spark definicion
DESCRIPTION
sparkTRANSCRIPT

Jesús Fernández Bes MLG – 3JUN2013

Índice
1. Instrucciones de instalación 2. Visión general de Spark 3. PySpark
1. Uso interacIvo 2. Uso standalone
4. Uso de Spark en nuestro cluster 5. Integración con Amazon EC2 6. Conclusiones 7. Referencias

INSTRUCCIONES DE INSTALACIÓN

Instrucciones de instalación: Prerrequisitos
• Java & Python 2.7
• SCALA (Versión 2.9) – Descarga Scala 2.9.2. (Spark necesita Scala para funcionar aunque
programemos en Python pero ATENCIÓN “no es compaIble” con la úlIma versión de Scala 2.10).
h^p://www.scala-‐lang.org/downloads/distrib/files/scala-‐2.9.2.tgz – Descomprime Scala donde desees.
• GIT – Por alguna razón, en Mac OSx necesitas el git. h^ps://code.google.com/p/git-‐osx-‐installer/

Instrucciones de instalación: Instalación de Spark
• Descarga la úlIma versión de Spark (0.7) de la página web. Versiones anteriores no se pueden usar con Python. h^p://www.spark-‐project.org/download-‐spark-‐0.7.0-‐sources-‐tgz
• Descomprime Spark donde desees. • Ahora es necesario o bien que Scala esté en el path o mejor
fijar una nueva variable de estado SCALA_HOME. • En la carpeta conf dentro del root de spark y crear ahí un fichero
spark-‐env.sh (se puede uIlizar para ello la planIlla que hay en el directorio spark-‐env.sh.template, cambiándole el nombre y en el fichero añadir: spark-‐env.sh
if [ -‐z "$SCALA_HOME" ] ; then SCALA_HOME=”<scala-‐path>”
fi

Instrucciones de instalación: Instalación de Spark (2)
Desde el directorio raiz de Spark ejecuta la siguiente instrucción que compilará Spark y descargará lo que le haga falta para instalarlo.
Comprobaciones (desde el raiz de Spark)
cuando se te abra la shell interacIva escribe sc . Salir ( Ctlr + D )
al igual que antes, cuando se te abra la shell interacIva escribe sc. Salir ( Ctlr + D ) Debería ejecutar el programa de ejemplo que calcula Pi. Deben salir una serie de mensajes y al final de todo el valor de pi (o una aproximación razonable)
$ sbt/sbt package
$ ./spark-‐shell
$ ./pyspark
$ ./run spark.examples.SparkPi local

DESCRIPCIÓN Y UTILIZACIÓN DE SPARK

¿Qué es Spark? • Spark es una infraestructura paralela con: – PrimiIvas eficientes para comparIr datos en memoria. – APIs en Scala, Java, SQL y Python. – Aplicable a muchos problemas emergentes.
• MapReduce simplificó el análisis de datos en clusters grandes y sujetos a fallos. Hoy los usuarios quieren más: – Aplicaciones más complejas, iteraDvas (p.e. Machine learning, graph algorithms).
– Consultas ad-‐hoc más interacDvas. – Procesado de flujo en Dempo real.

Memoria distribuida tolerante a fallos
• Necesario trabajar en memoria de manera distribuida para ser eficientes.
• Pero entonces ¿Como recuperarse ante fallos?
Solución: Resilient Distributed Datasets (RDD)

RDDs • Colección parIcionada inmutable de registros. • Se crean a parIr de transformaciones de ficheros Hadoop u otros RDD.
• Tiene información sobre lineage. Permite recuperarse ante fallos.
• Permite cierto control sobre el parGcionado y la persistencia.
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for
In-Memory Cluster Computing
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma,Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica
University of California, Berkeley
AbstractWe present Resilient Distributed Datasets (RDDs), a dis-tributed memory abstraction that lets programmers per-form in-memory computations on large clusters in afault-tolerant manner. RDDs are motivated by two typesof applications that current computing frameworks han-dle inefficiently: iterative algorithms and interactive datamining tools. In both cases, keeping data in memorycan improve performance by an order of magnitude.To achieve fault tolerance efficiently, RDDs provide arestricted form of shared memory, based on coarse-grained transformations rather than fine-grained updatesto shared state. However, we show that RDDs are expres-sive enough to capture a wide class of computations, in-cluding recent specialized programming models for iter-ative jobs, such as Pregel, and new applications that thesemodels do not capture. We have implemented RDDs in asystem called Spark, which we evaluate through a varietyof user applications and benchmarks.
1 IntroductionCluster computing frameworks like MapReduce [10] andDryad [19] have been widely adopted for large-scale dataanalytics. These systems let users write parallel compu-tations using a set of high-level operators, without havingto worry about work distribution and fault tolerance.
Although current frameworks provide numerous ab-stractions for accessing a cluster’s computational re-sources, they lack abstractions for leveraging distributedmemory. This makes them inefficient for an importantclass of emerging applications: those that reuse interme-diate results across multiple computations. Data reuse iscommon in many iterative machine learning and graphalgorithms, including PageRank, K-means clustering,and logistic regression. Another compelling use case isinteractive data mining, where a user runs multiple ad-hoc queries on the same subset of the data. Unfortu-nately, in most current frameworks, the only way to reusedata between computations (e.g., between two MapRe-duce jobs) is to write it to an external stable storage sys-tem, e.g., a distributed file system. This incurs substantialoverheads due to data replication, disk I/O, and serializa-
tion, which can dominate application execution times.Recognizing this problem, researchers have developed
specialized frameworks for some applications that re-quire data reuse. For example, Pregel [22] is a system foriterative graph computations that keeps intermediate datain memory, while HaLoop [7] offers an iterative MapRe-duce interface. However, these frameworks only supportspecific computation patterns (e.g., looping a series ofMapReduce steps), and perform data sharing implicitlyfor these patterns. They do not provide abstractions formore general reuse, e.g., to let a user load several datasetsinto memory and run ad-hoc queries across them.
In this paper, we propose a new abstraction called re-silient distributed datasets (RDDs) that enables efficientdata reuse in a broad range of applications. RDDs arefault-tolerant, parallel data structures that let users ex-plicitly persist intermediate results in memory, controltheir partitioning to optimize data placement, and ma-nipulate them using a rich set of operators.
The main challenge in designing RDDs is defining aprogramming interface that can provide fault toleranceefficiently. Existing abstractions for in-memory storageon clusters, such as distributed shared memory [24], key-value stores [25], databases, and Piccolo [27], offer aninterface based on fine-grained updates to mutable state(e.g., cells in a table). With this interface, the only waysto provide fault tolerance are to replicate the data acrossmachines or to log updates across machines. Both ap-proaches are expensive for data-intensive workloads, asthey require copying large amounts of data over the clus-ter network, whose bandwidth is far lower than that ofRAM, and they incur substantial storage overhead.
In contrast to these systems, RDDs provide an inter-face based on coarse-grained transformations (e.g., map,filter and join) that apply the same operation to manydata items. This allows them to efficiently provide faulttolerance by logging the transformations used to build adataset (its lineage) rather than the actual data.1 If a parti-tion of an RDD is lost, the RDD has enough informationabout how it was derived from other RDDs to recompute
1Checkpointing the data in some RDDs may be useful when a lin-eage chain grows large, however, and we discuss how to do it in §5.4.

PrimiIvas Spark
TransformaDons AcDons map
flatMap filter
groupBy join (…)
count reduce collect (…)
Dos Ipos. • Transformaciones: RDD à RDD’ • Acciones: RDD à resultado
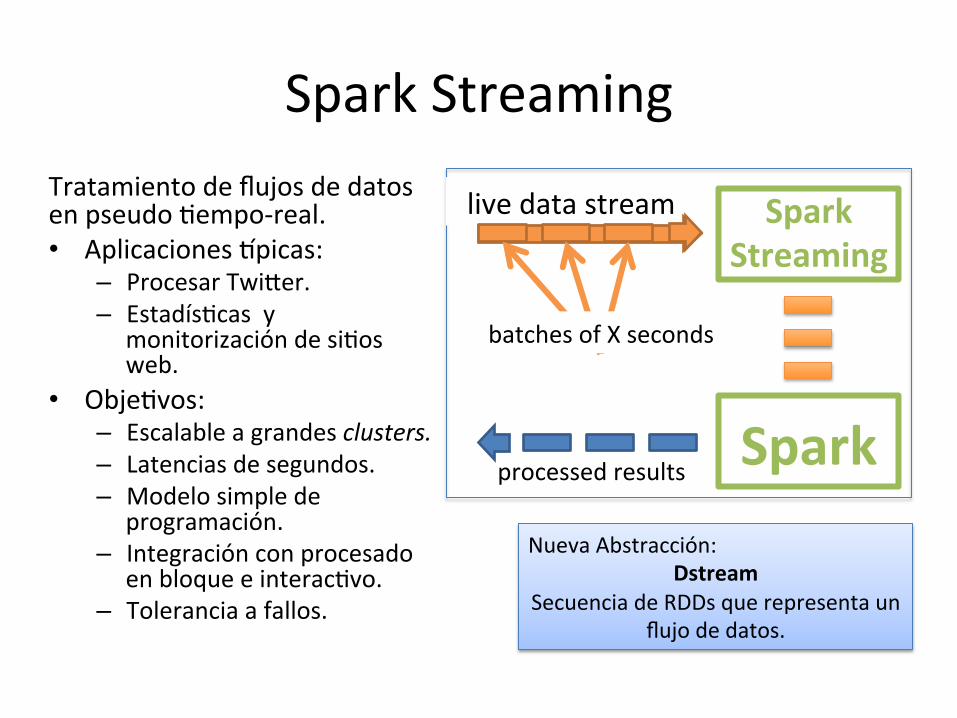
Spark Streaming Tratamiento de flujos de datos en pseudo Iempo-‐real. • Aplicaciones |picas:
– Procesar Twi^er. – EstadísIcas y
monitorización de siIos web.
• ObjeIvos: – Escalable a grandes clusters. – Latencias de segundos. – Modelo simple de
programación. – Integración con procesado
en bloque e interacIvo. – Tolerancia a fallos.
live data stream
Spark
Spark Streaming
batches of X seconds
processed results
Nueva Abstracción: Dstream
Secuencia de RDDs que representa un flujo de datos.

Shark
• Extensión de Hive para hacerlo compaIble con Spark.
• Sistema de almacén de datos (data warehouse).
• Permite hacer consultas Ipo SQL. – Hasta 100% más rápido que Hive.
– ConverIrlos en RDDs. • Usar Spark sobre ellos.

Programación
• API en Scala, Java y Python: – Originalmente en Scala (Recomendado). – En Java sólo modo standalone. – Python añadido recientemente (02/2013).
• Se puede uIlizar modo interacDvo o standalone. • No se puede uIlizar con Spark Stream (Desarrollo futuro). • Permite uIlizar cualquier biblioteca Python: numpy, scipy... (????)

PySpark: Uso InteracIvo
• Vamos a uIlizar el dataset de libros que uIlizamos en el nltk.
• Abrir la consola interacIva en python [ $./spark-‐shell (si quisiéramos usar Scala) ]
• Variable sc conIene un SparkContext. – Objeto que “sabe como interactuar con el cluster” y permite crear RDDs a parIr de ficheros o colecciones de python.
$./pyspark

Sintaxis Python lambda
• Python soporta el definir mini-‐funciones anónimas de una línea sobre la marcha. – Originalmente en Lisp
[ lambda variable: operación ]
– Muy úIl dentro de filter, map, reduce.
>>> g = lambda x: x**2 >>> g(3)
9
>>> words.filter(lambda w: w.startswith(‘a’))

Ejercicio Pyspark interacIvo
• Construir RDDs a parIr de un fichero (directorio)
• Ver los primeros campos del registro
>>>
>>>

Ejercicio Pyspark interacIvo
• Construir RDDs a parIr de un fichero (directorio)
• Ver los primeros campos del registro
>>> bookLines = sc.textFile('books')
>>> bookLines.take(10)

Ejercicio Pyspark interacIvo • Construir RDDs a parIr de un fichero (directorio)
• Ver los primeros campos del registro
• Un poco feo, ¿no?. Vamos a mostrarlo un poco más limpio
• Otras acciones
>>> bookLines = sc.textFile('books')
>>> bookLines.take(10)
>>>
>>>
>>>

Ejercicio Pyspark interacIvo • Construir RDDs a parIr de un fichero (directorio)
• Ver los primeros campos del registro
• Un poco feo, ¿no?. Vamos a mostrarlo un poco más limpio
• Otras acciones
>>> bookLines = sc.textFile('books')
>>> bookLines.take(10)
>>> for line in bookLines.take(10): print line
>>> bookLines.count()
>>> bookLines.collect()

Ejercicio Pyspark interacIvo (2)
• Pasar de lista de líneas a lista de palabras para contar número de palabras. 1. Transformar RDD: ¿flatMap or map?
2. Contar las palabras
>>>
>>>

Ejercicio Pyspark interacIvo (2)
• Pasar de lista de líneas a lista de palabras para contar número de palabras. 1. Transformar RDD: ¿flatMap or map?
2. Contar las palabras
>>> bookWords1 = bookLines.map( lambda x: x.split(' ') ) >>> bookWords1.take(50) >>>
>>>

Ejercicio Pyspark interacIvo (2)
• Pasar de lista de líneas a lista de palabras para contar número de palabras. 1. Transformar RDD: ¿flatMap or map?
2. Contar las palabras
>>> bookWords1 = bookLines.map( lambda x: x.split(' ') ) >>> bookWords1.take(50) >>> bookWords2 = bookLines.flatMap( lambda x: x.split(' ') ) >>> bookWords2.take(50) >>> bookWords2.take(50) >>>
>>>

Ejercicio Pyspark interacIvo (2)
• Pasar de lista de líneas a lista de palabras para contar número de palabras. 1. Transformar RDD: ¿flatMap or map?
2. Contar las palabras
>>> bookWords1 = bookLines.map( lambda x: x.split(' ') ) >>> bookWords1.take(50) >>> bookWords2 = bookLines.flatMap( lambda x: x.split(' ') ) >>> bookWords2.take(50) >>> bookWords2.take(50) >>> bookWords = bookWords2.cache() >>> bookWords2.take(50)
>>>

Ejercicio Pyspark interacIvo (2)
• Pasar de lista de líneas a lista de palabras para contar número de palabras. 1. Transformar RDD: ¿flatMap or map?
2. Contar las palabras
>>> bookWords1 = bookLines.map( lambda x: x.split(' ') ) >>> bookWords1.take(50) >>> bookWords2 = bookLines.flatMap( lambda x: x.split(' ') ) >>> bookWords2.take(50) >>> bookWords2.take(50) >>> bookWords = bookWords2.cache() >>> bookWords2.take(50)
>>> bookWords.count()

MapReduce en Spark
• Return a new distributed dataset formed by passing each element of the source through a funcIon func.
map( func )
• Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item).
flatMap( func )
• Aggregate the elements of the dataset using a funcIon func (which takes two arguments and returns one). The funcIon should be commutaIve and associaIve so that it can be computed correctly in parallel.
reduce( func )
• When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce funcIon.
reduceByKey( func )

Ejercicio Pyspark interacIvo (3)
• Calcula la línea de longitud máxima • Muestra las líneas de longitud máxima
>>>
>>>

Ejercicio Pyspark interacIvo (3)
• Calcula la línea de longitud máxima • Muestra las líneas de longitud máxima
>>> linesMax = bookLines.map(lambda line: len(line.split(' '))).reduce(max)
>>>

Ejercicio Pyspark interacIvo (3)
• Calcula la línea de longitud máxima • Muestra las líneas de longitud máxima
>>> linesMax = bookLines.map(lambda line: len(line.split(' '))).reduce(max)
>>> bookLines.filter(lambda line: len(line.split(' '))==linesMax ).collect()

Ejercicio Pyspark interacIvo (4) • Más MapReduce: WordCount • A parIr de los ficheros extraer pares (palabra,conteo)
• En primer lugar hace falta importar el operador suma para usarlo de manera funcional
A parIr del RDD de palabras bookWords:
1. Map: Generar pares (w,1) 2. Reduce: sumar aquellos pares que tengan la misma
clave w.
>>> from operator import add

Ejercicio Pyspark interacIvo (4)
1. Map: Generar pares (w,1) 2. Reduce: sumar aquellos pares que tengan la misma
clave w.
Mostrar el resultado
>>>
>>>

Ejercicio Pyspark interacIvo (4)
1. Map: Generar pares (w,1) 2. Reduce: sumar aquellos pares que tengan la misma
clave w.
Mostrar el resultado
>>> counts = bookWords.map(lambda x: (x,1) ).reduceByKey(add).cache()
>>>

Ejercicio Pyspark interacIvo (4)
1. Map: Generar pares (w,1) 2. Reduce: sumar aquellos pares que tengan la misma
clave w.
Mostrar el resultado
>>> counts = bookWords.map(lambda x: (x,1) ).reduceByKey(add).cache()
>>> counts.take(50) >>> for pair in counts.take(50): print pair

Modo standalone Hacer programas completos que se ejecuten en bloque en lugar de en la consola interacIva. Invocación |pica:
./pyspark file.py <master> <inputs> [En local ./pyspark file.py local <inputs> ]
Dos pasos básicos: 1. importar SparkContext
from pyspark import SparkContext 2. Crear SparkContext en el nodo
master, nombre del trabajo [y dependencias que hay que enviar al nodo.]
sc = SparkContext(sys.argv[1], ”job", pyFiles=['MyFile.py', 'lib.zip', 'app.egg’])
wordCount.py
import sys from operator import add from pyspark import SparkContext if __name__ == "__main__": if len(sys.argv) < 3: print >> sys.stderr, \ "Usage: PythonWordCount <master> <file>" exit(-‐1) sc = SparkContext(sys.argv[1], "PythonWordCount") lines = sc.textFile(sys.argv[2], 1) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counts.collect() for (word, count) in output: print "%s : %i" % (word, count)

Ejemplos ML de Pyspark • Junto con Spark hay una serie de ejemplos de algoritmos Ipo ML: – Regresión LogísIca – Kmeans – ALS
• Tienen graves errores de programación logisDc_regression.py
for i in range(1, ITERATIONS + 1): print "On iteraIon %i" % i gradient = points.map(lambda p: (1.0 / (1.0 + exp(-‐p.y * np.dot(w, p.x)))) * p.y * p.x ).reduce(add) w -‐= gradient

Spark en nuestro cluster
• Funciona sobre el gestor de recursos Apache Mesos. CompaIble con Hadoop.
• Dos formas principales de acceder: – Ordenador personal. Necesario instalar bibliotecas Mesos. h^p://spark-‐project.org/docs/latest/running-‐on-‐mesos.html
– Conectándose primero a amaterasu.tsc.uc3m.es .

Spark en nuestro cluster (2) • Conectarse a amaterasu
ssh amaterasu
• Invocar desde allí Spark en el masternode del cluster: 10.0.12.18:5050 o subserver1.tsc.uc3m.es:5050
• Modo interacDvo: MASTER=mesos://10.0.12.18:5050 /usr/local/spark/pyspark
• Modo standalone: – Introducir mesos://10.0.12.18:5050 como primer parámetro del
programa: /usr/local/spark/pyspark example.py mesos://10.0.12.18:5050
<params>
• Ver trabajos acIvos -‐> En el navegador 10.0.12.18:5050

Spark en nuestro cluster (3) • ¿cómo subir ficheros para procesar y descargar resultados?
– UIlizar el Hadoop FileSystem (HDFS). • Ver instrucciones de Harold h^p://www.tsc.uc3m.es/~miguel/MLG/adjuntos/Hadoop.pdf (pag. 12)
• A la hora de leer el fichero uIlizar la URL correcta: sc.textFile(‘hdfs://<namenode>:8080/path‘)
– UIlizar un directorio accesible desde el cluster: /export/clusterdata
$ hadoop -‐-‐config conf_cluster dfs -‐put src dest $ hadoop -‐-‐config conf_cluster dfs -‐copyFromLocal src dest
$ hadoop -‐-‐config conf_cluster dfs -‐get src dest $ hadoop -‐-‐config conf_cluster dfs –copyToLocal

• Spark provee de scripts para lanzar trabajos directamente a Amazon ElasIc Compute Cloud (EC2).
• Configuran automáIcamente Mesos, Spark y HDFS en el clúster para I.
• Necesario pagar Computo ($0,260 por instancia/hora para la predeterminada) + Coste de almacenamiento.
• Muy fácil de usar. • Grants!!!! h^p://aws.amazon.com/es/grants/

• Registrarse en Amazon Web Services (AWS). – h^p://aws.amazon.com/es/
• En la pantalla principal de mi cuenta crear Claves de acceso. – Pestaña de credenciales de
seguridad.
• Antes de ejecutar los scripts Ienes que fijar las variables de estado AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY_ID a esos valores.

• Generar par de claves: – Accede a tu consola AWS y allí entra en el servicio EC2.
– Selecciona keyPairs y crea el par
– Descargate el fichero y en Linux/Mac Osx cambiale los permiso a 600
– chmod 600 mykey.pem

• En el directorio ec2 de spark está el script para lanzar un cluster, acceder, pararlo, destruirlo.
• Más detalles aquí. h^p://spark-‐project.org/docs/latest/ec2-‐scripts.html
>>> ./spark-‐ec2 -‐k <keypair> -‐i <key-‐file> -‐s <num-‐slaves> launch <cluster-‐name>
>>> ./spark-‐ec2 -‐k <keypair> -‐i <key-‐file> login <cluster-‐name>
>>> ./spark-‐ec2 -‐k <keypair> -‐i <key-‐file> -‐s <num-‐slaves> launch <cluster-‐name>
>>> ./spark-‐ec2 destroy <cluster-‐name>

Conclusiones • Spark propone una infraestructura interesante para computación en clusters. – API Scala, Python y Java sencillo. Sobretodo para gente que sabe programación funcional.
– Modo interacIvo (extracción rápida de caracterísIcas de grandes datasets).
– Funciona bien con procesado secuencial. – Fácil de usar en EC2.
• Muy (demasiado) nuevo. Python en febrero de este año.
• No existe una comunidad de Machine Learning como Mahout en torno a Spark.

Algunas Referencias • Documentación oficial de Spark
h^p://spark-‐project.org/docs/latest/index.html
• Mini-‐Curso del AMPLAB sobre BigData: Spark, Shark y EC2. h^p://ampcamp.berkeley.edu/big-‐data-‐mini-‐course/
• Algunos vídeos con presentaciones de las desarrolladores. – NIPS 2011:
h^ps://www.youtube.com/watch?v=qLvLg-‐sqxKc – Berkley Analizing Big Data with twi^er (lesson 16):
h^ps://www.youtube.com/watch?v=rpXxsp1vSEs – PyData 2013:
h^p://vimeo.com/63274414
• Libro de O’Reilly en camino (Agosto de 2013): h^p://shop.oreilly.com/product/0636920028512.do