the cloud
DESCRIPTION
The goal of Skynet is to avoid human doing repetitive things and make a system doing them in a better way. System automation should be the way to go for any system management so that human can focus on stuff that really matters. Related blog post for more informations http://engineering.slideshare.net/2014/04/skynet-project-monitor-scale-and-auto-heal-a-system-in-the-cloud/TRANSCRIPT

Skynet ProjectMonitor, analyze, scale, and maintain an infrastructure in the Cloud
Or everything humans should not do
@SylvainKalache

What about me?
•Operations Engineer @SlideShare since 2011
•Fan of system automation
•@SylvainKalache on Twitter

The Cloud
The cloud is now everywhere, it's elastic, dynamic and far from the rigid infrastructures what we had before.Most of the modern architecture are using "The Cloud" because give so much possibilities that no one can ignore it.

What about our tools?
But what about our tools? Are they designed to deal with the cloud?Nagios and Ganglia, for example, are obviously not designed for. What are the alternative? Not much heh?Of course we could have use Cloudwatch because we are using EC2, but you the possibilities are still limited in term of granularity, personalization and you hit a limit at some point.
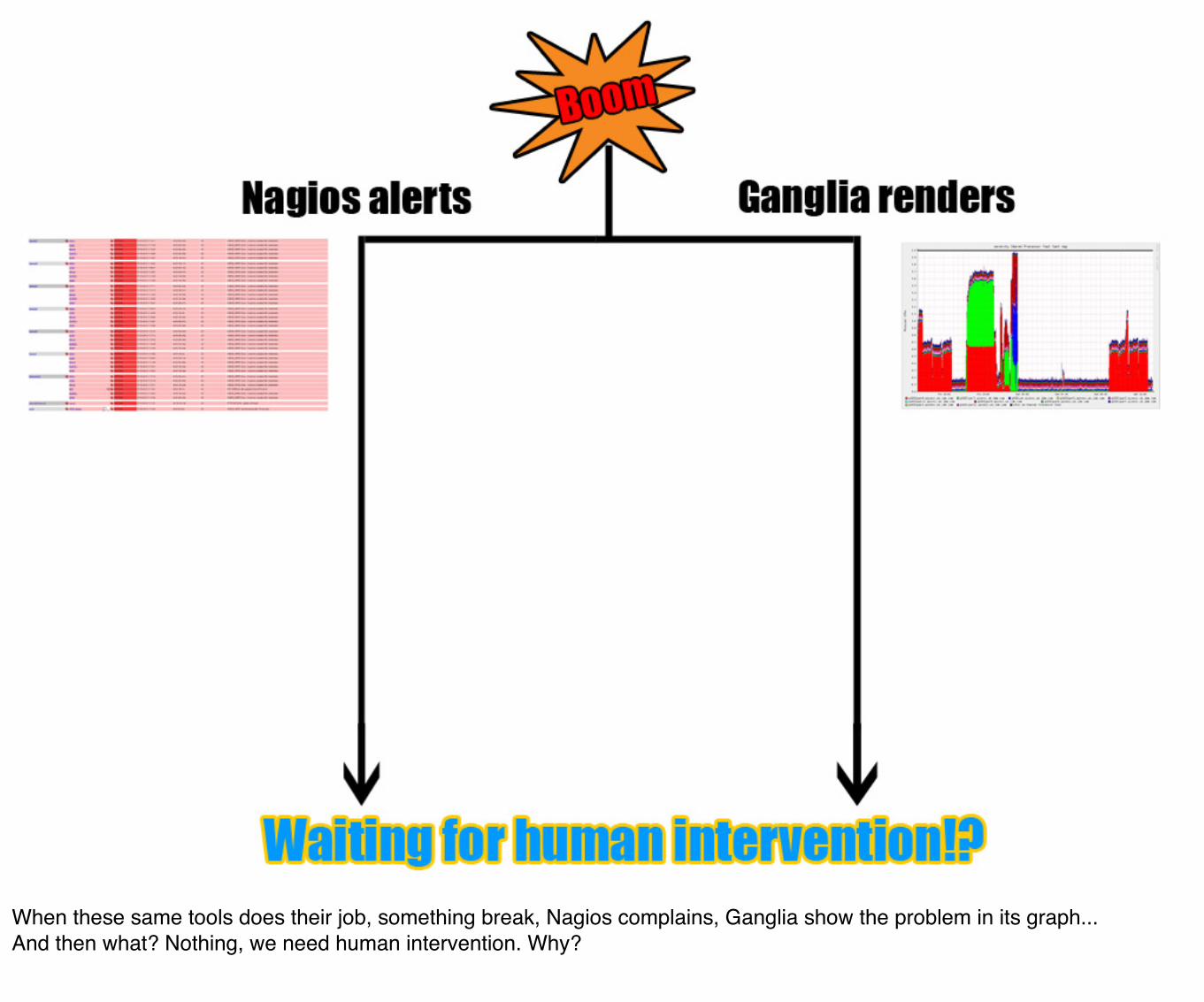
When these same tools does their job, something break, Nagios complains, Ganglia show the problem in its graph...And then what? Nothing, we need human intervention. Why?
Automation?
Why humans, still do repetitive things, have to react to events that system could handle?Why we aren't we automating the management of systems?

What brought Skynet to life?
Slideshare has an infrastructure hosted in EC2 for the document conversion.We have a lot of "factories" which are converting different types of documents.This infrastructure scale up and down on demand.
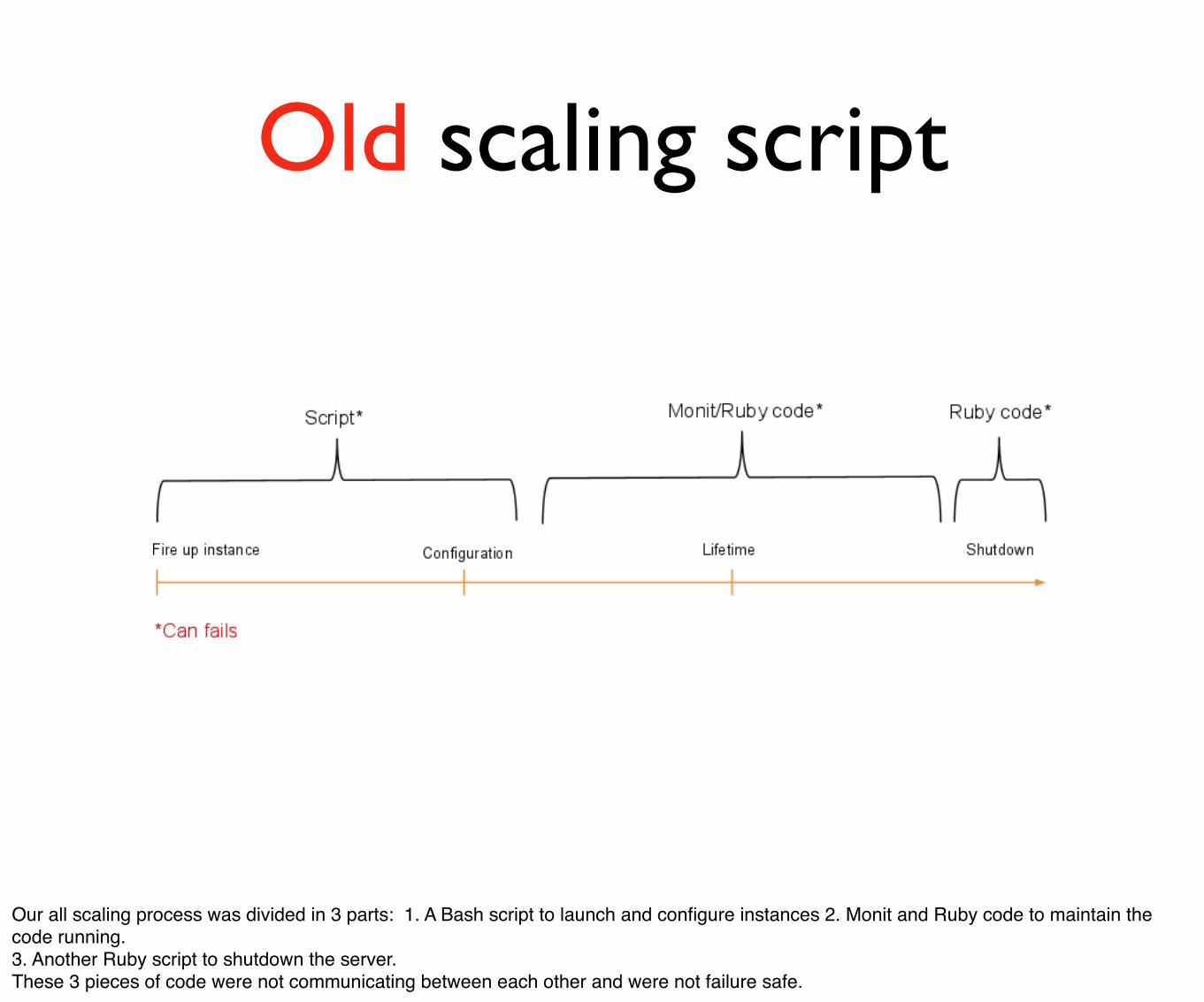
Old scaling script
Our all scaling process was divided in 3 parts: 1. A Bash script to launch and configure instances 2. Monit and Ruby code to maintain the code running.3. Another Ruby script to shutdown the server.These 3 pieces of code were not communicating between each other and were not failure safe.

•Idle
•Immortal
•Wasting money
Zombie instances
Meaning that we ended up with instances not running code.That would not shutdown themselves and were doing nothing but wasting money.
•No metrics - blind
•Wasting time fixing
Mummy Ops
For Ops we had issue with no visibility about what was going on with our infrastructure (we were only monitoring the SQS queue).We ended up wasting so much time investigating and then eventually fixing problem.There was also a lack of feedback for the developers working on the conversion code, are we converting faster? Better?
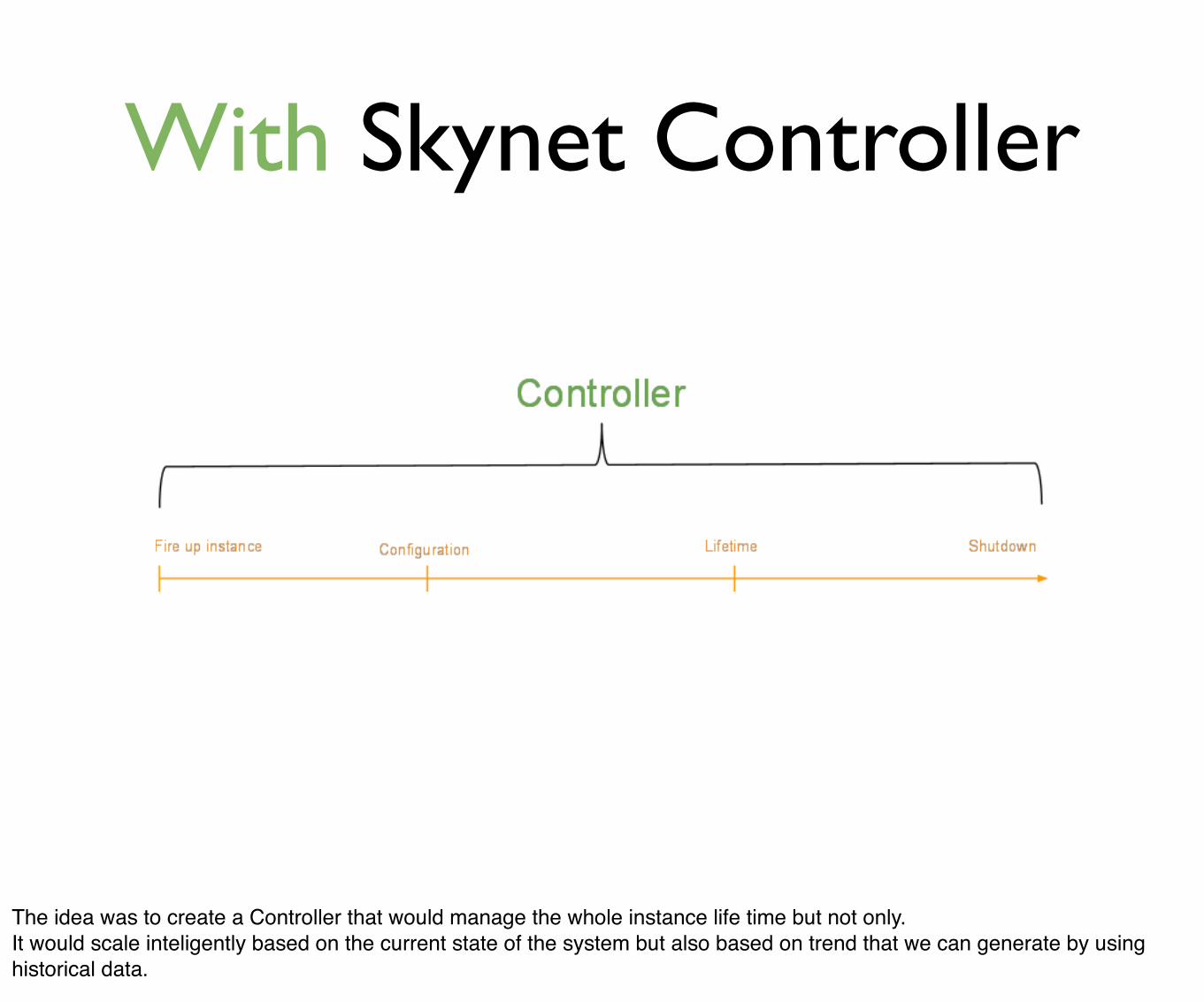
With Skynet Controller
The idea was to create a Controller that would manage the whole instance life time but not only.It would scale inteligently based on the current state of the system but also based on trend that we can generate by using historical data.

Skynet architecture
The idea of Skynet was to make something flexible so that we could use it elsewhere.It should not be architecture specifically for our problem but for any system.Why not open sourcing it at some point?
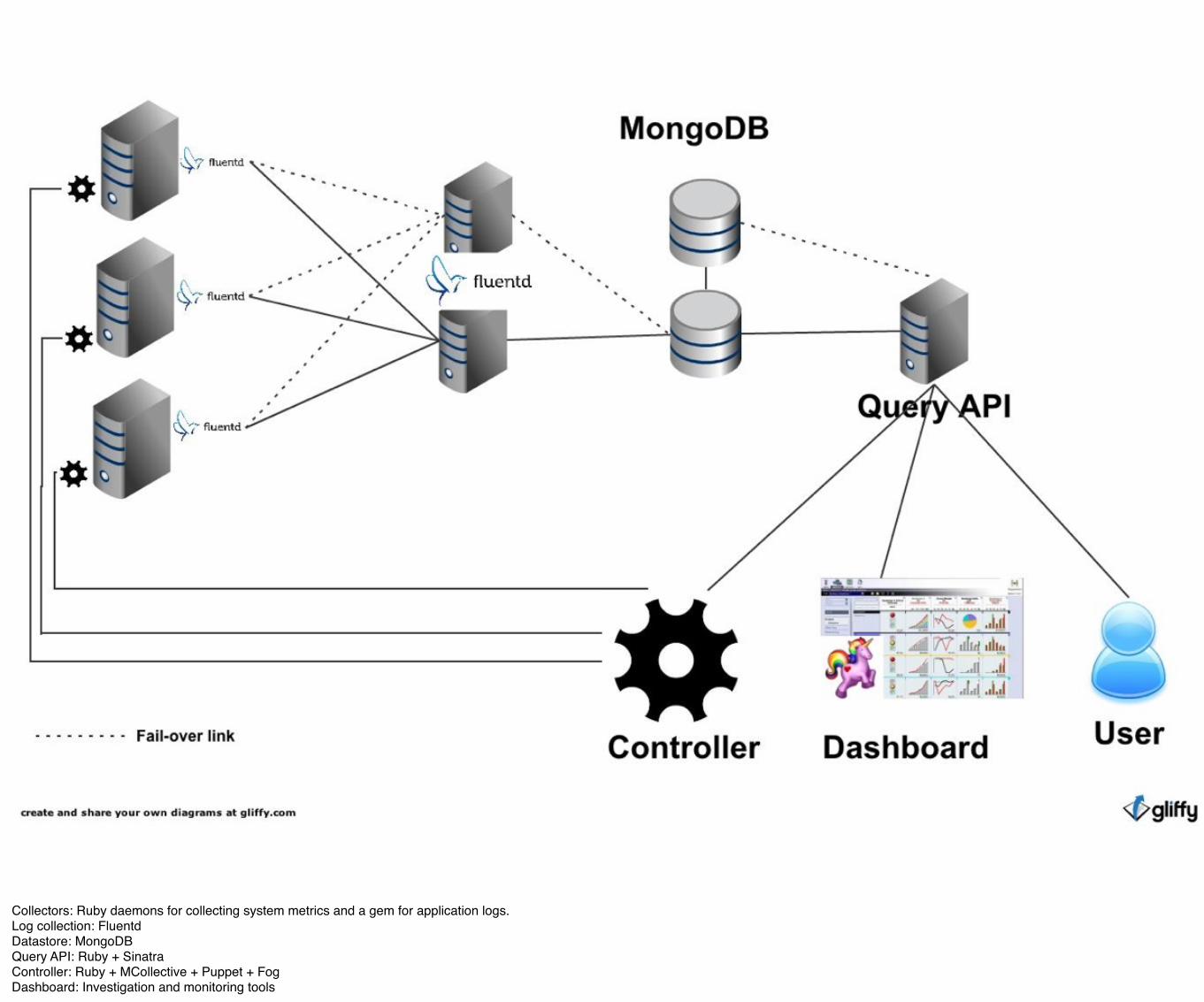
Collectors: Ruby daemons for collecting system metrics and a gem for application logs.Log collection: FluentdDatastore: MongoDBQuery API: Ruby + SinatraController: Ruby + MCollective + Puppet + FogDashboard: Investigation and monitoring tools

Collect system metrics
Collect applications logs
Collectors
Collect system metrics via a Ruby daemon running on each machine, we can collect any metrics via plugins.Collect application logs via a gem.Those 2 components send data to Fluentd locally.
Fluentd
•Light
•Written in Ruby
•Handle failure
•Plugins
•Local forwarder
•Aggregation & routing
•Stream processing
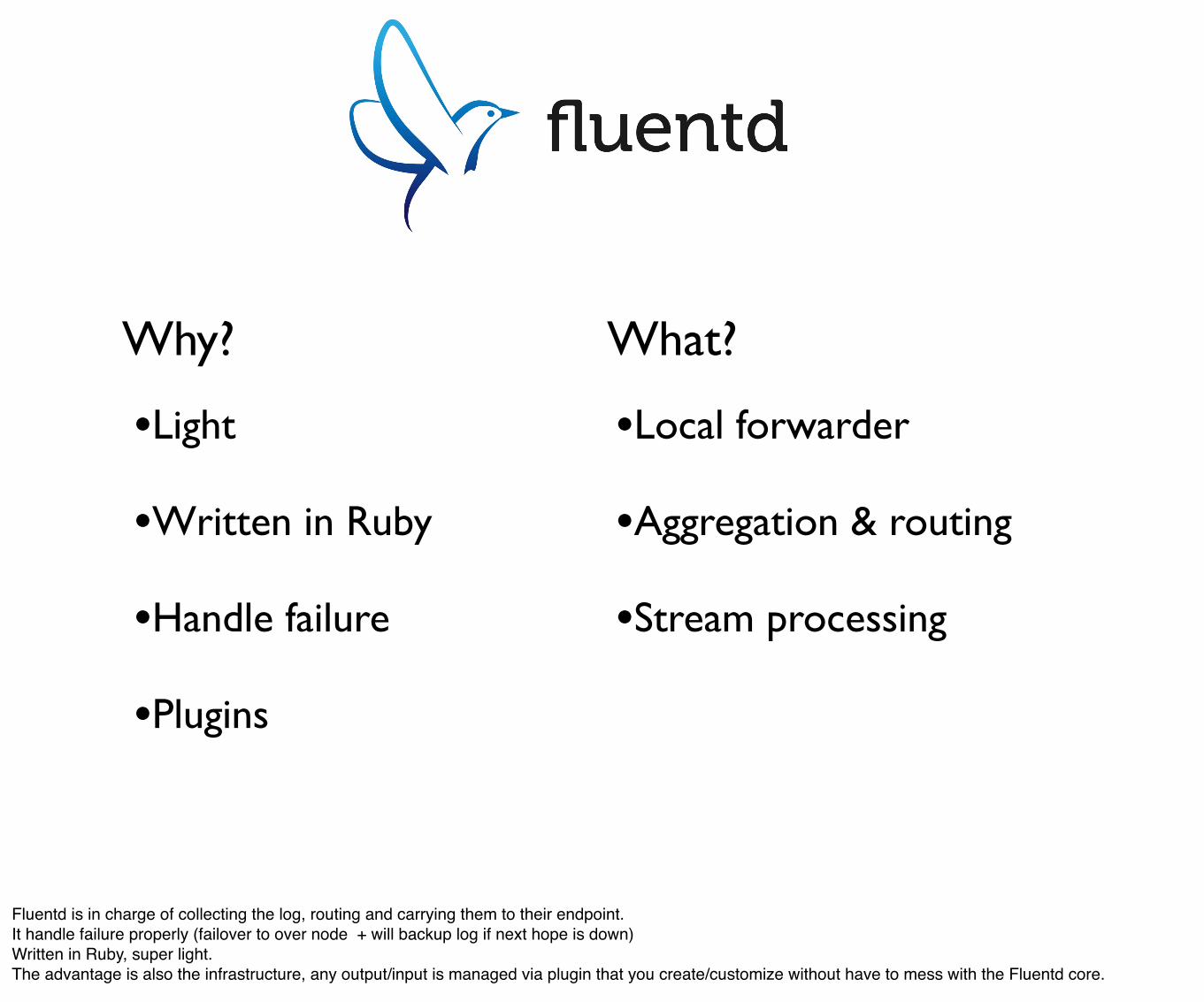
Why? What?
Fluentd is in charge of collecting the log, routing and carrying them to their endpoint.It handle failure properly (failover to over node + will backup log if next hope is down)Written in Ruby, super light.The advantage is also the infrastructure, any output/input is managed via plugin that you create/customize without have to mess with the Fluentd core.

•Schema less
•Key/value match log
format
•Store system metrics &
application logs
•Jobs metadata
Why? What?
MongoDB is schema less, which give us the possibility to make our data schema evolve very easily.MongoDB is fiting-ish the bill for the format 1 log entry one Mongo document.We store system metrics and informations (CPU, memory, top output, disk, Nginx active connection...) but also application logs.We know the status of application jobs, what is the status of this job that is converting that document...

Abstraction of the datastore
Easy REST interface
Keep control over requests processed
Post-request computing via plugin
API
The abstraction layer/REST API give use the possibility to use any datastore in the backend, we are now using MongoDB but we could use Elastic search in front of it later. Also depending of the type data, we store them in different MongoDB cluster, but this is totally transparent to the data consumer.We keep control over whatʼs possible to do so that a single data consumer does not crash the whole datastore.We offer the possibility to have computing plugin to process the data right on the API server before returning them to the requester. Better to process data as near as by the source to avoid having to transport big chunk of data over network.

Monitor all the things
Granular & global view
Investigation tool
Dashboard
We can monitor all kind of stuff, possibilities are infinite with the combination of the Rubym daemon and the gem.We can use all these data to have an global overview of our infrastructure but also have granularity and see that at this particular second there was a CPU spike for a job on this machine converting this document.It's also a useful debugging tool.

Automate
Scale
Fix
Alert
Controller
Can use all the data collected to scale, based on current state but also trends.Can take action if a system is in a abnormal state try to fix it via possibility trees.And finally Skynet Controller can also alert, in case the system reach its limit and finally need a human, again...!

Thank you!Let Skynet take over the world to make it a better place.
@SylvainKalache
If you are interested in Skynet please donʼt hesitate to reach me!