universidade federal do abc bacharelado em … · 1. introduÇÃo a constituição federal...
TRANSCRIPT

UNIVERSIDADE FEDERAL DO ABC
Bacharelado em Planejamento Territorial
Métodos e técnicas de análise da informação para o planejamento territorial
ANÁLISE ESPACIAL DOS ÍNDICES DE GRAVIDEZ NA ADOLESCÊNCIA EM 2010 NO ESTADO DE SÃO PAULO
Karina Vieira dos Santos
São Bernardo do Campo
Agosto/ 2015

Karina Vieira dos Santos
ANÁLISE DOS ÍNDICES DE GRAVIDEZ NA ADOLESCÊNCIA EM
2010 NO ESTADO DE SÃO PAULO Trabalho final da disciplina ‘Métodos e Técnicas de Análise da Informação para o Planejamento’, ministrada pela Profª Dra. Flávia Feitosa da Graduação de Planejamento Territorial, na Universidade Federal do ABC.
São Bernardo do Campo
Agosto/ 2015

SUMÁRIO
1. INTRODUÇÃO
2. METODOLOGIA
3. RESULTADOS E DISCUSSÃO
3.1. Preparação dos dados e análise exploratória
3.2. Análise de Regressão Clássica
4. CONCLUSÃO
5. REFERÊNCIAS BIBLIOGRÁFICAS

1. INTRODUÇÃO
A Constituição Federal estabelece em seu art.227: “É dever da família, da
sociedade e do Estado assegurar à criança, o adolescente e ao jovem, com
absoluta prioridade, o direito à vida, à saúde, à alimentação, à educação, ao lazer,
à profissionalização, à dignidade, ao respeito, à liberdade e a convivência
comunitária e familiar, além de colocála a salvo de toda forma de negligência,
discriminação, exploratória, violência, crueldade e opressão” conforme é também
contemplado no art.4º do Estatuto da Criança e do Adolescente.
Apesar de todo o aparato legislativo com uma série de recomendações,
normas e resoluções, alguns estudos apontam para uma realidade que submete
crianças e adolescentes à contextos de vulnerabilidade que compreendem as
dimensões econômicas(renda) e sociais (educação).
O estudo presente, tem como pretensão realizar um estudo em escala
estadual, utilizando como objeto de estudo os municipios do Estado de São Paulo. A
questão que norteará o diagnótisco será a relação entre a incidência de gravidez na
adolescência, que abrange a faixa etária de 10 à 17 anos, com indicadores
socioeconômicos do IDHM: longevidade, renda e educação.
De acordo com estudos do Fundo de População das Nações Unidas
instituição ligada a Organização das Nações Unidas somente no Brasil, cerca de
19,3% das crianças nascidas vivas em 2010 eram filhas de adolescentes, cujo fruto
da gravidez precoce é resultado da falta de acesso a escola e violência social.
Ressaltase, porém, que nos últimos anos o acesso aos serviços de saúde voltados
ao amparo de mulheres grávidas tem aumentado, como o prénatal, natal e pós
natal.
Ainda conforme aponta o relatório Situação da População Mundial 2013,
incidência de meninas grávidas precocemente ocorre em maior probabilidade em
meninas com perfil pobres, com baixa escolaridade e residentes em áreas rurais do
que com meninas ricas, com mais escolaridade e que vivem em área urbana.
Além disso, afirmase que a alta taxa de gravidez na adolescência está
relacionada a problemas sociais associados à pobreza, à cultura social machista,
quando não resultado de violência sexual ou coerção. Outro apontamento

importante e que incitou o desenvolvimento desse trabalho foi o de que “meninas
que permanecem na escola por mais tempo são menos propensas a engravidar”.
Portanto, esse trabalho tem como objetivo investigar se existe correlação
entre o indicador social de educação com a taxa de gravidez na adolescência nos
645 municípios do Estado de São Paulo com base nos Censos de 2000 e 2010,
possibilitando de certa forma observar se ao longo dos anos houve um movimento
de melhora, tanto no IDHM_E quanto na taxa de gravidez.
2. OBJETIVO
Verificar por meio de análises estatísticas quais as correlações que se pode
estabelecer entre as dimensões do Índice de Desenvolvimento Humano Municipal,
no que tange às dimensões: renda e educação. para isso será utilizado dados do
censo 1999 e 2010. Com base nisso, inicialmente, levantouse as seguintes
hipóteses:
Podese estabelecer correlação entre renda média domiciliar e
gravidez precoce?
A dimensão educação estão correlacionada com aumento ou
mesmo redução da taxa de gravidez na adolescência?
No entanto, durante a realização de testes que estabelecem essa correlação,
a dimensão que mais apresentou correlação foi a de educação. Sendo assim, todo o
trabalho se desdobrará na análise das variáveis: educação e taxa de gravidez na
adolescência no Estado de São Paulo.
3. METODOLOGIA
O desenvolvimento do trabalho contou com duas fontes de dados: a base do
Instituto Brasileiro de Geografia e Estatística IBGE (taxa de gravidez na
adolescência, tendo como base o universo do Censo 2010) e o ATLAS Brasil,
plataforma onde foram encontradas as informações relativas ao IDHM consolidadas
por Estado.

Para o realiza as análises espaciais foram utilizadas as seguintes
ferramentas: para a seleção dos dados necessários utilizouse o Excel, o cálculo e
espacialização da regressão clássica foi feita nosoftware Statistical Package for the
Social Sciences SPSS e para a manipulação do shapefile e join do mapa com a
tabela de atributos foi utilizado o Quantum GIS.
3.1. PREPARAÇÃO DOS DADOS E ANÁLISE EXPLORATÓRIA
Inicialmente se fez necessário a manipulação de dados no Excel para realizar
a seleção dos dados que compuseram a análise.Terminada a seleção dos dados
(variáveis dependente e independentes) a tabela foi salva no formato cujos valores
são separados por vírgula, em inglês Comma Separated Values (.csv).
Tabela em formato .csv para join com o mapa no QGIS e análise de dados no SPSS
O segundo passo foi realizar ojoin entre a tabela com as variáveis e oshapefile cujo
formato é o .shp do estado de São Paulo.
3.2. ANÁLISE DE REGRESSÃO CLÁSSICA
Para realizar uma análise de regressão clássica usarei o software SPSS. O
programa permitirá o desenvolvimento de análises estatísticas dos dado a partir da
identificação da correlação ou não entre os indicadores escolhidos, ou seja, verificar
se uma variável pode ser explicada por outras variáveis.

No primeiro momento serão realizadas as análises descritivas das variáveis,
ou seja, explanaremos modelos estatísticos simples: média, moda, mediana,
variância, desviopadrão, intervalo de confiança, assimetria e curtosis. A amostra
utilizada para análise apresenta um número de observações, ou seja, “n” igual a
645.
Antes de iniciar as análises, discorreremos rápida e superficialmente sobre as
medidas de posição central e as medidas de dispersão. A média é a soma dos
elementos de um conjunto dividido pelo numero de elementos do conjunto. A moda
é o elementos que aparece com maior frequência, ou melhor, o maior número de
vezes. A mediana é o valor que divide um conjunto ao meio e diferente da média é
menos sensível a valores extremos, não comprometendo a representação desejada.
(SARTORIS, 2013).
No grupo referente às medidas de dispersão temos a variância, que é a amis
comumente utilizada para indicar a variância de um conjunto de valores, assim
como o desviopadrão. No entanto, o desviopadrão elimina o efeito dos quadrados.
O intervalo de confiança significa estabelecer uma margem de erro para um
estimador e calcular o grau de confiança a essa margem(SARTORIS, 2013).
Para melhor visualização desses dados utilizaremos as ferramentas de
represenação gráfica:o histograma que representa a distribuição de determinada
categoria de dados agrupados em um gráfico de barras; o BoxPlot que representa a
variação de uma variável, onde fica claro a presença de outliers e de outros dados
estatísticos descritivos e o QPlot indica resultado esperados e o que foi observado.
Por fim, utilizaremos o modelo de regressão linear simples, ou seja, um
modelo baseado sobre uma linha reta para explicar a relação entre as variáveis. A
regressão é dada pelo modelo estimado por Yi= B0 + B1 X1 + e1 , sendo a equação
linear nos parâmetros Bo + B¹, onde Bo é o intercepto populacional, B1 é a
inclinação populacional e “Y” é a variável resposta. A inclinação da reta de
regressão indica que há mudança na média de Y quando é acrescido uma unidade
de X (FEITOSA,2015).
3.3. ANÁLISE DE REGRESSÃO ESPACIAL

O modelo de regressão espacial não será abracado no decorrer desse
trabalho, pois conforme indicado na tabela abaixo, gerada pelo GeoDa, os erros não
estão autocorrelacionados. A não existência de autocorrelação foi indicada pelo
Índice de Moran com 0,0076.
3.2 RESULTADOS E DISCUSSÃO (Análise de Regressão Clássica)
A tabela abaixo, gerada pelo software SPSS, apresenta estatísticas
descritivas, que visa sintetizar grandes quantidades de quantidades de da variável
em números informativos.

A variável escolhida para o desenvolvimento desse trabalho é IDHM_E
Índice de Desenvolvimento Humano Municipal da dimensão educação, conforme a
classificação do IBGE e Atlas Brasil. A tabela de resumo do processamento de caso
mostra que a mostra apresenta 645 observações válidas. Esse “N” representa os
municípios que compõem o Estado de São Paulo. Cabe ressaltar que dos casos
caracterizados como ausentes, ou seja, os 354 casos identificados representam
informações importadas da base que não fazem parte da amostra, não implicando,
portanto, em distorções nas análises.
3.2.1 Índice de Escolaridade
O histograma abaixo presenta a frequência em que dados estão distribuídos.
Observamos que há uma certa concentração em torno da média, ou seja, temos
poucos casos acima de ,700 e poucos abaixo de ,400. Contudo, chama a atenção
os casos que estão distantes da média pela discrepância. No mais, o histograma
apresenta curva semelhante à de uma distribuição normal. O desvio padrão
identificado foi 0,072.
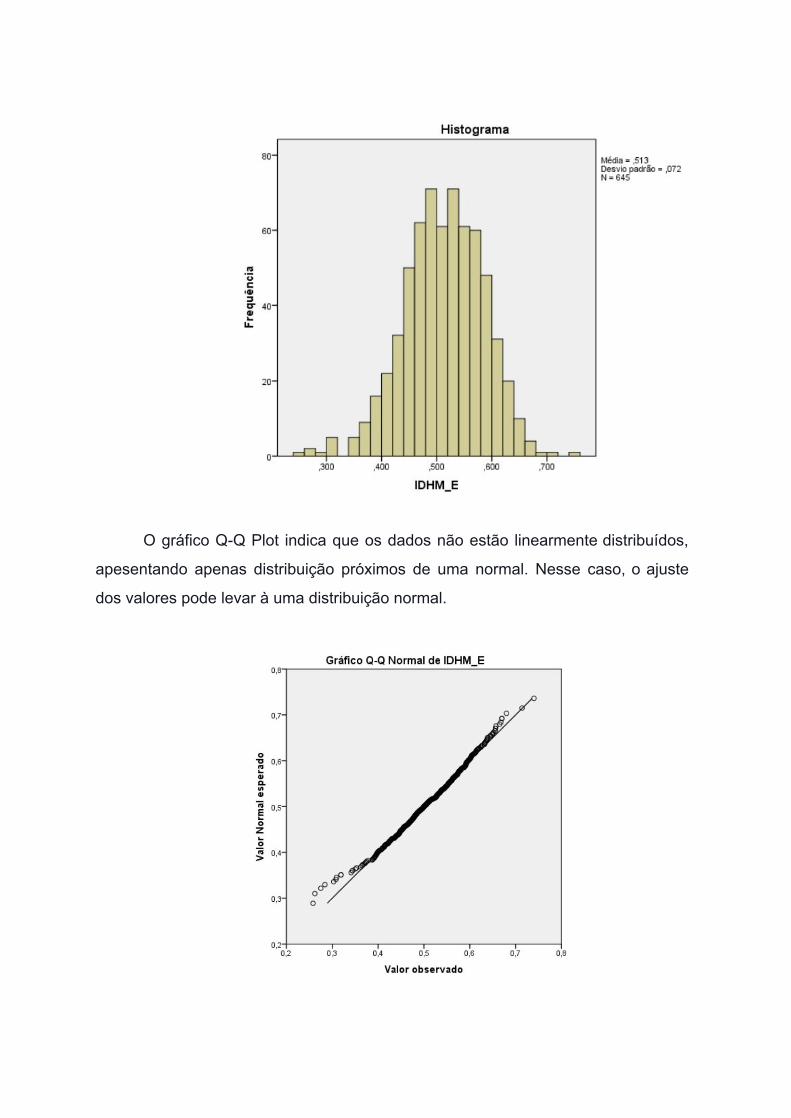
O gráfico QQ Plot indica que os dados não estão linearmente distribuídos,
apesentando apenas distribuição próximos de uma normal. Nesse caso, o ajuste
dos valores pode levar à uma distribuição normal.

O Boxplot caracterizase por consolidar em forma de gráfico todas as
informações relativas às estatísticas descritivas relativas aos dados analisados.
Abaixo identificase a presença de poucos outliers e casos observado inferiores ao
menor valor não discrepante. Isso indica que há casos que apresentam um índice
de educação extremamente baixo. Podemos supor que pode nesses municipios,
não haver oferta adequada ou suficiente de equipamentos de educação(escolas).
3.2.2 Índice de gravidez x Índice de escolaridade
Abaixo temos o Resumo do modelo temos em destaque o R² (R quadrado)
que é o coeficiente de correlação, este mostra o quanto o modelo captura da
variância e é dada pela seguinte equação: SQM/ SQT= R². O O SQM, significa a
soma dos quadrados do modelo divididos pela soma dos quadrados totais
(variância em relação à média). O R²=0, indica que o modelo não serve, enquanto o
R²=1 indica que o modelo explica algo. Nesse sentido, o nossoR² (0,064)indica que
o nosso modelo explica 6%. O teste de DurbinWatson pode variar entre 0 e 4e tem

o objetivo de detectar a presença de autocorrelação ou dependência dos resíduos.
A análise de regressão apresentada na tabela indica autocorrelação dos erros de
1,991.
A tabela de análise de variância, também conhecida comoANOVA,Analisys
of Variance em inglês, nos apresenta as somas dos quadrados da regressão com os
resíduos e a sua variância. Numa situação ideal a soma dos quadrados da
regressão deveria ser grande e a dos resíduos pequena, pois o resíduo indica a
diferença entre o modelo e a realidade(erro). A seguir a tabela ANOVA indica
testeF 44,001 e significância alta de ,000, ou seja ou seja, pvalor< 0,001. Isso
indica que com 99,9% de confiança podemos rejeitar a hipótese nula(Ho) que indica
a inexistência de relação entre o índice de gravidez na adolescência e o de
educação.
Correlação é uma inferência que mede o relacionamento linear entre duas ou
mais variáveis. Na tabela seguinte, temos a representação da inferência de relação
entre “Y”, onde a variável dependente é a taxa de gravidez na
adolescência(T_M10A17CF) com “X”, onde a variável independente é índice de
educação (IDHM_E) que mede pessoas em idade escolar que tenham concluído um

grau especificado pela metodologia do IDHM. A exploração da correlação se dará
pela equação: Y= aX + b. Vale ressaltar que embora determine uma relação entre
as variáveis, isso não significa que necessariamente ela exista. E mais uma vez,
com 99,9% de confiança podemos rejeitar a hipótese nula, pois temos uma
correlação de ,253. Caso a medida se aproximasse de zero, a correlação seria
menor.
Nos coeficientes explanados na próxima tabela a variável “X” (IDHM_E)
apresenta correlação negativa. Caso transformássemos o valor 18,31
multiplicandoo por 100, teríamos o valor 0,1831. Como estamos tratando do IDHM
que varia de 0 1, essa transformação no valor de “X” permitirá afirmar que o
aumento de 1 ponto no IDHM_E reduziria em 0,18 o índice de gravidez na
adolescência.
3.3.3 DISTRIBUIÇÃO ESPACIAL E GRÁFICA

No sentido de realizar uma análise espacial de forma superficial, os dois
mapas a seguir indicam: I) expressa a variável dependente (taxa de gravidez na
adolecência) e II) representa a distribuição espacial da variável independente(
IDHM_E). Observase que o mapa I apresenta maior concentração de incidência de
casos de gravidez na adolescência na região sul do estado. Podese perceber
também que não houve formação de clusteres e que os casos estão espacialmente
distribuidos aleatóriamente e portanto não é possível estabelecer uma correlação
espacial, como já fora indicado anteriormente pelo Indice de Moran.
O mapa II, apresenta o IDHM_E, e portanto quanto mais escuro for o laranja
maior é o índice de escolaridade. Podemos observar que apesar de não haver
clusteres bem definidos há uma certa “uniformidade” e concentração mais ao
centronorte do estado. Essas inferências estão expressas no histograma e no
boxplot quando observamos os valores “abaixo da média” e do “menor valor
discrepante” respectivamente.
Ao comparar ambos concomitantemente, podemos observar que na região
onde o índice de educação é baixo (gráfico II) a incidência de gravidez precoce é
alta (gráfico I). Podese observar a mesma condição em outros pontos. Cabe aqui a
ressalva de que em pontos onde não se estabelece essa relação são os casos que
não são explicados apenas pela variável independente educação.
Gráfico I: variável dependente Gráfico II: variável independente
3.3.4 Análise dos Resíduos

O mapa e diagrama de espalhamento de Moran permite realizar uma análise
quanto a existência de dependência espacial entre os resíduos. No primeiro mapa
percebemos que os pontos destacados em vermelho indicam pior ajuste do modelo
enquanto os azuis apontam para um melhor ajuste de modelo. Ou seja, a
espacialização indica que em azul há baixa escolaridade e baixos índices de
gravidez na adolescência(Lowlow) e nos pontos em vermelho alto índice de
escolaridade e alta taxa de gravidez(highhigh). Não obstante, percebese que não
há correlação espacial entre os resíduos visto que não há a formação de clusteres.
4. CONCLUSÃO
Tendo em vista os aspectos observados podemos considerar que há, ainda
que pequena, correlação entre os indicadores de gravidez e educação embora o
modelo indique que em alguns dos casos observados apenas a variável Educação
não é capaz de explicar a incidência de gravidez precoce.
Nesse sentido o modelo estimado para essa análise aponta que o indicador
não está autocorrelacionado espacialmente.
5. REFERÊNCIA BIBLIOGRÁFICA
1. Atlas do Desenvolvimento Humano no Brasil. Disponível em:
http://www.atlasbrasil.org.br/2013/pt/download/. <Acesso em 02/07/2015>

2. CEM CEBRAP CENTRO DE ESTUDOS DA METRÓPOLE. Disponível em:
http://www.fflch.usp.br/centrodametropole/758 <Acesso em 02/07/2015>
3. DATASUS. Disponível em: http://tabnet.datasus.gov.br/cgi/idb2012/matriz.htm <
Acesso em 02/07/2015>
4. MINISTÉRIO DA SAÚDE. Disponível em:
http://bvsms.saude.gov.br/bvs/publicacoes/pesquisa_conhecimentos_atitudes_pratic
as_populacao_brasileira.pdf. < Acesso em 13/08/2015>
5. FUNDO DE POPULAÇÂO DAS NAÇÔES UNIDAS. Disponível em
http://www.unfpa.org.br/Arquivos/Gravidez%20Adolescente%20no%20Brasil.pdf. <
Acesso em <17/07/2015>
6. INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Disponível
em:http://www.ibge.gov.br/home/mapa_site/mapa_site.php#populacao. < Acesso em
22/07/2015>
7. Ministério da Saúde/ Sinasc. Ver: Brasil/MS, 2012. Saúde Brasil 2011: uma
análise da situação de saúde e a vigilância da saúde da mulher. Brasília: MS/SVS.
Disponível em http://bvsms.saude.gov.br/bvs/publicacoes/saude_brasil_2011.pdf.
<Acesso em 13/08/2015>
8. Comissão Econômica para a América Latina e Caribenhas. Ver: Observatório
de Igualdade de Gênero da América Latina e o Caribe, 2012. Informe Anual.
Santiago do Chile: CEPAL. Disponível em
http://repositorio.cepal.org/bitstream/handle/11362/35446/S2013192_pt.pdf?sequenc
e=1. < Acesso em 13/08/2015>

